



ParallelStandardCell Placementona Clusterof Workstations�
FarisH. Khundakjie, PatrickH. MaddenNaelB. Abu-Ghazalehand MehmetCanYildiz
StateUniversityof New York atBinghamtonComputerScienceDepartment
Abstract
In this paperwe report experienceson a parallel implementationof a standardcell placementalgorithm on aclusterof myrinetconnectedPCs. Theproposedalgorithmis basedon a recentlydevelopedplacementtool (calledFeng Shui) thatextendsrecursive bisectionplacementto incorporateglobal aspectsof thedesign.This is achievedusinganefficientandnovel optimizationcallediterativedeletion.Weinvestigateseveralalgorithmicandsystem-leveloptimizations.Contraryto previousattemptsat parallelizingplacementalgorithms,initial experimentalresultsshowsignificantperformanceimprovementwith small reductionin the placementquality. Furthermore,the reductionintheplacementquality doesnot increasewith thenumberof processors.
1 Intr oduction
With advancesin VLSI fabricationtechnology, the size of circuits of interestshasbecomeextremely large and is
continuouslyexpanding. Physicaldesignautomationtools areneededto aid in designand layout of suchcircuits.
However, the sizeof the circuits presentsa similar challengeto the designautomationtools: they mustbe ableto
provide goodquality layoutswith acceptablerun times. In this paper, we considerVLSI standardcell placement
– an importantanddifficult problemin physicaldesignautomation.The placementimpactscircuit areasandwire
delaysprofoundly;a poorplacementmaypreventa circuit from operatingat anacceptablespeed,or make too large
for thedesignfloor-plan. Furthermore,if the placementalgorithmhashigh complexity, we will beunableto obtain
a placementin anacceptableamountof time. This in turn mayforceusto sacrificetheplacementquality to achieve
fasterplacementtime.
Parallel processingoffers the promiseof increasingthe performanceandcapacityof placementtools, enabling
themto providebettersolutionsin fastertimes.Theemergenceandcommercialsuccessof clusteringtechnologiesis
perhapsthemostexciting developmentyet in thefield of parallelprocessing:it finally allows scalablecost-effective
parallelprocessingmachinesto be built [1, 3, 29]. Clustersapproachthe performanceof customparallelmachines
by usinghigh-performanceLocal/Systemareanetworking technologiesandstandards(suchasMyrinet [5], SCI [10,
�This researchwassupportedin partby NSFunderawardsCCR-9988222andEIA-991099
1

17] andothers[4, 36, 37]) andlow-overheaduser-level spacecommunicationprotocols(suchastheBasicInterface
for Parallelism(BIP) [15], Illinois Fast Messages(IFM) [28] and others[11, 27]). Becausethey usecommodity
components,clustersareaffordable,scalableandeasyto build [32].
This paperpresentsour experiencesin parallelizinga state-of-the-artplacementtool on a clusterof myrinetcon-
nectedworkstations.The algorithmusesstandarditerative partitioningbut augmentsthat with an iterative deletion
stepthat incorporatesglobalaspectsof thepartition in additionto the local optimizationsobtainedthroughthe itera-
tivebisectionstep.
Thecontributionsof this paperarethe following: (i) the initial sequentialalgorithmis state-of-the-artboth from
a run-timecomplexity andsolutionquality perspectives;(ii) theparallelimplementationprovidessignificantspeedup
while maintainingveryhighqualitysolutionsregardlessof thenumberof processorsused.In contrast,existingparallel
implementationsgenerallysuffer significantdegradationin solutionquality; (iii) mostpublishedsolutionsarespecific
to an architectureandarenot directly portableto a clusterenvironment. To our knowledge,this is the first study
that investigatesthis importantproblemon a modernclusterenvironment;and(iv) we investigateseveralalgorithmic
optimizationsas well as system-level tradeoffs in the implementation. This includesa study of the effect of the
Myrinet network [5] runningthe BIP messagepassinglibrary relative to using100 Mbit/secswitchedEthernetfor
communication.
Theremainderof this paperis organizedasfollows. Section2 theplacementproblemandrelatedwork. Section3
discussesthesequentialplacementalgorithmin moredetail.Section4 presentsthedetailsof theparallelimplementa-
tion. Section5 presentstheexperimentalsetupandresults.Finally, Section6 presentssomeconcludingremarks.
2 Overview and RelatedWork
Placementalgorithmshave beenextensively studied;objectives suchas areaminimization, wire length mini-
mization,andtiming optimizationarecommon. For all but trivial problemsizes,we have only heuristicmethods;
optimizationis usuallyperformedon only a small subsetof the circuit at any given time. If we perturba subsetof
circuit elements,we canoptimizea placementfrom a local perspective,but have no guaranteethatour modifications
areappropriatefrom a global perspective.
We considerthe problemof standardcell placement:the objective is to placerectilinearcircuit elements(cells)
into oneor morehorizontalrows,minimizing total wire length. Therearea numberof establishedapproachesto the
placementproblem.For a comprehensive survey, the readeris referredto the following paper[33]. ForceDir ected
or LP basedapproachesrepeatedlysolve systemsof equations,determiningcell locationsiteratively (for example,
2

L R
First partitioning
SecondPartitioning
ThirdPartitioning
Figure1: Orderof bisectionsin a top-down recursive approach.Thepartitioningof L influencesthesolutionfor R,andviceversa.
[13]). This approachis popular in commercialplacementtools. Simulated Annealing basedapproachesobtain
cell placementsby swappingpositionsof cells randomly, guidedby a probabilisticacceptancefunction. A number
of currentcommercialplacementenginesutilize this approach;efficient cost estimatesallow the considerationof
large numbersof intermediatestates. A well known exampleof this approachis TimberWolf[35]. Partitioning
basedapproachesdeterminecell locationsby recursively dividing aninitial area(region)with successivebisectionsor
quadrisections.This approachhasbecomemoreattractiverecently;advancesin partitioningresearchhaveprovideda
numberof fastalgorithmswhich produceextremelygoodresults.This is theapproachusedin this paper.
Breuer[6] utilized repeatedgraphbisectionsto obtaina circuit placement;this approachis shown in Figure 1.
The bisectionsdivide the circuit netlist into a hierarchyof cells, with the resultinghierarchyroughly mappinginto
a rectilineargrid. Dunlop andKernighan[12] extendedthis approach,throughthe useof an improved partitioning
method[20]. Moving beyondsimplebisections,SuarisandKedem[34] exploredtheuseof quadrisection(a four way
partitioning). Huangand Kahng[16] also apply quadrisection,utilizing a multi-level clusteringbasedpartitioning
algorithm,andconsideringminimumspanningtreelengths,ratherthanthesimplemin-cutmetric.
Dunlop andKernighan[12] also introduceterminal propagation. Whenpartitioninga region, we canexpecta
numberof connectionsto berequiredto cellsor padsoutsideof theregion. Terminalpropagationprovidesa simple
methodto insertfixed“dummy” vertices,sothatthepartitioningconsiderstheseexternalconnections(Figure2). With
terminalpropagation,thepartitioningsof regionsbecomeinterdependent;if we begin with two regions,L andR, and
partition L first, this impactsthe optimal solutionfor R. Partitioning R first might result in a differentsolution,and
neitherof thesemightbegloballyoptimal,evenif theindividualpartitioningswere.Toaddresstheorderdependenceof
thepartitioning,both[34] and[16] employ repeatedpartitioningateachlevel. We mightwish to partitionL, followed
by R, andthenpartitionL a second time. Repeatedpartitioningsdo not,however, changea localoptimizationprocess
into a globalone.
