Reglas: 1. Calcular las relaciones y . 2. Crear tablas de dos columnas para cada par tal que . 3. Debajo de se colocan los simbolos tal que (últimos de ). 4. Debajo de se colocan los símbolos tal que (primeros de ). 5. La relación se obtiene tomando los , donde está en la segunda columna. 6. La relación se obtiene tomando los , donde esta en la primera columna y en la segunda columna (incluido ), siempre que sea un terminal. EJEMPLO DIAPOSITIVAS: S aSb | A A BC | c B ( C A) S aA aABc( bA bAcC) A Bc B(c Cc Cc) B ( ( ( ( C A ABc( ) ) a S S b A ) B C a A B c ( b A c C ) C c ) ( A B c ( S A B C a b c ( ) S = A > = B < < = < < C > > a = < < < < < b > c > > ( > > ) > >

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript
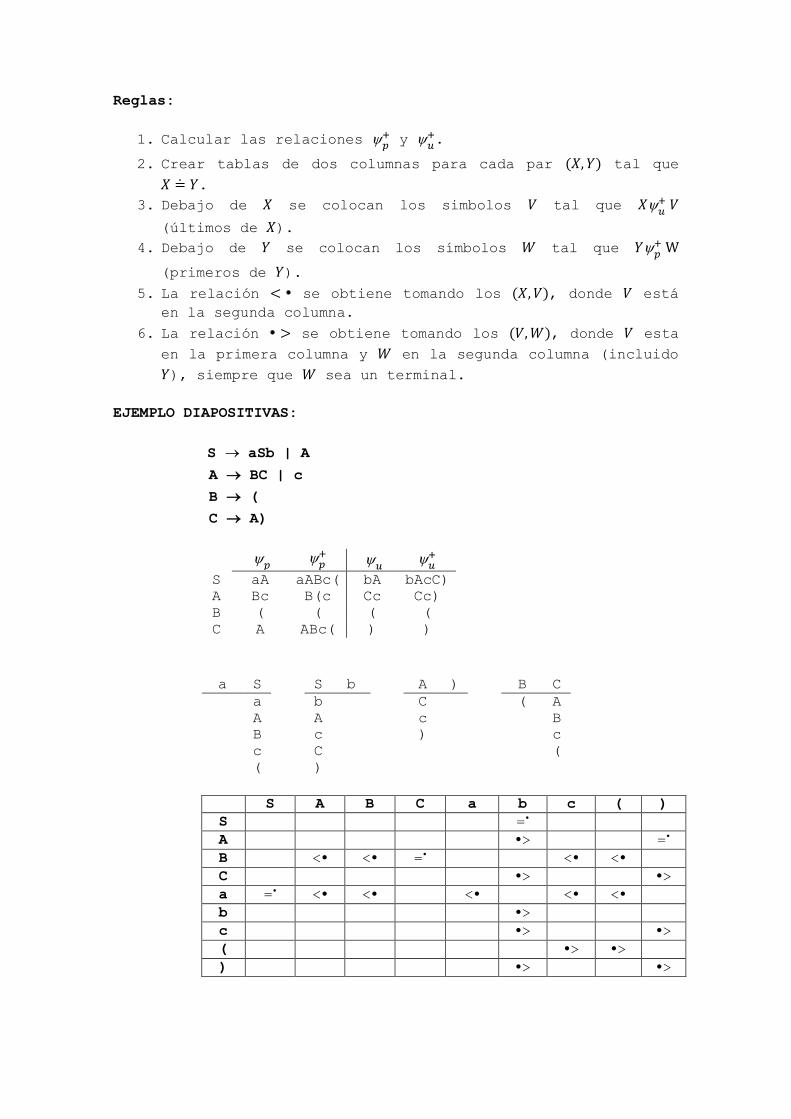
Reglas:
1. Calcular las relaciones y
.
2. Crear tablas de dos columnas para cada par tal que
.
3. Debajo de se colocan los simbolos tal que
(últimos de ).
4. Debajo de se colocan los símbolos tal que
(primeros de ).
5. La relación se obtiene tomando los , donde está
en la segunda columna.
6. La relación se obtiene tomando los , donde esta
en la primera columna y en la segunda columna (incluido
), siempre que sea un terminal.
EJEMPLO DIAPOSITIVAS:
S aSb | A
A BC | c
B (
C A)
S aA aABc( bA bAcC)
A Bc B(c Cc Cc)
B ( ( ( (
C A ABc( ) )
a S S b A ) B C
a
A
B
c
(
b
A
c
C
)
C
c
)
( A
B
c
(
S A B C a b c ( )
S =
A > =
B < < = < <
C > >
a = < < < < <
b >
c > >
( > >
) > >
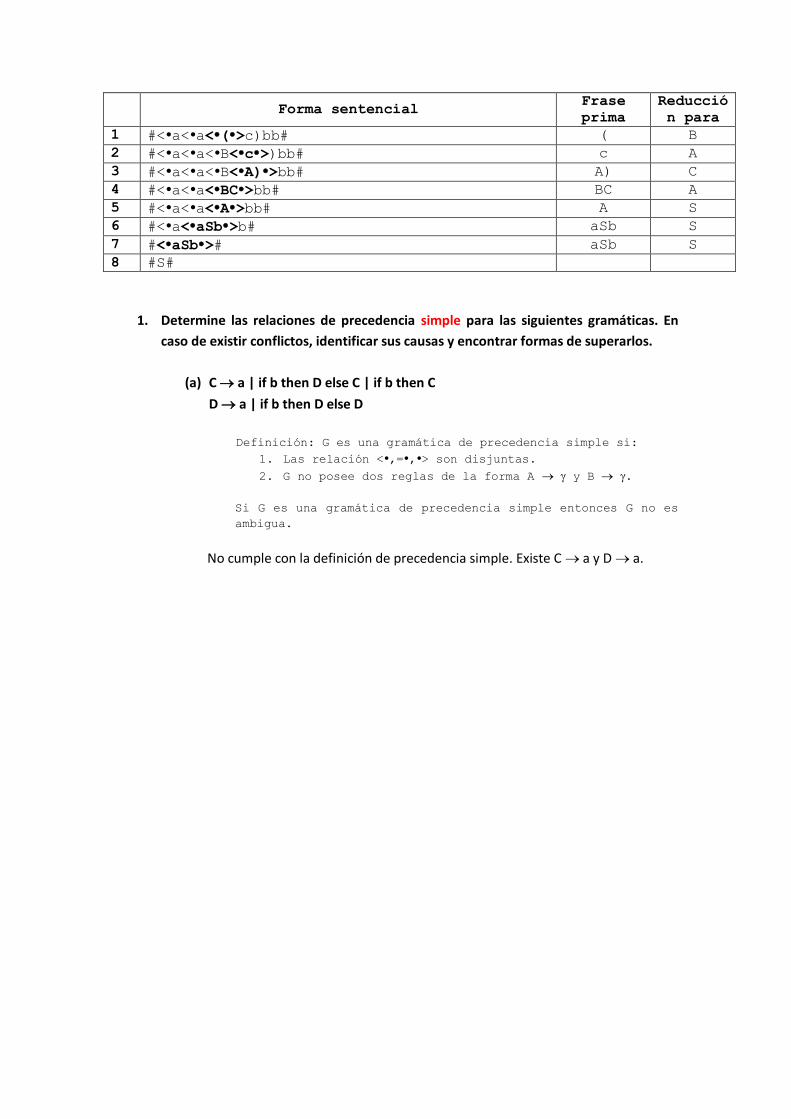
Forma sentencial Frase
prima
Reducció
n para
1 #< a< a< ( >c)bb# ( B
2 #< a< a< B< c >)bb# c A
3 #< a< a< B< A) >bb# A) C
4 #< a< a< BC >bb# BC A
5 #< a< a< A >bb# A S
6 #< a< aSb >b# aSb S
7 #< aSb ># aSb S
8 #S#
1. Determine las relaciones de precedencia simple para las siguientes gramáticas. En
caso de existir conflictos, identificar sus causas y encontrar formas de superarlos.
(a) C a | if b then D else C | if b then C
D a | if b then D else D
Definición: G es una gramática de precedencia simple si:
1. Las relación < ,= , > son disjuntas.
2. G no posee dos reglas de la forma A y B .
Si G es una gramática de precedencia simple entonces G no es
ambigua.
No cumple con la definición de precedencia simple. Existe C a y D a.

