




2011.02.02 - SLIDE 1IS 240 – Spring 2011
Prof. Ray Larson University of California, Berkeley
School of Information
Principles of Information Retrieval
Lecture 5: Boolean and Extended Boolean

2011.02.02 - SLIDE 2IS 240 – Spring 2011
Today
• Review– IR Components – Inverted Files
• IR Models
• The Boolean Model
• Fuzzy sets, Rubric, P-norm, etc.

2011.02.02 - SLIDE 3IS 240 – Spring 2011
Structure of an IR SystemSearchLine Interest profiles
& QueriesDocuments
& data
Rules of the game =Rules for subject indexing +
Thesaurus (which consists of
Lead-InVocabulary
andIndexing
Language
StorageLine
Potentially Relevant
Documents
Comparison/Matching
Store1: Profiles/Search requests
Store2: Documentrepresentations
Indexing (Descriptive and
Subject)
Formulating query in terms of
descriptors
Storage of profiles
Storage of Documents
Information Storage and Retrieval System
Adapted from Soergel, p. 19

2011.02.02 - SLIDE 4
Document Processing Steps

2011.02.02 - SLIDE 5IS 240 – Spring 2011
Boolean Implementation: Inverted Files
• We will look at “Vector files” in detail later. But conceptually, an Inverted File is a vector file “inverted” so that rows become columns and columns become rows
docs t1 t2 t3D1 1 0 1D2 1 0 0D3 0 1 1D4 1 0 0D5 1 1 1D6 1 1 0D7 0 1 0D8 0 1 0D9 0 0 1
D10 0 1 1
Terms D1 D2 D3 D4 D5 D6 D7 …
t1 1 1 0 1 1 1 0t2 0 0 1 0 1 1 1t3 1 0 1 0 1 0 0
2011.02.02 - SLIDE 6IS 240 – Spring 2011
How Are Inverted Files Created
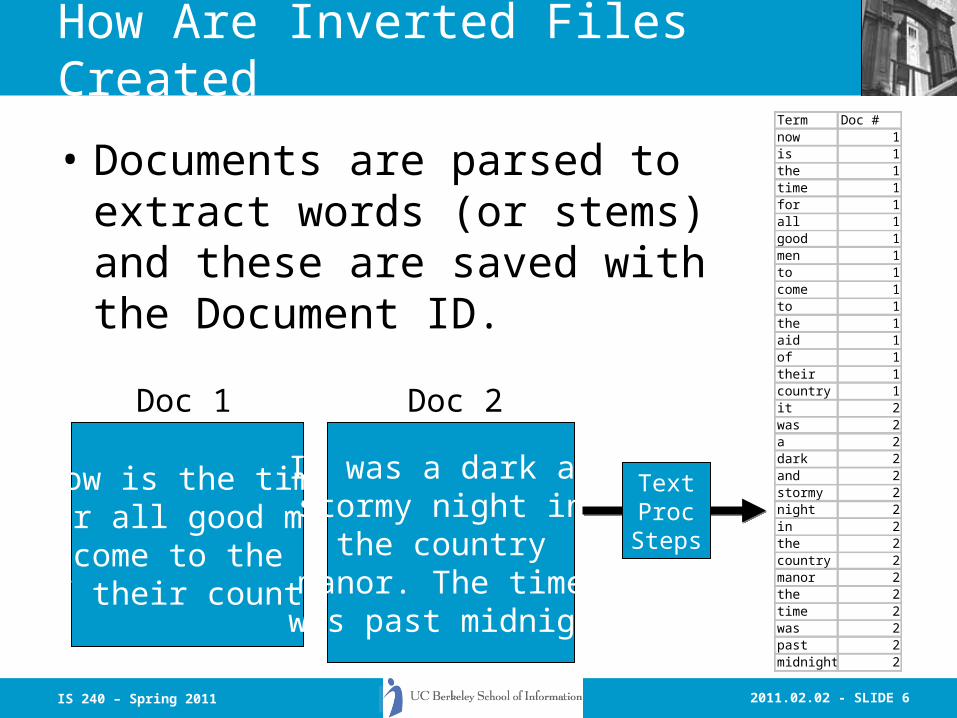
• Documents are parsed to extract words (or stems) and these are saved with the Document ID.
Now is the timefor all good men
to come to the aidof their country
Doc 1
It was a dark andstormy night in
the country manor. The time was past midnight
Doc 2
Term Doc #now 1is 1the 1time 1for 1all 1good 1men 1to 1come 1to 1the 1aid 1of 1their 1country 1it 2was 2a 2dark 2and 2stormy 2night 2in 2the 2country 2manor 2the 2time 2was 2past 2midnight 2
TextProcSteps

2011.02.02 - SLIDE 7IS 240 – Spring 2011
How Inverted Files are Created
• After all document have been parsed the inverted file is sorted
Term Doc #a 2aid 1all 1and 2come 1country 1country 2dark 2for 1good 1in 2is 1it 2manor 2men 1midnight 2night 2now 1of 1past 2stormy 2the 1the 1the 2the 2their 1time 1time 2to 1to 1was 2was 2
Term Doc #now 1is 1the 1time 1for 1all 1good 1men 1to 1come 1to 1the 1aid 1of 1their 1country 1it 2was 2a 2dark 2and 2stormy 2night 2in 2the 2country 2manor 2the 2time 2was 2past 2midnight 2

2011.02.02 - SLIDE 8IS 240 – Spring 2011
How Inverted Files are Created
• Multiple term entries for a single document are merged and frequency information added
Term Doc # Freqa 2 1aid 1 1all 1 1and 2 1come 1 1country 1 1country 2 1dark 2 1for 1 1good 1 1in 2 1is 1 1it 2 1manor 2 1men 1 1midnight 2 1night 2 1now 1 1of 1 1past 2 1stormy 2 1the 1 2the 2 2their 1 1time 1 1time 2 1to 1 2was 2 2
Term Doc #a 2aid 1all 1and 2come 1country 1country 2dark 2for 1good 1in 2is 1it 2manor 2men 1midnight 2night 2now 1of 1past 2stormy 2the 1the 1the 2the 2their 1time 1time 2to 1to 1was 2was 2

