




RecursiveNeuralNetworks
Dr.KiraRadinskyCTOSalesPredictVisi8ngProfessor/Scien8stTechnion
SlideswereadaptedfromlecturesbyRichardSocher

Overview
Firsthour:RecursiveNeuralNetworks
• Mo8va8on:Composi8onality
• Structurepredic8on:Parsing
• Backpropaga8onthroughStructure
• VisionExample
Secondhour:
• Matrix-VectorRNNs: Rela8onclassifica8on
• RecursiveNeuralTensorNetworks: Sen8mentAnalysis
• TreeLSTMs: PhraseSimilarity

BuildingonWordVectorSpaceModels
x10 1 2 3 4 5 6 7 8 9 10
x25
4
3
2
1
92Monday
Tuesday 9.51.5
Buthowcanwerepresentthemeaningoflongerphrases?Bymappingthemintothesamevectorspace!
France 22.5
Germany 13
thecountryofmybirth theplacewhereIwasborn

BuildingonWordVectorSpaceModels
x10 1 2 3 4 5 6 7 8 9 10
x25
4
3
2
1
92Monday
Tuesday 9.51.5
15
1.14
France 22.5
Germany 13
thecountryofmybirth theplacewhereIwasborn
Buthowcanwerepresentthemeaningoflongerphrases?Bymappingthemintothesamevectorspace!

Seman<cVectorSpaces
SingleWordVectors
• Distribu8onalTechniques• BrownClusters• Usefulasfeaturesinside
models,e.g.CRFsforNER,etc.• Cannotcapturelongerphrases
DocumentsVectors
• Bagofwordsmodels• PCA(LSA,LDA)• GreatforIR,document
explora8on,etc.• Ignorewordorder,no
detailedunderstanding
Vectorsrepresen8ngPhrasesandSentencesthatdonotignorewordorderandcaptureseman8csforNLPtasks

Howshouldwemapphrasesintoavectorspace?
0.40.3
the
2.33.6
birth
44.5
my
77
of
2.13.3
country
2.53.8
5.56.1
13.5
15
Useprincipleofcomposi8onalityThemeaning(vector)ofasentenceisdeterminedby(1) themeaningsofitswordsand(2) therulesthatcombinethem.
Modelsinthissec8oncanjointlylearnparsetreesandcomposi8onalvectorrepresenta8ons
x2
x10 1 2 3 4 5 6 7 8 9 10
5
4
3
2
1
thecountryofmybirth
theplacewhereIwasborn
Monday
Tuesday
GermanyFrance

SentenceParsing:Whatwewant
NP
91
53
cat
71
sat
85
on
91
the
43
mat.The
NP
PP
S
VP

LearnStructureandRepresenta<on
NPNP
PP
S
VP
52 3
3
83
54
73
91
53
cat
71
sat
85
on
91
the
43
mat.The

WhyLearnStructureandRepresenta<on?
• Thesyntac8crulesoflanguagearehighlyrecursive–needabeeermodeltorespectthat!
• Wecannowinputsentencesofarbitrarylength• wasahugeheadscratcherforusingNeuralNetsinNLP(see
tricksintroducedBengioetal.,2003;Henderson,2003;Collobert&Weston,2008)
• Whynotuseword2vecinfraandlearnbigram,trigram,etc?• infiniteamountofpossiblecombina8ons
ofwords.Storingandtraininganinfiniteamountofvectorswouldjustbeabsurd.
• Somecombina8onsofwordswhiletheymightbecompletelyreasonabletohearinlanguage,mayneverberepresentedinourtraining/devcorpus.Sowewouldneverlearnthem.

Sidenote:Recursivevsrecurrentneuralnetworks
0.40.3
the
2.33.6
birth
44.5
my
77
of
2.13.3
country
2.53.8
5.56.1
13.5
15
0.40.3
the
2.33.6
birth
44.5
my
77
of
2.13.3
country
1 1 5.5 4.5 2.53.5 5 6.1 3.8 3.8

Sidenote:Arelanguagesrecursive?
• Cogni8velydebatable• But:recursionhelpfulindescribingnaturallanguage• Example:“thechurchwhichhasnicewindows”,anounphrase
containingarela8veclausethatcontainsanounphrases• Argumentsfornow:1)Helpfulindisambigua8on:

