Proceedings of the 28th Annual Hawaii International Conference on System Sciences - 1995 Static Multiprocessor Scheduling of Periodic Real-Time Tasks with Precedence Constraints and Communication Costs Stefan Riinngren and Behrooz A. Shirazi Department of Computer Science and Engineering The University of Texas at Arlington Arlington, Texas 76019 Abstract The problem of allocating and scheduling real- time tasks, with Precedence Constraints and Communication Costs, on a multiprocessor architecture in order to meet the timing constraints is known to be NP-complete. Due to the growing complexity of real-time applications there is a need to find scheduling methods that can handle large task sets in a reasonable time. Also, scheduling methods should consider precedence and exclusion relations in order to support parallelism within tasks and to resolve mutual exclusion situations. In this paper four heuristic scheduling algorithms are developed and evaluated. In particular clustering vs. non-clustering techniques are investigated with some interesting results. 1. Introduction Scheduling of real-time tasks onto a multiprocessor architecture has been a topic under investigation in the past decades. As real-time applications are becoming more and more complex and demanding, the ways researchers model applications and attack the problem of scheduling are changing as well. In the past, much of the research focused on scheduling of simple, independent tasks. However, the increase in application complexity has inspired a need to parallelize even the execution of individual subtasks,and to model more complex inter- task relations, such as exclusion relations [ 161. The general problem of finding an optimal schedule on multiprocessors is known to be NP-complete. Due to the growing complexity of real-time applications, there is a need for scheduling algorithms that can handle large and complex applications. Real-time tasks, typically critical periodic tasks, whose timing constraints have to be guaranteed to be met in advance, may be scheduledbefore run-time. Such a scheduling strategy is called static or pre-run time scheduling. When using static scheduling, typically worst case timing estimates must be used for scheduling decisions. If a task’s completion time does not have to be guaranteedin advance,dynamic scheduling can be used [3]. With dynamic schedulingthe task is scheduled at run time, and more accurateestimates of the systemstate can be usedfor schedulingdecisions. Static and dynamic scheduling can be combinedwhen scheduling tasks for a real-time system.Tasks that must be guaranteed in advance can be statically scheduled, while the remaining tasks can be dynamically scheduIed, thereby taking advantage of both scheduling strategies. This paper deals with the problem of static scheduling of periodic tasks, where precedence relations and communication costs between subtasks must be taken into consideration. Some optimal static scheduling algorithms have been presentedthat can handle limited task sets [16][17]. In real-time scheduling, optimahty implies that if there is a feasible solution, then the scheduling algorithm will find it. A general optimal scheduling method is yet to be shown to work for large, complex task sets. When communication between subtasks have to be considered, the problem becomes even more complex. Thus, for large and complex problems heuristic scheduling techniques seem to be a promising approach for obtaining a schedule within a reasonable time. A variety of heuristic scheduling methods have been developed, using different ways of modeling the real-time applications [6][7][8][9][10][15]. Heuristics are guidelines that are used by the scheduling algorithm to quickly come up with scheduling decisions. Because the guidelines will not necessarily give the best possible scheduling decisions, heuristic scheduling algorithms will producesuboptimal results. Ramamritham [8] and Xu [16] both consider task sets where individual tasks are further divided into subtasks with precedence relations. With this approach, the scheduler can take advantage of parallelism within tasks. 143 1060-3425/95 $4.00 0 1995 IEEE Proceedings of the 28th Hawaii International Conference on System Sciences (HICSS'95) 1060-3425/95 $10.00 © 1995 IEEE

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Proceedings of the 28th Annual Hawaii International Conference on System Sciences - 1995
Static Multiprocessor Scheduling of Periodic Real-Time Tasks with Precedence Constraints and Communication Costs
Stefan Riinngren and Behrooz A. Shirazi
Department of Computer Science and Engineering The University of Texas at Arlington
Arlington, Texas 76019
Abstract
The problem of allocating and scheduling real- time tasks, with Precedence Constraints and Communication Costs, on a multiprocessor architecture in order to meet the timing constraints is known to be NP-complete. Due to the growing complexity of real-time applications there is a need to find scheduling methods that can handle large task sets in a reasonable time. Also, scheduling methods should consider precedence and exclusion relations in order to support parallelism within tasks and to resolve mutual exclusion situations.
In this paper four heuristic scheduling algorithms are developed and evaluated. In particular clustering vs. non-clustering techniques are investigated with some interesting results.
1. Introduction
Scheduling of real-time tasks onto a multiprocessor architecture has been a topic under investigation in the past decades. As real-time applications are becoming more and more complex and demanding, the ways researchers model applications and attack the problem of scheduling are changing as well. In the past, much of the research focused on scheduling of simple, independent tasks. However, the increase in application complexity has inspired a need to parallelize even the execution of individual subtasks, and to model more complex inter- task relations, such as exclusion relations [ 161.
The general problem of finding an optimal schedule on multiprocessors is known to be NP-complete. Due to the growing complexity of real-time applications, there is a need for scheduling algorithms that can handle large and complex applications.
