



Evolution of Big Data Architecture
Gang Tao
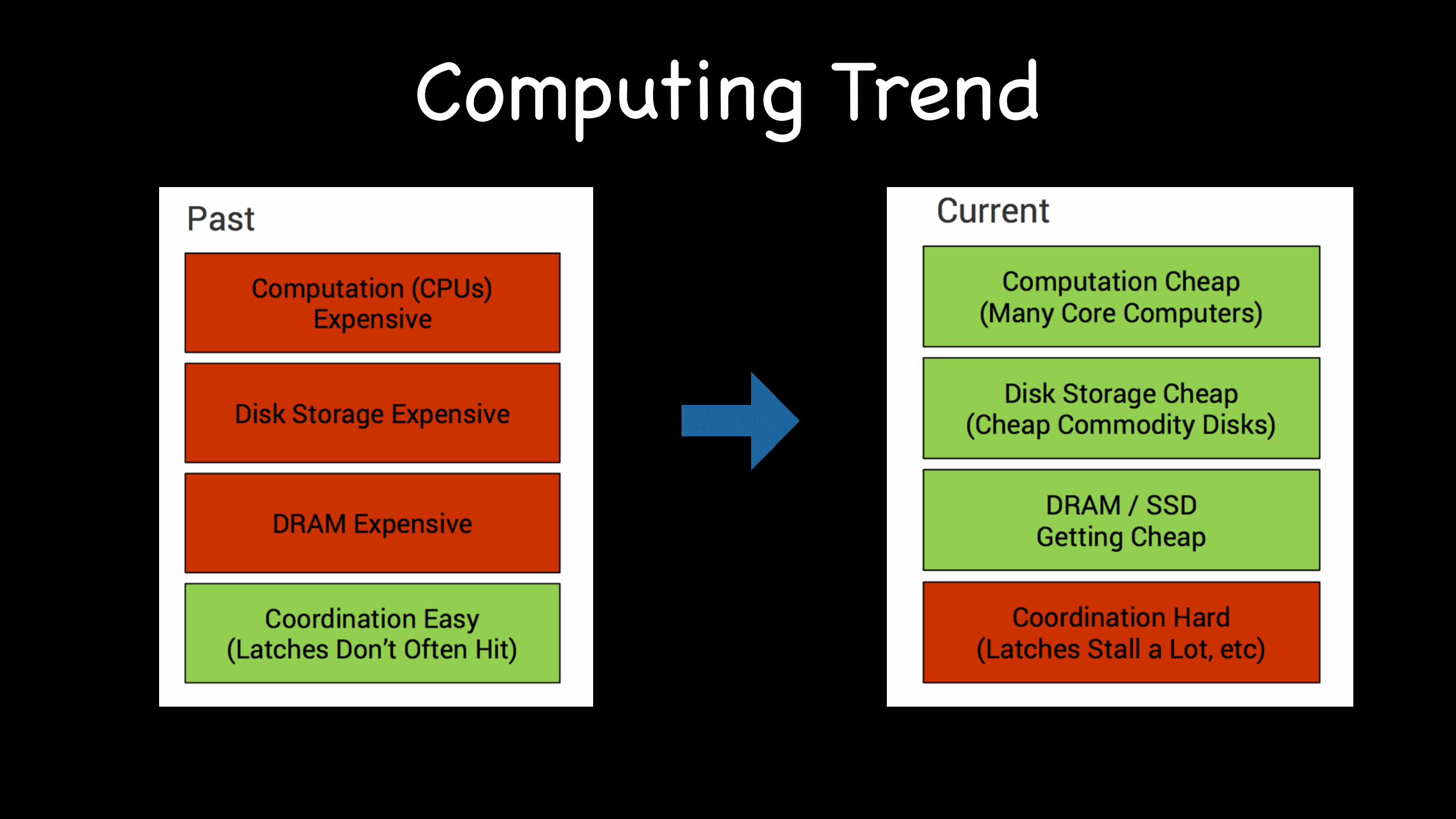
Computing Trend

Non Functional Requirements
• Latency
• Throughput
• Fault Tolerant
• Scalable
• Exactly Once Semantic

Hadoop
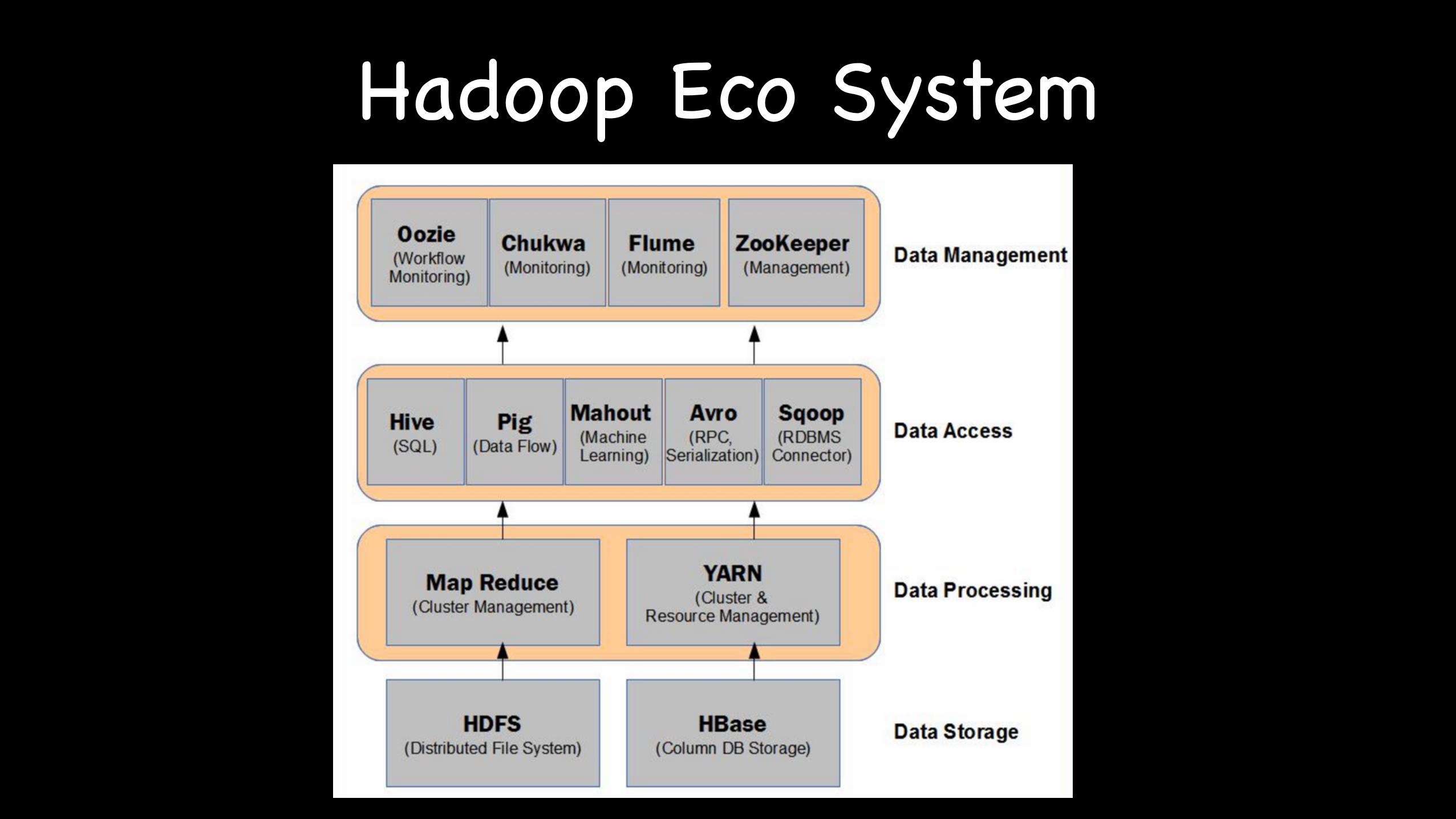
Hadoop Eco System
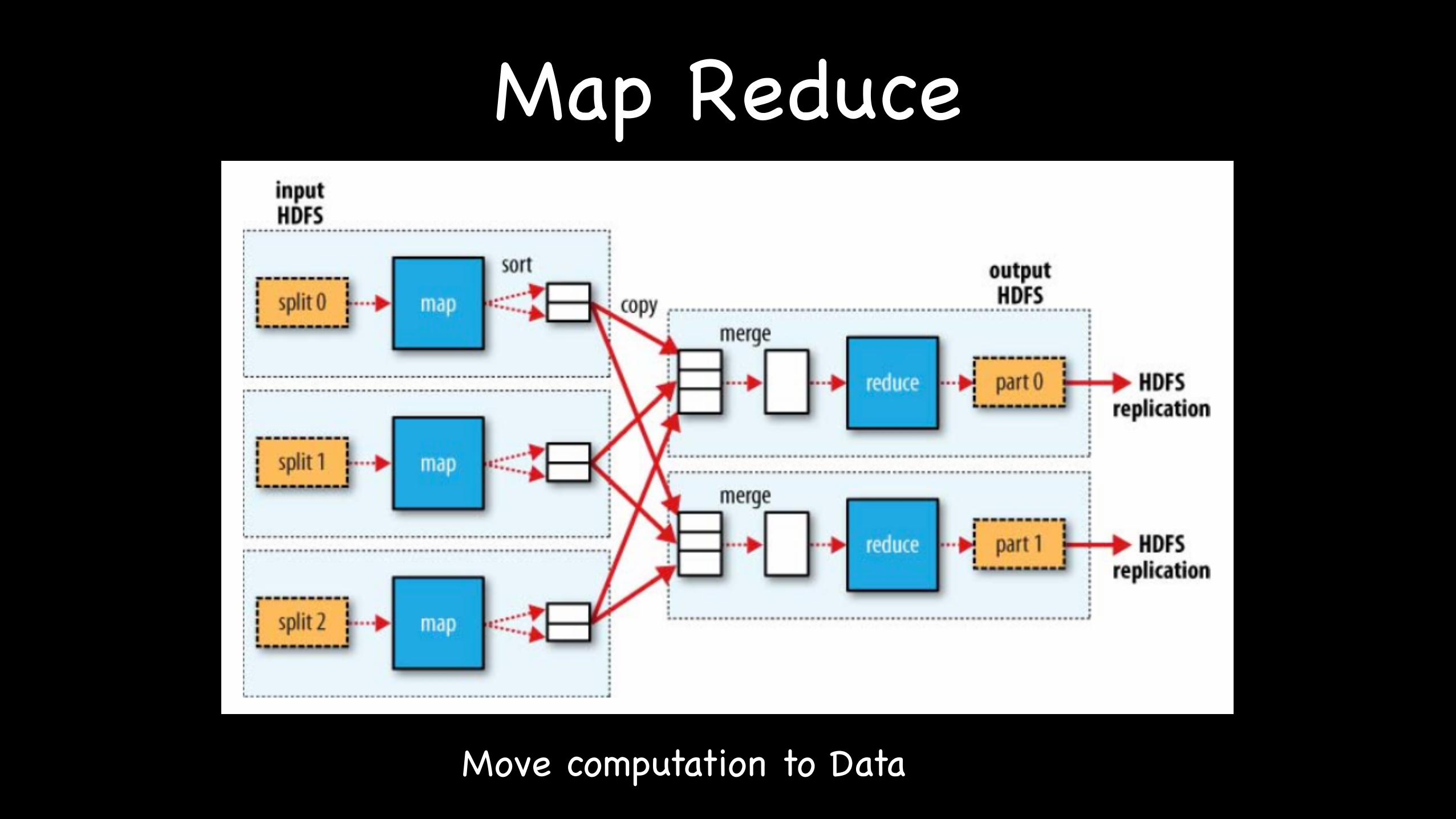
Map Reduce
Move computation to Data
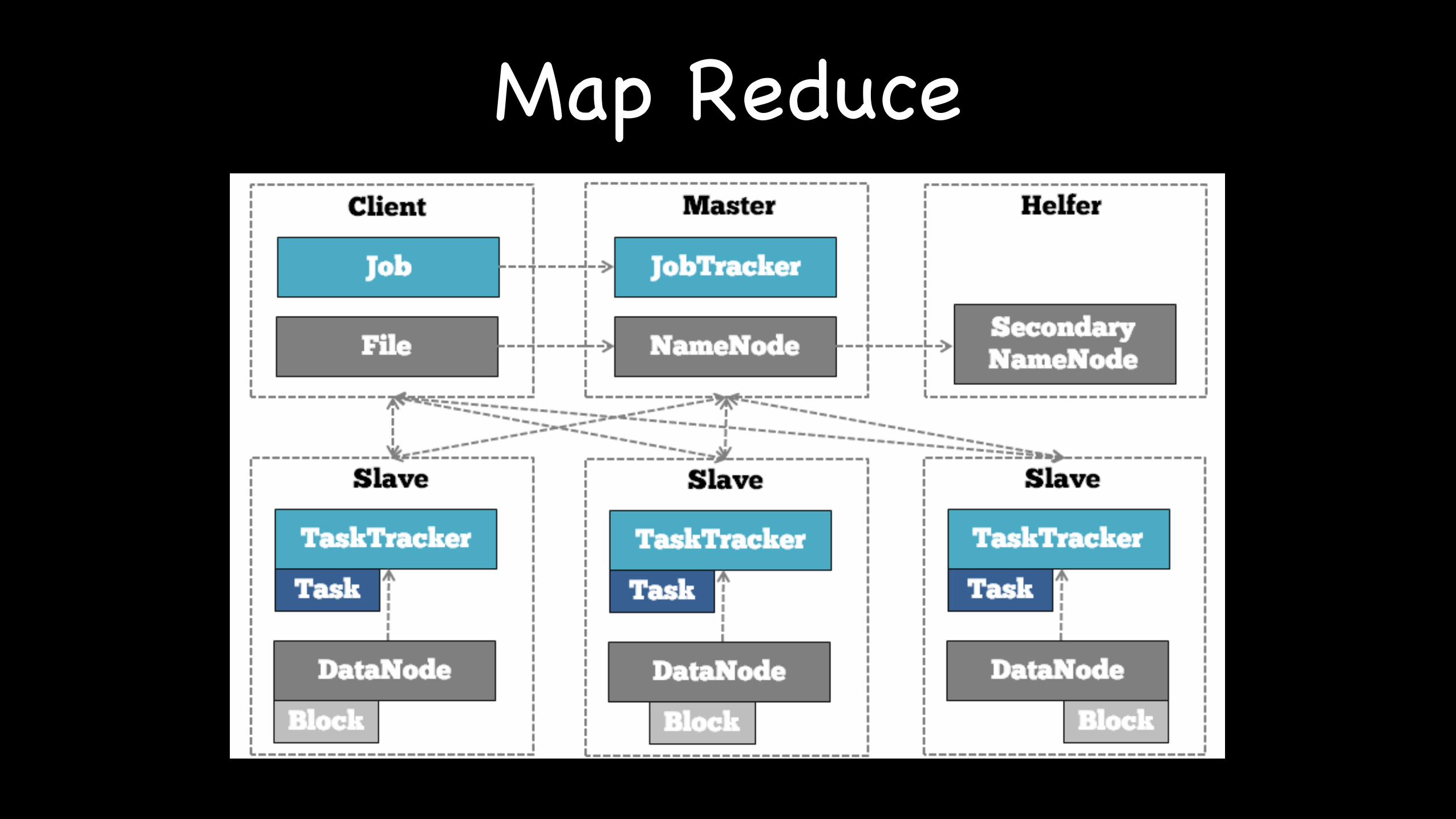
Map Reduce

