



Multiscale Topic Tomography
Ramesh Nallapati, William Cohen, Susan Ditmore, John Lafferty
&
Kin Ung(Johnson and Johnson Group)

8/13/2007 KDD 2007, San Jose, CA 2 / 22
Introduction
– Explosive growth of electronic document collections• Need for unsupervised techniques for summarization,
visualization and analysis
– Many probabilistic graphical models proposed in the recent past:
• Latent Dirichlet Allocation • Correlated Topic Models • Pachinko Allocation• Dirichlet Process Mixtures• …..
– All the above ignore an important dimension that reveals huge amount of information
• Time!

8/13/2007 KDD 2007, San Jose, CA 3 / 22
Introduction
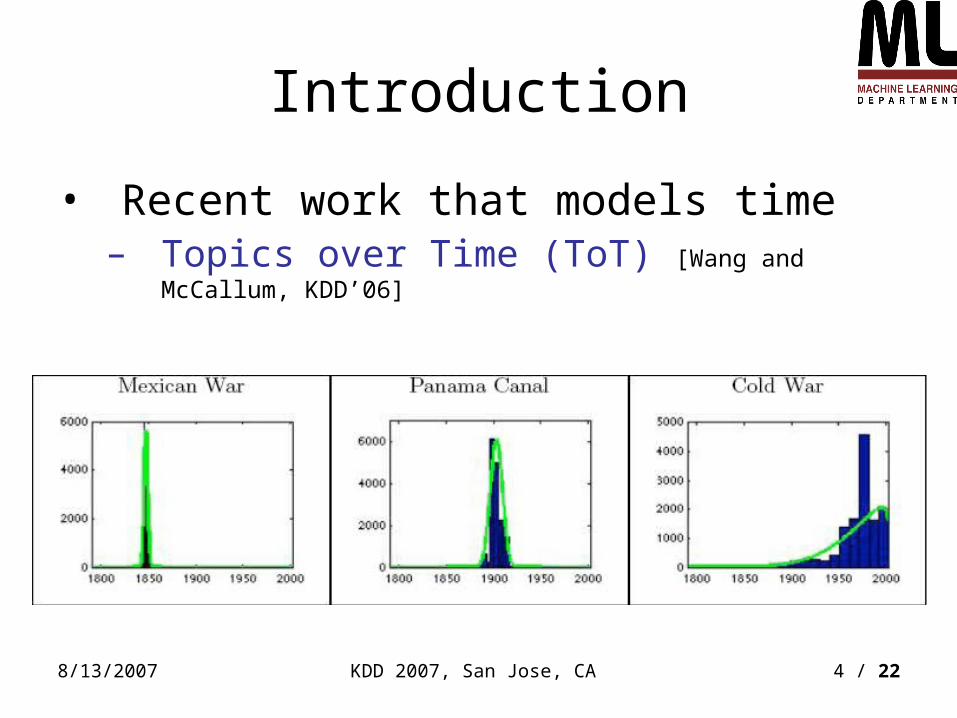
• Recent work that models time:– Topics over Time [Wang and McCallum, KDD’06]
Key ideas:
• Each sampled topic generates a word as well as a time stamp
• Beta distribution to model the occurrence probability of topics
• Collapsed Gibbs sampling for inference
8/13/2007 KDD 2007, San Jose, CA 4 / 22
Introduction
• Recent work that models time– Topics over Time (ToT) [Wang and McCallum, KDD’06]