Real-time tasks, typically critical periodic tasks, whose timing constraints have to be guaranteed to be met in advance, may be scheduled before run-time. Such a scheduling strategy is called static or pre-run time
scheduling. When using static scheduling, typically worst case timing estimates must be used for scheduling decisions.
If a task’s completion time does not have to be guaranteed in advance, dynamic scheduling can be used [3]. With dynamic scheduling the task is scheduled at run time, and more accurate estimates of the system state can be used for scheduling decisions.
Static and dynamic scheduling can be combined when scheduling tasks for a real-time system. Tasks that must be guaranteed in advance can be statically scheduled, while the remaining tasks can be dynamically scheduIed, thereby taking advantage of both scheduling strategies.
This paper deals with the problem of static scheduling of periodic tasks, where precedence relations and communication costs between subtasks must be taken into consideration. Some optimal static scheduling algorithms have been presented that can handle limited task sets [16][17]. In real-time scheduling, optimahty implies that if there is a feasible solution, then the scheduling algorithm will find it. A general optimal scheduling method is yet to be shown to work for large, complex task sets. When communication between subtasks have to be considered, the problem becomes even more complex.
Thus, for large and complex problems heuristic scheduling techniques seem to be a promising approach for obtaining a schedule within a reasonable time. A variety of heuristic scheduling methods have been developed, using different ways of modeling the real-time applications [6][7][8][9][10][15]. Heuristics are guidelines that are used by the scheduling algorithm to quickly come up with scheduling decisions. Because the guidelines will not necessarily give the best possible scheduling decisions, heuristic scheduling algorithms will produce suboptimal results.
Ramamritham [8] and Xu [16] both consider task sets where individual tasks are further divided into subtasks with precedence relations. With this approach, the scheduler can take advantage of parallelism within tasks.
143 1060-3425/95 $4.00 0 1995 IEEE
Proceedings of the 28th Hawaii International Conference on System Sciences (HICSS'95) 1060-3425/95 $10.00 © 1995 IEEE

Proceedings of the 28th Annual Hawaii International Conference on System Sciences - 1995
Xu [16] models real-time applications as sets of tasks with subtasks. An optimal approach is used that can handle moderately large task sets, but is yet to be shown to work for large and complex applications. Also, communication time between subtasks is ignored. The algorithm by Ramamritham [8] uses heuristics for scheduling in order to handle large task sets within reasonable time. A distributed system is assumed and communication costs are accounted for.
An ongoing project at The University of Texas at Arlington, named PARSA (PARallel program Scheduling and Assessment environment), deals, among other things, with scheduling of tasks onto multiprocessors with point-to-point interconnection networks [ll]. A main feature in PARSA is accurate communication cost estimates to be considered during the scheduling process.
The work presented in this paper is a step to enhance the existing tool set of PARSA with real-time scheduling capabilities [7][10]. Similar to [8], both communication costs and parallelism within tasks are considered.
In section 2, we present our method of modeling the applications. Section 3 shows how multiple complex tasks are combined for input to the scheduling algorithms. Section 4 presents a Base Algorithm and how it is used as the core of the four proposed different scheduling approaches. Section 5 displays and discusses our experimental evaluations of the different scheduling algorithms, and section 6 gives a time complexity analysis of the different scheduling algorithms. Finally, section 7 gives the conclusion and suggests some future directions for this work.
2. Application Model
The assumption is that the application to be scheduled onto the target architecture consists of a set of independent tasks. Each task is further divided into subtasks which have precedence relations to indicate
Task 1
dependencies and order of execution. Wherever a precedence relation exists, there is also a corresponding communication cost that must be accounted for between subtasks that are scheduled to execute on different processors.
Also, there can exist exclusion relations between subtasks (maybe from different tasks). Exclusion relations can be in time or in space. Time exclusions can be used to model mutual exclusion constraints [16]. By not allowing some subtasks to execute at the same time, predictability is enhanced and costly run-time overhead for mutual exclusion insurance is avoided. Space exclusions can be used to model cases where some subtasks cannot execute on the same processors. An example would be if some subtasks are replicated for fault tolerance. Obviously, the different replicas must execute on different processors.
The tasks are represented by Directed Acyclic Graphs (DAGs) where vertices represent subtasks and edges represent precedence relations and data dependencies with corresponding communication costs. Associated with each subtask are its execution cost, its release time, its deadline, and its exclusion relations with other subtasks.
Since we are considering periodic tasks, there is also a period associated with each task. The “release time” of a task; i.e., the time it can potentially begin it execution, is by default the beginning of its period and its “deadline” is the end of its period, unless explicitly specified.
3. Graph Expansion
In order to schedule tasks with different periods, a DAG is created that represents the different tasks over the Least Common Multiple of the task periods (LCM) [8][16]. Thus, the new expanded graph will contain multiple instances of each task. The release time will now be, for a task t and instance i, release=i x period(l), and the deadline will be deadline = (if I) x period(t).
