REAL-TIME SCHEDULING OF PERIODIC AND APERIODIC TASKS ON MULTIPROCESSOR SYSTEMS A Dissertation Presented by SHINPEI KATO Submitted to the School of Science for Open and Environmental Systems in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY at Keio University March 2008

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

REAL-TIME SCHEDULING OFPERIODIC AND APERIODIC TASKS ON
MULTIPROCESSOR SYSTEMS
A Dissertation Presentedby
SHINPEI KATO
Submitted tothe School of Science for Open and Environmental Systemsin partial fulfillment of the requirements for the degree of
DOCTOR OF PHILOSOPHY
at Keio University
March 2008

c© Copyright by Shinpei Kato
All rights reserved
i

To my parents.
ii

ACKNOWLEDGMENT
A great many people have supported and assisted me in so many ways during my stayhere at Keio University. I owe my gratitude to all those people who have made thisdissertation possible.
My first, and the most earnest, gratitude must go to my adviserProf. NobuyukiYamasaki. I have been fortunate to have such a great adviser who has outstandingskill and knowledge. He has always indicated me the right road to proceed when Ifaltered on my research. This dissertation could have been never completed without hisprofessional suggestion and advice.
I would like to give my sincere gratitude to Prof. Kenji Kono and Prof. HideharuAmano as well. They have dedicated their time and energy far beyond their duty tosubstitute a technical editor of this dissertation and an adviser of my research respec-tively instead of Prof. Yamasaki because of his sabbatical leave to the United Statesof America through this year. I wish to extend my gratitude toProf. Fumio Teraokaand Prof. Takahiro Yakoh for serving on my dissertation committee. Their constructivecriticism and invaluable advice have significantly improved this dissertation. I am alsothankful to my first adviser Prof. Kenji Harada who helped me take the very first stepto this point.
I appreciate the financial supports from the Research Fellowships of the Japan So-ciety for the Promotion of Science for Young Scientists and the Core Research forEvolutional Science and Technology of Japan Science and Technology Agency. I alsoappreciate the members of the National Institution of Advanced Industrial Science andTechnology for their technical advice to the part of my research.
I am grateful to Takahiro Sasaki, Seiichi Arai, and NobuhideKamata who havespent all the time with me for two years of the master’s course. I could not have survivedthe master’s research and achieved the thesis without theirkind cooperation. I am alsothankful to Dr. Hidenori Kobayashi and Dr. Tsutomu Ito for their technical assistanceof my research. My special thanks go to Naoki Inoue, NobuyasuTakahashi, and NaruKudo for their friendship from the undergraduate years.
My final, and the most heartfelt, acknowledgment must go to myparents and Mrs.Fumiko Omi. They have continuously encouraged, supported,and looked after meduring all my life. No words can adequately express my gratitude to them.
iii

ABSTRACT
REAL-TIME SCHEDULING OFPERIODIC AND APERIODIC TASKS ONMULTIPROCESSOR SYSTEMS
SHINPEI KATO
Real-time scheduling techniques for multiprocessor systems have attracted consider-able attention in recent years. However, the theoretical intricateness of scheduling pe-riodic tasks raises a controversial trade-off that improving a system utilization withguaranteeing timing constraints of periodic tasks leads tomore task preemptions andmigrations. In addition, the subject of scheduling aperiodic tasks has not been consid-ered very much. The research established herein considers the efficient scheduling ofboth periodic and aperiodic tasks on multiprocessor systems.
The dissertation first presents the portioned scheduling technique for improving theschedulability to periodic tasks with a small number of taskpreemptions and migra-tions. Like the traditional partitioned scheduling, most of tasks are scheduled on ded-icated processors with no migrations, however the portioned scheduling differs in thatspecial tasks are permitted to migrate within the restricted range. The RMDP algorithmis developed for the discipline of static-priority scheduling, in which the traditional RateMonotonic algorithm is combined with the portioned scheduling. The EDDHP algo-rithm is then devised for the discipline of dynamic-priority scheduling, in which thetraditional Earliest Deadline First algorithm is combined. Finally, the EDDP algorithmis invented by extending the prioritization policy of the EDDHP algorithm to improvethe worst-case system utilization with a guarantee of timing constraints.
The dissertation also presents the global dispatch technique and the temporal migra-tion technique for enhancing the responsiveness to aperiodic tasks without jeopardizingperiodic timing constraints. An aperiodic task is dispatched to a processor on which theresponse time is estimated to be minimized, and then periodic tasks with higher priori-ties are temporarily migrated onto different processors to moreover reduce the responsetime. The design of the traditional Priority Exchange algorithm and the Total Band-width Server algorithm is considered, in which the presented techniques are applied.
Beyond the theoretical analysis for the worst case, the effectiveness of the developedscheduling algorithms for general cases is also studied by several sets of simulations.
iv

Contents
1 INTRODUCTION 11.1 Multiprocessor Systems . . . . . . . . . . . . . . . . . . . . . . . . . . 41.2 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.3 Research Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.4 Organization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2 STATE OF THE ART 132.1 Classification of Scheduling Principles . . . . . . . . . . . . .. . . . . 132.2 Scheduling Algorithms . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.2.1 Pure RM and EDF . . . . . . . . . . . . . . . . . . . . . . . . 162.2.2 Partitioned Scheduling Approach . . . . . . . . . . . . . . . . 172.2.3 Global Scheduling Approach . . . . . . . . . . . . . . . . . . . 192.2.4 Another Scheduling Approach . . . . . . . . . . . . . . . . . . 23
2.3 Server Algorithms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252.3.1 Uniprocessor Approach . . . . . . . . . . . . . . . . . . . . . 252.3.2 Multiprocessor Approach . . . . . . . . . . . . . . . . . . . . . 27
2.4 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3 SYSTEM MODEL 303.1 Processor Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 303.2 Task Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4 PERIODIC TASK SCHEDULING 334.1 Basic Strategy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 344.2 The RMDP algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.2.1 Task Assigning Phase . . . . . . . . . . . . . . . . . . . . . . 364.2.2 Task Scheduling Phase . . . . . . . . . . . . . . . . . . . . . . 404.2.3 Schedulability Analysis . . . . . . . . . . . . . . . . . . . . . 44
4.3 The EDDHP algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . 554.3.1 Task Assigning Phase . . . . . . . . . . . . . . . . . . . . . . 554.3.2 Task Scheduling Phase . . . . . . . . . . . . . . . . . . . . . . 574.3.3 Schedulability Analysis . . . . . . . . . . . . . . . . . . . . . 57
v

CONTENTS
4.3.4 Improving Schedulable Utilization . . . . . . . . . . . . . . .. 644.4 The EDDP algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
4.4.1 Task Assigning Phase . . . . . . . . . . . . . . . . . . . . . . 674.4.2 Task Scheduling Phase . . . . . . . . . . . . . . . . . . . . . . 694.4.3 Schedulability Analysis . . . . . . . . . . . . . . . . . . . . . 714.4.4 Improving Schedulable Utilization . . . . . . . . . . . . . . .. 75
4.5 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
5 APERIODIC TASK SCHEDULING 775.1 Basic Strategy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 785.2 The PE-based Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . 80
5.2.1 Priority Exchange Review . . . . . . . . . . . . . . . . . . . . 805.2.2 Global Dispatch Procedure . . . . . . . . . . . . . . . . . . . . 825.2.3 Temporal Migration Procedure . . . . . . . . . . . . . . . . . . 83
5.3 The TBS-based Algorithm . . . . . . . . . . . . . . . . . . . . . . . . 865.3.1 Total Bandwidth Server Review . . . . . . . . . . . . . . . . . 865.3.2 Global Dispatch Procedure . . . . . . . . . . . . . . . . . . . . 875.3.3 Temporal Migration Procedure . . . . . . . . . . . . . . . . . . 87
5.4 Compatibility to Portioned Scheduling . . . . . . . . . . . . . .. . . . 915.5 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
6 PERFORMANCE EVALUATION 946.1 Simulation Studies for Periodic Task Scheduling . . . . . .. . . . . . . 94
6.1.1 Experimental Setup . . . . . . . . . . . . . . . . . . . . . . . . 956.1.2 Simulation Results of Static-Priority Scheduling . .. . . . . . 966.1.3 Simulation Results of Dynamic-Priority Scheduling .. . . . . . 105
6.2 Simulation Studies for Aperiodic Task Scheduling . . . . .. . . . . . . 1146.2.1 Experimental Setup . . . . . . . . . . . . . . . . . . . . . . . . 1146.2.2 Simulation Results of Static-Priority Scheduling . .. . . . . . 1166.2.3 Simulation Results of Dynamic-Priority Scheduling .. . . . . . 122
6.3 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
7 CONCLUSION 1337.1 Summary of Contributions . . . . . . . . . . . . . . . . . . . . . . . . 1337.2 Future Directions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
vi

List of Figures
1.1 Problematic scheduling onM processors . . . . . . . . . . . . . . . . . 8
2.1 Global scheduling approach . . . . . . . . . . . . . . . . . . . . . . . 142.2 Partitioned scheduling approach . . . . . . . . . . . . . . . . . . .. . 152.3 Partitioning problem . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.4 Pfair windows of task with utilization 8/11 . . . . . . . . . . . . . . . 202.5 RM-US scheduling example . . . . . . . . . . . . . . . . . . . . . . . 212.6 EDZL scheduling example . . . . . . . . . . . . . . . . . . . . . . . . 222.7 LNREF scheduling example . . . . . . . . . . . . . . . . . . . . . . . 232.8 EKG scheduling example . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.1 Periodic task model . . . . . . . . . . . . . . . . . . . . . . . . . . . . 313.2 Aperiodic task model . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.1 Portioning example . . . . . . . . . . . . . . . . . . . . . . . . . . . . 344.2 Portioned scheduling example . . . . . . . . . . . . . . . . . . . . . .354.3 RMDP assigning algorithm . . . . . . . . . . . . . . . . . . . . . . . . 374.4 rmdp_boundfunction . . . . . . . . . . . . . . . . . . . . . . . . . . . 384.5 RMDP assigning example . . . . . . . . . . . . . . . . . . . . . . . . 394.6 RMDP scheduling algorithm . . . . . . . . . . . . . . . . . . . . . . . 414.7 Job finishing functions . . . . . . . . . . . . . . . . . . . . . . . . . . 424.8 RMDP scheduling example . . . . . . . . . . . . . . . . . . . . . . . . 434.9 Preemption-cared RMDP scheduling example . . . . . . . . . . .. . . 434.10 Case in whichτ′′s is executed twice withinT1 andTn . . . . . . . . . . . 464.11 Case in whichτ′′s is executed three times withinT1 andTn . . . . . . . . 484.12 Case in whichτ′′s is executed twice withinT1 and three times withinTn . 504.13 EDDHP assigning algorithm . . . . . . . . . . . . . . . . . . . . . . . 564.14 eddhp_boundfunction . . . . . . . . . . . . . . . . . . . . . . . . . . 574.15 EDDHP scheduling algorithm . . . . . . . . . . . . . . . . . . . . . . 584.16 Unfeasible EDDHP scheduling . . . . . . . . . . . . . . . . . . . . . .594.17 Worst-case phasing of EDDHP scheduling . . . . . . . . . . . . .. . . 614.18 Absolute worst-case phasing of EDDHP scheduling . . . . .. . . . . . 634.19 MB heuristic . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
vii

LIST OF FIGURES
4.20 AIB heuristic . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 654.21 EDDP assigning algorithm . . . . . . . . . . . . . . . . . . . . . . . . 684.22 EDDP scheduling example . . . . . . . . . . . . . . . . . . . . . . . . 694.23 Latest completion of EDF scheduling . . . . . . . . . . . . . . . .. . 704.24 Latest completion of EDDP scheduling . . . . . . . . . . . . . . .. . 704.25 EDDP scheduling algorithm . . . . . . . . . . . . . . . . . . . . . . . 724.26 Case in whichτ′′i consumes the most time . . . . . . . . . . . . . . . . 73
5.1 Concept of global dispatch . . . . . . . . . . . . . . . . . . . . . . . . 785.2 Concept of temporal migration . . . . . . . . . . . . . . . . . . . . . .795.3 Priority Exchange example . . . . . . . . . . . . . . . . . . . . . . . . 815.4 Total Bandwidth Server example . . . . . . . . . . . . . . . . . . . . .865.5 Total Bandwidth Server with Temporal Migration example. . . . . . . 89
6.1 Success ratio (M = 4,Umin = 0.01,Umax= 0.5). . . . . . . . . . . . . . 976.2 Success ratio (M = 8,Umin = 0.01,Umax= 0.5). . . . . . . . . . . . . . 976.3 Success ratio (M = 16,Umin = 0.01,Umax= 0.5). . . . . . . . . . . . . 986.4 Success ratio (M = 4,Umin = 0.01,Umax= 1.0). . . . . . . . . . . . . . 986.5 Success ratio (M = 8,Umin = 0.01,Umax= 1.0). . . . . . . . . . . . . . 996.6 Success ratio (M = 16,Umin = 0.01,Umax= 1.0). . . . . . . . . . . . . 996.7 The number of preemptions (M = 4,Umin = 0.01,Umax= 0.5). . . . . . 1016.8 The number of preemptions (M = 8,Umin = 0.01,Umax= 0.5). . . . . . 1016.9 The number of preemptions (M = 16,Umin = 0.01,Umax= 0.5). . . . . . 1026.10 The number of preemptions (M = 4,Umin = 0.01,Umax= 1.0). . . . . . 1026.11 The number of preemptions (M = 8,Umin = 0.01,Umax= 1.0). . . . . . 1036.12 The number of preemptions (M = 16,Umin = 0.01,Umax= 1.0). . . . . . 1036.13 Success ratio (M = 4,Umin = 0.01,Umax= 0.5). . . . . . . . . . . . . . 1066.14 Success ratio (M = 8,Umin = 0.01,Umax= 0.5). . . . . . . . . . . . . . 1066.15 Success ratio (M = 16,Umin = 0.01,Umax= 0.5). . . . . . . . . . . . . 1076.16 Success ratio (M = 4,Umin = 0.01,Umax= 1.0). . . . . . . . . . . . . . 1076.17 Success ratio (M = 8,Umin = 0.01,Umax= 1.0). . . . . . . . . . . . . . 1086.18 Success ratio (M = 16,Umin = 0.01,Umax= 1.0). . . . . . . . . . . . . 1086.19 The number of preemptions (M = 4,Umin = 0.01,Umax= 0.5). . . . . . 1106.20 The number of preemptions (M = 8,Umin = 0.01,Umax= 0.5). . . . . . 1106.21 The number of preemptions (M = 16,Umin = 0.01,Umax= 0.5). . . . . . 1116.22 The number of preemptions (M = 4,Umin = 0.01,Umax= 1.0). . . . . . 1116.23 The number of preemptions (M = 8,Umin = 0.01,Umax= 1.0). . . . . . 1126.24 The number of preemptions (M = 16,Umin = 0.01,Umax= 1.0). . . . . . 1126.25 Mean response time for PE-GD (µ = 0.1). . . . . . . . . . . . . . . . . 1176.26 Mean response time for PE-GD (µ = 0.2). . . . . . . . . . . . . . . . . 1176.27 Mean response time for PE-GD-TM (M = 4, µ = 0.1). . . . . . . . . . . 1196.28 Mean response time for PE-GD-TM (M = 8, µ = 0.1). . . . . . . . . . . 1196.29 Mean response time for PE-GD-TM (M = 16, µ = 0.1). . . . . . . . . . 120
viii

LIST OF FIGURES
6.30 Mean response time for PE-GD-TM (M = 4, µ = 0.2). . . . . . . . . . . 1216.31 Mean response time for PE-GD-TM (M = 8, µ = 0.2). . . . . . . . . . . 1216.32 Mean response time for PE-GD-TM (M = 16, µ = 0.2). . . . . . . . . . 1226.33 Mean response time for TBS-GD (µ = 0.1). . . . . . . . . . . . . . . . 1236.34 Mean response time for TBS-GD (µ = 0.2). . . . . . . . . . . . . . . . 1236.35 Mean response time for TBS-GD-TM (M = 4, µ = 0.1). . . . . . . . . . 1256.36 Mean response time for TBS-GD-TM (M = 8, µ = 0.1). . . . . . . . . . 1256.37 Mean response time for TBS-GD-TM (M = 16, µ = 0.1). . . . . . . . . 1266.38 Mean response time for TBS-GD-TM (M = 4, µ = 0.2). . . . . . . . . . 1266.39 Mean response time for TBS-GD-TM (M = 8, µ = 0.2). . . . . . . . . . 1276.40 Mean response time for TBS-GD-TM (M = 16, µ = 0.2). . . . . . . . . 1276.41 Mean response time for TBS-TM (M = 4, µ = 0.1). . . . . . . . . . . . 1286.42 Mean response time for TBS-TM (M = 8, µ = 0.1). . . . . . . . . . . . 1286.43 Mean response time for TBS-TM (M = 16, µ = 0.1). . . . . . . . . . . 1296.44 Mean response time for TBS-TM (M = 4, µ = 0.2). . . . . . . . . . . . 1296.45 Mean response time for TBS-TM (M = 8, µ = 0.2). . . . . . . . . . . . 1306.46 Mean response time for TBS-TM (M = 16, µ = 0.2). . . . . . . . . . . 130
ix

Chapter 1
INTRODUCTION
The 21st century is an era of information and intelligence. We human beings expect asafe and secure lifestyle constructed by an intelligent social infrastructure. To this end,the mission imposed to us is to benefit properly from the experiences of the informationtechnology that has been seeing rapid development since the1990s, and then deserve anew look from the various points of view. The social infrastructure is such a complexsystem that supports our entire life. All nations around theworld have already launcheda study of new technologies, including embedded computing,ubiquitous computing,cyber-physical computing, etc. for the sake of the next generation society.
Most of the computing systems that will construct the intelligent social infrastruc-ture, so-called intelligent systems, are at the same time real-time systems. The pri-mary reason why the intelligent systems are real-time systems is that they operateautonomously in our real world, while the computing systemsproduced in the 20thcentury, such as personal computers and workstations, are mainly operated by humans.The intelligent systems are for instance that embedded computers and networks mon-itor and control physical processes, usually with feedbackloops where the physicalprocesses affect computations and vice versa. Since the physical processes in the realworld occur in the real time, the intelligent systems must react to stimuli with timingconstraints.
The real-time systems are technically characterized by thefact that they requiretemporal correctness as well as logical correctness. In other words, the correctnessof the systems depends on not only the computational resultsbut also the time whenthey are produced. More precisely, every real-time computation must complete in aninterval of certain length. The beginning of the interval iscalledrelease timeand theend is calleddeadline. There are mainly two types of deadlines depending on whatcould happen if a deadline is missed. The deadline is definedhard if the contributionto the system suddenly drops to zero due to a deadline miss. Onthe other hand, thedeadline is definedsoft if the contribution to the system does not suddenly becomeszero but gradually degrades as the completion time is further delayed from a deadline.For instance, robot systems have hard deadlines for their control. A catastrophe may
1

CHAPTER 1. INTRODUCTION
occur if actuators cannot complete processing sensor data within a certain feedbackperiod. Meanwhile, multimedia systems often have soft deadlines for image and au-dio processing, because the systems are able to continue to provide a service to userseven if some computations miss their deadlines, though the quality of service may de-grade compared to the case in which all computations meet their deadlines. In order tomaintain substantial quality, deadlines should not be missed even in soft real-time sys-tems. Most of commercial real-time systems have soft deadlines. In other words, mostof commercial real-time systems are not able to guarantee that all deadlines are met,because the theoretical aspect of real-time computing is not likely to be considered.The research established herein targets a theory to accomplish hard real-time systemswhere all deadlines are guaranteed to be met. Such a theory also supports soft real-timesystems in terms of the quality of service.
The question here is, how is real-time computing made possible? A huge amount ofresearch has been conducted for a long time to explore the answer to this question. Thefirst, and probably the greatest, contribution was a development of a real-time compu-tation model by Liu and Layland in 1973 [1]. Most of real-timecomputing techniquestoday have their bases on the Liu and Layland model. This classical computation modelpresumes that a task, a unit of required computations, is invoked at every certain inter-val calledperiod. A computation of the task in each period is often called ajob. Everyjob is assumed to have the same cost of execution and have the relative deadline equalto the period of the task. In other words, every job of the taskmust be completed beforethe next job of the task arrives. Other assumptions are: an execution time of a task isfixed; all jobs are independent; no resource or precedence constraint exists; no compu-tation suspends itself; and a job can be preempted at any moment, which means that ajob can be interrupted immediately upon a request to executeanother job and then beresumed some time after that.
Liu and Layland also focused on the scheduling of recurrent tasks so that all thejobs meet their deadlines under the assumptions described above. The scheduling withsuch timing constraints is widely calledreal-time schedulingnowadays. They thendeveloped two real-time scheduling algorithms: Rate Monotonic (RM) and EarliestDeadline First (EDF). Almost all real-time scheduling algorithms today are formed byeither of those initiatives. The RM algorithm schedules a task with the shortest periodfirst among all ready tasks. Since the period of a task is fixed in their computationmodel, the priority assignment in the RM algorithm is static. Meanwhile the EDF al-gorithm schedules a task with the earliest absolute deadline first, which implies that thepriority assignment is dynamic. Liu and Layland moreover carried out the theoreticalanalysis for the two algorithms to guarantee that all jobs meet their deadlines. If a taskset is determined to be feasible under a scheduling algorithm, it means that no task inthe set violates its timing constraints under any circumstance [2]. They proved that anyperiodic task set can be scheduled with no deadline misses bythe RM algorithm if thetotal utilization of the periodic task set is less than or equal to the following expression
2

CHAPTER 1. INTRODUCTION
whereN denotes the number of the periodic tasks.
N(21/N − 1) (1.1)
They also proved that any periodic task set can be scheduled with no deadline misses bythe EDF algorithm if the total utilization of the periodic task set is less than or equal to 1regardless the number of the periodic tasks, which means that the EDF algorithm is ca-pable of utilizing 100% of processor capacity without any timing violations. Ever sincethese two algorithms are invented, there have been a considerable number of argumentson which algorithm performs better in what conditions, someof which are summarizedby Buttazzo [3]. The broad consensus of the real-time computing community is forinstance that the RM algorithm has more predictability thanthe EDF algorithm due tothe characteristic of its static-priority assignment, while the EDF algorithm can achievehigher processor utilization with guaranteeing timing constraints in many cases. Sincethe two algorithms both have advantages, the superiority ofeach algorithm depends onthe requirement of the system. Even in recent years, the theory of the two algorithmshas been widely discussed and improved [4, 5, 6, 7].
Over the years, real-time systems have mainly focused on theperiodic computationmodel advocated by Liu and Layland. In fact, many types of control and multimediaapplications are covered by the periodic computation model. The scheduling of suchperiodic tasks has therefore been the subject of research onreal-time systems for a longtime. However, intelligent systems require more complex computation model. Forinstance, robot systems must operate in dynamic environments where human activitiesor physical processes occur at any moment. In such a case, some tasks may arriveaperiodically, and their arrival times are not known a priori. Most of thoseaperiodicrequests are desired to complete as soon as possible, while they usually have no criticaltiming constraints. Consider a speech recognition in robotsystems. When humansspeak to a robot, they expect the robot to respond quickly. Toachieve this, a systemneeds to reduce the response time of aperiodic tasks as much as possible in addition tosatisfying timing constraints of periodic tasks.
The most straightforward method for the scheduling of aperiodic tasks is to allocateavailable time slots that are left unused by periodic tasks.This kind of backgroundscheduling can be simply applied to the classical Liu and Layland model, since peri-odic tasks are never interfered by aperiodic tasks. However, a good responsiveness isnever attained by the background scheduling. In order to overcome the responsivenessissue of real-time scheduling, Lehoczkyet al. invented the server technique [8]. Theserver approach creates a special periodic task calledserverwhose purpose is to serviceaperiodic requests as soon as possible. Like any periodic task, a server is characterizedby a period and a fixed execution time called server capacity.The server is scheduledaccording to the same algorithm used for the periodic tasks,and, once active, it servesthe aperiodic requests within the limit of its server capacity. Having a basis on such aserver approach, a large number of efficient server algorithms have been presented forboth the discipline of static-priority scheduling and the discipline of dynamic-priority
3

CHAPTER 1. INTRODUCTION
scheduling [9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]. Compared to background schedul-ing where aperiodic tasks consumes time slots that are left unused by periodic tasks,the server algorithms reduce the response time of aperiodictasks dramatically. Contro-versially, they have pros and cons in terms of performance and complexity.
Adopting the priority-driven scheduling with server approaches, modern real-timesystems realize a guarantee of timing constraints as well asan enhancement of respon-siveness. Ever since such a basis of the scheduling model wasestablished, the real timecomputing community has moreover developed a lot of optional techniques, such assynchronization [20, 21], resource reservation [22, 23], adaptive computing [24, 25],dynamic voltage and frequency scaling [26, 27], and so on. Those techniques makesystems more reliable, dependable, and flexible. Far too many novel techniques to de-scribe here have been devised. Thus, today’s theoretical aspects of real-time computingfor uniprocessor systems are appreciably powerful.
In recent years, seeing performance limitations of uniprocessor platforms, high per-formance real-time computing has relied on a power of multiprocessor platforms. Withthe trend towards multicore architectures, kinds of multiprocessor systems are likely tobecome much more common for the next generation applications. The real-time com-puting community has been therefore challenging a domain ofmultiprocessor systems.Unfortunately, the conventional scheduling techniques are of no use due to the propertyof concurrency on multiprocessor systems. During the last decade, researchers havejust begun to understand the problematic scheduling of periodic tasks on multiproces-sor systems. This fact implies that the scheduling of aperiodically-arriving tasks onmultiprocessor systems is also controversial, because it definitely relies on the schedul-ing of periodic tasks. The motivation of this research exists here.
1.1 Multiprocessor Systems
Before moving on the problem definitions of multiprocessor real-time scheduling, thedissertation ought to explicit the reason why multiprocessor systems have received con-siderable attention in recent years, and also describe the background how the need formultiprocessor systems has arisen. The followings are the historical reviews of com-puter technologies.
Computer technology has made incredible progress for more than forty years fol-lowing the Moore’s Law [28], advocated in 1965, which the number of transistors thatcould be integrated into a single silicon chip would approximately double every 18 to24 months. During that time, increases in transistor density have driven roughly pro-portional increases in processor performance and price/performance. However, thoseperformance gains did not come about solely because of increasing transistor densi-ties. They have also relied heavily on another physical factor that is closely related totransistor size: processor clock frequency.
In general, as transistors get smaller, they can switch faster between one state and
4

CHAPTER 1. INTRODUCTION
another. This has allowed designers to continually increase processor clock frequenciesat the same time they have increased the total number of transistors. In many ways,increases in clock frequency have been more important than increases in density. Ittakes a great deal of engineering ingenuity to make efficient use of more transistors.Frequency gains, on the other hand, deliver instant and easily realizable performancebenefits. Existing software code runs faster, without requiring software engineers torevise or optimize their code. This has been a central fact ofthe computing industry formany years, and a great boon to business users.
Given this advantage, it is not surprising that frequency ramp has long been the pri-mary engine behind processor performance gains. The first Intel processor released in1971 and ran at 400 KHz. Today, some Intel processors supportclock speeds that arenearly ten thousand times as fast. Moore’s Law continues today and can be expected todeliver increasing transistor densities for at least several more generations. However,in recent years, the frequency ramp has faced mounting obstacles. Power consumptionand heat generation rise exponentially with clock frequency. Especially in the field ofembedded computers, those issues are very critical. Even inthe field of personal com-puters and workstations, system integrators devote considerable engineering resourcesto optimizing power and cooling systems to avoid overheating, which can dramaticallyreduce component longevity. For this reason, increasing clock frequency is no longerviable as the primary means for boosting processor performance. Clock frequencieswill continue to rise, but only incrementally. In consequence, the necessity of newstrategies from the viewpoint of microarchitectural techniques have arisen to maintainhistoric rates of performance and price/performance improvement.
Most of recent computers seeking throughput exploits instruction-level parallelism(ILP). With ILP, the processor dynamically evaluates software code streams to deter-mine which instructions are independent and can be safely processed simultaneously orout of order. If one instruction is waiting for data, the processor can then execute an in-dependent instruction to stay productive. This strategy has been increasingly importantas processor speed has outstripped memory speed. Today, a processor can wait throughhundreds of clock cycles if it has to retrieve data or instructions from main memory,which decreases the value of rising frequencies.
Over the years, processor designers have invested heavily in optimizing ILP to re-duce the impact of memory wait times. However, it takes a lot of complex, high-speedtransistor logic to examine software code during runtime, find opportunities for ILP,and reschedule the software code accordingly. For this reason, ILP is very resourceintensive, and accounts for considerable energy consumption and heat generation intoday’s processors. Like the ramp of processor clock frequency, it has reached a pointof diminishing returns. Such a performance limitation of ILP signals a historic switchfrom relying solely on ILP to thread-level parallelism (TLP) to gain further perfor-mance improvement. Whereas ILP tries to find the parallelismwithin one thread, TLPdoes from multiple threads. Hence the processor can processmore than one thread si-multaneously by interleaving the code streams. Since a single thread rarely uses all of
5

CHAPTER 1. INTRODUCTION
hardware resources, this enables greater processing efficiency and greater total through-put for multi-threaded applications.
ILP and TLP are not exclusive. Simultaneous multithreading(SMT) [29, 30] is atechnique that exploits both ILP and TLP. Hyperthreading [31] implemented in the In-tel’s processors is one of SMT derivations. SMT processors fetch and issue instructionsto functional units simultaneously from multiple threads.This creates horizontal andvertical sharing of resources within a core, which increases throughput and toleratesprocessor and memory latencies to increase processor efficiency. The issue of concernwith SMT is that layout blocks and circuit delays grow fasterthan linear with issuewidth. Besides, multiple threads share the same L1 cache, TLB, and branch predictorunits, hence contentions occur on hardware resources. The resulting increase in cachemisses and branch mispredict rates limits performance. As aresult, SMT will not de-liver the kind of massive performance increases needed to replace the frequency rampas a primary strategy for boosting performance.
The industry’s answer to today’s performance challenges isat this moment to takeadvantage of ongoing increases in transistor density, i.e.Moore’s Law, to integrate moreexecution cores on a processor chip. Such a technique is now widely called chip mul-tiprocessing (CMP) [32]. Similarly but contrary to SMT, CMPenables multiple coresto share more distantly-positioned resources such as memory controller, off-chip band-width, L2 cache, and so on. Other resources are partitioned among cores, namely eachcore has its own resources. CMP is also capable of increasinglayout efficiency, result-ing in more functional units within the same silicon area plus faster clock frequenciesthan SMT due to its simple logic. With multiple cores executing simultaneously, pro-cessor designers can turn down clock frequencies to containpower consumption andheat generation, while still delivering increases in totalthroughput for multithreadedsoftware. Individual threads might be processed slower dueto the lower clock fre-quencies, but total throughput can be dramatically increased. As a matter of practice,multicore processors (chip multiprocessors) are the wave of the future across all com-puting systems.
1.2 Motivation
Embedded computer systems, computers lodged in other devices where the presenceof the computers is not immediately obvious, are the fastest-growing portion of thecomputer market. These devices range from everyday machines (microwaves, wash-ing machines, printers, etc.) to futuristic devices (humanoid robots, intelligent build-ings/automobiles, virtual video game consoles, etc.) in one way or another. Since thosefuturistic systems are at the same time real-time systems, the demands for real-timecomputing are still continuously increasing. Meanwhile, embedded computers are onthe trend of multiprocessor platforms for their requirement of high processing capa-bility with low power consumption. For example, humanoid robots must(i) recognize
6

CHAPTER 1. INTRODUCTION
their states through a bunch of internal and external sensors, (ii) process a variety ofinformation based on the determined modeling,(iii) plan many kinds of actions ac-cording to circumstances, and(iv) actuate a number of modules. A sequence of thosecomputations must be done in the real time. In addition, the computations range fromtasks having feedback intervals of several tens of micro seconds such as current controland PWM control, to ones having feedback intervals of several seconds such as ac-tion planning based on environmental recognition. Humanoid robots are also requiredto operate with a battery for as long as possible, meaning that a processor with fastclock frequency is not preferred in the power consumption point of view, despite therequirement of high processing capability. The multiprocessor technology fulfill therequirements of high processing capability as well as low power consumption by par-allelism. Even if the clock frequency of every individual processor is configured to below for power consumption, the total performance is substantially boosted up by par-allel execution. Thus, the dissertation believes that multiprocessor platforms will benatural choices for humanoid robots.
Humanoid robots have been actually appearing recently. Honda Motor Corporationhas already released a well-known humanoid robot named ASIMO [33]. Sony Cor-poration has also released an entertainment robot QRIO [34]. Hitachi Corporation hasdeveloped EMIEW [35]. National Institution of Advanced Industrial Science and Tech-nology (AIST) has developed sophisticated humanoid robotsHRP-2 [36] and HRP-3[37], and is going for its next version HRP-4 [38]. More recently, Toyota Motor Cor-poration announced their Toyota Partner Robot [39]. Academic institutions have alsopresented fruits of their research. Bischoff et al. developed a wheel-type humanoidrobot HERMES [40]. Kagamiet al. invented a full-type humanoid robot H7 [41]. Un-fortunately, despite thus many requirements, real-time computing and multiprocessorsystems are not easily integrated. Especially, a crucial problem resides in scheduling.
For understanding the problem, an example of schedulingM + 1 periodic taskson M processors according to the RM algorithm is given. LetM tasks, indexed by1, 2, 3, ...,M respectively, have the same periods ofx and the same execution times of2ǫ. Let the remaining one task (this is a problematic task), indexed byM + 1, have aperiod ofx+ǫ and an execution time ofx. Notice that 2ǫ < x. Then, suppose that all thetasks are released at timet = 0. The resulting schedule is illustrated in Figure 1.1. Eachbox is indicative of a task execution. The number indicated within a box is the index ofthe task. TheM tasks whose periods are allx are dispatched in advance according to theRM algorithm. Then, all theM tasks consume 2ǫ time units and complete at timet = 2ǫat the same time. Hence, the problematic task begins execution at timet = 2ǫ on someprocessor. However, the problematic task can never avoid missing its deadline, sinceits execution time isx, which means that its completion time is at the earliest timet =x+2ǫ, whereas its deadline isx+ǫ. Lettingǫ → 0, theM tasks have the zero utilizationbecause their execution times become zero, and the remaining one task, indexed byM+1, has the 100% utilization because its period and executiontime become the same.Therefore, the total utilization of the tasks becomes 100%,namely the utilization of the
7

CHAPTER 1. INTRODUCTION
1
2
3
M + 1
M
Processor 1
Processor M
Processor 3
Processor 2
time0 2 x + 2x +
Figure 1.1: Problematic scheduling onM processors
whole system becomes 1/M×100%. So a deadline can be missed even if only the 1/Mof the system is utilized. Moreover lettingM → ∞, a deadline can be missed even if thesystem utilization is zero. The EDF algorithm also sees the same phenomenon with thesame task set. This phenomenon is often referred to as Dhall’s effect [42]. The Dhall’seffect occurs for the case in which heavy tasks (tasks that have high utilizations) exist.In consequence, the schedulable system utilization for theRM and EDF algorithms arepoorly low on multiprocessor systems in the presence of heavy tasks. Hereinafter theschedulable system utilization is abbreviated asschedulable utilizationfor simplicity ofdescription. The wordschedulabilityis also used to express a degree of the schedulableutilization.
One of the greatest merits of multiprocessor systems is needless to say their par-allelism. The performance of computations is expected to beimproved by executingmultiple tasks simultaneously on more than one processor. However, the traditionalscheduling algorithms that have been devised in the uniprocessor era may miss a dead-line when one of processors is fully utilized even if there are more processors. Thus,multiprocessor systems offer no benefits in terms of the worst-case schedulable uti-lization. Overcoming the Dhall’s effect requires inventing a new theory of real-timescheduling. Due to the backgrounds described above, real-time scheduling techniquesfor multiprocessor systems, which are qualified for achieving high schedulable utiliza-tions, have attracted considerable attention in recent years. As the situation now stands,though a lot of scheduling algorithms specific for multiprocessor systems have been de-
8

CHAPTER 1. INTRODUCTION
veloped, the theoretical intricateness of scheduling periodic tasks raises a controversialtrade-off that improving a system utilization with guaranteeing timing constraints of pe-riodic tasks leads to more task preemptions and migrations.Such a trade-off betweenschedulability and complexity has aggrieved the developedscheduling algorithms. So-lutions are still widely discussed. Since a basis of periodic task scheduling has notbeen strongly established yet, very little attention has been on the scheduling of aperi-odic tasks on multiprocessor systems.
This research is originally motivated by the controversialtrade-off between schedu-lability and complexity. In general, the traditional approaches aim to accomplish eitheran optimality or a practicality. The optimal approaches areliterally able to achievea system utilization of 100% in theory but may observe performance degradation inpractice due to complex computations. On the other hand, thepractical approaches areimplementable in practice but have potential limits in performance. Solving this trade-off requires establishing a good balancing point that offers both sufficient performanceand practical implementation. Thus, the dissertation considers a distinguished approachto establish such a good balancing point for the efficient scheduling of periodic tasks.This research is also motivated by the poverty of aperiodic task scheduling on multi-processor systems. Exploiting the advantage of parallel execution, the responsivenessto aperiodic tasks must be able to improve. The dissertationhence presents the efficientscheduling of aperiodic tasks on multiprocessor systems.
1.3 Research Overview
The goal of this research is to increase the total utilization of periodic tasks and to re-duce the response time of aperiodic tasks as much as possible, in addition to a guaranteeof timing constraints, on multiprocessor systems for embedded computers. Attainingthis goal allows constructing embedded multiprocessor systems that can provide high-performance real-time and responsive computing with low power consumption. There-fore, it contributes to a part of intelligent systems.
To achieve this goal, the research established herein considers the efficient schedul-ing of both periodic and aperiodic tasks on multiprocessor systems. For practical use,the approaches are retained elementary. The thesis established by this research is:
The migrative scheduling improves the schedulability to periodic tasks aswell as the responsiveness to aperiodic tasks, without causing complexcomputations and a lot of task preemptions.
In particular, this research makes contributions of theoretical significance as follows.
• A scheduling technique for the scheduling of periodic taskson multiprocessorsystems is proposed to overcome the trade-off between schedulability and com-plexity. The scheduling policy allows the selected tasks tomigrate among pro-cessors to improve schedulable utilization but limits a degree of the migrations to
9

CHAPTER 1. INTRODUCTION
retain acceptable computation complexity. More specifically, each of the selectedtasks is permitted to migrate between restrictive two processors and the othertasks are scheduled on dedicated processors with no migrations. This approachgives a breakthrough to the problematic scheduling on multiprocessor systems.Three scheduling algorithms are developed based on the proposed schedulingtechnique. One is designed for the discipline of static-priority scheduling andthe other two are for the discipline of dynamic-priority scheduling. Since bothdisciplines have pros and cons, system designers can choosewhich algorithm issuitable for the constructing system.
– The static-priority scheduling algorithm has its basis on the RM algorithmand exploits the notion of the proposed scheduling technique. The algorithmis not capable of improving the worst-case bound on schedulable utilizationover 50%, but it can improve schedulable utilization in general cases, com-pared to the traditional static-priority scheduling algorithms that have beendeveloped in prior work. In addition, the algorithm does notgenerate asmany task preemptions as the traditional ones.
– The dynamic-priority scheduling algorithms have their bases on the EDFalgorithm. The first algorithm is designed by applying the dynamic-priorityassignments to the static-priority scheduling algorithm stated above. Thealgorithm is also not capable of improving the worst-case utilization boundover 50%, but it can usually achieve higher schedulable utilization in prac-tice. Several dynamic-priority scheduling algorithms that have been devisedin prior work have greater utilization bounds than 50%, however those al-gorithms generally cause more task preemptions due to complex compu-tations. The second algorithm can even improve the worst-case utilizationbound up to 65%. To the best of my knowledge, no traditional algorithms,except for optimal ones that generate a great number of task preemptionsand migrations, have ever achieved utilization bounds over65%.
All the three algorithms are designed with concerning the practicality. They havethe almost same computation complexities as the RM and EDF algorithms. Thetheoretical superiority of the algorithms in the worst caseis presented in schedu-lability analysis. In addition, the performance advancement of the algorithms ingeneral cases are validated by several sets of simulation studies.
• Two techniques for the scheduling of aperiodic tasks on multiprocessor systemsare proposed to reduce the mean response time. The first technique dispatches anarriving aperiodic tasks to a processor on which the response time is estimatedto be minimized. The second technique makes efficient use of task migrations.More precisely, periodic tasks with higher priorities thanthe dispatched aperiodictask are temporarily migrated onto different processor to hand over processor
10

CHAPTER 1. INTRODUCTION
time to the pending aperiodic tasks, as long as the periodic tasks are guaranteedto meet their deadlines after migrations. Since aperiodic tasks obtain additionalprocessor times, their response time are expected to be reduced. Two serveralgorithms are designed, in which the proposed techniques are exploited undertwo priority disciplines.
– The static-priority server algorithm is designed based on the traditional Pri-ority Exchange algorithm [8] to work with RM scheduling. ThePE algo-rithm is known to be efficient in terms of performance and simplicity inthe domain of uniprocessor systems. Applying the proposed techniques tothe PE algorithm, the response time of aperiodic tasks can bedramaticallyreduced, compared to the pure PE algorithm.
– The dynamic-priority server algorithm is designed based onthe traditionalTotal Bandwidth Server (TBS) algorithm [16, 17] to perform with EDFscheduling. In addition to the fact that the TBS algorithm has been knownto be the most efficient in the traditional server algorithms developed in thedomain of uniprocessor systems, its characteristics are more suitable for theproposed techniques. Therefore, the potential performance of the algorithmis promising when the proposed techniques are combined.
The proposed techniques are able to be combined with the other traditional serveralgorithms. However, the dissertation believes that the PEalgorithm and the TBSalgorithm are the most suitable for the proposed techniques. The designs of thePE-based algorithm and the TBS-based algorithm, in which the proposed tech-niques are exploited, are also compatible to the schedulingalgorithms developedin this research, though the theoretical description of thealgorithms is based onthe traditional RM algorithm and EDF algorithm for simplicity. The algorithmshave chances to generate an additional task migration only when an aperiodictask arrives at the system. Thus, the prospective runtime overhead is not going tomatter as much. The theoretical superiority of the algorithms is presented throughsome examples. The practical performance of the algorithmsis validated throughseveral sets of the simulation studies.
The target area of real-time systems is extensive. Even within a humanoid robot,various types of tasks are submitted. For instance, the required performance of I/Ocontrol tasks is totally different from that of multimedia tasks. In general, the I/Ocontrol tasks have severe restrictions: deadlines are hardin a true sense, periodic jittersare not tolerated, computations are not preemptive and migrative, and so on. Suchtypes of tasks are usually scheduled in a simple manner. Thus, the target real-timecomputing of this research is limited to less-restricted computations. More specifically,real-time applications that require high schedulability and high responsiveness, suchas image/audio/speech processing, non-I/O control, action planning, map generation,
11

CHAPTER 1. INTRODUCTION
etc., are targeted in this research. Extensions for more restricted computing are notconsidered in this research, but left for the future work.
Finally, the scope of this research is limited to providing amethodology of schedul-ing periodic and aperiodic tasks on multiprocessor systems. In concrete terms, theresearch focuses on periodic scheduling algorithms and aperiodic server algorithms. Itis not the scope of this research to consider the entire design of the system. It is alsonot the scope of this research to provide optional techniques such as synchronization,resource reservation, adaptive computing, dynamic voltage and frequency, and so on.In addition, this research does not focus on hardware, language, and compiler supportfor real-time computing on multiprocessor systems. In particular, extracting appropri-ate time attributes such as the worst case execution time from programs, or developinga method that facilitates its precise estimation is out of concern in this research.
1.4 Organization
The rest of the dissertation is organized as follows. Chapter 2 summarizes the stateof the art techniques related to real-time scheduling on multiprocessor systems. Thetechniques are summarized in terms of performance and complexity. Chapter 3 definesthe system model of this research. Notice that the effectiveness of the scheduling tech-niques established in this research is not necessarily limited to on the defined systemmodel. Chapter 4 presents a new technique for the schedulingof periodic tasks on mul-tiprocessor systems. Three algorithms are developed basedon the presented schedulingtechnique. The schedulability analysis is also provided toderive the schedulable con-dition and the worst-case theoretical utilization bounds for the algorithms. In addition,several heuristic techniques are introduced to improve theschedulability of the algo-rithms in general cases. Chapter 5 presents two new techniques for the schedulingof aperiodic tasks on multiprocessor systems. Two server algorithms are consideredso that the presented techniques are exploited. The discussion of heuristic techniquesis given to improve the responsiveness of the algorithms. Chapter 6 evaluates the ef-fectiveness of the developed algorithms through simulation studies by comparing withthe traditional scheduling algorithms and server algorithms. Chapter 7 concludes thedissertation and gives insights to the future directions ofthis research.
12

Chapter 2
STATE OF THE ART
This chapter presents a survey on the state of the art techniques for the scheduling ofperiodic tasks on multiprocessor systems. The servery is conducted from the viewpointof improving system utilization of periodic tasks with a guarantee of timing constraints.Meanwhile, the scheduling of aperiodic tasks has received little attention comparedto the scheduling of periodic tasks in the domain of multiprocessor systems, hencethis chapter also presents a survey on the prior work of aperiodic server techniquesfor uniprocessor systems as well as those for multiprocessor systems. The survey isperformed from the viewpoint of reducing the mean response time of aperiodic tasks.
The survey begins with a classification of real-time scheduling principles for multi-processor systems, which dominates the form of scheduling algorithms. The survey ofscheduling algorithms for multiprocessor systems is givennext to establish the contextof periodic task scheduling. Then, the survey moves on server algorithms for uniproces-sor systems to study bases of aperiodic task scheduling. Forreference, a few extensionsof the server algorithms for multiprocessor systems are also introduced. In the survey,the trade-offs between achievable system utilization with real-time constraints and thecomplexity of the algorithms are discussed. The survey endswith summarizing thetraditional approaches in terms of performance and complexity.
2.1 Classification of Scheduling Principles
Traditionally, there have been two approaches for the real-time scheduling of periodictasks on multiprocessor systems:global schedulingandpartitioned scheduling[43].The form of scheduling algorithms is deeply dependent on which scheduling approachis based. In global scheduling, all eligible tasks are stored in a single priority-orderedqueue; the global scheduler selects for execution the same number of the highest prior-ity tasks as processors from this queue. The relative order of the task priorities variesdepending on which tasks are eligible, hence a task may change a processor to run ev-ery selection; a task may migrate among processors. Unfortunately, using this approach
13

