BAB I PENDAHULUAN 1.1 LATAR BELAKANG Tujuan analisis diskriminan adalah menguji ada-tidaknya hubungan sebab-akibat dari sebuah fenomena. Ciri khusus analisis diskriminan adalah keharusan variabel dependen bertipe kategori, sedangkan variabel independen bertipe rasio. Kegunaan utama analisis diskriminan adalah kemampuan memprediksi terjadinya variabel dependen dengan masukan data variabel independen, dan kemampuan memilih mana variabel yang secara nyata mempengaruhi dependen dan mana yang tidak. Berdasarkan kegunaan tersebut, maka penulis ingin menguji sebuah kasus yaitu tentang analisis faktor yang mempengaruhi seseorang memilih bekerja atau kuliah. Dimana variabel dependennya bertipe kategori, yaitu bekerja dan kuliah. Sedangkan umur responden, biaya kuliah, pendapatan orang tua, jumlah saudara, nilai SMA dan IQ adalah variabel independen, karena faktor inilah yang menjadi sebab responden memilih bekerja atau kuliah. Dengan demikan akan diuji apakah ada hubungan kausalitas antara sikap responden secara umum dengan atribut-atribut yang ada. 1.2 RUMUSAN MASALAH 1. Apakah memang ada perbedaan yang jelas antara perilaku responden, sehingga mereka yang memilih bekerja dibedakan jelas dengan mereka yang memilih kuliah. 1

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

BAB I
PENDAHULUAN
1.1 LATAR BELAKANG
Tujuan analisis diskriminan adalah menguji ada-tidaknya
hubungan sebab-akibat dari sebuah fenomena. Ciri khusus
analisis diskriminan adalah keharusan variabel dependen
bertipe kategori, sedangkan variabel independen bertipe rasio.
Kegunaan utama analisis diskriminan adalah kemampuan
memprediksi terjadinya variabel dependen dengan masukan data
variabel independen, dan kemampuan memilih mana variabel yang
secara nyata mempengaruhi dependen dan mana yang tidak.
Berdasarkan kegunaan tersebut, maka penulis ingin menguji
sebuah kasus yaitu tentang analisis faktor yang mempengaruhi
seseorang memilih bekerja atau kuliah. Dimana variabel
dependennya bertipe kategori, yaitu bekerja dan kuliah.
Sedangkan umur responden, biaya kuliah, pendapatan orang tua,
jumlah saudara, nilai SMA dan IQ adalah variabel independen,
karena faktor inilah yang menjadi sebab responden memilih
bekerja atau kuliah. Dengan demikan akan diuji apakah ada
hubungan kausalitas antara sikap responden secara umum dengan
atribut-atribut yang ada.
1.2 RUMUSAN MASALAH
1. Apakah memang ada perbedaan yang jelas antara perilaku
responden, sehingga mereka yang memilih bekerja
dibedakan jelas dengan mereka yang memilih kuliah.
1

2. Jika memang ada perbedaan diantara kedua kelompok
responden tersebut, faktor mana yang perbedaannya
memang nyata dan faktor mana yang sesungguhnya tidak
secara jelas berbeda?
1.3 TUJUAN
1. Mengetahui apakah ada perbedaan yang jelas antara
perilaku responden yang memilih bekerja dengan mereka
yang memilih kuliah.
2. Mengetahui faktor mana yang perbedaannya memang nyata
dan faktor mana yang sesungguhnya tidak secara nyata
jelas berbeda.
BAB II
PEMBAHASAN
UJI DATA1. Uji Missing Value
2

Univariate Statistics
N MeanStd.
Deviation
Missing No. of Extremesa
Count Percent Low High
Umur 41 19.0000 1.18322 9 18.0 0 0
BiayaKuliah 45 7.0178E2 127.40931 5 10.0 0 0
PendapatanOrangTua
44 9.3409E2 176.45499 6 12.0 0 0
JumlahSaudara 43 3.0698 .91014 7 14.0 0 0
NilaiSMA 46 81.0000 4.03320 4 8.0 0 0
IQ 44 1.1948E2 9.02577 6 12.0 0 0
Status 50 0 .0
a. Number of cases outside the range (Q1 - 1.5*IQR, Q3 + 1.5*IQR).
Pada tabel diatas, kolom N menunjukkan jumlah data yangterisi dan kolom missing pada count menunjukkan jumlah datayang hilang dalam jumlah nyata, sementara oercent untukmenghitung persentase dari data yang ada di bagian count. Padavariabel umur data yang terisi adalah 41, dan data yang hilangadalah 9 atau sebanyak 18%. Pada variabel biaya kuliah datayang terisi adalah 45, dan data yang hilang sebanyak 5 dataatau sebanyak 10%. Dan begitu seterusnya.
Kolom Mean dan Standard Deviation menunjukkan rata-ratadan deviasi standar untuk setiap variabel yang valid (tidakmissing). Untuk variabel umur, rata-rata usia 41 respondenadalah 19 tahun dengan standar deviasi 1,18 tahun. Untukvariabel jumlah saudara, dari 43 responden rata-ratanya adalah3,06 orang dengan standar deviasi 0,91. Dan seterusnya untukdata yang lain.
3

