Noise cross PSD estimation using phase information in diffuse noise field M. Rahmani a, , A. Akbari a , B. Ayad a , B. Lithgow b a Research Center for InformationTechnology, Iran University of Science and Technology, Iran b Centre for Biomedical Engineering, Monash University, Australia article info Article history: Received 25 February 2008 Received in revised form 1 September 2008 Accepted 10 October 2008 Available online 29 October 2008 Keywords: Coherence-based method Two-microphone noise reduction Cross power spectrum density Cross-SNR abstract Among various speech enhancement methods, two-microphone noise reduction systems are utilized for their low cost implementation and acceptable performance. Coherence-based methods are well known as efficient two-microphone noise reduction techniques. These techniques, however, do not work well when the received noise signals are correlated. Coherence-based methods can be improved when the cross power spectral density (CPSD) of input noises is available. In this paper, we propose a new method for estimating noise CPSD based on the assumption of a diffuse noise field. With this assumption, we estimate the noise CPSD using phase information. Then, the estimated noise CPSD is used to calculate a coherence-based gain filter which is then employed to enhance noisy signals. We compare the proposed phase-based noise CPSD estimation with a noise CPSD estimation technique based on a voice activity detector (VAD), both of which are herein separately employed in a two-microphone speech enhancement configuration. The comparison shows that the two-microphone speech enhancement scheme utilizing the proposed noise CPSD estimation technique outper- forms the enhancement system using the VAD-based noise CPSD estimation. & 2008 Elsevier B.V. All rights reserved. 1. Introduction With the development of new communication systems, speech enhancement has become more important than ever before. For instance, in new mobile headsets, when microphones are not close enough to mouth, the received signal can be very noisy. A noise reduction system can then improve the quality of the received speech signal. In general, speech enhancement approaches are di- vided into two main categories: single microphone and multi microphone methods. Single microphone methods have limitations in real environments. They introduce musical noise and speech distortion [1]. The advantage of multi-microphone over single microphone approaches is their ability to use spatial noise reduction, which is reduction of the noise based on the knowledge of the position of speech source. The performance of multiple channel noise reduction algorithms is improved by in- creasing the number of microphones [2,3]. However, a larger number of microphones imply higher costs and an increased computational load. We have chosen dual microphone approaches as a trade off between multi channel and single channel methods. Coherence-based methods are known as a subclass of dual microphone methods [4,5]. They provide good results in uncorrelated noise environments. But, their perfor- mance decreases if two captured noises are correlated. To deal with this problem, [6] proposed subtracting the CPSD of the noise sources from the CPSD of the noisy signals. The disadvantage of this method is the need for the Contents lists available at ScienceDirect journal homepage: www.elsevier.com/locate/sigpro Signal Processing ARTICLE IN PRESS 0165-1684/$ - see front matter & 2008 Elsevier B.V. All rights reserved. doi:10.1016/j.sigpro.2008.10.020 Corresponding author. Current address: Department of Computer Engineering, Iran University of Science and Technology, Narmak, Tehran 16846-13114, Iran. Tel.: +98 2177491192; fax: +98 2177491128. E-mail address: [email protected] (M. Rahmani). Signal Processing 89 (2009) 703–709

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

ARTICLE IN PRESS
Contents lists available at ScienceDirect
Signal Processing
Signal Processing 89 (2009) 703–709
0165-16
doi:10.1
� Cor
Enginee
16846-1
E-m
journal homepage: www.elsevier.com/locate/sigpro
Noise cross PSD estimation using phase informationin diffuse noise field
M. Rahmani a,�, A. Akbari a, B. Ayad a, B. Lithgow b
a Research Center for Information Technology, Iran University of Science and Technology, Iranb Centre for Biomedical Engineering, Monash University, Australia
a r t i c l e i n f o
Article history:
Received 25 February 2008
Received in revised form
1 September 2008
Accepted 10 October 2008Available online 29 October 2008
Keywords:
Coherence-based method
Two-microphone noise reduction
Cross power spectrum density
Cross-SNR
84/$ - see front matter & 2008 Elsevier B.V. A
016/j.sigpro.2008.10.020
responding author. Current address: Depart
ring, Iran University of Science and Technolo
3114, Iran. Tel.: +98 2177491192; fax: +98 21
ail address: [email protected] (M. Rahma
a b s t r a c t
Among various speech enhancement methods, two-microphone noise reduction
systems are utilized for their low cost implementation and acceptable performance.
Coherence-based methods are well known as efficient two-microphone noise reduction
techniques. These techniques, however, do not work well when the received noise
signals are correlated. Coherence-based methods can be improved when the cross
power spectral density (CPSD) of input noises is available. In this paper, we propose a
new method for estimating noise CPSD based on the assumption of a diffuse noise field.
With this assumption, we estimate the noise CPSD using phase information. Then, the
estimated noise CPSD is used to calculate a coherence-based gain filter which is then
employed to enhance noisy signals. We compare the proposed phase-based noise CPSD
estimation with a noise CPSD estimation technique based on a voice activity detector
(VAD), both of which are herein separately employed in a two-microphone speech
enhancement configuration. The comparison shows that the two-microphone speech
enhancement scheme utilizing the proposed noise CPSD estimation technique outper-
forms the enhancement system using the VAD-based noise CPSD estimation.
& 2008 Elsevier B.V. All rights reserved.