(b) S AB) | ()
A (
B aS | b | S
S A( A( ) ) A ( ( ( ( B abS abSA( bS bS)
B ) a S A B ( )
b S )
A (
( a b S A (
S A B a b ( )
S >
A < < = < < <
B =
a = < <
b >
( > > > =
) >
Forma sentencial Frase prima Reducción
para
1 #< ( >a ((b)))# ( A
2 #< A< a< ( >(b)))# ( A
3 #< A< a< A< ( >b)))# ( A
4 #< A< a< A< A< b >)))# b B
5 #< A< a< A< AB) >))# AB) S
6 #< A< a< A< S >))# S B
7 #< A< a< AB) >)# AB) S
8 #< A< aS >)# aS B
9 #< AB) ># AB) S
10 #S#

Reglas:
1. Calcular las relaciones ,
, y y las compuestas
y .
2. Crear tablas de dos columnas para cada secuencia
si ocurre en el lado derecho de alguna regla.
o pueden no existir.
3. En la primera columna se colocan los símbolos tal que
. No es necesario si no existe.
4. En la segunda columna se colocan los símbolos tal que
. No es necesario si no existe.
5. La relación se obtiene tomando lo s , donde esta
en la segunda columna.
6. La relación se obtiene tomando lo s , donde esta en
la primera columna.
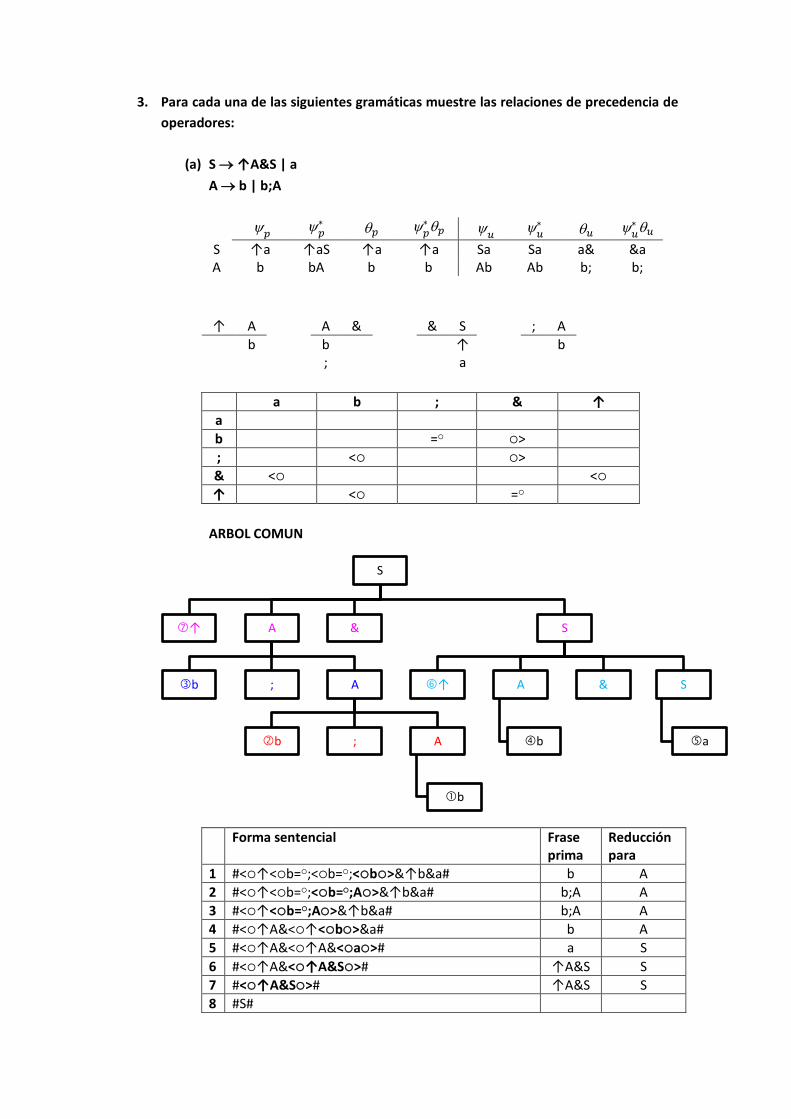
3. Para cada una de las siguientes gramáticas muestre las relaciones de precedencia de
operadores:
(a) S ↑A&S | a
A b | b;A
