Profesor: Manuel Espinoza Horario: 8:30-17:00 hrs

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript
Profesor: Manuel Espinoza
Horario:8:30-17:00 hrs

Versiones antiguas
• Solo se aceptan letras y números, menos “Ñ”• Carácter especial aceptado “ “
• Versión (64 bit) nueva omite estasrestricciones

• Archivo mas importante dg1• Luego base de datos de diseño, *.dgd.isis

Base de Datos
• Dsf: hasta 4 caracteres

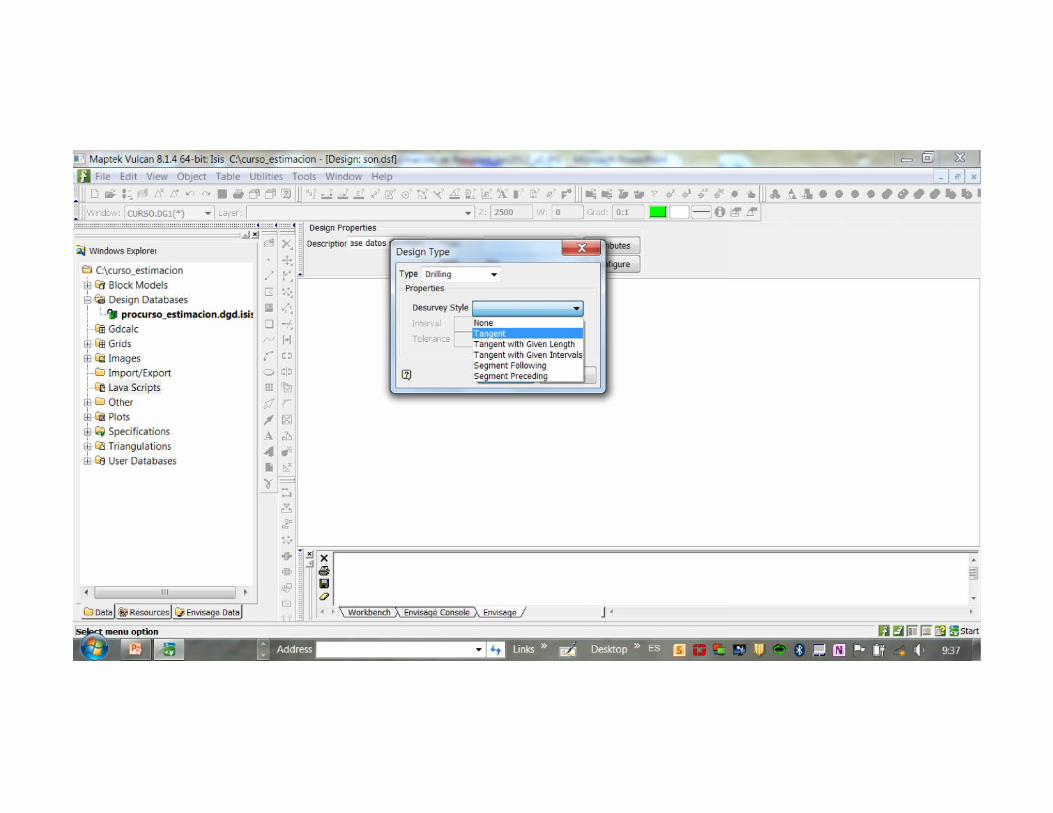

Definición de tablas
1. Collar2. Survey (si no se define Vc asume vertical)3. Leyes (Assays)4. otras

Double & Single
• 5000325,638: 11 caracteres incluye la coma. Sies single la precisión va desde a partir del 7carácter. El doble (8 bytes) a partir de la 14
• 16 tablas como máximo en Vc• Sinónimos: usar en las primeras 3 tablas.
Ayuda a Vulcan a identificar el tipo de variable• Primary solo en una tabla• Databse update: apendar nuevos sondajes o
atributos
Aleatorio, en single

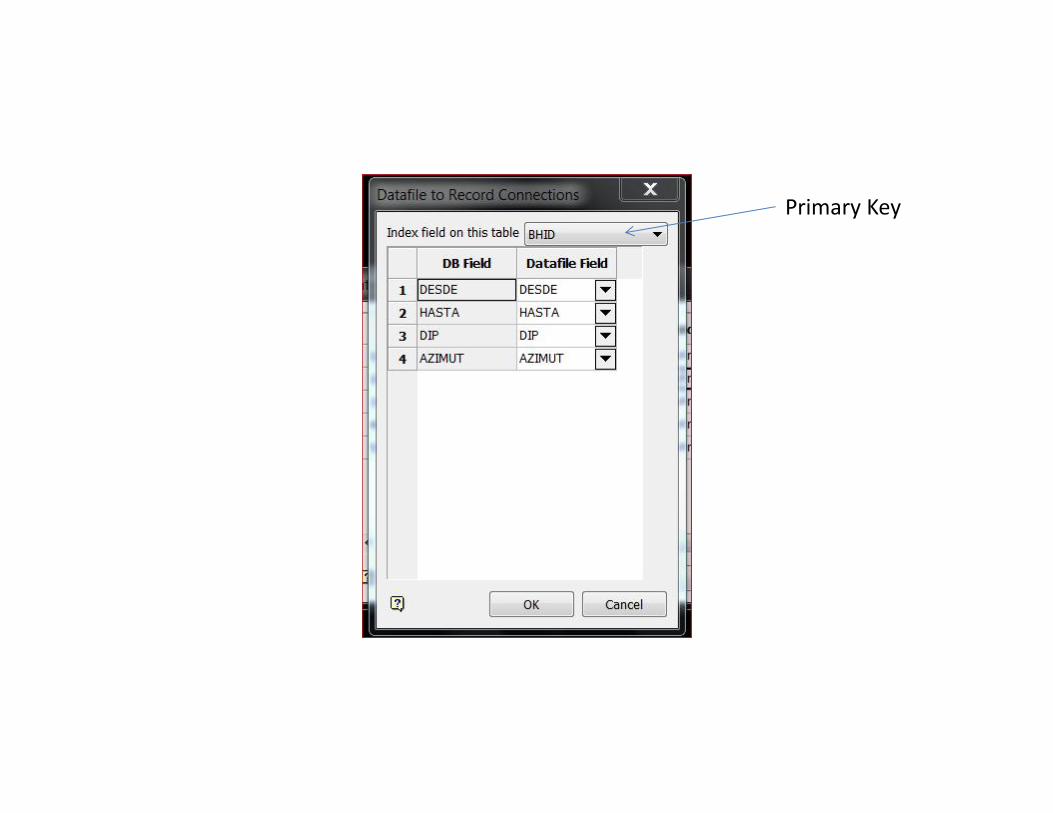
Primary Key

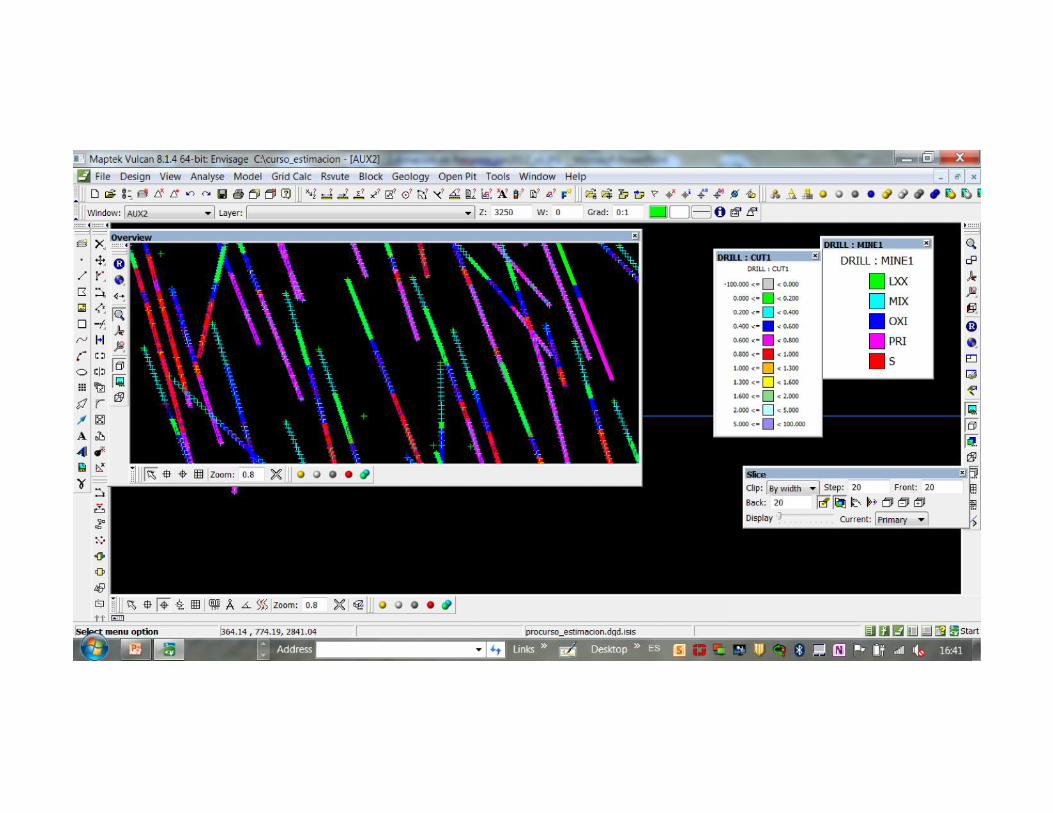
Ventana auxiliar
• Permite cambiar los dimensiones de vista paraver datos de otro proyecto en distinto lugar

colores

Break by geology
• No sirve mucho para regularizar• Straigth usa assay

DB SCRIPT• IF (CONDITION) THEN}• VAR2=X• ENDIF
• IF (CONDITION) THEN• VAR2=X• ELSE• VAR2=Y• ENDIF

Ejercicio
• Hacer dsf• Importar• Ventana auxiliar• Leyenda de colores “MINE” y “CUT”• Desplegar sondajes en pantalla• Compositar RUNLENGTH 4M• Desplegar BD compósitos RL

• Sobre 95% en la bd debe estar para serregularizado. En el ejemplo solo el 72% lo esta(2M) por tanto hay que compositar RL (2m)

• Advanced statistics, en Envisage aproxima yaque no tiene decimales en los gráficos
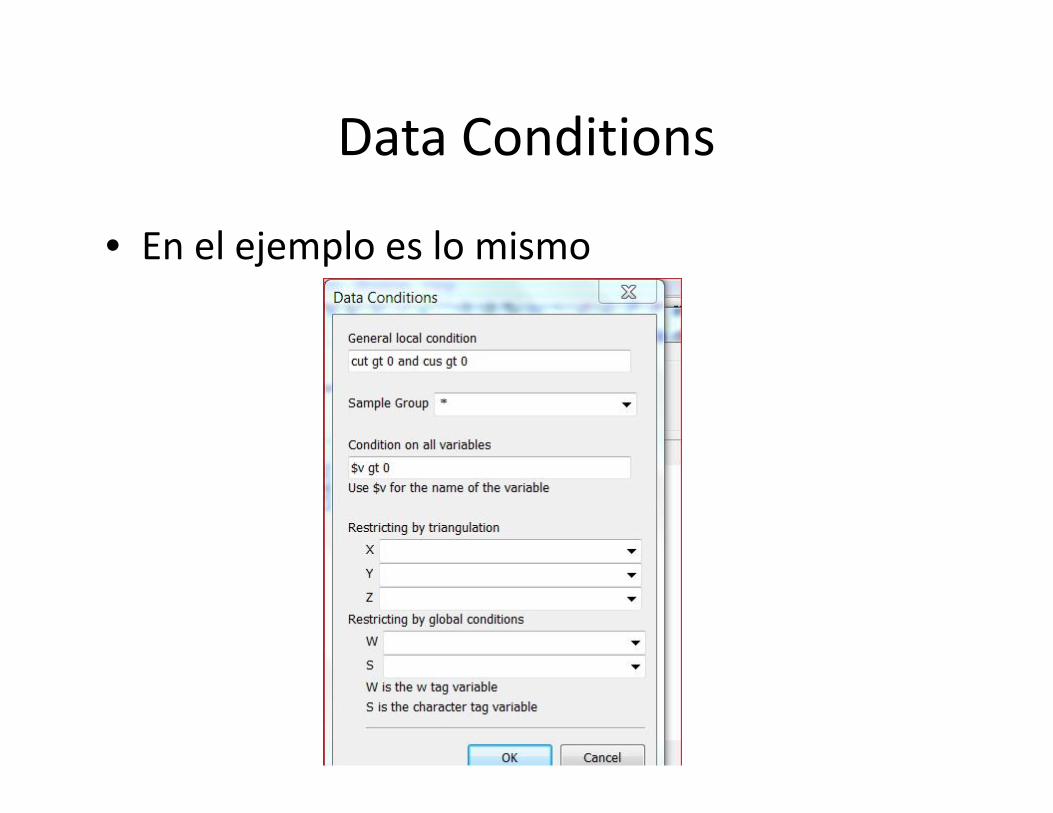
Data Conditions
• En el ejemplo es lo mismo

ZM
• 0:LIX• 1: OX• 2: SULF SEC• 3:MIXTOS• 4:SULF PRIMARIOS

EDA
• Encuentra la interpolación, es decir, que los datosestos tiendan a una media (Condiciones deEstacionaridad).
• Condiciones de Estacionaridad: tender a unaúnica media y minimizar la varianza. Esto se debehacer por cada unidad independiente.
• Boxplot para ver que se puede juntar en base alas medias
• Log normal (Prob P)define poblaciones (rectitud)en las unidades

