Haski1l8 Laboratories Statu. !Upon on Speech !Usearch 1991, SR·107/108, 243·254 Lexical Mediation Between Sight and Sound in Speechreading* Bruno H. Repp, Ram Frost, t and Elizabeth Zsiga tt In two experiments, we investigated whether simultaneous speechreading can influence the detection of speech in envelope-matched noise. Subjects attempted to detect the presence of a disyllabic utterance in noise while watching a speaker articulate a matching or a nonmatching utterance. Speech detection was not facilitated by an audio-visual match, which suggests that listeners relied on low-level auditory cues whose perception was immune to cross-modal top-down influences. However, when the stimuli were words (Experiment 1) there was a (predicted) relative shift in bias, suggesting that the masking noise itself was perceived as more speechlike when its envelope corresponded to the visual information. This bias shift was absent, however, with nonword materials (Experiment 2). These results, which resemble earlier findings obtained with orthographic visual input, indicate that the mapping from sight to sound is lexically mediated even when, as in the case of the articulatory-phonetic correspondence, the cross-modal relationship is nonarbitrary. INTRODUcnON The interaction of the visual and auditory modalities in word perception is of interest to psychologists concerned with the nature of the representation of words in the mental lexicon. That such an interaction exists has been demonstrated in many studies. For example, the popular cross-modal semantic priming paradigm (Swinney, Onifer, Prather, & Hirshkowitz, 1979) demonstrates facilitation of lexical access in one modality by the recent occurrence of a related word in the other modality. Visual articulatory information (i.e., a speaker's moving face) has long been known to aid the recognition of spoken words in noise (e.g., Erber, 1969; O'Neill, 1954), and, conversely, auditorily presented speech features which may not be intelligible by themselves can increase word recognition in speechreading (e.g., Breeuwer & Plomp, 1984, 1986). Cross-modal interactions can occur prior to word recognition: This research was supported by NICHD Grant HDOI994 to Haskins Laboratories. A brief report of the results was presented at the 31st Annual Meeting of the Psychonomic Society in New Orleans, LA, November 1990. 243 Printed single letters or nonword letter strings can facilitate the response to a phoneme presented in the auditory modality (Dijkstra, Schreuder, & -Frauenfelder, 1989; Layer, Pastore, & Rettberg, 1990). Prelexical cross-modal influences have also been demonstrated when the visual information consists of articulatory gestures (McGurk & MacDonald, 1976): Simultaneous presentation of a spoken CV syllable and of a speaker's face utter- ing a different syllable can lead to the illusion of hearing the syllable suggested by the visual modality. This interaction even takes place prior to the categorization of the phonemes involved (Massaro & Cohen, 1990; Summerfield, 1987). In a recent study, Frost, Repp, and Katz (1988) investigated whether influences from the visual modality can penetrate to earlier, precategorical levels of auditory perception by requiring their subjects to detect rather than recognize speech in noise. Auditory speech-plus-noise and noise-only trials were accompanied by a visual orthographic stimulus that either matched or did not match the masked speech. Frost et a1. (1980) found that matching visual input did not improve subjects' speech detection performance, which suggested that the information subjects relied on (probably

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Haski1l8 Laboratories Statu. !Upon on Speech !Usearch1991, SR·107/108, 243·254
Lexical Mediation Between Sight and Sound inSpeechreading*
Bruno H. Repp, Ram Frost,t and Elizabeth Zsigatt
In two experiments, we investigated whether simultaneous speechreading can influencethe detection of speech in envelope-matched noise. Subjects attempted to detect thepresence of a disyllabic utterance in noise while watching a speaker articulate a matchingor a nonmatching utterance. Speech detection was not facilitated by an audio-visualmatch, which suggests that listeners relied on low-level auditory cues whose perceptionwas immune to cross-modal top-down influences. However, when the stimuli were words(Experiment 1) there was a (predicted) relative shift in bias, suggesting that the maskingnoise itself was perceived as more speechlike when its envelope corresponded to the visualinformation. This bias shift was absent, however, with nonword materials (Experiment 2).These results, which resemble earlier findings obtained with orthographic visual input,indicate that the mapping from sight to sound is lexically mediated even when, as in thecase of the articulatory-phonetic correspondence, the cross-modal relationship isnonarbitrary.
INTRODUcnONThe interaction of the visual and auditory
modalities in word perception is of interest topsychologists concerned with the nature of therepresentation of words in the mental lexicon.That such an interaction exists has beendemonstrated in many studies. For example, thepopular cross-modal semantic priming paradigm(Swinney, Onifer, Prather, & Hirshkowitz, 1979)demonstrates facilitation of lexical access in onemodality by the recent occurrence of a relatedword in the other modality. Visual articulatoryinformation (i.e., a speaker's moving face) has longbeen known to aid the recognition of spoken wordsin noise (e.g., Erber, 1969; O'Neill, 1954), and,conversely, auditorily presented speech featureswhich may not be intelligible by themselves canincrease word recognition in speechreading (e.g.,Breeuwer & Plomp, 1984, 1986). Cross-modalinteractions can occur prior to word recognition:
This research was supported by NICHD Grant HDOI994 toHaskins Laboratories. A brief report of the results waspresented at the 31st Annual Meeting of the PsychonomicSociety in New Orleans, LA, November 1990.
243
Printed single letters or nonword letter stringscan facilitate the response to a phoneme presentedin the auditory modality (Dijkstra, Schreuder, &-Frauenfelder, 1989; Layer, Pastore, & Rettberg,1990). Prelexical cross-modal influences have alsobeen demonstrated when the visual informationconsists of articulatory gestures (McGurk &MacDonald, 1976): Simultaneous presentation of aspoken CV syllable and of a speaker's face uttering a different syllable can lead to the illusion ofhearing the syllable suggested by the visualmodality. This interaction even takes place priorto the categorization of the phonemes involved(Massaro & Cohen, 1990; Summerfield, 1987).
