



1/28
Efficient Top-k Queriesfor XML Information Retrieval
Gerhard Weikum
http://www.mpi-sb.mpg.de/~weikum/
Joint work with Ralf Schenkel and Martin Theobald
Max-Planck-Gesellschaft

2/28
A Few Challenging Queries(on Web / Deep Web / Intranet / Personal Info)
Which drama has a scene in which a woman makes a prophecyto a Scottish nobleman that he will become king?
Which professors from Saarbruecken (SB) are teaching IR and have research projects on XML?
SB IR
XML
Who was the woman from Paris that I met at the PC meetingwhere Alon Halevy was PC Chair?
Which gene expression data from Barrett tissue in theesophagus exhibit high levels of gene A01g?
Are there any published theorems that are equivalent toor subsume my latest mathematical conjecture?
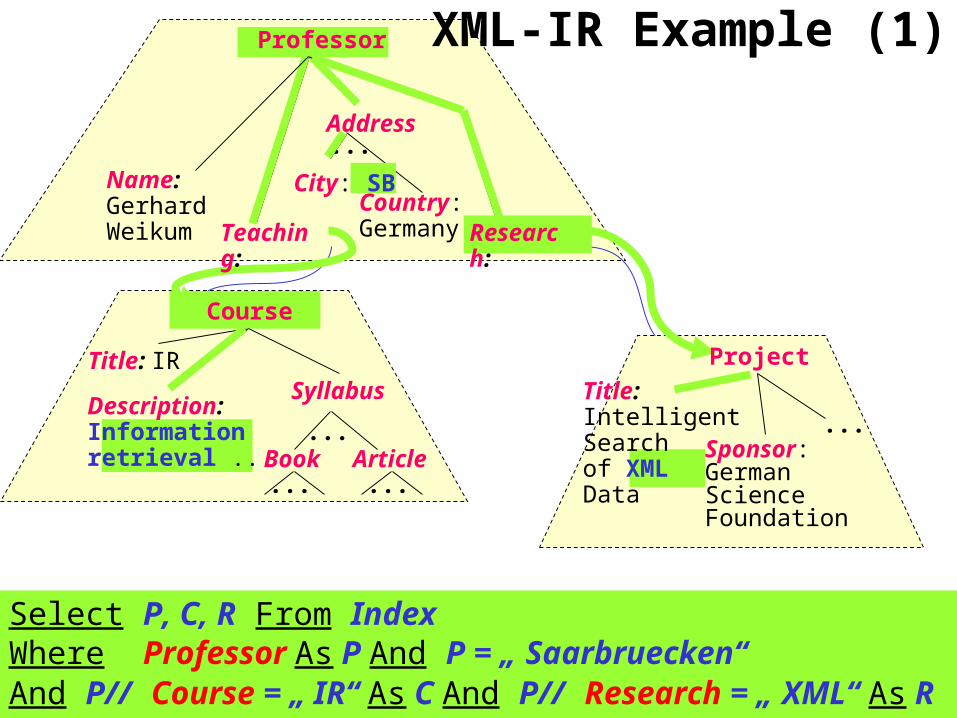
3/28
Professor
Name:GerhardWeikum
Address...
Country: GermanyTeaching: Research:
Course
Title: IR
Description: Information retrieval ...
Syllabus
...Book Article
... ...
Project
Title: Intelligent Search of XMLData
Sponsor:GermanScienceFoundation
...
XML-IR Example (1)
Select P, C, R From Index Where Professor As P And P = „ Saarbruecken“And P// Course = „ IR“ As C And P// Research = „ XML“ As R
City: SB

4/28
Article...
Select P, C, R From Index Where Professor As P And P = „ Saarbruecken“And P// Course = „ IR“ As C And P// Research = „ XML“ As R
Select P, C, R From Index Where ~Professor As P And P = „~Saarbruecken“And P//~Course = „~IR“ As C And P//~Research = „~XML“ As R
Professor
Name:GerhardWeikum
Address...
Country: GermanyTeaching: Research:
Course
Title: IR
Description: Information retrieval ...
Syllabus
...Book
...
Project
Title: Intelligent Search of XMLData
Sponsor:GermanScienceFoundation
...
XML-IR Example (2)
City: SB
Name:RalfSchenkel Teaching:
Literature
Book
Lecturer
Interests: Semistructured Data, IR
Address:Max-PlanckInstitute for CS,Germany
Seminar
Title: StatisticalLanguage Models
...
Contents: Ranked Search ...