pp
• Elegir escala• Design_transformatoin update

LOG NORMAL FINAL
1%

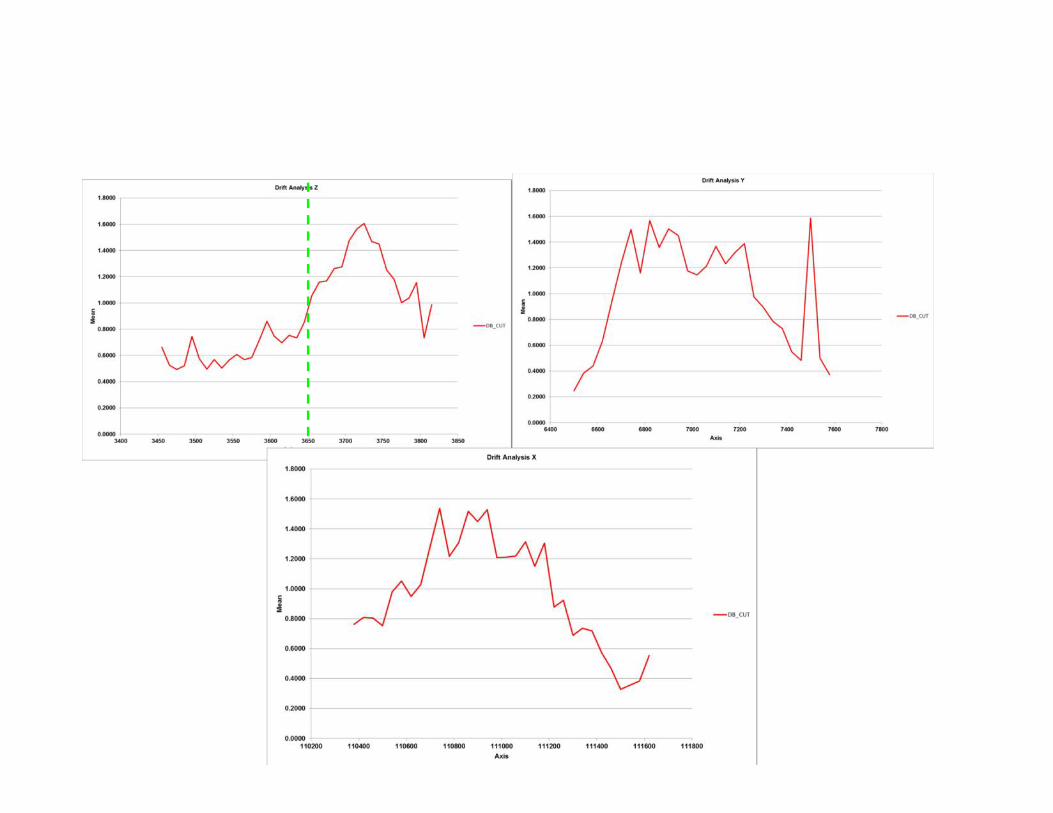
• A modo de introducción al análisis de derivacorresponde a una estadística espacial(tendencia) donde se ve la configuración de lasmuestras en el espacio, en las 3 direcciones (x, y,z). Archivo de especificación *.dpf
• Existe 2 tendencias claras en la cota 3650. Segenerará 2 UG (sobre= cota 3650,UG=21y bajocota 3650, UG=20)
• Agregamos variable UG en el diseño (Entry) de loscompósitos
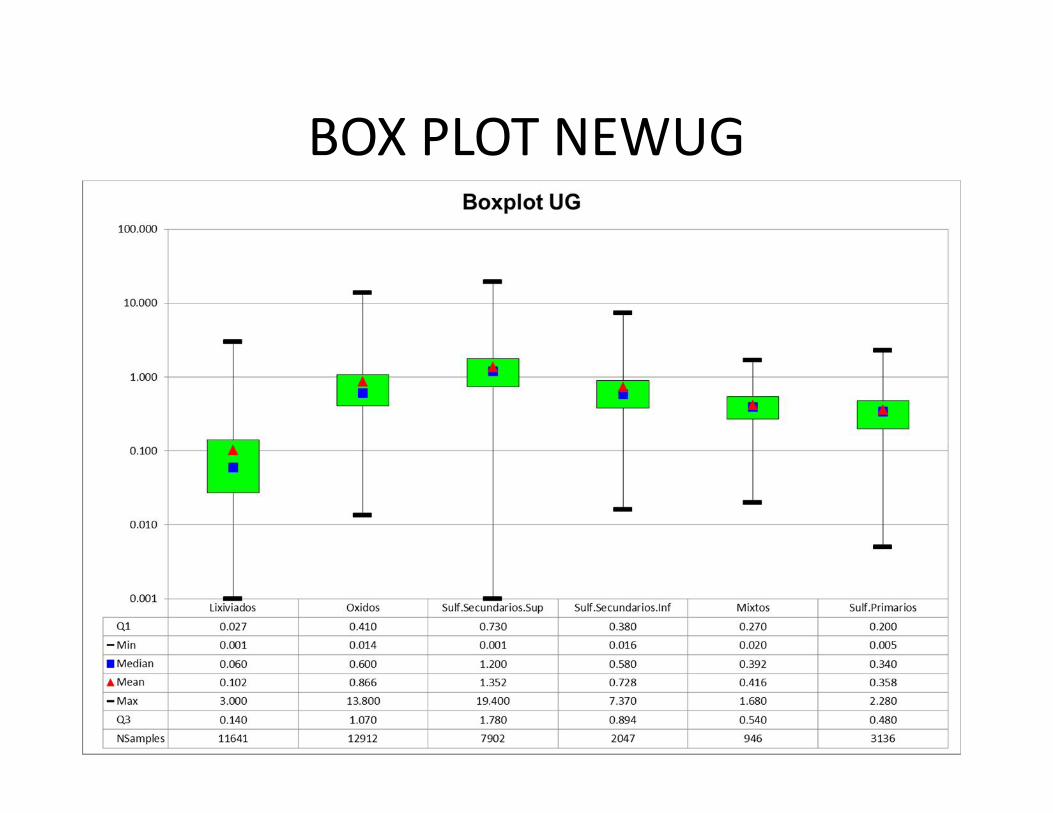
BOX PLOT NEWUG
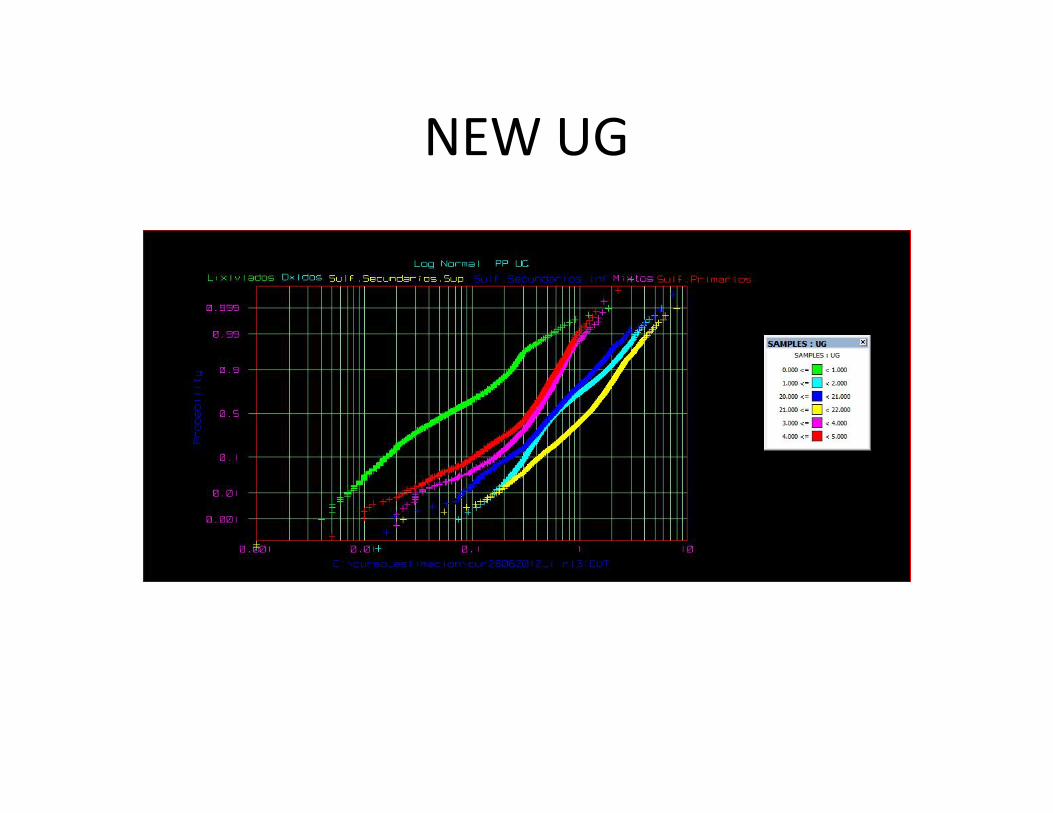
NEW UG
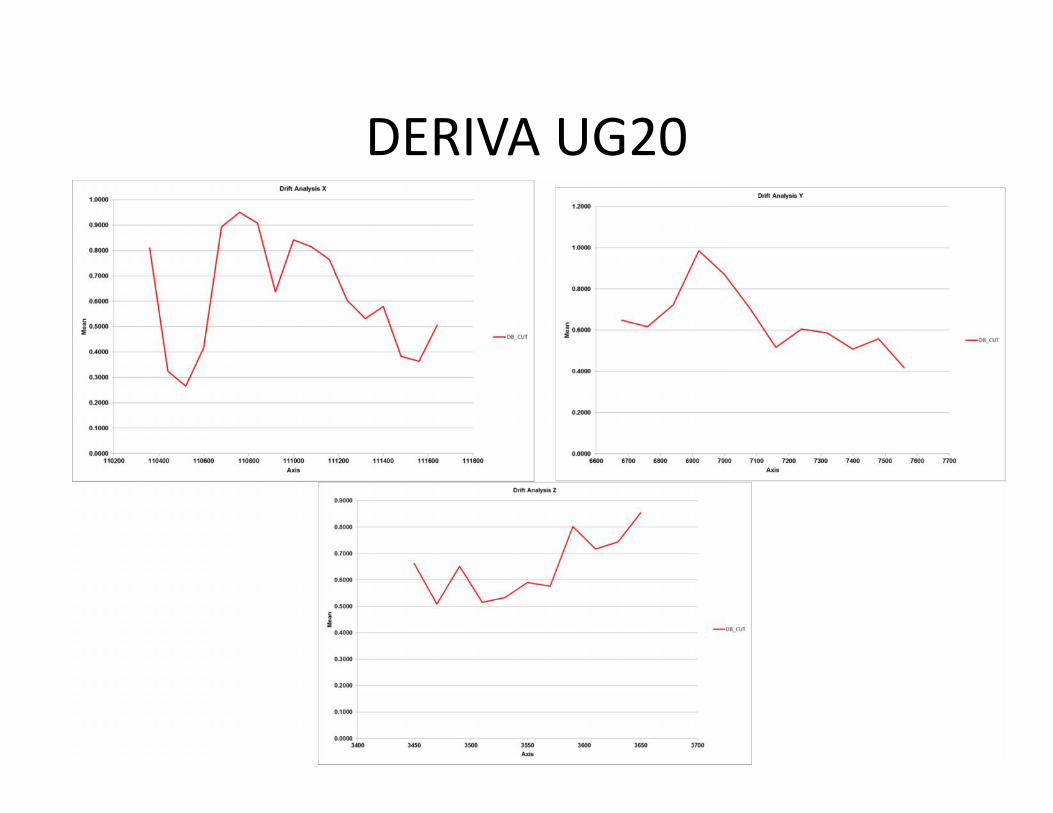
DERIVA UG20

DERIVA UG21

Tarea: hacer lo mismo para las demásUG (eda)

