2011.03.30 - SLIDE 1 IS 240 – Spring 2011 Prof. Ray Larson University of California, Berkeley School of Information Principles of Information Retrieval Lecture 24: NLP for IR

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

2011.03.30 - SLIDE 1IS 240 – Spring 2011
Prof. Ray Larson University of California, Berkeley
School of Information
Principles of Information Retrieval
Lecture 24: NLP for IR

2011.03.30 - SLIDE 2IS 240 – Spring 2011
Final Term Paper
• Should be about 8-12 pages on:– some area of IR research (or practice) that
you are interested in and want to study further– Experimental tests of systems or IR
algorithms– Build an IR system, test it, and describe the
system and its performance
• Due May 9th (First day of Final exam Week - or any time before)

2011.03.30 - SLIDE 3IS 240 – Spring 2011
Today
• Review - Filtering and TDT
• Natural Language Processing and IR– Based on Papers in Reader and on
• David Lewis & Karen Sparck Jones “Natural Language Processing for Information Retrieval” Communications of the ACM, 39(1) Jan. 1996
• Information from Junichi Tsuji, University of Tokyo
• Watson and Jeopardy

2011.03.30 - SLIDE 4IS 240 – Spring 2011
Major differences between IR and Filtering
• IR concerned with single uses of the system• IR recognizes inherent faults of queries
– Filtering assumes profiles can be better than IR queries
• IR concerned with collection and organization of texts– Filtering is concerned with distribution of texts
• IR is concerned with selection from a static database.– Filtering concerned with dynamic data stream
• IR is concerned with single interaction sessions– Filtering concerned with long-term changes

2011.03.30 - SLIDE 5IS 240 – Spring 2011
Contextual Differences
• In filtering the timeliness of the text is often of greatest significance
• Filtering often has a less well-defined user community
• Filtering often has privacy implications (how complete are user profiles?, what to they contain?)
• Filtering profiles can (should?) adapt to user feedback– Conceptually similar to Relevance feedback

2011.03.30 - SLIDE 6IS 240 – Spring 2011
Methods for Filtering
• Adapted from IR – E.g. use a retrieval ranking algorithm against
incoming documents.
• Collaborative filtering– Individual and comparative profiles

2011.03.30 - SLIDE 7IS 240 – Spring 2011
TDT Task Overview*
• 5 R&D Challenges:– Story Segmentation– Topic Tracking– Topic Detection– First-Story Detection– Link Detection
• TDT3 Corpus Characteristics:†– Two Types of Sources:
• Text • Speech
– Two Languages:• English 30,000
stories• Mandarin 10,000
stories
– 11 Different Sources:• _8 English__ 3
MandarinABC CNN VOAPRI VOA XINNBC MNB ZBNAPW NYT
** see http://www.itl.nist.gov/iaui/894.01/tdt3/tdt3.htm for details† see http://morph.ldc.upenn.edu/Projects/TDT3/ for details

2011.03.30 - SLIDE 8IS 240 – Spring 2011
Preliminaries
A topictopic is …a seminal eventevent or activity, along with all
directly related events and activities.
A storystory is …a topically cohesive segment of news that
includes two or more DECLARATIVE independent clauses about a single event.

2011.03.30 - SLIDE 9IS 240 – Spring 2011
Example Topic
Title: Mountain Hikers Lost– WHAT: 35 or 40 young Mountain Hikers were
lost in an avalanche in France around the 20th of January.
– WHERE: Orres, France – WHEN: January 1998– RULES OF INTERPRETATION: 5. Accidents

2011.03.30 - SLIDE 10IS 240 – Spring 2011
(for Radio and TV only)
Transcription:text (words)
Story:Non-story:
The Segmentation Task:
To segment the source stream into its constituent stories, for all audio sources.

2011.03.30 - SLIDE 11IS 240 – Spring 2011
The Topic Tracking Task:
To detect stories that discuss the target topic,in multiple source streams.
• Find all the stories that discuss a given target topic– Training: Given Nt sample stories that
discuss a given target topic,– Test: Find all subsequent stories that
discuss the target topic.
on-topicunknownunknown
training data
test dataNew This Year: not guaranteed to be off-topic

2011.03.30 - SLIDE 12IS 240 – Spring 2011
The Topic Detection Task:
To detect topics in terms of the (clusters of) storiesthat discuss them.
– Unsupervised topic training A meta-definition of topic is required independent of topic specifics.
– New topics must be detected as the incoming stories are processed.
– Input stories are then associated with one of the topics.
a topic!