Task
Execution txpanaea
Schedule
Task 2 Scheduler L
Task 3
Fig. 1 Overview of Scheduling Procedure
144
Proceedings of the 28th Hawaii International Conference on System Sciences (HICSS'95) 1060-3425/95 $10.00 © 1995 IEEE

Proceedings of the 28th Annual Hawaii International Conference on System Sciences - 1995
When a schedule has been produced using the expanded graph as input, it will be repeated with a period of LCM.
The procedure of expansion and scheduling is illustrated in Fig. 1.
4. Scheduling Algorithms
The scheduling algorithms presented here are related to the work of Ramamritham [8], which creates a schedule for a distributed system connected by a TDMA bus network, including a schedule for communication on the bus. In PARSA we consider parallel processors with point-to-point interconnection networks, where the number of available processors is not always small. Thus, some modifications to the original algorithm had to be made, and these will be explained as the algorithms are presented.
A base algorithm was developed, and four different algorithms emerged differentiated by if they used a clustering pre-scheduling step, and what clustering technique was employed.
4.1. Clustering Techniques
Pairwise Clustering: This is the clustering technique proposed in [8]. Here a clustering decision is made by pairwise examination of communicating subtasks. If the ratio of the sum of the execution costs and the communication cost is lower than some threshold value CF, then the subtasks must execute on the same processor.
The process of clustering and scheduling is repeated for different values of CF, starting ;;rith the maximum execution / communication ratio (maxCF) for the whole DAG plus one. The CF value is then decremented with (maxCF+l) / 10 each time clustering is done until CF<O. Communicating subtasks will thus be less and less likely to be clustered together.
Critical Path Linear Clustering: This clustering technique is a special case of the clustering algorithm proposed by Kim and Browne [5]. Here the critical path of the DAG is clustered and the operation is repeated for the remaining subtasks until all subtasks are included in some cluster.
4.2. Assigning Subtask Deadlines
As a pre-scheduling step performed by the scheduling algorithms, they assign deadlines to the individual subtasks. Initially, as we recall from section 2, the subtasks of a task were assigned the same deadline as the
whole task, unless otherwise specified. In order to help in finding scheduling decisions during the course of scheduling, we need more accurate values for the individual subtask deadlines.
The deadlines are calculated by subtracting the maximum path length from the current subtask to an exit subtask (a subtask without children), excluding the current subtask’s own execution time, from the deadline of the whole task.
When any of the clustering techniques has been used, we know which communicating subtasks are to be scheduled on the same processor, so the corresponding communication cost is set to zero. Thus that communication is ignored when calculating exit path lengths.
When no clustering is used, we do not know in advance whether two communicating subtasks are to be scheduled on the same processor or not. We can now make two choices, optimistic or pessimistic. We can include communication costs when calculating exit path lengths, which would give pessimistic deadlines to the subtasks, or we can ignore communication costs, giving optimistic deadlines. This is the difference between the “Pessimistic Algorithm” and the “Optimistic Algorithm” discussed later.
Note that the deadlines for the individual subtasks of a task are only for aiding in scheduling decisions. Only the deadlines given in the input graph (typically the deadline of the whole task) are used when checking whether a schedule is feasible or not. The reason for this is that, for example in the Pessimistic Algorithm, individual subtask deadlines can sometimes be violated without the whole task missing its deadline.
4.3. The Base Algorithm
After clustering is done (if any) the process of scheduling the subtasks begins. A ready list is initialized with the entry nodes (subtasks with no parents) in the DAG. The ready list will during the scheduling process contain subtasks which can be considered for scheduling, i.e. their parents have already been scheduled. The subtasks in the ready list are examined one by one and the subtask with the highest priority is selected for scheduling. The priorities are determined heuristically as discussed below; but first some definitions are presented:
DSM,: Desirable Starting Moment for subtask t on processor p. This is the time when all parents of subtask t have finished executing and all communication from them can reach processor p; i.e., the earliest time subtask t can be potentially executed.
145
Proceedings of the 28th Hawaii International Conference on System Sciences (HICSS'95) 1060-3425/95 $10.00 © 1995 IEEE

Proceedings of the 28th Annual Hawaii International Conference on System Sciences - 1995
Load,(Z): At any given time T, Load, is the finish time of the last subtask scheduled on processor p before time r; i.e., it represents the current load of processor p at time T.
ASMt,: Actual Starting Moment for subtask f on processor p. ASM+4AX@SM~, Load,(Z)); i.e., the earliest time that subtask t can actually start executing on processor p is ASM,.
For each subtask t in the ready list and for each processor p we calculate the following heuristic priority values to be used when deciding which subtask to use for the next scheduling step. The priority values are as follows, in order of decreasing importance:
1. ASM,, for subtask t on processor p. Min(ASM,,) is chosen.
2. Laxity, of subtask t on processor p (Laxily,,= deadline, - execution time, - ASM,,). Again, Min(Laxity,) is chosen.
3. Number of children of subtask t. The subtask with the most children is chosen.
4. Processor where the last scheduled subtask has no children in the same cluster is preferred.
5. Processor assignment which would result in lowest communication cost is preferred.
Heuristic 4 will prevent subtasks from different clusters to interfere with each other’s execution (cluster merging) when it is not necessary, and heuristic 5 will attempt to minimize communication.