CHAPTER 2. STATE OF THE ART
Figure 2.1: Global scheduling approach
with traditional optimal algorithms for uniprocessor systems, such as the RM algorithmand the EDF algorithm, may result in arbitrarily low system utilization in multiproces-sor systems [42]. However, recent research has overcome this crisis and even producedoptimal methods as stated in the next section.
In partitioned scheduling, on the other hand, each task is assigned to a single pro-cessor on which each of its jobs will be executed, and processors are scheduled inde-pendently. Therefore, a task is executed on a dedicated processor and never migratesamong processors. The main advantage of the partitioned scheduling is that they re-duce a multiprocessor scheduling problem to a set of uniprocessor ones. Unfortunately,the partitioned scheduling has two negative consequences.First, finding an optimalassignment of tasks to processors is a bin-packing problem,which is NP-hard in thestrong sense. Thus, tasks are usually partitioned using suboptimal heuristics. Second,as shown later, task sets exist that are schedulable if and only if tasks are not parti-tioned. Still, the partitioned scheduling approaches are widely used in real systems forsimplicity of computation.
In addition to the above classification in which the scheduling is categorized whetherinter-processor task migration is permitted or not, the conventional classification withrespect to the complexity of the priority assignment schemeis also subsistent. Along
14

CHAPTER 2. STATE OF THE ART
Figure 2.2: Partitioned scheduling approach
the dimension of the priority assignment scheme, scheduling disciplines are categorizedaccording to whether the priority order of tasks is static ordynamic. The two axes ofclassification, the migration-based classification and thepriority-based classification,are orthogonal to one another in the sense that restricting an algorithm along one axisdoes not restrict freedom along the other. Thus, there are atleast four different classesof scheduling algorithms for multiprocessor systems. Mostof scheduling algorithmscan belong to one of the four classes. More probing classification is cataloged in [44].
2.2 Scheduling Algorithms
Ever since Dhall and Liu exposed the problematic behaviors of the RM algorithm andthe EDF algorithm in multiprocessor systems [42], a great number of scheduling algo-rithms specific for multiprocessor systems have been discussed with the bases of boththe partitioned scheduling and the global scheduling. The primary goal of those algo-rithms is to manifest and improve the worst-case achievablesystem utilization at whichall the jobs are guaranteed to meet their deadlines. This worst-case achievable sys-tem utilization with a guarantee that all tasks are schedulable is often calledutilization
15

CHAPTER 2. STATE OF THE ART
bound. Note that, in the optimal case, a task set with the total utilization of tasks up toM is schedulable onM processors, which indicates that the utilization bound is alwaysmaintained to be 100%.
The following sections explain the well-known scheduling algorithms specific formultiprocessor systems. For understanding the worthinessof those algorithms, thecharacteristics and the problems of the RM algorithm and theEDF algorithm in mul-tiprocessor systems are first stated. Thosepure forms of the RM algorithm and theEDF algorithm are categorized into the global scheduling class. Then, the partitionedscheduling approaches, which have been preferred to the global scheduling approachesfor ages in terms of theoretical simplicity, are presented.The explanation finally backsin the sophisticated global scheduling approaches that break through the boundary ofthe partitioned scheduling approaches.
2.2.1 Pure RM and EDF
The dissertation first of all reviews the Dhall’s effect illustrated in Figure 1.1. It occursfor the case in which a system includes heavy tasks. Andersson et al. hence focusedon the schedulability of a system that does not include heavytasks [45]. Accordingto Anderssonet al., a periodic task set is defined to be a light system onM proces-sors, if it satisfies that(i) the utilization of every individual task is less than or equalto M/(3M − 2), and(ii) the total utilization does not exceedM2/(3M − 2). They thenproved that any periodic task set that is a light system onM processors is schedulableby the RM algorithm, if the tasks are all preemptive. Baruah and Goossens claimed thesimilar result that a set of tasks, all with deadline equal toperiod, is guaranteed to beschedulable by the RM algorithm, if(i) the utilization of every individual task is lessthan or equal to 1/3, and(ii) the total utilization does not exceedM/3. Those resultswere generalized by Baker [46] so that a set of periodic tasks, all with deadline equalto period and utilization less than or equal to one, is guaranteed to be schedulable onM processors using the RM algorithm, if the total utilizationof the tasks does not ex-ceedM(1 − Umax)/2 + Umin, whereUmax andUmin are respectively the maximum andminimum utilizations of every individual task. Baker also derived tighter (more pre-cise) schedulability tests for the multiprocessor RM algorithm in exchange for highercomputation orders.
The schedulability of the EDF algorithm for multiprocessorsystems has been pre-cisely clarified in the similar manner to the RM algorithm. Srinivasan and Baruahdefined a periodic task set to be light in the EDF-scheduled system onM processors,if it satisfies that(i) the utilization of every individual task is less than or equal toM/(2M−1), and(ii) the total utilization does not exceedM2/(2M−1). They then provedthat any periodic task set that is light onM processors is scheduled to meet all deadlinesby the EDF algorithm. This analysis was refined by Goossenset al. [47] so that anyperiodic task set which has the total utilization less than or equal toM(1−Umax)+Umax,whereUmax refers to the maximum utilization of every individual task,is guaranteed
16

CHAPTER 2. STATE OF THE ART
to be schedulable by the EDF algorithm. Baker moreover generalized those results andprovided more precise schedulability [48].
2.2.2 Partitioned Scheduling Approach
Recall that, in partitioned scheduling, each task is assigned to a processor on which itwill be exclusively executed. Finding an optimal assignment of tasks to processors isequivalent to a bin-packing problem, which is known to be NP-hard in the strong sense.Several polynomial-time heuristics have been proposed forsolving this problem. Thebin-packing problem is to pack a given set of items with different sizes into a minimumnumber of equal-sized bins. In those heuristics, the utilization of each task, which is theratio of its execution time and its period, is considered to be the size of each item andthe processor capacity, which is the per-processor utilization bound, is considered tobe the size of each bin. Examples include the first-fit (FF) andbest-fit (BF) heuristics.In the FF heuristic, each task is assigned to the first (i.e., lowest-indexed) processorthat can accept the task. On the other hand, in the BF heuristic, each task is assignedto a processor that(i) can accept the task, and(ii) will have minimal remaining sparecapacity after its addition. Whether a processor can accepta task or not depends onthe feasibility test corresponding to the uniprocessor scheduling algorithm being used.The feasibility test is for instance that a task can be appended to a processor if thetotal utilization of the tasks is less than or equal to 1 (100%) in the EDF algorithm orN(21/N − 1) in the RM algorithm whereN is the number of the tasks.
The two RM-based algorithms based on the partitioned scheduling are often re-ferred to. The first one is the RM with FF (RM-FF) algorithm [42] and the second oneis the RM with FF in decreasing utilization (RM-FFDU) algorithm [49]. The FFDUheuristic sorts a task set in decreasing order of task utilization before the FF heuris-tic is applied. It is known that the RM-FFDU algorithm succeeds in assigning moretasks to processors compared to the RM-FF algorithm [50]. Since the performanceof those algorithms highly depends on a feasibility test foreach processor assignment,Burchardet al. proposed new sufficient feasibility tests for RM-scheduled uniprocessorsystems that perform better when task periods satisfy certain relationships [51]. Theyalso proposed new heuristics that attempt to assign tasks satisfying those relationshipsto the same processor, thus leading to better overall utilization. The R-BOUND-MPalgorithm [52] is another efficient algorithm that takes similar schedulability tests andheuristics, in which tasks are initially sorted in order of increasing periods.
Although the scheduling algorithms stated above contributed to RM-based parti-tioned scheduling, no work have derived the absolute schedulability. Oh and Bakerproved that a task set is guaranteed to be schedulable by the RM-FF algorithm if thesystem utilization does not exceed
√2 − 1 ≃ 41% [53]. They also proved that no
partitioned static-priority scheduling algorithms can achieve a utilization bound greaterthan 50%. More recently, because 41% was a lower bound and there was still roomfor improvement, Lopezet al. presented a tighter utilization bound for the RM-FF al-
17

CHAPTER 2. STATE OF THE ART
gorithm by taking into account not only the number of processors but also the numberof tasks and their every individual utilization [54]. Usinga similar technique, Lopezet al. also clarified the utilization bound for the RM-FFDU algorithm in their laterwork [55, 56]. Anderssonet al. considered using the next-fit-ring (NFR) heuristic forthe R-BOUND-MP algorithm instead the FF heuristic [57]. Theutilization bound forthe improved algorithm, called R-BOUND-MP-NFR, was finallyderived to be 50%.Hence, the problem of partitioned static-priority scheduling was closed.
In contrast to a considerable amount of research on the static-priority scheme, therehave been less algorithms proposed for the dynamic-priority scheme of the partitionedscheduling. Lopezet al. showed that the EDF algorithm with the FF (or BF) heuristic,so-called EDF-FF and EDF-BF respectively, can successfully schedule any task setwith total utilization at most ((βM + 1)/(β + 1)) on M processors, whereβ = ⌊1/α⌋andα is the maximum utilization of every individual task [58, 59]. Lettingα = 1 andβ = 1, the worst-case utilization bound of (M+1)/2 is derived. They also demonstratedthat the EDF-BF algorithm offers slightly higher schedulable utilization than the EDF-FF algorithm in most situations. Baruah and Fisher proposedan algorithm that sorts atask set in order of increasing relative deadlines and combined it to the EDF algorithm[60]. To know what kinds of partitioning algorithms are efficient, Baker comparedthree partitioning algorithms from the viewpoint of task sorting methods [61]: the firstalgorithm sorts a task set in order of increasing utilization, the second algorithm does inorder of increasing density, and the third algorithm does inorder of increasing relativedeadline. The density is a ratio of an execution time and the minimum of a period anda relative deadline. The conclusion was that the method of sorting a task set in order ofincreasing density performs slightly better than the othertwo methods.
As stated above, a scheduling problem for multiprocessor systems can be reducedto a set of ones for uniprocessor systems in partitioned scheduling, since after a giventask is assigned and partitioned to processors, every subset of them is scheduled oneach processor independently according to the policy of conventional uniprocessorscheduling. Moreover, the partitioned scheduling often provides good performance,namely it achieves high schedulable utilization, despite its simplicity of algorithm de-sign. Therefore, partitioned scheduling approaches have been preferable for practicaluse. However, they have a critical disadvantage that the worst-case utilization boundis potentially limited to at most 50% regardless the priority assignment schemes. Fig-ure 2.3 depicts an example of such a partitioning problem. Consider thatM + 1 taskshave the same utilizations 1/2+ α%. Since an individual processor cannot be utilizedover 100%, there is no spare room for theM + 1th task in any processor when theMtasks are assigned. Lettingα∞0, a task set with a total utilization over (M + 1)/2 isnever schedulable. They also have online problems that whena new task is submittedto the system at runtime, the tasks may be required to be sorted again to accept the newtask. Such repartitioning can incur significant runtime overhead. Those drawbacks ofthe partitioned scheduling lead to revival of the global scheduling approaches to realizemore sophisticated scheduling of periodic tasks on multiprocessor systems.
18

CHAPTER 2. STATE OF THE ART
Processor 1
Processor M
Processor 3
Processor 2
processor utilization
0% 100%50+ %
Task 1
Task 2
Task 3
Task M
Task M +1
Figure 2.3: Partitioning problem
2.2.3 Global Scheduling Approach
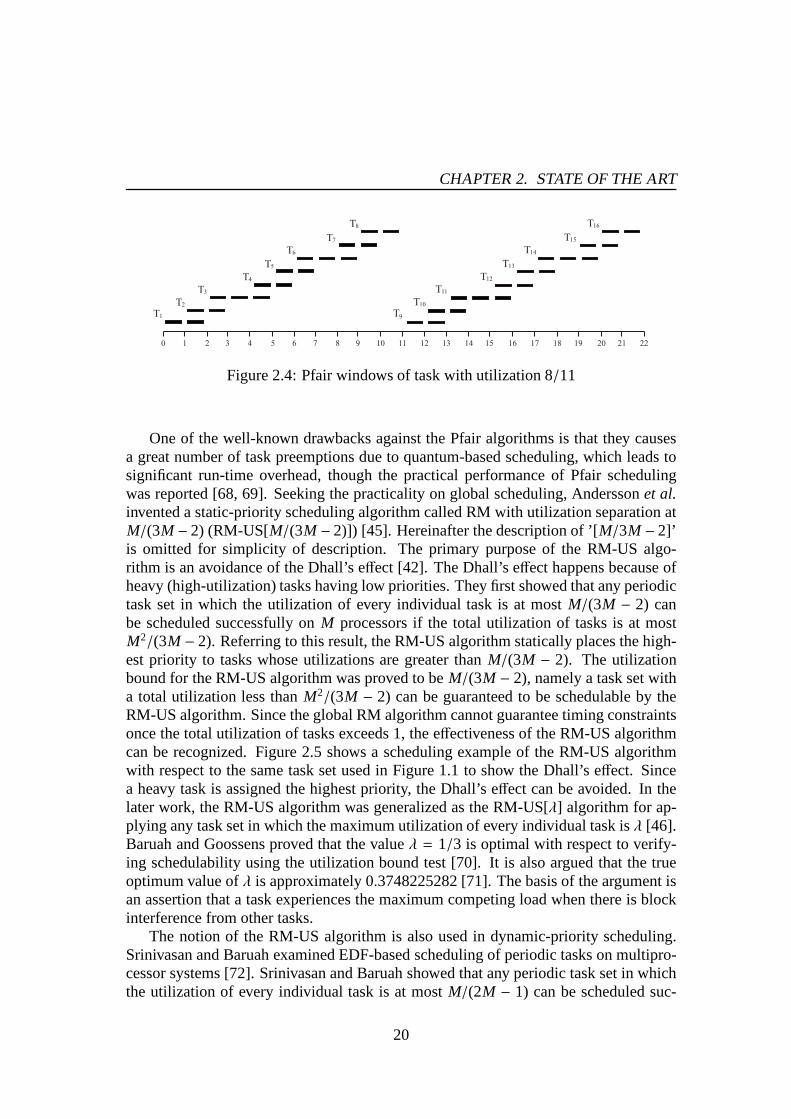
Baruahet al. proposed theproportionate fairness(Pfair) scheduling method that canproduce an optimal periodic execution on multiprocessor systems [62]. In Pfair schedul-ing, each periodic task is divided into quantum-size piecescalled subtasks. LetT bea periodic task and the utilization ofT is U. Let Ti be theith subtask ofT. In Pfairscheduling,Ti has a pseudo release time ofr(Ti) = ⌊(i − 1)/U⌋ and a pseudo deadlineof d(Ti) = ⌈i/U⌉ − 1. Then,Ti must be executed in a window of [r(Ti), d(Ti)]. Hence,T is guaranteed to be executed proportionately. If all the subtasks meet their pseudodeadline, the original task also meets its deadline. Figure2.4 shows Pfair windows of atask with utilization 8/11. Since the task has an execution time of 8 time units, it has8subtasks (windows) with every period 11. The three Pfair algorithms, PF [63], PD [62],and PD2 [64], are known to be optimal under any circumstances. The difference amongthe three algorithms is a rule of breaking ties in pseudo deadlines of subtasks. There isanother Pfair algorithm called EPDF [65] that is optimal fortwo-processor systems.
Taking the advancement of the Pfair scheduling method, Ramamurthyet al. pro-posed the Weight-Monotonic (WM) algorithm that applies a static-priority scheme tothe Pfair scheduling [66, 67]. While the original Pfair algorithms schedule subtasksaccording to the policy of earliest pseudo deadline first, the WM algorithm does ac-cording to the policy of highest weight (utilization) first.The utilization bound for theWM algorithm was proved to be 50% in the later work [57]. Sincethe common forstatic-priority scheduling on multiprocessor systems is that it can never have a utiliza-tion bound greater than 50% [53, 45], the WM algorithm is optimal for static-priorityscheduling as well as the R-BOUND-MP-NFR algorithm.
19
CHAPTER 2. STATE OF THE ART
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
T1
T2
T3
T4
T5
T6
T7
T8
T9
T10
T11
T12
T13
T14
T15
T16
Figure 2.4: Pfair windows of task with utilization 8/11
One of the well-known drawbacks against the Pfair algorithms is that they causesa great number of task preemptions due to quantum-based scheduling, which leads tosignificant run-time overhead, though the practical performance of Pfair schedulingwas reported [68, 69]. Seeking the practicality on global scheduling, Anderssonet al.invented a static-priority scheduling algorithm called RMwith utilization separation atM/(3M − 2) (RM-US[M/(3M − 2)]) [45]. Hereinafter the description of ’[M/3M − 2]’is omitted for simplicity of description. The primary purpose of the RM-US algo-rithm is an avoidance of the Dhall’s effect [42]. The Dhall’s effect happens because ofheavy (high-utilization) tasks having low priorities. They first showed that any periodictask set in which the utilization of every individual task isat mostM/(3M − 2) canbe scheduled successfully onM processors if the total utilization of tasks is at mostM2/(3M − 2). Referring to this result, the RM-US algorithm statically places the high-est priority to tasks whose utilizations are greater thanM/(3M − 2). The utilizationbound for the RM-US algorithm was proved to beM/(3M − 2), namely a task set witha total utilization less thanM2/(3M − 2) can be guaranteed to be schedulable by theRM-US algorithm. Since the global RM algorithm cannot guarantee timing constraintsonce the total utilization of tasks exceeds 1, the effectiveness of the RM-US algorithmcan be recognized. Figure 2.5 shows a scheduling example of the RM-US algorithmwith respect to the same task set used in Figure 1.1 to show theDhall’s effect. Sincea heavy task is assigned the highest priority, the Dhall’s effect can be avoided. In thelater work, the RM-US algorithm was generalized as the RM-US[λ] algorithm for ap-plying any task set in which the maximum utilization of everyindividual task isλ [46].Baruah and Goossens proved that the valueλ = 1/3 is optimal with respect to verify-ing schedulability using the utilization bound test [70]. It is also argued that the trueoptimum value ofλ is approximately 0.3748225282 [71]. The basis of the argument isan assertion that a task experiences the maximum competing load when there is blockinterference from other tasks.
The notion of the RM-US algorithm is also used in dynamic-priority scheduling.Srinivasan and Baruah examined EDF-based scheduling of periodic tasks on multipro-cessor systems [72]. Srinivasan and Baruah showed that any periodic task set in whichthe utilization of every individual task is at mostM/(2M − 1) can be scheduled suc-
20

CHAPTER 2. STATE OF THE ART
1
2
M - 1
M + 1
M
Processor 1
Processor M
Processor 3
Processor 2
time0 2 x x +
Figure 2.5: RM-US scheduling example
cessfully onM processors if the total utilization of tasks is at mostM2/(2M − 1). Theythen proposed a hybrid scheduling algorithm, called EDF with utilization separationat M/(2M − 1) (EDF-US[M/(2M − 1)]), that gives the highest priority to tasks withutilizations aboveM/(2M − 1), and proved that the algorithm is able to successfullyschedule any periodic task set with total utilization of tasks is up tom2/(2m−1). Theseresults were generalized in [47], where it is shown that any periodic task set can bescheduled successfully by the EDF algorithm if the total utilization of tasks is at mostM(1 − Umax) + Umax, whereUmax is the maximum utilization of every individual task.Baker analyzed this general case of the EDF-US[λ] algorithm, in which tasks withutilizations higher thanλ are always placed highest priority, and gave the conclusionthat the EDF-US[1/2] algorithm is optimal with a guaranteed worst-case schedulablesystem utilization of (M + 1)/2 [48].
In a broad sense, the approach of placing the highest priority to heavy tasks iseffectual to improve schedulability. A similar idea was used inthe Earliest DeadlineZero Laxity (EDZL) algorithm [73]. The EDZL algorithm places the highest priority totasks which have zero laxity. The laxity of a task indicates the remaining time amountto the deadline from the current time in which the remaining execution time of the taskis subtracted. Lettingd be the deadline,t be the current time, ande be the remainingexecution time of a task respectively, the laxity is expressed by (d − t) − e. Since thelaxity of a task varies at every moment, the priority of the task becomes the highest inmid-flow of execution when the task has zero laxity. The authors in [73] proved thatthe EDZL algorithm is at least as effective as the EDF algorithm. In other words, anytask sets that are schedulable under EDF scheduling is always schedulable under EDZL
21

CHAPTER 2. STATE OF THE ART
1
2
3
M + 1
M
Processor 1
Processor M
Processor 3
Processor 2
time0 2 x +
1
Figure 2.6: EDZL scheduling example
scheduling. Figure 2.6 shows a scheduling example of the EDZL algorithm with respectto the same task set used in Figure 1.1 to show the Dhall’s effect. At timeǫ, theM+1thtask reaches the zero laxity, and the first task is preempted.As a result, all the deadlinesare met. It has been shown that any task sets can be scheduled successfully by the EDZLalgorithm onM processors if the total utilization of tasks does not exceed(M + 1)/2[74]. Cirinei and Baker gave more precise schedulability tests for the EDZL algorithm[75], using similar techniques presented in their previouswork [76, 77]. They alsoexamined experimental evaluations to compare the performance of the EDZL algorithmwith other EDF-based global scheduling algorithms. Weiet al. moreover investigatedthe schedulability of the EDZL algorithm [78]. They derivedthat the utilization boundfor the EDZL algorithm on two processors is 3/2 + |Umax − 1/2| whereUmax is themaximum utilization of individual tasks. The common opinion in the work on EDZLscheduling is that there is room for improvement in the utilization bound.
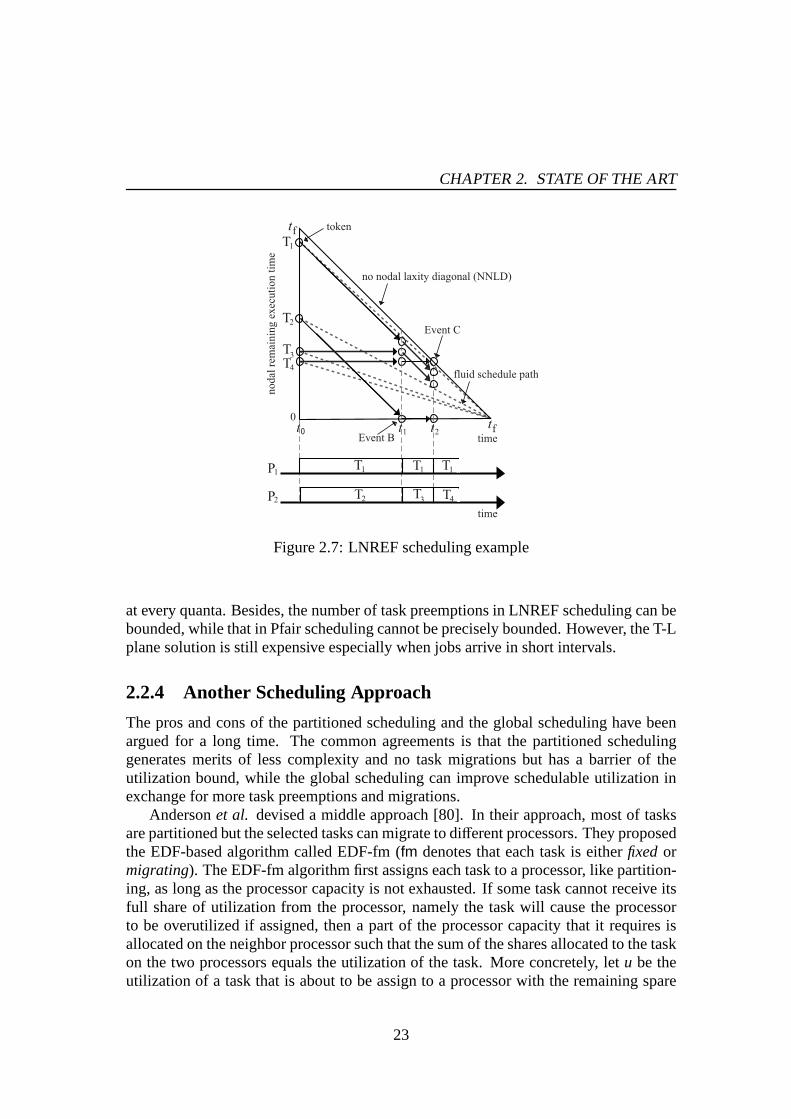
Cho et al. backed in the optimal scheduling problem again, with considering lesstask preemptions [79]. They proposed an optimal algorithm that schedules a task withthe largest nodal remaining execution time first (LNREF). Unlike the Pfair algorithms,the LNREF algorithm does not rely on the quantum-based scheduling approach but onthe original notion called T-L plane solution. The algorithm makes a fluid schedulepath every interval of job arrivals. When a task sees a time atwhich it cannot meet thefluid schedule path at the end of the interval, the task is assigned the highest priority. Ascheduling example of four tasks by the LNREF algorithm is illustrated in Figure 2.7.The authors claimed that the LNREF algorithm may reduce the number of task pre-emptions compared to the Pfair algorithms, since it does notneed to invoke a scheduler
22
CHAPTER 2. STATE OF THE ART
Event B
Event C
tf0
tf
nodal
rem
ainin
g e
xec
uti
on t
ime
timet1 t2
T1
T3
T4
T2
P1
P2
time
T1
T2
T1 T1
T3 T4
token
no nodal laxity diagonal (NNLD)
fluid schedule path
t
Figure 2.7: LNREF scheduling example
at every quanta. Besides, the number of task preemptions in LNREF scheduling can bebounded, while that in Pfair scheduling cannot be preciselybounded. However, the T-Lplane solution is still expensive especially when jobs arrive in short intervals.
2.2.4 Another Scheduling Approach
The pros and cons of the partitioned scheduling and the global scheduling have beenargued for a long time. The common agreements is that the partitioned schedulinggenerates merits of less complexity and no task migrations but has a barrier of theutilization bound, while the global scheduling can improveschedulable utilization inexchange for more task preemptions and migrations.
Andersonet al. devised a middle approach [80]. In their approach, most of tasksare partitioned but the selected tasks can migrate to different processors. They proposedthe EDF-based algorithm called EDF-fm (fm denotes that each task is eitherfixedormigrating). The EDF-fm algorithm first assigns each task to a processor, like partition-ing, as long as the processor capacity is not exhausted. If some task cannot receive itsfull share of utilization from the processor, namely the task will cause the processorto be overutilized if assigned, then a part of the processor capacity that it requires isallocated on the neighbor processor such that the sum of the shares allocated to the taskon the two processors equals the utilization of the task. More concretely, letu be theutilization of a task that is about to be assign to a processorwith the remaining spare
23

CHAPTER 2. STATE OF THE ART
Processor 1
Processor 2
Task 1
Task 2
Task 3
Time
Time
Task 1 Task 2' Task 2" Task 3 Task release
Figure 2.8: EKG scheduling example
capacity ofs that is less thanu. In this case, the task cannot fit in the processor becauseof s< u. The EDF-fm algorithm assignsu′ = s/u share of its utilization to the proces-sor and the remainingu′′ = (u− s)/u share of its utilization to the neighbor processor.Hence, each task is assigned to either one or two processors in the EDF-fm algorithm.The tasks assigned to two processors are called migrating tasks, while the task assignedto one processor are called fixed tasks. The jobs of migratingtasks are assigned toprocessors using static rules that are independent of runtime dynamics so that the jobsthat form the migrating task are not executed in parallel on two processors. The rest ofthe jobs are scheduled according to the EDF algorithm. This priority scheme ensuresthat migrating tasks never miss their deadlines. However, the scheduling methodologyof the EDF-fm algorithm cannot guarantee fixed tasks to meet their deadlines, insteadit can guarantee theirtardinesswhich is a delay from the deadline. Thus, the targetdomains of the EDF-fm algorithm are restricted to soft real-time systems. The EDF-fmalgorithm also has a limitation on the utilization of every individual task at most 1/2.
The advantage of this approach is that it can allocate the full processor capacityto tasks, since a task inducing overutilization of a processor is alwayssplit into twoportions and the share of its first portion being assigned to the processor is same as theremaining spare capacity of the processor. In addition, thenumber of migrating tasks isbounded at mostM − 1 on M processors. As a result, the number of task preemptionsand migrations is limited, while a system can be fully utilized. The matter of the EDF-fm algorithm in dispute is that fixed tasks cannot have hard deadlines.
Andersson and Tavor settled the matter of the EDF-fm algorithm by partially intro-ducing a notion of fluid scheduling [81]. The algorithm they proposed is called EDFwith task splitting and K processors in a Group (EKG). The task assignment rule of theEKG algorithm is almost same as that of the EDF-fm algorithm,which means that atmostM − 1 tasks are split onM processors. While the EDF-fm algorithm prioritizedthe split tasks statically over the rest of the tasks, the EKGalgorithm schedules all the
24

CHAPTER 2. STATE OF THE ART
tasks based on dynamic priorities so that every split task isnot executed in parallel ontwo processors. Letu′ andu′′ be the utilizations of a split task on Processor 1 andProcessor 2 respectively. Also lett1 be the release time of any job on any processor,and lett1 be the release time of the next job of any task on any processor. The splittask begins execution at timet1 and consumes the time units ofu′(t2 − t1) without anypreemptions on Processor 1, then consumes the time units ofu′′(t2− t1) and ends execu-tion at timet2 without any preemptions on Processor 2 after migrating fromProcessor1. Figure 2.8 depicts a scheduling example of the EKG algorithm on two processorswith respect to three tasks, Task 1, Task 2, and Task 3, where Task 2 is split into Task2′ and Task 2′′. According to the EKG algorithm, all the tasks can be guaranteed tomeet their deadlines and a system can be fully utilized. Thatis, the EKG algorithm isoptimal. The problem described there is that a split task maycause many preemptionsif jobs are released in short intervals. The authors hence gave a trade-off solution. Theyintroduced a parameterk that indicates the number of processors in each group. Taskscan be split only within a group. When the task assignment moves to a processor in thenext group, a task cannot be split. In the case ofk = 2, at mostM/2 tasks are split,while at mostM − 1 tasks are split in the case ofk = M on M processors. Higherutilization bound is obtained with larger value ofk that incurs more task preemptions.The utilization bound becomes 2/3 ≃ 66% for k = 2 and 100% fork = M, whichmeans that the algorithm is optimal fork = M. The EKG algorithm however generatesan unacceptable number of task preemptions for a large valueof k. Another drawbackof the EKG algorithm is that the scheduling of split tasks requires fine-grained timers,since it relies on the fluid scheduling model.
2.3 Server Algorithms
This section looks back the traditional techniques for the scheduling of aperiodic taskson uniprocessor systems to study basic approaches. Then, the extensions for multipro-cessor systems are explored.
The survey focuses on improving the response time of aperiodic tasks without caus-ing timing violations of periodic tasks. This can be usuallyachieved by the use of aserver. A server is a special periodic task whose purpose is to service aperiodic requestsas soon as possible. Like any periodic task, a server is characterized by a period anda fixed execution time, called server capacity. The server isscheduled with the samealgorithm used for the periodic tasks, and, once active, it serves the aperiodic requestswithin the limit of its server capacity.
2.3.1 Uniprocessor Approach
The most simple server algorithm is Polling Server (PS) [8, 10]. In the PS algorithm, atregular intervals equal to its period, the server becomes active and services any pending
25

CHAPTER 2. STATE OF THE ART
aperiodic requests within the limit of its capacity. As the server services aperiodicrequests, the capacity is consumed. When the capacity becomes zero, the server cannotcontinue to service until it becomes active again. If no aperiodic requests are pending,the server suspends itself until the beginning of its next period, and the time originallyallocated for aperiodic service is not preserved for the next aperiodic service but isused by periodic tasks. Note that if an aperiodic task arrives just after the server hassuspended, it must wait until the beginning of the next polling period, when the servercapacity is replenished at its full value.
Lehoczkyet al. invented Deferrable Server (DS) to improve the response time ofaperiodic tasks with respect to polling service [8]. As the PS algorithm, the DS algo-rithm creates a periodic task, usually having the highest priority, for servicing aperiodicrequests. However, unlike polling, the DS algorithm preserves the server capacity ifno aperiodic requests are pending upon the invocation of theserver. The capacity ismaintained until the end of the period, so that aperiodic requests can be serviced at thesame priority as the server at anytime, as long as the capacity has not been exhausted.At the beginning of any server period, the capacity is replenished at its full value. Thus,the DS algorithm provides much better aperiodic responsiveness than polling. How-ever, the schedulable utilization somewhat decreases whenthe DS algorithm is appliedto static-priority scheduling, since the server defers itsexecution, which may cause aviolation of the basic assumption that every time the task with the highest priority is ex-ecuted under static-priority scheduling. The schedulability for the RM algorithm whenthe DS algorithm is applied was analyzed in detail by Strosnideret al. [15].
Lehoczkyet al. also invented Priority Exchange (PE). With respect to the DSal-gorithm, the PE algorithm has a slightly worse performance in terms of aperiodic re-sponsiveness but provides better schedulable utilizationfor periodic tasks. Like theDS algorithm, the PE algorithm uses a periodic server, usually at a high priority, forservicing aperiodic tasks. However, it differs from the DS algorithm in the manner inwhich the capacity is preserved. Unlike the DS algorithm, the PE algorithm preservesits high-priority capacity by exchanging it for the execution time of a lower-priorityperiodic task. At the beginning of each server period, the capacity is replenished at itsfull value. If aperiodic requests are pending and the serveris the ready task with thehighest priority, then the requests are serviced using the available capacity; otherwisethe remaining capacity is exchanged for the execution of theactive periodic task withthe highest priority.
Spruntet al. proposed two server algorithms: Extended Priority Exchange (EPE)[9] and Sporadic Server (SS) [10] Those algorithms are the extensions of the above twoserver algorithms in the manner of capacity preservation and capacity replenishment.Unfortunately, despite their computation complexity, theEPE algorithm and the SSalgorithm could not offer outstanding performance improvement compared to the DSalgorithm and the PE algorithm. Thus, the prior two algorithms are often preferable.
Slack Stealing [11, 12] is another aperiodic service technique, proposed by Lehoczkyand Ramos-Thuel, which offers substantial improvements in response time over the
26

CHAPTER 2. STATE OF THE ART
previous service methods, i.e. PS, DS, PE, EPE, and SS. Unlike these methods, theSlack Stealing algorithm does not create a periodic server for servicing aperiodic tasks.Rather it creates a passive task which attempts to make time for servicing aperiodictasks by stealing the processing time as much as possible from the periodic tasks with-out causing their deadlines to be missed. Unfortunately, itis widely known that theSlack Stealing algorithm needs a huge memory space to store the slack available ateach task arrival, whereas it offers excellent performance. In order to reduce the re-quired memory space, Daviset al. developed the Dynamic Slack Stealing algorithm[13] and the Dual Priority Scheduling algorithm [14], whichsteal the processor timedynamically. However, those algorithms sacrifice unacceptable runtime overhead inexchange for static memory requirements.
All the techniques described above are basically used with the RM scheduling algo-rithm. It is well known that the lowest bound of the CPU utilization in the RM algorithmis only 69%, whereas dynamic priority scheduling, such as the EDF algorithm and theLeast Laxity First (LLF) algorithm [82], have a schedulableutilization of 100% in anycases. Spuriet al. proposed several aperiodic service techniques performingunder dy-namic priority scheduling [16, 17]. They firstly proposed the Dynamic Sporadic Server(DSS) algorithm and the Dynamic Priority Exchange (DPE) algorithm that are the ex-tensions from the static-priority server algorithms of DS and PE so that they work un-der dynamic-priority scheduling. Because those algorithms have restrictions taken overfrom the original static-priority algorithms, they have certain performance boundaries.Spuri et al. also developed an efficient, probably the most efficient, algorithm calledTotal Bandwidth Server (TBS), which is more suitable for deadline-based scheduling.The TBS algorithm performs based on the assigned bandwidth,and offer excellentperformance with retaining the optimality of dynamic-priority scheduling. Moreover,they invented an optimal algorithm called Earliest Deadline as Late as possible (EDL)server, and a suboptimal algorithm called Improved Priority Exchange (IPE). The EDLalgorithm is an dynamic extension of the static-priority Slack Stealing algorithm. TheIPE algorithm, on the other hand, is derived from the static-priority DPE algorithm andis motivated to make efficient use of idle times in the EDL algorithm.
2.3.2 Multiprocessor Approach
While many researchers have proposed server algorithms performing in uniprocessorscheduling, it is surprising that there have been very few server algorithms specific formultiprocessor systems. Baruahet al. considered a multiprocessor implementation ofthe TBS algorithm [83]. They derived the schedulable condition of the global EDFscheduling with the TBS algorithm. However, the design and policy of their algorithmare subject to the original TBS algorithm, rather the purpose of their work is to applythe TBS algorithm to multiprocessor systems, but not to improve the performance ofthe TBS algorithm.
Anderssonet al. investigated both the global scheduling and the partitioned schedul-
27

CHAPTER 2. STATE OF THE ART
ing of aperiodic tasks on multiprocessor systems [84, 85]. They designed a global ape-riodic scheduling algorithm that meets all deadlines if 50%or less of the capacity isrequired. They also devised a partitioned aperiodic scheduling algorithm that meets alldeadlines if 31% or less of the capacity is required. The contributions are significantwith taking into account that no algorithms have ever guaranteed timing constraints ofaperiodic tasks with those utilizations. However, the responsiveness to aperiodic tasksis never focused on in their work.
Banuset al. extended the Dual Priority algorithm so that it can applied on multipro-cessor systems [86]. The extended algorithm works in such a way that periodic taskscan be migrated to other processors to reduce the response time of aperiodic tasks, butthe periodic tasks must be executed on the dedicated processors after the certain times.The former is called dynamic phase and the latter is called static phase. The conclud-ing remarks was that their algorithm can even offer better performance than the SlackStealing algorithm when the system is overloaded. Althoughthey succeeded in reduc-ing the response time on multiprocessor systems, the algorithm is based on the DualPriority algorithm that takes complex computations at runtime. Thus, the practicalityof the algorithm must be more discussed.
2.4 Summary
This chapter first gave a survey of the state of the art techniques for the scheduling ofperiodic tasks on multiprocessor systems. The scheme of scheduling is mainly classi-fied into global scheduling and partitioned scheduling. In global scheduling, all tasksare managed by a unique scheduler with global priorities, and they are able to be exe-cuted on any processors. On the other hand, tasks are assigned to particular processorsand a local scheduler on each processor manages the assignedtasks independently inpartitioned scheduling. Scheduling algorithms are characterized as follows.
• The scheduling algorithms based on the global scheduling scheme are able toachieve optimal schedulable utilizations of 100%. However, they inevitably pro-duce a great number of task preemptions and migrations, which incurs unaccept-able overhead at runtime. In addition, implementation of the algorithms is likelyto be more complicated.
• The scheduling algorithms based on the partitioned scheduling scheme requireelementary computations and generate no migrations. However, they can nevertranscend a worst-case utilization bound of 50%. They also have online problemswhen a new task is submitted to the system at runtime.
The global scheduling and the partitioned scheduling have pros and cons. Thescheduling algorithms designed based on those scheduling schemes suffer from thetrade-off between schedulability and complexity. Recently, there has been propounded
28

CHAPTER 2. STATE OF THE ART
another scheme which takes advantage of both the global scheduling and the parti-tioned scheduling. The EKG algorithm designed based on thisnew scheme can achievean optimal schedulable utilization of 100% with less task preemptions than the globalscheduling algorithms. However, the partial scheduling ofthe EKG algorithm becomesof complicated and the number of task preemptions is still expensive. In addition, im-plementation issues have not been argued very much.
This chapter also provided a survey on the traditional techniques for the schedulingof aperiodic tasks on uniprocessor systems, since the scheduling on multiprocessorsystems has received little attention. The domain of uniprocessor systems have severalefficient algorithms that offer good responsiveness with less complexity. However, onlya few algorithms have been considered in the domain of multiprocessor systems. Thus,the basic form of aperiodic task scheduling on multiprocessor systems is required.
29

Chapter 3
SYSTEM MODEL
3.1 Processor Model
The system targeted in this research is a memory-shared multiprocessor composed ofMprocessors:P1,P2, ...,PM. The code and data of programs (tasks) are shared among theprocessors. This research neglects the overhead of inter-processor communications. Inother words, the cost of task migrations is not taken into account. Such an assumptionhas not been preferable in the traditional large scale multiprocessor systems such as on-board symmetric multiprocessors and network-connected processors. However, recentadvancement of processor technology has somewhat allowed this kind of assumption.For example, the current multithreading techniques are able to eliminate the overheadof context switches dramatically, though the impact of eliminations depends on proces-sor architectures. When threads are managed by hardware, the code and data are alsoeasily shared and synchronized using particular registersand instructions. In fact, theresponsive multithreaded (RMT) processor invented by Yamasaki [87, 88] has hard-ware functions to support fast context switches. For a good reference, every contextswitch can be done within four clocks in the RMT processor regardless of the contextlocations. In addition, the cost of switching contexts between processors can be deemedto be almost equal to that within a processor, when the code and data are shared amongthe processors. Thus, the overhead of switching and migrating contexts is vanishinglysmall. Those functions are fairly implementable. In fact, recent commercial processorshave similar features that reduce the cost of context switches.
Notice that it still takes a cost to preempt tasks, since an operating system enqueuesand dequeues tasks. However, the queuing cost is highly dominated by the processorperformance. Thus, there is little point in taking notice ofthe cost of every task pre-emption. From the viewpoint of scheduling, it is more variant to focus on the numberof task preemptions to assess the runtime overhead of the system. Hence, this researchtakes the number of task preemptions as a performance metricof runtime overhead.
This research also ignores the behavior of a cache system, because the configurationof caches is varied depending on processor performance and architectures. The perfor-
30

CHAPTER 3. SYSTEM MODEL
Ti Ti Ti
Ci
i,j i,j+1 i,j+2 i,j+3
Time
Figure 3.1: Periodic task model
mance deterioration of computations due to transient degradation of the cache hit ratiocaused by task preemptions and migrations is out of focus. Infact, such a deteriorationaffects estimation of the worst-case execution time (WCET). The real-time schedulingwith a guarantee of timing constraints is not achievable in most cases, if the WCETof each task is not known a priori. However, the WCET of each task cannot be easilyanalyzed in the presence of cache systems, especially on multiprocessor systems. Thus,when the WCET analysis is concerned in the scheduling established in this research,using scratch-pad memories rather than cache systems is more suitable. Otherwise, theexperimental WCET analysis [89] is also effective.
3.2 Task Model
Figure 3.1 illustrates the periodic task model. The system has a set ofN periodic tasks,denoted byΓ = {τ1, τ2, ..., τN}. Theith periodic task is defined byτi = (Ci ,Ti) whereCi
is its worst-case execution time andTi is its period (Ci ≤ Ti). The processor utilizationof τi is defined byUi = Ci/Ti . A task generates a sequence of jobs periodically. Thejthjob of τi is denoted byτi, j that is released at timer i, j and has a deadline at timedi, j equalto the release time of the next job, i.e.di, j = r i, j+1 = r i, j + Ti. The consumed executiontime and the remaining execution time ofτi, j at time t are denoted byci, j and ci, j(t)respectively. The total utilization of the given task set isdefined byU(Γ) =
∑
τi∈ΓUi.LettingΛ be any subset of the given task set, the total utilization of the subset is alsodenoted byU(Λ) =
∑
τi∈ΛUi. In the scheduling algorithms developed in this research,periodic tasks are executed on dedicated processors. In other words, each processor hasits own task set. Thus, the set of the tasks executed on processorPx is denoted byΠx.
Figure 3.2 indicates the aperiodic task model. Aperiodic tasks arrive on each pro-cessor sequentially. Thekth aperiodic task arriving on the system is defined byαk(ak,Ek)whereak is its arrival time andEk is its worst-case estimated execution time. Lettingfkbe the finish time ofαk, the response time ofαk is denoted byRk = fk − ak. The con-sumed execution time and the remaining execution time ofαk at timet are denoted by
31

CHAPTER 3. SYSTEM MODEL
ak ak+1
Rk
k k+1
Time
ak+2
k+2
Rk+1
Rk+2
Figure 3.2: Aperiodic task model
ek(t) andek(t) respectively, whereek(t)+ ek(t) is satisfied for anyt. For anyk, ak < ak+1
is satisfied. The load of the aperiodic tasks is denoted byU(α) = λ/µ whereµ is theaverage service rate andλ is the average arrival rate.
All the tasks are preemptive and independent. Thus, no tasksare assumed to havecritical sections and synchronize with any other tasks. When the critical sections andthe synchronizations are concerned in the scheduling established in this research, theschedulability analysis must be extended so that it can accept non-preemptive schedul-ing model and real-time synchronization protocols such as the priority ceiling protocol(PCP) [20] and the stack resource policy (SRP) [21]. Any jobsof a task cannot beexecuted in parallel, meaning thatτi, j cannot be executed in parallel on more than oneprocessor for anyi and j. Although the previous section stated that the performancede-terioration of periodic tasks due to transient degradationof the cache hit ratio is ignoredin this research, the performance deterioration of aperiodic tasks must be concerned,since it results in prolongation of aperiodic executions, while the goal of the aperiodicexecutions is to reduce the response time of aperiodic tasksas much as possible. There-fore, this research establishes the algorithms based on thepolicy that periodic tasks canbe migrated, but no aperiodic tasks can be migrated.
32

