



Area-Efficient Instruction Set Synthesis for Reconfigurable
System on Chip Designs
Philip Brisk Adam Kaplan Majid Sarrafzadeh
Embedded and Reconfigurable Systems LabComputer Science Department
University of California, Los Angeles
[email protected] [email protected]@cs.ucla.edu
DAC ’04. June 9, 2004. San Diego Convention Center, San Diego, CA

Outline
• Custom Instruction Generation and Selection
• Resource Sharing
• Algorithm Description with Examples
• Datapath Synthesis Techniques
• Experimental Methodology and Results
• Summary

Custom Instruction Generation
• Compiler Profiles Application Code• Extracts Favorable IR Patterns• Synthesizes Patterns as Hardware Datapaths
Custom Instruction Selection
• Area Constraints Limit on-Chip Functionality• NP-Hard 0-1 Knapsack Problem• Formulated as an Integer Linear Program (ILP)
Custom Instruction Generation and Selection

For each custom instruction iGain(i) : Estimated Performance Gain of iArea(i) : Estimated Area of iSelected(i) : 1 if i is Selected; 0 Otherwise
Goal Maximize Gain of Selected Instructions
ConstraintArea of Selected Instructions FPGA Area
<
ILP Formulation forInstruction Selection Problem
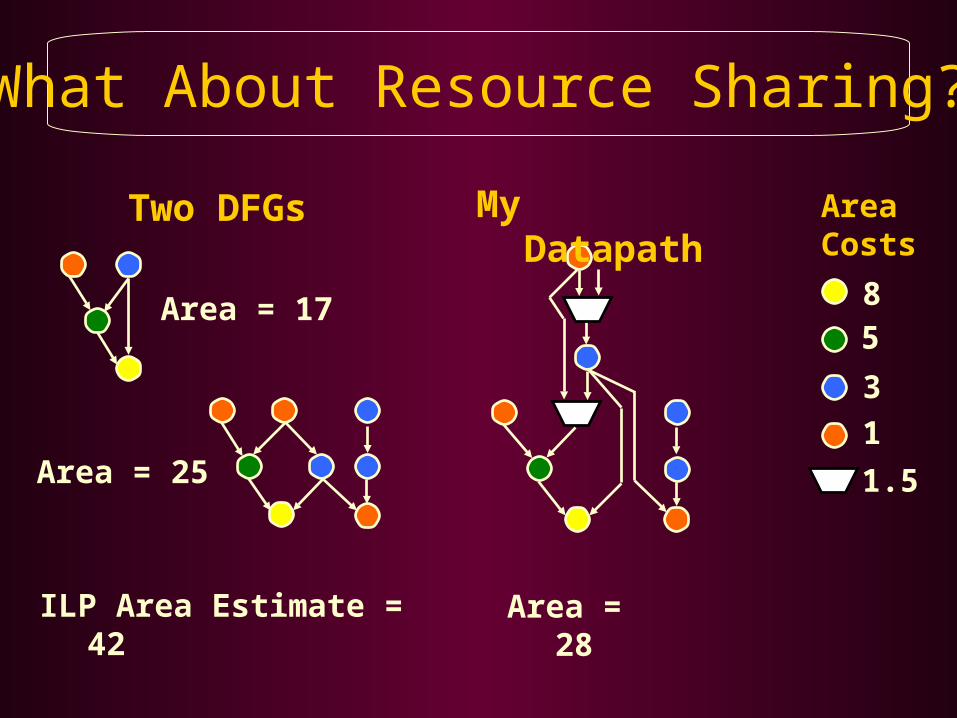
What About Resource Sharing?
Area = 17
Area = 25
Two DFGs
1.5
My Datapath
Area = 28ILP Area Estimate = 42
AreaCosts
85
1
3

Analysis
0-1 Knapsack Problem Formulation Over-Estimated Area by 150%
• ILP Solvers Do Not Consider Resource Sharing
How to Remedy This
• Develop a Resource Sharing Algorithm
• Avoid Additive Area Estimates Based on per-Instruction Costs