In a recent study, Frost, Repp, and Katz (1988)investigated whether influences from the visualmodality can penetrate to earlier, precategoricallevels of auditory perception by requiring theirsubjects to detect rather than recognize speech innoise. Auditory speech-plus-noise and noise-onlytrials were accompanied by a visual orthographicstimulus that either matched or did not match themasked speech. Frost et a1. (1980) found thatmatching visual input did not improve subjects'speech detection performance, which suggestedthat the information subjects relied on (probably

244 Reppetal.
bursts of low-frequency spectral energy) wasimmune to cross-modal top-down influences.However, the visual input did have a strong effecton the bias parameter in this signal detectiontask: Subjects claimed to hear speech more oftenwhen they saw the word to be detected than whenthey saw a different printed word or no word atall. This bias shift, which may represent a genuineperceptual effect (viz., an illusion of hearingspeech in noise), was evidently due to the factthat, in that study, the amplitude envelopes of themasking noises had been matched to those of thewords to be masked. This so-called signalcorrelated noise has very desirable properties as amasking agent (it enables precise specification ofthe signal-to-noise ratio and keeps that ratioconstant as the signal changes over time) but itdoes retain some speechlike features. Althoughthese features are not sufficient to causeperception of the noise as speech, let alone toidentify a specific utterance, they do conveycODSlderable prosodic and phonetic information.MOTtl specifically, the amplitude envelope conveysinformation about rate of speech (Gordon, 1988),number of syllables (Remez & Rubin, 1990),relative stress (Behne, 1990), and several majorclasses of consonant manner (Van Tasell, Soli,Kirby, & Widin, 1987). (See also Smith, Cutler,Butterfield, & Nimmo-Smith, 1989, who employedspeech heavily masked by unmodulated noise.)Apparently, the subjects in the Frost et al. (1988)study automatically detected the correspondencebetween a printed word and an auditorilypresented noise amplitude envelope. As a result,they perceived the masking noise as morespeechlike and concluded that there was "speechin the noise.· Frost et al. (1988) considered this aninteresting and novel demonstration of rapid andautomatic phonetic recoding in silent reading:Since signal-correlated noise is too impoverishedto suggest a definite orthographic representation,the cross-modal correspondence must beestablished by mapping the print into an internalspeechlike representation, specific enough tocontain amplitude envelope features matchingthose of the noise and accessed rapidly enough tobe linked to the transitory auditory stimulus.
According to many models of visual wordrecognition, the mapping from print to speech maybe accomplished either via stored phonologicalcodes attached to lexical entries or via prelexicalspelling-to-sound conversion rules (see Patterson& Coltheart, 1987; Van Orden, Pennington, &Stone, 1990, for reviews). Hence it was especiallyinteresting to find that the bias shift just
described was reduced considerably when thematerials were meaningless pseudowords (Frostet al., 1988: Exp. 2). Frost (1991) has replicatedthis finding in the Hebrew orthography, both withand without vowel symbols, using a within-subjectdesign. His results suggest that the stronger biasshift for words than for nonwords is independentof spelling-to-sound regularity, and of the speed ofprocessing the printed stimuli. It seems, therefore,that subjects' ability to detect the orthographicacoustic correspondence in the speech detectionparadigm is, at least in part, lexically mediated.That is, when the visual input is a word, itactivates a lexical entry and, with it, an internalspeechlike representation containing considerablephonetic detail, including amplitude envelopefeatures. In contrast, when the visual input is anonword, its internal phonetic representation (ifany) must be assembled via analogy with knownlexical items (Glushko, 1979) or via spelling-tosound translation rules, and because of thispiecemeal construction it may be less coherent orless vivid than the phonetic representation of afamiliar word; hence the match with an auditoryamplitude envelope is less evident.
Our aim in the present study was to furtherexamine the hypothesis that detailed phoneticinformation is stored with, or is part of, lexicalrepresentations. We conducted two experimentsanalogous to Experiments 1 and 2 of Frost et a1.(1988), but instead of print we employed a videorecording of a speaker's face.
Visual articulatory information differs from orthography in several important ways. On onehand, whereas the relations of graphemic forms tophonologic structures are a cultural artifact, therelations of articulatory movements to phonological and phonetic structure are nonarbitrary. Thereis a natural isomorphism between visible articulatory movements and some acoustic properties ofspeech, particularly between the degree of mouthopening and overall amplitude. Therefore, lexicalmediation may not be required for viewer-listeners to perceive a correspondence between the timing of opening/closing gestures and variations insignal amplitude. l On the other hand, visual articulatory information is less specific than printand generally conveys only distinctions amongmajor consonant and vowel classes, the so-calledvisemes (see, e.g., Owens & Blazek, 1985).Visually observed speech gestures are often compatible with a number of lexical candidates. Itmay be hypothesized, therefore, that in order for aspeechread utterance to be associated with thesound of a particular word, lexical access may be

Laiaz1 Mediation Between Sight and Sound in Speechremling 245
necessary, after all. Finally, we must note that articulatory information unfolds over time, whereasprint is static and presents all information at once(provided it can be viewed in a single fixation).Thus there is an added dimension of temporalsynchrony in audio-visual speech perception,which may enhance the interaction of the twomodalities.
These considerations led us to hypothesize thatthe original finding of lexical mediation in theaccess of speechlike representations fromorthography (Frost et aI., 1988) might bereplicated when the visual information consists ofarticulatory gestures: Subjects might be able todetect a correspondence between the speaker'sgestures and auditory amplitude envelopes, butonly when the stimuli are familiar words. In thatcase, the auditory envelope information wouldsupplement the visual gestural information toconstrain word identification. 2 A lexicalrepresentation would automatically link the twotypes of information, and a significant increase inperceptual bias on "matching" trials would be theresult. However, when the speechread stimuli areclearly nonwords, lexical mediation would notoccur, and this might also eliminate the bias shift,if it indeed originates at the lexical level.
Although the bias shift. (i.e., the influence ofvisual information on perception of the maskingnoise) was of primary interest in our study, wealso examined whether the detectability of themasked speech signal was influenced by seeingmatching articulatory information. Our earlierstudies with orthographic stimuli revealedabsolutely no change in subjects' sensitivity tomasked speech. However, because of the closerelationship between visible articulatoryinformation and speech acoustics, and because ofthe added dimension of audio-visual synchrony,we considered it possible that the speech gestureswould aid listeners in separating the·speech signalfrom the accompanying noise.
EXPERIMENT 1Experiment 1 employed words as stimuli.
Because we suspected that low-frequency energyprovided the major cues for speech detection, andthat utilization of these cues may be insensitive tocross-modal top-down influences, we included inExperiment 1 two auditory conditions, the firstemploying natural phonated speech and thesecond using whispered speech, which containslittle low-frequency energy. These conditionsprovide very different opportunities forspeechread information to exert an influence on
auditory detection performance, as well assomewhat different amplitude envelopes forindividual words to test the generality of theexpected bias shift.
MethodStimuli and design. The stimuli were 48
disyllabic English words with stress on the firstsyllable (examples: mountain, baby, canvas, etc.).A female speaker was recorded twice producingthese words, once with normal phonation and listintonation, and once in a whisper, with themicrophone much closer to her mouth. The firstsession was also videotaped, with the pictureshowing a frontal view of the speaker's face. Halfthe recorded words were used to generate theauditory stimuli. The same 24 words in eachproduction mode (phonated and whispered) weredigitized at 20 kHz and low-pass filtered at 9.6kHz. Signal-correlated noise was generated fromeach word by a simple procedure that randomlyreversed the polarity of half the digital samplingpoints (Schroeder, 1968). Such noise has exactlythe same amplitude envelope as the originalsignal (obviously, since the envelope is derivedfrom the rectified signal, i.e., regardless of thedirection of the sound pressure change) but a flatspectrum, like white noise.S Speech-plus-noisestimuli were generated by adding the digitalwaveforms of each word and of its signalcorrelated noise after multiplying them withweighting factors that added up to 1, so that theoverall amplitude of the sum remained virtuallythe same. Two such weightings were used that, onthe basis of pilot results, were expected to yielddetection performance of 70-80 percent correct. Inthe phonated condition they corresponded tosignal-to-noise (SIN) ratios of -12 and -14 dB. Inthe whispered condition, which was much moredifficult, the SIN ratios used were -4 and -6 dB. Allthese ratios were well below the speechrecognition threshold.
