



...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Обзор средств разработки длявычислений на GPGPU
Артур Молчанов
2016

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
О чем пойдет речь?
GPGPU General Purpose Graphics Processing UnitGPGPU General-purpose computing for graphics
processing unit
Общее в определениях — в вычислениях общегоназначения участвует графический процессор.

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Зачем?Вычислительная мощность GPU в разы выше мощностиCPU с сопоставимой ценой и потребляемой энергией.
Таблица 1: Сравнение CPU и GPU
Устройство GFLOPS Мощ-ность(макс.),Вт
Цена,$
64bit
32bit
i7-5960X (8 cores@3GHz) 384 768 140 1100GeForce GTX Titan Black 1707 5121 250 999GeForce GTX Titan X 192 6144 250 999Radeon R9 Fury X 537 8602 275 649

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Зачем?Разрыв в скорости CPU и GPU в последнее время лишьрастет (знаменитые +5% у новых процессоров Intel)

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Причины превосходства GPUВ CPU вычислительные блоки занимают меньшую частькристалла. Площадь кристалла CPU, как правило,меньше площади GPU.
(a) i7-5960X (355мм2, 2.6 млрд.транзисторов)
(b) GM200 (601 мм2, 8 млрд.транзисторов)
Рис. 1: Кристаллы CPU и GPU

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Причины превосходства GPU
CPU оптимизирован для выполнения однопоточныхприложений с малой задержкой:• Большой кэш• Длинный конвейер• Сложные блоки предсказания ветвлений
Intel и GPGPUIntel тоже хочет заработать на SIMD устройствах ивыпустила ряд решений на архитектуре MIC (ManyIntegrated Core Architecture), который включает в себя иотносительно известный Xeon Phi, представляющий изсебя процессор имеющий до 61 x86 ядра с 16 GB GDDR5и интерфейс PCI-e (только стоит это ∼$4000).

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Общее у CPU и GPUCPU тоже является SIMD устройством — в немсодержатся блоки, выполняющие за один тактарифметические операции над 256-битными векторами,что эквивалентно 16 операциям над 16-битнымичислами.Также CPU может выполнять несколько независимыхопераций одновременно.
Рис. 2: Исполнительное устройство CPU Haswell

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
История развития видеокарт
2002-2003 гг. Выход видеокарт на чипах NV30 (NVIDIAGeForce FX) и R300 (AMD (ATI) Radeon 9500). Вних была реализована программируемаяшейдерная архитектура второй версии,точность вычислений значительноповысилась, что заметно расширило областьприменения.
2006 г. NVIDIA представила GeForce 8800 — первуювидеокарту с унифицированной шейдернойархитектурой.GeForce 8800 имел 128 унифицированныхпотоковых процессоров, способных работатьс любыми данными в формате с плавающейзапятой.

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
История развития средств разработки
2003 г. BrookGPU — компилятор, позволившийабстрагироваться от графического API(OpenGL, Direct3D)
2007 г. релиз публичной бета-версии CUDA SDK2008 г. AMD официально предоставила доступ к
Stream для массовых пользователей2009 г. релиз Mac OS X 10.6 с поддержкой OpenCL.
Релиз NVIDIA и ATI SDK с поддержкой OpenCL2009 г. релиз DirectX 11, включающий DirectCompute2012 г. релиз Visual Studio с поддержкой C++AMP2012 г. релиз Android 4.2 с поддержкой ускорения
Renderscript на GPU2015 г. релиз GCC 5.1 с поддержкой OpenACC

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
CUDA
Задачи, выполняемые на GPU, представляют собойфункции со спецификатором __global__, называемыеkernel.Синтаксис — расширенный C99/C++11.
1 __global__ void SumVectors(float const* a, float const* b, intsize, float* c)↪→
2 {3 int const i = threadIdx.x + blockIdx.x * blockDim.x;4
5 if (i >= size)6 {7 return;8 }9
10 c[i] = a[i] + b[i];11 }

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Выполнение kernel
Вызов kernel аналогичен любой другой функции.Отличие — в ”<<<...>>>” указывается конфигурацияпотоков выполнения.
1 int main()2 {3 // ...4 int const threadsPerBlock = 512;5 int const blocksCount = (size - 1) / threadsPerBlock + 1;6
7 dim3 const dimBlock(threadsPerBlock, 1, 1);8 dim3 const dimGrid(blocksCount, 1, 1);9
10 vecAdd<<<dimGrid, dimBlock>>>(deviceA, deviceB, size,deviceC);↪→
11 }

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Модель выполнения I
ПотокиВыполнением kernel занимаются потоки.
БлокиПотоки группируются в блоки.Причина — не все потоки имеют общую быструюразделяюмую память (shared memory) и могутсинхронизироваться, а лишь те, кто выполняется наодном мультипроцессоре.

