ICO Learning
Gerhard Neumann
Seminar A, SS06

Overview
Short Overview of different control methods Correlation Based Learning ISO Learning Comparison to other Methods ([Wörgötter05])
TD Learning STDP
ICO Learning ([Porr06]) Learning Receptive Fields ([Kulvicius06])

Comparison of ISO learning to other Methods
Comparison for Classical Conditioning learning Problems (open loop control)
Relating RL to Classical Conditioning Classical Conditioning: Pairing of two subsequent
stimuli is learned such that the presentation of the first stimulus is taken as a predictor of the second one.
RL: Maximization of Rewards:
v … Predictor of future reward

RL for Classical Conditioning
TD-Error: Derivation Term :
Weight Change: => Nothing new so far…
Goal: Output v should react after learning to the onset of the CS xn, and remains active until the reward terminates
Present CS internally by a chain of n + 1 delayed pulses xi
Replace the states from traditional RL with time steps

RL for Classical Conditioning
Special kind of E-Trace Serial Compound
Representation Learning Steps:
Rectangular response of v Special Treatment of the
reward not necessary x0 can replace the reward
when setting w0 to 1 at the beginning

Comparison for Classical Conditioning
Correlation Based Learning
„Reward“ x0 is not an independent term as in TD learning
TD-Learning

Comparison for Classical Conditioning TD-Learning
ISO-Learning
Uses another form of E-Traces (Band-pass filters) Used for all input pathways
-> also for calculating the output
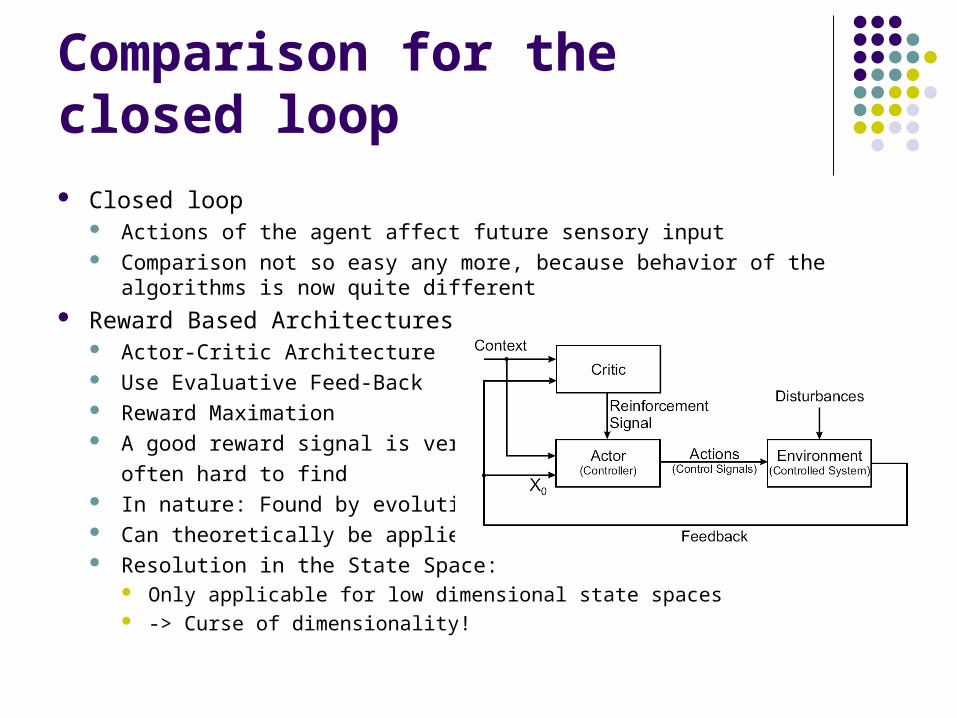
Comparison for the closed loop Closed loop
Actions of the agent affect future sensory input Comparison not so easy any more, because behavior of the algorithms is now
quite different Reward Based Architectures
Actor-Critic Architecture Use Evaluative Feed-Back Reward Maximation A good reward signal is very
often hard to find In nature: Found by evolution Can theoretically be applied to any learning problem Resolution in the State Space:
Only applicable for low dimensional state spaces -> Curse of dimensionality!