Becauseof thecomputationalcomplexity of placement,therehasbeensignificantinterestin parallelizingplace-
3

L1
L2
R2
R1
p
c2
c1
n1
Figure2: Terminalpropagationasperformedby DunlopandKernighan.Whenrecursively partitioninga netlist,wecaninsertdummy terminals to influencethepartitioner. If a netspansmorethanoneregion, the locationof dummyterminalscanimprovetheplacementquality.
mentalgorithmssincethe1980’s(seefor example[8, 9, 18, 21, 22, 23, 24, 26]; agoodsummaryis availablehere[2]).
Thesestudieshaveexperimentedwith parallelizingmostof theplacementalgorithmsonavarietyof parallelarchitec-
tures.Mostof thesestudiesarequiteold andarespecificto thearchitecturesthatwereusedto testthem;it is difficult
to compareperformancedirectly with them. In addition,the objective functionsthat the differentstudiesoptimize
aregenerallydifferent.Furthermore,researchin placementsuffersfrom thelack of uniform metricsfor reportingthe
results– wire lengthsarereported,but the resultscanvary by a multiplicative factordependingon the underlying
assumptions(suchascell spacingandthemethodof measuringwire length).Thismakesit difficult to fairly compare
the algorithms,even whenthe samemodelsareused.However, while direct comparisonis difficult, comparisonof
relativemeasuresbetweenthesequentialandparallelversionsof eachalgorithm(suchasspeedup,andquality degra-
dation)arestill possible. In the following paragraphwe will overview someof the mostrecentof theseworks. In
Section5 they arealsoreviewedaswe compareour resultsto them.
Banerjee’s researchgrouphasdonethe mostextensive work in the areaof parallelplacementalgorithms. For
example,within the ProperPLACE CAD tool they discussa parallel placementalgorithm basedon simulatedan-
nealing[21]. In contrastto otherparallelplacementimplementations,they work with an abstractparallelmachine
modelallowing the implementationto be directly portedacrossdifferentarchitectures.They studysharedmemory
anddistributedmemoryimplementations.Thespeedupacrossdifferentimplementationswerereportedon theISCAS
benchmarks.Koideet al presenta parallelimplementationof their POPINStiming drivenplacementtool [23]. They
usea bisectionapproachsimilar to our own, with non-linearprogrammingusedin a secondphaseoptimization.The
parallel implementationusessharedmemory. In this study, the drop of quality in the parallel implementationwas
significant(anaverageof 14%).
4

Split each region intoa pair of smaller regions,using Iterative Deletion
Partition eachpair of regions withhMetis
Largest regionremaining smallerthan threshold?
Branch-and-Bound optimizationof each row
Begin with a singleregion, comprising theentire placement area.
N
Y
Figure3: Flowchartof theplacementapproach.Thepartitioningandbranch-and-boundimprovementstepsarewellknown. New to theapproachis thepre-processingperformedby iterative deletion.
3 Algorithm Formulation
Thispaperconsidersparallelizinga placementtool (calledFeng Shui [38]) developedby two of theauthors.Feng
Shi adaptsa recentlypresentedpartitioningapproachfor k-waypartitioning.It differsfrom thatsolutionin thatit uses
a techniquecallediterative deletion [25] to allow someglobal issuesto becapturedresultingin improvedplacement
quality at significantly lower cost thank-way partitioning. Feng Shui integratesa variantof k-way partitioningap-
proachinto a traditional framework. The generalflow of our placementtool is asshown in Figure3. Whenfaced
with large numbersof regionsto bisect,iterative deletion is appliedfirst (to obtaina goodquality global solution),
followedby repartitioningof regionswith a traditionalbisectionapproach(to improve solutionquality from a local
perspective). Theremainderof this sectiondescribesthesestepsin moredetail.
3.1 Bisection
Theframework for theplacementtool is atextbookimplementationof theapproachof DunlopandKernighan[12]. The
circuit is repeatedlydividedby eitherhorizontalor verticalcut lines.A recentmulti-level clusteringbasedpartitioning
algorithmhMetis[19], version1.5.3 is used. At eachpartitioning,we attemptto obtaina nearlyexact bisectionif
cutting vertically. If the cut line is horizontal(splitting a numberof rows), the rows aresplit asevenly aspossible.
If the region beingbisectedcontainsan odd numberof standardcell rows, fixed andweighteddummyverticesare
addedto allow a nearlyexactbisectionto bemappedinto theavailablespace.Thepartitioningobjective is min-cut;
thehMetispartitionerattemptsto minimizethenumberof cuthyperedges.
5

The recursive bisectionprocessdividesplacementregionsinto progressively smallerareas,ultimately assigning
eachcell to a singlerow, but possiblyhaving severalcells remainingwithin a region. To establishpositionsfor each
cell, thecellsareorderedby region locationwithin eachrow; thecellsarepackedtogetherwithout spacesor overlap.
Thepositionsof cellswhich werewithin thesameregion will bearbitraryat this point; they werenot orderedby the
partitioningprocess.To optimizethesepositions,we applybranch-and-boundreordering,modifying thepositionsof
a smallsetof consecutivecellsin asinglerow.
Feng Shui allowsthespecificationof a“window size,” controllingthenumberof cellsinvolvedin any branch-and-
boundoptimization. This window passesover eachcell row (in order),traveling alongeachrow at stepsof half the
window size.At eachstep,theoptimalorderfor cells foundunderthewindow is determined.Thenumberof passes
over theplacement,andthesizeof thewindow, arebothparameterswhich canbecontrolledby theuser. In practice,
we find thatwindow sizesof 6 to 8 cells,and4 passesof improvement,aresufficient for goodoverall performance.
Increasingthewindow sizemayimpactrun timessubstantially(asthecomplexity of thebranch-and-boundprocedure
is O�w! � worstcase,wherew is thesizeof theoptimizationwindow). In [7], a numberof waysto implementbranch-
and-boundreorderingsefficiently wereexplored.
3.2 k-Way Partitioning
Thefocusof ourwork hasbeenontheglobal aspectsof theplacementproblem.With partitioning,wecanoptimizethe
numberof edgescut within a region effectively, but have no way of knowing if this local optimizationis appropriate
from a global perspective. Similarly, our branch-and-boundreorderingis alsoa local optimization.
A carefulexaminationof placementby recursive bisectionrevealsa numberof instanceswhereglobalobjectives
may be lost. The examplein Figure4 shows a simplecasewherelocal optimizationis insufficient; thereare four
regionsto bisect,eachwith two cells. If theproblemis approachedasa seriesof independentbisections,a numberof
configurationswhich arebothstableandsuboptimalcanbeencountered.Thesub-optimalityof theglobalsolutionis
not relatedto thequality of thebisectionsof eachregion; simply improving thebisectionalgorithmwill not improve
theglobalconfiguration.
As we progressthroughtheplacementprocess,thenumberof regionsincreases,doublingrepeatedly. If thereare
k regionsthatareto besplit (obtaining2k new regions),thetraditionalapproachis iterative,bisectinga singleregion
at a time. Instead,Feng Shui attemptsbisectionof all regionsat the sametime, obtaininga solutionthat is of good
quality globally. Themethodusedto performthis massivebisectionis basedon partitioningby iterativedeletion[25].