1. Introduction
With the development of new communication systems,speech enhancement has become more important thanever before. For instance, in new mobile headsets, whenmicrophones are not close enough to mouth, the receivedsignal can be very noisy. A noise reduction system can thenimprove the quality of the received speech signal.
In general, speech enhancement approaches are di-vided into two main categories: single microphone andmulti microphone methods. Single microphone methodshave limitations in real environments. They introduce
ll rights reserved.
ment of Computer
gy, Narmak, Tehran
77491128.
ni).
musical noise and speech distortion [1]. The advantageof multi-microphone over single microphone approachesis their ability to use spatial noise reduction, whichis reduction of the noise based on the knowledge of theposition of speech source. The performance of multiplechannel noise reduction algorithms is improved by in-creasing the number of microphones [2,3]. However, alarger number of microphones imply higher costs andan increased computational load. We have chosen dualmicrophone approaches as a trade off between multichannel and single channel methods.
Coherence-based methods are known as a subclass ofdual microphone methods [4,5]. They provide good resultsin uncorrelated noise environments. But, their perfor-mance decreases if two captured noises are correlated. Todeal with this problem, [6] proposed subtracting the CPSDof the noise sources from the CPSD of the noisy signals.The disadvantage of this method is the need for the

ARTICLE IN PRESS
M. Rahmani et al. / Signal Processing 89 (2009) 703–709704
estimation of the CPSD of the received noise signals.Guerin et al. [7] proposed to estimate the noise CPSD as afunction of a posteriori SNR and the CPSD of the noisysignals. They demonstrated that using a posteriori SNRand the CPSD of the noisy signals the noise CPSD can beestimated in all frames. Zhang et al. [8] proposed a softdecision based technique for the noise CPSD estimationduring speech pauses. They employed minimum statisticson each channel to estimate the noise power spectraldensity (PSD) in that channel. They exploited theseestimated noise PSDs as a criterion to distinguish speechand pause frames.
In [9], a spectral modification filter is proposed whichestimates the spectral filter based on the phase informa-tion of the noisy signal. This method is based on theestimating a parameter, introduced as phase error andcalculating a spectral modification filter based on thisphase error. In [10], authors proposed a method based ona diffuse noise field hypothesis. They estimated the speechPSD using the theoretically known coherence function ofthe noise field.
In this paper, we propose a new method for estimatingthe noise CPSD using the phase of the signals in diffusenoise environments. The proposed method is suitablewhere the speech source is close to the microphones suchas mobile Bluetooth headsets. Our method is capable ofestimating the noise CPSD without using a VAD or otherconventional noise estimation techniques.
The rest of the paper is organized as follows. In thenext section, we introduce the two microphone speechenhancement system. In Section 3, the proposed noiseCPSD estimation method is presented. Section 4 presentsexperiments and evaluation results and finally, Section 5concludes the paper.
2. Basic two-microphone noise reduction system
In two-microphone noise reduction systems, thereceived signals on microphone i can be written as
Xiðf ;nÞ ¼ Siðf ;nÞ þ Niðf ;nÞ i ¼ f1;2g (1)
where Xi(f,n), Si(f,n) and Ni(f,n) represent the noisy speech,the clean speech and the noise in frequency domain,respectively. Furthermore, f and n are the frequency andthe frame indexes, respectively. We use both X1 and X2 inEq. (1) in order to compute the spectral modification filterfor enhancing speech and reducing noise (Fig. 1).
x1 (t)
x2 (t)
X2 (f,n)
X1 ( f ,n)
H ( f ,n)
s (t)
STFT
STFT
s (f,n)^ ISTFT
Fig. 1. Block diagram of the two-microphone speech enhancement
system. H(f, n) is the two-microphone modification filter.
Spectral modification filter H(f,n), can be computed asa function of the coherence between the two noisy signals[4]. The simplest way to exploit coherence of two signalsin modification filter is to use its magnitude as thespectral modification filter. The coherence magnitude oftwo signals X1 and X2 is defined as:
GX1X2ðf ;nÞ ¼jPX1X2ðf ;nÞjffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi
PX1X1ðf ;nÞPX2X2ðf ;nÞp (2)
where PX1X1(f,n), PX2X2(f,n) and PX1X2(f,n) are the powerspectrum density (PSD) of X1(f,n), PSD of X2(f,n) and CPSDof X1(f,n) and X2(f,n), respectively.
The CPSD and the PSDs can be estimated as in [5,6]:
PXiXjðf ;nÞ ¼ gPXiXjðf ;n� 1Þ þ ð1� gÞXiðf ;nÞXjðf ;nÞ�
i; j 2 f1;2g (3)
where * is the complex conjugate operator and g is thesmoothing factor. We chose a value of 0.7 for g assuggested in [6].
In the coherence based methods, it is assumed that thereceived speech signals are correlated and the receivednoise signals are uncorrelated. Thus, higher values of thecoherence function (Eq. (2)) correspond to increased levelof desired speech in the signal. On the other hand, lowervalues of the coherence function correspond to increasedlevel of noise in the signal. This behavior leads us to usecoherence function in noise reduction systems.
Nevertheless, the assumption of uncorrelated receivednoise is often violated in realistic conditions. In [6], theauthors proposed a technique to improve the coherence-based filter. They adapted coherence methods to reducethe effect of coherent noises. In their approach, anestimation of the CPSD of the noise signals is subtractedfrom the CPSD of the original noisy signals as in Eq. (4).Hereafter, we refer to this method as cross power spectralsubtraction (CPSS).