Comparison for the closed loop Correlation Based Architectures
Non-evaluative feedback, all signals are value free Minimize Disturbance
Valid Regions are usually much bigger than in for reward maximation Better Convergence !! Restricted Solutions
Evaluations are implicitely build into the sign of the reaction behavior Actor and Critic are the same architectureal building block Only for a restricted set of learning problems
Hard to apply for complex tasks Resolution in Time:
Only looks at temporal correlation of the input variables Can be applied for high dimensional state spaces

Comparison of ISO learning and STDP ISO learning generically produces a bimodal weight change
curve Similiar to the STDP (Spike timing dependent plasticity) learning
weight change curve
ISO learning STDP rule: Potential from the synapse: Filtered version of a spike Gradient Dependent Model
Much faster time scale used in STDP Can model different kind of synapses with different filters easily

Overview
Short Overview of different control methods Correlation Based Learning ISO Learning Comparison to other Methods ([Wörgötter05])
TD Learning STDP
ICO Learning ([Porr06]) Learning Receptive Fields([Kulvicius06])

ICO (Input Correlation Only) Learning
Drawback of Hebbian Learning Auto-Correlation can result in divergence even if x0 = 0 ISO learning:
Relies on orthogonal filters of different inputs Orthogonal to its derivative Only works for if steady state is assumed
Auto correlation does not vanish any more if the weights are changed during the impulse response of the filters
-> can not be applied for large learning rates => Can be used only for small learning rates, otherwise
Auto-Correlation causes divergence of the weights
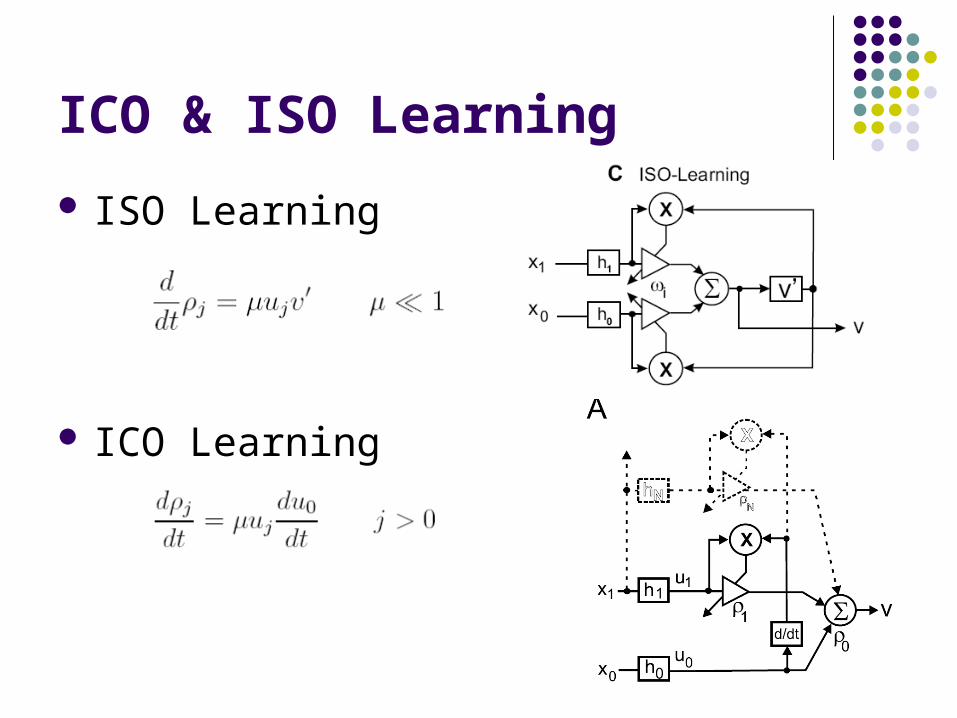
ICO & ISO Learning
ISO Learning
ICO Learning

ICO Learning
Simple adaption of the ISO Learning rule Correlate only inputs with each other No correlation with the output
-> No Auto Correlation Define one Input as the reflex input x0 Drawback:
Loss of Generality: Not Isotropic any more Not all inputs are treated equally any more
Advantage: Can use much higher learning rates (up to 100x faster) Can use almost arbitrary types of filter No Divergence in weights any more