6

c4
c1
c2
c5
c3
c6
c7
c8
pad1
pad2
Netlistc
1c
2
c3
c4
c5
c6
c7
c8
pad1
pad2
c2
c4
c6
c8
pad1
pad2
c1
c3
c5
c7
Stable Placement Optimal Placement
R2
R3
R1
R4
Figure4: Giventhenetlistabove,we mayassignpairsof cellsto theregionsshown. If we partitionor applybranch-and-boundreorderingto thefour regions,we maybeunableto find anoptimalsolution.If we determinetheorderingin region R1 first, we arrive at a stableandsuboptimalsolution. Repeatedlocal optimization(throughrepartitioning)will fail to find thegloballyoptimalsolution.
3.3 NewFormulation – Iterati veDeletion
To captureglobalobjectiveseffectively, a variantof multi-way partitioning is used(ratherthanasa seriesof biparti-
tions). We partitionall regionssimultaneously, with the intermediatestateof eachregion influencingtheothers.We
areconcernedwith partitioningverylargenumbersof regions,andourcostobjectiveis wire lengthratherthanmin-cut.
Theproblemwe consideris given a set of regions (with physical constraints) and a set of elements mapped to these
regions, bisect all regions to minimize the resulting bounding-box wire length. Solutionof this problemoptimizesthe
circuit from a global perspective. Multi-way partitioninghasprovenquitechallenging[31]; for traditionalobjectives
suchasmin-cut, thegreatestsuccesshasbeenobtainedwith recursivepartitioning.
In [25], hypergraphpartitioningwasconsidered.A new methodbasedon iterative deletion waspresented;in this
approach,verticesareduplicated,with oneinstanceof eachvertex beingassignedto a partition. Redundantelements
areremovedoneat a time until no duplicatesremain.While theapproachwasrelatively simple,it provedeffective in
someareaswheretraditionalmethodshaddifficulty. For bipartitioning,cut sizesfrom a singlelinear-time passwere
comparableto many passesof a traditionalFM[14] algorithm.Multi-waycutsizesweresuperiorto adirectflat multi-
waypartitioningalgorithm[31]. For problemswith avarietyof hyperedgeweights,acombinationof iterativedeletion
andFM partitioningprovedsubstantiallymoreeffectivethanFM partitioningalone.Theapproachis computationally
attractive: with integerhyperedgeweights,it maybeimplementedin O�n � time.
Our variationof the iterative deletionapproachfor placementoperatesin the following manner. Eachcell in a
region is assignedto both subregions;if thereis morethana singleinstanceof acell, it is consideredto beredundant.
Werepeatedlyremoveredundantcellsfrom subregionswhichhavehighutilization,andselectthehighestcostcell for
removal.
In theexisting implementationof theplacementengine,thecell costis evaluatedbasedon thecenterof massfor
7

c1
c2
c1
c2 pad
n1
n2
c1
c1
c2 pad
n1
n2
c1 c
2 pad
n1
n2
Initial configuration,with duplicates forboth cells
On instance of has beenremoved, resulting in a changein the center of mass for somenets, and also new cell costs.
A second redundantinstance is removed.
Figure5: Two instancesof eachcell in thenetlistaregenerated,andassignedto bothsubregionsof any region. Cellcostsarebasedon thecenterof massfor thevertices;high costcellsareremovedoneat a time from any region of theentire placement problem. In this way, thepartitioningis performedon a globalbasis,ratherthanwith only a pair ofsubregionsat a time.
thecomponentnets.For eachnetni, thecenterof massfor this netis theaverageX andY locationof thecellswhich
it connects.Thecostof any cell ci is thesumof thedistancesbetweenthecell andthecenterof massof eachnet to
which the cell is connected.In this way, a cell which is far from thecenterof massof eachnet to which thecell is
connectedhashigh cost. Eachregion hasa numberof cellsassignedto it, andanavailablecapacity;redundantcells
(thoseintroducedby iterativedeletion)with highcostsareremovedfrom theregionwhichhasthehighestratioof cell
areato capacity.
Heapsareusedto maintaintheorderingof cellswithin any givenregion andtheorderingof regions. In this way,
maintenanceandcell selectionarebothatworstO�log n � for eachcell removed.As thenumberof redundantelements
to beremovedin any passis n, eachpassis O�nlog n � . Regionsizesdecreaseby a factorof 2 with eachpass,resulting
in a logarithmicnumberof passesrequired.Thus,theiterative deletion portionof thealgorithmis atworstO�nlog2n � .
To illustratethe iterative deletionprocess,we presentFigure5. In this figure,we duplicatecellsc1, in region R1,
andcell c2 in region R2, andassumethata netconnectsc1 to c2, andthata secondnetconnectsc2 to a pad.
Theorderof cell deletionsin this figure is asfollows. Note thatothercell deletionsmaybeinterspersedwith the
following; we focusonly on thesecellsto clarify theprocess.
� Thecenterof massfor thenetsconnectedto cell c2 is closestto thepad;we removetheinstanceof c2 which is
furthestfrom this location(asthis is theinstancewhich hashighestcost).
� Thecenterof massfor netsconnectedto cell c2 is recalculated,andthis is propagatedto theothercells.
� Netn1 now hastwo instancesof c1 andoneinstanceof c2 connectedto it: thecenterof massfor thisnetchanges,
influencingthecostfor eachinstanceof c1.
� An instanceof c1 is removed.
8

4 Parallel Cell Placement
Theoptimizedsequentialimplementationof theplacementalgorithmdiscussedabovewasinstrumentedto isolate
theportionsthataremostcomputationallydemanding.Thebulk of theexecutiontime wasspentin partitioningand
reorderingphases– iterativedeletionupdatescontributedvery little overheadaftereachpartitioningpass.Theparallel
implementationandoptimizationsto it (both thosewe have alreadyimplementedandonesthatareplanned)will be
discussedin this section.TheimplementationwasperformedusingMPICH runningon top of theBasicInterfacefor
Parallelism(BIP) [30] on a myrinetconnectedPCclusterrunningLinux.
4.1 Parallel Partitioning
In order to maintainthe global optimizationachieved by iterative deletion,parallel processingis restrictedto the
growing list of regions to be partitionedin eachpass. In the first passthe main region is partitionedby a master
processinto two. In thesecondpasstheresultingtwo regionsarepartitionedinto four in parallelby themasteranda
slaveandsoonuntil theprocessorlimit is reached.As thelist grows,regionsabovea certainthresholdaredistributed
evenlyby themasteramongall processes.An exampleis shown in Figure6.
Tp/n
Step 1
Step 2
Step 3
Send Regions OutTu
Tp
Step log(n)2
Figure6: ParallelPartitioning
Initially, we implementedthedatadistributionusingamessageperwork unit (i.e. region). Thus,themasterwalks
the list andsendsa messagefor eachregion to the slavesin a round-robin fashion.We optimizedthis implementa-
tion by generatinga messageper eachbatchof work units usingMPI’s vector scatter-gather. Obviously, the latter
9

outperformsthefirst becauseit increasesthecomputationgranularityby requiringthemasterto communicatefewer
messageswith largersize.Loadbalanceis maintainedby theaforementionedevendistribution of regionsandby the
factthatthepartitioningengineproducesbalancedregioncutsaswell.
