



www.opendaylight.org
Time Series Data Repository (TSDR) Project Proposal

www.opendaylight.org2
TSDR Functional Objectives To capture ODL data into a persistent time series data repository
This includes: Statistics counters Performance data
Health status information Operational configuration data
To facilitate various applications built on top of TSDRApplications include:
Security risk detection Performance analysis
Operational configuration optimization Traffic engineering Network analytics with automated intelligence
Major functions Data Collection Data Storage Data Queries
Data Aggregation Data Purge
Lithium Focus TSDR functionalities on OpenFlow Statistics data

www.opendaylight.org3
TSDR Design Objectives
Generic and Extensible architectural framework Generic and extensible TSDR Data Model. Abstract and generic TSDR Persistence Layer
− with TSDR Persistence APIs Allow implementation of various data store plugins under TSDR
Persistence Layer− with HBase Plugin as an example TSDR Data Store implementation.
Scalable with high performance Providing both integrated and distributed architectures
− to handle different scales of time series data Fully utilizing MD-SAL’s clustering capability
− to handle performance and scalability in large scale deployment scenarios
www.opendaylight.org4
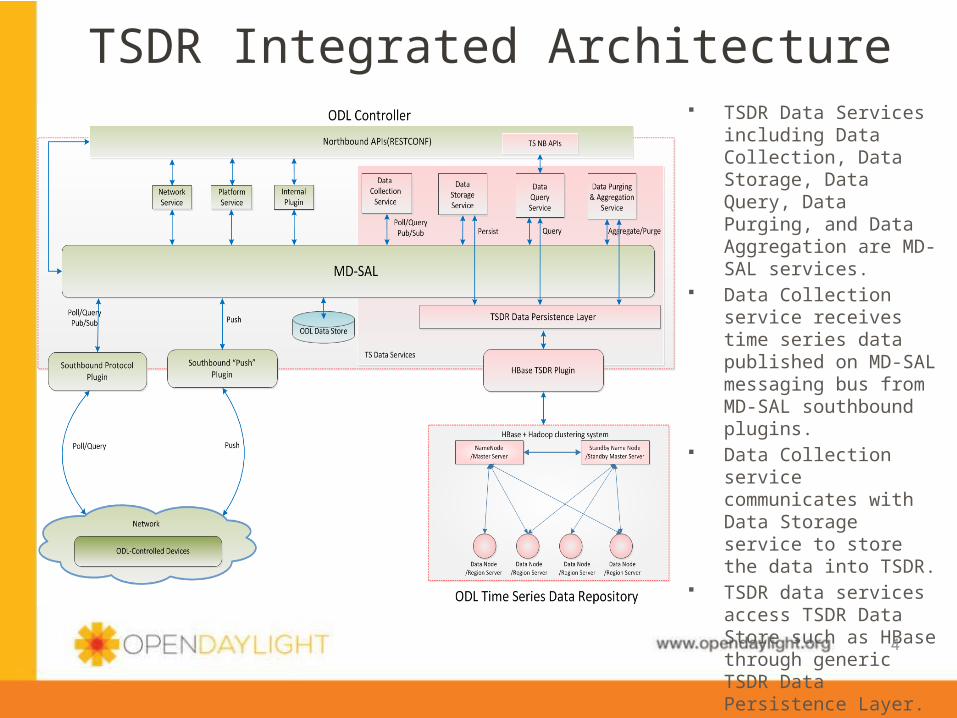
TSDR Data Services including Data Collection, Data Storage, Data Query, Data Purging, and Data Aggregation are MD-SAL services.
Data Collection service receives time series data published on MD-SAL messaging bus from MD-SAL southbound plugins.
Data Collection service communicates with Data Storage service to store the data into TSDR.
TSDR data services access TSDR Data Store such as HBase through generic TSDR Data Persistence Layer.
Needs MD-SAL notification subsystem support.
TSDR Integrated Architecture