Summary of Estimated Means
UmurBiayaKul
iah
PendapatanOrangT
ua
JumlahSaudara
NilaiSMA IQ
Listwise 18.7692 7.6308E2 9.3462E2 2.8462 83.1538 1.2438E2
All Values
19.0000 7.0178E2 9.3409E2 3.0698 81.0000 1.1948E2
EM 19.0278 7.0292E2 9.3246E2 3.0715 80.9106 1.1895E2
Jika digunakan metode LISTWISE, maka rata-rata umurmenjadi 18,76 tahun, jumlah saudara menjadi 2,84, nilai SMAmenjadi 83,15 dan begitu seterusnya.Jika digunakan ALL VALUE, maka nilai rata-rata umur menjadi19,00, jumlah saudara 3,06, nilai SMA menjadi 81,00.Jika digunakan metode EM, maka rata-rata umur menjadi 19,02tahun, jumlah saudara menjadi 3,07 orang, nilai SMA menjadi80,91. Dan begitu seterusnya.
Status
Total Bekerja Kuliah
Umur Present Count 41 20 21
Percent 82.0 80.0 84.0
Missing % SysMis 18.0 20.0 16.0
BiayaKuliah Present Count 45 23 22
Percent 90.0 92.0 88.0
Missing % SysMis 10.0 8.0 12.0
PendapatanOtangTua Present Count 44 21 23
Percent 88.0 84.0 92.0
Missing % SysMis 12.0 16.0 8.0
JumlahSaudara Present Count 43 20 23
Percent 86.0 80.0 92.0
Missing % SysMis 14.0 20.0 8.0
NilaiSMA Present Count 46 24 22
Percent 92.0 96.0 88.0
Missing % SysMis 8.0 4.0 12.0
4
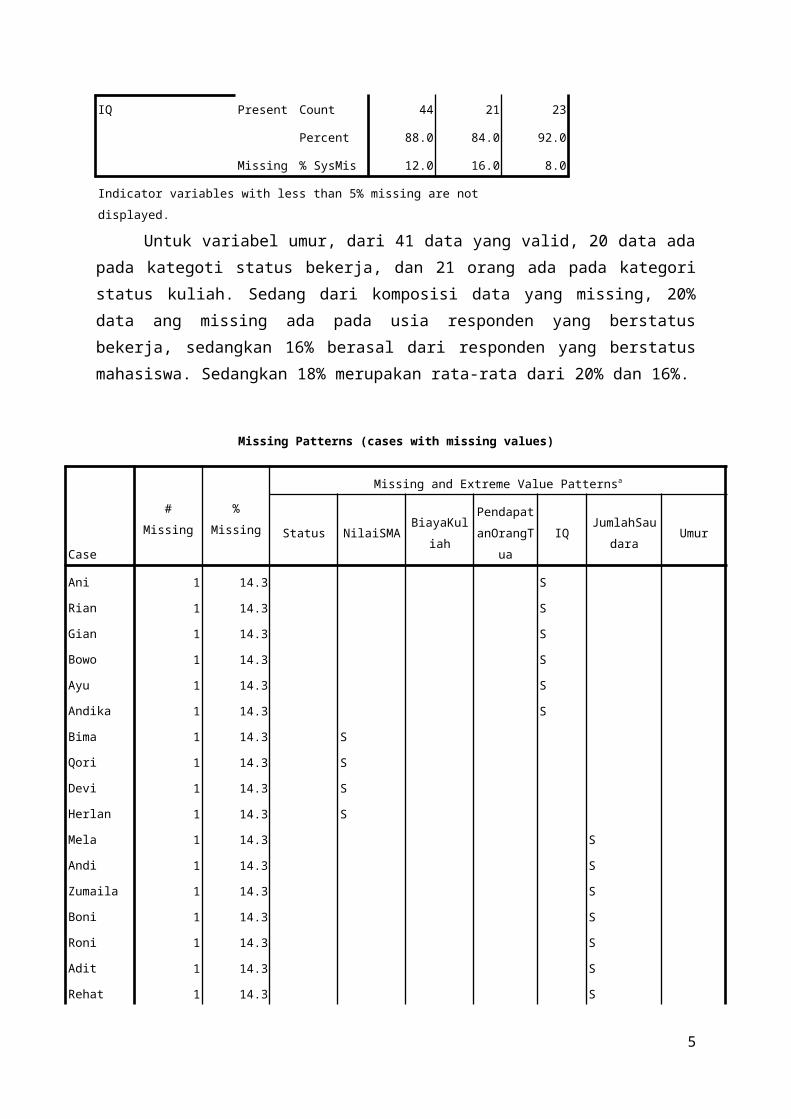
IQ Present Count 44 21 23
Percent 88.0 84.0 92.0
Missing % SysMis 12.0 16.0 8.0
Indicator variables with less than 5% missing are not displayed.
Untuk variabel umur, dari 41 data yang valid, 20 data adapada kategoti status bekerja, dan 21 orang ada pada kategoristatus kuliah. Sedang dari komposisi data yang missing, 20%data ang missing ada pada usia responden yang berstatusbekerja, sedangkan 16% berasal dari responden yang berstatusmahasiswa. Sedangkan 18% merupakan rata-rata dari 20% dan 16%.
Missing Patterns (cases with missing values)
Case
#Missing
%Missing
Missing and Extreme Value Patternsa
Status NilaiSMABiayaKul
iah
PendapatanOrangT
uaIQ
JumlahSaudara
Umur
Ani 1 14.3 S
Rian 1 14.3 S
Gian 1 14.3 S
Bowo 1 14.3 S
Ayu 1 14.3 S
Andika 1 14.3 S
Bima 1 14.3 S
Qori 1 14.3 S
Devi 1 14.3 S
Herlan 1 14.3 S
Mela 1 14.3 S
Andi 1 14.3 S
Zumaila 1 14.3 S
Boni 1 14.3 S
Roni 1 14.3 S
Adit 1 14.3 S
Rehat 1 14.3 S
5

Dela 1 14.3 S
Efal 1 14.3 S
Reisa 1 14.3 S
Noufal 1 14.3 S
Fais 1 14.3 S
Gilang 1 14.3 S
Romario 1 14.3 S
Putri 1 14.3 S
Yulia 1 14.3 S
Ami 1 14.3 S
Mita 1 14.3 S
Niken 1 14.3 S
Dini 1 14.3 S
Naila 1 14.3 S
Rani 1 14.3 S
Hamda 1 14.3 S
Hana 1 14.3 S
Alif 1 14.3 S
Nika 1 14.3 S
Ari 1 14.3 S
- indicates an extreme low value, while + indicates an extreme high value. The range used is (Q1 - 1.5*IQR, Q3 + 1.5*IQR).
a. Cases and variables are sorted on missing patterns.
Tabel diatas menggambarkan penyebaran data yang hilanghanya untuk responden yang datanya tidak lengkapdan bukanseluruh responden. Responden yang bernama Ani mempunyai satumissing value data pada variabel IQ, karena missing ada pada 1dari 7 variabel, maka persentase missing adalah 14,3%.
Responden yang bernama Bima, mempunyai satu missing valuedata pada variabel nilai SMA, karena missing ada pada 1 dari 7variabel, maka persentase missing adalah 14,3%. Dan begituseterusnya.
6