Hadoop the Limitation
• Map/Reduce is hard to use
• Latency is high
• inevitable data movement

Lambda

Lambda Architecture
query = function(all data)

Design Principle
human fault-tolerance – the system is unsusceptible to data loss or data corruption because at scale it could be irreparable.
data immutability – store data in it’s rawest form immutable and for perpetuity. (INSERT/ SELECT/DELETE but no UPDATE !)
recomputation – with the two principles above it is always possible to (re)-compute results by running a function on the raw data.
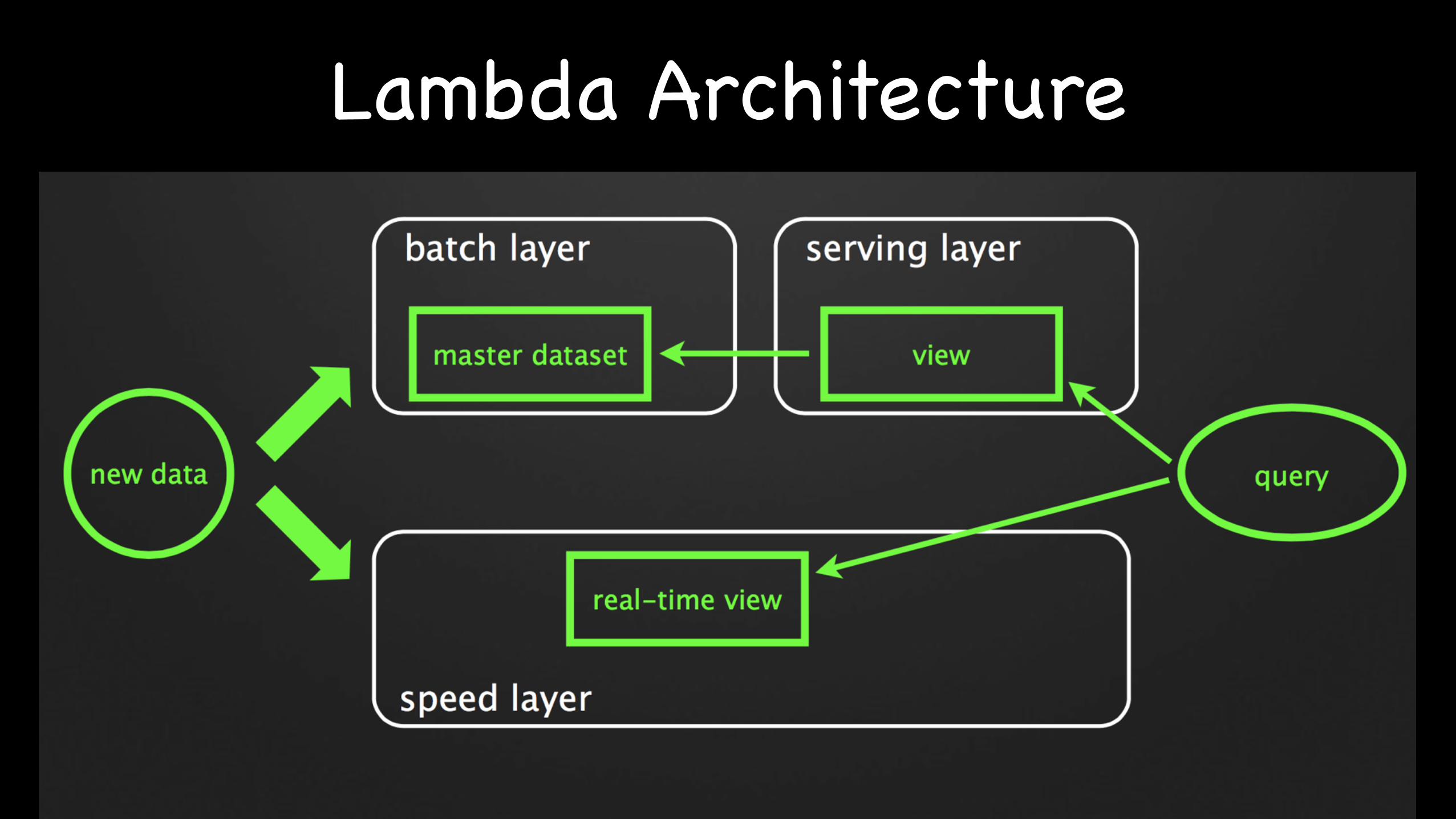
Lambda Architecture
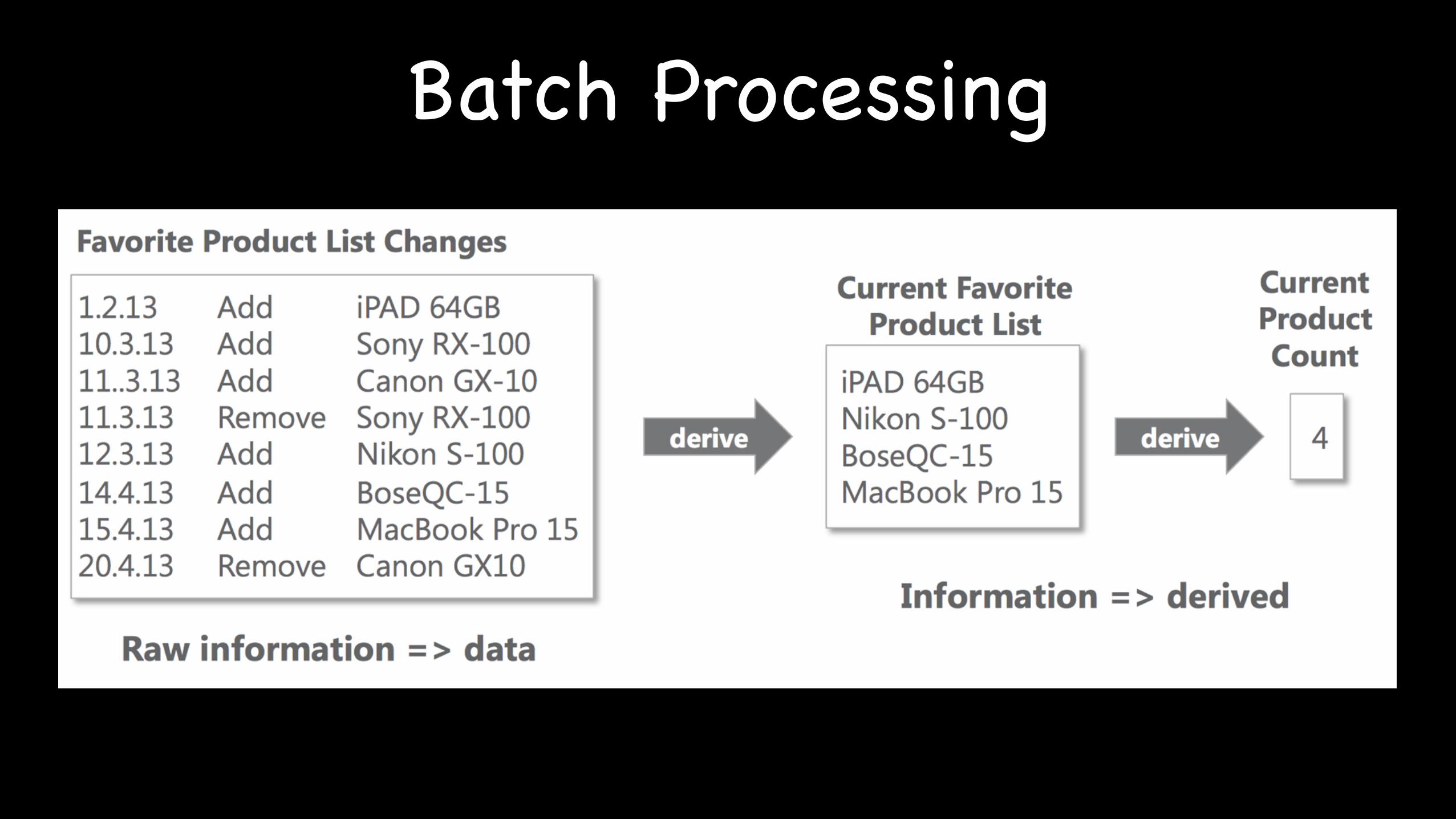
Batch Processing
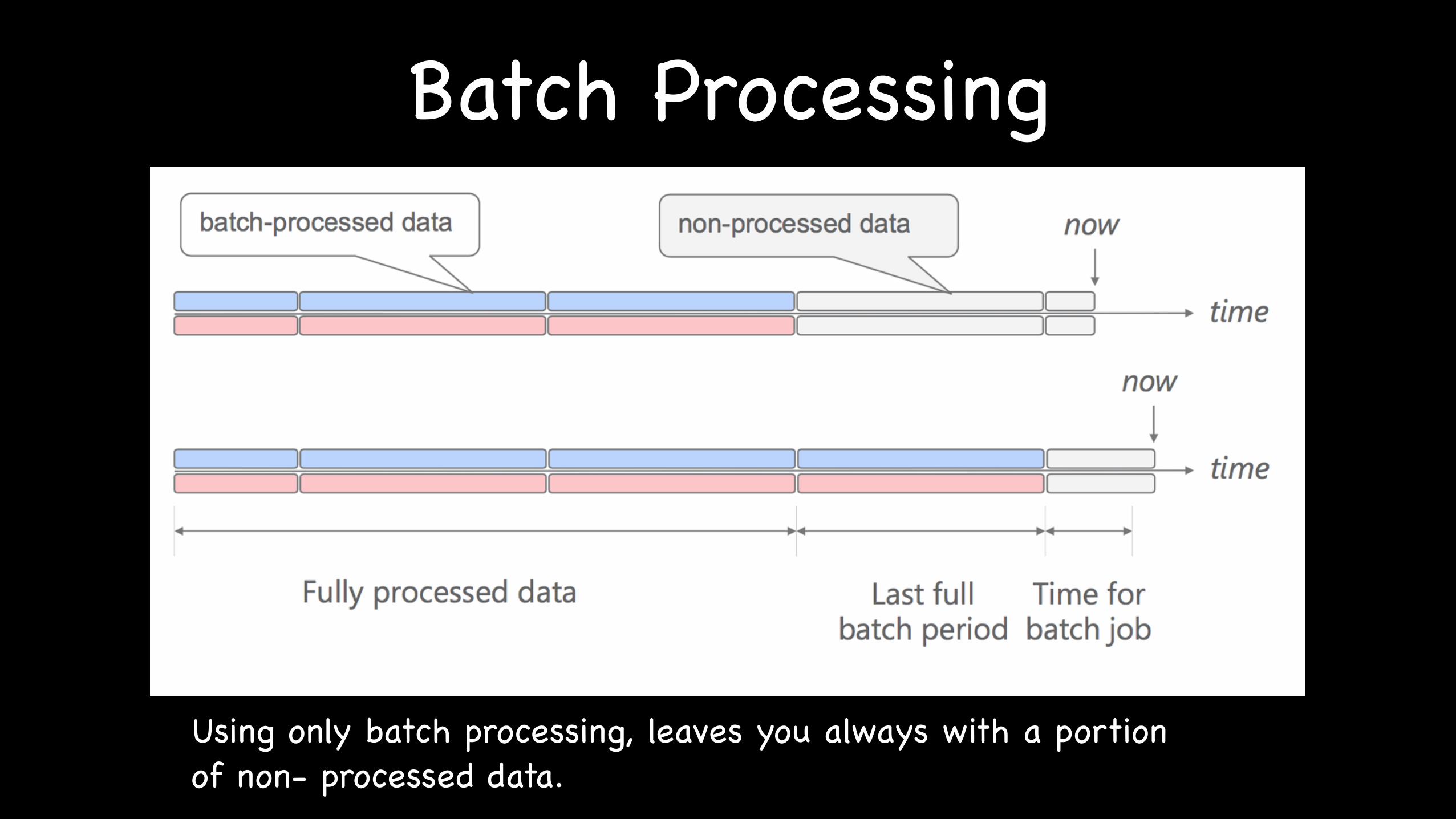
Batch Processing
Using only batch processing, leaves you always with a portion of non- processed data.
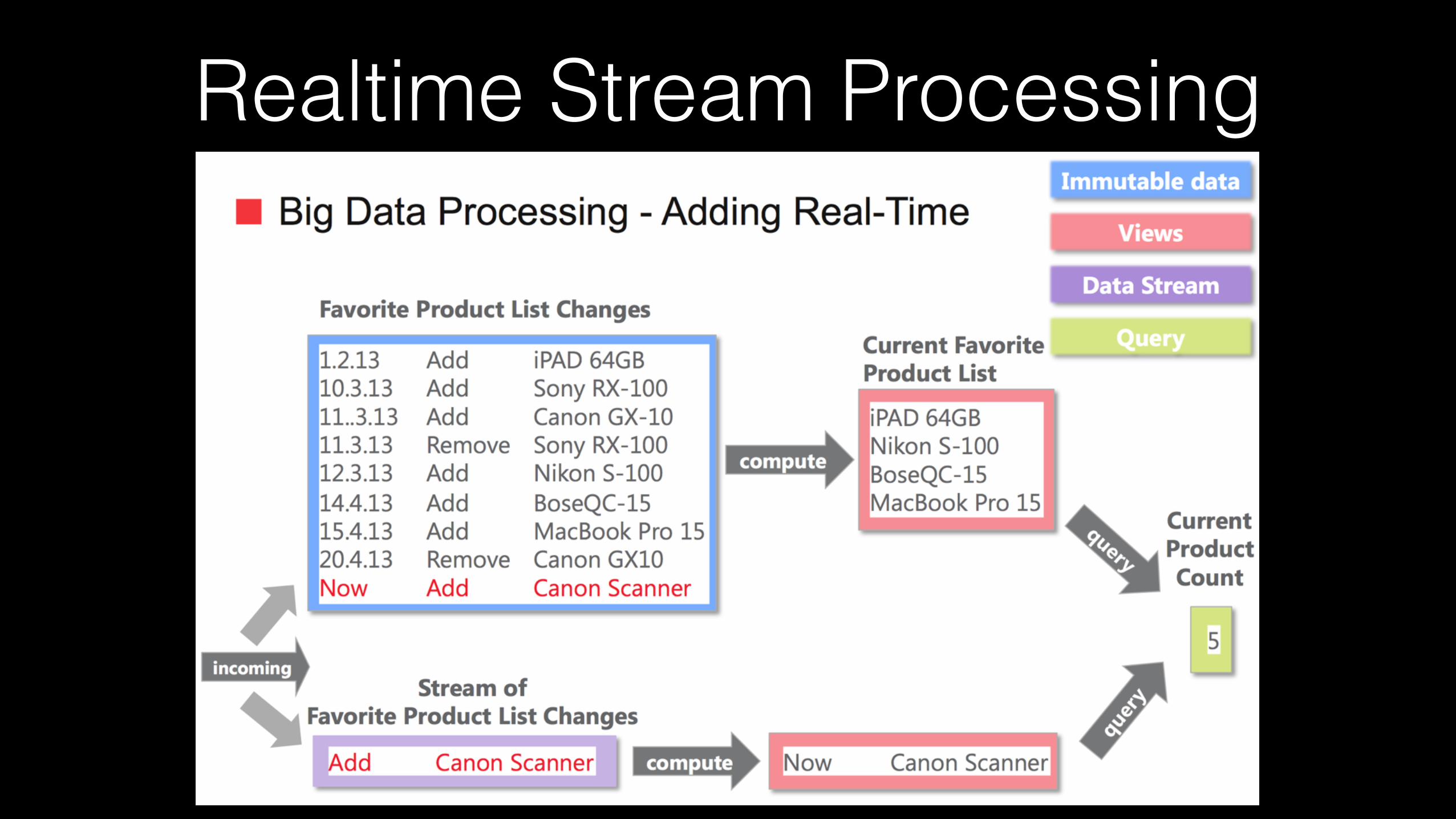
Realtime Stream Processing