www.opendaylight.org5
TSDR Distributed Architecture In large data center
deployment scenarios, TSDR Distributed Architecture would be needed to handle the performance and scalability.
In distributed architecture, TSDR data services are deployed in a separate MD-SAL instance.
The data pushed onto MD-SAL messaging bus by ODL southbound plugin are propagated to the other MD-SAL instance for TSDR data services to process into TSDR data repository.
Needs ODL clustering support.
www.opendaylight.org6
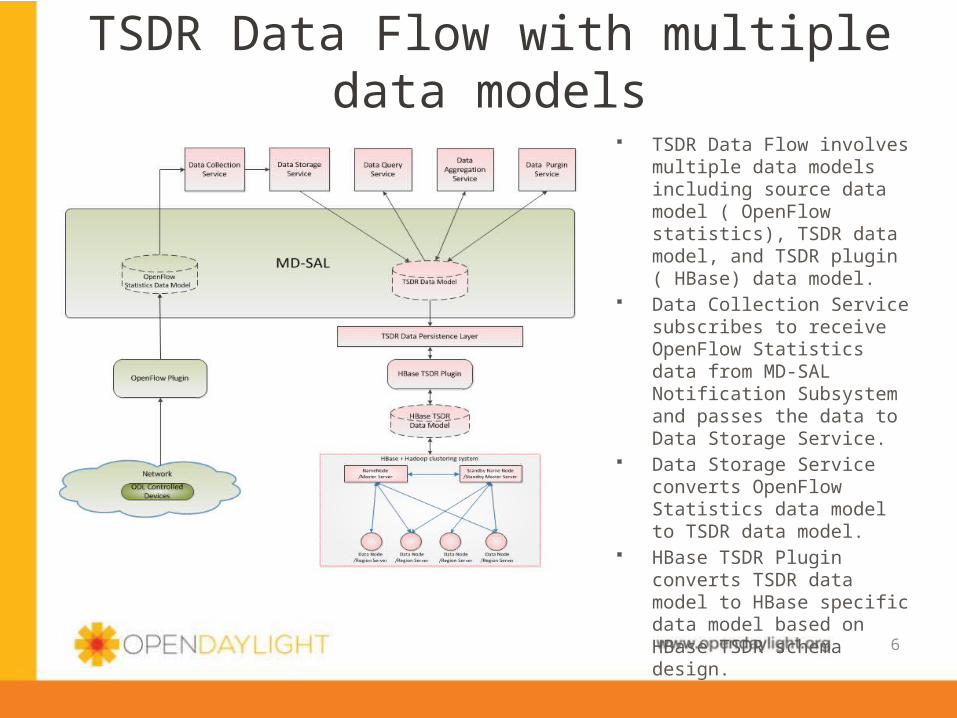
TSDR Data Flow with multiple data models
TSDR Data Flow involves multiple data models including source data model ( OpenFlow statistics), TSDR data model, and TSDR plugin ( HBase) data model.
Data Collection Service subscribes to receive OpenFlow Statistics data from MD-SAL Notification Subsystem and passes the data to Data Storage Service.
Data Storage Service converts OpenFlow Statistics data model to TSDR data model.
HBase TSDR Plugin converts TSDR data model to HBase specific data model based on HBase TSDR schema design.

