The Pennsylvania State University The Graduate School Department of Computer Science and Engineering A FRAMEWORK FOR MIME TYPE IDENTIFICATION AND CONTENT FILTERING IN THE FIREFOX WEB BROWSER A Thesis in Computer Science and Engineering by Matthew James Rummel c 2012 Matthew James Rummel Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science December 2012

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

The Pennsylvania State University
The Graduate School
Department of Computer Science and Engineering
A FRAMEWORK FOR MIME TYPE IDENTIFICATION AND
CONTENT FILTERING IN THE FIREFOX WEB BROWSER
A Thesis in
Computer Science and Engineering
by
Matthew James Rummel
c© 2012 Matthew James Rummel
Submitted in Partial Fulfillmentof the Requirements
for the Degree of
Master of Science
December 2012

The thesis of Matthew James Rummel has been reviewed and approved* by the following:
Patrick McDanielProfessor of Computer Science and EngineeringThesis Adviser
Trent JaegerAssociate Professor of Computer Science and Engineering
Lee CoraorAssociate Professor of Computer Science and EngineeringDirector of Graduate Affairs
*Signatures are on file in the Graduate School

iii
Abstract
Modern Web browser architectures allow for extensibility in order to support
an evolving variety of content. Each supported plugin interacts with the browser and
underlying host through a diverse set of operations that bring new challenges to the
security model. These capabilities provide the means for a growing number of attack
vectors that leverage the lax MIME type verification utilities in browsers to disguise
malicious files. Once loaded by a browser, these objects take advantage of the escalated
privileges available to their concealed payload in order to execute commands on the
client. Such attacks can be launched from files shared on social media sites, through
email, or from a server controlled by the attacker. To protect against these threats, we
offer MIME Detector, a Firefox browser extension to identify and monitor the browser’s
use of loading objects. By utilizing a collection of open source tools and internal browser
components, the tool is able to determine the MIME type of incoming content and
enforce an acceptable use policy. Our testing shows that this research provides a solid
framework towards providing users with a greater level of control over how Web based
content interacts with their client.

iv
Table of Contents
List of Tables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . v
List of Figures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . vi
Acknowledgments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . vii
Chapter 1. Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.1 Camouflaging Malicious Content . . . . . . . . . . . . . . . . . . . . 2
1.1.1 GIFAR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.1.2 Flash and ZIP Archives . . . . . . . . . . . . . . . . . . . . . 51.1.3 Chameleon Files . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.2 Research Statement . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
Chapter 2. Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.1 Client Filtering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.1.1 String Based Filtering . . . . . . . . . . . . . . . . . . . . . . 102.1.2 Control Flow Detection . . . . . . . . . . . . . . . . . . . . . 12
2.2 Server Filtering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.2.1 Common Approaches . . . . . . . . . . . . . . . . . . . . . . . 142.2.2 Automata Based . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.3 Comparison to Project . . . . . . . . . . . . . . . . . . . . . . . . . . 16
Chapter 3. Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183.1 User Interface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.1.1 Site Elements . . . . . . . . . . . . . . . . . . . . . . . . . . . 183.1.2 Settings . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193.1.3 Action Log . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2 Browser Interaction . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233.2.1 Channel Proxy . . . . . . . . . . . . . . . . . . . . . . . . . . 233.2.2 Content Evaluation . . . . . . . . . . . . . . . . . . . . . . . . 24
3.3 MIME Identification and HTML Parsing . . . . . . . . . . . . . . . . 26
Chapter 4. Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 294.1 Rule Set Tests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 294.2 MIME Identification Tests . . . . . . . . . . . . . . . . . . . . . . . . 324.3 Web Browsing Test . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
Chapter 5. Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
Appendix. Web Browsing Test Results . . . . . . . . . . . . . . . . . . . . . . . 40
References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52

v
List of Tables
3.1 Monitored HTML tags and their associated reference attribute. . . . . . 19
4.1 The result of the tag test evaluation. . . . . . . . . . . . . . . . . . . . . 314.2 The results of the camouflaged objects evaluation. . . . . . . . . . . . . 33
A.1 A sample rule set for general Web browsing. . . . . . . . . . . . . . . . . 41A.2 An evaluation of identification results. . . . . . . . . . . . . . . . . . . . 44A.3 A listing of items blocked by the extension. . . . . . . . . . . . . . . . . 48A.4 A comparison of collected performance metrics. . . . . . . . . . . . . . . 51

vi
List of Figures
1.1 Sample Java and HTML code to launch a GIFAR attack that lists auser’s files [9]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.2 A Postscript file modified to contain HTML code and an HTML file witha GIF header [7]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3.1 The user interface tabs . . . . . . . . . . . . . . . . . . . . . . . . . . . . 223.2 The stages of a file’s evaluation . . . . . . . . . . . . . . . . . . . . . . . 27

vii
Acknowledgments
I am appreciative of the guidance I have received from my advisor, Dr. Patrick
McDaniel. His perspective and feedback were instrumental in leading this thesis to
successful completion. I am also grateful for the support of my family and friends. Their
unwavering encouragement has always been a positive influence in all of my endeavors.
Most of all, I would like to express my deepest gratitude to Allison for her understanding,
patience, and reassurance throughout the duration of this project — I couldn’t have done
it without her.

1
Chapter 1
Introduction
The incorporation of Web 2.0 technologies in the World Wide Web has brought
substantial changes to both the user experience and security model of Internet appli-
cations. As a platform for services and user content, Web based products allow for in-
creased ease of collaboration and data dissemination amongst distributed parties. This
vast dispersion of files originating from end users combined with the execution of client
side code can also be leveraged to compromise the privacy of users and the integrity of
their devices. A recent report by Symantec lists blogs and Web communication as the
category of websites most frequently utilized to launch such an attack [1]. The report
further cites plugins, including Oracle Java; Adobe Flash; and Adobe Acrobat Reader,
as commonly providing a mechanism for many malicious exploits. Research has shown
these manipulations to include cross site forgeries [8], cross site script attacks [7], and
malware [10]. Additionally, it has been revealed that any type of file, even those as seem-
ingly benign as images, can be used to exploit properties of Web architectures [9] [7].
Thus, the ability to add media to websites coupled with the requirement that browsers
support rich content presents an ongoing challenge in browser security.
In this research, we examined a particular category of Web based attacks in which
an object loaded into a browser is embedded with the payload of a malicious object of
a different MIME type. By disguising malicious files in this manner, attackers are able

2
to circumvent content policies enforced by both browsers and servers. Such attacks
have been described as content repurposing by Sundareswaran and Squicciarini [29] and
“chameleons” by Barth et al [8]. The objective of this project was to develop a framework
to prevent such exploits implemented as a browser extension.
1.1 Camouflaging Malicious Content
Regardless of the method used to repurpose content, there are some common
characteristics that can be recognized in each approach. Each attack implements some
form of digital steganography, or the practice of disguising data by placing it within
other data, thereby concealing the secret payload [4]. Although standard MIME types
have recognizable signatures, the process of finding all signatures within a given payload
of data has proven to be a difficult task at both the client and server. Furthermore, when
MIME types are inferred through different recognition techniques, it is possible that the
server will identify the object as being of one type, while the client attempts to utilize it
as though it were another. The following descriptions exemplify the attack vectors and
capabilities of hidden Web content.
1.1.1 GIFAR
To date, the most highly publicized repurposing attack is the GIFAR, so named
for its construction as a concatenation of an image, such as a GIF and a Java archive,
or JAR. The GIFAR vulnerability was presented at the Black Hat USA Conference in
2008 based on research by Billy Rios and Petko Petkov. The attack was regarded as
one of the top Web hacking techniques of that year based on its simplicity and ability

3
to compromise a victim’s privacy [14]. The vulnerability was patched shortly after the
presentation and is no longer a threat in versions of Java since 1.6.0.11 and 1.5.0.17 [9].
A notable property that contributed to the effectiveness of the GIFAR is its
distribution through images. While most Web applications will not allow executable
code to be uploaded, images are frequently permitted and wildly shared in social media
and content management applications. In addition to third party sites, an attacker may
consider storing the malicious content on their own domain and attract users to their
site through advertisements or other means. Once the GIFAR is stored on a third party
server, the attacker must find a way to embed HTML code that enables the JAR to
execute. This code can be inserted into the webpage due to lax text input sanitation
or other attack methods whereby HTML can be injected. An additional method is to
upload the GIFAR to a server and then send an HTML email to the victim. The HTML
message would contain the an <a> tag that embeds the <img> tag, thus referencing the
GIFAR as a link. When the user clicks on the link, a page is loaded that invokes the
applet and thus carries out the attack [29].
The overall extent of the a GIFAR’s effectiveness is largely based on the security
measures in place on the client, the browser settings, and the security awareness of
a potential victim. A number of these scenarios were discussed by Ron Brandis, a
researcher at EWA-Australia [9]. If the firewall setting on the user’s local machine
prohibits the GIFAR from establishing a connection back to a server controlled by the
attacker, then no information can be retrieved. If a TCP tunnel can be established,
then a fairly low level set of attacks could be launched to return information such as the
target’s internal IP address, send spam emails, or forward commands to botnets. The

4
// Included in Evil.class in a JAR concatenated to evil.gifpublic class Evil extends JApplet {
public void start() {Socket socket=new Socket(attackerIP , attackterPort);OutDataStream out=new DataOutputStream(sock.getOutputStream ());
Process p=Runtime.getRuntime ().exec("ls -l"):BufferedReader in= new
BufferedReader(new InputStreamReader(p.getInputStream ()));String line = "";while ((line = in.readLine ()) !=null)
out.writeUTF(line +"\n");}
}<!-- Included in loading HTML code --><html >
<body ><img src=evil.gif ><applet archive=evil.gif code=Evil.class >
</body ></html >
Fig. 1.1 Sample Java and HTML code to launch a GIFAR attack that lists a user’sfiles [9].
attacker could also potentially establish connections to a third party server, which on a
large scale could lead to a distributed denial of service attack [29].
More detrimental attacks to the user’s system would require a signed applet in
order to satisfy the restrictions enforced by the JVM’s Security Manager on access to
the local system. If the applet in the GIFAR is signed with a fake certificate that
lists a seemingly trusted source as its publisher, the user may be inclined to accept the
certificate. This action would provide the GIFAR unrestricted access to run a number
of attacks. Such attacks include executing commands, modifying files, or retrieving
persistent cookies. Sample code for executing a command in a GIFAR and returning the
results to an attacker is shown in Figure 1.1.
In addition to the use of image files for which GIFFARs are named, they can
also be used to launch attacks from Microsoft Office Open XML files (.docx, .pptx, and

5
.xlsx), which use an XML format and ZIP compression to store office documents. Using
a ZIP utility, one can insert the contents of the JAR file into the archive. As in the
GIF version, the attack is launched when the file is loaded and the JAR invoked by the
HTML.
1.1.2 Flash and ZIP Archives
Another camouflaging technique that uses Adobe Flash was presented by Michael
Bailey, a Senior Researcher at Foreground Security, at the Black Hat USA conference in
2010 [6]. Flash content contained in .swf files are controlled by executable code called
ActionScript. ActionScript is restricted by a same origin policy similar to that which
governs JavaScript; ActionScript loaded from one domain cannot execute code, access
cookies, or read content that originated from another domain unless permission has been
explicitly granted. Of course if the Flash file is hosted on a server in the domain being
attacked, then that file can execute scripts in the context of that domain. This enables
a malicious Flash object to steal information or cookies from the domain under attack.
Unlike the GIFAR attack, a Flash executable does not require any additional HTML
code in order to be invoked.
Simply changing the extension of a .swf file to a MIME type that the server
permits may be sufficient to upload a Flash file in poorly secured applications. If the
server has more restrictive filtering, the attacker could attempt to disguise the SWF by
prepending it to a file that conforms to the ZIP format. As in the GIFAR attack, the
ZIP format is a good candidate to disguise Flash files as a ZIP file can be appended
to any binary format and remain valid. However, unlike JARs, SWF files will not be

6
executed if concatenated at the end of another file. The solution is to append the ZIP
files to the SWF and then attempt the upload [5]. Baily reports that several server
side validators will recognize the file to be of the ZIP format and thus the attack can
commence. Currently, there have not been any published fixes from Adobe.
1.1.3 Chameleon Files
An attack technique developed by Barth et al. introduced a way of hiding HTML
elements inside of Postscript and image files, creating what they described as “chamele-
ons” [7]. The attack was implemented by editing the header of a Postscript file to include
HTML tags that executed JavaScript. The attack was tested by loading the modified
Postscript file into a HotCRP server, which is a content management product used for
conference paper submissions. When a hypothetical reviewer of the paper accessed the
page containing the modified file, the JavaScript was executed with the credentials of
the logged in reviewer in the domain of the conference server and was able to rate the
submitted paper with presumably high marks.
Chameleon image files were created by placing a GIF88 signature at the beginning
of an HTML file. The constructed file was then uploaded into Wikipedia, a collaborative
online encyclopedia. Although Wikipedia does search for embedded HTML in uploaded
files, it checks for only a limited set of potential tags. Using these unchecked tags, the
file was able to be uploaded. When the page was viewed with Internet Explorer, the
JavaScript contained in the HTML was executed.
Both sample attacks executed by Barth et al. are examples of content sniffing
cross site script attacks. The attacks relied on the privilege escalation that occurs in

7
% Post script file to execute HTML!PS -Adobe -2.0%% Creator: <script > .... .... </script >
%% Title: evil.dvi%% Pages: 3
<-- HTML file hidden as gif -->GIF88 <object src=" about:blank" onerror ="... javascript ...">
</object >
Fig. 1.2 A Postscript file modified to contain HTML code and an HTML file with a GIFheader [7].
the browser when HTML tags are detected. Because HTML is able to run scripts, it is
regarded as being of a higher privilege in comparison to other elements such as an image.
The inability of both the browser and the server to detect this mixing of privileges allows
the attack to occur. A sample code segment depicting the Postscript and GIF attacks is
shown in Figure 1.2.
1.2 Research Statement
The success of these attacks reveals that current techniques used to determine
MIME types on both the server and client are lacking in uniformity and effectiveness. It
also highlights that browsers can make use of a file in the manner specified by the HTML
without any verification of the content or the use intended by the application. Although
the intended use could be inferred by the Content-Type header defined in the HTTP
protocol, this field can be left empty by some servers, filtered by an external proxy, or
be disregarded by a receiving browser based on it’s own MIME identification scan [7].
This research attempts to address the issue of acceptable content use in the
browser by constructing a tool to determine an object’s MIME type and appropriately
filter content based on its context. We developed a tool called MIME Detector as an

8
extension to the Firefox browser to fulfill this ambition. This tool listens for incoming
content as it enters the browser, performs scans on the data to identify the MIME types
of the objects being loaded, and then determines which objects should be allowed or
denied. Load requests are evaluated based on the default criteria of whether an object
can be identified and if so, how many identities are recognized. If a type cannot be
determined or more than one MIME type is detected, the object load is canceled. If
it does evaluate to a single MIME value, the context of the object’s use as an element
loading in an HTML page or in the browser window itself is evaluated by a user-defined
rule set. Although many experts believe that ultimately MIME type filtering is an issue
that must be solved by Web applications, the short term prevention of these security
deficiencies can best be addressed by users in the client [18].

