



Mining Sequential PatternsRakesh Agrawal, Ramakrishana Srikant (1995)
IBM Almaden Research Center 650 Harry Road, San Jose, CA 95120
데이터 연구실 이세린지도 교수 박종수
2014. 3. 28

Contents
• Abstract1. Introduction2. Finding Sequential Patterns3. The Sequence Phase4. Performance5. Conclusions and Future Work
2

Abstract
• Introduces the problem of mining sequential pat-terns over a large database.
• Presents 3 algorithms to solve this problem.
• Shows their results of performance and scale-up experiments.
3

1. Introduction
• 1.1 Problem Statement
• The problem of mining sequential patterns is to find the maximal sequences among all sequences that have a certain user-specified minimum sup-port.
• Each such maximal sequence represents a se-quential pattern.
4

1. Introduction
• 1.2 Related Work– R. Agrawal, T. Imielinski, and A. Swami, “Mining association rules between
sets of items in large databases” (1993)– T. G. Dietterich and R. S. Michalski, “Discovering patterns in sequences of
events, Artificial Intelligence” (1985)– A. Califano and I. Rigoutsos, “Flash: A fast look-up algorithm for string homol-
ogy” (1993)– S. Wu and U. Manber, “Fast text searching allowing errors” (1992)– M. Waterman, “Mathematical Methods for DNA Sequence Analysis” (1989)– S. Altschul, W. Gish, W. Miller, E. Myers, and D. Lipman, “A basic local align-
ment search tool” (1990)– M. Roytberg, “Computer Applications in the Biosciences: A search for common
patterns in many sequences” (1992)– M. Vingron and P. Argos, “Computer Applications in the Biosciences: A fast
and sensitive multiple sequence alignment algorithm” (1992)– J. T.-L. Wang, G.-W. Chrin, T. G. Marr, B. Shapiro, D. Shasha, and K. Zhang.
“Combinatorial pattern discovery for scientific data: Some preliminary re-sults” (1994)
5

1. Introduction
• 1.2 Related Work– Finding of items bought together in a transac-
tion. (Intra-transaction patterns)– AI prediction of the sequential pattern.– Finding matches for pattern in text subse-
quences.– Discovering similarities in a database of ge-
netic sequences.
6
Compari-son

1. Introduction
• 1.2 Related Work
7
• Element is a character• Not guaranteed to be complete.• Algorithm was main-memory based and was tested
against a database of 150 sequences
“Combinatorial pattern discovery for scien-tific data: Some preliminary results” (1994)
• Element is a set of character• Guarantee that we have discovered all sequential patterns
of interest that are present in a specified minimum number of sequences.
• Our Solution is targeted at millions of customer sequences.
“Mining sequential pattern” (1995)

1. Introduction
• 1.3 Organization of the Paper
• Section 2. Gives this problem decomposition.• Section 3. Examines the sequence phase in detail and presents al-
gorithms for this phase. • Section 4. Empirically evaluate the performance of these algo-
rithms and study their scale-up properties.• Section 5. conclusion - summary and directions for future work.
8

Terminology
9
Length of a sequence
the number of itemsets in the sequence.
K-sequence a sequence of length k.
x.y. sequence formed by the concatenation of two se-quences x and y.
Support for an item
fraction of customers who bought the items in I in a single transaction. (Thus, the itemset I and the 1-sequence <i> have the same support.)
litemset the itemset with minimum support.
Large se-quence
must be a list of litemsets.
Maximal se-quence
Final sequence pattern that satisfy the minimum sup-port.