query = function(all data) + function(new data)
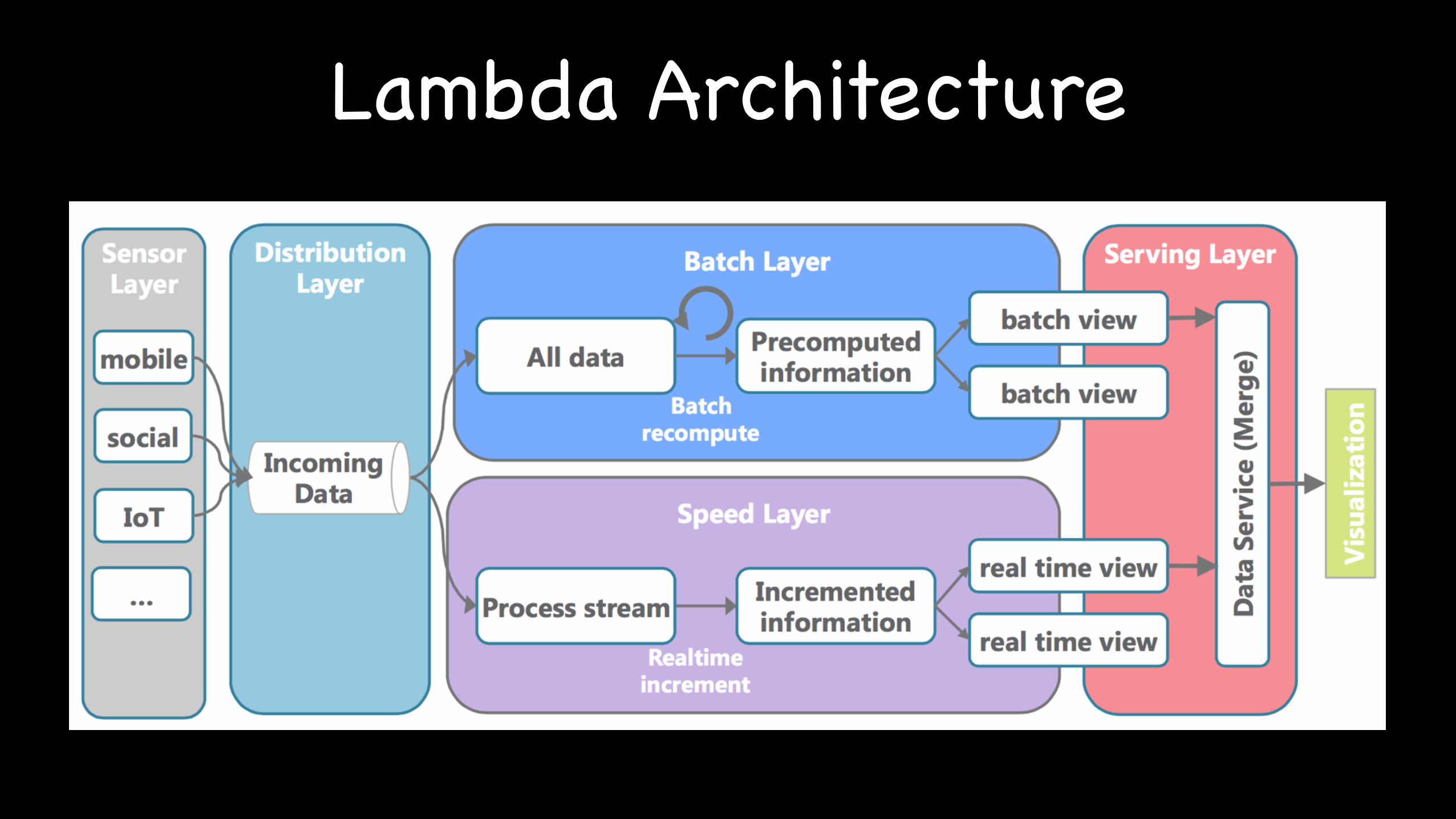
Lambda Architecture
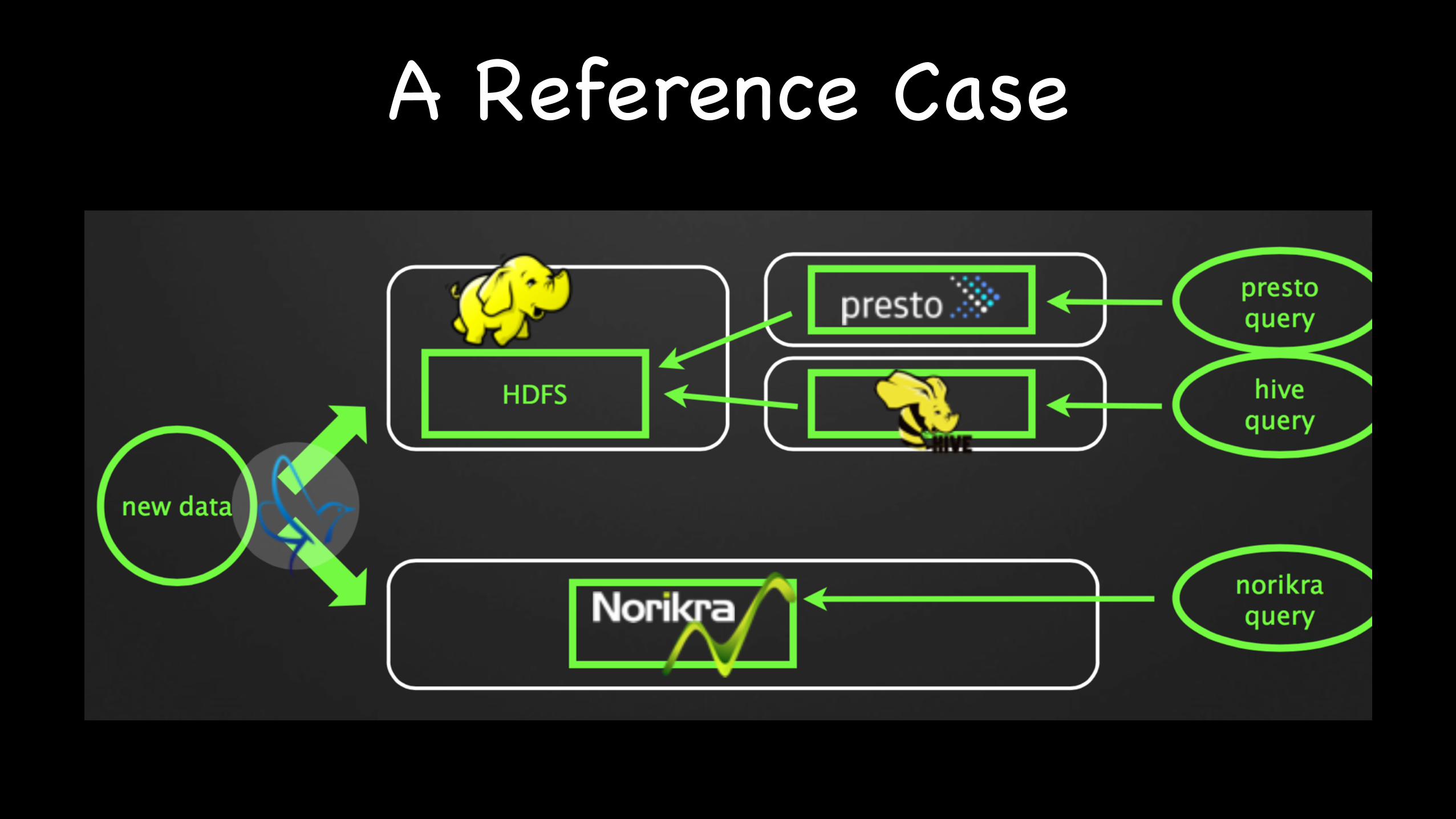
A Reference Case
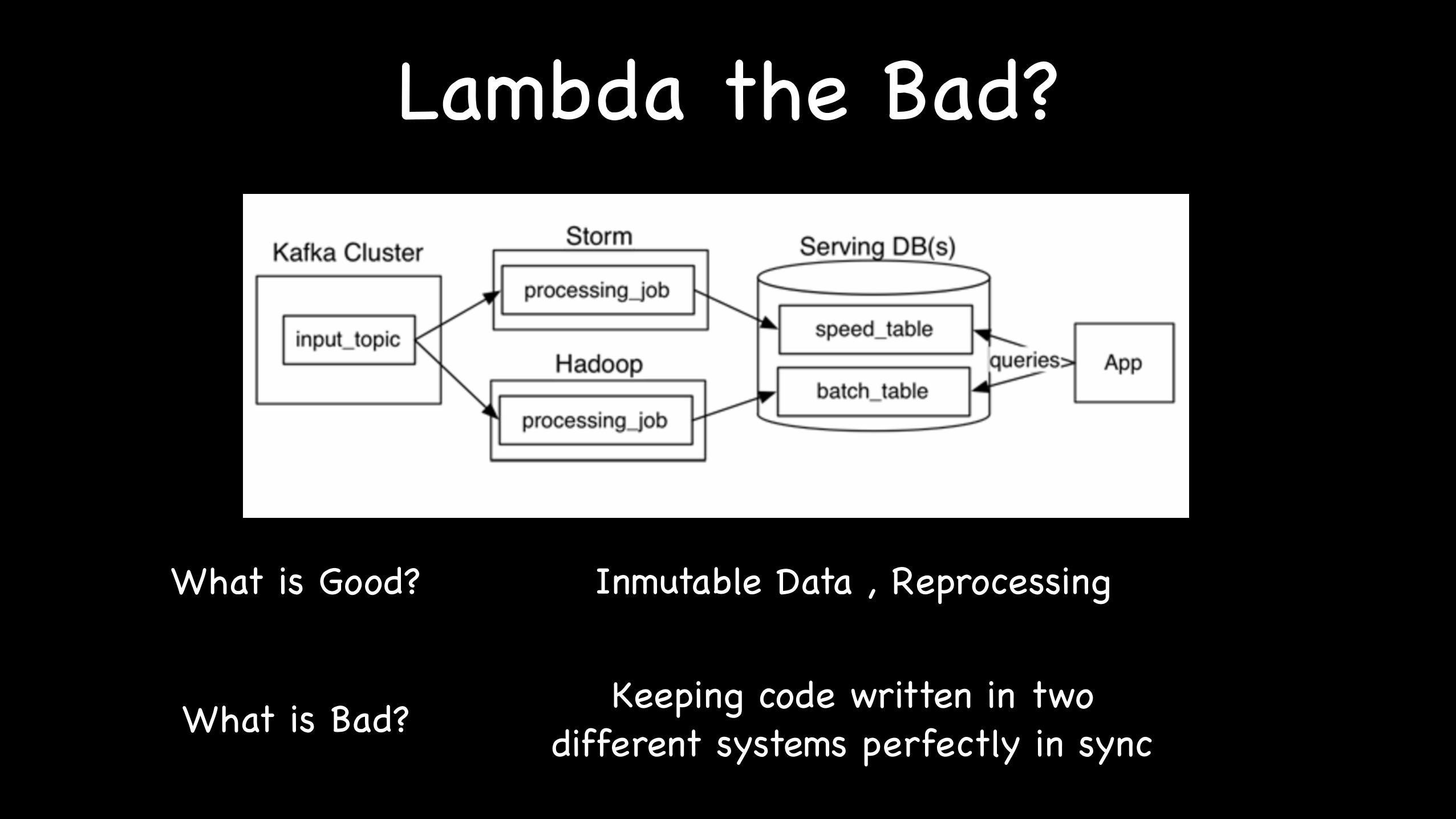
Lambda the Bad?
What is Good?
What is Bad?
Inmutable Data , Reprocessing
Keeping code written in two different systems perfectly in sync
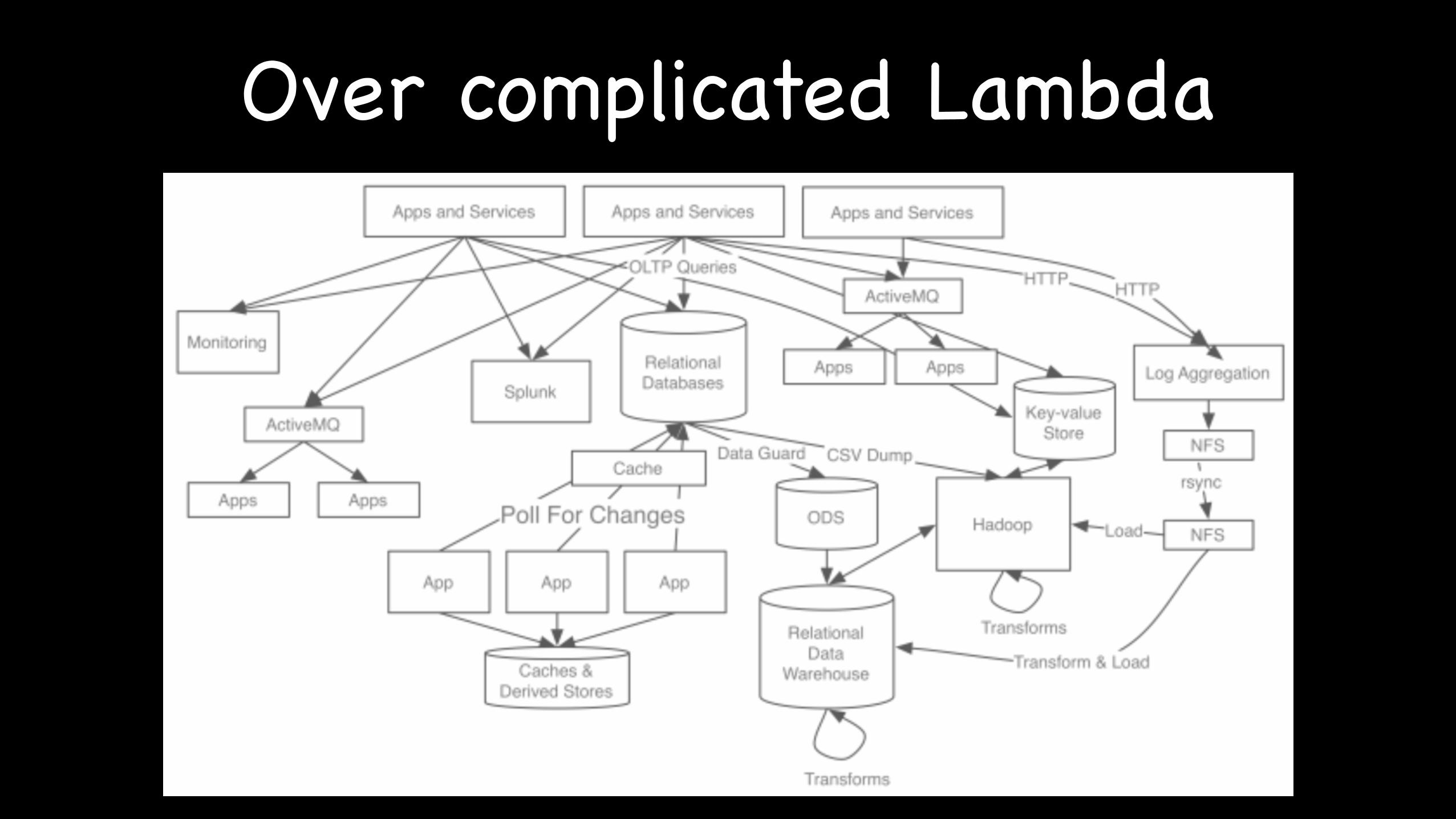
Over complicated Lambda