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Модель выполнения II
Грид (grid)Блоки объединяются в грид (grid),Блоки и грид имеют 3 измерения.Причина — чаще всего массив данных имеет до 3измерений.

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Модель выполнения III
Рис. 3: Модель выполнения CUDA

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Сборка
Для компиляции используется nvcc.Код, выполняемый на CPU перенаправляется системномукомпилятору (GCC, MS VC++).nvcc генерирует PTX код и/или cubin.PTX”Ассемблер” для GPU. Во время запуска приложенияпроисходит трансляция в бинарный формат cubin,подходящий GPU.
cubinELF-файл, содержащий код, для выполнения на GPU,

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Состав CUDAПомимо Runtime и Driver API в состав CUDA входятбиблиотеки:
cuBLAS реализация BLAS (Basic Linear AlgebraSubprograms)
cuFFT реализация библиотеки быстрогопреобразования Фурье
cuRand библиотека генерации случайных чиселcuSPARSE библиотека линейной алгебры разреженных
матрицNPP набор GPU-ускоренных функций для
обработки изображений, видео и сигналовcuSOLVER набор решателей для плотных и
разреженных матрицThrust STL-подобные шаблонные интерфейсы для
некоторых алгоритмов и структур данных

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Системные требования I
Аппаратное обеспечениеВидеокарты NVIDIA начиная с G80 (GeForce 8800 GTX)Спектр поддерживаемых возможностей (computecapability) отличается для разных поколенийвидеокарт.
ОС• Windows• Linux• Mac OS X
Компиляторы• Visual C++ 10.0 - Visual C++ 12.0• GCC 4.3.4 - 4.9.2

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Системные требования II
IDE (плагин)• Visual Studio 2010 - 2013• Eclipse (поставляется в комплекте с SDK для Linux)
...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
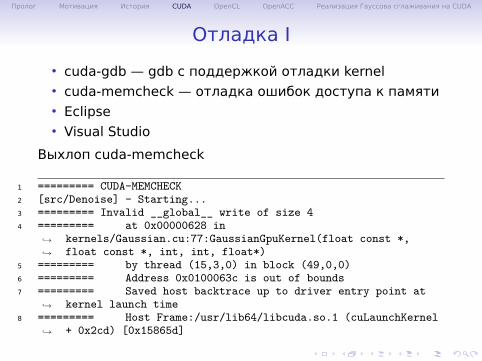
Отладка I• cuda-gdb — gdb с поддержкой отладки kernel• cuda-memcheck — отладка ошибок доступа к памяти• Eclipse• Visual Studio
Выхлоп cuda-memcheck
1 ========= CUDA-MEMCHECK2 [src/Denoise] - Starting...3 ========= Invalid __global__ write of size 44 ========= at 0x00000628 in
kernels/Gaussian.cu:77:GaussianGpuKernel(float const *,float const *, int, int, float*)
↪→
↪→
5 ========= by thread (15,3,0) in block (49,0,0)6 ========= Address 0x0100063c is out of bounds7 ========= Saved host backtrace up to driver entry point at
kernel launch time↪→
8 ========= Host Frame:/usr/lib64/libcuda.so.1 (cuLaunchKernel+ 0x2cd) [0x15865d]↪→