ICO Learning
Weight change curve (open loop, just one Filter bank) Same as for ISO
learning
Weight changing curve ISO learning contains
exponential instability Even after setting x0 to
0 after 100000 timesteps
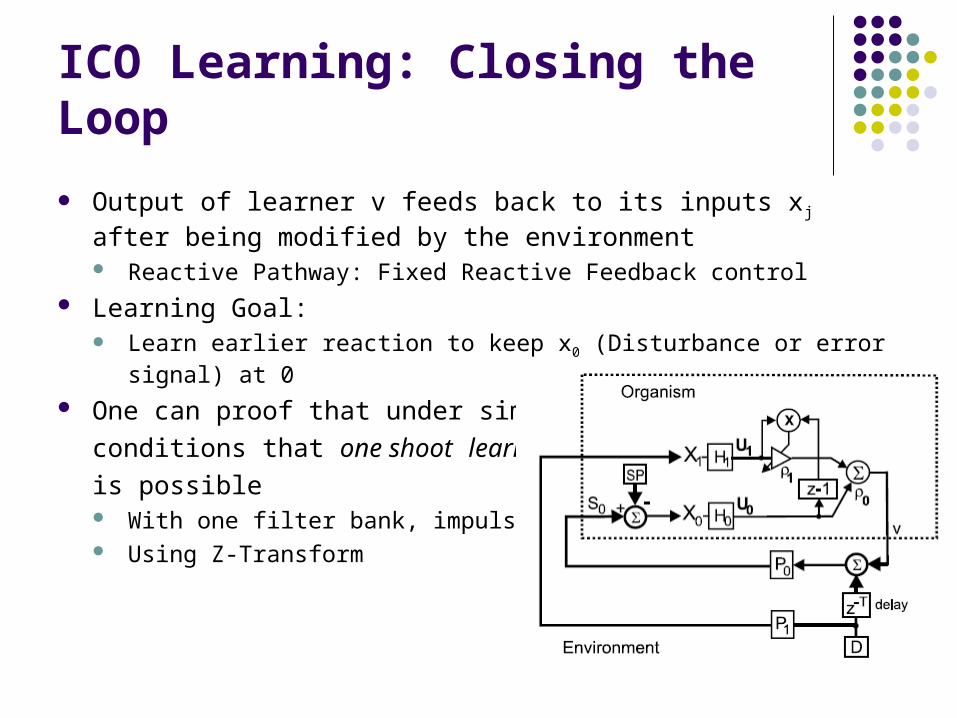
ICO Learning: Closing the Loop
Output of learner v feeds back to its inputs xj after being modified by the environment Reactive Pathway: Fixed Reactive Feedback control
Learning Goal: Learn earlier reaction to keep x0 (Disturbance or error signal) at 0
One can proof that under simplified
conditions that one shoot learning
is possible With one filter bank, impulse signals Using Z-Transform

ICO Learning: Applications
Simulated Robot Experiment: Robot has to find food (disks in the environment) Sensors for Uncondition Stimulus:
2 Touchsensors (Left + Right) Reflex: Robot elicits a sharp turn as it touches a disk
Pulls the robot into the centre of the disk Sensors for predictive Stimulus
2 Sound (Distance) Sensors (Left + Right), Disks Can measure distance to the disk Stimulus: Difference between Left + Right sound signals Use 5 filters (resonators) in the filter bank
Output v: Steering angle of the Robot

ICO Learning: Simulated Robot
Only One experience has been sufficient to show an adapted behavior Only Possible with ICO learning

Simulated Robot Comparison for different Learning rates
ICO Learning ISO Learning
Learning was successful if for a sequence of four contacts Equivalent for small learning rates
Small Auto correlation term

