



Spark MLlibでリコメンドエンジンを作った話
2016/12/21 株式会社オプト 柴田 幸輝

Agenda・自己紹介
・SparkをEMRで動かす話
・MLlibでリコメンドエンジン作った(チューニングした)話
・作ってみての振り返り
話さないこと:
・Sparkのアーキテクチャ(みなさんご存知ですよね?)
・MLlib以外のリコメンドロジックや各種パラメータ

前置き
注意事項:
・記載している内容は一部古いかもしれません
・プロダクトでの内部ロジックを含む箇所は適当にぼかす&省略しています
・Spark自体の話でない周辺のシステムの話も含んでいます
単語について:
・Spark → ○Apache Spark ☓Spark Framework
・YARN→ ○Yet Another Resource Negotiator ☓npmのアレ

自己紹介
名前:柴田 幸輝(@uryyyyyyy)
会社:株式会社オプト
役割:遊撃手(Spark / スクラムマスター / React / 組織改善 etc...)
趣味:副業でReact Native書いてる。来年はKubernetesやりたい。
その他:「それって何が嬉しいんですか?」おじさん

「それって何が嬉しいんですか?」とは
「D言語をプロダクトに突っ込もうぜ」などと言われた時に、
「それって何が嬉しいんですか?」と聞くだけの簡単なお仕事。
社内のD言語マンの記事 http://qiita.com/cedretaber/items/90b7b34ee710eb5cc965
(投入したくないとは言っていません。本当に価値があるのかを考えるだけ。)

Opt Technologiesについて
オプトのエンジニア組織の総称。カッコイイ括りにしたかった
・Geek Night定期的にやっています。
https://ichigayageek.connpass.com/
・技術マガジンも書いています。
http://tech-magazine.opt.ne.jp/
・エンジニア採用中です。
(僕からの紹介ということにして頂ければ、お互いに得しますヨ!)

SparkをEMRで動かす話

AWS EMR概要:
HadoopクラスタをSaaSとして提供してくれるサービス
ほぼ最新のHadoop / Spark / Ganglia / Hiveなどが使えて便利
http://docs.aws.amazon.com//ElasticMapReduce/latest/ReleaseGuide/emr-release-components.html
インスタンスタイプも調整可。パラメータ調整済み
http://docs.aws.amazon.com/ElasticMapReduce/latest/ReleaseGuide/emr-hadoop-daemons.html
AWSに乗っかれる(CLIツール・権限制御 etc...)
→とりあえず試す環境としては最適だと思っています。
(Google Cloud Dataprocは試してない)

EMR上でSparkを動かす
・Spark2.0をEMRで試す
http://qiita.com/uryyyyyyy/items/15f2e8f153aa86375227
↑に全部書いてあります。

EMRの特徴(S3連携)
データストレージとしてS3が使える
→HDFSを使わなくて良くなるので、Hadoopクラスタをいつでも落とせる。
→普通のHadoopクラスタでもaws-hadoopパッケージがあれば動くが、
EMR上のHadoopにはデフォルトで入ってる
※LocalでSparkを動かす際には、spark-submit / shellの引数に
`--packages org.apache.hadoop:hadoop-aws:2.7.2` などを付けます。
※EMR 4系当時、HadoopからS3へ出力する際には
`DirectOutputCommitter` 相当のハックを用意する必要がありました。
http://qiita.com/uryyyyyyy/items/e9ec40a8c748d82d4bc4

EMRの特徴(自動でログ集約)
EMRでは、自動で定期的にログを集約してS3に送ってくれます。
どのようにログが格納されるかはこちら、http://docs.aws.amazon.com/ElasticMapReduce/latest/ManagementGuide/emr-manage-view-web-log-files.html
エラー時にどう追うかはこちらをご参照ください。
・EMRのログをS3/Localから追うhttp://qiita.com/uryyyyyyy/items/8bf386da45bcd8fde387
※ログがS3に置かれるまでにはタイムラグ(5分毎)があるため、
S3にまだ上がってきてないときは、sshして中身を確認する必要があります。

EMRの特徴(Spot Instance)
EMRは内部的にEC2で構成されますが、Spot Instanceの調達が容易です。
→ただしMaster Nodeに関してはオンデマンドを使うことをオススメします
(落ちたらクラスタ自体が死んでしまうので)
(大量にアプリ起動したりしなければm1.mediumで十分です)

