



G. Alaghband Fundamentals of Parallel Processing
1, MIMD
MIMD COMPUTERS

G. Alaghband Fundamentals of Parallel Processing
2, MIMD
MIMD Computers or Multiprocessors
There are several terms which are often used in a confusing way.Definition: Multiprocessors are computers capable of running multiple instruction streams simultaneously to cooperatively execute a single program.
Definition: Multiprogramming is the sharing of computing equipment by many independent jobs. They interact only through their requests for the same resources. Multiprocessors can be used to multiprogram single stream programs.
Definition: A process is a dynamic instance of an instruction stream. It is a combination of code and process state, for example program counter and the status words.
Processes are also called tasks, threads, or virtual processors.

G. Alaghband Fundamentals of Parallel Processing
3, MIMD
Definition:
Multiprocessing is either:
a) running a program on a multiprocessor (it may be a sequential one), [not of interest to us],
or
b) running a program consisting of multiple cooperating processes.

G. Alaghband Fundamentals of Parallel Processing
4, MIMD
Two main types of MIMD or multiprocessor architectures.
Shared memory multiprocessor Distributed memory multiprocessor
Distributed memory multiprocessors are also known as explicit communication multiprocessors.

G. Alaghband Fundamentals of Parallel Processing
5, MIMD
Notations: A summary of notations used in the following figures are given below:
L: Link a component that transfers information from one place to another place.
K: Controller, a component that evokes the operation of other components in the system.
S: Switch, constructs a link between components. It has associated with it a set of possible links, it sets some and breaks other links to establish connection.
T: Transducer, a component that changes the i-unit (information) used to encode a given meaning. They don’t change meaning, but format.

G. Alaghband Fundamentals of Parallel Processing
6, MIMD
Some Example ConfigurationsFully Shared Memory Architecture:

G. Alaghband Fundamentals of Parallel Processing
7, MIMD
Adding private memories to the previous configuration produces a hybrid architecture.
Shared Plus Private Memory Architecture:

G. Alaghband Fundamentals of Parallel Processing
8, MIMD
If local memories are managed by hardware, they are called cache.
NUMA (Non-uniform Memory Access ) Machines:
There is an important impact on performance if some locations in shared memory take longer to access than others.
UMA (Uniform Memory Access ) Machines:
Cluster:
Is referred to connecting few processor shared memory multiprocessors, often called clusters, using a communication
network accessed by send and receive instructions.
The shared memory of a cluster is private WRT other clusters

G. Alaghband Fundamentals of Parallel Processing
9, MIMD
Characteristics of Shared memory multiprocessors:
Interprocessor communication is done in the memory interface by read and write instructions.
Memory may be physically distributed, and reads and writes from different processors may take different amounts of time and may collide in the interconnection network.
Memory latency (time to complete a read or write) may be long and variable.Messages through the interconnecting switch are the size of single memory words (or perhaps cache lines).
Randomization of requests (as by interleaving words across memory modules) may be used to reduce the probability of collision.

G. Alaghband Fundamentals of Parallel Processing
10, MIMD
Characteristics of Message passing multiprocessors:
Interprocessor communication is done by software using data transmission instructions (send and receive).
Read and write refer only to memory private to the processor issuing them.
Data may be aggregated into long messages before being sent into the interconnecting switch.
Large data transmissions may mask long and variable latency in the communications network.
Global scheduling of communications can help avoid collisions between long messages.

G. Alaghband Fundamentals of Parallel Processing
11, MIMD
Distributed memory multiprocessors are characterized by their network topologies
Both Distributed and Shared memory multiprocessors use an InterconnectionNetwork.
The distinctions are often in the details of the low level switching protocol rather than in high level switch topology:
Indirect Networks: often used in shared memory architectures, resources such as processors, memories and I/O devices are attached externally to a switch that may have a complex internal structure of interconnected switching nodes
Direct Networks: more common to message passing architectures, associate resources with the individual nodes of a switching topology

G. Alaghband Fundamentals of Parallel Processing
12, MIMD
Ring Topology
An N processor ring topology can take up to N/2 steps to transmit a message from one processor to another (assuming bi-directional ring).

G. Alaghband Fundamentals of Parallel Processing
13, MIMD
A rectangle mesh topology is also possible:
An N processor mesh topology can take up to steps to transmit a message from one processor to another.

G. Alaghband Fundamentals of Parallel Processing
14, MIMD
The hypercube architecture is another interconnection topology:
Each processor connects directly with log2N others, whose
indices are obtained by changing one bit of the binary number of the reference processor (gray code). Up to
log2N steps are needed to transmit a message between processors.
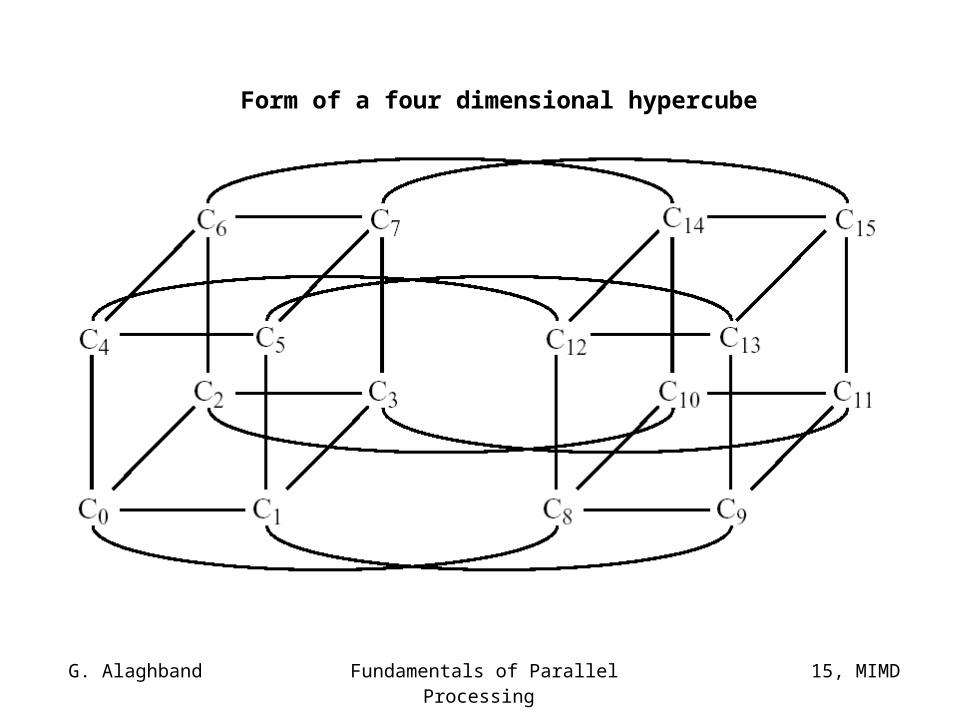
G. Alaghband Fundamentals of Parallel Processing
15, MIMD
Form of a four dimensional hypercube

G. Alaghband Fundamentals of Parallel Processing
16, MIMD
Classification of real systemsOverview of CM* Architecture, An early system

G. Alaghband Fundamentals of Parallel Processing
17, MIMD
Five clusters with ten PEs each were built.
The cm* system illustrates a mixture of shared and distributed memory ideas.
There are 3 answers to the question:Is cm* a shared memory multiprocessor?
1. At the level of mcode in the K.map, there are explicit send and receive instructions and message passing software \ No it is not shared memory.
2. At the level of LSP-11 instruction set, the machine has shared memory. There are no send and receive instructions, any memory address could be accessed by any processor in the system \ Yes it is shared memory.
3. 2 operating systems were built for the machine. STAROS and MEDUSA. The processes which these operating systems supported could not share any memory. They communicated by making operating system calls to pass messages between processors \ No it is not shared memory.
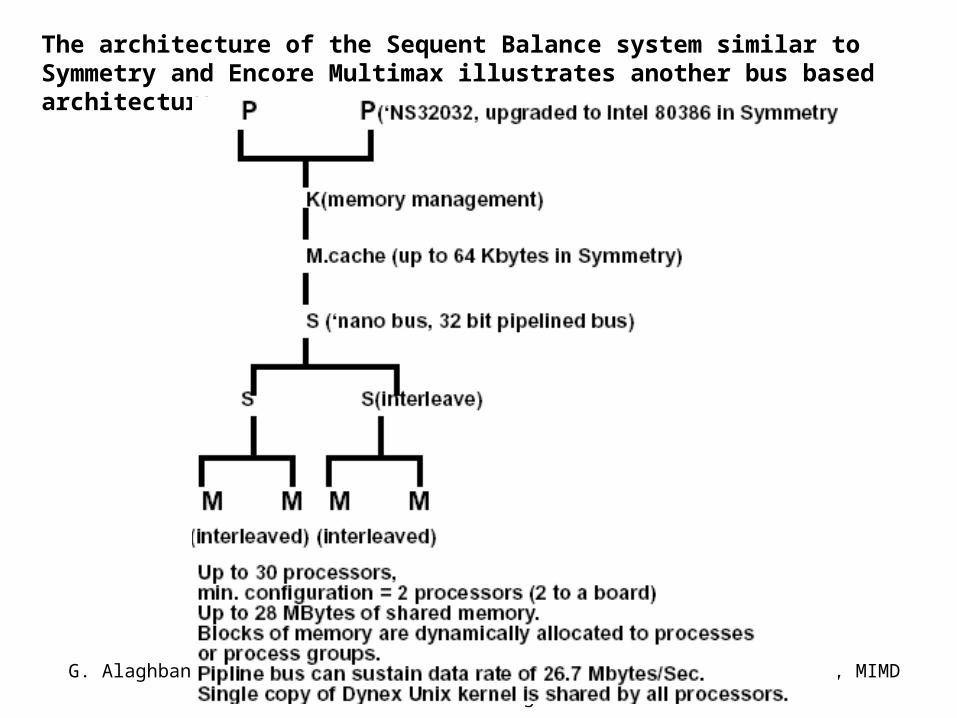
G. Alaghband Fundamentals of Parallel Processing
18, MIMD
The architecture of the Sequent Balance system similar to Symmetry and Encore Multimax illustrates another bus based architecture.