BecauseVLSI CAD applicationsrequirelargememoryspace,it is necessaryto utilize memoryefficiently. In order
to doso,unicastmaster-to-slaveandbroadcastcommunicationmessagesareusedto instructslavesto allocateonly the
spacerequiredfor storingandprocessingtheirworkloadin theroundrobinandvectorscatter-gatherimplementations
respectively. Suchmessagesincurslight overheadthatis negligible for non-trivial placementproblems.
An approximateanalysisof theparallelpartitioningfollows. Considera region of areaR to bepartitionedinto N
regionsjustbelow thethreshold.Assumingalinearruntimecomplexity of thepartitioningengineandahomogeneous
distribution of circuit elements,if it takestime Tp to partitionR, thenpartitioninga regionof areaRn requiresTp
n . The
progressionof region partitioningis modeledby thetreein Figure6. A sequentialimplementationperformsn steps,
with steptime Tpn , at eachpassto partition n regionsinto 2n regionswith a total time of Tp. The numberof passes
is log2N, andso the total amountof partitioningtime is Tp � log2N. On the otherhand,usingP processors,the first
log2P � 1 passeshave n �� P andeachtakes Tpn to complete(i.e. a maximumof oneregion perprocessor)while the
resthaven p andeachtakesceil(n/p)x Tp/n to complete(i.e. ceil(n/p)regionsperprocessor).Thetotal time for the
first groupof passesis:
log2P
∑i � 0
Tp
2i (1)
andthetotal time for therestis:log2N � 1
∑i � log2P 1
Tp
P� Tp
P � � log2N � log2P � 1� (2)
For machineswith smallP, overawide rangeof problemsize,N is muchlargerthanP (i.e. thenumberof passeswith
n �� p is muchlessthanthosewith n P), andif log2N � log2P � 1, thenthe total time is givenby thesecond
formula andis approximatedby Tpp � log2N. The bestcasespeedup(sequential/paralleltime) is hencelinear in the
numberof processors.
Costupdateandcommunicationtimescouldbeincorporatedby time Tu aftereachpass.Thetotalof thisoverhead
is thegeometricseriesandis givenby:
log2N � 1
∑i � 0
2i � Tu � Tu ��2 � log2N � � 1��
2 � 1� � �N � 1� � Tu (3)
SinceTu is largerin theparallelimplementationdueto communicationtime,theactualspeedupcannotbeexpected
to belinear.
10

4.2 Parallel Reordering
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
��������������������������������������� � � � � � � � � � � � � � � � � � � !�!�!�!�!�!�!!�!�!�!�!�!�!!�!�!�!�!�!�!"�"�"�"�"�""�"�"�"�"�""�"�"�"�"�"#�#�#�#�#�#�##�#�#�#�#�#�##�#�#�#�#�#�#$�$�$�$�$�$$�$�$�$�$�$$�$�$�$�$�$%�%�%�%�%�%�%%�%�%�%�%�%�%%�%�%�%�%�%�%&�&�&�&�&�&�&&�&�&�&�&�&�&&�&�&�&�&�&�&'�'�'�''�'�'�''�'�'�'(�(�(�((�(�(�((�(�(�()�)�)�)�)�))�)�)�)�)�))�)�)�)�)�)*�*�*�*�*�**�*�*�*�*�**�*�*�*�*�*
+�++�++�++�++�+,�,,�,,�,,�,,�,
-�-�-�-�--�-�-�-�--�-�-�-�-.�.�.�.�..�.�.�.�..�.�.�.�. /�/�/�//�/�/�//�/�/�/0�0�0�00�0�0�00�0�0�01�1�1�1�1�1�11�1�1�1�1�1�11�1�1�1�1�1�11�1�1�1�1�1�11�1�1�1�1�1�12�2�2�2�2�2�22�2�2�2�2�2�22�2�2�2�2�2�22�2�2�2�2�2�22�2�2�2�2�2�2
3�3�3�33�3�3�33�3�3�34�4�4�44�4�4�44�4�4�45�5�55�5�55�5�55�5�55�5�56�66�66�66�66�6
7�7�7�7�7�7�77�7�7�7�7�7�77�7�7�7�7�7�77�7�7�7�7�7�77�7�7�7�7�7�78�8�8�8�8�8�88�8�8�8�8�8�88�8�8�8�8�8�88�8�8�8�8�8�88�8�8�8�8�8�8
9�9�9�99�9�9�99�9�9�9:�:�:�::�:�:�::�:�:�: ;�;�;;�;�;;�;�;;�;�;;�;�;<�<�<<�<�<<�<�<<�<�<<�<�<=�=�=�==�=�=�==�=�=�==�=�=�==�=�=�=>�>�>�>>�>�>�>>�>�>�>>�>�>�>>�>�>�>
?�?�?�??�?�?�??�?�?�?@�@�@�@@�@�@�@@�@�@�@A�A�A�A�AA�A�A�A�AA�A�A�A�AB�B�B�B�BB�B�B�B�BB�B�B�B�BP0Master Slave
P1Slave
Odd Pass Windows
P2
Data Set
Even Pass Windows
Individual cells
Figure7: ParallelReorderingPasses
Branchandboundcell reorderingis a secondphaseoptimizationthat is performedafter the placementstepto
improve thesolutionquality. A reorderingwindow of a prespecifiedwidth in numberof cells is slid acrosstheeach
row in stepsof half the window size. All combinationsof reorderingsof the cells within the currentwindow are
consideredandthe bestwindow kept. Thus,the smallestwork unit is the block of consecutive cells definedby the
reorderingwindow. The larger the window size the larger the block and the large the numberof cells considered
for reorderingat a time, but the smallerthe numberof blockssincerows areof fixed length. All cellsexcepthalf a
window’s worth at thebeginningof eachrow areconsideredfor reorderingtwice. To keepthis key for quality in the
parallelimplementation,only non-overlappingblocksarereorderedin parallel.Thus,eachrow undergoestwo passes
of reorderingwhereawindow now movesatstepsof full size.Thefirst passconsidersevenblocksonly andthesecond
considersoddblocksonly or viceversa.
The sameprinciplesfor partitioning load balanceandcommunicationare followed here;blocksaredistributed
evenlyamongall processorsusingvectorscatter-gatherasshown in Figure7. Becausethereis oftena largenumberof
rows in a placement,it is crucial to optimizememoryreallocation;allocatedmemoryis not releasedunlessthespace
requiredto holdblocksof anew row is largerthantheavailablespace.