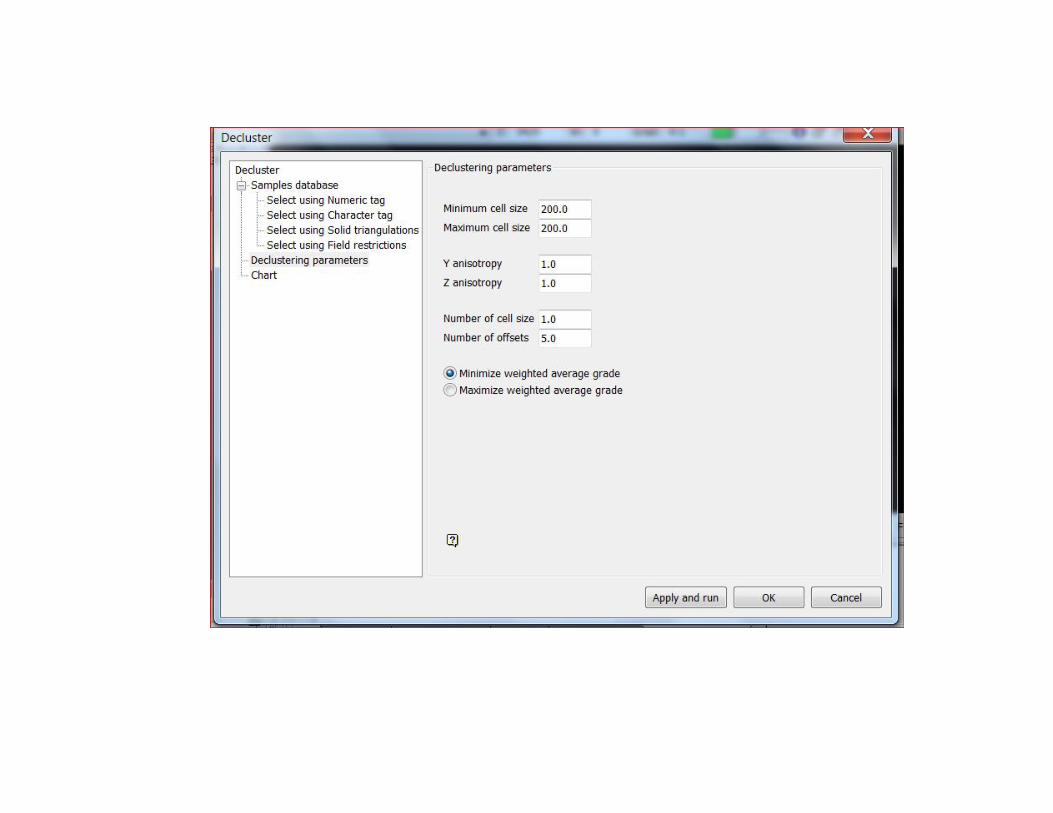
DESAGRUPAMIENTO ó DESCLUTERIZACIÓN(geology/sampling/cell decluster)
• Aglomeración de mayor información en zonas de alta ley. Meconviene desagrupar? Hay que conocer cual fue la orientación delas campañas de sondajes.
• La idea es repartir le peso de las muestras con el fin de obtener unpromedio en la configuración del espacio de las muestras.
• Métodos:– Polígonos: (lados en los puntos medio del distancia entre c/ muestra,
muestras mas alejadas tienen mayor área por lo tanto mayor peso que lasmas cercanas)
– Celdas: método iterativo y la idea es encontrar el tamaño de celdaadecuado que hace que la ley media sea la menor. Este método es elutilizado por Vulcan. (Peso Celda=N° Muestras/N° Celdas; PesoMuestra=Peso c/ celda/ N° muestras en la celda)
• Con kriging no es necesario declusterización, pero si se podríaconsiderar par ID^n si hay información efectivamente agrupada
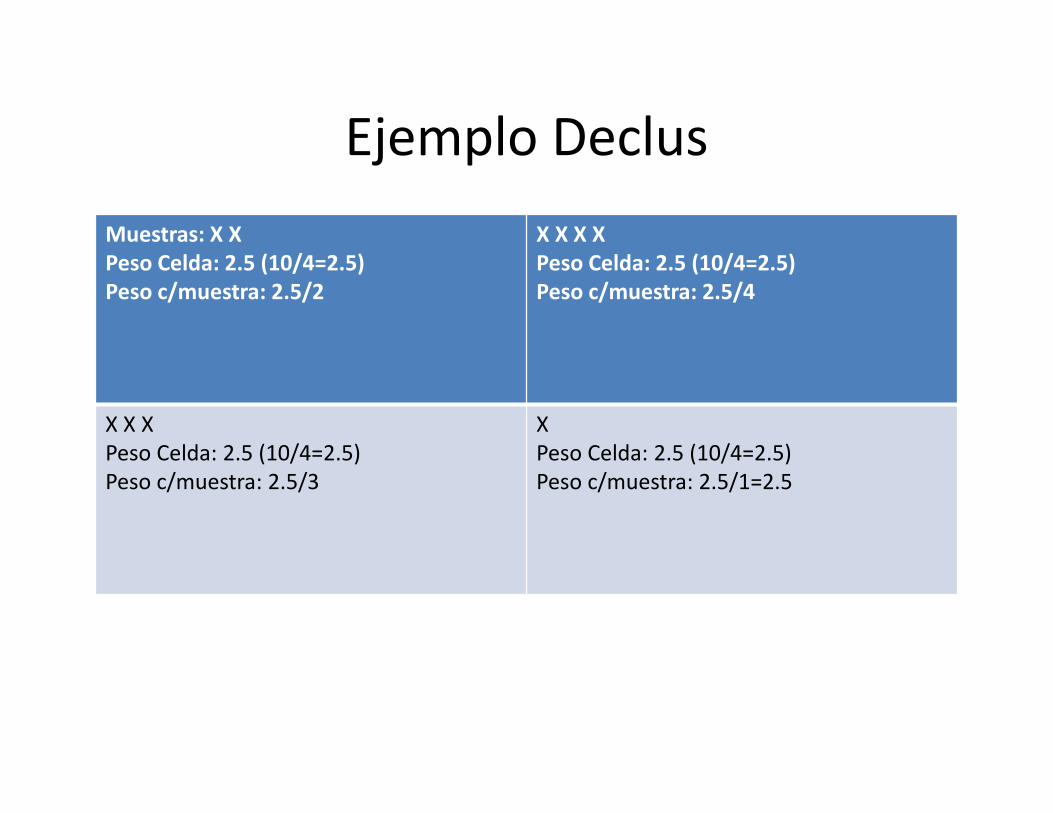
Ejemplo DeclusMuestras: X XPeso Celda: 2.5 (10/4=2.5)Peso c/muestra: 2.5/2
X X X XPeso Celda: 2.5 (10/4=2.5)Peso c/muestra: 2.5/4
X X XPeso Celda: 2.5 (10/4=2.5)Peso c/muestra: 2.5/3
XPeso Celda: 2.5 (10/4=2.5)Peso c/muestra: 2.5/1=2.5
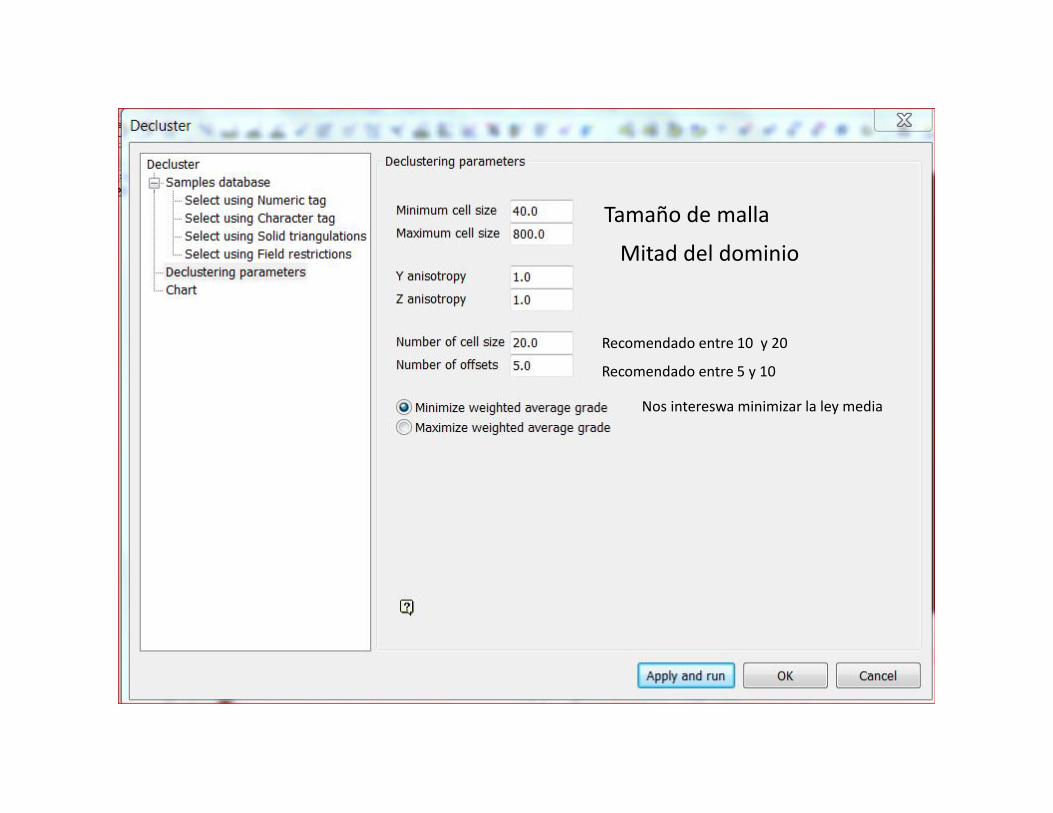
Tamaño de malla
Mitad del dominio
Recomendado entre 5 y 10
Recomendado entre 10 y 20
Nos intereswa minimizar la ley media
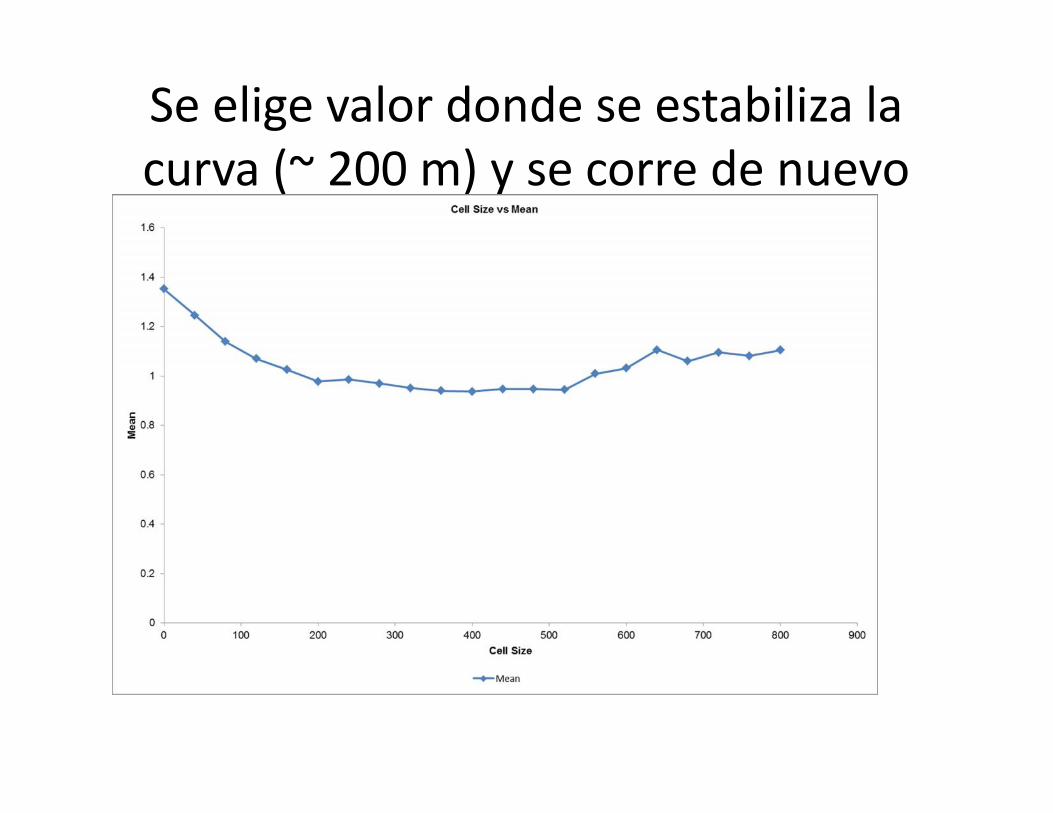
Se elige valor donde se estabiliza lacurva (~ 200 m) y se corre de nuevo
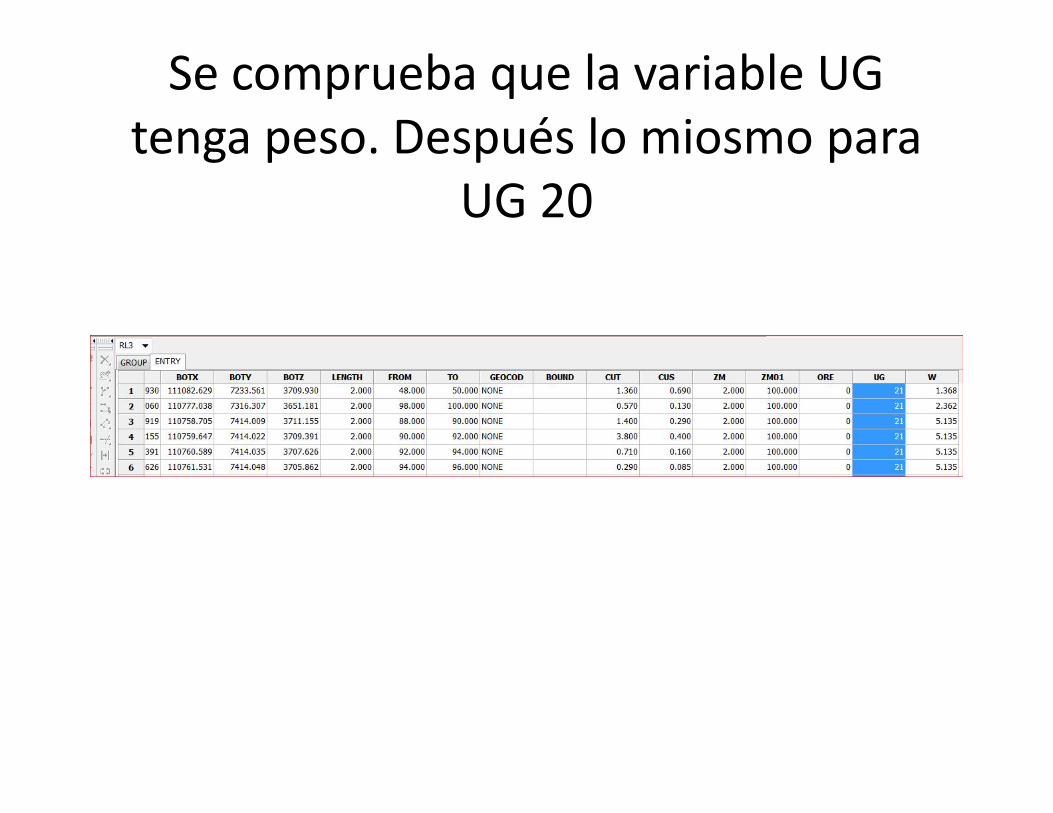
Se comprueba que la variable UGtenga peso. Después lo miosmo para
UG 20
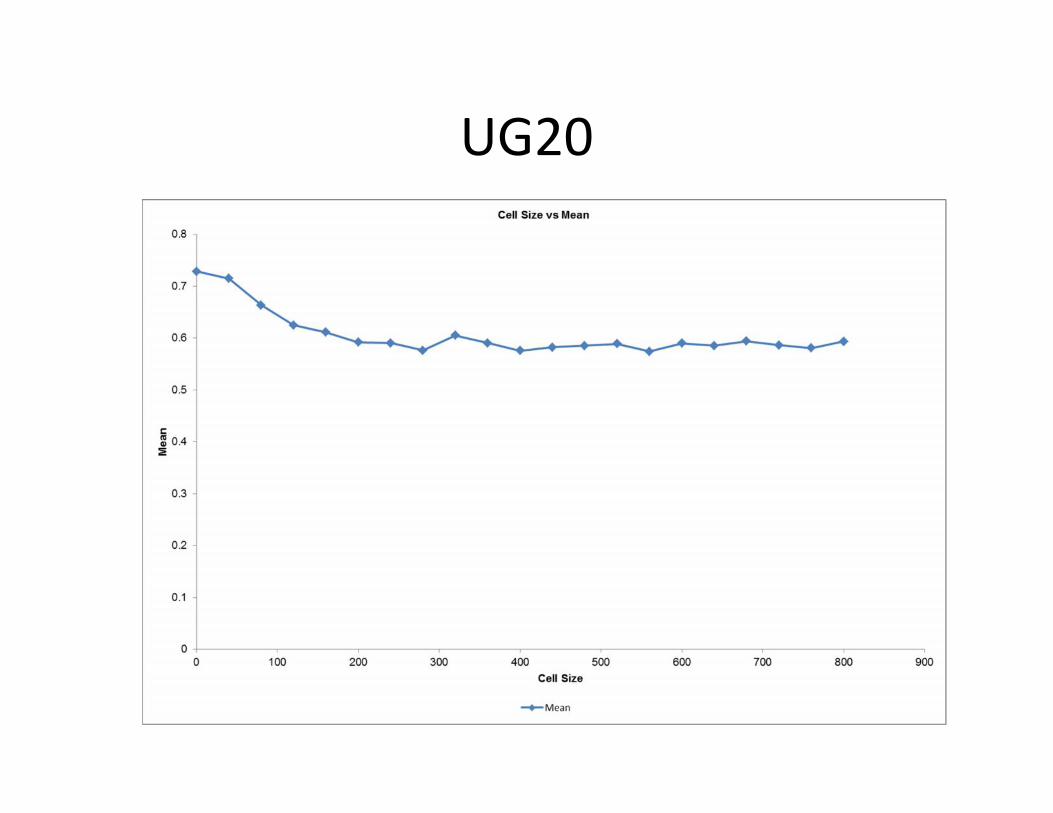
UG20
UG20
Box Plot para UG 20 y 21
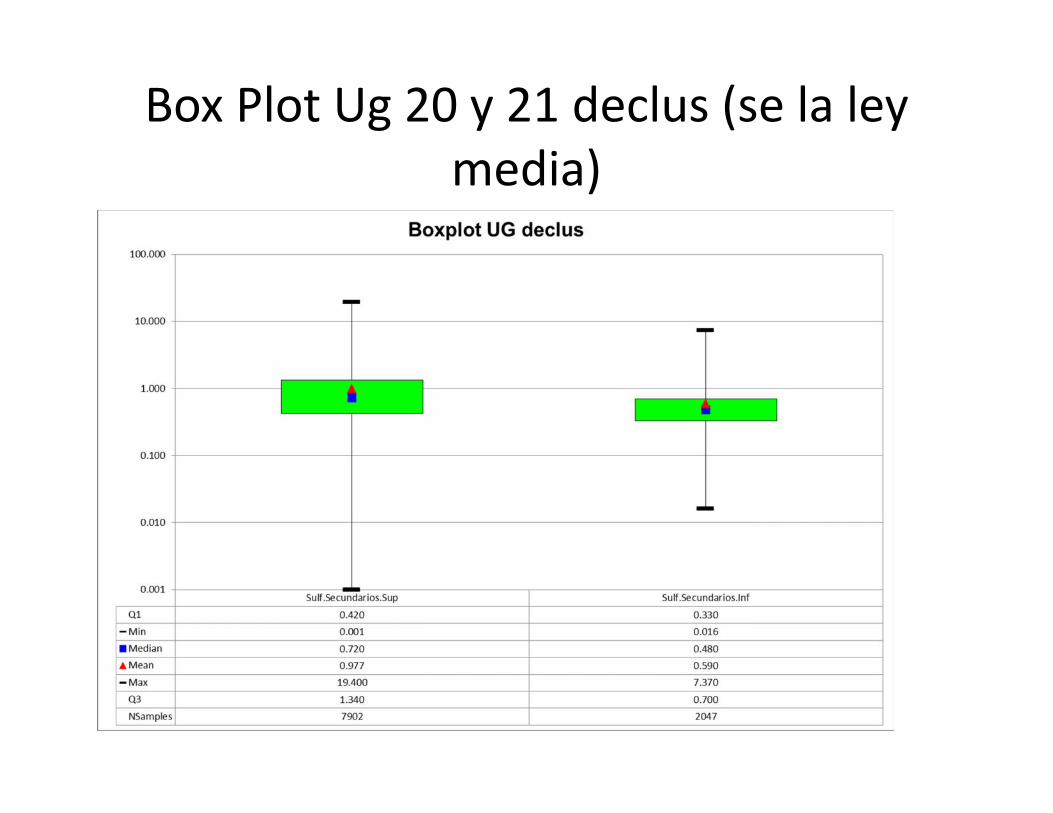
Box Plot Ug 20 y 21 declus (se la leymedia)
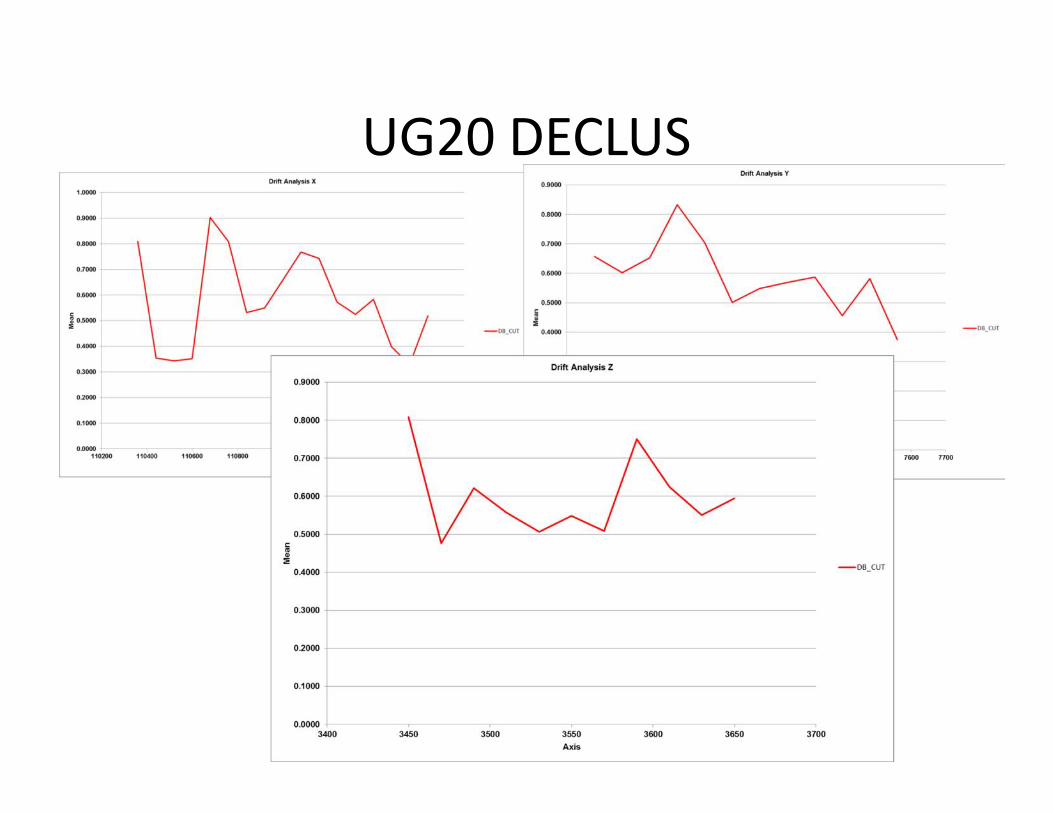
UG20 DECLUS

Analisis de Contacto
• Es cuando existe un transición de leyes de unaunidad a otra. Esta transición se manifiesta auna distancia X. Esta transición, puede sersuave o brusca (contacto duro), en esta últimano habría transición de leyes.
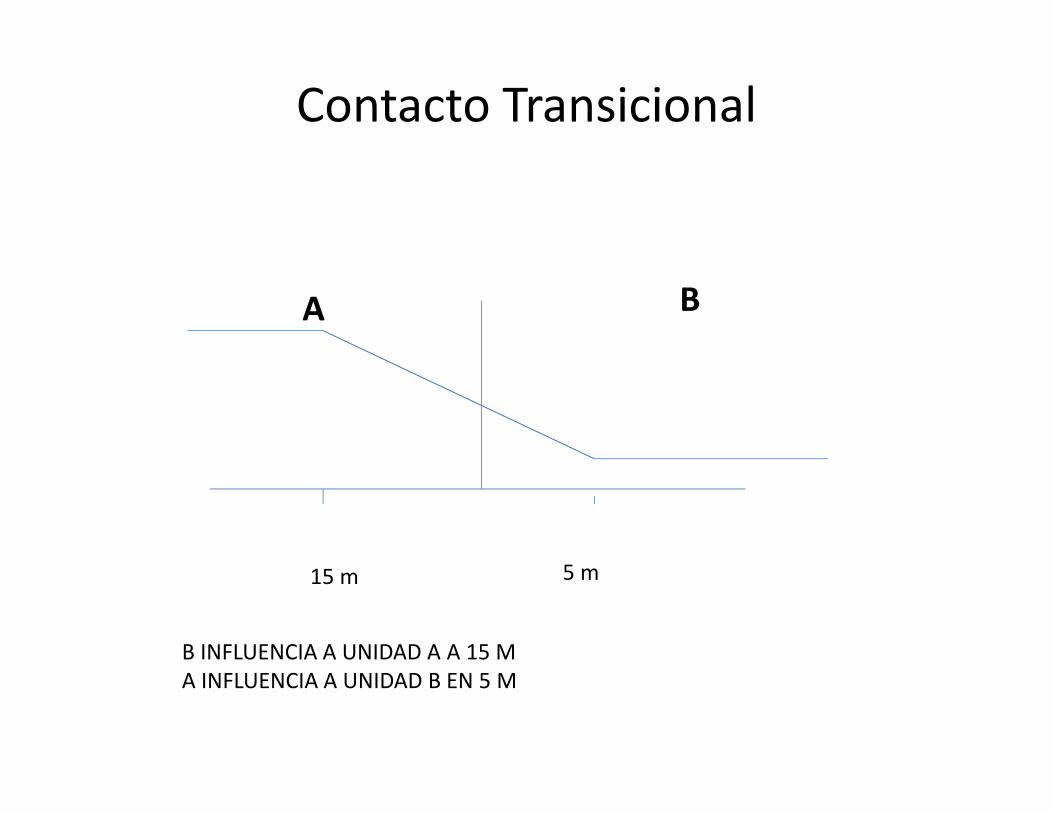
Contacto Transicional
15 m 5 m
A B
B INFLUENCIA A UNIDAD A A 15 MA INFLUENCIA A UNIDAD B EN 5 M
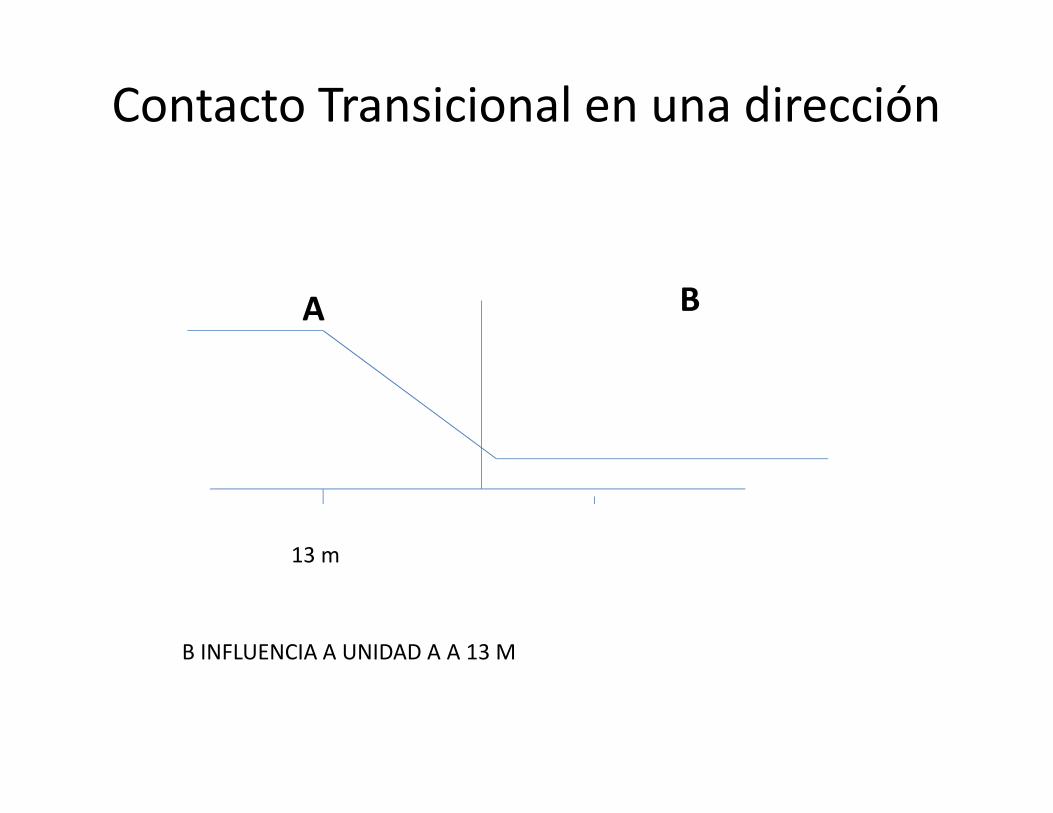
Contacto Transicional en una dirección
13 m
A B
B INFLUENCIA A UNIDAD A A 13 M