www.opendaylight.org7
Unstructured or Semi-Structured data consideration – for future release
For unstructured or semi-structured data such as syslog data, MD-SAL receives the data in the format of syslog specifica data model.
Data Filtering and Preprocessing can be added to filter out the data noise and optionally extract structured information from the semi-structured data.
Third party specific TSDR plugin such as Splunk Plugin could be added under TSDR Data Persistence Layer to work with proprietary data stores.
Data Aggregation Service is not needed when handling unstructured data.
Third party tools such as Splunk could leverage Data Query Service to obtain the unstructured data from TSDR and add application specific processing on top of it.
www.opendaylight.org8
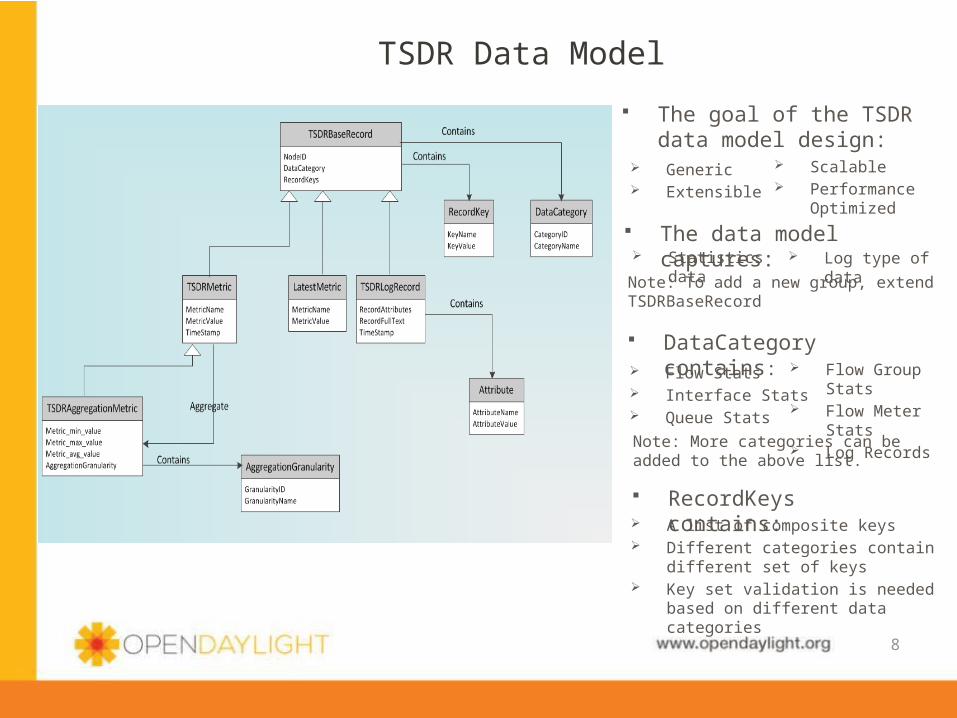
TSDR Data Model
The goal of the TSDR data model design:
Generic Extensible
Scalable Performance
Optimized
The data model captures: Statistics data Log type of data
DataCategory contains: Flow Stats Interface Stats Queue Stats
Flow Group Stats Flow Meter Stats Log Records
RecordKeys contains: A list of composite keys Different categories contain different
set of keys Key set validation is needed based on
different data categories
Note: To add a new group, extend TSDRBaseRecord
Note: More categories can be added to the above list.

www.opendaylight.org9
TSDR Persistence APIsInterface Name Description/comments Extends from ODL
Common APIs?Specific to TSDR Persistence API?
Will be implemented in HBase plugin in Lithium?
save() Including saving one or a list of objects
Yes No Yes
find() Including query based on a list of IDs, with specified criteria, and paging support
Yes No No
count() Yes No Yes
delete() Including delete with one or a list of IDs, and delete the entire table
Yes No No
exists() Including query based on one or a list of IDs
Yes No Yes
min(), max(), avg() For Data Aggregation purpose No Yes No