2011.03.30 - SLIDE 13IS 240 – Spring 2011
• There is no supervised topic training (like Topic Detection)
Time
First Stories
Not First Stories
= Topic 1= Topic 2
The First-Story Detection Task:
To detect the first story that discusses a topic, for all topics.

2011.03.30 - SLIDE 14IS 240 – Spring 2011
The Link Detection Task
To detect whether a pair of stories discuss the same topic.
• The topic discussed is a free variable.• Topic definition and annotation is
unnecessary.• The link detection task represents a basic
functionality, needed to support all applications (including the TDT applications of topic detection and tracking).
• The link detection task is related to the topic tracking task, with Nt = 1.
same topic?

2011.03.30 - SLIDE 15IS 240 – Spring 2011
Today
• Review - Filtering and TDT
• Natural Language Processing and IR– Based on Papers in Reader and on
• David Lewis & Karen Sparck Jones “Natural Language Processing for Information Retrieval” Communications of the ACM, 39(1) Jan. 1996
• Text summarization: Lecture from Ed Hovy (USC)
• Watson and Jeopardy

2011.03.30 - SLIDE 16IS 240 – Spring 2011
Natural Language Processing and IR
• The main approach in applying NLP to IR has been to attempt to address
– Phrase usage vs individual terms
– Search expansion using related terms/concepts
– Attempts to automatically exploit or assign controlled vocabularies

2011.03.30 - SLIDE 17IS 240 – Spring 2011
NLP and IR
• Much early research showed that (at least in the restricted test databases tested)– Indexing documents by individual terms
corresponding to words and word stems produces retrieval results at least as good as when indexes use controlled vocabularies (whether applied manually or automatically)
– Constructing phrases or “pre-coordinated” terms provides only marginal and inconsistent improvements

2011.03.30 - SLIDE 18IS 240 – Spring 2011
NLP and IR
• Not clear why intuitively plausible improvements to document representation have had little effect on retrieval results when compared to statistical methods– E.g. Use of syntactic role relations between
terms has shown no improvement in performance over “bag of words” approaches

