



Memory-Savvy Distributed Interactive Ray Tracing
David E. DeMarle
Christiaan Gribble
Steven Parker

Impetus for the Paper
• data sets are growing
• memory access time is a bottleneck
• use parallel memory resources efficiently
• three techniques for faster access to scene data

System Overview
• base system presented at IEEE PVG’03
• cluster port of an interactive ray tracer for shared memory supercomputers IEEE VIS’98
• image parallel work division• fetch scene data over from peers and cache
locally

Three Techniques forMemory Efficiency
• ODSM PDSM
• central work queue distributed work sharing
• polygonal mesh reorganization

Distributed Shared Memory• data is kept in memory blocks• each node has 1/nth of the blocks• fetch rest over the network from peers• cache recently fetched blocks
1 2 3 4 6 75 8 9abstract view of memory
1 4 7 2node 1’s memory
2 5 8 3node 2’s memory
3 6 9 2 4node 3’s memory
resident set cache

Object Based DSM
• each block has a unique handle• application finds handle for each datum• acquire and release for every block access
//locate datahandle, offset = ODSM_location(datum);block_start_addr = acquire(handle);//use datadatum = *(block_start_addr + offset);//relinquish spacerelease(handle);

ODSM Observations
• handle = level of indirection > 4 GB
• mapping scene data to blocks is tricky• acquire and release add overhead• address computations add overhead
7.5 GB Richtmyer-Meshkov time step
64 CPUs ~3fps,
with view and isovalue changes

Page Based DSM
• like ODSM: • each node keeps 1/nth of scene• fetches from peers• uses caching
• difference is how memory is accessed• normal virtual memory addressing• use addresses between heap and stack• PDSM installs a segmentation fault signal handler:
on a miss obtain page from peer, return

PDSM Observations
• no handles, normal memory access• no acquire/release or address computations • easy to place any type of scene data in shared space • limited to 2^32 bytes • hard to make thread safe
• DSM acts only in the exceptional case of a miss• ray tracing acceleration structure > 90 % hit rates
ODSM PDSM
Hit time 10.2 µs 4.97 µs
Miss time 629 µs 632 µs

Head-to-Head Comparison
• compare replication, PDSM and ODSM
• use a small 512^3 volumetric data set
• PDSM and ODSM keep only 1/16th locally
• change viewpoint and isovalue throughout • first half, large working set• second half, small working set

Head-to-Head Comparison
note - accelerated ~2x for presentation

Head-to-Head Comparison
0
2
4
6
8
10
12
Frame #
Fra
mes
/Sec
REP
PDSM
ODSM

Head-to-Head Comparison
0
2
4
6
8
10
12
Frame #
Fra
mes
/Sec
REP
PDSM
ODSM
replicated 3.74 frames/sec average

Head-to-Head Comparison
0
2
4
6
8
10
12
Frame #
Fra
mes
/Sec
REP
PDSM
ODSM
ODSM 32% speed of replication
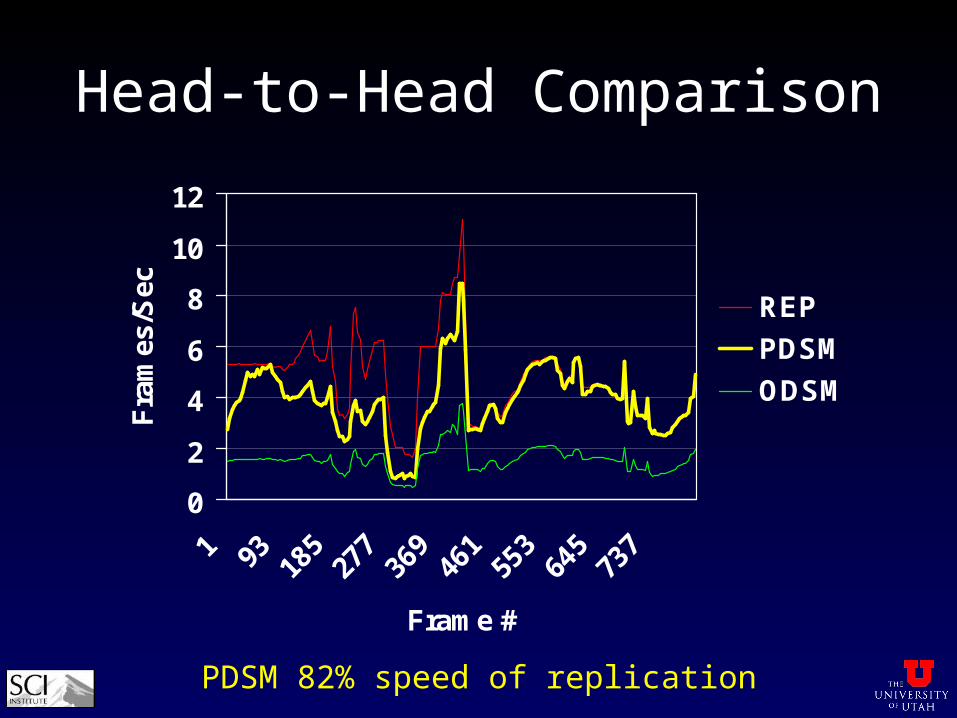
Head-to-Head Comparison
0
2
4
6
8
10
12
Frame #
Fra
mes
/Sec
REP
PDSM
ODSM
PDSM 82% speed of replication