2011.02.02 - SLIDE 9IS 240 – Spring 2011
Inverted Files• The file is commonly split into a Dictionary
and a Postings fileTerm Doc # Freqa 2 1aid 1 1all 1 1and 2 1come 1 1country 1 1country 2 1dark 2 1for 1 1good 1 1in 2 1is 1 1it 2 1manor 2 1men 1 1midnight 2 1night 2 1now 1 1of 1 1past 2 1stormy 2 1the 1 2the 2 2their 1 1time 1 1time 2 1to 1 2was 2 2
Doc # Freq2 11 11 12 11 11 12 12 11 11 12 11 12 12 11 12 12 11 11 12 12 11 22 21 11 12 11 22 2
Term N docs Tot Freqa 1 1aid 1 1all 1 1and 1 1come 1 1country 2 2dark 1 1for 1 1good 1 1in 1 1is 1 1it 1 1manor 1 1men 1 1midnight 1 1night 1 1now 1 1of 1 1past 1 1stormy 1 1the 2 4their 1 1time 2 2to 1 2was 1 2

2011.02.02 - SLIDE 10IS 240 – Spring 2011
Inverted files
• Permit fast search for individual terms
• Search results for each term is a list of document IDs (and optionally, frequency and/or positional information)
• These lists can be used to solve Boolean queries:– country: d1, d2– manor: d2– country and manor: d2

2011.02.02 - SLIDE 11IS 240 – Spring 2011
Inverted Files
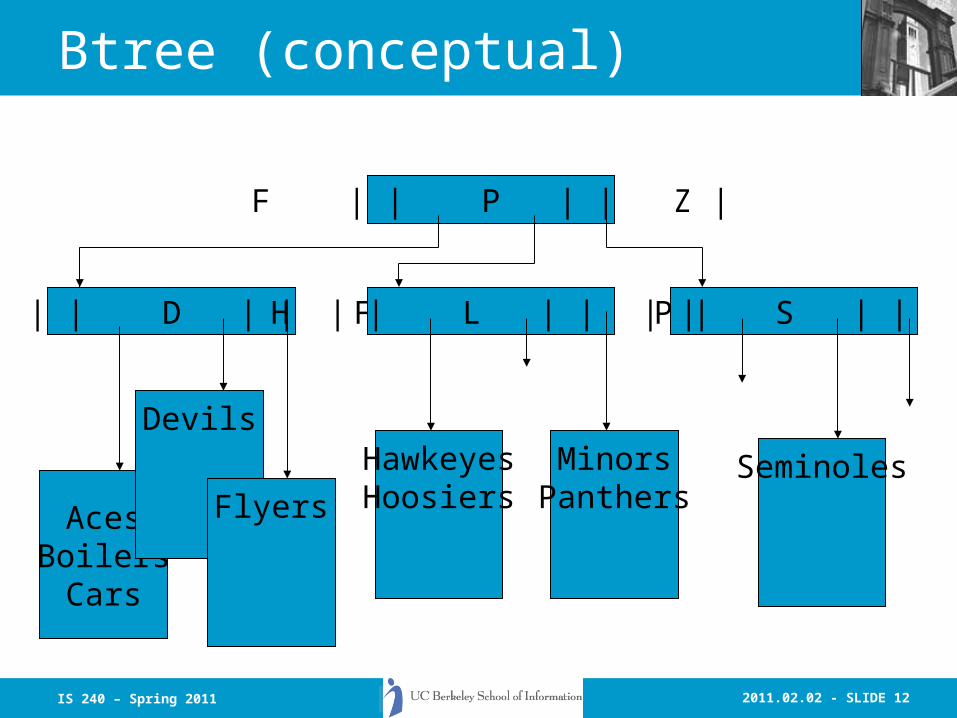
• Lots of alternative implementations – E.g.: Cheshire builds within-document
frequency using a hash table during document parsing. Then Document IDs and frequency info are stored in a BerkeleyDB B-tree index keyed by the term.
2011.02.02 - SLIDE 12IS 240 – Spring 2011
Btree (conceptual)
B | | D | | F |
AcesBoilers
Cars
F | | P | | Z |
R | | S | | Z |H | | L | | P |
DevilsMinors
PanthersSeminoles
Flyers
HawkeyesHoosiers

2011.02.02 - SLIDE 13IS 240 – Spring 2011
Btree with Postings
B | | D | | F |
AcesBoilers
Cars
F | | P | | Z |
R | | S | | Z |H | | L | | P |
DevilsMinors
PanthersSeminoles
FlyersHawkeyesHoosiers
2,4,8,122,4,8,122,4,8,12
2,4,8,12
2,4,8,12
2,4,8,125, 7, 200
2,4,8,122,4,8,128,120

2011.02.02 - SLIDE 14IS 240 – Spring 2011
Inverted files
• Permit fast search for individual terms
• Search results for each term is a list of document IDs (and optionally, frequency and/or positional information)
• These lists can be used to solve Boolean queries:– country: d1, d2– manor: d2– country and manor: d2

2011.02.02 - SLIDE 15IS 240 – Spring 2011
Today
• Review– IR Components – Inverted Files
• IR Models
• The Boolean Model
• Fuzzy sets, Rubric, P-norm, etc.

2011.02.02 - SLIDE 16IS 240 – Spring 2011
IR Models
• Set Theoretic Models– Boolean– Fuzzy– Extended Boolean
• Vector Models (Algebraic)
• Probabilistic Models (probabilistic)
• Others (e.g., neural networks, etc.)