Sidenote:Arelanguagesrecursive?
2) Helpfulforsometaskstorefertospecificphrases:• JohnandJanewenttoabigfes8val.Theyenjoyedthetripandthemusicthere.
• “they”:JohnandJane(co-referenceresul8on)• “thetrip”:wenttoabigfes8val• “there”:bigfes8val
3) Labelinglessclearifspecifictoonlysubphrases• Ilikedthebrightscreenbutnotthebuggyslowkeyboardofthephone.Itwasapaintotypewith.Itwasnicetolookat.
4) Worksbeeerforsometaskstousegramma8caltreestructure(butmaybewecanjusthaveaverydeepLSTMmodel?)
• Thisiss8llupfordebate.
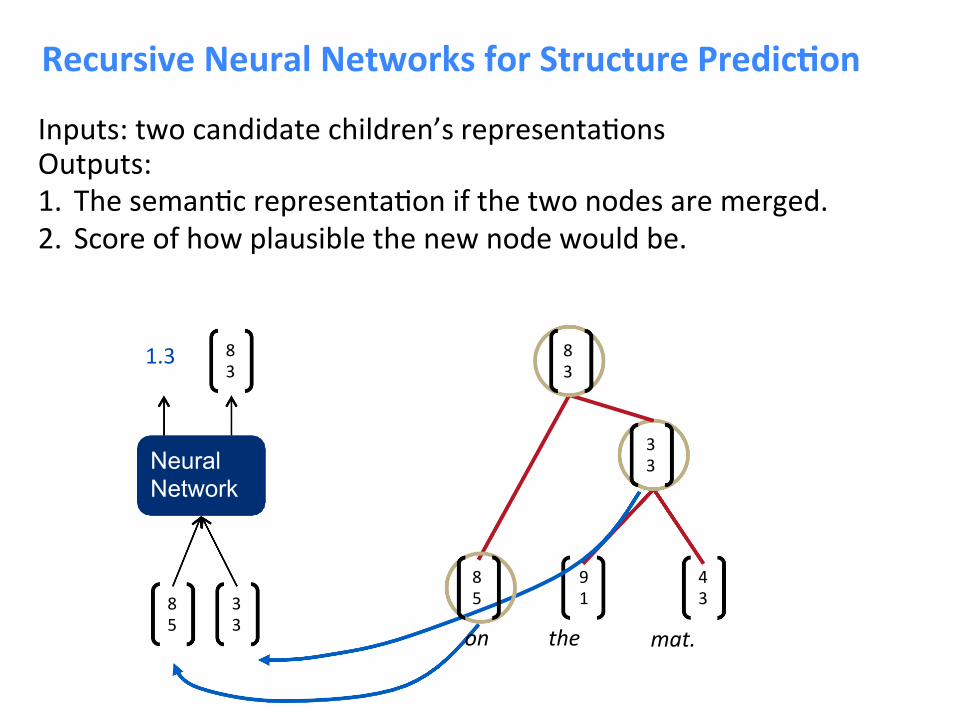
RecursiveNeuralNetworksforStructurePredic<on
mat.
91
the
43
33
83
85
33
Neural Network
83
1.3
Inputs:twocandidatechildren’srepresenta8onsOutputs:1. Theseman8crepresenta8onifthetwonodesaremerged.2. Scoreofhowplausiblethenewnodewouldbe.
85
on

RecursiveNeuralNetworkDefini<on
score=UTp
SameWparametersatallnodesofthetree
85
33
Neural Network
83
1.3score = =parent
c1 c2
p=tanh(Wc1+b),c2

hisapointinthesamewordvectorspaceforthebigram”thisassignment”
RecursiveNeuralNetworksforStructurePredic<on

RecursiveNeuralNetworksforStructurePredic<on
AstandardRecursiveNeuralNetwork

ParsingasentencewithanRNN
Neural Network
0.120
Neural Network
0.410
Neural Network
2.333
91
5 7 8 9 43 1 5 1 3
Neural Network
3.152
Neural Network
0.301
The cat sat on the mat.

Parsingasentence
91
52
Neural Network
1.121
Neural Network
0.120
Neural Network
0.410
Neural Network
2.333
5 7 8 9 43 1 5 1 3
18
The cat sat on the mat.

Parsingasentence
52
Neural Network
1.121
Neural Network
0.120
33
Neural Network
3.683
91
5 7 8 9 43 1 5 1 3
The
19
cat sat on the mat.