HCPSSðf ;nÞ ¼jPX1X2ðf ;nÞj � jPN1N2ðf ;nÞjffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi
PX1X1ðf ;nÞPX2X2ðf ;nÞp (4)
2.1. A priori SNR
The subtraction in the numerator of Eq. (4) is done inorder to produce the clean signal CPSD [6]:
HCPSSðf ;nÞ ¼jPS1S2ðf ;nÞjffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi
PX1X1ðf ;nÞPX2X2ðf ;nÞp (5)
This subtraction, however, may introduce musical noiseand high distortion in estimated speech signal. To reducethe amount of musical noise and distortion, we proposedin [11] to employ a decision directed approach. In thisapproach, using the assumption that noise and signal aremutually uncorrelated, the numerator of the right side ofEq. (5) is changed as in [11] to:
jPS1S2ðf ;nÞj ¼ jPX1X2ðf ;nÞjjPS1S2ðf ;nÞj
jPS1S2ðf ;nÞj þ jPN1N2ðf ;nÞj
¼ jPX1X2ðf ;nÞjSNRcsðf ;nÞ
SNRcsðf ;nÞ þ 1(6)
ARTICLE IN PRESS
M. Rahmani et al. / Signal Processing 89 (2009) 703–709 705
SNRcs(f,n) is the ratio between the clean speech CPSD andthe noise CPSD. We call it cross-SNR. To estimate thecross-SNR, a technique similar to a priori SNR estimationis employed. Using a priori SNR, we can reduce theamount of musical noise and distortion [12,13]. A prioricross-SNR, similar to single channel a priori SNR [12], isestimated as follows [11]:
Rpoðf ;nÞ ¼ maxX1ðf ;nÞX2ðf ;nÞ
��� ��
PN1N2ðf ;nÞ�� �� � 1;0
" #
Rprðf ;nÞ ¼ lDDHðf ;n� 1Þ2jX1ðf ;n� 1ÞX2ðf ;n� 1Þ�j
jPN1N2ðf ;n� 1Þj
þ ð1� lDDÞRpoðf ;nÞ (7)
where H(f,n) can be any two-microphone modificationfilter, lDD, is a smoothing factor in the range of (0–1), andis set to a value close to one. For example, it is set to 0.97in [11] (the same as [12] for single microphone case).Rpr(f,n) and Rpo(f,n) are a priori cross-SNR and a posterioricross-SNR, respectively.
Using Eqs. (5) and (6) and considering cross-SNRestimation in Eq. (7), HCPSS(f,n) is modified as follows
HCPSS;Rprðf ;nÞ ¼jPX1X2ðf ;nÞjffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi
PX1X1ðf ;nÞPX2X2ðf ;nÞp Rprðf ;nÞ
Rprðf ;nÞ þ 1(8)
We have shown in [11] that this filter has less musicalnoise and speech distortion in comparison with theoriginal CPSS method (Eq. (4)). To compute HCPSS,Rpr(f,n),an estimation of Rpr(f,n) and consequently an estimationof the noise CPSD is required.
2.2. Noise CPSD estimation using VAD
A precise estimation of the noise CPSD is crucial inobtaining an accurate estimation of the speech signal. Atechnique for estimation of the noise CPSD is to employ aVAD. In a VAD-based technique, the estimation is updatedin non-speech (pause) regions and is stopped in speech
1.5
1
1.5
-0.5
0
cohe
renc
e
cohe
renc
e
0 500 1000 1500 2000 2500 3000 3500 4000Frequency (Hz)
Theory (real part)
Practical (real part)Practical (imaginary part)
Theory (imaginary part)
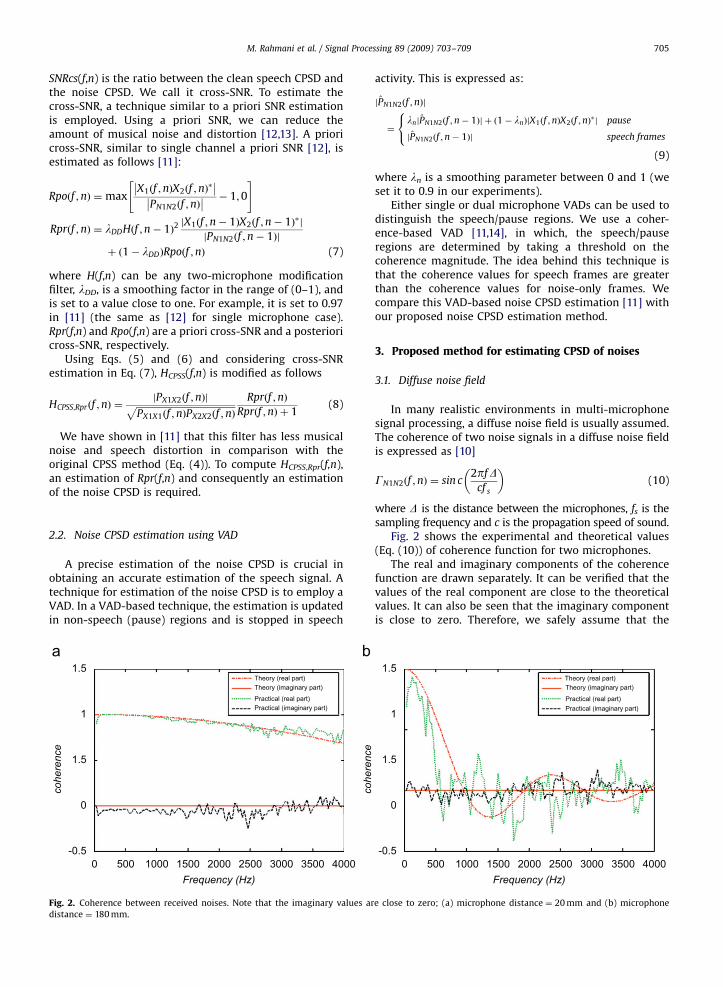
Fig. 2. Coherence between received noises. Note that the imaginary values ar
distance ¼ 180 mm.