9
Chapter 2
Related Work
Every browser and properly configured server that allows user uploads utilizes
a method to determine a file’s MIME type. This is accomplished through various ap-
proaches. Thus, the problem of identifying hidden malicious content is compounded
by the disjointed methods used to determine a file’s type. Many attack vectors in the
domain of content repurposing are made possible because a server determines a file to
be of one type, while the browser interprets it as another. While a universal recognition
technique may be beneficial to both content providers and users, no standard has yet
been adopted. The following work highlights attempts to improve MIME type detection,
content filtering, and security best practices at both the client and server.
2.1 Client Filtering
Browsers use their MIME identification utilities to determine how loading content
should be rendered when the MIME type is not supplied by the server or is overruled
by the browser. MIME sniffing is typically achieved by comparing the leading bytes of
data to well known signatures. Common implementations of these methods have proven
to be ineffective in stopping content based attacks. This has lead to the development of
alternative techniques that attempt to improve upon standard capabilities.

10
2.1.1 String Based Filtering
Barth et al. blended the detection abilities of several content sniffing algorithms
in popular Web browsers to form a single MIME recognition method [7]. The browsers
incorporated in this experiment were Internet Explorer 7, Firefox 3, Safari 3.1 and Google
Chrome. As Firefox and Chrome are open source, the content sniffing algorithms in these
browsers were determined by source code inspection. Since Safari and Internet Explorer
utilize proprietary algorithms, their detection abilities were modeled using a technique
call string-enhanced white-box-exploration.
White-box-exploration executes code in an environment that records the con-
straints of conditional statements encountered in the execution path of a given input.
The module then negates one of the recorded predicates in the execution path such that
the opposite path is explored. For instance, if the condition x < 0 was satisfied in
the current execution, this statement would be negated to x > 0. An input generator
then analyzes the new constraints list and generates inputs that will exercise the chosen
negated condition. These items are added to the set of inputs under consideration for
successive rounds. A prioritized list of new inputs based on overall code coverage is
selected from this set. The highest priority inputs start the next round and execution
continues until all conditional paths have been explored.
Enhancements to white-box-exploration introduced by Barth el al. provide an
abstraction of string conditional statements documented during execution. This is ac-
complished by recording constraints on the output of string operations rather then the
conditionals themselves. Thus, an independent representation of the operation is saved

11
instead of the byte level string comparison operations. A solver component that un-
derstands these inputs is then utilized and a new generation of inputs was created. By
analyzing string operations in a manner decoupled from their low level operations, con-
tent sniffing algorithms were able to be modeled and compared regardless of the language
in which the browser was written.
After modeling the proprietary MIME detection capabilities, the team’s com-
parison of the browsers revealed significant differences in the byte length examined for
signature matching, the conditions on which content sniffing is triggered, and signature
definitions. These methods were consolidated through combining the induced properties
of the browsers’ content recognition algorithms to create an improved browser content
sniffer. This comprehensive algorithm was then pared in accordance with two key de-
sign principles: avoiding privilege escalation and ensuring signatures are prefix disjoint.
Privilege escalation occurs when an object of one type is elevated to have the privileges
of another type. For example, an object that is received with a Content-Type header of
type image/jpeg should never be interpreted as application/x-shockwave-flash as
these applications have the ability to run scrips whereas images do not. A signature set
is said to be prefix-disjoint if any signature it uses to recognize HTML does not share a
prefix with any other signature. HTML is considered to have the highest privilege of all
MIME types due to its ability to run JavaScript. Using these principals, the new con-
tent sniffer proved to be more effective at recognizing hidden objects than each browser’s
independent methods. This content sniffing procedure was adopted in Google Chrome
and partially implemented in Internet Explorer 8.

12
2.1.2 Control Flow Detection
Sundareswaran and Squicciarini introduced a technique that focuses on modeling
the browser’s actions as opposed to detecting component types. This procedure is im-
plemented in the DeCore tool, or Detecting Content Repurposing Attacks on Clients’
Systems [28]. This process involves constructing control flow graphs with nodes that
represent the current state of the browser and transitions depicting events on the local
system or between the client and a server. The tool was developed as a browser extension
compatible with both Firefox and Chrome. Using the the control flow model, the exten-
sion is able to detect operations that indicate a repurposing attack may be occurring.
The DeCore system relies on two main components: an auditor and a detector.
The auditor monitors deviations in a browser’s behavior from what is expected
through a series of verifications. First, it compares a file’s extension to a list of extensions
that are acceptable for the given target. The target could be the main browser window
or a contained plugin. For example, the component would specify that the Java plugin
should only receive files with a .jar or .class extension and the Acrobat plugin should
only be provided files of type .pdf. The auditor also analyzes interactions between the
user and the browser and between the browser and servers. When a page is loaded, the
auditor constructs a control flow graph by monitoring the DOM. This is achieved by
analyzing the components in the DOM tree and mapping the possible interactions and
events that can take place. Thus in the graph, the nodes represent the client state and
the edges the action or IO necessary to move the bowser to a different state. When
events occur, they are analyzed in the context of the browser’s state and the state of

13
associated files on the client’s device. An interaction is deemed to be suspicious if a state
transition occurs that does not match an allowable transition in the control flow graph.
The detector is notified when such an unmapped transition occurs. These vio-
lations are regarded as the signature of a potential content repurposing attack. The
detector has various methods by which it determines if an attack is actually occurring,
based on a defined interaction policy. Sundareswaran and Squicciarini experimented with
several policies that included contingencies such as the state of the local file system, the
number of loading pages per user interaction, and the state of cookies or other stored
content, to determine if the unexpected transition was an attack. They were able to
develop a policy that was successful in blocking a number of content repurposing attacks
involving Flash and Java. They also reported that the monitoring required very little
overhead in regards to system resources.
2.2 Server Filtering
An alternative approach to content filtering is to perform file analysis at the server
side. As the creators and administrators of Web applications ultimately posses the most
insight with respect to what MIME types should be permitted in their domain, server
side approaches can offer site specific guarantees of security and functionality beyond
that of generalized browser based measures. Furthermore, rendering speed is a critical
metric for browsers and can have a significant impact on their market share [30]. Thus
having protection methods that use client resources can have an appreciable impact on
the Web browsing experience as well as the popularity of a given browser. The following
techniques attempt to enforce content security at the server.

14
2.2.1 Common Approaches
Currently, upload filtering is the most commonly practiced method of protect-
ing domains from malicious MIME types [28]. As in client side filtering, scanning for
signatures and HTML tags are the most prevalent techniques. The advantage of per-
forming this action at the server side is that servers likely have more resources available
to perform such scans and thus can handle more resource intensive procedures for ex-
amining files. The number of bytes examined by each browser also differs with some
older browsers using as little as 256 bytes [2]. Furthermore, as new MIME formats are
constantly evolving, browser filtering methods must continually be updated to support
content that servers choose to provide. This concern can be mitigated by having servers
handle the filtering and choosing only to allow signatures they recognize. Nevertheless,
from the user’s prospective this protection is insufficient as it requires one to place their
trust in the servers they visit on the Internet.
Perhaps the easiest method to ensure files uploaded by users do not exhibit script-
ing concerns is to store them on servers with a separate domain [28]. Because the domain
is different from that of a loaded HTML page, any included attacks that attempt to mis-
use the same origin principal will be prevented. While the simplicity of this approach
lends it to be highly effective, it may be cost prohibitive for smaller organizations. Fur-
thermore, some attacks can still be launched from malicious content linked to the site
from other servers.
Another protection technique is to restrict servers to only execute authenticated
scripts [28]. In this scenario, scripts would be subjected to a hash function or another

15
form of verification to ensure that they were loaded from a legitimate source. This
approach prevents malicious scripts from requesting or submitting information on behalf
of the user as in the case of a cross site forgery. Nonetheless, this method does not
guarantee that the authenticated scripts will not exhibit some form of information leakage
that can be exploited. Furthermore, this method does not protect access to the client’s
cookies or other exploits that can occur on the client side.
The most limited protection procedures involve performing a transformation on
uploaded files [28]. For instance, software on a server could apply a conversion algorithm
on uploaded images. Many websites use such tools for uploaded images by modifying
the size and pixel rate in order to conserve storage space. Such conversions would have a
high probability of destroying any hidden files encapsulated in the images. However, this
technique is only applicable to images as there is no other practical means of transforming
binaries of other types without destroying the usable data. Furthermore, there is no
guarantee of disabling hidden content by using these methods as it is possible for an
attack to be designed that can withstand a known transformation.
2.2.2 Automata Based
A more complex server side solution is presented by Gebree et al. who developed
an automata based script to filter MIME types. This method examines uploaded files
for selected HTML tags that have attributes that could reference code [12]. Exam-
ples of tags that could contain scripts include <embed src=*>,<object data=*>, and
<iframe src=*>. They also took into account how imperfect HTML syntax is handled

16
by browsers. For instance a <script> element will not execute scripts without a clos-
ing </script>, whereas a <object> element can still execute code even when lacking a
</object>. Using these defined patterns and rules, they developed a finite state machine
to match the selected tags and their properties, taking into account partial syntaxes and
rejecting states. This automaton was then consolidated to a rule set of regular expres-
sions used to scan all uploaded content. The syntax matching algorithm was defined to
contain sufficient information to match the HTML elements but also concise enough to
maintain an efficient scanning process. Their experiments show that regular expression
filtering can be both more efficient and accurate than standard string based matching
algorithms commonly used. They also report a much lower false positive rate when
comparing their algorithm to the MIME identification technique developed by Barth et
al [7].
2.3 Comparison to Project
As related in previous research, there are several different approaches one can
take to detect and filter content in both the client and the server. This project builds
on the work of past analyses in utilizing a new detection technique and employing cus-
tom filtering capabilities to help ensure user privacy. The tool we developed is called
Mime Detector which was implemented as an extension to the Firefox Web browser.
The tool’s MIME identification abilities are made possible by utilizing the most accurate
open source Java utilities currently available. These tools employ both binary signature
recognition as well as string recognizers. Similar to the extension developed by Sun-
dareswaran and Squicciarini, the context of an object is also taken into consideration. A

17
file’s use in a website is governed by a rule set maintained by the user. This ensures, for
instance, that content identified to contain a JAR file cannot be referenced as the source
of an <img> tag. Thus this work’s contribution includes providing automated detection
capabilities along with the flexibility of user specified control.

18
Chapter 3
Implementation
Mindful of the challenges and previous research in browser security, we developed
a new framework to effectively identify and prevent hidden malicious objects at the
client side. This approach was implemented as a Web browser extension called MIME
Detector. MIME Detector was developed in Mozilla Firefox 14 running in a Ubuntu
Linux 11.10 environment utilizing Java JRE 1.6.0.24. The tool is comprised of three main
components: The front end interface, the browser interaction layer, and the identification
and parsing utilities.
3.1 User Interface
The user interface is defined in Mozilla XUL, or XML User Interface Language,
and is controlled by JavaScript code [23]. As the name implies, XUL specifies interface
objects through a series of nested XML tags. The components used in this project include
buttons, trees, input boxes, and drop down menus. The interface screens are accessed by
the tools menu in the browser window menu bar. The interface window contains three
tabs: “Site Elements”, “Settings”, and “Action Log”.
3.1.1 Site Elements
The “Site Elements” tab displays the results of all the objects identified in an open
browser tab session. The results of this identification are stored in a SQLite database

19
Tag Ref. Attribute Tag Ref. Attribute
* <object> data
<source> src <script> src
<body> background <img> src
<frame> src <table> background
<iframe> src <applet> code
<embed> src window
<link> href
Table 3.1 Monitored HTML tags and their associated reference attribute.
called mimeIdentifier.sqlite created in the user’s Mozilla profile directory. The data
is displayed in the pane as a group of root elements labeled with the domain of the
server from which the data was received. A user can click on a domain to toggle a list of
child elements that contain the fully qualified name, a short file name, and any identified
MIME/PUID types for each of the displayed objects. A PUID is a PRONOM Persistent
Unique Identifier, derived from the PRONOM Digital Archive database developed by
the National Archives of the United Kingdom [25]. Whereas the signature of a given
MIME type may evolve over time, PUIDs are a static property given to a particular
version. Thus many MIME types have several associated PUIDs. The object display
view is continually updated as new elements arrive for an open tab and is removed when
the tab session is closed.
3.1.2 Settings
The “Settings” tab is the interface used to define the rule set that governs the
tool’s filtering capabilities. The controls to add, delete, or modify the precedence order
of rules are located at the bottom section of the pane. The rule settings persist between
browser sessions and are saved in the mimeIdentifierSettings.sqlite database in

20
the user’s Mozilla profile directory. The tag drop down list contains the HTML tags
governed by these rules as well as the options “window” and “*”. The “window” option
refers to items that load directly in the browser window. With this selection, a user
can create a rule such that only documents of a particular type can be loaded in the
browser. The “*” character denotes a match of any context. This is used to prevent a
particular MIME type from being used in any way. If a selection other than window or
“*” is made, the appropriate attribute that references an external file is filled in as the
attribute label. A list of the HTML tags and corresponding reference attribute is shown
in Table 3.1.
The MIME Type/PUID drop down list displays the available identification types
for a rule. Selecting a type binds the rule to the identification of files associated with the
tag selection. A rule will only be enforced if the file identification matches the provided
MIME type. Like the tag attribute, the identification drop down also has a “*” option
that allows an identified file of any MIME type to be acted on in the selected context.
The additional attributes text box is an optional field that allows supplemen-
tary attributes to be entered as criteria for matching a given tag. This option is
not available if window or “*” are selected in the tag list. Additional attributes are
entered as a comma-delimited list of attribute value pairs. For instance, suppose a
user wishes to specify a rule that pertains to <object> tags. Using additional at-
tributes, he may also specify a particular value for the type attribute of the tag such as
type=application/x-shockwave-flash. If the user also wanted this rule to only affect
objects from a particular codebase, he would enter type=application/x-shockwave-flash,
codebase="http://ftp.adobe.com/.../swflash.cab".

