




© 2013 IBM Corporation
1
Scalable Parallel File I/O with IBM GPFS
Klaus Gottschalk HPC Architect Germany

© 2013 IBM Corporation
2
Best Practices for Scalable I/O are not always straight forward
• Scaling of parallel Applications sometimes reveals bad file access patterns
• Assumptions on local disk file systems don’t scale to parallel file system
• Straight forward approach works fine until application is scaled to large node
counts
• Collaboration with LRZ to develop best practice recommendation started
– Co-workers needed
Agenda
• GPFS Features and new GPFS 3.5 Update
– GPFS Storage Server (GSS) – Friday Karsten Kutzer, IBM
– Active File Management (AFM)
– File Placement Optimizer (FPO)
• File Access Problems and Best Practice Examples

© 2013 IBM Corporation
3
File system
263 files per file system
Maximum file system
size: 299 bytes
Production 19PB file
system
Number of nodes
1 to 8192 (16284
Extreme Scalability
No special nodes
Add/remove nodes
and storage on the fly
Rolling upgrades
Administer from any
node
Data replication
Snapshots
File system journaling
Proven Reliability
Integrated tiered storage
Storage pools
Quotas
Policy-Driven automation
Clustered NFS
SNMP monitoring
TSM / HPSS (DMAPI)
Manageability
The IBM General Parallel File System (GPFS) Shipping since 1998

© 2013 IBM Corporation
4
IBM General Parallel File System (GPFS™) – History and evolution
2006 2005 2002 1998
HPC
GPFS
General File
Serving
Standards
Portable
operating
system
interface
(POSIX)
semantics
-Large block
Directory and
Small file perf
Data
management
Virtual
Tape Server
(VTS)
Linux®
Clusters
(Multiple
architectures)
IBM AIX®
Loose Clusters
GPFS 2.1-2.3
HPC
Research
Visualization
Digital Media
Seismic
Weather
exploration
Life sciences
32 bit /64 bit
Inter-op (IBM AIX
& Linux)
GPFS Multicluster
GPFS over wide
area networks
(WAN)
Large scale
clusters
thousands of
nodes
GPFS 3.1-3.2
2009
First
called
GPFS
GPFS 3.4
Enhanced
Windows cluster
support
- Homogenous
Windows Server
Performance and
scaling
improvements
Enhanced
migration and
diagnostics
support
2010
GPFS 3.3
Restricted
Admin
Functions
Improved
installation
New license
model
Improved
snapshot and
backup
Improved ILM
policy engine
2012
Ease of administration Multiple-networks/ RDMA Distributed Token Management Windows 2008 Multiple NSD servers NFS v4 Support Small file performance
Information lifecycle management (ILM)
Storage Pools
File sets
Policy Engine
GPFS 3.5
Caching via
Active File
Management
(AFM)
GPFS Storage
Server
GPFS File
Placement
optimizer (FPO)

© 2013 IBM Corporation
5
GPFS introduced
concurrent file
system access from
multiple nodes.
Evolution of the global namespace:
GPFS Active File Management (AFM)
Multi-cluster expands the global
namespace by connecting
multiple sites
AFM takes global namespace
truly global by automatically
managing asynchronous
replication of data
GPFS
GPFS
GPFS
GPFS
GPFS
GPFS
1993 2005 2011