S ↑a ↑aS ↑a ↑a Sa Sa a& &a A b bA b b Ab Ab b; b;
↑ A A & & S ; A
b b
; ↑
a b
a b ; & ↑
a
b = >
; < >
& < <
↑ < =
ARBOL COMUN
Forma sentencial Frase
prima Reducción para
1 #<↑<b=;<b=;<b>&↑b&a# b A
2 #<↑<b=;<b=;A>&↑b&a# b;A A
3 #<↑<b=;A>&↑b&a# b;A A
4 #<↑A&<↑<b>&a# b A
5 #<↑A&<↑A&<a># a S
6 #<↑A&<↑A&S># ↑A&S S
7 #<↑A&S># ↑A&S S
8 #S#
S
↑ A
b ; A
b ; A
b
& S
↑ A
b
& S
a
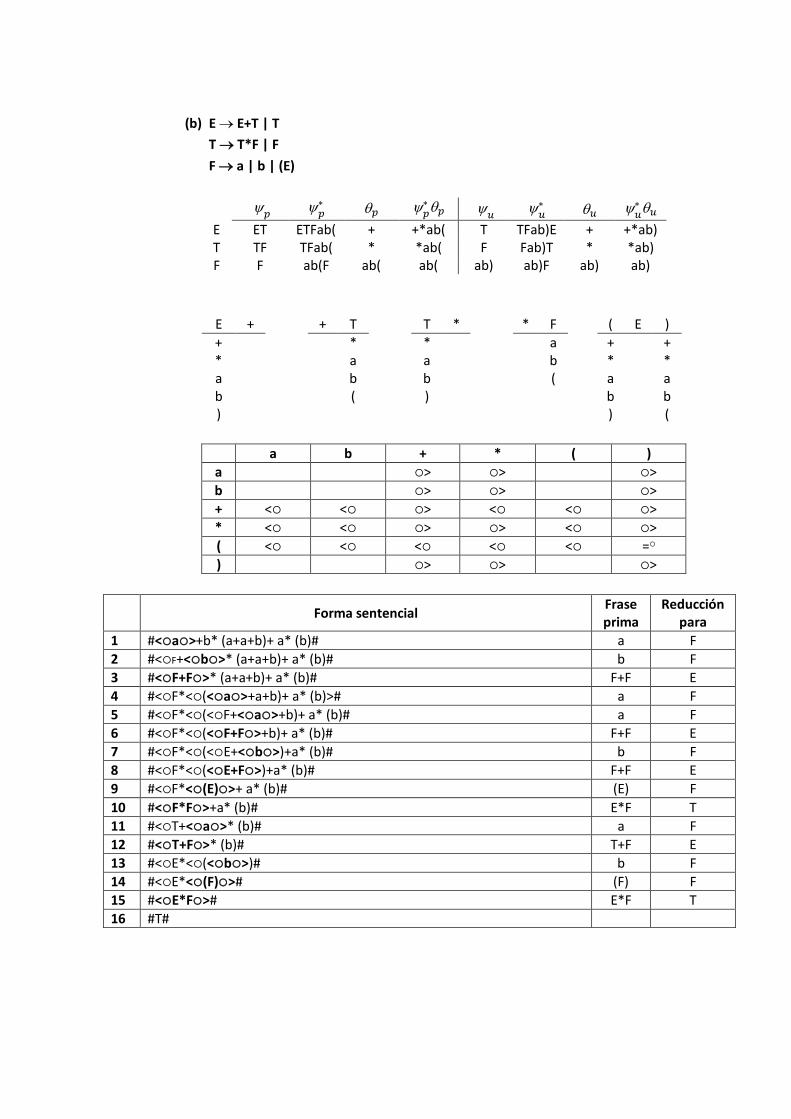
(b) E E+T | T
T T*F | F
F a | b | (E)
E ET ETFab( + +*ab( T TFab)E + +*ab) T TF TFab( * *ab( F Fab)T * *ab) F F ab(F ab( ab( ab) ab)F ab) ab)
E + + T T * * F ( E )
+ * a b )
* a b (
* a b )
a b (
+ * a b )
+ * a b (
a b + * ( )
a > > >
b > > >
+ < < > < < >
* < < > > < >
( < < < < < =
) > > >
Forma sentencial Frase prima
Reducción para
1 #<a>+b* (a+a+b)+ a* (b)# a F
2 #<F+<b>* (a+a+b)+ a* (b)# b F
3 #<F+F>* (a+a+b)+ a* (b)# F+F E
4 #<F*<(<a>+a+b)+ a* (b)># a F
5 #<F*<(<F+<a>+b)+ a* (b)# a F
6 #<F*<(<F+F>+b)+ a* (b)# F+F E
7 #<F*<(<E+<b>)+a* (b)# b F
8 #<F*<(<E+F>)+a* (b)# F+F E
9 #<F*<(E)>+ a* (b)# (E) F
10 #<F*F>+a* (b)# E*F T
11 #<T+<a>* (b)# a F
12 #<T+F>* (b)# T+F E
13 #<E*<(<b>)# b F
14 #<E*<(F)># (F) F
15 #<E*F># E*F T
16 #T#