5 Experiments
Theparallelimplementationof theplacementtool wasevaluatedfor executiontime andquality of solutionon a
11
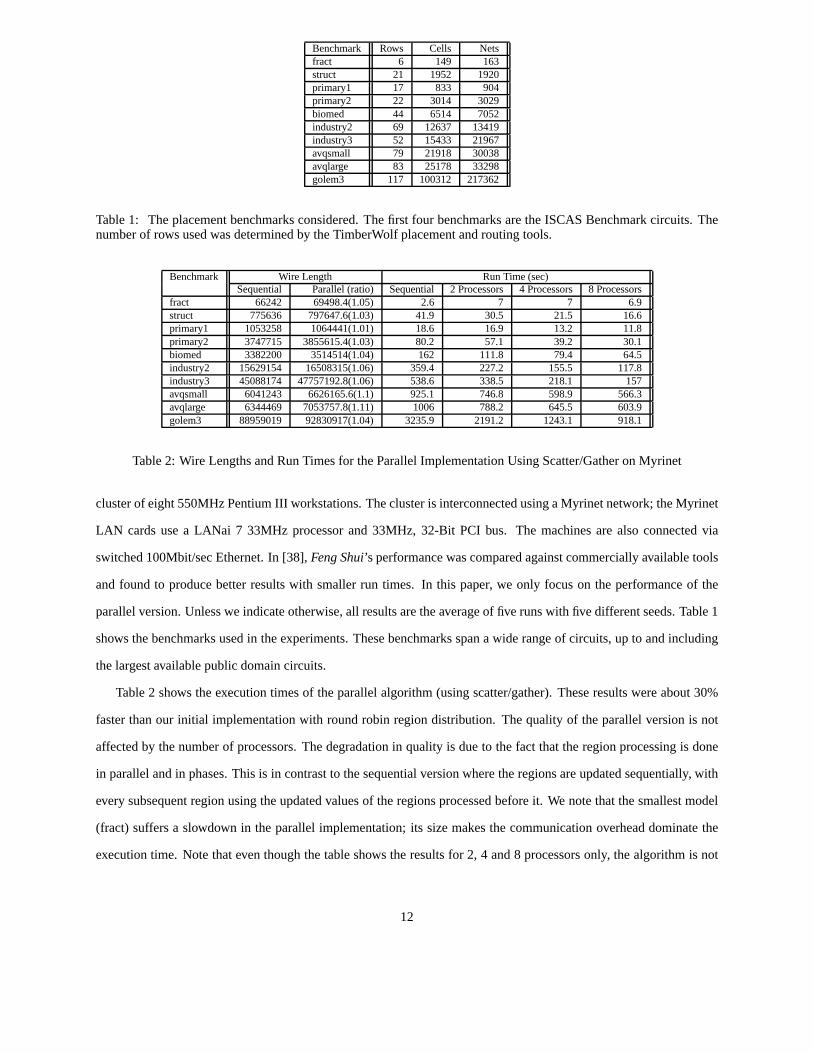
Benchmark Rows Cells Netsfract 6 149 163struct 21 1952 1920primary1 17 833 904primary2 22 3014 3029biomed 44 6514 7052industry2 69 12637 13419industry3 52 15433 21967avqsmall 79 21918 30038avqlarge 83 25178 33298golem3 117 100312 217362
Table1: Theplacementbenchmarksconsidered.Thefirst four benchmarksaretheISCASBenchmarkcircuits. Thenumberof rowsusedwasdeterminedby theTimberWolf placementandroutingtools.
Benchmark Wire Length RunTime(sec)Sequential Parallel(ratio) Sequential 2 Processors 4 Processors 8 Processors
fract 66242 69498.4(1.05) 2.6 7 7 6.9struct 775636 797647.6(1.03) 41.9 30.5 21.5 16.6primary1 1053258 1064441(1.01) 18.6 16.9 13.2 11.8primary2 3747715 3855615.4(1.03) 80.2 57.1 39.2 30.1biomed 3382200 3514514(1.04) 162 111.8 79.4 64.5industry2 15629154 16508315(1.06) 359.4 227.2 155.5 117.8industry3 45088174 47757192.8(1.06) 538.6 338.5 218.1 157avqsmall 6041243 6626165.6(1.1) 925.1 746.8 598.9 566.3avqlarge 6344469 7053757.8(1.11) 1006 788.2 645.5 603.9golem3 88959019 92830917(1.04) 3235.9 2191.2 1243.1 918.1
Table2: Wire LengthsandRunTimesfor theParallelImplementationUsingScatter/Gatheron Myrinet
clusterof eight550MHzPentiumIII workstations.Theclusteris interconnectedusingaMyrinet network; theMyrinet
LAN cardsusea LANai 7 33MHz processorand33MHz, 32-Bit PCI bus. The machinesare also connectedvia
switched100Mbit/secEthernet.In [38], Feng Shui’sperformancewascomparedagainstcommerciallyavailabletools
andfound to producebetterresultswith smallerrun times. In this paper, we only focuson the performanceof the
parallelversion.Unlesswe indicateotherwise,all resultsaretheaverageof fiverunswith fivedifferentseeds.Table1
shows thebenchmarksusedin theexperiments.Thesebenchmarksspana wide rangeof circuits,up to andincluding
thelargestavailablepublicdomaincircuits.
Table2 shows theexecutiontimesof theparallelalgorithm(usingscatter/gather).Theseresultswereabout30%
fasterthanour initial implementationwith roundrobin region distribution. Thequality of theparallelversionis not
affectedby thenumberof processors.Thedegradationin quality is dueto thefact that theregion processingis done
in parallelandin phases.This is in contrastto thesequentialversionwheretheregionsareupdatedsequentially, with
every subsequentregion usingtheupdatedvaluesof theregionsprocessedbeforeit. We notethatthesmallestmodel
(fract) suffersa slowdown in the parallelimplementation;its sizemakesthe communicationoverheaddominatethe
executiontime. Note thateventhoughthetableshows theresultsfor 2, 4 and8 processorsonly, thealgorithmis not
12
restrictedto powerof two processorconfigurations.
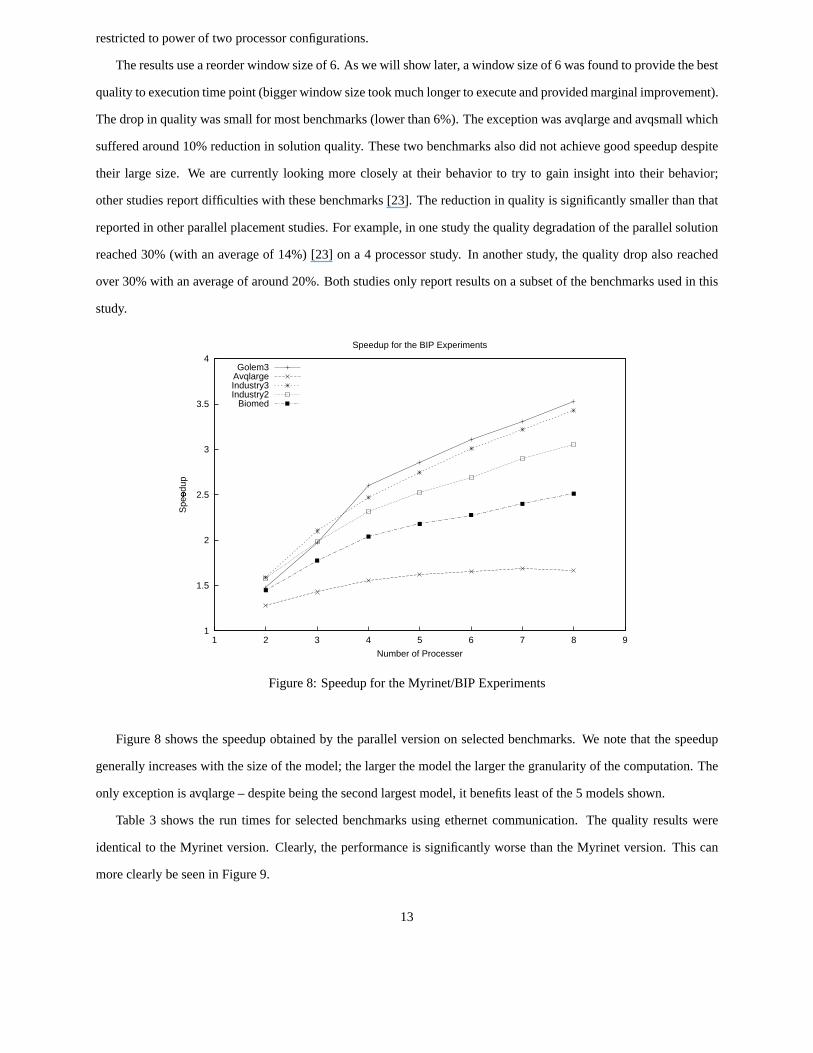
Theresultsuseareorderwindow sizeof 6. As wewill show later, awindow sizeof 6 wasfoundto providethebest
qualityto executiontimepoint(biggerwindow sizetookmuchlongerto executeandprovidedmarginalimprovement).