Only scheduling decisions that do not violate clustering constraints or exclusion constraints are considered. Let RT, be the release time of task t and let ts be the set of subtask scheduled by time T. At any given time T, if RT, > Min(ASM,.,,,,), for all tasks in ts-t, then t will no longer be considered for this particular scheduling step.
The above heuristic values provide a priority listing among the tasks eligible for scheduling during each step. This priority list will give the subtask to be chosen from the -ready list (the one with the highest priority), the processor on which it should execute, and the starting time for the subtask.
After the chosen subtask has been scheduled, its children are checked to see if all their parents have been scheduled. If so, they are moved into the ready list. The process of selecting, scheduling, and moving ready children into the ready list is repeated until the ready list is empty or no scheduling decision can be found that does
not violate deadlines, clustering constraints, or exclusion relations.
In the algorithm proposed by Ramamritham [S] a clock is maintained and at each scheduling step it is advanced to the minimum of the earliest start time of subtasks that can be scheduled and the time when next processor becomes available. A ready list will contain subtasks that can start executing at the given time, sorted in order of increasing latest start time. A mapping of the subtasks in the ready list to the available processors is generated, and if the mapping violates some constraints, another mapping is generated in a systematic fashion (lexicographic order). Such a scheme relies heavily on being able to schedule communications before scheduling the children subtasks. In a point-to-point network we cannot make such an assumption. In particular, the earliest start time for a subtask and the path for communication will depend on where the subtask will execute in relation to its parent subtasks. We also want to be able to schedule communications over possibly more than one communication link.
Furthermore, if the number of processors is not small, the number of mappings that might have to be tried before a valid mapping is found grows unreasonably large. The argument that the scheme requires minimal information to be kept for each search point should be considered only if backtracking is allowed, but backtracking was shown to have minimal effect [S].
The approach proposed here maintains the rule of letting the subtask in the ready list with the earliest possible start time (ASM) and the smallest latest start time (laxity) have the best opportunity to be scheduled. It also allows for scheduling communication at the time of scheduling the child subtasks, by considering communication at the time of calculating the DSM values.
The pairwise clustering technique and even the Critical Path clustering technique will sometimes result in conflicting constraints. As an example, suppose subtasks A and B are scheduled on the same processor. They have a common child subtask, C, which we are now trying to schedule. A is clustered with C, but B is not. Therefore, C should be scheduled on the same processor as A, but on a different processor than B - an obvious conflict. This can be taken care of by removing the second clustering constraint that requires communicating subtasks assigned to different clusters to be scheduled on different processors.
An addition to the scheduling algorithm is that, if a feasible scheduling decision cannot be made, remove all clustering constraints for this particular scheduling step
146
Proceedings of the 28th Hawaii International Conference on System Sciences (HICSS'95) 1060-3425/95 $10.00 © 1995 IEEE

Proceedings of the 28th Annual Hawaii International Conference on System Sciences - 1995
and try again. This gives the algorithm a “second chance” to find a feasible scheduling decision at a given scheduling step.
For the pairwise clustering, the subtask deadlines might have to be modified to account for the cases where independent subtasks (subtasks that have no ancestor/ descendant relationship) are included in the same cluster and thus must execute on the same processor [8]. For each subtask, this is taken care of by calculating the accumulated execution time, sumexe, for all descendants of the subtask within the same cluster, and also the latest deadline, maxdeadline, of the same descendants. The deadline for the current subtask must be less than or equal to maxdeadline - sumexe.
5. Experimental Evaluation
The scheduling algorithms presented here were evaluated by using them on a large number of randomly generated task graphs as well as on some real applications. Again, the four algorithms are: (i) the pairwise clustering algorithm, (ii) the Critical Path clustering algorithm, and the non-clustering Base Algorithm with (iii) pessimistic and (iv) optimistic deadline assignments.
For performance metric, we used the Success Patio, which is defined as the number of feasible schedules produced by a given algorithm divided by the number of different tested input graphs. We also compared the average execution times of the algorithms. This time is of course computer dependent, but it will nevertheless reflect relative performance among the proposed algorithms.
For each input graph, three different graphs representing three different tasks were expanded as explained in section 2. Each scheduling algorithm was then applied to the resulting graph. In order to investigate the effectiveness of a scheduling algorithm with relation to the tightness or looseness of the real-time deadlines, scheduling of a graph was attempted several times after scaling the deadlines of the input tasks. The scaling was achieved by multiplying the release times and deadlines by a Deadline Scaling Factor, DSF. For example, if the deadline of a task is time 100 (considered a tight deadline) and DSF=1.5, then during the next scheduling experiment, this task’s deadline is considered to be time 150 (a looser deadline by a factor of 50%). Each data point, based on the DSF values, was obtained by using 400 different input graphs.
The initial assignment of periods to the tasks is based on the average path length from top to bottom when ignoring communication costs. This would give a loose
lower bound on execution time of the tasks. Since the average execution time of the subtasks, the average number of subtasks per level, and the maximum number of subtasks in a task were known, the average path length from top to bottom could be calculated.