Variografía• Primero ver ordenar de menor a mayor• Insertar 2 columnas en excel del prob plot para ver valores escapados
(como criterio se puede optar en diferencias sobre 10%, se consideracomo último valor para usar en el variograma)

Capping
• UG0=• UG1=• UG2=• UG

VARIOGRAFÍA
• Promedio sumatoria de diferencias. Si nosotrosvisualizamos el gráfico nos tenemos que dar cuenta dela tendencia de los datos donde la variabilidad va a sermenor entre los datos mas cercanos entre si y mayorentre los datos mas alejados entre sí.
• El efecto pepita es una sumatoria de variabilidades.Entre ellas el error de muestreo.
• Los datos escapados aumentan significativamente lavariabilidad en el variograma.
• En resumen cuando se habla de correlación se estahablando de lo contrario a variabilidad.

VARIOGRAMA
S2=sillN=efecto pepitaA=alcanceH=pasoN=n° pares de datosX=ley
(h)=1/2n∑(Xi-Xj)^2i [1,n]

• Mas alta la pepa se alcanza mas rápido elalcance por tanto implica mayor variabilidad
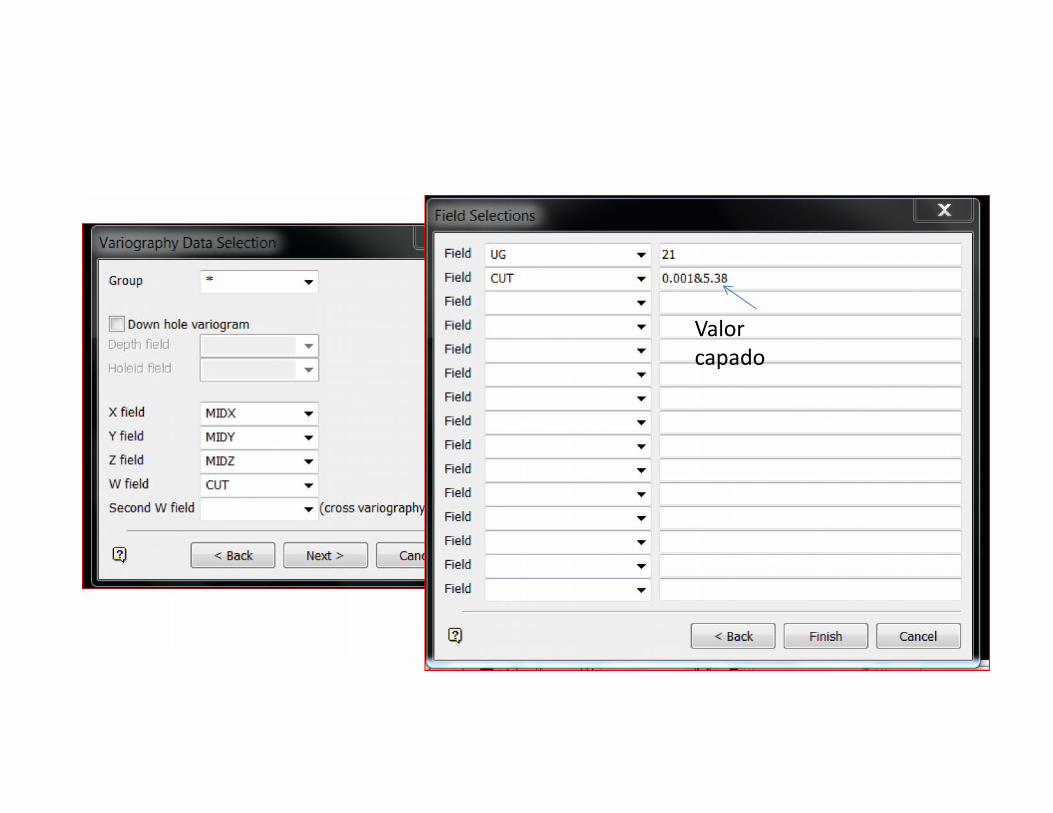
Valorcapado
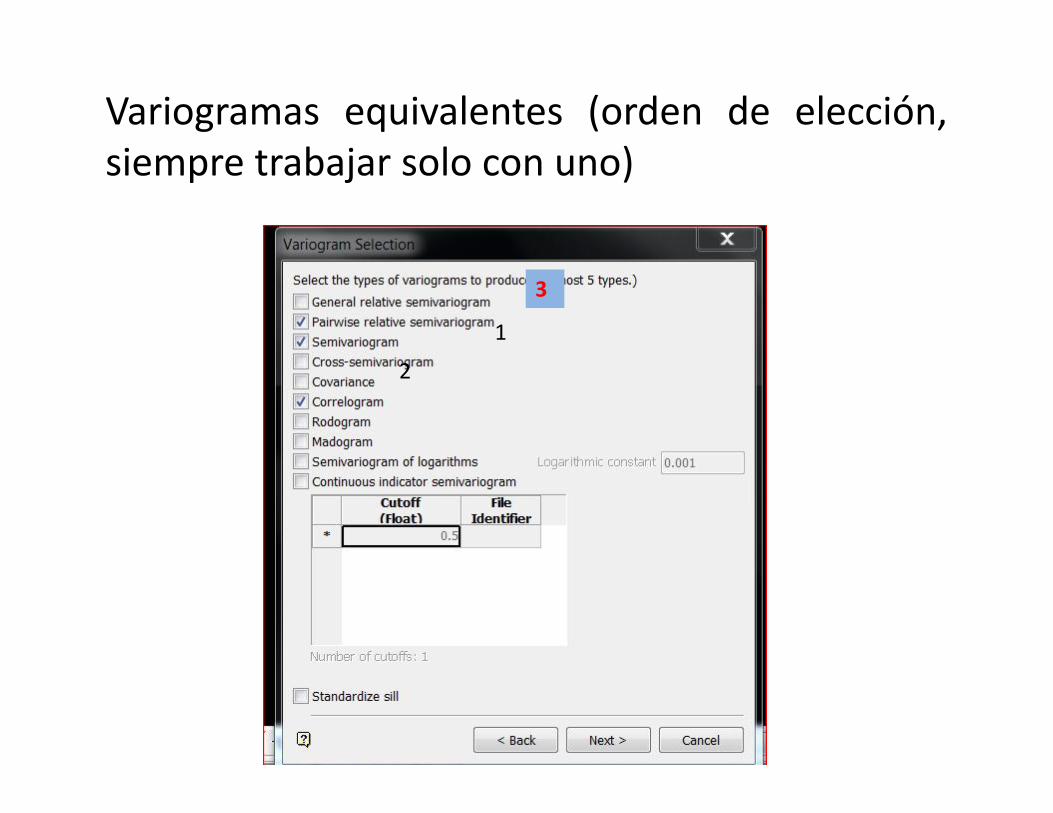
Variogramas equivalentes (orden de elección,siempre trabajar solo con uno)
1
2
3
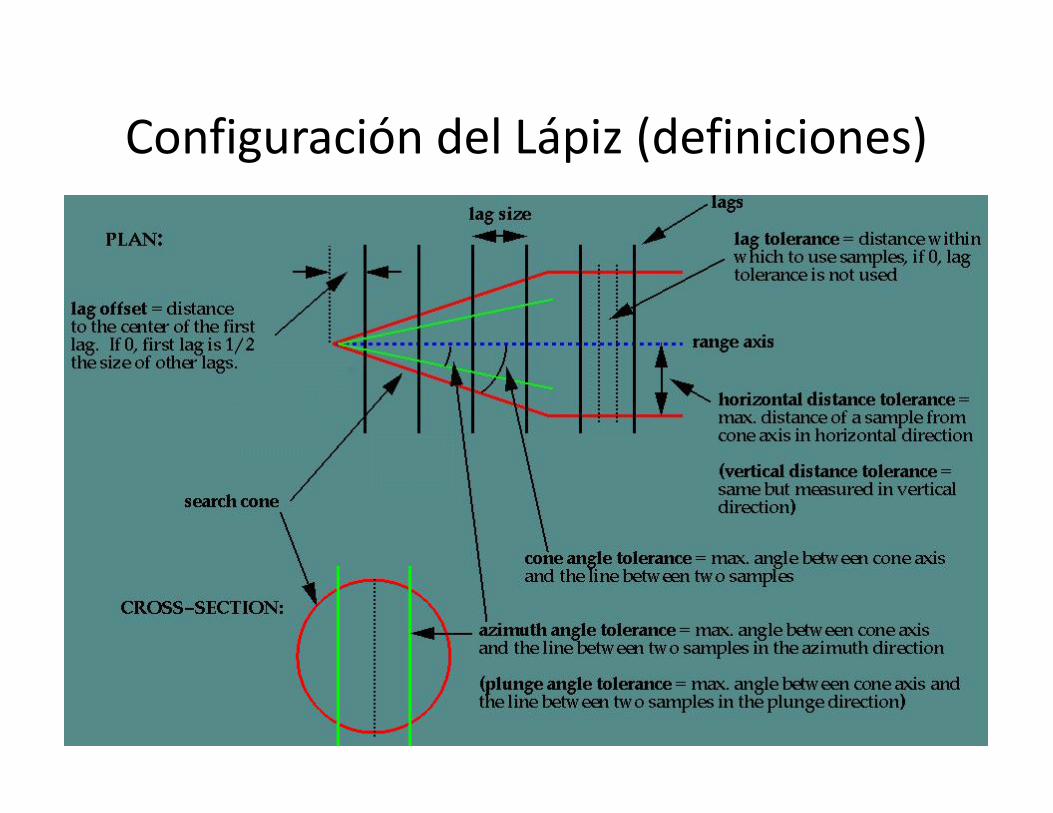
Configuración del Lápiz (definiciones)

Configuración del Lápiz (no hay regla)
• Búsqueda paso o h (lag)• Lag tolerance =lag/2• Lag offset (solo para el punto inicial): entre
origen y primera búsqueda
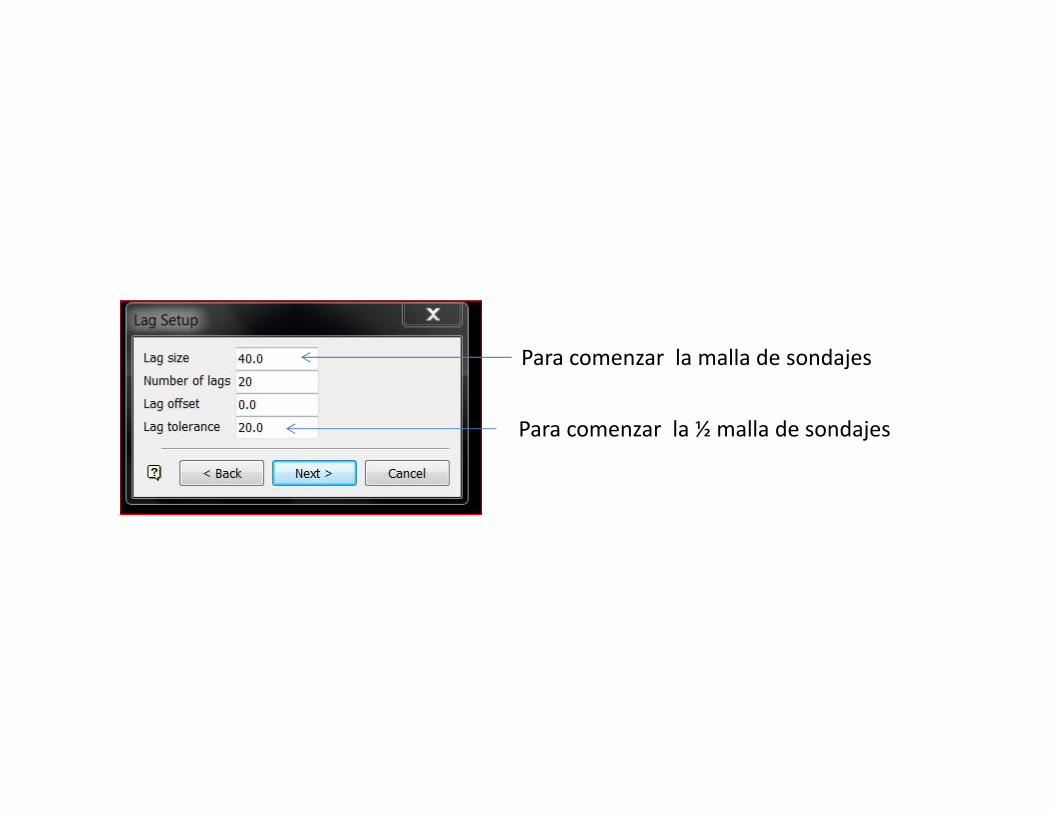
Para comenzar la malla de sondajes
Para comenzar la ½ malla de sondajes
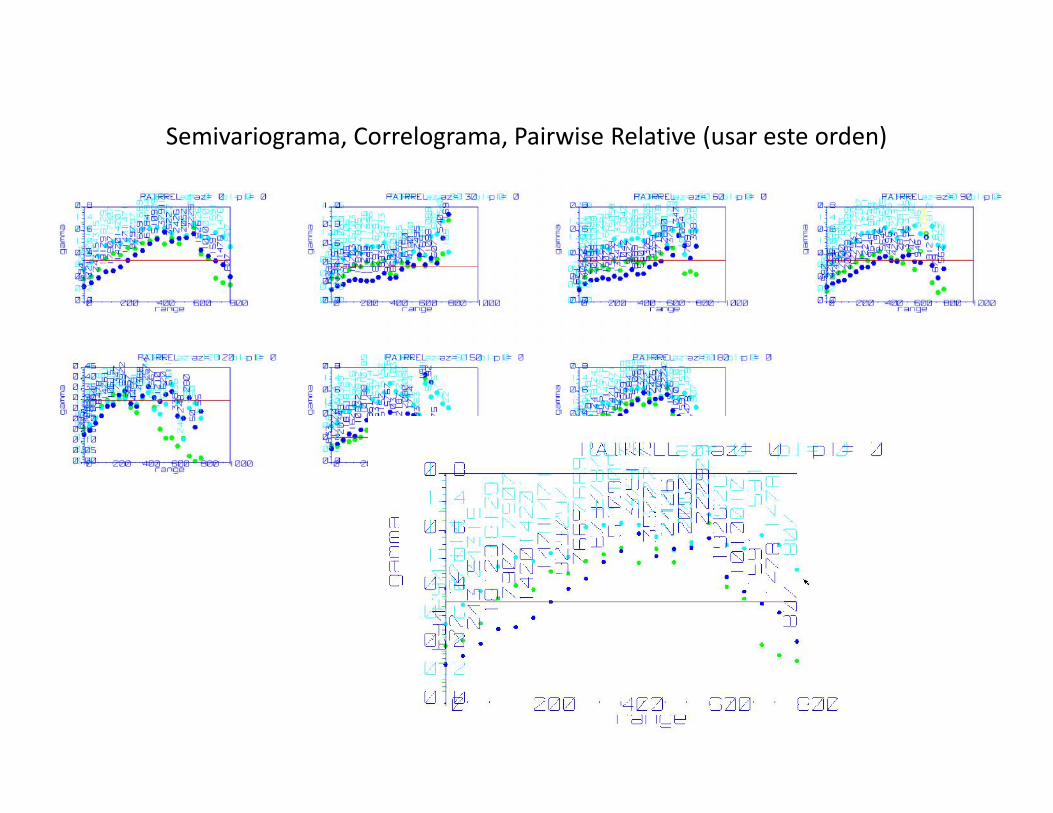
Semivariograma, Correlograma, Pairwise Relative (usar este orden)