activity. This is expressed as:
jP̂N1N2ðf ;nÞj
¼lnjP̂N1N2ðf ;n� 1Þj þ ð1� lnÞjX1ðf ;nÞX2ðf ;nÞ
�j pause
jP̂N1N2ðf ;n� 1Þj speech frames
8<:
(9)
where ln is a smoothing parameter between 0 and 1 (weset it to 0.9 in our experiments).
Either single or dual microphone VADs can be used todistinguish the speech/pause regions. We use a coher-ence-based VAD [11,14], in which, the speech/pauseregions are determined by taking a threshold on thecoherence magnitude. The idea behind this technique isthat the coherence values for speech frames are greaterthan the coherence values for noise-only frames. Wecompare this VAD-based noise CPSD estimation [11] withour proposed noise CPSD estimation method.
3. Proposed method for estimating CPSD of noises
3.1. Diffuse noise field
In many realistic environments in multi-microphonesignal processing, a diffuse noise field is usually assumed.The coherence of two noise signals in a diffuse noise fieldis expressed as [10]
GN1N2ðf ;nÞ ¼ sin c2pfD
cf s
� �(10)
where D is the distance between the microphones, fs is thesampling frequency and c is the propagation speed of sound.
Fig. 2 shows the experimental and theoretical values(Eq. (10)) of coherence function for two microphones.
The real and imaginary components of the coherencefunction are drawn separately. It can be verified that thevalues of the real component are close to the theoreticalvalues. It can also be seen that the imaginary componentis close to zero. Therefore, we safely assume that the
1.5
1
1.5
-0.5
0
0 500 1000 1500 2000 2500 3000 3500 4000Frequency (Hz)
Theory (real part)
Practical (real part)Practical (imaginary part)
Theory (imaginary part)
e close to zero; (a) microphone distance ¼ 20 mm and (b) microphone

ARTICLE IN PRESS
4
3.5
3
2.5
2
1.5
1
0.5
00 500 1000 1500 2000 2500 3000 3500 4000
Frequency (Hz)
Pha
se (r
adia
n)
Fig. 3. Phase of noisy CPSD for inter-microphone distance of 40 mm.
Dash line: theoretical values of +PS1S2(f, n), solid: +PX1X2(f, n) for 20 dB
noisy signal and dot line: +PX1X2(f, n) for 0 dB noisy signal.
M. Rahmani et al. / Signal Processing 89 (2009) 703–709706
imaginary component of the coherence and so the CPSD iszero. In other words, we assume that the noise CPSD isreal. Based on this assumption, we derive a new formulafor our proposed method.
3.2. Phase-based noise estimator
Some speech enhancement techniques have recentlyexploited phase information for speech spectrum estima-tion [9,15]. In [9], authors have demonstrated that how aspectral modification filter can be computed using speechphase spectrum information. They applied this filter to anoisy spectrum in order to reduce the noise.
We consider that the noise field is diffuse and thencalculate the value of PN1N2(f,n) in terms of PX1X2(f,n) andphase information.
Starting from Eq. (1), and assuming that noise andspeech are uncorrelated, the CPSD of X1 and X2 can bewritten as:
PX1X2ðf ;nÞ ¼ PS1S2ðf ;nÞ þ PN1N2ðf ;nÞ (11)
This can be separated into its real and imaginarycomponents:
jPX1X2j cosðffPX1X2Þ ¼ jPS1S2j cosðffPS1S2Þ
þjPN1N2j cosðffPN1N2Þ
jPX1X2j sinðffPX1X2Þ ¼ jPS1S2j sinðffPS1S2Þ
þjPN1N2j sinðffPN1N2Þ
8>>>><>>>>:
(12)
With the assumption that the noise field is diffuse (i.e.,noise CPSD is real), we have:
jPX1X2j cosðffPX1X2Þ ¼ jPS1S2j cosðffPS1S2Þ � jPN1N2j
jPX1X2j sinðffPX1X2Þ ¼ jPS1S2j sinðffPS1S2Þ
((13)
We use the operator (7) because the noise CPSD is anegative or positive real number.
If we assume that the amplitude of noisy spectrum andthe phase information of the clean and noisy signals areknown, we can calculate |PN1N2(f, n)| in Eq. (13) as
jPN1N2j ¼ � jPX1X2j
�cosðffPS1S2Þ sinðffPX1X2Þ � sinðffPS1S2Þ cosðffPX1X2Þ
sinðffPS1S2Þ
¼ � jPX1X2jsinðffPS1S2 �ffPX1X2Þ
sinðffPS1S2Þ(14)
The sign + or � is chosen in order to obtain a positive valuefor |PN1N2(f, n)|. This results in the following equation:
jPN1N2j ¼ jPX1X2jsinðffPS1S2 �ffPX1X2Þ
sinðffPS1S2Þ
�������� (15)
Now, the spectral modification filters in (4) or (8) can becomputed using Eq. (15).