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Отладка II9 ========= Host Frame:src/Denoise [0x25bf1]10 ========= Host Frame:src/Denoise [0x40403]11 ========= Host Frame:src/Denoise
(_Z17GaussianGpuKernelPKfS0_iiPf + 0xb0) [0x109a0]↪→
12 ========= Host Frame:src/Denoise(_Z12GaussianGpu0RKSt6vectorIS_IfSaIfEESaIS1_EEPKfiiRS3_ +0x311) [0x10d71]
↪→
↪→
13 ========= Host Frame:src/Denoise (main + 0x4cd) [0x988d]14 ========= Host Frame:/lib64/libc.so.6 (__libc_start_main +
0xf5) [0x21b05]↪→
15 ========= Host Frame:src/Denoise [0x9d1f]16 CUDA error at kernels/Gaussian.cu:176
code=4(cudaErrorLaunchFailure) "cudaDeviceSynchronize()"↪→
17 ========= Program hit cudaErrorLaunchFailure (error 4) due to"unspecified launch failure" on CUDA API call tocudaDeviceSynchronize.
↪→
↪→
18 ========= Saved host backtrace up to driver entry point aterror↪→
19 ========= Host Frame:/usr/lib64/libcuda.so.1 [0x2f31b3]20 ========= Host Frame:src/Denoise [0x443f6]21 ========= Host Frame:src/Denoise
(_Z12GaussianGpu0RKSt6vectorIS_IfSaIfEESaIS1_EEPKfiiRS3_ +0x1f1) [0x10c51]
↪→
↪→
...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
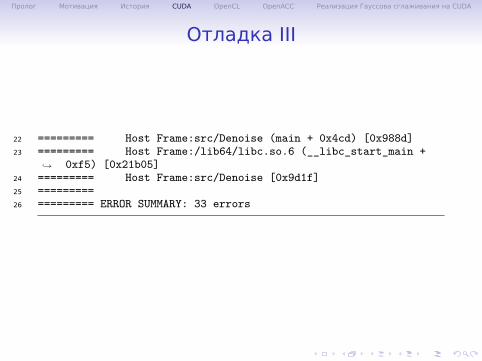
Отладка III
22 ========= Host Frame:src/Denoise (main + 0x4cd) [0x988d]23 ========= Host Frame:/lib64/libc.so.6 (__libc_start_main +
0xf5) [0x21b05]↪→
24 ========= Host Frame:src/Denoise [0x9d1f]25 =========26 ========= ERROR SUMMARY: 33 errors

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Отладка IV
Рис. 4: Отладка CUDA в Eclipse

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Профилирование I• nvprof• NVIDIA Visual Profiler (как отдельное приложение, таки часть плагинов для Visual Studio и Eclipse)
Рис. 5: Профилирование CUDA в Eclipse

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Продукты использующие CUDA I• библиотеки
cuDNN библиотека с поддержкой GPUпримитивов для глубинных нейронныхсетей
ArrayFire библиотека C/C++/Java/Fortran,содержащая сотни функцийиспользуемых в арифметике, линейнаяалгебре, статистике, обработке сигналов,обработке изображений и связанных сними алгоритмов
OpenCV библиотека для машинного зрения,обработки изображений и машинногообучения
NVBIO C++ фреймворк для анализагенетических последовательностей
HiPLAR пакеты для R, позволяющие ускоритьфункции линейной алгебры

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Продукты использующие CUDA II
FFmpeg набор мультимедиа библиотек, которыепозволяют записывать, конвертировать ипередавать цифровые аудио- ивидеозаписи в различных форматах
NVIDIA Video Codec SDK библиотеки для аппаратногокодирования/декодирования H.264 иH.265и множество других

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
OpenCL
Фреймворк для написания параллельных приложенийбез привязки к производителю.OpenCL разрабатывается и поддерживаетсянекоммерческим консорциумом Khronos Group. В егосостав входит и NVIDIA. Этим объясняется схожесть сCUDA.

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Отличия от CUDA I
• Широкий спектр поддерживаемых устройствCPU Intel, AMD, IBM Power, Qualcomm
SnapdragonGPU NVIDIA, AMD, Intel, Mali, Qualcomm AdrenoFPGA Altera, XilinxDSP TI AM57x, TI 66AK2H SoC
Intel MIC Xeon Phi• Отсутствие необходимости в специальномкомпиляторе

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Отличия от CUDA II
Таблица 2: Эквиваленты CUDA и OpenCL
OpenCL CUDAhost hostdevice devicekernel kernelhost program host programNDRange (index space) gridwork item threadwork group block

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
KernelЗадачи, выполняемые на GPU, представляют собойфункции со спецификатором __kernel, называемыеkernel.Синтаксис — расширенный C99/C++14 (начиная с версии2.1).
1 __kernel void SumVectors(__global float const* a, __global floatconst* b, int size, __global float* c)↪→
2 {3 int const i = get_global_id(0);4
5 if (i >= size)6 {7 return;8 }9
10 c[i] = a[i] + b[i];11 }