Resource Sharing for DFGs
Given: • A Set of DFGs G* = {G1, …, Gn}
Goal: • Construct a Consolidation Graph GC of Minimal Cost
Constraints:• GC Must be Acyclic• GC Must be a Supergraph of each Gi in G*
That’s Life: • The Problem is NP-Hard
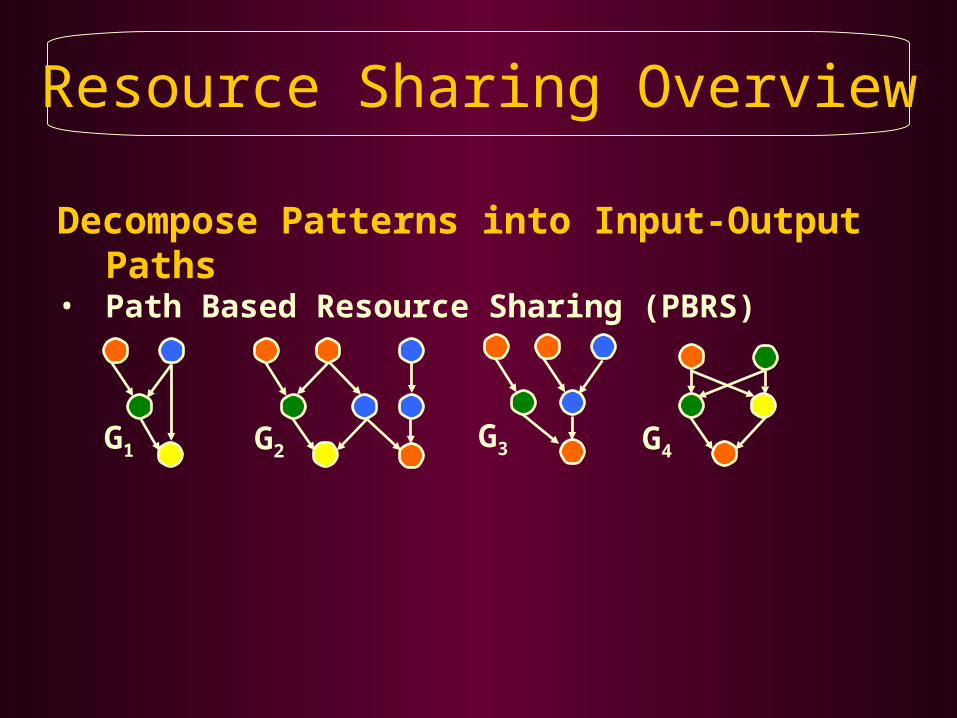
Resource Sharing Overview
G3 G4G1 G2
Decompose Patterns into Input-Output Paths• Path Based Resource Sharing (PBRS)

Resource Sharing Overview
G3 G4G1 G2
Decompose Patterns into Input-Output Paths• Path Based Resource Sharing (PBRS)
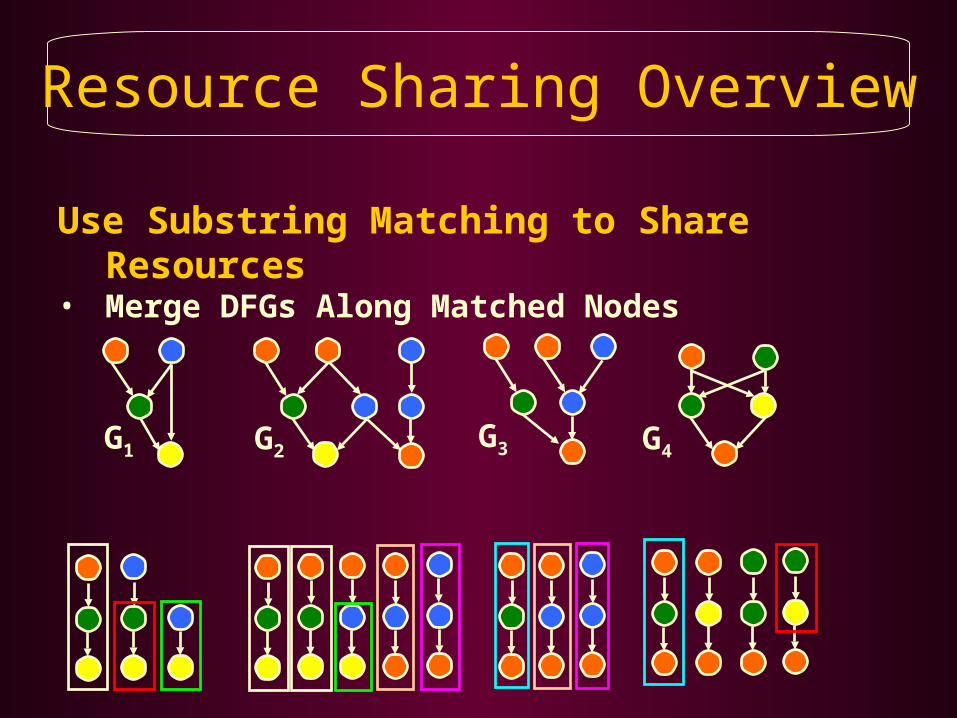
Resource Sharing Overview
Use Substring Matching to Share Resources• Merge DFGs Along Matched Nodes
G3 G4G1 G2

