




Cloud Storage and Parallel File SystemsSNIA Storage Developer Conference (SDC09), Sept 2009
Garth Gibson Carnegie Mellon University and Panasas Inc [email protected] and [email protected]

Garth Gibson, Sept 15, 2009 2
Birth of RAID (1985-1991) • Member of 4th Berkeley RISC CPU design team (SPUR: 84-89)
• CPU design is a “solved” problem • SYSTEM PERFORMANCE depends on data storage, so
• IBM 3380 disk is 4 arms in a 7.5 GB washing machine box • SLED: Single Large Expensive Disk
• New PC industry demands cost effective 100 MB 3.5” disks • Enabled by new SCSI embedded controller architecture
• Use many PC disks for parallelism: ACM SIGMOD 1988 “RAID” paper

Garth Gibson, Sept 15, 2009 3
Object Storage (CMU NASD, 95-99) • Before NASD there was store&forward Server-Attached Disks (SAD) • Move access control, consistency out-of-band and cache decisions • Raise storage abstraction: encapsulate layout, offload data access • Now ANSI T10 SCSI command set standard (v2 emerging soon)

Garth Gibson, Sept 15, 2009 4
File manager
NASD
Client
1: Request for access
Secret Key
Secret Key
NASD Integrity/Privacy
ReqMAC = MACCapKey(Req,NonceIn)
ReplyMAC = MACCapKey(Reply,NonceOut)
4: Reply, NonceOut, ReplyMAC
2: CapArgs, CapKey
Private Communication
CapKey= MACSecretKey(CapArgs)CapArgs= ObjID, Version, Rights, Expiry,....
3: CapArgs, Req, NonceIn, ReqMAC
Fine Grain Access Enforcement • State of art is VPN of all out-of-band clients, all sharable data and metadata
• Accident prone & vulnerable to subverted client; analogy to single-address space computing
Object Storage uses a digitally signed, object-specific capabilities on each request

Panasas Inc. Spins Out (1999)
• Storage that accelerates the world’s highest performance and most data-intensive applications - 10,000+ clients, 50+ GB/s, 1,000+ storage nodes - Primary storage on first & fastest computer (Los Alamos)
• Founded 1999, shipping solutions since 2003 - Software innovation, packaged with industry-standard HW - Scalable RAID over storage nodes, end-to-end check codes - Integrated SSD, extensive HA, snapshot, async mirroring
• Record Q2 growth despite economy - 50% growth in revenue YoY vs -18% WW - Strong growth with partners,
international, new accounts - Strong balance sheet
Garth Gibson, Sept 15, 2009#5

Panasas Storage Cluster
DirectorBlade StorageBlade
Integrated 10GE Switch
Shelf Front 1 DB, 10 SB
Shelf Rear
Midplane routes GE, power
Battery Module (2 Power units)
Garth Gibson, Sept 15, 2009#6

Leaders in HPC choose Panasas
SWIFT ENERGY COMPANY
Garth Gibson, Sept 15, 2009#7

# The world's first Linpak sustained 1.0 petaflops system.
# #1 on TOP500 - Achieved 1.026 petaflops on May 25, 2008
# #3 on Green 500
# Time Magazine’s 10th Top Innovation for 2008
# Been in development since 2002
# Open science phase in progress now
# More than 4 PB of Panasas
# Greater than 50 GB/s to apps
# Computational chemistry at 369 Tflops
World's Fastest Computer – Los Alamos’ RoadRunner
Ref: http://en.wikipedia.org/wiki/IBM_Roadrunner
Panasas Performance Scales

Garth Gibson, 11/21/2008 www.pdsi-scidac.org
SciDAC Petascale Data Storage Institute • Eight organizations on the team
• Carnegie Mellon University, Garth Gibson, PI • U. of California, Santa Cruz, Darrell Long • U. of Michigan, Ann Arbor, Peter Honeyman • Lawrence Berkeley Nat. Lab, John Shalf • Oak Ridge National Lab, Phil Roth • Pacific Northwest National Lab, Evan Felix • Los Alamos National Lab, Gary Grider • Sandia National Lab, Lee Ward