2011.02.02 - SLIDE 17IS 240 – Spring 2011
Boolean Model for IR
• Based on Boolean Logic (Algebra of Sets).
• Fundamental principles established by George Boole in the 1850’s
• Deals with set membership and operations on sets
• Set membership in IR systems is usually based on whether (or not) a document contains a keyword (term)

2011.02.02 - SLIDE 18IS 240 – Spring 2011
• Intersection – Boolean ‘AND’ -- --
• Union – Boolean ‘OR’ -- --
• Negation – Boolean ‘NOT’ -- --– Usually means “AND NOT” in IR
• Exclusive OR – ‘XOR’ – seldom used,– Instead
Boolean Operations on Sets
IU¬
∧∨
X
)()( BABAAxorB ∧∧∨=

2011.02.02 - SLIDE 19IS 240 – Spring 2011
Boolean Logic
A B
BABA
BABA
BAC
BAC
AC
AC
∩=∪
∪=∩
∪=∩=
=
=
:Law sDeMorgan'

2011.02.02 - SLIDE 20IS 240 – Spring 2011
Query Languages
• A way to express the query (formal expression of the information need)
• Types: – Boolean– Natural Language– Stylized Natural Language– Form-Based (GUI)

2011.02.02 - SLIDE 21IS 240 – Spring 2011
Simple query language: Boolean
• Terms + Connectors– terms
• words• normalized (stemmed) words• phrases• thesaurus terms
– connectors• AND• OR• NOT
– parentheses (for grouping operations)

2011.02.02 - SLIDE 22IS 240 – Spring 2011
Boolean Queries
• Cat
• Cat OR Dog
• Cat AND Dog
• (Cat AND Dog)
• (Cat AND Dog) OR Collar
• (Cat AND Dog) OR (Collar AND Leash)
• (Cat OR Dog) AND (Collar OR Leash)
2011.02.02 - SLIDE 23IS 240 – Spring 2011
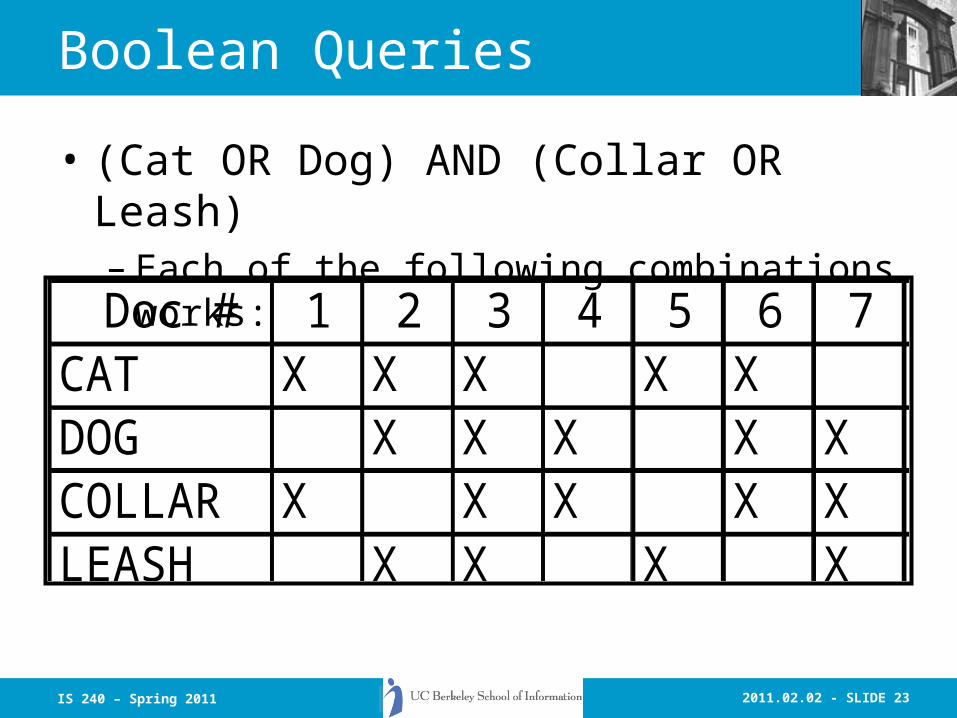
Boolean Queries
• (Cat OR Dog) AND (Collar OR Leash)– Each of the following combinations works:
Doc # 1 2 3 4 5 6 7CAT X X X X XDOG X X X X XCOLLAR X X X X XLEASH X X X X

2011.02.02 - SLIDE 24IS 240 – Spring 2011
Boolean Queries
• (Cat OR Dog) AND (Collar OR Leash)– None of the following combinations works:
Doc # 1 2 3 4 5 6 7CAT X XDOG X XCOLLAR X XLEASH X X

