Batch Codes and Their Applications Y.Ishai, E.Kushilevitz, R.Ostrovsky, A.Sahai Preliminary version in STOC 2004

Batch Codes and Their Applications Y.Ishai, E.Kushilevitz, R.Ostrovsky, A.Sahai Preliminary version in STOC 2004.
Dec 22, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Batch Codes and Their Applications
Y.Ishai, E.Kushilevitz, R.Ostrovsky, A.Sahai
Preliminary version in STOC 2004

Talk Outline
• Batch codes
• Amortized PIR– via hashing– via batch codes
• Constructing batch codes
• Concluding remarks

A Load-Balancing Scenario
x

What’s wrong with a random partition?
• Good on average for “oblivious” queries.• However:
– Can’t balance adversarial queries– Can’t balance few random queries– Can’t relieve “hot spots” in multi-user setting

Example• 3 devices, 50% storage overhead.• By how much can the maximal load be reduced?
– Replicating bits is no good: device s.t.1/6 of the bits can only be found at this device.
– Factor 2 load reduction is possible:
L R
L R LR
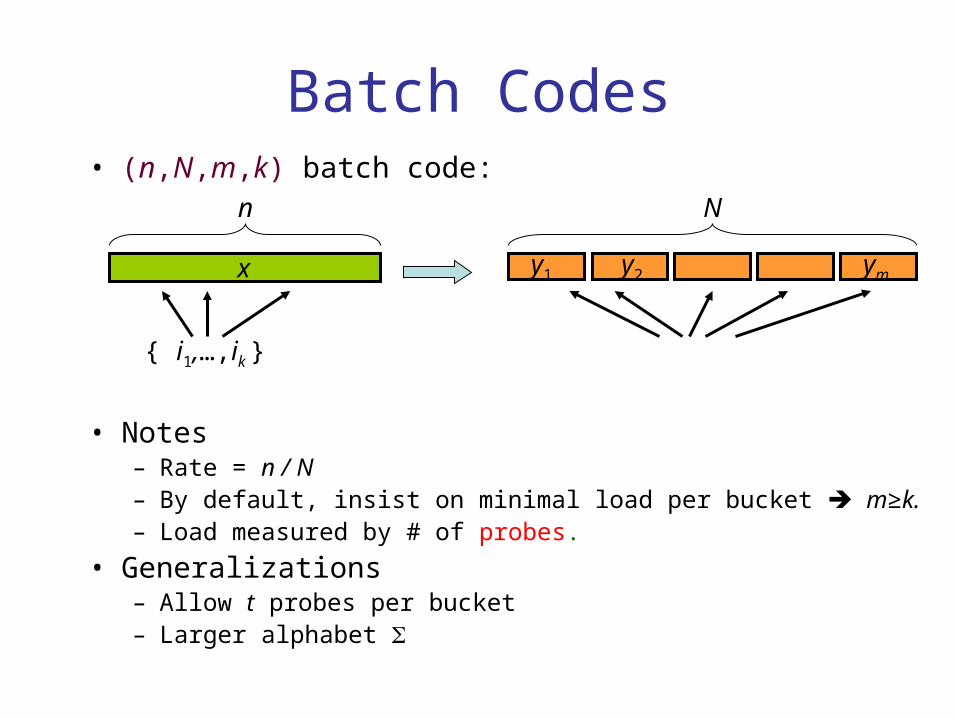
Batch Codes• (n,N,m,k) batch code:
• Notes – Rate = n / N– By default, insist on minimal load per bucket m≥k. – Load measured by # of probes.
• Generalizations – Allow t probes per bucket– Larger alphabet
x
n
y1 y2 ym
N
i1,…,ik
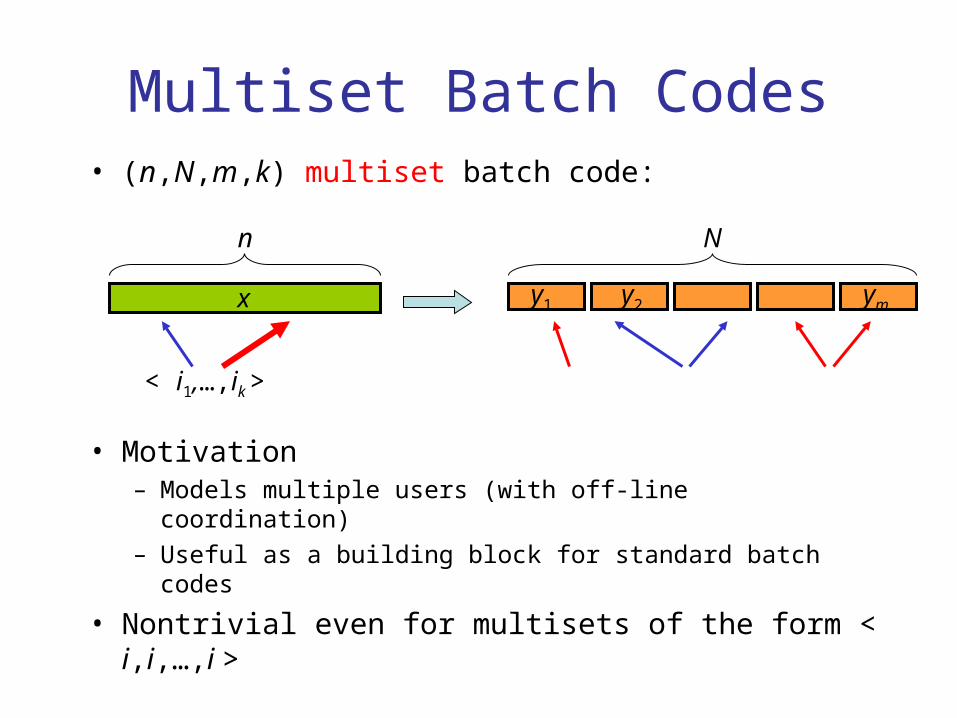
Multiset Batch Codes• (n,N,m,k) multiset batch code:
• Motivation– Models multiple users (with off-line coordination)– Useful as a building block for standard batch codes
• Nontrivial even for multisets of the form < i,i,…,i >
x
n
y1 y2 ym
N
< i1,…,ik >