2011.03.30 - SLIDE 19IS 240 – Spring 2011
General Framework of NLP
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 20IS 240 – Spring 2011
General Framework of NLP
Morphological andLexical Processing
Syntactic Analysis
Semantic Analysis
Context processingInterpretation
John runs.
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 21IS 240 – Spring 2011
General Framework of NLP
Morphological andLexical Processing
Syntactic Analysis
Semantic Analysis
Context processingInterpretation
John runs.
John run+s. P-N V 3-pre N plu
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 22IS 240 – Spring 2011
General Framework of NLP
Morphological andLexical Processing
Syntactic Analysis
Semantic Analysis
Context processingInterpretation
John runs.
John run+s. P-N V 3-pre N plu
S
NP
P-N
John
VP
V
run
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 23IS 240 – Spring 2011
General Framework of NLP
Morphological andLexical Processing
Syntactic Analysis
Semantic Analysis
Context processingInterpretation
John runs.
John run+s. P-N V 3-pre N plu
S
NP
P-N
John
VP
V
runPred: RUN Agent:John
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 24IS 240 – Spring 2011
General Framework of NLP
Morphological andLexical Processing
Syntactic Analysis
Semantic Analysis
Context processingInterpretation
John runs.
John run+s. P-N V 3-pre N plu
S
NP
P-N
John
VP
V
runPred: RUN Agent:John
John is a student.He runs.
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 25IS 240 – Spring 2011
General Framework of NLP
Morphological andLexical Processing
Syntactic Analysis
Semantic Analysis
Context processingInterpretation
Domain AnalysisAppelt:1999
Tokenization
Part of Speech Tagging
Term recognition(Ananiadou)
Inflection/Derivation
Compounding
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 26IS 240 – Spring 2011
General Framework of NLP
Morphological andLexical Processing
Syntactic Analysis
Semantic Analysis
Context processingInterpretation
Difficulties of NLP
(1) Robustness: Incomplete Knowledge
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 27IS 240 – Spring 2011
General Framework of NLP
Morphological andLexical Processing
Syntactic Analysis
Semantic Analysis
Context processingInterpretation
Difficulties of NLP
(1) Robustness: Incomplete Knowledge Incomplete Lexicons
Open class words TermsTerm recognitionNamed Entities Company names Locations Numerical expressions
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 28IS 240 – Spring 2011
General Framework of NLP
Morphological andLexical Processing
Syntactic Analysis
Semantic Analysis
Context processingInterpretation
Difficulties of NLP
(1) Robustness: Incomplete Knowledge
Incomplete Grammar Syntactic Coverage Domain Specific Constructions Ungrammatical Constructions
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 29IS 240 – Spring 2011
Syntactic Analysis
General Framework of NLP
Morphological andLexical Processing
Semantic Analysis
Context processingInterpretation
Difficulties of NLP
(1) Robustness: Incomplete Knowledge
Incomplete Domain Knowledge Interpretation Rules
PredefinedAspects of
Information
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 30IS 240 – Spring 2011
General Framework of NLP
Morphological andLexical Processing
Syntactic Analysis
Semantic Analysis
Context processingInterpretation
Difficulties of NLP
(1) Robustness: Incomplete Knowledge
(2) Ambiguities:Combinatorial
Explosion
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 31IS 240 – Spring 2011
General Framework of NLP
Morphological andLexical Processing
Syntactic Analysis
Semantic Analysis
Context processingInterpretation
Difficulties of NLP
(1) Robustness: Incomplete Knowledge
(2) Ambiguities:Combinatorial
Explosion
Most words in Englishare ambiguous in terms of their parts of speech. runs: v/3pre, n/plu clubs: v/3pre, n/plu and two meanings
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 32IS 240 – Spring 2011
General Framework of NLP
Morphological andLexical Processing
Syntactic Analysis
Semantic Analysis
Context processingInterpretation
Difficulties of NLP
(1) Robustness: Incomplete Knowledge
(2) Ambiguities:Combinatorial
Explosion
Structural Ambiguities
Predicate-argument Ambiguities
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 33IS 240 – Spring 2011
Structural Ambiguities
(1)Attachment Ambiguities John bought a car with large seats. John bought a car with $3000.
(2) Scope Ambiguities
young women and men in the room
(3)Analytical Ambiguities Visiting relatives can be boring.
The manager of Yaxing Benz, a Sino-German joint ventureThe manager of Yaxing Benz, Mr. John Smith
John bought a car with Mary.$3000 can buy a nice car.
Semantic Ambiguities(1)
Semantic Ambiguities(2)
Every man loves a woman.
Co-reference Ambiguities
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 34IS 240 – Spring 2011
General Framework of NLP
Morphological andLexical Processing
Syntactic Analysis
Semantic Analysis
Context processingInterpretation
Difficulties of NLP
(1) Robustness: Incomplete Knowledge
(2) Ambiguities:Combinatorial
Explosion
Structural Ambiguities
Predicate-argument Ambiguities
CombinatorialExplosion
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 35IS 240 – Spring 2011
Note:
Ambiguities vs Robustness
More comprehensive knowledge: More Robust
big dictionariescomprehensive grammar
More comprehensive knowledge: More ambiguities
Adaptability: Tuning, LearningSlides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 36IS 240 – Spring 2011
Framework of IE
IE as compromise NLP
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 37IS 240 – Spring 2011
Syntactic Analysis
General Framework of NLP
Morphological andLexical Processing
Semantic Analysis
Context processingInterpretation
Difficulties of NLP
(1) Robustness: Incomplete Knowledge
Incomplete Domain Knowledge Interpretation Rules
PredefinedAspects of
Information
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 38IS 240 – Spring 2011
Syntactic Analysis
General Framework of NLP
Morphological andLexical Processing
Semantic Analysis
Context processingInterpretation
Difficulties of NLP
(1) Robustness: Incomplete Knowledge
Incomplete Domain Knowledge Interpretation Rules
PredefinedAspects of
Information
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 39IS 240 – Spring 2011
Techniques in IE
(1) Domain Specific Partial Knowledge: Knowledge relevant to information to be extracted
(2) Ambiguities: Ignoring irrelevant ambiguities Simpler NLP techniques
(4) Adaptation Techniques: Machine Learning, Trainable systems
(3) Robustness: Coping with Incomplete dictionaries (open class words) Ignoring irrelevant parts of sentences
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 40IS 240 – Spring 2011
General Framework of NLP
Morphological andLexical Processing
Syntactic Analysis
Semantic Anaysis
Context processingInterpretation
Open class words: Named entity recognition (ex) Locations Persons Companies Organizations Position names
Domain specific rules: <Word><Word>, Inc. Mr. <Cpt-L>. <Word>Machine Learning: HMM, Decision TreesRules + Machine Learning
Part of Speech TaggerFSA rulesStatistic taggers
95 %
F-Value90
DomainDependent
Local ContextStatistical Bias
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 41IS 240 – Spring 2011
General Framework of NLP
Morphological andLexical Processing
Syntactic Analysis
Semantic Anaysis
Context processingInterpretation
FASTUS
1.Complex Words: Recognition of multi-words and proper names
2.Basic Phrases:Simple noun groups, verb groups and particles
3.Complex phrases:Complex noun groups and verb groups
4.Domain Events:Patterns for events of interest to the application
Basic templates are to be built.
5. Merging Structures:Templates from different parts of the texts are merged if they provide information about the same entity or event.
Based on finite states automata (FSA)
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 42IS 240 – Spring 2011
General Framework of NLP
Morphological andLexical Processing
Syntactic Analysis
Semantic Anaysis
Context processingInterpretation
FASTUS
1.Complex Words: Recognition of multi-words and proper names
2.Basic Phrases:Simple noun groups, verb groups and particles
3.Complex phrases:Complex noun groups and verb groups
4.Domain Events:Patterns for events of interest to the application
Basic templates are to be built.
5. Merging Structures:Templates from different parts of the texts are merged if they provide information about the same entity or event.
Based on finite states automata (FSA)
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 43IS 240 – Spring 2011
General Framework of NLP
Morphological andLexical Processing
Syntactic Analysis
Semantic Analysis
Context processingInterpretation
FASTUS
1.Complex Words: Recognition of multi-words and proper names
2.Basic Phrases:Simple noun groups, verb groups and particles
3.Complex phrases:Complex noun groups and verb groups
4.Domain Events:Patterns for events of interest to the application
Basic templates are to be built.
5. Merging Structures:Templates from different parts of the texts are merged if they provide information about the same entity or event.
Based on finite states automata (FSA)
Slides from Prof. J. Tsujii, Univ of Tokyo and Univ of Manchester