2011.02.02 - SLIDE 25IS 240 – Spring 2011
Boolean Queries
• Usually expressed as INFIX operators in IR– ((a AND b) OR (c AND b))
• NOT is UNARY PREFIX operator– ((a AND b) OR (c AND (NOT b)))
• AND and OR can be n-ary operators– (a AND b AND c AND d)
• Some rules - (De Morgan revisited)– NOT(a) AND NOT(b) = NOT(a OR b)– NOT(a) OR NOT(b)= NOT(a AND b)– NOT(NOT(a)) = a
2011.02.02 - SLIDE 26IS 240 – Spring 2011
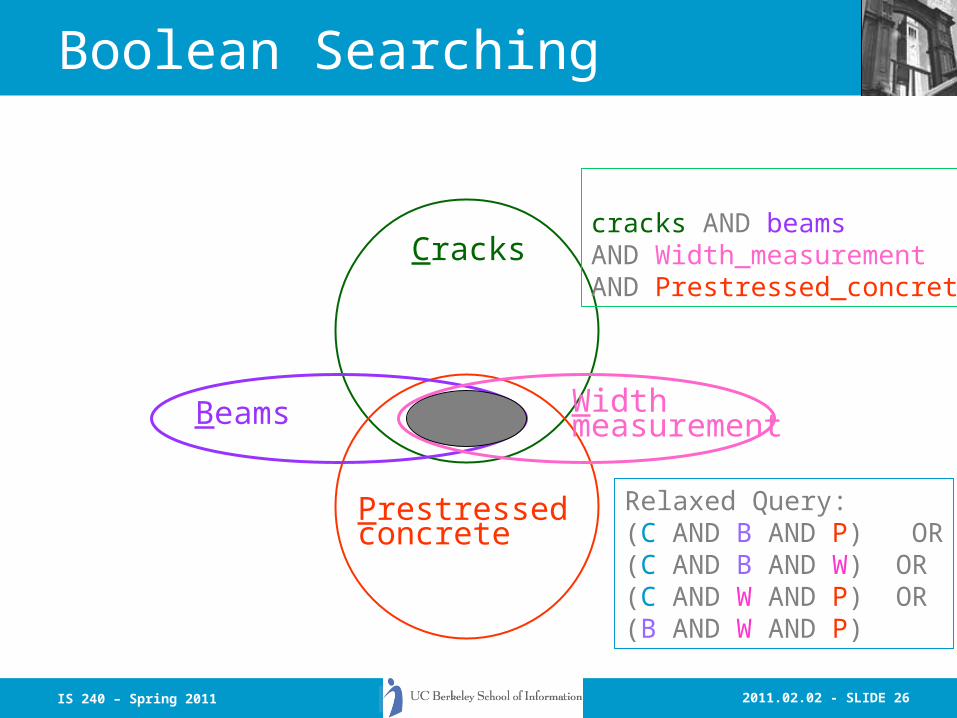
Boolean Searching
Formal Query:cracks AND beamsAND Width_measurementAND Prestressed_concrete
Cracks
Beams Widthmeasurement
Prestressedconcrete
Relaxed Query:(C AND B AND P) OR(C AND B AND W) OR(C AND W AND P) OR(B AND W AND P)
Relaxed Query:(C AND B AND P) OR(C AND B AND W) OR(C AND W AND P) OR(B AND W AND P)

2011.02.02 - SLIDE 27IS 240 – Spring 2011
Boolean Logic
t33
t11 t22
D11D22
D33
D44D55
D66
D88D77
D99
D1010
D1111
m1
m2
m3m5
m4
m7m8
m6
m2 = t1 t2 t3
m1 = t1 t2 t3
m4 = t1 t2 t3
m3 = t1 t2 t3
m6 = t1 t2 t3
m5 = t1 t2 t3
m8 = t1 t2 t3
m7 = t1 t2 t3

2011.02.02 - SLIDE 28IS 240 – Spring 2011
Precedence Ordering
• In what order do we evaluate the components of the Boolean expression?– Parenthesis get done first
• (a or b) and (c or d)• (a or (b and c) or d)
– Usually start from the left and work right (in case of ties)
– Usually (if there are no parentheses)• NOT before AND• AND before OR

2011.02.02 - SLIDE 29IS 240 – Spring 2011
Faceted Boolean Query
• Strategy: break query into facets (polysemous with earlier meaning of facets)
– conjunction of disjunctions(a1 OR a2 OR a3)
(b1 OR b2)
(c1 OR c2 OR c3 OR c4)
– each facet expresses a topic(“rain forest” OR jungle OR amazon)
(medicine OR remedy OR cure)
(Smith OR Zhou)
AND
AND

2011.02.02 - SLIDE 30IS 240 – Spring 2011
Ordering of Retrieved Documents
• Pure Boolean has no ordering• In practice:
– order chronologically– order by total number of “hits” on query terms
• What if one term has more hits than others?• Is it better to one of each term or many of one term?
• Fancier methods have been investigated – p-norm is most famous
• usually impractical to implement• usually hard for user to understand

2011.02.02 - SLIDE 31IS 240 – Spring 2011
Faceted Boolean Query
• Query still fails if one facet missing
• Alternative: – Coordination level ranking– Order results in terms of how many facets (disjuncts)
are satisfied– Also called Quorum ranking, Overlap ranking, and
Best Match
• Problem: Facets still undifferentiated
• Alternative: – Assign weights to facets

2011.02.02 - SLIDE 32IS 240 – Spring 2011
Boolean Processing
• Boolean Processing (classic Boolean)– Data structures for Query representation and
Boolean Operations
• Boolean processing logic and algorithms
• Extended Boolean Models– Fuzzy Logic– Others

2011.02.02 - SLIDE 33IS 240 – Spring 2011
Boolean Processing
• All processing takes place on postings lists
• Different methods can be used for sorted or unsorted postings lists