G. Alaghband Fundamentals of Parallel Processing
19, MIMD

G. Alaghband Fundamentals of Parallel Processing
20, MIMD
Sequent Balance
System bus: 80 Mbytes/second system bus. It links CPU, memory, and IO processors. Data and 32-bit addresses are time-multiplexed on the bus. Sustain transfer rate of 53 Mbytes/second.
Multibus: Provides access to standard peripherals.
SCSI: Small Computer System Interface, provides access to low-cost peripherals for entry-level configurations and for software distribution.
Ethernet: Connect systems in a local area network.

G. Alaghband Fundamentals of Parallel Processing
21, MIMD
Sequent BalanceAtomic Lock Memory, ALM:
User accessible hardware locks are available to allow mutual exclusion of shared data structures.
There are 16K such hardware locks in a set.
One or more sets can be installed in a machine, one/multibus adapter board.
Each lock is a 32-bit double word. The least significant bit determines the state of a lock:
locked (1), and unlocked (0)Reading the lock returns the value of this bit and sets it to 1, thus locking the lock.Writing 0 to a lock, unlocks it.
Locks can support a variety of synchronization techniques including: busy waits, Counting/queuing semaphores, and barriers.

G. Alaghband Fundamentals of Parallel Processing
22, MIMD
Alliant FX/8: Was designed to exploit parallelism found in scientific programs automatically.
Up to 8 processors called Computational Elements (CE’s) and up to 12 Interactive Processors (IP’s) shared a global memory of up to 256 Mbytes.
All accesses of CE’s and IP’s to the bus are through cache memory.
There can be up to 521 Kbytes of cache shared by CE’s and up to 128 Kbytes of cache shared by IP’s. Every 3 Ip’s share 32 Kbytes of cache.
CE’s are connected together directly through a concurrency control bus.
Each IP contains a Motorola 68000 CPU. IP’s are used for interactive processes and IO.
CE’s have custom chips to support M68000 instructions and floating point instructions (Weitek processor chip), vector arithmetic instructions, and concurrency instructions.
The vector registers are 32-element long for both integers and floating point types

G. Alaghband Fundamentals of Parallel Processing
23, MIMD

G. Alaghband Fundamentals of Parallel Processing
24, MIMD
Programming Shared Memory MultiprocessorsKey Features needed to Program Shared memory MIMD Computers:
• Process Management:– Fork/Join– Create/Quit– Parbegin/Parend
• Data Sharing:– Shared Variables– Private Variables
• Synchronization:– Controlled-based:
» Critical Sections» Barriers
– Data-based:» Lock/Unlock» Produce/Consume

G. Alaghband Fundamentals of Parallel Processing
25, MIMD
In the introduction to the MIMD pseudo code we presented minimal extensions for process management and data sharing to sequential pseudo codes. we saw:
Fork/Join for basic process management
Shared/Private storage class for data sharing by processes.
We will discuss these in more details a little later, but
Another essential mechanism for programming shared memory multiprocessors is synchronization.
Synchronization guarantees some relationship between the rate of progress of the parallel processes.

G. Alaghband Fundamentals of Parallel Processing
26, MIMD
Lets demonstrate why synchronization is absolutely essential:
Example:Assume the following statement is being executed by n processes in a parallel program:
where
Sum: Shared variable, initially 0Psum: Private variable.
Assume further that P1 calculates Psum = 10P2 calculates Psum = 3
Therefore, the final value of Sum must be 13.
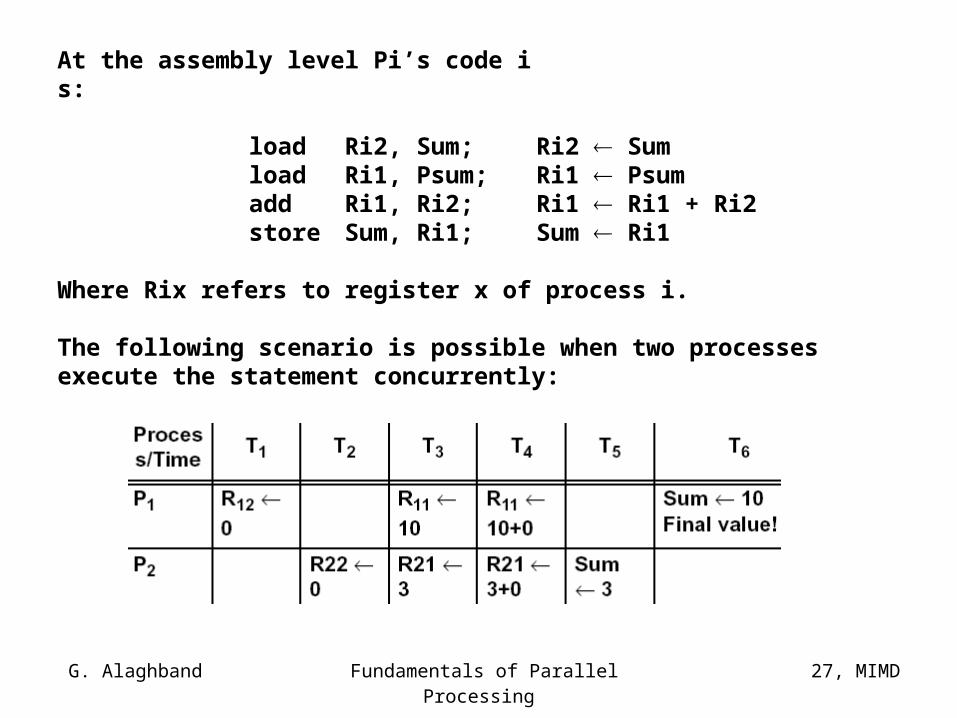
G. Alaghband Fundamentals of Parallel Processing
27, MIMD
At the assembly level Pi’s code is:
load Ri2, Sum; Ri2 Sumload Ri1, Psum; Ri1 Psumadd Ri1, Ri2; Ri1 Ri1 + Ri2store Sum, Ri1; Sum Ri1
Where Rix refers to register x of process i.
The following scenario is possible when two processes execute the statement concurrently:

G. Alaghband Fundamentals of Parallel Processing
28, MIMD
Synchronization operations can be divided into 2 basic classes:
• Control Oriented: Progress past some point in the program is controlled.(Critical Sections)
• Data Oriented:Access to data item is controlled by the state of the data item. (Lock and Unlock)
An important concept is atomicity. The word atomic is used in the sense of invisible.
Definition: Let S be a set of processes and q be an operation, perhaps composite. q is atomic with respect to S iff for any process P S which shares variables with q, the state of these variables seen by P is either that before the start of q or that resulting from completion of q. In other words, states internal to q are invisible to processes of S.

G. Alaghband Fundamentals of Parallel Processing
29, MIMD
Synchronization Examples
Control Oriented Synchronization:Critical section is a simple control oriented based synchronization:
Process 1 Process 2
• • • • • • • • • • • • • • Critical Critical
code body1 code body2End critical End critical

G. Alaghband Fundamentals of Parallel Processing
30, MIMD
Software Solution:
We first implement the critical section using software methods only. These solutions are all based on the fact that read/write (load/ store) are the atomic machine level (hardware) instructions available.
We must ensure that only one process at a time is allowed in the critical section, and once a process is executing in its critical section, no other process is allowed to enter the critical section.

G. Alaghband Fundamentals of Parallel Processing
31, MIMD
We first present a solution for 2 process execution only.Shared variable:
Var want-in[0..1] of Boolean;turn: 0..1;
Initially want-in[0] = want-in[1] = false turn = 0
Next, we present a software solution for N processes.