Tabulated Patterns
Numberof Cases
Missing Patternsa
Completeif ...bStatus NilaiSMA
BiayaKuliah
PendapatanOtangT
uaIQ
JumlahSaudara
Umur
13 13
6 X 19
4 X 17
7 X 20
5 X 18
9 X 22
6 X 19
a. Variables are sorted on missing patterns.
b. Number of complete cases if variables missing in that pattern (marked with X)are not used.
Tabel diatas menunjukkan sisi lain dari penyebaranmissing value,dimana missing value dinyatakan per variabel.Pada baris pertama, angka 13 menyatakan ada 13 data yangvalid, artinya tidak terdapat missing value pada semuavariabelnya.
Angka 6 pada baris kedua menunjukkan adanya 5 data yangmissing pada variabel IQ. Jika dilihat pada tabel sebelumnya,maka responden yang mempunyai data missing pada variabel IQadalah Ani, Rian, Gian, Bowo, Ayu, Andika.
Angka 4 menunjukkan adanya 4 data yang missing padavariabel Nilai SMA. Maka responden yang mempunyai missing padavariabel nilai SMA adalah Bima, Devi, Qori, Herlan. Danseterusnya untuk baris berikutnya.
Dan pada kolom complete, jika 6 data yang missing divariabel IQ diperbaiki sehingga menjadi tidak missing, makasemua data yang tidak missing menjadi: 13+6=19 data yanglengkap. Jika data yang missing di variabel di nilai SMA ada 4
7
data diperbaiki maka semua data yang tidak missing menjadi :13+4 = 17 dan begitu seterusnya.
Listwise Correlations
UmurBiayaKul
iah
PendapatanOtangT
ua
JumlahSaudara
NilaiSMA IQ
Umur 1
BiayaKuliah .520 1
PendapatanOrangTua -.172 .101 1
JumlahSaudara -.190 -.243 -.139 1
NilaiSMA -.031 -.317 .103 .044 1
IQ .139 -.261 -.145 .181 .628 1
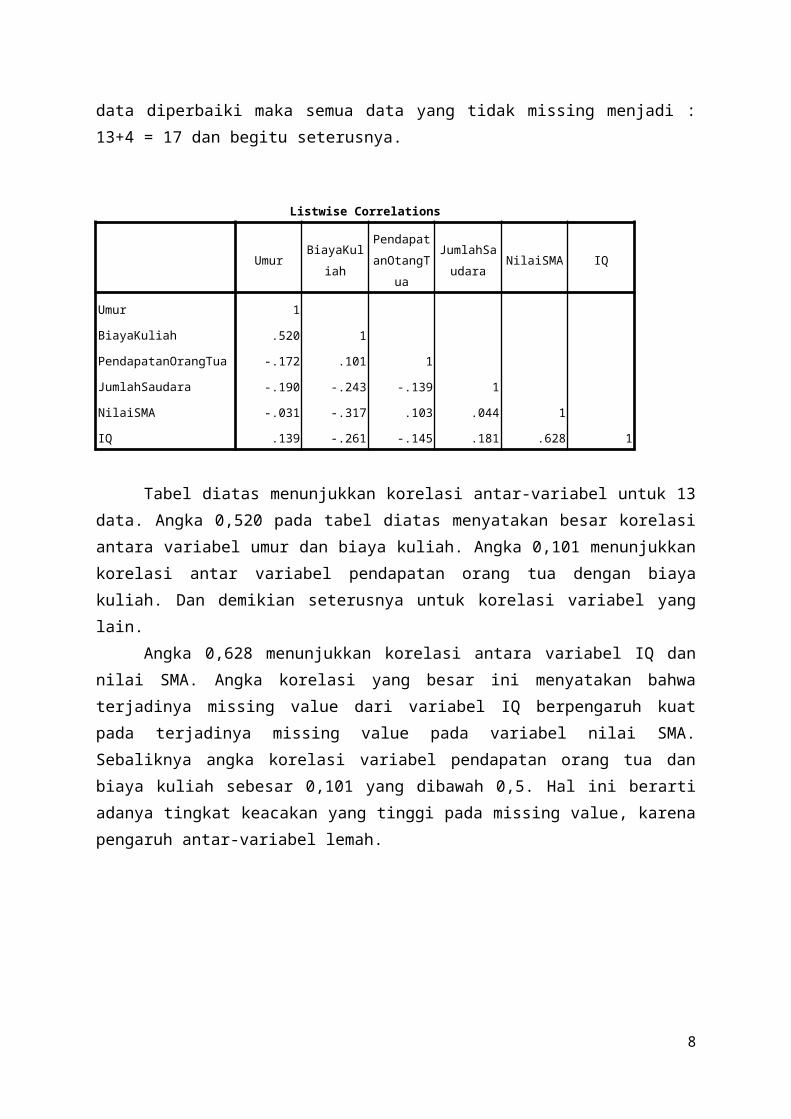
Tabel diatas menunjukkan korelasi antar-variabel untuk 13data. Angka 0,520 pada tabel diatas menyatakan besar korelasiantara variabel umur dan biaya kuliah. Angka 0,101 menunjukkankorelasi antar variabel pendapatan orang tua dengan biayakuliah. Dan demikian seterusnya untuk korelasi variabel yanglain.
Angka 0,628 menunjukkan korelasi antara variabel IQ dannilai SMA. Angka korelasi yang besar ini menyatakan bahwaterjadinya missing value dari variabel IQ berpengaruh kuatpada terjadinya missing value pada variabel nilai SMA.Sebaliknya angka korelasi variabel pendapatan orang tua danbiaya kuliah sebesar 0,101 yang dibawah 0,5. Hal ini berartiadanya tingkat keacakan yang tinggi pada missing value, karenapengaruh antar-variabel lemah.
8