2011.02.02 - SLIDE 34IS 240 – Spring 2011
Boolean Query Processing
• The query must be parsed to determine what the:– Search Words– Optional field or index qualifications– Boolean Operators
• Are and how they relate to one-another• Typical parsing uses lexical analysers (like lex or
flex) along with parser generators like YACC, BISON or Llgen– These produce code to be compiled into programs.– Example…
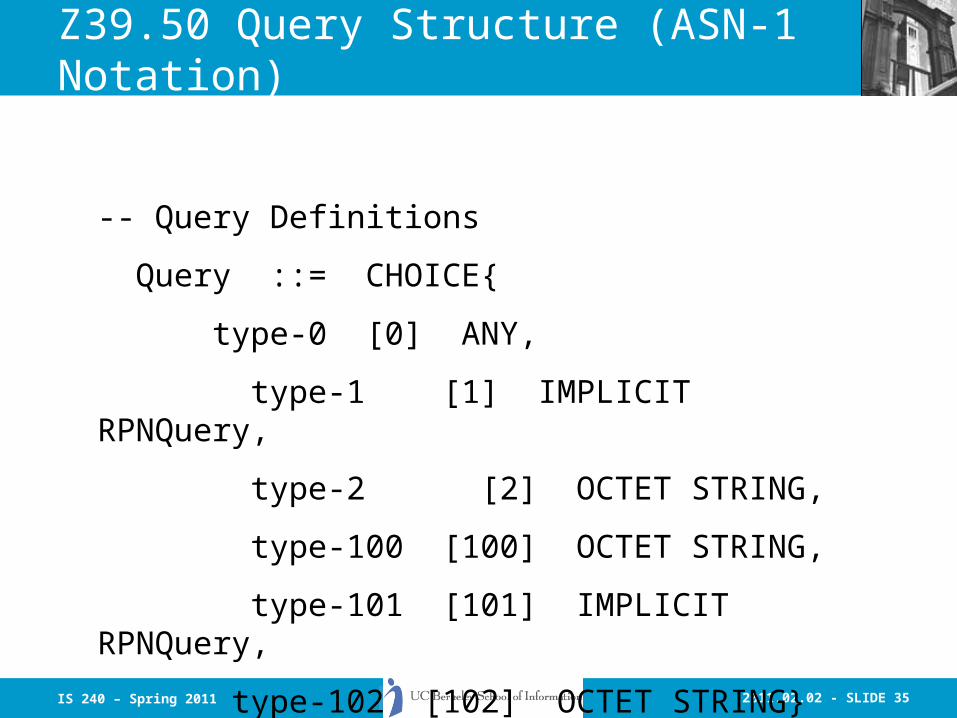
2011.02.02 - SLIDE 35IS 240 – Spring 2011
Z39.50 Query Structure (ASN-1 Notation)
-- Query Definitions
Query ::= CHOICE{
type-0 [0] ANY,
type-1 [1] IMPLICIT RPNQuery,
type-2 [2] OCTET STRING,
type-100 [100] OCTET STRING,
type-101 [101] IMPLICIT RPNQuery,
type-102 [102] OCTET STRING}

2011.02.02 - SLIDE 36IS 240 – Spring 2011
Z39.50 RPN Query (ASN-1 Notation)
-- Definitions for RPN query
RPNQuery ::= SEQUENCE{
attributeSet AttributeSetId,
rpn RPNStructure}

2011.02.02 - SLIDE 37IS 240 – Spring 2011
RPN Structure
RPNStructure ::= CHOICE{
op [0] Operand,
rpnRpnOp [1] IMPLICIT SEQUENCE{
rpn1 RPNStructure,
rpn2 RPNStructure,
op Operator }
}

2011.02.02 - SLIDE 38IS 240 – Spring 2011
Operand
Operand ::= CHOICE{
attrTerm AttributesPlusTerm,
resultSet ResultSetId,
-- If version 2 is in force:
-- - If query type is 1, one of the above two must be
chosen;
-- - resultAttr (below) may be used only if query type is
101.
resultAttr ResultSetPlusAttributes}