Simulated Robot
Two Different Learning Rates
Divergent Behavior of ISO learning for high learning rates Robot shows avoidance behavior from food disks
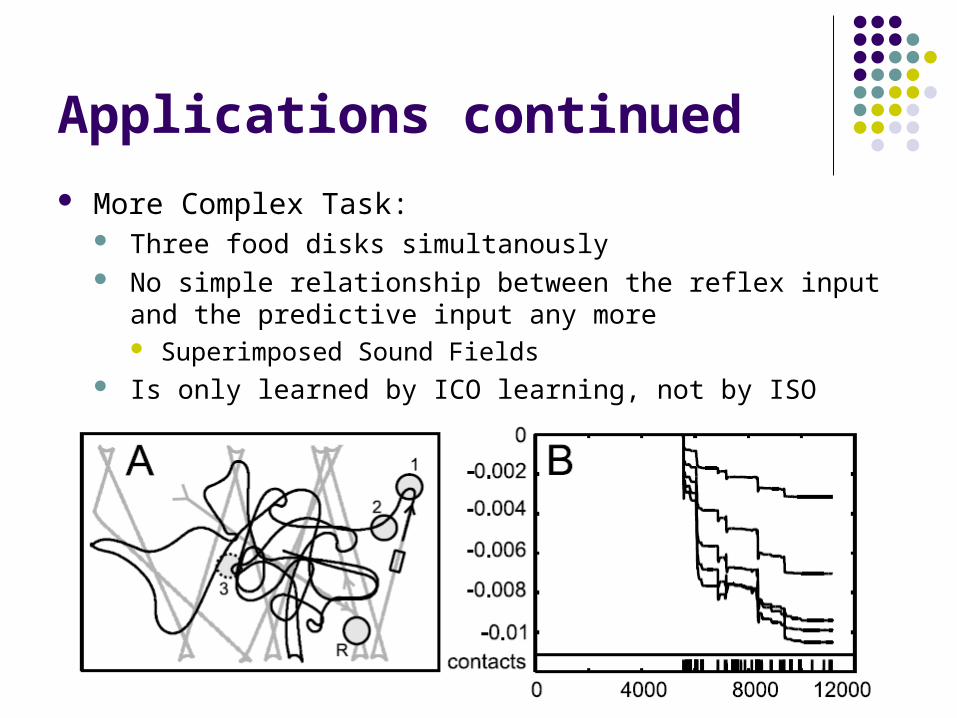
Applications continued
More Complex Task: Three food disks simultanously No simple relationship between the reflex input and the
predictive input any more Superimposed Sound Fields
Is only learned by ICO learning, not by ISO learning

ICO: Real Robot Application
Real Robot: Target White disk from a distance Reflex: Pulls the robot into the white disk just at the
moment the robot drives over the disk Achieved by analysing the bottom-scanline of a camera
Predictive input: Analysing Scanline from the top of the image
Filter Bank 5 FIR Filters with different filter length
All coefficients set to 1 -> smear out signal Narrow viewing angle of the camera
Put robot more or less in front of the disk

ICO: Real Robot Experiment Processing the input
Calculate the deviation of the positions of all white points in a scanline to the center of the scanline
1D signal Results:
A before learning B & C After learning
14 contacts Weights oscillate around
their best values, but do
not diverge

ICO Learning: Other Applications
Mechanical Arm Arm is always controlled with a PI controller to a
specified set point Input of the PI controller: Motor position PI controller is used as reactive filter
Disturbance: Pushing force of a second small arm mounted to the
main arm Fast reacting touch sensors measures D.
Use 10 resonator filters in the filter bank
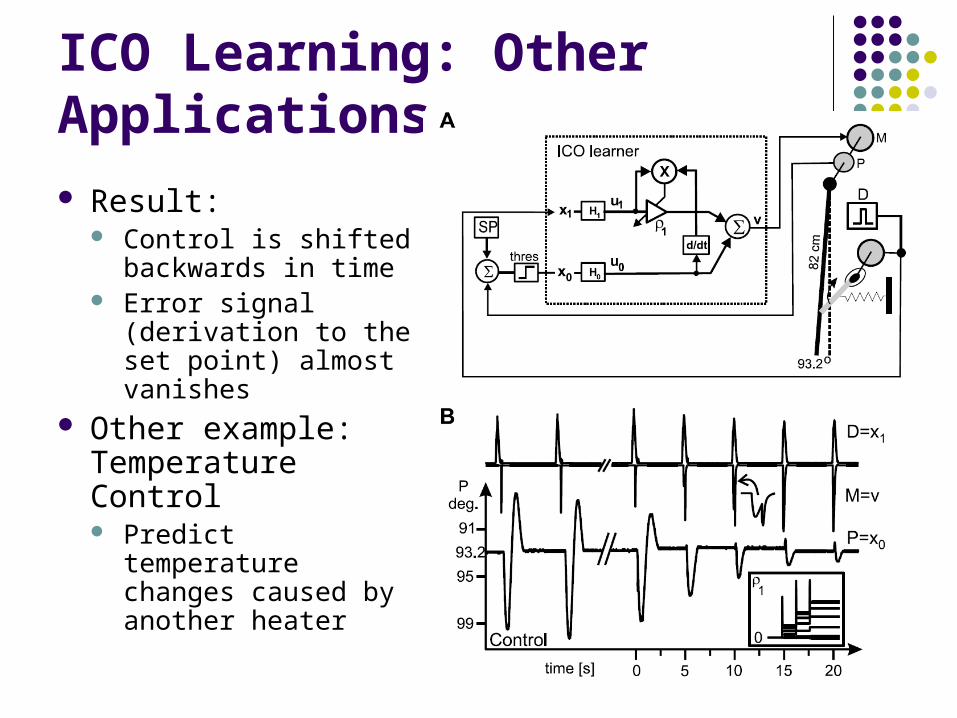
ICO Learning: Other Applications
Result: Control is shifted
backwards in time Error signal
(derivation to the set point) almost vanishes
Other example: Temperature Control Predict temperature
changes caused by another heater