Within each production type (i.e., phonated orwhispered) and SIN ratio condition, each of the 24words appeared 6 times, 3 times as signal-plusnoise and 3 times as signal-correlated noise only.Each of these two auditory presentations occurredin three visual conditions: In the matchingcondition, the subjects saw the speaker producethe word that had been used to generate theauditory stimulus. In the nonmatching condition,they saw the speaker say a different disyllabicword, drawn from the 24 words not used asauditory stimuli. In the neutral condition, theysaw the speaker's still face. The 6 audiovisual

246 ReppetQl.
conditions for each of the original 24 words weredistributed across 6 blocks of24 trials according toa Latin square design. Thus each of the 24 words(in one of its two auditory incarnations) occurredexactly once in each block, and each of the 6audiovisual conditions occurred 4 times per block(with different words). The 24 trials within eachblock were randomized. The more difficultcondition with the lower SIN ratio always followedthat with the higher SIN ratio, with the 144 trialsof each following the same sequence. Thephonated and whispered conditions also used thesame stimulus sequences. The order of theseproduction type conditions was counterbalancedacross subjects.
The experimental video tapes were generated asfollows. First, using professional video dubbingequipment, the video recordings from thephonated condition (with the original sound trackon audio channel A) were copied one by one fromthe master tape onto the experimental tape,according to the randomized stimulus sequence forthe video track. Each video segment started about1 sec before, and ended about 1 sec after, theaudible utterance. A view of the speaker's stillface, of similar total duration, served as theneutral stimulus. About 3 s of black screenintervened between successive video segments.Second, the resulting audio track was digitized inportions, and the exact intervals between theonsets of the original spoken words weremeasured in displays of the digitized waveforms.(Most words began with stop consonants; for a fewthat began with nasals, the point of oral releasefollowing the nasal murmur was considered theonset.) Third, a computer output sequence wascreated containing the audio items to besubstituted for the original utterances, accordingto the experimental stimulus schedule for theaudio track, with exactly the same onset-to-onsetintervals as those measured on audio channel AAudio trials for the neutral condition were timedto start about 1 sec after the onset of the still facevideo. Finally, this auditory substitute sequencewas output and recorded onto audio channel B,which was the one played back during theexperiment.4
Subjects and procedure. The subjects were 12paid volunteers, all native speakers of AmericanEnglish and claiming to have normal hearing.They were tested singly in a quiet room. The subject sat in front of a color monitor at a comfortableviewing distance and listened to the audio outputover the video loudspeaker at a comfortable intensity. The task was described as one of speech de-
tection in noise, and 24 practice trials using ahigher signal-to-noise ratio (-10 dB in thephonated condition, 0 dB in the whisperedcondition) were provided without any accompanying video; these trials contained words notused as audio stimuli later on. Subjects wereinformed that a spoken word (either phonated orwhispered, depending on the condition) waspresent in the noise on some of the trials. Theywere told to watch the video screen, but it wasemphasized that what they saw had nothing to dowith whether or not a word was hidden in thenoise. The subjects wrote down their response (Sfor speech or N for noise only) on an answer formin the interval between trials. The wholeexperimental session (4 x 144 trials) lasted about60 minutes.
Analysis. The data were analyzed in terms ofthe detectability and bias indices proposed byLuce (1963), which we call d and b here forsimplicity, and which are comparable to the , andBeta indices of Signal Detection Theory. They aredefined as
d = In[p(H)P(l-FA)lp(l-H)p(FA)]12and
b = In[p(H)P(FA)lp(1-H)p(1-FA>Y2where p(H) and p(FA) are the proportions of hitsand false alarms, respectively.5 The d index(normally) assumes positive values similar to d',and a positive b index indicates a bias to respond"s" (i.e., "speech present"). The indices we reportbelow were computed for each subject and thenaveraged; however, we also computed indices foreach item and did statistical analyses both ways.Separate analyses of variance were conducted onthe phonated and whispered conditions, with SINratio and visual condition as within-subject factors; the F ratios for the subject and item analyseswill be reported as Fl and F2, respectively.
ResultsDetectability. In the phonated condition, the
average d indices for the two SIN ratios were 2.14(-12 dB) and 1.88 (-14 dB). This difference, whichpitted the positive effect of practice against thenegative effects of reducing the SIN ratio, wassignificant across items [Fl(l,l1) = 3.83, p < .08;F2(l,23) = 18.63, p < .0004l, but is of littleinterest. The important result was that detectionperformance was unaffected by visual condition[Fl(2,22) = 0.38, p > .5; F2(2,46) = 2.19, p > .1l;the average ratios in the three conditions were1.95 (match), 2.02 (mismatch), and 2.07 (neutral).Thus, seeing a matching articulation did not aidspeech detection. If anything, a match reduced
LexiazJ MediJltion Between Sight and Sound in Sper:ehreading 247
sensitivity: In the item analysis, but not in thesubject analysis, there was a significant SIN ratioby visual condition interaction [F1(2,22) = 1.00, p> .3; F2(2,46) = 5.48, p < .008]: At the higher SINratio, performance was best in the neutralcondition and worst in the matching condition;this difference disappeared at the lower SIN ratio.
The average d indices were lower in the whispered than in the phonated condition, despite themuch higher SIN ratios: 1.44 and 1.12, respectively, at the -4 dB and -6 dB ratios. The decline insensitivity as a function of SIN ratio was signifiant[F1(l,11) = 16.10, p < .003; F2(l,23) = 23.51, p <.0002]. The performance levels were ideal forobserving effects of visual condition. Still, therewas no trace of a visual condition main effect [F1,F2 < 1]; the average values in the three conditionswere 1.34 (match), 1.20 (mismatch), and 1.31(neutral). Thus, even when low-frequency cueswere eliminated, an audiovisual match did not facilitate detection performance. The SIN ratio byvisual condition interaction was likewise nonsignificant [F1, F2 < 1].