8/13/2007 KDD 2007, San Jose, CA 5 / 22
Introduction
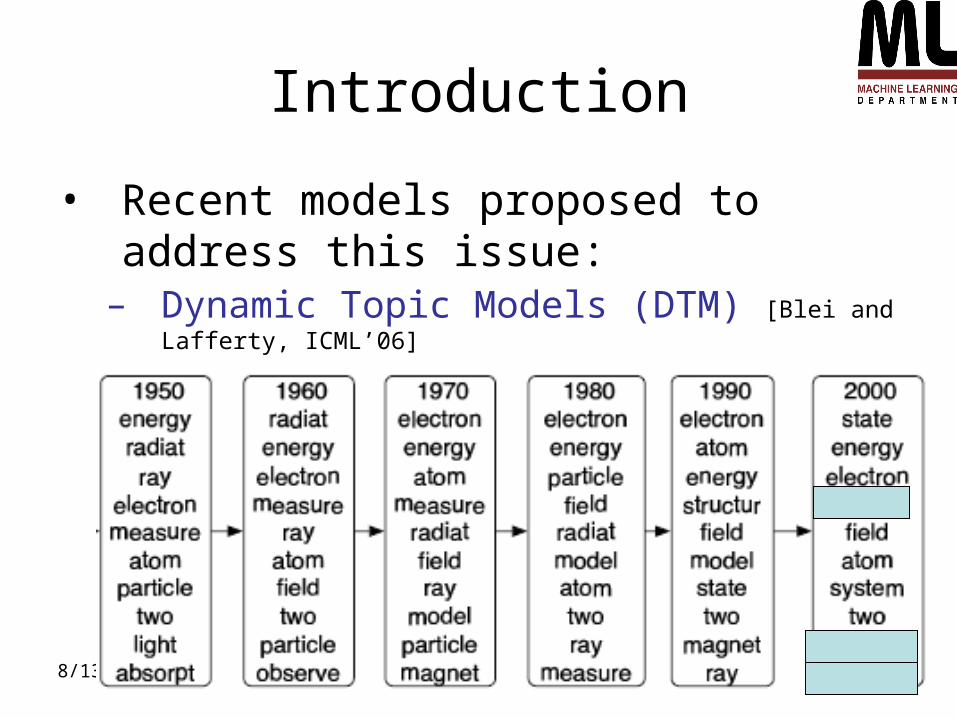
• Recent models proposed to address this issue:
– Dynamic Topic Models (DTM) [Blei and Lafferty, ICML’06]
Key ideas:
• Models evolution of “topic content”, not just topic occurrence
• Evolution of topic multinomials modeled using logistic-normal prior
• approximate variational inference
8/13/2007 KDD 2007, San Jose, CA 6 / 22
Introduction
• Recent models proposed to address this issue:
– Dynamic Topic Models (DTM) [Blei and Lafferty, ICML’06]

8/13/2007 KDD 2007, San Jose, CA 7 / 22
Introduction
• Issues with DTM– Logistic normal not a conjugate to the multinomial
• Results in complicated inference procedures
• Topic tomography: a new time series topic model– Uses a Poisson process to model word counts– A wedding of multiscale wavelet analysis with topic
models• Uses conjugate priors
– Efficient inference
• Allows Visualization of topic evolution at various time-scales
8/13/2007 KDD 2007, San Jose, CA 8 / 22
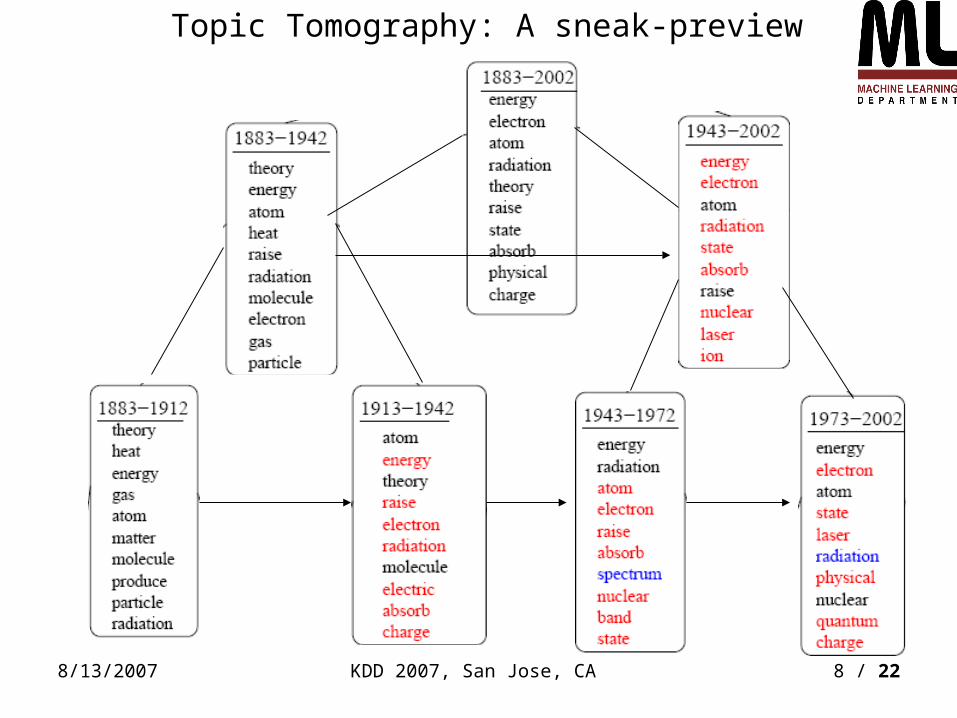
Topic Tomography: A sneak-preview