Examples• Trivial codes
– Replication: N=kn, m=k • Optimal m, bad rate.
– One bit per bucket: N=m=n• Optimal rate, bad m.
• (L,R,LR) code: rate=2/3, m=3, k=2.
• Goal: simultaneously obtain– High rate (close to 1)– Small m (close to k)
multiset
multiset

Private Information Retrieval (PIR)
• Goal: allow user to query database while hiding the identity of the data-items she is after.
• Motivation: patent databases, web searches, ...• Paradox(?): imagine buying in a store without the
seller knowing what you buy. Note: Encrypting requests is useful against third parties;
not against server holding the data.

Modeling
• Database: n-bit string x
• User: wishes to– retrieve xi and
– keep i private

Server
User
nx 1,0
,...,1 ni
xi
???

Some “Solutions”
1. User downloads entire database. Drawback: n communication bits (vs. logn+1 w/o privacy). Main research goal: minimize communication complexity.
2. User masks i with additional random indices. Drawback: gives a lot of information about i.
3. Enable anonymous access to database. Note: addresses the different security concern of hiding
user’s identity, not the fact that xi is retrieved.
Fact: PIR as described so far requires (n) communication bits.

Two Approaches
• Computational PIR [KO97, CMS99,...] – Computational privacy
– Based on cryptographic assumptions
• Information-Theoretic PIR [CGKS95,Amb97,...] – Replicate database among s servers– Unconditional privacy against t servers– Default: t=1

Communication Upper Bounds
• Computational PIR– O(n), polylog(n), O(logn), O(+logn)
[KO97,CMS99,…]
• Information-theoretic PIR– 2 servers, O(n1/3) [CGKS95]
– s servers, O(n1/c(s)) where c(s)=Ω(slogs / loglogs)[CGKS95,Amb97,BIKR02]
– O(logn/loglogn) servers, polylog(n)

Time Complexity of PIR
• Given low-communication protocols, efficiency bottleneck shifts to servers’ time complexity.– Protocols require (at least) linear time per query.– This is an inherent limitation!
• Possible workarounds:– Preprocessing– Amortize cost over multiple queries

Previous Results [BIM00]
• PIR with preprocessing– s-server protocols with O(n) communication and O(n1/s+) work
per query, requiring poly(n) storage.– Disadvantages:
• Only work for multi-server PIR• Storage typically huge
• Amortized PIR– Slight savings possible using fast matrix multiplication– Require a large batch of queries and high communication– Apply also to queries originating from different users.
• This work:– Assume a batch of k queries originate from a single user.– Allow preprocessing (not always needed).– Nearly optimal amortization