Batch VS. Stream

Stream & Realtime
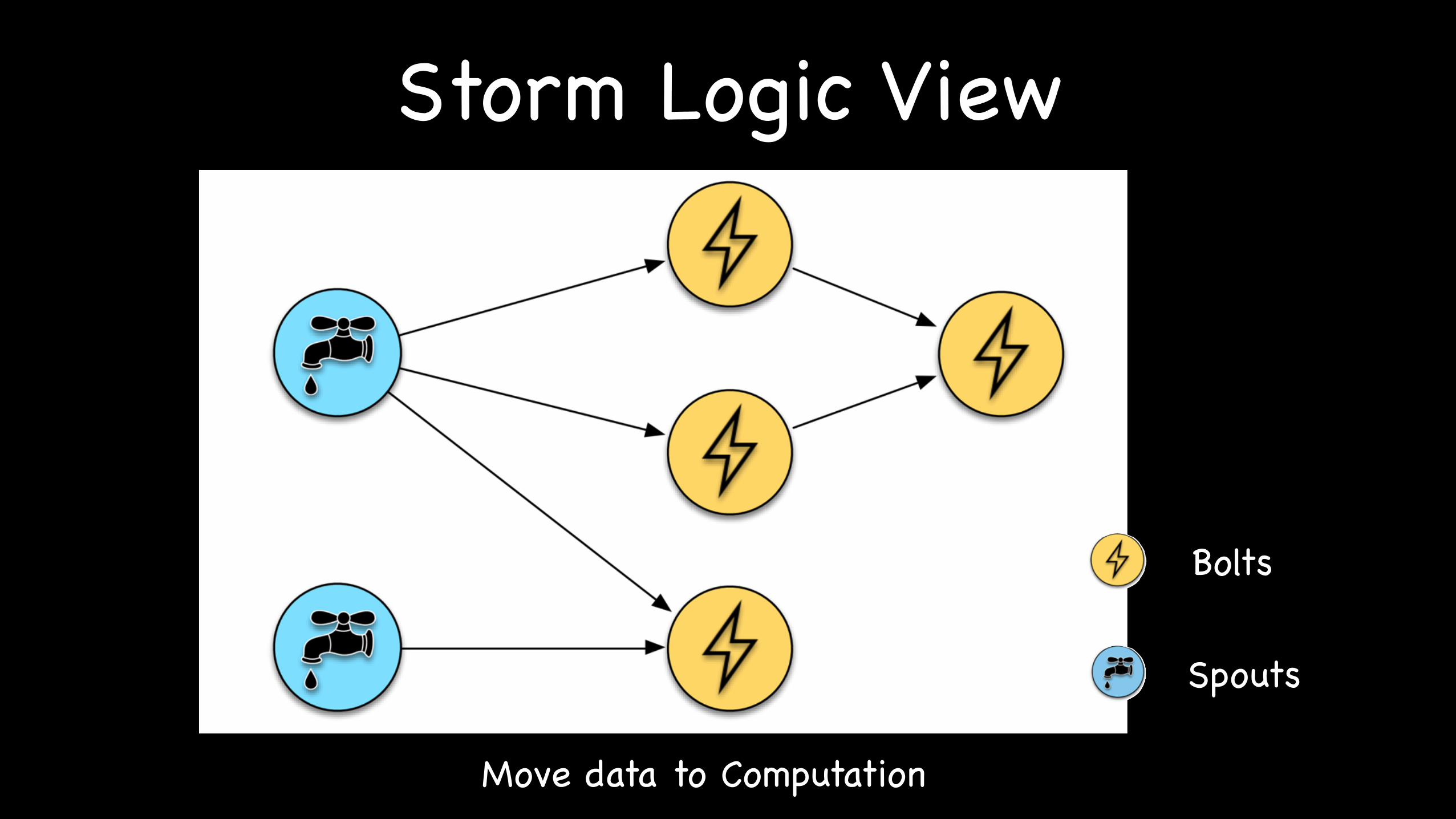
Storm Logic View
Bolts
Spouts
Move data to Computation
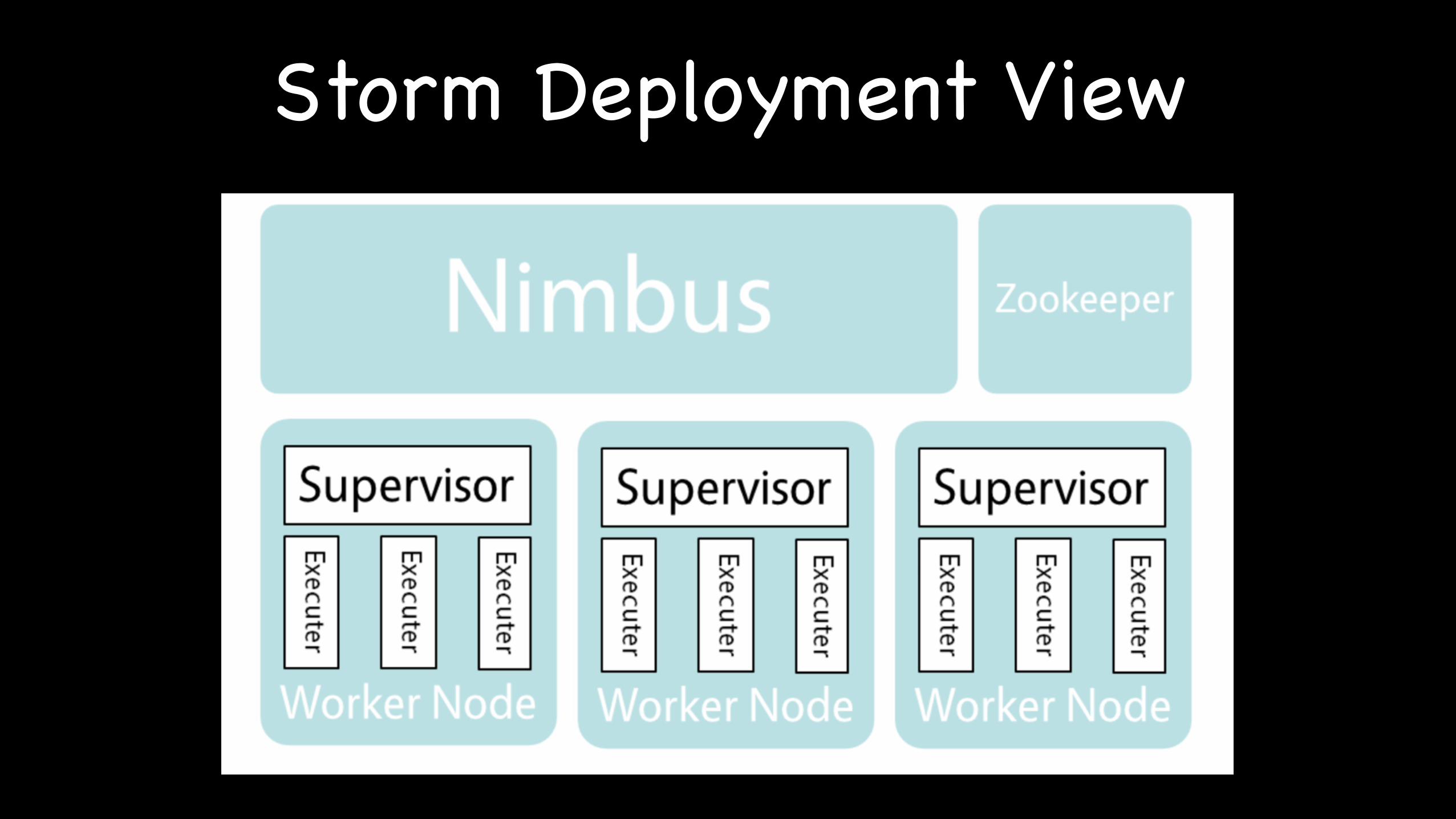
Storm Deployment View
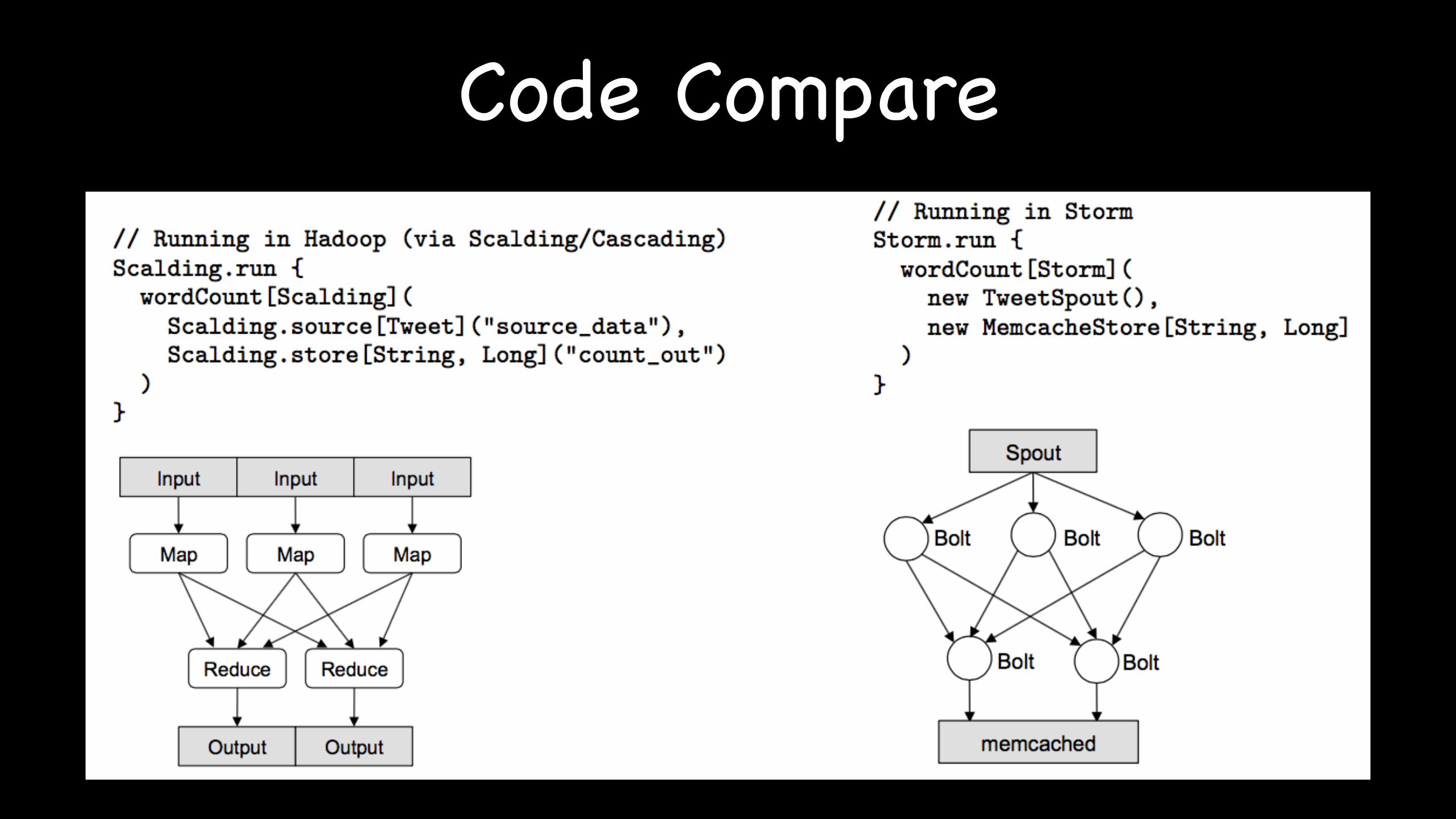
Code Compare
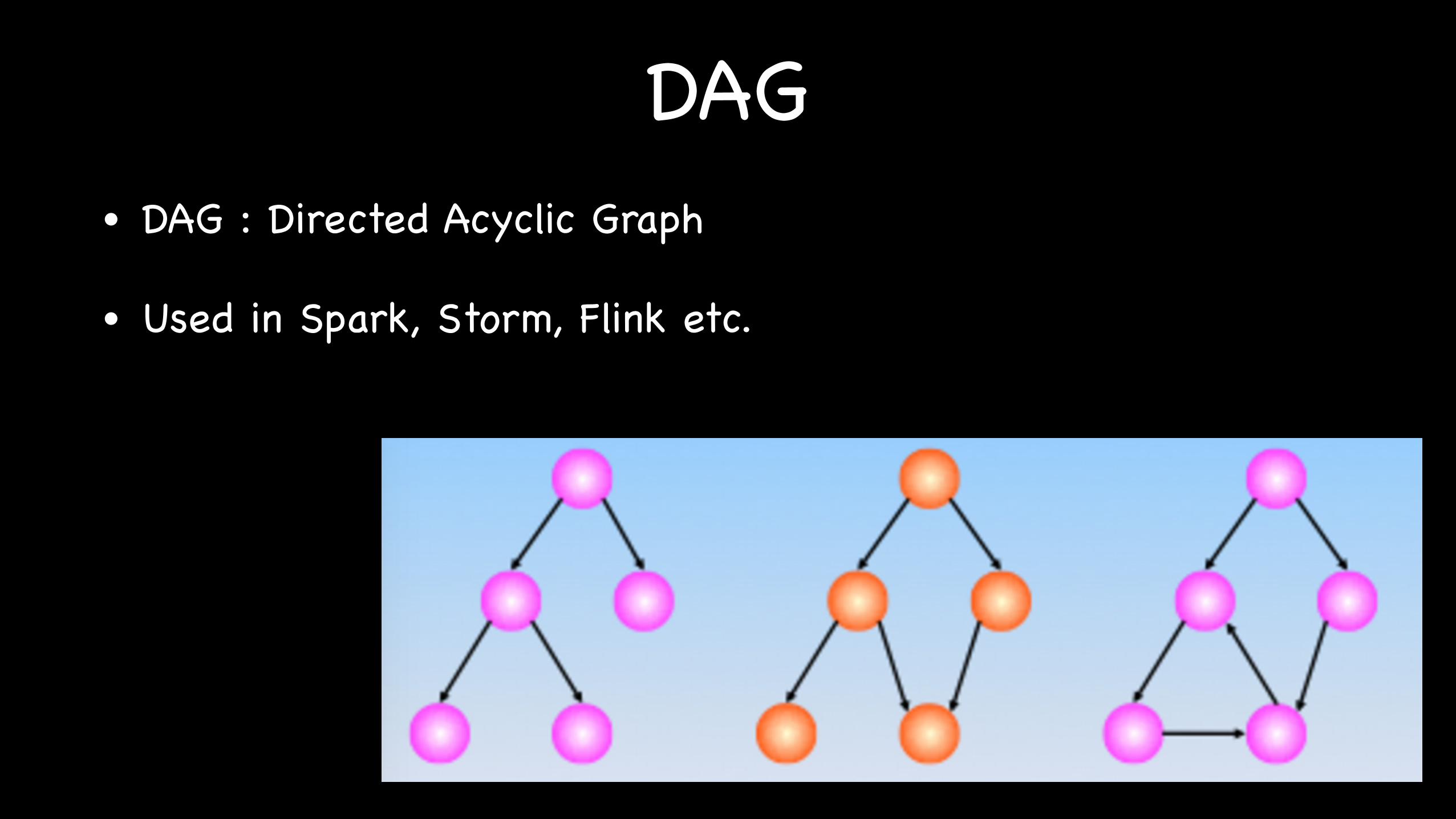
DAG• DAG : Directed Acyclic Graph
• Used in Spark, Storm, Flink etc.