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Выполнение kernel IВ отличие от CUDA, исходный код OpenCL компилируетсяво время выполнения, т.к. используются стандартныекомпиляторы.
1 int main()2 {3 // ...4 char const* sumVectorsSrc =5 "__kernel void SumVectors(__global float const* a, __global
float const* b, int size, __global float* c)"↪→
6 "{"7 " int const i = get_global_id(0);"8 ""9 "if (i >= size)"10 "{"11 " return;"12 "}"13 ""14 "c[i] = a[i] + b[i];"15 "}";

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Выполнение kernel II
16
17 std::string const clCompileFlags = "-cl-mad-enable";18
19 cl_program sumProgram = clCreateProgramWithSource(clContext,1, &sumVectorsSrc, NULL, &clError);↪→
20 CL_CHECK_ERROR(clBuildProgram(sumProgram, 0, NULL,clCompileFlags.c_str(), NULL, NULL));↪→
21 cl_kernel const sumKernel = clCreateKernel(sumProgram,"SumVectors", &clError);↪→
После компиляции мы получили kernel — sumKernel.

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Выполнение kernel III
Теперь необходимо задать значения аргументов kernel.
22 // ...23 CL_CHECK_ERROR(clSetKernelArg(sumKernel, 0, sizeof(deviceA),
(void *) &deviceA));↪→
24 CL_CHECK_ERROR(clSetKernelArg(sumKernel, 1, sizeof(deviceB),(void *) &deviceB));↪→
25 CL_CHECK_ERROR(clSetKernelArg(sumKernel, 2, sizeof(size),&size));↪→
26 CL_CHECK_ERROR(clSetKernelArg(sumKernel, 3, sizeof(deviceC),(void *) &deviceC));↪→
27 // ...
Теперь необходимо задать конфигурацию потоков изапустить kernel.
...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
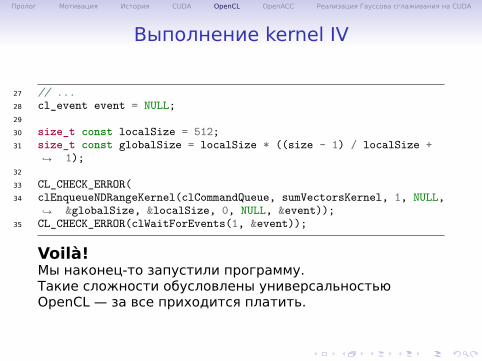
Выполнение kernel IV
27 // ...28 cl_event event = NULL;29
30 size_t const localSize = 512;31 size_t const globalSize = localSize * ((size - 1) / localSize +
1);↪→
32
33 CL_CHECK_ERROR(34 clEnqueueNDRangeKernel(clCommandQueue, sumVectorsKernel, 1, NULL,
&globalSize, &localSize, 0, NULL, &event));↪→
35 CL_CHECK_ERROR(clWaitForEvents(1, &event));
Voilà!Мы наконец-то запустили программу.Такие сложности обусловлены универсальностьюOpenCL — за все приходится платить.

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Сборка
Т.к. нет привязки к компилятору, то достаточно лишьиметь заголовочные файлы и библиотеку OpenCL.

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Системные требования
OpenCL не накладывает никаких ограничений. Задачапроизводителя оборудования обеспечить поддержкуOpenCL.Удобство программирования и отладки зависит от IDE.

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Отладка
• GDB >= 7.3• Intel OpenCL debugger для Visual Studio (только CPU)• AMD CodeXL• IBM OpenCL SDK

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Профилирование
• NVIDIA Visual Profiler• Intel System Analyzer и Platform Analyzer из OpenCLSDK
• Intel VTune Amplifier• AMD CodeXL

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Продукты использующие OpenCL I• библиотеки
ArrayFire библиотека C/C++/Java/Fortran,содержащая сотни функцийиспользуемых в арифметике, линейнаяалгебре, статистике, обработке сигналов,обработке изображений и связанных сними алгоритмов
Bolt STL-подобная библиотека, использующаяOpenCL или C++AMP для ускоренияалгоритмов
Boost.Compute STL-подобная библиотека,использующая OpenCL и CUDA
clMath реализации FFT и BLASMainConcept SDK библиотеки для аппаратного
кодирования/декодирования H.264, H.265и MPEG-2и множество других