Resource Sharing Overview
Synthesize GC
• Requires Less Area than Synthesizing G1…G4 Separately
Gc
G3 G4
G1 G2

AreaCosts
85
1
3
Path-BasedResource Sharing
P1: ()
P2: ()

P1: ()
P2: ()
MACStrO(L) L – Length of String
( )
Area of MACStr = 26
Maximum Area Common Substring
AreaCosts
85
1
3

P1: ()
P2: ()
MACSeqO(L2/logL) L – Length of String
( )
Area of MACSeq = 43
AreaCosts
85
1
3
Maximum Area Common Subsequence

Resource Sharing Algorithm
Global Phase
Determine:Which DFGs to MergeAn Initial Path to Merge
Local PhaseAggressively Apply PBRS to Share Resources Between the DFGs Selected by the Global Phase
Repeat Until all DFGs are Merged, or no Further Resource Sharing is Possible

Resource Sharing Algorithm
AreaCosts
85
1
3
G1 G2G3 G4

Global Phase
AreaCosts
85
1
3
G3 G4G1 G2

Global Phase
AreaCosts
85
1
3
G3 G4G1 G2
MACSeq/MACStr

Entering Local Phase
AreaCosts
85
1
3
G1 G2
MACSeq/MACStr
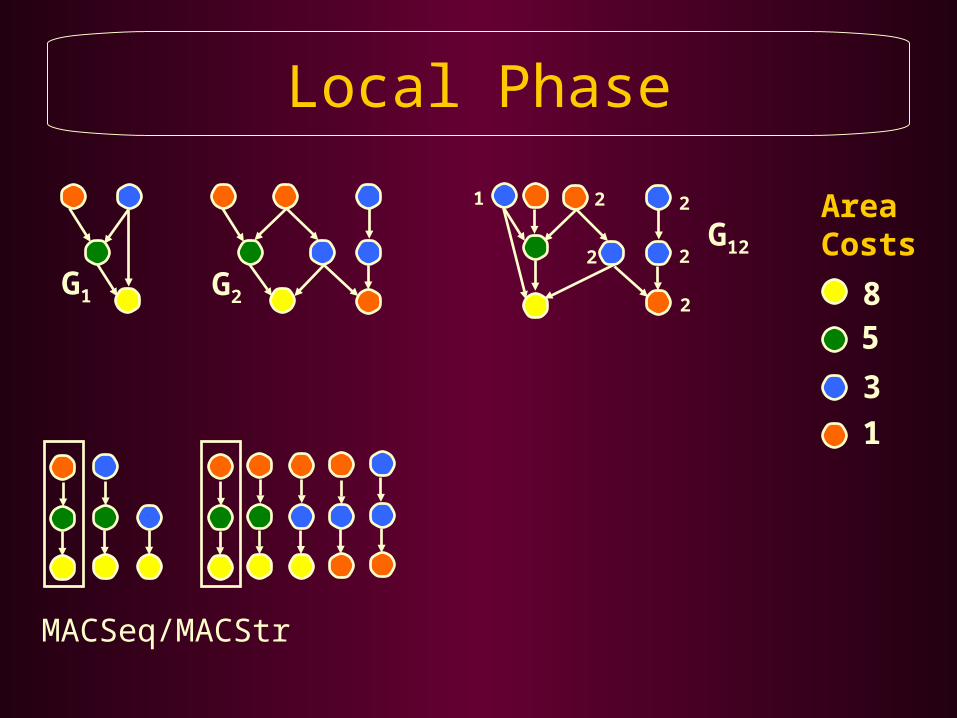
Local Phase
AreaCosts
85
1
3
G1 G2
1 2
2
2
2
2
G12
MACSeq/MACStr