www.opendaylight.org10
HBase TSDR Schema – Raw DataTableName RowKey Column Family:
Column Qualifier = Cell Value
FlowMetrics MetricID_NodeID_TableID(_FlowID)_timestamp ‘raw’ = metric_value
InterfaceMetrics MetricID_NodeID_TableID(_PortID)_timestamp ‘raw’ = metric_value
QueueMetrics MetricID_NodeID_TableID_PortID_QueueID_timestamp ‘raw’ = metric_value
GroupMetrics MetricID_NodeID_GroupID(_GroupBucketID)_timestamp ‘raw’ = metric_value
MeterMetrics MetricID_NodeID_GroupID(_MeterID)_timestamp ‘raw’ = metric_value
Schema Design considerations: General HBase Schema Design Rules applied:
Keep RowKey, Column Family Key, Column Qualifier as short as possible.
Design the RowKey properly so as to keep rows evenly distributed in multiple data nodes.
Keep the number of column family low
Other performance considerations:
Multiple tables are created based on the data categories in the TSDR data model.
Data storage and query operations run much faster on smaller data sets stored in HBase tables with structured keys.
www.opendaylight.org11
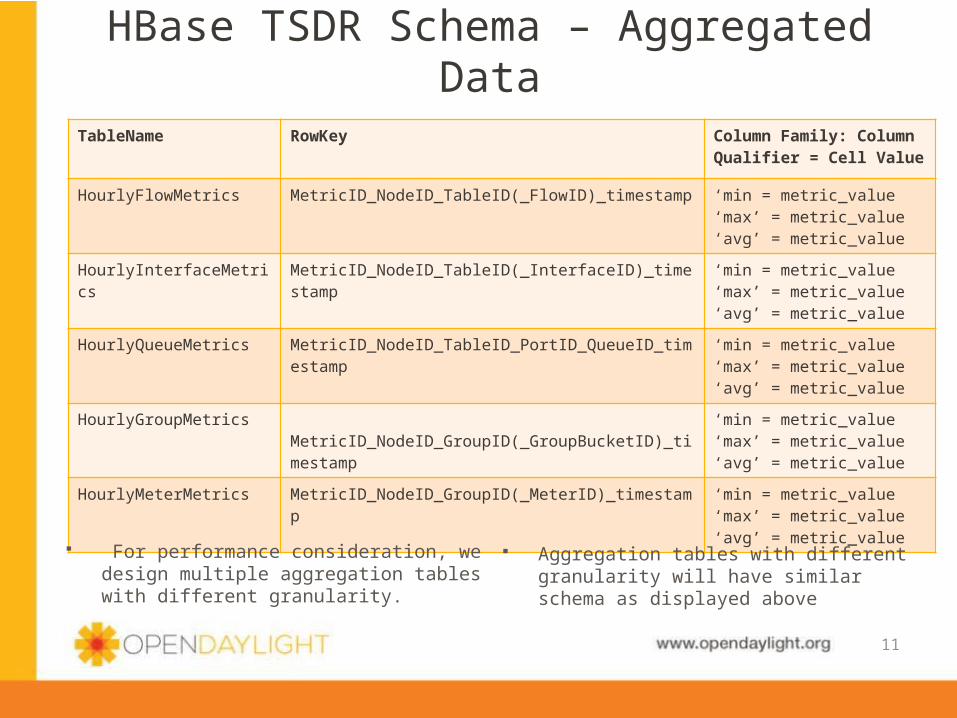
HBase TSDR Schema – Aggregated Data
TableName RowKey Column Family: Column Qualifier = Cell Value
HourlyFlowMetrics MetricID_NodeID_TableID(_FlowID)_timestamp ‘min = metric_value‘max’ = metric_value‘avg’ = metric_value
HourlyInterfaceMetrics MetricID_NodeID_TableID(_InterfaceID)_timestamp ‘min = metric_value‘max’ = metric_value‘avg’ = metric_value
HourlyQueueMetrics MetricID_NodeID_TableID_PortID_QueueID_timestamp ‘min = metric_value‘max’ = metric_value‘avg’ = metric_value
HourlyGroupMetrics MetricID_NodeID_GroupID(_GroupBucketID)_timestamp
‘min = metric_value‘max’ = metric_value‘avg’ = metric_value
HourlyMeterMetrics MetricID_NodeID_GroupID(_MeterID)_timestamp ‘min = metric_value‘max’ = metric_value‘avg’ = metric_value
For performance consideration, we design multiple aggregation tables with different granularity.
Aggregation tables with different granularity will have similar schema as displayed above

www.opendaylight.org12
HBase TSDR Data Model
TSDR HBase Plugin converts the generic TSDR data model into HBase specific data model based on HBase schema design.
TSDR HBase Plugin leverages this HBase specific data model to implement the generic
TSDR Persistence APIs including storage, query, purging, and aggregation to complete the TSDR data services in HBase.

www.opendaylight.org13
TSDR Scope in Lithium
TSDR Integrated Architecture HBase on Hadoop single node
deployment scenario
OpenFlow Statistics
Architectural framework as specified in the architectural
design
Implement Pub/Sub collection mechanism
Functionality implementation Data Collection Data Storage
Complete TSDR Persistence APIs with interface definition
TSDR Data Model to support OpenFlow Statistics
HBase Data Model for HBase Plugin implementation
In the Lithium release, we will focus on the following deliverables:
Data Type Support
Deployment scenarios support
Data Collection mechanisms
Data Persistence Layer
TSDR Plugin HBase plugin as an example
implementation Focus on the storage API
implementation in HBase plugin to support Data Storage Service in Lithium
Data Model implementation






