(c) S (L) | a
L L,S | S
S (a (aS (a (a )a )aS )a )a L LS LS , (a, S SL , )a,
( L L ) L , , S
( a ,
) a ,
) a ,
( a
a , ( )
a > >
, < > < >
( < < < =
) > >
Forma sentencial
Frase prima
Reducción para
1 #<(<a>, ( (a, a), (a, a)))# a S
2 #<(<S,<(<(<a>,a), (a, a)))# a S
3 #<(<S,<(<(<S,<a>), (a, a)))# a S
4 #<(<S,<(<(<S,S>), (a, a)))# S,S L
5 #<(<S,<(<(L)>, (a, a)))# (L) S
6 #<(<S,<(<S,<(<a>,a)))# a S
7 #<(<S,<(<S,<(<S,<a>)))# a S
8 #<(<S,<(<S,<(<S,S>)))# S,S L
9 #<(<S,<(<S,<(L)>))# (L) S
10 #<(<S,<(<S,S>))# S,S L
11 #<(<S,<(L)>)# (L) S
12 #<(<S,S>)# S,S L
13 #<(L)># (L) S
14 #S#

Árbol con precedencia de operadores
5. ¿Puede ser ambigua una gramática de precedencia de operadores? Justique.
Si puede. El algoritmo de análisis de precedencia de operadores siempre reduce la
frase prima mas a la izquierda de la forma sentencial.
Para gramáticas no ambiguas, esta frase es única.
7. Considere la siguiente gramática G2:
A aA | B
B CdB | C
C cCbCeC | DfC | D
D + | - | +- | -+
(a) Obtenga una tabla con las relaciones precedencia de operadores de G2. A partir
de la tabla, determine si la gramática es una gramática de precedencia de
operadores.
A aB aBCcDA+- a adcf+- AB ABCD+- a adef+- B C CcD+-B d dcf+- BC BCD+- d def+- C cD cD+-C cf cf+- CD CD+- ef ef+- D +- +-D +- +- +- +-D +- +-
a A C d d B C b b C
a d c f + -
e f + -
d c f + -
e f + -
c f + -
S
( L
S
a
, S
( L
S
( L
S
a
, S
a
)
, S
( L
S
a
, S
a
)
)
)
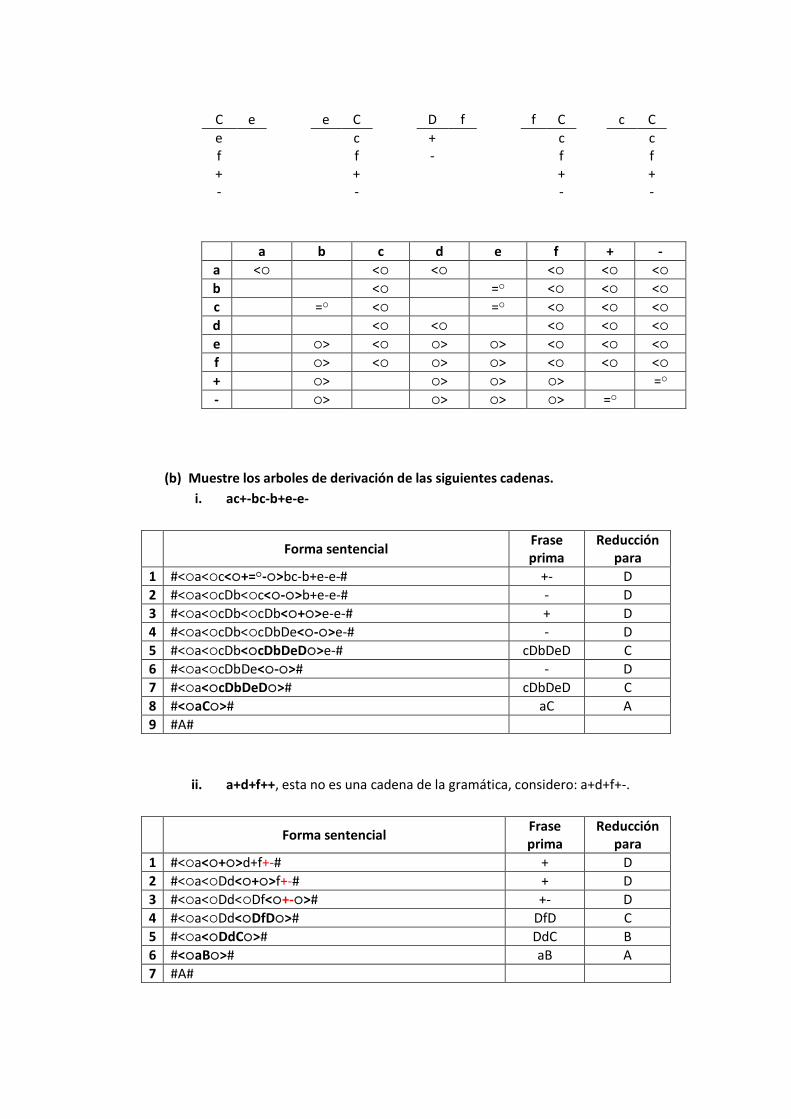
C e e C D f f C c C
e f + -
c f + -
+ -
c f + -
c f + -
a b c d e f + -
a < < < < < <
b < = < < <
c = < = < < <
d < < < < <
e > < > > < < <
f > < > > < < <
+ > > > > =
- > > > > =
(b) Muestre los arboles de derivación de las siguientes cadenas.
i. ac+-bc-b+e-e-
Forma sentencial
Frase prima
Reducción para
1 #<a<c<+=->bc-b+e-e-# +- D
2 #<a<cDb<c<->b+e-e-# - D
3 #<a<cDb<cDb<+>e-e-# + D
4 #<a<cDb<cDbDe<->e-# - D
5 #<a<cDb<cDbDeD>e-# cDbDeD C
6 #<a<cDbDe<-># - D
7 #<a<cDbDeD># cDbDeD C
8 #<aC># aC A
9 #A#
ii. a+d+f++, esta no es una cadena de la gramática, considero: a+d+f+-.
Forma sentencial
Frase prima
Reducción para
1 #<a<+>d+f+-# + D
2 #<a<Dd<+>f+-# + D
3 #<a<Dd<Df<+-># +- D
4 #<a<Dd<DfD># DfD C
5 #<a<DdC># DdC B
6 #<aB># aB A
7 #A#