2011.03.30 - SLIDE 44IS 240 – Spring 2011
Using NLP
• Strzalkowski (in Reader)
Text NLP represDbasesearch
TAGGERNLP: PARSER TERMS

2011.03.30 - SLIDE 45IS 240 – Spring 2011
Using NLP
INPUT SENTENCEThe former Soviet President has been a local hero ever sincea Russian tank invaded Wisconsin.
TAGGED SENTENCEThe/dt former/jj Soviet/jj President/nn has/vbz been/vbn a/dt local/jj hero/nn ever/rb since/in a/dt Russian/jj tank/nn invaded/vbd Wisconsin/np ./per

2011.03.30 - SLIDE 46IS 240 – Spring 2011
Using NLP
TAGGED & STEMMED SENTENCEthe/dt former/jj soviet/jj president/nn have/vbz be/vbn a/dt local/jj hero/nn ever/rb since/in a/dt russian/jj tank/nn invade/vbd wisconsin/np ./per

2011.03.30 - SLIDE 47IS 240 – Spring 2011
Using NLP
PARSED SENTENCE
[assert
[[perf [have]][[verb[BE]]
[subject [np[n PRESIDENT][t_pos THE]
[adj[FORMER]][adj[SOVIET]]]]
[adv EVER]
[sub_ord[SINCE [[verb[INVADE]]
[subject [np [n TANK][t_pos A]
[adj [RUSSIAN]]]]
[object [np [name [WISCONSIN]]]]]]]]]