Out of Control
Build Complexity with Simplicity
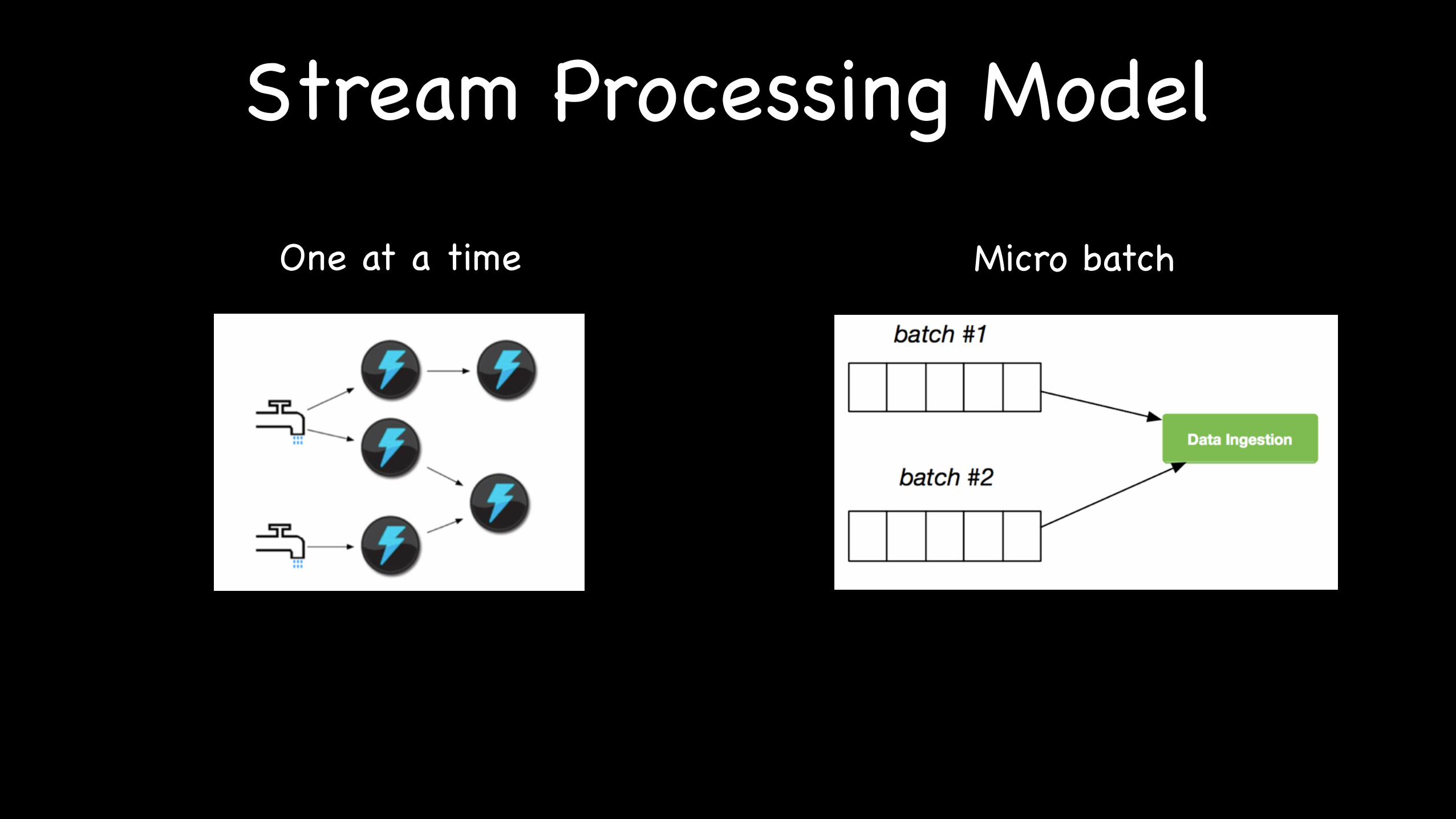
Stream Processing Model
One at a time Micro batch

Stream Processing Model
One at a time Micro Batch
Low Latency Y N
High Throughput N Y
at least once Y Y
excatly once Sometimes Y
simple programing model Y N

Stream Computing the Limitation• Queries must be written before data
• There should be another way to query past data
• Queries cannot be run twice
• All results will be lost when any error occurs All data have gone when bugs found
• Disorders of events break results
• Recorded time based queries? Or arrival time based queries?