Thedropin qualitywassmallfor mostbenchmarks(lower than6%). Theexceptionwasavqlargeandavqsmallwhich
sufferedaround10%reductionin solutionquality. Thesetwo benchmarksalsodid not achievegoodspeedupdespite
their large size. We arecurrently looking morecloselyat their behavior to try to gain insight into their behavior;
otherstudiesreportdifficultieswith thesebenchmarks[23]. Thereductionin quality is significantlysmallerthanthat
reportedin otherparallelplacementstudies.For example,in onestudythequalitydegradationof theparallelsolution
reached30% (with an averageof 14%) [23] on a 4 processorstudy. In anotherstudy, the quality dropalsoreached
over30%with anaverageof around20%. Both studiesonly reportresultson a subsetof thebenchmarksusedin this
study.
1
1.5
2
2.5
3
3.5
4
1 2 3 4 5 6 7 8 9
Spe
edupC
Number of Processer
Speedup for the BIP Experiments
Golem3AvqlargeIndustry3Industry2
Biomed
Figure8: Speedupfor theMyrinet/BIP Experiments
Figure8 shows the speedupobtainedby the parallelversionon selectedbenchmarks.We notethat the speedup
generallyincreaseswith thesizeof themodel;thelargerthemodelthelargerthegranularityof thecomputation.The
only exceptionis avqlarge– despitebeingthesecondlargestmodel,it benefitsleastof the5 modelsshown.
Table3 shows the run times for selectedbenchmarksusingethernetcommunication.The quality resultswere
identicalto the Myrinet version. Clearly, the performanceis significantlyworsethanthe Myrinet version. This can
moreclearlybeseenin Figure9.
13
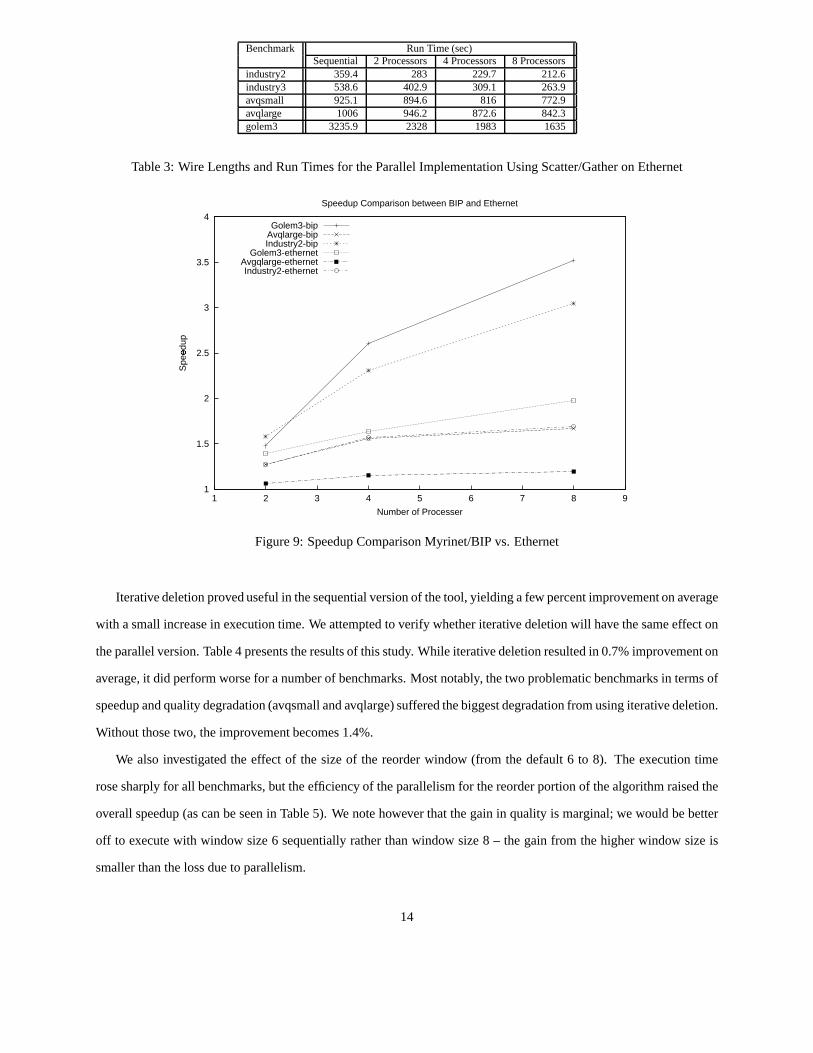
Benchmark RunTime(sec)Sequential 2 Processors 4 Processors 8 Processors
industry2 359.4 283 229.7 212.6industry3 538.6 402.9 309.1 263.9avqsmall 925.1 894.6 816 772.9avqlarge 1006 946.2 872.6 842.3golem3 3235.9 2328 1983 1635
Table3: Wire LengthsandRunTimesfor theParallelImplementationUsingScatter/Gatheron Ethernet
1
1.5
2
2.5
3
3.5
4
1 2 3 4 5 6 7 8 9
Spe
edupC
Number of Processer
Speedup Comparison between BIP and Ethernet
Golem3-bipAvqlarge-bipIndustry2-bip
Golem3-ethernetAvgqlarge-ethernetIndustry2-ethernet
Figure9: SpeedupComparisonMyrinet/BIPvs. Ethernet
Iterativedeletionprovedusefulin thesequentialversionof thetool,yieldingafew percentimprovementonaverage
with asmallincreasein executiontime. Weattemptedto verify whetheriterativedeletionwill havethesameeffecton
theparallelversion.Table4 presentstheresultsof thisstudy. While iterativedeletionresultedin 0.7%improvementon
average,it did performworsefor anumberof benchmarks.Mostnotably, thetwo problematicbenchmarksin termsof
speedupandqualitydegradation(avqsmallandavqlarge)sufferedthebiggestdegradationfrom usingiterativedeletion.
Without thosetwo, theimprovementbecomes1.4%.
We alsoinvestigatedthe effect of the sizeof the reorderwindow (from the default 6 to 8). The executiontime
rosesharplyfor all benchmarks,but theefficiency of theparallelismfor thereorderportionof thealgorithmraisedthe
overall speedup(ascanbeseenin Table5). We notehowever thatthegainin quality is marginal;we would bebetter
off to executewith window size6 sequentiallyratherthanwindow size8 – the gain from thehigherwindow sizeis
smallerthanthelossdueto parallelism.