21
The final rule input is the action drop down from which the user specifies “allow”
or “deny”. If the context and properties of an object under evaluation match the tag,
MIME Type/PUID, and additional attributes settings, then an action is enforced to
either allow the referenced file to be loaded or to block it by canceling the load request.
The rule set is evaluated from top to bottom and once an action has been enforced on a
loading object, that object is no longer evaluated against any subsequent rules for that
context. In addition to the user specified rules, there is a default rule that is enforced
on all objects. This rule specifies that any object being loaded has to have exactly one
MIME type. This means that an item that is either unable to be identified or identified
as having two or more different MIME types by the tool is blocked. This is enforced
irrespective of the rule set and cannot be overridden using the “*” selections. Updates
made to the rule set are enforced starting with the next page load.
We can formally model the enforcement of rules on a loading HTML page as a set
of predicates. Let us define the following variables: an object o in the set of all loading
objects O used in tag context t and a rule r in position i of rule set R. Let us also
define predicates isTag(ot, ri), that returns true if the tag of t matches the tag in rule ri;
isMime(ot, ri), that returns true if the file o has an identified MIME type that matches
the type in ri; isAdd(ot, r), that returns true if either no additional attributes are set in
ri or the attribute value pairs specified also exist in t; and isDefault(ot), that returns
true if and only if there is one MIME type identified for ot. The evaluation of an object
can result in the functions fAction(ot, ri), which will block or allow ot depending on the
setting in ri; fBlock(ot), which blocks ot; or fAllow(ot), which will allow ot to load. The

22
Fig. 3.1 The user interface tabs
analysis of objects in MIME Detector can therefore be expressed as follows:
∀ot ∈ O
(¬isDefault(ot)) → fBlock(ot) ,
(∃rmin(i) ∈ R | isTag(ot, rmin(i))∧
isMime(ot, rmin(i)) ∧ isAdd(ot, rmin(i)) → fAction(ot, rmin(i)) ,
fAllow(ot)
3.1.3 Action Log
The final component of the user interface is the “Action Log” panel. This compo-
nent displays the name and determined MIME type of all items that have been blocked
during a browser session. The items displayed are retrieved from the MimeLog.sqlite
database stored in the user’s Mozilla profile. As items are added, the displayed list is
refreshed. The log is reset when the browser window is closed. Screen shots of each of
the user interface tabs are shown in Figure 3.1.

23
3.2 Browser Interaction
The browser interaction layer is an intermediary between the standard browser
modules and the extended capabilities provided by the tool. Upon initialization, the
components in this layer set listeners and observers on browser interfaces, retrieve the
rule set for object evaluation, and invoke Java based utilities.
3.2.1 Channel Proxy
Data is intercepted in the extension by listening for state changes on browser
tabs. When a tab is opened, it is assigned a unique tabId property. A new value is
assigned to this property every time a URL is visited. This property is used to associate
intercepted data to the tab that requested it. Each tab is also assigned three observers
that wait for incoming data channels initiated by server or the cache requests: “http-on-
examine-response”, “http-on-examine-cached-response”, and “http-on-examine-merged-
response”. When data arrives on a channel, a new listener is set on the channel im-
plementing the nsITraceableChannel interface [20]. Setting a listener on the channel
returns a reference to the previous listener for that channel set by the browser. This
old listener is then set as a field in the new listener and is forwarded data from the new
channel listener. This data capture method has been utilized by several other browser
extensions including Firebug [24]. These listeners effectively create a proxy capable of
filtering incoming data channels. Whereas a typical proxy is external to the browser,
implementing this functionality inside the browser allows the extension to examine any

24
data that may have been encrypted during transport. This allows MIME Detector to
support filtering data received via HTTPS connections.
3.2.2 Content Evaluation
A item received by the channel proxy is sent as an array of bytes to a Java
based identification utility. This process is discussed in Section 3.3. The results of the
identification process are used to populate the mimeIdentifier.sqlite database and
refresh the “Site Elements” display as described in Section 3.1.1. The item is then
evaluated based on its target, determined MIME type, and the rule set.
There are two possible targets for an item being loaded into the browser: it
is either being loaded directly into the browser window or is referenced by an HTML
page contained in the window. Included with the data intercepted on a channel is
the corresponding request. The header of this request is examined to determine if the
appropriate flag is set to indicate that the target of the response is the main browser
window. If this flag is not set, then the object must have been requested by the HTML
content in the browser window. If the target is the window, then the item is evaluated
using any rules that specify a tag of window or *. The rule evaluation process was
discussed in Section 3.1.2. If based on this evaluation the item should be blocked, the
request is then canceled.
If an item is not blocked, the next evaluation is based on whether the MIME type
was identified to be HTML. If the item is HTML, then it is sent to the Java component
to be parsed. This process builds an internal structure of any tags listed in Table 3.1 that
match each rule in the current rule set and the full URL of the items referenced by these

25
tags. This information is stored in a mapping component called the MimeHTMLMapper.
The saved tag information is associated to the tabId of the tab that received the HTML.
If an internal tag structure already exists for a given tabId, it is combined with the newly
parsed results. This information will be used to evaluate objects the HTML references
as they are loaded in the browser session.
After the HTML page has been parsed, it must be “cleaned” in order to remove
any references to content already loaded in the session that is not permitted according
to the rule set. This could occur, for instance, if an HTML page is loaded that contains
an <iframe> tag that references an additional HTML source. The page loaded in the
<iframe> could reference elements that were already loaded by it’s containing page.
Thus, the HTMLCleaner component scans the code and compares it to already identified
objects for the given tabId in the MimeIdentifier.sqlite database. If accessing any
of the objects already loaded would constitute a violation of the rule set, the HTML is
modified by replacing the object reference with an empty string before it is passed to
the original listener.
Items that are not HTML are evaluated by submitting their URL and tabId to
the MimeHTMLMapper. If an HTML object has already been parsed and through it’s
comparison to the rule set it was determined that this URL should not be allowed, it
will be blocked by canceling the request as done in case of window targets.
Although the HTMLCleaner and MimeHTMLMapper are able to block static con-
tent, they cannot account for changes that occur due to script modification. This
is accomplished through the use of another construct, the MimeMutationManager. A
MimeMutationManager is attached to every browser tab and receives notifications on

26
updates to the DOM through a DOM mutation observer [21]. A MimeMutationManager
works in conjunction with the MimeHTMLMapper to keep the tool’s internal mapping of
HTML elements consistent with the displayed page. Whenever tags are added, deleted,
or modified, any resulting HTML fragments from these operations are captured by a
MimeMutationManager and sent to the MimeHTMLMapper to update its internal mapping.
The MimeMutationManager also blocks changes that violate rules by substituting the
object reference with an empty string.
3.3 MIME Identification and HTML Parsing
The final set of modules in the tool handle the identification of objects and the
parsing of HTML. These tasks are accomplished through the use of several open source
Java projects integrated with the extension using LiveConnect [19]. LiveConnect is a
package that brokers communication between Java and JavaScript code and has been
included in versions of Java since 1.6.0.12. The MIME Identifier tool uses this technique
to allow the JavaScript-based extension to interact with a Java module. The Java then
utilizes open source utilities for parsing and MIME identification.
The identification component is written as a series of filters, each of which scans
an incoming object and returns a type if one can be determined. The primary tool in
this process is the DROIDS application or Digital Record Object IDentification. This
tool was developed by the National Archives of the United Kingdom to recognize dig-
ital media files by utilizing advanced digital signature matching techniques [25]. As
DROIDS was developed to be a stand alone application, the source code was reconsti-
tuted to fit into the MIME Identifier framework. DROIDS is limited in that it can only

27
Channel Proxy
File
IsHTML?
Eval WinRules
HTMLCleaner
MimeMutationManager
File Yes
NoPass
Pass
Fail
HTML Parser
No
Yes
HTML
ParsedTags
File
HTTP/HTTPS Cache
HTML
Browser TabWindow
No ID/Mult IDs
ID
ModHTML MimeHTMLManager
Context Eval
MimeHTMLMapperTag Mapping
IsTargetWin?
HTMLFIle
MIME Identifier
Fail
Block
Block
Block
Fig. 3.2 The stages of a file’s evaluation
recognize binary formats. Thus other filters were constructed that contain recognizers
for text based objects. These include Apache Tika for HTML [11], Mozilla Rhino for
JavaScript [22], and CSSParser for CSS [26]. The aggregation of these tools provides an
effective mechanism for file identification. An additional utility provided by this com-
ponent is the ability to parse HTML text. This capability is used in the evaluation of
HTML through the use of a parsing utility called JSoup [15]. JSoup parses both full
text and HTML fragments using various configurations to match the parsing output of
several different browsers. This project utilizes the Mozilla setting in JSoup to emulate
Firefox’s parsing behavior.
Comprised of all of these described functional units, the MIME Detector tool is
able to add a potentially valuable set of interactions to the Firefox browser. In Chapter
4, we will evaluate the effectiveness of this framework in detecting and filtering browser

28
content. A flowchart depicting a file’s evaluation through the tool’s back end components
is shown in Figure 3.2.

29
Chapter 4
Evaluation
The accuracy and effectiveness of MIME Detector was evaluated through a series
of test suites. The first assessment examined the tool’s rule set enforcement capabilities
to allow or deny content from loading. A test was created for each of the items listed in
the tag drop down menu shown in Table 3.1. These tests ensure that all of the contexts
under evaluation are properly secured by the tool. Next, we analyzed the tool’s MIME
detection abilities against each of the camouflaged MIME types mentioned in Chapter 1:
the GIFAR attack, the “chameleon” JavaScript based attack, and the prepended Flash
movie to ZIP file attack. These tests compare our tool’s MIME detection abilities against
attacks that have proven to be operative against standard browsers. The final experiment
was to visit each of the top 100 frequently viewed websites in the United States as
reported by Alexa, Inc [3]. This test examined the tool’s ability to identify MIME types
commonly encountered on the Internet and measured the overhead incurred during the
tool’s use.
4.1 Rule Set Tests
The rule set test was constructed by assembling a group of sample websites avail-
able through a local Apache 2.4.3 HTTP server. Each of these test sites were used to
evaluate one of the tags monitored by the tool. A rule set was created for each one

30
such that blocking and allowing of an element referenced by the tag was exercised. The
results of these tests are shown in Table 4.1.
Tests 1-13 pertained to loading an object inside of a tag and allowing or denying
this operation. All of these operations were successful except for testing the <source>
and <applet> tags. Adding a rule that caused the browser to deny loading an object
in the <source> tag caused the browser to crash. This experiment was repeated with
a variety of MIME types each of which led to the same result. It is possible that the
inability to stop content from loading in the <source> tag is a failing caused by the
methods used in the browser interaction. However, the <source> tag is a new element
added to the HTML5 standard that is not yet supported in all browsers [2]. Therefore, it
may also the the case that this is an early implementation of <source> that will become
more stable in future releases of Firefox.
The tool’s failure on the <applet> test was due to the Java class file still being
loaded and executed even though a rule specified that it should be blocked. We hypoth-
esize that this deficiency is caused by the request for the class file being made through
the invoked JVM and not the browser. This is based on our observations using the
Tamper Data add-on. Tamper Data is a tool that traces all the incoming and outgoing
HTTP requests made from the browser [16]. We ran the <applet> test with Tamper
Data invoked and verified that there was no request or response for the class file. All
of the other tests in our test suite produce the expected requests and responses. This
brings to light a noteworthy caveat that was not previously considered — some plugins
have the ability to make requests outside of the browser framework.

31
TestNo.
Context Description Result
1 bodyTested allow and deny actions on a GIF back-ground image.
passed
2 embedTested allow and deny actions an embeddedWAV music file.
passed
3 imageTested allow and deny actions on a JPEG im-age.
passed
4 frameTested allow and deny actions for a PDF docu-ment loaded in a frame.
passed
5 iframeTested allow and deny actions and an HTMLdocument.
passed
6 objectTested allow and deny actions for a Shockwavefile.
passed
7 tableTested allow and deny actions for a JPEG im-age.
passed
8 scriptTested allow and deny actions for a JavaScriptfile.
passed
9 link Tested allow and deny actions for a CSS file. passed
10 window Tested allow and deny actions for a PDF file. passed
11 “*” Tested allowing and blocking all page content. passed
12 appletTested allow and deny actions for a Java classfile.
failed
13 sourceTested allow and deny actions for a sourcenested in an audio tag for a WAV file.
failed
14DOMchange
Tested allow and deny actions for a JavaScriptoperation to change an image element in theDOM.
passed
15DOMinsert
Tested allow and deny options for a JavaScriptoperation to insert an image into the DOM.
passed
16iframechange
Tested allow and deny actions for a JavaScriptoperation to load and iframe element with aGIF that already exists on the main page
passed
17HTTPS
loadTesting loading page over HTTPS passed
Table 4.1 The result of the tag test evaluation.