5/28
XML-IR: History and Related WorkIR on structured docs (SGML):
1995
2000
2005
IR on XML:
XIRQL (U Dortmund)XXL (U Saarland / MPI)
XRank (Cornell U)
JuruXML (IBM Haifa )
Commercial software(MarkLogic, Verity?, Oracle?, Google?, ...)
XML query languages:
XQuery (W3C)
XPath 2.0 (W3C)INEX benchmark
Compass (U Saarland / MPI)
XPath 1.0 (W3C)XML-QL (AT&T Labs)
Web query languages:
Lorel (Stanford U)Araneus (U Roma)W3QS (Technion Haifa)
TeXQuery (AT&T Labs)FleXPath (AT&T Labs)
ELIXIR (U Dublin)
HyperStorM (GMD Darmstadt)HySpirit (U Dortmund)
WHIRL (CMU)
PowerDB-IR (ETH Zurich)
ApproXQL (U Berlin / U Munich)
Timber (U Michigan)XSearch (Hebrew U)

6/28
XML-IR Concepts
Where clause: conjunction of restricted path expressions with binding of variables
Select P, C, R From IndexWhere ~Professor As PAnd P = „Saarbruecken“And P//~Course = „Information Retrieval“ As CAnd P//~Research = „~XML“ As R
Elementary conditions on names and contents
„Semantic“ similarity conditions on names and contents
Relevance scoring based on tf*idf similarity of contents, ontological similarity of names,
aggregation of local scores into global scores
~Research = „~XML“
Query result:• query is a path/tree/graph pattern• results are isomorphic paths/subtrees/subgraphs of the data graph
Query result:• query is a pattern with relaxable conditions• results are approximate matches to query with similarity scores
applicable to both XML and HTML data graphs
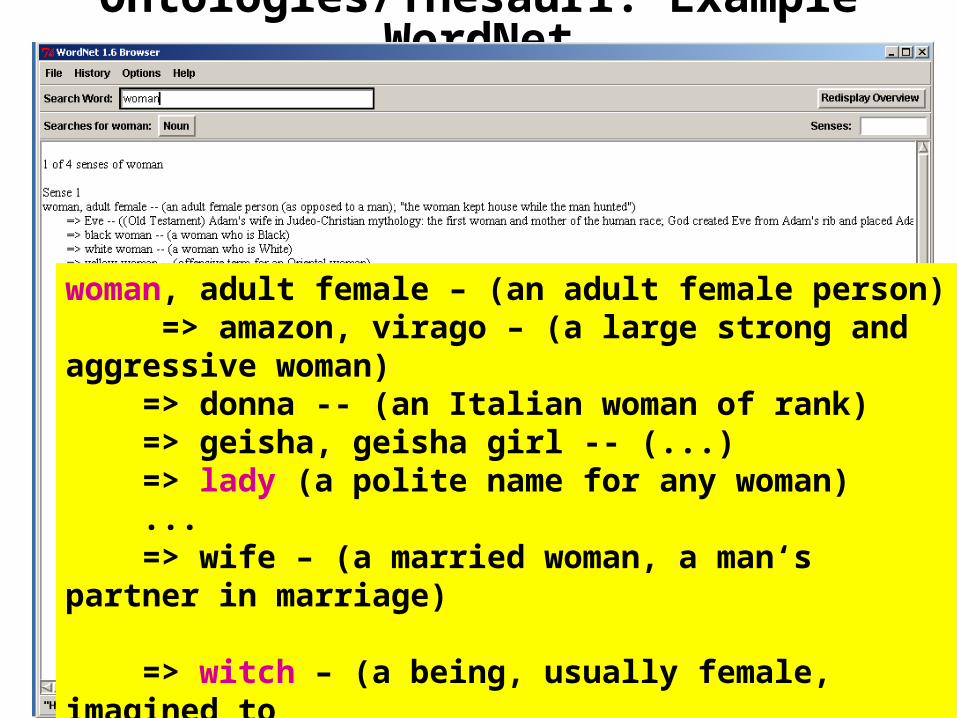
7/28
Ontologies/Thesauri: Example WordNet
woman, adult female – (an adult female person) => amazon, virago – (a large strong and aggressive woman) => donna -- (an Italian woman of rank) => geisha, geisha girl -- (...) => lady (a polite name for any woman) ... => wife – (a married woman, a man‘s partner in marriage) => witch – (a being, usually female, imagined to have special powers derived from the devil)