LR (left-to-right and rightmost derivation)
Cada estado en el autómata LR(0) representa un conjunto de ítems
de la colección canónica-LR(0). Una colección de conjunto de
ítems LR(0) es llamada canonical LR(0).
Antes que nada, una gramática extendida es aquella a la que se
le agrega la regla S’S, donde S’ es el nuevo símbolo inicial y
S era el anterior símbolo inicial, esto se agrega para indicarle
al parser cuando debe parar y aceptar la cadena.
Clausura de conjunto de ítems:
Si I es un conjunto de ítem para la gramática G, entonces
clausura(I) es un conjunto de ítems construido desde I con:
1. Inicialmente, agregar cada ítem I a clausura(I).
2. Si A.B esta en clausura(I) y B es una producción,
entonces agregar el ítem B. a la clausura(I), si no
está. Aplicar hasta que no haya mas ítems para agregar.
Goto:
GOTO(I,X) donde I es un conjunto de ítems y X es un símbolo de
la gramática. GOTO(I,X) está definido para ser la clausura del
conjunto de todos los ítems [A.X] tal que [AX.] está en
I.
Estructura de la tabla del parser LR
La tabla del parser consiste en dos partes: una función de
acción y una función GOTO.
1. La función acción toma como argumento un estado i y un
terminal a ($). El valor de ACCION[i,a]:
(a) Desplazar a j, donde j es un estado. La acción
tomada es poner a en la pila y se mueve a j.
(b) Reducción A. Se reduce y se pone A como cabeza
de la pila.
(c) Aceptar.
(d) Error.
2. Extendemos la función GOTO, definimos un conjunto de
ítems, a estados: si GOTO[Ii,A] = Ij, entonces GOTO también
mapea a estado i y un no terminal A a un estado j.
Construcción la tabla para el parser SLR

1. Construir C = {I0,I1,…,In}, la colección de conjuntos de
ítems LR(0) para G’.
2. El estado i se construye a partir del conjunto Ii. Las
acciones de análisis sintáctico para el estado i se
construyen según:
(a) Si [A.a] Ii y GOTO(Ii,a) = Ij, asignar “shift j”
a acción[i,a], siendo a VT.
(b) Si [A.] Ii, entonces asignar “reducir A” a
acción[i,a], para todo a Seguidores(A).
(c) Si [S’S.] Ii, entonces asignar “aceptar” a
acción[i,$].
3. Las transacciones GOTO para el estado i se construyen,
para todos los A VN utilizando la regla
Si GOTO[Ii,A] = Ij entonces GOTO[i,A] = j.
4. Todas las entradas de la tabla no actualizadas por 2 y 3
son consideradas error.
5. El estado inicial es el construido a partir del conjunto
que contiene a [S’.S].
La tabla construida con el algoritmo anterior es llamada tabla
SLR(1) para G. Un analizador (parser) LR que utiliza la tabla
SLR(1) es llamado analizador SLR(1) y una gramática que tiene un
analizador SLR(1) es considerada una gramática SLR(1).
Usualmente el 1 se omite.
Un analizador LR más poderoso
1. El método canónico-LR o LR, que hace uso de los símbolos
del lookahead. Este utiliza un gran conjunto de ítems,
llamados ítems LR(1).
2. El método lookahead-LR o LALR, que se basa los ítem LR(0),
y tiene menos estados que los típicos analizadores basado
en LR(1).
Ítem canónico-LR(1)
Recordemos que el método SLR, el estado i llama a la reducción
por A si el conjunto de ítems Ii contiene el ítem [A.] y a
es un siguiente(A). En algunas situaciones, sin embargo, cuando
el estado i aparece en el tope de la pila, el prefijo viable
en la pila es tal que A no puede ser seguido por a en ninguna
forma sentencial derecha. Así es, la reducción por A debería
ser invalida en la entrada a.
Es posible cargar más información en el estado que nos permitirá
descartar algunas reducciones inválidas.