Chapter 4
PERIODIC TASK SCHEDULING
This chapter proposes a novel scheduling technique specificfor multiprocessor sys-tems, calledportioned scheduling, to achieve high schedulable utilizations with a smallnumber of task preemptions and migrations. The scheduling algorithms designed basedon the portioned scheduling strategy are presented. The optimal scheduling algorithms,such as Pfair [62, 63, 64], LLREF [79], and EKG(k = M) [81], can by definitionachieve optimal schedulable utilizations of 100% literally. No better performancesthan the optimal algorithms can be obtained in the sense of schedulability. However, asstated already, the optimal algorithms suffer from the computation complexity that maybring unacceptable runtime overhead in the forms of task preemptions and migrations.In fact, non-optimal algorithms, such as EDF-FF [58], EDF-BF [58], EDF-US [47],EDZL [73], and EKG(k < M), are preferred to the optimal algorithms for practicaluse in real environments. Although those efficient algorithms usually perform well, theschedulable utilizations drop down to 50% in the worst case.
The objective of the proposed scheduling algorithms is to achieve higher schedula-ble utilizations than the traditional non-optimal efficient algorithms with a small num-ber of task preemptions and migrations. An important point to concern is that thescheduling algorithms must be designed so that they are practically implementable.Even if an algorithm performs well in theory, it does not necessarily perform well inpractice. For example, the EDZL and EKG(k < M) algorithms perform efficiently inthe theoretical point of view, but they have problematic implementations issues such ashandling the zero laxity and using fine-grained timers.
This chapter begins with explaining the basic strategy of the portioned schedulingtechnique. Then, three scheduling algorithms are presented. The first algorithm isRateMonotonic Deferrable Portion(RMDP). The RMDP algorithm is developed for static-priority scheduling that is usually preferred to dynamic-priority scheduling in termsof predictability, release jitter and runtime overhead. The second algorithm isEarli-est Deadline Deferrable Highest-priority Portion(EDDHP). The EDDHP algorithm isderived from the notion of the RMDP algorithm but is developed for dynamic-priorityscheduling that is superior to static-priority schedulingin terms of schedulability. Those
33

CHAPTER 4. PERIODIC TASK SCHEDULING
Portioning (Split into two portions)
Py
k
Utilization bound of Px
Cannot fit in PxPx i j
k
i j k'
k"Py
Px
Figure 4.1: Portioning example
two algorithms outperform the traditional efficient algorithms in the sense of generalschedulable utilizations but never improve the utilization bounds. In other words, theutilization bounds of the RMDP and EDDHP algorithms are 50% in the worst case.The final algorithm, which is the major contribution of this research, isEarliest Dead-line Deferrable Portion(EDDP). The EDDP algorithm is an extension of the EDDHPalgorithm by releasing the restriction of the static-priority assignment derived from theRMDP algorithm and it achieves a utilization bound of 65%.
4.1 Basic Strategy
The portioned scheduling technique established in this research is not a brand newinsight. In the past work, Andersonet al. [80] and Anderssonet al. [81] studied verysimilar scheduling techniques. However, the form of those scheduling approaches isnever strongly defined, compared to the conventional globalscheduling and partitionedscheduling techniques. First of all, the form of the portioned scheduling technique istechnically defined in this research.
The portioned scheduling strategy is composed of the two phases: the task assigningphase and the task scheduling phase. In the task assigning phase, each task is assignedto a particular processor like partitioning, as long as the task does not cause the totalutilization of the processor to exceed its utilization bound. When the total utilization ofthe processor exceeds the utilization bound, the task on theassignment is virtually splitinto two portions in the sense of utilization, whereas in thepartitioning strategy the task
34

CHAPTER 4. PERIODIC TASK SCHEDULING
k
k'
k"
and denote task migration of k
is a portion served by and is a portion served by k' k"
Tk
Figure 4.2: Portioned scheduling example
is assigned to another processor which can receive the full utilization of the task. Asfor the virtually-split task, one portion is assigned to theprocessor to which the tasksare being assigned, and the other portion is assigned to the next processor to which therest of the tasks will be assigned. Notice that “virtually-split” means that the task isnot really divided into two blocks, but its utilization is shared on the two processors. Inother words, the processor capacity that the virtually-split task will use for execution isreserved on the two processors. From the scheduling point ofview, the split portionsare pseudo tasks to make a schedule time for the original task.
Figure 4.1 shows an example of splitting task, definedportioning in this research.The width of the box in which the task name is indicated is the processor utilizationof the task. This example presumes the case in which two tasks, τi andτ j, are alreadyassigned to processorPx, and another taskτk is causing the total utilization ofPx toexceed its utilization bound. In this case, the partitioning approach just assignsτk toanother processorPy. The portioning approach, on the other hand, virtually splits τkinto τ′k andτ′′k . In the dissertation,τ′k is defined thefirst portionof τk andτ′′k is definedthesecond portionof τk. Then,τ′k is assigned toPx andτ′′k is assigned toPy. Hence,the portioning approach obviously improves the total utilization ofPx. The executiontimes ofτ′k andτ′′k , which are namely the reserved processor capacities ofτk withinevery periodTk on the two processors, are denoted byC′k andC′′k respectively. LettingU∗x be the utilization bound ofPx, C′k andC′′k are calculated as follows.
C′k = Tk(U∗x − Ui − U j)
C′′k = Ck −C′k
This means thatτk consumesC′k time units onPx andC′′k units onPy within every
35

CHAPTER 4. PERIODIC TASK SCHEDULING
Tk. Notice thatτ′k andτ′′k form the same job ofτk, thereby they are not allowed tobe executed in parallel. Apart from that, they are treated asgeneral periodic tasks interms of theoretical real-time scheduling. Thus, they can be executed in any order. Theimplementation concern is only that the scheduler needs to track their execution timesto recognize the completions of split portionsτ′k and τ′′k . The portion that exhaustsits capacity in first must be preempted by the scheduler, because it does not recognizeconsuming its all capacity by itself. Hence, the scheduler must preempt the split taskτk when it exhausts eitherC′k on Px or C′′k on Py, so as not to letτ′k andτ′′k overrun theircapacities. Such a mechanism is similar to the resource reservation technique [22, 23].
The split portionsτ′k and τ′′k are for instance scheduled as shown in Figure 4.2.They are scheduled onPx andPy individually but exclusively. Whenτ′k is scheduled,τk is actually executed onPx. Whenτ′′k is scheduled, on the other hand,τk is actuallyexecuted onPy. The result scheduling ofτk is that it is executed with migrating betweentwo processorsPx and Py. As described above, the ordering ofτ′k and τ′′k does nothave any limitations. As long as they are scheduled exclusively, they can be scheduledsequentially, alternately, and randomly.
4.2 The RMDP algorithm
This section presents the RMDP algorithm that integrates the portioned schedulingstrategy with the well-known RM algorithm [1]. At first, the task assigning algo-rithm and the task scheduling algorithm are proposed. Then,the schedulable conditionand the utilization bound for the RMDP algorithm are analyzed. The dissertation alsoproves that the RMDP algorithm performs optimally, i.e. it achieves a utilization boundof 100%, for the special case of harmonic task sets.
4.2.1 Task Assigning Phase
The task assigning algorithm of RMDP is straightforward. The algorithm assumes thatthe given task set is sorted so that the period ofτi is smaller than or equal to that ofτi+1
for any i. Then, the algorithm assigns the tasks to the processors sequentially, whichmeans that it always assignsτi+1 afterτi, and if some task causes the total utilization ofa processor to exceed its utilization bound, its splits the task into two portions. The firstportion is assigned to the processor which is caused to exceed its utilization bound, andthe second portion is assigned to the next processor to whichthe following tasks willbe sequentially assigned. The algorithm continues this procedure until all the tasks areassigned or no processors remain the spare capacities.
Figure 4.3 shows the pseudo code of the RMDP assigning algorithm. First of all,the indexes of the tasks and the processors, and the number ofthe assigned tasks areinitialized (1st line). The variables related to the calculation of the utilization bound arealso initialized (2nd line). Then, all the per-processor task sets are emptied (3rd line).
36

CHAPTER 4. PERIODIC TASK SCHEDULING
Assumption:i is the index of the tasks.x is the index of the processors.n is the number of the tasks assigned toPx.cs1 is the execution time of the first portion of a split task.cs2 is the execution time of the second portion of a split task.ts is the period of a split task.tm is the minimal period of the tasks assigned toPx.U∗(Px) is the utilization bound ofPx.Γ is sorted so thatT1 ≤ T2 ≤ ... ≤ Tn.1. i = x = n = 1 ;2. cs1 = cs2 = ts= tm= 0 ;3. ∀Πx = ∅ ;4. U∗x = rmdp_bound(n, Ti, cs1, cs2, ts, tm) ;5. if U(Πx) + Ui ≤ U∗x6. Πx = Πx ∪ τi ;7. else if x < M8. C′i = {U∗x − U(Πx)}Ti ;9. C′′i = Ci −C′i ;
10. splitτi into τ′i (C′i ,Ti) andτ′′i (C′′i ,Ti) ;
11. Πx = Πx ∪ τ′i ;12. Πx+1 = {τ′′i } ;13. x = x+ 1 ;14. n = 0 ;15. if i + 1 ≤ N16. cs1 = C′i ;17. cs2 = C′′i ;18. ts= Ti ;19. tm= Ti+1 ;20. else21. return FAILURE ;22. i = i + 1 ;23. n = n+ 1 ;24. if i ≤ N25. go back to step 4 ;26. return SUCCESS ;
Figure 4.3: RMDP assigning algorithm
37

CHAPTER 4. PERIODIC TASK SCHEDULING
Arguments: (n, Ti, C′s, C′′s , Ts, Tmin)1. if C′′s = 02. returnn(21/n − 1) ;3. else4. L = ⌈(Ti − Ts +C′s)/Ts⌉ ;5. U′′s= C′′s /Ts ;6. Rs = Tmin/Ts ;7. returnU′′s + n{(2− LU′′s /Rs)1/n − 1} ;
Figure 4.4:rmdp_boundfunction
When the initializations are done, the algorithm calls thermdp_boundfunction, whichis indicated in Figure 4.4, to calculate the utilization bound of processorPx to whicha taskτi will be assigned (4th line). The content of thermdp_boundfunction, i.e. themethod of calculating the utilization bound, is particularly described in Section 4.2.3.Once the utilization boundU∗x is calculated, the algorithm assignsτi to a processorPx,i.e. insertsτi toΠx, as long as the total utilization ofPx, denoted byU(Πx)+Ui, does notexceed the utilization bound (5th and 6th lines). Ifτi causesPx to exceed the utilizationbound and more than one empty processor is still left,τi is going to be split into twoportions according to the following procedure. At first, theexecution times of the firstportion and the second portion ofτi, denoted byC′i andC′′i respectively, are calculatedbased on the spare schedulable utilization ofPx, denoted byU∗x − U(Πx) (8th and 9thlines). Then,τi is split intoτ′i = (C′i ,Ti) andτ′′i = (C′′i ,Ti) (10th line).τ′i is assigned toPx (11th line) andτ′′i is assigned toPx+1 (12th line). Since the assignment will moveon the next processor, the index for the processors is incremented (13th line), and thenumber of the tasks assigned to the next processor is reset byzero (14th line). Notethat n must be reset by zero, not one, thoughτ′′i is already assigned to the processor,becausen does not include the split task according to the schedulability analysis inSection 4.2.3. The task splitting procedure finally saves the values ofC′i ,C
′′i , Ti and
Ti+1 into the variablescs1, cs2, ts, andtm respectively (16th to 19th lines) for carryingout thermdp_boundfunction in the next iteration. Note that if no empty processorsare left when the algorithm tries to splitτi, then the algorithm is failed (21st line). Ifτi is successfully assigned toPx (or split intoPx andPx+1), the index for the tasks andthe number of the assigned tasks are incremented (22nd and 23rd lines). Finally, thealgorithm goes back to the step 4 as long as there are still tasks remaining to assign tothe processors (24th and 25th lines). When all the tasks are successfully assigned, thealgorithm is succeeded (26th line).
Figure 4.5 depicts an example of task assignments by the RMDPassigning algo-rithm. Consider a task setΓ composed of eight tasks:Ti ≤ Ti+1: τ1(1, 5), τ2(2, 5),τ3(1, 8), τ4(5, 10), τ5(3, 12), τ6(2, 12), τ7(12, 20), andτ8(4, 20). Note thatΓ is alreadysorted so thatTi ≤ Ti+1 is satisfied for anyi where ties of periods are broken arbi-
38

CHAPTER 4. PERIODIC TASK SCHEDULING
1 2 3 '4
"4 5 '
6
"6 7 8
U*1 = 83%
U*2 = 78%
U*3 = 92%
P1
P2
P3
Figure 4.5: RMDP assigning example
trarily. As stated above, the algorithm sequentially assigns the tasks. Evaluating thermdp_boundfunction withn = 1, the utilization bound of 100% is obtained, and henceτ1 can be assigned toP1. Next, the algorithm is supposed to evaluate thermdp_boundfunction with n = 2. Here, the example applies the notion of harmonic chains formore practical use. According to Kuo and Mok [90], the numberof the tasks is re-duced to the number of the harmonic chains in RM scheduling. Aharmonic chain isa group of the tasks whose periods have the same least common multiple. Taking theharmonic chains into account, the 23rd line of Figure 4.3 is extended so that it is carriedout only if the period of the next task is not included in any harmonic chains. Thus,the example evaluates thermdp_boundfunction with n = 1 due toT1 = T2, andτ2can be of course assigned toP1. τ3 does not have a period with the same least com-mon multiple asτ1 andτ2, thenn = 2 is input to thermdp_boundfunction, whileτ4has a period with the same least common multiple as them, and hencen = 2 is re-mained to thermdp_boundfunction. The resulting utilization bound of about 83% isobtained by thermdp_boundfunction for n = 2. SinceU1 + U2 + U3 + U4 = 1.225exceeds the utilization bound of 0.83, τ4 is split into τ′4(1, 10) andτ′′4 (4, 10) so thatU1 + U2 + U3 + U′4 = 0.825≤ 0.83 andU′′4 = U4 − U′4. By the same token, the rest ofthe tasks are classified intoΠ2 = {τ′′4 (4, 10), τ5, τ′6(1, 12)} andΠ3 = {τ′′6 (1, 12), τ7, τ8},though the utilization bounds are calculated with taking into account that split tasks areassigned in those sets. Recall that the utilization bound analysis is explained in detailin Section 4.2.3.
39

CHAPTER 4. PERIODIC TASK SCHEDULING
The resulting assignment guarantees that the second portion of a split task has theshortest period on each processor. This characteristic helps to derive the schedulablecondition for the algorithm. The details are described in Section 4.2.3. The resultingassignment also has such a characteristic that there are at most M − 1 tasks that willmigrate between two processors. The degree of task migrations is hence restricted dra-matically compared to global scheduling, while those restricted migrations enable thealgorithm to improve the schedulability sufficiently compared to partitioned schedul-ing, as the dissertation explains in the following sections.
4.2.2 Task Scheduling Phase
This section explains the task scheduling algorithm of RMDP. Like partitioned schedul-ing, each processor has its own scheduler to schedule the assigned tasks on the proces-sor. All the scheduler have the same scheduling policies. However, portioned schedul-ing differs from partitioned scheduling in that the schedulers are not completely inde-pendent from each other, since some two processors may sharethe same task that issplit into those two processors. According to the RMDP assigning algorithm, each pro-cessorPx may have at most two split tasks. One is the second portion of atask thatis split intoPx−1 andPx. The other is the first portion of another task that is split intoPx andPx+1. Lettingτi be such a task that its second portionτ′′i is assigned toPx andτk be such a task that its first portionτ′k is assigned toPx. The following descriptionsfocus on the scheduling on a processorPx whereτi submits its second portionτ′′i andτk submits its first portionτ′k. The schedulers on other processors perform in the samemanner, since the same scheduling policies are applied.
The basic policy of the scheduling algorithm is that the tasks are scheduled accord-ing to the RM algorithm except for the case in whichτ′′i is ready but its correspondingfirst portionτ′i is on execution on a neighbor processorPx−1. In this case, the RMDPscheduler dispatches a task with the second highest priority so as not to execute the firstportion and the second portion ofτi simultaneously. In other words, the second portionis deferrable to the RM scheduling policy. Notice that the RMDP scheduling com-pletely follows the RM scheduling if the processor does not have the second portion ofa split task.
Figure 4.6 shows the pseudo code of the RMDP scheduler. Everytime any tasks arereleased onPx, theschedule_Px function is invoked (1st to 9th lines). Lett be such atime. At timet, if the split tasksτi andτk that have their first portion or second portionon Px are released, the scheduler needs to reset the variablesti, tk, ei andek, in order totrack the remaining execution times of those tasks. Note that τi andτk are not allowedto consume the processor time ofPx over the capacitiesC′′i andC′k respectively, but thetasks cannot recognize voluntarily that they exhaust the capacities. Thus, the schedulerneeds to track the remaining execution times of those tasks to preempt their executionsusing timer functions.
The scheduler function proceeds as follows. First of all, ifthe currently-running
40

CHAPTER 4. PERIODIC TASK SCHEDULING
Assumption:τi is a split task betweenPx−1 andPx.τk is a split task betweenPx andPx+1.t is the current time.ti is the last time at whichτi is dispatched onPx.tk is the last time at whichτk is dispatched onPx.ei is the remaining execution time ofτi .ek is the remaining execution time ofτk.1. function system_tick2. if any tasks are released onPx
3. if τi is released4. ei = C′′i ;5. ti = t ;6. if τk is released7. ek = C′k ;8. tk = t ;9. callschedule_Px ;
10. function schedule_Px11. if Px is idling12. go to step 17 ;13. if τi is currently running14. ei = ei − (t − ti) ;15. else ifτk is currently running16. ek = ek − (t − tk) ;17. letτ j be a task with the shortest period ;18. if τ j refers toτi19. if τi is in execution onPx−1
20. letτ j be a task with the second shortest period ;21. else22. update the timer to invokep2_finishedat t + ei ;23. ti = t ;24. else ifτ j refers toτk25. update the timer to invokep1_finishedat t + ek ;26. tk = t ;27. if τk is in execution onPx+1
28. invokeschedule_Px+1 on Px+1 ;29. dispatch and executeτ j on Px ;
Figure 4.6: RMDP scheduling algorithm
41

CHAPTER 4. PERIODIC TASK SCHEDULING
1. function job_end2. remove the caller task from a ready set ;3. callschedule_Px ;
4. function first_end5. removeτr from a ready set ;6. callschedule_Px ;7. if τk is ready onPx+1
8. invokeschedule_Px+1 on Px+1 ;
9. function second_end10. removeτi from a ready set ;11. callschedule_Px ;
Figure 4.7: Job finishing functions
task is either a split portion ofτi or τ j, the scheduler saves its remaining execution time(13th to 15th lines). Then, it selects a task with the shortest period according to theRM scheduling policy (17th line). If the selected highest-priority task isτi that has itssecond portion on the processor (18th line), then the scheduler firstly examines whetherτi is currently in execution on a neighbor processorPx+1 (19th line). Ifτi is in executionon Px+1, then the scheduler re-selects a task with the second shortest period (20th line).Otherwise,τi is going to be dispatched and executed, so the scheduler updates thetimer to invoke thesecond_endfunction at timet + ei, which interrupts and preemptsthe execution ofτi so that it does not overrun the capacityC′′i on Px (22nd line). Noticethat thesecond_endfunction may not be invoked at timet + ei, since it may be updatedif τi is preempted and later dispatched again within the same period. Timet + ei is justthe earliest time at whichτi may possibly exhaustC′′i . It is guaranteed thatτi cannotcontinue to be executed after timet+ei if it is never preempted until then. As long as theremaining execution time ofτi is tracked,τi is guaranteed not to overrun the capacityC′′i on Px. After updating the timer, the scheduler must save the current time as the lastdispatched time ofτi, in order to track its remaining execution time at the 14th line. Bythe same token, if the selected task isτk that has its first portion on the processor (24thline), then the scheduler updates another timer to invoke the first_endfunction at timet + ek, which interrupts and preempts the execution ofτk so that it does not overrun thecapacityC′k onPx, and saves the current time as the last dispatched time ofτk (25th and26th lines). Unlike the case ofτi, if the corresponding second portion ofτk is currentlyin execution onPx+1 (27th line), the scheduler needs to invoke the scheduler functionoperating onPx+1 to reschedule the tasks onPx+1, sinceτk that has the highest priorityon Px+1 must be deferred while its corresponding first portion is executed onPx (28thline). Because of this part, the schedulers are not independent from each other. Finally,the scheduler dispatches and executes the selected task onPx (29th line).
42

CHAPTER 4. PERIODIC TASK SCHEDULING
6 14 220 4 8 10 12 16 18 20
4
1 2 21 21 21 21 213 3 3 34 4 4
4 4 4 45 5
24
56 5 6 6
6 6 67 7 8 7 7
26 282
6 14 220 4 8 10 12 16 18 20 24 26 282
6 14 220 4 8 10 12 16 18 20 24 26 282
P1
P2
P3
Figure 4.8: RMDP scheduling example
6 14 220 4 8 10 12 16 18 20
4
1 2 21 21 21 21 213 3 3 34
4 45
24
56 6 6
6 6 67 7 8 7 7
26 282
6 14 220 4 8 10 12 16 18 20 24 26 282
6 14 220 4 8 10 12 16 18 20 24 26 282
P1
P2
P3
5
Figure 4.9: Preemption-cared RMDP scheduling example
The job finishing functions are indicated in Figure 4.7. Whenany jobs except forthe jobs of the split tasks are completed, the jobs call thejob_endfunction (1st to3rd lines). Thefirst_endandsecond_endfunctions are called only through the timers.Those finishing functions call the scheduler function to reschedule the tasks (3rd, 6th,and 11th lines). Only whenτk consumes the capacityC′k onPx but has not consumed thecapacityC′′k on Px+1, the scheduler invokes the scheduler operating onPx+1 to dispatchand executeτk on Px+1, sinceτk has the shortest period onPx+1 but has been deferred.
Figure 4.8 indicates how the three task sets ofΠ1 = { τ1(1, 5), τ2(2, 5), τ3(1, 8),τ′4(1, 10)},Π2 = { τ′′4 (4, 10),τ5(3, 12),τ′6(1, 12)} andΠ3 = { τ′′6 (1, 12),τ7(12, 20),τ8(4, 20)},are scheduled according to the RMDP scheduling policy. SinceΠ1 does not include thesecond portion of a split task, the task set is scheduled completely according to the RMscheduling policy. Meanwhile,Π2 includeτ′′4 that is the second portion ofτ4, so it isinterfered by its corresponding first portionτ′4 when it is in execution onP1. At time
43

CHAPTER 4. PERIODIC TASK SCHEDULING
t = 0, τ′′4 is scheduled onP2 and then completed at timet = 4 without any interferencefrom τ′4, becauseτ′4 is scheduled at timet = 4 on P1. As for the second job ofτ4, onthe other hand,τ′′4 is scheduled at timet = 10 onP2 but is preempted at timet = 13,becauseτ′4 is scheduled at this time onP1. Hence,τ5 is scheduled instead ofτ′′4 andτ′′4 is later resumed whenτ′4 is completed at timet = 14. The third job ofτ4 also hasthe same situation. In this case, there are no ready tasks onP1 whenτ′′4 is preemptedat time t = 23. Therefore, the time slot is left idle. AlthoughΠ3 also includes thesecond portionτ′′6 , the tasks onP3 can be scheduled without any restrictions within theexample, since the scheduling times ofτ′6 andτ′′6 are never overlapped.
Here, the dissertation provides an idea of reducing the number of task preemptionscaused by unnecessary task migrations in the RMDP algorithm, though a specific im-plementation of this idea is left for the future work. Figure4.9 shows the idea of reduc-ing preemptions. In the example of Figure 4.8, two split tasks of τ4 andτ6 migrate toanother processor unnecessarily. The idea is that ifτ5 is migrated toP1 from P2 insteadof τ4 at timet = 13 and ifτ4 stays onP2 at timet = 23, unnecessary preemptions canbe eliminated as shown in Figure 4.9. Note that this the implementation of this idea isout of concern in this research.
The costs for checking the state of a task on a different processor and invoking thescheduler operating on a different processor are not necessarily expensive, since recentmemory-shared multiprocessors, especially multicore processors, have shared regis-ters and hardware synchronization mechanisms which reducethe overhead of inter-processor communications dramatically. In addition, making only two fine-grainedtimers for preventing the split tasks from overrunning their reserved capacities are notso expensive from the implementation point of view. If the practicality of the algorithmis criticized because of those issues, the traditional sophisticated algorithms must be re-vised. For instance, the Pfair algorithms obviously need a fine-grained timer to realizequantum-based scheduling. The LLREF algorithm may preempttasks many times andEKG algorithm may preempt tasks twice within each interval of job arrivals, so theyalso require a fine-grained timer. The EDZL algorithm has less preemption timings butneeds to find the event of the zero laxity that can happen at anymoment, hence it needa fine-grained timer after all. In consequence, this paper believes that the proposedalgorithm is as practical as the traditional efficient scheduling algorithms.
4.2.3 Schedulability Analysis
This section provides the schedulability analysis of the RMDP algorithm. In order toguarantee the system to satisfy the required real-time constraints, the schedulable con-dition must be evinced. Besides, system designers desire that the utilization bound forthe scheduling algorithm are clarified so that they can make adependable system with-out considering a complex array of factors, and can explain the worst-case performanceof the system to users. Now therefore, the dissertation firstly presents the schedulablecondition of the RMDP algorithm, and secondly derives the utilization bound for the
44

CHAPTER 4. PERIODIC TASK SCHEDULING
worst case. Throughout the analysis, the dissertation has the following assumptions.In the task assigning phase, some taskτs is split and its second portionτ′′s is assignedto processorPx. Then the followingn tasks, denoted byτ1, τ2, ..., τn for simplicity ofdescription, are also assigned toPx. Note that the first portion of a split task is not aconcern, because the RMDP scheduler deals with it in the samemanner as the non-split tasks. Only the second portion of a split task is scheduled in a different manner,since it may be differed. The analysis considersτ′′s to be an individual task, though it isactually the second portion ofτs, sinceτ′′s behaves as an individual task in theoreticalscheduling point of view.
The goal of the analysis is to derive a formula leading to the schedulable conditionof processorPx. Once the schedulable condition ofPx is obtained, the schedulableconditions of other processors can be also obtained using the same formula, becauseall the schedulers on those processors have the same scheduling policy in the RMDPalgorithm. The approach of the analysis is that the processor utilization is never belowU′′s , because the second portion ofτs is always assigned first, and hence the mission isreduced to obtain the minimum of the remaining schedulable utilization for n tasks.
According to the RM schedulability analysis [1], the minimal schedulable utiliza-tion for n tasks with respect to RM scheduling occurs for the case in which all thetasks are released at the same time and the following relations exist:T1 < Tn < 2T1,Ci = Ti+1−Ti (1 ≤ i ≤ n− 1) andCn = 2T1−Tn. This fact derives that the minimum ofthe schedulable utilization forn tasks in the RMDP algorithm also occurs for this con-dition. Now therefore, the worst-case phasing ofτ′′s is a concern. For a fixed value ofU′′s , the remaining utilization ofPx is obviously minimized whenτ′′s submits as manyjobs as possible. It occurs for the case in which an arbitraryjob of τ′′s is deferred asmuch as possible and the following jobs ofτ′′s are started without any preemption assoon as they are released. Consequently there are three conceivable worst-case phasesas shown in Figure 4.10, Figure 4.11 and Figure 4.12. The difference between the threephases is thatτ′′s is executed(i) twice within T1 andTn in the phase 1,(ii) three timeswithin T1 andTn in the phase 2, and(iii) twice with in T1 and three times withinTn inthe phase 3. The analysis does not need to consider the case inwhich τ′′s is executedmore than three times withinT1 or Tn, since the condition of the worst-case phasingincludesT1 < Tn < 2T1.
For simplicity of description, the fraction ofTs andT1 is definedRs = T1/Ts and thatof the periods of two consecutive tasksτi andτi+1 is definedRi = Ti+1/Ti henceforth.Notice that∀k,R1R2 · · ·Rk−1 = Tk/T1. Also it is necessary to have the minimum slackS in the figures to obtain the schedulable utilization. Sinceτ′′s always has the highestpriority on the processor according to the RMDP algorithm,τ′′s is interfered only by itscorresponding first portionτ′s running on the neighbor processor. Therefore, the latestfinish time ofτ′′s is rs,k + C′s + C′′s = rs,k + Cs = rs,k+1 − (Ts − Cs). As a result, theminimal slack can be expressed byS = Ts − Cs. If Ts = Cs, the worst-case phases arecompletely equal to those of the Deferrable Server (DS) algorithm [15] so-called theback-to-back hits phenomenon.
45

CHAPTER 4. PERIODIC TASK SCHEDULING
0 Tn
Tn-1
T1
T2
Tn-Ts
1
2
n-1
n
'sS
Figure 4.10: Case in whichτ′′s is executed twice withinT1 andTn
Case of Phase 1
The analysis begins with the simplest case in whichτ′′s is executed twice withinT1
andTn as shown in Figure 4.10. Under this relation, the execution time of each task isdefined as follows.
Ci = Ti+1 − Ti (1 ≤ i ≤ n− 1)Cn = T1 − 2C′′s −
∑n−1j=1 C j = 2T1 − 2C′′s − Tn
Hence the resulting utilization is written as Equation (4.1).
U =C′′sTs+
C1
T1+
C2
T2+ · · · + Cn
Tn
= U′′s +n−1∑
i=1
Ti+1 − Ti
Ti+
2T1 − 2C′′k − Tn
Tn
= U′′s +n−1∑
i=1
Ti+1
Ti+ 2
(
1−C′′sT1
)
T1
Tn− n
= U′′s +n−1∑
i=1
Ri +2(
1− U′′sRs
)
R1R2 · · ·Rn−1− n (4.1)
46

CHAPTER 4. PERIODIC TASK SCHEDULING
In order to minimizeU over Ri, the above expression is partially differentiated withrespect toRi.
∂U∂Ri= 1−
2(
1− U′′sRs
)
R2i (∏n−1
j,i Rj)
Now,U is minimized when eachRi satisfies the following equation whereP = R1R2 · · ·Rn−1.
RiP = 2
(
1−U′′sRs
)
(1 ≤ i ≤ n− 1)
That is,U is minimized when all theRi have the same value.
R1 = R2 = · · · = Rn−1 =
{
2
(
1−U′′sRs
)}1/n
By substituting the value of eachRi to Equation (4.1), the utilization boundUb is ob-tained as follows. Here, letK = 2(1− U′′s /Rs) due to limitation of space.
Ub = U′′s + (n− 1)K1/n +K
Kn−1/n− n
= U′′s + nK1/n − K1/n + K1/n − n
= U′′s + n(K1/n − 1)
The above expression implies thatUb is moreover minimized by reducing the value ofRs. According to Figure 4.10, the condition below must be satisfied.
n∑
i=1
Ci = T1 − 2C′′s ≥ S = Ts −Cs
Dividing by Ts, the range ofRs is acquired as follows.
Rs− 2U′′s ≥ 1− Us
Rs ≥ 2U′′s − Us + 1
The condition ofTs ≤ T1 leads toRs ≥ 1. Hence,Ub is minimized whenRs =
max{1, 2U′′s−Us+1}. Finally,Ub is described by Equation (4.2) whereRs = max{1, 2U′′s−Us + 1}.
Ub = U′′s + n
{
2
(
1−U′′sRs
)}1/n
− 1
(4.2)
Taking the limit asn→ ∞, the worst case is derived.
limn→∞
Ub = U′′s + ln
{
2
(
1−U′′sRs
)}
(4.3)
47

CHAPTER 4. PERIODIC TASK SCHEDULING
0 Tn
Tn-1
T1
T2
C''s+Ts+S
1
2
n-1
n
'sS
Figure 4.11: Case in whichτ′′s is executed three times withinT1 andTn
With Rs = 1, Equation (4.3) is minimized to Equation (4.4).
Ub = U′′s + ln{2(1− U′′s )}
Consequently, the absolute minimum value of the utilization bound becomesUb = 0.5whenU′′s = 0.5 andUs = 1. Note that this bound is given only for the special situationin which Ts = T1 = T2 = · · · = Tn andC1 = C2 = · · · = Cn = 0.
Case of Phase 2
The analysis secondly focuses on the case in whichτ′′s is executed three times withinT1 andTn as shown in Figure 4.11. Under this relation, the execution time of each taskis defined as follows.
Ci = Ti+1 − Ti (1 ≤ i ≤ n− 1)Cn = T1 − 3C′′s −
∑n−1j=1 C j = 2T1 − 3C′′s − Tn
Hence, the resulting utilization is written as Equation (4.4).
U = U′′s +n−1∑
i=1
Ti+1
Ti+
(
2−3C′′sT1
)
T1
Tn− n
= U′′s +n−1∑
i=1
Ri +2− 3U′′s
Rs
R1R2 · · ·Rn−1− n (4.4)
48

CHAPTER 4. PERIODIC TASK SCHEDULING
Calculating the value ofRi that minimizes Equation (4.4) by the same step in Section4.2.3, the utilization bound is obtained by the following expression.
Ub = U′′s + n
(
2−3U′′sRs
)1/n
− 1
The above expression is minimized by reducing the value ofRs. Figure 4.11 derivesT1
as follows.
T1 = Ts + 2C′′s + S = 2Ts + 2C′′s −Cs
Dividing by Ts, the value ofRs is acquired as follows.
Rs = 2U′′s − Us + 2
Hence,Ub is now expressed by Equation (4.5).
Ub = U′′s + n
(
2−3U′′s
2U′′s − Us + 2
)1/n
− 1
= U′′s + n
(
U′′s − 2Us+ 4
2U′′s − Us + 2
)1/n
− 1
(4.5)
Taking the limit asn→ ∞, the worst case is appeared.
limn→∞
Ub = U′′s + ln
(
U′′s − 2Us + 4
2U′′s − Us + 2
)
(4.6)
In order to find the value ofU′′s minimizing Ub, Equation (4.6) is derived with respectto U′′s .
∂Ub
∂U′′s=
2U′′s2 + (10− 5Us)U′′s + 2U2
s − 5Us + 2
(U′′s − 2Us + 4)(2U′′s − Us+ 2)
Finally, the value ofU′′s that minimizesUb is obtained by Equation (4.7).
U′′s =5Us− 10+
√
9U2s − 60Us+ 84
4
SinceU′′s ≥ 0, the absolute minimum value of the bound becomesUb ≃ 0.652 whenU′′s ≃ 0.186 andUs = 1.
49

CHAPTER 4. PERIODIC TASK SCHEDULING
Tk+1
Tk
T1
T2
1
2
k
k+1
0 Tn
Tn-1n-1
n
'sS
Figure 4.12: Case in whichτ′′s is executed twice withinT1 and three times withinTn
Case of Phase 3
The final case the analysis considers is a combination of the previous two cases. Like-wise the previous two cases, the execution time of each task is defined as follows.
Ci = Ti+1 − Ti (1 ≤ i ≤ k− 1)Ck = Tk+1 −C′′s − Tk
Ci = Ti+1 − Ti (k + 1 ≤ i ≤ n− 1)Cn = T1 − 2C′′s −
∑n−1j=1 C j = 2T1 −C′′s − Tn
50

CHAPTER 4. PERIODIC TASK SCHEDULING
Then, the resulting utilization is written as Equation (4.7).
U = U′′s +k−1∑
i=1
Ti+1 − Ti
Ti+
Ck
Tk+
n−1∑
i=k+1
Ti+1 − Ti
Ti+
2T1 −C′′s − Tn
Tn
= U′′s +k−1∑
i=1
Ti+1
Ti+ Uk +
n−1∑
i=k+1
Ti+1
Ti+
(
2−C′′sT1
)
T1
Tn− (n− 1)
= U′′s +k−1∑
i=1
Ri + Uk +
n−1∑
i=k+1
Ri +2− U′′s
Rs
R1R2R3 · · ·Rn−1− (n− 1) (4.7)
It is too complicated to obtain the value ofRi that minimizes Equation (4.7) with respectto two variables ofn andk. LeadingUk = Rk − C′′s /Tk − 1 from Ck = Tk+1 − C′′s − Tk,Equation (4.7) can be transformed as follows.
U = U′′s +n−1∑
i=1
Ri −C′′sTk+
2− U′′sRs
R1R2R3 · · ·Rn−1− n
The above expression implies that Equation (4.7) is obviously minimized fork = 1 dueto T1 ≤ T2 ≤ · · · ≤ Tn. Therefore, Equation (4.7) is reduced as follows.
U = U′′s + U1 +
n−1∑
i=2
Ri +2Rs− U′′s
RsR1R2R3 · · ·Rn−1− (n− 1)
In order to minimizeU, the above expression is derived with respect toRi as followswhere 2≤ i ≤ n− 1.
∂U∂Ri
= 1−2Rs− U′′s
RsR1R2i
∏n−1j,i Rj
That is,U is minimized when all theRi have the same value.
R2 = R3 = · · · = Rn−1 =
(
2Rs− U′′sRsR1
)1/(n−1)
Now, the minimum value ofU is described as follows.
U = U′′s + U1 + (n− 2)
(
2Rs− U′′sRsR1
)1/(n−1)
+2Rs− U′′s
RsR1
(
2Rs−U′′sRsR1
)1−1/(n−1)− (n− 1)
= U′′s + U1 + (n− 1)
(
2Rs− U′′sRsR1
)1/(n−1)
− 1
51

CHAPTER 4. PERIODIC TASK SCHEDULING
Ck = Tk+1 −C′′s − Tk andk = 1 lead toR1 = U1 + U′′s /Rs+ 1. Also, the value ofRs thatminimizes the above expression is max{1, 2U′′s −Us+1} as in Section 4.2.3. Finally, theutilization boundUb is described by Equation (4.8) whereRs = max{1, 2U′′s − Us + 1}andm= n− 1.
Ub = U′′s + U1 +m
{
2Rs− U′′sRs(U1 + 1)+ U′′s
}1/m
− 1
(4.8)
Taking the limit asn→ ∞, the worst case is appeared.
limn→∞
Ub = U′′s + U1 + ln
{
2Rs− U′′sRs(U1 + 1)+ U′′s
}
(4.9)
By the same token as the first case, the minimum of Equation (4.9) is expressed byEquation (4.10).
Ub = U′′s + U1 + ln
(
2− U′′sU′′s + 1+ U1
)
Seeking the values ofU′′s andU1 that minimizesUb, the absolute minimum bound isobtainedUb ≃ 0.5 whenU′′s = 1/2 andU1 = 0. This bound occurs only for thesituation in whichTs = T1 = T2 = · · · = Tk, Tk+1 = Tk+2 = · · · = Tn = Ts + C′′s andC1 = C2 = · · · = Cn = 0. Comparing the analyzed three cases, the worst-case utilizationbound of each processor is finally derived 50%. That is, the utilization bound of theentire system is also 50%.
General Case
Remember that the tasks are sorted so thatTi ≤ Ti+1. Hence,T1 is a known value whenτs is split, which means thatRs is also a known value. Therefore, the utilization boundcan be calculated by either Equation (4.2), Equation (4.5),or (4.8).
The analysis now proceeds to consider the general case. Equation (4.4) can berewritten as follows.
U = U′′s +n−1∑
i=1
Ti+1
Ti+
(
2−3C′′sT1
)
T1
Tn− n
= U′′s +n−1∑
i=1
Ti+1
Ti+
(
2−C′′sT1
)
T1
Tn− n−
2C′′sTn
(4.10)
52

CHAPTER 4. PERIODIC TASK SCHEDULING
Equation (4.7) can be also rewritten as follows.
U = U′′s +k−1∑
i=1
Ti+1
Ti+ Uk +
n−1∑
i=k+1
Ti+1
Ti+
(
2−C′′sT1
)
T1
Tn− (n− 1)
= U′′s +k−1∑
i=1
Ti+1
Ti+
Tk+1 − Tk −C′′sTk
+
n−1∑
i=k+1
Ti+1
Ti+
(
2−C′′sT1
)
T1
Tn− (n− 1)
= U′′s +n−1∑
i=1
Ti+1
Ti+
(
2−C′′sT1
)
T1
Tn− n−
C′′sTk
= U′′s +n−1∑
i=1
Ti+1
Ti+
(
2−C′′sT1
)
T1
Tn− n−
Tn
TkC′′s
Tn(4.11)
Notice thatTn/Tk in Equation (4.11) never exceeds 2, becauseτ′′s must be executedtwice within Tk and three times withinTn. Hence, Equation (4.4) is always smallerthan Equation (4.7) with respect to the same set of{Ts,T1,T2, ...,Tn}. This fact impliesthat the utilization bound for the case in whichτ′′s is executedL times withinT1 andTn
is always smaller than that for the case in whichτ′′s is executedF < L times withinT1
and is executedL times withinTn. Therefore, the analysis needs to concern only thecase in whichτ′′s is executedL times withinTn for the general case. Referring to Figure4.11,L can be described by the following expression.
L = 1+
⌈
Tn −C′′s − S
Ts
⌉
= 1+
⌈
Tn − Ts +C′sTs
⌉
Finally, the utilization utilization for the general case is obtained by Equation (4.12).
Ub = U′′s + n
(
2−LU′′sRs
)1/n
− 1
(4.12)
The value of Equation (4.12) is 50% whenL = 2, Us = 1 andU′′s = 0.5. Hence, theworst case is contained. LettingU′′s = 0, the analysis also contains the case in whichthere is no task that has the second portion onPx. In fact, this case leads to Equation(4.13) which is the well-known utilization bound of the RM algorithm [1].
Ub = n(21/n − 1) (4.13)
Harmonic Case
This section introduces the special characteristic of the RMDP algorithm for harmonictask sets. Kuo and Mok showed that considering the number of harmonic chains im-proves the utilization bound of the RM algorithm [90]. Sincethe RMDP algorithm is
53

CHAPTER 4. PERIODIC TASK SCHEDULING
designed based on the RM algorithm, the value ofn in Equation (4.12) can be obvi-ously deemed as the number of the harmonic chains. However, the fact thatn does notinclude the second portion of a split task must be concerned.In other words, applyingn = 1 to Equation (4.12) does not refer to the utilization bound for harmonic task setsbut indicates the utilization bound for the case in which a split task that submits itssecond portion and one harmonic chain exist. The objective of this section is to analyzethe schedulability of the RMDP algorithm for the harmonic case.
As already mentioned, if there is no task that submits its second portion onPx,the scheduling of the RMDP algorithm completely follows thescheduling of the RMalgorithm, hence the utilization bound obviously becomes 100% for the harmonic case.Now therefore, the existence of the second portion of a splittask is taken into account.The two cases are considered here:(i) the case in which all then tasks are released atthe same time, and(ii) the case in which all then tasks released with different phases.The followings prove that the utilization bound for the firstcase is 100% and that forthe second case is not and is calculated by Equation (4.12) with n = 1. The harmoniccase analysis is helpful for practical use, because the tasks are often released at thesame time when the system begins in real environments.
The analysis for the first case is as follows. Assume thatτ′′i is suspended at timetwhenτ′i ∈ Πx−1 is scheduled, and resumed at times > t whenτ′i is completed. In thiscase, whileτ′′i is behind schedule fors− t temporarily, the other tasks inΠx are neverbehind schedule. The reason is as follows. The task set is harmonic and the period ofτ′′i is the shortest inΠx, so∀τ j ∈ Πx,T j = KTi is certainly satisfied (K is an integerconstant greater than 0). Then at the time at which any job ofτ′′i is released, all the restof the tasks inΠx, i.e. {τ j ∈ Πx}, are also released. Hence the time interval ofs− t canbe allocated to{τ j ∈ Πx}. That is,{τ j ∈ Πx} are never behind schedule, though theycan be ahead schedule. ThereforeΠx is schedulable even if the processor utilization is100% unlessτ′′i misses the deadline. Sinceτ′′i is behind schedule for at mostC′i , it isguaranteed to meet the deadline ifC′i +C′′i ≤ Ti is satisfied. BecauseC′i +C′′i = Ci ≤ Ti
is true, the condition is always satisfied. Hence the schedulable utilization of the RMDPalgorithm is certainly 100% for the harmonic case.
Unlike the first case, the utilization bound for the second case does not become100%. This reason is easily validated by the following example. Consider a set of threetasks assigned to a processorPx: τ′′i (4, 10), τ j(8, 20), andτk(8, 40). This task set isharmonic with the total utilization 100%. Suppose that there exists a time at whichτ′′iarrives and none of the other tasks arrive. Lett = 30 be such a time. Ifτ′i is scheduledat this time, there are obviously no tasks in execution onPx, while there must be noidle times in order to achieve an optimal utilization bound of 100%. Therefore, theoptimality is never achieved for the second case, which means that Equation (4.12)with n = 1 must be used to work out the utilization bound of the RMDP algorithm.
54