8/28
Ontology GraphAn ontology graph is a directed graph withconcepts (and their descriptions) as nodes and semantic relationships as edges (e.g., hypernyms).
woman
human
body
personality
character
lady
witch
nanny
MaryPoppins fairy
Lady Di
heart
...
...
...
syn (1.0)
hyper (0.9)
part (0.3)
mero (0.5)
part (0.8)
hypo (0.77)
hypo (0.3)hypo (0.35)
hypo (0.42)
instance(0.2)
instance (0.61)
instance (0.1)
Weighted edges capture strength of relationships key for identifying closely related concepts

9/28
Query Expansion
Threshold-based query expansion:substitute ~w by (c1 | ... | ck) with all ci for which sim(w, ci)
„Old hat“ in IR; highly disputed for danger of topic dilution
Approach to careful expansion:• determine phrases from query or best initial query results (e.g., forming 3-grams and looking up ontology/thesaurus entries)• if uniquely mapped to one concept then expand with synonyms and weighted hyponyms
Problem: choice of threshold see Top-k QP

10/28
Outline
Motivation & Preliminaries
Prob-k: Efficient Approximative Top-k
• TopX: Top-k for XML
•
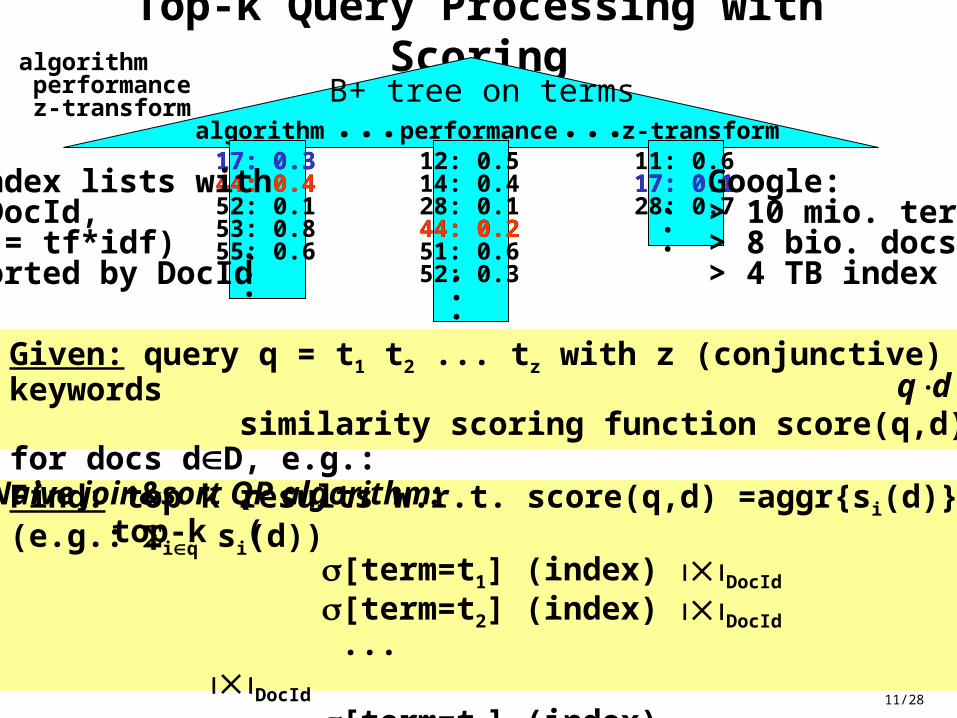
11/28
Top-k Query Processing with Scoring
Naive join&sort QP algorithm:
algorithm
B+ tree on terms
17: 0.344: 0.4
...
performance... z-transform...
52: 0.153: 0.855: 0.6
12: 0.514: 0.4
...
28: 0.144: 0.251: 0.652: 0.3
17: 0.128: 0.7
...
17: 0.317: 0.144: 0.4
44: 0.2
11: 0.6index lists with(DocId, s = tf*idf)sorted by DocId
Given: query q = t1 t2 ... tz with z (conjunctive) keywords similarity scoring function score(q,d) for docs dD, e.g.: Find: top k results w.r.t. score(q,d) =aggr{si(d)}(e.g.: iq si(d))
Google:> 10 mio. terms> 8 bio. docs> 4 TB index
q d
q: algorithm performance z-transform
top-k ( [term=t1] (index) DocId
[term=t2] (index) DocId
... DocId
[term=tz] (index) order by s desc)