G. Alaghband Fundamentals of Parallel Processing
32, MIMD
Bakery Algorithm (due to Leslie Lamport)
Definitions/Notations:
• Before a process enters its critical section, it receives a number. The process holding the smallest number is allowed to enter the critical section.
• Two processes Pi and Pj may receive the same number. In this case if i < j, then Pi is served first.
• The numbering scheme generates numbers in increasing order of enumeration.For example: 1, 2, 2, 3, 4, 4, 4, 5, 6, 7, 7,...
• (A,B) < (C, D) if:1. A < C or2. A = C and B < D

G. Alaghband Fundamentals of Parallel Processing
33, MIMD
Bakery Algorithm:Shared Data:VAR piknum: ARRAY[0..N-1] of BOOLEAN;
number :ARRAY[0..N-1] of INTEGER;Initially
piknum[i] = false, for i = 0, 1, ..., N-1number[i] = 0, for i = 0, 1, ..., N-1

G. Alaghband Fundamentals of Parallel Processing
34, MIMD
Hardware Solutions:
Most computers provide special instruction to ease implementation of critical section code. In general an instruction is needed that can read and modify the contents of a memory location in one cycle. These instructions, referred to as rmw (read-modify-write), can do more than just a read (load) or write (store) in one memory cycle.
Test&Set -- is a machine-level instruction (implemented in hardware) that can test and modify the contents of a word in one memory cycle. Its operation can be described as follows:
Function Test&Set(Var v: Boolean): Boolean;BeginTest&Set := v;v:= true;End.
In other words Test&Set returns the old value of v and sets it to true regardless of its previous value.

G. Alaghband Fundamentals of Parallel Processing
35, MIMD
Swap -- Is another such instruction. This instruction swaps the contents of two memory locations in one memory cycle. This instruction is common in IBM computers. Its operation can be described as follows:
Procedure Swap(Var a, b : Boolean);Var temp: Boolean;Begintemp:= a;a:= b;b:= temp;End
Now we can implement the critical section entry and exit sections using Test&Set and Swap instructions:
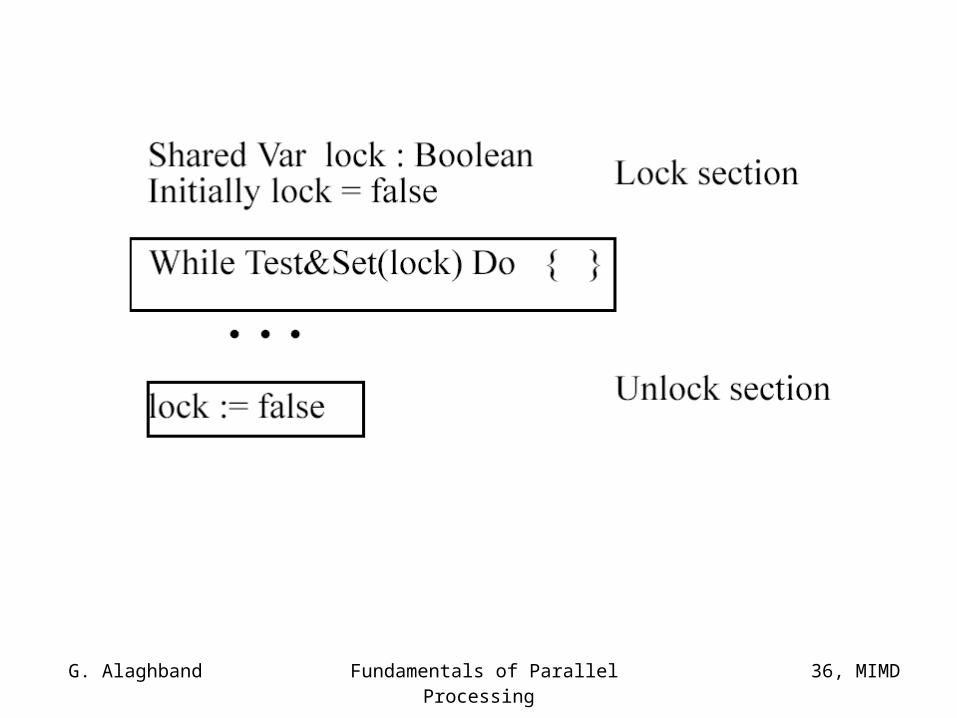
G. Alaghband Fundamentals of Parallel Processing
36, MIMD

G. Alaghband Fundamentals of Parallel Processing
37, MIMD
The implementation with Swap requires the use of two variables, one shared and one private:

G. Alaghband Fundamentals of Parallel Processing
38, MIMD
The above implementation suffer from Busy Waiting. That is while a process is in its critical section, the other processes attempting to enter their critical section are waiting in either the While loop (Test$Set case) or in the Repeat loop (Swap case). The amount of busy waiting by processes is proportional to the number of processes to execute the critical section and to the length of the critical section.
When fine-grain parallelism is used, then busy-waiting of processes may be the best performance solution. However, if most programs are designed with coarse-grain parallelism in mind, then busy-waiting becomes very costly in terms of performance and machine resources. The contention problems resulting from busy-waiting of other processes, will result in degraded performance of even the process that is executing in its critical section.

G. Alaghband Fundamentals of Parallel Processing
39, MIMD
Semaphores are one way to deal with cases with potentially large amounts of busy-waiting. Usage of semaphore operations can limit the amount of busy-waiting .
Definition:Semaphore S is a• Shared Integer variable and• can only be accessed through 2 indivisible operations P(S) and V(S)
P(S) : S:= S - 1;If S < 0 Then Block(S);
V(S) : S:= S + 1;If S 0 Then Wakeup(S);
• Block(S) -- results in the suspension of the process invoking it.
• Wakeup(S) -- results in the resumption of exactlyone process that has previously invoked Block(S).
Note: P and V are executed atomically.

G. Alaghband Fundamentals of Parallel Processing
40, MIMD
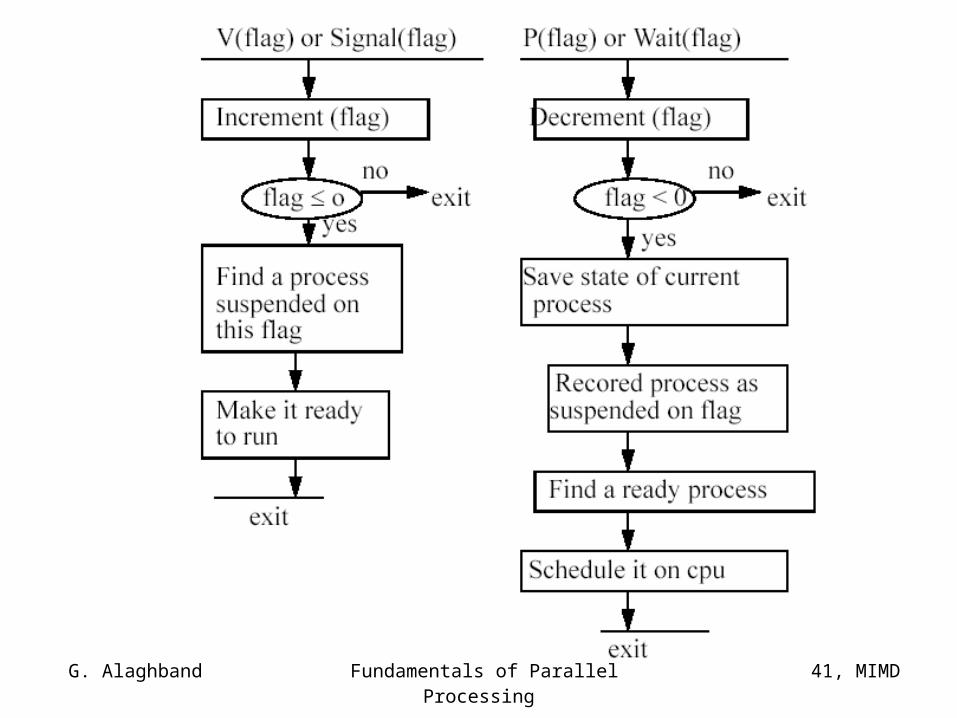
Given the above definition, the critical section entry and exit can be implemented using a semaphore as follows:
Shared Var mutex : Semaphore;Initially mutex = 1
P(mutex);• • •Critical section
V(mutex);
G. Alaghband Fundamentals of Parallel Processing
41, MIMD

G. Alaghband Fundamentals of Parallel Processing
42, MIMD
Semaphores are implemented using machine-level instructions such asTest&Set or Swap.
Shared Var lock : BooleanInitially lock = false
• P(S): While Test&Set(lock) Do { };BeginS:= S - 1;If S < 0 Then
Block process;lock := flase;End
• V(S): While Test&Set(lock) Do { };BeginS := S + 1;If S 0 Then
Make a suspended process ready;lock := flase;End

G. Alaghband Fundamentals of Parallel Processing
43, MIMD
Problem:
Implement the semaphore operations using the Swap instruction.

G. Alaghband Fundamentals of Parallel Processing
44, MIMD
Shared Var lock Initially lock = false
Private Var key
•P(S): key = true;Repeat
Swap(lock, key);Until key = false;S := S - 1;If S < 0 Then
Block process;lock := flase

G. Alaghband Fundamentals of Parallel Processing
45, MIMD
Data Oriented Synchronization:
• LOCK L - If LOCK L is set then wait; if it is clear, set it and proceed.
• UNLOCK L - Unconditionally clear lock L.
Using Test&Set LOCK and UNLOCK correspond to the following:
LOCK L: Repeat y = Test&Set(L) Until y=0
UNLOCK L: L = 0

G. Alaghband Fundamentals of Parallel Processing
46, MIMD
Relationship between locks and critical sections:Critical sections are more like locks if we consider named critical sections. Execution inside a named critical section excludes simultaneous execution inside any other critical section of the same name. However there may be processes that are exectuing concurrently in critical sections of different names.A simple correspondance between locks and critical sections is:
Critical max LOCK maxcritical code critical code
End critical UNLOCK max
Both synchronizations are used to solve the mutual exclusion problem. However,

G. Alaghband Fundamentals of Parallel Processing
47, MIMD
Locks are more general than critical sections, since UNLOCK does not have to appear in the same process as LOCK.