Local Phase
AreaCosts
85
1
3
G1 G2
1 2
2
2
2
2
G12
0
0
0
0
MACSeq/MACStr

Local Phase
AreaCosts
85
1
3
G1 G2
0
0
0
0
1 2
2
2
2
2
G12

Local Phase
AreaCosts
85
1
3
G1 G2
0
0
0
0
1 2
2
2
2
2
G12
MACSeq/MACStr
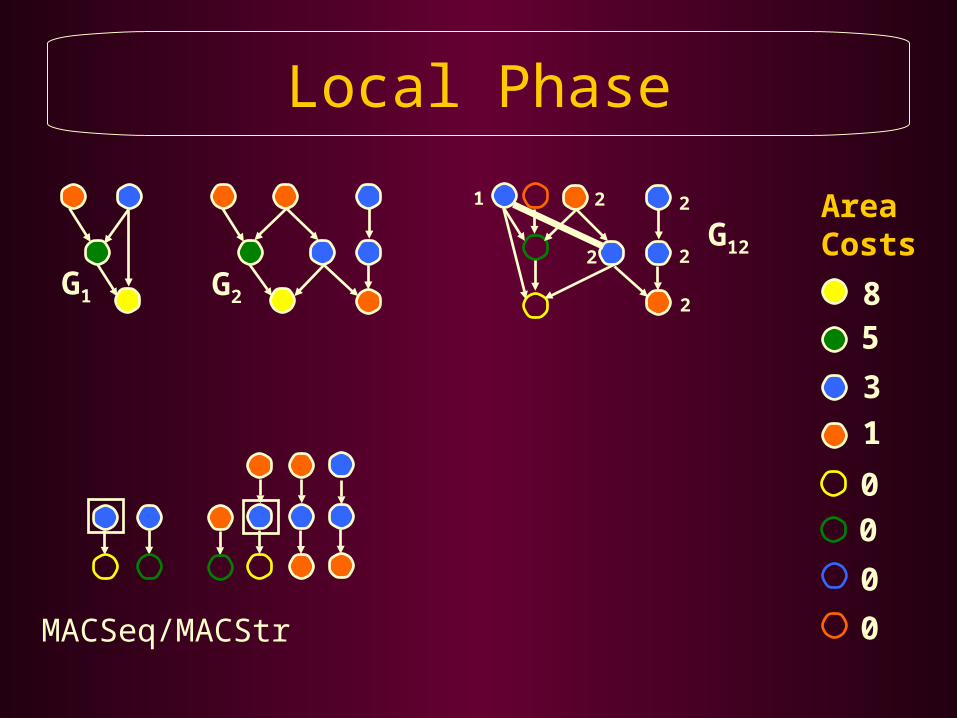
Local Phase
AreaCosts
85
1
3
G1 G2
0
0
0
0
1 2
2
2
2
2
G12
MACSeq/MACStr

Local Phase
AreaCosts
85
1
3
G1 G2
0
0
0
0
2
2
2
2
G12
MACSeq/MACStr
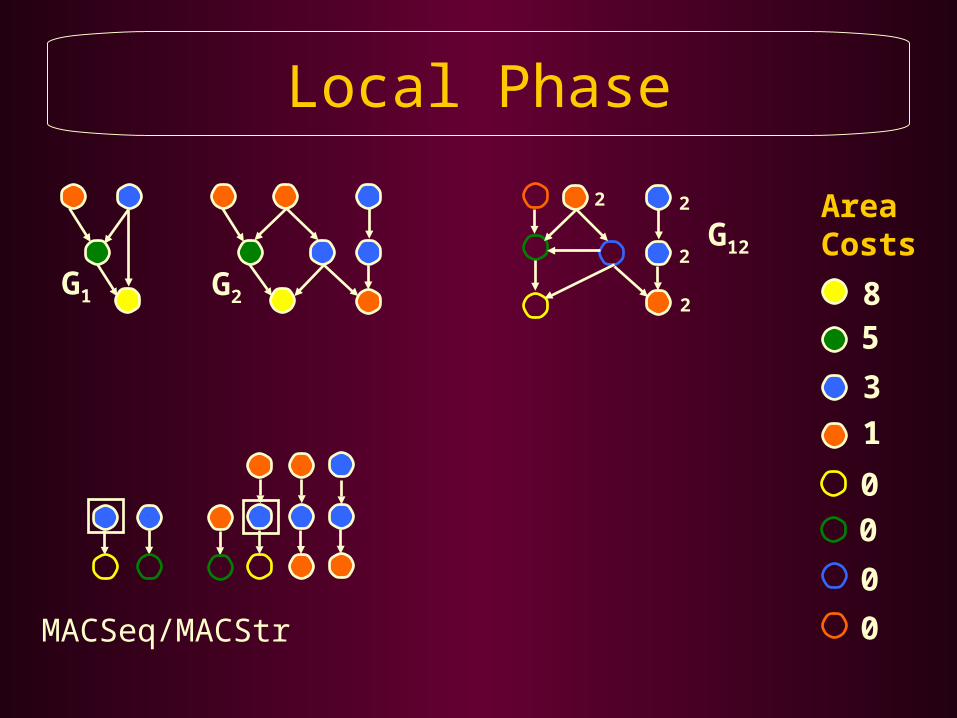
Local Phase
AreaCosts
85
1
3
G1 G2
0
0
0
0
2
2
2
2
G12
MACSeq/MACStr
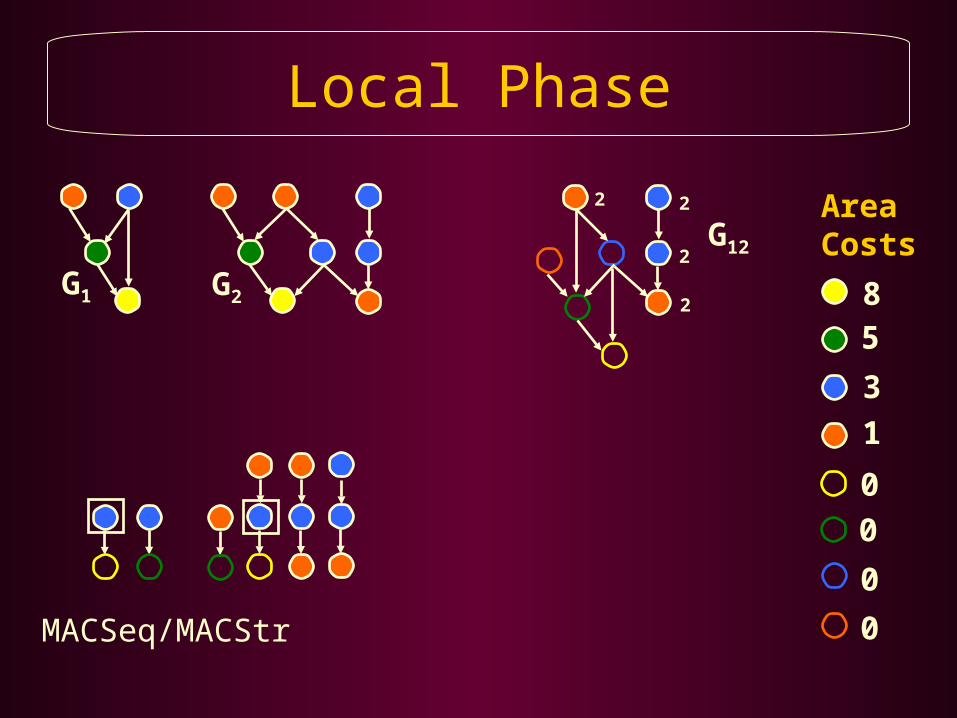
Local Phase
AreaCosts
85
1
3
G1 G2
0
0
0
0
2
2
2
2
G12
MACSeq/MACStr