EMRのツラミ(Black Box)Spark 1系はassemblyがscala 2.10でビルドされている(2系では2.11)
→Scala2.11で作ったアプリが動かないので、自前でビルドして上書きした
Hadoop系がLog4Jに依存していて、SLF4Jでログ出力出来なかった。
→色々依存をいじりましたが、EMRの中が覗けないので諦めてLog4Jに。。
(書いてて思いましたが、これEMR特有の話じゃないですね。。。)

Spark MLlibでリコメンドシステムを作った話

求められる要件の概要
概要
・協調フィルタリングを用いてリコメンドエンジンを作る
・データ量(500k Product, 10M User)規模
・応答速度 100ms以下
・秒間●リクエストを想定
・Feed毎に異なる推薦ロジックの適用
・少なくとも1回/日でモデルを作り直して鮮度を保つ
プロダクト:unis → http://lp.unis.tokyo/
Criteoとだいたい同じことをしてます。
http://www.slideshare.net/RomainLerallut/recsys-2015-largescale-realtime-product-recommendation-at-criteo

協調フィルタリングの概要
疎な行列を再現できるように要素分解し、空欄に入る値を推測する。
青い四角 -> 縦 10M * 横 500k
のデータを
赤い四角 -> 縦 10M * 横 100(rank)
緑の四角 -> 縦 100(rank) * 横 500k
にする(モデル化)
from http://www.slideshare.net/jeykottalam/mllib

初期に考えた構成
配信サーバ
生ログ収集
広告アクション
推薦サーバ
格納 前処理
モデル生成
マスタデータ
学習結果のキャッシュ
内部LB(~100ms) リコメンド
ロジック

初期に考えた構成
1. S3に格納されたデータをRedShiftで前処理
2. Sparkでモデル生成して、全ユーザーの推薦結果をCacheに格納
3. 推薦サーバは、Cacheのデータに独自ロジックを掛けて返却
進め方:
・参照実装で性能要件・予算感を満たせるかを調査する
・最初はランダム生成したデータで作っていき、
上手く行ったら本番のデータを使っても実現できるかを確認する

作っていく中で起きた問題
問題1:データサイズが増えるとOoMEで落ちる
問題2:RedShiftからの読み込みで失敗する
問題3:全てを事前計算はムリ
問題4:推薦サーバが立てられない
問題5:推薦が100ms以上かかる
問題6:大きいデータでSpark Jobが急に死ぬ
問題7:処理中に突然のエラー
問題8:stagingに乗せるとSparkが重くなった
順番に見ていきます→

問題1:データサイズが増えるとOoMEで落ちる
事象:
一定規模以上のデータで試すと、OoMEが出た。
(超巨大クラスタで数時間かけたら通ったが、明らかに予算超過)

問題1:データサイズが増えるとOoMEで落ちる
原因:
recommendProductsForUsersがクッソ遅い
https://github.com/apache/spark/blob/branch-1.6/mllib/src/main/scala/org/apache/spark/mllib/recommendation/MatrixFactoriz
ationModel.scala#L283
何をしてるかというと、Product * Userの要素数のArrayを毎回作っている
→500k * 10Mサイズのデータを何回も作っていてGCが発生しまくっていた。
対策:
recommendProductsを何度も何度も呼ぶ形に変更

問題2:RedShiftからの読み込みで失敗する
事象:
データ量が大きいと発生。どうやら10分程度経つと落ちている
原因:
redshift側のクエリの結果が待ちきれなかった場合に起きる様子。
spark-redshiftパッケージのバグっぽい
対策:
前処理の中でS3への格納までやってしまい、SparkからはS3だけ見る
(そもそも毎回RedShift見る形は、処理時間が増えて動作確認も面倒だった)