14
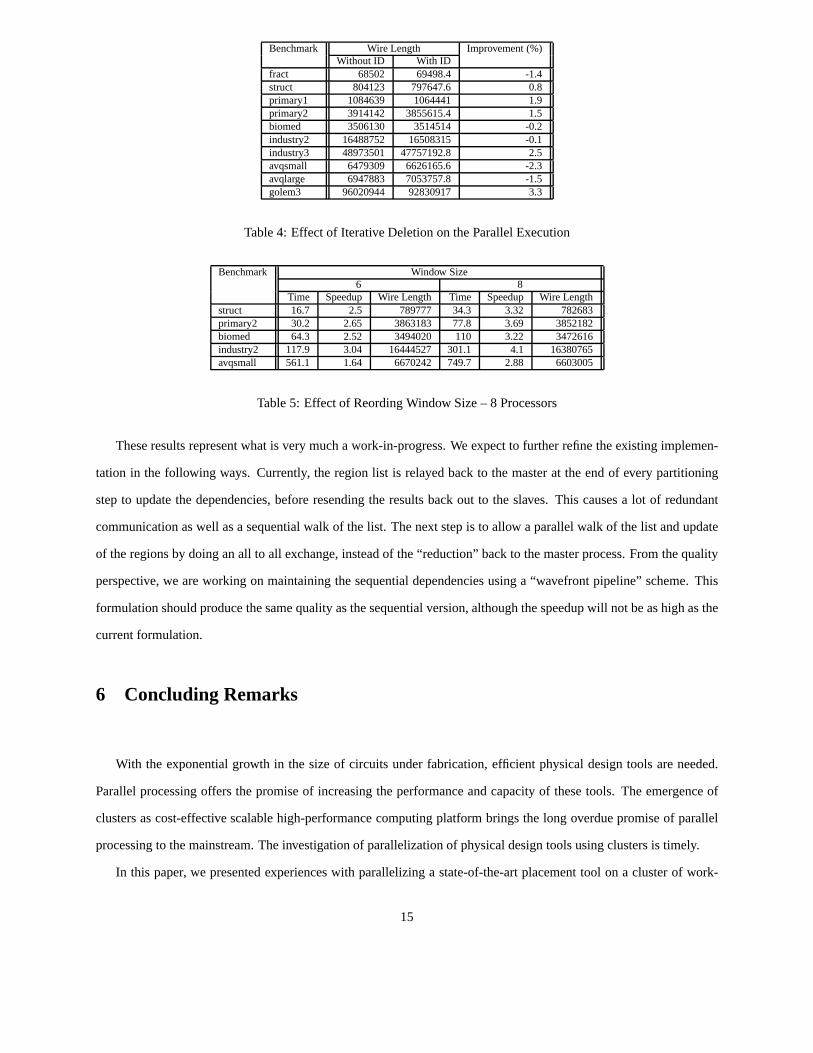
Benchmark Wire Length Improvement(%)Without ID With ID
fract 68502 69498.4 -1.4struct 804123 797647.6 0.8primary1 1084639 1064441 1.9primary2 3914142 3855615.4 1.5biomed 3506130 3514514 -0.2industry2 16488752 16508315 -0.1industry3 48973501 47757192.8 2.5avqsmall 6479309 6626165.6 -2.3avqlarge 6947883 7053757.8 -1.5golem3 96020944 92830917 3.3
Table4: Effectof IterativeDeletionon theParallelExecution
Benchmark Window Size6 8
Time Speedup Wire Length Time Speedup Wire Lengthstruct 16.7 2.5 789777 34.3 3.32 782683primary2 30.2 2.65 3863183 77.8 3.69 3852182biomed 64.3 2.52 3494020 110 3.22 3472616industry2 117.9 3.04 16444527 301.1 4.1 16380765avqsmall 561.1 1.64 6670242 749.7 2.88 6603005
Table5: Effectof ReordingWindow Size– 8 Processors
Theseresultsrepresentwhatis very mucha work-in-progress.We expectto furtherrefinetheexisting implemen-
tation in the following ways. Currently, the region list is relayedbackto the masterat the endof every partitioning
stepto updatethe dependencies,beforeresendingthe resultsbackout to the slaves. This causesa lot of redundant
communicationaswell asa sequentialwalk of thelist. Thenext stepis to allow a parallelwalk of thelist andupdate
of theregionsby doinganall to all exchange,insteadof the“reduction”backto themasterprocess.Fromthequality
perspective, we areworking on maintainingthesequentialdependenciesusinga “wavefrontpipeline” scheme.This
formulationshouldproducethesamequalityasthesequentialversion,althoughthespeedupwill notbeashighasthe
currentformulation.
6 Concluding Remarks
With the exponentialgrowth in the sizeof circuits underfabrication,efficient physicaldesigntools areneeded.
Parallel processingoffers the promiseof increasingthe performanceandcapacityof thesetools. The emergenceof
clustersascost-effective scalablehigh-performancecomputingplatformbringsthe long overduepromiseof parallel
processingto themainstream.Theinvestigationof parallelizationof physicaldesigntoolsusingclustersis timely.
In this paper, we presentedexperienceswith parallelizinga state-of-the-artplacementtool on a clusterof work-
15

stations.Thesequentialtool provideswire lengthscomparableto thoseof a well known commercialtool, andresults
reportedfor thetool Capo indicatethatplacementsarenotdifficult to route.Thesequentialimplementationis efficient;
thegrowth in run timesis nearlylinearwith thesizeof thecircuit. Thetool usesa novel iterative deletionapproach
to allow the considerationof global objectivesfrom within a traditionaltop-down placementframework. For more
detailspleasereferto thefollowing paper[38].
Contraryto othereffortsatparallelplacement,wewereableto obtainsignificantimprovementin performancewith
minimal degradationin thequalityof thelayout.Thedegradationin thequality of thesolutiondoesnot increasewith
thedegreeof parallelism.Weexploredseveralalgorithmicandsystemoptimizationsandevaluatedtheimplementation
ona myrinetaswell asaswitchedEthernetnetwork. We arestill in theprocessof optimizingtheimplementationand
arehopefulof achieving higherspeedupin time for thefinal versionof this paper.
Weexpectto continueto refinethis tool bothfrom animplementationandfunctionalityperspectives.For example,
timing drivenplacementisasignificantconcernfor moderndesign.Wearecurrentlyworkingwith anindustryresearch
groupto evaluatethe performanceof our approachon large designsunderrealisticdelayrules. We notethat delay
optimizationis perhapsmoreof a globalphenomenathanwire lengthminimization: meetingtiming objectivesmay
requiremodificationsin many areasof aplacement,andreductionsin delayfor somenetsmayrequireincreaseddelay
in others.
References
[1] T. Anderson,D. Culler, andD. Patterson.The casefor NOW (network of workstations). IEEE Micro, 15(1),February1995.
[2] P. Banerjee.Parallel Algorithms for VLSI Computer-Aided Design. PrenticeHall, EnglewoodCliffs, New Jersey,1994.(Chapter3).
[3] D. Becker, T. Sterling,D. Savarese,J.Dorband,U. Ranawak,andC. Packer. BEOWULF: A parallelworkstationfor scientificcomputation.In International Conference on Parallel Processing, 1995.