32
Tests 14-17 were created to ensure all aspects of the tool’s functionality were eval-
uated. The “DOM change” and “DOM insert” tests rely on the MimeMutationManager
to correctly monitor and changes made to the DOM. The “iframe change” was included
to assess the HTMLCleaner’s role in removing references contained in incoming HTML
that would cause a rule violation. Finally, the “HTTPS load” test ensures that the tool
is able to evaluate content delivered on encrypted connections.
4.2 MIME Identification Tests
The MIME Identification tests were administered using a test suite of sample
websites that contained references to files modeled after the hidden content attacks
discussed in Chapter 1. Although none of these objects were designed to perform any
malicious action, their construction is consistent with the methods described by their
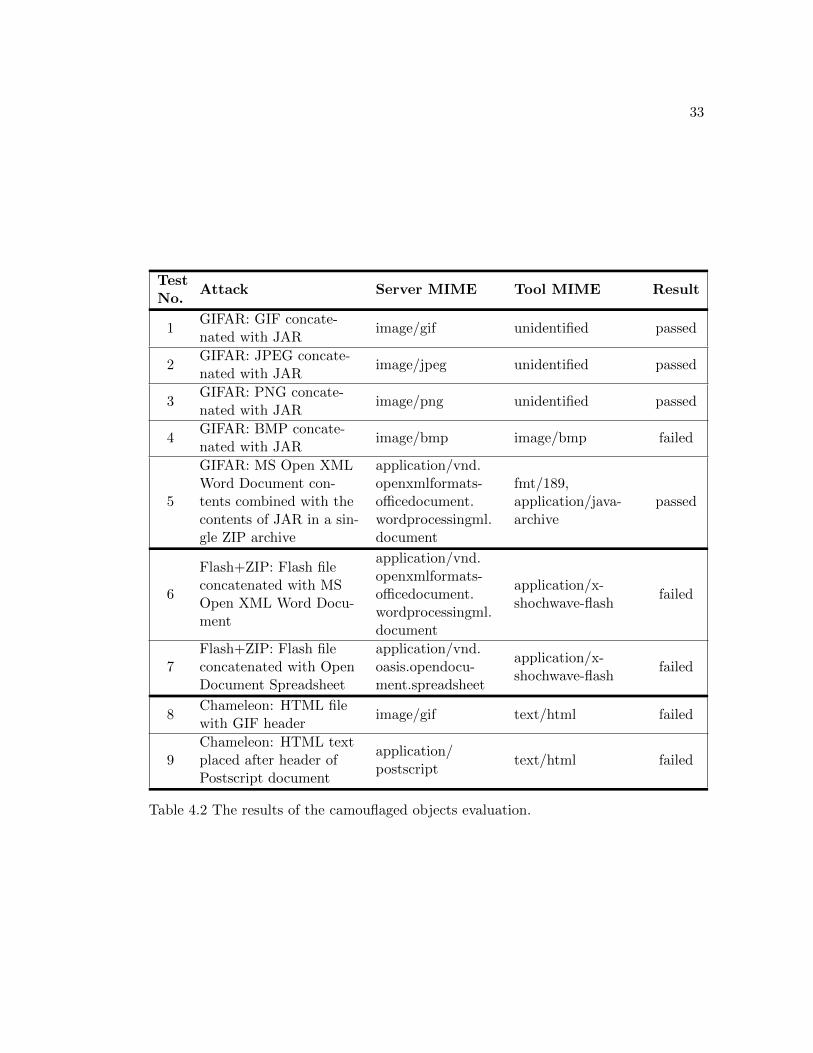
respective originators. The results of these tests are shown in Table 4.2.
Tests 1-5 were all examples of the the GIFAR attacks. The tool was successful
in recognizing all the GIFAR varieties except for test 5. Each of the successful image
tests featured a disproportionately small JAR size relative to the image. The images
tested were all over 900K and the JAR only contained one small file, leaving it at less
than 1K. The ability to detect the small JAR inside the much larger file was a notable
achievement of the tool. The tool was unable to identify the JAR hidden within the
BMP image. These images have a standardized format similar to GIFs or JPEGs; we
were unable to determine a plausible explanation as to why the tool would struggle with
this file type. The identification of the GIFAR created by combining a Microsoft Open
33
TestNo.
Attack Server MIME Tool MIME Result
1GIFAR: GIF concate-nated with JAR
image/gif unidentified passed
2GIFAR: JPEG concate-nated with JAR
image/jpeg unidentified passed
3GIFAR: PNG concate-nated with JAR
image/png unidentified passed
4GIFAR: BMP concate-nated with JAR
image/bmp image/bmp failed
5
GIFAR: MS Open XMLWord Document con-tents combined with thecontents of JAR in a sin-gle ZIP archive
application/vnd.openxmlformats-officedocument.wordprocessingml.document
fmt/189,application/java-archive
passed
6
Flash+ZIP: Flash fileconcatenated with MSOpen XML Word Docu-ment
application/vnd.openxmlformats-officedocument.wordprocessingml.document
application/x-shochwave-flash
failed
7Flash+ZIP: Flash fileconcatenated with OpenDocument Spreadsheet
application/vnd.oasis.opendocu-ment.spreadsheet
application/x-shochwave-flash
failed
8Chameleon: HTML filewith GIF header
image/gif text/html failed
9Chameleon: HTML textplaced after header ofPostscript document
application/postscript
text/html failed
Table 4.2 The results of the camouflaged objects evaluation.

34
Office XML document and a JAR was also a strong achievement. Both the document
and the JAR’s formats were correctly distinguished.
Tests 6 and 7 were both cases of Flash and ZIP based attacks. In each case,
the files were correctly classified as Flash, but the ZIP identity was not recognized. As
Flash has the ability to execute scripts, it is of a higher precedence and its recognition
is therefore more pertinent than ZIP formats. Nonetheless, these tests failed as the tool
did not label the created file as either undefined or both ZIP and Flash.
Tests 8 and 9 exemplified the “chameleon” attack of HTML tags hidden in files.
In both cases only HTML was recognized. Thus, as in the case of the Flash and ZIP
tests, only one of the combined formats could be identified. The tool failed these tests
as these results do not demonstrate sufficient detection capabilities.
4.3 Web Browsing Test
The final experiment was to perform a general browsing of the top 100 most pop-
ular websites viewed in the United States as per Alexa, Inc [3]. This procedure was used
to analyze MIME Detector’s ability to recognize objects commonly encountered while
browsing the Internet. Additionally, metrics were collected to compare the overhead as-
sociated with the extension’s operations to a browser session where the tool is disabled.
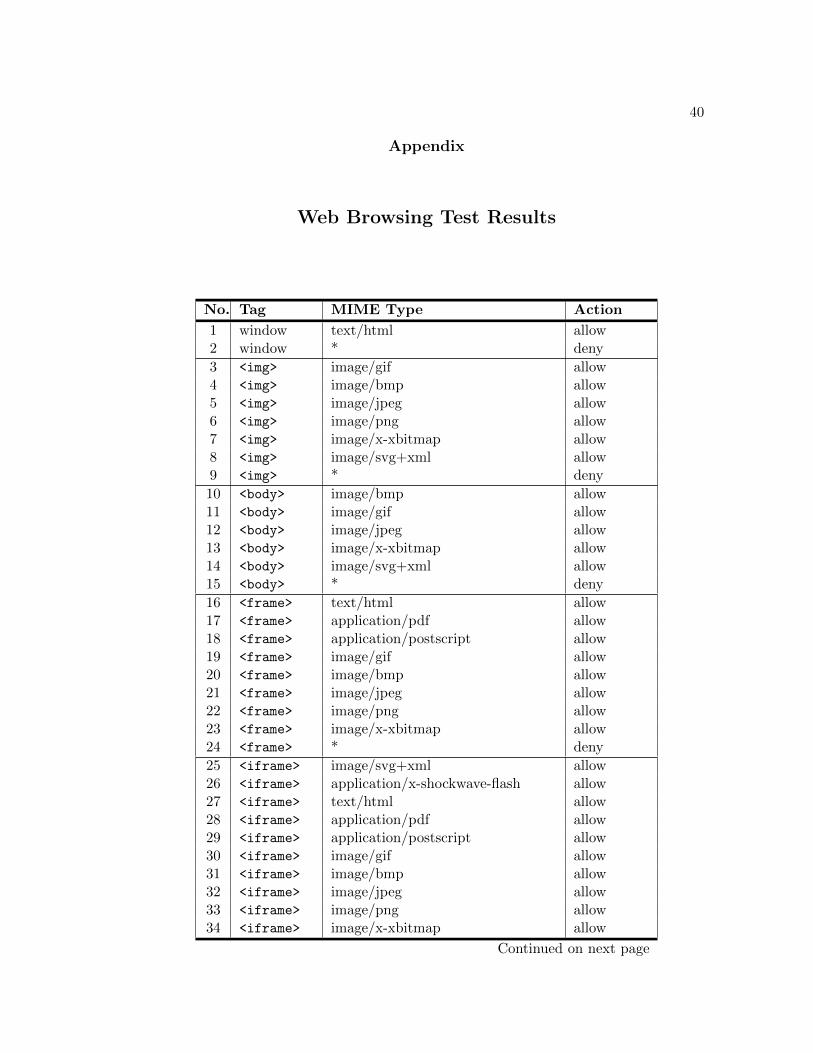
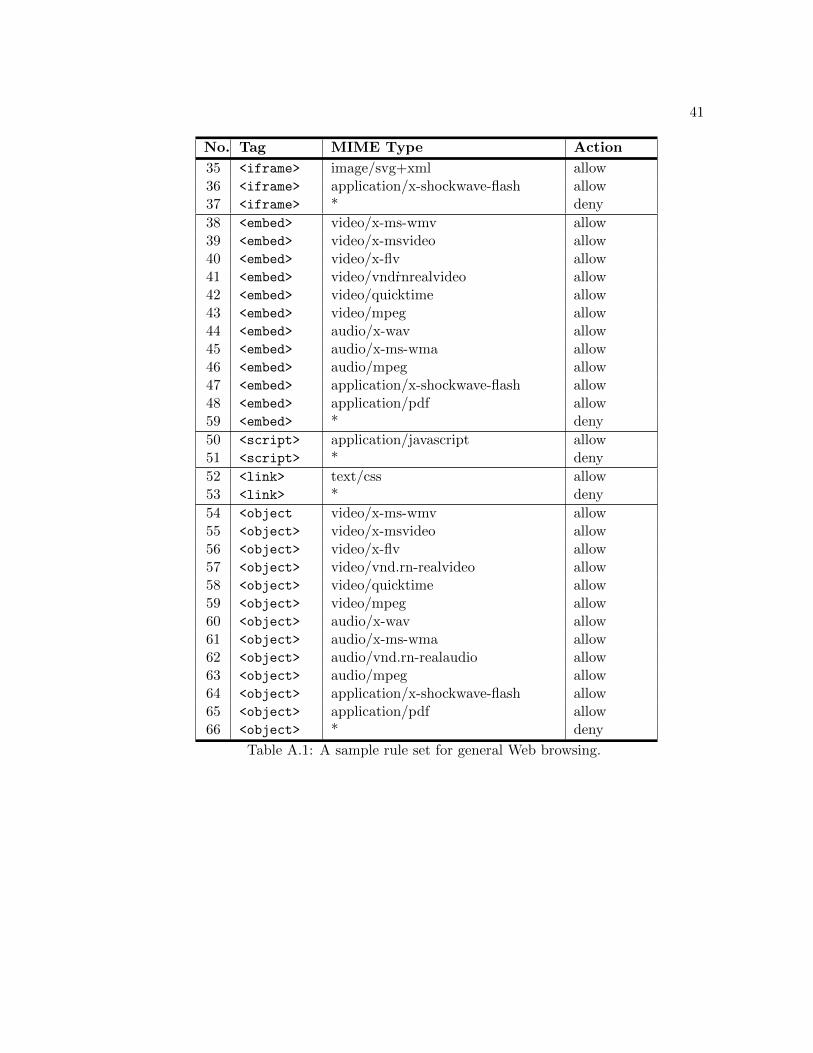
The load times were measured using the Lori browser extension [17]. The browsing tests
were facilitated through the use of a sample rule set listed in Table A.1. This rule set is
expected to be suitable for common browser usage. The <applet> and <source> tags
were omitted from the rules as these proved to be ineffective in the testing discussed in
Section 4.1. The results of these tests can be viewed in Appendix A.