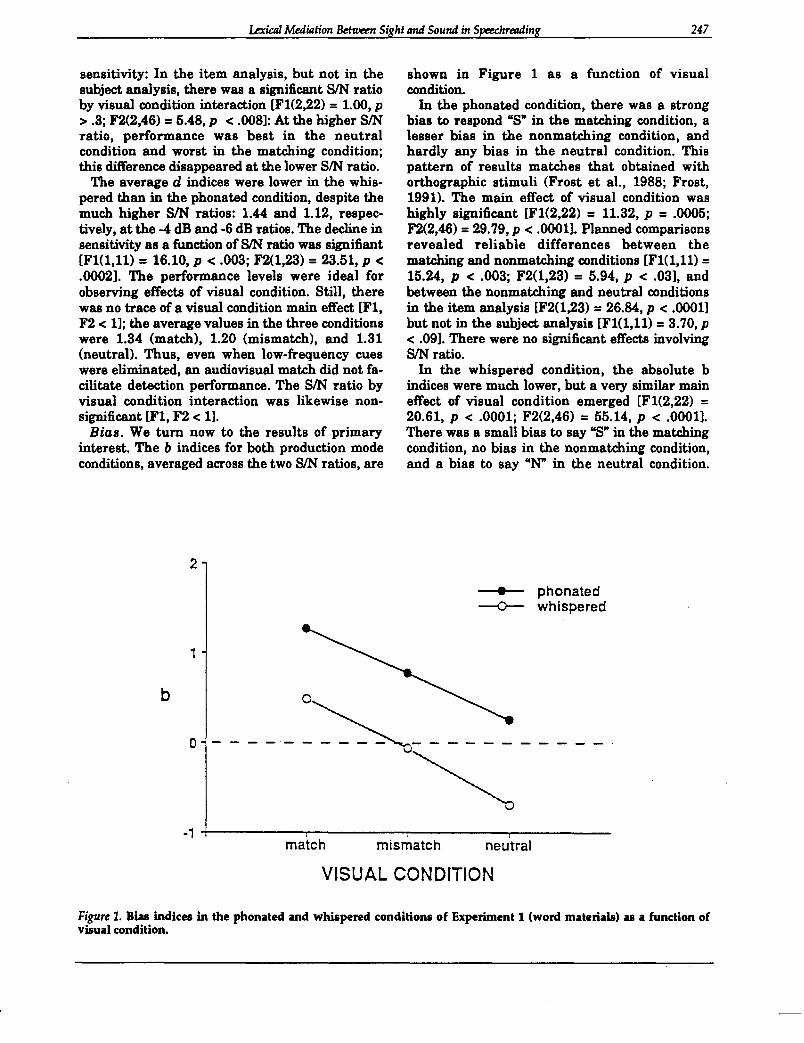
Bias. We tum now to the results of primaryinterest. The b indices for both production modeconditions, averaged across the two SIN ratios, are
2
shown in Figure 1 as a function of visualcondition.
In the phonated condition, there was a strongbias to respond lOS· in the matching condition, alesser bias in the nonmatching condition, andhardly any bias in the neutral condition. Thispattern of results matches that obtained withorthographic stimuli (Frost et a1., 1988; Frost,1991). The main effect of visual condition washighly significant [F1(2,22) =11.32, p =.0005;F2(2,46) = 29.79, p < .0001]. Planned comparisonsrevealed reliable differences between thematching and nonmatching conditions [F1(1,11) =15.24, p < .003; F2(1,23) = 5.94, p < .03], andbetween the nonmatching and neutral conditionsin the item analysis [F2(1,23) = 26.84, p < .0001]but not in the subject analysis [F1(1,11) = 3.70, p< .09]. There were no significant effects involvingSIN ratio.
In the whispered condition, the absolute bindices were much lower, but a very similar maineffect of visual condition emerged [F1(2,22) =20.61, p < .0001; F2(2,46) = 55.14, p < .0001].There was a small bias to say "S" in the matchingcondition, no bias in the nonmatching condition,and a bias to say "N" in the neutral condition.
• phonated--0- whispered
1
b
0-----
-1 +-----,..-----or-----r------match mismatch neutral
VISUAL CONDITION
Figure 1. Bias indices in the phonated and whispered conditions of Experiment 1 (word materials) as a function ofvisual condition.

248 Reppetal.
Planned comparisons showed reliable differencesbetween the matching and nonmatchingconditions [F1(1,1l) =14.42, p < .004; F2(1,23) =20.08, p < .0003], and between the nonmatchingand neutral conditions [F1(1,1l) = 12.81, p < .005;F2(1,23) = 38.87, p < .0001]. There were nosignificant effects involving SIN ratio.
In summary, the results of Experiment 1 replicate almost exactly the findings of Frost et a1.(1988) with orthographic word stimuli. Clearly,subjects were able to perceive a correspondencebetween speech gestures presented visually andamplitude envelopes presented auditorily. Likematching printed information, matching articulatory information, too, seems to create an illusionof hearing speech in amplitude-modulated noise.The bias shifts in the phonated and whisperedconditions were equivalent. The difference between these conditions in absolute bias valuesmust have a different origin (see GeneralDiscussion); whatever its cause, it is orthogonal tothe relative bias shift that we are concerned with.
In order to determine whether the detection ofcorrespondence between the speaker's articulatorygestures and the noise amplitude envelopes islexically mediated, we examined in Experiment 2whether nonword materials would produce thesame effect.
EXPERIMENT 2Since similar bias shifts were obtained in
Experiment 1 regardless of production mode, onlya phonated condition was employed in Experiment2. Otherwise, except for the difference in materials, the experiment was an exact replication ofExperiment 1. If there is a direct (i.e., prelexical)link between visible articulatory movements andthe auditory amplitude envelope, then the resultsof Experiment 2 should replicate those ofExperiment 1. If, on the other hand, thisconnection can only be established via the lexicon,then there should be no effect of audio-visualmatch on response bias. In particular, thereshould be no difference between the matching andnonmatching conditions; since it is conceivablethat the mere presence versus absence ofarticulatory movements has an independent effecton response bias (see discussion below), thecomparison with the neutral condition is lesscrucial.
MethodsThe stimuli were 48 disyllabic nonwords
stressed on the first syllable, produced by thesame female speaker and videotaped. In Frost etal. (1988), orthographic nonwords had been gener-
ated from words by changing one or two letters.This would not do for speechreading because ofthe phonological ambiguity of visemes. To ensurethat our stimuli were not speechread as Englishwords, we used phonotactically atypical but easilypronounceable utterances containing the pointvowels /a,i,u1 and visually distinctive consonants.(Examples: "vumuv: "kichaf: "fafiz: etc.).Twenty-four of the nonwords were used as auditory stimuli, the other 24 as nonmatching visualstimuli. The generation of stimulus tapes, the testsequences, and the procedure were identical withthose in Experiment 1. Because detectabilityscores in the phonated condition of Experiment 1had been somewhat high, the SIN ratios were setslightly lower in Experiment 2, at -13 and -16 dB.The subjects were 12 volunteers from the samegeneral population. Twc, of them had participatedin Experiment 1. They were informed that theutterances were meaningless.