[4] M. Blumrich,R.Alpert,Y. Chen,D. Clark,S.Damianakis,C.Dubnicki,E.Felten,L. Iftode,K. Li, M. Martonosi,andR. Shillner. Designchoicesin the shrimpsystem:An empiricalstudy. In Proceedings of the 25th AnnualACM/IEEE International Symposium on Computer Architecture, June1998.
[5] N. Boden,D. Cohen,andW.-K. Su. Myrinet: A gigabit-per-secondlocal areanetwork. IEEE Micro, 15(1),February1995.
[6] M. A. Breuer. A classof min-cutplacementalgorithms.In Proc. Design Automation Conf, pages284–290,1997.
[7] A. E. Caldwell, A. B. Kahng,and I. L. Markov. Optimal partitionersandend-caseplacersfor standardcelllayout. In Proc. Int. Symp. on Physical Design, pages90–96,1999.
[8] A. CasottoandA. Sangiovanni-Vincentelli. Placementof standardcellsusingsimulatedannealingon thecon-nectionmachine.In Proceedings of the International Conference on Computer-Aided Design, pages350–353,November1987.
16

[9] F. Darema,S. Kirkpatrick, andV. Norton. Parallelalgorithmsfor chip placementby simulatedannealing.IBMJournal of Research and Development, May 1987.
[10] Dolphin Internconnects.The Dolphin SCI interconnect– whitepaper, February1996. Availablefrom DFEGEIHKJLGLIMINGOQPSRUTIVQPXWYTQP[ZG\FL HF]I^Y_`^badc`edf LdgbhIi DjakEYedlFmnHbe`f P HF]I^ .
[11] C. Dubnicki,A. Bilas,Y. Chen,S.Damianakis,andK. Li. VMMC-2: Efficient supportfor reliable,connection-orientedcommunication.In Hot Interconnects V, August1997.
[12] A. E. DunlopandB. W. Kernighan.A procedurefor placementof standard-cellVLSI circuits. IEEE Trans. onComputer-Aided Design of Integrated Circuits andSystems, CAD-4(1):92–98,January1985.
[13] H. EisenmannandF. M. Johannes.Genericglobal placementandfloorplanning. In Proc. Design AutomationConf, pages269–274,1998.
[14] CharlesM. FiducciaandR. M. Mattheyses. A linear-time heuristicfor improving network partitions. In Pro-ceedings of the 19th IEEE Design Automation Conference, pages175–181,1982.
[15] P. Geoffray, L. Prylli, andBernardTourancheau.BIP-SMP:High performancemessagepassingoveraclusterofcommoditySMPs.In Proceedings of Supercomputing (SC99), November1999.
[16] D. J.-H.HuangandA. B. Kahng. Partitioningbasedstandardcell globalplacementwith anexactobjective. InProc. Int. Symp. on Physical Design, pages18–25,1997.
[17] M. Ibel, K. Schauser, C. Scheiman,and M. Weis. High performanceclustercomputingusing SCI. In HotInterconnects V, August1997.
[18] R. JayaramanandR. Rutenbar. Floorplanningby annealingon a hypercubemultiprocessor. In Proceedings ofthe International Conference on Computer-Aided Design, pages346–349,November1987.
[19] G. Karypis,R. Aggarwal, V. Kumar, andS. Shekhar. Multilevel hypergraphpartitioning: Application in VLSIdomain.In Proc. Design Automation Conf, pages526–529,1997.
[20] Brian W. KernighanandS. Lin. An efficient heuristicprocedurefor partitioninggraphs.Bell System TechnicalJournal, 49:291–307,1970.
[21] S. Kim, B. Ramkumar, J. Chandy, S. Parkes,andP. Banerjee.ProperPLACE: a portableparallelalgorithmforstandardcell placement.In Proceedings of the 8th International Parallel Processing Symposium (IPPS’94), April1994.
[22] R. Kling andP. Banerjee.ConcurrentESP:a placementalgorithmfor executionon distributedprocessors.InProceedings of the International Conference on Computer-Aided Design, pages354–357,November1987.
[23] T. Koide,M. Ono,S.Wakabayashi,andY. Nishimaru.Par-POPINS:a timing-drivenparallelplacementmethodwith the elmoredelay model for row basedVLSIs. In Proceedings of the Design Automation Conference(DAC’97), 1997.
[24] S. Kravitz and R. Rutenbar. Placementby simulatedannealingon a multiprocessor. IEEE Transactions onComputer Aided Design of Integrated Circuits and Systems, 6(4):534–549,June1987.
[25] P. H. Madden.Partitioningby iterativedeletion.In Proc. Int. Symp. on Physical Design, pages83–89,1999.
[26] S.MohanandP. Mazumder. Wolverines:Standardcell placementon anetwork of workstations.IEEE Transac-tions on Computer Aided Design of Integrated Circuits and Systems, 12(9):1312–1326,September1993.
[27] M-VIA: Virtual interfacearchitecturefor linux, 2001. DGEGEIHKJ LILnoGoGoKPqp e`fsrGt PXuYvnwbL fYeFrdeGmnfstxD LnyIgFzGLdw a{m L .[28] S.Pakin, M. Lauria,andA. Chien. High performancemessagingon workstations:Illinois FastMessages(FM)
for Myrinet. In Proceedings of Supercomputing (SC’95), 1995.
[29] G. Pfister. In Search of Clusters, 2nd Ed. PrenticeHall, 1998.
17

[30] L. Prylli. BIP messagesusermanual,1998. Available at DFEGE`HKJ LGL c{DGH|tdm Pq}Gp a wFh cd~ vdp�R�P ^`f LU�j� l hd� m pI} mFc La p ]Ge`� P DFE � c .[31] L. A. Sanchis. Multiple-way network partitioningwith differentcost functions. IEEE Trans. on Computers,
42(22):1500–1504,1993.
[32] ScalableComputingLab. SCL clustercookbook:Building your own clustersfor parallelcomputation,1998.DFEGE`HKJ LGLnoIoGoKP rGtdc P m � eYr`cIm{� P�uFvdwbL l`f vI� ebtUEsr L`� c } rUEYenf �Fv`v`� � vIvd� .
[33] K. ShahookarandP. Mazumder. Vlsi cell placementtechniques.ACM Computing Surveys, 23(2):143–220,June1991.
[34] P. R. SuarisandG. Kedem.An algorithmfor quadrisectionandits applicationto standardcell placement.IEEETrans. on Circuits and Systems, 35(3):394–303,1988.
[35] W.-J. SunandC. Sechen.Efficient andeffective placementfor very largecircuits. IEEE Trans. on Computer-Aided Design of Integrated Circuits andSystems, 14(3):349–359,1995.
[36] Virtual interfacearchitecture(VIA) specification,2001. DFEGE`HKJ LGLnoIoGoKPXw a{m`fstUD P�v f u .
[37] M. Welsh,A. Basu,andT. von Eicken. Atm andfastethernetnetwork interfacesfor user-level communication.In Proceedings of the Third High-Performance Computer Architecture Conference (HPCA’97), February1997.
[38] M. Yeldiz andP. H. Madden.Globalobjectivesfor standardcell placement.In Design Automation Conference(DAC’2000), 2000.
18






