Pairwise Frequencies
UmurBiayaKul
iah
PendapatanOtangT
ua
JumlahSaudara
NilaiSMA IQ Status
Umur 41
BiayaKuliah 36 45
PendapatanOtangTua 35 39 44
JumlahSaudara 34 38 37 43
NilaiSMA 37 41 40 39 46
IQ 35 39 38 37 40 44
Status 41 45 44 43 46 44 50
Metode pairwise akan memasangkan (pair) variabel yangmempunyai data lengkap, dan tidak menghilangkan sebuah barisbegitu saja. Dengan demikian jumlah data bisa berbeda-bedatergantung kelengkapan data dua variabel yang dipasangkan.
Jika yang dipasangkan variabel umur dan biaya kuliah,maka akan ada 36 data yang valid. Namun jika yang dipasangkanvariabel biaya kuliah dengan IQ maka akan ada 39 data yangvalid. Demikian seterusnya untuk kombinasi variabel lainnya.
Pairwise Correlations
UmurBiayaKul
iah
PendapatanOtangT
ua
JumlahSaudara
NilaiSMA IQ
Umur 1
BiayaKuliah .028 1
PendapatanOtangTua -.447 .312 1
JumlahSaudara -.063 -.107 -.038 1
NilaiSMA -.076 -.017 .112 .008 1
IQ .025 .154 .003 .148 .563 1
Tabel diatas mempunyai tafsiran yang sama dengan analisiskorelasi antar-variabel dengan metode listwise. Angka korelasiyang diatas 0,5 berjumlah sangat sedikit, sehingga bisa
9
dikatakan missing value adalah acak (random). Pada tabeldiatas angka diatas 0,5 tidak ada sehingga bisa dikaan missingadalah acak.
EM Correlationsa
UmurBiayaKul
iah
PendapatanOrangT
ua
JumlahSaudara
NilaiSMA IQ
Umur 1
BiayaKuliah -.003 1
PendapatanOrangTua -.426 .307 1
JumlahSaudara .015 -.088 -.054 1
NilaiSMA -.076 -.031 .045 .014 1
IQ .012 .156 -.044 .144 .551 1
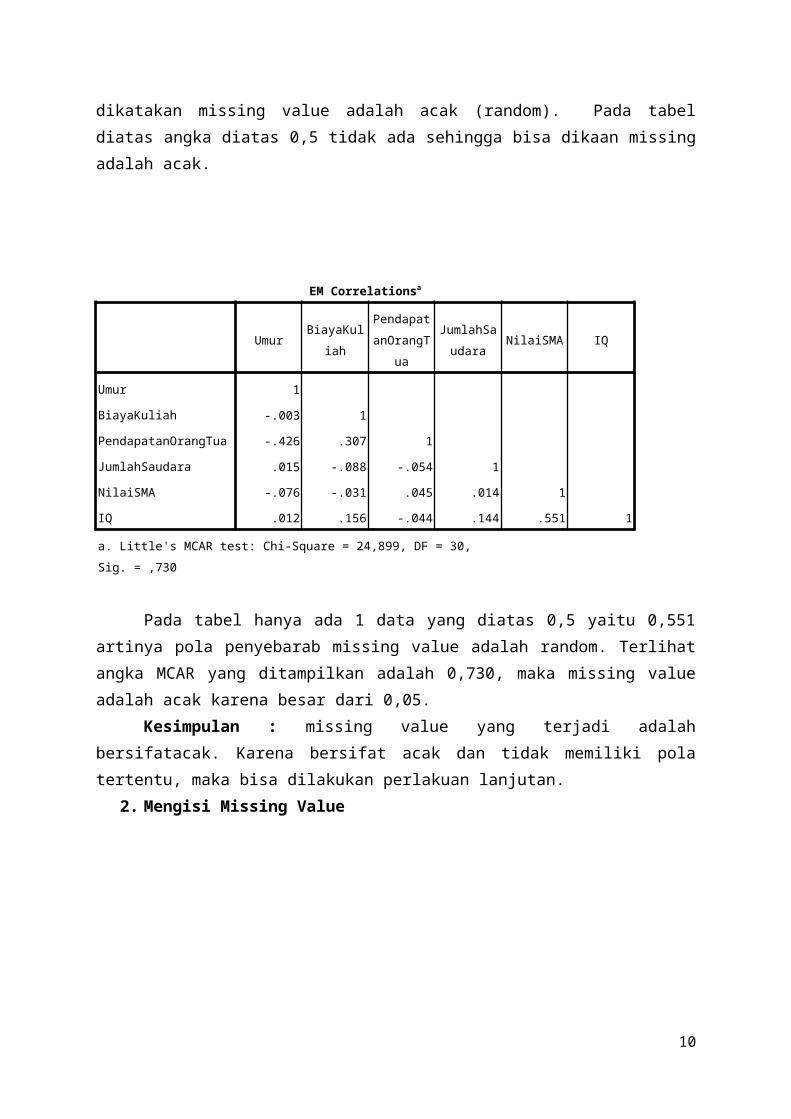
a. Little's MCAR test: Chi-Square = 24,899, DF = 30, Sig. = ,730
Pada tabel hanya ada 1 data yang diatas 0,5 yaitu 0,551artinya pola penyebarab missing value adalah random. Terlihatangka MCAR yang ditampilkan adalah 0,730, maka missing valueadalah acak karena besar dari 0,05.
Kesimpulan : missing value yang terjadi adalahbersifatacak. Karena bersifat acak dan tidak memiliki polatertentu, maka bisa dilakukan perlakuan lanjutan.
2. Mengisi Missing Value
10