ResultsDetectability. The average d indices for the two
SIN ratios were 1.62 and 1.11, respectivelysignificantly lower than the corresponding indicesfor phonated words in Experiment 1 [F1(1,22) =5.84, p < .03; F2(1,46) = 10.96, p < .002, in acombined ANOVA], in part due to the somewhatlower SIN ratios used,6 The main effect of SINratio was significant [F1(1,1l) =49.84, p < .0001;F2(l,23) = 24.88, p < .0001]. Surprisingly, therewas also a significant main effect of visualcondition here [F1(2,22) = 10.00, p < .0009;F2(2,46) = 6.50, p < .004], This effect was due to alower d index in the nonmatching condition (1.17)than in either the matching condition (1.51) or theneutral condition (1.42). In a combined ANOVA onthe data of Experiment 1 (phonated condition) andof Experiment 2, with the added factor of lexicalstatus (word/nonword), a significant interaction ofvisual condition and lexical status was obtained[F1(2,22) =3.46, p < .05; F2(2,46) =4.14, p < .02].This suggests some inhibition or distractioncaused by an audiovisual mismatch for nonwords,but no facilitation due to a match. The SIN ratioby visual condition interaction was nonsignificant.
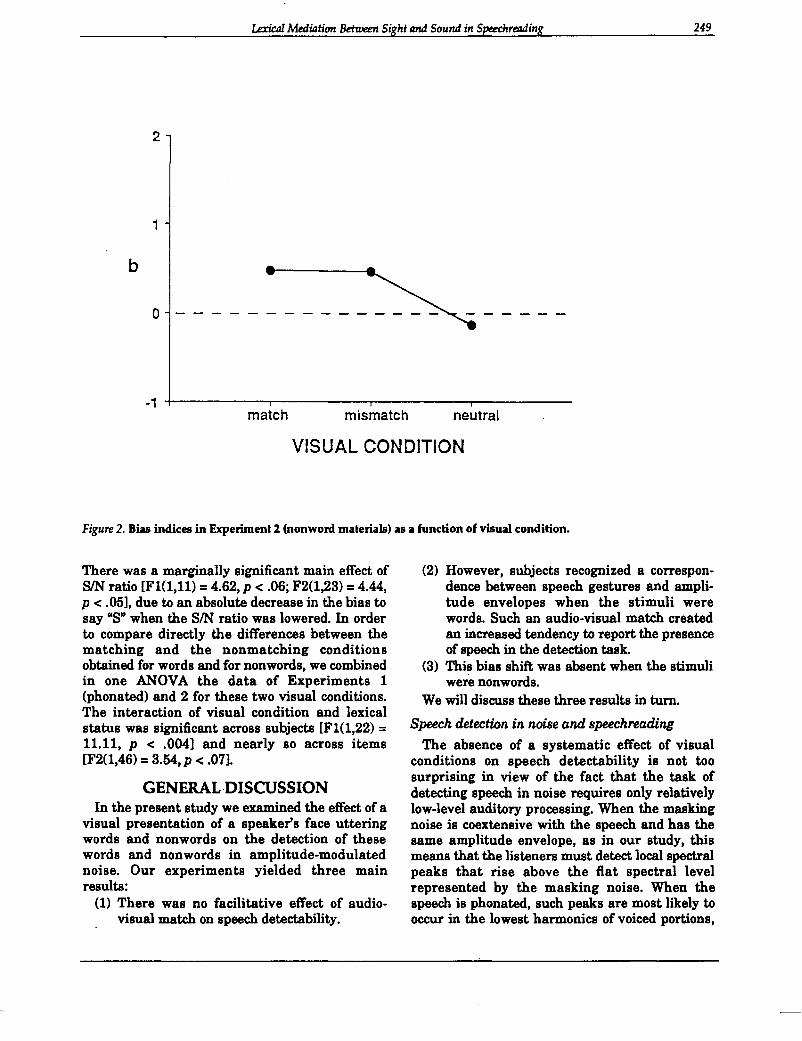
Bias. The bias results are shown in Figure 2,averaged over the two SIN ratios. There was asignificant effect of visual condition [F1(2,22) =11.86, p < .0004; F2(2,46) = 13.68, p < .0001] but,as can be seen in the figure, it was entirely due tothe matching and nonmatching conditions versusthe neutral condition. There was absolutely nodifference between the former two conditions, bothof which exhibited a small positive bias. The effectof visual condition did not interact with SIN ratio.
b
Leriall Mediation Between Sight tmd Sound in SpeechreJUiing
2
1
0---------------
·1 +------,-----,-------.-----
249
match mismatch neutral
VISUAL CONDITION
Figure 2. Bias indices in Experiment 2 (nonword materials) as a function of visual condition.
There was a marginally significant main effect ofSIN ratio [Fl(l,l1) =4.62, p < .06; F2(1,23) =4.44,p < .05l, due to an absolute decrease in the bias tosay "S" when the SIN ratio was lowered. In orderto compare directly the differences between thematching and the nonmatching conditionsobtained for words and for nonwords, we combinedin one ANOVA the data of Experiments 1(phonated) and 2 for these two visual conditions.The interaction of visual condition and lexicalstatus was significant across subjects [Fl(l,22) =11.11, p < .004l and nearly so across items[F2(l,46) = 3.54, p < .07].
GENERAL DISCUSSIONIn the present study we examined the effect of a
visual presentation of a speaker's face utteringwords and nonwords on the detection of thesewords and nonwords in amplitude-modulatednoise. Our experiments yielded three mainresults:
(1) There was no facilitative effect of audiovisual match on speech detectability.
(2) However, subjects recognized a correspondence between speech gestures and amplitude. envelopes when the stimuli werewords. Such an audio-visual match createdan increased tendency to report the presenceof speech in the detection task.
(3) This bias shift was absent when the stimuliwere nonwords.
We will discuss these three results in tum.
Speech detection in noise and speechreadingThe absence of a systematic effect of visual
conditions on speech detectability is not toosurprising in view of the fact that the task ofdetecting speech in noise requires only relativelylow-level auditory processing. When the maskingnoise is coextensive with the speech and has thesame amplitude envelope, as in our study, thismeans that the listeners must detect local spectralpeaks that rise above the flat spectral levelrepresented by the masking noise. When thespeech is phonated, such peaks are most likely tooccur in the lowest harmonics of voiced portions,

250 Reppetili.
and listeners therefore hear snippets of a humanvoice somewhere in the noise. Since speechreadingdoes not provide information about the presenceor absence of voicing, it cannot guide the listenerto any portions of the signal that are especiallylikely to yield spectral evidence ofvoicing.
When the speech is whispered, listenersprobably detect spectral prominences in the regionof the second formant, or at higher frequencies ifthe word contains fricatives with strong noisecomponents, such as lsi. This task is difficultbecause the speech itself has a noise source, andthe SIN ratio must be raised considerably toachieve above-chance accuracy. Speechreading canprovide some limited information about theoccurrence of fricatives, but the most visibleconsonant articulations (lbpm/, IvfI, 19iH) haveweak acoustic correlates, and fricatives such as lsiwere rare in our stimuli. Thus, there is not muchto be gained from speechreading here either, andauditory detection strategies therefore seem to beuninfluenced by visual input.