Overview
Short Overview of different control methods Correlation Based Learning ISO Learning Comparison to other Methods ([Wörgötter05])
TD Learning STDP
ICO Learning ([Porr06]) Learning Receptive Fields([Kulvicius06])

Development of Receptive fields through temporal Sequence learning [Kulvicius06]
Develop receptive fields by ICO learning Learn behavior and receptive fields simultanously Usually these 2 learning processes are considered seperately
First approach where the receptive field and the behavior is trained simultanously!!
Shows the application of ICO learning for high dimensional input spaces
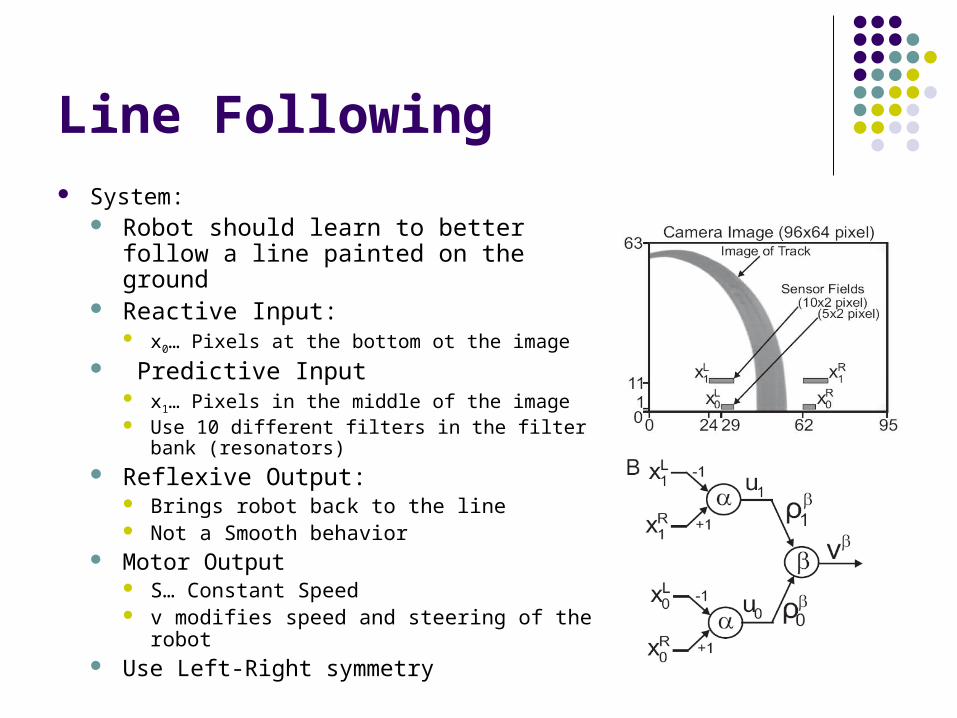
Line Following System:
Robot should learn to better follow a line painted on the ground