Model
Server/s
User
Nn yx 1,01,0
,...,1,...,, 21 niii k
???
xi , xi ,…, xi1 2 k

Amortized PIR via Hashing
• Let P be a PIR protocol.• Hashing-based amortized PIR:
– User picks hRH , defining a random partition of x into k buckets of sizen/k, and sends h to Server/s.
• Except for 2- failure probability, at most t=O(logk) queries fall in each bucket.
– P is applied t times for each bucket.
• Complexity:– Time kt T(n/k) t T(n)– Communication ktC(n/k)– Asymptotically optimal up to “polylog factors”

So what’s wrong?
• Not much…• Still:
– Not perfect• introduces either error or privacy loss
– Useless for small k• t=O(logk) overhead dominates
– Cannot hash “once and for all” h bad k-tuple of queries
• Sounds familiar?

Amortized PIR via Batch Codes
• Idea: use batch-encoding instead of hashing.• Protocol:
– Preprocessing: Server/s encode x as y=(y1,y2,…,ym).
– Based on i1,…,ik, User computes the index of the bit it needs from each bucket.
– P is applied once for each bucket.
• Complexity– Time 1jmT(Nj) T(N)
– Communication 1jmC(Nj) mC(n)
• Trivial batch codes imply trivial protocols.• (L,R,LR) code: 2 queries,1.5 X time, 3 X communication

Constructing Batch Codes

Overview• Recall notion
• Main qualitative questions:1.Can we get arbitrarily high constant rate (n/N=1-)
while keeping m feasible in terms of k (say m=poly(k))?2.Can we insist on nearly optimal m (say m=O(k)) and
still get close to a constant rate? • Several incomparable constructions• Answer both questions affirmatively.
x
n
y1 y2 ym
N
i1,…,ik
~

Batch Codes from Unbalanced Expanders
• By Hall’s theorem, the graph represents an (n,N=|E|,m,k) batch code iff every set S containing at most k vertices on the left has at least |S| neighbors on the right.
• Fully captures replication-based batch codes.
n m

Parameters
• Non-explicit: N=dn, m=O(k (nk)1/(d-1))– d=3: rate=1/3, m=O(k3/2n1/2).– d=logn: rate=1/logn, m=O(k) Settles Q2
• Explicit (using [TUZ01],[CRVW02])– Nontrivial, but quite far from optimal
• Limitations:– Rate < ½ (unless m=(n))– For const. rate, m must also depend on n.– Cannot handle multisets.

The Subcube Code
• Generalize (L,R,LR) example in two ways– Trade better rate for larger m
• (Y1,Y2,…,Ys,Y1 … Ys)
• still k=2
– Handle larger k via composition
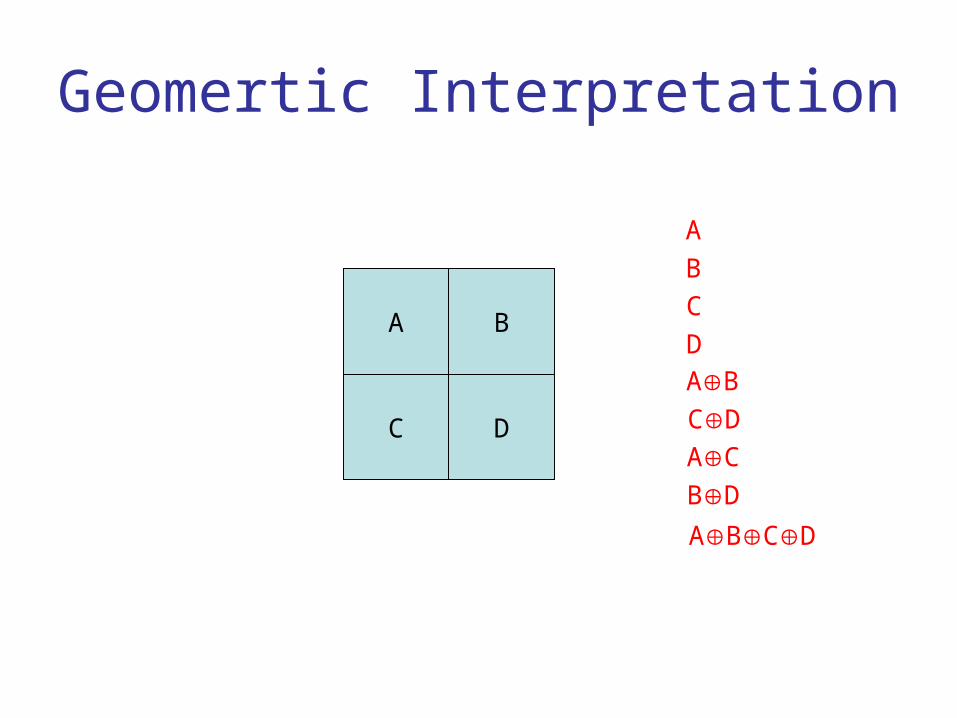
Geomertic Interpretation
A B
C D
A
B
C
DAB
CD
AC
BD
ABCD