2011.02.02 - SLIDE 39IS 240 – Spring 2011
Operator
Operator ::= [46] CHOICE{
and [0] IMPLICIT NULL,
or [1] IMPLICIT NULL,
and-not [2] IMPLICIT NULL,
-- If version 2 is in force:
-- - For query type 1, one of the above three must be
chosen;
-- - prox (below) may be used only if query type is 101.
prox [3] IMPLICIT ProximityOperator}
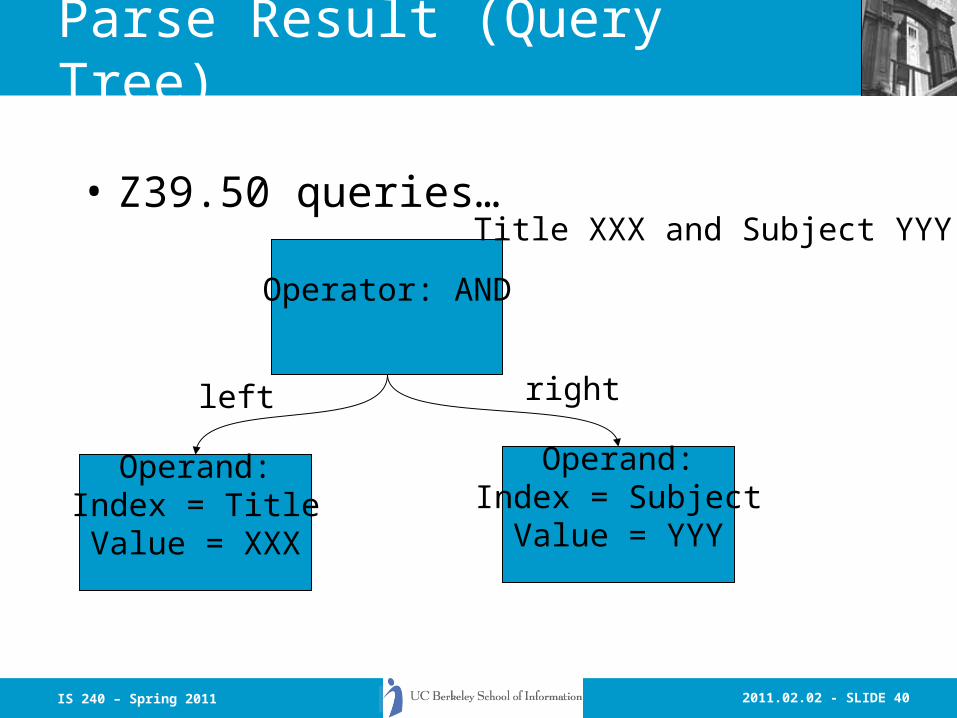
2011.02.02 - SLIDE 40IS 240 – Spring 2011
Parse Result (Query Tree)
• Z39.50 queries…
Operator: AND
Title XXX and Subject YYY
Operand:Index = TitleValue = XXX
Operand:Index = SubjectValue = YYY
left right
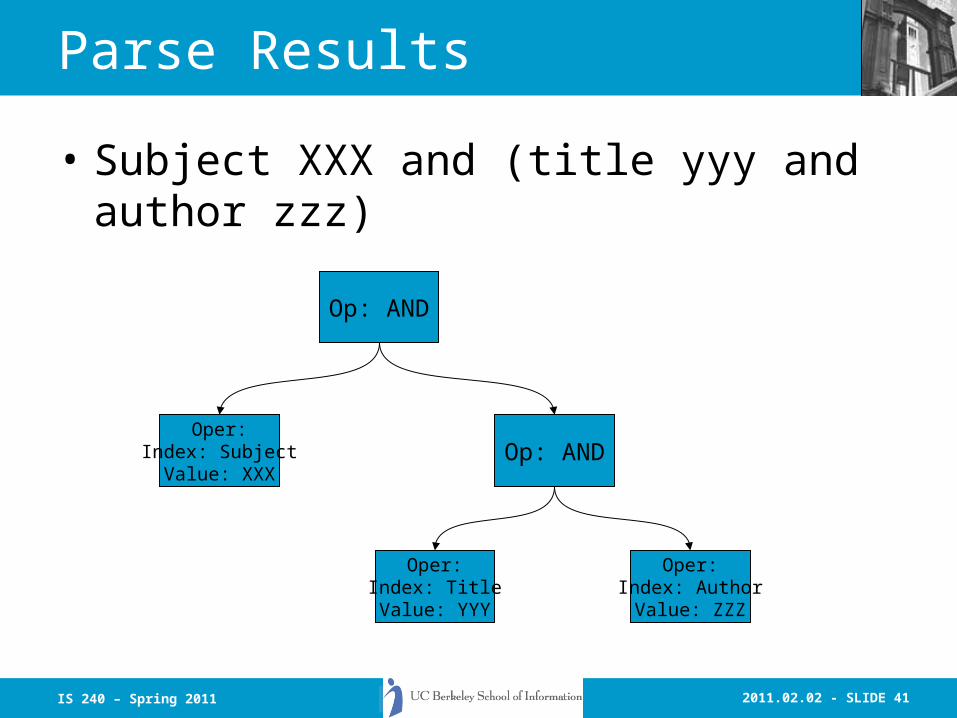
2011.02.02 - SLIDE 41IS 240 – Spring 2011
Parse Results
• Subject XXX and (title yyy and author zzz)
Op: AND
Op: ANDOper:
Index: SubjectValue: XXX
Oper:Index: TitleValue: YYY
Oper:Index: AuthorValue: ZZZ

2011.02.02 - SLIDE 42IS 240 – Spring 2011
Boolean AND (Sorted) Algorithm
• Choose the shortest list (why?)
• Create new list the same length as the short list– For each item in the short list
• Compare next item in longer list – If greater than – go to next item in longer list
– If equal - add to new list and go to next item in both lists
– If less than - go to next item in short list

2011.02.02 - SLIDE 43IS 240 – Spring 2011
Boolean AND Algorithm
2578
152935
100135140155189190195198
28
15100135155189195
289
1215222850687784
100120128135138141150155188189195
AND =

2011.02.02 - SLIDE 44IS 240 – Spring 2011
Boolean OR (Sorted) Algorithm
• Choose the longer list• Create new list the same length both lists
combined– For each item in the longer list
• If less than or equal to the first item in the short list– Add to new list
• Otherwise– Add item from short list– Compare next items in short and long lists
» If long item less then short item add long item and go to next long item
» Otherwise – add from short list and go to next short item
– Once the short list runs out, add the remaining items in the long list

2011.02.02 - SLIDE 45IS 240 – Spring 2011
Boolean OR Algorithm
2578
152935
100135140155189190195198
25789
12152228293550687784
100120128135138141150155188189190195198
289
1215222850687784
100120128135138141150155188189195
OR =

2011.02.02 - SLIDE 46IS 240 – Spring 2011
Boolean AND NOT(Sorted) Algorithm
Create new list the same length as the left-hand list– For each item in the left-hand list
• Compare next item in not list – If greater than – add to new list and go to next item in not
list– If equal - go to next item in both lists– If less than - go to next item in not list

2011.02.02 - SLIDE 47IS 240 – Spring 2011
Boolean AND NOTAlgorithm
2578
152935
100135140155189190195198
57
152935
140190198
289
1215222850687784
100120128135138141150155188189195
AND NOT =

2011.02.02 - SLIDE 48IS 240 – Spring 2011
Hashed Boolean AND (unsorted)
• Put each item in shortest list into hash table– For each item in other lists
• If hash entry exists, set flag in hash table entry (or increment counter)
• Scan hash table contents– If flag set (or counter == number of lists) add
to new list

2011.02.02 - SLIDE 49IS 240 – Spring 2011
Hashed Boolean OR (unsorted)
• Put each item in EACH list into hash table– If match increment counter (optional)
• Scan hash table contents and add to new list

2011.02.02 - SLIDE 50IS 240 – Spring 2011
Hashed Boolean AND NOT (unsorted)
• Put each item in left-hand list into hash table– For each item in NOT list
• If hash entry exists, remove it
• Scan hash table contents and add to new list