Parsingasentence
54
73
83
52
33
91
53
85
91
43
71
The cat sat on the mat.

Max-MarginFramework-Details
• Thescoreofatreeiscomputedbythesumoftheparsingdecisionscoresateachnode:
85
33
RNN
831.3

Max-MarginFramework---Details
• Similartomax-marginparsing(Taskaretal.2004),asupervisedmax-marginobjec8ve.Maximizetheobjec8veof:
• Theloss penalizesallincorrectdecisions
• StructuresearchforA(x)wasmaximallygreedy• Instead:BeamSearchwithChart

Backpropaga<onThroughStructure
IntroducedbyGoller&Küchler(1996)
Principallythesameasgeneralbackpropaga8on
Threedifferencesresul8ngfromtherecursionandtreestructure:1. Sumderiva8vesofWfromallnodes2. Splitderiva8vesateachnode3. Adderrormessages

BTS:1)Sumderiva<vesofallnodesYoucanactuallyassumeit’sadifferentWateachnodeIntui8onviaexample:
Ifwetakeseparatederiva8vesofeachoccurrence,wegetsame:

BTS:2)Splitderiva<vesateachnode
85
33
Duringforwardprop,theparentiscomputedusing2children83
c1
c1p= tanh(W c +b)2c2
85
33
Hence,theerrorsneedtobecomputedwrteachofthem:83
whereeachchild’serrorisn-dimensional
c1 c2
25

BTS:3)Adderrormessages
• Ateachnode:• Whatcameup(fprop)mustcomedown(bprop)• Totalerrormessageserrormessagesfromparent+errormessagefromownscore
85
33
83
c1 c2
parentscore

BTSPythonCode:forwardProp
Many8mesyoucangetanoverflow(especiallywithRelu)– sothisisatricktosolvethis

BTSPythonCode:backProp
Upperleveldelta(deltat+1)
Errorsforscoresfromcurrentandprevious

BTS:Op<miza<on • Asbefore,wecanplugthegradientsintoastandardoff-the-shelfL-BFGSop8mizerorSGD
• BestresultswithAdaGrad(Duchietal,2011):
• Fornon-con8nuousobjec8veusesubgradientmethod(Ratliffetal.2007)
26

Discussion:SimpleRNN• GoodresultswithsinglematrixRNN(morelater)
• SingleweightmatrixRNNcouldcapturesomephenomenabutnotadequateformorecomplex,higherordercomposi8onandparsinglongsentences
• Thecomposi8onfunc8onisthesameforallsyntac8ccategories,punctua8on,etc
c2
Wscore
W
c1
sp

Solu<on:Syntac<cally-Un<edRNN
• Idea:Condi8onthecomposi8onfunc8ononthesyntac8ccategories,“un8etheweights”
• Allowsfordifferentcomposi8onfunc8onsforpairsofsyntac8ccategories,e.g.Adv+AdjP,VP+NP
• Combinesdiscretesyntac8ccategorieswithcon8nuousseman8cinforma8on

Solu<on:Composi<onalVectorGrammars
• Problem:Speed.Everycandidatescoreinbeamsearchneedsamatrix---vectorproduct.
• Solu8on:Computescoreonlyforasubsetoftreescomingfromasimpler,fastermodel(PCFG)• Prunesveryunlikelycandidatesforspeed• Providescoarsesyntac8ccategoriesofthechildrenforeachbeamcandidate
• Composi8onalVectorGrammars:CVG=PCFG+RNN

Details:Composi<onalVectorGrammar
• Scoresateachnodecomputedbycombina8onofPCFGandSU---RNN:
• Interpreta8on:Factoringdiscreteandcon8nuousparsinginonemodel:
• Socheretal.(2013)

Relatedworkforrecursiveneuralnetworks
Pollack(1990):Recursiveauto-associa8vememories PreviousRecursiveNeuralNetworksworkbyGoller&Küchler(1996),Costaetal.(2003)assumedfixedtreestructureandusedonehotvectors. Hinton(1990)andBoeou(2011):Relatedideasaboutrecursivemodelsandrecursiveoperatorsassmoothversionsoflogicopera8ons