Three Techniques forMemory Efficiency
• ODSM PDSM
• central work queue distributed work sharing
• polygonal mesh reorganization

Load Balancing Options
• central work queue• legacy from original shared memory implementation• display node keeps task queue• render nodes get tiles from queue
• now distributed work sharing• start with tiles traced last frame
hit rates increase• workers get tiles from each other
communicate in parallel, better scalability• steal from random peers, slowest worker gives work
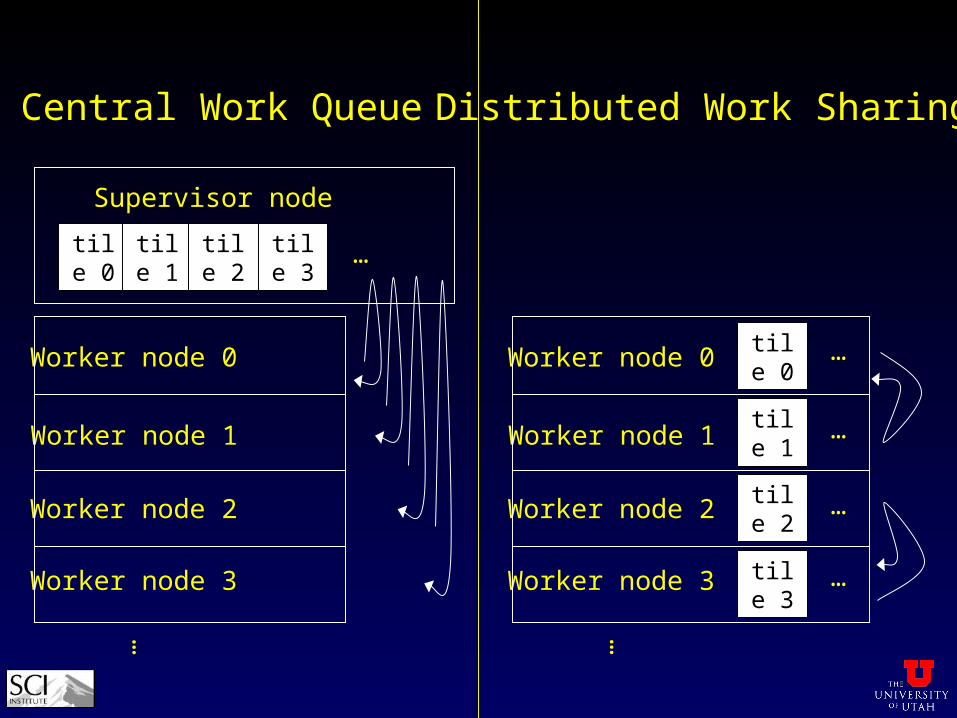
Supervisor node
tile 0 tile 1 tile 2 tile 3 …
Worker node 0
Worker node 1
Worker node 2
Worker node 3
…
Worker node 0
Worker node 1
Worker node 2
Worker node 3
…tile 0
tile 1
tile 2
tile 3
…
…
…
…
Central Work Queue Distributed Work Sharing