Result Variables
ResultVariable
N ofReplacedMissingValues
Case Number of Non-MissingValues
N of ValidCases
CreatingFunctionFirst Last
1 Umur_1 9 1 50 50 SMEAN(Umur)
2 BiayaKuliah_1
5 1 50 50SMEAN(BiayaKuliah)
3PendapatanOtangTua_1
6 1 50 50SMEAN(PendapatanOtangTua)
4 JumlahSaudara_1
7 1 50 50SMEAN(JumlahSaudara)
5NilaiSMA_1 4 1 50 50
SMEAN(NilaiSMA)
6 IQ_1 6 1 50 50 SMEAN(IQ)
Dari tabel result variables diatas terlihat ada 9 data untukvariabel umur yang diganti, 5 variabel biaya kuliah, 6variabel pendapatan orang tua, 7 variabel jumlah saudara, 4variabel nilai SMA san 6 vriabel IQ.
3. Uji Data Outliera. Standarisasi Data
Descriptive Statistics
N Minimum Maximum MeanStd.
Deviation
SMEAN(Umur) 50 17.00 21.00 19.0000 1.06904
SMEAN(BiayaKuliah) 50 500.00 980.00 7.0178E2 120.73396
SMEAN(PendapatanOtangTua)
50 600.00 1200.00 9.3409E2 165.29896
SMEAN(JumlahSaudara) 50 1.00 5.00 3.0698 .84262
SMEAN(NilaiSMA) 50 75.00 90.00 81.0000 3.86507
SMEAN(IQ) 50 105.00 135.00 1.1948E2 8.45514
Valid N (listwise) 50
Dari tabel diatas dapat dilihat bahwa rata-rata umurresponden adalah 19,00 tahun dengan standar deviasi 1,06
11
tahun. Rata-rata jumlah saudara responden adalah 3,06 orangdengan standar deviasi 0,84. Dan begitu seterusnya.
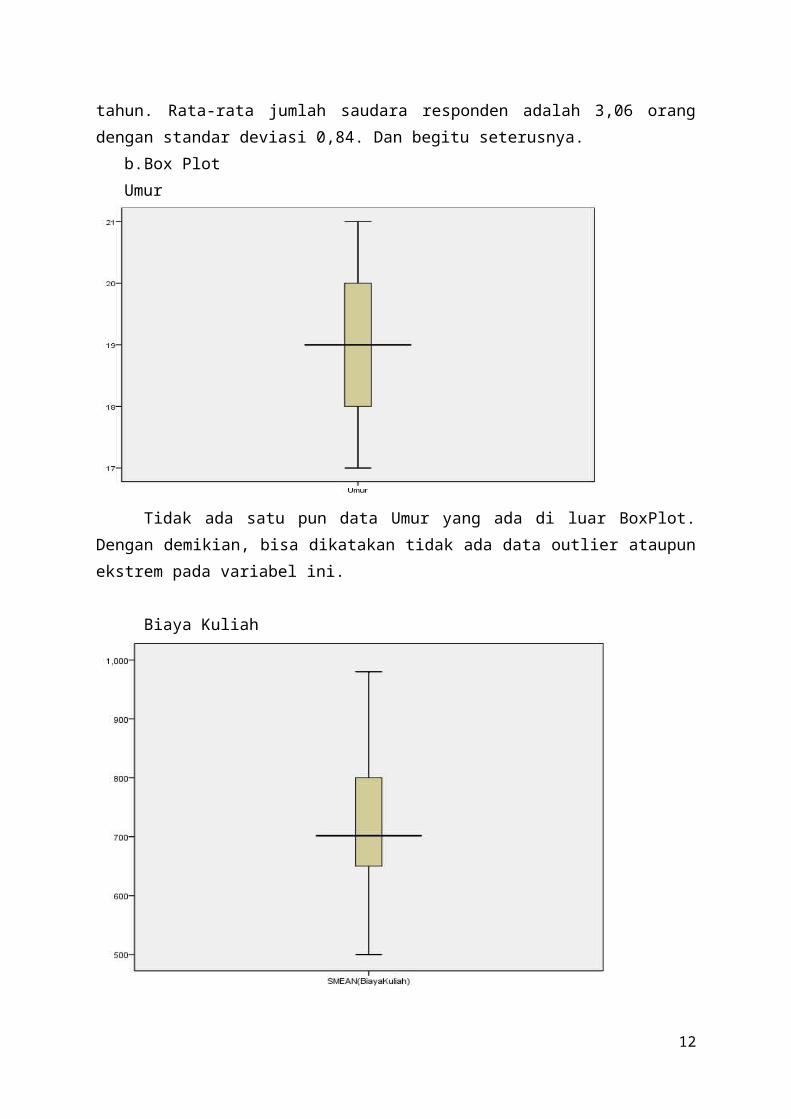
b.Box PlotUmur
Tidak ada satu pun data Umur yang ada di luar BoxPlot.Dengan demikian, bisa dikatakan tidak ada data outlier ataupunekstrem pada variabel ini.
Biaya Kuliah
12

Terlihat tidak ada satu pun data biaya kuliah yang ada diluar BoxPlot. Dengan demikian Dengan demikian, bisa dikatakantidak ada data outlier ataupun ekstrem pada variabel ini.
4. Uji Normalitas Data
Terlihat sebaran data dari variabel IQ bergerombol di sekitar garis uji yang mengarah ke kanan atas, dan tidak ada data yang terletak jauh dari sebaran data. Dengan demikian, data tersebut bisa dikatakan normal.
13