G. Alaghband Fundamentals of Parallel Processing
48, MIMD
Asynchronous Variables:
A second type of data oriented synchronization. These variables have both a value and a state which is either full or empty.
Asynchronous variables are accesses by two principal atomic operations:
• Produce: Wait for the state of the Asynch variable to be empty, write a value, and set the state to full.
• Consume: Wait for the state of the Asynch variable to be full, read the value, and set the state to emply.

G. Alaghband Fundamentals of Parallel Processing
49, MIMD
A more complete set of operations on Asynchronous variables are those provided by the Force parallel programming language:
Produce asynch var = expression
Consume private var = asynch var
Copy private var = asynch var - wait for full, read value,don’t change state.
Void asynch var - Initialize the state to empty.
Asynchronous variables can be imlemented in terms of critical sections.

G. Alaghband Fundamentals of Parallel Processing
50, MIMD
Represent an asynchronous variable by the following data structure:V valueVf state -- true corresponds to full,
false corresponds to emptyVn name
Pseudo code to implement the Produce operation is:1. L: Critical Vn2. privf := Vf3. If not(privf) Then4. Begin5. V := vlue-of-expression;6. Vf := true;7. End;8. End critical9. If privf Then goto L;
Note: Private variable privf is used to obtain a copy of the shared Vf, the state of the asynch variable, before the process attempts to perform the Produce operation. This way if the test in statement number 3 reveals that the state is full, then the process returns to 1 and tries again.

G. Alaghband Fundamentals of Parallel Processing
51, MIMD
Problem (4-11):
A multiprocessor supports synchronization with lock/unlock hardware. The primitives are represented at the compiler language level by two subroutine calls, lock(q) and unlock(q). The lock(q) operation waits for the lock to be clear, sets it and returns, while unlock(q) clears the lock unconditionally. It is desired to implement produce and consume on full/empty variables where produce(x,v) waits for x empty, writes it with value v and sets full while consume(x,v) waits for x full, copies its value to v and sets x to empty. Using sequential pseudo code extended by the two operators lock(q) and unlock(q), write code sections which implement produce(x,v) and consume(x,v) on an asynchronous variable x and normal variable v. Carefully describe your representation for an asynchronous variable. No synchronization operations other than lock and unlock may be used.

G. Alaghband Fundamentals of Parallel Processing
52, MIMD
First SolutionWe will represent the asynchronous variable X by a record of three items: the value of X, a boolean full flag and a unique lock for the variable X. record X{value : real;
full : boolean; l : lock }
Produce and consume can then be implemented as follows:
procedure produce(X,V) {R : lock(X.l)if X.full then
{ unlock(X.l) ;goto R }
else{X.full := true ;X.value := V ;unlock(X.l) } }

G. Alaghband Fundamentals of Parallel Processing
53, MIMD
procedure consume(X,V){R : lock(X.l)
if not X.full then{ unlock(X.l) ;
goto R }else{ V := X.value ;
X.full := false ;unlock(X.l) }}

G. Alaghband Fundamentals of Parallel Processing
54, MIMD
(Alternate Solution)
A simpler solution is possible by using only the lock operation to do a wait, but only if it is recognized that one lock is not enough. Two different conditions are being waited for in produce and consume, so two locks are needed.
record X { value : real ; State X.f X.ef : lock ; full 1 0e : lock } empty 0 1
locked 1 1unused 0 0
procedure produce(X,V) { procedure consume(X,V) {lock(X.f) ; lock(X.e);X.value := V; V := X.value;unlock(X.e) } unlock(X.f) }

G. Alaghband Fundamentals of Parallel Processing
55, MIMD
Control oriented: Barrier Implementation:Initial state and values: unlock (barlock)
lock (barwit)barcnt = 0
lock (barlock)if (barcnt < NP -1 ) then All processes except the
barcnt := barcnt +1 ; last will increment the unlock (barlock) ; counter and wait at the lock (barwit) ; lock(barwit).
endif ;if (barcnt = NP -1) then Last process executes
… the code body and code body unblocks barwit.
endif ;if (barcnt = 0) then
unlock (barlock) ;else All processes except the
barcnt := barcnt -1 ; last, will decrement the unlock (barwit) ; counter and unlock (barwit)The
endif last process unlocks barlock for correct state of the next barrier
execution.

G. Alaghband Fundamentals of Parallel Processing
56, MIMD
Alternatives for Process Management:
Different systems provide alternative ways to fork and join processes. Some common alternatives are outlined bellow:
• Instead of Fork Label, the Unix fork gives two identical processes returning from the fork call with a return value being the only distinction between the two processes.
• The join operation may combine process management and synchronization. New processes can just quit when finished and some other operation may be used to synchronize with their completion. Therefore, if processes are to wait for other processes to complete before they can quit, we may use a barrier synchronization before the join.
• Parameter passing can be included in a fork using a create statement (as was done in the HEP multiprocessor). The create statement is similar to a subroutine call, except that a new process executes the subroutine in parallel with the main program, which continues immediately.

G. Alaghband Fundamentals of Parallel Processing
57, MIMD
Multiprocessors provide some basic synchronization and process management tools (machine dependent). On these machines, sequential language must be extended so that parallel programming becomes possible.
Fortran for example can be extended by a coherent set of synchronization and process management primitives to allow for parallel programming.
Lets use:
CREATE subr (A, B, C, ...) starts a subroutine in parallel with the main program. parameters are passed by reference.
RETURN in a created subroutine means quit. While RETURN in a called subroutine means a normal return to the calling program.

G. Alaghband Fundamentals of Parallel Processing
58, MIMD
Parameter passing to parallel programs has some pitfalls:
Consider the following:
Do 10 I = 1, N-110 CREATE sub(I)
The intent is to assign and index value to each of the created processes.
Problem?

G. Alaghband Fundamentals of Parallel Processing
59, MIMD
By the time the subroutine gets around reading I, it will have changed!!
In parallel processing call-by-reference and call-by-value are not the same, even for read-only parameters.
To come up with a solution remember that neither the subroutine nor the program may change the parameter during parallel execution.
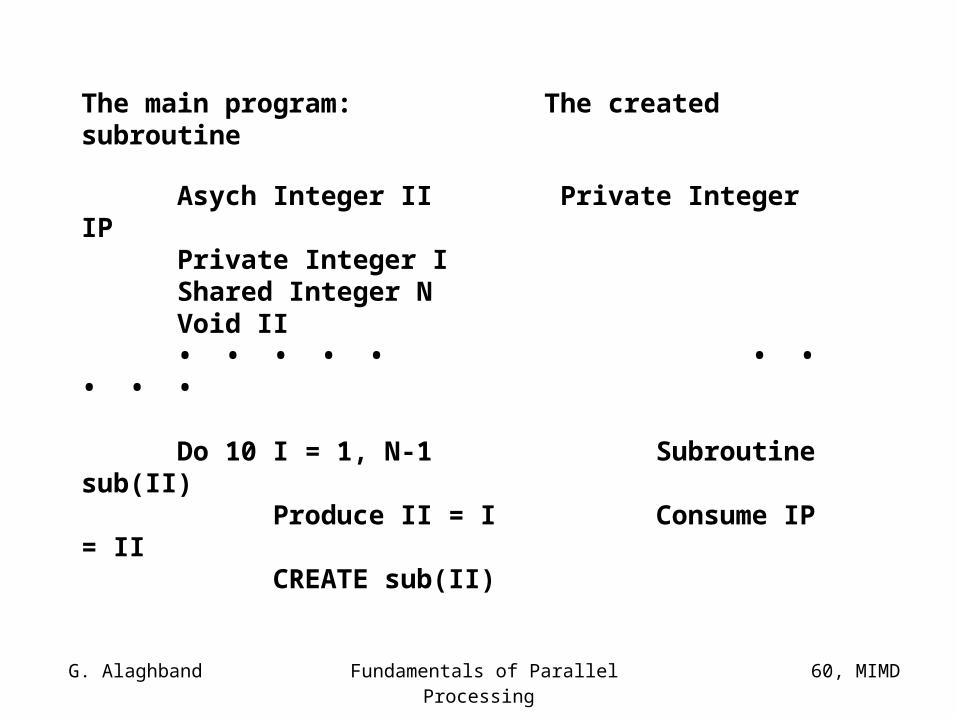
Next we show how to pass an argument by value to a created subroutine:
G. Alaghband Fundamentals of Parallel Processing
60, MIMD
The main program: The created subroutine
Asych Integer II Private Integer IPPrivate Integer IShared Integer NVoid II• • • • • • • • • •
Do 10 I = 1, N-1 Subroutine sub(II)Produce II = I Consume IP = IICREATE sub(II)
G. Alaghband Fundamentals of Parallel Processing
61, MIMD
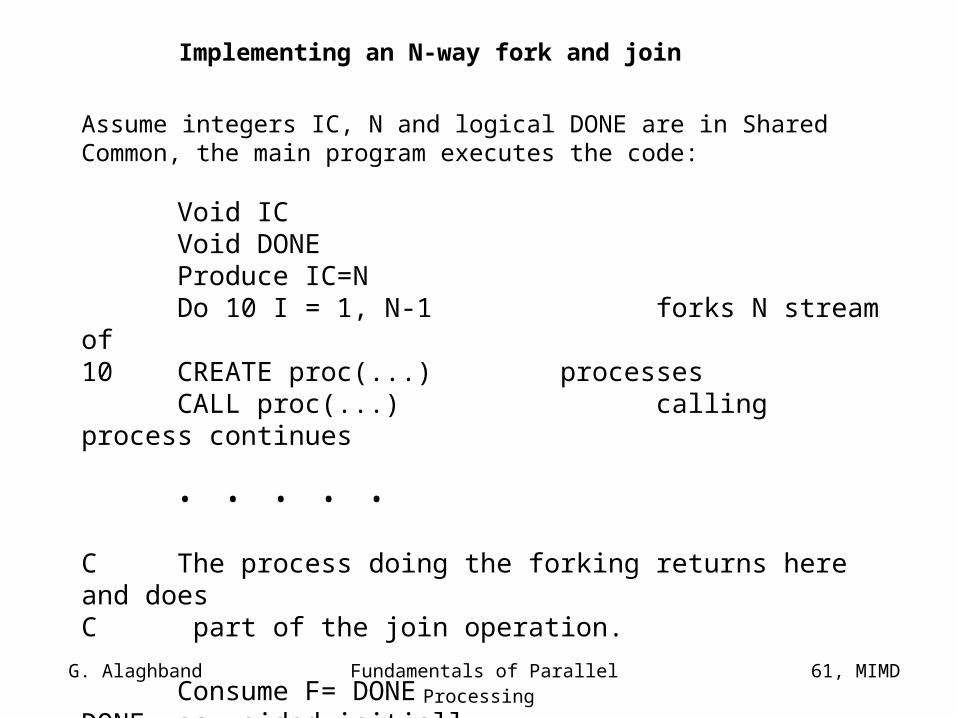
Implementing an N-way fork and join
Assume integers IC, N and logical DONE are in Shared Common, the main program executes the code:
Void ICVoid DONEProduce IC=NDo 10 I = 1, N-1 forks N stream of
10 CREATE proc(...) processesCALL proc(...) calling process continues
• • • • •
C The process doing the forking returns here and doesC part of the join operation.
Consume F= DONEDONE was voided initially