+PS1S2(f, n) in (15) depends on the position of thespeaker relative to the microphones and can be estimatedbased on the time delay of arrival. For a given time delayof arrival T, +PS1S2(f, n) is calculated as:
ffPS1S2ðf ;nÞ ¼ 2pfT (16)
Although the behavior of +PS1S2(f, n) may not be exactlyas in Eq. (16), especially in reverberant environments, weuse this equation as an approximation.
Fig. 3 shows +PS1S2(f, n) and +PX1X2(f, n) for twomicrophones with a distance of 40 mm. It can be seen thatas the noise level increases, the phase of noisy CPSDdeviates from the theoretical value.
In case the denominator of the Eq. (15) is zero(+PS1S2(f, n) ¼ 0), the proposed method fails to estimatethe noise CPSD, and cannot be used in such configurations.Moreover, the proposed method considers zero-phaseCPSDs as a noise CPSD. As a result, it may remove thediffuse parts of the speech signal. This limits the proposedmethod to the scenarios where the speech source is closeto microphones.
3.3. Noise CPSD estimation in non-diffuse field
In order to investigate the performance of the pro-posed estimator in non-diffuse environments, we startagain from Eq. (12), wherein the hypothesis of a diffusenoise field is not applied. In this case, we can compute|PN1N2(f, n)| as:
jPN1N2j ¼ jPX1X2j
detcosðffPS1S2Þ cosðffPX1X2Þ
sinðffPS1S2Þ sinðffPX1X2Þ
24
35
0@
1A
detcosðffPS1S2Þ cosðffPN1N2Þ
sinðffPS1S2Þ sinðffPN1N2Þ
24
35
0@
1A
¼ jPX1X2jsinðffPS1S2 �ffPX1X2Þ
sinðffPS1S2 �ffPN1N2Þ
�������� (17)
where det denotes the determinant operator.We define R as the ratio between estimation in (17) and
the estimation of noise in Eq. (15). It is calculated as
R ¼PNhyp
PNnohyp¼jPN1N2jEq: ð15Þ
jPN1N2jEq: ð17Þ
¼sinðffPS1S2Þ
sinðffPS1S2 �ffPN1N2Þ
�������� (18)
where PNhyp and PNnohyp are estimations of noise CPSDfor diffuse noise and non-diffuse noise field, respectively.
ARTICLE IN PRESS
10
5
0
-5
-10
-15
-20
-25
-30
R (d
B)
π3
− π6
− π6
π3
0
∠PN1N 2 (radian)
∠PS1S2π/12π/6π/4π/3
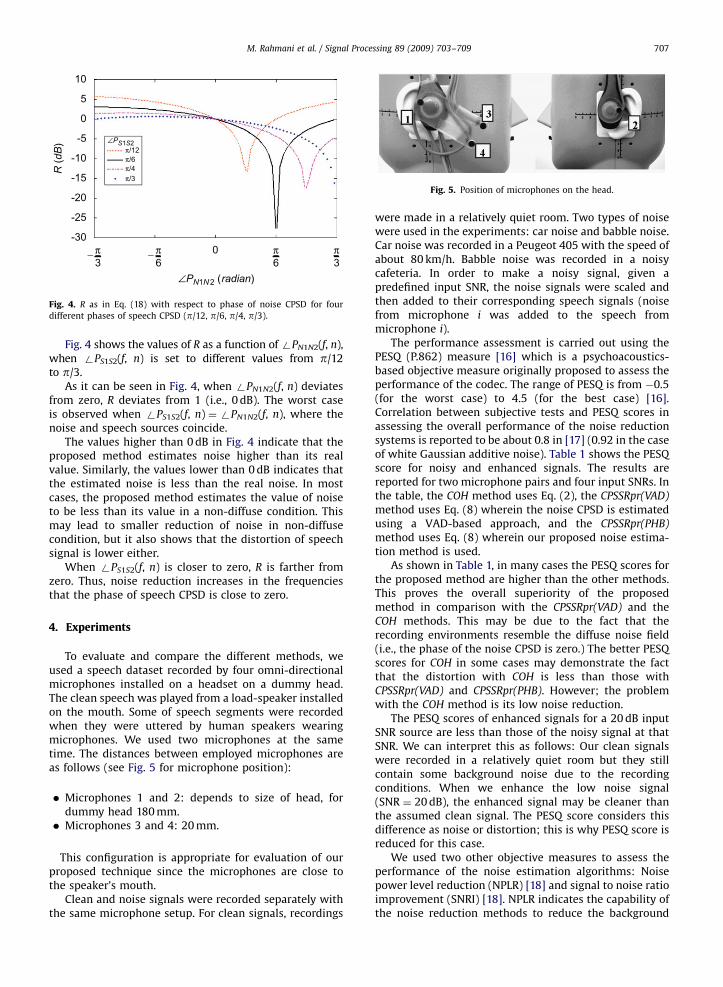
Fig. 4. R as in Eq. (18) with respect to phase of noise CPSD for four
different phases of speech CPSD (p/12, p/6, p/4, p/3).