La forma general de un ítem ahora es [A.,a], donde A es
una producción y a es un terminal o $. El lookahead no tiene
efecto en un ítem de la forma [A.,a], donde no es , pero
el ítem de la forma [A.,a] requiere una reducción por A
solo si el siguiente símbolo es a. Los a’s siempre serán un
subconjuntos de siguientes(A).
Formalmente, decimos que el ítem LR(1) [A.,a] es valido para
un prefijo viable si hay una derivación S Aw w,
donde:
1. = , y
2. A es el primer símbolo de w, o w es y a es $.
8. Construya la tabla de análisis SLR para la siguiente gramática:
E E+T | T
T TF | F
F F* | a | b
Realice el análisis sintáctico de la cadena “b * a 2 * +b" e indique la derivación
determinada por el análisis.
I0: E’ .E
E .E+T
E .T
T .TF
T .F
F .F*
F .a
F .b
I5: F b. I6: E E+.T
T .TF
T .F
F .F*
F .a
F .b
I1: E’ E.
E E.+T
I7: T TF.
F F.*
I2: E T.
T T.F
F .F*
F .a
F .b
I8: F F*.
I3: T F.
F F.*
I9: E E+T.
T T.F
F .F*
F .a
F .b
I4: F a.

SIG(E’) = {$}
SIG(E) = {+, $}
SIG(T) = {a, b, +, $}
SIG(F) = {a, b, +, *, $}
E’ E
E E+T
E T
T TF
T F
F F*
F a
F b
a b + * $ E T F
0 d4 d5 1 2 3 1 d6 2 d4 d5 r3 r3 7 3 r5 r5 r5 d8 r5 4 r7 r7 r7 r7 r7 5 r8 r8 r8 r8 r8 6 d4 d5 9 3 7 r4 r4 r4 d8 r4 8 r6 r6 r6 r6 r6 9 d4 d5 r2 r2 7
Paso Pila Entrada Acción
1 0 b*a*+b$ d5 2 0b5 *a*+b$ r8: F b 3 0F3 *a*+b$ d8 4 0F3*8 a*+b$ r6: F F* 5 0F3 a*+b$ r5: T F 6 0T2 a*+b$ d4 7 0T2a4 *+b$ r7: F a 8 0T2F7 *+b$ d8 9 0T2F7*8 +b$ r6: F F* 10 0T2F7 +b$ r4: T TF 11 0T2 +b$ r3: E T 12 0E1 +b$ d6 13 0E1+6 b$ d5 14 0E1+6b5 $ r8: F b 15 0E1+6F3 $ r5: T F 16 0E1+6T9 $ r2: E E+T 17 0E1 $
9. Considere la siguiente gramática aumentada G:
S’ S
S aSb | a
(a) Obtenga la colección canónica de ítems LR(0) para G.
I0: S’ .S
S .aSb
S .a
I2: S a.Sb
S a.
S .aSb

S .a I1: S’ S. I3: S aS.b
I4: S aSb.
(b) ¿Cuál de todos los métodos estudiados considera el más adecuado para
construir una tabla de análisis sintáctico LR para G?
SLR
Como la colección canónica de ítems LR(0), trato de construir la tabla SLR:
S’ S
S aSb
S a
SIG(S’) = {$}
SIG(S) = {$, b}
a b $ S
0 d2 1 1 2 d2 r3 r3 3 3 d4 4 r2 r2
Como no hay ningún problema en la tabla, se puede decir que el mejor método,
por ser el más sencillo y rápido, es el SLR.
LR-canónico
Regla:
Dado agrego para cada con
.
I0: [S’ .S, $]
[S .aSb, $]
[S .a, $]
I1: [S’ S., $]
I3: [S aS.b, $]
I2: [S a.Sb, $]
[S a., $]
[S .aSb, b]
[S .a, b]
I4: [S a.Sb, b]
[S a., b]
[S .aSb, b]
[S .a, b]
I5: [S aSb., $] I6: [S aS.b, b]
I7: [S aSb., b]

a b $ S
0 d2 1 1 2 d4 r3 3 3 d5 4 d4 r3 6 5 r2 6 d7 7 r2
LALR
I0: [S’ .S, $]
[S .aSb, $]
[S .a, $]
I1: [S’ S., $]
I36: [S aS.b, $/b]
I24: [S a.Sb, $/b]
[S a., $/b]
[S .aSb, b]
[S .a, b]
I57: [S aSb., $/b]
a b $ S
0 d24 1 1
24 d24 r3 r3 36 36 d57 57 r2 r2