Obviously, using this lower bound as the task period, results in graphs that may not be schedulable (being able to meet the deadlines) for DSF = 1.0. However, as DSF becomes larger, we can observe a clear difference in the performance of the algorithms. The problem of finding if a graph is schedulable at all is computationally intractable, but Success Patio (as a performance measure based on the number of scheduled graphs over total number of graphs), provides a relative measure of performance among the compared algorithms.
In all of our experiments, the clustering techniques resulted in a worse performance compared to non- clustering algorithms. Apparently, the clustering constraints were too rigid to allow good scheduling decisions.
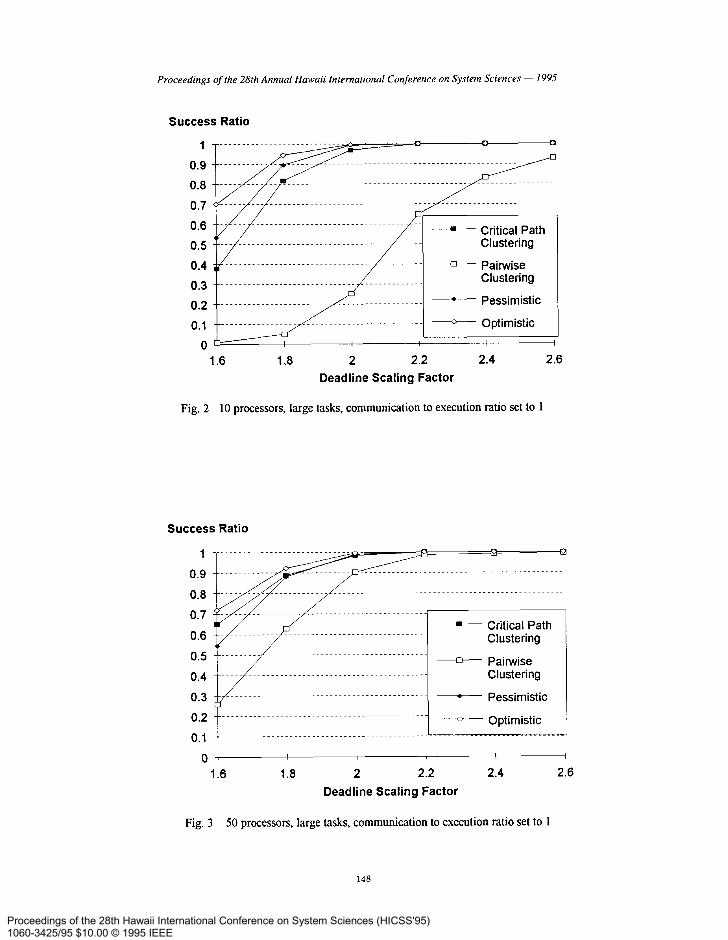
Fig 2 displays the results from experiment 1. Task 1 has a maximum of 20 subtasks, task 2 has a maximum of 40 subtasks, and task 3 has a maximum of 60 subtasks. The subtask execution times were chosen randomly between 1 and 10 and the communication to execution ratio was set to 1. Also, the number of subtasks per level was random between 4 and 10. The period of each task was proportional to its number of subtasks since the average number of subtasks per level was fixed and the period was set to be the average path length from top to bottom. Since the graph was expanded over LCM of the task periods, this means that 6 instances of task 1, 3 instances of task 2, and 2 instances of task 3 were included. This gave resulting task graphs with 360 subtasks on the average.
The algorithms attempted to create schedules on a fully connectedl, 10 processor target architecture. As can be seen, the clustering techniques produced a lower performance. Also, it is interesting to notice that for the non-clustering algorithms we got a slightly better performance by using an optimistic approach when assigning timing constrains; i.e., ignoring communication costs.
Fig 3 shows the results from a similar experiment but assuming a 50 processor architecture. The purpose for this was to see how the algorithms would perform when they were given close to unlimited (for the given problem sizes) access to processors. Again, the clustering techniques performed worse than the Base Algorithm by
I A fully connected network is assumed for simplicity. The algorithms can be easily modified to become applicable to any point-tc-point connected set of processing elements.
147
Proceedings of the 28th Hawaii International Conference on System Sciences (HICSS'95) 1060-3425/95 $10.00 © 1995 IEEE
Proceedings of the 28th Annual Hawaii International Conference on System Sciences - 1995
Success Ratio
1
0.9
- Critical Path
- Pessimistic
1.6 1.8 2 2.2 Deadline Scaling Factor
2.4 2.6
Fig. 2 10 processors, large tasks, communication to execution ratio set to 1
Success Ratio
_______.-....
____________--___-__.--_.. - Critical Path
---- A Pessimistic
--+--- Optimistic . . . .._.-.----..