G. Alaghband Fundamentals of Parallel Processing
62, MIMD
…
AT THE END OF SUBROUTINE
…The rest of the join operation is done at the end of the subroutine proc.At the end of proc, processes will execute the following:
Consume J= IC IC was initialized to N.J = J - 1 decrement number ofIf (J .ne. 0) Then processes in the critical
Produce IC = J section.RETURN quit if it was a created
Endif process, return if called.Produce DONE = .true. last process will execute RETURN the last 2 statements.

G. Alaghband Fundamentals of Parallel Processing
63, MIMD
Single Program, Multiple Data, or SPMD
We will decouple process creation from parallel program code.
Processes can be created at the beginning of the program, execute a common set of code that distributes work in the parallel loop by either prescheduling or self scheduling, and terminate at the end of the program.
Multiple processes, each with a unique process identifier, 0 id P-1, execute a single program simultaneously but not necessarily synchronously.
Private data may cause processes to execute if-then-else statements differently or to execute a loop a different number of times.
The SPMD style of programming is almost the only choice for managing many processes in a so-called massively parallel processor (MPP) with hundreds or thousands of processors.

G. Alaghband Fundamentals of Parallel Processing
64, MIMD
Process creation for a SPMD program P: shared, number of processes id: private, unique process identifier, available to all the processes
executing the parallel main program (parmain), id is passed by value.
processes may be required to synchronize before ending parmain, or exit may be able to automatically wait for processes that have not finished (join).
shared P;private id;for id := 0 step 1 until P-2
create parmain(id, P);id := P-1;call parmain(id, P);call exit();
P and id make up a parallel environment in which the MIMD processes execute.

G. Alaghband Fundamentals of Parallel Processing
65, MIMD
SPMD program for the recurrence solver
procedure parmain(value id, P)shared P, n, a[n, n], x[n], c[n];private id, i, j, sum, priv;
forall i := 1 step 1 until n void x[i];barrier;forall i := 1 step 1 until n begin sum := c[i]; for j := 1 step 1 until i-1 {copy x[j] into priv; sum := sum + a[i, j]*priv;} produce x[i] := sum; endbarrier; code to use x[]
end procedure
In forall, no value of i should be assigned to a process before all preceding values have been assigned.
This prevents infinite waits at the copy operation.
Some use doacross this purpose and doall for completely independent body instances (forall here).

G. Alaghband Fundamentals of Parallel Processing
66, MIMD
Work distribution
Parallel regions are most often tied to a forall construct, Which indicates that all instances of a loop body for different index values can be executed in parallel.
The potential parallelism is equal to the number of values of the loop index (N) and is
usually much larger than the number of processors (P)(or processes if there is time multiplexing)
used to execute the parallel region.

G. Alaghband Fundamentals of Parallel Processing
67, MIMD
Prescheduled loop code for an individual process
shared lwr, stp, upr, np;private i, lb, ub, me;
/* Compute private lower and upper bounds from lwr, upr, stp, process number me and number np of processes.*/
for i := lb step stp until ubloop body(i);
Block mapping

G. Alaghband Fundamentals of Parallel Processing
68, MIMD
Prescheduled loop code for an individual process
Cyclic mapping
shared lwr, upr, np;private i, me;
for i := lwr + me*stp step np*stp until upr
loop body(i);

G. Alaghband Fundamentals of Parallel Processing
69, MIMD
SPMD code for one of np processes having identifier me
executing its portion of a prescheduled loop
forall i := lwr step stp until upr
Block mapping requires computing lower and upper bounds
for each process.

G. Alaghband Fundamentals of Parallel Processing
70, MIMD
self-scheduling code for one process executing the same forall
shared lwr, stp, upr, np, isync;private i;barrier
void isync;produce isync := lwr;
end barrierwhile (true) dobegin
consume isync into i;if (i > upr) then {produce isync := i; break;}/* End while loop */else {produce isync := i + stp; loop body(i);}
end

G. Alaghband Fundamentals of Parallel Processing
71, MIMD
Parallelizing a simple imperfect loop nest
for i := 0 step 1 until n-1 begin s := f(i); for j := 0 step 1 until m-1
loop body(i, j, s); end
Serial imperfect two loop nest Split into parallel perfect nests
forall i := 0 step 1 until n-1 s[i] := f(i);forall k := 0 step 1 until m*n-1 i := k/m; j := k mod m;
loop body(i, j, s[i]);

G. Alaghband Fundamentals of Parallel Processing
72, MIMD
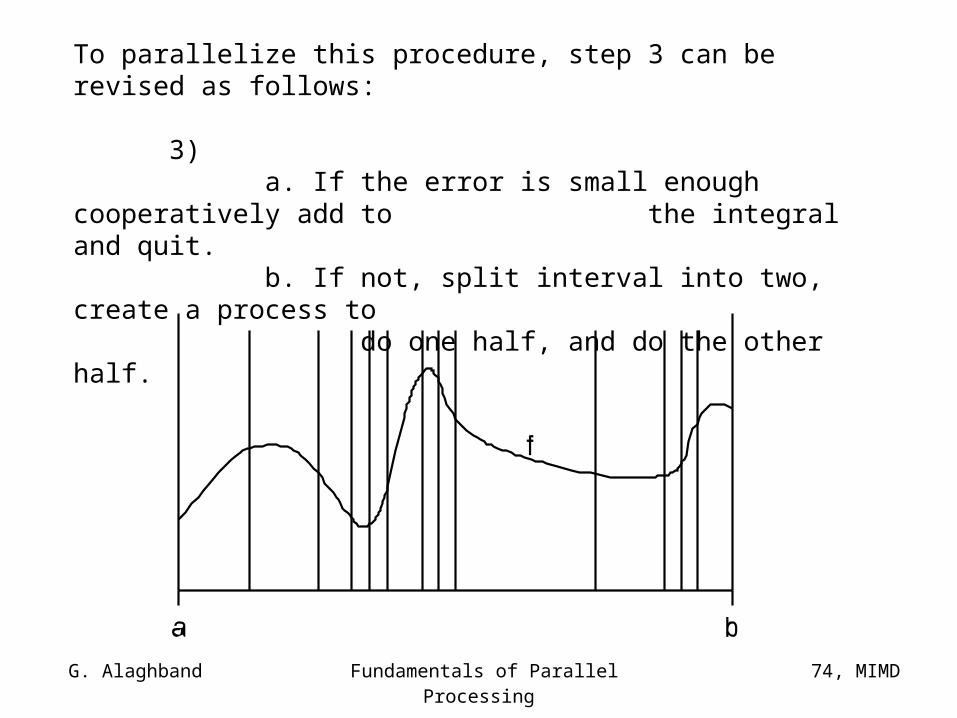
Adaptive Quadrature Integration Method
A simple example to show the dynamic scheduling concept where the amount of work to be done depends on the outcome of the ongoing computation.
In this method two basic operations are needed:
First the integral is approximated on the interval (a, b),Then the error is estimated in the approximation on $ (a, b)
a b
f

G. Alaghband Fundamentals of Parallel Processing
73, MIMD
Sequential procedure for this integration can be described with the following steps:
1) Apply the approximation to the interval, approx(a, b, f)
2) Apply the error estimate. Accurate(a, b, f)
3) a. If the error is small enough add contribution to
the integral.b. If not, split the interval in two and recursively
do each half.
4) Return from this recursion level.
G. Alaghband Fundamentals of Parallel Processing
74, MIMD
To parallelize this procedure, step 3 can be revised as follows:
3)a. If the error is small enough cooperatively add to
the integral and quit.b. If not, split interval into two, create a process to
do one half, and do the other half.