Fig. 5. Position of microphones on the head.
M. Rahmani et al. / Signal Processing 89 (2009) 703–709 707
Fig. 4 shows the values of R as a function of +PN1N2(f, n),when +PS1S2(f, n) is set to different values from p/12to p/3.
As it can be seen in Fig. 4, when +PN1N2(f, n) deviatesfrom zero, R deviates from 1 (i.e., 0 dB). The worst caseis observed when +PS1S2(f, n) ¼+PN1N2(f, n), where thenoise and speech sources coincide.
The values higher than 0 dB in Fig. 4 indicate that theproposed method estimates noise higher than its realvalue. Similarly, the values lower than 0 dB indicates thatthe estimated noise is less than the real noise. In mostcases, the proposed method estimates the value of noiseto be less than its value in a non-diffuse condition. Thismay lead to smaller reduction of noise in non-diffusecondition, but it also shows that the distortion of speechsignal is lower either.
When +PS1S2(f, n) is closer to zero, R is farther fromzero. Thus, noise reduction increases in the frequenciesthat the phase of speech CPSD is close to zero.
4. Experiments
To evaluate and compare the different methods, weused a speech dataset recorded by four omni-directionalmicrophones installed on a headset on a dummy head.The clean speech was played from a load-speaker installedon the mouth. Some of speech segments were recordedwhen they were uttered by human speakers wearingmicrophones. We used two microphones at the sametime. The distances between employed microphones areas follows (see Fig. 5 for microphone position):
�
Microphones 1 and 2: depends to size of head, fordummy head 180 mm. � Microphones 3 and 4: 20 mm.This configuration is appropriate for evaluation of ourproposed technique since the microphones are close tothe speaker’s mouth.
Clean and noise signals were recorded separately withthe same microphone setup. For clean signals, recordings
were made in a relatively quiet room. Two types of noisewere used in the experiments: car noise and babble noise.Car noise was recorded in a Peugeot 405 with the speed ofabout 80 km/h. Babble noise was recorded in a noisycafeteria. In order to make a noisy signal, given apredefined input SNR, the noise signals were scaled andthen added to their corresponding speech signals (noisefrom microphone i was added to the speech frommicrophone i).
The performance assessment is carried out using thePESQ (P.862) measure [16] which is a psychoacoustics-based objective measure originally proposed to assess theperformance of the codec. The range of PESQ is from �0.5(for the worst case) to 4.5 (for the best case) [16].Correlation between subjective tests and PESQ scores inassessing the overall performance of the noise reductionsystems is reported to be about 0.8 in [17] (0.92 in the caseof white Gaussian additive noise). Table 1 shows the PESQscore for noisy and enhanced signals. The results arereported for two microphone pairs and four input SNRs. Inthe table, the COH method uses Eq. (2), the CPSSRpr(VAD)
method uses Eq. (8) wherein the noise CPSD is estimatedusing a VAD-based approach, and the CPSSRpr(PHB)
method uses Eq. (8) wherein our proposed noise estima-tion method is used.
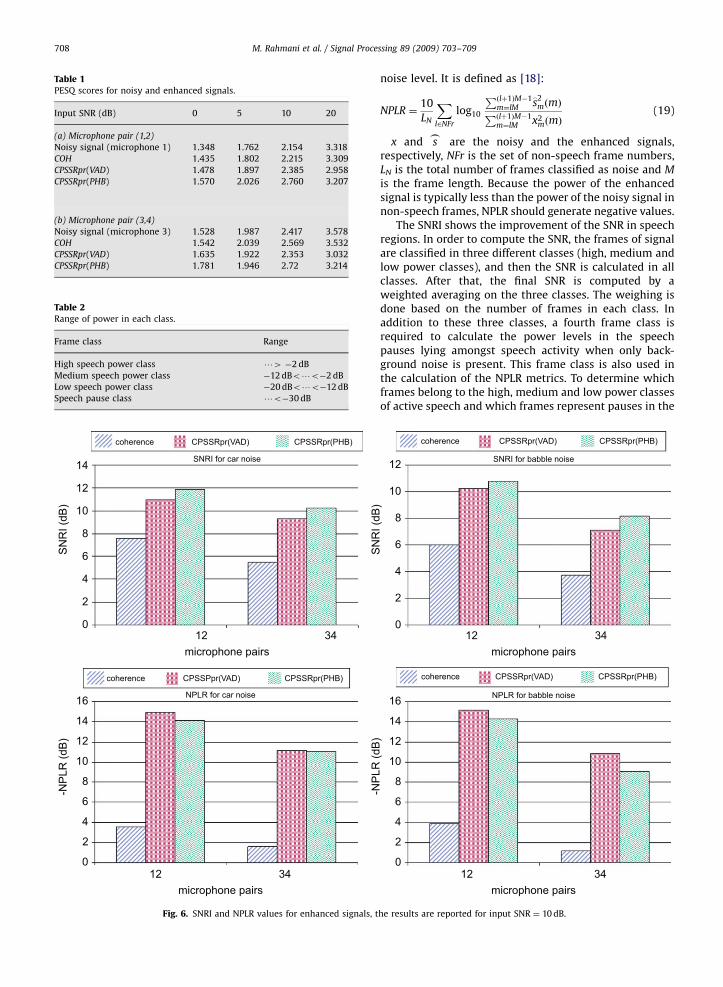
As shown in Table 1, in many cases the PESQ scores forthe proposed method are higher than the other methods.This proves the overall superiority of the proposedmethod in comparison with the CPSSRpr(VAD) and theCOH methods. This may be due to the fact that therecording environments resemble the diffuse noise field(i.e., the phase of the noise CPSD is zero.) The better PESQscores for COH in some cases may demonstrate the factthat the distortion with COH is less than those withCPSSRpr(VAD) and CPSSRpr(PHB). However; the problemwith the COH method is its low noise reduction.