12/28
TA (Fagin’01; Güntzer/Kießling/Balke; Nepal et al.)
scan all lists Li (i=1..m) in parallel: consider dj at position posi in Li; highi := si(dj); if dj top-k then { look up s(dj) in all lists L with i; // random access compute s(dj) := aggr {s(dj) | =1..m}; if s(dj) > min score among top-k then add dj to top-k and remove min-score d from top-k; };if min score among top-k aggr {high | =1..m} then exit;
m=3aggr: sumk=2
f: 0.5b: 0.4c: 0.35a: 0.3h: 0.1d: 0.1
a: 0.55b: 0.2f: 0.2g: 0.2c: 0.1
h: 0.35d: 0.35b: 0.2a: 0.1c: 0.05f: 0.05
f: 0.75
a: 0.95
top-k:
b: 0.8
but random accesses are expensive ! TA-sorted Prob-sorted
applicable to XML data: course = „~ Internet“ and ~topic = „performance“

13/28
TA-Sorted (aka. NRA)scan index lists in parallel: consider dj at position posi in Li; E(dj) := E(dj) {i}; highi := si(q,dj); bestscore(dj) := aggr{x1, ..., xm) with xi := si(q,dj) for iE(dj), highi for i E(dj); worstscore(dj) := aggr{x1, ..., xm) with xi := si(q,dj) for iE(dj), 0 for i E(dj); top-k := k docs with largest worstscore; if min worstscore among top-k max bestscore{d | d not in top-k} then exit;
m=3aggr: sumk=2
a: 0.55b: 0.2f: 0.2g: 0.2c: 0.1
h: 0.35d: 0.35b: 0.2a: 0.1c: 0.05f: 0.05
top-k:
candidates:
f: 0.5b: 0.4c: 0.35a: 0.3h: 0.1d: 0.1
f: 0.7 + ? 0.7 + 0.1
a: 0.95
h: 0.35 + ? 0.35 + 0.5
b: 0.8
d: 0.35 + ? 0.35 + 0.5c: 0.35 + ? 0.35 + 0.3
g: 0.2 + ? 0.2 + 0.4
h: 0.45 + ? 0.45 + 0.2
d: 0.35 + ? 0.35 + 0.3