1.6 1.8 2 2.2
Deadline Scaling Factor
2.4 2.6
Fig. 3 50 processors, large tasks, communication to execution ratio set to 1
148
Proceedings of the 28th Hawaii International Conference on System Sciences (HICSS'95) 1060-3425/95 $10.00 © 1995 IEEE

Proceedings of the 28th Annual Hawaii International Conference on System Sciences - 1995
itself. However, the difference was less pronounced and, in fact, the Critical Path clustering algorithm performed better or at least as well as the pessimistic version of the Base Algorithm. To allow unlimited access to processors might be unreasonable, so the first experiment should be of more interest than the second.
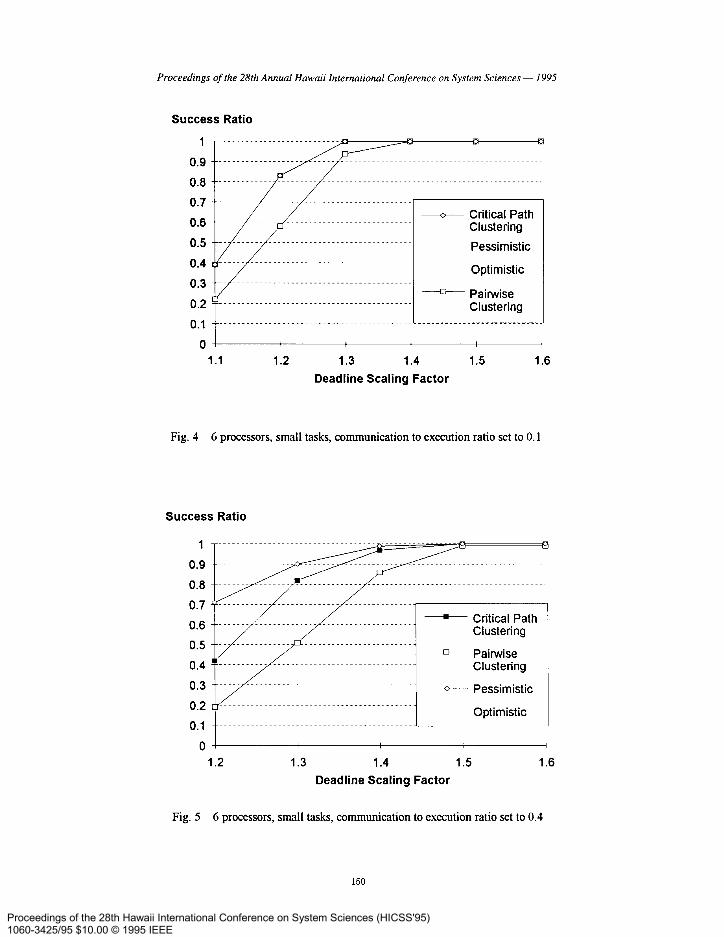
Fig 4 gives the results of the third experiment, where the three tasks had 4, 8, and 12 subtasks respectively. The resulting expanded graph had 12 subtasks and was less complex than in experiments one and two, in order to make the experiment close to the ones in [8]. In this third run, the communication to execution ratio was set to 0.1, we assumed 6 processors, and the execution times of the subtasks were randomly selected between 50 and 100 time units. Here, the pessimistic, optimistic, and the critical path algorithms performed equally well, with the exception of the pairwise clustering algorithm, which performed worse.
Fig 5 shows the results from a similar experiment, but with a communication to execution ratio of 0.4. These graphs were harder to schedule due to the increased communication cost, and noticeably the Base Algorithm again performed better without clustering. The performance of the optimistic and pessimistic algorithms were identical.
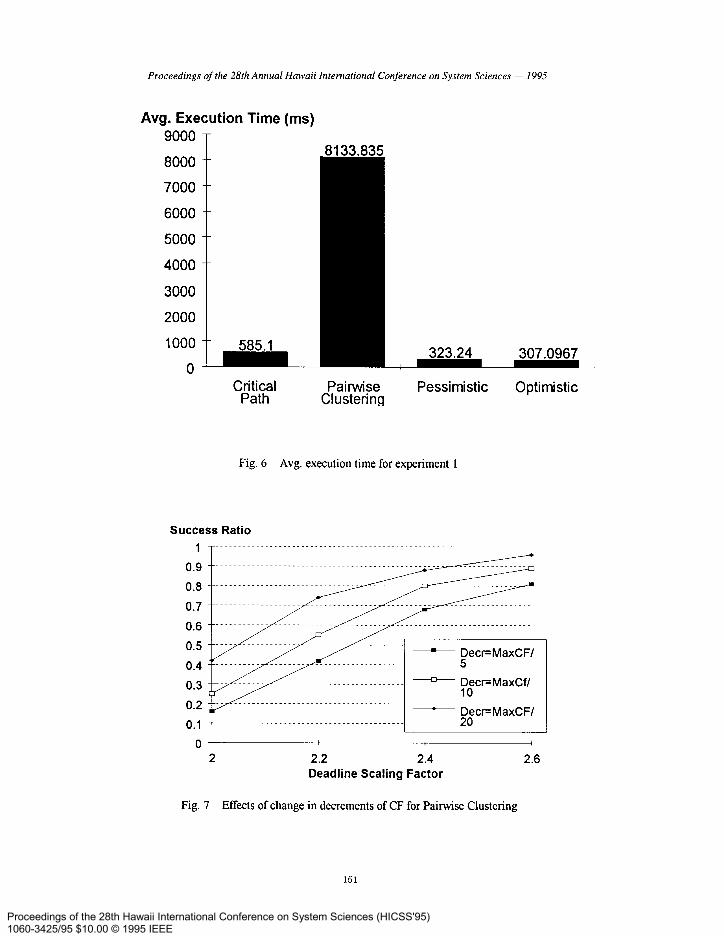
Fig 6 shows the average execution times for the algorithms during the first experiment. Again, the times are computer dependent but reflect relative performances. The clustering overhead is somewhat noticeable for the Critical Path clustering algorithm, but it shows its profound impact on the execution time of the pair-wise clustering algorithm. Another overhead of the pair-wise clustering algorithm is due to the fact that it repeatedly tries to schedule the input graph for different values of the threshold CF.