Garth Gibson, Sept 15, 2009#
Future is data-led
NIST: translate 100 articles – Arabic-English competition
2005 outcome: Google wins! Qualitatively better on 1st entry Brute force statistics with
more data & compute !! 200M words from UN translations 1 billion words of English grammar 1000 processor cluster
BLEU Score
0.6
0.5
0.4
0.3
0.2
0.1
0.0
Google ISI IBM+CMU UMD JHU+CU Edinburgh
Systran
Mitre
FSC
0.7
Topic identification
Human-edittable translation
Usable translation
Expert human translator
Useless
10

Science of many types is data-led Contact Field Comments J Lopez, CSD Astrophysics SDSS digital sky survey including spectroscopy, 50TB
T Di Matteo, Physics Astrophysics Bigben BHCosmo hydrodynamics (1B particles simulated), 30TB
F Gilman, Physics Astrophysics Large Synoptic Survey Telescope, LSST (2012) digital sky survey, 15TB/day
C Langmead,CSD Biology Xray, NMR, CryoEM images; Sim’d molecular dynamics trajectories
J Bielak, CE Earth sciences USGS sensor images; Sim’d 4D earthquake wavefields >10TB/run
D Brumley, ECE Cyber security Worldwide Malware Archive; 2TB doubling each year
O Mutlu, ECE Genomics 50GB per compressed genome sequencing; expands to TBs to process
B Yu, ECE Neuroscience Neural recordings (electrodes, optical) for prosthetics; 10-100GB each
J Callan, LTI Info Retrieval ClueWeb09, 25TB, 1B high rank web pages, 10 languages
T Mitchell, MLD Machine Learning English sentences of ClueWeb for continuous automated reading (5TB)
M Herbert, RI Image Understanding Flickr archive (>4TB); broadcast TV archive; street video; soldier video
Y Sheikh, RI Virtual Reality Terascale VR sensor, 1000 camera+ 200 microphone, up to 5TB/sec
C Guestrin, CSD Machine Learning Blog update archives, 2TB now + 2.7TB/yr (about 500K blogs/day)
C Faloutsos, CSD Data Mining Wikipedia change archive (1TB), Fly embryo images (1.5TB), links from Yahoo web
S Vogel, LTI Machine Translation Pre-filtered N-gram language model based on statistics on word alignment, 100 TB
J Baker, LTI Machine Translation Spoken language recording archive, many languages, many sources, up to 1PB
B Becker, RI Computer Vision Social network image/video archive for training computer vision systems, 1-5TB
Garth Gibson, Sept 15, 2009#11

Cloud as Home for Massive Data • Moving massive data is not a good idea
• PanStarrs:1 TB/day over nationally funded networks • Large Synoptic Survey Telescope: 15 TB/day planned • South African firm: homing pigeon faster than net • Seismic survey firms use trucks and helicopters
• Build processing for massive data & share • Share cost of storage, buy your own processing • Private clouds share among units, college depts
• What semantics for storage in cloud? • R. Wolski (Eucalytus): “we haven’t seen the cloud
storage model yet”
Garth Gibson, Sept 15, 2009#12

Why do I care about common semantics? • Programmer productivity & ease of deployment • HPC FSs are more mature, wider feature set
• In the comfort zone of programmers (vs cloud FS) • High concurrent reads and writes
• Wide support, adoption, acceptance possible • pNFS (NFS v4.1) working to be equivalent
– NetApp, EMC, Sun, IBM, Panasas, … • Reuse standard data management tools
– Backup, disaster recovery, tiering, …
Garth Gibson, Sept 15, 2009#13

Cloud HDFS & HPC PVFS • Meta-data servers
• Store all file system metadata • Handle all metadata operations
• Data servers • Store actual file system data • Handle all read and write operations
• Files are divided into chunks (objects) • Chunks of a file are distributed across servers
• Designed for collocation of disks & compute • HDFS is, PVFS is not (Amazon-like) but can do it
Garth Gibson, Sept 15, 2009#14