10. Considere la siguiente gramática G:
S’ S
S aSa
S a
(a) Muestre que ninguno de los métodos estudiados es suficientemente
poderoso para construir una tabla de análisis sintáctico LR para G.
SLR
I0: S’ .S
S .aSa
S .a
I1: S’ S.
I2: S a.Sa
S a.
S .aSa
S .a
I3: S aS.a I4: S aSa.
SIG(S’) = {$}
SIG(S) = {$, a}
a $ S
0 d2 1 1 2 d2/r3 r3 3 3 d4 4 r2 r2
LR-canónico
Regla:
Dado agrego para cada con
.
I0: [S’ .S, $]
[S .aSa, $]
[S .a, $]
I1: [S’ S., $] I3: [S aS.a, $]
I2: [S a.Sa, $]
[S a., $]
[S .aSa, a]
[S .a, a]
I4: [S a.Sa, a]
[S a., a]
[S .aSa, a]
[S .a, a] I5: [S aS.a, a] I6: [S aSa., $] I7: [S aSa., a]
SIG(S’) = {$} SIG(S) = {$, a}

a $ S
0 d2 1 1 2 d4 r3 3 3 d6 4 d4/r3 5 5 d7 6 r2 7 r2
LALR
I0: [S’ .S, $]
[S .aSa, $]
[S .a, $]
I1: [S’ S., $] I35: [S aS.a, $/a]
I24: [S a.Sa, $/a]
[S a., $/a]
[S .aSa, a]
[S .a, a]
I67: [S aSa., $/a]
a $ S
0 d24 1 1
24 d24/r3 r3 35 35 d67 67 r2 r2
(b) Considere L(G). Es posible obtener una gramática alternativa G’ con L(G) igual
a L(G’) y tal que sea factible construir una tabla de análisis sintáctico LR para
G’.
(c) Defina L(G).
L(G) = a aa*
(d) Defina G’.
S a | aT
T aaT | aa
(e) ¿Cuál de todos los métodos estudiados es el más simple para construir una
tabla de análisis sintáctico LR para G’?
El más simple siempre es SLR.

SLR
r0: S’ S
r1: S a
r2: S aT
r3: T aaT
r4: T aa
I0: S’ .S
S .a
S .aT
I1: S’ S.
I2: S a.
S a.T
T .aaT
T .aa
I3: T a.aT
T a.a
I4: S aT. I5: T aa.T
T aa.
T .aaT
T .aa I6: T aaT. I7: T a.aT
T a.a
SIG(S’) = {$} SIG(S) = {$} SIG(T) = {$}
a $ S T
0 d2 1 1 2 d3 r1 4 3 d5 4 r2 5 d7 r4 6 6 r3 7 d5

LR-canónico
I0: [S’ .S, $]
[S .a, $]
[S .aT, $]
I1: [S’ S., $]
I2: [S a., $]
[S a.T, $]
[T .aaT, $]
[T .aa, $]
I3: [T a.aT, $]
[T a.a, $]
I4: [S aT., $] I5: [T aa.T, $]
[T aa., $]
[T .aaT, $]
[T .aa, $] I6: [T aaT., $] I7: [T a.aT, $]
[T a.a, $]
a $ S T
0 d2 1 1 2 d3 r1 4 3 d5 4 r2 5 d7 r4 6 6 r3 7 d5
LALR
Queda igual, porque no puedo fusionar nada.
11. Considere la siguiente gramática:
r1 : E (L)
r2 : E a
r3 : L L,E
r4 : L E
a. Hallar la colección canónica de ítems LR(0) para esta gramática. No se olvide de
introducir la producción inicial S’ E.
I0: S’ .E
E .(L)
E .a
I5: L E.
I1: S’ E. I6: E (L).

I2: E (.L)
L .L,E
L .E
E .(L)
E .a
I7: L L,.E
E .(L)
E .a
I3: E .a I8: L L,E. I4: E (L.)
L L.,E
b. Determine el conjunto SIGUIENTE de los elementos no terminales (inclusive S’)
SIG(S’) = {$}
SIG(E) = {,, ), $}
SIG(L) = {,, )}
c. Construya la tabla de análisis SLR(1).
a ( ) , $ E L
0 d3 d2 1 1 2 d3 d2 5 4 3 r2 r2 r2 4 d6 d7 5 r4 r4 6 r1 r1 r1 7 d3 d2 8 8 r3 r3
d. Muestre el funcionamiento con la siguiente cadena de entrada:
((a),a)
Paso Pila Entrada Acción
1 0 ((a),a)$ d2 2 0(2 (a),a)$ d2 3 0(2(2 a),a)$ d3 4 0(2(2a3 ),a)$ r2: E a 5 0(2(2E5 ),a)$ r4: L E 6 0(2(2L4 ),a)$ d6 7 0(2(2L4)6 ,a)$ r1: E (L) 8 0(2E5 ,a)$ r4: L E 9 0(2L4 ,a)$ d7
10 0(2L4,7 a)$ d3 11 0(2L4,7a3 )$ r2: E a