Central Work Queue Distributed Work Sharing

Central Work Queue Distributed Work Sharing

Central Work Queue Distributed Work Sharing

Central Work Queue Distributed Work Sharing

Comparison
• bunny, dragon, and acceleration structures in PDSM
• measure misses and frame rates
• vary local memory to simulate data much larger than physical memory
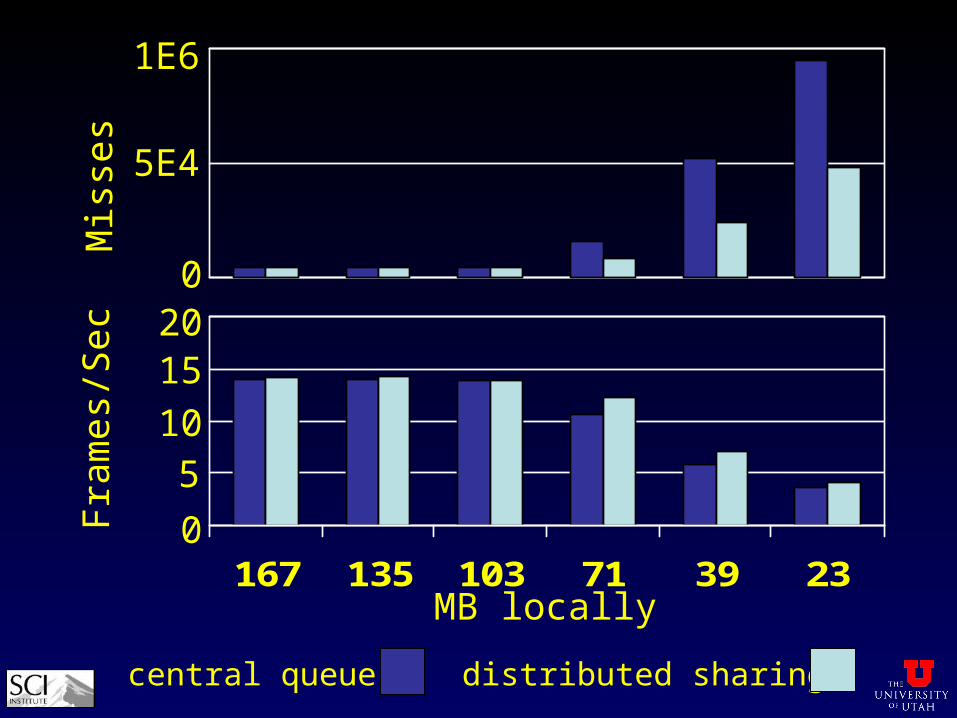
167 135 103 71 39 23
Mis
ses
Fra
mes
/Sec
0
1E6
0
20
MB locally
15
105
5E4
central queue distributed sharing

167 135 103 71 39 23
Mis
ses
Fra
mes
/Sec
0
1E6
0
20
MB locally
15
105
5E4
central queue distributed sharing
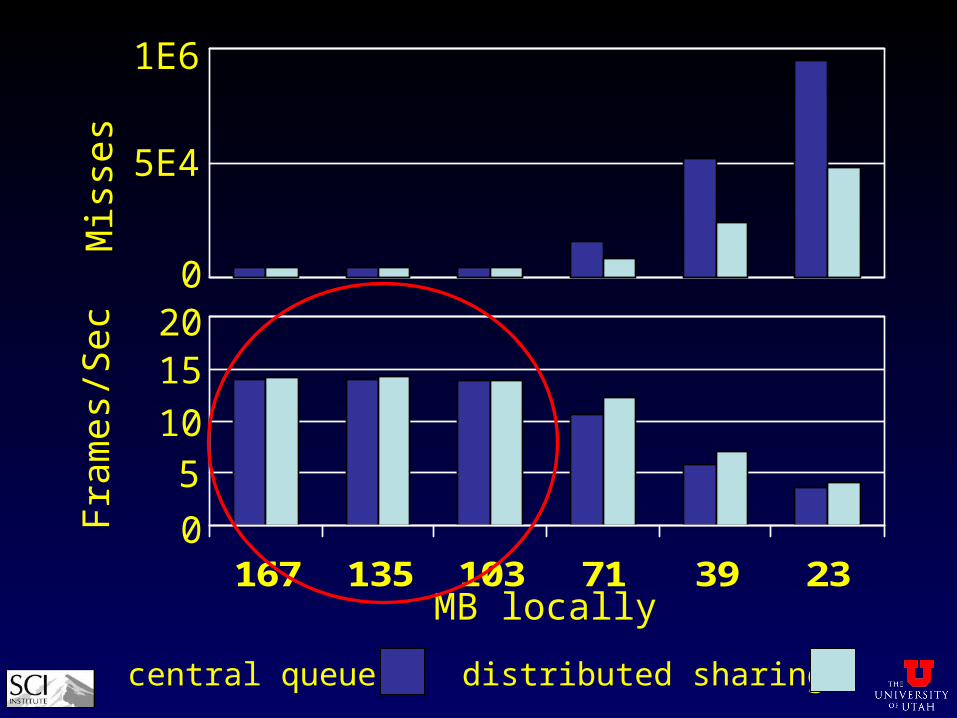
167 135 103 71 39 23
Mis
ses
Fra
mes
/Sec
0
1E6
0
20
MB locally
15
105
5E4
central queue distributed sharing