Local Phase
AreaCosts
85
1
3
G1 G2
0
0
0
0
2
2
2
2
G12

Returning To Global Phase
AreaCosts
85
1
3
G12
G3 G4

Global Phase
AreaCosts
85
1
3
G3 G4
G12

Global Phase
AreaCosts
85
1
3
G3 G4
G12
MACSeq/MACStr

Entering Local Phase
AreaCosts
85
1
3
G12
G4
MACSeq/MACStr

Local Phase
AreaCosts
85
1
3
G4
0
0
0
0
G12 G124
4
4
4
12
12
12
12
12
12
MACSeq/MACStr

Local Phase
AreaCosts
85
1
3
G4
0
0
0
0
G12 G124
4
4
4
12
12
12
12
12
12
MACSeq/MACStr

Local Phase
AreaCosts
85
1
3
G4
0
0
0
0
G12 G124
4
4
4
12
12
12
12
12
12

Local Phase
AreaCosts
85
1
3
G4
0
0
0
0
G12 G124
4
4
4
12
12
12
12
12
12
MACSeq/MACStr

Local Phase
AreaCosts
85
1
3
G4
0
0
0
0
G12 G124
4
4
4
12
12
12
12
12
12
MACSeq/MACStr

A Local Decision
AreaCosts
85
1
3
0
0
0
0
G4
G12 G124
4
4
12
12
12
12
12
MACSeq/MACStr

A Local Decision
AreaCosts
85
1
3
0
0
0
0
G4
G12 G124
4
4
12
12
12
12
12

A Local Decision
AreaCosts
85
1
3
0
0
0
0
G4
G12 G124
4
4
12
12
12
12
12
MACSeq/MACStr

A Local Decision
AreaCosts
85
1
3
0
0
0
0
G4
G12 G124
4
4
12
12
12
12
12
MACSeq/MACStr

Cycles are Illegal
AreaCosts
85
1
3
0
0
0
0
ILLEGAL!
4
12
12
12
12
G124
4
4
12
12
12
12 12
G124
MACSeq/MACStr

Cycles are Illegal
AreaCosts
85
1
3
0
0
0
0
G124
4
4
12
12
12
12 12LEGAL!
4
12
12
12
12G124
MACSeq/MACStr