Reactive Input: x0… Pixels at the bottom ot the image
Predictive Input x1… Pixels in the middle of the image Use 10 different filters in the filter bank
(resonators) Reflexive Output:
Brings robot back to the line Not a Smooth behavior
Motor Output S… Constant Speed v modifies speed and steering of the robot
Use Left-Right symmetry
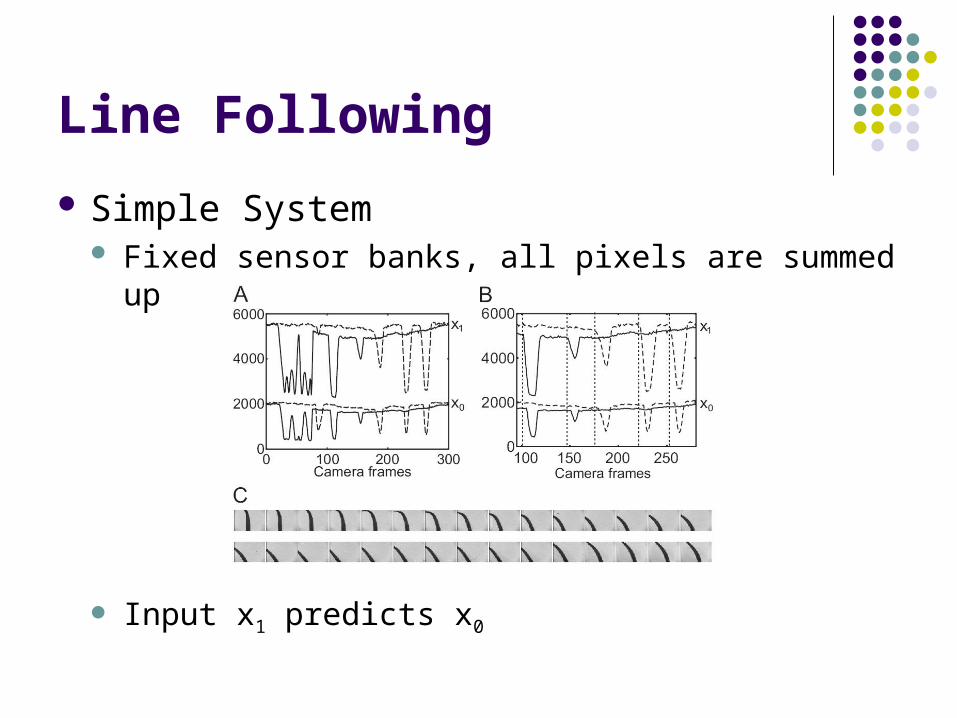
Line Following
Simple System Fixed sensor banks, all pixels are summed up
Input x1 predicts x0
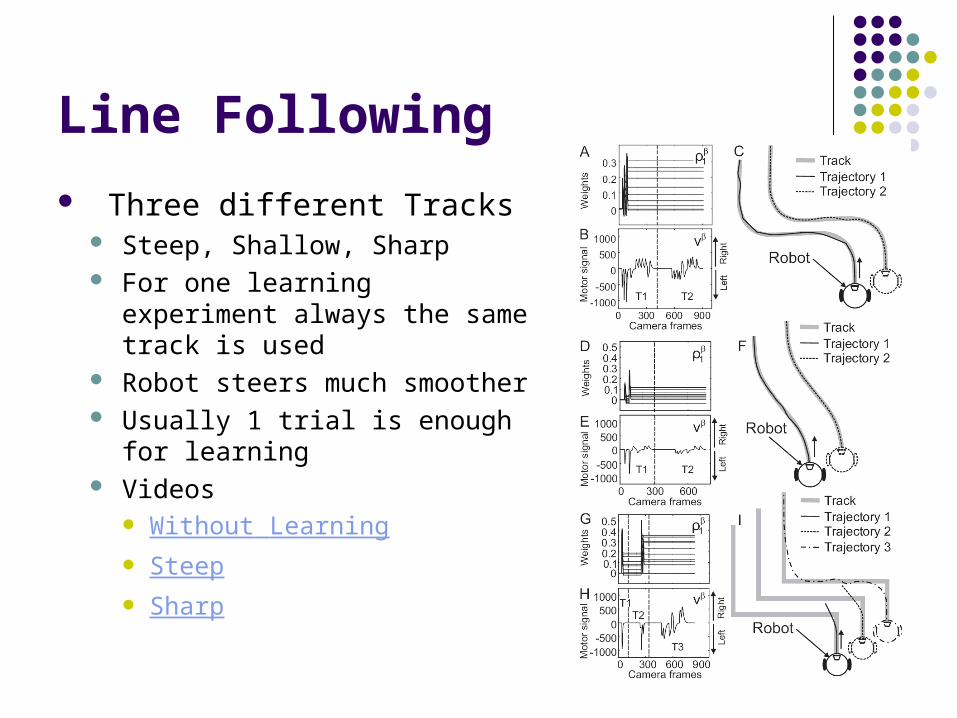
Line Following
Three different Tracks Steep, Shallow, Sharp For one learning experiment
always the same track is used Robot steers much smoother Usually 1 trial is enough for
learning Videos
Without Learning Steep Sharp