8/13/2007 KDD 2007, San Jose, CA 9 / 22
Topic Tomography (TT): what’s with the name?
LDA models how topics are distributed in each document
• Normalization is per document
TT models how each topic is distributed among documents !
• Normalization is per topic
• From the Greek words " tomos" (to cut or section) and "graphein" (to write)

8/13/2007 KDD 2007, San Jose, CA 10 / 22
Topic Tomography model

8/13/2007 KDD 2007, San Jose, CA 11 / 22
Multiscale parameter generation
Haar multiscale wavelet representation
scal
e
epochs

8/13/2007 KDD 2007, San Jose, CA 12 / 22
Multiscale parameter generation

8/13/2007 KDD 2007, San Jose, CA 13 / 22
Multiscale Topic Tomography:where is the conjugacy?
• Recall: multiscale canonical parameters are generated using Beta distribution
• Data likelihood w.r.t. the Poissons can be equivalently expressed in terms of the binomials:
•

8/13/2007 KDD 2007, San Jose, CA 14 / 22
Multiscale Topic Tomography
• Parameter learning using mean-field variational EM

8/13/2007 KDD 2007, San Jose, CA 15 / 22
Experiments
• Perplexity analysis on Science data– Spans 120 years: split into 8 epochs each spanning
15 years– Documents in each epoch split into 50-50 training and
test sets
• Trained three different versions of TT– Basic TT: basic tomography model with no multiscale
analysis, applied to the whole training set– Multiple TT: same as above, but one model for each
epoch– Multiscale TT: full multiscale version
8/13/2007 KDD 2007, San Jose, CA 16 / 22
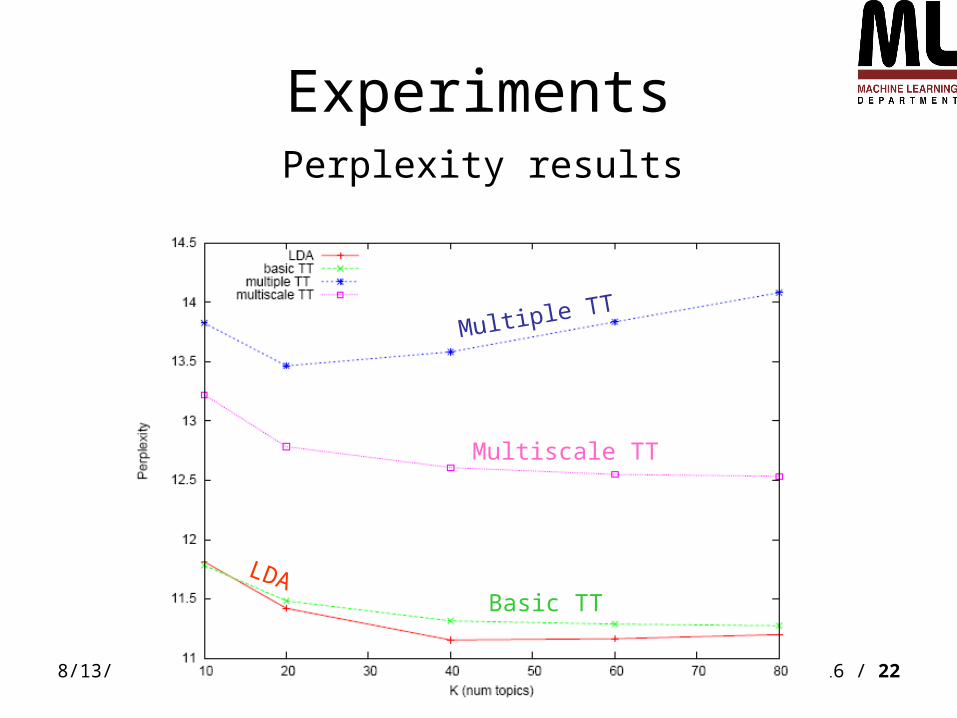
ExperimentsPerplexity results
Multiscale TT
Multiple TT
Basic TT
LDA

8/13/2007 KDD 2007, San Jose, CA 17 / 22
Experiments: Topic visualization of “Particle physics”

8/13/2007 KDD 2007, San Jose, CA 18 / 22
ExperimentsTopic visualization: “Particle physics”