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
OpenACC I
OpenACC (Open Accelerators) — программный стандартдля параллельного программирования.Как и в OpenMP для указания участков кода,выполняющихся параллельно, используются директивыкомпилятора.Отличие — код может выполняться как на CPU так и наGPU.
1 void SumVectors(float const * a, float const * b, int size, float* restrict c) {↪→
2 #pragma acc kernels copyin(a[0:size],b[0:size]),copyout(c[0:size])↪→
3 for (int i = 0; i < size; ++i)4 {5 c[i] = a[i] + b[i];6 }7 }

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
OpenACC II
#pragma acc kernels нижележащий блок кода будетскомпилирован в kernel
copyin(a[0:size],b[0:size]) данные из массивов a и bбудут скопированы из локальной памяти впамять девайса
[0:size] диапазон индекса массива длякопирования
copyout(c[0:size])) данные из массива с будутскопированы из памяти девайса в локальнуюпамять
...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Сборка
Для компиляции требуется лишь компилятор,поддерживающий OpenACC.

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Системные требования I
OpenACC не налагает никаких ограничений напрограммное или аппаратное обеспечение.Дело за разработчиками компиляторов.Аппаратное обеспечение• видеокарты NVIDIA Tesla с compute capability 2.0 ивыше
• видеокарты AMD Radeon HD Graphics 7x00• AMD APU с AMD Radeon HD Graphics R7• CPU• Xeon Phi

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Системные требования II
ОС• Windows• Linux• Mac OS X
Компиляторы• PGI Accelerator Compilers• Cray compiler• GCC 5.1• NVIDIA OpenACC Toolkit (основан на компиляторе PGI)

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Отладка
• GDB• cuda-gdb (для NVIDIA)• TotalView OpenACC debugger

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Профилирование
• запуск приложения, собранного компилятором PGI, спеременной окружения PGI_ACC_TIME=1
• NVIDIA Visual Profiler

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Что осталось за кадром
Кроме низкоуровневых API таких как OpenCL и CUDAсуществуют и вспомогательные библиотеки,предоставляющие алгоритмы и структуры данных,способных использовать ресурсы GPU.C++AMP Обертка над DirectCompute. Есть ”из
коробки” в Visual Studio с версии 2012Thrust Входит в состав CUDABolt Поддерживает OpenCL и C++AMP
Boost.Compute использует OpenCLArrayFire CUDA, OpenCL

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Реализация Гауссова сглаживания на CUDAГауссово сглаживание заключается в суммированиизначения цветовых каналов соседних пикселей скоэффициентами равными значению функции Гаусса.
0.195
0.078 0.078
0.0780.078
0.123
0.123
0.123
0.123
Рис. 6: Коэффициенты Гаусcова сглаживания

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Входной файл и железо I
В качестве входного файла использоваласьфотогорафия 24 МП (6016x4000).Видеокарта — GeForce GTX 980 TiCPU — i7-5960X
...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
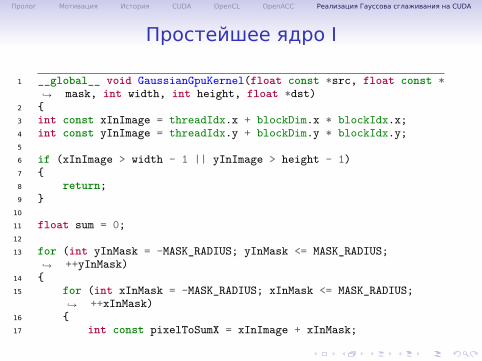
Простейшее ядро I
1 __global__ void GaussianGpuKernel(float const *src, float const *mask, int width, int height, float *dst)↪→
2 {3 int const xInImage = threadIdx.x + blockDim.x * blockIdx.x;4 int const yInImage = threadIdx.y + blockDim.y * blockIdx.y;5
6 if (xInImage > width - 1 || yInImage > height - 1)7 {8 return;9 }10
11 float sum = 0;12
13 for (int yInMask = -MASK_RADIUS; yInMask <= MASK_RADIUS;++yInMask)↪→
14 {15 for (int xInMask = -MASK_RADIUS; xInMask <= MASK_RADIUS;
++xInMask)↪→
16 {17 int const pixelToSumX = xInImage + xInMask;