Parameters
• Nklog(1+1/s)n, mklog(s+1)
– s=O(logk) gives an arbitrary constant rate with m=kO(loglogk). “almost” resolves Q1
• Advantages:– Arbitrary constant rate– Handles multisets– Very easy decoding
• Asymptotically dominated by subsequent construction.

The Gadget Lemma
• From now on, we can choose a “convenient” n and get same rate and m(k) for arbitrarily larger n.
Primitive multiset batch code

Batch Codes vs. Smooth Codes• Def. A code C:n m is q-smooth if there exists a
(randomized) decoder D such that– D(i) decodes xi by probing q symbols of C(x).– Each symbol of C(x) is probed w/prob q/m.
• Smooth codes are closely related to locally decodable codes [KT00].
• Two-way relation with batch codes:– q-smooth code primitive multiset batch code with k=m/q2
(ideally would like k=m/q).– Primitive multiset batch code (expected) q-smooth for q=m/k
• Batch codes and smooth codes are very different objects:– Relation breaks when relaxing “multiset” or “primitive”– Gap between m/q and m/q2 is very significant for high rate case
• Best known smooth codes with rate>1/2 require q>n1/2
• These codes are provably useless as batch codes.

Batch Codes from RM Codes
• (s,d) Reed-Muller code over F– Message viewed as s-variate polynomial p
over F of total degree (at most) d.– Encoded by the sequence of its evaluations
on all points in Fs
– Case |F|>d is useful due to a “smooth decoding” feature: p(z) can be extrapolated from the values of p on any d+1 points on a line passing through z.

s=2, d(2n)1/2
x2
x1 xn
• Two approaches for handling conflicts:1.Replicate each point t times
2.Use redundancy to “delete” intersections• Slightly increases field size, but still allows constant rate.

Parameters
• Rate = (1/s!-), m=k1+1/(s-1)+o(1)
– Multiset codes with constant rate (< ½)
• Rate = (1/k), m=O(k) resolves Q2 for multiset codes as well
• Main remaining challenge: resolve Q1
~

The Subset Code
• Choose s,d such that n • Each data bit i[n] is associated T • Each bucket j[m] is associated S
• Primitive code: yS=TSxT
x
y
s
d
( )[s]d
( )[s]d
( )sd

Batch Decoding the Subset Code
• Lemma: For each T’T, xT can be decoded from all yS such that ST=T’.– Let LT,T’ denote the set of such S.– Note: LT,T’ : T’T defines a partition of
xT
yT’
( )[s]d
0011110000**0110****

Batch Decoding the Subset Code (contd.)
• Goal: Given T1,…,Tk, find subsets T’1,…,T’k such that LTi,T’i are pairwise disjoint.– Easy if all Ti are distinct or if all Ti are the same.
• Attempt 1: T’i is a random subset of Ti
– Problem: if Ti,Tj are disjoint, LTi,T’i and LTj,T’j intersect w.h.p.• Attempt 2: greedily assign to Ti the largest T’i such that LTi,T’i does
not intersect any previous LTj,T’j
– Problem: adjacent sets may “block” each other.• Solution: pick random T’i with bias towards large sets.
x3 x1 x2

Parameters
• Allows arbitrary constant rate with m=poly(k) Settles Q1
• Both the subcube code and the subset code can be viewed as sub-codes of the binary RM code. – The full binary RM code cannot be batch
decoded when the rate>1/2.

Concluding Remarks: Batch Codes
• A common relaxation of very different combinatorial objects– Expanders – Locally-decodable codes
• Problem makes sense even for small values of m,k.– For multiset codes with m=3,k=2, rate 2/3 is optimal.– Open for mk+2.
• Useful building block for “distributed data structures”.

Concluding Remarks: PIR
• Single-user amortization is useful in practice only if PIR is significantly more efficient than download.– Certainly true for multi-server PIR– Most likely true also for single-server PIR
• Killer app for lattice-based cryptosystems?
Single user
Multiple users
AdaptiveNon-adaptive
? ?
?
Related Documents











