




CS252 Project PresentationOptimizing the Leon Soft Core
Marghoob Mohiyuddin
Zhangxi Tan Alex Elium
Dept. of EECSUniversity of California, Berkeley

2CS252 Spring 2007
Project Outline
Goal: Reduce the size of Leon on FPGAs Our motivation for using Leon:
RAMP research: emulation of multiprocessors
Analysis:LUT breakdown
Optimizations:Circuit LevelArchitectural Level

3CS252 Spring 2007
Leon Overview
32-bit SPARC V8 compliant processor 7 stage pipeline, in-order Separate L1 Instruction & Data caches
Configurable cache size, associativity, replacement policy Optional Memory Management Unit AMBA bus interface to memory and peripherals
Supports Symmetric Multiprocessing Open-source (Gaisler Research)

4CS252 Spring 2007
Area analysis Configuration
MMU: Combined I/D-TLB, 2-entry only Integer MUL/DIV enableCache: Direct-map I/D cache
VariablesDSU - Debug support unitTarget clock
20 MHz - easy to achieve 200 MHz - over constrained

5CS252 Spring 2007
Resource break down
Relaxed Constraint (20 MHz), no DSU
Relaxed Constraint (20 MHz) with DSU
Over constrained (200 MHz)no DSU
Over constrained (200 MHz) with DSU
LUT Register LUT % LUT Register LUT % LUT Regs LUT % LUT
Regs LUT %
Integer Pipeline 2684 907 52.48% 3435 971 57.15% 3085 1057 54.21% 4034 1224 58.56%
MUL 200 135 3.91% 200 135 3.33% 226 116 3.97% 224 108 3.25%
DIV 391 81 7.65% 383 81 6.37% 388 119 6.82% 431 123 6.26%
MMU 446 276 8.72% 495 318 8.23% 451 283 7.92% 481 332 6.98%
ICache 320 89 6.26% 320 89 5.32% 354 90 6.22% 379 105 5.50%
DCache 943 285 18.44% 1058 289 17.60% 1057 292 18.57% 1227 304 17.81%
Bus IF 130 8 2.54% 120 8 2.00% 130 7 2.28% 113 10 1.64%
Total 5114 1781 6011 1891 5691 1964 6889 2206

6CS252 Spring 2007
Why it’s BIG Debugging Support
More MUXes One additional pipeline stage Useful for RAMP emulation / bootstrapping
IU is over 50% Barrel shifter Pipeline control (forwarding)

7CS252 Spring 2007
Circuit Level Optimizations
Store LRU bits in Block RAMs instead of Flip Flops Also saves LUTs
One-hot encoding for signals Synthesis tool does a good job of 1-hot encoding for many
signals (e.g., state encoding) Applied this to the cache output
Instead of data(set), we can use data(0) or data(1) or data(2) or data(3)
Useful only for multiway caches LUT savings: ~ 100 LUTs

8CS252 Spring 2007
Circuit Level Optimizations
Use fast-carry chain logic Provided 30% savings in LUT usage for TLB entries
Multipliers for barrel shifter Right shift by b is same as multiplication by 2^b Savings of ~ 100 LUTs

9CS252 Spring 2007
LUTs for Integer Mul / Div
2195 / 18429* for entire two core system (12%)
11.5% of Leon3 core
*(Xilinx ISE)