G. Alaghband Fundamentals of Parallel Processing
75, MIMD
Therefore, one process starts the integration and every time the intervalis split a new process is created.
The unlimited recursive creation of processes will produce a breath first expansion of a exponentially large problem, and is unnecessary. In spite of virtual processes, no parallel system will execute this approach efficiently.
The method to implement the adaptive quadrature integration efficientlyis to allow a single process to be responsible for integrating a subinterval. Define two intervals for a process:
Interval (a, b) for which the process is responsible for computing an answer.
Interval ( au, bu) which is the currently active subinterval.

G. Alaghband Fundamentals of Parallel Processing
76, MIMD
A high level description of the algorithm can now be presented.
0. Initialize (au, bu) to (a, b) .
1. Apply approximation to (au, bu) .
2. Estimate the error on (au, bu) .3.
a. If the result is accurate add it to the total integral,report process free and quit.
b. If not accurate enough, split (au,bu) and make theleft half the new active interval.
4. Assign a free process, if there is one, to integrate a remaining inactive interval.
5. Go to step 1.

G. Alaghband Fundamentals of Parallel Processing
77, MIMD
approx(a, b, f): Returns an approximation to the integral of f over the interval (a, b),
accurate(a, b, f): Returns true if the approximation is accurate enough and false otherwise.
workready(): Returns true if the work list is not empty and false otherwise,
getwork(task): Returns true and a task from the work list is not empty and false otherwise,
putwork(task): Puts a new task on the work list, returning false if the list was full and true otherwise.
task is a structure consisting of:Interval endpoints: task.a and task.b, and the function: task.f.

G. Alaghband Fundamentals of Parallel Processing
78, MIMD
Initially, the program starts with :one task, (a, b, f) on the shared work list
&idle = P, number of idle processors, shared
Other variable:
Integral: Result of the integration of function f, shared
More: true if work list is not empty, private
T: approximate integral over an interval, private
Ok: true if approximation is accurate enough, private
Cent: midpoint for interval splitting, private
Task, task1, task2: current task and the two tasks (1 & 2) resultingfrom task split, private
shared P, idle, integral;private more, t, ok, cent, task, task1, task2;

G. Alaghband Fundamentals of Parallel Processing
79, MIMD
while (true) begincritical work;
more := workready() or (idle P);if (more) then idle := idle - 1;
end critical;if (not more) then break;while (getwork(task)) begin
t := approx(a, b, f); ok := accurate(a, b, f);if (ok) then
critical int;integral := integral + t;
end critical;else begin
cent := (task.a + task.b)/2.0;task1.a := task.a; task1.b := cent;task2.a := cent; task2.b := task.b;task1.f := task2.f := task.f;if (not putwork(task1) or not putwork(task2)) then
Report no room in task set.;end;
end; /* of while loop over available tasks */critical work;
idle := idle + 1;end critical;
end; /* of while loop over available tasks or active processes. */

G. Alaghband Fundamentals of Parallel Processing
80, MIMD
The inner while loop terminates when there is no more work in the list,but there is a chance more work will be added if any processes are still executing tasks,
so the outer while does not terminate until all processes have failed to find more work to do (break statement).
The order of putting work onto, and taking it from, the list is important.
This is similar to traversing a binary tree constructed as intervals are split in two. Managing the work list in last-in, first-out order gives depth-first traversal, while using first-in, first-out order gives breadth-first traversal.
Breadth-first order adds more and more tasks to the work list, generating new work much faster than work is completed until the end of the
computation nears. NOT DESIRABLE. Properly managed, the framework of a set of processes cooperatively accessing a shared work list can be a very effective form of dynamic scheduling.

G. Alaghband Fundamentals of Parallel Processing
81, MIMD
OpenMP
• A language extension
• Extensions exists for C, C++. And Fortran (API)
• OpenMP constructs are limited to compiler directives and library subroutine calls (!$OMP), so the base language, so OpenMP programs also correspond to legal programs in the base language.

G. Alaghband Fundamentals of Parallel Processing
82, MIMD
OpenMP has • one process management construct,
the parallel region, • three parallel variable scopes,
shared, private, and threadprivate, • four work distribution constructs,
loops, sections, single execution, and master execution,
• six synchronization methods,locks, critical sections, barriers, atomic update, ordered sections, and flush.
This moderate sized set of constructs is sufficient for simple parallelization of sequential programs, but may present challenges for more complex parallel programs.

G. Alaghband Fundamentals of Parallel Processing
83, MIMD
The OpenMP Fortran Applications Program Interface (API)
Parallelism is introduced into an OpenMP program by the parallel region construct
!$OMP PARALLEL [clause[[,] clause ]
block!$OMP END PARALLEL
block is a single entry, single exit group of statements executed by all threads of the team created on entry to the parallel region in SPMD fashion. Branching into/out of the block is illegal, except for subroutine or function calls, but different threads may follow different paths through the block.

G. Alaghband Fundamentals of Parallel Processing
84, MIMD
The number of threads, num_threads, is set by calling
SUBROUTINE OMP_SET_NUM_THREADS(integer)
where the integer argument may be an expression.
The number of running threads is returned by
INTEGER FUNCTION OMP_GET_NUM_THREADS()
Each thread gets its own unique integer between 0 and num_threads - 1 by calling
INTEGER FUNCTION OMP_GET_THREAD_NUM()
The integer 0 is always assigned to the master thread.

G. Alaghband Fundamentals of Parallel Processing
85, MIMD
The parallel scope of variables inside a parallel region is specified by clauses attached to the !$OMP PARALLEL directive,
except that threadprivate common blocks are specified by a directive.
A list of variables or labeled common blocks can be specified as private by the clause
PRIVATE(list)
or shared by the clause
SHARED(list)
All copies of private variables disappear at the end of the parallel region except for the master thread’s copy.

G. Alaghband Fundamentals of Parallel Processing
86, MIMD
A more complex parallel scope specification is that for reduction variables
REDUCTION({operator | intrinsic}: list)
A variable X in list will appear inside the parallel region only in reduction statements of the form
X = X operator expressionor
X = intrinsic(X, expression)
operator may be +, *, -, .AND., .OR., .EQV., or .NEQV. and intrinsic may be MAX, MIN, IAND, IOR, or IEOR. The variable has shared scope,

G. Alaghband Fundamentals of Parallel Processing
87, MIMD
PROGRAM MAININTEGER KREAL A(10), XCALL INPUT(A)CALL OMP_SET_NUM_THREADS(10)
!$OMP PARALLEL SHARED(A, X) PRIVATE(K) REDUCTION(+:X)
K = OMP_GET_THREAD_NUM()X = X + A(K+1)
!$OMPEND PARALLELPRINT *, ‘Sum of As: ‘, XSTOPEND
A Simple Example

G. Alaghband Fundamentals of Parallel Processing
88, MIMD
Constructs of the OpenMP Fortran API
Thread management constructs in OpenMP Fortran

G. Alaghband Fundamentals of Parallel Processing
89, MIMD
Thread management constructs in OpenMP Fortran

G. Alaghband Fundamentals of Parallel Processing
90, MIMD
Run-time library routines
SUBROUTINE OMP_SET_NUM_THREADS(integer)
Set number or max number of threads.
INTEGER FUNCTION OMP_GET_NUM_THREADS()
INTEGER FUNCTION OMP_GET_MAX_THREADS()
Return number of threads in use
Return max number of threads
INTEGER FUNCTION OMP_GET_THREAD_NUM()
Return number of the calling thread
INTEGER FUNCTION OMP_GET_NUM_PROCS()
Return number of processors available.
Thread management constructs in OpenMP Fortran

G. Alaghband Fundamentals of Parallel Processing
91, MIMD
LOGICAL FUNCTION OMP_IN_PARALLEL()
True if called from dynamic extent of a parallel region.
SUBROUTINE OMP_SET_DYNAMIC(logical)
Allow (true) or disallow (false) dynamic change in number of threads.
LOGICAL FUNCTION OMP_GET_DYNAMIC()
Return true or false setting of dynamic
SUBROUTINE OMP_SET_NESTED(logical)Allow nested parallelism or not
LOGICAL FUNCTION OMP_GET_NESTED()
Return true if nested parallelism allowed
Thread management constructs in OpenMP Fortran