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Простейшее ядро II18 int const pixelToSumY = yInImage + yInMask;19
20 if (pixelToSumX < 0 || pixelToSumX > width - 1 ||21 pixelToSumY < 0 || pixelToSumY > height - 1)22 {23 continue;24 }25
26 float const coefficient = mask[(yInMask + MASK_RADIUS) *MASK_SIZE + xInMask + MASK_RADIUS];↪→
27 float const pixelValue = src[pixelToSumY * width +pixelToSumX] * coefficient;↪→
28
29 sum += pixelValue;30 }31 }32
33 dst[yInImage * width + xInImage] = sum;34 }

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Простейшее ядро - профилирование I
Рис. 7: Профилирование простейшего ядра
Таблица 3: Результаты выполнения простейшего ядра
Операция Время, мс.cudaMalloc 200Memcpy HostToDevice 29Memcpy DeviceToHost 23Compute 27 (3 * 9)Total 279 мс

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Простейшее ядро - профилирование II
ПроблемаВремя, затраченное на аллокацию памяти в видеокарте(200 мс) значительно больше времени затраченного навычисления и передачу данных (79 мс).
РешениеПричина — инициализация контекста CUDA занимаетмного времениИнициализацию контекста можно провестипринудительно во время запуска приложения, напримервызовом cudaFree(nullptr).

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Простейшее ядро - профилирование III
Рис. 8: Профилирование простейшего ядра послеинициализации контекста
cudaMalloc вместо 200 мс заняло 0.3 мс.Суммарное время снизилось с 279 мс до 79 мс.

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Ядро с использованием кэша I
ПроблемаСреди наших данных есть 2 не модифицирующихсямассива — mask и src. Они, хотя и помечены как floatconst *, но компилятор не может быть уверенным, что этимассивы или их части не модифицируется (например,из-за перекрывающихся областей). Поэтомукэшироваться данные в них не будут.
РешениеПометить аргумент как __restrict__
NVIDIA Visual Profiler позволяет получить подробнуюинформацию об использовании ресурсов (и даже датьсоветы по поводу оптимизации производительности).

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Ядро с использованием кэша II
(a) До оптимизации
(b) После оптимизации
Рис. 9: Использование кэша

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Ядро с использованием кэша III
Время выполнения ядра снизилось с 9 мс до 1.6 мсСуммарное время выполнения — с 79 мс до 56 мс.
1 __global__ void GaussianGpuKernel(float const * __restrict__ src,float const * __restrict__ mask, int width, int height, float*dst)
↪→
↪→
2 {3 // ...4 }

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Ядро с асинхронным выполнением I
ПроблемаВо время копирования данных в девайс или из девайсаGPU не выполняет следующее ядро.В итоге вычислительная мощность простаивает.
РешениеCUDA (и видеокарты на аппаратном уровне)поддерживает параллельное копирование и выполнениеядер (нескольких параллельно, если позволяетмощность).Для этого необходимо использовать стримы плюспометить область памяти на хосте как non pageable.
...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
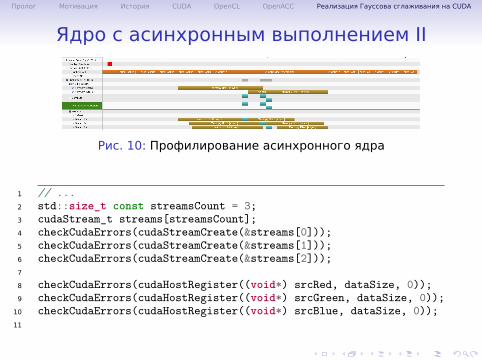
Ядро с асинхронным выполнением II
Рис. 10: Профилирование асинхронного ядра
1 // ...2 std::size_t const streamsCount = 3;3 cudaStream_t streams[streamsCount];4 checkCudaErrors(cudaStreamCreate(&streams[0]));5 checkCudaErrors(cudaStreamCreate(&streams[1]));6 checkCudaErrors(cudaStreamCreate(&streams[2]));7
8 checkCudaErrors(cudaHostRegister((void*) srcRed, dataSize, 0));9 checkCudaErrors(cudaHostRegister((void*) srcGreen, dataSize, 0));10 checkCudaErrors(cudaHostRegister((void*) srcBlue, dataSize, 0));11