8/13/2007 KDD 2007, San Jose, CA 19 / 22
Experiments: Evolution of content-bearing words in “particle physics”
quan
tum
heat
electron
atom
8/13/2007 KDD 2007, San Jose, CA 20 / 22
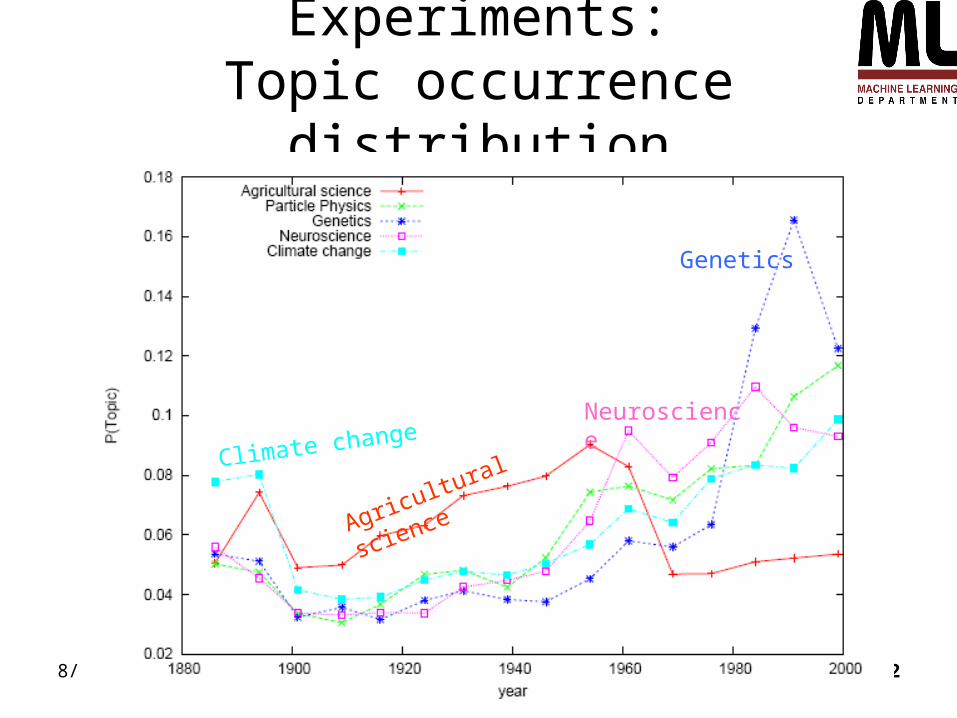
Experiments:Topic occurrence distribution
Agricultural science
Genetics
Climate changeNeuroscience

8/13/2007 KDD 2007, San Jose, CA 21 / 22
Conclusion
• Advantages:– Multiscale tomography has the best features of both
DTM and ToT• In addition, it provides a “zoom” feature for time-scales
– A natural model for sequence modeling of counts data• Conjugate priors, easier inference
• Limitations:– Cannot generate one document at a time– Not easily parallelizable
• Future work:– Build a GaP like model with Gamma weights

8/13/2007 KDD 2007, San Jose, CA 22 / 22
Demo
• Analysis of 32,000 documents from PubMed containing the word “cancer”, spanning 32 years
• Will be shown this evening at poster # 9
• Also available at: http://www.cs.cmu.edu/~nmramesh/cancer_demo/multiscale_home.html
• Local copy

8/13/2007 KDD 2007, San Jose, CA 23 / 22
Inference: Mean field variational EM
• E-step:
• M-step:
Variational multinomial
Variational Dirichlet

8/13/2007 KDD 2007, San Jose, CA 24 / 22
Related Work
• Poisson distribution used in 2-Poisson model in IR– Not successful, but inspired the famous BM25
• Gamma-Poisson topic model [Canny, SIGIR’04]– Poisson to model word counts and Gamma to model topic
weights– does not follow the semantics of a “pure” generative model
• Optimizes the likelihood of complete-data
– Topic tomography model is very similar• We optimize the likelihood of observed-data
• Use Dirichlet to model topic weights

8/13/2007 KDD 2007, San Jose, CA 25 / 22
Related Work
• Multiscale Topic Tomography model originally introduced by Nowak et al [Nowak and Kolaczyk, IEEE ToIT’00]– Called “Poisson inverse” problem – Applied to model gamma ray bursts– Topic weights assumed to be known
• a simple EM algorithm proposed
• We cast topic modeling as a Poisson inverse problem– Topic weights unknown– Variational EM proposed

8/13/2007 KDD 2007, San Jose, CA 26 / 22
Outline
• Introduction/Motivation• Related work• Topic Tomography model
– Basic model– Multiscale analysis– Learning and Inference
• Experiments– Perplexity analysis– Topic visualizations
• Demo (if time permits)

8/13/2007 KDD 2007, San Jose, CA 27 / 22
Experiments:Multiple senses of word “reaction”
particle phys
ics
chemistry
Blood tests
Total count






