VARIOGASRAMA DTH• Vulcan ofrece entregar un único variograma
pero dentro del sondajes independiente de sutrayectoria. El paso en este caso va a ser eltamaño de soporte. Este es mejor variogramaque podríamos obtener, pero es una soladirección por lo que solamente se utiliza paraobtener el Efecto Pepita. Con pozos detronadora se debería utilizar el variogramaomnidireccional.
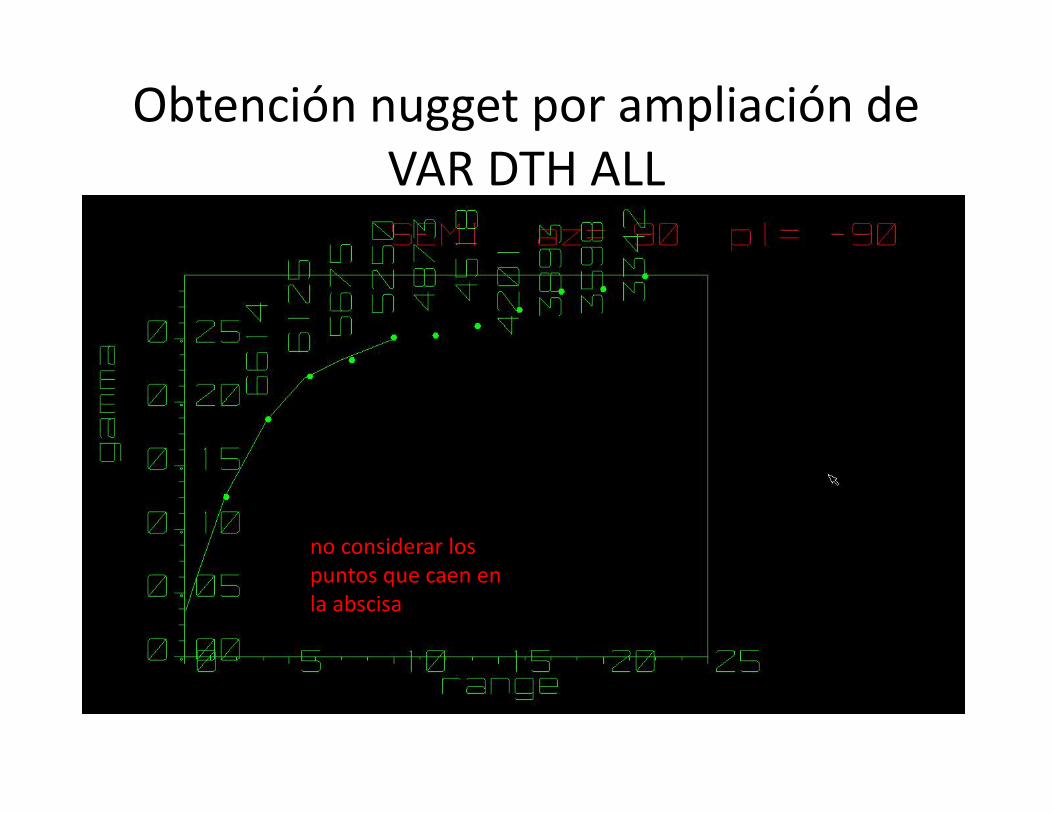
Obtención nugget por ampliación deVAR DTH ALL
• Efecto Pepita UG21= 0.038
no considerar lospuntos que caen enla abscisa

• Efecto pepita 20 a 30 % de la meseta esrazonable (dependiendo del yacimiento)

Tarea dth y omni para ug20
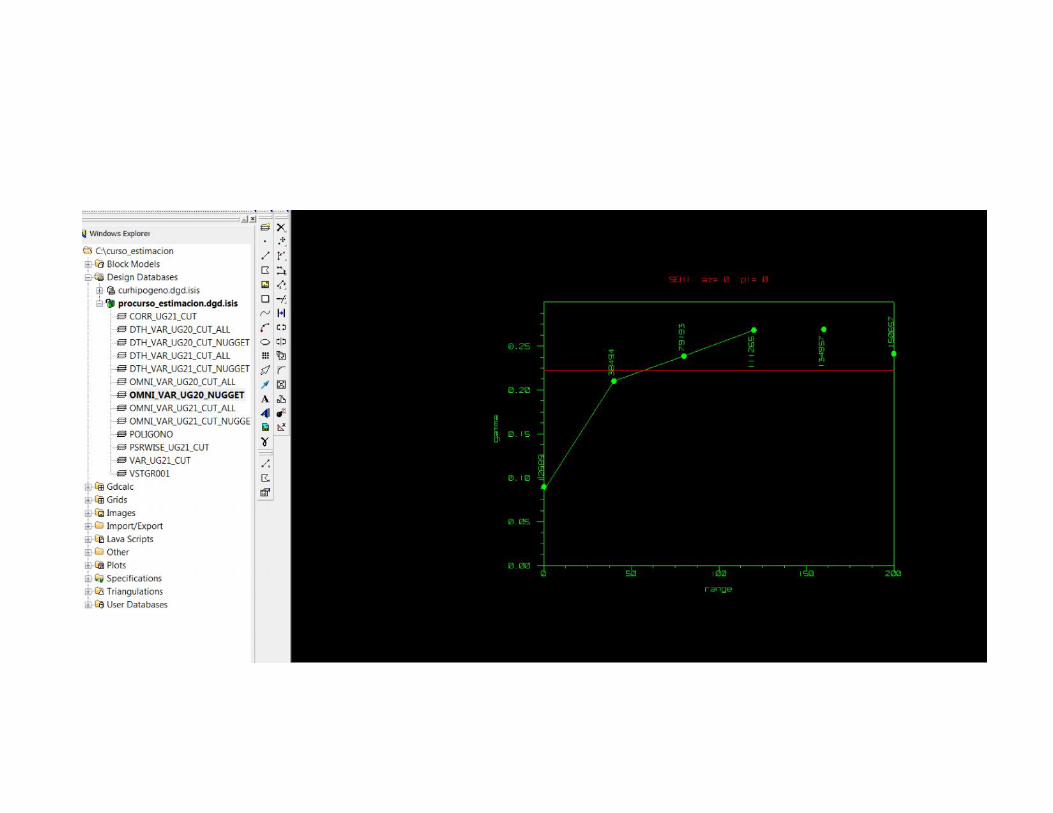

MAPA VARIOGRÁFICO• Es un mapa de isovalores donde observamos como se comporta la
correlación de los datos en un plano o planta. Despliega el valor queentrega el variograma en las distintas direcciones. P.e. en el caso deuna veta lo recomendables sería orientar el variograma a lo largo dela corrida ya que ahí donde se podría encontrar la mayorcorrelación. En Vulcan se utilizará el modelo de bloques (en ventanaauxiliar) para visualizar estos variogramas donde el centro delModelo de bloques no es el cero sino que va representar el efectopepita. Si esto lo vemos en 3D sería una elipsoide que representaun vector. Este vector, contiene 3 direcciones (o lo forman) ydeterminaremos la dirección del vector en términos de bearing,plunge y dip. Cada UG va a tener distintos vectores dediscontinuidad de leyes.
• Plunge: va por la misma dirección del bearing (mano)• Dip: va oblicuo al bearing (mano)

Rotaciones
Bearing
Plunge
Dip
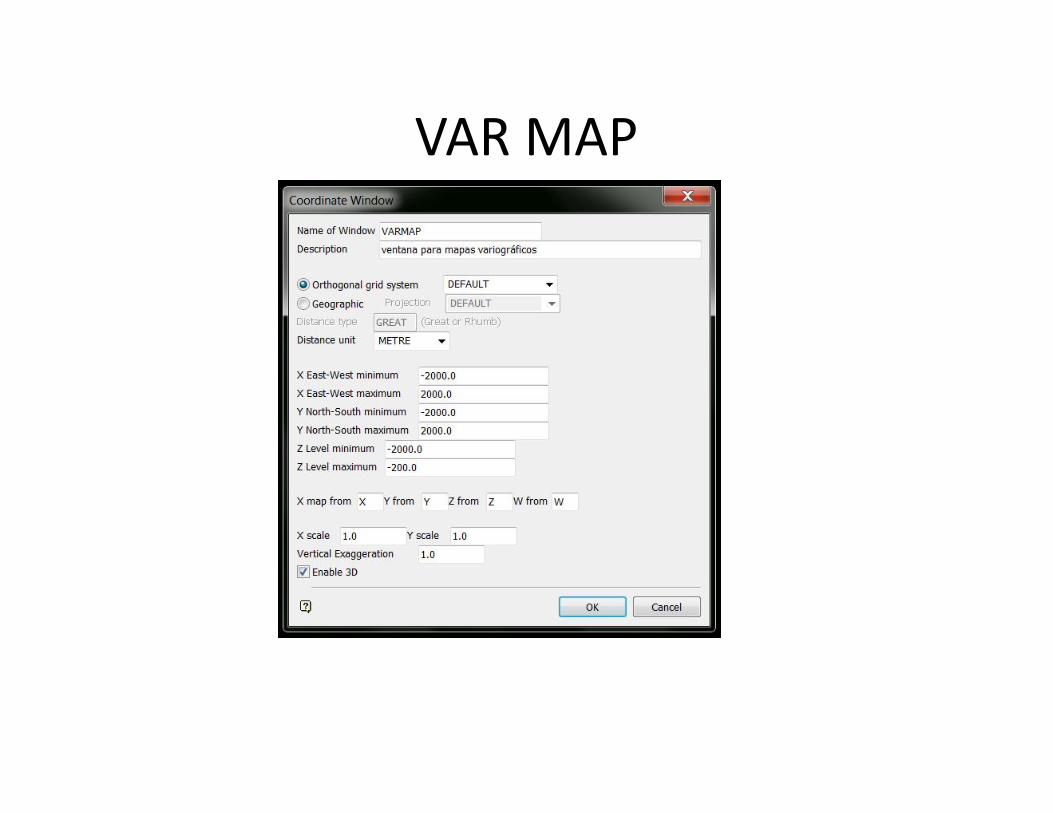
VAR MAP
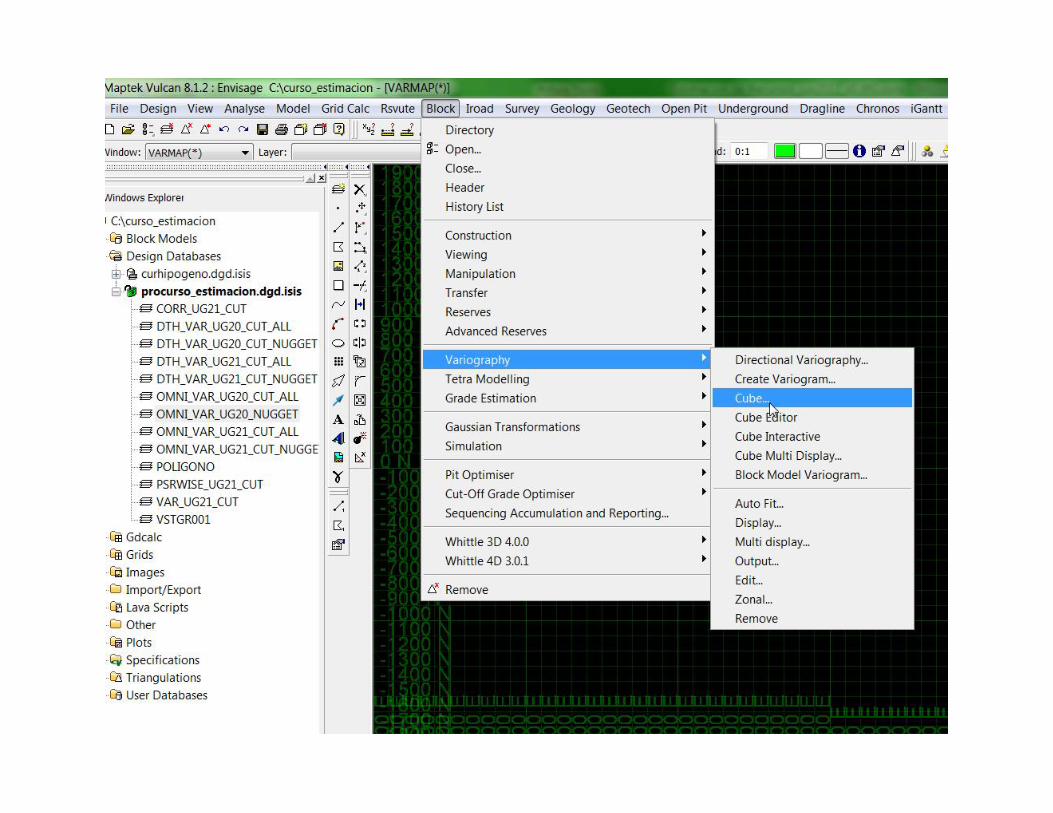
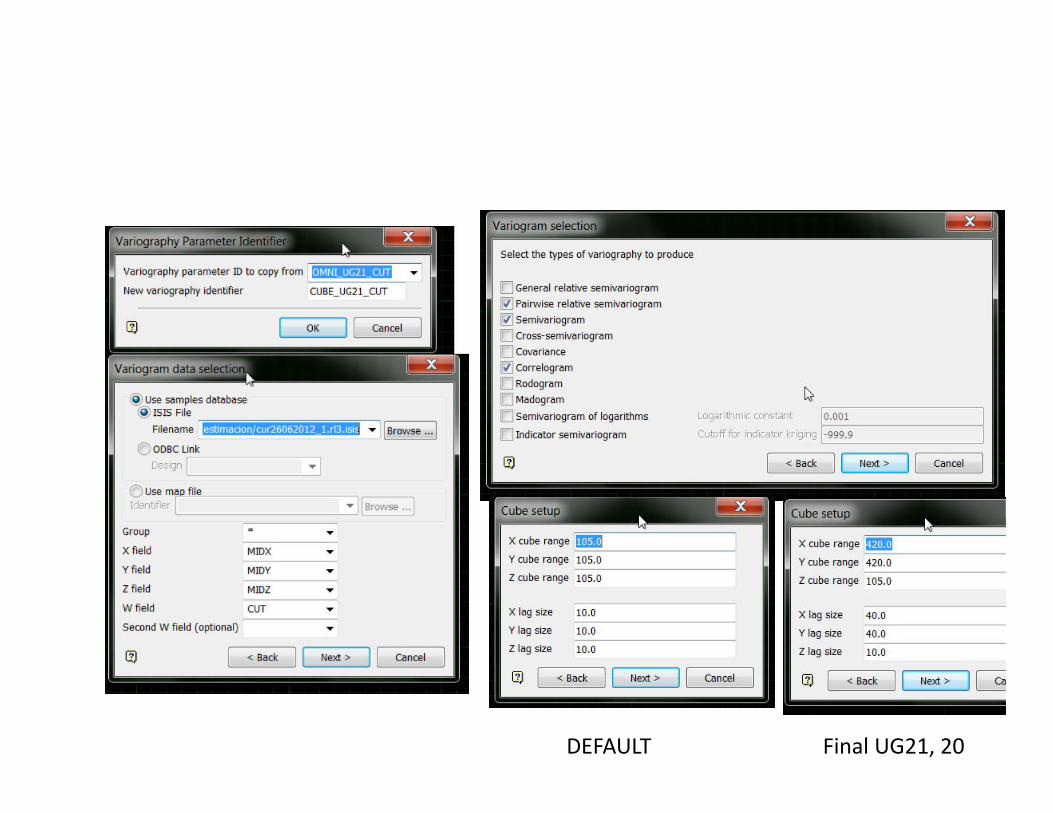
DEFAULT Final UG21, 20
CUBEX
X
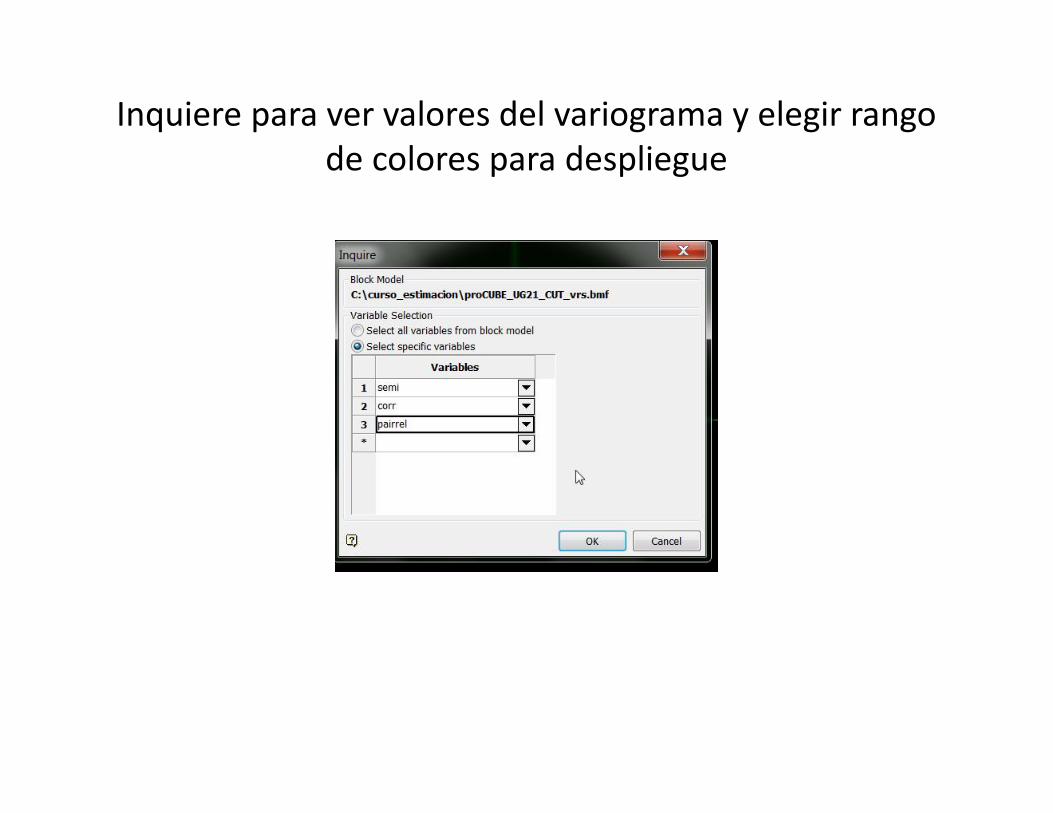
Inquiere para ver valores del variograma y elegir rangode colores para despliegue

