



Open SourceData Collection/Ingestion
Treasure Data, Inc.www.treasuredata.com

Hello!
- “Committer” of Fluentd
- Treasure Data, Inc.
- Former Algorithmic Trader
- Stanford Math and CS

Table of Contents
1. Why you should care2. Data Collection v. Data Ingestion3. Examples: Data Collection Tools4. Examples: Data Ingestion Tools5. Case Study: Async App Logging
Links to be added after the talk.

Data Collection/Ingestion is HARD
Data Sources Raw Data Storage
Processed Data
AnalysisEnvironment
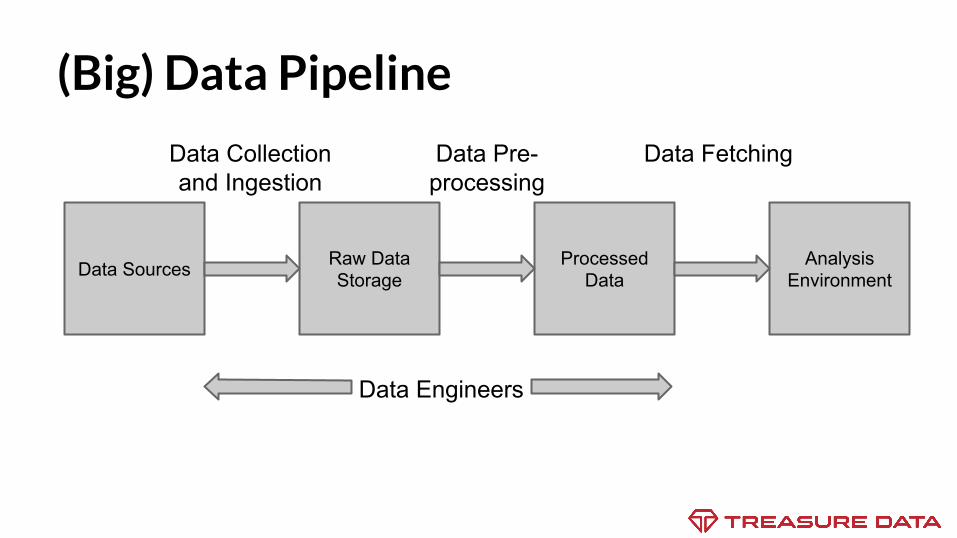
(Big) Data Pipeline
Data Collection and Ingestion
Data Pre-processing
Data Fetching
Data Engineers

Data Sources Raw Data Storage
Processed Data
AnalysisEnvironment
If Data Collection Goes Awry...
Data Collection and Ingestion
Data Pre-processing
Data Fetching
Data Engineers

Collection v. Ingestion

Data Collection
- Happens where data originates
- “logging code”
- Batch v. Streaming
- Pull v. Push
log.error(“FUUUUU....WHY!?”)
cln.send({“uid”:1,”action”:”died”})
200 GET a.com/?utm=big%20data

Data Ingestion
- Receives data
- Sometimes coupled with storage
- Routing data Data Ingestion Layer

ex. Data Collection Tools

rsyslog
- The grandfather of data collectors
- Streaming
- Installed by default, widely understood
- Not as easy to extend/configure

rsyslog
https://github.com/rsyslog/rsyslog/blob/master/ChangeLog

Scribe
- Written originally at Facebook
- Streaming
- Fast (C++)
- Nightmare to build, largely
abandoned

Flume-ng- Written and maintained by
Cloudera (successor to Flume)
- Commercial support by
Cloudera. Track record for
Hadoop
- Java can be heavy-handed for
some orgs/cases

Logstash
- Pluggable architecture, rich
ecosystem
- The “L” of the ELK stack by
Elastic
- JRuby
- HA uses Redis as a queuehttp://apuntesdetrabajo.es/?p=263