G. Alaghband Fundamentals of Parallel Processing
92, MIMD
Directive
!$OMP THREADPRIVATE(/cb/[, /cb/])Specifies that previously declared common blocks cb are private and persist across parallel regionsClauses
PRIVATE(list) Variables or common blocks in list are private in block introduced by the directive.
SHARED(list Variables or common blocks in list are shared
DEFAULT(PRIVATE|SHARED|NONE) Default scope for all variables in block
FIRSTPRIVATE(list) Private variables in list are initialized to values on entry to block
LASTPRIVATE(list) The values of variables on list are set to values written by last iteration or section.
REDUCTION({operator | intrinsic}: list) Reduce across threads by specified operation.
COPYIN(list) Initialize threadprivate variables or common blocks on list to master’s value on entry.
Parallel data scope specification in OpenMP Fortran

G. Alaghband Fundamentals of Parallel Processing
93, MIMD
Allowed clauses: PRIVATE, FIRSTPRIVATE, LASTPRIVATE, REDUCTION, SCHEDULE, ORDERED
OpenMP Fortran work distribution constructs

G. Alaghband Fundamentals of Parallel Processing
94, MIMD
OpenMP Fortran work distribution constructs
setenv OMP_SCHEDULE "STATIC, 10Prescheduling with chunk size of 10 iterations

G. Alaghband Fundamentals of Parallel Processing
95, MIMD
Allowed clauses: PRIVATE, FIRSTPRIVATE, LASTPRIVATE, REDUCTION,
OpenMP Fortran work distribution constructs

G. Alaghband Fundamentals of Parallel Processing
96, MIMD
Allowed clauses: PRIVATE, FIRSTPRIVATE,
OpenMP Fortran work distribution constructs

G. Alaghband Fundamentals of Parallel Processing
97, MIMD
OpenMP Fortran work distribution constructs

G. Alaghband Fundamentals of Parallel Processing
98, MIMD
OpenMP Fortran synchronization constructs

G. Alaghband Fundamentals of Parallel Processing
99, MIMD
OpenMP Fortran synchronization constructs
Implicit in: BARRIER, CRITICAL, END CRITICAL, END DO, END SECTIONS,END PARALLEL, END SINGLE, ORDERED, END ORDERED (unless
NOWAIT)

G. Alaghband Fundamentals of Parallel Processing
100, MIMD
OpenMP Fortran synchronization constructs

G. Alaghband Fundamentals of Parallel Processing
101, MIMD
Run-time library routines
SUBROUTINE OMP_INIT_LOCK(var) Create and initialize lock with name var
SUBROUTINE OMP_DESTROY_LOCK(var)
Destroy lock var, where var is type integer
SUBROUTINE OMP_SET_LOCK(var) Wait until lock var is unset, then set it
SUBROUTINE OMP_UNSET_LOCK(var) Release lock var owned by this thread.
LOGICAL FUNCTION OMP_TEST_LOCK(var)
Attempt to set lock var; return .TRUE. on success and .FALSE. on failure.
OpenMP Fortran synchronization constructs

G. Alaghband Fundamentals of Parallel Processing
102, MIMD
Allowed clauses: PRIVATE, SHARED, DEFAULT, FIRSTPRIVATE, LASTPRIVATE, REDUCTION, SCHEDULE, ORDERED, IF, COPYIN
OpenMP Fortran combined process management and work distribution

G. Alaghband Fundamentals of Parallel Processing
103, MIMD
Allowed clauses: PRIVATE, SHARED, DEFAULT, FIRSTPRIVATE, LASTPRIVATE, REDUCTION, IF, COPYIN
OpenMP Fortran combined process management and work distribution
OpenMP Fortran combined process management and work distribution

G. Alaghband Fundamentals of Parallel Processing
104, MIMD
do i = 1, nsteps call compute(n, pos, vel, mass, f, pot, kin) call update(n, pos, vel, f, a, mass, dt)enddo
Time stepping loop central to the main particle dynamics program
An OpenMP ExampleA particle dynamics program to compute position, p, velocity, v, Acceleration, a, force, f, potential and kinetic energy pot and kin.
n particles are represented by four 3 by n arrays First dimension for x, y, z space dimension
Second for particles

G. Alaghband Fundamentals of Parallel Processing
105, MIMD
pot = 0.0kin = 0.0
!$OMP PARALLEL DO&!$OMP& DEFAULT(SHARED)&!$OMP& PRIVATE(i, j, k, rij, d)&!$OMP& REDUCTION(+: pot, kin)
do i = 1, n do k = 1, 3 f(k, i) = 0.0 enddo do j = 1, n if (i .ne. j) then call dist(pos(1, i), pos(1, j), rij, d) pot = pot + 0.5*v(d) do k = 1, 3 f(k, i) = f(k, i) - rij(k)*dv(d)/d enddo endif enddo kin = kin + dot(vel(1, i), vel(1, i))enddo
!$OMP END PARALLEL DOkin = kin*0.5*mass
Body of the compute subroutine

G. Alaghband Fundamentals of Parallel Processing
106, MIMD
!$OMP PARALLEL DO&!$OMP& DEFAULT(SHARED)&!$OMP& PRIVATE(i, k)
do i = 1, n do k = 1, 3 pos(k,i) = pos(k,i) + vel(k,i)*dt + 0.5*dt*dt*a(k,i) vel(k,i) = vel(k,i) + 0.5*dt*(f(k,i)/mass + a(k,i)) a(k,i) = f(k,i)/mass enddoenddo
!$OMP END PARALLEL DO
Body of the update subroutine
This is a minimal change to the program, but threads are created and terminated twice for each time step. If process management overhead is large, this can slow the program significantly.
A better method is described in the text, see Program 4-13,
We will present the idea of global parallelism by introducing the
FORCE Parallel Language

G. Alaghband Fundamentals of Parallel Processing
107, MIMD
Development of Parallel Programming Languages
Issues to consider:
• Explicit vs. Implicit Parallelism
• Efficiency of Parallel Constructs
• Portability of Programs to Multiprocessors of the Same Type

G. Alaghband Fundamentals of Parallel Processing
108, MIMD
Main Features of the Force:
• Parallel constructs as extensions to Fortran
• SPMD: Single program executed by many processes
• Global parallelism: parallel execution is the norm,
sequential execution must be explicitly specified
• Arbitrary number of processes: Execution with one process is fine,
it allows program logic bugs to be separated from
synchronization bugs.

G. Alaghband Fundamentals of Parallel Processing
109, MIMD
Main Features of the Force continued:
• Process management is suppressed: There are no fork, Join, Create or Kill operations.
Only the rate of progress is influenced by synchronizations.
• All processes are identical in their capability
• Data is either private to one, or uniformly sharedby all processes.

G. Alaghband Fundamentals of Parallel Processing
110, MIMD
Main Features of the Force continued
• Generic Synchronizations:Synch. operations do not identify specific
processes. They use quantifiers such as all, none,only one, or state of a variable.
• The Force supports both fine and coarse grain parallelism.
• Force is designed as a two-level macro processor.The parallel construct macros are machine
independent, are built on top of a hand-full of machine dependent macros. To port Force to anew platform, few macros need to be re-written

G. Alaghband Fundamentals of Parallel Processing
111, MIMD
Force has been ported to:HEP, Flex/32,Encore Multimax, Sequent Balance and Symmetry, Alliant Fx8, Convex,IBM 3090, Cray multiprocessors, KSR-1

G. Alaghband Fundamentals of Parallel Processing
112, MIMD
c Establish the number of processes requested by the executec command, and set up the parallel environment.
Force PROC of NP ident MEc
Shared real X(1000), GMAXPrivate real PMAXPrivate integer IEnd Declarations
cBarrier *********************
read(*,*)(X(I), I=1,1000) Strictly sequential
GMAX=0.0End barrier *********************

G. Alaghband Fundamentals of Parallel Processing
113, MIMD
c *********************PMAX=0.0 Replicated sequential
ccPresched Do 10 I = 1,1000 *********************
If ( X(I) .gt. PMAX) PMAX = X(I) Multiple sequential
10 End presched do *********************c
Critical MAX *********************if (PMAX .gt. GMAX) GMAX = PMAX
Strictly sequentialEnd critical *********************
cBarrier
write(*,*) GMAXEnd barrier
cJoinEnd

G. Alaghband Fundamentals of Parallel Processing
114, MIMD
Compilation of Force programs in Unix environment

G. Alaghband Fundamentals of Parallel Processing
115, MIMD
Compilation of Force programs in Unix environment
1. The SED pattern matcher translates the Force statements into parameterized function macros.
2. The M4macro processor replaces the function macros with Fortran code and the specific parallel programming extensions of the target Fortran language. The underlying Fortran language must include mechanisms for process creation, memory sharing among processes, and synchronized access to shared variables.
3. The Fortran compiler translates the expanded code, links it with the Force driver and multiprocessing libraries.
4. The Force driver is responsible for creation of processes, setting up the Force parallel environment, and shared memory.