Local Phase
AreaCosts
85
1
3
0
0
0
0
G4
G12 G124
4
12
12
12
12

Returning To Global Phase
AreaCosts
85
1
3
G3
G124

Global Phase
AreaCosts
85
1
3
G3
G124

Global Phase
AreaCosts
85
1
3
G3
G124
MACSeq/MACStr

Global Phase
AreaCosts
85
1
3
G3
G124
3
33124124
124 124
124
124
G1234
MACSeq/MACStr

Global Phase
AreaCosts
85
1
3
G3
G124
3
33124124
124 124
124
124
0
0
0
0
G1234
MACSeq/MACStr

Local Phase
AreaCosts
85
1
3
0
0
0
0
G3
G124
3
33124124
124 124
124
124
G1234
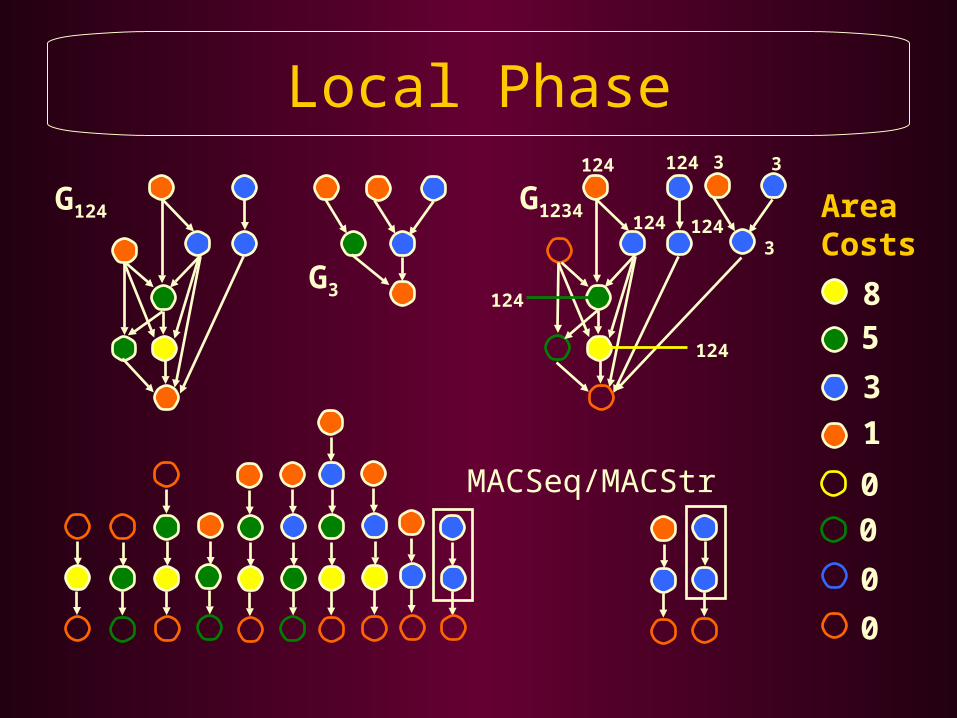
Local Phase
AreaCosts
85
1
3
0
0
0
0
G3
G124 G1234
3
33124124
124 124
124
124
MACSeq/MACStr

Local Phase
AreaCosts
85
1
3
0
0
0
0
G3
G124 G1234
3
33124124
124 124
124
124
MACSeq/MACStr

Local Phase
AreaCosts
85
1
3
0
0
0
0
G3
G124 G1234
3124
124
124
124
MACSeq/MACStr

Local Phase
AreaCosts
85
1
3
0
0
0
0
G3
G124 G1234
3124
124
124
124
MACSeq/MACStr

Local Phase
AreaCosts
85
1
3
0
0
0
0
G3
G124 G1234
3124
124
124
124

Local Phase
AreaCosts
85
1
3
0
0
0
0
G3
G124 G1234
3124
124
124
124
MACSeq/MACStr

Local Phase
AreaCosts
85
1
3
0
0
0
0
G3
G124 G1234
3124
124
124
124
MACSeq/MACStr