35
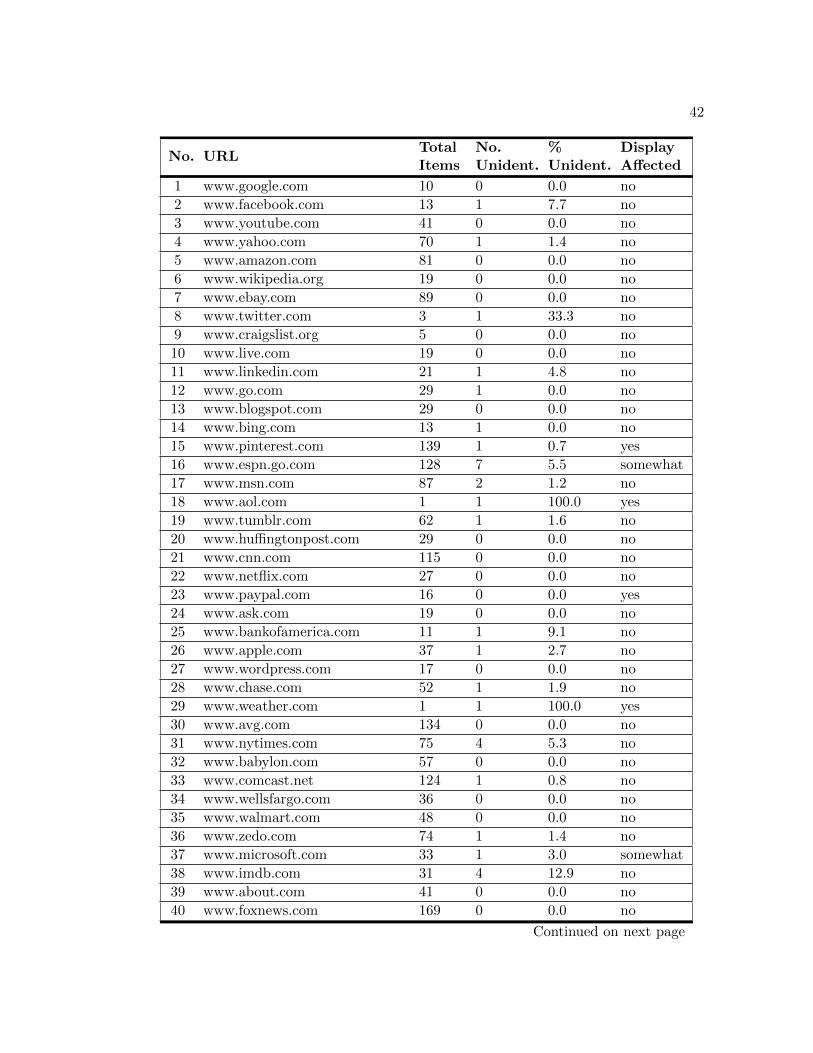
The first browsing exercise measured MIME Detector’s ability to determine a
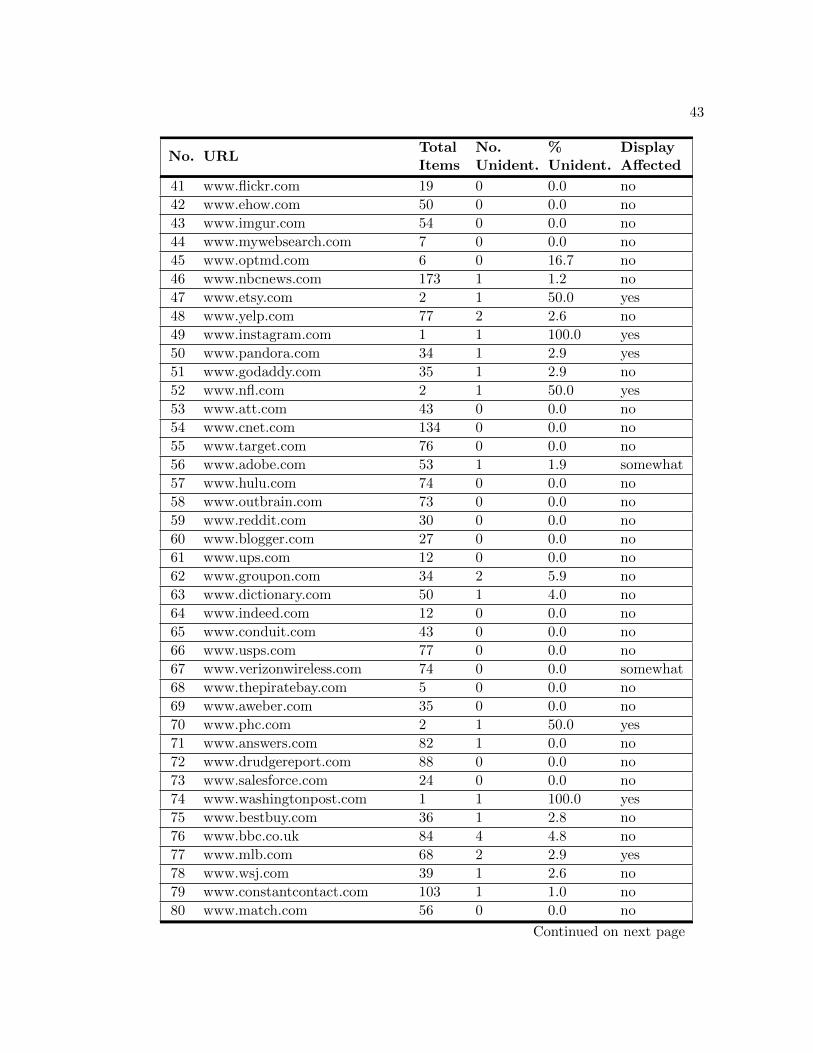
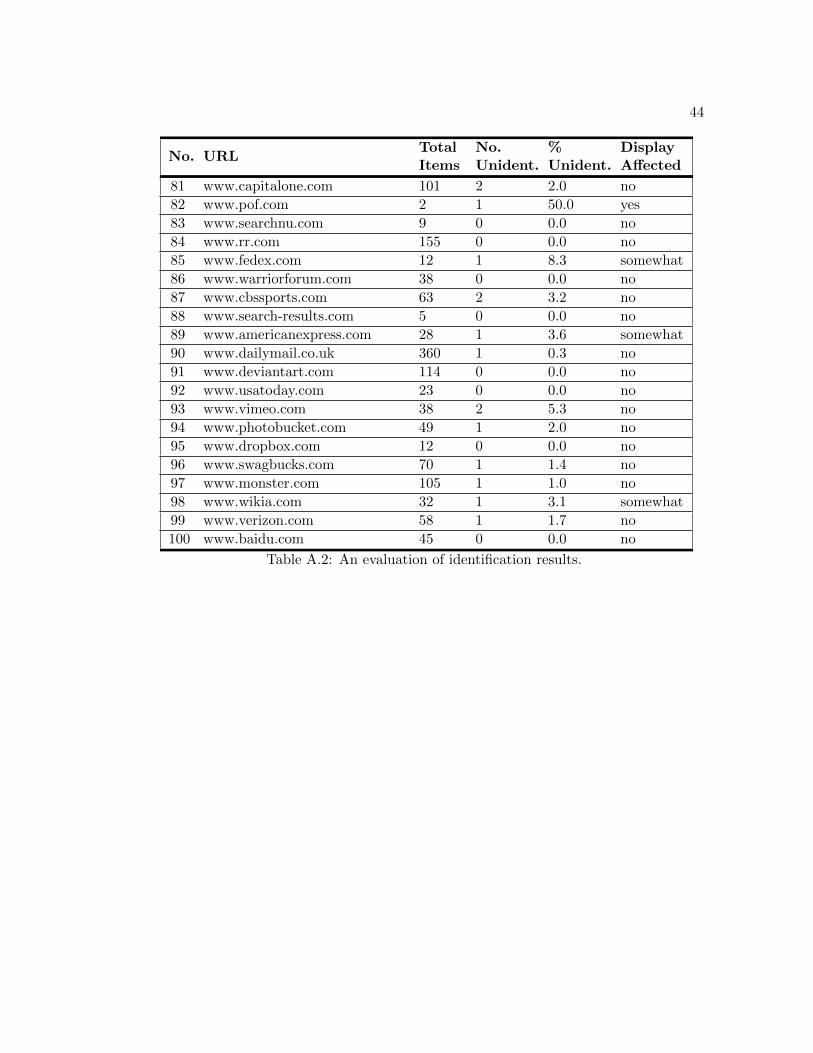
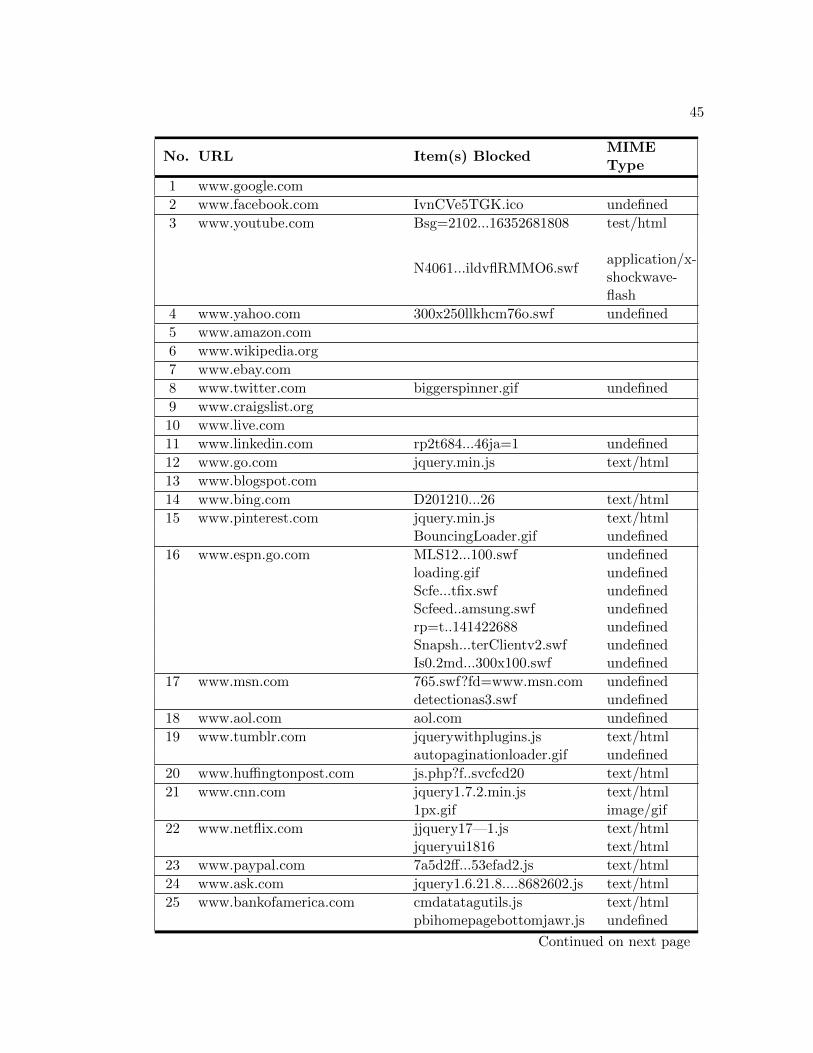
MIME type for all encountered objects. Table A.2 displays the total number of items
evaluated for each URL, the number of items not able to be identified, and the overall
percentage of unrecognized objects. The “Display Affected” column indicates if there
was an observed deviation from the site’s standard functionally or appearance when the
tool was enabled. Overall, MIME Detector did quite well in determining a MIME type
for each of the files examined. The comprehensive percentage of files unidentified by the
tool was only 1.4 percent.
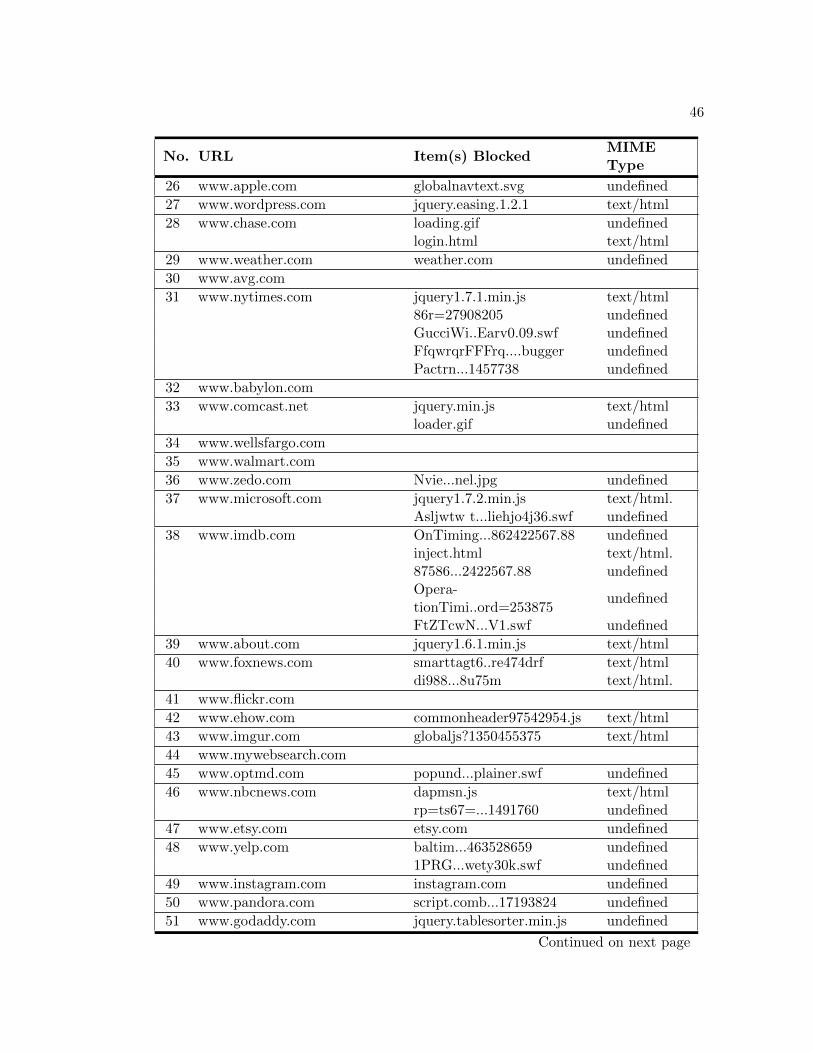
Nonetheless, these detection abilities must be considered in conjunction with the
items blocked during the browser session presented in Table A.3. The recorded data
reveals several instances of items being blocked due to misidentification. In particular,
variations of the JQuery JavaScript library were frequently misidentified as being of
MIME type “text/html”. Additionally, the tool was unable to identify numerous HTML
files. Based on these observations, we can conclude that MIME Detector has difficulty
in some instances classifying text based elements. In regards to binary formats, the tool
was frequently unable to identify Shockwave objects. It is possible that these files were
part of a streaming Shockwave video. A noted deficiency of the binary recognition filter
is it’s inability to recognize streaming content.
Accompanying the identification experiment were load time measurements taken
during the browser session. Following the tool’s evaluation, a new browser session was
initiated and each of the top 100 sites were again viewed with the tool disabled. The
browser cache was cleared between sessions to provide a suitable load time comparison.
These metrics are listed in Table A.4. The percent increase column, labeled“% Incr.”,

36
contains the value “N/A” for sites where the tool affected the display. These load times
were excluded from the comparison because in some cases, not all of the content from
affected sites was loaded. The data from these sessions show that the extension slows
down page loads substantially. With the tool enabled, the cumulative load times of
sites increased 408.5 percent. Consequently, the speed of our proposed identification
framework would have to be substantially increased before this type of protection could
be offered as a common practice in secure browsing.
The undertaken analysis yielded mixed results for the MIME Detector framework.
While in most cases the tool was able to provide adequate protection and correct identi-
fication, there were also tests that revealed marked deficiencies. The policy enforcement
mediation provided by the tool failed in certain contexts. Additionally, for some web-
sites, components were unable to be identified or incorrectly determined, which adversely
affected the page’s appearance or functionally. Furthermore, page load times were sig-
nificantly inhibited when the tool was enabled. Such limitations would prevent the tool
from being adopted for mainstream usage. Regardless of these detriments, we consider
this approach to be a promising step towards providing users with a greater level of
control in their interactions with Web based content.