CHAPTER 4. PERIODIC TASK SCHEDULING
4.3 The EDDHP algorithm
This section presents the EDDHP algorithm that extends the notion of the RMDP algo-rithm to dynamic-priority scheduling. The EDDHP shares in the manner of the RMDPalgorithm that the second portion of a split task has the highest priority on a processor.The extension is that the rest of the tasks on the processor isscheduled according to theEDF algorithm. By the same token as Section 4.2, the task assigning algorithm and thetask scheduling algorithm are firstly described. Then, the schedulable condition and theutilization bound of the EDDHP algorithm are analyzed. In addition, this section intro-duces several heuristics to improve the schedulable utilization of the EDDHP algorithmin practice.
4.3.1 Task Assigning Phase
The task assigning algorithm of EDDHP is similar to that of RMDP. The algorithmdiffers from the RMDP algorithm in the manner of calculation of the utilization boundfor each processor. While the RMDP algorithm carries out thecalculation every timea new task is assigned to a processor, the EDDHP algorithm does only when the taskassignment moves on a new processor. Since the schedulable condition of the EDDHPalgorithm does not depend on the number of the assigned tasks, as explained in Section4.3.3 later, the algorithm can calculate the utilization bound when the properties ofa split task that submits its second portion on the target processor are revealed. TheRMDP algorithm, on the other hand, requires the informationof the number of theassigned tasks to calculate the utilization bound according to Equation (4.12), henceit needs to recalculate the utilization bound every time a new task is assigned to aprocessor, because the number of the assigned tasks is incremented.
Figure 4.13 shows the pseudo code of the EDDHP task assignment. The assump-tion in the algorithm is same as that in the RMDP assigning algorithm (Figure 4.3),except that some variables are removed due to its simplicityof the schedulability test.Unlike the RMDP assigning algorithm, the EDDHP assigning algorithm needs not totrack the number of the assigned tasks, since the utilization bound is not dominatedby the number of the assigned tasks. This simplicity yields another simplicity that thealgorithm also needs not to save the properties of a split task every time the task is split,since the utilization bound can be calculated when the task is split.
First of all, the algorithm initializes the variables (1st and 2nd lines). The utilizationbound of the first processor is always set 1.0 (3rd line), because the first processorproduces the EDF scheduling due to the absence of the second portion of a split task.Like the RMDP assigning algorithm, the EDDHP assigning algorithm assigns a taskτi to a processorPx, i.e. insertsτi to Πx, as long as the total utilization ofPx doesnot exceed the utilization bound (4th and 5th lines). If the total utilization exceeds theutilization bound and empty processors are still left,τi is going to be split and assignedto Px andPx+1 as follows. Similarly to the RMDP assigning algorithm, the execution
55

CHAPTER 4. PERIODIC TASK SCHEDULING
i is the index of the tasks.x is the index of the processors.U∗x is the utilization bound ofPx.Γ is sorted so thatT1 ≤ T2 ≤ ... ≤ Tn.1. i = x = 1 ;2. ∀Πx = ∅ ;3. U∗x = 1.0 ;4. if U(Πx) + Ui ≤ U∗x5. Πx = Πx ∪ τi ;6. else if x < M7. C′i = {U
∗x − U(Πx)}Ti ;
8. C′′i = Ci −C′i ;9. splitτi into τ′i (C
′i ,Ti) andτ′′i (C′′i ,Ti) ;
10. Πx = Πx ∪ τ′i ;11. Πx+1 = {τ′′i } ;12. if i + 1 ≤ N13. U∗x+1 = eddhp_bound(C′i , C′′i , Ti , Ti+1) ;14. x = x+ 1 ;15. else16. return FAILURE ;17. i = i + 1 ;18. if i ≤ N19. go back to step 4 ;20. return SUCCESS ;
Figure 4.13: EDDHP assigning algorithm
times of the first portion and the second portion ofτi are calculated based on the spareschedulable utilization ofPx (7th and 8th lines). Then,τi is split into τ′i = (C′i ,Ti)andτ′′i = (C′′i ,Ti) (9th line), which are assigned toPx andPx+1 respectively (10th and11th lines). Unlike the RMDP assigning algorithm, the utilization bound of the nextprocessor is calculated at this point if more than one task isremaining (12th and 13thlines). The procedure of theeddhp_boundfunction is illustrated in Figure 4.14, whichis in detail presented in Section 4.3.3. Since the function requires onlyC′s, C′′s , Ts, andTi+1 for its arguments, the calculation of the utilization boundcan be done here. Theindex for the processors is incremented for the task assignment on the next processor(14th line). Ifτi is successfully assigned toPx (or split intoPx andPx+1), the index forthe tasks is incremented (15th line), and then the algorithmgoes back to the step 4, aslong as it still has the tasks to assign to the processors (18th and 19th lines). When allthe tasks are successfully assigned, the algorithm is succeeded (20th line).
The characteristics of the resulting assignment in the EDDHP assigning algorithmare also same as that in the RMDP assigning algorithm. Since the tasks are sorted
56

CHAPTER 4. PERIODIC TASK SCHEDULING
Arguments: (C′s, C′′s , Ts, Tmin)1. F = ⌊(Tmin −C′s)/Ts⌋ ;2. G = F + 1 ;3. if Tmin ≥ FTs +C′′s −C′s4. X1 = (Tmin −GC′′s )/Tmin ;5. X2 = (G(Ts −C′′s )C′s)/(GTs +C′′s −C′s) ;6. returnU′′s +min{X1,X2} ;7. else8. returnU′′s + {F(Ts −C′′s ) −C′s}/(FTs +C′′s −C′s) ;
Figure 4.14:eddhp_boundfunction
in increasing order of periods, the algorithm easily finds the task with the minimumperiod, which dominates the utilization bound of each processor as presented in Section4.3.3 later, when theeddhp_boundfunction is called. If the algorithm did not have sucha characteristic, it would take more overhead to find the taskwith the minimum periodto calculate the utilization bound.
4.3.2 Task Scheduling Phase
The task scheduling algorithm of EDDHP is also incremental,since it differs from theRMDP scheduling algorithm only in that the tasks but the second portion of a splittask are scheduled according to the EDF scheduling policy. The pseudo code of thealgorithm is shown in Figure 4.15. The procedures of tracking the remaining executiontimes of the split tasks perform in the same manner as the RMDPscheduling algo-rithm. In EDDHP scheduling, the second portion of a split task is statically assignedthe highest priority on the processor, soτi is dispatched whenever it is ready and is notin execution on a neighbor processorPx−1. Then, the timer needs to be set to invoke thesecond_endfunction, depicted in Figure 4.7, to preemptτi when it exhausts the capac-ity C′′i . If τi is in execution onPx−1, it is deferred in spite of the highest priority. Exceptfor τi, the tasks are scheduled according to the EDF scheduling policy. Whenτk, whichsubmits its first portion on the processor, has the earliest deadline, the scheduler needsto update the timer to invoke thefirst_endfunction, depicted in Figure 4.7, to preemptτk when it exhausts the capacityC′k.
4.3.3 Schedulability Analysis
This section derives the schedulable condition and the utilization bound of the EDDHPalgorithm. As in the schedulability analysis of the RMDP algorithm in Section 4.2.3,the analysis assumes that a taskτs is split and its second portionτ′′s is assigned to aprocessorPx. Note that the first portion of a split task is not a concern, because the
57

CHAPTER 4. PERIODIC TASK SCHEDULING
Assumption:τi is a split task betweenPx−1 andPx.τk is a split task betweenPx andPx+1.t is the current time.ti is the last time at whichτi is dispatched onPx.tk is the last time at whichτk is dispatched onPx.ei is the remaining execution time ofτi .ek is the remaining execution time ofτk.1. function system_tick2. if any tasks are released onPx
3. if τi is released4. ei = C′′i ;5. ti = t ;6. if τk is released7. ek = C′k ;8. tk = t ;9. callschedule_Px ;
10. function schedule_Px11. if Px is idling12. go to step 17.;13. if τi is currently running14. ei = ei − (t − ti) ;15. else if τk is currently running16. ek = ek − (t − tk) ;17. if τi is ready and is not in execution onPx−1
18. letτ j refer toτi ;19. update the timer to invokesecond_endat t + ei ;20. ti = t ;21. else22. letτ j be a task with the earliest deadline ;23. if τ j refers toτk24. update the timer to invokefirst_endat t + ek ;25. tk = t ;26. if τk is in execution onPx+1
27. invokeschedule_Px+1 on Px+1 ;28. dispatch and executeτ j on Px ;
Figure 4.15: EDDHP scheduling algorithm
58

CHAPTER 4. PERIODIC TASK SCHEDULING
deadline miss
t1 t2
s
s
i
j
k
'
"
Pm-1
Pm
Pm
Pm
Pm
Execution of the tasks that have a higher priority than 's on Pm-1
Deferred execution of "s on Pm due to execution of 's on Pm-1
Figure 4.16: Unfeasible EDDHP scheduling
EDDHP scheduler dispatches it in the same manner as the non-split tasks. Only thesecond portion of a split task is scheduled in a different manner. In the analysis,τ′′s isdeemed to be one task that can be deferred. Now therefore, theanalysis focuses on theschedulable utilization ofPx.
Figure 4.16 shows an example of unfeasible EDDHP scheduling. Note that thesecond portion ofτs, denoted byτ′′s , is always assigned the highest priority onPx unlessits first portion, denoted byτ′s, is in execution onPx−1. Now assume that any jobτ j,c
missed its deadline as shown in the figure. Lett1 be the last time at which the processoris idle or a job whose deadline is later than the deadline ofτ j,c is executed. Lett2 bethe time at whichτ j,c missed its deadline, that is, the deadline ofτ j,c. In order to haveτ j,c miss its deadline, the following condition needs to be satisfied whereS(t1, t2) is thetotal amount of the time at whichτ′′s is not executed within [t1, t2], namely the totalslack amount with respect toτ′′s within [t1, t2].
S(t1, t2) <∑
τi∈Λm\τ′′s
⌊
t2 − t1Ti
⌋
Ci
Being as⌊x⌋ ≤ x for any x, the following condition must be satisfied in order thatτ j,c
59

CHAPTER 4. PERIODIC TASK SCHEDULING
may miss its deadline.S(t1, t2) <
∑
τi∈Λm\τ′′s
(t2 − t1)Ui
In other words, any jobτ j,c is guaranteed to meet its deadline if the following conditionis satisfied for any (t1, t2).
∑
τi∈Λm\τ′′s
Ui ≤S(t1, t2)t2 − t1
Now the analysis seeks to obtain the minimum value ofR(t1, t2) = S(t1, t2)/(t2− t1).Note that we havet2 − t1 ≥ min{Ti | τi ∈ Λm \ τ′′s }, sincet1 should be before or atthe release time ofτ j,c. It is obvious thatτ′′s consumes the most processor time within[t1, t2] when its first job within [t1, t2] is deferred for the longest time and its last jobwithin [t1, t2] is executed immediately with no preemptions. This phasingresults inminimizingR(t1, t2). Taking this worst-case phasing into account, we need to take intoaccount two cases to obtain the minimum value ofR(t1, t2). The first one is the caseof Tmin ≥ FTs + C′′s − C′s and the second one is the case ofTmin ≤ FTs + C′′s − C′s.Hereinafter the analysis definesTmin andF as follows for simplicity of description.
Tmin = min{Ti | τi ∈ Λm \ τ′′s }
F =
⌊
Tmin +C′sTs
⌋
The two cases are shown in Figure 4.17. The goal of the analysis is to obtain theminimum value ofR(t1, t2) for each case.
The dissertation firstly proves that the minimum value ofR(t1, t2) in the case ofTmin ≥ FTs + C′′s − C′s is described by Equation (4.14) whereG representsG = F + 1for limitation of space.
min{R(t1, t2)} = min
{
1−GC′′sTmin,
G(Ts −C′′s ) −C′sGTs +C′′s −C′s
}
(4.14)
The proof is as follows. At first, the analysis assumest1 = a and t2 = b in Figure4.17(a). Then,R(t1, t2) is described as follows.
R(t1, t2) = R(a, b) =S(a, b)b− a
=Tmin −GC′′s
Tmin= 1−
GC′′sTmin
If t2 is b < t2 ≤ c, R(t1, t2) can be written as follows where 0< α ≤ c− b.
R(t1, t2) = R(a, b+ α) =S(a, b) + αb− a+ α
Since xy <
x+zy+z is always true for anyx > 0, y > 0 andz > 0, we haveR(a, b) <
R(a, b+ α). Next, the analysis assumest1 = a andt2 = d. Then,R(t1, t2) is described asfollows.
R(t1, t2) = R(a, d) =S(a, d)d − a
=G(Ts −C′′s ) −C′sGTs +C′′s −C′s
60

CHAPTER 4. PERIODIC TASK SCHEDULING
Pm
a b c d
C"s C"s C"s C"s C"s
fTmin
Ts
e
C's
(a) Case 1:Tmin ≥ FTs+C′′s −C′s
Pm
a b c
C"s C"s C"s C"s C"s
eTmin
Ts
d
C's
(b) Case 2:Tmin ≤ FTs +C′′s −C′s
Figure 4.17: Worst-case phasing of EDDHP scheduling
If t2 is b ≤ t2 < d, R(t1, t2) can be written as follows where 0< β ≤ d− c.
R(t1, t2) = R(a, d− β) = S(a, d)d − a− β
Sincexy <
xy−z is always true for anyx > 0,y > 0 andz> 0, we haveR(a, d) < R(a, d−β).
Also if t2 is d < t2 ≤ e, R(t1, t2) can be written asR(a, d+γ) where 0< γ ≤ e−d. Then,we haveR(a, d) < R(a, d + γ) by the same reason ofR(a, b) < R(a, b+ α). At last if t2is e < t2 ≤ f , R(t1, t2) is minimized whent2 = f , since we haveR(a, f ) < R(a, f − δ)by the same reason ofR(a, d) < R(a, d − γ). For anyC′s > 0 andC′′s > 0, the followingcondition is obviously satisfied.
R(a, d) =S(a, d)d − a
<Ts −C′′s
Ts
MeanwhileR(a, f ) can be written as follows.
R(a, f ) =S(a, d) + (e− d)(d − a) + ( f − d)
=S(a, d) + (Ts −C′′s )
(d − a) + Ts
Hence we haveR(a, d) < R(a, f ), which impliesR(a, d) < R(a, g) for anyd < g. So theminimum value ofR(t1, t2) is either ofR(a, b) or R(a, d). AssumingR(a, b) < R(a, d),
61

CHAPTER 4. PERIODIC TASK SCHEDULING
then the following condition must be satisfied.
Tmin −GC′′sTmin
<G(Ts −C′′s ) −C′sGTs +C′′s −C′s
(Tmin −GC′′s )(GTs +C′′s −C′s) < Tmin(GTs −GC′′s −C′s)
Tmin(G+ 1)C′′s < GC′′s (GTs +C′′s −C′s)
Tmin <G(GTs +C′′s −C′s)
G+ 1=
GG+ 1
(d − a)
Here the above inequation is not always true. It is easy to prove it if the analysisconsiders the case ofC′s ≃ 0 andC′′s ≃ 0. In this case, we can approximated−a ≃ d ≃ c.Since 1> G
G+1 >F
F+1 is always true, we haveFF+1(d − a) ≃ F
F+1c ≃ b < GG+1(d − a) <
(d − a) ≃ c. Being asC′s ≃ 0 andC′′s ≃ 0, Tmin can take any length within [b, c].Hence it depends on the length ofTmin whether the above inequation is true or false.Consequently the minimum value ofR(t1, t2) is described by Equation (4.14).
Next, the dissertation proves that the minimum value ofR(t1, t2) in the case ofTmin ≤FTs +C′′s −C′s is described by Equation (4.15).
min{R(t1, t2)} =F(Ts −C′′s ) −C′sFTs +C′′s −C′s
(4.15)
The analysis of the proof takes the same step as the one provedEquation (4.15). Theanalysis firstly assumest1 = a, then findst2 that minimizesR(t1, t2). According to thefirst discussion as for Equation (4.14), we can easily obtainR(a, b) > R(a, c). We canalso easily obtainR(a, c) < R(a, e) < R(a, d). ThereforeR(t1, t2) is minimized whent1 = a andt2 = c.
R(t1, t2) = R(a, c) =S(a, c)c− a
=F(Ts −C′′s ) −C′sFTs +C′′s −C′s
Hence the minimum value ofR(t1, t2) is described by Equation (4.15).From the above lemmas, the dissertation now provides the theorem that the utiliza-
tion bound of processorPx for the EDDHP algorithm is described by Equation (4.16)if Tmin ≥ FTs +C′′s −C′s, otherwise by Equation (4.17).
Ub =C′′sTs+min
{
Tmin −GC′′sTmin
,G(Ts −C′′s ) −C′sGTs +C′′s −C′s
}
(4.16)
Ub =C′′sTs+
F(Ts −C′′s ) −C′sFTs +C′′s −C′s
(4.17)
Theeddhp_boundfunction in Figure 4.13 corresponds to either Equation (4.16) orEquation (4.17), which is a function ofC′s, C′′s , Ts andTmin. Since theeddhp_boundfunction is called when taskτs is split,C′s, C′′s andTs are already known. Also the tasks
62

CHAPTER 4. PERIODIC TASK SCHEDULING
Pm C"s C"s
Ts
Ts
C's
t1 t2
Figure 4.18: Absolute worst-case phasing of EDDHP scheduling
are sorted so thatTi ≤ Ti+1. Thereby the algorithm can presumeTmin asTs+1. If thetasks are not sorted in increasing order of period, the algorithm moreover needs to findwhich task will have the shortest period in the tasks assigned to Px. This procedureis not easy since the number of the assigned tasks cannot be known priori before theutilization bound is computed. That is why the algorithm assigns the tasks in increasingorder of period.
This section finally proves that the worst-case utilizationbound for the EDDHPalgorithm is 50%. The proof is as follows. For the case of Equation (4.14), it is obviousthatR(a, b) is monotonically increasing inTmin andF. Since we have the condition ofTmin ≥ FTs+C′′s −C′s in this case,R(a, b) is minimized whenTmin = FTs+C′′s −C′s andF = 1. MeanwhileR(a, d) can be rewritten as follows.
R(a, d) =G(Ts −C′′s ) −C′sGTs +C′′s −C′s
=GTs+C′′s −GC′′s −C′s
GTs +C′′s −C′s
= 1−(G+ 1)C′′s
GTs +C′′s −C′s
= 1−2C′′s + FC′′s
(C′′s −C′s + Ts) + FTs
SinceC′′s ≤ Ts is always true,R(a, d) is monotonically increasing inF and it is mini-mized whenF = 1. TakingTmin = FTs +C′′s −C′s ≥ Ts into account, we can derive thefollowing relations.
R(a, b) ≥Tmin − 2C′′s
Tmin= 1−
2C′′sTmin
≥ 1−2C′′sTs
R(a, d) ≥ 1−3C′′s
2Ts +C′′s −C′s= 1−
2C′′s +C′′sTs+ (Ts +C′′s −C′s)
63

CHAPTER 4. PERIODIC TASK SCHEDULING
Assumption:the algorithm is applied only wheni + 1 ≤ N.let s be the index of a task that is going to be split.let τ′′k be the second portion of a split task that was assigned toPx if there exists.1. s= i ;2. U∗x+1 = 0.0 ;3. for eachτ j ∈ Πx \ τ′′k4. Urem = U∗x − {U(Πx) + Us − U j} ;5. if Urem ≥ 06. C′j = UremT j andC′′j = C j −C′j ;7. b = eddhp_bound(C′j, C′′j , T j, Ti+1) ;8. if U∗x+1 < b9. U∗x+1 = b ;
10. s= j ;11. Πx = Πx ∪ τi \ τs ;12. C′s = {U∗x − U(Πx)}Ts andC′′s = Cs −C′s ;13. splitτs into τ′s(C
′s,Ts) andτ′′s (C′′s ,Ts) ;
14. Πx = Πx ∪ τ′s andΠx+1 = {τ′′s } ;
Figure 4.19: MB heuristic
C′′s ≤ Ts + C′′s − C′s is always true fromC′s ≤ Ts. Also xy >
x+zy+w is always true for any
w > z > 0, soR(a, b) < R(a, d) is derived in the case of minimization. Namely theminimization ofUb occurs for Figure 4.18. That is, the minimum value ofUb can bedescribed as followingU∗b.
U∗b =C′′sTs+ 1−
2C′′sTs= 1−
C′′sTs
Because ofC′s = C′′s andC′s + C′′s = Cs ≤ Ts, C′′s takes the range of 0≤ C′′s ≤ Ts/2.Hence the absolute minimum value ofU∗b is 50%. As for the case of Equation (4.15),it is monotonically increasing inF by the same reason as the aboveR(a, d), so it isminimized whenF = 1. This is completely the same phasing as the one in Figure4.18. Namely the minimum value ofU∗b is also 50% in this case. Since the worst-case utilization bound of the schedulable per-processor utilization is 50%, that of theschedulable whole system utilization is also 50%.
4.3.4 Improving Schedulable Utilization
According to the previous section, the worst-case utilization bound for the EDDHP al-gorithm is only 50%. However, as the dissertation mentioned, this bound is obtainedonly in the special case. The values of Equation (4.16) and Equation (4.17) are often
64

CHAPTER 4. PERIODIC TASK SCHEDULING
Assumption:the algorithm is applied only wheni + 1 ≤ N.let s be the index of a task that is going to be split.let τ′′k be the second portion of a split task that was assigned toPx if there exists.1. if {U∗x − U(Πx)} + U∗x+1 > 1.02. C′s = {U∗x − U(Πx)}Ts andC′′s = Cs −C′s;3. splitτs into τ′s(C
′s,Ts) andτ′′s (C′′s ,Ts);
4. Πx = Πx ∪ τ′s andΠx+1 = {τ′′s };5. else6. Πx+1 = {τs};7. U∗x+1 = 1.0;
Figure 4.20: AIB heuristic
higher than 50%. Also it can be moreover improved if the task assigning phase effi-ciently chooses a task to split, because the utilization bound is a function of the periodand the execution time of the split task. The necessity condition for calculating theutilization bound of processorPx is described by the following expression.
Ts ≤ min{Ti | τi ∈ Πx \ τ′′s }
Since the EDDHP assigning algorithm always holds the following condition, the aboveinequation is always satisfied.
max{T j | τ j ∈ Πx−1} ≤ min{Ti | τi ∈ Πx}
Hence, the task assigning phase can choose any task residingon Px−1 to split intoPx−1
andPx.Based on this foundation, the dissertation presents a heuristic technique calledMax-
imizing Bound(MB) to maximize the utilization bound of each processor. The MBheuristic can be combined with the EDDHP assigning algorithm by replacing the pro-cedure in Figure 4.19 with the 7th to the 11th line in Figure 4.13. This procedure seeksa task that can maximize the utilization bound of the next processor if the task is splitinstead ofτi in Figure 4.13. s indicates the index of a task that will be split, and isinitialized with i (1st line). The utilization bound of the next processor is initializedwith zero (2nd line). Then, the procedure tests each taskτ j whether it can be split (4thand 5th lines). IfU∗x−{U(Πx+Us−U j)}, which is the remaining schedulable utilizationof Px under the assumption that the entire portion ofτs is assigned toPx instead ofτ j,is below zero, there is no room for any portion ofτ j to be assigned toPx. For only thetasks that passed this test, the procedure finds the task thatmaximizes the utilizationbound of the next processor (6th to 10th lines). After findingthe task maximizing theutilization bound, the procedure removesτs fromΠx and, appendsτi toΠx instead (11th
65

CHAPTER 4. PERIODIC TASK SCHEDULING
line). This replacement is valid only wheni , s. Finally, the procedure splitsτs (12thto 14th lines).
There is another approach to improve the schedulable utilization for the EDDHPalgorithm. As the dissertation already discussed, the utilization bound for the EDDHPalgorithm could be 50% in the worst case, whereas that for theEDF algorithm is al-ways 100%. Therefore, the approach of splitting a task may degrade the schedulableutilization for the algorithm compared to the case in which the task is not split. Thedissertation gives an example of this degradation. Consider the case that four tasks,τ1(2, 5), τ2(2, 5), τ3(6, 10), andτ4(4, 11)}, are assigned to two processors,P1 andP2.Being asU1 +U2 = 0.8 < 1.0 andU1 +U2 +U3 = 1.4 > 1.0, the EDDHP assigning al-gorithm splitsτ3 into P1 andP2. Then, we haveC′s = 2,C′′s = 4,Ts = 10, andTmin = 11.Because these values meets the condition ofTmin > FTs+C′′s −C′s, the utilization boundcan be calculated using Equation (4.16) and isUb ≃ 0.733. Here, the EDDHP assigningalgorithm cannot assign all the tasks successfully due toU′′3 +U4 ≃ 0.763> Ub. Mean-while, the algorithm can successfully assign the tasks ifτ3 is not split but is assigned toP2 instead due toU3 + U4 ≃ 0.963< 1.0. This example indicates that the approach ofsplitting a task can decrease schedulability.
Taking this situation into account, the dissertation presents another heuristic tech-nique calledAbsolutely-Increasing Bound(AIB). The AIB heuristic can be moreovercombined with the MB heuristic by replacing the procedure shown in Figure 4.20 withthe line 12∼14 in Figure 4.19. Note that the AIB heuristic can be also combined withthe EDDHP assigning algorithm alone by lettings = i in Figure 4.20. The procedureis straightforward. If taskτs is not split but is entirely assigned toPx+1, the remainingschedulable utilization ofPx, denoted byU∗x − U(Πx), is wasted, instead the utilizationbound ofPx+1, denoted byU∗x+1, is boosted up to 1.0. Therefore, lettingU∗x+1 be theutilization bound ofPx+1 for the case in whichτs is split, the AIB heuristic splits a taskonly if U∗x − U(Πx) + U∗x+1 > 1.0 (1st to 4th lines), otherwise it assignsτs to the nextprocessor (5th to 7th lines).
4.4 The EDDP algorithm
This section proposes the EDDP algorithm, which is the majorcontribution of this re-search. The algorithm is incremental to the RMDP and EDDHP algorithm presentedin the previous sections. However, the EDDP algorithm has different concepts in bothtask assigning and task scheduling, which results in the worst-case utilization boundof 65% that is greater than most of the traditional algorithms. At first, the task assign-ing algorithm and the task scheduling algorithm are presented. Then, the schedulablecondition, including the worst-case utilization bound, isderived.
66

CHAPTER 4. PERIODIC TASK SCHEDULING
4.4.1 Task Assigning Phase
This section describes the task assigning algorithm of EDDP. First of all, letU∗ denotethe utilization bound for the EDDP algorithm, whose specificvalue is demonstrated inSection 4.4.3. Then,τi is defined to be aheavy taskin the EDDP algorithm if it holdsa condition expressed by Inequation (4.18). Otherwise it isdefined to be alight task.
Ui > U∗ (4.18)
Figure 4.21 shows the pseudo code of the EDDP assigning algorithm. The algo-rithm assumes that the given task set includesh heavy tasks andN − h light tasks,where the heavy tasks are indexed 1∼ h and the light tasks are indexedh + 1 ∼ N.The set of the light tasks is sorted so that the period ofτi is smaller than or equal tothat of τi+1. Basically, the algorithm assigns the tasks to the processors sequentially,which means that it always assignsτi+1 afterτi. If a task causes the total utilization ofa processor to exceed its utilization bound, it splits the task into two portions. Thenit continues to assign the rest of the tasks from the next processor. A set of the tasksassigned to a processorPx is denoted byΠx.
The procedure of the algorithm is as follows. If the number ofthe heavy tasks issmaller than the number of the processors, the heavy tasks are first assigned to dedicatedprocessors (2nd to 5th lines). Note that each processorPx (1 ≤ x ≤ h) has onlyone heavy task. Then, the light tasks are assigned to the restof the processors in thesame manner as the EDDHP assigning algorithm shown in Figure4.13 that sequentiallyassigns the tasks in the order of increasing period. The firstprocessor containing lighttasks does not have the second portion of a split task, thereby the utilization bound is100% according to the EDF scheduling policy (7th line). Then, each light taskτi isassigned to a processorPx as long as the total utilization ofPx is less than or equal toits utilization bound, denoted byU∗x (8th and 9th lines). If the total utilization ofPx
exceeds the utilization bound,τi is going to be split into two portions and assigned toPx andPx+1 in the same manner as the RMDP and EDDHP assigning algorithms(12thto 16th lines). Finally, the utilization bound of the next processor is calculated usingthe formula that is specifically presented in Section 4.4.3 (19th line). Notice that theutilization bound formula does not depend of the relation between the split taskτi andthe task with the minimum periodτi+1, meanwhile the RMDP and EDDHP algorithmshave different formulas depending on the relation as shown in Figure 4.4 and Figure4.14. Therefore, it is more straightforward. If all the tasks are successfully assigned tothe processors, the algorithm is succeeded.
As mentioned above, the EDDP assigning algorithm is similarto the EDDHP as-signing algorithm but differs from in that the tasks are defined to be heavy or light, andthe heavy tasks are assigned to dedicated processors. Such apolicy is rather similarto the task assigning algorithm of EKG [81]. However, the reason of separating heavytasks and light tasks in the EDDP algorithm is arisen by a different factor. The EDDPassigning algorithm separates the heavy tasks, because theutilization bound, derived in
67

CHAPTER 4. PERIODIC TASK SCHEDULING
Assumption:i is the index of the tasks.x is the index of the processors.h is the number of the heavy tasks.U∗x is the utilization bound ofPx.Γ is sorted as follows:(i) {τi | 1 ≤ i ≤ h} are heavy tasks.(ii) {τ j | h+ 1 ≤ j ≤ N} are light tasks.
The light tasks are also sorted in increasing order of periods.1. ∀Πx = ∅ ;2. if h > M3. return FAILURE;4. for 1 ≤ i ≤ h5. Πi = {τi} ;6. x = h+ 1 ;7. U∗x = 1.0 ;8. for h+ 1 ≤ i ≤ N9. if U(Πx) + Ui ≤ U∗x
10. Πx = Πx ∪ τi ;11. else if x < M12. C′i = {U∗x − U(Πx)}Ti ;13. C′′i = Ci −C′i ;14. splitτi into τ′i (C
′i ,Ti) andτ′′i (C′′i ,Ti) ;
15. Πx = Πx ∪ τ′i ;16. Πx+1 = {τ′′i } ;17. x = x+ 1 ;18. if i + 1 ≤ N
19. U∗x = 1.0− C′i (Ti+min{C′i ,C′′i }−C′′i )
TiTi+1;
20. else21. return FAILURE;22. return SUCCESS;
Figure 4.21: EDDP assigning algorithm
68

CHAPTER 4. PERIODIC TASK SCHEDULING
execution of
Px
Px-1
i i j k
i
execution of j
execution of k
ri di dj dkt1 t4t
t2 t3
Figure 4.22: EDDP scheduling example
Section 4.4.3, is dominated by the maximal utilization of every individual task. That is,the larger the maximal utilization is, the smaller the utilization bound becomes. There-fore, the EDDP assigning algorithm lets the heavy tasks havetheir own processors sothat the heavy tasks are schedulable on their dedicated processors and the utilizationbounds of the remaining processors are increased due to the absence of the heavy tasks.
4.4.2 Task Scheduling Phase
This section describes the task scheduling algorithm of EDDP. A processor containinga heavy task needs no scheduler, since there is only one heavytask assigned. The restof the processors containing light tasks have their own schedulers that have the samescheduling policies. Assume thatτ′′i , τ′k, and{τ j | i < j < k} (i < k) are assigned toPx.More specifically,τi is split intoPx−1 andPx, and its second portionτ′′i is assigned toPx. In addition,τk is also split intoPx andPx+1, and its first portion is assigned toPx.The EDDP scheduling policy onPx is as follows.
1. If the task with the earliest deadline isτ′′i but τ′i is currently executed onPx−1,then the task with the second earliest deadline is dispatched, sinceτ′i and τ′′i ,which form a same job, cannot be executed in parallel.
2. Otherwise the task with the earliest deadline is dispatched.
In other words, the tasks are scheduled according to the EDF except thatτ′′i has the ear-liest deadline but and its corresponding first portionτ′i also has the earliest deadline and
69

CHAPTER 4. PERIODIC TASK SCHEDULING
d
C"iPx
Figure 4.23: Latest completion of EDF scheduling
C'iPx-1
d
C"i
Px
(a) Case 1:C′i ≥ C′′i
C'iPx-1
d
C'i
Px
C"i
(b) Case 2:C′i < C′′i
Figure 4.24: Latest completion of EDDP scheduling
is in execution on the neighbor processorPx−1. In this exceptional case, the schedulerdefers execution ofτ′′i until τ′i completes so thatτ′i andτ′′i are executed simultaneously.
Figure 4.22 depicts an example of EDDP scheduling in whichτi is a split taskmigrating betweenPx−1 andPx. Suppose thatτi is released at timer i with deadlinedi
that is the earliest onPx but is not onPx−1, and there are two active tasks,τ j andτk, onPx with deadlines ofd j anddk respectively, both of which are later thandi. In such acase,τ′′i starts execution onPx at timer i. Assume thatτ′i receives the earliest deadlineon Px−1 at time t1. Then,τ′i is dispatched onPx−1 andτ′′i is preempted even if it hasthe earliest deadline onPx. Instead,τ j with the second earliest deadline is dispatchedon Px. Hence,τ′′i is deferred, though it has the earliest deadline. Assume that τ′i ispreempted by a task released with an earlier deadline at timet2 and is later resumedat timet3. Then,τ′′i can be executed during a time interval [t2, t3). Also, assumingτ′icompletes, namelyτi consumesC′i time units at timet2, τ′′i is resumed again.
The scheduling policy described above has a potential problem with respect to dead-line assignments. Consider a job ofτ′′i with deadlined. If a set of the tasks assignedto Px, whose total utilization is less than or equal to 1, is scheduled according to theEDF algorithm without taking into account the exclusion betweenτ′i andτ′′i , the job ofτ′′i never misses the deadline ofd, though the job may begin at timed − C′′i and com-plete at timed in the latest case as shown in Figure 4.23. However, applyingthe EDDPscheduling policy to scheduleτ′i andτ′′i exclusively, the completion time of the job maybe delayed until timed + min{C′i ,C′′i }, if the job of τ′i is executed during [d − C′i , d)
70

CHAPTER 4. PERIODIC TASK SCHEDULING
on Px−1. Figure 4.24 depicts such a problematic scheduling. Due to execution of thecorresponding job ofτ′i , the job ofτ′′i can be deferred at mostC′i if C′i < C′′i , otherwiseit can be deferred at mostC′′i .
Taking the delay ofτ′′i into account, the EDDP algorithm takes the following poli-cies for assigning job deadlines.
• For a job ofτ′′i with deadlined, its deadline is virtually transformed tod −min{C′i ,C′′i }.
• For a job of{τ j | i < j < k} andτ′k with deadlined, its deadline is remainedd.
In other words,τ′′i is deemed to have a relative deadline ofTi − min{C′i ,C′′i }. Oncea job of τ′′i has the earliest deadline onPx, no other jobs have earlier deadlines untilthe job ofτ′′i completes, since the period (relative deadline) ofτ′′i is guaranteed to bethe smallest inΠx by the characteristic of the task assigning algorithm presented in theprevious section. Therefore, lettingd = d − min{C′i ,C′′i }, if a job of τ′′i is guaranteedto complete by timed in EDF scheduling, it is also guaranteed to complete by timed + min{C′i ,C′′i } = d. The other jobs are never deferred, so they are guaranteed tocomplete by their deadlines in EDDP scheduling if they are inEDF scheduling. Thedetailed schedulable condition for the EDDP algorithm is presented in the next section.
Figure 4.25 shows the pseudo code of the EDDP scheduling algorithm. The algo-rithm is an extension of the EDDHP scheduling algorithm so that the second portion ofa split task also has a dynamic-priority based on the EDF algorithm. In other words,the algorithm is an extension of the RMDP scheduling algorithm so that the prioriti-zation policy is based on the earliest deadline but not the shortest period. Hence, thedissertation skips the explanation of the algorithm.
4.4.3 Schedulability Analysis
This section derives the schedulable condition for the EDDPalgorithm. No deadlinemisses occur on a processor containing a heavy task, since 100% of processor time isallocated to every heavy task. Hence, the analysis focuses on the schedulable conditionsof processors where the light tasks are assigned. Like the previous section, letΠx =
{τ′′i , {τ j | i < j < k}, τ′k} (i < k) be a set of the light tasks assigned to a processorPx.The goal of this section is to derive the schedulable condition and the utilization boundof Px.
Suppose that a job of some non-split task, i.e.τs ∈ Πx \ τ′′i , misses its deadline attime d. Let t (< d) be the latest time instant at which the processor is either idle or isexecuting a job whose deadline is afterd. The total amount of processor time consumedby τ′′i in the interval of (t, d] is at most equal toW′′ expressed by Equation (4.19).
W′′ = C′′i +
⌊
d +min{C′i ,C′′i } − t −C′′iTi
⌋
C′′i (4.19)
71

CHAPTER 4. PERIODIC TASK SCHEDULING
Assumption:τi is a split task betweenPx−1 andPx.τk is a split task betweenPx andPx+1.t is the current time.ti is the last time at whichτi is dispatched onPx.tk is the last time at whichτk is dispatched onPx.ei is the remaining execution time ofτi.ek is the remaining execution time ofτk.1. function system_tick2. if any tasks are released onPx
3. if τi is released4. ei = C′′i ;5. ti = t ;6. if τk is released7. ek = C′k ;8. tk = t ;9. callschedule_Px ;
10. function schedule_Px11. if Px is idling12. go to step 17.;13. if τi is currently running onPx
14. ei = ei − (t − ti) ;15. else ifτk is currently running onPx
16. ek = ek − (t − tk) ;17. letτ j be a task with the earliest ;18. if τ j refers toτi19. if τi is in execution onPx−1
20. letτ j be a task with the second earliest deadline;21. else22. update the timer to invokesecond_endat t + ei ;23. ti = t ;24. else ifτ j refers toτk25. update the timer to invokefirst_endat t + ek ;26. tk = t ;27. if τk is in execution onPx+1
28. invokeschedule_Px+1 on Px+1 ;29. dispatch and executeτ j on Px;
Figure 4.25: EDDP scheduling algorithm
72

CHAPTER 4. PERIODIC TASK SCHEDULING
t d
C"i C"i C"iC"i
Pseudo deadline
min{C'i, C"i}Ti Ti Ti
t + C"i
Figure 4.26: Case in whichτ′′i consumes the most time
Figure 4.26 shows the case in whichτ′′i consumes this amount of time. At timet,a deferred job ofτ′′i starts with the laxity of zero and finishes att + C′′i without beingpreempted. Sinced must be after the pseudo deadline of the last job ofτ′′i in Figure4.26,τ′′i is executed at most⌊{(d+C′i )− (t+C′′i )}/Ti⌋ aftert+C′′i . Hence the maximumtotal execution time ofτ′′i in the interval of (t, d] is calculated by Equation (4.19). Since⌊a⌋ ≤ a for anya, W′′ must satisfy the following condition.
W′′ ≤ C′′i +d +min{C′i ,C′′i } − t −C′′i
TiC′′i
= U′′i (d− t + Ti +min{C′i ,C′′i } −C′′i )
Here the total amount of processor time consumed by each taskτ j ∈ Πx \ τ′′i in theinterval of (t, d] is at mostC j(d − t)/T j, since the tasks except forτ′′i are scheduledaccording to the EDF policy. In order to cause the job ofτs to miss its deadline at timed, the total amount of processor time consumed by all the jobs with deadlines beforeor at d needs to exceed the interval of (t, d]. Hence the following inequality must besatisfied whereL = d− t.
L <∑
τ j∈Πx\τ′′i
C j
T jL + U′′i (L + Ti +min{C′i ,C′′i } −C′′i )
If the above inequality is not satisfied, the job never missesits deadline. Dividing bothsides of the above inequality and consideringTs ≤ d − t, we have the schedulablecondition forτs as described by Equation (4.20).
∑
τ j∈Πx\τ′′i
U j + U′′i
(
1+Ti +min{C′i ,C′′i } −C′′i
Ts
)
≤ 1 (4.20)
Equation (4.20) implies that all the tasks must satisfy thiscondition if the task with theshortest period satisfies this condition. Since the light tasks are sorted in the order ofincreasing period,Ti+1 is the shortest in{T j | τ j ∈ Πx \ τ′′i }. Hence Equation (4.21) is
73

CHAPTER 4. PERIODIC TASK SCHEDULING
the schedulable condition for all the tasks assigned toPx.
∑
τ j∈Πx\τ′′i
U j + U′′i
(
1+Ti +min{C′i ,C′′i } −C′′i
Ti+1
)
≤ 1
⇔∑
τ j∈Πx\τ′′i
U j + U′′i ≤ 1−C′′i (Ti +min{C′i ,C′′i } −C′′i )
TiTi+1(4.21)
Notice that the left-hand side of Equation (4.21) is equal tothe total utilization ofPx.Therefore the right-hand side of Equation (4.21) is the utilization bound ofPx. Thetask assigning algorithm presented in Section 4.4.1 uses the right-hand side of Equation(4.21) as a formula of obtaining the utilization bound at theline 16 in Figure 4.21.
Now the analysis seeks to obtain the worst-case utilizationbound for the EDDPalgorithm by minimizing the right-hand side of Equation (4.21). LetU denote the right-hand side of Equation (4.21). SinceTi ≤ Ti+1, U is minimized whenTi+1 is reduced toTi.
U ≥ 1−C′′i (Ti +C′i −C′′i )
T2i
The analysis firstly considers the case ofC′i ≥ C′′i . In this case, the relations ofU′i ≥ U′′i andUi = U′i + U′′i deriveU′′i ≤ Ui/2. HenceU is minimized as follows.
U ≥ 1−C′′i (Ti +C′′i −C′′i )
T2i
≥ 1− Ui
2
Remember that the utilization of a light task is at mostU∗ according to Equation (4.18).It means thatU is minimized whenUi = U∗. Hence the worst-case utilization boundfor the case ofC′i ≥ C′′i is U∗ = 1 − U∗/2, that is,U∗ = 2/3 ≃ 66%. The analysissecondly considers the case ofC′i ≤ C′′i . In this case,U is minimized as follows withtakingU′i = Ui − U′′i into account.
U ≥ 1−C′′i (Ti +C′i −C′′i )
T2i
= 1− U′′i (1+ U′i − U′′i )
= 1− U′′i (1+ Ui − 2U′′i )
= 2U′′i2 − (1+ Ui)U
′′i + 1
= 2
(
U′′i −1+ Ui
4
)2
+ 1− (1+ Ui)2
8
≥ 1− (1+ Ui)2
8
74

CHAPTER 4. PERIODIC TASK SCHEDULING
By the same token as the case ofC′i ≥ C′′i , U is minimized whenUi = U∗. Hence,the worst-case utilization bound for the case ofC′i ≤ C′′i is U∗ = 1 − (1 + U∗)2/8,that is,U∗ = 4
√2 − 5 ≃ 65%. This is the absolute worst-case utilization bound for
the EDDP algorithm. This utilization bound is valid for any processor where the lighttasks are assigned. In addition, the utilization of any processor where a heavy task isassigned is equal to the utilization of the heavy task that ishigher thanU∗ = 4
√2− 5.
In consequence, the schedulable utilization of the whole system is always higher than4√
2− 5 ≃ 65%.
4.4.4 Improving Schedulable Utilization
In Section 4.3.4, two heuristics were introduced to improvethe schedulable utilizationfor the EDDHP algorithm. Both of the heuristics are applied when a task is split in thetask assigning phase. The first heuristic is splitting a taskthat maximizes the utilizationbound. This heuristic can be used in the EDDP algorithm, since the utilization bounddefined by Equation (4.21) is a function ofC′i , C′′i , Ti andTi+1 that can be all acquiredwhen a task is split in the task assigning algorithm. The second heuristic is splittinga task only if necessary. This heuristic can be also used in the EDDP algorithm. Theschedulable utilization for the EDDP algorithm degrades due to existence of the secondportion of a split task according to the schedulability analysis. Consider the case inwhich τi is about to be split intoτ′i assigned toPx andτ′′i assigned toPx+1. Let U(Px)be the current utilization ofPx beforeτ′i is assigned and letU∗x+1 be the utilization boundof Px+1 for the case in whichτ′′i is assigned to. If taskτi is not split intoPx andPx+1 butjust assigned toPx+1 like the partitioning approach, the schedulable utilization of Px+1
is 100%. Therefore it is better not to splitτi if U(Px) + C′i + U∗x+1 < U(Px) + 100%.This heuristic also has an effectiveness of reducing task preemptions, since it reducesunnecessary split tasks that cause more task preemptions.
This section also considers another heuristic technique specific for the EDDP algo-rithm. According to the EDDP assigning algorithm, a processor where a heavy task isassigned may leave the schedulable utilization, since the schedulable utilization boundof such processor is always 100%. The the heuristic is partitioning the remaining lighttasks to the processors where a heavy task is assigned. This heuristic tries to assignthe remaining light tasks to the processors where a heavy task is assigned by the par-titioning method such as the first-fit algorithm and the best-fit algorithm when the taskassigning algorithm fails. Using this heuristic, the processors are utilized more effi-ciently.
4.5 Summary
This chapter first described the basic strategy of the portioned scheduling technique.It then gave the theoretical descriptions of the three scheduling algorithms: RMDP,
75

CHAPTER 4. PERIODIC TASK SCHEDULING
EDDHP, and EDDP. It also presented the schedulability analyses of those algorithms.The important characteristics of the developed algorithmsare:
• The RMDP algorithm has a worst-case utilization bound of 50%that is equal tothe maximum utilization bound of the existing RM-based scheduling algorithms.The utilization bound of the RMDP algorithm is boosted up to 65% for the casein which the second portion of a split task is executed three times within anyperiods.
• The EDDHP algorithm is an dynamic-priority extension of theRMDP algorithmand has a worst-case utilization bound of 50%. Unlike the RMDP algorithm,the utilization bound does not rely on the number of the tasks, and hence thecalculation of the utilization bound is done only once for each processor. Thischaracteristic enables the algorithm to exploit the heuristics to improve a utiliza-tion bound.
• The EDDP algorithm is an further extension of the EDDHP algorithm. Whilethe RMDP and EDDHP algorithms have similar manners in task assigning andtask scheduling, the EDDP algorithm has different manners. It has a worst-caseutilization bound of 65% that is higher than most of the traditional efficient al-gorithms. Only the EKG algorithm transcends this bound, however in imple-mentation it requires more fine-grained timers than the one used in the EDDPalgorithm. The heuristics to improve a utilization bound can be also applied tothe EDDP algorithm.
• The developed algorithms are implementable enough for practical use. Theyrequire only a single timer invocation for either the first portion or second portionof a split task within each period.
76