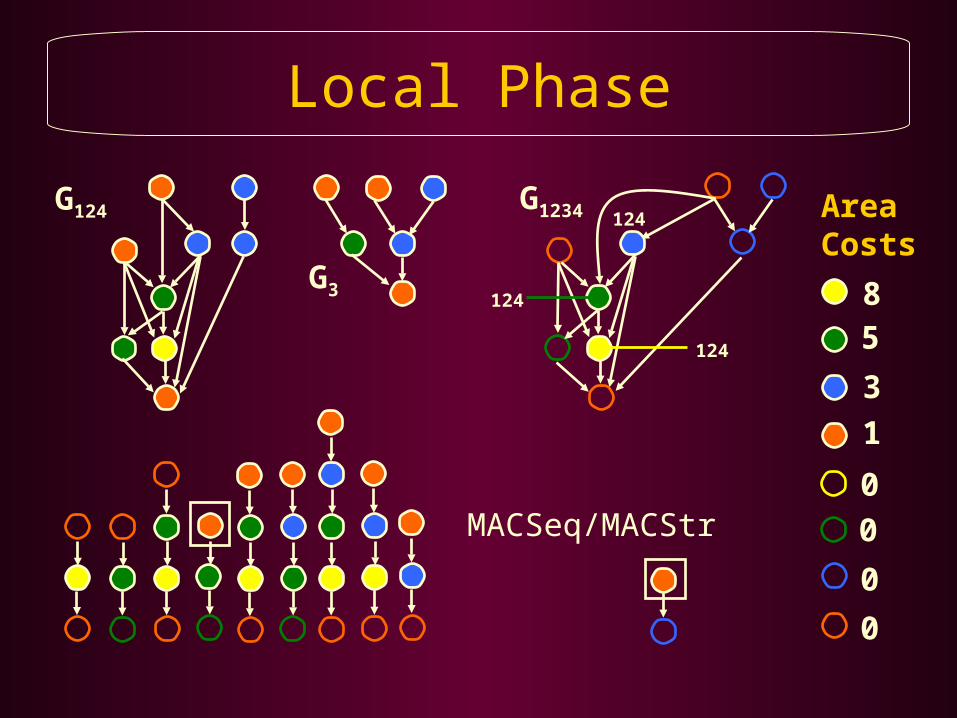
Local Phase
AreaCosts
85
1
3
0
0
0
0
G3
G124 G1234
124
124
MACSeq/MACStr
124
Local Phase
AreaCosts
85
1
3
0
0
0
0
G3
G124 G1234
124
124
MACSeq/MACStr
124

Local Phase
AreaCosts
85
1
3
0
0
0
0
G3
G124 G1234
124
124
124
MACSeq/MACStr

Local Phase
AreaCosts
85
1
3
0
0
0
0
G3
G124 G1234
124
124
124
We’re Done
AreaCosts
85
1
3
G1 G2
G3 G4
G1234