© 2013 IBM Corporation
6
NAS key building block of cloud storage architecture
Enables edge caching in the cloud
DR support within cloud data repositories
Peer-to-peer data access among cloud edge sites
Global wide-area filesystem spanning multiple sites in the cloud
HPC Distributed NAS Storage Cloud
AFM Use Cases
WAN Caching: Caching across WAN between SoNAS clusters or SoNAS and another NAS vendor
Data Migration: Online cross-vendor data migration
Disaster Recovery: multi-site fileset-level replication/failover
Shared Namespace:
across SoNAS clusters
Grid computing: allowing data to move transparently during grid workflows
Facilitates content distribution for global enterprises, “follow-the-sun” engineering teams
© 2013 IBM Corporation
7
pNFS/NFS over the WAN
GW Nodes SoNAS layer
Cache Cluster Site1
(GPFS+Panache)
Cache Cluster Site 2
(GPFS+Panache)
Home Cluster Site
(Any NAS box or SOFS)
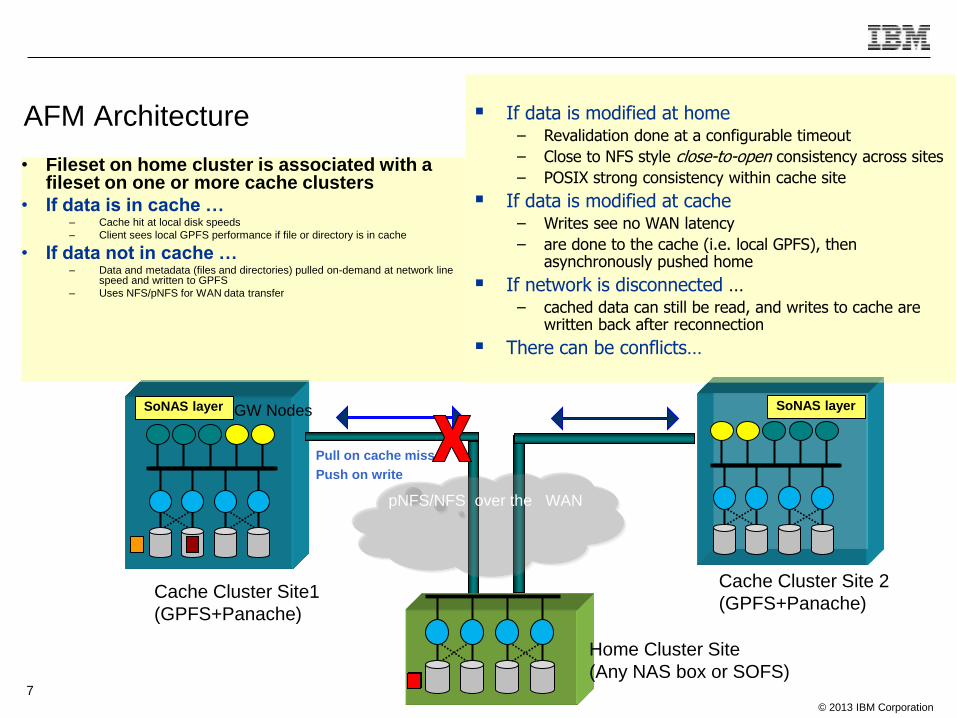
• Fileset on home cluster is associated with a fileset on one or more cache clusters
• If data is in cache … – Cache hit at local disk speeds
– Client sees local GPFS performance if file or directory is in cache
• If data not in cache … – Data and metadata (files and directories) pulled on-demand at network line
speed and written to GPFS
– Uses NFS/pNFS for WAN data transfer