2. Finding Sequential Patterns
• 2.1 The Algorithm• 1. Sort Phase• Converts the original transaction database into a
database of customer sequences.
10

2. Finding Sequential Patterns
• 2.1 The Algorithm• 2. Litemset Phase• Find the set of all litemsets L including the set of
all 1-sequences.
• The set of litemsets is mapped to a set of con-tiguous integers.
11

2. Finding Sequential Patterns
• 2.1 The Algorithm• 3. Transformation Phase• To process repetitive determination in the follow-
ing step faster,• Each transaction is replaced by the set of all
litemsets contained in that transaction.
12

2. Finding Sequential Patterns
• 2.1 The Algorithm• 4. Sequence Phase• Use the set of litemsets to find the desired se-
quences.
• 5. Maximal Phase• Find the maximal sequences among the set of
large sequences.
13

3. The Sequence Phase
• Make multiple passes over the data to generate candidate sequences from seed set of large se-quences.
14
Candi-date Seq.
<1>
<2>
<3>
<4>
<5>
Cus-tomer Id
Transformed Cus-tomer Seq. (After
Mapping)
1 <{1} {5}>
2 <{1} {2, 3, 4}>
3 <{1, 3}>
4 <{1} {2, 3, 4}, {5}>
5 <{5}>
25% (Support > 1.25)
Sup-port
4
2
3
2
3

3. The Sequence Phase
• 2 Families of algorithms
Count-all AprioriAll
Count-some
15
AprioriSome
DynamicSome
AprioriSome DynamicSome
Both have forward phase and Backward phase .
using only the large se-quences and then makes a pass over the data to find
their support.
on-the-fly using the large sequences and the cus-tomer sequences read
from the database.

3. The Sequence Phase
• 3.1 Algorithm AprioriAll
16
Large 1-sequence
<1>
<2>
<3>
<4>
<5>
litemsetphase
<1>
<2>
<3>
<4>
<5>
①
②Candi-
date Seq.Sup-port
<1 2> 2
<1 3> 2
<1 4> 2
<1 5> 1
︙ ︙<5 4> 0
Large 2-se-
quence
Sup-port
<1 2> 2
<1 3> 3
<1 4> 2
<1 5> 2
<2 3> 2
<2 4> 2
<3 4> 2
③Maximal Se-
quences
<1 2 3 4>
<1 3 5>
<4 5>
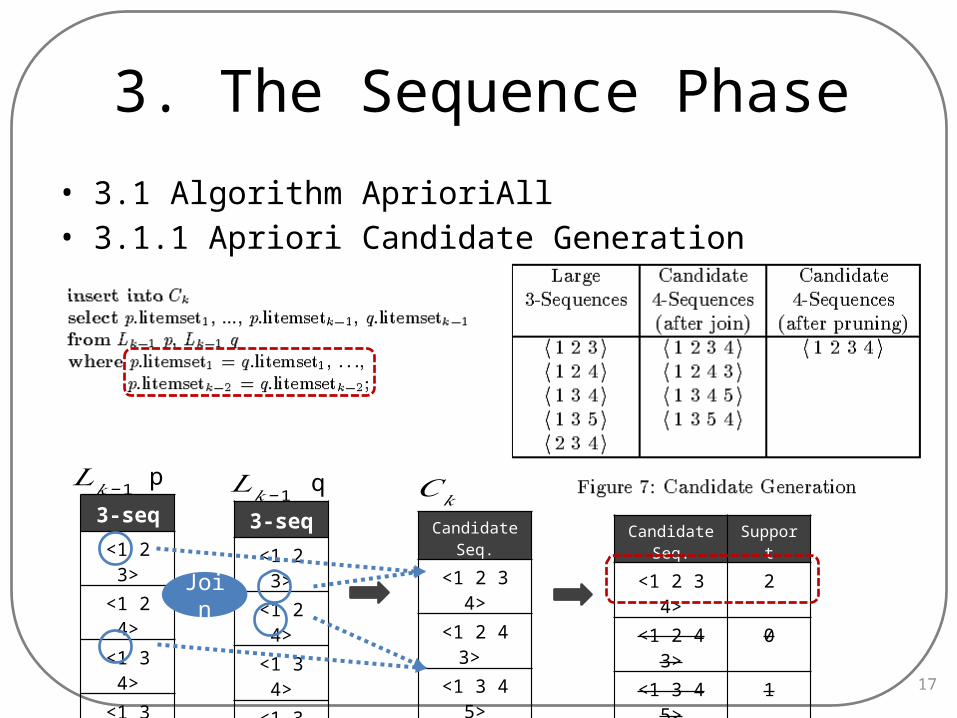
3. The Sequence Phase
• 3.1 Algorithm AprioriAll• 3.1.1 Apriori Candidate Generation
17
p q3-seq
<1 2 3>
<1 2 4>
<1 3 4>
<1 3 5>
<2 3 4>
Candidate Seq.
<1 2 3 4>
<1 2 4 3>
<1 3 4 5>
<1 3 5 4>
3-seq
<1 2 3>
<1 2 4>
<1 3 4>
<1 3 5>
<2 3 4>
Candidate Seq.
Support
<1 2 3 4>
2
<1 2 4 3>
0
<1 3 4 5>
1
<1 3 5 4>
0
𝐶𝑘𝐿𝑘−1 𝐿𝑘−1
Join