ANALIZAR ANISOTRPÍAS

MAPA VARIOGRÁFICO
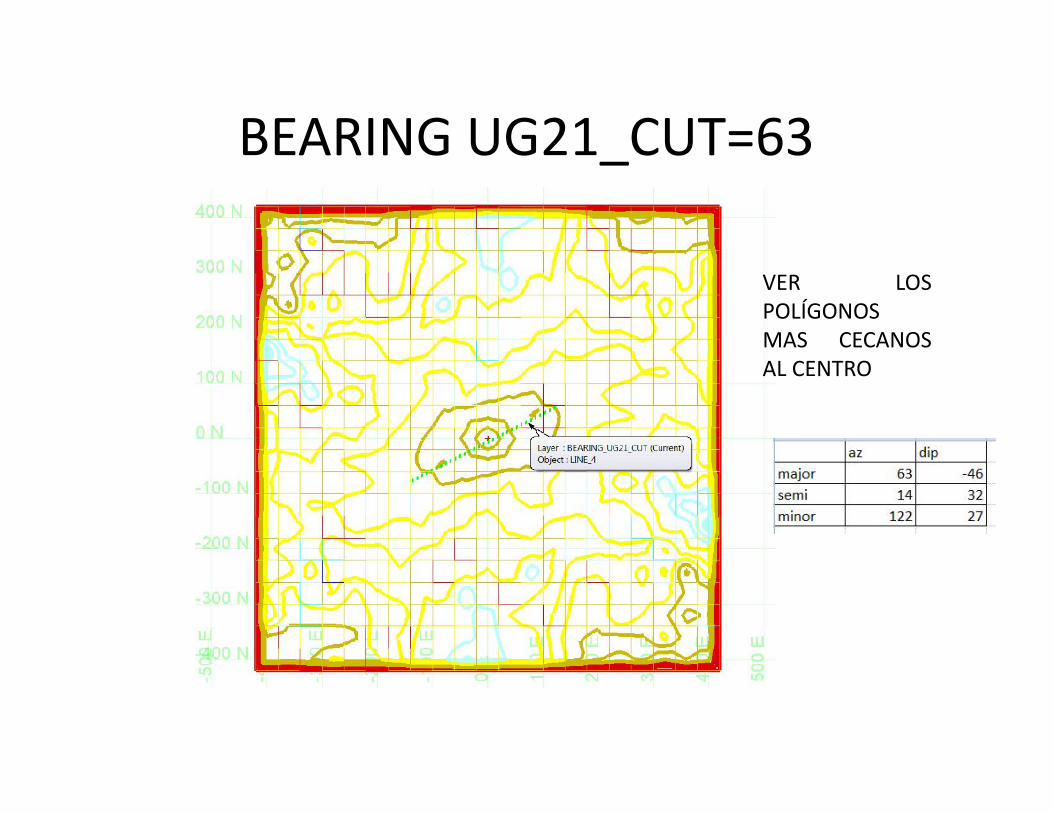
BEARING UG21_CUT=63
VER LOSPOLÍGONOSMAS CECANOSAL CENTRO
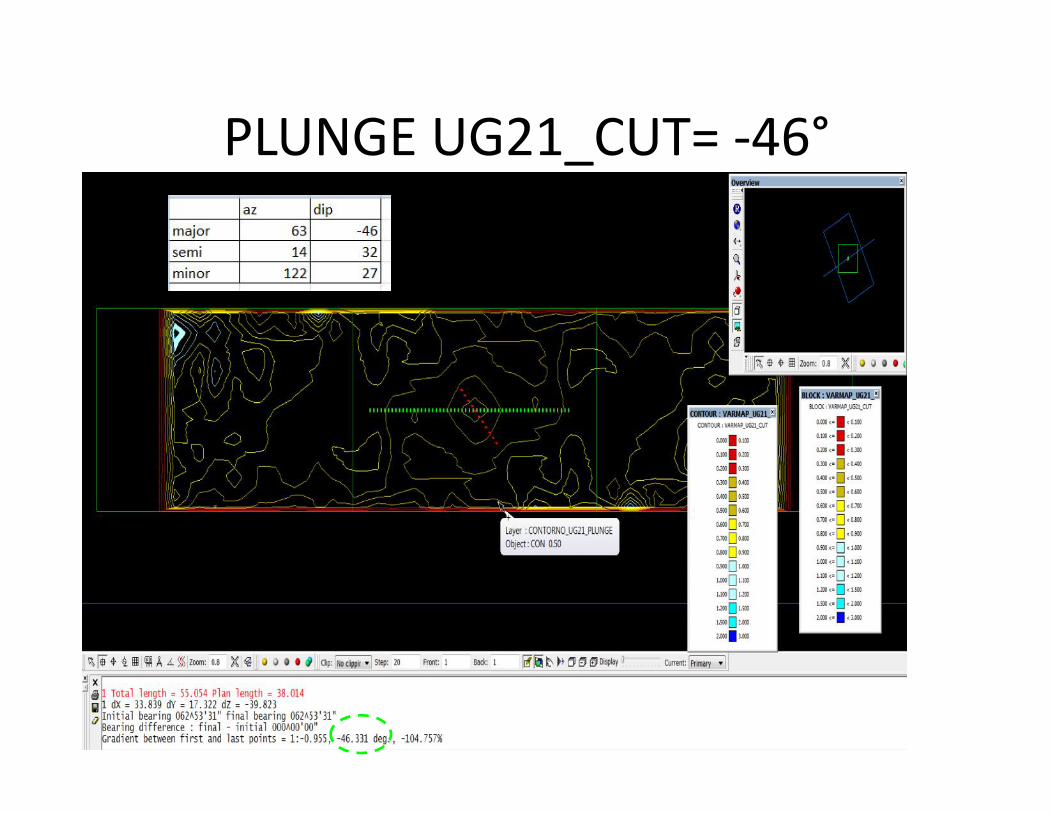
PLUNGE UG21_CUT= -46°

DIP UG21_CUT= -50(USE DESIGN/TRANSFORMATION/ROTATE ARBITRARY)

Ejes elipsoide UG 21

Tarea: Mapa variográfico UG20
Bearing: 170°
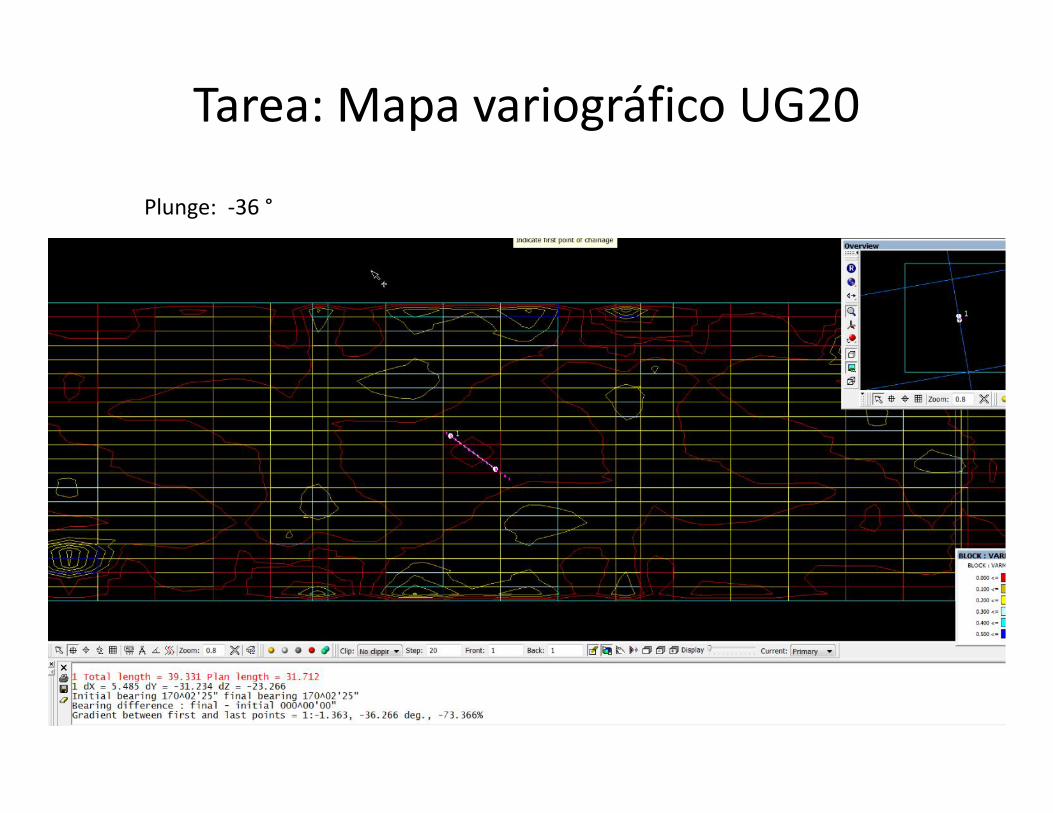
Tarea: Mapa variográfico UG20
Plunge: -36 °

Tarea: Mapa variográfico UG20
Plunge: -36°
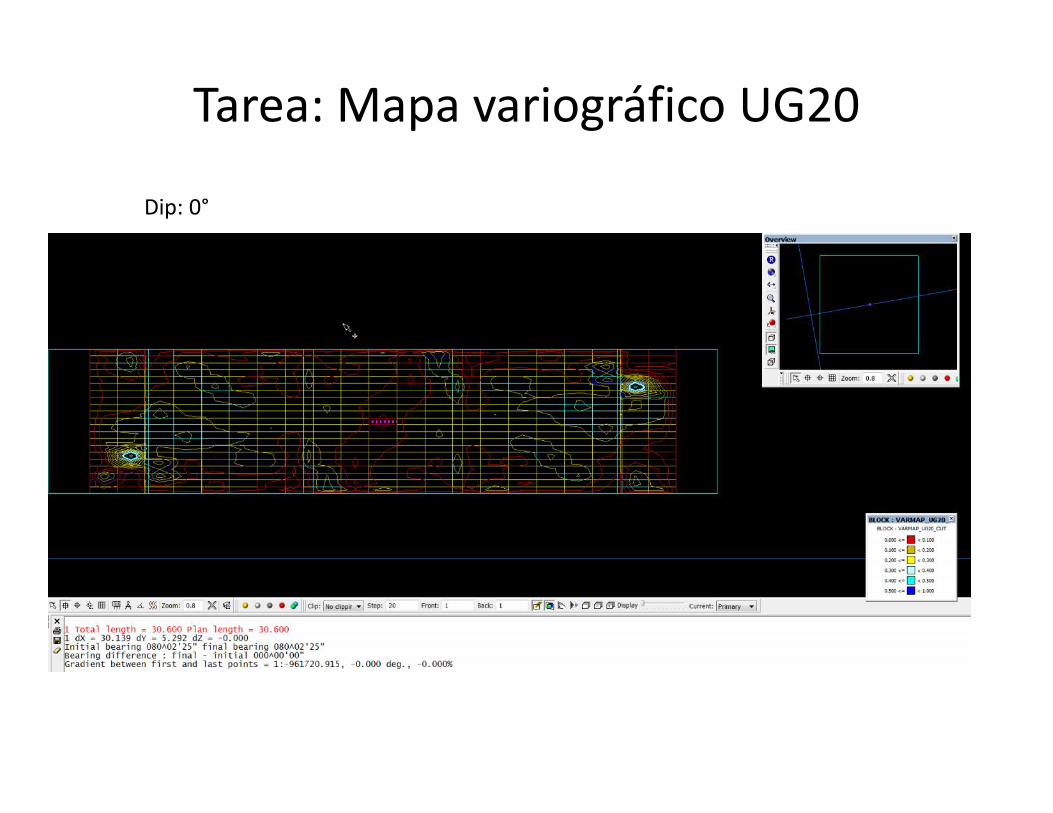
Tarea: Mapa variográfico UG20
Dip: 0°

Ejes elipsoide UG 20
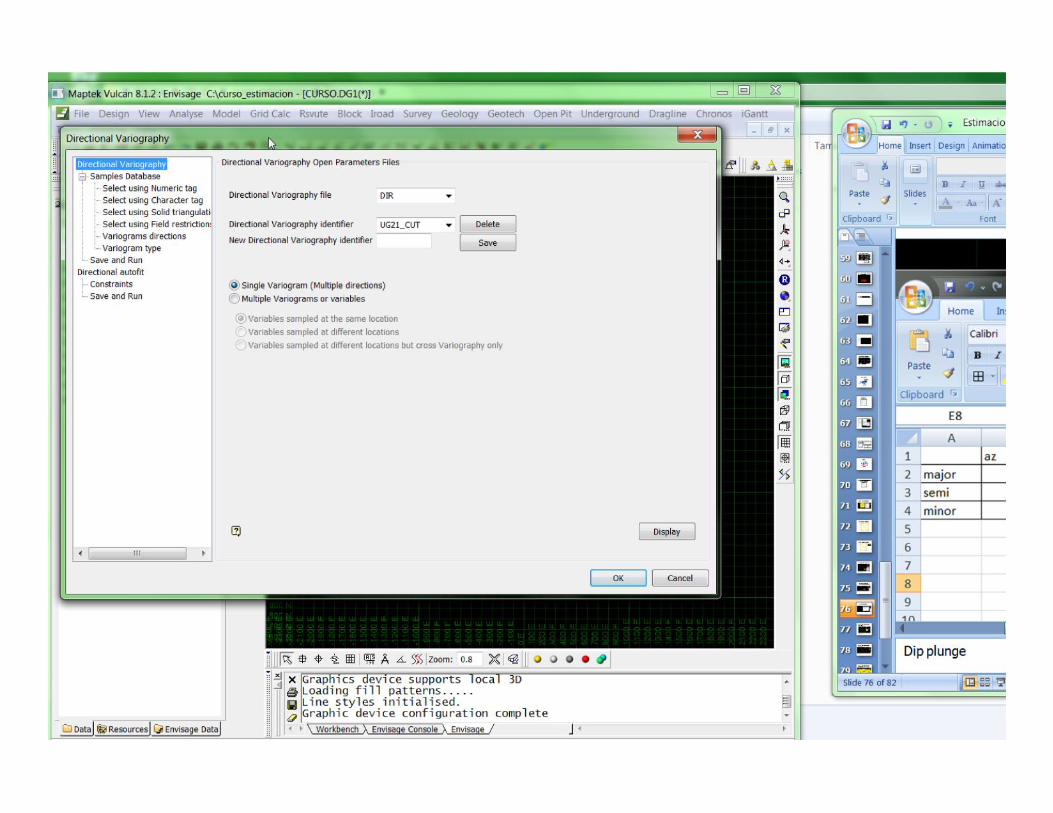
Directional variography