Chapter 5
APERIODIC TASK SCHEDULING
This chapter presents two efficient techniques, calledglobal dispatchandtemporal mi-gration, for the scheduling of aperiodic tasks on multiprocessor systems. The primaryfocus under aperiodic task scheduling is at reducing the response time of aperiodic tasksas much as possible, without violating timing constraints of periodic tasks. Timing con-straints of aperiodic tasks are not taken into account, meaning that no aperiodic tasksare assumed to have deadlines. It is also assumed that periodic tasks are partitionedamong processors. Though the portioned scheduling algorithms presented in Chapter 4should be applied for the scheduling of periodic tasks when the total integration of thescheduling techniques established in this research is concerned, the dissertation designsthe scheduling of aperiodic tasks with the simple partitioned scheduling algorithms inthis chapter, since the theoretical description of the aperiodic task scheduling becomesfar complicated if the periodic tasks are portioned. Instead, the dissertation mentionsthe compatibility of the techniques to the portioned scheduling algorithms in Section5.4. Concrete integration of the established scheduling techniques and its precise theo-retical analysis are left for the future work.
The global dispatch technique and the temporal migration technique are used bycombining with traditional server algorithms. Since the dissertation covers both thestatic-priority scheduling scheme and the dynamic-priority scheduling scheme, the Pri-ority Exchange (PE) algorithm [8] and the Total Bandwidth Server (TBS) algorithm[17], which are known to be efficient algorithms in the domain of uniprocessor sys-tems, are adopted as bases for the two scheduling schemes respectively. Then, theobjective of this chapter is to extend the designs of the PE algorithm and the TBS algo-rithm, in which the global dispatch technique and the temporal migration technique areexploited, to reduce the response time of aperiodic tasks.
This chapter begins with describing the basic strategies ofthe global dispatch tech-nique and the temporal migration technique. Then, the designs of the PE-based algo-rithm and the TBS-based algorithm, in which those two techniques are exploited, arepresented. The compatibility of the presented algorithms to the portioned schedulingalgorithms is also discussed.
77

CHAPTER 5. APERIODIC TASK SCHEDULING
P1 P2 P3
Aperiodic task
Aperiodic
handlerDispatch
Figure 5.1: Concept of global dispatch
5.1 Basic Strategy
First of all, the basic strategies of the global dispatch technique and the temporal mi-gration technique are explained. To the best of my knowledge, no work have stronglydefined the scheduling model of aperiodic tasks on multiprocessor systems, especiallyfor the partitioned scheduling. In this research, every processor has its local aperiodicserver. The capacities, periods, and utilizations (bandwidths) of the servers are not nec-essarily symmetric. The arrival processor of each aperiodic task is not determined inadvance; that is, aperiodic tasks can arrive on any processors.
In partitioned scheduling, it is fairly easy to partition aperiodic tasks as well as pe-riodic tasks. In other words, the arrival processor is fixed for each aperiodic task. How-ever, this partitioning raises unbalanced loads among the processors, which may resultin furiously-low responsiveness on some processors. In order to enhance the respon-siveness on every processor, the global dispatch techniquesubmits the unique aperiodichandler implemented in one of the local schedulers, which receives all the arrivals ofaperiodic tasks. The handler dispatches an arriving aperiodic task to a processor onwhich the response time of the aperiodic task is estimated tobe minimized. After dis-patching, the execution of the aperiodic task is handled by the local server. Thus, everyprocessor is always maintained to be responsive. Figure 5.1depicts the concept of theglobal dispatch technique. In the figure, the first processorP1 carries out a global ape-riodic handler and it dispatches an aperiodic task toP3. The policy of the dispatch,i.e. the procedure to find the effective processor, depends on a server (scheduling) al-gorithm. The idea of the global dispatch technique is very straightforward, however nospecific algorithms based on such a technique have ever been discussed. The disserta-
78

CHAPTER 5. APERIODIC TASK SCHEDULING
Task migrations
P1 P2 P3
Periodic task
Aperiodic task
Figure 5.2: Concept of temporal migration
tion designs the server algorithms based on the traditionalPE algorithm and the TBSalgorithm in Section 5.2 and Section 5.3 respectively.
In addition to the global dispatch technique, the dissertation presents the temporalmigration technique. This technique stands on the idea thatperiodic tasks with higherpriorities than an arriving aperiodic task are temporarilymigrated onto other processorsto hand over processor time to the arriving aperiodic task, as long as the periodic taskscan be guaranteed to meet their deadlines after temporal migrations. Figure5.2 illus-trates the concept of the temporal migration technique. In the figure, the first processorP1 has two periodic tasks stored in a priority-ordered queue inadvance of an aperiodictask. Without migrations, the pending aperiodic task has a long wait for completionsof the prior two periodic tasks so that the timing constraints of the periodic tasks areguaranteed. Migrating those two periodic tasks to the neighbor processors, on the otherhand, the pending aperiodic task can be immediately executed on the processor. As aresult, the response time of the aperiodic task is reduced. The issue of concern hereis that the migrating periodic tasks must be maintained schedulable on the destinationprocessors, and should not affect the responsiveness to the already-pending aperiodictasks. The migration policy needs to take those kinds of affairs into account.
As for the concept of the temporal migration technique, there can be an idea thataperiodic tasks are also migrative. However, the task migrations inevitably degrade thecache hit ratios, which leads to the performance deterioration in practice. The require-ments of periodic tasks are meeting deadlines and the performance deterioration is nota matter as much, because they are supposed to be scheduled based on the worst-caseexecution time from the theoretical point of view. In contrast, the performance dete-
79

CHAPTER 5. APERIODIC TASK SCHEDULING
rioration is problematic for aperiodic tasks, because the aperiodic tasks are desired tocomplete as soon as possible. Therefore, the temporal migration technique is estab-lished based on the policy that no aperiodic tasks are migrated onto different processorsfrom the processor on which they are released (dispatched).
5.2 The PE-based Algorithm
This section presents the PE-based algorithm that combinesthe global dispatch tech-nique and the temporal migration technique with the traditional PE algorithm. It ispresumed that periodic tasks are partitioned and are scheduled according to the RMalgorithm on every processor.
The PE algorithm is often compared with the Deferrable Server (DS) algorithm[8], since their performances are competitive. With respect to the DS algorithm, thePE algorithm has slightly worse performance in terms of aperiodic responsiveness butachieves better schedulable utilization for periodic tasks. More precisely, the DS algo-rithm declines the utilization bound of the RM algorithm, where a server is assignedthe highest priority, down to either of 50% or 65% depending on the characteristic of atask set [15]. By contrast, the PE algorithm never declines the utilization bound of theRM algorithm, i.e. the bound is never less than 69% for any task set [1], though theaperiodic responsiveness is slightly worse than the DS algorithm.
Considering the integration with the RMDP algorithm presented in Section 4.2,this research adopts the PE algorithm to design the specific procedures of the globaldispatch and temporal migration techniques due to the following reasons:(i) the factthat the DS algorithm declines the utilization bound of the RM algorithm down to 50%in the worst case, which is originally 69%, implies that it would moreover decline theutilization bound of the RMDP algorithm, which is originally 50%, and(ii) the analysisof the schedulability for the RMDP algorithm combined with the DS algorithm is morecomplicated, since there exists two deferrable tasks; thatis, the second portion of a splittask and a server.
5.2.1 Priority Exchange Review
First of all, the design of the PE algorithm is reviewed. The PE algorithm uses a peri-odic server, usually at a high priority, for servicing aperiodic requests. While the DSalgorithm differs the server capacity when there are no pending aperiodic tasks, the PEalgorithm preserves the server capacity by exchanging it for the execution time of alower-priority periodic task.
At the beginning of each server period, the capacity is replenished at its full value.If aperiodic tasks are pending and the server is the ready task with the highest priority,then the aperiodic tasks are serviced using the available capacity. Otherwise, the ca-pacity is exchanged for the execution time of the active periodic task with the highest
80
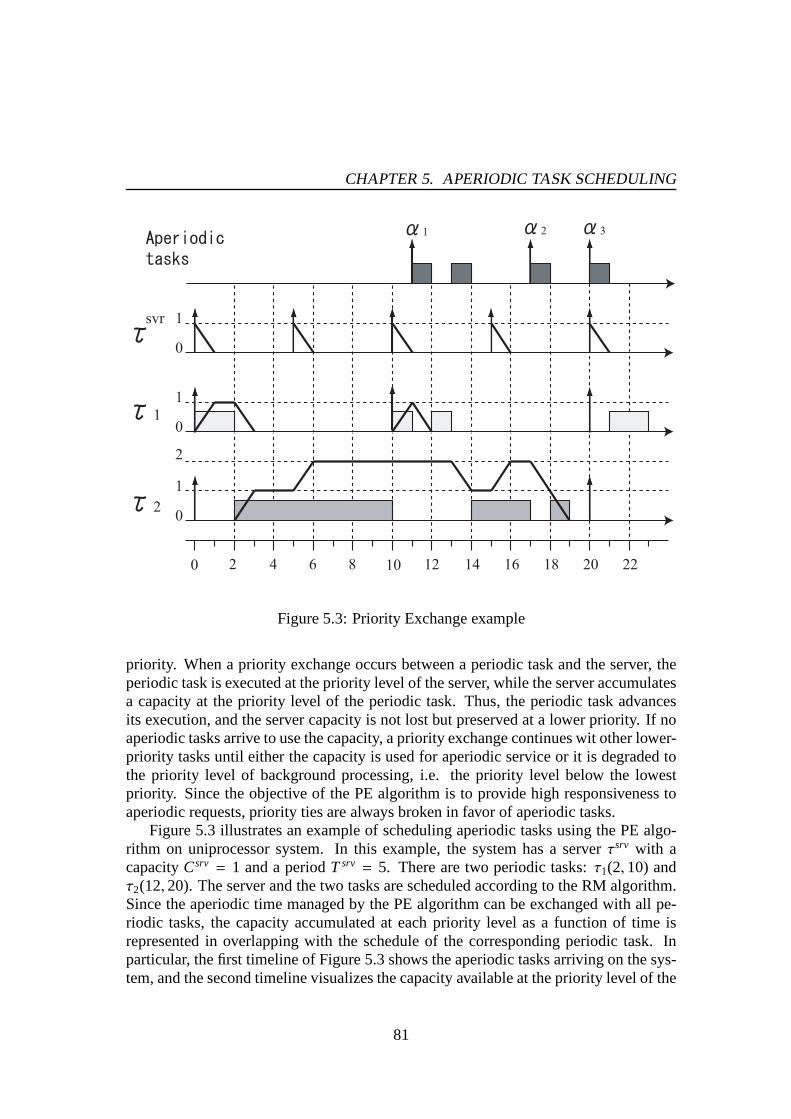
CHAPTER 5. APERIODIC TASK SCHEDULING
1 2
1
2
0 10 20
svr
0
1
0
1
0
1
2
2 124 146 168 18
3
22
Figure 5.3: Priority Exchange example
priority. When a priority exchange occurs between a periodic task and the server, theperiodic task is executed at the priority level of the server, while the server accumulatesa capacity at the priority level of the periodic task. Thus, the periodic task advancesits execution, and the server capacity is not lost but preserved at a lower priority. If noaperiodic tasks arrive to use the capacity, a priority exchange continues wit other lower-priority tasks until either the capacity is used for aperiodic service or it is degraded tothe priority level of background processing, i.e. the priority level below the lowestpriority. Since the objective of the PE algorithm is to provide high responsiveness toaperiodic requests, priority ties are always broken in favor of aperiodic tasks.
Figure 5.3 illustrates an example of scheduling aperiodic tasks using the PE algo-rithm on uniprocessor system. In this example, the system has a serverτsrv with acapacityCsrv = 1 and a periodTsrv = 5. There are two periodic tasks:τ1(2, 10) andτ2(12, 20). The server and the two tasks are scheduled according to the RM algorithm.Since the aperiodic time managed by the PE algorithm can be exchanged with all pe-riodic tasks, the capacity accumulated at each priority level as a function of time isrepresented in overlapping with the schedule of the corresponding periodic task. Inparticular, the first timeline of Figure 5.3 shows the aperiodic tasks arriving on the sys-tem, and the second timeline visualizes the capacity available at the priority level of the
81

CHAPTER 5. APERIODIC TASK SCHEDULING
server, whereas the third and the fourth ones refer to the capacities accumulated at thecorresponding priority levels as a consequence of the priority exchange mechanism.
In the figure, at timet = 0, the server is brought at its full capacity, but no aperiodictasks are pending, so the capacity is exchanged with the execution time ofτ1. As aresult, τ1 advances its execution and the server accumulates one unit of time at thepriority level of τ1. At time t = 2, τ1 completes andτ2 begins execution. Since noaperiodic tasks are pending at this time, another priority exchange takes place betweenτ1 andτ2. At time t = 5, the capacity is replenished at the server priority, and butno aperiodic tasks are pending again, the server accumulates one unit of time at thepriority level ofτ2, sinceτ1 is idle. So does at the priority level ofτ1 at timet = 10. Attime t = 11, when the first aperiodic taskα1(11, 2) arrives, it is interesting to observethat the first unit of its computation time is immediately executed by using the capacityaccumulated at the priority level ofτ1. Then, since the remaining capacity is availableat the lowest-priority level andτ1 is still active,α1 is preempted byτ1 and is resumed attimet = 13, whenτ1 completes. At timet = 17, the capacity accumulated at the prioritylevel of τ2 is used to execute the second aperiodic taskα2(17, 1). At time t = 20, thecapacity is replenished at the server priority, and it is used to execute the third aperiodictaskα3(20, 1).
Assume thatn periodic tasks,τ1, τ2, ..., τn, are scheduled on the system with aPriority Exchange serverτsrv that has a capacityCsrv and a periodTsrv. Accordingto Lehoczkyet al. [8], the processor is guaranteed to be schedulable if the serverhas the highest priority on the system and the following condition is satisfied whereUsrv = Csrv/Tsrv.
n∑
i=1
Ui ≤ n
(
2Usrv
+ 1
)1/n
− 1
(5.1)
5.2.2 Global Dispatch Procedure
The global dispatch procedure of the PE algorithm dispatches an arriving aperiodic taskto a processor on which the worst-case response time of the aperiodic task is minimized.The procedure expects that if the worst-case response time is low, the real response timewould be also low. Hence, the worst-case response time of theaperiodic task in the PEalgorithm must be analyzed.
Consider that an aperiodic taskαk is arriving on the system with an execution timeof Ek at timeak. Let csrv
x (t) be the remaining capacity of the server, not including theexchanged ones, on a processorPx at timet. With respect to the latest finish time ofαk,whenαk arrives at timet = ak, the following three cases can occur, whereWx(t) be thetotal amount of the remaining execution times of pending aperiodic tasks onPx.
1. Ek +Wx(t) ≤ csrvx (t). Hence,αk completes at timet + Ek +Wx(t).
82

CHAPTER 5. APERIODIC TASK SCHEDULING
2. Ek +Wx(t) > csrvx (t), andcsrv
x (t) is completely consumed within the current periodof the server. In this case, time units of∆k = csrv
x (t) are consumed byαk and theprior pending aperiodic tasks.
3. Ek + Wx(t) > csrvx (t), but the current period of the server ends before ˜csrv
x (t) iscompletely consumed. In this case, time units of∆ = GTsrv
x − t, whereG =⌈t/Tsrv
x ⌉, are consumed byαk and the prior pending aperiodic tasks.
In the last two cases, the time units consumed byαk and the prior pending aperi-odic tasks within the current period of the server can be computed by the followingexpression.
∆ = min{csrvx (t),GTsrv
x − t}
Thus, the latest finish timefk of αk can be derived as follows.
fk =
{
t + Ek +Wx(t) if Ek +Wx(t) ≤ csrvx (t)
(F +G)Tsrvx + H otherwise
Here,F andH are expressed as follows.
{
F =⌊
Ek+Wx(t)−∆Csrv
x
⌋
H = Ek +Wx(t) − ∆ − FCsrvx
The global aperiodic handler then dispatchesαk to a processorPx which has the smallestvalue of fk, because it expects that if the latest finish time ofαk is minimized onPx,the real finish time ofαk would be also minimized. Notice thatαk may complete muchearlier than fk, if idle times unused by periodic tasks are left enough, soPx is notnecessarily a processor on whichαk can have the earliest finish time.
5.2.3 Temporal Migration Procedure
The temporal migration procedure of the PE algorithm is straightforward. Periodictasks are assumed to be sorted so thatTi ≤ Ti+1, namelyτi has a higher priority thanτi+1. The kth aperiodic task dispatched to a processorPx by the aperiodic handler,presented in the previous section, is defined byαx,k(ax,k,Ex,k) whereax,k is its arrivaltime andEx,k is its worst-case execution time. The finish time ofαx,k is denoted byfx,k
and the response time ofαx,k is denoted byRx,k = fx,k − ax,k. The consumed executiontime and the remaining execution time ofαx,k at timet are denoted byex,k(t) andex,k(t)respectively.
Assume that at timet any aperiodic taskαx,k is dispatched toPx, which has a localserverτsrv
x with a capacityCsrvx ) and a periodTsrv
x . The utilization of the server isdenoted byUsrv
x = Csrvx /T
srvx . At this moment, temporal migrations occur according to
the procedure described as follows.
83

CHAPTER 5. APERIODIC TASK SCHEDULING
1. LetΛx be the set of the periodic tasks whose indexes are lower than the lowestindex of the tasks that hold the preserved (exchanged) capacities of the server.The procedure searches for a ready periodic jobτi, j with the shortest period (thehighest priority) inΛx, which is not being temporarily migrated within its period.If such a task is not found, the procedure exits and no temporal migrations occurat timet.
2. The procedure estimates the latest finish time ofτi, j when it is served by the PEserver on every processorPy as follows. LetWy(t) be the total amount of theremaining execution times of pending aperiodic tasks onPy andAy(t) be the totalamount of the accumulated capacities at the higher prioritylevels thanτi, j on Py.Then, taking the same step described in Section 5.2.2, the worst-case finish timefi, j of τi, j on Py is obtained by the following expression where ˜ci, j(t) and csrv
y (t)denote the remaining execution time and the remaining capacity of τi, j andτsrv
yrespectively.
fi, j =
{
t + ci, j(t) +Wy(t) if ci, j +Wy(t) ≤ csrvy (t)
(F +G)Tsrvy + H otherwise
(5.2)
Here,G, ∆, F andH are replaced as follows.
G =
⌊
tTsrv
y
⌋
∆ = min{csrvy (t),GTsrv
y − t}F =
⌊
ci, j+Wy(t)−∆−Ay(t)Csrv
y
⌋
H = ci, j +Wy(t) − ∆ − Ay(t) − FCsrvy
3. If the procedure finds more than one processor that satisfies fi, j ≤ di, j, τi, j ismigrated onto one of such processors. Otherwise, the procedure removesτi, jfromΛx, i.e.Λx = Λx \ {τi, j}, and goes back to Step 1.
4. Let Pz be a processor onto whichτi, j is migrated and there arel aperiodic taskswhich have already arrived before timet. Then,τi, j is transformed into and istreated as thel + 1th aperiodic task onPz.
5. The procedure accumulates a capacity of ˜ci, j(t) at the priority leveli.
6. At timer i, j+1, τi is migrated back ontoPx. That is,τi, j+1 is released onPx.
7. The procedure goes back to Step 1.
84

CHAPTER 5. APERIODIC TASK SCHEDULING
Responsiveness
The response time of an arriving aperiodic task can be reduced by the temporal migra-tion procedure, since the processor time of migrated periodic tasks which were sup-posed to be executed preferentially is allocated to the pending aperiodic tasks. In ad-dition, the response times of the aperiodic tasks which havebeen already pending arenever affected by the temporal migrations, since the migrated periodic tasks are treatedas the latest aperiodic tasks and they are never serviced in advance of the pending ape-riodic tasks. However, it is not theoretically guaranteed that the overall response timeof aperiodic tasks is reduced, because the response time of aperiodic tasks arriving ina future will be affected by the executions of the migrated periodic tasks. Thus, a the-oretical guarantee is needed. Although such a guarantee is left for the future work,the dissertation demonstrates that the temporal migrationtechnique has a capability toreduce the response time of aperiodic tasks dramatically inthe simulation studies.
Schedulability
Periodic tasks are temporarily migrated only when their latest finish times, described byEquation (5.2), are guaranteed to be earlier than or equal totheir deadlines. In addition,the migrated periodic tasks are serviced by the PE servers, and hence the schedulabilityof the other periodic tasks is never jeopardized. As a result, the system is obviouslymaintained schedulable after temporal migrations.
Processor Selection
The concern here is a selection of the processors, if more than one processor is foundat Step 2, so that the response time of aperiodic tasks is reduced as much as possible.Note that obtaining the optimal selection is out of concern in this research, because(i)the definition of the optimal selection is vague, and(ii) even if the optimal selection isdefined, the selection itself is reduced to a bin-packing problem which is NP-hard in astrong sense. Therefore, this research focuses on the heuristic approaches to select aprocessor onto which a task is migrated. The dissertation introduces the three heuris-tics: first-fit (FF), best-fit (BF), and worst-fit (WF). The three heuristics determines atarget processor as follows.
• The FF heuristic migratesτi, j to the first (i.e., lowest-indexed) processor thatsatisfiesfi, j ≤ di, j.
• The BF heuristic migratesτi, j to a processor that(i) satisfies the condition offi, j ≤ di, j and(ii) minimizes the value ofdi, j − fi, j.
• The WF heuristic, on the other hand, migratesτi, j to a processor that(i) satisfiesthe condition offi, j ≤ di, j and(ii) maximizes the value ofdi, j − fi, j.
85

CHAPTER 5. APERIODIC TASK SCHEDULING
0 6 12
1 2 3v1 v2 v3
18 24
2 107 14 17 25
0 8 16 24
1
2
Figure 5.4: Total Bandwidth Server example
The order of the performance superiority in the three algorithms cannot be analyzedtheoretically, hence it is evaluated in the simulation studies in Chapter 6.
5.3 The TBS-based Algorithm
This section presents the TBS-based algorithm that combines the global dispatch tech-nique and the temporal migration technique with the traditional TBS algorithm for thediscipline of dynamic-priority scheduling. The TBS algorithm is known to be an ef-ficient dynamic-priority server algorithm in the domain of uniprocessor systems. Theassumption herein is that periodic tasks are partitioned and scheduled according to theEDF algorithm on every processor.
5.3.1 Total Bandwidth Server Review
The TBS algorithm is known to be an efficient, probably the most efficient, algorithmin the traditional dynamic-priority server algorithms from the viewpoints of implemen-tation complexity, memory requirement, runtime overhead and so on. Every time anaperiodic task arrives, the server assigns the possible earliest deadline to the aperiodictask, which is of course the virtual one. Once the aperiodic task is assigned the vir-tual deadline, it is scheduled with other periodic tasks according to the EDF algorithm.The virtual deadline of the aperiodic task is determined based on the bandwidth of theserver. Suppose that the system has a serverτsrv with a bandwidthUsrv. Assuming thatthe kth aperiodic taskαk arrives on the system at timeak with an execution timeEk,then its virtual deadlinevk is calculated by Equation (5.3), wherev0 = 0 by definition.
vk = max{ak, vk−1} +Ek
Usrv(5.3)
86

CHAPTER 5. APERIODIC TASK SCHEDULING
Figure5.4 shows an example of EDF scheduling produced by twoperiodic tasks,τ1(3, 6) andτ2(2, 8), and a server with a bandwidthUsrv = 1−(U1+U2) = 0.25. The firstaperiodic task, denoted byα1(2, 2), arrives at timea1 = 2 with an execution timeE1 = 2and is serviced with a virtual deadlinev1 = a1 + E1/Usrv = 2 + 2/0.25 = 10. Beingv1 a deadline later than the deadlines ofτ1,1 andτ2,1, the aperiodic task cannot beginexecution untilτ1,1 and τ2,1 complete. Similarly, the second aperiodic taskα2(7, 1),which arrives at timea2 = 7 with an execution timeE2 = 1, receives a virtual deadlinev2 = max{a2, v1} + E2/Usrv = 10+ 4 = 14, but it is not serviced immediately, sinceat time 7τ1 is still active with an earlier deadline of 12. Finally, the third aperiodictaskα3(17, 2) arrives at timea3 = 17 with an execution timeE3 = 2 and gets a virtualdeadlinev3 = a3 + E3/Usrv = 25. It does not receive immediate service, since at time17τ1 andτ2 are active and have deadlines of 24 earlier thanα3.
5.3.2 Global Dispatch Procedure
The global dispatch procedure of the TBS algorithm is much more straightforward thanthat of the PE algorithm. Unlike the PE algorithm, it is far hard to analyze the worst-case response time of each aperiodic task in the TBS algorithm, since the priority orderof tasks is dynamically changed based on deadlines. Therefore, another indicator of theresponse time is needed.
As described in the previous section, every aperiodic task is assigned the virtualdeadline in the TBS algorithm. Then, no aperiodic tasks misstheir virtual deadlines aslong as the total processor utilization is less than or equalto 1. In other words, everyaperiodic task is guaranteed to complete before the assigned virtual deadline. Thus, thevirtual deadline can be deemed to be the worst-case responsetime, though the aperiodictask usually completes much earlier than the virtual deadline. By the same reason as thePE algorithm, it is expected that the response time of the aperiodic task is minimizedby dispatching it to a processor on which the earliest virtual deadline is assigned. Inconsequence, the global aperiodic handler for the TBS algorithm is designed so thatit dispatches an arriving aperiodic task to a processor on which the virtual deadlineexpressed by Equation (5.3) is minimized.
5.3.3 Temporal Migration Procedure
This section describes the temporal migration procedure ofthe TBS algorithm. Likein Section 5.2.3, thekth aperiodic task dispatched to a processorPx by the aperiodichandler is defined byαx,k(ax,k,Ex,k) whereax,k is its arrival time andEx,k is its worst-case execution time. The virtual deadline assigned toαx,k is described byvx,k. Then,the finish time ofαx,k is denoted byfx,k and the response time ofαx,k is denoted byRx,k = fx,k − ax,k. The consumed execution time and the remaining execution time ofαx,k at timet are denoted byex,k(t) andex,k(t) respectively.
87

CHAPTER 5. APERIODIC TASK SCHEDULING
Suppose that at timet any aperiodic taskαx,k arrives on any processorPx, which hasits own server with a bandwidthUsrv
x , and is assigned a virtual deadlinevx,k according toEquation (5.3). At this moment, temporal migrations occur according to the followingprocedure.
1. The procedure searches for a periodic jobτi, j with the earliest deadline, whichhas not been already migrated in its period. If such a job doesnot exist, theprocedure exits.
2. The algorithm seeks any processorPy that satisfies Inequation (5.4) wherevy,l isthe virtual deadline assigned to the last aperiodic taskαy,l that arrived onPy, andci, j(t) is the remaining execution time ofτi, j.
di, j ≥ max{t, vy,l} +ci, j(t)
Usrvy
(5.4)
3. The procedure migratesτi, j onto Py and virtually deals with it as thel + 1thaperiodic task onPy with a virtual deadlinevy,l+1, expressed by Equation (5.6).Note that the next aperiodic task arriving onPy after timet is indexed byl + 2.
vy,l+1 = max{t, vy,l} +ci, j(t)
Usrvy
(5.5)
4. The algorithm reassigns the improved virtual deadlinev′x,k, expressed by Equation(5.6), toαx,k.
v′x,k = max{t, vx,k−1} +Ex,k
Usrvx +
ci, j (t)Ti
(5.6)
5. The procedure then makes sure that its next jobτi, j+1 is migrated back ontoPx attime r i, j+1, and it may be temporarily migrated again.
The procedure assumes that the migrated jobτi, j transforms into the aperiodic taskαy,l+1. Hence, it must usevy,l+1 to calculate the virtual deadline of the next arrivingaperiodic task. Note that assigningvy,l+1 to τi, j is not desirable from the responsivenesspoint of view, because it is a periodic job and does not required to complete as soonas possible. In order to execute the pending aperiodic tasksearlier, the true deadlinedi, j should be assigned. However, such a deadline assignment leads a schedulabilityanalysis to be complicated. In consequence, this research takes a simple approach inwhich the virtual deadlinevy,l+1 is assigned to the migrating jobτi, j. More sophisticateddeadline assignments are left for the future work. Notice that the Step 1 of the procedureguarantees that any migrated job is never migrated again to another processor in thesame period. In other words, two-level migrations are not permitted.
88

CHAPTER 5. APERIODIC TASK SCHEDULING
0 6 12
x,1 x,2 x,3vx,1 vx,2 vx,3
18 24
2 107 14 17 25
0 8 16 24
1
2
0 4 12
1 2vy,1 vy,2
20 24
2 6 2117
0
8 16
20
3
4
v'x,1
6.8
v'x,3
22.3
10
Figure 5.5: Total Bandwidth Server with Temporal Migrationexample
Figure 5.5 depicts an example of the TBS algorithm in which the temporal migrationtechnique is applied. Suppose that there are two processors: Px and Py. The sameperiodic tasksτ1(3, 6) andτ2(2, 8) in the example of Figure 5.4 are scheduled onPx.In addition, two more tasksτ3(1, 4) andτ4(5, 10) are scheduled onPy. The servers onboth of the processors have bandwidths of 0.25. The periodic tasks are scheduled by theEDF algorithm. For simplicity of explanation, no aperiodictasks are expected to arriveonP2. At time t = 2, the first aperiodic taskαx,1(2, 2) arrives onPx. Without a temporalmigration, it receives a virtual deadline of 10. Meanwhile,exploiting the temporalmigration technique,τ1 can be temporarily migrated ontoPy, since it satisfies Equation(5.4) and receives a virtual deadlinevy,1 = t+ c1,1(t)/Usrv
y = 2+1/0.25= 6 according toEquation (5.5). Then,αx,1 is assigned an improved virtual deadlinev′x,1 = 2+2/(0.25+1/6) = 6.8 according to Equation (5.6).αx,1 gets an virtual deadline earlier thanτ2 andτ1 is temporarily absent onPx, αx,1 can be executed immediately. In contrast,τ1 cannotbe temporarily migrated when the second aperiodic taskαx,2 arrives at timet = 7, sinceit would receive a virtual deadlinet + c1,2(t)/Usrv
y = 7+ 2/0.25 = 15 that is later thanthe original deadline 12. Hence,αx,2 does not receive an improved virtual deadline
89

CHAPTER 5. APERIODIC TASK SCHEDULING
in this case. However,αx,2 can be executed one time unit earlier than the example ofFigure5.4, because at time 2τ1 consumes one time unit onPy by a temporal migration,and hence the whole schedule is advanced one time unit. Finally, at timet = 17 the thirdaperiodic taskαx,3 arrives andτ2 can be migrated ontoPy. αx,3 therefore receives animproved virtual deadlinev′x,3 = 17+2/(0.25+1/8) = 22.3 and is serviced immediately,since it has a deadline earlier thanτ1 andτ2. Comparing Figure5.5 with Figure5.4, theeffectiveness of temporal migrations can be clearly observed.The response time ofαx,1
is reduced toRx,1 = 4 − 2 = 2 from 7− 2 = 5 . Similarly, the response times ofαx,2
andαx,3 are reduced toRx,2 = 10− 7 = 3 andRx,3 = 19− 17 = 2 from 11− 7 = 4 and23− 17= 6 respectively.
Responsiveness
Two benefits for reducing the response time of an aperiodic task.are obtained by thismigration policy. The first one is that the turn of the aperiodic execution comes faster,since a periodic job with an earlier deadline may be migratedonto another processor,and hence it disappears from the processor. Such a benefit is observed in the responsetime of αx,2 in Figure5.5. Although it does not an improved virtual deadline, but itcan be executed one time unit earlier, becauseτ1 disappears from the processor at time2. The temporal migration procedure presented in Section 5.3.3 can be recursive tomoreover improve the responsiveness to the arriving aperiodic task. More precisely,though the algorithm targets only one job with an earlier deadline at the Step 1 of theprocedure, if the algorithm chooses more than one job with anearlier deadline to betemporarily migrated onto different processors, it is expected that the response timeof the arriving aperiodic task can be moreover reduced. However, such a recursiveprocedure requires much more computation cost and is not adopted in the algorithm,because this work aims practical approaches.
The second benefit is that the server bandwidth is temporarily broaden due to tem-poral absences of migrating periodic jobs, which enables anaperiodic task to have anearlier virtual deadline as expressed by Equation (5.6). Such a benefit is observed inαx,1 andαx,3 in Figure5.5. For example,τx,1 is supposed to have a virtual deadline of 10without temporal migrations, but it actually receives a virtual deadline of 6.8 with tem-poral migrations, and the improved virtual deadline skips over the deadline ofτ2 equalto 8. The same deadline skip can be seen for the case ofαx,3. In addition, the respon-siveness to the already-pending aperiodic tasks onPy is never affected by a migratingjob τi, j, since the migration condition of Inequation (5.4) guarantees that the migrat-ing job is inevitably assigned a virtual deadline later thanany virtual deadlines of thepending aperiodic tasks. Therefore, the migrating job is never scheduled in advance ofthe pending aperiodic tasks, which means that the completion time of the pending ape-riodic tasks is never prolonged. Meanwhile, the response time of the aperiodic tasksarriving in the future within [t, vi,l+1] on Py can be worse unfortunately, because thevirtual deadlines assigned to them are shifted forvy,l+1 − vy,l time units, compared to
90

CHAPTER 5. APERIODIC TASK SCHEDULING
the ones without the temporal migration techniques. However, when there are periodictasks with deadlines earlier than the assigned virtual deadlines of the arriving aperiodictasks, the algorithm attempt temporal migrations after all, and the response time canbe reduced as much as possible again. In consequence, the expectation is that the totalresponsiveness to aperiodic tasks is improved after all.
Schedulability
In temporal migrations, a migrating jobτi, j and the original jobs scheduled onPy areguaranteed to be schedulable. The proof is as follows. According to the TBS theory[16, 17], assigning a deadlinevy,l+1 to τi, j, which is earlier than its true deadlinedi, j, onPy does not jeopardize the schedulability of the EDF algorithm. This fact implies thatthe original jobs are still guaranteed to be schedulable forthe case ofτi, j having a truedeadlinedi, j according to the sustainability of the EDF algorithm, whichis introducedby Baruahet al. [91]. As a result, the real-time constraints of the periodictasks nevercollapse due to the temporal migration procedure.
Processor Selection
The next step is a selection of the processors, if more than one processor is found atStep 1, so that the response time of aperiodic tasks is reduced as much as possible. Likethe case of the PE-based algorithm described in Section 5.2.3, obtaining the optimalselection is not considered here, and instead the three heuristics introduced in Section5.2.3 are applied again. The three heuristics migrateτi, j as follows.
• The FF heuristic migratesτi, j to the first (i.e., lowest-indexed) processor thatsatisfies Inequation (5.4).
• The BF heuristic migratesτi, j to a processor that(i) satisfies Inequation (5.4), and(ii) minimizes the difference betweendi, j andvy,l+1.
• The WF heuristic, on the other hand, migratesτi, j to a processorPw that(i) satis-fies Inequation (5.4), and(ii) maximizes the difference betweendi, j andvy,l+1.
Like the PE-based algorithm again, the order of the performance superiority in thethree algorithms cannot be analyzed theoretically, hence it is evaluated in the simulationstudies in Chapter 6.
5.4 Compatibility to Portioned Scheduling
The previous sections presented the designs of the PE algorithm and the TBS algo-rithm, in which the global dispatch technique and the temporal migration techniqueare applied, based on the partitioned scheduling. In this section, the compatibility of
91

CHAPTER 5. APERIODIC TASK SCHEDULING
the PE-based algorithm and the TBS-based algorithm to the portioned scheduling algo-rithms presented in Chapter 4 is discussed.
The following factors derive that the PE-based algorithm can be compatible withthe RMDP algorithm.
• Equation (5.1) implies that the server can be objectified as aperiodic task withthe priority level of the server in terms of schedulability analysis.
• The schedulability analysis of the RMDP algorithm allows any periodic taskwhose priority is lower than the second portion of a split task on each proces-sor to be deemed as a periodic task in the RM algorithm.
• Like the RM algorithm, the schedulability analysis of the RMDP algorithm alsodepends on the number of tasks executing on the processor.
Consequently, the schedulability of the RMDP algorithm in which the PE algorithm iscombined can be analyzed by considering the server to beτ1 in Figure 4.10, Figure 4.11,and Figure 4.12 respectively. Taking into account that the schedulable condition of thePE-based algorithm is same as that of the PE algorithm, it holds that the incremental PE-based algorithm presented in this chapter can be also used with the RMDP algorithmwith a guarantee of schedulability,
The proof of the TBS-based algorithm to be compatible to the EDDHP and EDDPalgorithms is more straightforward. The temporarily-migrating jobs are scheduled ac-cording to the EDF algorithm with the virtual deadline of theTBS algorithm. Since allthe tasks are still scheduled based on the deadlines, the algorithm is obviously compat-ible to the EDDHP and EDDP deadline-driven scheduling algorithms.
5.5 Summary
This chapter first described the strategies of the global dispatch technique and the tem-poral migration technique which can improve the responsiveness to aperiodic tasksdramatically. It then presented the PE-based algorithm andthe TBS-based algorithm inwhich the global dispatch procedure and the temporal migration procedure are imple-mented. It also discussed the compatibility of the presented algorithms to the portionedscheduling algorithms presented in Chapter 4. The important characteristics of the pre-sented algorithms are:
• The PE-based algorithm is developed to work with the RM scheduling. When anaperiodic task arrives, it is dispatched to a processor on which the worst-case re-sponse time is minimized. After dispatching, periodic jobswith priorities higherthan the PE server are temporarily migrated onto different processors within theirperiods and are serviced by the PE servers performing on the destination proces-sors.
92

CHAPTER 5. APERIODIC TASK SCHEDULING
• The TBS-based algorithm is invented to work with the EDF scheduling. When anaperiodic task arrives, it is dispatched to a processor on which the assigned virtualdeadline is minimized. After dispatching, periodic jobs with deadlines earlierthan the virtual deadline of the dispatched aperiodic task are temporarily migratedonto different processors within their periods and are scheduled according to theTBS algorithm on the destination processors.
• Both PE-based algorithm and the TBS-based algorithm guarantee all periodicjobs to be schedulable.
• Both PE-based algorithm and the TBS-based algorithm are or can be compatibleto the portioned scheduling algorithms developed in this research.
93

Chapter 6
PERFORMANCE EVALUATION
This chapter presents the results of simulations conductedto evaluate the performanceadvancement of the proposed techniques and algorithms. A series of simulations esti-mates the theoretical capability of the algorithms. Thus, no overheads are accountedfor and all processor time units can be used for task workloads. In other words, no timeunits are consumed for task queuing, context switching, interruption handling, and anyother run-time calculations.
The effectiveness of the portioned scheduling technique is first described by the sim-ulation studies for periodic task scheduling. The RMDP algorithm is compared with thetraditional static-priority scheduling algorithms. The EDDHP and EDDP algorithms,on the other hand, are compared with the traditional dynamic-priority scheduling algo-rithms. The simulation results show that the proposed threealgorithms outperform mostof the traditional algorithms in terms of schedulable utilization, with a small numberof task preemptions. Then, the effectiveness of the global dispatch technique and thetemporal migration technique is demonstrated by the simulation studies for aperiodictask scheduling. The PE-based algorithm and the TBS-based algorithm which exploitglobal dispatches and temporal migrations are respectively compared with the PE al-gorithm and the TBS algorithm designed for the scheduling onuniprocessor systems.The simulation results illustrate that the response time ofaperiodic tasks is dramaticallyreduced by using the developed techniques.
6.1 Simulation Studies for Periodic Task Scheduling
This section shows the superiority of the developed scheduling algorithms for peri-odic tasks by comparing the traditional scheduling algorithms, including both efficientand optimal ones, in terms of schedulable utilization and the number of task preemp-tions. The worst-case utilization bounds for the developedscheduling algorithms werealready derived by the schedulability analysis, and hence the algorithms can be com-pared with the traditional algorithms from the theoreticalpoint of view. However, in
94

CHAPTER 6. PERFORMANCE EVALUATION
order to estimate the performance of an algorithm truly, thesufficient number of tasksets with different properties must be submitted to the algorithm, since the utilizationbound for an algorithm actually varies depending on the property of a given task set.The performance of the algorithm is also dominated by the number of task preemptions.Even if the algorithm achieves high schedulable utilization in a simulation, the practicalperformance may be much worse than the simulated result, if the algorithm generatesa great number of task preemptions. Thus, the dissertation evaluates the algorithms interms of both schedulable utilization and the number of taskpreemptions.
In this section, the performances of the static-priority scheduling algorithms arefirst examined. The RMDP algorithm is compared with the traditional static-priorityscheduling algorithms: RM-FF [42], RM-FFDU [50], R-BOUND-MP-NFR [57], RM-US [45], and WM [67, 66]. Secondly, the performances of the dynamic-priority schedul-ing algorithms are estimated. The EDDHP and EDDP algorithmsare compared withthe traditional dynamic-priority scheduling algorithms:EDF-FF [58], EDF-BF [58],EDF-US [47], EDZL [73, 75], and EKG [81]. The EDDP and EDDHP algorithms ex-ploit the heuristic procedures for improving schedulable utilizations, which were pre-sented in Section 4.4.4 and Section 4.3.4 respectively. TheEKG algorithm takes twoparameters with a consideration of the trade-off. The first one, denoted by EKG-2, takesa parameterk = 2 with a lower utilization bound of 66% and fewer task preemptions.On the other hand, the second one, denoted by EKG-M, takes a parameterk = M withthe optimal utilization bound of 100% in exchange for more task preemptions. Theoptimal Pfair algorithms [62, 63, 64] and the LLREF algorithm [79] are not includedin the simulations, since they are known to be optimal as wellas the EKG-M algorithmbut generate much more task preemptions than the EKG-M algorithm.
6.1.1 Experimental Setup
The simulations estimate the schedulability of an algorithm as follows. Every systemutilization Usys ranging from 30% to 100%, 1000 task sets with different properties,whose system utilizations are allUsys equally, are generated and submitted to the algo-rithm. Then, the success ratio, defined by the following expression, is measured.
the number of successfully scheduled task setsthe number of scheduled task sets
A successfully scheduled task set is defined as follows.
• For the partitioned scheduling algorithms and the portioned scheduling algo-rithms, a task set is said to be successfully scheduled, if and only if all the tasksin the task set can be assigned to the processors without breaking the utilizationbounds of any processors.
• For the global scheduling algorithms, a task set is said to besuccessfully sched-uled, if and only if the task set is accepted by the offered schedulability test.
95