Batch/Stream Unification
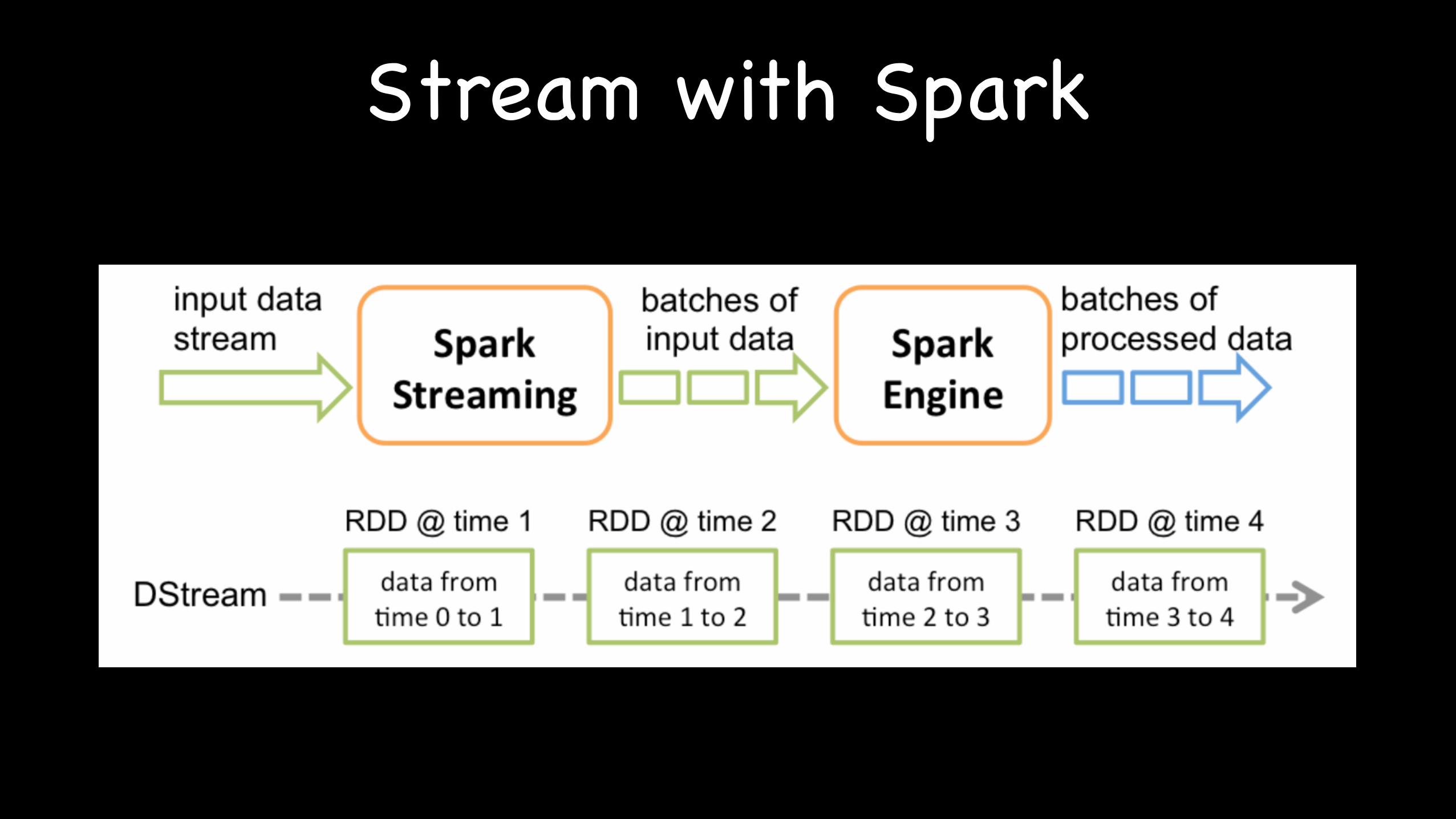
Stream with Spark
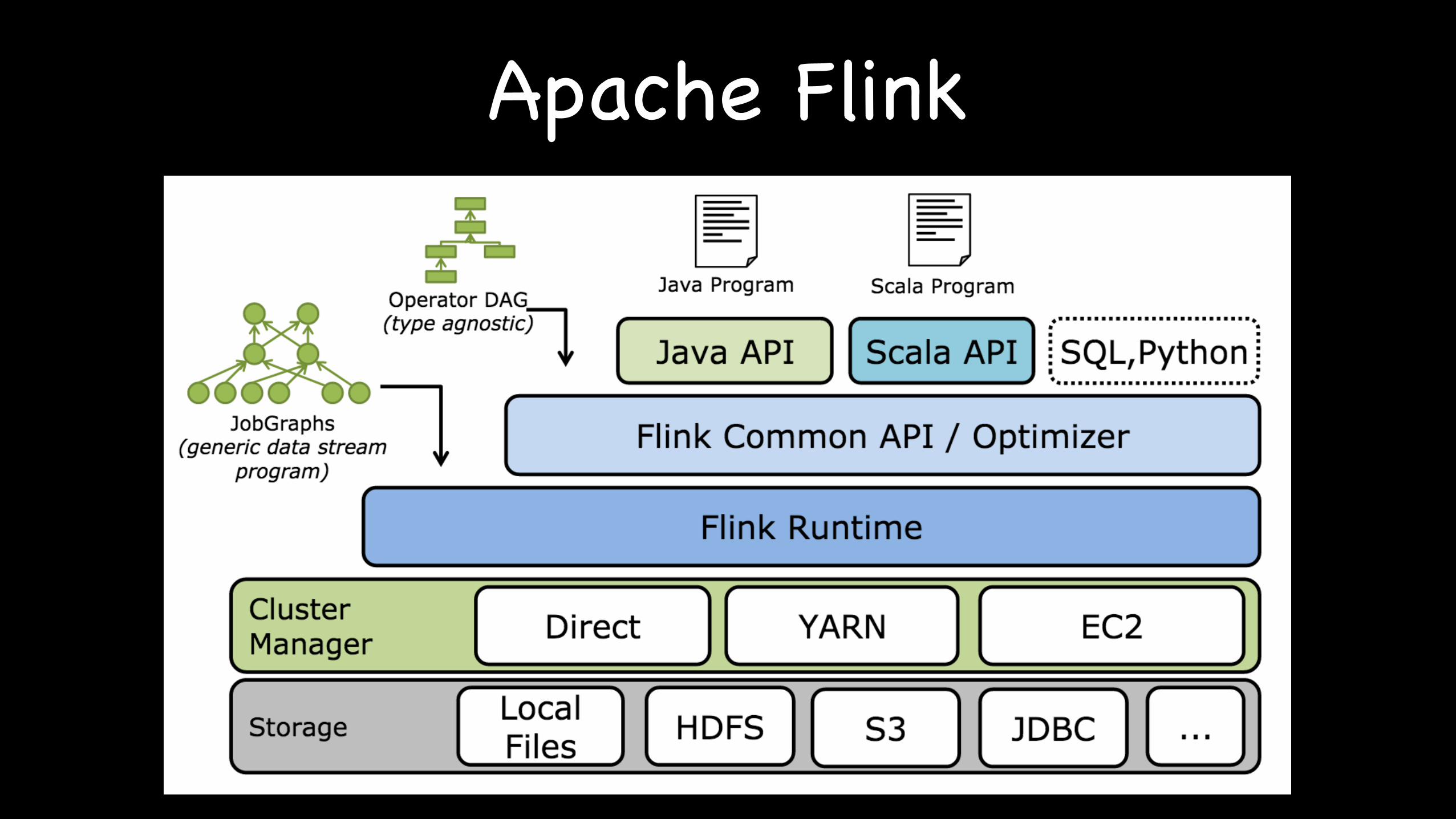
Apache Flink
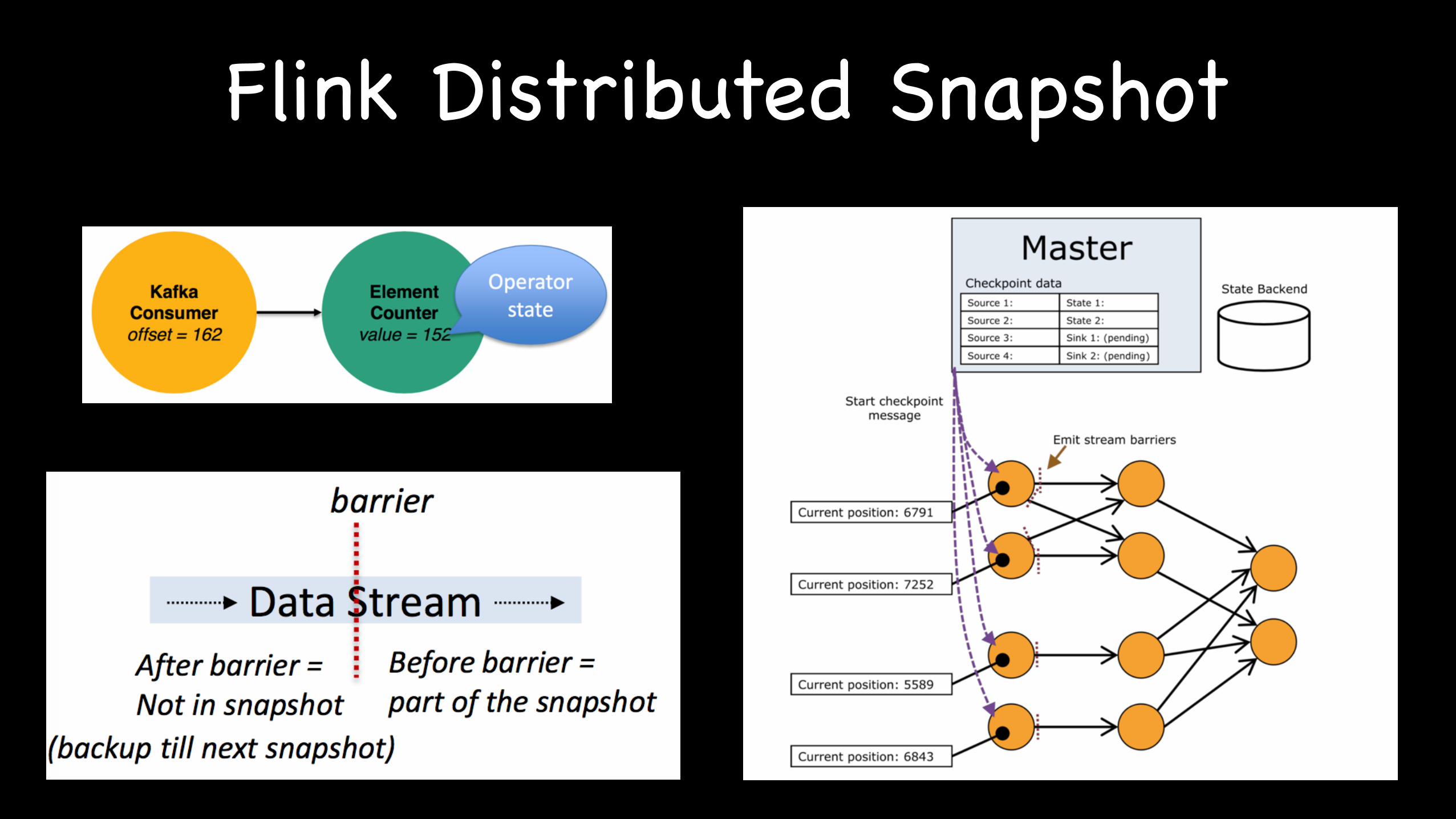
Flink Distributed Snapshot

Fault Tolerance in Stream
• At Least Once : ensure all operators see all events
• Stream -> Replay on failure
• Exactly Once :
• Flink : distributed Snapshot
• Spark : Micro Batch
Jay Kreps