3. The Sequence Phase
• 3.2 Algorithm AprioriSome
18

3. The Sequence Phase
• 3.2 Algorithm AprioriSome• In the forward pass, we only count sequences of
certain lengths.
length1 length2 length3 length4 length5 length6
Forward phase
Backward phase
• Forward phase procedure
𝐶1 𝐿1 𝐶2 𝐿2 𝐶3 𝐶4 𝐿4 …
19
pruning pruning

3. The Sequence Phase
• 3.2 Algorithm AprioriSome• Next() takes as parameter the length of se-
quences counted in the last pass and returns the length of sequences to be counted in the next pass.
20
𝒉𝒊𝒕𝒌=|𝐿𝑘|/¿𝐶𝑘∨¿

3. The Sequence Phase
• 3.3 Algorithm DynamicSome
21
𝐶1 𝐶𝑠𝑡𝑒𝑝∧𝐿1 𝐿𝑠𝑡𝑒𝑝
Has to be initialized
If step = 3,After initialization of 1, 2, 3, Generate 6, 9, 12 …
* Backward phase is same as AprioriSome.

3. The Sequence Phase
• 3.3 Algorithm DynamicSome
22
𝐶1𝐿1 𝐶2 𝐿2 𝐶3 𝐿3 𝐶4 𝐿4 …
𝐶1𝐿1 𝐶2 𝐿2 𝐶3 𝐶4 𝐿4 …
𝐶1𝐿1 𝐶2 𝐿2 𝐶4 𝐿4 …
Apriori-All
AproriSome
DynamicSome