2011.03.30 - SLIDE 48IS 240 – Spring 2011
Using NLP
EXTRACTED TERMS & WEIGHTS
President 2.623519 soviet 5.416102
President+soviet 11.556747 president+former 14.594883
Hero 7.896426 hero+local 14.314775
Invade 8.435012 tank 6.848128
Tank+invade 17.402237 tank+russian 16.030809
Russian 7.383342 wisconsin 7.785689

2011.03.30 - SLIDE 49IS 240 – Spring 2011
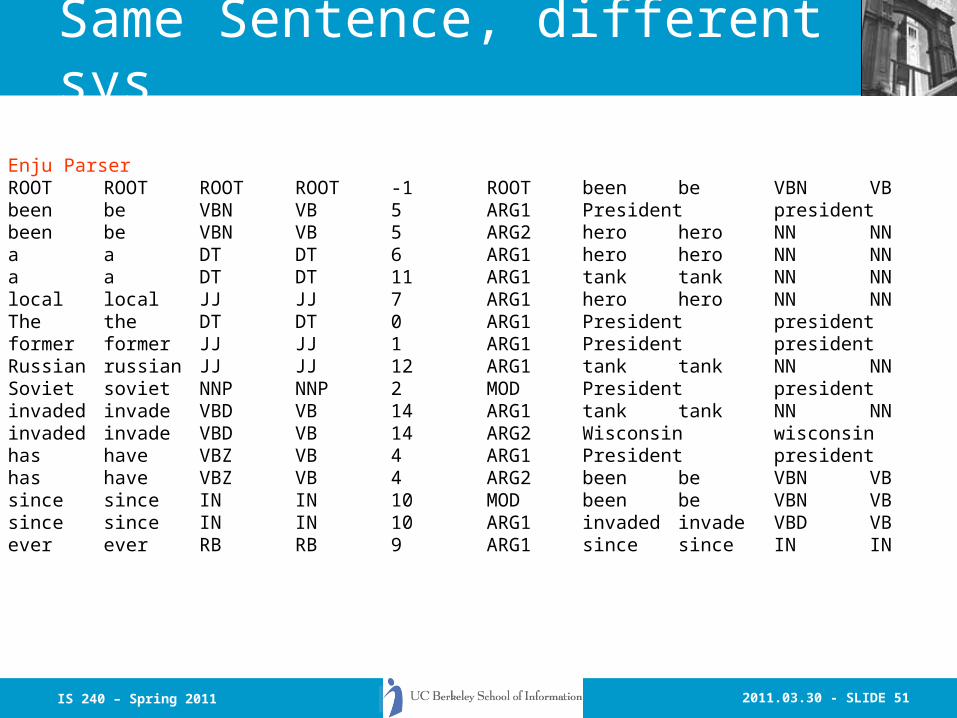
Same Sentence, different sys
INPUT SENTENCEThe former Soviet President has been a local hero ever sincea Russian tank invaded Wisconsin.
TAGGED SENTENCE (using uptagger from Tsujii)The/DT former/JJ Soviet/NNP President/NNP has/VBZ been/VBN a/DT local/JJ hero/NN ever/RB since/IN a/DT Russian/JJ tank/NN invaded/VBD Wisconsin/NNP ./.

2011.03.30 - SLIDE 50IS 240 – Spring 2011
Same Sentence, different sys
CHUNKED Sentence (chunkparser – Tsujii)(TOP (S (NP (DT The) (JJ former) (NNP Soviet) (NNP President) ) (VP (VBZ has) (VP (VBN been) (NP (DT a) (JJ local) (NN hero) ) (ADVP (RB ever) ) (SBAR (IN since) (S (NP (DT a) (JJ Russian) (NN tank) ) (VP (VBD invaded) (NP (NNP Wisconsin) ) ) ) ) ) ) (. .) ) )
2011.03.30 - SLIDE 51IS 240 – Spring 2011
Same Sentence, different sys
Enju ParserROOT ROOT ROOT ROOT -1 ROOT been be VBN VB 5been be VBN VB 5 ARG1 President president NNP NNP 3been be VBN VB 5 ARG2 hero hero NN NN 8a a DT DT 6 ARG1 hero hero NN NN 8a a DT DT 11 ARG1 tank tank NN NN 13local local JJ JJ 7 ARG1 hero hero NN NN 8The the DT DT 0 ARG1 President president NNP NNP 3former former JJ JJ 1 ARG1 President president NNP NNP 3Russian russian JJ JJ 12 ARG1 tank tank NN NN 13Soviet soviet NNP NNP 2 MOD President president NNP NNP 3invaded invade VBD VB 14 ARG1 tank tank NN NN 13invaded invade VBD VB 14 ARG2 Wisconsin wisconsin NNP NNP 15has have VBZ VB 4 ARG1 President president NNP NNP 3has have VBZ VB 4 ARG2 been be VBN VB 5since since IN IN 10 MOD been be VBN VB 5since since IN IN 10 ARG1 invaded invade VBD VB 14ever ever RB RB 9 ARG1 since since IN IN 10