37
Chapter 5
Conclusions
The evaluation of MIME Detector revealed the capabilities and limitations of our
approach. The tool was able to identify the majority of objects correctly, but struggled
in recognizing some text based MIME types and streaming media. The defined content
policies were correctly enforced in most instances but can be circumvented by some plu-
gins. Taking these results into consideration, we offer an assessment of this architecture
and a road map for potential improvements.
The speed and accuracy of object identification could be enhanced by using a
single classification component. The multi-stage approach that we developed relied on
several integrated utilities as there was no single tool available that could provide this
functionality. Passing data through each of these filters proved to be time consuming and
the employed identification techniques varied with each tool. Furthermore, an effective
identification component should be designed specifically for examining data received
from the Internet — including streaming content. The identification tools used in MIME
Detector were adapted to fill this role. These tools were intended to be used on files
stored on a local file system. It was not surprising that JavaScript and HTML were
frequently identified incorrectly. Both of these formats have many variations and can be
used by websites even if not all of the contained syntax is correct.

38
The enforcement of content policies could be strengthened by integrating compo-
nents as a lower level. This would allow for tighter control over plugins. As a model for
this improvement, we can look to the OP browser [13]. OP enforces security policies for
plugins through a browser kernel. Each plugin invocation runs as a separate process with
an enforced security label assigned by the kernel. This label is used to make decisions
pertaining to the plugin’s interaction with the browser and the local machine. A browser
kernel could be a good addition to our security model. In this scenario, labels would be
assigned to loading objects based on the item’s identity and the context of it’s use. This
information could then be used by the kernel to govern the components of the browser
with which the object can interact.
Policy enforcement would also benefit from a refined definition of an object’s
context. The only contexts evaluated were the browser window and HTML tags. The
tool does not consider CSS, which can be also be used to reference objects. Also, more
advanced rules pertaining to nested tags may be of benefit. The interface used to define
a context policy was appropriate for the purposes of our testing but impractical for users.
A security mechanism that must be actively maintained by users is likely not well-suited
for mainstream use.
Regardless of MIME Detector’s features and capabilities, browser content moni-
toring will always be a reactive measure necessitated by the lack of restrictions specified
by Web applications. The optimal solution may be a comprehensive policy involving
both clients and servers. Perhaps the best example of this approach is Content Se-
cure Policies introduced by Stamm et al [27]. Under this model, an additional header,
X-Content-Security-Policy, is add to HTTP responses. This header denotes the