167 135 103 71 39 23
Mis
ses
Fra
mes
/Sec
0
1E6
0
20
MB locally
15
105
5E4
central queue distributed sharing

Three Techniques forMemory Efficiency
• ODSM PDSM
• central work queue distributed work sharing
• polygonal mesh reorganization

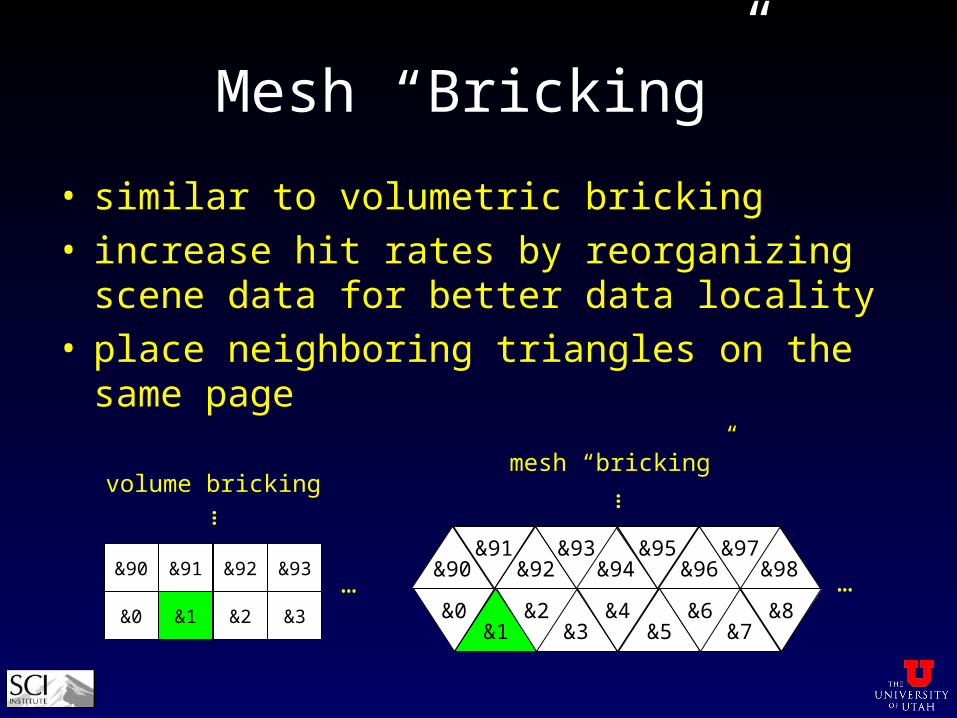
Mesh “Bricking”
• similar to volumetric bricking• increase hit rates by reorganizing scene data for
better data locality• place neighboring triangles on the same page
&0 &1
&90 &91
&2
&92
&3
&93
volume bricking
&3 &5&4
&7&8
&1&0 &2 &6
&94 &96&95
&98&90 &92&91 &93 &97
…
…
……
mesh “bricking”
Mesh “Bricking”
• similar to volumetric bricking• increase hit rates by reorganizing scene data for
better data locality• place neighboring triangles on the same page
&0 &1
&90 &91
&2
&92
&3
&93
volume bricking
&3 &5&4
&7&8
&1&0 &2 &6
&94 &96&95
&98&90 &92&91 &93 &97
…
…
……
mesh “bricking”