SoNAS layer
AFM Architecture
Pull on cache miss
Push on write
If data is modified at home – Revalidation done at a configurable timeout
– Close to NFS style close-to-open consistency across sites
– POSIX strong consistency within cache site
If data is modified at cache – Writes see no WAN latency
– are done to the cache (i.e. local GPFS), then asynchronously pushed home
If network is disconnected … – cached data can still be read, and writes to cache are
written back after reconnection
There can be conflicts…
© 2013 IBM Corporation
8
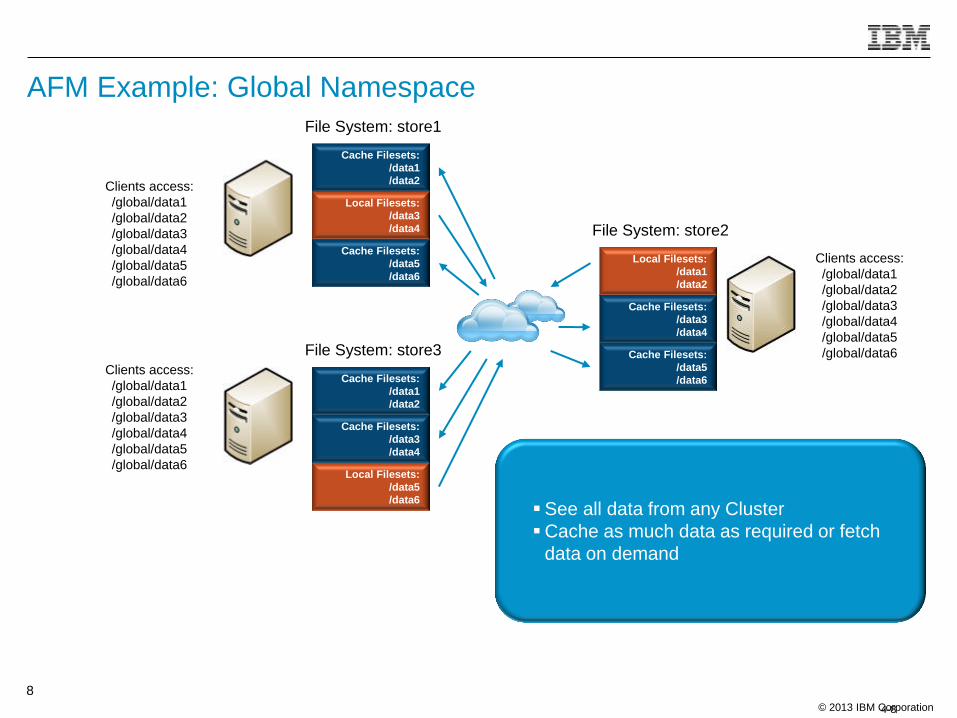
AFM Example: Global Namespace
4-8
Clients access:
/global/data1
/global/data2
/global/data3
/global/data4
/global/data5
/global/data6
Clients access:
/global/data1
/global/data2
/global/data3
/global/data4
/global/data5
/global/data6
Clients access:
/global/data1
/global/data2
/global/data3
/global/data4
/global/data5
/global/data6
Cache Filesets:
/data1
/data2
Local Filesets:
/data3
/data4
Cache Filesets:
/data5
/data6
File System: store1
Local Filesets:
/data1
/data2
Cache Filesets:
/data3
/data4
Cache Filesets:
/data5
/data6
File System: store2
Cache Filesets:
/data1
/data2
Cache Filesets:
/data3
/data4
Local Filesets:
/data5
/data6
File System: store3
See all data from any Cluster
Cache as much data as required or fetch
data on demand