10CS252 Spring 2007

11CS252 Spring 2007
Didn’t your mother teach you to share? Savings of ~350 LUTs for prototype
Only multiplier shared Only two cores
10% could become 5%..2.5%...1%…. Even more for MAC
12CS252 Spring 2007
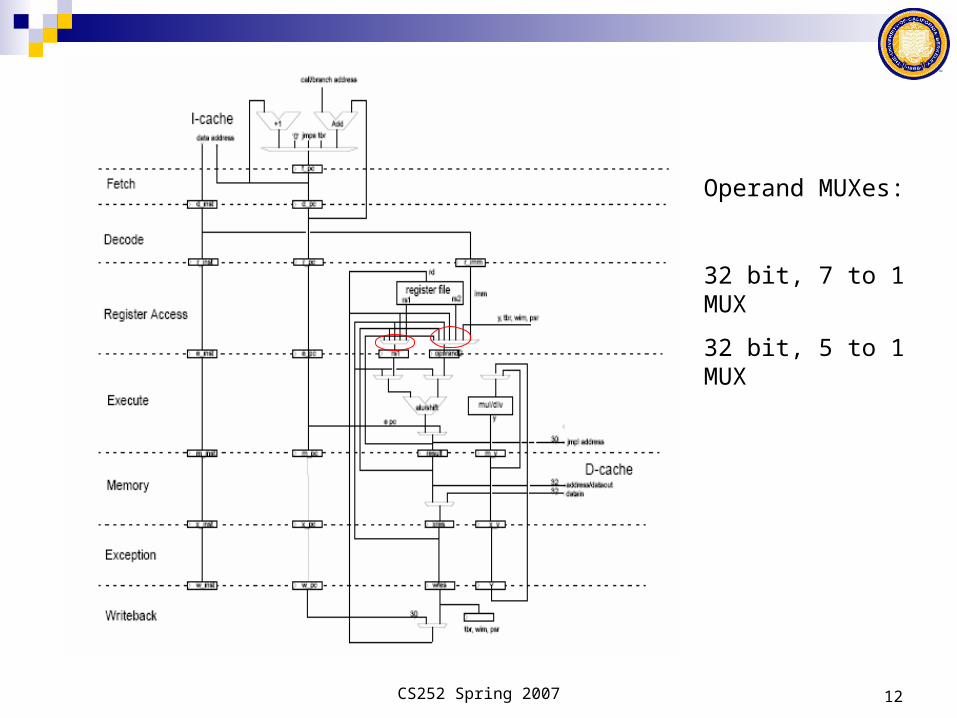
Operand MUXes:
32 bit, 7 to 1 MUX
32 bit, 5 to 1 MUX
13CS252 Spring 2007
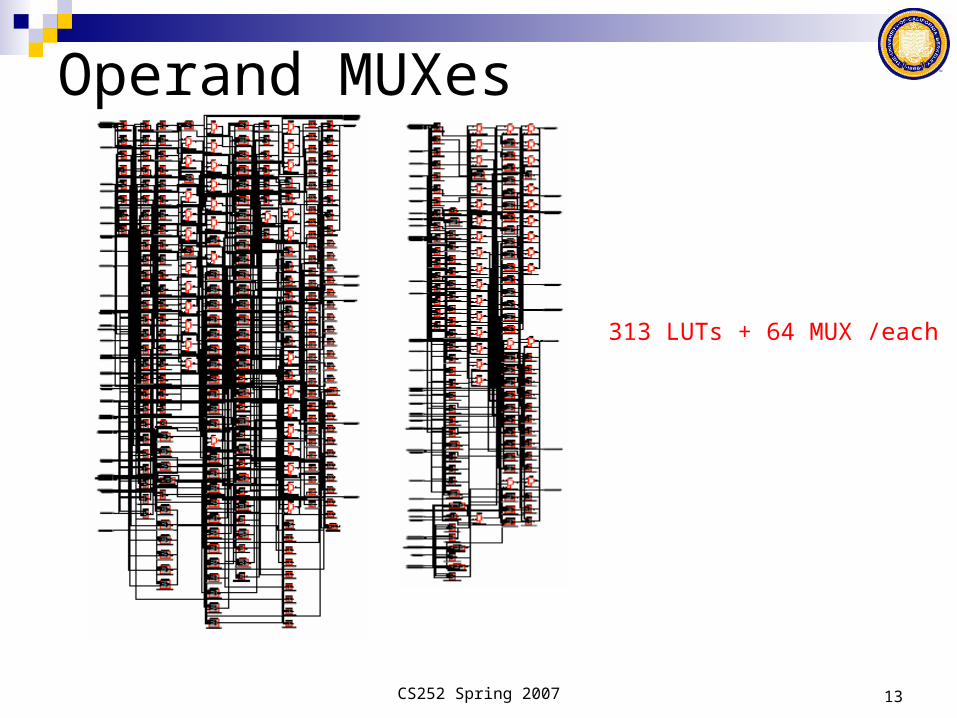
Operand MUXes
313 LUTs + 64 MUX /each

14CS252 Spring 2007
Integer Pipeline Changes Remove all forwarding
Single thread: Just stall Fine Grain Multithreading could boost performance LUTs saved: 27-37 % Maximum Freq improvement: 20%
LUTs Regs LUTs Regs LUTs Regs LUTs Regs
Standard Improved
47.4 MHz 49.3 MHz 73.3 MHz 77.7 MHz
2683 907 2637 907 1953 684 1943 684
108.5 MHz 114.6 MHz 127.6 MHz 136.1 MHz
3053 960 3013 1048 1928 715 2035 768Standard w. DSU
Improved w DSU
55.9 MHz 52.7 MHz 84.7 MHz 85.2 MHz
3477 971 3320 971 2469 744 2457 744
113.9 MHz 123 MHz 125 MHz 144.9 MHz
4202 1049 4198 1147 2610 778 2938 1371

15CS252 Spring 2007
Conclusions
CAD tools already perform many optimizationsRemove unused logic Infer technology dependent logic from HDL
source, e.g. Fast carry chain logicOptimize logic globally

16CS252 Spring 2007
Conclusions
Optimization is possibleHigher levels yield (much) greater savings
Circuit Level: 200-300 LUTs Architectural Level: 1000+ of LUTs Sharing: ~700 per core Total: 35-40% savings

