Terlihat sebaran data dari variabel IQ bergerombol di sekitar garis uji yang mengarah ke kanan atas, dan tidak ada data yang terletak jauh dari sebaran data. Dengan demikian, data tersebut bisa dikatakan normal.
5. Uji Homokedastisitas Data
Test of Homogeneity of Variance
LeveneStatistic df1 df2 Sig.
SMEAN(BiayaKuliah)
Based on Mean .859 1 48 .359
Based on Median .959 1 48 .332
Based on Median and with adjusted df
.959 1 47.764 .332
Based on trimmed mean .861 1 48 .358
SMEAN(NilaiSMA) Based on Mean 1.683 1 48 .201
Based on Median .133 1 48 .717
Based on Median and with adjusted df
.133 1 40.406 .717
Based on trimmed mean 1.441 1 48 .236
14
Pada baris Biaya Kuliah dari tabel output diatas, dan dengan dasar Mean, didapat angka SIG adalah 0,359. Karena angka SIG > 0,05, maka Ho diterima. Hal ini berarti varians dari data biaya kuliah responden yang memilih bekerja relatif sama dengan data biaya kuliah responden yang memilih kuliah. Sehingga bisa disimpulkan telah terjadi homoskedastisitas variabel biaya kuliah dengan dasar grup status.
Pada baris nilai SMA, dan dengan dasar Mean didapat angkaSIG adalah 0,201 maka Ho diterima. Hal ini berarti varians dari data nilai SMA responden yang memilih bekerja relatif sama dengan data nilai SMA responden yang memilih kuliah. Sehingga terjadi homoskedastisitas variabel nilai SMA dengan dasar grup Status.
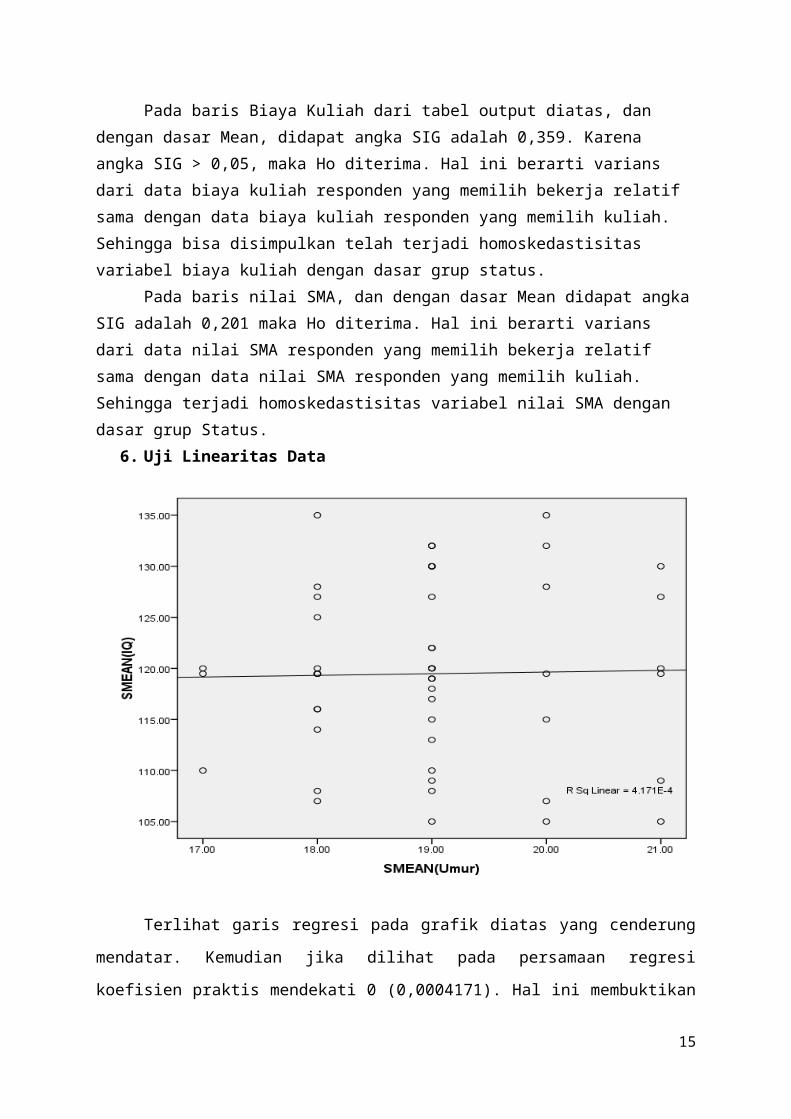
6. Uji Linearitas Data
Terlihat garis regresi pada grafik diatas yang cenderung
mendatar. Kemudian jika dilihat pada persamaan regresi
koefisien praktis mendekati 0 (0,0004171). Hal ini membuktikan
15

tidak adanya linearitas pada hubungan dua variabel tersebut,
yang berarti semakin besar atau semakin kecil umur seseorang
tidak ada hubungannya dengan tingginya IQ seseorang
Pada gambar diatas dapat dilihat garis regresi yangmengarah kekanan atas, ini membuktikan adanya linearitas padahubungan dua variabel tersebut yaitu variabel biaya kuliahdengan variabel pendapatan orang tua. Artinya semakin tinggibiaya kuliahnya maka semakin tinggi pula pendapatan orangtuanya.
16

ANALISIS DISKRIMINAN
1. Menilai Variabel Yang Layak Untuk Analisis
Tests of Equality of Group Means
Wilks'Lambda F df1 df2 Sig.
SMEAN(Umur) .930 3.613 1 48 .063
SMEAN(BiayaKuliah) .994 .314 1 48 .578
SMEAN(PendapatanOtangTua)
.834 9.542 1 48 .003
SMEAN(JumlahSaudara) .970 1.478 1 48 .230
SMEAN(NilaiSMA) .779 13.642 1 48 .001
SMEAN(IQ) .767 14.587 1 48 .000
a. Dengan angka Wilk’s LambdaAngka Wilks’s Lambda berkisar 0 sampai1. Jika angka
mendekati 0 maka data tiap grup cenderung berbeda, sedang jikaangka mendekati 1, data tiap grup cenderung sama.
Dari tabel diatas terlihat angka Wilk’s Lambda berkisarantara 0,767 sampai0,994 (mendekati 1). Dari kolom Sig bisadilihat bahwa hanya variabel biaya kuliah yang cenderung tidakberbeda. Hal ini berarti biaya kuliah untuk mereka yangbekerja atau kuliah ternyata tidak berbeda secara nyata. Hanyadisini mendekati angka 1 dulit ditentukan secara pasti, karenahampir semua variabel diatas mempunyai angka Wilk’s Lambdayang besar, namun hanya satu variabel yang tidak lolos. Untukitu dilakukan pengujian ANOVA
b. Dengan F test
17

Variabel pendapatan orang tua, angka Sig nya dibawah 0,05(0,003). Artinya ada perbedaan antar-grup atau respondenyang memilih bekerja atau kuliah. Mungkin mereka yangpendapatan orang tuanya lebih tinggi akan memilih kuliahdibanding mereka yang orang tuanya berpendapatan lebihrendah. Atau mungkin sebaliknya.
Variabel Nilai SMA, angka Sig nya 0,001. Artinya adaperbedaan antar grup. Mungkin mereka yang nilai SMAnyalebih tinggi akan memilih untuk kuliah daripada merekayang nilai SMAnya lebih rendah. Atau sebaliknya.
Variabel Biaya Kuliah, angka Signya 0,578. Halini berartibiaya kuliah seorang responden tidak mempengaruhi merekauntuk memilih bekerja atau kuliah. Kesimpulan ini hampirsama dengan jika berpatokan pada angka Wilk’s Lambda yanghampir mendekati 1 untuk variabel biaya kuliah.
Variabel jumlah saudara, angka Signya adalah jauh diatas0,05 yaitu 0,230. Artinya jumlah saudara seorang respondentidak memengaruhi seorang responden untuk memilih bekerjaatau kuliah.Dari enam variabel, ada tiga varibel yang berbeda secarasignifikan untuk dua grup signifikan, yaitu pendapatanorang tua, nilai SMA dan IQ. Dengan demikian, seorangresponden memilih bekerja atau kuliah dipengaruhi olehpendapatan orang tua responden tersebut, nilai ketika diSMA, dan IQ yang dimiliki oleh responden tersebut.
Test Results
Box's M 23.940
F Approx. .986
df1 21
df2 8.474E3
Sig. .477
Tests null hypothesis of equal population covariance matrices.
18