HPC PVFS shim under Hadoop
Garth Gibson, Sept 15, 2009#
Hadoop framework
Extensible file system API
PVFS shim layerHDFS client library
Hadoop applications
Unmodified PVFS client library (C)
Unmodified PVFS serversHDFS servers
Client
Server
Hadoop framework
Extensible file system API
PVFS shim layerHDFS client library
Hadoop applications
Unmodified PVFS client library (C)
PVFS shim layer
Readahead buffer
File layout info
Replication
Unmodified PVFS serversHDFS servers
Client
Server
~1,700 lines of code
15

It takes a little work, but PVFS gets there • No changes in PVFS, just “stdio”-class shim library • Out of the box, a big difference
• PVFS cache coherent by not prefetching; HDFS immutable • Prefetching in the shim pretty much trivial but not enough
• HDFS exposes IP of each block’s data server • Hadoop schedules read on best node • Exposing layout in PVFS
simple, given an API • Architecture is issue:
where are disks? RAID? In nodes/HDFS or not/S3
– Or not using all nodes • Rack awareness similar
but smaller differences
Garth Gibson, Sept 15, 2009#16

A closer look: reading a single file
• N clients, each reads 1/N of a single file (left) • Round-robin file layout in PVFS avoids contention that
occurs with random allocation in HDFS
• But if Hadoop is given all work at once (right) • Scheduling lots of work overcomes contention
Garth Gibson, Sept 15, 2009#
0
100
200
300
400
500
600
700
800
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Agg
rega
te re
ad th
roug
hput
(MB
/s)
Number of Clients
PVFS (no replication)
HDFS (no replication)
0
5
10
15
20
25
30
35
Com
plet
ion
Tim
e (s
ec)
Read (16GB, 16 nodes)
PVFS HDFS
17 http://www.pdl.cmu.edu/

Writing has larger differences
• Writing: N clients to N files (left) • HDFS writes locally first, so linear • PVFS writes over net, shifting work to idle clients
• Writing: N clients to one file (right) • HDFS does not support multiple concurrent writers
Garth Gibson, Sept 15, 2009#
0
100
200
300
400
500
600
700
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Agg
rega
te w
rite
thro
ughp
ut (M
B/s
)
Number of Clients
PVFS (no replication)
HDFS (no replication)
0
100
200
300
400
500
600
700
Com
plet
ion
Tim
e (s
ec)
Parallel Copy (16GB, 16 nodes)
PVFS (16 writers) HDFS (1 writer)
18

OpenCirrus/Yahoo M45 tests
Garth Gibson, Sept 15, 2009#
• PVFS & HDFS similar for reading as before • HDFS non-striped local copy saves network traffic
in network-limited write-intensive sort • How fundamental is “network-limited” in the cloud? • Cloud “surge protection”: data rarely local to “small” compute
0
200
400
600
800
1000
1200
Com
plet
ion
Tim
e (s
ec)
Sort (100GB, 50 nodes)
PVFS HDFS PVFS(2 copies)
0
200
400
600
800
1000
Net
wor
k Tr
affic
(GB
)
Sort (100GB, 50 nodes)
PVFS HDFS PVFS(2 copies)
0
25
50
75
100
125
Com
plet
ion
Tim
e (s
ec)
Grep (100GB, 50 nodes)
PVFS HDFS
19

CMU testbeds: 10 GE networking • Combined: 3 TF, 2.2 TB, 142 nodes, 1.1K cores, ½ PB • 1 GE vs 10 GE
• Network vs disk bottleneck
• OpenCloud writes remote as fast a local
• EtherCLOS networks at SigCOMM
• No need for datacenter network to be big limit
Garth Gibson, Sept 15, 2009#20

Revisit HDFS Triplication • GFS & HDFS triplicate every data block
• Triplication: one local + two remote copies • 200% space overhead
• But RAID5 *is* simple?
B
A
A
A
B
B
Garth Gibson, Sept 15, 2009#21

Revisit HDFS Triplication • GFS & HDFS triplicate every data block
• Triplication: one local + two remote copies • 200% space overhead
• But RAID5 is simple? • Can be done at scale
– Panasas does it with Object RAID over servers
– >1PF, >50GB/s, >10Kclients B
A
A
A
B
B
Garth Gibson, Sept 15, 2009#22