配信サーバ
生ログ収集
広告アクション
推薦サーバ
格納前処理
モデル生成
マスタデータ
学習結果のキャッシュ
内部LB(~100ms) リコメンド
ロジック

小ネタ:恥ずかしいTypo推薦サーバの死活監視用のエンドポイントを作ったのですが、
稼働させた後に、URLが/heathCheckになっていたのが発覚しました。
稼働後だったので直すのに時間がかかったため、
チーム内ではしばらく「へぁすちぇっくしてる?」とバカにされました orz…お気をつけ下さい...
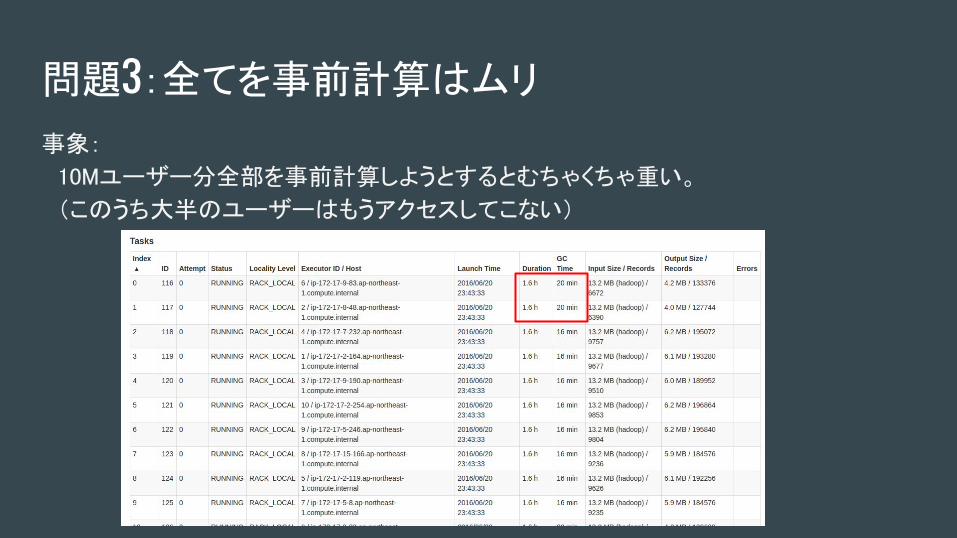
問題3:全てを事前計算はムリ
事象:
10Mユーザー分全部を事前計算しようとするとむちゃくちゃ重い。
(このうち大半のユーザーはもうアクセスしてこない)

問題3:全てを事前計算はムリ
原因:
事前計算が済んだとしても、
10M(user) * 100(product) * 1kB(record) = 1000GBくらいの容量が
必要になる。計算時間もバカにならず、データの鮮度が失われる。
対応:
とても全部計算しきれないので、
推薦サーバ側にモデルを読ませてリアルタイム推薦を試みる

配信サーバ
生ログ収集
広告アクション
推薦サーバ
格納前処理
モデル生成
マスタデータ
学習結果&モデルのキャッシュ
内部LB(~100ms) リコメンド
ロジック

問題4:推薦サーバが立てられない
事象:
Sparkでモデルを生成したものの、それが分散して保存される。
分散されたデータを読み込むために
Finagle上でSparkをlocal Modeで動かして返すという無茶を試みる...
(手法はトリッキーすぎるので割愛します。使わないでください!)
案の定めちゃくちゃ遅い
運用もめっちゃ辛そう。。

問題4:推薦サーバが立てられない
原因:
RDDでリアルタイム処理させてるから遅い←
対応:
RDDをただの行列になおして自前で計算してみると、
10倍くらい速くなる。しかしまだ足りない。
そもそもただの行列に直してしまうなら最初からそうすればいいので、
Sparkでのモデル生成の結果をただの配列に直してから保存することにする。
serializeの際に、kryoのみだとネストしたクラスをうまく扱えなかったので、
chill-bijectionを使用。

小ネタ:異論・激論・Bijectionタイトルに特に意味は無いです... 逃げ恥ファンなら伝わるはず
使い方はこんな感じです。
また、モデルの他にBiMapのserializeにも使いました。
MLlibのAPIはproductとuserのIDにIntを要求するのですが、
元データは両方ともStringで持っていたのでBiMapを使って変換しました。

問題5:推薦が100ms以上かかる
事象:
小さいデータなら余裕だが、大きいデータで呼ばれるとまだ遅い。
手元PCでpython(numpy)で同様の処理をしたところ、
800k商品 * 100rankでも内積計算は110msくらい で動く
推薦サーバのスペックならもっと速くできるはず
原因:
Scala上で処理していて効率が悪かった
※計測は、内訳を見たいのとuserIdを列挙して叩きたかったため、abでなくgatlingを利用しました
※100msは大規模モデルでの都度計算の場合の最大値です。普通は10msくらいです。