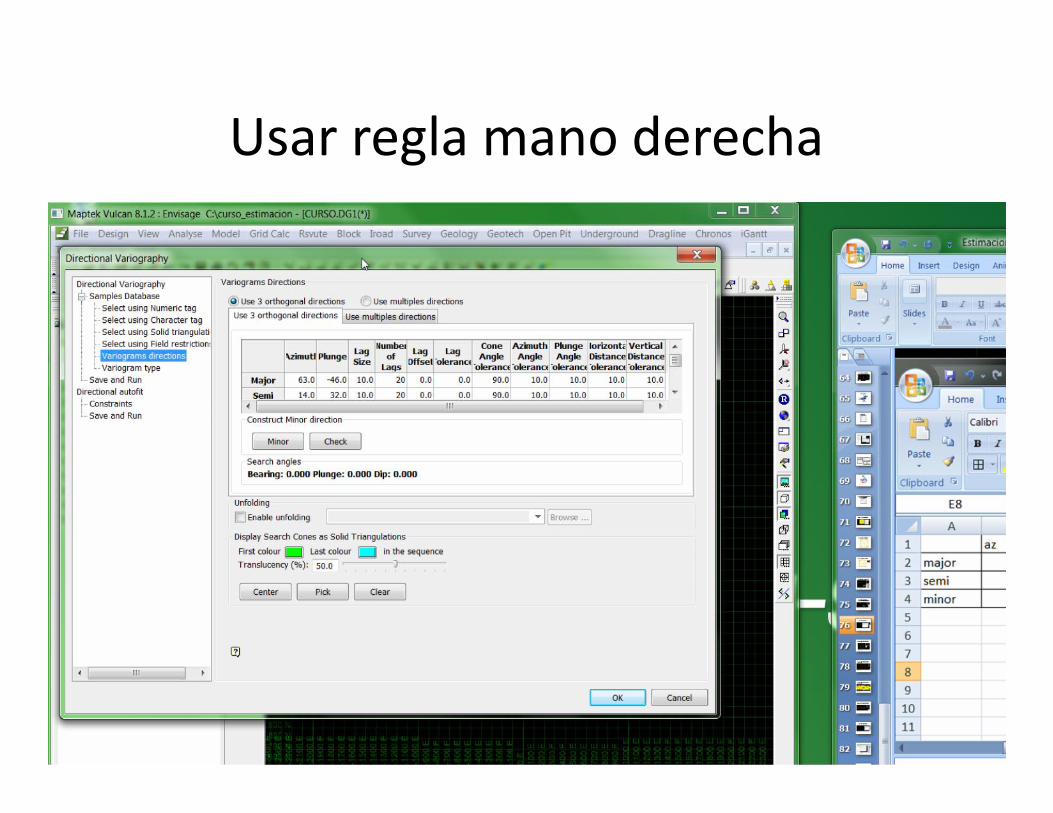
Usar regla mano derecha
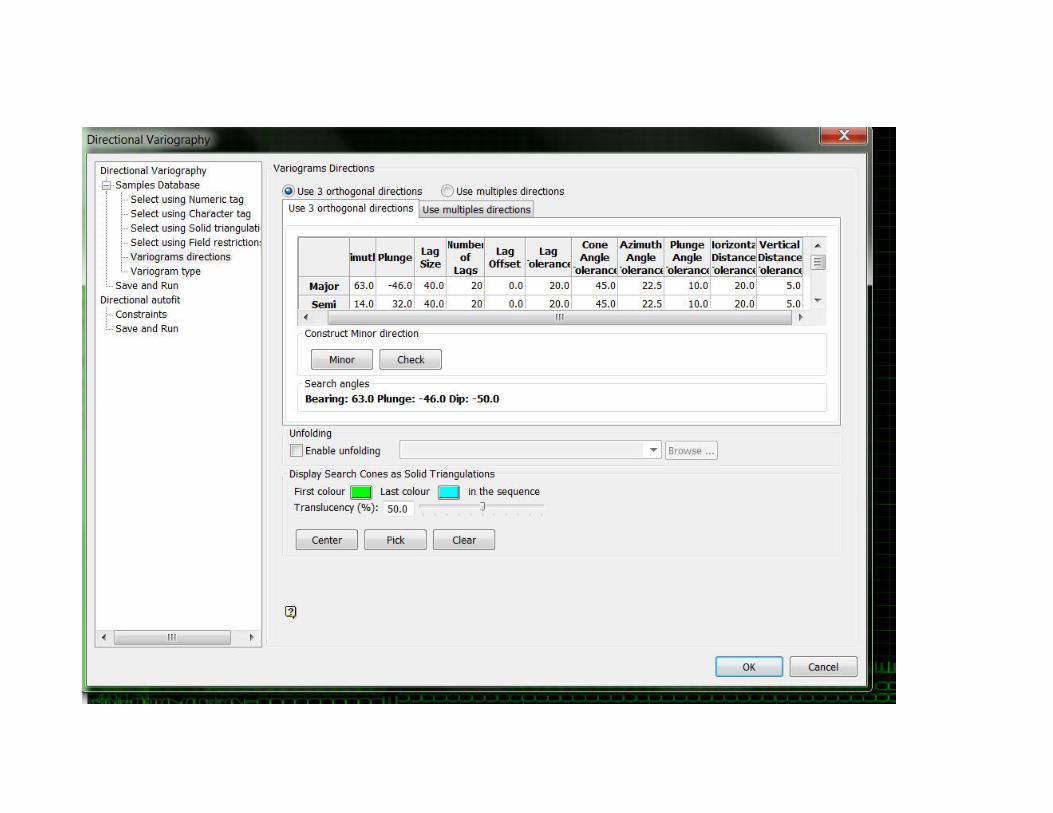
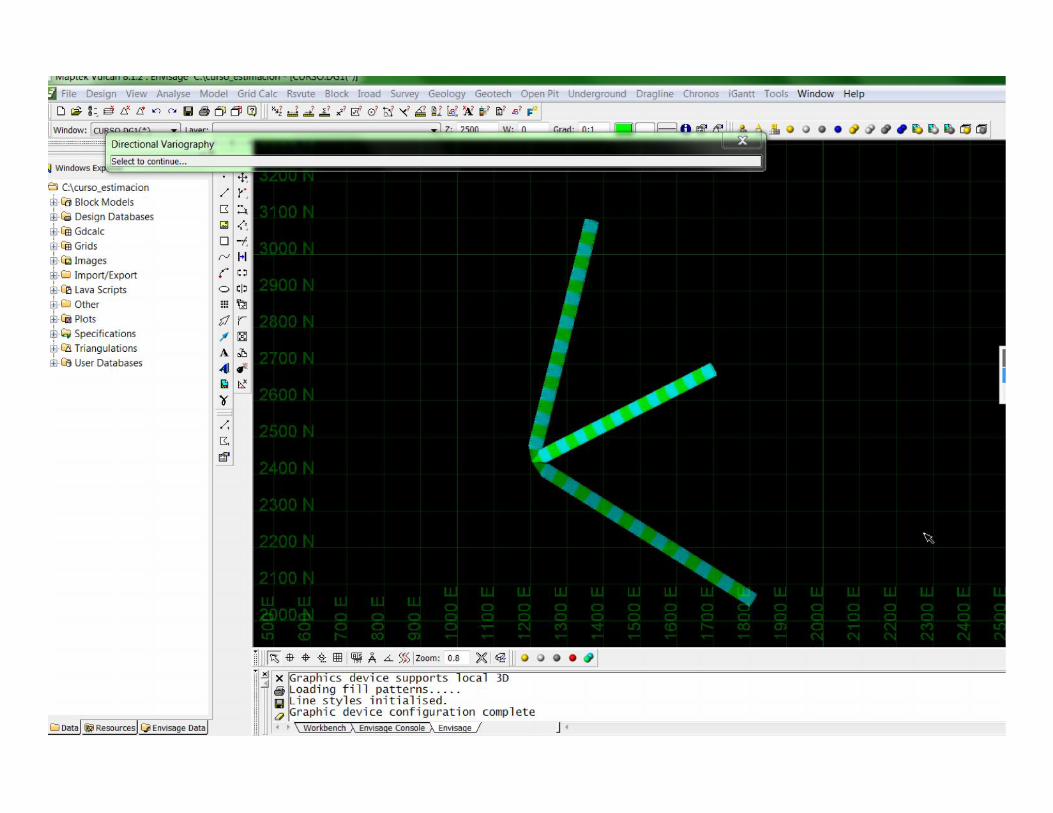

Major, semi, menor
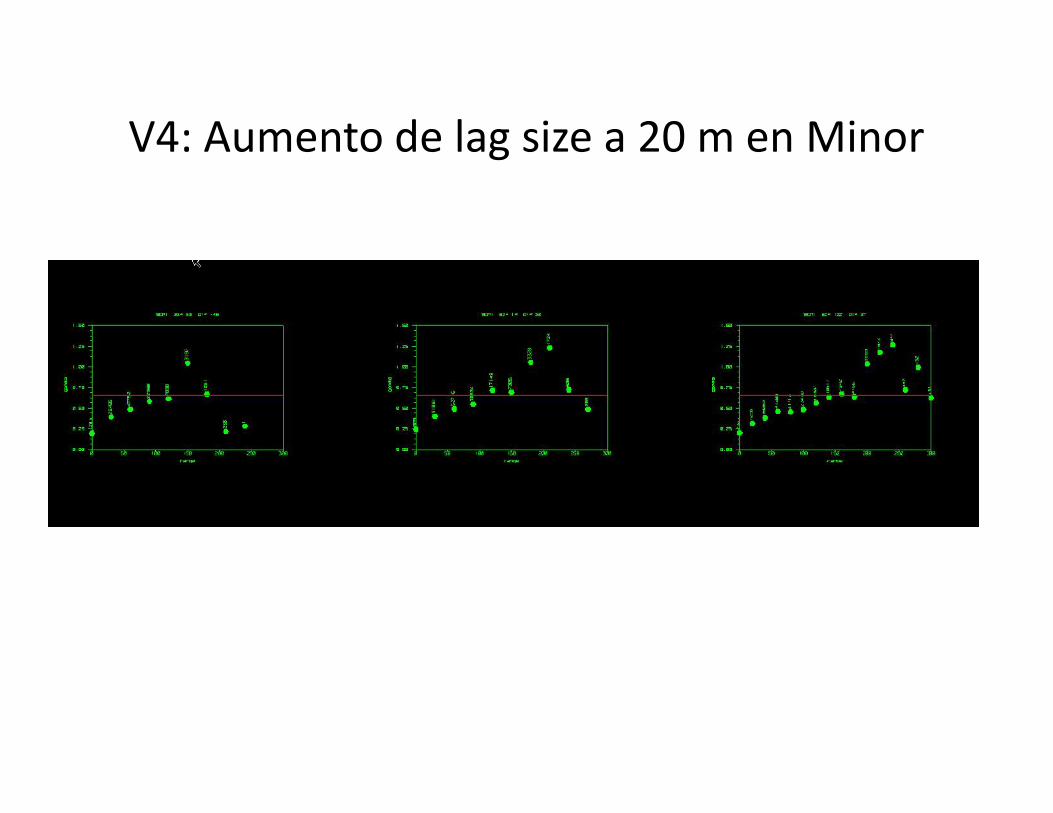
V4: Aumento de lag size a 20 m en Minor

VARIOGRAMA TEÓRICO• El Kriging necesita generar su función usando la información del variograma
experimental.• Los valores que adquiera esta función van ser representados en cualquiera
de los 3 variogramas obtenidos del experimental.• Casi siempre se utilizará la forma esférica y el variograma en términos de
función constituye la suma de estructura del tipo: pepita+función delvariograma (pe. Una función esférica); Si con estas 2 estructuras no essuficiente para representar el variograma experimental sumo una 3raestructura que podría ser una 2da función esférica.
• Para proceder necesito conocer el efecto pepita y la varianza de los datos
Autofit
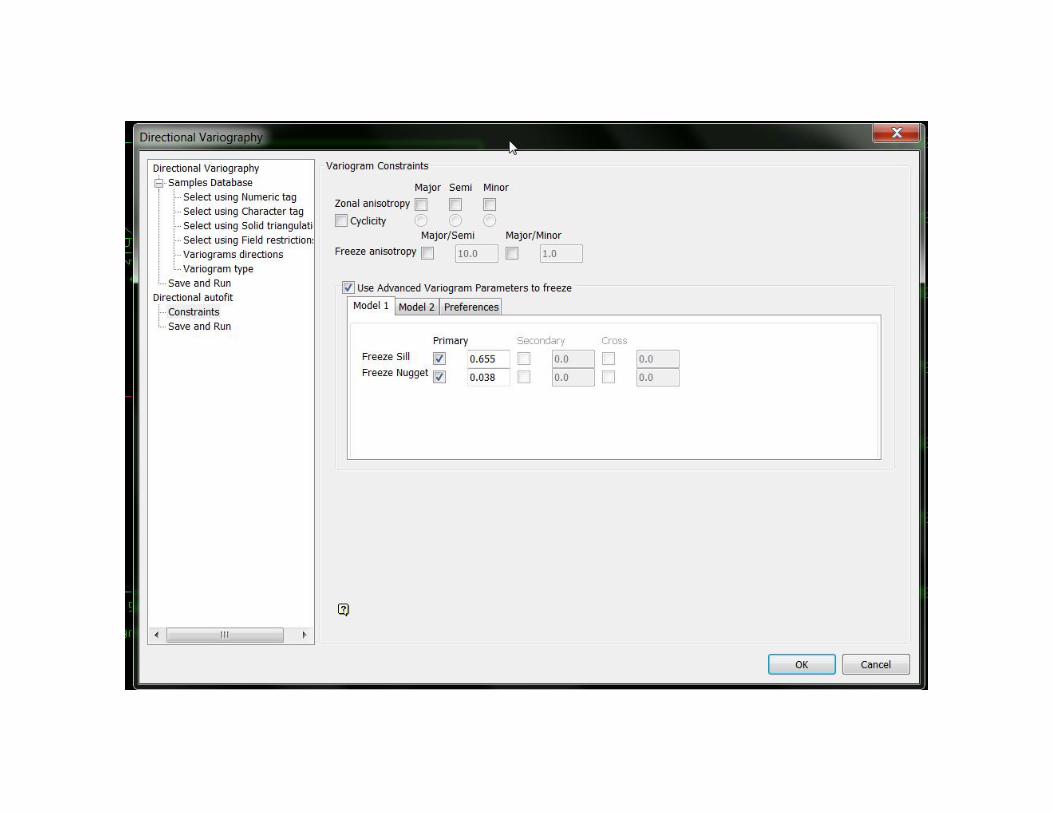
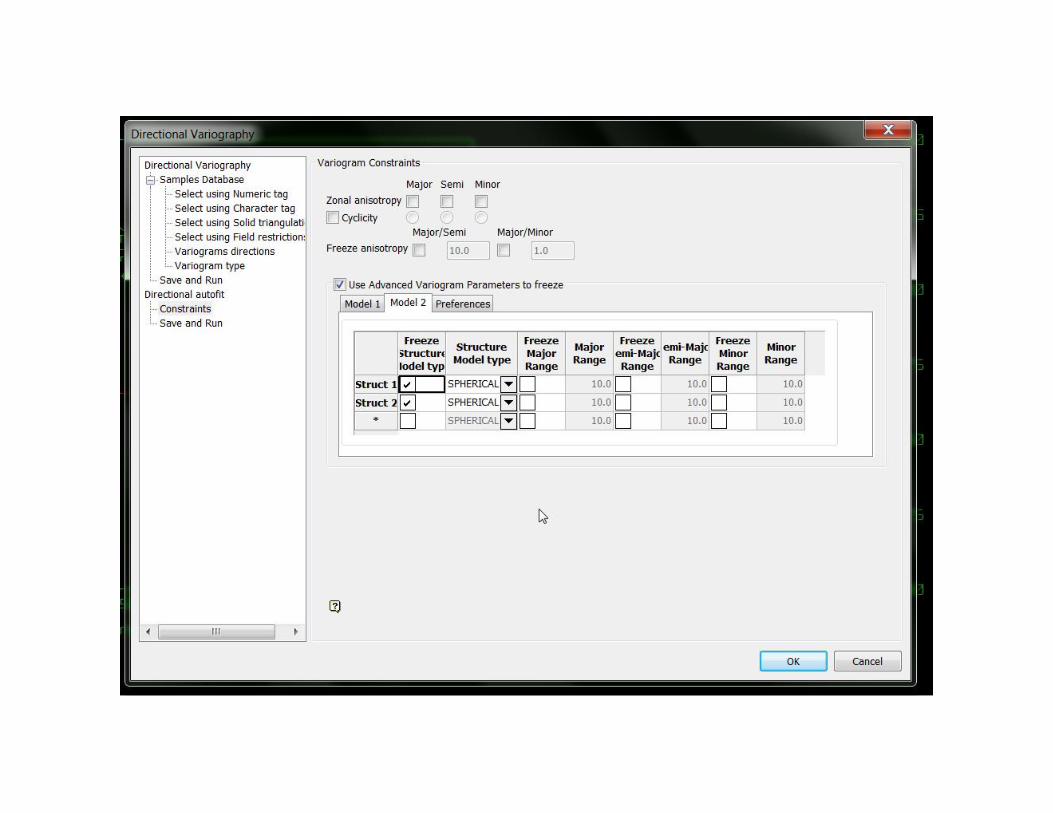

Autofit v0, en EDIT se debe ajustarmanualmente con “Move Sill”

Autofit v0, en EDIT se debe ajustar manualmente, cuando seconforme botón derecho y aceptar
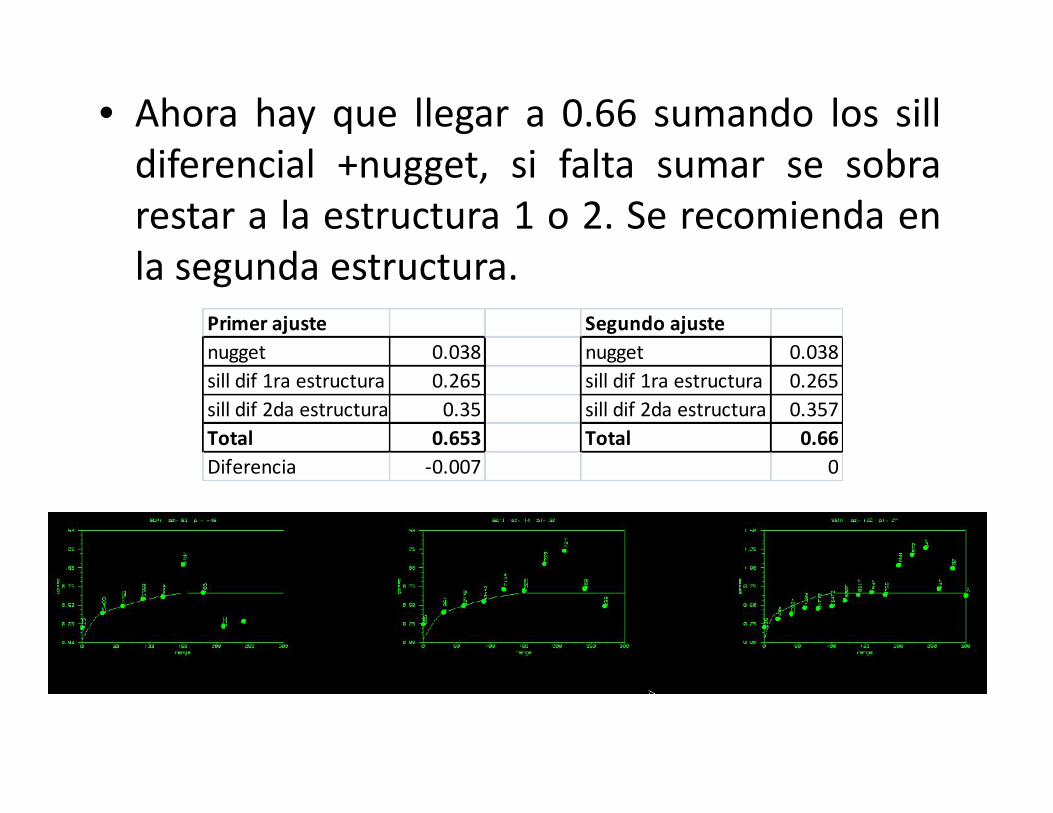
• Ahora hay que llegar a 0.66 sumando los silldiferencial +nugget, si falta sumar se sobrarestar a la estructura 1 o 2. Se recomienda enla segunda estructura.
Primer ajuste Segundo ajustenugget 0.038 nugget 0.038sill dif 1ra estructura 0.265 sill dif 1ra estructura 0.265sill dif 2da estructura 0.35 sill dif 2da estructura 0.357Total 0.653 Total 0.66Diferencia -0.007 0

Categorización (variography display)
• Medido= ½ alcance, Indicado =Alcance,Inferido= >Alcance
• Para cada una de las pasadas

Métodos de Estimación No GeoStats
• ID: Calcula el promedio en función de la distanciade las muestras. El valor de la potencia oscilaentre 1, 2 o 3 y va ser el aporte a ley de lamuestras a la media, mientras mas aumento lapotencia mayor es aporte la ley de la muestramas cercana al promedio.
• Vecino mas cercano: genera polígonos y estima elvalor de un bloque tomando el valor de lamuestra mas cercana y lo copia. Se recomiendausar este método para comparar.