Heka
- Developed at Mozilla
- Written in Go, extensible w/ Lua
- Plugin system, but compilation
needed (Go’s limitation, may
change)
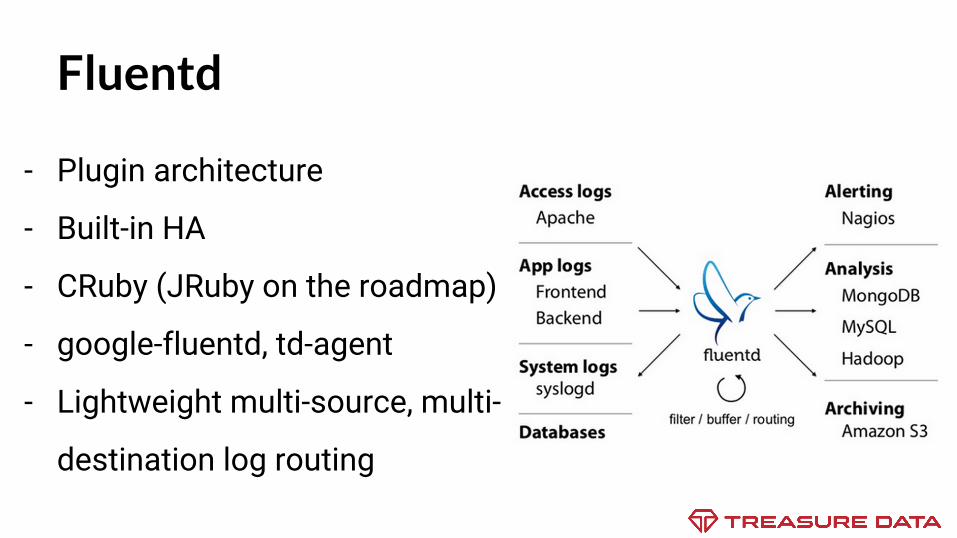
Fluentd
- Plugin architecture
- Built-in HA
- CRuby (JRuby on the roadmap)
- google-fluentd, td-agent
- Lightweight multi-source, multi-
destination log routing

Embulk
- Plugin architecture
- Focuses on Batch workloads
- Java/JRuby
- Very new! (looking for
contributors!)

ex. Data Ingestion Tools

RabbitMQ
- Written in Erlang, supported by
Pivotal
- Implements AMQP

Kafka
- Begun at LinkedIn, now Confluent
- Topic-based Message Broker:
Producer/Broker/Consumer
- Distributed design
- Provides at least once, at most
once by consumers

Fluentd!?
- Used (abused?) as a bus/MQ
- tag-based event routing
- Can be combined with
RabbitMQ/Kafka, etc.

case study: Async App Logging
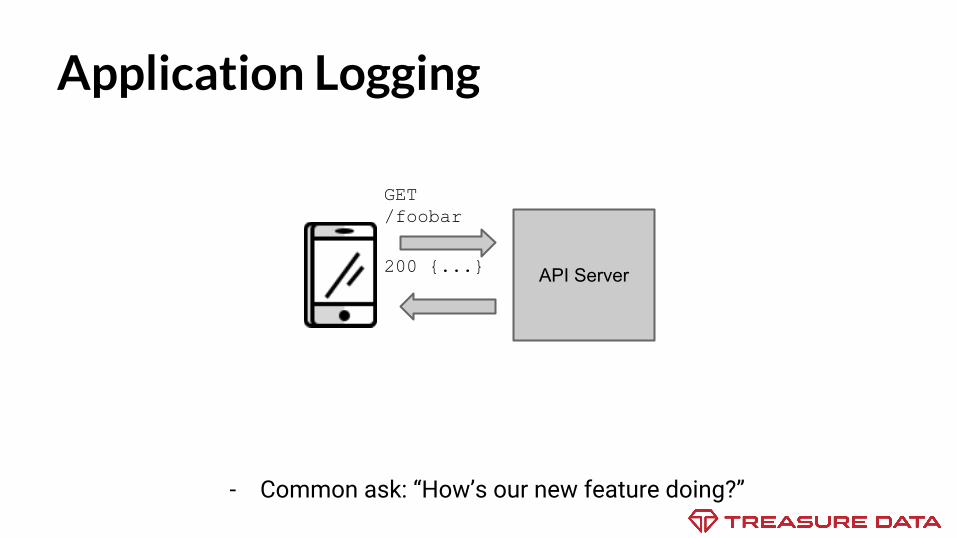
Application Logging
- Common ask: “How’s our new feature doing?”
GET /foobar
API Server200 {...}

Application Logging
- What NOT to do: synchronous logging
GET /foobar
API Server200 {...} Data Backend
write
ack

Application Logging
- What NOT to do: synchronous logging
GET /foobar
API Server200 {...} Local Data Collector
write Flush
DataBackendack
Buffer

- Is writing to a local log collector safe?
- What if the log collector retries by error?
But wait...
- A lot of problems to think about!

“Much of the blame, little of the glory”(Just kidding. The entire data team relies on YOU!)

Thank you!(...and we are hiring!)
www.treasuredata.com/careers

- Software- www.fluentd.org- hekad.readthedocs.org- logstash.org- kafka.apache.org- Embulk.org- www.rabbitmq.com
- Ideas- https://engineering.linkedin.com/distributed-systems/log-what-every-
software-engineer-should-know-about-real-time-datas-unifying- http://radar.oreilly.com/2015/04/the-log-the-lifeblood-of-your-data-
pipeline.htmlL
Bibliography






