3. The Sequence Phase
• 3.3 Algorithm DynamicSome
23
otf-generates (On-the-fly) gen-erates more candidates than apriori-generate.
Avoid overlap-ping
𝐿𝑘⋈𝐿 𝑗=𝐶𝑘+ 𝑗
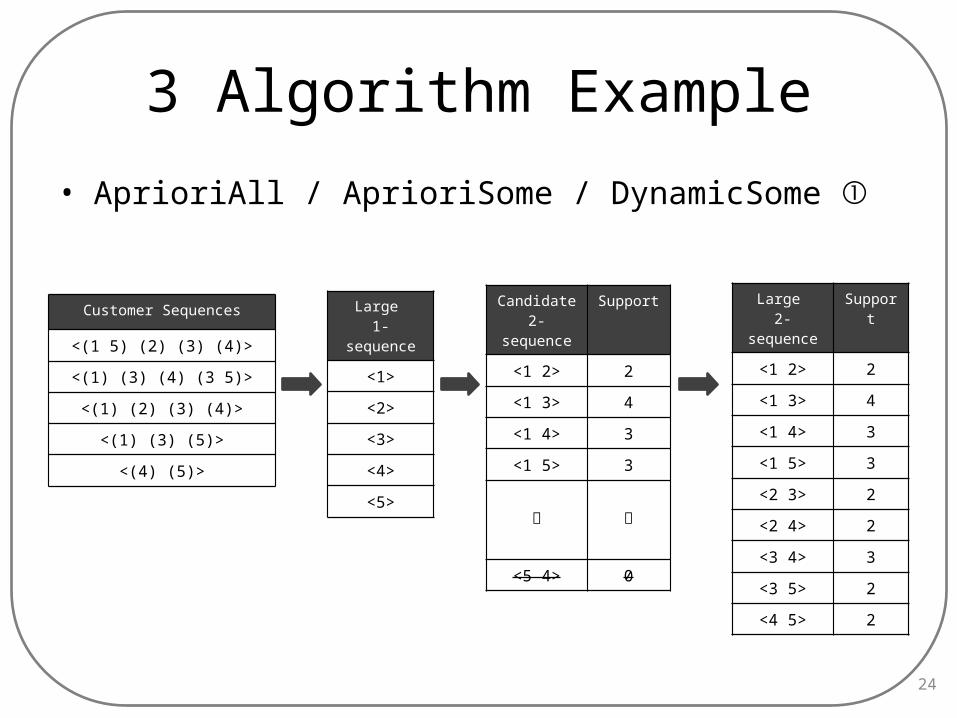
3 Algorithm Example
• AprioriAll / AprioriSome / DynamicSome ①
24
Large 1-sequence
<1>
<2>
<3>
<4>
<5>
Candidate2-se-
quence
Support
<1 2> 2
<1 3> 4
<1 4> 3
<1 5> 3
︙ ︙
<5 4> 0
Large 2-se-
quence
Sup-port
<1 2> 2
<1 3> 4
<1 4> 3
<1 5> 3
<2 3> 2
<2 4> 2
<3 4> 3
<3 5> 2
<4 5> 2
Customer Sequences
<(1 5) (2) (3) (4)>
<(1) (3) (4) (3 5)>
<(1) (2) (3) (4)>
<(1) (3) (5)>
<(4) (5)>

3 Algorithm Example
• AprioriAll ②
25
Large 2-se-
quence
Sup-port
<1 2> 2
<1 3> 4
<1 4> 3
<1 5> 3
<2 3> 2
<2 4> 2
<3 4> 3
<3 5> 2
<4 5> 2 Maximal Se-quences
<1 2 3 4>
<1 3 5>
<4 5>
Large3-se-
quence
Support
<1 2 3> 2
<1 2 4> 2
<1 3 4> 3
<1 3 5> 2
<2 3 4> 2
Candidate 3-se-
quence
Support
<1 2 3> 2
<1 2 4> 2
<1 2 5> 0
︙ ︙
<3 4 5> 1
Candidate 4-sequence
Sup-port
<1 2 3 4> 2
<1 2 4 3> 0
<1 3 4 5> 1
<1 3 5 4> 0
Large4-sequence
Sup-port
<1 2 3 4> 2

3 Algorithm Example
• AprioriSome ②
26
Large 2-se-
quence
Sup-port
<1 2> 2
<1 3> 4
<1 4> 3
<1 5> 3
<2 3> 2
<2 4> 2
<3 4> 3
<3 5> 2
<4 5> 2
Candidate 3-se-
quence
<1 2 3>
<1 2 4>
<1 2 5>
︙
<3 4 5>
Candidate 4-sequence
Sup-port
<1 2 3 4> 2
<1 2 3 5> 0
︙ ︙
<2 3 4 5> 0
Large4-sequence
Sup-port
<1 2 3 4> 2