There were two instances in which visual inputdid affect detectability scores, but the influencewas negative rather than positive. In thephonated condition of Experiment 1, there was atendency for detection to be best in the neutralcondition, but only at the higher SIN ratio. Morestrikingly, in Experiment 2 detection scores weredepressed in the nonmatching condition. Seeingarticulatory movements may have had a slightdistracting effect on listeners, especially whenthere was an obvious mismatch with the auditoryinput. Mismatches may have been more obvious inthe nonword experiment, due to the differentconstruction of the materials.
The bias shift for words
The result of primary interest is the relativechange in bias as a consequence of audiovisualmatch. Our findings suggest that the visualpresentation of speech gestures matching theauditory amplitude envelope causes an auditoryillusion of hearing speech, similar to the illusionobtained by Frost et a1. (1988) with printedstimuli. This may not seem surprising: If subjectscan detect the correspondence between theauditory amplitude envelope and print, whoserelationship to each other is merely conventional,then they certainly should also detect thecorrespondence between the envelope andarticulatory movements, which are intrinsicallylinked. In particular, the visible time course ofjawopening is a direct optic correlate of the grossamplitude envelope. It is not necessary to invoke
lexical access to explain the results for words.Lexical access probably did occur, however, due tothe joint constraints effected by the auditoryamplitude envelope and the visual articulatoryinformation, and it probably happened more oftenin the matching than in the nonmatchingcondition.
Two aspects of subjects' sensitivity to audiovisual matches deserve comment. First, an effectof match was obtained even though the auditoryand visual inputs were not in perfect synchrony;this suggests, in accordance with earlier findings(see Footnote 4), that temporal offsets smaller(and occasionally larger) than 100 ms do notinterfere substantially with the detection of audiovisual correspondence, especially if the sound lagsbehind. Second, the bias shift was obtained forboth phonated and whispered speech, even thoughthe amplitude envelope of a given word wasdifferent in the two production modes. Since thesame video was used in both conditions andrelative bias shifts of the same magnitude wereobtained, this means that the audio-visual matchwas equally good for both kinds of amplitudeenvelopes. The amplitude envelopes thus musthave retained crucial phonetic properties acrossthe change in phonation type (cf. Tartter, 1989, onphonetic information in whispered speech). Theextent to which the speech amplitude envelopeconveys invariant phonetic features is aworthwhile topic for investigation that hasreceived only very limited attention so far (e.g.,Mack & Blumstein, 1983; Nittrouer & StuddertKennedy, 1985).
There was one difference, however, between thephonated and whispered conditions: The absolutebias indices were considerably lower in the whispered condition. Since the masking noises wererather· similar in the two conditions, the differencein bias must reflect differences in subjects' expectations of hearing speech. The greater difficulty ofthe whispered condition and the atypicality ofwhispered speech may have been sufficient reasons for subjects' relative conservatism, as reflected in the absolute bias indices.
So far, we have focused on the differencebetween the matching and nonmatchingconditions for words, which constitutes thepredicted bias shift. However, there was also areliable difference between the nonmatching andneutral conditions, with the bias to say "s" beingrelatively greater in the nonmatching condition.This difference was also obtained in the earlierstudy with print (Frost et at, 1988). There are twopossible interpretations: (1) The effect may

Le:riaI1 Mediation Between Sight and Sound in Speechrettding 251
represent a different kind of response bias, causedby any structured visual input (print or articulation) regardless of match. According to thisview, there are really two bias shifts: a lessinteresting one (postperceptual response bias)that accounts for the difference between neutraland non-neutral conditions, and a moreinteresting one (perceptual in origin) thataccounts for the difference between the matchingand nonmatching conditions. (2) Alternatively, thedifference between the neutral and nonmatchingconditions may represent an effect of partialmatch. After all, the nonmatching.stimuli had thesame general prosodic pattern as the matchingstimuli (i.e., two syllables with stress on the first).This may have been sufficient to obtain a smallbias shift. According to this view, there is a singlebias shift effect which is present in varyingdegrees in the matching and nonmatchingconditions; the "nonmatching" condition reallyshould have been called "partially matching" inthat case.
The present data for word stimuli cannot decidebetween these two alternatives. However, aprevious experiment that bears on the issue isExperiment 3 of Frost et at (1988), which usedorthographic visual stimuli. In that experiment,white noise without amplitude modulation wasused as a masker. Thus, there was no auditorybasis for either whole or partial matches. Yet, adifference in bias was obtained between theneutral condition and the other two conditions.This suggests that the first explanation givenabove is correct, at least for print.
The absence ofa bias shift for nonwords
This suggestion seems to be confirmed by thepresent results: The difference in bias between thematching and nonmatching conditions, obtainedfor word stimuli in Experiment 1, was absent fornonword stimuli in Experiment 2. There was,however, a reliable difference between the neutralcondition and the other two visual conditions evenfor nonwords, and this difference was similar inmagnitude to that between the neutral andnonmatching conditions for words. If the relativebias increase in the nonmatching conditionrepresented an effect of partial match, then itwould be difficult to explain why an additionaleffect of complete match was obtained for wordsonly. Therefore, the difference between theneutral and nonmatching conditions may wellrepresent an "uninteresting" response bias, due tothe occurrence of any verbal event in the visualmodality.
However, the partial match explanation can stillbe upheld by noting that the partial match reflectsonly general prosodic characteristics (number ofsyllables, stress pattern) whereas the completematch reflects the added effect of matchingsegmental envelope characteristics as well asprosodic detail such as the exact timing pattern.To account for the effect of lexical status, one isthen led to the interesting (but highly speculative)conclusion that the detection of segmental (andexact prosodic) cross-modal matches requireslexical access, whereas the detection of grossprosodic matches can occur without theinvolvement of the lexicon.
A similar conclusion was reached independently,and on the basis of quite different kinds ofevidence, by Cutler (1986): In a cross-modalpriming task, auditorily presented words drawnfrom semantically distinct pairs that differed onlyin stress pattern but not in segmental structure(quite rare in English; e.g., FORbear-forBEAR)had equal priming effects on lexical decision forvisual targets that were semantically related toone or the other member of the pair. In otherwords, the auditory stress pattern did not
.constrain lexical access and only postlexicallydisambiguated the two semantic alternatives. Ourresults are complementary to those of Cutler inthat they suggest that global prosodic information,including stress pattern, is processedindependently of lexical access. This result makessense when we consider the fact that prosodicparameters are not specific to speech but also playan important role in music, in animalcommunication, and even in environmentalsounds. Lexical access, perhaps necessarily, isgoverned by speech-specific (segmental anddetailed prosodic) properties of the acoustic signal;global prosodic properties, on the other hand, feedinto the nonverbal systems of auditory eventperception and emotion. They may also beprocessed in different parts of the brain.