Line Following: Receptive Fields
Receptive fields Use 225 pixels for the far sensors Use individual filter banks for each pixel
10 filters per pixel Left-Right Symmetry:
Left Receptive field is a mirror of the right
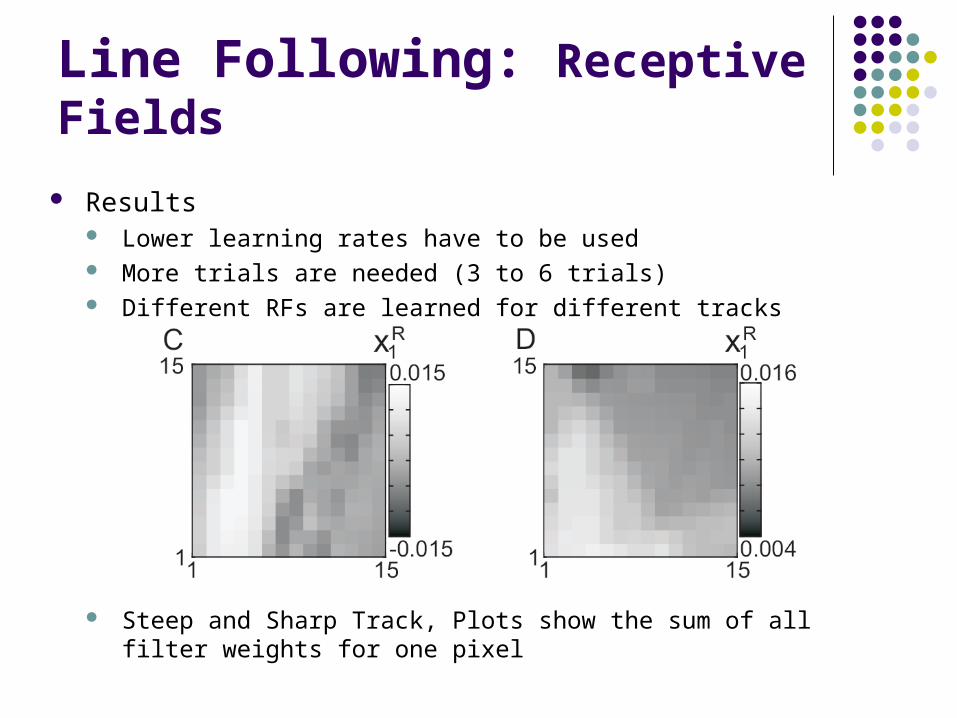
Line Following: Receptive Fields
Results Lower learning rates have to be used More trials are needed (3 to 6 trials) Different RFs are learned for different tracks
Steep and Sharp Track, Plots show the sum of all filter weights for one pixel

Conclusion Correlation Based Learning
Tries to minimize the influence of disturbances Easier to learn than Reinforcement Learning The framework is less general
Questions: When to apply Correlation Based Learning and when
Reinforcement Learning How is it done by Animals/Humans?
How can these two methods be combined Correlation learning in early learning stage RL for fine tuning
ICO Learning Improvement of ISO learning More Stable, higher learning rates can be used
One Shoot Learning is possible

Literature: [Porr05]: F. Wörgötter and B. Porr, Temporal Sequence
Learning, Prediction and Control, A Review of different control methods and their relation to biological mechanisms
[Porr03]: B. Porr, F. Wörgötter, Isotropic Sequence Order Learning
[Porr06]: B. Porr, F. Wörgötter, Strongly improved stability and faster convergence of temporal sequence learning by utilising input correlations only
[Kulvicius06]: T. Kulvicius, B. Porr and F. Wörgötter, Behaviourally Guided Development of Primary and Secondary Receptive Fields through temporal sequence learning