CHAPTER 6. PERFORMANCE EVALUATION
Having a high success ratio means that the schedulability atthe system utilization isalso high. Hereinafter, the schedulable utilization for analgorithm refers to the max-imum system utilization at which the algorithm achieves thesuccess ratio of 100%.Meanwhile, the simulations estimate the number of task preemptions for an algorithmby calculating its average number, defined by the following expression.
the total number of task preemptionsthe number of scheduled task sets
Each simulation is characterized by the four parameters:M, Umax, Umin andUsys. Mis the number of the processors.Umax andUmin are the maximum and minimum valuesof the processor utilization of every individual task in a given task set.Usys refers tothe utilization of the system, which ranges from 0% to 100%. Note thatUsys× M isequal to the total utilization of all the generated tasks. Although many combinations ofthe parameters can be considered, the simulations attempt the following combinationsdue to the limitation of space. The system utilization is determined within the range of[30%, 100%]. Most of the existing algorithms can successfully schedule a task set witha system utilization below 30%, hence system utilizations below 30% are removed.As for the number of the processors, the simulations preparethe three sets:M = 4,M = 8, andM = 16, since embedded processors hardly offer more than 16 cores due tolimitation of the scale and the resource. In a humanoid robotsystem [92] that has beendeveloped in my laboratory, no tasks seldom utilize more than 50% of an individualprocessor (core). However, the quality of the activities isrequired to be enhanced,heavier tasks (tasks with high utilizations) are submitted. Thus, for both of the cases,the simulations prepare the two sets ofUmin andUmax: (Umin,Umax) = (0.01, 0.5) and(Umin,Umax) = (0.01, 1.0).
A task setΓ is generated as follows. A new periodic task is appended toΓ as longas U(Γ) ≤ Utotal is satisfied. For each taskτi, its utilization Ui is computed basedon a uniform distribution within the range of [Umin,Umax]. Only the utilization of thetask generated at the very end is adjusted so thatU(Γ) becomes equal toUtotal. Ti isdetermined within the range of [100, 3000] randomly, since the feedback periods ofcontrol and multimedia tasks in humanoid robots are usuallyabout 1ms ∼ 30ms. Inother words, a minimum time unit simulates 10µs. Then, the execution time of the taskCi = UiTi is calculated.
6.1.2 Simulation Results of Static-Priority Scheduling
Schedulable Utilization
Figure 6.1, Figure 6.2, and Figure 6.3 show the success ratios for the static-priorityscheduling algorithms, RMDP, RM-FF, RM-FFDU, R-BOUND-MP,RM-US, with re-spect to task sets in which the utilization of every individual task ranges from within[0.01, 0.5]. The schedulable utilization for the proposed RMDP algorithm is around70 ∼ 73%, which is much higher than the other efficient algorithms, such as RM-FF,
96
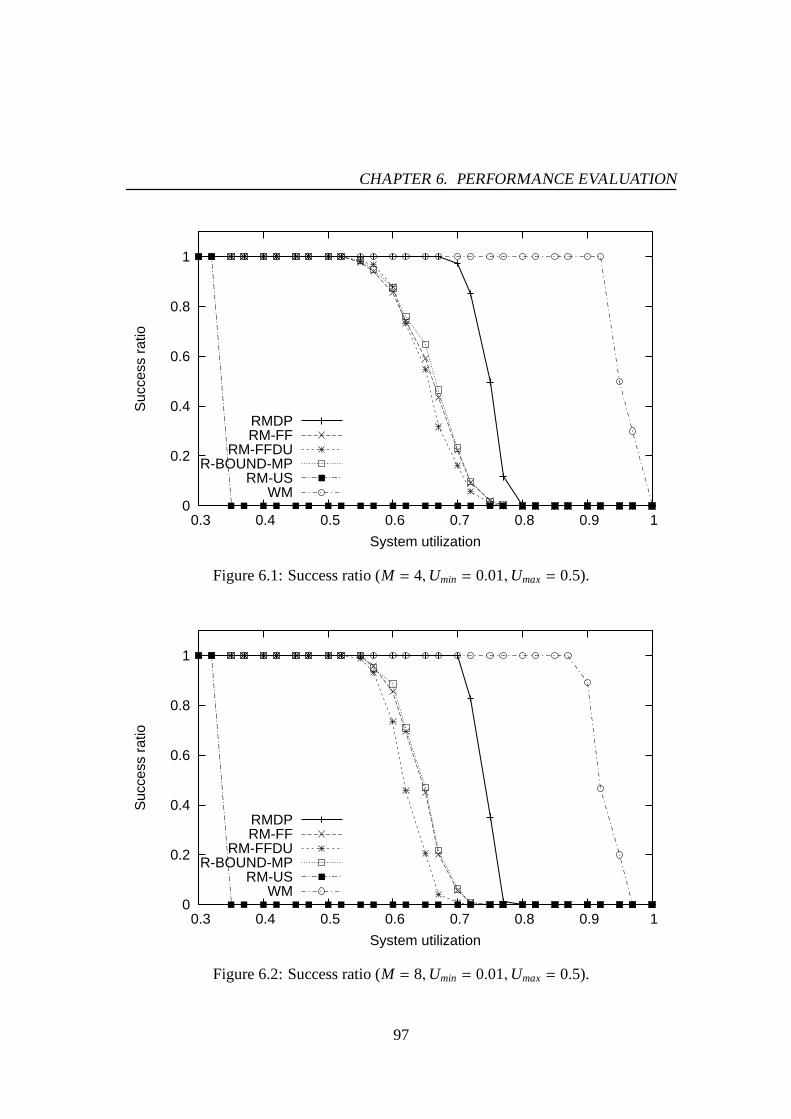
CHAPTER 6. PERFORMANCE EVALUATION
0
0.2
0.4
0.6
0.8
1
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Suc
cess
rat
io
System utilization
RMDPRM-FF
RM-FFDUR-BOUND-MP
RM-USWM
Figure 6.1: Success ratio (M = 4,Umin = 0.01,Umax= 0.5).
0
0.2
0.4
0.6
0.8
1
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Suc
cess
rat
io
System utilization
RMDPRM-FF
RM-FFDUR-BOUND-MP
RM-USWM
Figure 6.2: Success ratio (M = 8,Umin = 0.01,Umax= 0.5).
97
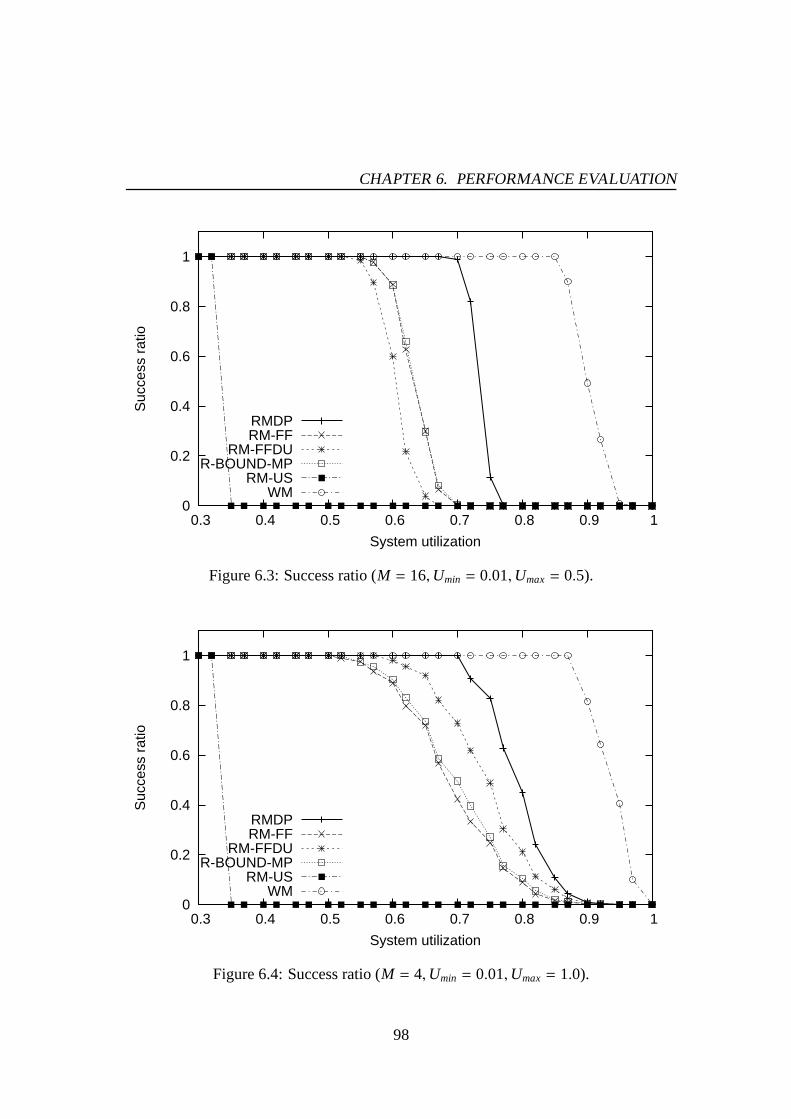
CHAPTER 6. PERFORMANCE EVALUATION
0
0.2
0.4
0.6
0.8
1
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Suc
cess
rat
io
System utilization
RMDPRM-FF
RM-FFDUR-BOUND-MP
RM-USWM
Figure 6.3: Success ratio (M = 16,Umin = 0.01,Umax= 0.5).
0
0.2
0.4
0.6
0.8
1
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Suc
cess
rat
io
System utilization
RMDPRM-FF
RM-FFDUR-BOUND-MP
RM-USWM
Figure 6.4: Success ratio (M = 4,Umin = 0.01,Umax= 1.0).
98
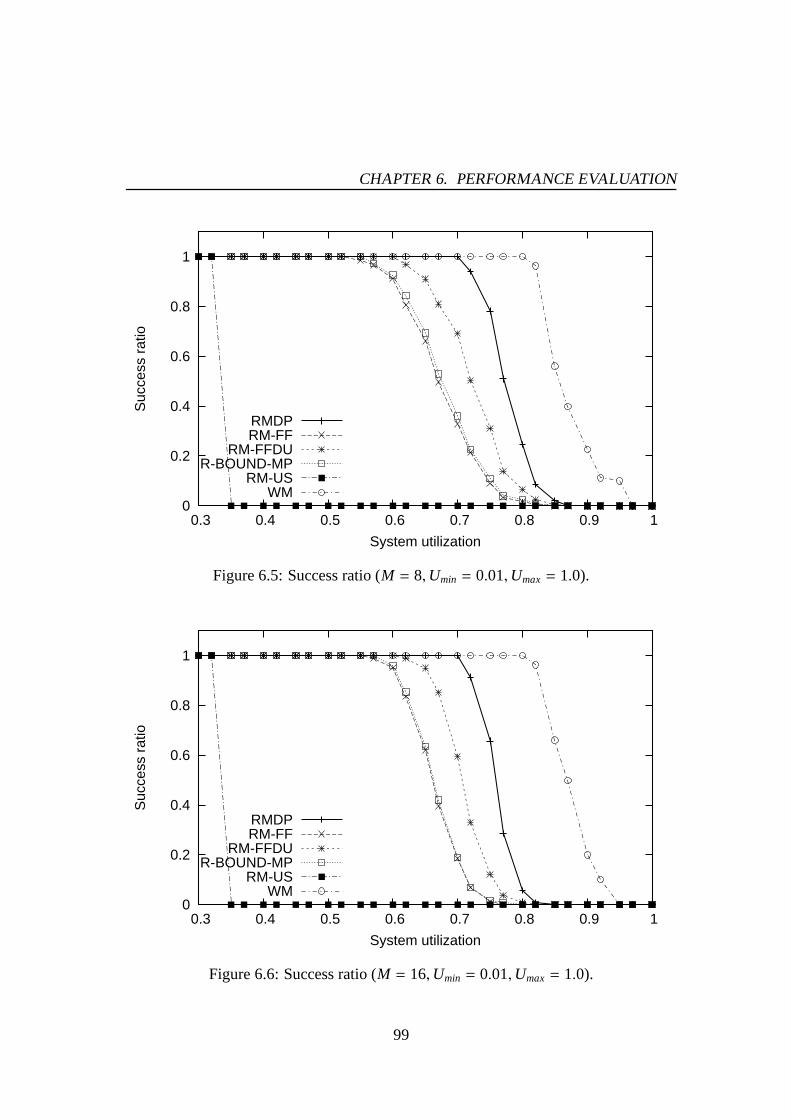
CHAPTER 6. PERFORMANCE EVALUATION
0
0.2
0.4
0.6
0.8
1
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Suc
cess
rat
io
System utilization
RMDPRM-FF
RM-FFDUR-BOUND-MP
RM-USWM
Figure 6.5: Success ratio (M = 8,Umin = 0.01,Umax= 1.0).
0
0.2
0.4
0.6
0.8
1
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Suc
cess
rat
io
System utilization
RMDPRM-FF
RM-FFDUR-BOUND-MP
RM-USWM
Figure 6.6: Success ratio (M = 16,Umin = 0.01,Umax= 1.0).
99

CHAPTER 6. PERFORMANCE EVALUATION
RM-FFDU, R-BOUND-MP, and RM-US. The RM-FF, RM-FFDU, and R-BOUND-MP algorithms are very competitive. The schedulable utilizations for those algorithmare around 57∼ 60%. Those algorithms actually differ from each other only in taskassigning methods. The RM-FFDU algorithm, which sorts the tasks in order of decreas-ing utilization before assigning, slightly performs worsethan the other two algorithms.Meanwhile, the R-BOUND-MP algorithm, which sorts the tasksin order of increas-ing period before assigning, slightly performs better thanthe other two algorithms.However, the performance difference among the three algorithms is only a little, hencesorting the tasks does not dominate a schedulable utilization very much for the case inwhich the utilization of every individual task is less than 50%. The RM-US algorithmperforms quite badly compared to the other algorithms. Notethat the schedulability testof the RM-US algorithm is not tight, since the schedulability test presumes the abso-lute worst-case performance. Therefore, the RM-US algorithm may schedule a task setwith a higher system utilization successfully. The WM algorithm achieves schedulableutilizations of around 90%, which are much better than the other algorithms. This su-periority is acquired from its characteristic of fairness.Since the WM algorithm has itsbasis on Pfair scheduling, which is able to make an optimal schedule on multiprocessorsystems if the task priorities can be assigned dynamically,it offers an excellent perfor-mance, though it does not reach the optimality due to the restriction of the static-prioritydiscipline.
Figure 6.4, Figure 6.5, and Figure 6.6 show the success ratios for the static-priorityscheduling algorithms with respect to task sets in which theutilization of every indi-vidual task ranges within [0.01, 1.0]. Although this ranging generates several heavytasks, the order of superiority in the algorithms has no changes compared to the previ-ous cases in which only light tasks reside. The remarkable point is that the schedulableutilization for the WM algorithm decreases as the number of the processors increases.That is because the utilization bound for the WM algorithm depends on the numberof the processors. Meanwhile, the schedulable utilizationfor the proposed RMDP al-gorithm is stable around 73% regardless of the number of the processors, because theutilization bound for the RMDP algorithm does not depend on the number of the pro-cessors. Therefore, the expectation is that the RMDP algorithm may outperform theWM algorithm for the case of many processors.
The Number of Task Preemptions
For calculation of task preemptions, the interval of the simulations is set the smallerof the least common multiple of the task periods in the given task set and 232 that isthe maximum length on a 32-bit computer. For each algorithm,the average number oftask preemptions in the 1000 task sets is calculated every system utilization. Then, thenumber of task preemptions for each algorithm relative to that for the RMDP algorithmis calculated only only for the case in which both the target algorithm and the RMDPalgorithm have a schedulable utilization of 100%. Otherwise, the comparison becomes
100

CHAPTER 6. PERFORMANCE EVALUATION
0.6
0.8
1
1.2
1.4
1.6
1.8
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
The
num
ber
of p
reem
ptio
ns r
elat
ive
to R
MD
P
System utilization
RMDPRM-FF
RM-FFDUR-BOUND-MP
RM-US
Figure 6.7: The number of preemptions (M = 4,Umin = 0.01,Umax= 0.5).
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
The
num
ber
of p
reem
ptio
ns r
elat
ive
to R
MD
P
System utilization
RMDPRM-FF
RM-FFDUR-BOUND-MP
RM-US
Figure 6.8: The number of preemptions (M = 8,Umin = 0.01,Umax= 0.5).
101
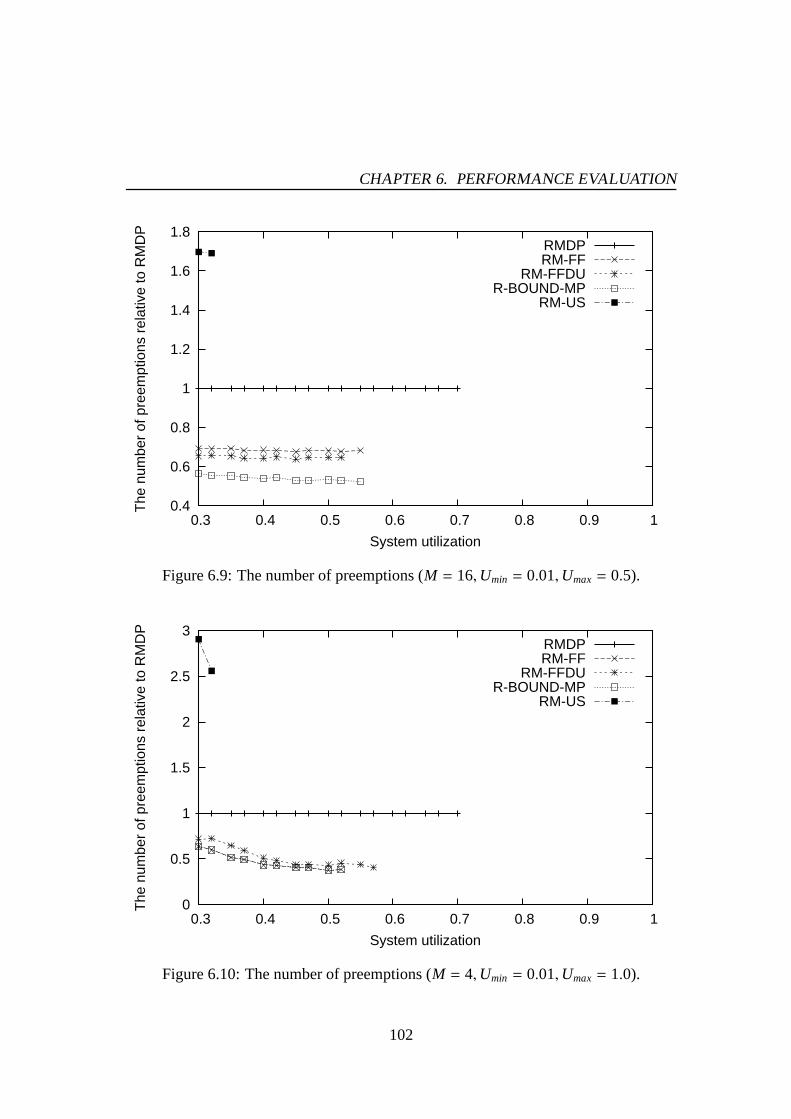
CHAPTER 6. PERFORMANCE EVALUATION
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
The
num
ber
of p
reem
ptio
ns r
elat
ive
to R
MD
P
System utilization
RMDPRM-FF
RM-FFDUR-BOUND-MP
RM-US
Figure 6.9: The number of preemptions (M = 16,Umin = 0.01,Umax= 0.5).
0
0.5
1
1.5
2
2.5
3
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
The
num
ber
of p
reem
ptio
ns r
elat
ive
to R
MD
P
System utilization
RMDPRM-FF
RM-FFDUR-BOUND-MP
RM-US
Figure 6.10: The number of preemptions (M = 4,Umin = 0.01,Umax= 1.0).
102
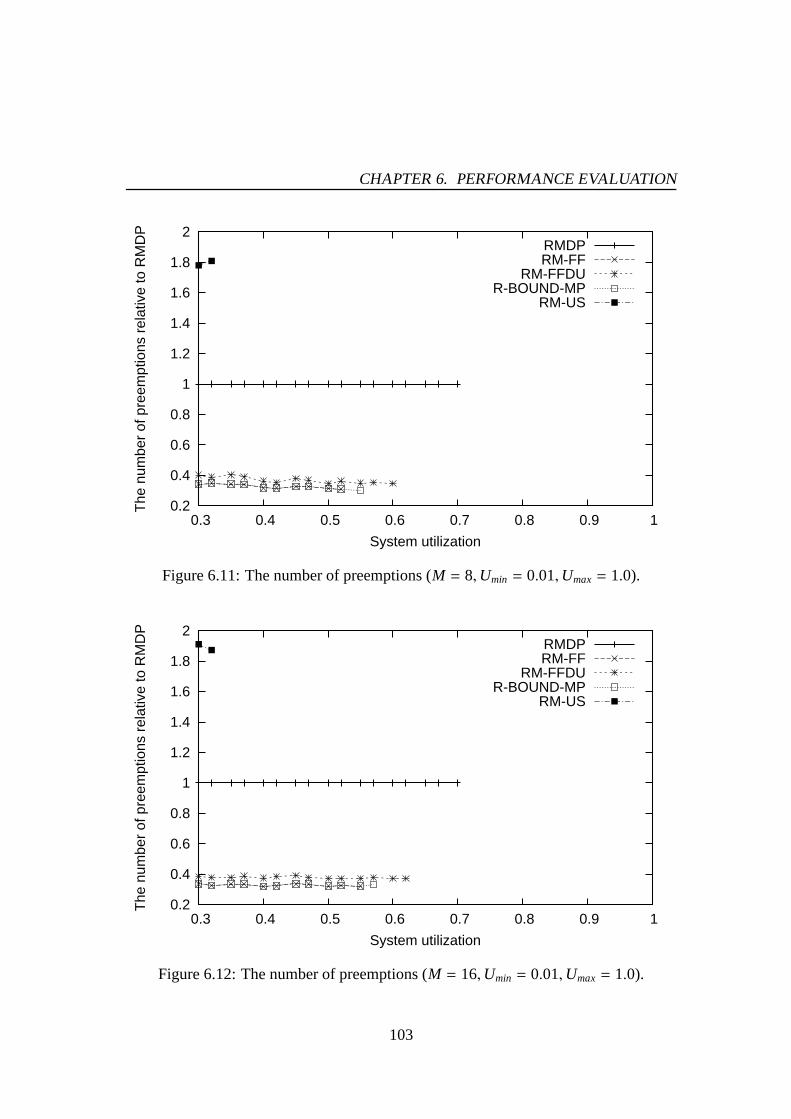
CHAPTER 6. PERFORMANCE EVALUATION
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
The
num
ber
of p
reem
ptio
ns r
elat
ive
to R
MD
P
System utilization
RMDPRM-FF
RM-FFDUR-BOUND-MP
RM-US
Figure 6.11: The number of preemptions (M = 8,Umin = 0.01,Umax= 1.0).
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
The
num
ber
of p
reem
ptio
ns r
elat
ive
to R
MD
P
System utilization
RMDPRM-FF
RM-FFDUR-BOUND-MP
RM-US
Figure 6.12: The number of preemptions (M = 16,Umin = 0.01,Umax= 1.0).
103

CHAPTER 6. PERFORMANCE EVALUATION
unfair. Note that the WM algorithm consistently causes morethan fifty times as manytask preemptions as the RMDP algorithm, hence the evaluation of the WM algorithmis not included in this section.
Figure 6.7, Figure 6.8, and Figure 6.9 show the numbers of task preemption forthe static-priority scheduling algorithms relative to that for the RMDP algorithm, withrespect to task sets in which the utilization of every individual task ranges within[0.01, 0.5]. The RMDP algorithm causes about 1.3 ∼ 1.8 times as many task pre-emptions as the RM-FF, RM-FFDU, and R-BOUND-MP algorithms.Since the RMDPalgorithm preempts the second portion of a split task when its corresponding first por-tion is dispatched on the neighbor processor, it incurs additional preemptions to the RMscheduling. Meanwhile the RM-FF, RM-FFDU, and R-BOUND-MP algorithms neverincur such additional preemptions, since those algorithmscompletely partition the tasksamong the processors. However, the RMDP algorithm has fewertask preemptions thanthe RM-US algorithm. The RM-US algorithm deals with all the tasks globally. Hence,the ordering of the task priorities in the RM-US algorithm ischanged more frequentlythan in the other algorithms. As a result, the RM-US algorithm totally causes more taskpreemptions than the other algorithms.
Figure 6.10, Figure 6.11, and Figure 6.12 show the numbers oftask preemption forthe static-priority scheduling algorithms relative to that for the the RMDP algorithm,with respect to task sets in which the utilization of every individual task ranges within[0.01, 1.0]. This case expands the performance difference between the RMDP algo-rithm and the partitioned scheduling algorithms. Since each task is likely to have highutilization due toUmax = 1.0, which means that the execution time of the task is alsolikely to be long, the scheduled timings of the first and second portions of a split areeasily overlapped on two processors. According to the RMDP algorithm, the secondportion of a split task is preempted when its corresponding first portion is scheduled,and hence the number of task preemptions are increased compared to the previous casesin which only light tasks exist. As a result, the RMDP algorithm causes about 2.0 ∼ 2.5times, which is worse than the previous light task set cases,as many task preemptions asthe RM-FF, RM-FFDU, and R-BOUND-MP algorithms, though the RM-US algorithmcauses more due to the characteristic of global scheduling.
The impact of the performance difference in the number of task preemptions to thesystem depends on the ratio of the CPU time of task executionsand the CPU timeof task preemptions. For example, the RMDP algorithm has a schedulable utilizationabout 13% higher than the RM-FFDU algorithm in Figure 6.4. However, the numberof task preemptions for the RMDP algorithm is about twice as many as that for theRM-FFDU algorithm in this case. This relation means that theRM-FFDU algorithmmay be better than the RMDP algorithm, if a scheduler consumes more than 13% ofthe entire system time for task preemptions. System designers should take this factinto account when they choose a scheduling algorithm. As forthis example, since thescheduler hardly consumes 13% of the system time for task preemptions, consideringthe performance of recent processors, the RMDP algorithm isprobably a better choice.
104

CHAPTER 6. PERFORMANCE EVALUATION
6.1.3 Simulation Results of Dynamic-Priority Scheduling
Schedulable Utilization
Figure 6.13, Figure 6.14, and Figure 6.15 show the success ratios for the dynamic-priority scheduling algorithms, EDDP, EDDHP, EDF-FF, EDF-BF, EDF-US, EDZL,EKG-2(k = 2), and EKG-M(k = M), with respect to task sets in which the utilizationof every individual task ranges within [0.01, 0.5]. The results show that the EDDP, ED-DHP, EDF-FF, and EKG-2 algorithms are very competitive. TheEDDHP algorithmslightly offers a better performance than the other algorithms. While the schedulableutilization for the EDDHP algorithm is around 90%, those forthe EDDP and EKG-2algorithms are around 87%, and that for the EDF-BF algorithmis around 85%. It isremarkable that the EDDHP algorithm outperforms the EDDP algorithm, though theworst-case utilization bound for the EDDP algorithm is about 65% that is higher than50% for the EDDHP algorithm. This fact implies that the approach of assigning thehighest static-priority to the second portion of a split task can provide a better schedu-lability in practice than the approach of assigning the virtual deadline. Note that thesuccess ratio for the EKG-M algorithm drops down below 100% before the systemutilization reaches 100%, though the EKG algorithm is supposed to become optimalfor k = M. Since the execution time of a task cannot be split less than the minimumtime unit of 1 in the simulations, each processor inevitablyremains a little room unlessits remaining utilization in splitting taskτi is an integer multiple of 1/Ti. As a result,a few tasks may fail to be assigned to any processor, if the system utilization is veryclose to 100%. The EDF-FF algorithm performs relatively well, but its schedulable uti-lization is around 77% that is 8% behind the EDF-BF algorithm. This inferiority of theEDF-FF algorithm to the EDF-BF algorithm is attributed by the performance differencebetween the FF heuristic and the BF heuristic. Since the BF heuristic packs items moreefficiently than the FF heuristic, the performance of the EDF-BFalgorithm is also betterthan the EDF-FF algorithm. The EDF-US and EDZL algorithms, which have their basison global scheduling, have quite low schedulable utilizations that are around 50%. Likethe RM-US algorithm, since the schedulability tests of those algorithms are not tightvery much, the EDF-US and EDZL algorithms may reject many task sets which can beactually scheduled without missing any job deadlines. The EDZL algorithm is slightlyworse than the EDF-US algorithm in terms of schedulable utilization, though their suc-cess ratios are reversed on the way. The authors claimed in [78] that the schedulabilityanalysis of the EDZL algorithm has a room for improvement. Therefore, the potentialschedulability of the EDZL algorithm may be better than the simulated results.
Figure 6.16, Figure 6.17, and Figure 6.18 show the success ratios for the dynamic-priority scheduling algorithms with respect to task sets inwhich the utilization of everyindividual task ranges within [0.01, 1.0]. The EDDP, EDDHP, and EKG-2 algorithmsare still competitive. However, contrary to the previous cases in which only light tasksexists, the EDDP algorithm slightly outperforms the EDDHP algorithm as well as theEKG-2 algorithm in most cases. In general, the schedulability of an algorithm tends to
105
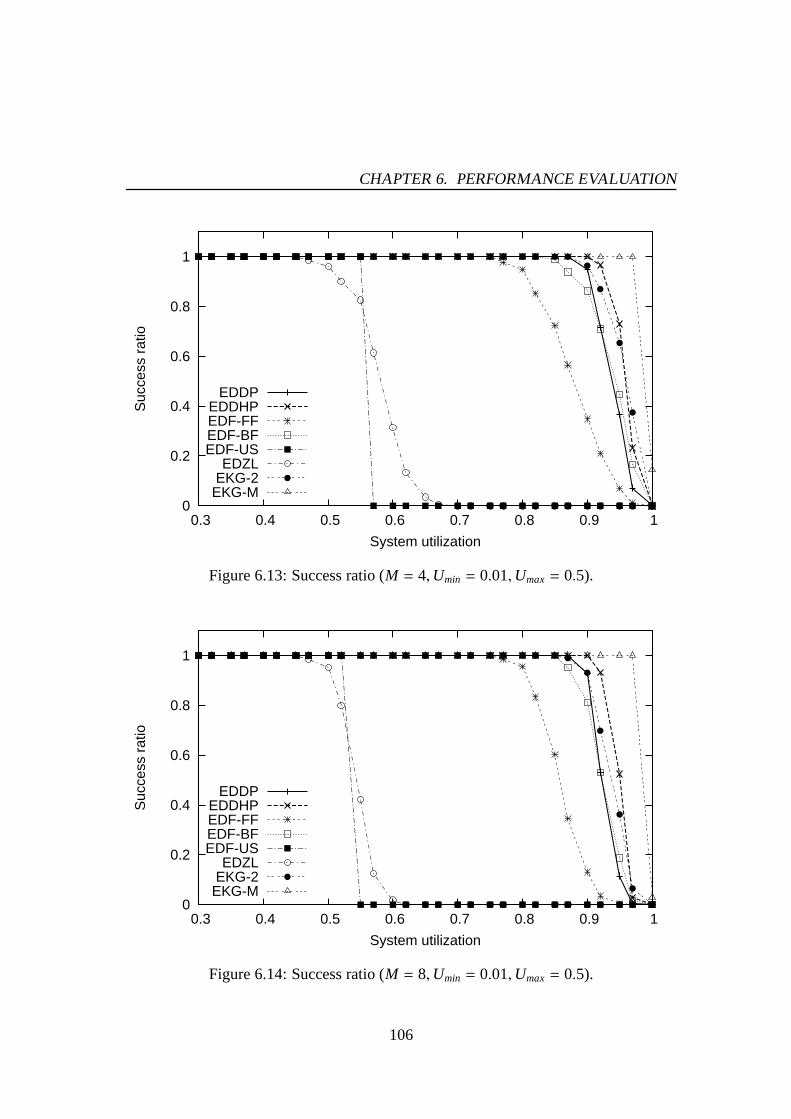
CHAPTER 6. PERFORMANCE EVALUATION
0
0.2
0.4
0.6
0.8
1
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Suc
cess
rat
io
System utilization
EDDPEDDHPEDF-FFEDF-BFEDF-US
EDZLEKG-2EKG-M
Figure 6.13: Success ratio (M = 4,Umin = 0.01,Umax= 0.5).
0
0.2
0.4
0.6
0.8
1
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Suc
cess
rat
io
System utilization
EDDPEDDHPEDF-FFEDF-BFEDF-US
EDZLEKG-2EKG-M
Figure 6.14: Success ratio (M = 8,Umin = 0.01,Umax= 0.5).
106
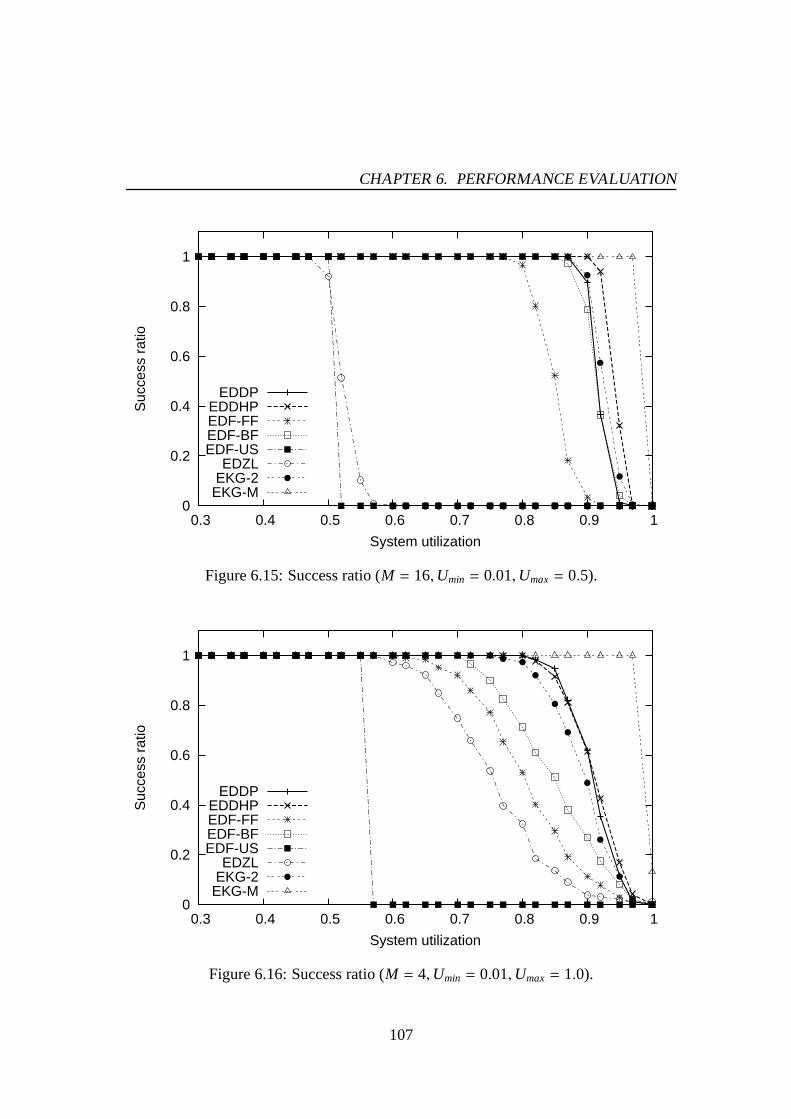
CHAPTER 6. PERFORMANCE EVALUATION
0
0.2
0.4
0.6
0.8
1
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Suc
cess
rat
io
System utilization
EDDPEDDHPEDF-FFEDF-BFEDF-US
EDZLEKG-2EKG-M
Figure 6.15: Success ratio (M = 16,Umin = 0.01,Umax= 0.5).
0
0.2
0.4
0.6
0.8
1
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Suc
cess
rat
io
System utilization
EDDPEDDHPEDF-FFEDF-BFEDF-US
EDZLEKG-2EKG-M
Figure 6.16: Success ratio (M = 4,Umin = 0.01,Umax= 1.0).
107

CHAPTER 6. PERFORMANCE EVALUATION
0
0.2
0.4
0.6
0.8
1
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Suc
cess
rat
io
System utilization
EDDPEDDHPEDF-FFEDF-BFEDF-US
EDZLEKG-2EKG-M
Figure 6.17: Success ratio (M = 8,Umin = 0.01,Umax= 1.0).
0
0.2
0.4
0.6
0.8
1
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Suc
cess
rat
io
System utilization
EDDPEDDHPEDF-FFEDF-BFEDF-US
EDZLEKG-2EKG-M
Figure 6.18: Success ratio (M = 16,Umin = 0.01,Umax= 1.0).
108

CHAPTER 6. PERFORMANCE EVALUATION
decrease under the presence of heavy tasks, since the condition of a system approachesthe worst case. Therefore, the EDDP algorithm performs better than the EDDHP al-gorithm due to its higher worst-case utilization bound of 65%. Although the EKG-2algorithm moreover has a higher utilization bound of 66%, the heuristic proceduresintroduced in Section 4.4.4 assist the performance of the EDDP algorithm, and hencethe EDDP algorithm outperforms even the EKG-2 algorithm. While the above threealgorithms are very competitive and maintain schedulable utilizations as high as thosein the previous light task set cases, the EDF-BF algorithm declines a schedulable uti-lization down to 67% that is about 15% inferior to the ones in the previous light taskset cases. The schedulable utilization for the EDF-FF algorithm is also declined downto around 60% that is about 15% inferior to the ones in the previous light task set cases.This inferiority of the EDF-BF and EDF-FF algorithms is involved by the the presenceof heavy tasks. Even if the total remaining utilization of all the processors is sufficient,a heavy task may fail to be assigned to any processor, since the acceptance of a taskdoes not depend on the total remaining utilization but on theremaining utilization ofevery individual processor. As a result, the task assignment can return the failure inthose algorithms even for a low system utilization. The EDZLalgorithm, on the otherhand, improves a schedulable utilization up to 60% that is about 15% higher than theprevious light task set cases. According to Cirineiet al. [75], the schedulable utilizationfor the EDZL algorithm is dominated by the opportunity that the number of the taskswhich can have the zero laxity at the same time becomes greater than the number of theprocessors. The case in which there are heavy tasks obviously leads the total number ofthe tasks to be smaller than the case in which there are only light tasks, which results ina less opportunity that the number of the tasks have can have the zero laxity at the sametime is greater than the number of the processors. As a result, the schedulable utiliza-tion for the EDZL algorithm is improved compared to the previous light task set cases.The EDF-US algorithm still has a schedulable utilization ofaround 50%, because itsutilization bound is anywayM/(2M − 1).
The Number of Task Preemptions
By the same token as Section 6.1.2, the interval of the simulations is set the smaller ofthe least common multiple of the task periods in the given task set and 232 for calcula-tion of task preemptions. For each algorithm, the average number of task preemptionsin the 1000 task sets is calculated every system utilization. Then, the number of taskpreemptions for each algorithm relative to that for the EDDPalgorithm is calculatedonly in the case in which both the target algorithm and the EDDP algorithm have theschedulable utilization of 100%. Otherwise, the comparison becomes unfair.
Figure 6.19, Figure 6.20, and Figure 6.21 show the numbers oftask preemptionsfor the dynamic-priority scheduling algorithms relative to the number of task preemp-tions for the EDDP algorithm, with respect to task sets in which the utilization of everyindividual task ranges within [0.01, 0.5]. The EDDP algorithm has slightly fewer task
109
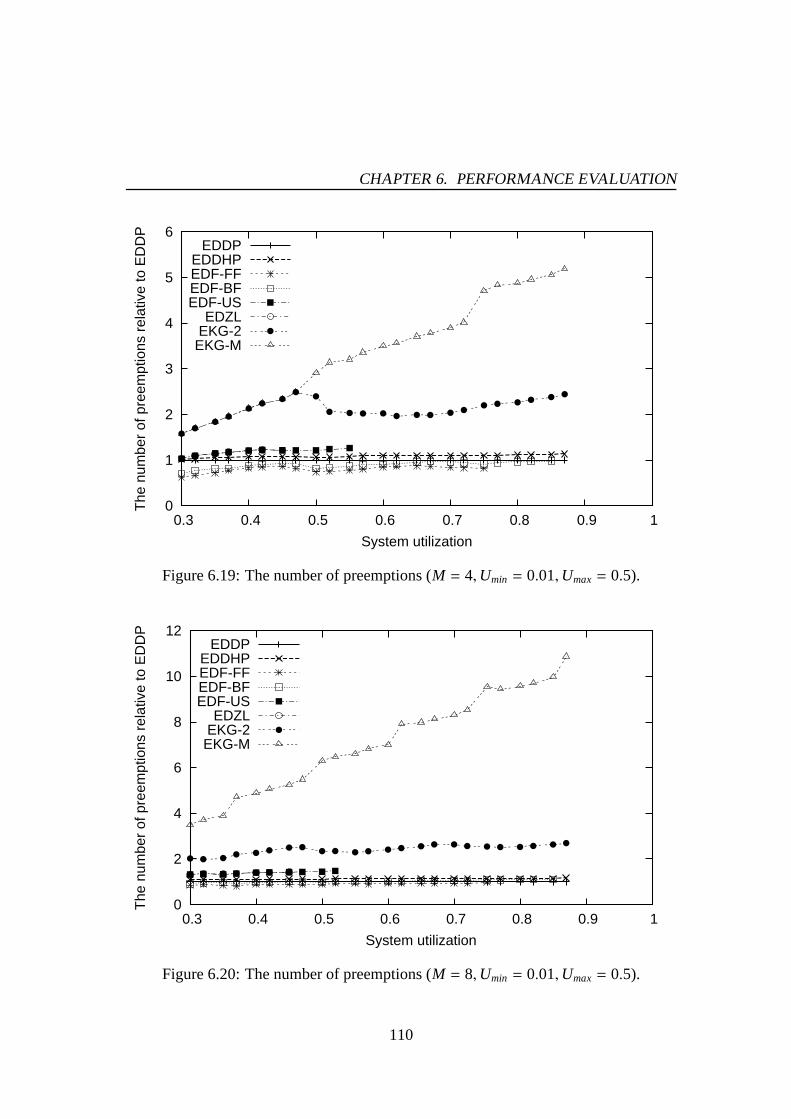
CHAPTER 6. PERFORMANCE EVALUATION
0
1
2
3
4
5
6
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
The
num
ber
of p
reem
ptio
ns r
elat
ive
to E
DD
P
System utilization
EDDPEDDHPEDF-FFEDF-BFEDF-US
EDZLEKG-2EKG-M
Figure 6.19: The number of preemptions (M = 4,Umin = 0.01,Umax= 0.5).
0
2
4
6
8
10
12
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
The
num
ber
of p
reem
ptio
ns r
elat
ive
to E
DD
P
System utilization
EDDPEDDHPEDF-FFEDF-BFEDF-US
EDZLEKG-2EKG-M
Figure 6.20: The number of preemptions (M = 8,Umin = 0.01,Umax= 0.5).
110
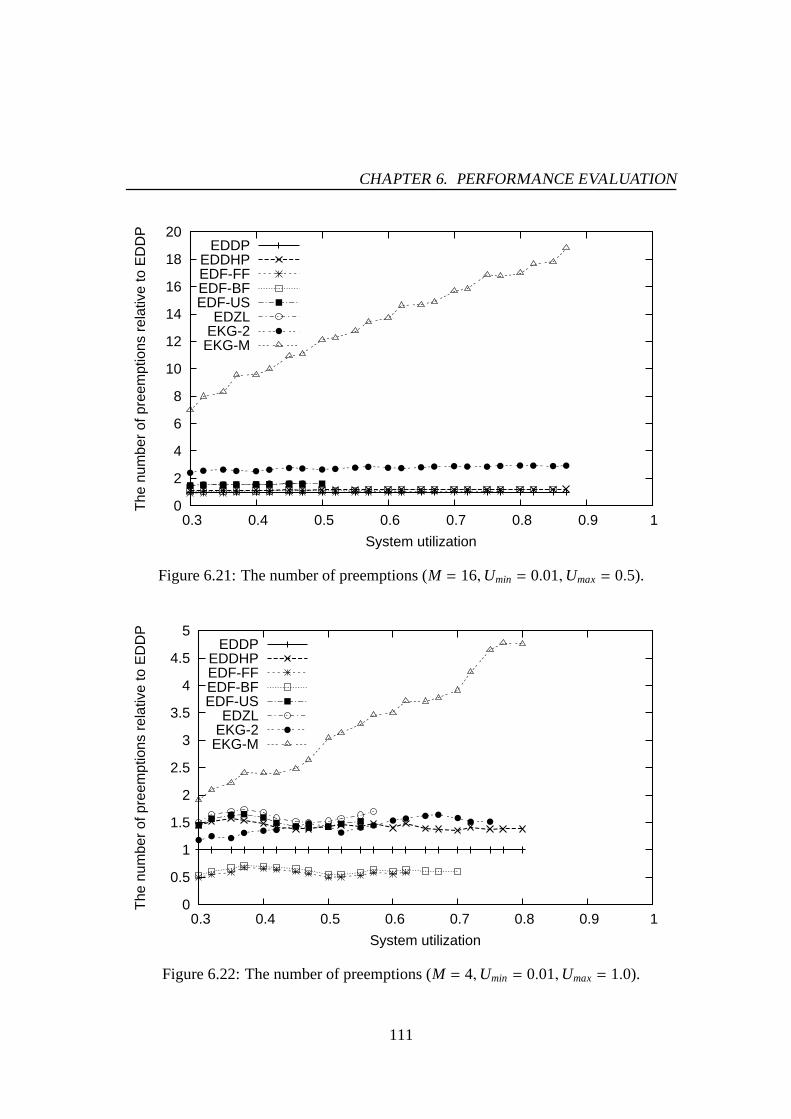
CHAPTER 6. PERFORMANCE EVALUATION
0
2
4
6
8
10
12
14
16
18
20
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
The
num
ber
of p
reem
ptio
ns r
elat
ive
to E
DD
P
System utilization
EDDPEDDHPEDF-FFEDF-BFEDF-US
EDZLEKG-2EKG-M
Figure 6.21: The number of preemptions (M = 16,Umin = 0.01,Umax= 0.5).
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
The
num
ber
of p
reem
ptio
ns r
elat
ive
to E
DD
P
System utilization
EDDPEDDHPEDF-FFEDF-BFEDF-US
EDZLEKG-2EKG-M
Figure 6.22: The number of preemptions (M = 4,Umin = 0.01,Umax= 1.0).
111
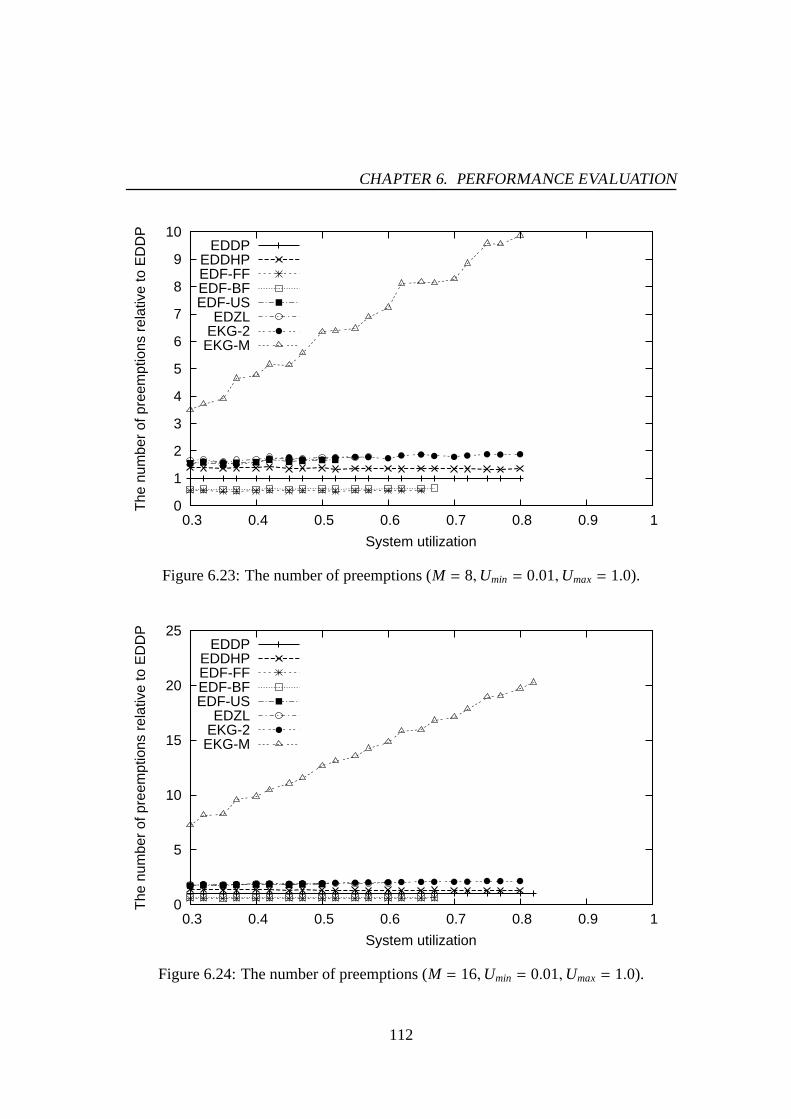
CHAPTER 6. PERFORMANCE EVALUATION
0
1
2
3
4
5
6
7
8
9
10
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
The
num
ber
of p
reem
ptio
ns r
elat
ive
to E
DD
P
System utilization
EDDPEDDHPEDF-FFEDF-BFEDF-US
EDZLEKG-2EKG-M
Figure 6.23: The number of preemptions (M = 8,Umin = 0.01,Umax= 1.0).
0
5
10
15
20
25
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
The
num
ber
of p
reem
ptio
ns r
elat
ive
to E
DD
P
System utilization
EDDPEDDHPEDF-FFEDF-BFEDF-US
EDZLEKG-2EKG-M
Figure 6.24: The number of preemptions (M = 16,Umin = 0.01,Umax= 1.0).
112