The above interpretation remains speculativebecause we do not know what would happen ontrials on which there is a striking prosodicmismatch between the auditory and visual inputs.An experiment including such trials remains to beconducted. Our results show very clearly,however, that an audio-visual match of segmental(and detailed prosodic) characteristics leads to abias shift only for words, not for nonwords. Thisresults replicates earlier findings obtained withprint (Frost et al., 1988; Frost, 1991) and in fact ismore dramatic: Whereas a small differencebetween matching and nonmatching conditions

252 Reppetal.
was consistently obtained with printed nonwords,there was no difference at all with speechreadnonwords, perhaps because the latter were lesssimilar to English words than the printednonword stimuli. In the case of print, the resultssuggested that lexical access through the visualmodality results in a detailed phoneticrepresentation that shares amplitude envelopefeatures with a matching signal-correlated noise.The alternative process of letter-to-soundtranslation by rule or analogy, which-accordingto traditional dual-route models-must beemployed for nonwords, is either too slow toenable subjects to relate its product to theauditory stimulus or, more likely, does not resultin a detailed, complete, or coherent phoneticrepresentation. The latter interpretation isfavored by Frost's (1991) recent results, whichshow that manipulations known to affect speed ofword recognition (viz., word frequency andHebrew vowel diacritics) have no effect on themagnitude of the bias shift for words; byimplication, the absence of a bias shift fornonwords is probably not due to a slowerprocessing speed. Can the same arguments bemade in the case of speechreading?
In the introduction, we pointed out threeimportant differences between print and visualarticulatory information. Two specific aspects ofspeechreading, the temporal nature of theinformation and its nonarbitrary relation to thesounds of speech (including the amplitudeenvelope), led to the expectation that an effect ofaudio-visual match might be obtained regardlessof lexical status. This was clearly not the case;thus, speechread information is not directlytranslated into a phonetic representation. Thereason for this lies probably in the third aspect:The visual information is not specific enough.Inner speech consists of the sounds of words, notjust of their amplitude envelopes, which arefeatures of the complete. sound patterns.Speechread information rarely specifies a uniqueword, however, and hence it does not (or onlyrarely) lead to lexical access in the case of isolatedwords, nor does it enable a viewer to construct adetailed sound pattern by direct translation,bypassing the lexicon. Normally, the incompleteinformation needs to be supplemented byadditional information that constrains thepossible lexical choices. The auditorily presentedamplitude envelope probably functioned as such asource of supplementary information (seeFootnote 2). In addition, its spectral maskingpower may have created the auditory illusion of
hearing speech, as in the phonemic restorationeffect (d. Warren, 1984).
This role of the auditory amplitude envelope inconjunction with speechreading is somewhatdifferent from the role Frost et a1. (1988)attributed to it in their studies with print, wherethey saw it as probing into the process of lexicalaccess from (unambiguous) print. In the case ofspeechreading, the noise envelope is not so much aprobe as an active ingredient in the processesleading to lexical access. (When printed stimuliare made ambiguous, as in a recent, stillunpublished study by Frost, the same is probablytrue.) The best way, then, to characterize whathappened in our present experiments is thatamplitude envelope information and speechreadinformation often converged onto a lexical entry inthe case of words, but failed to do so in the case ofnonwords. Whether the bias shift for words was adirect consequence of this lexical convergence, orwhether a separate postlexical process detectedthe match between the phonetic representationstored in the lexicon and the noise envelope, is amoot and probably unresolvable question. It maybe concluded, however, that it is the lexicallymediated activation of an internal phoneticrepresentation that accounts for the illusion ofhearing speech in the noise, and hence for the biasshift.
REFERENCESBehne, D. M. (1990). The position of the amplitude peak as an
acoustic correlate of stress in English and French. Jounull of theAcoustiad SocietyofAmerictl, 8&7, S6S-66 (A)
Blamey, P. J., Martin, L. F. A., tIr Clark, G. M. (1985). Acomparison of three speech coding strategies using an acousticmodel of a cochlear implant. JOUrtIIII of the Aooustiall Society ofAmerictl, 77,209-217.
Breeuwer, M., tIr Plomp, R. (1984). Speechreading supplementedwith frequency-selective sound-pressure information. JOUrtIIII ofthe Acoustiall Society ofAmerictl, 76,686-691.
Breeuwer, M., tIr Plomp, R. (1986). Speechreading supplementedwith auditorily presented speech parameters. Jounlld of theAcoustiall SocietyofAmerictl, 79, 481-499.
Cutler, A. (1986). Forbear is a homophone: Lexical prosody doesnot constrain lexical access. LAngUilge lind Speech, 29, 201-220.
Dijkstra, T., Schreuder, R., tIr Frauenfelder, U. H. (1989).Grapheme context effects on phonemic processing. LangUllgeand Sp«ch, 32, 89-108.
Dixon, N. F., tIr Spitz, L. (1980). The detection of audiovisualdesynchrony. Perception, 9, 719-721.
Erber, N. P. (1969). Interaction of audition and vision in therecognition of oral speech stimuli. Journal ofSp«ch lind HearingResearch, 12, 423-425.
Frost, R. (1991). Phonetic recoding of print and its effect on thedetection of concurrent speech in noise. Manuscript submittedfor publication.
Frost, R., Repp, B. H., tIr Katz, L. (1988). Can speech perception beinfluenced by simultaneous presentation of print? JOUrtIIII ofMemory and LangUllge, 27, 741-755.

Le:riCIU Mediation~ Sight and Sound in SpeechretUling 253
Glushko, R. J. (1979). The organization of activation oforthographic knowledge in reading aloud. /ounlld ofExperiment"z Psychology: HJmUln Perception lInd Perj'rm,l/",ce, 9,674-691.
Gordon. P. C. (1988). Induction of rate-dependent processing bycoarse-grained aspects of speech. Perception it Psychophysics, 43,137-146.
Grant, I(. W., Ardell, L H., Kuhl, P. K., &t Sparks, D. W. (1985).The contribution of fundamental frequency, amplitudeenvelope, and voicing duration cues to speechreading innormal-hearing subjects. /oumlll of tire AcoustiCAl Society ofAmeriC'll, 77, 671~77.
Kuhl, P. K., &t Meltzoff, A. N. (1982). The bimodal perception ofspeech in infancy. Science, 218, 1138-1141.
Layer, J. 1(., Pastore, R. E., &t Rettberg, E. (1990). The influence oforthographic information on the identification of an auditoryspeech event. /0U17IIIl of tire AcoustiCAl Society of AmeriCA, 87,Su~. 1,5125. (A)
Luce, R. D. (1963). Detection and recognition. In R. D. Luce, R. R.Bush, &t E. Galanter (Eds.), liIIndbook of"",t1remlltiC'llI psychology.New York: Wiley.
Mack, M., &t mumstein, S. E. (1983). Further evidence of acousticinvariance in speech production: The stop-glide contrast./ounl/d oftire AcoustiCill Society ofAmerial, 73,1739-1750.
Massaro, D. W., &t Cohen. M. M. (1990). Perception of synthesizedaudible and visible speech. PsychologiClll Science, I,~.