2011.03.30 - SLIDE 52IS 240 – Spring 2011
NLP & IR
• Indexing– Use of NLP methods to identify phrases
• Test weighting schemes for phrases
– Use of more sophisticated morphological analysis
• Searching– Use of two-stage retrieval
• Statistical retrieval• Followed by more sophisticated NLP filtering

2011.03.30 - SLIDE 53IS 240 – Spring 2011
NPL & IR
• Lewis and Sparck Jones suggest research in three areas– Examination of the words, phrases and sentences
that make up a document description and express the combinatory, syntagmatic relations between single terms
– The classificatory structure over document collection as a whole, indicating the paradigmatic relations between terms and permitting controlled vocabulary indexing and searching
– Using NLP-based methods for searching and matching

2011.03.30 - SLIDE 54IS 240 – Spring 2011
NLP & IR Issues
• Is natural language indexing using more NLP knowledge needed?
• Or, should controlled vocabularies be used
• Can NLP in its current state provide the improvements needed
• How to test

2011.03.30 - SLIDE 55IS 240 – Spring 2011
NLP & IR
• New “Question Answering” track at TREC has been exploring these areas– Usually statistical methods are used to
retrieve candidate documents– NLP techniques are used to extract the likely
answers from the text of the documents

2011.03.30 - SLIDE 56IS 240 – Spring 2011
Mark’s idle speculation
• What people think is going on always
Keywords
NLPFrom Mark Sanderson, University of Sheffield

2011.03.30 - SLIDE 57IS 240 – Spring 2011
Mark’s idle speculation
• What’s usually actually going on
KeywordsNLPFrom Mark Sanderson, University of Sheffield

2011.03.30 - SLIDE 58IS 240 – Spring 2011
What we really need is…
• The reason NLP fails to help is because the machine lacks the human flexibility of interpretation and knowledge of context and content
• So what about AI?– There are many debates on whether human-
like AI is or is not possible
• “the question of whether machines can think is no more interesting than the question of whether submarines can swim”
– Edsger Dijkstra

2011.03.30 - SLIDE 59IS 240 – Spring 2011
Today
• Review - Filtering and TDT
• Natural Language Processing and IR– Based on Papers in Reader and on
• David Lewis & Karen Sparck Jones “Natural Language Processing for Information Retrieval” Communications of the ACM, 39(1) Jan. 1996
• Information from Junichi Tsuji, University of Tokyo
• Watson and Jeopardy

2011.03.30 - SLIDE 60IS 240 – Spring 2011
Building Watson and the Jeopardy Challenge
Slides based on the article by David Ferrucci, et al.
“Building Watson: An Overview of the DeepQA Project”
In AI Magazine - Fall 2010

2011.03.30 - SLIDE 61IS 240 – Spring 2011
The Challenge
• “the open domain QA is attractive as it is one of the most challenging in the realm of computer science and artificial intelligence, requiring a synthesis of information retrieval, natural language processing, knowledge representation and reasoning, machine learning and computer-human interfaces.”
– “Building Watson: An overview of the DeepQA Project”,
AI Magazine, Fall 2010

2011.03.30 - SLIDE 62IS 240 – Spring 2011
Technologies
• Parsing• Question Classification• Question Decomposition• Automatic Source Acquisition and
Evaluation• Entity and Relation detection• Logical form generation• Knowledge representation• Reasoning