CHAPTER 6. PERFORMANCE EVALUATION
preemptions than the EDDHP algorithm. Since the EDDP algorithm makes severalprocessors which have only one heavy task and no light tasks,no preemptions occuron those processors. As a result, the number of task preemptions for the EDDP algo-rithm is totally reduced compared to the EDDHP algorithm. The EDF-FF and EDF-BFalgorithms have around 0.65 ∼ 0.85 times (around 0.80 times in most cases) as manytask preemptions as the EDDP algorithm. The primary reason why the numbers oftask preemptions for the EDF-FF and EDF-BF algorithms are smaller than those forthe others is that those algorithms simply schedule the tasks according to the EDF al-gorithm on each processor without any interference from other processors, while theother algorithms have more or less interference among the processors. The EDF-USand EDZL algorithm have slightly more task preemptions, which is about 1.3 ∼ 1.5times, than the EDDP algorithm. Since those algorithms haveonly one global sched-uler which handles all the tasks, the ordering of the task priority is likely to be changed.A preemption occurs every time the ordering of the task priority is changed, and hencethose algorithms cause more task preemptions than the otheralgorithms except for theEKG algorithms. While the EDDP, EDDHP, EDF-FF, EDF-BF, EDF-US, and EDZLalgorithms are competitive, the EKG algorithms cause much more task preemptions.The EKG-2 algorithm causes around 2.0 ∼ 2.5 times as many task preemptions as theEDDP algorithm, though the schedulable utilization is lessthan or almost equal to theEDDP algorithm. The optimal EKG-M algorithm causes far too many task preemp-tions. The EKG algorithm preempts the first and second portions of a split task oncefor every interval of task releases on the related two processors in addition to the EDFscheduling, whereas the EDDP algorithm preempts only the second portion of a splittask only when its corresponding first portion is dispatchedon the neighbor processorin addition to the EDF scheduling. In the case ofM = 16, as shown in Figure 6.21, thenumber of task preemptions for the EKG-M algorithm finally reaches nearly 20 timesas many as that for the EDDP algorithm.
Figure 6.22, Figure 6.23, and Figure 6.24 show the numbers oftask preemptionsfor the dynamic-priority scheduling algorithms relative to the number of task preemp-tions for the EDDP algorithm, with respect to task sets in which the utilization of everyindividual task ranges within [0.01, 1.0]. In this case, the EDDP algorithm has about1.3 ∼ 2.0 times as many task preemptions as the EDF-FF and EDF-BF algorithms,while the EDDP algorithm is competitive with the EDF-FF and EDF-BF algorithms inthe case of (Umin,Umax) = (0.01, 0.5). According to the EDDP algorithm, the secondportion of a split task is preempted when its corresponding first portion portion is dis-patched on the neighbor processor, while such an extra preemption never occurs for theEDF-FF and EDF-BF algorithms. Since the execution time of each task tends to belong due toUmax= 1.0, the scheduled timings of the first and second portions of a splittask are easily overlapped. As a result, the EDDP algorithm causes more extra preemp-tions to schedule the first and the second portions of a split task exclusively. However,the EDDP algorithm suppresses the number of task preemptions to about 0.5 ∼ 0.7times as many as the EKG-2 algorithm that takes a similar approach of splitting tasks.
113

CHAPTER 6. PERFORMANCE EVALUATION
The EKG-M algorithm causes at most about 20 times as many taskpreemptions as theEDDP algorithm as the previous cases in exchange for its optimality. Meanwhile,theEDF-US and EDZL algorithms cause about 1.3 ∼ 1.5 times as many task preemptionsas the EDDP algorithm, which is almost the same result as the previous cases.
6.2 Simulation Studies for Aperiodic Task Scheduling
This section studies the performance advancement of the global dispatch and temporalmigration techniques for the aperiodic task scheduling on multiprocessor systems. Theimpact of the proposed techniques for static-priority scheduling in which periodic tasksare scheduled by the RM-FF algorithm and aperiodic tasks arehandled by the PE al-gorithm is evaluated. Meanwhile, the impact for dynamic-priority scheduling in whichperiodic tasks are scheduled by the EDF-FF algorithm and aperiodic tasks are handledby the TBS algorithm is evaluated. For each evaluation, the global dispatch techniqueis first compared with the simple partitioned dispatch technique. Then, the effective-ness of the temporal migration technique is estimated for the case in which the globaldispatch technique is applied. The purpose of this section is to study the effectivenessof the global dispatch and temporal migration techniques, so the conventional RM-FFand EDF-FF algorithms are used in the simulations for simplicity. As described in Sec-tion 5.4, the techniques are also valid for the RMDP, EDDHP, and EDDP algorithmsestablished in this research, as well as the other traditional partitioned scheduling al-gorithms, thereby the performance advancement shown in this section is estimated toappear in those algorithms. More precise evaluation for theintegrated scheduling is leftfor the future work.
The performance metric of this section is the mean response time of aperiodic tasks.Remember that this research is established under the assumption that the cost of taskmigrations is covered by that of task preemptions. Thus, thenumber of task migrationsis not measured in the simulations and not discussed in this section.
6.2.1 Experimental Setup
The evaluation environment is setup as follows. The three types of multiprocessorsystems are simulated. The first system has 4 processors, thesecond system has 8 pro-cessors, and the last system has 16 processors. Taking into account the scale of thecurrent embedded platforms, the systems with more than 16 processors are not studiedin the dissertation. For each system, a periodic task set is randomly generated so thatthe system utilization of the task set becomesUsys, whereUsys is set 0.5 for the simula-tions of static-priority scheduling and is set 0.7 for the simulations of dynamic-priorityscheduling. Note that system utilizations higher than 0.5 and 0.7 are not schedulableby the RM-FF and EDF-FF algorithms. Meanwhile, the sophisticated techniques arenot required in low system utilizations, since aperiodic tasks can be responded quickly
114

CHAPTER 6. PERFORMANCE EVALUATION
enough by using processor time unused left by periodic tasks. Therefore, it is reason-able to set 0.5 and 0.7.
The task set is generated as follows. A new periodic task is appended to the taskset as long as the total utilization of the tasks is less than or equal toUsys× M. Theparameters of each task are determined in the same manner as Section 6.1.1, namelythey refer to the characteristics of applications implemented in a humanoid robot [92]that has been developed in my laboratory. No tasks are supposed to utilize more than50% of the processor time. Thus, the utilization of each taskis computed based on theuniform distribution within the range of [0.01, 0.5]. The utilization of the last task gen-erated is only adjusted so that the total utilization is equal to Usys× M. Assuming bothcontrol tasks and multimedia tasks, the time units of the period of each task is randomlydetermined within the range of [100, 3000], simulating the range of [1ms, 30ms]. Then,the execution time calculated byCi = UiTi.
The aperiodic workloads refer to the M/M/1 queuing model. The arrival times ofaperiodic tasks are computed based on the Poisson distribution, and the execution timesare computed based on the exponential distribution. In other words, the arrival timesand the execution times are calculated based on the average service rate and the averagearrival rate. In general, the response time of aperiodic tasks depends on the system loadas well as the relation of the average service rate and the average arrival rate. Hence,two values of the average service rates,µ = 0.1 andµ = 0.2, are prepared in the sim-ulations. The setup ofµ = 0.1 generates aperiodic tasks with the average executiontime of 10 time units, simulating the average execution timeof 100µs. The setup ofµ = 0.2, on the other hand, generates aperiodic tasks with the average execution timeof 5 time units, simulating the average execution time of 50µs. Notice that, for theglobal dispatch policy, it does not matter which processorsthe aperiodic tasks arriveon, since the tasks are automatically dispatched to processors on which the responsetime can be reduced the most, whereas it matters for the simple partitioned dispatchpolicy. Thus, the arrival processors are determined randomly for fairness in the simula-tions of partitioned dispatch scheduling. The aperiodic load, denoted byλ/µ, is variedacross the range from the system utilization unused by the periodic tasks to the systemutilization overloaded by 10%. In particular, the range is varied (i) from 0.3 to 0.6for static-priority scheduling, and(ii) from 0.1 to 0.4 for dynamic-priority scheduling.Then, the mean response time of aperiodic tasks, denoted by the following expression,is measured for every aperiodic load.
the sum of the response time of all aperiodic tasksthe number of aperiodic tasks
For the simulations of static-priority scheduling, a periodic task set with a systemutilization of 0.5 is scheduled by the RM-FF algorithm. Every processor has a serverwith a policy of the PE algorithm, whose period is equal to theshortest period in thegiven periodic task set so that the responsiveness of the server is enhanced as muchas possible. The server utilization is set to the maximum value for which the periodic
115

CHAPTER 6. PERFORMANCE EVALUATION
tasks are guaranteed to be schedulable. That is, lettingU(Πx) be the total utilization ofa processorPx andnx be the number of tasks assigned toPx, the utilization of a serverperforming onPx is calculated as follows.
Usrvx =
2(
U(Πx)nx+ 1
)nx− 1
The server capacity is then calculated based on the period and the utilization. For thesimulations of dynamic-priority scheduling, on the other hand, a periodic task set witha system utilization of 0.7 is scheduled by the EDF-FF algorithm. Every processor hasa server with a policy of the TBS algorithm. The bandwidth of aserver performing onPx is set to all the utilization left by the periodic tasks; thatis, Usrv
x = 1− U(Πx).
6.2.2 Simulation Results of Static-Priority Scheduling
Figure 6.25 and Figure 6.26 show the mean response times, with different numbers ofthe processors, for the PE algorithm with exploiting the global dispatch technique, de-noted by PE-GD, relative to that of the PE algorithm without using the global dispatchtechnique but using the alternative simple partitioned dispatch policy.
For the case of the average service rateµ = 0.1, the responsiveness of the systemis dramatically improved for any aperiodic load regardlessthe number of the proces-sors. The mean response time is maximally reduced by about 98% compared to thescheduling in which the global dispatch technique is not exploited, though the reducedamount of the mean response time in each aperiodic load is varied with respect to thenumber of the processorsM. When the number of the processors isM = 4 andM = 8,the reduced amount of the mean response time takes a similar curve; that is, the meanresponse time relative to the simple PE algorithm is around 0.1 ∼ 0.15 in the aperiodicload of 0.3 and it is gradually reduced as the aperiodic load becomes higher. However,once the aperiodic load exceeds 0.5, the system falls into overload and the performancesuperiority to the simple PE algorithm begins to decrease asthe aperiodic load becomeshigher. When the system is overloaded, the processor time that can be allocated to theaperiodic tasks is more limited, and hence such a performance degradation is entailed.Notice that the mean response time is nonetheless reduced byaround 60∼ 70% in thehighest aperiodic load of 0.6. In contrast, the relative mean response time is maintainedaround 0.02, i.e. a reduction of 98%, even in high aperiodic loads whenthe number ofthe processors isM = 16. The conceivable reason is that the scheduler has more chanceto find processors that reduce the response time of aperiodictasks by global dispatchesif the system offers more processors, whereas a few choices of dispatch destinationsdecrease the chance of reducing the response time.
For the case of the average service rateµ = 0.2, even though the number of theprocessors is 8, the reduced amount of the mean response timeis not decreased inhigh aperiodic loads, unlike the case of the average servicerateµ = 0.1. Furthermore,the mean response time is maintained about 3% of the scheduling in which the global
116

CHAPTER 6. PERFORMANCE EVALUATION
0
0.1
0.2
0.3
0.4
0.5
0.3 0.35 0.4 0.45 0.5 0.55 0.6
Mea
n re
spon
se ti
me
rela
tive
to P
E
Aperiodic load
M = 4M = 8
M = 16
Figure 6.25: Mean response time for PE-GD (µ = 0.1).
0
0.1
0.2
0.3
0.4
0.5
0.3 0.35 0.4 0.45 0.5 0.55 0.6
Mea
n re
spon
se ti
me
rela
tive
to P
E
Aperiodic load
M = 4M = 8
M = 16
Figure 6.26: Mean response time for PE-GD (µ = 0.2).
117

CHAPTER 6. PERFORMANCE EVALUATION
dispatch technique is not exploited, which is 7% smaller than the setup in which thenumber of the processors isM = 16. Since the setup ofµ = 0.2 generates aperiodictasks with shorter execution times than the setup ofµ = 0.1, the response time of eachaperiodic task can be reduced substantially by even a slightincrease of the processortime available to the aperiodic task. However, such a decrease of the execution timesalso helps the simple partitioned dispatch technique to reduce the mean response time,and the reduced amount is obviously greater for more processors. Therefore, the per-formance improvement by the global dispatch technique is slightly decreased comparedto the case of the average service rateµ = 0.1 when the number of the processors isM = 16. Thus, having more processors does not necessarily achieve more performanceimprovement. Notice that the global dispatch technique still reduces the mean responsetime by about 90% when the number of the processors isM = 16. By comparison withthe case of the average service rateµ = 0.1, the reduced amount of the mean responsetime is not differentiated very much when the number of the processors isM = 4.
In summary, the global dispatch technique is basically moreeffective for the sys-tem with more processors, however it is not necessarily truewhen the average executiontime of aperiodic tasks is likely to be small. The mean response time is especially re-duced a lot in middle aperiodic loads. When the system falls into overload, the reducedamount of the mean response time over the simple partitioneddispatch technique isgradually decreased when the number of the processors is relatively small. Nonethe-less, the global dispatch technique offers a dramatic improvement of the mean responsetime, even if the system is overloaded.
Figure 6.27, Figure 6.28, and Figure 6.27 show the mean response times for thePE algorithm using the temporal migration technique in addition to the global dispatchtechnique, denoted by PE-GD-TM, relative to that of the PE-GD algorithm with re-spect to the average service rate ofµ = 0.1. Little performance difference is observedamong the three heuristics applied to the temporal migration technique. Since the loadof each processor is balanced by global dispatches, the choice of destination processorsfor temporal migrations is very limited. As a result, the three heuristics exert similarperformances. Notice that the mean response time is alreadyreduced dramatically bythe global dispatch technique, hence the reduced amount of mean response time by thetemporal migration technique is not that much. Nonetheless, the mean response timeis reduced by 60% compared to the scheduling in which only theglobal dispatch tech-nique is applied. It is interesting that when the system is close to or in overload, thereduced amount begins to decrease drastically as the aperiodic load becomes higherwhen the number of the processors isM = 4 andM = 8, whereas that keeps to in-crease moderately when the number of the processors isM = 16. In the aperiodic loadof 0.6, though no performance improvements are acquired by the temporal migrationtechnique when the number of the processors isM = 4 andM = 8, the relative meanresponse time is reduced to 0.4 when the number of the processors isM = 16. In gen-eral, the more processors the system has, the more destinations for temporal migrationsthe scheduler tends to find. Thus, a performance improvementis observed even if the
118
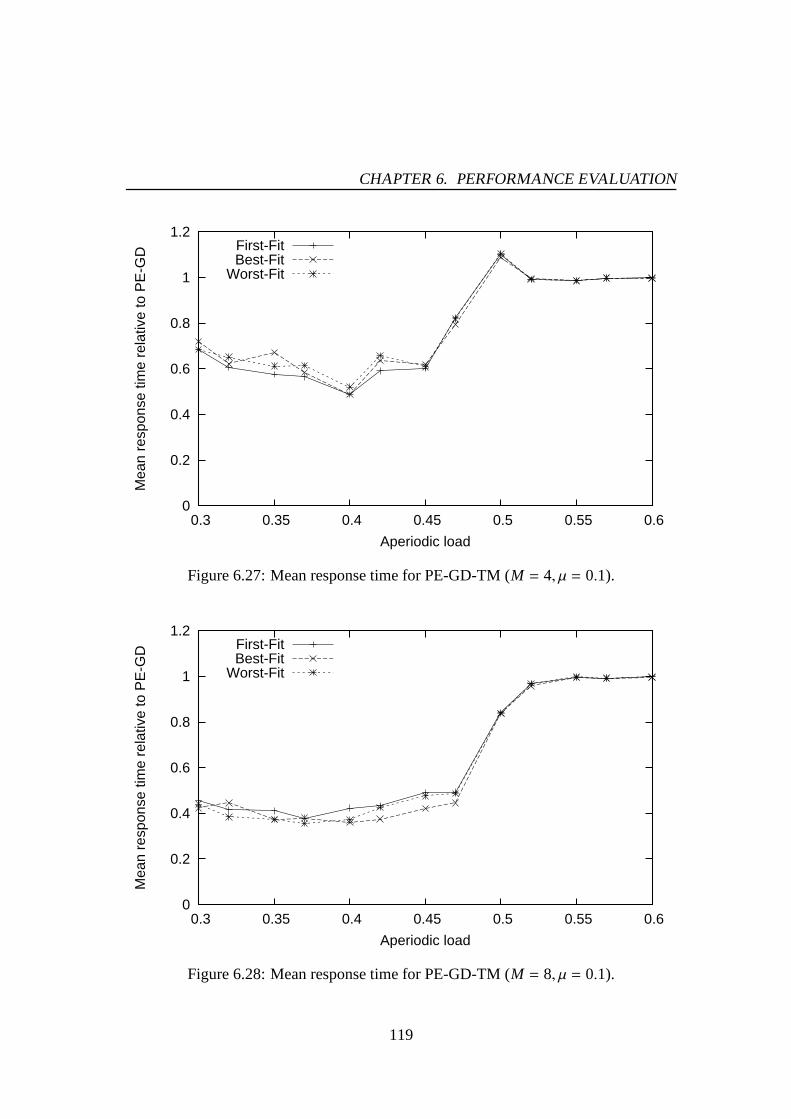
CHAPTER 6. PERFORMANCE EVALUATION
0
0.2
0.4
0.6
0.8
1
1.2
0.3 0.35 0.4 0.45 0.5 0.55 0.6
Mea
n re
spon
se ti
me
rela
tive
to P
E-G
D
Aperiodic load
First-FitBest-Fit
Worst-Fit
Figure 6.27: Mean response time for PE-GD-TM (M = 4, µ = 0.1).
0
0.2
0.4
0.6
0.8
1
1.2
0.3 0.35 0.4 0.45 0.5 0.55 0.6
Mea
n re
spon
se ti
me
rela
tive
to P
E-G
D
Aperiodic load
First-FitBest-Fit
Worst-Fit
Figure 6.28: Mean response time for PE-GD-TM (M = 8, µ = 0.1).
119
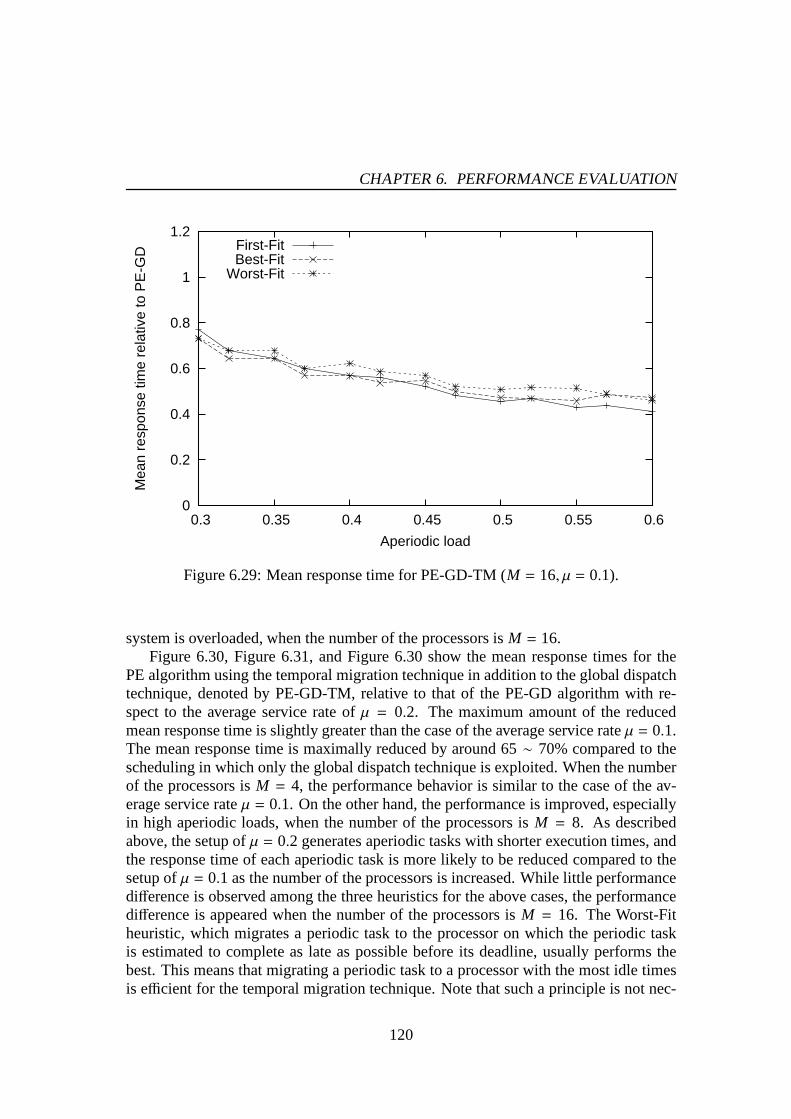
CHAPTER 6. PERFORMANCE EVALUATION
0
0.2
0.4
0.6
0.8
1
1.2
0.3 0.35 0.4 0.45 0.5 0.55 0.6
Mea
n re
spon
se ti
me
rela
tive
to P
E-G
D
Aperiodic load
First-FitBest-Fit
Worst-Fit
Figure 6.29: Mean response time for PE-GD-TM (M = 16, µ = 0.1).
system is overloaded, when the number of the processors isM = 16.Figure 6.30, Figure 6.31, and Figure 6.30 show the mean response times for the
PE algorithm using the temporal migration technique in addition to the global dispatchtechnique, denoted by PE-GD-TM, relative to that of the PE-GD algorithm with re-spect to the average service rate ofµ = 0.2. The maximum amount of the reducedmean response time is slightly greater than the case of the average service rateµ = 0.1.The mean response time is maximally reduced by around 65∼ 70% compared to thescheduling in which only the global dispatch technique is exploited. When the numberof the processors isM = 4, the performance behavior is similar to the case of the av-erage service rateµ = 0.1. On the other hand, the performance is improved, especiallyin high aperiodic loads, when the number of the processors isM = 8. As describedabove, the setup ofµ = 0.2 generates aperiodic tasks with shorter execution times, andthe response time of each aperiodic task is more likely to be reduced compared to thesetup ofµ = 0.1 as the number of the processors is increased. While little performancedifference is observed among the three heuristics for the above cases, the performancedifference is appeared when the number of the processors isM = 16. The Worst-Fitheuristic, which migrates a periodic task to the processor on which the periodic taskis estimated to complete as late as possible before its deadline, usually performs thebest. This means that migrating a periodic task to a processor with the most idle timesis efficient for the temporal migration technique. Note that such aprinciple is not nec-
120

CHAPTER 6. PERFORMANCE EVALUATION
0
0.2
0.4
0.6
0.8
1
1.2
0.3 0.35 0.4 0.45 0.5 0.55 0.6
Mea
n re
spon
se ti
me
rela
tive
to P
E-G
D
Aperiodic load
First-FitBest-Fit
Worst-Fit
Figure 6.30: Mean response time for PE-GD-TM (M = 4, µ = 0.2).
0
0.2
0.4
0.6
0.8
1
1.2
0.3 0.35 0.4 0.45 0.5 0.55 0.6
Mea
n re
spon
se ti
me
rela
tive
to P
E-G
D
Aperiodic load
First-FitBest-Fit
Worst-Fit
Figure 6.31: Mean response time for PE-GD-TM (M = 8, µ = 0.2).
121
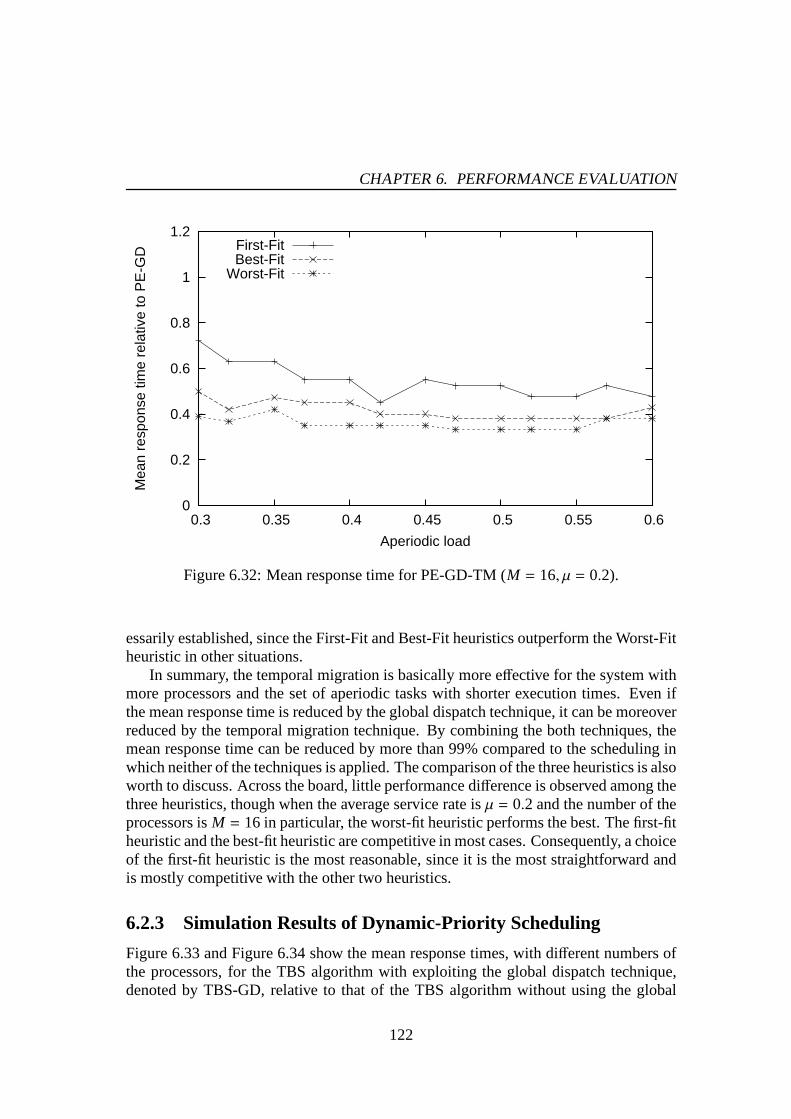
CHAPTER 6. PERFORMANCE EVALUATION
0
0.2
0.4
0.6
0.8
1
1.2
0.3 0.35 0.4 0.45 0.5 0.55 0.6
Mea
n re
spon
se ti
me
rela
tive
to P
E-G
D
Aperiodic load
First-FitBest-Fit
Worst-Fit
Figure 6.32: Mean response time for PE-GD-TM (M = 16, µ = 0.2).
essarily established, since the First-Fit and Best-Fit heuristics outperform the Worst-Fitheuristic in other situations.
In summary, the temporal migration is basically more effective for the system withmore processors and the set of aperiodic tasks with shorter execution times. Even ifthe mean response time is reduced by the global dispatch technique, it can be moreoverreduced by the temporal migration technique. By combining the both techniques, themean response time can be reduced by more than 99% compared tothe scheduling inwhich neither of the techniques is applied. The comparison of the three heuristics is alsoworth to discuss. Across the board, little performance difference is observed among thethree heuristics, though when the average service rate isµ = 0.2 and the number of theprocessors isM = 16 in particular, the worst-fit heuristic performs the best.The first-fitheuristic and the best-fit heuristic are competitive in mostcases. Consequently, a choiceof the first-fit heuristic is the most reasonable, since it is the most straightforward andis mostly competitive with the other two heuristics.
6.2.3 Simulation Results of Dynamic-Priority Scheduling
Figure 6.33 and Figure 6.34 show the mean response times, with different numbers ofthe processors, for the TBS algorithm with exploiting the global dispatch technique,denoted by TBS-GD, relative to that of the TBS algorithm without using the global
122
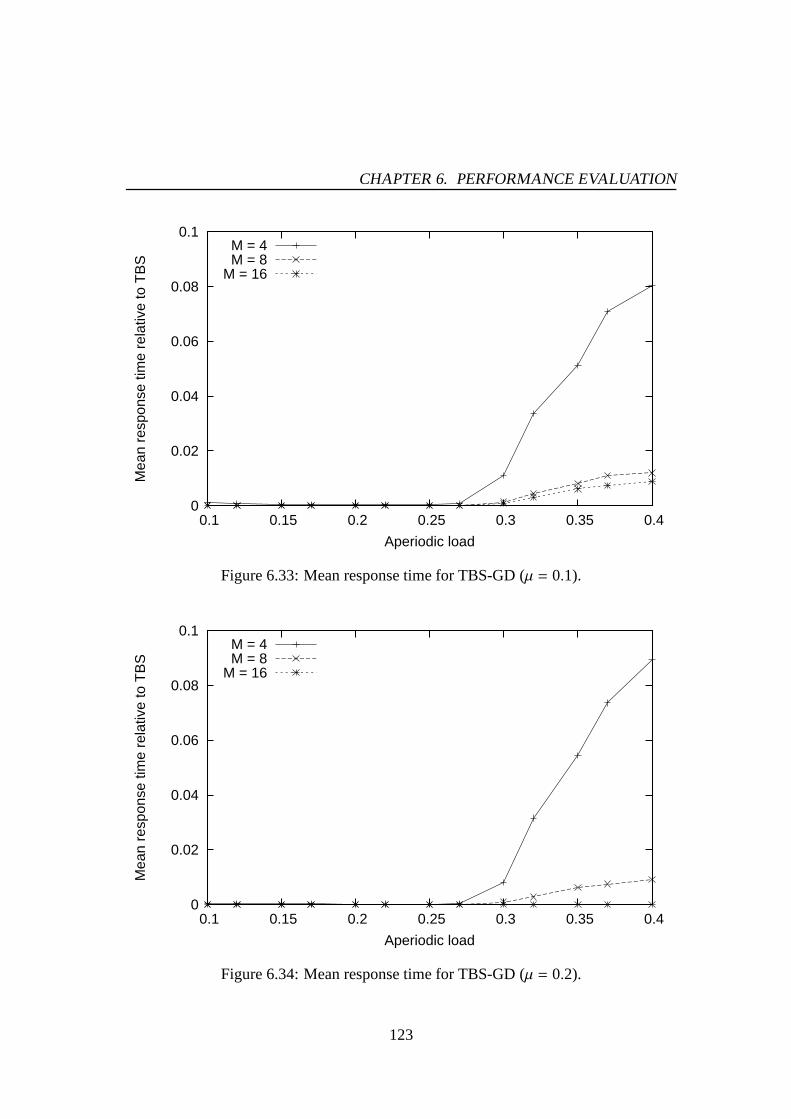
CHAPTER 6. PERFORMANCE EVALUATION
0
0.02
0.04
0.06
0.08
0.1
0.1 0.15 0.2 0.25 0.3 0.35 0.4
Mea
n re
spon
se ti
me
rela
tive
to T
BS
Aperiodic load
M = 4M = 8
M = 16
Figure 6.33: Mean response time for TBS-GD (µ = 0.1).
0
0.02
0.04
0.06
0.08
0.1
0.1 0.15 0.2 0.25 0.3 0.35 0.4
Mea
n re
spon
se ti
me
rela
tive
to T
BS
Aperiodic load
M = 4M = 8
M = 16
Figure 6.34: Mean response time for TBS-GD (µ = 0.2).
123

CHAPTER 6. PERFORMANCE EVALUATION
dispatch technique but using the alternative simple partitioned dispatch policy.For the cases of both the average service ratesµ = 0.1 andµ = 0.2, the respon-
siveness of the system is amazingly enhanced, especially when the system is not over-loaded. More specifically, in low aperiodic loads below 0.3, the mean response timeis reduced to about 0.1% of the scheduling in which the global dispatch technique isnot used. Even though the system is overloaded, the mean response time is reduced toaround 0.1 ∼ 1% when the number of the processors isM = 8 or M = 16. When thenumber of the processors isM = 4, it is also reduced to about 8∼ 9% in the highestaperiodic load of 0.4. The reduced amount of the mean response time by the global dis-patch technique is much greater than the case of the PE algorithm. Since the server isassigned the fixed highest priority on every processor in thePE algorithm, the aperiodictasks can be executed at certain rate every time the server becomes active. In contrast,the server is assigned the virtual deadline which can be far late in the TBS algorithm,and hence the aperiodic tasks may be waited for a long time. Therefore, the potentialamount of the response time that can be reduced is much greater in the TBS algorithmthan the PE algorithm.
In summary, likewise the PE algorithm, the global dispatch technique prefers thesystem with more processors and the set of aperiodic tasks with shorter execution timesin the TBS algorithm. A substantial performance improvement is observed even if thesystem is overloaded. The priority of aperiodic tasks is determined based on the virtualdeadline assigned by the TBS algorithm, hence the aperiodictasks can be never exe-cuted in advance to the periodic tasks with earlier deadlines. However, using the globaldispatch technique, the aperiodic tasks are dispatched to the processors so that the aperi-odic tasks can have as early virtual deadlines as possible. Therefore, the responsivenessto the aperiodic tasks can be dramatically improved by the global dispatch technique inthe TBS algorithm. On the whole, the impact of the global dispatch technique is greaterfor the dynamic-priority scheduling than the static-priority scheduling.
Figure 6.35, Figure 6.36, Figure 6.37, Figure 6.38, Figure 6.39, and Figure 6.37depict the mean response times for the TBS algorithm using the temporal migrationtechnique in addition to the global dispatch technique, denoted by TBS-GD-TM, rel-ative to that of the TBS-GD algorithm, with respect to the average service rates ofµ = 0.1 andµ = 0.2.
In contrast to the PE algorithm, no performance improvementis obtained by thetemporal migration technique. The mean response time is even worse than the schedul-ing in which only the global dispatch technique is taken as shown by the Worst-Fitheuristic in the aperiodic load of 0.27 of Figure 6.37. In addition, the performancedifference among the three heuristics is very little. The conceivable reason is that, asshown in Figure 6.33 and Figure 6.34, the mean response time is ultimately reducedby the global dispatch technique already, and hence there isvery little room left forresponsiveness improvement. Therefore, the performance is seldom improved by thetemporal migration technique. The results also indicate that, despite little room forimprovement, abusing temporal migrations may decline the responsiveness.
124

CHAPTER 6. PERFORMANCE EVALUATION
0
0.2
0.4
0.6
0.8
1
1.2
0.1 0.15 0.2 0.25 0.3 0.35 0.4
Mea
n re
spon
se ti
me
rela
tive
to T
BS
-GD
Aperiodic load
First-FitBest-Fit
Worst-Fit
Figure 6.35: Mean response time for TBS-GD-TM (M = 4, µ = 0.1).
0
0.2
0.4
0.6
0.8
1
1.2
0.1 0.15 0.2 0.25 0.3 0.35 0.4
Mea
n re
spon
se ti
me
rela
tive
to T
BS
-GD
Aperiodic load
First-FitBest-Fit
Worst-Fit
Figure 6.36: Mean response time for TBS-GD-TM (M = 8, µ = 0.1).
125
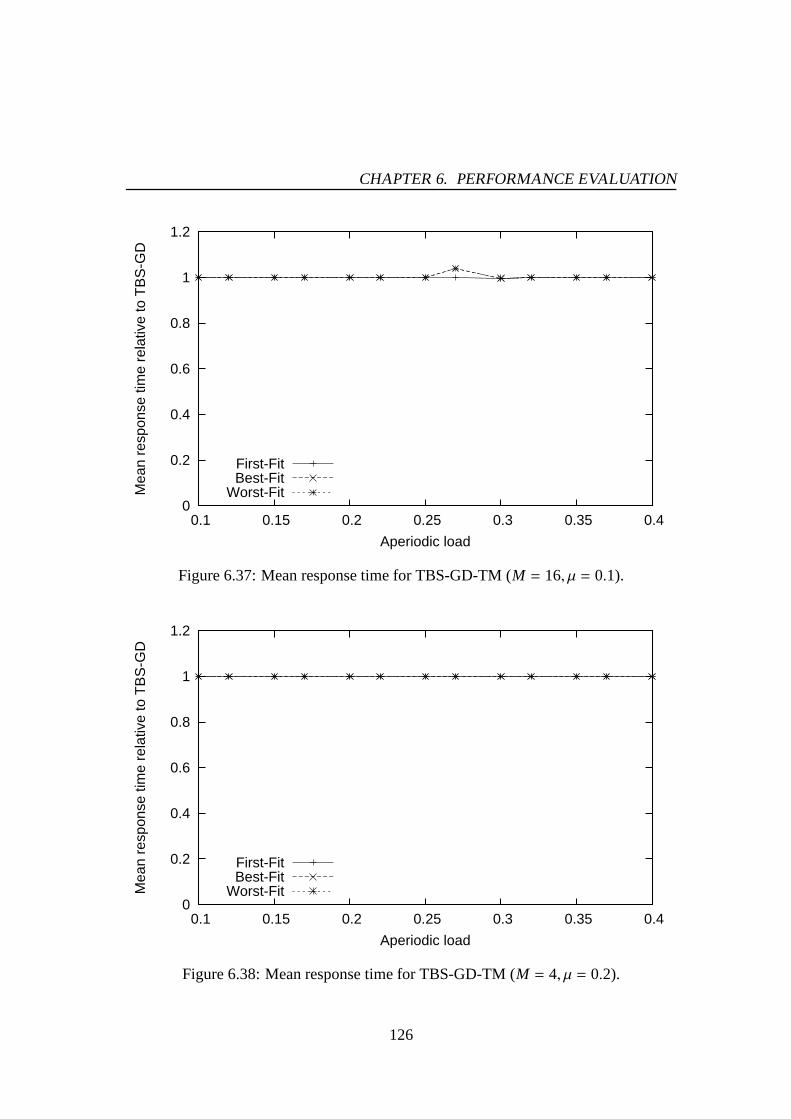
CHAPTER 6. PERFORMANCE EVALUATION
0
0.2
0.4
0.6
0.8
1
1.2
0.1 0.15 0.2 0.25 0.3 0.35 0.4
Mea
n re
spon
se ti
me
rela
tive
to T
BS
-GD
Aperiodic load
First-FitBest-Fit
Worst-Fit
Figure 6.37: Mean response time for TBS-GD-TM (M = 16, µ = 0.1).
0
0.2
0.4
0.6
0.8
1
1.2
0.1 0.15 0.2 0.25 0.3 0.35 0.4
Mea
n re
spon
se ti
me
rela
tive
to T
BS
-GD
Aperiodic load
First-FitBest-Fit
Worst-Fit
Figure 6.38: Mean response time for TBS-GD-TM (M = 4, µ = 0.2).
126
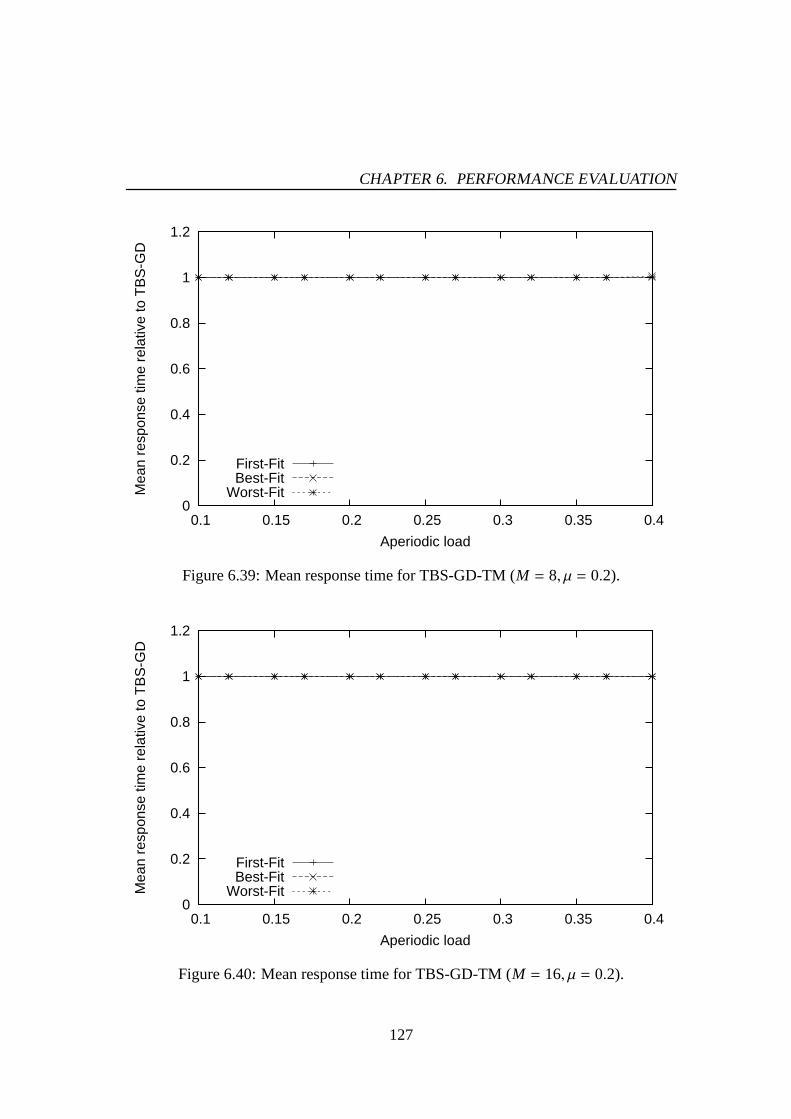
CHAPTER 6. PERFORMANCE EVALUATION
0
0.2
0.4
0.6
0.8
1
1.2
0.1 0.15 0.2 0.25 0.3 0.35 0.4
Mea
n re
spon
se ti
me
rela
tive
to T
BS
-GD
Aperiodic load
First-FitBest-Fit
Worst-Fit
Figure 6.39: Mean response time for TBS-GD-TM (M = 8, µ = 0.2).
0
0.2
0.4
0.6
0.8
1
1.2
0.1 0.15 0.2 0.25 0.3 0.35 0.4
Mea
n re
spon
se ti
me
rela
tive
to T
BS
-GD
Aperiodic load
First-FitBest-Fit
Worst-Fit
Figure 6.40: Mean response time for TBS-GD-TM (M = 16, µ = 0.2).
127
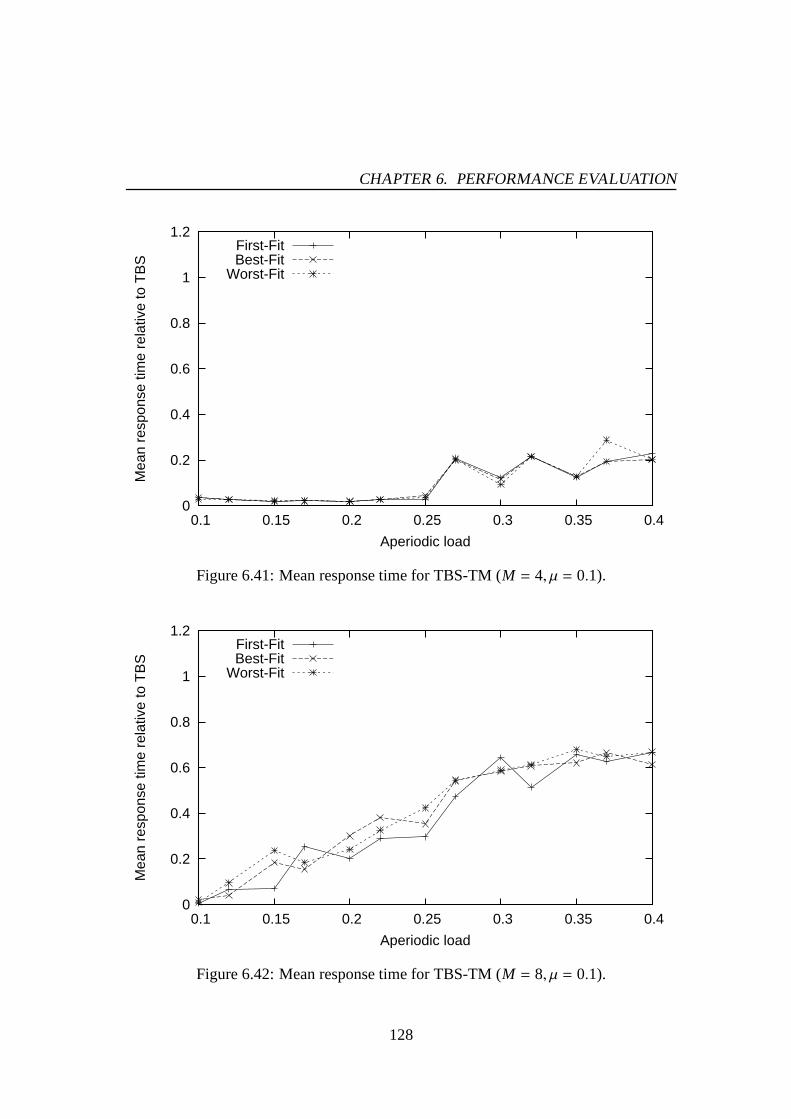
CHAPTER 6. PERFORMANCE EVALUATION
0
0.2
0.4
0.6
0.8
1
1.2
0.1 0.15 0.2 0.25 0.3 0.35 0.4
Mea
n re
spon
se ti
me
rela
tive
to T
BS
Aperiodic load
First-FitBest-Fit
Worst-Fit
Figure 6.41: Mean response time for TBS-TM (M = 4, µ = 0.1).
0
0.2
0.4
0.6
0.8
1
1.2
0.1 0.15 0.2 0.25 0.3 0.35 0.4
Mea
n re
spon
se ti
me
rela
tive
to T
BS
Aperiodic load
First-FitBest-Fit
Worst-Fit
Figure 6.42: Mean response time for TBS-TM (M = 8, µ = 0.1).
128
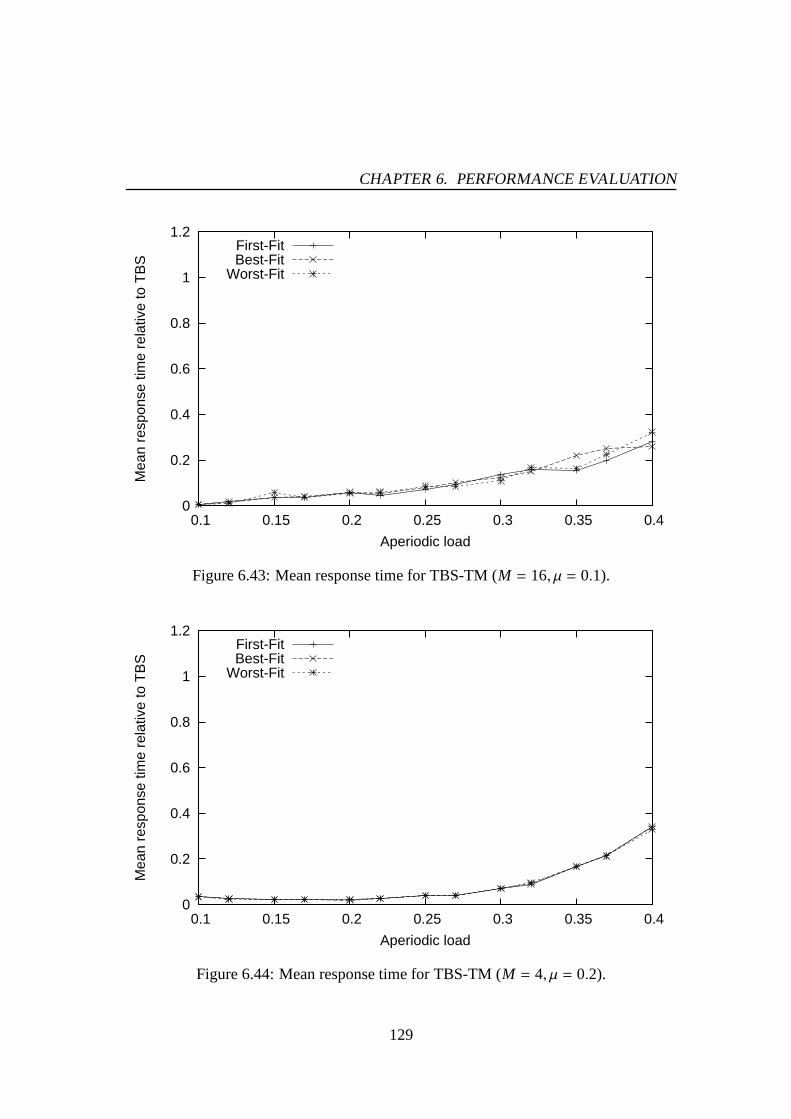
CHAPTER 6. PERFORMANCE EVALUATION
0
0.2
0.4
0.6
0.8
1
1.2
0.1 0.15 0.2 0.25 0.3 0.35 0.4
Mea
n re
spon
se ti
me
rela
tive
to T
BS
Aperiodic load
First-FitBest-Fit
Worst-Fit
Figure 6.43: Mean response time for TBS-TM (M = 16, µ = 0.1).
0
0.2
0.4
0.6
0.8
1
1.2
0.1 0.15 0.2 0.25 0.3 0.35 0.4
Mea
n re
spon
se ti
me
rela
tive
to T
BS
Aperiodic load
First-FitBest-Fit
Worst-Fit
Figure 6.44: Mean response time for TBS-TM (M = 4, µ = 0.2).
129
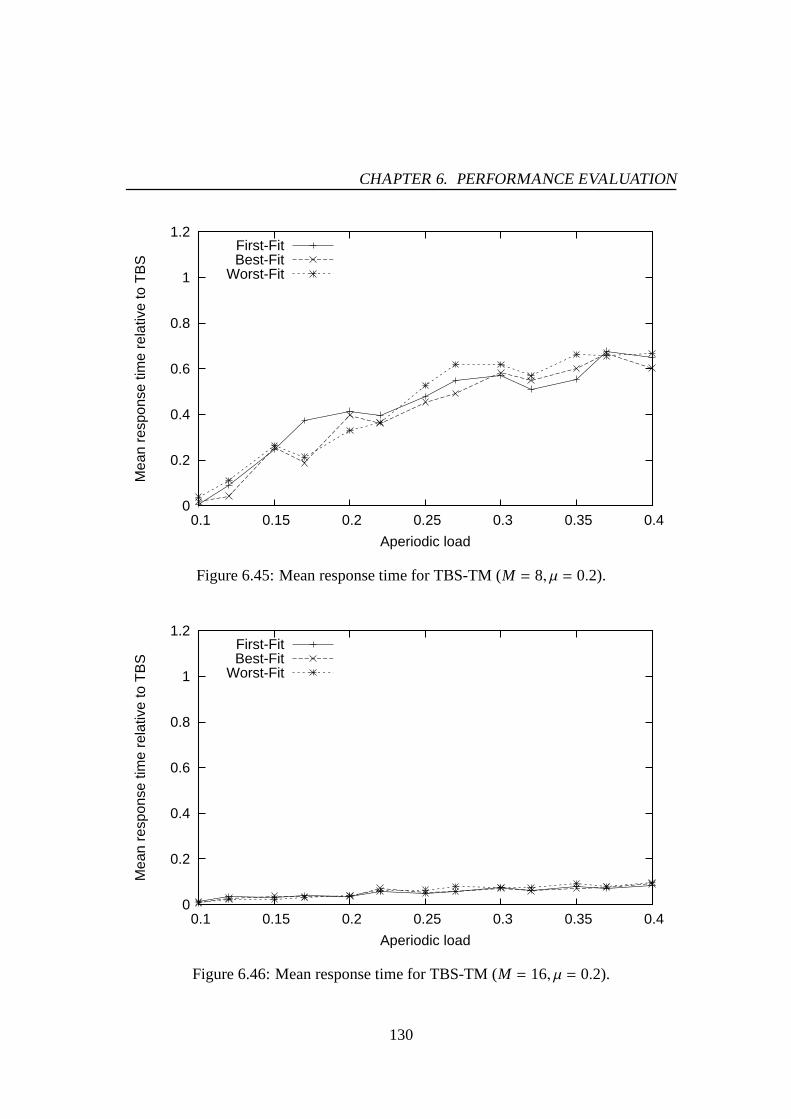
CHAPTER 6. PERFORMANCE EVALUATION
0
0.2
0.4
0.6
0.8
1
1.2
0.1 0.15 0.2 0.25 0.3 0.35 0.4
Mea
n re
spon
se ti
me
rela
tive
to T
BS
Aperiodic load
First-FitBest-Fit
Worst-Fit
Figure 6.45: Mean response time for TBS-TM (M = 8, µ = 0.2).
0
0.2
0.4
0.6
0.8
1
1.2
0.1 0.15 0.2 0.25 0.3 0.35 0.4
Mea
n re
spon
se ti
me
rela
tive
to T
BS
Aperiodic load
First-FitBest-Fit
Worst-Fit
Figure 6.46: Mean response time for TBS-TM (M = 16, µ = 0.2).
130