Métodos de Estimación GeoStats
• Kriging Simple: Busca mejorar la ponderaciónde los datos al tomar en cuenta lo siguiente:– 1 sus distancias la sitio a estimar,– la redundancia de sus datos (posibles
agrupamiento),– la continuidad de la variable regionalizada
• Este método trabaja bajo el supuesto de que lamedia es constante en todo el deposito siendoque esto no es asi.

• Kriging Ordinario: Desconoce el valorpromedio de la variable regionalizada. Por lotanto se adapta mejor a la situación real de lasmuestras.

Kriging Ordinario (Criterios):• Discretización 4x4x3 (en el rango)• Search Orientation: la misma que la obtenida en el mapa variográfico• Search Distance: La mitad valor de los alcances del variograma Teórico modelado
(mayor distancia muestras mas alejadas llegando a la meseta del variograma). Estopara la primera pasada. La segunda usa el alcance y la 3ra mas alla del alcance segúnse definión como criterio
• Octante-: divide el elipsoide en 8
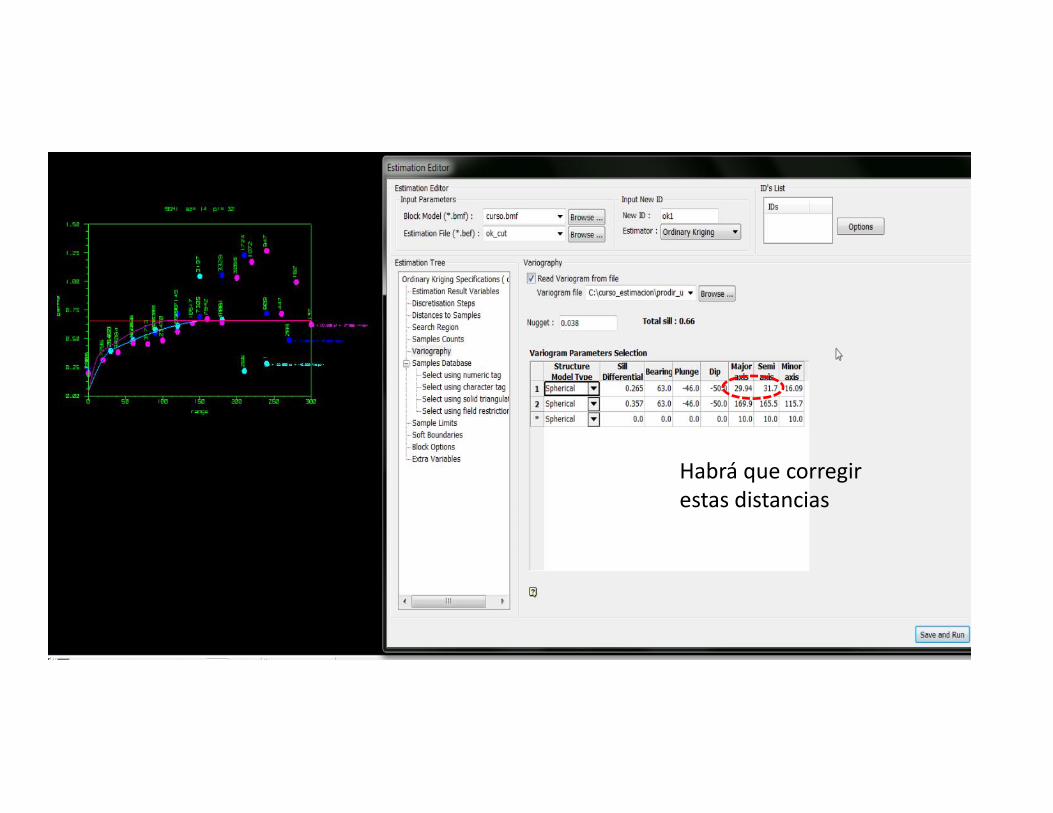
Habrá que corregirestas distancias
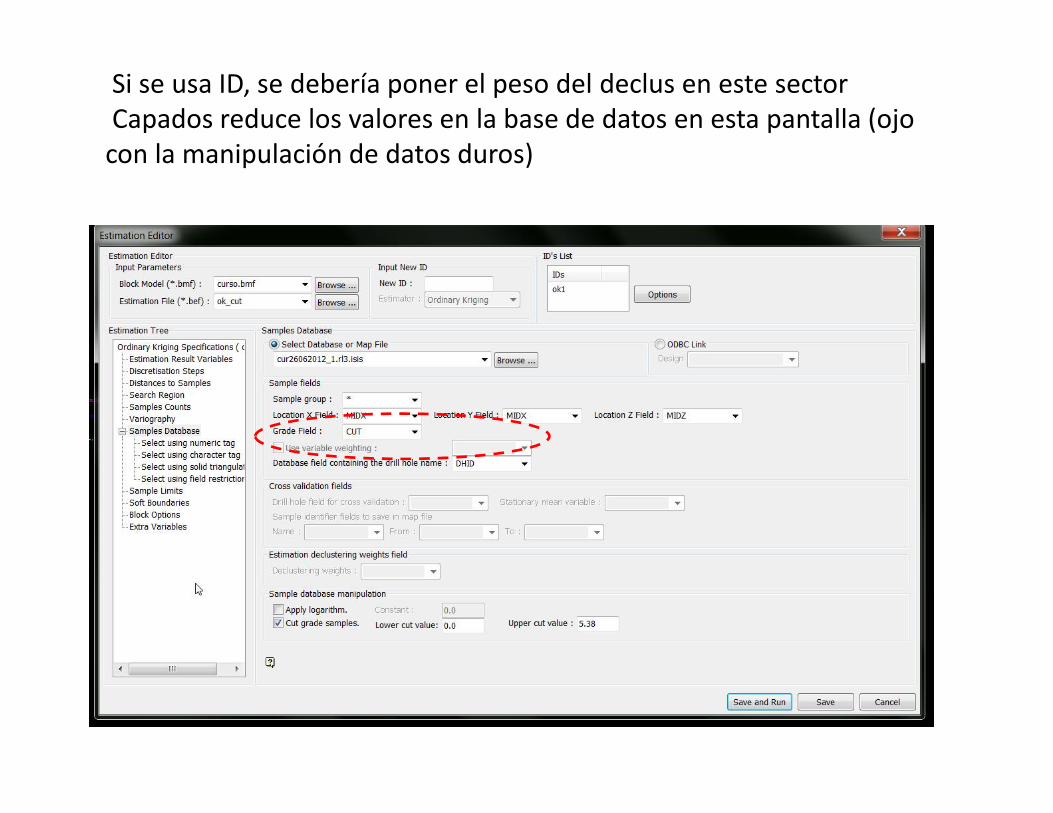
Si se usa ID, se debería poner el peso del declus en este sectorCapados reduce los valores en la base de datos en esta pantalla (ojo
con la manipulación de datos duros)
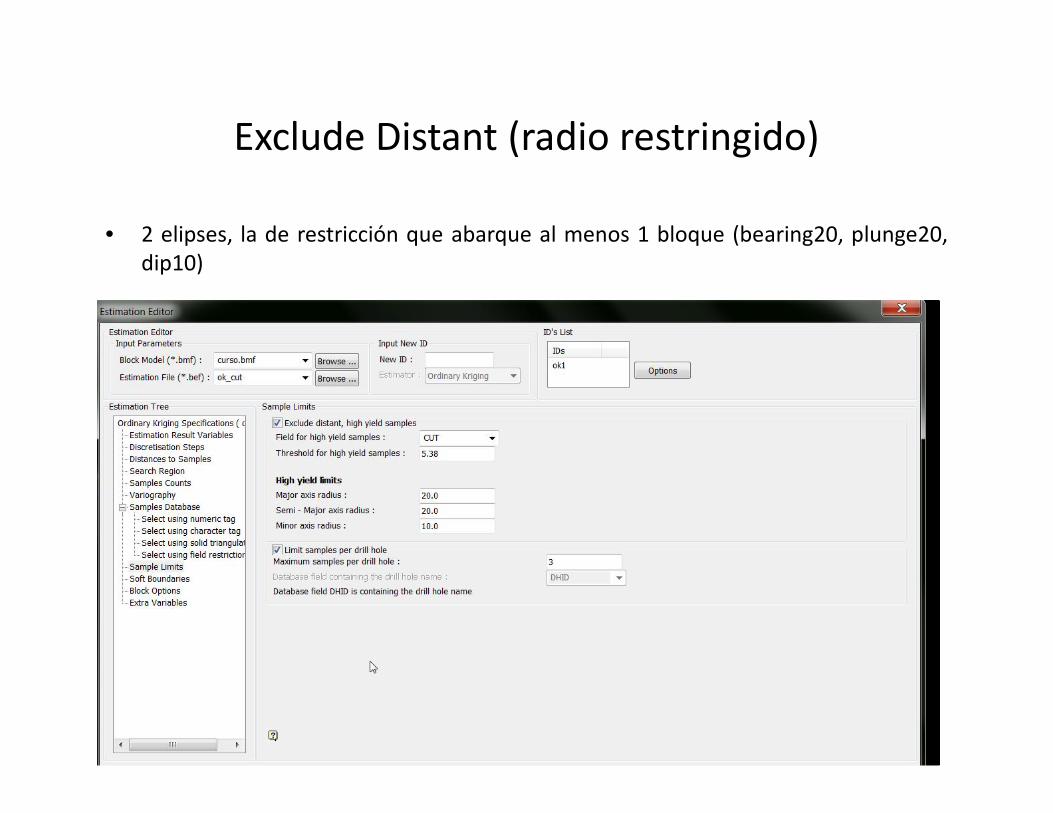
Exclude Distant (radio restringido)
• 2 elipses, la de restricción que abarque al menos 1 bloque (bearing20, plunge20,dip10)
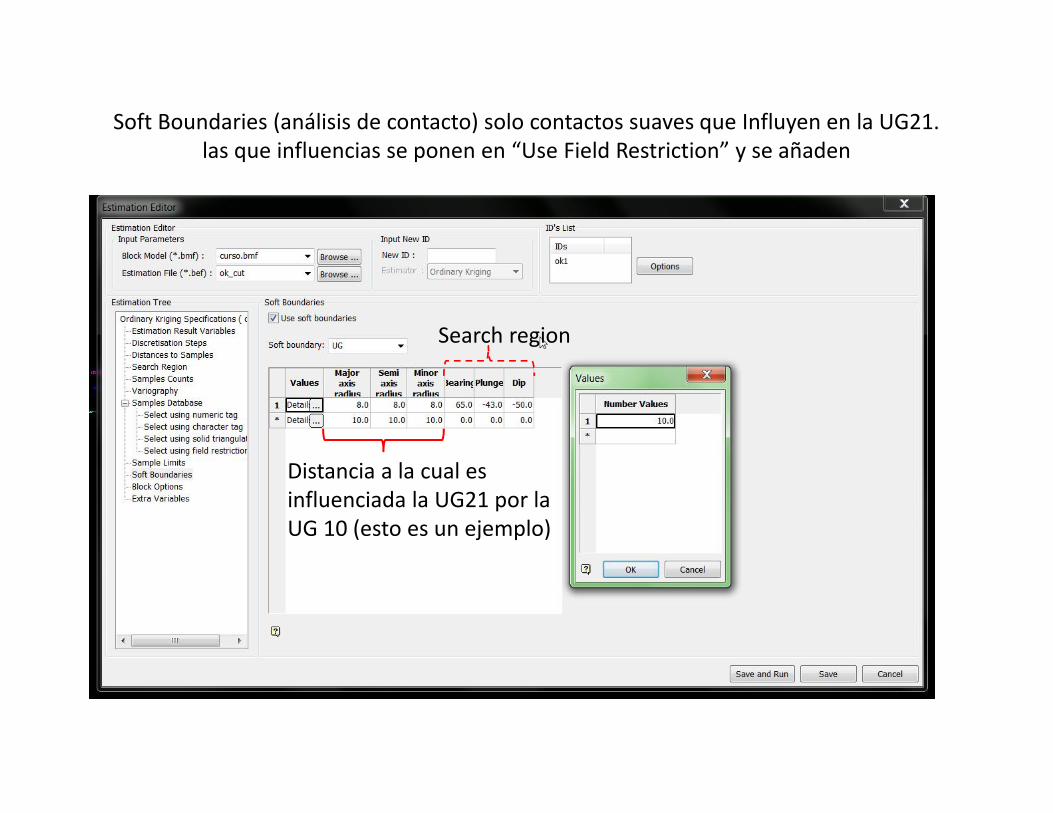
Soft Boundaries (análisis de contacto) solo contactos suaves que Influyen en la UG21.las que influencias se ponen en “Use Field Restriction” y se añaden
Search region
Distancia a la cual esinfluenciada la UG21 por laUG 10 (esto es un ejemplo)

EXTRA VARIABLES
• Para estimar una 2da variable con los mismosparámetros de la primera o principal
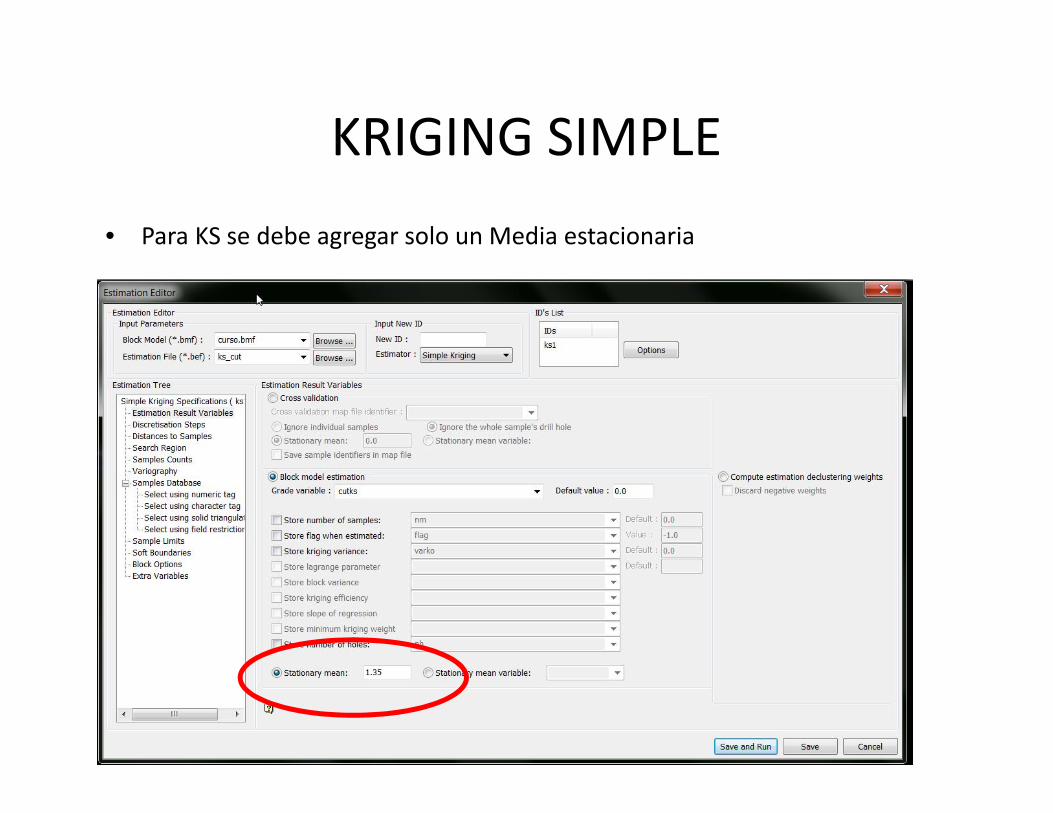
KRIGING SIMPLE• Para KS se debe agregar solo un Media estacionaria

Inverso a la distancia
• Normalise para las distancias anisotrópicas• Tick this box if you want to calculate the
anisotropic weightings normalised to thesearch radii

PROMEDIO (cut prom)
• Power 0• Muestras 3 y 10

Validación Cruzada
• Real vs Estimación• Si se elige no considerar solo la muestra se
cambia eso nada mas y se elige ignorar todaslas muestras del sondajes hay que ir a samplesdatabase y elegir variable DHID en crossvalidation
• Hacer scatter con REAL en Y y EST en X

Deriva
• Registrar diferencias (subestiamción osobrestimación)
Related Documents