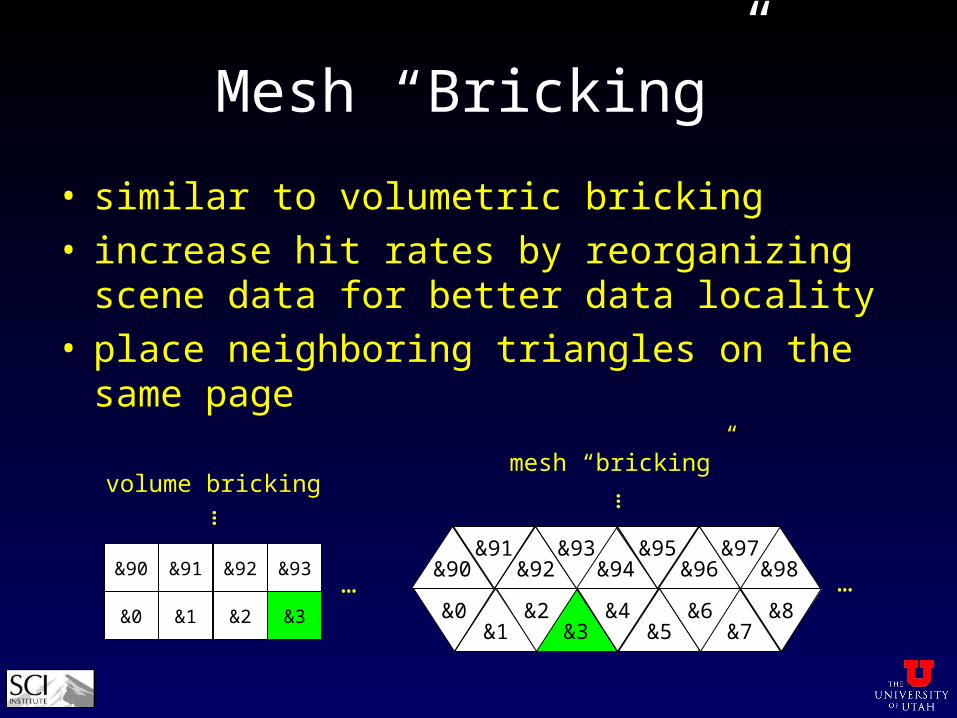
Mesh “Bricking”
• similar to volumetric bricking• increase hit rates by reorganizing scene data for
better data locality• place neighboring triangles on the same page
&0 &1
&90 &91
&2
&92
&3
&93
volume bricking
&3 &5&4
&7&8
&1&0 &2 &6
&94 &96&95
&98&90 &92&91 &93 &97
…
…
……
mesh “bricking”
Mesh “Bricking”
• similar to volumetric bricking• increase hit rates by reorganizing scene data for
better data locality• place neighboring triangles on the same page
&0 &1
&90 &91
&2
&92
&3
&93
volume bricking
&3 &5&4
&7&8
&1&0 &2 &6
&94 &96&95
&98&90 &92&91 &93 &97
…
…
……
mesh “bricking”
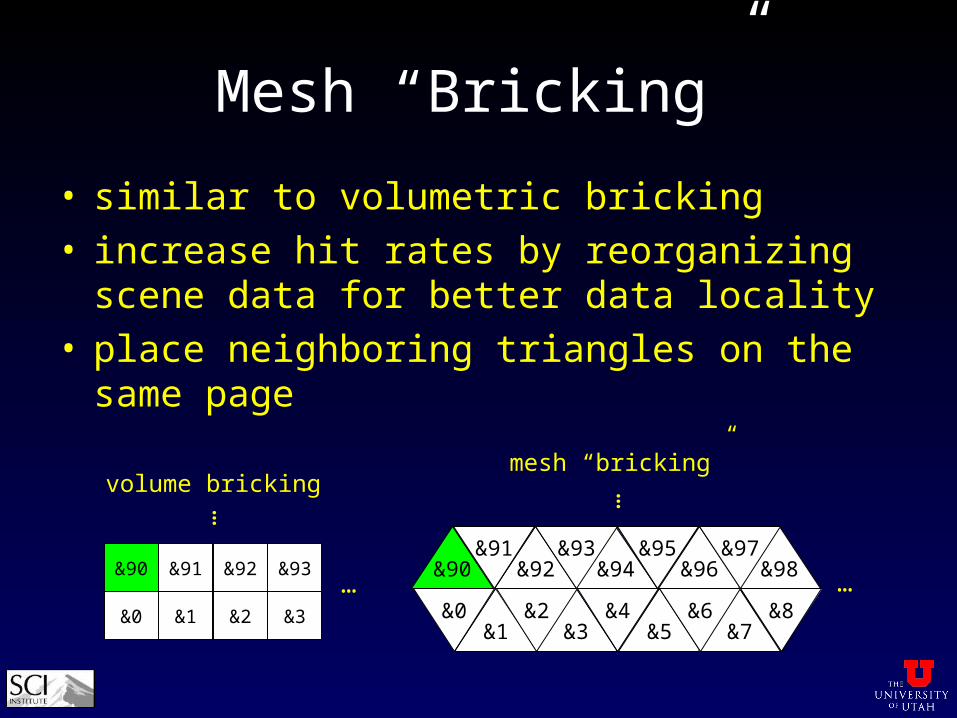
Mesh “Bricking”
• similar to volumetric bricking• increase hit rates by reorganizing scene data for
better data locality• place neighboring triangles on the same page
&0 &1
&90 &91
&2
&92
&3
&93
volume bricking
&3 &5&4
&7&8
&1&0 &2 &6
&94 &96&95
&98&90 &92&91 &93 &97
…
…
……
mesh “bricking”