© 2013 IBM Corporation
9
Policy based Pre-fetching and Expiration of Data
• Policy-based pre population
• Periodically runs parallel inodescan at home
– Selects files/dirs based on policy criterion
• Includes any user defined metadata in xattrs or other file attributes
• SQL like construct to select
• RULE LIST „prefetchlist' WHERE FILESIZE > 1GB AND MODIFICATION_TIME
> CURRENT_TIME- 3600 AND USER_ATTR1 = “sat-photo” OR USER_ATTR2 =
“classified”
• Cache then pre-fetches selected objects
– Runs asynchronously in the background
– Parallel multi-node prefetch
– Can callout when completed
• Staleness Control
– Defined based on time since disconnection
– Once cache is expired, no access is allowed to cache
– Manual expire/unexpire option for admin
• Mmafmctl –expire/unexpire, ctlcache in sonas
– Allowed onlys for ro mode cache
– Disabled for SW & LU as they are sources of data themselves

© 2013 IBM Corporation
10
Architecture
Use disk local to each server
All nodes are NSD servers and NSD clients
Designed for MapReduce workloads
File Placement Optimizer (FPO)
GPFS
© 2013 IBM Corporation
11
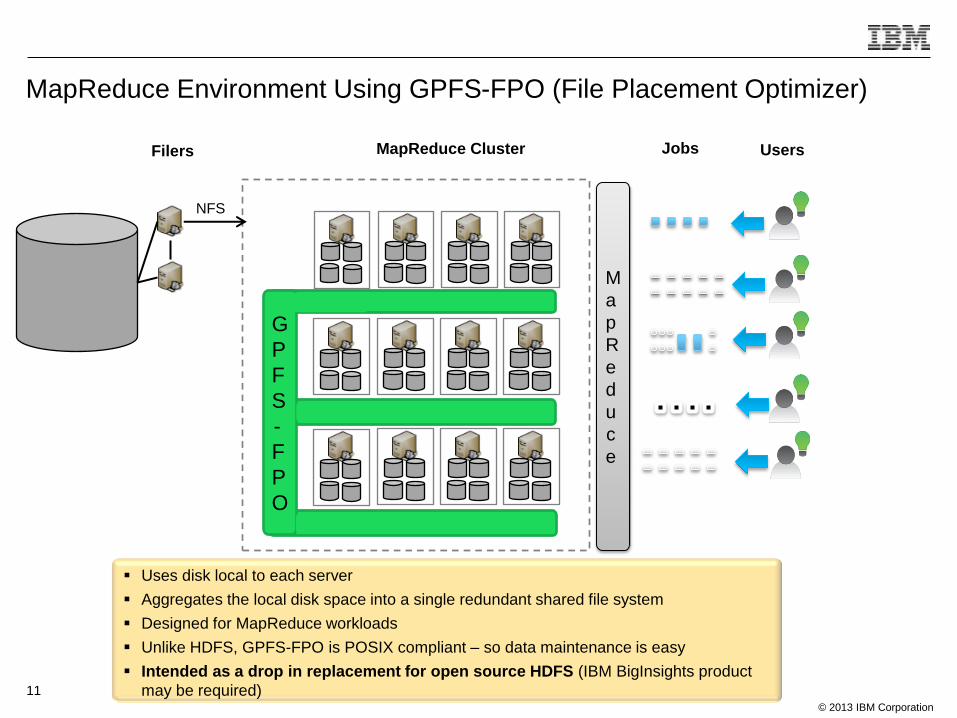
MapReduce Environment Using GPFS-FPO (File Placement Optimizer)
MapReduce Cluster
NFS
Filers
M
a
p
R
e
d
u
c
e
Users Jobs
G
P
F
S
-
F
P
O
Uses disk local to each server
Aggregates the local disk space into a single redundant shared file system
Designed for MapReduce workloads
Unlike HDFS, GPFS-FPO is POSIX compliant – so data maintenance is easy
Intended as a drop in replacement for open source HDFS (IBM BigInsights product
may be required)

© 2013 IBM Corporation
12
Another GPFS-FPO Use Case – Typical In HPC
HPC Cluster
NFS
Filers
Project 1
Project 2
L
S
F
Users Jobs
Local file systems
Local file systems used for high speed scratch space
Usually scratch space is RAID 0 (for speed) so reliability can be an issue
Disk capacity for scratch space can be a limiting factor
Inaccessible scratch disk renders the compute node useless
File systems used: EXT2, EXT3, XFS
© 2013 IBM Corporation
13
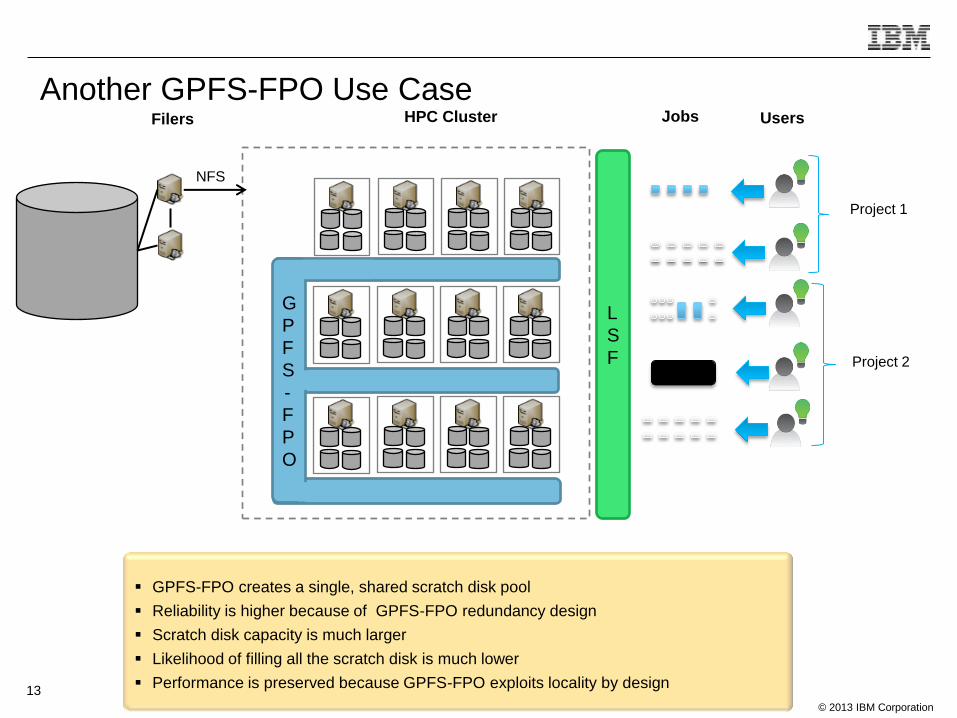
Another GPFS-FPO Use Case HPC Cluster
NFS
Filers
Project 1
Project 2
L
S
F
Users Jobs
G
P
F
S
-
F
P
O
GPFS-FPO creates a single, shared scratch disk pool
Reliability is higher because of GPFS-FPO redundancy design
Scratch disk capacity is much larger
Likelihood of filling all the scratch disk is much lower
Performance is preserved because GPFS-FPO exploits locality by design