• GFS & HDFS triplicate every data block • Triplication: one local + two remote copies
• 200% space overhead • But RAID5 is simple? • Can be done at scale
– Panasas does it >PF, >50 GB/s, >10K clients
• But sync error handling hard
• GFS & HDFS defer repair • Background task repairs copies
– Notably less scary to developers
A
A
B
B
✗ B
B A
Garth Gibson, Sept 15, 2009#23
Revisit HDFS Triplication

DiskReduce: Background Repair for RAID • Start the same: triplicate every data block
• Triplication: one local + two remote copies • 200% space overhead
B
A
A
A
B
B
Garth Gibson, Sept 15, 2009#24

DiskReduce: Background Repair for RAID • Start the same: triplicate every data block
• Triplication: one local + two remote copies • 200% space overhead • Background encoding • In coding terms:
• Data is A, B • Check is A, B, f(A,B)=A+B
A
A
B
B
B A
A+B
Garth Gibson, Sept 15, 2009#25

DiskReduce: Background Repair for RAID • Start the same: triplicate every data block
• Triplication: one local + two remote copies • 200% space overhead • Background encoding • In coding terms:
• Data is A, B • Check is A, B, f(A,B)=A+B
• Std single failure recovery
A
A
B
B
✗ B
Garth Gibson, Sept 15, 2009#
A+B
26

DiskReduce: Background Repair for RAID • Start the same: triplicate every data block
• Triplication: one local + two remote copies • 200% space overhead • Background encoding • In coding terms:
• Data is A, B • Check is A, B, f(A,B)=A+B
• Std single failure recovery • Double failure recovery uses
parity and related data blocks – Then applies standard single failure recovery
A
A
B
B
✗ B
✗
Garth Gibson, Sept 15, 2009#
A+B
27

Preliminary Evaluation • Pre-OpenCirrus testbed
• 16 nodes, PentiumD dual-core 3.00GHz • 4GB memory, 7200 rpm SATA 160GB disk • Gigabit Ethernet
• Implementation specification: • Hadoop/HDFS version 0.17.1
• Test conditions • File size distribution from Yahoo! M45 sample • Benchmarks modeled on Google FS paper • Benchmark input after “all parity groups are encoded” • Benchmark output has “encoding in background” • No failures during tests
Garth Gibson, Sept 15, 2009#28

The Obvious Little Degradation
0
50
100
150
200 O
rigin
al
Had
oop
3
repl
icas
Par
ity
Gro
up
Siz
e 8
Par
ity
Gro
up
Siz
e 16
Com
plet
ion
Tim
e
Sort with 7.5G data
0 50
100 150 200 250 300 350 400
Orig
inal
H
adoo
p
3 re
plic
as
Par
ity
Gro
up
Siz
e 8
Par
ity
Gro
up
Siz
e 16
Com
plet
ion
Tim
e
Grep with 45G data
Garth Gibson, Sept 15, 2009#29

DiskReduce v2.0 • Only 33% saving with v1.0
• Stopped work on v1.0 b/c encoding didn’t scale • Started v2.0 model based on “codeword” selection
– Select a RAID group before creating data – Retain random distribution
• Worry more about “cleaning” post block delete – Return of Small Write bottleneck of RAID 5 & 6 – Select blocks in group to promote co-deletion
• We’ll get to performance degradation …. – Backup jobs like having a second copy
Garth Gibson, Sept 15, 2009#30

Closing: Clouds & Parallel File Systems • Big similarity between cloud & parallel file systems
• Similar scale – 1000s of nodes • Two layer implementation, object-based • PVFS can match HDFS performance • Datacenter network bottleneck & colocation overplayed
– 10GE & fat trees coming; surge protected = non-local
• Differences stem from maturity & simplicity • Simpler semantics works sooner • But users want familiar semantics
– Writing, directories, concurrency, low overhead, …. • Integrates into broader infrastructure seamlessly
• My view: layer Parallel NFS under cloud APIs • Exposing it as customers ask for richer semantics
Garth Gibson, Sept 15, 2009#31