Mesh “Bricking”
• similar to volumetric bricking• increase hit rates by reorganizing scene data for
better data locality• place neighboring triangles on the same page
&0 &1
&2 &3
&4
&6
&5
&7
volume bricking
&6 &8&7
&13&14
&1&0 &2 &12
&10 &15&11
&17&3 &5&4 &9 &16
…
…
……
mesh “bricking”

Mesh “Bricking”
• similar to volumetric bricking• increase hit rates by reorganizing scene data for
better data locality• place neighboring triangles on the same page
&0 &1
&2 &3
&4
&6
&5
&7
volume bricking
&6 &8&7
&13&14
&1&0 &2 &12
&10 &15&11
&17&3 &5&4 &9 &16
…
…
……
mesh “bricking”

Input Mesh

Sorted Mesh

Reorganizing the Mesh
• based on a grid acceleration structure• each grid cell contains pointers to triangles within• our grid structure is bricked in memory
1. create grid acceleration structure2. traverse the cells as stored in memory3. append copies of the triangles to a new mesh
• new mesh has triangles sorted in space and memory

Comparison
• same test as before
• compare input and sorted mesh

0
20000
40000
60000
80000
100000
120000
140000
160000
0
2
4
6
8
10
12
72.8 40.8 32.8 24.8 20.8 16.8 14.8
Mis
ses
Fra
mes
/Sec
MB locally
input mesh sorted mesh

0
20000
40000
60000
80000
100000
120000
140000
160000
0
2
4
6
8
10
12
72.8 40.8 32.8 24.8 20.8 16.8 14.8
Mis
ses
Fra
mes
/Sec
MB locally
input mesh sorted mesh

0
20000
40000
60000
80000
100000
120000
140000
160000
0
2
4
6
8
10
12
72.8 40.8 32.8 24.8 20.8 16.8 14.8
Mis
ses
Fra
mes
/Sec
MB locally
input mesh sorted mesh

0
20000
40000
60000
80000
100000
120000
140000
160000
0
2
4
6
8
10
12
72.8 40.8 32.8 24.8 20.8 16.8 14.8
Mis
ses
Fra
mes
/Sec
MB locally
input mesh sorted mesh

0
2
4
6
8
10
12
72.8 40.8 32.8 24.8 20.8 16.8 14.8
Fra
mes
/Sec
MB locally
input mesh sorted mesh
• grid based approach duplicates split triangles

Summary
three techniques for more efficientmemory use:
1. PDSM adds overhead only in the exceptional case of data miss
2. reuse tile assignments with parallel load balancing heuristics
3. mesh reorganization puts related triangles onto nearby pages

Future Work
• need 64-bit architecture for very large data
• thread safe PDSM for hybrid parallelism
• distributed pixel result gathering
• surface based mesh reorganization

Acknowledgments
• Funding agencies• NSF 9977218, 9978099• DOE VIEWS• NIH
• Reviewers - for tips and seeing through the rough initial data presentation
• EGPGV Organizers
• Thank you!






