Large3-se-
quence
Support
<1 2 3> 2
<1 2 4> 2
<1 3 4> 3
<1 3 5> 2
<2 3 4> 2
Candidate 3-se-
quence
Support
<1 2 3> 2
<1 2 4> 2
<1 2 5> 0
︙ ︙
<3 4 5> 1
3 Algorithm Example
• AprioriSome ③
27
Maximal Se-quences
<1 2 3 4>
<1 3 5>
<4 5>
Large4-sequence
Sup-port
<1 2 3 4> 2
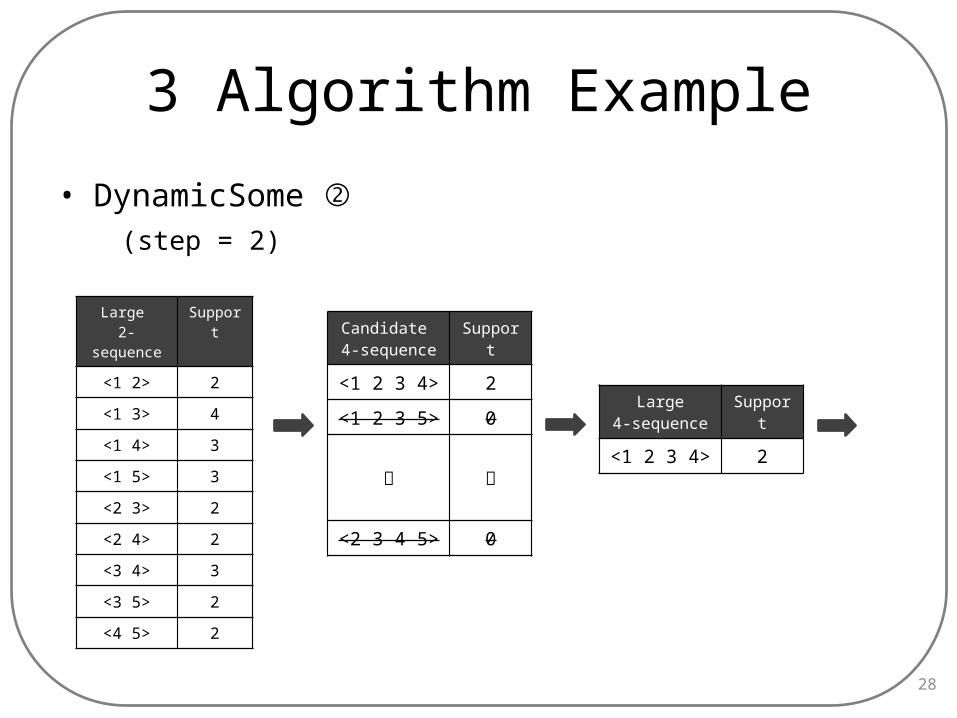
3 Algorithm Example
• DynamicSome ② (step = 2)
28
Large 2-se-
quence
Sup-port
<1 2> 2
<1 3> 4
<1 4> 3
<1 5> 3
<2 3> 2
<2 4> 2
<3 4> 3
<3 5> 2
<4 5> 2
Large4-sequence
Sup-port
<1 2 3 4> 2
Candidate 4-sequence
Sup-port
<1 2 3 4> 2
<1 2 3 5> 0
︙ ︙
<2 3 4 5> 0

3 Algorithm Example
• DynamicSome ③
29
Maximal Se-quences
<1 2 3 4>
<1 3 5>
<4 5>
Large3-se-
quence
Support
<1 2 3> 2
<1 2 4> 2
<1 3 4> 3
<1 3 5> 2
<2 3 4> 2
Candidate 3-se-
quence
Support
<1 2 3> 2
<1 2 4> 2
<1 2 5> 0
︙ ︙
<3 4 5> 1
Large4-sequence
Sup-port
<1 2 3 4> 2