Dari tabel terlihat bahwa angka Signya jauh diatas 0,05 yaitu 0,477, yang berarti group covariance matrices adalah sama. Hal ini berarti data diatas sudah memenuhi asumsi analisis diskriminan, sehingga proses bisa dilanjutkan.
Asumsinya adalah: Varians variabel bebas untuk tiap grup seharusnya sama.
Jika demikian, seharusnya varians dari responden yang memilih bekerja sama dengan varians responden yang memilihkuliah.
Varians diantara variabel-variabel bebas seharusnya juga sama. Jika denikian, seharusnya varians dari umur sama dengan varians dari biaya kuliah, sama dengan variabel biaya kuliah, pendapatan orang tua dan sebagainya.
Log Determinants
Status RankLog
Determinant
Bekerja 6 25.049
Kuliah 6 24.532
Pooled within-groups
6 25.289
The ranks and natural logarithms of determinants printed are those of the group covariance matrices.
Terlihat angka Log determinant untuk kategori bekerja 25,049 dan kuliah (24,532) tidak berbeda banyak, sehingga group covariance matrices akan relatif sama untuk kedua grup.
2. Proses Diskriminan.
Group Statistics
Status MeanStd.
Deviation
Valid N (listwise)
Unweighted Weighted
Bekerja SMEAN(PendapatanOtangTua)
8.6745E2 125.94122 25 25.000
SMEAN(NilaiSMA) 79.2000 3.24037 25 25.000
19
SMEAN(IQ) 1.1544E2 7.79536 25 25.000
Kuliah SMEAN(PendapatanOtangTua)
1.0007E3 175.13980 25 25.000
SMEAN(NilaiSMA) 82.8000 3.64005 25 25.000
SMEAN(IQ) 1.2352E2 7.15340 25 25.000
Total SMEAN(PendapatanOtangTua)
9.3409E2 165.29896 50 50.000
SMEAN(NilaiSMA) 81.0000 3.86507 50 50.000
SMEAN(IQ) 1.1948E2 8.45514 50 50.000
Tabel Group Statistics pada dasarnya berisi data statistik
(deskriptif) yang utama, yakni rata-rata dan standar deviasi,
dari kedua grup responden.
Responden yang memilih bekerja, rata-rata nilai SMA nya
adalah 79,20 sedangkan responden yang memilih kuliah rata-rata
nilai SMA nya adalah 82, 80. Sedangkan responden yang memilih
bekerja, rata-rata pendapatan orang tuanya adalah 867,550 dan
responden yang memilih kuliah, rata-rata pendapatan
orangtuanya adalah 1,000,000. Dan responden yang memilih
bekerja juga rata-rata memiliki IQ sekitar 115,44 sedangkan
responden yang memilih kuliah, rata-rata memiliki IQ sekitar
123,52.
Dari tabel diatas juga terlihat bahwa ada 25 responden
yang memilih bekerja, dan 25 responden yang memilih kuliah.
Jika melihat semua variabel terisi angka 25 dan 25 semuanya,
maka pada kasus ini tidak ada data yang hilang (missing),
sehingga total data untuk semua variabel adalah 50 responden.
20

Variables Entered/Removeda,b,c,d
Step Entered
Min. D Squared
Statistic
BetweenGroups
Exact F
Statistic df1 df2 Sig.
1 SMEAN(IQ)
1.167Bekerja and Kuliah
14.587 1 48.000 .000
2 SMEAN(PendapatanOtangTua)
2.552Bekerja and Kuliah
15.617 2 47.000 6.302E-6
At each step, the variable that maximizes the Mahalanobis distance between the two closest groups is entered.
a. Maximum number of steps is 6.
b. Maximum significance of F to enter is .05.
c. Minimum significance of F to remove is .10.
d. F level, tolerance, or VIN insufficient for further computation.
Tabel ini menyajikan variabel mana saja dari enam variabel
input yang bisa dimasukkan dalam persamaan diskriminan. Karena
proses adalah stepwise (beratahap) maka akan dimulai dengan
variabel yang mempunyai angka F hitung (statistik) terbesar.
Tahap pemasukan variabel bebas :
Pada tahap pertama, angka F hitung variabel IQ adalah
14,587, maka pada tahap pertama ini variabel IQ terpilih.
Pada tahap kedua, angka F hitung mencapai 15,617, maka
pada tahap kedua ini variabel Pendapatan orang tua
terpilih.
Kedua variabel tersebut memiliki 2 variabel yang tentunya
mempunyai Sig dibawah 0,05, seperti variabel IQ Signya 0,000
dan variabel pendapatan mempunyai Sig jauh dibawah 0,05 yaitu
6,301E-6 atau 0,000006301.
21

Dengan demikian, dari tiga variabel yang dimasukkan, hanya
ada dua variabel yang signifikan. Atau bisa dikatakan IQ dan
pendapatan orang tua mempengaruhi perilaku responden untuk
memilih bekerja atau kuliah. Atau mereka yang memiliki IQ dan
pendapatan orang tua diatas rata-rata akan memilih untuk
kuliah, dan begitu seterusnya.
Variables in the Analysis
Step ToleranceSig. of F to
RemoveMin. DSquared
BetweenGroups
1 SMEAN(IQ) 1.000 .000
2 SMEAN(IQ).939 .000 .763
Bekerja and Kuliah
SMEAN(PendapatanOtangTua)
.939 .001 1.167Bekerja and Kuliah
Pada step 1, variabel IQ adalah variabel pertama yang
dimasukkan kedalam model diskriminan. Hal ini disebabkan
variabel tersebut mempunyai angka Sig. Of F to Remove yang
paling sedikit yaitu 0,000 (jauh di bawah 0,05).
Kemudian pada step 2, dimasukkan variabel kedua yakni,
variabel pendapatan orang tua. Variabel tersebut memenuhi
syarat, karena mempunyai angka Sig. Of F to Remove dibawah
0,05 yakni 0,001.
22