Fig 7 shows the results from an extra experiment that was conducted to evaluate the pair-wise clustering algorithm’s performance as we change the size of the decrements of CF. The scenario used was the same as in the first experiment, but with 100 input graphs, and an improvement in performance was noted as the decrements were made smaller. However, this was achieved at the cost of longer execution times, so the increments were kept at (maxCF+l) / 10 which would make it consistent with the experiments in [8].
As a last experiment, we tried the algorithms on three task graphs derived from matrix multiplication programs. The communication to execution ratio was set to 1, the assumed number of processors was 10, and the result was that the expanded graph could be scheduled at a Deadline Scaling Factor of 2.1 by the Critical Path clustering algorithm and by the two non-clustering algorithms, and at 2.2 by the pair-wise clustering algorithm.
It should be noted that none of the experiments involved any exclusion relations, the reason being that all these algorithms will treat such relations in the same way and thus, in a relative comparison, will not show any different performance results. However, it is important to emphasize the need for scheduling algorithms to support the use of such relations or similar approaches to allow for general modeling of real-time applications.
6. Time Complexity Analysis
Before presenting a time complexity analysis of the scheduling algorithms, here are some definitions:
N,: The number of subtasks in the input graph, including all task instances.
N: The number of subtasks in the input graph, counting only one instance of each task.
E: The number of edges in the input graph. P: The number of processors in the target architecture. I: The number of different values of the CF parameter
used by the pairwise clustering algorithm.
The Base Algorithm has to make Ni scheduling decisions. For each scheduling decision, all subtasks in the ready list must be considered, and for each of those subtasks (at least those which cannot be ignored directly), all processors are considered. The number of subtasks in the ready list will be, in the worst case, proportional to Ni, but the number of subtasks in the ready list that will not be ignored directly (a subtask can be ignored if its release time puts it out of competition) is proportional to N. Thus, the time complexity will be O(N,NP).
The assignment of subtask deadlines involves traversing each edge in the input graph, making the total time complexity for the Base Algorithm O(E+N,NP).
The pairwise clustering technique involves investigating each edge in the input graph, so that does not add to the complexity of the Base Algorithm, but since many values for the CF parameter will be tried, the total time complexity for the pairwise clustering algorithm is O(Ix(E+N;NP)).
The Critical Path clustering algorithm adds a time of O(EN) for the clustering step which gives a total time complexity of O(EN+N,NP).
7. Conclusion and Future Work
Four algorithms were developed here for static scheduling of periodic real-time tasks on a multiprocessor architecture, taking communication costs into account. The core of the algorithms, the Base
149
Proceedings of the 28th Hawaii International Conference on System Sciences (HICSS'95) 1060-3425/95 $10.00 © 1995 IEEE
Proceedings of the 28th Annual Hawaii International Conference on System Sciences - 199.5
Success Ratio
___________________ -__ - Critical Path _____. -.-------------- Clustering
_____________.___. -.-- Pessimistic -___--_------.----...-
Optimistic ________ --_--_-___-.-_
- Paitwise _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ Clustering 0.1 ---------------------------------------------~
0 1.1
I 1.2 1.3 1.4 1.5 1.6
Deadline Scaling Factor
Fig. 4 6 processors, small tasks, communication to execution ratio set to 0.1
Success Ratio
Clustering
- Pessimistic
0 i I
1.2 1.3 1.4 1.5 1.6 Deadline Scaling Factor
Fig. 5 6 processors, small tasks, communication to execution ratio set to 0.4
150
Proceedings of the 28th Hawaii International Conference on System Sciences (HICSS'95) 1060-3425/95 $10.00 © 1995 IEEE
Proceedings of the 28th Annual Hawaii International Conference on System Sciences -- 1995
Avg. Execution Time (ms) 9000 T
8000
7000
6000
5000
4000
3000
2000
1000
0 307.0967
Pairwise Clustering
Pessimistic Optimistic
Fig. 6 Avg. execution time for experiment 1
Success Ratio
2.2 2.4 Deadline Scaling Factor
2.6
Fig. 7 Effects of change in decrements of CF for Painvise Clustering
151
Proceedings of the 28th Hawaii International Conference on System Sciences (HICSS'95) 1060-3425/95 $10.00 © 1995 IEEE

Algorithm, was developed as a fairly straight-forward and efficient way of applying heuristics when achieving a scheduling decision.