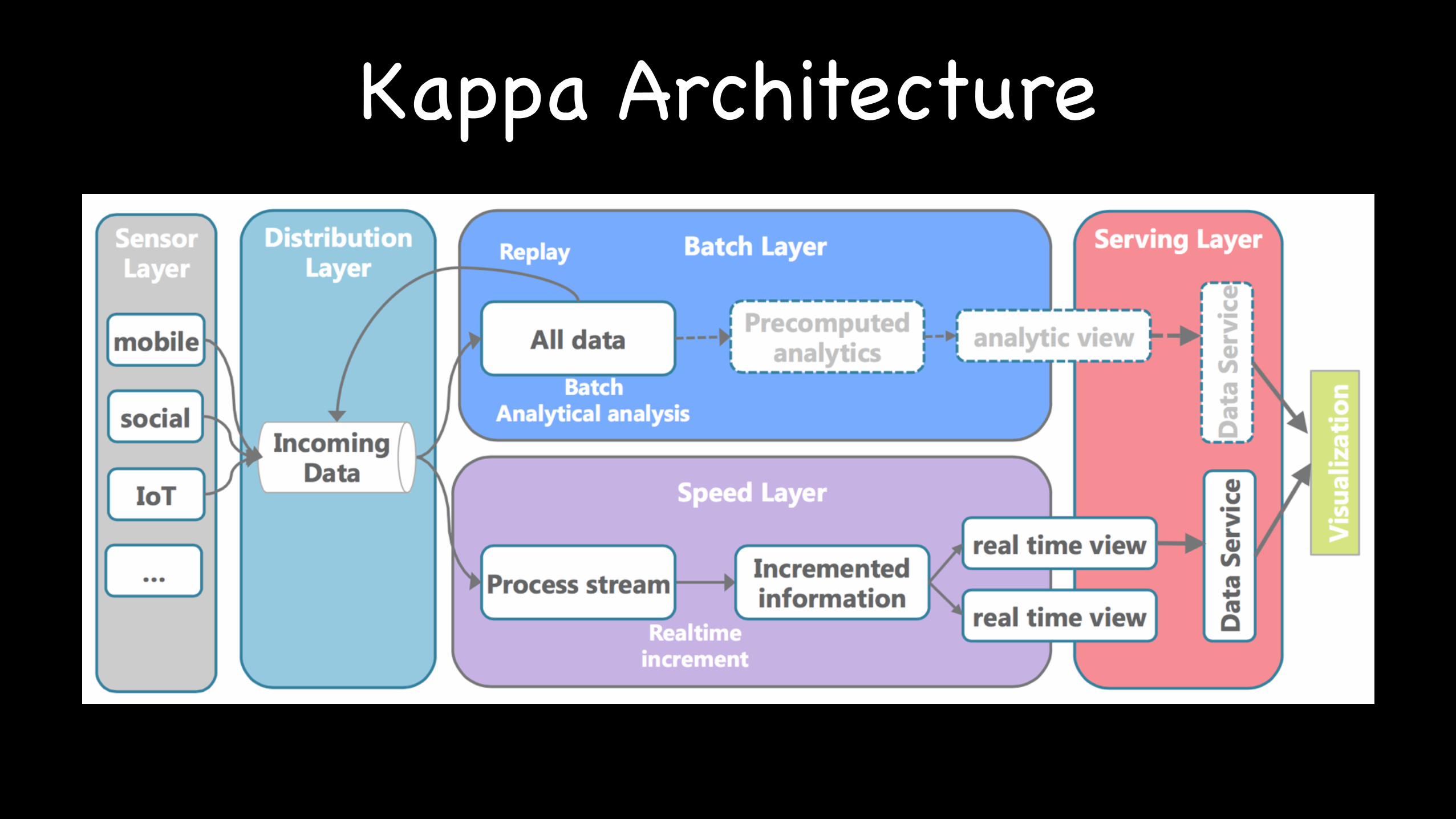
Kappa Architecture























![Cluster Computing Architecture Intel Labs - 01.org · Cluster Computing Architecture 10 *[Neo4j] ... GraphBuilder makes it easy. ... Our Wikipedia Graphs 38 Cluster Computing Architecture](https://static.cupdf.com/doc/110x72/5b552dd37f8b9a0d398dead8/cluster-computing-architecture-intel-labs-01org-cluster-computing-architecture.jpg)