G. Alaghband Fundamentals of Parallel Processing
116, MIMD
Program Structure:"Force <name> of <NP> ident <process id>
<declaration of variables>[Externf <Force module name>]
End declarations<Force program>
Join
Forcesub <name> ([parameters]) of <NP> ident <process id><declarations>[Externf <Force module name>]
End declarations<subroutine body>
Return
Forcecall <name>([parameters])

G. Alaghband Fundamentals of Parallel Processing
117, MIMD
Variable Declarations (6 Types):
Private <Fortran type> <variable list>Private Common /<label>/ <Fortran type> <variable list>
Shared <Fortran type> <variable list>Shared Common /<label>/ <Fortran type> <variable list>
Async <Fortran type> <variable list>Async Common /<label>/ <Fortran type> <variable list>

G. Alaghband Fundamentals of Parallel Processing
118, MIMD
Work Distribution Macros (9 Constructs, 2 commonly used):Presched Do <n> <var> = <i1>, <i2> [,<i3>]
<loop body><n> End Presched Do
Prescheduled DOALLs require no synchronization;Each process computes its own index values; Best performance is achieved when the amount of work for each index value is the same. Indices are allocated in a fixed way at compile time.
Cyclic mapping: Shared i1, i2, np; Private var, me; for var := i1+ me*i3 step np*i3 until i2,
loop body

G. Alaghband Fundamentals of Parallel Processing
119, MIMD
VPresched Do <n> <var> = <i1>, <i2> [,<i3>, <b2>]<loop body>
<n> End Presched Do
Block mapping:
Shared i1, i2, i3, np; Private var, lb, ub, me; /* Compute private lower & upper bounds (lb, ub) from i1, i2, i3, me and np */
for var := lb, i3, until ub<loop body.

G. Alaghband Fundamentals of Parallel Processing
120, MIMD
Selfsched Do <n> <var> = <i1>, <i2> [,<i3>]<loop body>
<n> End Selfsched Do
Pre2do <n> <var1> = <i1>, <i2> [,<i3>]; <var2> = <j1>, <j2> [,<j3>]
<doubly indexed loop body><n> End Presched Do
Selfscheduled DOALLs adapt to varying workload.
Synchronized access to a shared index is needed.
Each process obtains the next index value by incrementing a shared variable at run time.

G. Alaghband Fundamentals of Parallel Processing
121, MIMD

G. Alaghband Fundamentals of Parallel Processing
122, MIMD
self-scheduling code for one process executing the same forall
shared lwr, stp, upr, np, isync;private i;barrier
void isync;produce isync := lwr;
end barrierwhile (true) dobegin
consume isync into i;if (i > upr) then {produce isync := i; break;}/* End while loop */else {produce isync := i + stp; loop body(i);}
end

G. Alaghband Fundamentals of Parallel Processing
123, MIMD
Self2do <n> <var1> = <i1>, <i2> [,<i3>]; <var2> = <j1>, <j2> [,<j3>]
<doubly indexed loop body><n> End Selfsched Do
Askfor Do <n> Init = <i> /* # of initial work units*/<loop body>Critical <var>
More work <j> /* add j work units to loop*/<put work in data structure>
End critical<loop body>
<n> End Askfor Do
Work Distribution Macros continued

G. Alaghband Fundamentals of Parallel Processing
124, MIMD
Pcase on <var> Scase on <var><code block> <code block>
[Usect] [Usect]<code block> <code block>
[Csect (<condition>)] [Csect (<condition>)] . . . .End Pcase End Scase
Work Distribution Macros continued

G. Alaghband Fundamentals of Parallel Processing
125, MIMD
Resolve into <name>Component <name> strength <number or var>
.
.Component <name> strength <number or var>
Unify

G. Alaghband Fundamentals of Parallel Processing
126, MIMD
Synchronization:
Consume <async var> into <variable>Produce <async var> = <expression>Copy <async var> into <variable>Void <async var>
Isfull (<async var>)Critical <lock var>
<code block>End critical
Barrier<code block>
End barrier

G. Alaghband Fundamentals of Parallel Processing
127, MIMD
Consume waits for the state of the variable to be full, reads the value into a private variable and sets it to empty.
Produce waits for the state of the variable to be empty, sets its value to the expression and sets it to full.
Copy waits for the asynchronous variable to become full, copies its value into a private variable, but leaves its state as full.
Void sets the state of its asynchronous variableto empty regardless of its previous state.
Isfull Returns a boolean value indicating whetherthe state of an asynchronous variable is full or empty.

G. Alaghband Fundamentals of Parallel Processing
128, MIMD
Synchronization:
• Data oriented:
procedure produce(x, expr); shared struct {real var; boolean f} x; private ok;
ok := false;repeat
criticalif (not x.f) then
{ok := true; x.f := true; x.var := expr;};
end critical;until ok;
end procedure;

G. Alaghband Fundamentals of Parallel Processing
129, MIMD

G. Alaghband Fundamentals of Parallel Processing
130, MIMD
Control oriented: Barrier Implementation:Initial state and values: unlock (barlock)
lock (barwit)barcnt = 0
lock (barlock)if (barcnt < NP -1 ) then All processes except the
barcnt := barcnt +1 ; last will increment the unlock (barlock) ; counter and wait at the lock (barwit) ; lock(barwit).
endif ;if (barcnt = NP -1) then Last process executes
… the code body and code body unblocks barwit.
endif ;if (barcnt = 0) then
unlock (barlock) ;else All processes except the
barcnt := barcnt -1 ; last, will decrement the unlock (barwit) ; counter and unlock (barwit)The
endif last process unlocks barlock for correct state of the next barrier
execution.

G. Alaghband Fundamentals of Parallel Processing
131, MIMD
Forcesub bsolve(n) of nprocs ident meShared common /matrix/real a(500,500),b(500)Async common /sol/ real x(500)Private integer i,jPrivate real psum,tempEnd declarations
c Initialize the asynchronous vector x to empty.
Presched Do 100 i=1,n Void x(i)
100 End presched do

G. Alaghband Fundamentals of Parallel Processing
132, MIMD
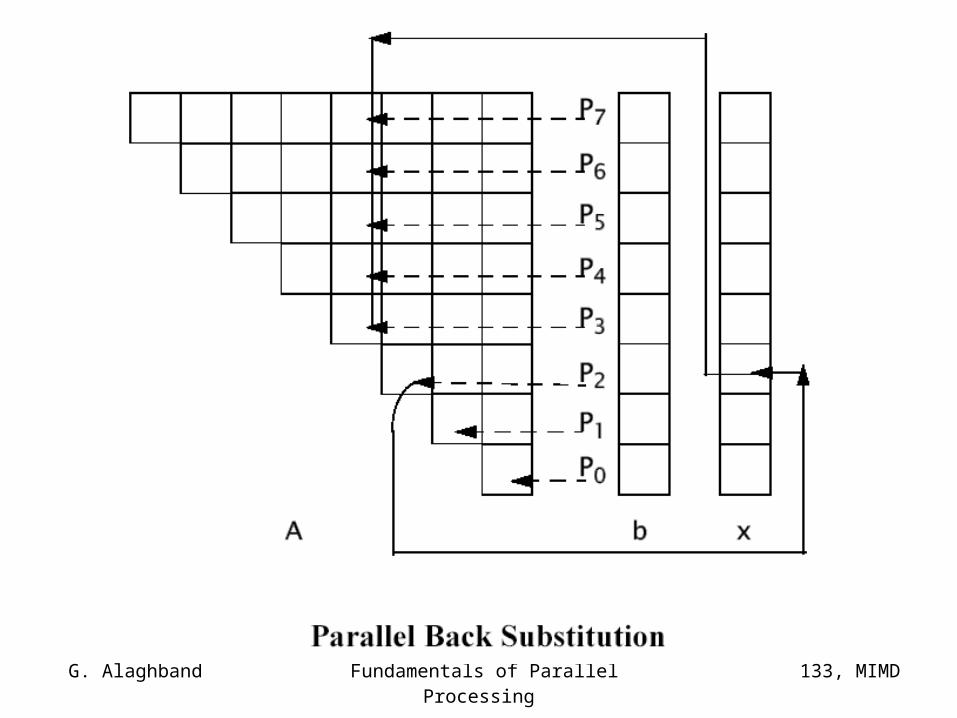
c The back solve process
c Produce value of x(n) to be used in the first loop iterationBarrierProduce x(n)=b(n)/a(n,n)End Barrier
Selfsched Do 200 i= n-1, 1, -1 psum=0.0
Do 150 j=n, i+1, -1c wait for X(j) to become full and copy its value
Copy x(j) into temppsum = psum + a(i,j) * temp
150 continuec produce the value of x(i) and mark it as full.
Produce x(i)=(b(i) -psum)/a(i,i) 200 End Selfsched Doc
Returnend
G. Alaghband Fundamentals of Parallel Processing
133, MIMD

















![Parallel database systems: Open problems and new issues · 138 VALDURIEZ purpose MIMD parallel computers using standard microprocessors and parallel programming techniques [55] will](https://static.cupdf.com/doc/110x72/5c9f5c1688c993452d8d31ac/parallel-database-systems-open-problems-and-new-issues-138-valduriez-purpose.jpg)