39
trusted domains that may be referenced by the “src” attributes for each type of HTML
tag. The policy specified by the server is then enforced by the receiving client. This
model could be extended to a more fine-grained specification that lists the plugins or
scripting execution abilities that should be available for each item sent. This would
ensure that an object is only used in the manner intended by content providers. Until
such a time when more stringent content policies are commonly enforced, users will rely
on utilities such as MIME Detector to help safeguard their browsing sessions.
40
Appendix
Web Browsing Test Results
No. Tag MIME Type Action
1 window text/html allow2 window * deny
3 <img> image/gif allow4 <img> image/bmp allow5 <img> image/jpeg allow6 <img> image/png allow7 <img> image/x-xbitmap allow8 <img> image/svg+xml allow9 <img> * deny
10 <body> image/bmp allow11 <body> image/gif allow12 <body> image/jpeg allow13 <body> image/x-xbitmap allow14 <body> image/svg+xml allow15 <body> * deny
16 <frame> text/html allow17 <frame> application/pdf allow18 <frame> application/postscript allow19 <frame> image/gif allow20 <frame> image/bmp allow21 <frame> image/jpeg allow22 <frame> image/png allow23 <frame> image/x-xbitmap allow24 <frame> * deny
25 <iframe> image/svg+xml allow26 <iframe> application/x-shockwave-flash allow27 <iframe> text/html allow28 <iframe> application/pdf allow29 <iframe> application/postscript allow30 <iframe> image/gif allow31 <iframe> image/bmp allow32 <iframe> image/jpeg allow33 <iframe> image/png allow34 <iframe> image/x-xbitmap allow
Continued on next page
41
No. Tag MIME Type Action
35 <iframe> image/svg+xml allow36 <iframe> application/x-shockwave-flash allow37 <iframe> * deny
38 <embed> video/x-ms-wmv allow39 <embed> video/x-msvideo allow40 <embed> video/x-flv allow41 <embed> video/vndrnrealvideo allow42 <embed> video/quicktime allow43 <embed> video/mpeg allow44 <embed> audio/x-wav allow45 <embed> audio/x-ms-wma allow46 <embed> audio/mpeg allow47 <embed> application/x-shockwave-flash allow48 <embed> application/pdf allow59 <embed> * deny
50 <script> application/javascript allow51 <script> * deny
52 <link> text/css allow53 <link> * deny
54 <object video/x-ms-wmv allow55 <object> video/x-msvideo allow56 <object> video/x-flv allow57 <object> video/vnd.rn-realvideo allow58 <object> video/quicktime allow59 <object> video/mpeg allow60 <object> audio/x-wav allow61 <object> audio/x-ms-wma allow62 <object> audio/vnd.rn-realaudio allow63 <object> audio/mpeg allow64 <object> application/x-shockwave-flash allow65 <object> application/pdf allow66 <object> * deny
Table A.1: A sample rule set for general Web browsing.
42
No. URLTotalItems
No.Unident.
%Unident.
DisplayAffected
1 www.google.com 10 0 0.0 no
2 www.facebook.com 13 1 7.7 no
3 www.youtube.com 41 0 0.0 no
4 www.yahoo.com 70 1 1.4 no
5 www.amazon.com 81 0 0.0 no
6 www.wikipedia.org 19 0 0.0 no
7 www.ebay.com 89 0 0.0 no
8 www.twitter.com 3 1 33.3 no
9 www.craigslist.org 5 0 0.0 no
10 www.live.com 19 0 0.0 no
11 www.linkedin.com 21 1 4.8 no
12 www.go.com 29 1 0.0 no
13 www.blogspot.com 29 0 0.0 no
14 www.bing.com 13 1 0.0 no
15 www.pinterest.com 139 1 0.7 yes
16 www.espn.go.com 128 7 5.5 somewhat
17 www.msn.com 87 2 1.2 no
18 www.aol.com 1 1 100.0 yes
19 www.tumblr.com 62 1 1.6 no
20 www.huffingtonpost.com 29 0 0.0 no
21 www.cnn.com 115 0 0.0 no
22 www.netflix.com 27 0 0.0 no
23 www.paypal.com 16 0 0.0 yes
24 www.ask.com 19 0 0.0 no
25 www.bankofamerica.com 11 1 9.1 no
26 www.apple.com 37 1 2.7 no
27 www.wordpress.com 17 0 0.0 no
28 www.chase.com 52 1 1.9 no
29 www.weather.com 1 1 100.0 yes
30 www.avg.com 134 0 0.0 no
31 www.nytimes.com 75 4 5.3 no
32 www.babylon.com 57 0 0.0 no
33 www.comcast.net 124 1 0.8 no
34 www.wellsfargo.com 36 0 0.0 no
35 www.walmart.com 48 0 0.0 no
36 www.zedo.com 74 1 1.4 no
37 www.microsoft.com 33 1 3.0 somewhat
38 www.imdb.com 31 4 12.9 no
39 www.about.com 41 0 0.0 no
40 www.foxnews.com 169 0 0.0 no
Continued on next page
43
No. URLTotalItems
No.Unident.
%Unident.
DisplayAffected
41 www.flickr.com 19 0 0.0 no
42 www.ehow.com 50 0 0.0 no
43 www.imgur.com 54 0 0.0 no
44 www.mywebsearch.com 7 0 0.0 no
45 www.optmd.com 6 0 16.7 no
46 www.nbcnews.com 173 1 1.2 no
47 www.etsy.com 2 1 50.0 yes
48 www.yelp.com 77 2 2.6 no
49 www.instagram.com 1 1 100.0 yes
50 www.pandora.com 34 1 2.9 yes
51 www.godaddy.com 35 1 2.9 no
52 www.nfl.com 2 1 50.0 yes
53 www.att.com 43 0 0.0 no
54 www.cnet.com 134 0 0.0 no
55 www.target.com 76 0 0.0 no
56 www.adobe.com 53 1 1.9 somewhat
57 www.hulu.com 74 0 0.0 no
58 www.outbrain.com 73 0 0.0 no
59 www.reddit.com 30 0 0.0 no
60 www.blogger.com 27 0 0.0 no
61 www.ups.com 12 0 0.0 no
62 www.groupon.com 34 2 5.9 no
63 www.dictionary.com 50 1 4.0 no
64 www.indeed.com 12 0 0.0 no
65 www.conduit.com 43 0 0.0 no
66 www.usps.com 77 0 0.0 no
67 www.verizonwireless.com 74 0 0.0 somewhat
68 www.thepiratebay.com 5 0 0.0 no
69 www.aweber.com 35 0 0.0 no
70 www.phc.com 2 1 50.0 yes
71 www.answers.com 82 1 0.0 no
72 www.drudgereport.com 88 0 0.0 no
73 www.salesforce.com 24 0 0.0 no
74 www.washingtonpost.com 1 1 100.0 yes
75 www.bestbuy.com 36 1 2.8 no
76 www.bbc.co.uk 84 4 4.8 no
77 www.mlb.com 68 2 2.9 yes
78 www.wsj.com 39 1 2.6 no
79 www.constantcontact.com 103 1 1.0 no
80 www.match.com 56 0 0.0 no
Continued on next page
44
No. URLTotalItems
No.Unident.
%Unident.
DisplayAffected
81 www.capitalone.com 101 2 2.0 no
82 www.pof.com 2 1 50.0 yes
83 www.searchnu.com 9 0 0.0 no
84 www.rr.com 155 0 0.0 no
85 www.fedex.com 12 1 8.3 somewhat
86 www.warriorforum.com 38 0 0.0 no
87 www.cbssports.com 63 2 3.2 no
88 www.search-results.com 5 0 0.0 no
89 www.americanexpress.com 28 1 3.6 somewhat
90 www.dailymail.co.uk 360 1 0.3 no
91 www.deviantart.com 114 0 0.0 no
92 www.usatoday.com 23 0 0.0 no
93 www.vimeo.com 38 2 5.3 no
94 www.photobucket.com 49 1 2.0 no
95 www.dropbox.com 12 0 0.0 no
96 www.swagbucks.com 70 1 1.4 no
97 www.monster.com 105 1 1.0 no
98 www.wikia.com 32 1 3.1 somewhat
99 www.verizon.com 58 1 1.7 no
100 www.baidu.com 45 0 0.0 no
Table A.2: An evaluation of identification results.
45
No. URL Item(s) BlockedMIMEType
1 www.google.com
2 www.facebook.com IvnCVe5TGK.ico undefined
3 www.youtube.com Bsg=2102...16352681808 test/html
N4061...ildvflRMMO6.swfapplication/x-shockwave-flash
4 www.yahoo.com 300x250llkhcm76o.swf undefined
5 www.amazon.com
6 www.wikipedia.org
7 www.ebay.com
8 www.twitter.com biggerspinner.gif undefined
9 www.craigslist.org
10 www.live.com
11 www.linkedin.com rp2t684...46ja=1 undefined
12 www.go.com jquery.min.js text/html
13 www.blogspot.com
14 www.bing.com D201210...26 text/html
15 www.pinterest.com jquery.min.js text/htmlBouncingLoader.gif undefined
16 www.espn.go.com MLS12...100.swf undefinedloading.gif undefinedScfe...tfix.swf undefinedScfeed..amsung.swf undefinedrp=t..141422688 undefinedSnapsh...terClientv2.swf undefinedIs0.2md...300x100.swf undefined
17 www.msn.com 765.swf?fd=www.msn.com undefineddetectionas3.swf undefined
18 www.aol.com aol.com undefined
19 www.tumblr.com jquerywithplugins.js text/htmlautopaginationloader.gif undefined
20 www.huffingtonpost.com js.php?f..svcfcd20 text/html
21 www.cnn.com jquery1.7.2.min.js text/html1px.gif image/gif
22 www.netflix.com jjquery17—1.js text/htmljqueryui1816 text/html
23 www.paypal.com 7a5d2ff...53efad2.js text/html
24 www.ask.com jquery1.6.21.8....8682602.js text/html
25 www.bankofamerica.com cmdatatagutils.js text/htmlpbihomepagebottomjawr.js undefined
Continued on next page
46
No. URL Item(s) BlockedMIMEType
26 www.apple.com globalnavtext.svg undefined
27 www.wordpress.com jquery.easing.1.2.1 text/html
28 www.chase.com loading.gif undefinedlogin.html text/html
29 www.weather.com weather.com undefined
30 www.avg.com
31 www.nytimes.com jquery1.7.1.min.js text/html86r=27908205 undefinedGucciWi..Earv0.09.swf undefinedFfqwrqrFFFrq....bugger undefinedPactrn...1457738 undefined
32 www.babylon.com
33 www.comcast.net jquery.min.js text/htmlloader.gif undefined
34 www.wellsfargo.com
35 www.walmart.com
36 www.zedo.com Nvie...nel.jpg undefined
37 www.microsoft.com jquery1.7.2.min.js text/html.Asljwtw t...liehjo4j36.swf undefined
38 www.imdb.com OnTiming...862422567.88 undefinedinject.html text/html.87586...2422567.88 undefinedOpera-tionTimi..ord=253875
undefined
FtZTcwN...V1.swf undefined
39 www.about.com jquery1.6.1.min.js text/html
40 www.foxnews.com smarttagt6..re474drf text/htmldi988...8u75m text/html.
41 www.flickr.com
42 www.ehow.com commonheader97542954.js text/html
43 www.imgur.com globaljs?1350455375 text/html
44 www.mywebsearch.com
45 www.optmd.com popund...plainer.swf undefined
46 www.nbcnews.com dapmsn.js text/htmlrp=ts67=...1491760 undefined
47 www.etsy.com etsy.com undefined
48 www.yelp.com baltim...463528659 undefined1PRG...wety30k.swf undefined
49 www.instagram.com instagram.com undefined
50 www.pandora.com script.comb...17193824 undefined
51 www.godaddy.com jquery.tablesorter.min.js undefined
Continued on next page
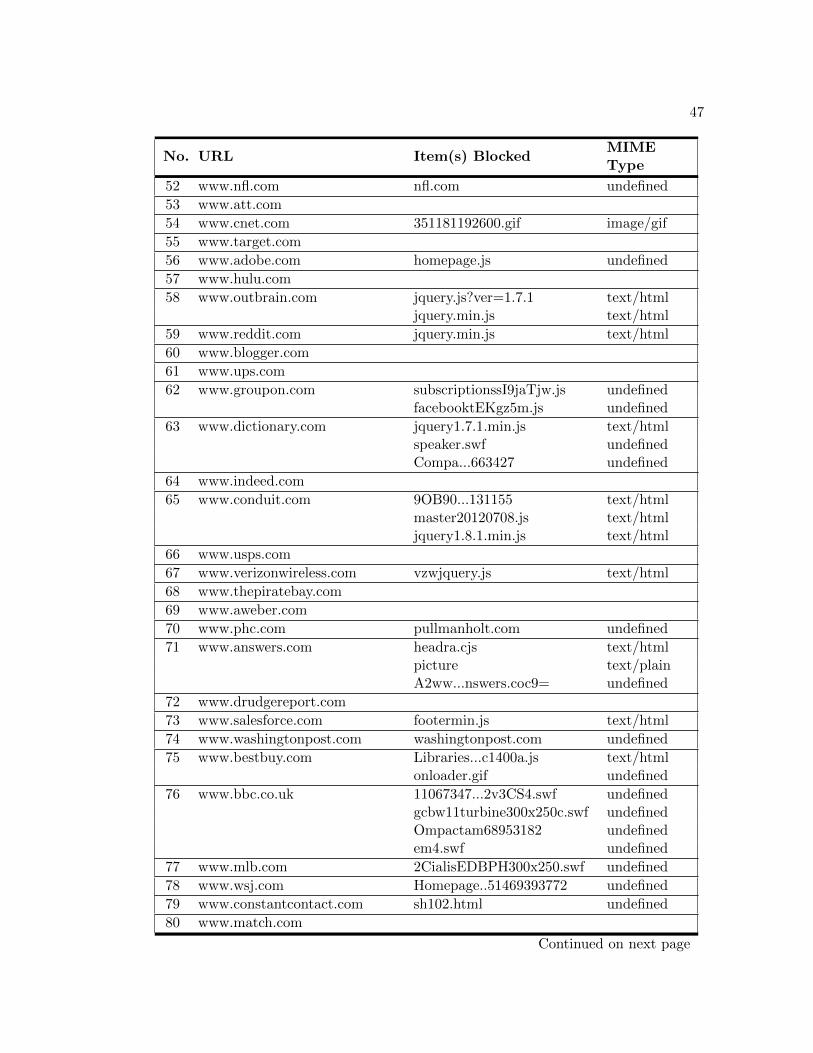
47
No. URL Item(s) BlockedMIMEType
52 www.nfl.com nfl.com undefined
53 www.att.com
54 www.cnet.com 351181192600.gif image/gif
55 www.target.com
56 www.adobe.com homepage.js undefined
57 www.hulu.com
58 www.outbrain.com jquery.js?ver=1.7.1 text/htmljquery.min.js text/html
59 www.reddit.com jquery.min.js text/html
60 www.blogger.com
61 www.ups.com
62 www.groupon.com subscriptionssI9jaTjw.js undefinedfacebooktEKgz5m.js undefined
63 www.dictionary.com jquery1.7.1.min.js text/htmlspeaker.swf undefinedCompa...663427 undefined
64 www.indeed.com
65 www.conduit.com 9OB90...131155 text/htmlmaster20120708.js text/htmljquery1.8.1.min.js text/html
66 www.usps.com
67 www.verizonwireless.com vzwjquery.js text/html
68 www.thepiratebay.com
69 www.aweber.com
70 www.phc.com pullmanholt.com undefined
71 www.answers.com headra.cjs text/htmlpicture text/plainA2ww...nswers.coc9= undefined
72 www.drudgereport.com
73 www.salesforce.com footermin.js text/html
74 www.washingtonpost.com washingtonpost.com undefined
75 www.bestbuy.com Libraries...c1400a.js text/htmlonloader.gif undefined
76 www.bbc.co.uk 11067347...2v3CS4.swf undefinedgcbw11turbine300x250c.swf undefinedOmpactam68953182 undefinedem4.swf undefined
77 www.mlb.com 2CialisEDBPH300x250.swf undefined
78 www.wsj.com Homepage..51469393772 undefined
79 www.constantcontact.com sh102.html undefined
80 www.match.com
Continued on next page
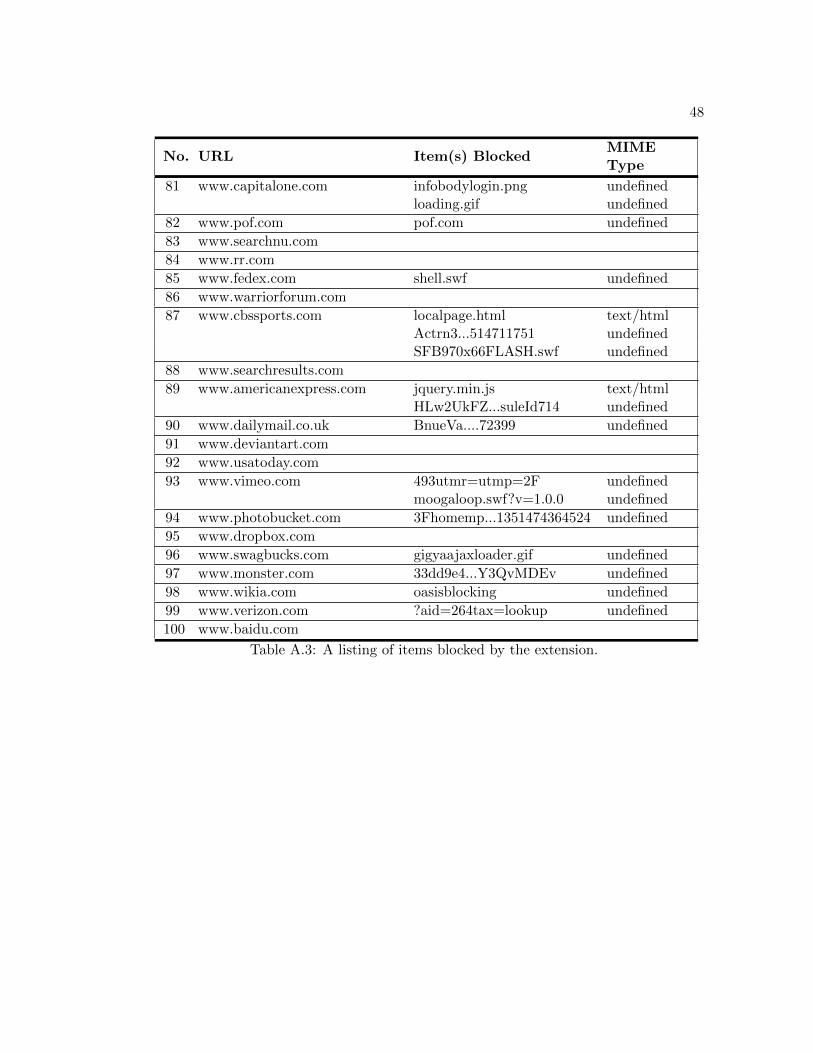
48
No. URL Item(s) BlockedMIMEType
81 www.capitalone.com infobodylogin.png undefinedloading.gif undefined
82 www.pof.com pof.com undefined
83 www.searchnu.com
84 www.rr.com
85 www.fedex.com shell.swf undefined
86 www.warriorforum.com
87 www.cbssports.com localpage.html text/htmlActrn3...514711751 undefinedSFB970x66FLASH.swf undefined
88 www.searchresults.com
89 www.americanexpress.com jquery.min.js text/htmlHLw2UkFZ...suleId714 undefined
90 www.dailymail.co.uk BnueVa....72399 undefined
91 www.deviantart.com
92 www.usatoday.com
93 www.vimeo.com 493utmr=utmp=2F undefinedmoogaloop.swf?v=1.0.0 undefined
94 www.photobucket.com 3Fhomemp...1351474364524 undefined
95 www.dropbox.com
96 www.swagbucks.com gigyaajaxloader.gif undefined
97 www.monster.com 33dd9e4...Y3QvMDEv undefined
98 www.wikia.com oasisblocking undefined
99 www.verizon.com ?aid=264tax=lookup undefined
100 www.baidu.com
Table A.3: A listing of items blocked by the extension.
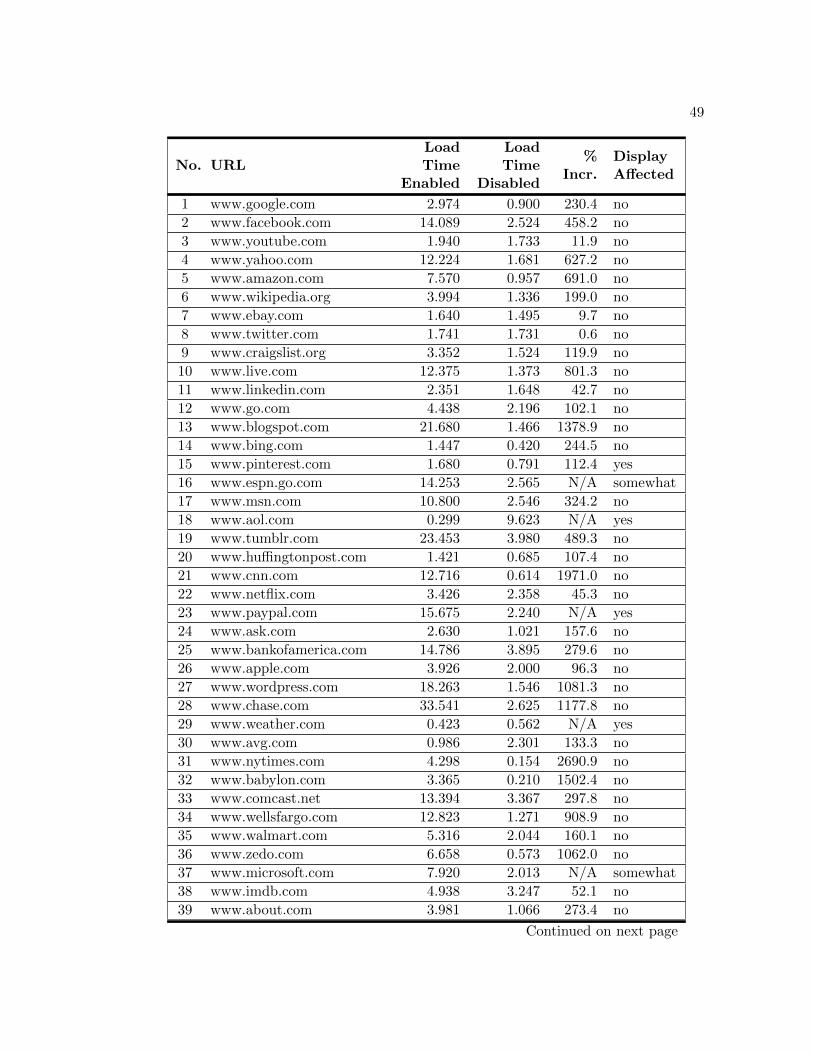
49
No. URLLoadTime
Enabled
LoadTime
Disabled
%Incr.
DisplayAffected
1 www.google.com 2.974 0.900 230.4 no
2 www.facebook.com 14.089 2.524 458.2 no
3 www.youtube.com 1.940 1.733 11.9 no
4 www.yahoo.com 12.224 1.681 627.2 no
5 www.amazon.com 7.570 0.957 691.0 no
6 www.wikipedia.org 3.994 1.336 199.0 no
7 www.ebay.com 1.640 1.495 9.7 no
8 www.twitter.com 1.741 1.731 0.6 no
9 www.craigslist.org 3.352 1.524 119.9 no
10 www.live.com 12.375 1.373 801.3 no
11 www.linkedin.com 2.351 1.648 42.7 no
12 www.go.com 4.438 2.196 102.1 no
13 www.blogspot.com 21.680 1.466 1378.9 no
14 www.bing.com 1.447 0.420 244.5 no
15 www.pinterest.com 1.680 0.791 112.4 yes
16 www.espn.go.com 14.253 2.565 N/A somewhat
17 www.msn.com 10.800 2.546 324.2 no
18 www.aol.com 0.299 9.623 N/A yes
19 www.tumblr.com 23.453 3.980 489.3 no
20 www.huffingtonpost.com 1.421 0.685 107.4 no
21 www.cnn.com 12.716 0.614 1971.0 no
22 www.netflix.com 3.426 2.358 45.3 no
23 www.paypal.com 15.675 2.240 N/A yes
24 www.ask.com 2.630 1.021 157.6 no
25 www.bankofamerica.com 14.786 3.895 279.6 no
26 www.apple.com 3.926 2.000 96.3 no
27 www.wordpress.com 18.263 1.546 1081.3 no
28 www.chase.com 33.541 2.625 1177.8 no
29 www.weather.com 0.423 0.562 N/A yes
30 www.avg.com 0.986 2.301 133.3 no
31 www.nytimes.com 4.298 0.154 2690.9 no
32 www.babylon.com 3.365 0.210 1502.4 no
33 www.comcast.net 13.394 3.367 297.8 no
34 www.wellsfargo.com 12.823 1.271 908.9 no
35 www.walmart.com 5.316 2.044 160.1 no
36 www.zedo.com 6.658 0.573 1062.0 no
37 www.microsoft.com 7.920 2.013 N/A somewhat
38 www.imdb.com 4.938 3.247 52.1 no
39 www.about.com 3.981 1.066 273.4 no
Continued on next page
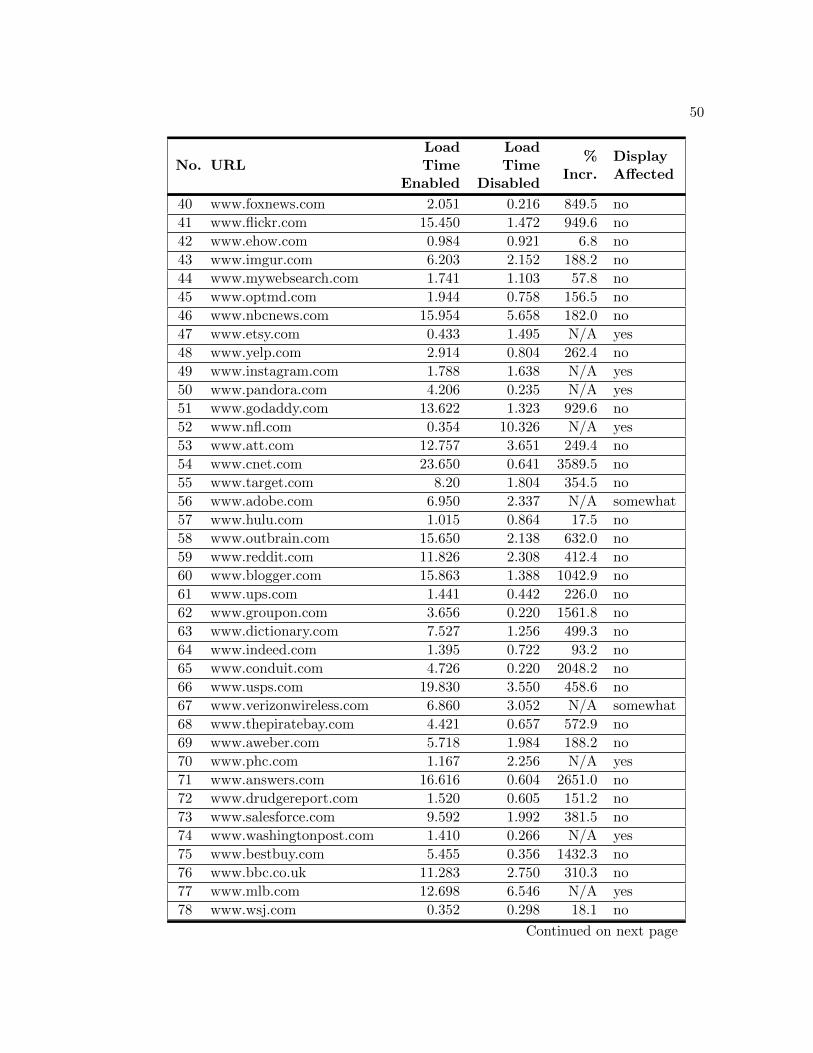
50
No. URLLoadTime
Enabled
LoadTime
Disabled
%Incr.
DisplayAffected
40 www.foxnews.com 2.051 0.216 849.5 no
41 www.flickr.com 15.450 1.472 949.6 no
42 www.ehow.com 0.984 0.921 6.8 no
43 www.imgur.com 6.203 2.152 188.2 no
44 www.mywebsearch.com 1.741 1.103 57.8 no
45 www.optmd.com 1.944 0.758 156.5 no
46 www.nbcnews.com 15.954 5.658 182.0 no
47 www.etsy.com 0.433 1.495 N/A yes
48 www.yelp.com 2.914 0.804 262.4 no
49 www.instagram.com 1.788 1.638 N/A yes
50 www.pandora.com 4.206 0.235 N/A yes
51 www.godaddy.com 13.622 1.323 929.6 no
52 www.nfl.com 0.354 10.326 N/A yes
53 www.att.com 12.757 3.651 249.4 no
54 www.cnet.com 23.650 0.641 3589.5 no
55 www.target.com 8.20 1.804 354.5 no
56 www.adobe.com 6.950 2.337 N/A somewhat
57 www.hulu.com 1.015 0.864 17.5 no
58 www.outbrain.com 15.650 2.138 632.0 no
59 www.reddit.com 11.826 2.308 412.4 no
60 www.blogger.com 15.863 1.388 1042.9 no
61 www.ups.com 1.441 0.442 226.0 no
62 www.groupon.com 3.656 0.220 1561.8 no
63 www.dictionary.com 7.527 1.256 499.3 no
64 www.indeed.com 1.395 0.722 93.2 no
65 www.conduit.com 4.726 0.220 2048.2 no
66 www.usps.com 19.830 3.550 458.6 no
67 www.verizonwireless.com 6.860 3.052 N/A somewhat
68 www.thepiratebay.com 4.421 0.657 572.9 no
69 www.aweber.com 5.718 1.984 188.2 no
70 www.phc.com 1.167 2.256 N/A yes
71 www.answers.com 16.616 0.604 2651.0 no
72 www.drudgereport.com 1.520 0.605 151.2 no
73 www.salesforce.com 9.592 1.992 381.5 no
74 www.washingtonpost.com 1.410 0.266 N/A yes
75 www.bestbuy.com 5.455 0.356 1432.3 no
76 www.bbc.co.uk 11.283 2.750 310.3 no
77 www.mlb.com 12.698 6.546 N/A yes
78 www.wsj.com 0.352 0.298 18.1 no
Continued on next page
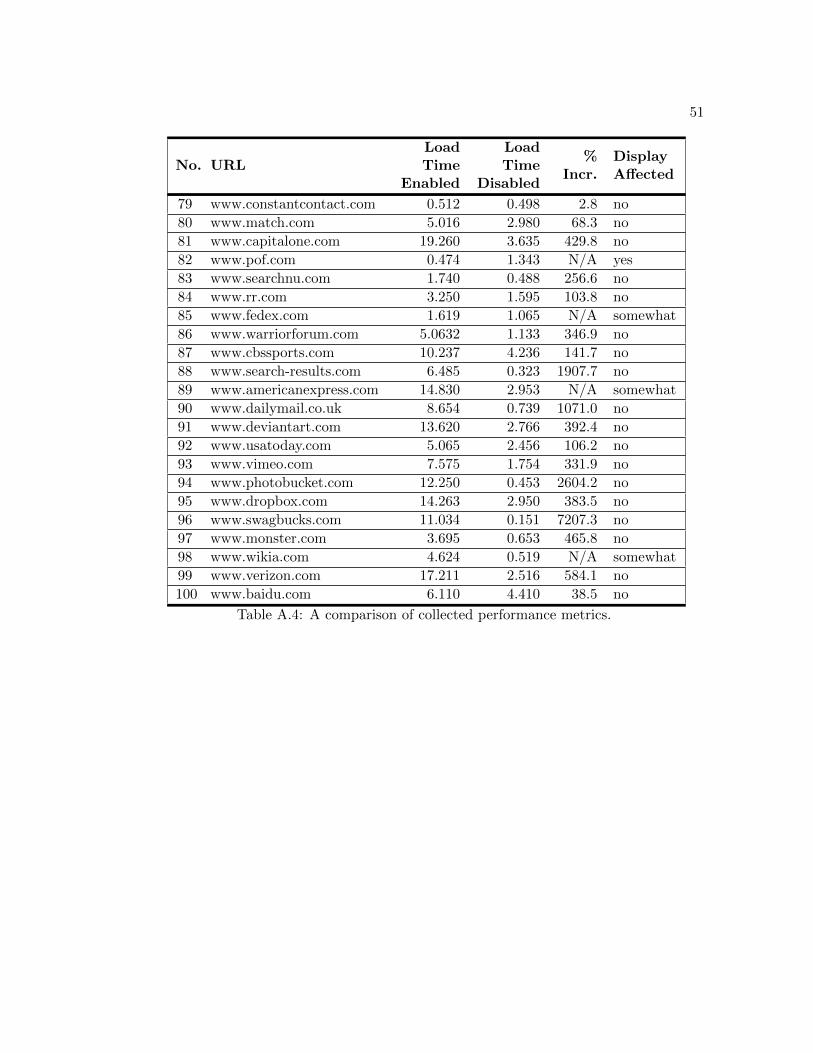
51
No. URLLoadTime
Enabled
LoadTime
Disabled
%Incr.
DisplayAffected
79 www.constantcontact.com 0.512 0.498 2.8 no
80 www.match.com 5.016 2.980 68.3 no
81 www.capitalone.com 19.260 3.635 429.8 no
82 www.pof.com 0.474 1.343 N/A yes
83 www.searchnu.com 1.740 0.488 256.6 no
84 www.rr.com 3.250 1.595 103.8 no
85 www.fedex.com 1.619 1.065 N/A somewhat
86 www.warriorforum.com 5.0632 1.133 346.9 no
87 www.cbssports.com 10.237 4.236 141.7 no
88 www.search-results.com 6.485 0.323 1907.7 no
89 www.americanexpress.com 14.830 2.953 N/A somewhat
90 www.dailymail.co.uk 8.654 0.739 1071.0 no
91 www.deviantart.com 13.620 2.766 392.4 no
92 www.usatoday.com 5.065 2.456 106.2 no
93 www.vimeo.com 7.575 1.754 331.9 no
94 www.photobucket.com 12.250 0.453 2604.2 no
95 www.dropbox.com 14.263 2.950 383.5 no
96 www.swagbucks.com 11.034 0.151 7207.3 no
97 www.monster.com 3.695 0.653 465.8 no
98 www.wikia.com 4.624 0.519 N/A somewhat
99 www.verizon.com 17.211 2.516 584.1 no
100 www.baidu.com 6.110 4.410 38.5 no
Table A.4: A comparison of collected performance metrics.