CHAPTER 6. PERFORMANCE EVALUATION
In order to show the effectiveness of the temporal migration technique for the TBSalgorithm, the mean response times for the TBS algorithm with using only the temporalmigration technique, denoted by TBS-TM, relative to that ofthe pure TBS algorithm,with respect to the average service rates ofµ = 0.1 andµ = 0.2 in Figure 6.41, Figure6.42, Figure 6.43, Figure 6.44, Figure 6.45, and Figure 6.46.
Using the temporal migration technique, the mean response time is reduced dra-matically, especially when the number of the processors isM = 4 andM = 16. In thiscase, the relative mean response time is maximally reduced to 0.02 in low aperiodicloads. Even though the system is overloaded, it is reduced toaround 0.1 ∼ 0.2. It is aremarkable result that the reduce amount of the mean response time when the numberof the processors isM = 8 is small. Likewise the previous results, little performancedifference is observed among the three heuristics. As a result, the First-Fit is esti-mated to be the most reasonable, since it is well performed aswell as straightforward.Remember that the performance advancement of the temporal migration technique isassimilated by that of the global dispatch technique in dynamic-priority scheduling asalready described.
6.3 Summary
This chapter presented the results of simulation studies. For periodic scheduling algo-rithms, the success ratios and the number of task preemptions with respect to randomly-generated 1000 task sets in different system loads were measured. Meanwhile for ape-riodic server algorithms, the mean response times of Poisson-modeled aperiodic tasksets in different loads were measured.
The RMDP, EDDHP, and EDDP scheduling algorithms developed in this researchprovided high success ratios with small numbers of task preemptions. By comparison,most of the traditional algorithms showed lower success ratios. In the traditional static-priority scheduling algorithms, only the WM algorithm showed higher success ratiosthan the RMDP algorithm. However, the WM algorithm generated a huge number oftask preemptions, that is, it is not a choice for practical use. In contrast, the RM-FFDUalgorithm offered a smaller number of task preemptions than the RMDP algorithm.Unfortunately, the RM-FFDU occasionally failed to schedule task sets with system uti-lizations above 60%, while the RMDP algorithm never failed to schedule task sets withsystem utilizations below 70%. Meanwhile in the traditional dynamic-priority schedul-ing algorithms apart from the optimal ones, only the EKG algorithm with a parameterof k = 2, denoted by EKG-2, was competitive with the EDDHP and EDDP algorithmsin terms of success ratio. However, the EKG-2 algorithm constantly generated moretask preemptions than the EDDHP and EDDP algorithms. The results indicate the ad-vancement of the developed algorithms. The EDDHP and EDDP algorithms were alsocompetitive in the simulations. However, the EDDP algorithm has a higher utilizationbound of 65%. The optimal algorithms, represented by the EKG-M algorithm in the
131

CHAPTER 6. PERFORMANCE EVALUATION
simulations, of course outperform the developed algorithms in terms of success ratio,since they always achieve the utilization bound of 100%, butthe implementation costsand the numbers of task preemptions occurred in those algorithms are not acceptablefor practical use. Therefore, the developed scheduling algorithms are very effective forpractical use, since they are well implementable and offer high schedulable utilizationswith small numbers of task preemptions.
The PE-based algorithm and the TBS-based algorithm in whichthe global dispatchtechnique and the temporal migration techniques are exploited reduced the mean re-sponse times of aperiodic tasks dramatically, compared to the pure PE and TBS algo-rithms. For both the PE-based algorithm and the TBS-based algorithm, the responsive-ness improvements to aperiodic tasks were boosted up as the number of the processorsincreased. Especially, the impact of the global dispatch technique for the TBS-based al-gorithm was remarkable. The effectiveness of the temporal migration technique was incontrast more greater for the PE-algorithm. As for the traded overhead, task migrationsoccur at most once for every aperiodic task arrival, therebythe dissertation believes thatthe performance improvement of the temporal migration technique is definitely worthexchanging for that overhead. Little performance difference was observed among theFF heuristic, the BF heuristic, and the WF heuristic in temporal migrations.
132

Chapter 7
CONCLUSION
This dissertation presented research on the real-time scheduling of periodic and aperi-odic tasks on multiprocessor systems. The developed scheduling techniques take ad-vantage of task migrations to accomplish high schedulability and high responsivenesswith elementary computations. The research explored both the scheme of static-priorityscheduling and the scheme of dynamic-priority scheduling.Three scheduling algo-rithms were developed for increasing the system utilization of periodic tasks with guar-anteeing timing constraints as well as restraining the occurrences of task preemptions.Two server algorithms were also designed for reducing the mean response time of ape-riodic tasks. The thesis supported by this dissertation is that the migrative schedulingimproves the schedulability to periodic tasks as well as theresponsiveness to aperiodictasks, without causing complex computations and a lot of task preemptions.
7.1 Summary of Contributions
This research made contributions of theoretical significance to real-time computingupon multiprocessor systems. The contributions lead to improvements of the periodicschedulability as well as the aperiodic responsiveness andadvance the development ofhigh-performance real-time systems for a part of the intelligent social infrastructure.
The first contribution is made in the proposal of the portioned scheduling techniquefor increasing the total utilization of multiprocessor systems with guaranteeing timingconstraints of periodic tasks. The portioned scheduling technique takes advantage ofboth the traditional global scheduling and partitioned scheduling techniques. The ba-sic strategy of the portioned scheduling is that, like the partitioned scheduling, most oftasks are scheduled on dedicated processors and never migrate to different processors,while special tasks are permitted to migrate between two restrictive processors like theglobal scheduling. Such a scheduling policy draws the advancement that the schedu-lable system utilization is increased by exploiting a smallnumber of task migrationsand at the same time the scheduling overhead is reduced by restricting the number of
133

CHAPTER 7. CONCLUSION
tasks and the range of processors related to the migrations.The dissertation thereforeadvocates that the portioned scheduling technique is capable of breaking through thetrade-off between schedulability and complexity.
The major contribution of this research is the development of three scheduling al-gorithms designed based on the portioned scheduling technique. The scheduling algo-rithms are developed by taking into account the two types of the priority assignmentscheme: the static-priority assignment and the dynamic-priority assignment. For thediscipline of static-priority scheduling, in which the priority order of tasks is neverchanged, the RMDP algorithm is developed. In the domain of uniprocessor systems,the RM algorithm is well known to be optimal for static-priority scheduling. Thus, theRMDP algorithm has its basis on the RM algorithm. On every processor, the schedulingpolicy of the RMDP algorithm is distinguished from the RM algorithm when specialtasks that are split into two processors by portioning are scheduled. While the highest-priority task is never deferred in the RM algorithm, its partial portion, i.e. the secondportion of the split task, can be deferred so that two portions of the same split task arescheduled exclusively. Such a deferrable scheduling policy is expected to improve theschedulability to periodic tasks, though the worst-case utilization bound for the RMDPalgorithm is proved to be 50%, which is equal to the prior known bound. In a senseof the worst case, no performance improvement is obtained bythe RMDP algorithmcompared to traditional static-priority scheduling algorithms. However, the simulationresults show that the performance of the RMDP algorithm in general cases is often bet-ter than the traditional algorithms. The EDDHP and EDDP algorithms, on the otherhand, are invented to perform for the discipline of dynamic-priority scheduling. Inthe EDDHP algorithm, the second portion of the split task is statically assigned thehighest priority and is deferrable like the RMDP algorithm,then the rest of the tasksis scheduled according to the EDF algorithm, which is well known to be optimal fordynamic-priority scheduling in the domain of uniprocessorsystems. Unfortunately, theworst-case utilization bound of every processor for the EDDHP algorithm is no greaterthan 50% due to restriction of the static-priority assignment to the second portion ofthe split task. The EDDP algorithm is an extension of the EDDHP algorithm in thatall the tasks, including the second portion of the split task, are assigned the prioritiesdynamically based on the deadlines. If the priority of the second portion of the splittask is assigned based on its true deadline, the worst-case schedulability is far declined,and that is a reason why the EDDHP algorithm statically assigns the highest priorityto it. In the EDDP algorithm, the schedulability is maintained by assigning the virtualdeadline, which is set earlier than the true deadline, to thesecond portion of the splittask. Such a deadline assignment achieves a worst-case utilization bound of 65%. Tothe best of my knowledge, no traditional algorithms, exceptfor complex optimal ones,have ever achieved a worst-case utilization bound greater than 65%. The optimal algo-rithms literally achieve an optimal utilization of 100% in any case, however they raisea lot of task preemptions and a run-time overhead. Although the EKG algorithm is ableto trade the worst-case utilization bound with the number oftask preemptions, the sim-
134

CHAPTER 7. CONCLUSION
ulation results showed that the EKG algorithm with the utilization bound of 66% stillgenerates more task preemptions than the EDDP algorithm. The general performanceof the developed algorithms also outperform the traditional algorithms in most casesaccording to the simulation results.
Another contribution of this research is made in the proposals of the global dis-patch technique and the temporal migration technique for reducing the response timeof aperiodic tasks. For the domain of multiprocessor systems, very few schedulingtechniques for improving the responsiveness to aperiodic tasks have been discussedand considered. To the best of my knowledge, this research isthe first contributionfor improving the responsiveness to aperiodic tasks on multiprocessor systems. Thepresented techniques target the partitioned scheduling strategy for simplicity, but theyare compatible to the portioned scheduling strategy. The global dispatch technique im-proves the responsiveness by dispatching an arriving aperiodic task to a processor onwhich the response time of the aperiodic task is estimated tobe reduced the most. Thetemporal migration technique, on the other hand, improves the responsiveness in sucha way that if processor time cannot be allocated to an arriving aperiodic task immedi-ately due to executions of periodic tasks, periodic tasks with higher priorities than theaperiodic task are temporarily migrated to different processors to devolve the processortime, as long as the timing constraints of the periodic tasksare still guaranteed. Thebehavior of the global dispatch and temporal migration procedures is similar to loadbalancing. Since the global dispatch technique assigns every aperiodic task to an ef-fective processor when it arrives, which is not a migration,the overhead is expect to bevanishingly low. The temporal migration technique, on the other hand, generates addi-tional migrations, however they occur only when aperiodic tasks arrive and cannot beserved immediately. Thus, the expectation is that the incurred overhead is not a crisis.
For the disciplines of static-priority scheduling and dynamic-priority scheduling,the designs of the PE and TBS algorithms are respectively considered to integrate theglobal dispatch and temporal migration techniques. In the PE algorithm, an arrivingaperiodic task is dispatched to a processor on which its worst-case response time isminimized. Then, temporal migrations occur in such a way that when an arriving aperi-odic task is not served by a server immediately, a periodic task with the highest priorityis migrated to a different processor as long as its latest finish time served by thePE al-gorithm on the new processor is earlier than or at its deadline. The remaining executiontime of the migrated periodic task is accumulated as the server capacity at its prioritylevel. On the other hand, in the TBS algorithm, an arriving aperiodic task is dispatchedto a processor on which its assigned virtual deadline is minimized. Then, temporalmigrations occur in such a way that when an arriving aperiodic task is not served bya server immediately, a periodic task with the earliest deadline is migrated to a differ-ent processor as long as its virtual deadline assigned by theTBS algorithm on the newprocessor is earlier than or at its deadline. Since the server bandwidth can be broadentemporarily due to the absence of the migrated periodic task, a new virtual deadline,which is obviously earlier than the original one, is assigned to the arriving aperiodic
135

CHAPTER 7. CONCLUSION
task. According to the simulation results, the mean response time of aperiodic tasksis dramatically reduced by the global dispatch and temporalmigration techniques withrespect to both the PE and TBS algorithms. Especially, the global dispatch techniqueis more effective for the TBS algorithm, though the impact of the temporal migrationtechnique is decreased instead, compared to the PE algorithm.
7.2 Future Directions
In the end, the dissertation gives several insights to the future work. It is worth consid-ering an extension of the portioned scheduling technique soas to have applicability tomore realistic system model. In this research, periodic tasks are assumed preemptive.However, non-preemptive periodic tasks are often submitted in real-time systems. Forinstance, motor control tasks in robot systems may use I/O functions which cannot bepreempted in general. If the periodic tasks are partially not preemptive, which meansthat they are also non migrative, the scheduling is not precisely produced accordingto the theory of the portioned scheduling. It is also worth considering a problem ofperiodic jitters. In the portioned scheduling, the second portion of a split task can bedeferred. However, such a deferrable approach generates periodic jitters which maydegrade the accuracy of control. Thus, a theoretical analysis of the portioned schedul-ing in which some tasks cannot be preempted or cannot be deferred is needed. If theportioned scheduling technique can be extended to be even available for those types oftasks, the value of the technique is boosted.
There is also room for improvement in the presented scheduling model. First, amigration manner of portioned (split) tasks can be moreoverimproved. As pointedout in Chapter 4, inessential task preemptions and migrations occur for the presentedalgorithms. A kind of a look-ahead approach is wanted to prevent the algorithm fromgenerating redundant task preemptions and migrations.
The portioned scheduling technique presented in this dissertation focused on theidea that the second portion of a portioned task is deferrable. The resulting utilizationbound was 65%, which is actually a significant contribution,because no traditional ef-ficient algorithms have ever transcended a utilization bound of 50%. In addition, thepresented approaches are well practical. Hence, the discussion of this idea is closed.However, it is worth considering an idea that the first portion of a portioned task isdeferrable. The expectation is that it can reduce the numberof task preemptions, sincethe second portion is always assigned the shortest period orthe earliest relative dead-line, which means that it is usually a high-priority task, and is not often preempted,that is, the deferred first portion is not unnecessarily preempted. A specific schedulingalgorithm and its schedulability analysis are desired.
The global dispatch technique and the temporal migration technique also have roomfor improvement. First of all, they also exploit task migrations, and hence the extendedscheduling model in which some tasks are not preemptive and migrative is required to
136

CHAPTER 7. CONCLUSION
be applicable to various types of tasks. The dissertation believes that the global dis-patch technique itself is very efficient and there is technically little room for improve-ment. In contrast, the temporal migration technique is arguable. As stated in Chapter5, the policy of processor selections for temporal migrations must be discussed, sinceit dominates the responsiveness to aperiodic tasks very much. The timing of a tempo-ral migration occurrence is also controversial. In the presented approaches, a temporalmigration occurs for an arrival of aperiodic tasks. The response time may be reducedmore if a temporal migration can also occur for another event. However, an increase oftemporal migration results in larger scheduling overhead.Thus, the trade-off must betaken into account.
One of the largest future work is to integrate the portioned scheduling techniquewith the global dispatch technique and the temporal migration technique. The impactof the integrated scheduling is far promising to next generation real-time systems. Asdiscussed in Section 5.4, it is actually possible to integrate those scheduling techniques,thereby the theoretical analysis of the integrated scheduling is planned as well as thedesign and implementation.
The final insight to the future work is the development of an operating systems inwhich the scheduling techniques established in this research are implemented. The to-tal costs of scheduling techniques are then able to be assessed. Since the theoreticalsuperiority of the established techniques is demonstratedby the simulation studies, itis next required to report the practical superiority of the established techniques. Toachieve this, the development of an embedded real-time and multicore-oriented operat-ing system in which the established techniques are implemented is on going.
137

Bibliography
[1] C.L. Liu and J.W. Layland. Scheduling Algorithms for Multiprogramming in aHard Real-Time Environment.Journal of the ACM, Vol. 20, No. 1, pp. 46–61,1973.
[2] J.A. Stankovic, M. Spuri, K. Ramamritham, and G.C. Buttazzo. DeadlineScheduling for Real-Time Systems. Kluwer Academic Publishers, 1998.
[3] G.C. Buttazzo. Rate Monotonic vs. EDF: Judgment Day.Real-Time Systems, Vol.29, pp. 5–26, 2005.
[4] E. Bini, G.C. Buttazzo, and G.M. Buttazzo. A Hyperbolic Bound for the RateMonotonic Algorithm. InProceedings of the Euromicro Conference on Real-TimeSystems, pp. 59–66, 2002.
[5] T. Kuo, L.P. Chang, Y.H. Liu, and K.J. Lin. Efficient On-Line SchedulabilityTests for Real-Time Systems.IEEE Transactions on Software Engineering, Vol.29, No. 8, pp. 734–751, 2003.
[6] S. Lauzac, R. Melhem, and D. Mosses. An improved rate monotonic admissioncontrol and its applications.IEEE Transactions on Computers, Vol. 52, No. 3, pp.337–350, 2003.
[7] W.C. Lu, H.W. Wei, and K.J. Lin. Rate Monotonic Schedulability ConditionsUsing Relative Period Ratios. InProceedings of the IEEE International Confer-ence on Embedded and Real-Time Computing Systems and Applications, pp. 3–9,2006.
[8] J.P. Lehoczky, L. Sha, and J.K. Strosnider. Enhanced Aperiodic Responsivenessin Hard Real-Time Environments. InProceedings of the IEEE Real-Time SystemsSymposium, pp. 261–270, 1987.
[9] B. Sprunt, J.P. Lehoczky, and L. Sha. Exploiting Unused Periodic Time for Ape-riodic Service using the Extended Priority Exchange Algorithm. InProceeding ofthe IEEE Real-Time Systems Symposium, pp. 251–258, 1988.
138

BIBLIOGRAPHY
[10] B. Sprunt, L. Sha, and J.P. Lehoczky. Aperiodic Task Scheduling for Hard Real-Time Systems.Real-Time Systems, Vol. 1, No. 1, pp. 27–60, 1989.
[11] J.P. Lehoczky and S. Ramos-Thuel. An Optimal Algorithmfor Scheduling Soft-Aperiodic Tasks in Fixed-Priority Preemptive Systems. InProceedings of theIEEE Real-Time Systems Symposium, pp. 110–123, 1992.
[12] S. Ramos-Thuel and J.P. Lehoczky. On-line Scheduling of Hard Deadline Ape-riodic Tasks in Fixed-Priority Systems. InProceedings of the IEEE Real-TimeSystems Symposium, pp. 160–171, 1993.
[13] R.I. Davis, K.W. Tindell, and A. Burns. Scheduling Slack Time in Fixed PriorityPre-emptive Systems. InProceedings of the IEEE Real-Time Systems Symposium,pp. 222–231, 1993.
[14] R.I. Davis and A. Wellings. Dual Priority Scheduling. In Proceedings of the IEEEReal-Time Systems Symposium, pp. 100–109, 1995.
[15] J.K. Strosnider, J.P. Lehoczky, and L. Sha. The Deferrable Server Algorithmfor Enhanced Aperiodic Responsiveness in Hard Real-Time Environments.IEEETransactions on Computers, Vol. 44, No. 1, pp. 73–91, 1995.
[16] M. Spuri and G.C. Buttazo. Efficient Aperiodic Service under Earliest DeadlineScheduling. InProceedings of the IEEE Real-Time Systems Symposium, pp. 2–11,1994.
[17] M. Spuri and G.C. Buttazo. Scheduling Aperiodic Tasks in Dynamic PrioritySystems.Real-Time Systems, Vol. 10, No. 2, pp. 179–210, 1996.
[18] L. Abeni and G.C. Buttazzo. Integrating Multimedia Applications in Hard Real-Time Systems. InProceedings of the IEEE Real-Time Systems Symposium, pp.3–13, 1998.
[19] G.C. Buttazzo and F. Sensini. Deadline Assignment Methods for Soft AperiodicScheduling in Hard Real-Time Systems.IEEE Transactions on Computers, Vol.48, No. 10, pp. 1035–1052, 1999.
[20] L. Sha, R. Rajkumar, and J.P. Lehoczky. Priority Inheritance Protocols: An Ap-proach to Real-Time Synchronization.IEEE Transactions on Computers, Vol. 39,No. 9, pp. 1175–1185, 1990.
[21] T.P. Baker. Stack-Based Scheduling of Real-Time Processes.Real-Time Systems,Vol. 3, No. 1, pp. 67–99, 1991.
[22] C.W. Mercer, S. Savage, and H. Tokuda. Processor Capacity Reserves: OperatingSystem Support for Multimedia Application. InProceedings of the IEEE Inter-national Conference on Multimedia Computing and Systems, pp. 90–99, 1994.
139

BIBLIOGRAPHY
[23] R. Rajkumar, C. Lee, J. Lehoczky, and D. Siewiorek. A Resource AllocationModel for QoS Management. InProceedings of the IEEE Real-Time SystemsSymposium, pp. 298–307, 1997.
[24] J.A. Stankovic, C. Lu, S.H. Son, and G. Tao. The Case for Feedback ControlReal-Time Scheduling. InProceedings of the Euromicro Conference on Real-Time Systems, pp. 11–20, 1999.
[25] L. Abeni and G. Buttazzo. Adaptive Bandwidth Reservation for Multimedia Com-puting. InProceedings of the IEEE International Conference on Real-Time Com-puting Systems and Applications, pp. 70–77, 1999.
[26] P. Pillai and K.G. Shin. Real-Time Dynamic Voltage Scaling for Low-Power Em-bedded Operating Systems. InProceedings of the ACM Symposium on OperatingSystems Principles, pp. 89–102, 2001.
[27] G. Quan, L. Niu, X.S. Hu, and B. Mochocki. Fixed-Priority Scheduling for Re-ducing Overall Energy on Variable Voltage Processor. InProceedings of the IEEEReal-Time Systems Symposium, pp. 309–318, 2004.
[28] G.E. Moore. Cramming More Components onto Integrated Circuits. Electronics,Vol. 38, No. 8, 1965.
[29] D.M. Tullsen, S.J. Eggers, and H.M. Levy. SimultaneousMultithreading: Maxi-mizing On-Chip Parallelism. InProceeding of the Annual International Sympo-sium on Computer Architecture, pp. 392–403, 1995.
[30] D.M. Tullsen, S.J. Eggers, H.M. Levy, J.L. Lo, and R.L. Stamm. ExploitingChoice: Instruction Fetch and Issue on an Implementable Simultaneous Multi-threading Processor. InProceedings of the Annual International Symposium onComputer Architecture, pp. 191–202, 1996.
[31] D. Koufaty and D. T. Marr. Hyperthreading Technology inthe Netburst Microar-chitecture.IEEE Macro, Vol. 23, pp. 56–65, 2003.
[32] K. Olukotun, B.A. Nayfe, L. Hammond, K. Wilson, and K. Chang. The Case fora Single-Chip Multiprocessor. InProceedings of the International Conference onArchitectural Support for Programming Languages and Operating Systems, pp.2–11, 1996.
[33] Y. Sakagami, R. Watanabe, C. Aoyama, S. Matsunaga, N. Higaki, and K. Fu-jimura. The Intelligent ASIMO: System Overview and Integration. In Proceed-ings of the IEEE/RSJ International Conference on Intelligent Robots and Systems,pp. 2478–2483, 2002.
140

BIBLIOGRAPHY
[34] T. Ishida. Development of a Small Biped Entertainment Robot QRIO. InPro-ceedings of the International Symposium on Micro-Nanomechatronics and Hu-man Science, pp. 23–28, 2004.
[35] Y. Hosoda, S. Egawa, J. Tamamoto, K. Yamamoto, R. Nakamura, and M. Togami.Basic Design of Human-Symbiotic Robot EMIEW. InProceedings of theIEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 5079–5084, 2006.
[36] K. Kaneko, F. Kanehiro, S. Kajita, K. Yokoyama, K. Akachi, T. Kawasaki, S. Ota,and T. Isozumi. Open Architecture Humanoid Robotics Platform. In Proceedingsof the IEEE/RSJ International Conference on Robotics and Automation, pp. 24–30, 2002.
[37] K. Akachi, K. Kaneko, N. Kanehira, S. Ota, G. Miyamori, M. Hirata, S. Kajita,and F. Kanehiro. Development of Humanoid Robot HRP-3P. InProceedings ofthe IEEE/RSJ International Conference on Humanoid Robots, pp. 50–55, 2005.
[38] T. Matsui, H. Hirukawa, Y. Ishikawa, N. Yamasaki, S. Kagami, F. Kanehiro,H. Saito, and T. Inamura. Distributed Real-Time Processingfor HumanoidRobots. InProceedings of the IEEE International Conference on Embedded andReal-Time Computing Systems and Applications, pp. 205–210, 2005.
[39] Toyota Mortor Corporation. Toyota partner robot. http://www.toyota.co.jp/.
[40] R. Bischoff and V. Graefe. Touch and Natural Language in the Control of aSituation-Oriented Behavior-Based Humanoid Robot. InProceedings of the IEEEInternational Conference on Systems, Man, and Cybernetics, pp. 199–1004, 1999.
[41] S. Kagami, K. Nishiwaki, J. Kuffner, Y. Kuniyoshi, M. Inaba, and H. Inoue. On-line 3D Vision, Motion Planning and Bipedal Locomotion Control Coupling Sys-tem of Humanoid Robot: H7. InProceedings of the IEEE/RSJ International Con-ference on Intelligent Robots and Systems, pp. 2557–2562, 2002.
[42] S.K. Dhall and C.L. Liu. On a Real-Time Scheduling Problem. Operations Re-search, Vol. 26, No. 1, pp. 127–140, 1978.
[43] B. Andersson and J. Jonsson. Some Insights on Fixed-Priority Preemptive Non-Partitioned Multiprocessor Scheduling. InProc. of the IEEE Real-Time SystemsSymposium - Work-in-Progress Session, 2000.
[44] J. Carpenter, S. Funk, P. Holman, A. Srinivasan, J. Anderson, and S.K. Baruah.A Categorization of Real-Time Multiprocessor Scheduling Problems and Algo-rithms. In Handbook of SCHEDULING Algorithms, Models and PerformanceAnalysis, pp. 30.1–30.19. CHAPMAN & HALL/CRC, 2004.
141

BIBLIOGRAPHY
[45] B. Andersson, S.K. Baruah, and J. Jonsson. Static-priority Scheduling on Mul-tiprocessors. InProc. of the IEEE Real-Time Systems Symposium, pp. 193–202,2001.
[46] T.P. Baker. An Analysis of Fixed-Priority Schedulability on a Multiprocessor.Real-Time Systems, Vol. 32, pp. 49–71, 2006.
[47] J. Goossens, S. Funk, and S.K. Baruah. Priority-drivenScheduling of PeriodicTask Systems on Multiprocessors.Real-Time Systems, Vol. 25, pp. 187–205,2003.
[48] T.P. Baker. An Analysis of EDF Schedulability on a Multiprocessor.IEEE Trans-actions on Parallel and Distributed Systems, Vol. 16, No. 8, pp. 760–768, 2005.
[49] S. Davari and S.K. Dhall. An On-Line Algorithm for Real-Time Tasks Allocation.In Proceedings of the IEEE Real-Time Systems Symposium, pp. 194–2000, 1986.
[50] Y. Oh and S. Son. Allocating Fixed-Priority Periodic Tasks on MultiprocessorSystems.Real-Time Systems, Vol. 9, No. 3, pp. 207–239, 1995.
[51] A. Burchard, J. Liebeherr, Y. Oh, and S. Son. Assigning Real-Time Tasks toHomogeneous Multiprocessor Systems.IEEE Transactions on Computers, Vol.44, No. 12, pp. 1429–1442, 1995.
[52] S. Lauzac, R. Melhem, and D. Mosses. An Efficient RMS Admission Controland Its Application to Multiprocessor Scheduling. InProceedings of the IEEEInternational Parallel Processing Symposium, pp. 511–518, 1998.
[53] D. Oh and T. Baker. Utlization Bounds for N-Processor Rate Monotonic Schedul-ing with Static Processor Assignment.Real-Time Systems, Vol. 15, No. 2, pp.183–192, 1998.
[54] J.M. Lopez, M. Garcia, J.L. Diaz, and D.F. Garcia. Utlization Bounds for Mul-tiprocessor Rate-Monotonic Scheduling.Real-Time Systems, Vol. 24, pp. 5–28,2003.
[55] J.M. Lopez, J.L. Diaz, and D.F.Carcia. Minimum and Maximum UtilizationBounds for Multiprocessor RM Scheduling. InProceedings of the EuromicroConference on Real-Time Systems, pp. 67–75, 2001.
[56] J.M. Lopez, J.L. Diaz, and D.F. Garcia. Minimum and Maximum UtilizationBounds for Multiprocessor Rate-Monotonic Scheduling.IEEE Transactions onParallel and Distributed Systems, Vol. 28, pp. 39–68, 2004.
[57] B. Andersson and J. Jonsson. The Utilization Bounds of Partitioned and PfairStatic-Priority Scheduling on Multiprocessors are 50%. InProceedings of theEuromicro Conference on Real-Time Systems, pp. 33–40, 2003.
142

BIBLIOGRAPHY
[58] J.M. Lopez, M. Carcia, J.L. Diaz, and D.F.Carcia. Worst-Case Utilization Boundfor EDF Scheduling on Real-Time Multiprocessor Systems. InProceedings of theEuromicro Conference on Real-Time Systems, pp. 25–33, 2000.
[59] J.M. Lopez, J.L. Diaz, and D.F. Garcia. Utlization Bounds for EDF Schedulingon Real-Time Multiprocessor Systems.Real-Time Systems, Vol. 28, pp. 39–68,2004.
[60] S.K. Baruah and N. Fisher. The Partitioned Multiprocessor Scheduling of Non-Preemptive Sporadic Task Systems. InProceedings of the IEEE Real-Time Sys-tems Symposium, pp. 321–329, 2005.
[61] T.P. Baker. An Comparison of Global and Paritioned EDF Schedulability Testsfor Multiprocessors. InProceedings of the International Conference on Real-Timeand Network Systems, pp. 119–127, 2006.
[62] S.K. Baruah, J. Gehrke, and C.G. Plaxton. Fast Scheduling of Periodic Taskson Multiple Resources. InProceedings of the International Parallel ProcessingSymposium, pp. 280–288, 1995.
[63] S.K. Baruah, N. Cohen, C.G. Plaxton, and D. Varvel. Proportionate Progress: ANotion of Fairness in Resource Allocation.Algorithmica, Vol. 15, pp. 600–625,1996.
[64] J. Anderson and A. Srinivasan. Early-Release Fair Scheduling. In Proc. of theEuromicro Conference on Real-Time Systems, pp. 35–43, 2000.
[65] A. Srinivasan and J.H. Anderson. Efficient Scheduling of Soft Real-Time Ap-plications on Multiprocessors. InProceedings of the Euromicro Conference onReal-Time Systems, pp. 51–59, 2003.
[66] S. Ramamurthy and M. Moir. Static-Priority Periodic Scheduling on Multipro-cessors. InProceedings of the IEEE Real-Time Systems Symposium, pp. 69–78,2000.
[67] S. Ramamurthy. Scheduling Periodic Hard Real-Time Tasks with Arbitrary Dead-lines on Multiprocessors. InProceedings of the IEEE Real-Time Systems Sympo-sium, pp. 59–68, 2002.
[68] A. Srinivasan, P. Holman, J.H. Anderson, and S.K. Baruah. The Case for FairMultiprocessor Scheduling. InProceedings of the IEEE International Paralleland Distributed Processing Symposium, pp. 22–26, 2003.
[69] J.M. Calandrino, H. Leontyev, A. Block, U.C. Devi, and J.H. Anderson.LITMUSRT: A Testbed for Empirically Comparing Real-Time MultiprocessorSchedulers. InProceedings of the IEEE Real-Time Systems Symposium, pp. 111–123, 2006.
143

BIBLIOGRAPHY
[70] S.K. Baruah and N. Goossens. Rate-Monotonic Scheduling on Uniform Multi-processors.IEEE Transactions on Computers, Vol. 52, No. 7, pp. 966–970, 2003.
[71] I. Lundberg. Analyzing Fixed-Priority Global Multiprocessor Scheduling. InProceedings of the IEEE Real-Time and Embedded Technology and ApplicationsSymposium, pp. 145–153, 2002.
[72] A. Srinivasan and S.K. Baruah. Deadline-based Scheduling of Peroidic Task Sys-tems on Multiprocessors.Information Processing Letters, Vol. 84, No. 2, pp.93–98, 2002.
[73] S. Cho, S.K. Lee, A. Han, and K.J. Lin. Efficient Real-Time Scheduling Algo-rithms for Multiprocessor Systems.IEICE Transactions on Communications, Vol.E85-B, No. 12, pp. 2859–2867, 2002.
[74] X. Piao, S. Han, H. Kim, M. Park, Y. Cho, and S. Cho. Predictability of Earli-est Deadline Zero Laxity Algorithm for Multiprocessor Real-Time Systems. InProceedings of the IEEE International Symposium on Object and Component-Oriented Real-Time Distributed Computing, pp. 359–364, 2006.
[75] M. Cirinei and T.P. Baker. EDZL Scheduling Analysis. InProceedings of theEuromicro Conference on Real-Time Systems, pp. 9–18, 2007.
[76] T.P. Baker. Multiprocessor EDF and Deadline MonotonicSchedulability Anal-ysis. InProceedings of the IEEE Real-Time Systems Symposium, pp. 120–129,2003.
[77] M. Bertogna, M. Cirinei, and G. Lipari. Improved EDF Multiprocessor Schedu-lability Analysis. InProceedings of the Euromicro Conference on Real-Time Sys-tems, pp. 209–218, 2005.
[78] H.W. Wei, Y.H. Chao, S.S. Lin, K.J. Lin, and W.K. Shih. Current Results onEDZL Scheduling for Multiprocessor Real-Time Systems. InProceedings of theIEEE International Conference on Embedded and Real-Time Computing Systemsand Applications, pp. 120–130, 2007.
[79] H. Cho, B. Ravindran, and E.D. Jensen. An Optimal Real-Time Scheduling Algo-rithm for Multiprocessors. InProceedings of the IEEE Real-Time Systems Sym-posium, pp. 101–110, 2006.
[80] J. Anderson, V. Bud, and U.C. Devi. An EDF-based Scheduling Algorithm forMultiprocessor Soft Real-Time Systems. InProc. of the Euromicro Conferenceon Real-Time Systems, pp. 199–208, 2005.
144

BIBLIOGRAPHY
[81] B. Andersson and E. Tovar. Multiprocessor Scheduling with Few Preemptions. InProceedings of the IEEE International Conference on Embedded and Real-TimeComputing Systems and Applications, pp. 322–334, 2006.
[82] A. Mok and M. Dertouzos. Multiprocessor Scheduling in aHard Real-Time En-vironment. InProceedings of the Texas Conference on Computer System, 1978.
[83] S.K. Baruah and G.Lipari. A Multiprocessor Implementation of the Total Band-width Server. InProceedings of the IEEE International Parallel and DistributedProcessing Symposium, pp. 40–47, 2004.
[84] B. Andersson, T. Abdelzaher, and J. Jonsson. Global Priority-Driven AperiodicScheduling on Multiprocessors. InProceedings of the IEEE International Paralleland Distributed Processing Symposium, 2003.
[85] B. Andersson, T. Abdelzaher, and J. Jonsson. Partitioned Aperiodic Schedulingon Multiprocessors. InProceedings of the IEEE International Parallel and Dis-tributed Processing Symposium, 2003.
[86] J.M. Banus, A. Arenas, and J. Lebarta. Dual Priority Algorithm to ScheduleReal-Time Tasks in a Shared Memory Multiprocessor. InProceedings of theInternational Parallel and Distributed Processing Symposium, 2003.
[87] N. Yamasaki. Design Concept of Responsive Multithreaded Processor for Dis-tributed Real-Time Control.Journal of Robotics and Mechatronics, Vol. 16, No.2, pp. 194–199, 2004.
[88] N. Yamasaki. Responsive Multithreaded Processor for Distributed Real-TimeSystems.Journal of Robotics and Mechatronics, Vol. 17, No. 2, pp. 130–141,2005.
[89] J. Stohr, A. Bulow, and G. Farber. Bounding Worst-Case Access Times in ModernMultiprocessor Systems. InProceedings of the Euromicro Conference on Real-Time Systems, pp. 189–198, 2005.
[90] T. Kuo and A. Mok. Load Adjustment in Adaptive Real-TimeSystems. InPro-ceedings of the IEEE Real-Time Systems Symposium, pp. 160–171, 1991.
[91] S.K. Baruah and A. Burns. Sustainable Scheduling Analysis. InProceedings ofthe IEEE Real-Time Systems Symposium, pp. 159–168, 2006.
[92] T. Taira, N. Kamata, and N. Yamasaki. Design and Implementation of Reconfig-urable Modular Robot Architecture. InProceedings of the IEEE/RSJ InternationalConference on Intelligent Robots and Systems, pp. 3566–3571, 2005.
145

LIST OF PAPERS
Articles on Periodicals
• Shinpei Kato and Nobuyuki Yamasaki, “Dynamic-Priority Scheduling Based onPortioning Method,”IPSJ Transactions on Advanced Computing Systems, vol.49, no. SIG 2, Mar. 2008 (to be appeared).
• Shinpei Kato and Nobuyuki Yamasaki, “RMd2-SIP: A Real-TimeSchedulingAlgorithm for Multiprocessors,”IPSJ Transactions on Advanced Computing Sys-tems, vol. 48, no. SIG 13, pp. 270-286, Aug. 2007.
• Shinpei Kato, Hidenori Kobayashi, and Nobuyuki Yamasaki, “Real-Time Schedul-ing to Increase Execution Efficiency on SMT Processors,”IPSJ Transactions onAdvanced Computing Systems, vol. 47, no. SIG 12, pp. 133-146, Sep. 2006.
Articles on International Conference Proceedings
• Shinpei Kato and Nobuyuki Yamasaki, “Portioned Static-Priority Scheduling onMultiprocessors,” inProceedings of the 22nd IEEE International Parallel andDistributed Processing Symposium, Apr. 2008 (to be appeared).
• Shinpei Kato and Nobuyuki Yamasaki, “Real-Time Schedulingwith Task Split-ting on Multiprocessors,” inProceedings of the 13th IEEE International Con-ference on Embedded and Real-Time Computing Systems and Applications, pp.441-450, Aug. 2007.
• Shinpei Kato and Nobuyuki Yamasaki, “Extended U-Link Scheduling to IncreaseExecution Efficiency for SMT Real-Time Systems,” inProceedings of the 12thIEEE International Conference on Embedded and Real-Time Computing Systemsand Applications, pp. 373-377, Aug. 2006.
• Shinpei Kato, Hidenori Kobayashi, and Nobuyuki Yamasaki, “U-Link Schedul-ing: Bounding Execution Time of Real-Time Tasks with Multi-Case ExecutionTime on SMT Processors,” inProceedings of the 11th IEEE International Con-ference on Embedded and Real-Time Computing Systems and Applications, pp.193-197, Aug. 2005.
146
Related Documents