RelatedWorkforparsing
• Resul8ngCVGParserisrelatedtopreviousworkthatextendsPCFGparsers
• KleinandManning(2003a):manualfeatureengineering• Petrovetal.(2006):learningalgorithmthatsplitsandmerges
syntac8ccategories• Lexicalizedparsers(Collins,2003;Charniak,2000):describeeach
categorywithalexicalitem• HallandKlein(2012)combineseveralsuchannota8onschemesina
factoredparser.• CVGsextendtheseideasfromdiscreterepresenta8onstoricher
con8nuousones

Experiments• StandardWSJsplit,labeledF1• BasedonsimplePCFGwithfewerstates• Fastpruningofsearchspace,fewmatrix---vectorproducts• 3.8%higherF1,20%fasterthanStanfordfactoredparser
Parser Test,AllSentences
StanfordPCFG,(KleinandManning,2003a) 85.5
StanfordFactored(KleinandManning,2003b) 86.6
FactoredPCFGs(HallandKlein,2012) 89.4
Collins(Collins,1997) 87.7
SSN(Henderson,2004) 89.4
BerkeleyParser(PetrovandKlein,2007) 90.1
CVG(RNN)(Socheretal.,ACL2013) 85.0
CVG(SU---RNN)(Socheretal.,ACL2013) 90.4
Charniak---SelfTrained(McCloskyetal.2006) 91.0
Charniak---SelfTrained---ReRanked(McCloskyetal.2006) 92.1

SU---RNNAnalysis
• Learnsno8onofsouheadwords
DT---NP
VP---NP

Analysisofresul<ngvectorrepresenta<ons
Allthefiguresareadjustedforseasonalvaria8ons1. Allthenumbersareadjustedforseasonalfluctua8ons2. Allthefiguresareadjustedtoremoveusualseasonalpaeerns
Knight-Ridderwouldn’tcommentontheoffer1. Harscodeclinedtosaywhatcountryplacedtheorder2. Coastalwouldn’tdisclosetheterms
Salesgrewalmost7%to$UNKm.from$UNKm.1. Salesrosemorethan7%to$94.9m.from$88.3m.2. Salessurged40%toUNKb.yenfromUNKb.

SU-RNNAnalysis • Cantransferseman8cinforma8onfromsinglerelatedexample
• Trainsentences:• Heeatsspaghewwithafork.• Sheeatsspaghewwithpork.
• Testsentences• Heeatsspaghewwithaspoon.• Heeatsspaghewwithmeat.