McGurk, H., &t MacDonald, J. W. (1976). Hearing lips and seeingvoices. N"ture, 264, 7~748.
McGrath, M., &t Summerfield, Q. (1985). Intermodal timingrelations and audio-visual speech recognition by normalhearing adults. /oumlll of tire AcoustiCAl Society of Amerial, 77,676-685.
Nittrouer, 5., &t Studdert-Kennedy, M. (1985). The stop-glidedistinction: Acoustic analysis and perceptual effect of variationin syllable amplitude envelope for initial fbI and IwI. /oumlllof tire AcousticAl Society ofAmerial, 80, 1026-1029.
O'Neill, J. J. (1954). Contributions of the visual components of oralsymbols to speech comprehension. /OUmIII ofSpeech "nd HtrlringDisorders, 19,429-439.
Owens, E., &t mazek, B. (1985). Visemes observed by hearingimpaired and normal-hearing adult viewers. /OUmIII of Speech""d Htrlring ReseIlrch, 28, 381-393.
Patterson, K., &t Coltheart, V. (1987). Phonological processes inreading: A tutorial review. In M. Coltheart (Ed), Attention lIndperjuml/",ce XlI: Tire psychology of t'trIding (pp. 421-447). Hove,East Sussex. UK: Lawrence Erlbaum Associates.
Remez. R. E., &t Rubin, P. E. (1990). On the perception of speechfrom time-varying acoustic information: Contributions ofamplitude variation. Perception it Psychophysics, 48, 313-325.
Repp, B. H., &t Frost, R. (1988). Detectability of words andnonwords in two kinds of noise. /OUmIII of the AcoustiCAl SocietyofAmerial, 84, 1929-1932.
Schroeder, M. R. (1968). Reference signal for signal qualitystudies. /oumill oftire AcoustiC'llI Society ofAmerial, 43, 1735-1736.
Smith, M. R., Cutler, A., Butterfield, 5., &t Nimmo-Smith, I. (1989).The perception of rhythm· and word boundaries in noisemasked speech. /ounl/d of Speech "nd Hearing ReseIlrch, 32, 912920.
Summerfield, Q. (1987). Some preliminaries to a comprehensiveaccount of audio-visual speech perception. In B. Dodd &t R.Campbell (Eds.), Htrlring by eye; The psychology oflip-t'trIding (pp.3-51). Hillsdale, NJ: Lawrence Erlbaum Associates.
Swinney, D. A., Onifer, W., Prather, P., &t Hirshkowitz, M. (1979).Semantic facilitation across sensory modalities in theprocessing of individual words and sentences. Memory itCognition, 7, 159-165.
Tartter, V. C. (1989). What's in a whisper? JoumIII of tire AroustiazlSocietyofAmerial, 86, 167S-1683.
TJ1lmarln. H. G., Pompilio-Marschall, B., &t Porzig, U. (1984). ZumEinfluss visuell dargebotener Sprechbewegungen auf dieWahmehmung der akustisch kodierten Artikulation.Forschungsberichte des Instituts fur Phoneti1c und sprtlchliclreKommIUli1adion (University of Munich. FRG),19, 318-336-
Van Orden,. G. C., Pennington. B. F., &t Stone, G. O. (1990). Wordidentification in reading and the promise of subsymbolicpsycho1inguistics. PsychologictU Ret7iew, 97, 488-522.
Van TaseU. D. J., Soli, S. D., Kirby, V. M., &t Widin, G. P. (1987).Speech waveform envelope cues for consonant recognition./oumIII oftire AcoustiC'llI Society ofAmerial, 82, 1152-1161.
Warren, R. M. (1984). Perceptual restontion of obliterated sounds.Psychological Bulletin. 96, 371-383.
FOOTNOTES·Qu/lrlerly /0UmIIl ofExperimentill Psychology, in press.tHebrew University of Jerusalem.
ttAlso Yale UniVersity.lKuhl and Meltzoff (1982) have shown that infants 18-20 weeks
old perceive the correspondence between visually presentedIiI and lal articulations and the corresponding speechsounds. However, the infants did not recognize any relationship when the amplitude envelopes of these vowels were imposed on a pure tone, so they probably relied on spectral ratherthan amplitude information when listening to speech.
2It is known from research on possible aids for the hearingimpaired that the auditory speech amplitude envelope, evenwhen carried just on a single pure tone, constitutes an effectivesupplement to speechreading (Blamey, Martin, &t Clark, 1985;Breeuwer ok Plomp, 1984, 1986; Grant, Ardell, Kuhl, &t Sparks,1985). Note that, in our experiments, it does not matter whetherthe word recognized is "correct" (i.e., the one intended by thespeaker) or not, as long as it fits both the auditory and thevisual information.
- 3Although the noise had a flat spectrum in its digital form, it wasoutput through hardware designed to remove high-frequencypre-emphasis and thus had a sloping spectrum in its acousticform. For the purposes of the present experiments, this wasirrelevanl
<4As we did not have equipment available to trigger the outputsequence precisely and thus to ensure exact audio-visualsynchrony, we started and restarted the output sequencemanually until it seemed in synchrony with the video channel.Subsequently, we measured the onset asynchrony betweenaudio channels A and B on matching trials, using two-channeldigitization and digital waveform displays. If any asynchronyexceeded ±loo ms, we re-recorded the output sequence.Asynchronies within this range are difficult to detect (Dixon okSpitz. 1980; McGrath &t Summerfield, 1985) and seem to haveonly a negligible effect on audiovisual speech perception(McGrath &t Summerfield, 1985; Tillmann, Pompino-Marschall,&t Porzig, 1984). Although we believed at the time to havesatisfied this criterion. postexperimental checks revealed someinaccuracies in the test sequence specifications that led to onsetasynchronies in excess of 100 ms for some stimuluscombinations. These asynchronies were always such that thesound lagged behind the visual stimulus, which is lessdetectable than the opposite (Dixon &t Spitz, 1980), and theyoccurred only in the phonated condition. Although this aspectshould have been under better control, we have no indicationthat audil>-visual asynchrony had any effect whatsoever on ourresults; in particular, as will be seen, the phonated andwhispered conditions yielded very similar bias shifts.

254 Reppetll1.
SValues of 1/2N and 1-1/2N were substituted for proportions of 0and 1, respectively. Due to the different frequencies of thesesubstitutions and the nonlinear nature of the indices, the avenged and b indices were not identical when computed aaosssubjects and aa'OIi6 items.
6performance for·nonwords was somewhat lower than expectedon these grounds alone. Of course, this could have re6ected a
random difference between subject samples. However, Frost etal. (1988), too, found lower detection performance for nonwordsthan for wOlds in diffen!nt experiments, even though the wordsand nonwords were equally detectable when presentedrandomly within the same experiment (Repp &.: Frost. 1988; Frostet aL, 1988: Exp. 3). It is as if subjects listened less carefully whenthey are presented with non;en&e.
Related Documents