Variables Not in the Analysis
Step ToleranceMin.
ToleranceSig. of F to
EnterMin. DSquared
BetweenGroups
0 SMEAN(IQ)1.000 1.000 .000 1.167
Bekerja and Kuliah
SMEAN(NilaiSMA)1.000 1.000 .001 1.091
Bekerja and Kuliah
SMEAN(PendapatanOtangTua)
1.000 1.000 .003 .763Bekerja and Kuliah
1 SMEAN(NilaiSMA).867 .867 .038 1.655
Bekerja and Kuliah
SMEAN(PendapatanOtangTua)
.939 .939 .001 2.552Bekerja and Kuliah
2 SMEAN(NilaiSMA).865 .826 .050 3.114
Bekerja and Kuliah
Tabel diatas merupakan kebalikan dari tabel sebelumnya,
dimana pada tabel ini adalah proses pengeluaran. Pada step 0
(awal) ketiga variabel tersebut secara lengkap ditayangkan
dengan angka Sig. Of F to Remove sebagai faktor penguji.
Terlihat angka Sig. Terkecil adalah pada variabel IQ yaitu
0,00. Maka variabel IQ dikeluarkan dari step 0 tersebut, yang
berarti variabel tersebut bukan termasuk variabel yang tidak
dianalisis.
Pada step 1, terlihat ada 2 variabel, dan variabel
pendapatan orang tua dengan Sig of F to Remove adalah 0,001
sehingga variabel tersebut dikeluarkan. Sekarang hanya ada
satu variabel yaitu variabel nilai SMA, dan variabel tersebut
mempunyai Sig of F to Remove diatas 0,05 (yakni 0,826). Karena
sudah tidak ada data variabel yang memenuhi syarat, maka
proses pengeluaran variabel berhenti, dan variabel tersebut
tidak bisa dikeluarkan, yang berarti variabel tersebut
23

termasuk pada variable not in the analysis, atau variabel yang
tidak dianalisis lebih lanjut.
Wilks' Lambda
StepNumber ofVariables Lambda df1 df2 df3
Exact F
Statistic df1 df2 Sig.
1 1 .767 1 1 48 14.587 1 48.000 .000
2 2 .601 2 1 48 15.617 2 47.000 .000
Wilks’s Lambda pada prinsipnya adalah varians total dalamdiskriminant scores yang tidak bisa dijelaskan oleh perbedaandiantara grup-grup yang ada. Pada step 1, jumlah variabel yangdimasukkan ada satu (IQ), dengan angka Wilk’s Lambda adalah0,767. Hal ini berarti 76,7% varans tidak dapat dijelaskanoleh perbedaan antar grup-grup. Kemudian pada step 2, dengantambahan variabel pendapatan orang tua, angka Wilk’s Lambdaturun menjadi 0,601 atau 60,1%. Penurunan angka Wilk’s Lambdatentu baik bagi model diskriminan, karena varians yang tidakbisa dijelaskan juga semakin kecil.
Dari kolom F dan Sig-nya, erlihat baik pada pemasukanvariabel 1 dan 2, semuanya adalah signifikan secara statistik.Hal ini berarti kedua variabel tersebut (IQ dan pendapatanorang tua) memang berbeda untuk kedua pilihan responden.
Eigenvalues
Function Eigenvalue
% ofVariance Cumulative %
CanonicalCorrelation
1 .665a 100.0 100.0 .632
a. First 1 canonical discriminant functions were used inthe analysis.
Canonical Correlation mengukur keeratan hubungan antaradiskriminant score dengan grup. Angka 0,632 menunjukkankeeratan yang cukup tinggi, dengan ukuran skala asosiasi 0sampai 1.
24

Wilks' Lambda
Test of Function(s)
Wilks'Lambda Chi-square Df Sig.
1 .601 23.949 2 .000
Tabel diatas menyatakanangka akhir dari Wilk’s Lambda, yang sebenarnya sama saja dengan angka terakhir dari step 2 pembuatan model diskriminan. Angka Chi-Square sebesar 23,949 dengan signifikan yang tinggi menunjukkan perbedaan yang jelasantara dua grup responden.
Structure Matrix
Function
1
SMEAN(IQ) .676
SMEAN(PendapatanOtangTua)
.547
SMEAN(NilaiSMA)a .217
Pooled within-groups correlationsbetween discriminating variables and standardized canonical discriminant functions Variables ordered by absolute size of correlation within function.
a. This variable not used in the analysis.
Tabel Structure Matrix menjelaskan korelasi antaravariabel independen dengan fungsi diskriminan yang terbentukterlihat variabel IQ paling erat hubungannya dengan fungsidiskriminan, diikuti oleh variabel pendapatan orang tua dannilai SMA.
25

Prior Probabilities for Groups
Status Prior
Cases Used inAnalysis
Unweighted Weighted
Bekerja .500 25 25.000
Kuliah .500 25 25.000
Total 1.000 50 50.000
Tabel diatas memperlihatkan komposisi ke 50 responden,yang dengan model diskriminan menghasilkan 25 responden ada digrup bekerja,dan 25 responden digrup kuliah.
26

BAB III
PENUTUP
3.1 KESIMPULAN
Dari proses uji data sampai analisis output, dapat
disimpulkan bahwa ada perbedaan yang signifikan antara
responden yang memilih bekerja dan responden yang memilih
kuliah. Hal ini dibuktikan pada analisis Wilk’s Lambda, dimana
variabel yang terlihat berbeda adalah variabel IQ dan
pendapatan orang tua.
Variabel yang membuat perilaku seseorang yang memilih
bekerja atau kuliah berbeda adalah variabel Iqdan pendapatan
27

orang tua. Hal ini terlihat pada step analisis awal, baik
bagian Variable In Analysis maupun Variable Not In Analysis.
Jadi, IQ dan pendapatan orang tua mempengaruhi perilaku
responden untuk memilih bekerja atau kuliah. Atau mereka yang
memiliki IQ dan pendapatan orang tua diatas rata-rata akan
memilih untuk kuliah, dan sebaliknya mereka yang memiliki IQ
dan pendapatan orang tua yang lebih rendah memilih untuk
bekerja.
3.2 SARAN
Kritik dan saran sangat penulis harapkan dalam makalah
ini, segala kekurangan yang ada dalam makalah ini mungkin
karena kelalaian atau ketidaktahuan penulis dalam
penyusunannya. Segala hal yang tidak relevan, kekurangan dalam
pengetikan atau bahkan ketidakjelasan dalam makalah ini
merupakan proses penulis dalam mempelajari bidang studi ini
dan diharapkan bagi pembaca dapat mengambil manfaat dari
makalah ini.
DAFTAR PUSTAKA
28

Santoso , Singgih. 2012. Aplikasi SPSS pada Statistik Multivariat. Elex Media Komputindo : Jakarta.
29
Related Documents