SU---RNNAnalysis

LabelinginRecursiveNeuralNetworks
Neural Network
83
• Wecanuseeachnode’srepresenta8onasfeaturesforaso4maxclassifier:
• Trainingsimilartomodelinpart1withstandardcross-entropyerror+scores
Softmax Layer
NP
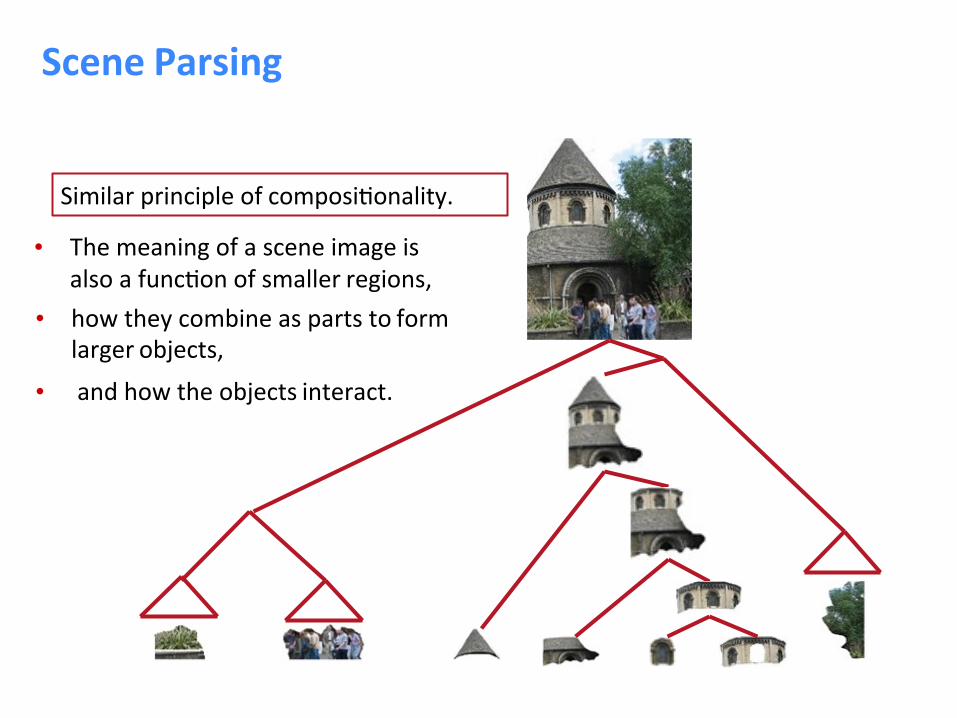
SceneParsing
• Themeaningofasceneimageisalsoafunc8onofsmallerregions,
• howtheycombineaspartstoformlargerobjects,
• andhowtheobjectsinteract.
Similarprincipleofcomposi8onality.
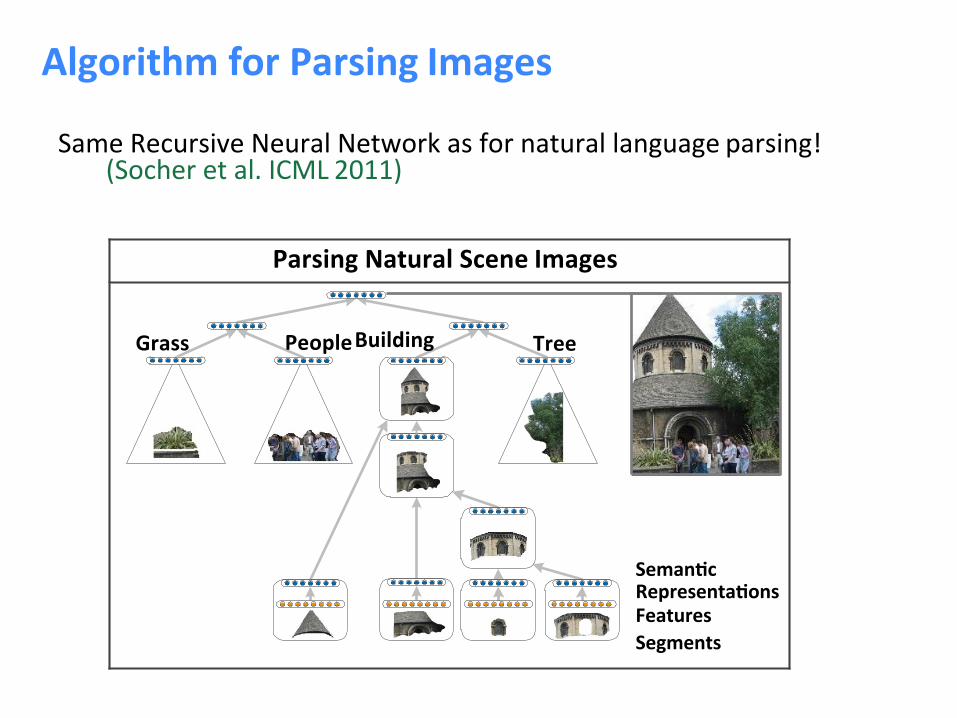
AlgorithmforParsingImages
SameRecursiveNeuralNetworkasfornaturallanguageparsing!(Socheretal.ICML2011)
ParsingNaturalSceneImages
Grass
PeopleBuilding
Tree
Seman<cRepresenta<onsFeatures
Segments

Mul<---classsegmenta<on
Method Accuracy
PixelCRF(Gouldetal.,ICCV2009) 74.3
Classifieronsuperpixelfeatures 75.9
Region---basedenergy(Gouldetal.,ICCV2009) 76.4
Locallabelling(Tighe&Lazebnik,ECCV2010) 76.9
SuperpixelMRF(Tighe&Lazebnik,ECCV2010) 77.5
SimultaneousMRF(Tighe&Lazebnik,ECCV2010) 77.5
RecursiveNeuralNetwork 78.1
StanfordBackgroundDataset(Gouldetal.2009)


























![CS229 Project: 3-D Image segmentation using Recursive ...cs229.stanford.edu/...3DImageSegmentationUsingRecursiveNeuralN… · So we explore how a Recursive Neural Network (RNN) Algorithm[2]](https://static.cupdf.com/doc/110x72/5b5fdcac7f8b9a7f038ba94b/cs229-project-3-d-image-segmentation-using-recursive-cs229-so-we-explore.jpg)