The PESQ scores of enhanced signals for a 20 dB inputSNR source are less than those of the noisy signal at thatSNR. We can interpret this as follows: Our clean signalswere recorded in a relatively quiet room but they stillcontain some background noise due to the recordingconditions. When we enhance the low noise signal(SNR ¼ 20 dB), the enhanced signal may be cleaner thanthe assumed clean signal. The PESQ score considers thisdifference as noise or distortion; this is why PESQ score isreduced for this case.
We used two other objective measures to assess theperformance of the noise estimation algorithms: Noisepower level reduction (NPLR) [18] and signal to noise ratioimprovement (SNRI) [18]. NPLR indicates the capability ofthe noise reduction methods to reduce the background
ARTICLE IN PRESS
Table 1PESQ scores for noisy and enhanced signals.
Input SNR (dB) 0 5 10 20
(a) Microphone pair (1,2)
Noisy signal (microphone 1) 1.348 1.762 2.154 3.318
COH 1.435 1.802 2.215 3.309
CPSSRpr(VAD) 1.478 1.897 2.385 2.958
CPSSRpr(PHB) 1.570 2.026 2.760 3.207
(b) Microphone pair (3,4)
Noisy signal (microphone 3) 1.528 1.987 2.417 3.578
COH 1.542 2.039 2.569 3.532
CPSSRpr(VAD) 1.635 1.922 2.353 3.032
CPSSRpr(PHB) 1.781 1.946 2.72 3.214
Table 2Range of power in each class.
Frame class Range
High speech power class ?4 �2 dB
Medium speech power class �12 dBo?o�2 dB
Low speech power class �20 dBo?o�12 dB
Speech pause class ?o�30 dB
12
14
12
10
8
6
4
2
034
-NP
LR (d
B)
14
16
12
10
8
6
4
2
0
SN
RI (
dB)
12 34microphone pairs
microphone pairs
coherence CPSSPpr(VAD) CPSSRpr(PHB)
NPLR for car noise
SNRI for car noise
coherence CPSSRpr(VAD) CPSSRpr(PHB)
Fig. 6. SNRI and NPLR values for enhanced signals, t
M. Rahmani et al. / Signal Processing 89 (2009) 703–709708
noise level. It is defined as [18]:
NPLR ¼10
LN
Xl2NFr
log10
Pðlþ1ÞM�1m¼lM
_s
2mðmÞPðlþ1ÞM�1
m¼lM x2mðmÞ
(19)
x and s
Þ
are the noisy and the enhanced signals,respectively, NFr is the set of non-speech frame numbers,LN is the total number of frames classified as noise and M
is the frame length. Because the power of the enhancedsignal is typically less than the power of the noisy signal innon-speech frames, NPLR should generate negative values.
The SNRI shows the improvement of the SNR in speechregions. In order to compute the SNR, the frames of signalare classified in three different classes (high, medium andlow power classes), and then the SNR is calculated in allclasses. After that, the final SNR is computed by aweighted averaging on the three classes. The weighing isdone based on the number of frames in each class. Inaddition to these three classes, a fourth frame class isrequired to calculate the power levels in the speechpauses lying amongst speech activity when only back-ground noise is present. This frame class is also used inthe calculation of the NPLR metrics. To determine whichframes belong to the high, medium and low power classesof active speech and which frames represent pauses in the
10
12
8
6
4
2
0
SN
RI (
dB)
14
16
12
10
8
6
4
2
0
-NP
LR (d
B)
12 34
12 34microphone pairs
microphone pairs
coherence CPSSRpr(VAD) CPSSRpr(PHB)
NPLR for babble noise
SNRI for babble noise
coherence CPSSRpr(VAD) CPSSRpr(PHB)
he results are reported for input SNR ¼ 10 dB.

ARTICLE IN PRESS
M. Rahmani et al. / Signal Processing 89 (2009) 703–709 709
speech activity, the active speech level of the clean speechis first determined according to [19]. Thereafter, theframes are classified into the four classes based upon acomparison of the power in each frame to predefinedthreshold values. The ranges of power corresponding todifferent classes are presented in Table 2.
More details about calculation of SNRI and NPLR canbe found in [18,20]. The SNRI and NPLR results are shownin Fig. 6.
The results show that the SNRI for proposed method ismore than that of the VAD-based method, while, the NPLRfor the VAD-based method is higher than that of theproposed method (considering absolute values). It showsthat the VAD-based method attenuates noise more, butCPSSRpr(PHB) operates better in speech frames.