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Ядро с асинхронным выполнением III12 checkCudaErrors(cudaMemcpyAsync(deviceSrcRed, src[0].data(),
dataSize, cudaMemcpyHostToDevice, streams[0]));↪→
13 checkCudaErrors(cudaMemcpyAsync(deviceSrcBlue, src[1].data(),dataSize, cudaMemcpyHostToDevice, streams[1]));↪→
14 checkCudaErrors(cudaMemcpyAsync(deviceSrcGreen, src[2].data(),dataSize, cudaMemcpyHostToDevice, streams[2]));↪→
15
16 GaussianGpuKernel<<<dimGrid, dimBlock, 0,streams[0]>>>(deviceSrc, deviceMask, width, height,deviceDst);
↪→
↪→
17 GaussianGpuKernel<<<dimGrid, dimBlock, 0, streams[1]>>>(deviceSrc+ pixelsCount, deviceMask, width, height,↪→
18 deviceDst + pixelsCount);19 GaussianGpuKernel<<<dimGrid, dimBlock, 0, streams[2]>>>(deviceSrc
+ 2 * pixelsCount, deviceMask, width, height,↪→
20 deviceDst + 2 * pixelsCount);21
22 checkCudaErrors(cudaHostRegister((void*) dst[0].data(), dataSize,0));↪→
23 checkCudaErrors(cudaHostRegister((void*) dst[1].data(), dataSize,0));↪→

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Ядро с асинхронным выполнением IV
24 checkCudaErrors(cudaHostRegister((void*) dst[2].data(), dataSize,0));↪→
25
26 checkCudaErrors(cudaMemcpyAsync(dst[0].data(), deviceDst,dataSize, cudaMemcpyDeviceToHost, streams[0]));↪→
27 checkCudaErrors(cudaMemcpyAsync(dst[1].data(), deviceDst + height* width, dataSize, cudaMemcpyDeviceToHost, streams[1]));↪→
28 checkCudaErrors(cudaMemcpyAsync(dst[2].data(), deviceDst + 2 *height * width, dataSize, cudaMemcpyDeviceToHost,streams[2]));
↪→
↪→
29
30 checkCudaErrors(cudaDeviceSynchronize());
Суммарное время выполнения снизилось с 56 мс до43 мс.

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Оптимизация ядра. Итоги I
Что еще можно оптимизировать:Частота обращения к глобальной памяти Нужно
использовать shared memory, т.к. длякаждого пикселя мы запрашиваем значения9 пикселей. А скорость памяти у видеокартыхоть и высока (∼330 GB/s), но полнойзагрузки всех ядер мы не получим.
Выравнивание доступа к памяти Оперативная памятьможет за один запрос отдавать до 128 байт.Для получения максимальной пропускнойспособности потоки внутри warp-а должныобращаться к регионам памяти выровненнымна величину транзакции и последовательно.

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Оптимизация ядра. Итоги II
Оптимизация алгоритма Вместо использованиядвухмерной матрицы с коэффициентамиможно применить последовательно 2одномерные, что снизит число операций сk2wh до 2kwh, где k — ширина матрицы, w —ширина изображения, h — высотаизображения.Плохому алгоритму и на топовом железемало места.

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Оптимизация ядра. Итоги III
Таблица 4: Результаты выполнения асинхронного ядра
Операция Время, мс.MemcpyAsync HostToDevice 20MemcpyAsync DeviceToHost 18Compute 4.8 (3 * 1.6)Total 43 мсCPU 500 мс (OpenMP)
Если еще раз взглянуть на результаты, то можнозаметить, что в нашем случае оптимизация ядра ничегоне даст — мы упираемся в копирование данных междухостом и девайсом.Задача для GPU оказалась слишком простой.

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Итого
Использование GPU может дать большой приростпроизводительности. Но при разработке требуетсяучитывать особенности программно-аппаратнойархитектуры.Не все задачи смогут выполниться на GPU быстрее чемна CPU (имеющие, например, множество ветвлений).Однако GPGPU уже нашло широкое применение вразличных приложениях от научных и до мультимедиа.И чтобы быть не хуже конкурентов необходимо ужесегодня начать рассматривать GPGPU как реальныйспособ увеличить производительность.

...
.
...........................
.
...
.
...
.
Пролог Мотивация История CUDA OpenCL OpenACC Реализация Гауссова сглаживания на CUDA
Конец
Спасибо за внимание.






