Graph expansion, as discussed in [8][16], was implemented as a pre-scheduling step in order to represent multiple tasks with possibly different periods.
The algorithms were evaluated through extensive experimentation and it was found that the Base Algorithm by itself performed better than when the clustering techniques were used before the scheduling process. Also, it was found that the Base Algorithm without clustering performed better when deadlines were assigned by ignoring communication costs.
The algorithms here were developed as a part of the PARSA project at The University of Texas at Arlington. One main feature of this environment is the ability to accurately estimate communication delays in a point-to- point multiprocessor interconnection network. Therefore, a next step would be to perform link scheduling when considering interprocessor communication.
Link scheduling can be introduced to the Base Algorithm in the following way. When calculating the DSM values for a subtask on a processor and communication from a parent subtask is considered, traverse the architecture graph from source to destination and account for all delays, including contention, that occur on every link on the path. When a subtask and processor is chosen for a decision, the same procedure is repeated, but now the communication is added to the schedules of the involved links.
References
[l] Burns, A., “Scheduling Hard Real-Time Systems: A Review,” Software Engineering Journal, May 199 1, pp. 116-128.
[2] Chen, G-H., and Yur, J-S. “A Branch-and Bound- with-underestimates Algorithm for the Task Assignment Problem with Precedence Constraint,” IEEE 10th International Conference on Distributed Computing Systems, 1990, pp.494-501.
[3] Cheng, S-C., Stankovic, J. A., and Ramamritham, K, “Scheduling Groups of Tasks in Distributed Hard Real-Time Systems,” COINS Technical Report, Department of Computer and Information Science, University of Massachusetts at Amherst, Nov. 9, 1987.
[41 ---, “Scheduling Algorithms for Hard Real-Time Systems: A Brief Survey,” Tutorial Hard Real-Time Systems, 1988, pp. 150-173.
[5] Kim, S.J., and Browne, J.C., “A General Approach to Mapping of Parallel Computation upon
Proceedings of the 28th Annual Hawaii International Conference on System Sciences - 1995
Multiprocessor Architectures,” International Conference on Parallel Processing, 1988, Vol 3, pp.
[6] iz C-M “Distributed Real-Time Scheduling Based on ‘the RTG Model,” Master’s Thesis, Dept. of Computer Science and Engineering, The University of Texas at Arlington, 1993.
[7] Lin, Shihchung, “A Comparative Study of Real-Time Scheduling Methods,” Technical Report, Department of Computer Science and Engineering, University of Texas at Arlington, April 1993.
[8] Ramamritham, K., “Allocation and Scheduling of Complex Periodic Tasks”, IEEE 10th International Conference on Distributed Computing Systems, 1990, pp. 108-l 15.
[9] Ramamritham, K., Stankovic, J. A., and Shiah, P-F, “Efficient Scheduling Algorithms for Real-Time Multiprocessor Systems,” IEEE Trans. Parallel and Distributed Systems, Vol. 1, No. 2, April 1990, pp. 184-194.
[lo] Ronngren, Stefan, Lorts, Dan, and Shirazi, Behrooz, “Empirical Evaluation of Compound Static Scheduling Heuristics for Real-Time Multiprocessing,” Proceedings of the 2nd Workshop on Parallel and Distributed Real-time Systems, April 1994.
[ 1 l] Shirazi, B., Kavi, K., Hurson, A.R., Biswas, P., “PARSA: a PARallel program Scheduling and Assessment environment,” 1993 Int’l Conf on Parallel Processing, Aug. 1993.
[12] Stankovic, J. A., ” Misconceptions About Real-Time Computing,” Computer, Oct. 1988.
[13] ---, “Real-Time Computing Systems: The Next Generation,” Tutorial Hard Real-Time Systems, 1988, pp. 14-38.
[14] Stankovic, J. A., and Ramamritham, K., “What is Predictability for Real-Time Systems?, n The Journal of Real-Time Systems, 2, 1990, pp. 247-254.
[ 151 Verhoosel, J. P. C., Luit, E. J., and Hammer, D. K., “A Static Scheduling Algorithm for Distributed Hard Real-Time Systems,” The Journal of Real-Time Systems, 3, 1991, pp.227-246.
[ 161 Xu, J, “Multiprocessor Scheduling of Processes with Release Times, Deadlines, Precedence, and Exclusion Relations,” IEEE Trans. SofiWare Engineering, Vol. 19, No. 2, Feb. 1993, pp. 139-154.
[17] Xu, J., and Parnas, D. L., “On Satisfying Timing Constraints in Hard Real-Time Systems,” IEEE Trans. Software Engineering, Vol. 19, No. 1, Jan. 1993, pp. 70-83.
152
Proceedings of the 28th Hawaii International Conference on System Sciences (HICSS'95) 1060-3425/95 $10.00 © 1995 IEEE
Related Documents