We investigated the behavior of the proposed estima-tor in noise-only regions to find the reason for thelower NPLR. Comparing the proposed method with theVAD-based method, one reason for less noise reduction innoise-only regions might be the difference betweensmoothing parameters in Eqs. (3) and (9). In the proposedmethod, the noise CPSD is equal to noisy CPSD which iscalculated using Eq. (3) (smoothing parameter ¼ 0.7).While, in the VAD-based method, this is estimated usingEq. (9) (smoothing parameter ¼ 0.9). Moreover, when aVAD-based estimator distinguishes the speech/pauseregions correctly, it can estimate the noise statistics withhigh accuracy in noise-only regions. We have used analmost ideal VAD, so its performance in noise-only regionsis perfect, while for the proposed method, due to theerrors originating from the diffuse field assumption(discussed in Section 3) the estimate is less accurate.
5. Conclusions
In this paper, we presented a dual microphone methodfor estimation of noise CPSD in diffuse noise field. Wederived an analytical formula for estimating CPSD of thenoise. Using this estimation, we calculated the spectralmodification filter. The proposed method does not needVAD or other conventional methods for estimation of thenoise CPSD. Using objective measures, we demonstratedthat the performance of our proposed method is higherthan that of the VAD-based methods.
Acknowledgment
The authors wish to thank Iran TelecommunicationResearch Center (ITRC) for their financial support.
References
[1] J.R. Deller, J.H.L. Hansen, J.G. Proakis, Discrete-Time Processing ofSpeech Signals, second ed., IEEE Press, New York, 2000.
[2] B.D. Van, K.M. Buckley, Beamforming: a versatile approach to spatialfiltering, IEEE ASSP Mag. 5 (2) (1988) 4–24.
[3] S. Ahn, H. Ko, Background noise reduction via dual-channel schemefor speech recognition in vehicular environment, in: IEEE Interna-tional Conference on Consumer Electronics, January 2005.
[4] R. Le Bouquin, G. Faucon, Using the coherence function for noisereduction, IEE Proc. 139 (3) (1992) 276–280.
[5] J.B. Allen, D.A. Berkley, J. Blauert, Multi microphone signalprocessing technique to remove room reverberation from speechsignals, J. Acoust. Soc. Amer. 62 (4) (1977) 912–915.
[6] R. Le Bouquin, A.A. Azirani, G. Faucon, Enhancement ofspeech degraded by coherent and incoherent noise using across-spectral estimator, IEEE Trans. Speech Audio Process. 5 (5)(1997).
[7] A. Guerin, R. Le Bouquin, G. Faucon, A two-sensor noise reductionsystem: applications for hands-free car kit, EURASIP JASP (2003)1125–1134.
[8] X. Zhang, Y. Jia, A soft decision based noise cross power spectraldensity estimation for two-microphone speech enhancementsystems, in: ICASSP 2005, Philadelphia, March 2005.
[9] P. Aarabi, G. Shi, Phase-based dual-microphone robust speechenhancement, IEEE Trans. Syst. Man Cybern. 34 (2004) 1763–1773.
[10] I. McCowan, H. Bourlard, Microphone array post-filter for diffusenoise field, in: Proceedings of IEEE International Conference onAcoustics, Speech, 2002.
[11] M. Rahmani, A. Akbari, B. Ayad, A modified coherence based methodfor dual microphone speech enhancement, in: IEEE InternationalConference on Signal Processing and Communication, Dubai,November 2007.
[12] Y. Ephraim, D. Malah, Speech enhancement using a minimummean-square error short-time spectral amplitude estimator, IEEETrans. Acoust. Speech Signal Process. 32 (1984) 1109–1121.
[13] P. Scalart, J.V. Filho, Speech enhancement based on a-priorisignal to noise estimation, in: ICASSP1996, vol. 2, May 1996,pp. 629–632.
[14] R. Le Bouquin, G. Faucon, Voice activity detector based on theaveraged magnitude squared coherence, in: International Confer-ence on Signal Processing Applications and Technology, October1995.
[15] I. Schwetz, G. Gruhler, K. Obermayer, A cross-spectrum weightingalgorithm for speech enhancement and array processing: combin-ing locating and long-term statistics, J. Acoust. Soc. Amer. 119(2006) 952–964.
[16] ITU-T Recommendation P.862, Perceptual evaluation of speechquality (PESQ): an objective method for end-to-end speech qualityassessment of narrowband telephone networks and speech codecs,February 2001.
[17] T. Rohdenburg, et al., Objective perceptual quality measures for theevaluation of noise reduction schemes, in: Proceedings of NinthInternational Workshop on Acoustic Echo and Noise Control,Eindhoven, NL, September 2005, pp. 169–172.
[18] E. Paajanen, V.V. Mattila, Improved objective measures forcharacterization of noise suppression algorithms, in: Proceed-ings of IEEE Workshop on Speech Coding, 6–9 October 2002,pp. 77–79.
[19] ITU-T Recommendation P.56, Objective measuring apparatus,objective measurement of active speech level, March 1993.
[20] E. Paajanen, B. Ayad, V.-V. Mattila, New objective measuresfor characterisation of noise suppression algorithms, in: IEEESpeech Coding Workshop, Delavan, Wisconsin, USA, September2000.
Related Documents








![W2F.1 Suppression Scheme ICI Noise based on Partial ... · mean and finite power. The power spectral density (PSD) of phase noise is given in [11] as: f 1-a, 0](https://static.cupdf.com/doc/110x72/5fc5a0c68d1aaa684c5a5b26/w2f1-suppression-scheme-ici-noise-based-on-partial-mean-and-finite-power-the.jpg)