2011.03.30 - SLIDE 63IS 240 – Spring 2011
Goals
• “To create general-purpose, reusable natural language processing (NLP) and knowledge representation and reasoning (KRR) technology that can exploit as-is natural language resources and as-is structured knowledge rather than to curate task-specific knowledge as resources”

2011.03.30 - SLIDE 64IS 240 – Spring 2011
Excluded Jeopardy categories• Audiovisual questions (where part of the
clue is a picture, recording, or video)
• Special Instruction Questions (where the category or clues require a special verbal explanation from the host)
• All others, including “puzzle” clues are considered fair game

2011.03.30 - SLIDE 65IS 240 – Spring 2011
Approaches
• Tried adapting and combining systems used for TREC QA task, but never worked adequately for the Jeopardy tests
• Started a collaborative effort with academic QA researchers call “Open Advancement of Question Answering” OAQA

2011.03.30 - SLIDE 66IS 240 – Spring 2011
DeepQA
• The DeepQA system finally developed (and continuing to be developed) is described as:– A massively parallel probabilistic evidence-
based architecture– Uses over 100 different techniques for
analyzing natural language, identifying sources, finding and generating hypothesis, finding and scoring evidence, and merging and ranking hypotheses
– What is important is how these are combined

2011.03.30 - SLIDE 67IS 240 – Spring 2011
DeepQA
• Massive parallelism: Exploits massive parallelism in the consideration of multiple interpretations and hypotheses
• Many Experts: Facilitates the integration, application and contextual evaluation of a wide range of loosely coupled probabilistic question and content analytics
• Pervasive confidence estimation: No component commits to an answer; all components produce features and associated confidences, scoring different question and content interpretations.
– An underlying confidence-processing substrate learns how to stack and combine the scores.

2011.03.30 - SLIDE 68IS 240 – Spring 2011
DeepQA
• Integrate shallow and deep knowledge: Balance the use of strict semantics and shallow semantics, leveraging many loosely formed ontologies

2011.03.30 - SLIDE 69IS 240 – Spring 2011
DeepQA
DeepQA High-Level Architecture from “Building Watson” AI Magazine Fall 2010

2011.03.30 - SLIDE 70IS 240 – Spring 2011
Question Analysis
• Attempts to discover what kind of question is being asked (usually meaning the desired type of result - or LAT Lexical Answer Type)– I.e. “Who is…” needs a person, “Where is…”
needs a location.
• DeepQA uses a number of experts and combines the results using the confidence framework

2011.03.30 - SLIDE 71IS 240 – Spring 2011
Hypothesis Generation
• Takes the results of Question Analysis and produces candidate answers by searching the system’s sources and extracting answer-sized snippets from the search results.
• Each candidate answer plugged back into the question is considered a hypothesis
• A “lightweight scoring” is performed to trim down the hypothesis set– What is the likelihood of the candidate answer being
an instance of the LAT from the first stage?

2011.03.30 - SLIDE 72IS 240 – Spring 2011
Hypothesis and Evidence Scoring
• Candidate answers that pass the lightweight scoring then undergo a rigorous evaluation process that involves gathering additional supporting evidence for each candidate answer, or hypothesis, and applying a wide variety of deep scoring analytics to evaluation the supporting evidence
• This involves more retrieval and scoring (one method used involves IDF scores of common words between the hypothesis and the source passage)

2011.03.30 - SLIDE 73IS 240 – Spring 2011
Final Merging and Ranking
• Based on the deep scoring, the hypotheses and their supporting sources are ranked and merged to select the single best-supported hypothesis
• Equivalent candidate answers are merged• After merging the system must rank the
hypotheses and estimate confidence based on their merged scores. (A machine-learning approach using a set of know training answers is used to build the ranking model)

2011.03.30 - SLIDE 74IS 240 – Spring 2011
Running DeepQA
• A single question on a single processor implementation of DeepQA typically could take up to 2 hours to complete
• The Watson system used a massively parallel version of the UIMA framework and Hadoop (both open source from Apache now :) that was running 2500 processors in parallel
• They won the public Jeopardy Challenge (easily it seemed)
Related Documents