14/28
Evolution of a Candidate’s Score
scan depth
drop dfrom thecandidate queue
Approximate top-k “What is the probability that d qualifies for the top-k ?”
bestscore(d)
worstscore(d)
min-k
score
??Worst- and best-scores slowly converge to final scoreAdd d to top-k result, if worstscore(d) > min-kDrop d only if
bestscore(d) < min-k, otherwise keep it in candidate queue
Overly conservative threshold & long sequential index scans
TA family of algorithms based on invariant (with sum as aggr)i i i
i E( d ) i E( d ) i E( d )s ( d ) s( d ) s ( d ) high
worstscore(d) bestscore(d)

15/28
Top-k Queries with Probabilistic Guarantees
TA family of algorithms based on invariant (with sum as aggr)i i i
i E( d ) i E( d ) i E( d )s ( d ) s( d ) s ( d ) high
Relaxed into probabilistic invarianti i
i E( d ) i E( d )p( d ) : P [ s( d ) ] P [ s ( d ) S threshold ]
i i ii E( d ) i E( d ) i E( d )
P [ S threshold s ( d )] : P [ S ']
where the RV Si has some (postulated and/or estimated) distribution in the interval (0,highi]
f: 0.5b: 0.4c: 0.35a: 0.3h: 0.1d: 0.1
a: 0.55b: 0.2f: 0.2g: 0.2c: 0.1
h: 0.35d: 0.35b: 0.2a: 0.1c: 0.05f: 0.05
S1S2 S3
• Discard candidates with p(d) ≤ • Exit index scan when candidate list empty
highi
0
0,2
0,4
0,6
0,8
1
1,2
worstscore(d) bestscore(d)