52
References
[1] Symantec internet security threat report: 2011 trends. Technical report, SymantecInc, 2012.
[2] 3WC. HTML5. http://dev.w3.org/html5/spec, October 2012.
[3] Alexa. Top Sites in the United States.http://www.alexa.com/topsites/countries/US, October 2012.
[4] D. Artz. Digital steganography: hiding data within data. Internet Computing,IEEE, 5(3):75–80, May/June 2001.
[5] M. Bailey. Flash origin policy issues.http://www.foregroundsecurity.com/component/content/article/1/49.
[6] M. Bailey. Neat new ridiculous flash hacks.http://www.blackhat.com/presentations/bh-dc-10/Bailey_Mike/BlackHat-
DC-2010-Bailey-Neat-New-Ridiculous-flash-hacks-slides.pdf, July 2010.
[7] A. Barth, J. Caballero, and D. Song. Secure content sniffing for web browsers, orhow to stop papers from reviewing themselves. In Proceedings of the 30th IEEESymposium on Security and Privacy, S&P 2009, New York, NY, USA, May 2009.IEEE.
[8] A. Barth, C. Jackson, and J. Mitchell. Robust defenses for cross-site request forgery.In Proceedings of the 15th ACM Conference on Computer and CommunicationsSecurity, CCS 2008, pages 75–88, New York, NY, USA, October 2008. ACM.
[9] R. Brandis. Exploring below the surface of the gifar iceberg. Technical report,EWA-Australia, February 2009.
[10] S. Ford, M. Cova, C. Kruegel, and G. Vigna. Analyzing and detecting maliciousflash advertisements. In Proceedings of the 25th Computer Security ApplicationsConference, ACSAC 2009, pages 363–372, December 2009.
[11] The Apache Software Foundation. Tika.http://tika.apache.org/, October 2012.
[12] M. Gebre, L. Kyung-Suk, and M. Hong. A robust defense against content-sniffingxss attacks. In Proceedings of 6th International Conference on Digital Content,Multimedia Technology and its Applications, IDC 2010, New York, NY, USA, 2010.IEEE.
[13] C. Grier, S. Tang, and S. King. Secure web browsing with the op web browser.In Proceedings of the 29th IEEE Symposium on Security and Privacy, S&P 2008,pages 402–416, New York, NY, USA, 2008. IEEE.

53
[14] J. Grossman. Top ten web hacking techniques of 2008. http://jeremiahgrossman.blogspot.com/2009/02/top-ten-web-hacking-techniques-of-2008.html,February 2009.
[15] J. Hedley. jsoup: Java html parser.http://http://jsoup.org/, October 2012.
[16] A. Judson. Tamper Data. https://addons.mozilla.org/en-US/firefox/addon/tamper-data, October 2012.
[17] H. Le. lori (Life-of-request info). https://addons.mozilla.org/en-us/firefox/addon/lori-life-of-request-info, October 2012.
[18] R. McMillan. A photo than can steal your online credentials.http://www.infoworld.com/d/security-central/photo-can-steal-your-
online-credentials-306, August 2008.
[19] Mozilla Developer Network. Liveconnect.https://developer.mozilla.org/en-US/docs/LiveConnect, October 2012.
[20] Mozilla Developer Network. nsitraceablechannel.https://developer.mozilla.org/en-US/docs/XPCOM_Interface_Reference/
NsITraceableChannel, October 2012.
[21] Mozilla Developer Network. Progress listeners.https://developer.mozilla.org/en-US/docs/DOM/DOM_Mutation_Observers,October 2012.
[22] Mozilla Developer Network. Rhino.https://developer.mozilla.org/en-US/docs/Rhino, October 2012.
[23] Mozilla Developer Network. XUL.https://developer.mozilla.org/en-US/docs/XUL, October 2012.
[24] J. Odvarko. nsitraceablechannel, intercept http traffic.http://www.softwareishard.com/blog/firebug/nsitraceablechannel-
intercept-http-traffic, October 2012.
[25] The National Archives of the United Kingdom. Droids.http://www.nationalarchives.gov.uk/information-management/our-
services/dc-file-profiling-tool.htm, October 2012.
[26] D. Schweinsberg. Cssparser.http://cssparser.sourceforge.net/, October 2012.
[27] S. Stamm, B. Sterne, and G. Markham. Reining in the web with content securitypolicy. In Proceedings of the 19th International Conference on the World Wide Web,WWW 2010, pages 921–930, New York, NY, USA, 2010. ACM.

54
[28] S. Sundareswaran and A. Squicciarini. Decore: detecting content repurposing at-tacks on clients systems. In Proceeding of the 6th International ICST Conference onSecurity and Privacy in Communication Networks, SECURECOMM 2010, Septem-ber 2010.
[29] S. Sundareswaran and A. Squicciarini. Image repurposing for gifar-based attacks.In Proceedings of the 7th Conference on Collaboration, Electronic Messaging, Anti-Abuse and Spam, CEAS 2010, July 2010.
[30] H. Weinreich, H. Obendorf, E. Herder, and M. Mayer. Off the beaten tracks: ex-ploring three aspects of web navigation. In Proceedings of the 15th InternationalConference on the World Wide Web, WWW 2006, pages 133–142, New York, NY,USA, May 2006. ACM.
Related Documents