4. Performance
• 4.1 Generation of Synthetic Data
30
• Customer-sequence sizes are typically clustered around a mean and a few customers may have many transactions.
• Transaction sizes are usually clustered around a mean and a few transactions have many items.
• Setting: = 5,000 = 25,000N = 10,000
4. Performance
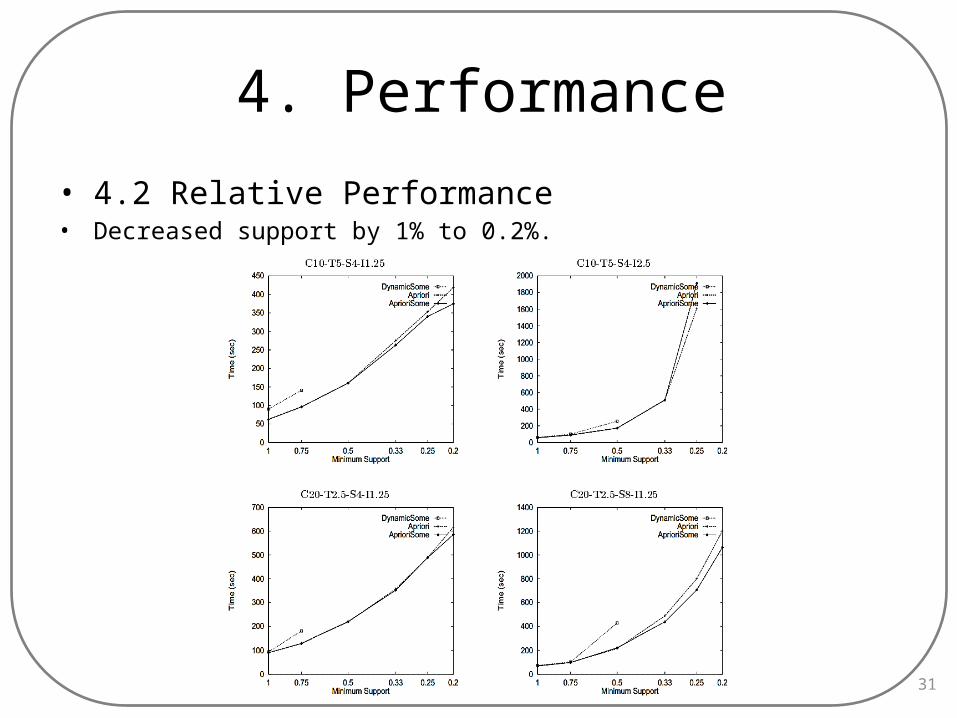
• 4.2 Relative Performance• Decreased support by 1% to 0.2%.
31

Advantages Disadvantages
Avoids counting many non-maximal sequences
Faster for lower supports.
1.Number of candidates generated using AprioriSome can be larger. ( ⊇ )
2.Have to generate skipped candidates of some lengths and stay memory res-ident.
4. Performance
• 4.2 Relative Performance• Observation:- Execution time support- DynamicSome performs worse.- AprioriSome shows:
32

4. Performance
• 4.3 Scale-up• Scale-up experiments for the AprioriSome algo-
rithm.(AprioriSome and AprioriAll results to be very similar.)
33

4. Performance
• 4.3 Scale-up
34

5. Conclusions and Future Work
• Introduced a new problem of mining sequential patterns from a database of customer sales transactions.
• Presented 3 algorithms for solving this problem.• AprioriSome and AprioriAll have comparable perfor-
mance. AprioriSome performs a little better for the lower values of
the minimum number of customers that must support a se-quential pattern.
Both scale linearly with the number of customer transactions. Both have excellent scale-up properties with respect to the
number of transactions in a customer sequence and the number of items in a transaction.
• AprioriAll is preferred in some cases that need detail counts of the number of people.
35

5. Conclusions and Future Work
In the future,• Extension of the algorithms to discover
sequential patterns across item cate-gories.
• Transposition of constraints into the dis-covery algorithms. There could be item constraints or time constraints.
36

Thank You
37








![Pattern Discovery: an Example with Sequential Patterns [Agrawal and Srikant 1996]](https://static.cupdf.com/doc/110x72/56813d11550346895da6ccc1/pattern-discovery-an-example-with-sequential-patterns-agrawal-and-srikant.jpg)





