12 0(2L4,7E8 )$ r3: L L,E 13 0(2L4 )$ d6 14 0(2L4)6 $ r1: E (L) 15 0E1 $
12. Considere la siguiente gramática, en la que los paréntesis son símbolos terminales:
r1 : S S(S)
r2 : S
(a) Hallar la colección de elementos LR(1) para esta gramática.
I0: [S’ .S, $]
[S .S(S), $/(]
[S ., $/(]
I1: [S’ S., $]
[S S.(S), $/(]
I2: [S S(.S), $/(]
[S .S(S), )/(]
[S ., )/(]
I3: [S S(S.), $/(]
[S S.(S), )/(]
I4: [S S(S)., $/(] I5: [S S(.S), )/(]
[S .S(S), )/(]
[S ., )/(] I6: [S S(S.), )/(]
[S S.(S), )/(]
I7: [S S(S)., )/(]
(b) Fusione los elementos necesarios para lograr una tabla de análisis sintáctico LALR.
I0: [S’ .S, $]
[S .S(S), $/(]
[S ., $/(]
I1: [S’ S., $]
[S S.(S), $/(]
I25: [S S(.S), $/)/(]
[S .S(S), )/(]
[S ., )/(]
I36: [S S(S.), $/)/(]
[S S.(S), )/(]
I47: [S S(S)., $/)/(]
( ) $ S
0 r2 r2 1 1 d25
25 r2 r2 36 36 d25 d47 47 r1 r1 r1

(c) Muestre el funcionamiento con la siguiente cadena de entrada
()(())
Paso Pila Entrada Acción
1 0 ()(())$ r2: S 2 0S1 ()(())$ d25 3 0S1(25 )(())$ r2: S 4 0S1(25 S 36 )(())$ d47 5 0S1(25 S 36)47 (())$ r1: S S(S) 6 0S1 (())$ d25 7 0S1(25 ())$ r2: S 8 0S1(25 S 36 ())$ d25 9 0S1(25 S 36(25 ))$ r2: S
10 0S1(25 S 36(25 S 36 ))$ d47 11 0S1(25 S 36(25 S 36)47 )$ r1: S S(S) 12 0S1(25 S 36 )$ d47 13 0S1(25 S 36)47 $ r1: S S(S) 14 0S1 $
13. Dada la siguiente gramática:
S SS+ | SS* | a
(a) Construir las tablas de análisis LR canónico y LALR.
LR-Canónico
r0: S’ S
r1: S SS+
r2: S SS*
r3: S a
I0: [S’ .S, $]
[S .SS+, $/a]
[S .SS*, $/a]
[S .a, $/a]
I1: [S’ S., $]
[S S.S+, $/a]
[S S.S*, $/a]
[S .SS+, +/*/a]
[S .SS*, +/*/a]
[S .a, +/*/a]
I2: [S a., $/a]
I4: [S a., +/*/a] I3: [S SS.+, $/a]
[S SS.*, $/a]
[S S.S+, +/*/a]
[S S.S*, +/*/a]
[S .SS+, +/*/a]
[S .SS*, +/*/a]
[S .a, +/*/a]
I5: [S SS+., $/a] I6: [S SS*., $/a] I8: [S SS+., +/*/a]
I9: [S SS*., +/*/a]
I7: [S SS.+, +/*/a]
[S SS.*, +/*/a]
[S S.S+, +/*/a]
[S S.S*, +/*/a]
[S .SS+, +/*/a]
[S .SS*, +/*/a]
[S .a, +/*/a]

a + * $ S
0 d2 1 1 d4 3 2 r3 r3 3 d4 d5 d6 7 4 r3 r3 r3 5 r1 r1 6 r2 r2 7 d4 d8 d9 7 8 r1 r1 r1 9 r2 r2 r2
LALR
I0: [S’ .S, $]
[S .SS+, $/a]
[S .SS*, $/a]
[S .a, $/a]
I1: [S’ S., $]
[S S.S+, $/a]
[S S.S*, $/a]
[S .SS+, +/*/a]
[S .SS*, +/*/a]
[S .a, +/*/a]
I24: [S a., $/a/+/*]
I58: [S SS+., $/a/+/*] I37: [S SS.+, $/a/+/*]
[S SS.*, $/a/+/*]
[S S.S+, +/*/a]
[S S.S*, +/*/a]
[S .SS+, +/*/a]
[S .SS*, +/*/a]
[S .a, +/*/a]
I69: [S SS*., $/a/+/*]
a + * $ S
0 d24 1 1 d24 37
24 r3 r3 r3 r3 37 d24 d58 d69 37 58 r1 r1 r1 r1 69 r2 r2 r2 r2
(b) Comparar el funcionamiento (considerando cada analizador por separado) con las
siguientes cadenas de entrada:
i. aaa+*aa++
LR-canónico
Paso Pila Entrada Acción
1 0 aaa+*aa++$ d2
2 0a2 aa+*aa++$ r3: S a 3 0S1 aa+*aa++$ d4
4 0S1a4 a+*aa++$ r3: S a

5 0S1S3 a+*aa++$ d4
6 0S1S3a4 +*aa++$ r3: S a
7 0S1S3S7 +*aa++$ d8
8 0S1S3S7+8 *aa++$ r1: S SS+ 9 0S1S3 *aa++$ d6
10 0S1S3*6 aa++$
LALR
Paso Pila Entrada Acción
1 0 aaa+*aa++$ d24
2 0a24 aa+*aa++$ r3: S a
3 0S1 aa+*aa++$ d24
4 0S1a24 a+*aa++$ r3: S a 5 0S1S37 a+*aa++$ d24
6 0S1S37a24 +*aa++$ r3: S a
7
8
9
10
11
12
13
14
15
16
17
18
ii. aa+*aa++
Paso Pila Entrada Acción
1 0 aa+*aa++$
iii. aaaaaa++
Paso Pila Entrada Acción
1 0 aaaaaa++$
Related Documents