2011.02.02 - SLIDE 51IS 240 – Spring 2011
Boolean Summary
• Advantages– simple queries are easy to understand– relatively easy to implement
• Disadvantages– difficult to specify what is wanted, particularly
in complex situations– too much returned, or too little– ordering not well determined
• Dominant IR model in commercial systems until the WWW

2011.02.02 - SLIDE 52IS 240 – Spring 2011
Basic Concepts for Extended Boolean
• Instead of binary values, terms in documents and queries have a weight (importance or some other statistical property)
• Instead of binary set membership, sets are “fuzzy” and the weights are used to determine degree of membership.
• Degree of set membership can be used to rank the results of a query

2011.02.02 - SLIDE 53IS 240 – Spring 2011
Fuzzy Sets
• Introduced by Zadeh in 1965.
• If set {A} has value v(A) and {B} has value v(B), where 0 v 1
• v(AB) = min(v(A), v(B))
• v(AB) = max(v(A), v(B))
• v(~A) = 1-v(A)

2011.02.02 - SLIDE 54IS 240 – Spring 2011
Fuzzy Sets
• If we have three documents and three terms…– D1=(.4,.2,1), D2=(0,0,.8), D3=(.7, .4,0)
For search: t1t2 t3
v(D1) = max(.4, .2, 1) = 1v(D2) = max(0, 0, .8) = .8v(D3) = max(.7, .4, 0) = .7
For search: t1t2 t3
v(D1) = min(.4, .2, 1) = .2v(D2) = min(0, 0, .8) = 0v(D3) = min(.7, .4, 0) = 0

2011.02.02 - SLIDE 55IS 240 – Spring 2011
Fuzzy Sets
• Fuzzy set membership of term to document is f(A)[0,1]
• D1 = {(mesons, .8), (scattering, .4)}
• D2 = {(mesons, .5), (scattering, .6)}
• Query = MESONS AND SCATTERING
• RSV(D1) = MIN(.8,.4) = .4
• RSV(D2) = MIN(.5,.6) = .5
• D2 is ranked before D1 in the result set.

2011.02.02 - SLIDE 56IS 240 – Spring 2011
Fuzzy Sets
• The set membership function can be, for example, the relative term frequency within a document, the IDF or any other function providing weights to terms
• This means that the fuzzy methods use sets of criteria for term weighting that are the same or similar to those used in other ranked retrieval methods (e.g., vector and probabilistic methods)

2011.02.02 - SLIDE 57IS 240 – Spring 2011
Robertson’s Critique of Fuzzy Sets
• D1 = {(mesons, .4), (scattering, .4)}• D2 = {(mesons, .39), (scattering, .99)}• Query = MESONS AND SCATTERING• RSV(D1) = MIN(.4,.4) = .4• RSV(D2) = MIN(.39,.99) = .39• However, consistent with the Boolean
model:– Query = t1t2t3…t100
– If D not indexed by t1 then it fails, even if D is indexed by t2,…,t100

2011.02.02 - SLIDE 58IS 240 – Spring 2011
Robertson’s critique of Fuzzy
• Fuzzy sets suffer from the same kind of lack of discrimination among the retrieval results almost to the same extent as standard Boolean
• The rank of a document depends entirely on the lowest or highest weighted term in an AND or OR operation

2011.02.02 - SLIDE 59IS 240 – Spring 2011
Other Fuzzy Approaches
• As described in the Modern Information Retrieval (optional) text, a keyword correlation matrix can be used to determine set membership values, and algebraic sums and products can be used in place of MAX and MIN
• Not clear how this approach works in real applications (or in tests like TREC) because the testing has been on a small scale

2011.02.02 - SLIDE 60IS 240 – Spring 2011
Extended Boolean (P-Norm)
• Ed Fox’s Dissertation work with Salton• Basic notion is that terms in a Boolean
query, and the Boolean Operators themselves can have weights assigned to them
• Binary weights means that queries behave like standard Boolean
• 0 < Weights < 1 mean that queries behave like a ranking system
• The system requires similarity measures

2011.02.02 - SLIDE 61IS 240 – Spring 2011
Probabilistic Inclusion of Boolean
• Most probabilistic models attempt to predict the probability that given a particular query Q and document D, that the searcher would find D relevant
• If we assume that Boolean criteria are to be ANDed with a probabilistic query…
€
P(R |Q,D) = P(R |Qbool ,D)P(R |Qprob ,D)
P(R |Qbool ,D) =1: if Boolean eval successful for D
0 : Otherwise
⎧ ⎨ ⎩

2011.02.02 - SLIDE 62IS 240 – Spring 2011
Rubric – Extended Boolean
• Scans full text of documents and stores them• User develops a hierarchy of concepts which
becomes the query• Leaf nodes of the hierarchy are combinations of
text patterns• A “fuzzy calculus” is used to propagate values
obtained at leaves up through the hierarchy to obtain a single retrieval status value (or “relevance” value)
• RUBRIC returns a ranked list of documents in descending order of “relevance” values.

2011.02.02 - SLIDE 63IS 240 – Spring 2011
RUBRIC Rules for Concepts & Weights
• Team | event => World_Series• St._Louis_Cardinals | Milwaukee_Brewers =>
Team• “Cardinals” => St._Louis_Cardinals (0.7)• Cardinals_full_name => St._Louis_Cardinals
(0.9)• Saint & “Louis” & “Cardinals” =>
Cardinals_full_name• “St.” => Saint (0.9)• “Saint” => Saint• “Brewers” => Milwaukee_Brewers (0.5)

2011.02.02 - SLIDE 64IS 240 – Spring 2011
RUBRIC Rules for Concepts & Weights
• “Milwaukee Brewers” => Milwaukee_Brewers (0.9)
• “World Series” => event• Baseball_championship => event (0.9)• Baseball & Championship =>
Baseball_championship• “ball” => Baseball (0.5)• “baseball” => Baseball• “championship” => Championship (0.7)