Thank you
Garth Gibson, Sept 15, 2009#32
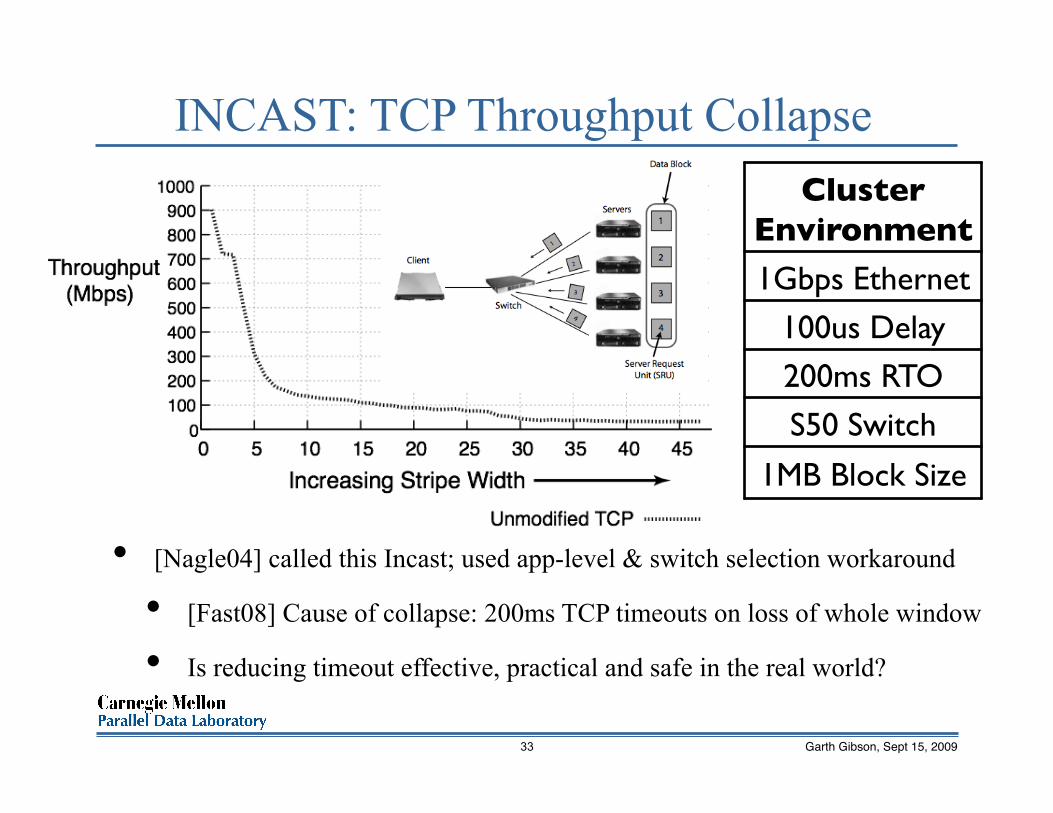
INCAST: TCP Throughput Collapse Cluster
Environment
1Gbps Ethernet
100us Delay
200ms RTO
S50 Switch
1MB Block Size
• [Nagle04] called this Incast; used app-level & switch selection workaround
• [Fast08] Cause of collapse: 200ms TCP timeouts on loss of whole window
• Is reducing timeout effective, practical and safe in the real world?
Garth Gibson, Sept 15, 2009#33

Mitigating Incast Cluster
Environment
1Gbps Ethernet
100us Delay
S50 Switch
1MB Block Size
• Eliminating RTO bound: 5ms timeouts - clock granularity limit • Single line, server-only change is effective at medium scales
• Eliminating RTO bound + Microsecond TCP timeouts avoids Incast
• Exploits “High resolution timers” to avoid high interrupt overhead
Garth Gibson, Sept 15, 2009#34

The Need for Microsecond Timeouts
Simulation Environment
10Gbps Ethernet
20us Delay
40MB Block Size
• Future datacenters: More bandwidth, less delay, more servers • Retransmission timeouts should not be bounded below • Accepted into SIGCOMM 2009
Garth Gibson, Sept 15, 2009#35





