© 2013 IBM Corporation
14
GPFS Features and Internal Structures
• Wide striping to all NSDs in a GPFS Pool
• Token based locking
• Byte Range Locking
• Fine granular directory locking

© 2013 IBM Corporation
15
GPFS Concept – Wide Striping
disk
node
disk
node
node
node
disk
1 2 3 4 5 6 file
GPFS storage
client node
GPFS storage
server node
disk storage
30 MB/s per job
10 MB/s per disk

© 2013 IBM Corporation
16
GPFS Concepts - Locking and Tokens
A
A 0 0
B C D
2 4 6 8
lock range 0 – 2 GB 2 – 4 GB 5 - 7 GB 4 – 6 GB
file
GB B C
D
Overlapping
lock range Node D has to wait for
Node C to release token
GPFS uses a token based locking mechanism • On a lock request the token system manager grants access for the token validity time
• No further connect to the manager is required – reduced locking overhead
• After token expiration no client is required for recovery
GPFS provides byte-range tokens for synchronizing parallel access to file
• With valid token, each task can independently write in its file region

© 2013 IBM Corporation
17
Parallel File Access
• Parallel write requires byte-range locking of independent regions
• Overlapping regions cause serialization of write access
– A Task needs to wait until token expires or is freed by holding task
– Potential race conditions for overlapping region
• Parallel I/O Libraries ease use and hide complexity of locking mechanism
• Additional provide block aggregation and caching
– Examples: MPI-IO, MIO
• Data Region per task should be large enough

© 2013 IBM Corporation
18
Fine Granular Directory Locking (FGDL)
GPFS Optimization to improve write sharing
• GPFS directories use extendible hashing to map file names to directory blocks
– Last n bits of hash value determine directory block number
– Example: hash(“NewFile") = 10111101 means the directory entry goes in block 5
• File create now only locks the hash value of the file name
– lock ensures against multiple nodes simultaneously creating the same file
– actual update shipped to metanode
– If create requires directory block split, lock upgraded to cover both old and new block
– Parallel file create performance no longer depends upon whether or not the files are in the same directory
Traditional file systems implemented directories as linear file. A File create locked the entire directory
• Fine if files are in different directories
• Not the best if they’re in the same directory
• Unfortunately, this is a natural way to organize files, and programmers are hard to re-educate
• Checkpoints, output for a time-step
hash(“NewFile") = 10111101

© 2013 IBM Corporation
19
Many files created in single Directory
Examples
• Parallel Application writes checkpoint file from each task
• Serial application used to process high number of data files is parallelized using
trivial SPMD mode (i.e. rendering film, compressing multiple files)
Problem
• Creation of files is serialized in traditional file systems
• With GPFS FGDL feature parallel creation of files in single directory scales
nicely, but only up to certain number of tasks
– Max. parallel tasks is depending of file system configuration (>1000)
• How small can a byte-range of a directory object be
• How many tokens can be managed for a single object
Solution
• Parallel Task creates sub-directory per node (or task) and stores its files there

© 2013 IBM Corporation
20
Many Directories created from a parallel Task
A parallel application creates a directory per task to place its file in them
• Follow on problem to many files in same directory
Problem
• Parent directory becomes a bottleneck
• Application startup time does not scale linearly
– Startup time with 1000 tasks ~10min
• Directory Write Tokens “bounces” around between nodes
Solution
• Directories are created by single task (task0 or within the job start script)
• One write token is required for task0
– Startup time with 1000 ~20sec

© 2013 IBM Corporation
21











![IBM General Parallel File System (GPFS) and Oracle RAC [ID 302806.1]](https://static.cupdf.com/doc/110x72/544a8f96af79596c4d8b48c9/ibm-general-parallel-file-system-gpfs-and-oracle-rac-id-3028061.jpg)

