2011.02.02 - SLIDE 65IS 240 – Spring 2011
RUBRIC combination methods
V(V1 or V2) = MAX(V1, V2)V(V1 and V2) = MIN(V1, V2)i.e., classic fuzzy matching,but with the addition…V(level n) = Cn*V(level n-1)

2011.02.02 - SLIDE 66IS 240 – Spring 2011
Rule Evaluation Tree
World_Series (0)
Event (0)
“World Series” Baseball_championship (0)
Baseball (0)
Championship (0)
St._Louis_Cardinals (0)
Team (0)
“Cardinals” (0)
Milwaukee_brewers (0)
Cardinals_full_name (0)
“Milwaukee Brewers” (0)“Brewers” (0)
Saint (0) “Louis” (0)
“Saint” (0)“St.” (0)
“Cardinals” (0)
“baseball” (0) “championship” (0)“ball” (0)0.9
0.90.7 0.90.5
0.9
0.50.7

2011.02.02 - SLIDE 67IS 240 – Spring 2011
Rule Evaluation Tree
World_Series (0)
Event (0)
“World Series” Baseball_championship (0)
Baseball (0)
Championship (0)
St._Louis_Cardinals (0)
Team (0)
“Cardinals” (0)
Milwaukee_brewers (0)
Cardinals_full_name (0)
“Milwaukee Brewers” (0)“Brewers” (0)
Saint (0) “Louis” (0)
“Saint” (0)“St.” (0)
“Cardinals” (0)
“baseball” (1.0)“championship” (1.0)“ball” (1.0)0.9
0.90.7 0.90.5
0.9
0.50.7
Document containing “ball”, “baseball” & “championship”

2011.02.02 - SLIDE 68IS 240 – Spring 2011
Rule Evaluation Tree
World_Series (0)
Event (0)
“World Series” Baseball_championship (0)
Baseball (1.0)
Championship (0.7)
St._Louis_Cardinals (0)
Team (0)
“Cardinals” (0)
Milwaukee_brewers (0)
Cardinals_full_name (0)
“Milwaukee Brewers” (0)“Brewers” (0)
Saint (0) “Louis” (0)
“Saint” (0)“St.” (0)
“Cardinals” (0)
“baseball” (1.0)“championship” (1.0)“ball” (1.0)0.9
0.90.7 0.90.5
0.9
0.50.7

2011.02.02 - SLIDE 69IS 240 – Spring 2011
Rule Evaluation Tree
World_Series (0)
Event (0)
“World Series” Baseball_championship (0.7)
Baseball (1.0)
Championship (0.7)
St._Louis_Cardinals (0)
Team (0)
“Cardinals” (0)
Milwaukee_brewers (0)
Cardinals_full_name (0)
“Milwaukee Brewers” (0)“Brewers” (0)
Saint (0) “Louis” (0)
“Saint” (0)“St.” (0)
“Cardinals” (0)
“baseball” (1.0)“championship” (1.0)“ball” (1.0)0.9
0.90.7 0.90.5
0.9
0.50.7

2011.02.02 - SLIDE 70IS 240 – Spring 2011
Rule Evaluation Tree
World_Series (0)
Event (0.63)
“World Series” Baseball_championship (0.7)
Baseball (1.0)
Championship (0.7)
St._Louis_Cardinals (0)
Team (0)
“Cardinals” (0)
Milwaukee_brewers (0)
Cardinals_full_name (0)
“Milwaukee Brewers” (0)“Brewers” (0)
Saint (0) “Louis” (0)
“Saint” (0)“St.” (0)
“Cardinals” (0)
“baseball” (1.0)“championship” (1.0)“ball” (1.0)0.9
0.90.7 0.90.5
0.9
0.50.7

2011.02.02 - SLIDE 71IS 240 – Spring 2011
Rule Evaluation Tree
World_Series (0.63)
Event (0.63)
“World Series” Baseball_championship (0.7)
Baseball (1.0)
Championship (0.7)
St._Louis_Cardinals (0)
Team (0)
“Cardinals” (0)
Milwaukee_brewers (0)
Cardinals_full_name (0)
“Milwaukee Brewers” (0)“Brewers” (0)
Saint (0) “Louis” (0)
“Saint” (0)“St.” (0)
“Cardinals” (0)
“baseball” (1.0)“championship” (1.0)“ball” (1.0)0.9
0.90.7 0.90.5
0.9
0.50.7

2011.02.02 - SLIDE 72IS 240 – Spring 2011
RUBRIC Terrorism Query
Terrorism
Event Actor effect
Reason
Takeover Killing Bombing
Encounter
Device
ExplosionSlaying Shooting
Specificactor
Generalactor
0.7 0.2 0.30.1
0.80.6
Kidnapping
ransom
Kidnapevent
0.70.5

2011.02.02 - SLIDE 73IS 240 – Spring 2011
Non-Boolean IR
• Need to measure some similarity between the query and the document
• The basic notion is that documents that are somehow similar to a query, are likely to be relevant responses for that query
• We will revisit this notion again and see how the Language Modelling approach to IR has taken it to a new level

2011.02.02 - SLIDE 74IS 240 – Spring 2011
Similarity Measures (Set-based)
|)||,min(|
||
||||
||
||||
||||
||2
||
21
21
DQ
DQ
DQ
DQ
DQDQ
DQ
DQ
DQ
∩×
∩∪∩+∩
∩ Simple matching (coordination level match)
Dice’s Coefficient
Jaccard’s Coefficient
Cosine Coefficient
Overlap Coefficient
Assuming that Q and D are the sets of terms associated with a Query and Document:

2011.02.02 - SLIDE 75IS 240 – Spring 2011
Next Week
• Moving beyond Boole…
• The vector space model





