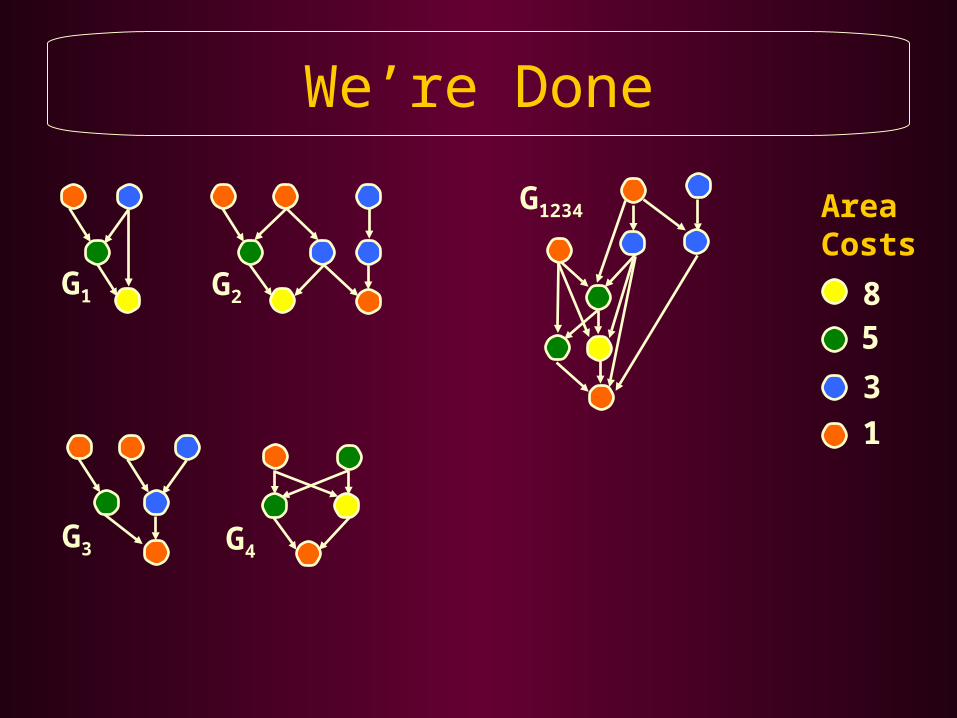
We’re Done
AreaCosts
85
1
3
G1 G2
G3 G4
Area = 17 Area = 25
Area = 14 Area = 20
G1234 Area = 30
Total Area of DFGs = 76
G1234
VLIW Synthesis
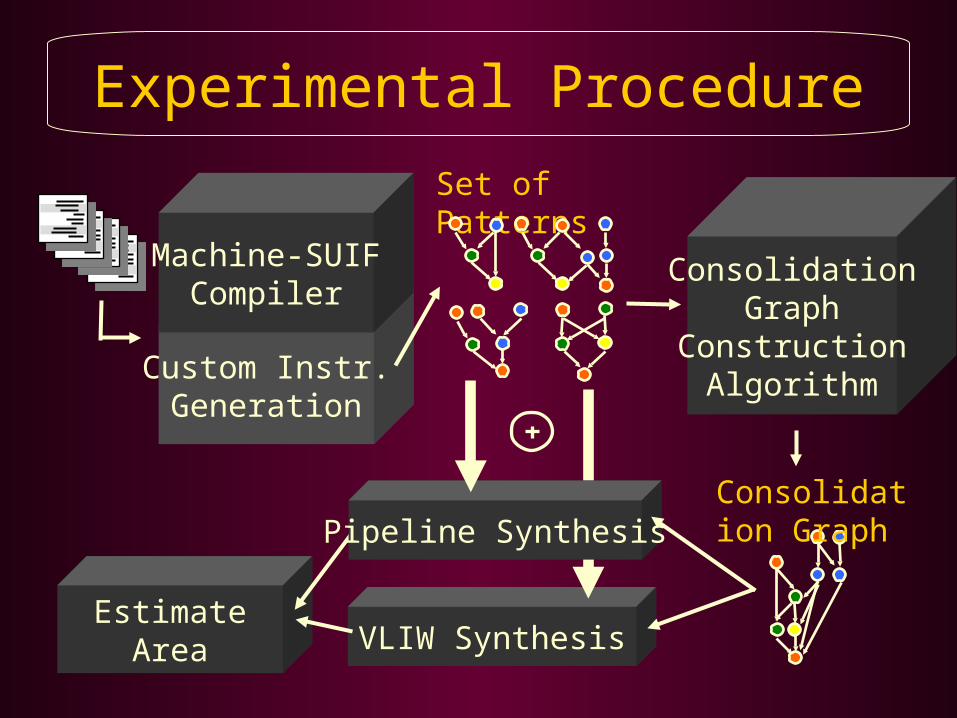
Experimental Procedure
Custom Instr.Generation
Set of Patterns
Machine-SUIFCompiler
ConsolidationGraph
ConstructionAlgorithm
Consolidation Graph
EstimateArea
Pipeline Synthesis

Pipelined Datapath Synthesis
Compiler
Loop Bodies• 80-90% of Program Execution Time• Parallelism Exists Across Multiple
Iterations• Pipelined Datapath Yields Maximal
Throughput.
Data Flow Graph
Insert Registers& Muxes

Pipelined Datapath Synthesis
Gc
G1 G2 G3 G4

VLIW Datapath Synthesis
Compiler
Non-Loop Computations• Instruction-Level Parallelism• Similar to Latency-Constrained
Scheduling in High-Level Synthesis
Data Flow Graph

Benchmark Suite
MediaBench Benchmark Suite
Exp. Benchmark File/FunctionNum. Instrs.
Largest Instr. (Operations)
Avg. Ops per Instr.
1234
567891011
MesaPGPRasta
EpicJPEGJPEGJPEGMPEG2MPEG2Rasta
Rasta
blend.cidea.cmul_mdmd_md.c
collapse_pyrjpeg_fdct_ifastjpeg_idct_4x4jpeg_idct_2x2idct_col
FR4TR
Lqsolve.c
idct_row
61457
2158794
10
18864
917125
303725
5.53.23.03.0
4.47.05.93.17.2
20.07.5

Experimental Results
0
5000
10000
15000
20000
25000
Slic
es
1 2 3 4 5 6 7 8 9 10 11
Pipelined Datapath Area Estimates
Additive
CG/PBRS
XilinxE-1000 Area

Experimental Results
0
5000
10000
15000
20000
25000
Slic
es
1 2 3 4 5 6 7 8 9 10 11
VLIW Datapath Area Estimates
Additive
CG/PBRS
XilinxE-1000 Area

Summary
• Area Estimates Based on Resource Sharing
• 0-1 Knapsack Problem Formulation Does Allow for Resource Sharing Estimates
• Resource Sharing Algorithm
• PBRS applied to Data Flow Graphs
• Experimental Results
• ILP Overestimates Area Costs by as much as 374% and 582% for Pipelined and VLIW Datapaths






