問題5:推薦が100ms以上かかる
対応:
netlib-javaを使って行列計算を行うことで高速化。
boxingコストが気になったので全部Javaで書いてチューニング!
同時リクエスト時にGCで詰まったので、さらにチューニング!!
Scalaのみで書いた場合と比べ10倍以上高速化。QPSも大幅向上

問題6:大きいデータでSpark Jobが急に死ぬ
事象:
なぜか処理中にSparkアプリが死ぬ。
ログを見てもDriver NodeにError系のログが出てない。。。
→DriverNodeがYARNにkillされてる?
Ganglia上でみるとDriverNodeのメモリが毎回●GBのところで死んでいる。
→MLlibで変にキャッシュされてる?(そんなことなかった)
https://github.com/apache/spark/blob/branch-2.0/mllib/src/main/scala/org/apache/spark/ml/recommendation/ALS.scala#L690

問題6:大きいデータでSpark Jobが急に死ぬ
原因:
上述の通り、Driver Nodeにデータを集約しているせいだった。
対応:
・Driver Nodeのメモリ割り当てを増やす。
・--conf spark.driver.maxResultSize=●g を設定し、
Driver Nodeへのデータ集約を許容する。

小ネタ:リコメンドエンジンの名前
プロダクト名がunisなので、それっぽい名前を考えました
unitem(ゆにてむ)
uniquery(ゆにーくりー)
unicorn(ゆにこーん)
etc...
(unis + unique + queryから来ています。)
外向けに使おうと思ったら既に会社名であったorz → http://uniquery.jp/(外には出さずチーム内でひっそり使ってます)

問題7:処理中に突然のエラー
事象:
Kryo serialization failed: Buffer overflow. Available: 0, required: 10. To avoid this,
increase spark.kryoserializer.buffer.max value.
原因:
kryoのシリアライズでデータサイズ超過で落ちている
対応:
--conf spark.kryoserializer.buffer.max=1296m で解決

問題8:stagingに乗せるとSparkが重くなった
事象:
dev環境では速かったのに
staging環境に載せて前処理合わせて実行すると遅くなった。
違いは入力のみのはず,,,と思い、
一度ファイル出力して読み込み直すと何故か速くなった
さらに調査すると、CPU振り切ってるNodeと途中で遊んでるNodeがあった。

問題8:stagingに乗せるとSparkが重くなった
原因:
staging環境ではS3にunloadされたファイルが2つしか置かれてなく、
適切にpartitionが分けられていなかった。
対応:
データ読み込み後にHashPartitionを掛けることで解消
(180は適当に決めました。。)

振り返り

振り返り
・推測するな、計測しろ
→JVM系ツールや可視化ツールを使って特定するの大事
特にGangliaとSpark WebUIは重宝しました。
・リソース試算
とりあえず問題なく動くレベルで予算を抑えておきましょう。
それで予算超過なら、設計や仕様を見直します。
(インスタンスサイズの調整程度で変わるコストは数割くらいです)
落ち着いてからオンプレ検討するなど

振り返り
・小さく試す
→ボトルネックの特定がしやすいように、
また繰り返し試しやすいように、最小構成を持っておくと良いです。
(そういうときにEMRおすすめです)
・早めに本番データで試す
→机上で上手く行っても、本番データでは結構バグります。
これはデータサイズだけでなく、データのばらつき具合も影響します。
・有識者に聞く(居なければ外部から招聘する)
→めっちゃ重要。行き詰まったり、明後日の方向に進むのを防げます。

Appendix

分散処理基盤としてSparkを活用した際のTipsSpark on EMR(YARN)の個人的Tipshttp://qiita.com/uryyyyyyy/items/f8bb1c4a4137e896de7f
リソースチューニング例http://www.slideshare.net/hadooparchbook/top-5-mistakes-when-writing-spark-applications
EMRでのリソース割り当て例http://qiita.com/uryyyyyyy/items/5cc7fa8957ad5953f111






