16/28
Probabilistic Threshold Test
• postulating uniform or Zipf score distribution in [0, highi]
• compute convolution using LSTs• use Chernoff-Hoeffding tail bounds or generalized bounds for correlated dimensions (Siegel 1995)
• fitting Poisson distribution (or Poisson mixture)• over equidistant values:• easy and exact convolution
• distribution approximated by histograms:• precomputed for each dimension• dynamic convolution at query-execution time
with independent Si‘s or with correlated Si‘s
)!1(][
1
jevdP
jii
j
engineering-wise histograms work best!
0
f2(x)
1 high2
Convolution(f2(x), f3(x))
2 0δ(d)
f3(x)
high31 0
cand doc dwith 2 E(d),3 E(d)
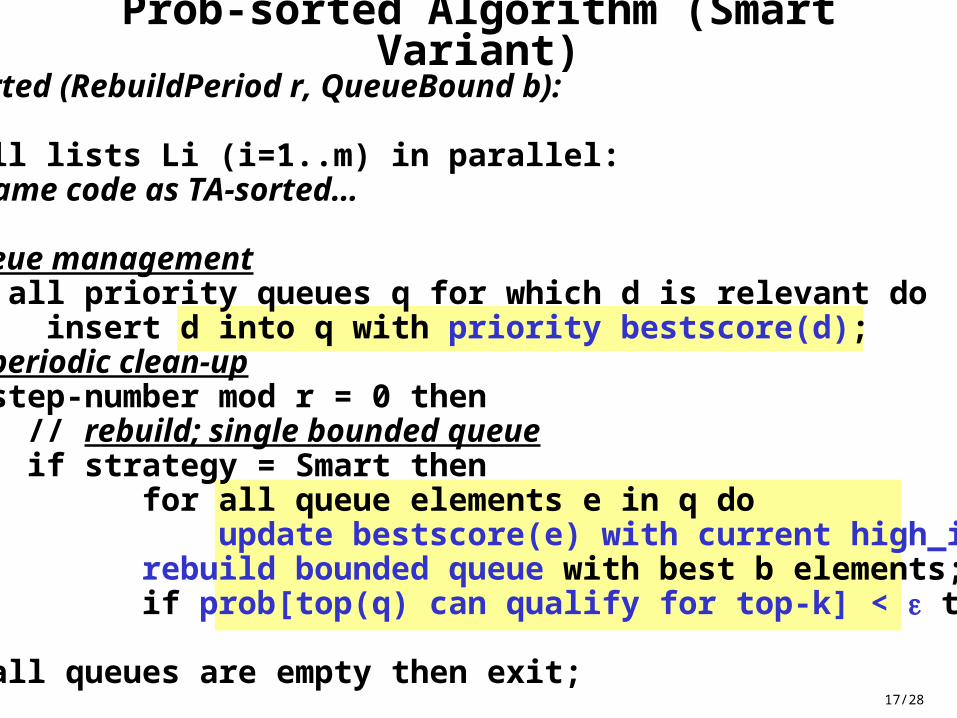
17/28
Prob-sorted Algorithm (Smart Variant)Prob-sorted (RebuildPeriod r, QueueBound b):...scan all lists Li (i=1..m) in parallel: …same code as TA-sorted…
// queue management for all priority queues q for which d is relevant do insert d into q with priority bestscore(d); // periodic clean-up if step-number mod r = 0 then // rebuild; single bounded queue if strategy = Smart then for all queue elements e in q do update bestscore(e) with current high_i values; rebuild bounded queue with best b elements; if prob[top(q) can qualify for top-k] < then exit; if all queues are empty then exit;
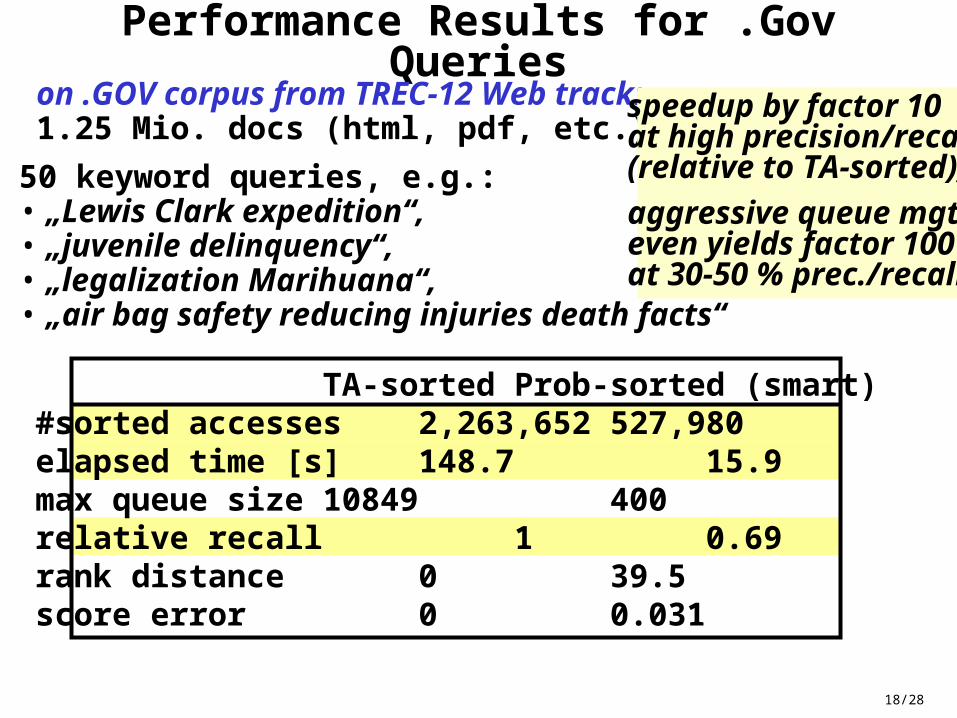
18/28
TA-sorted Prob-sorted (smart)#sorted accesses 2,263,652 527,980elapsed time [s] 148.7 15.9max queue size 10849 400relative recall 1 0.69rank distance 0 39.5score error 0 0.031
Performance Results for .Gov Querieson .GOV corpus from TREC-12 Web track:1.25 Mio. docs (html, pdf, etc.)
50 keyword queries, e.g.: • „Lewis Clark expedition“, • „juvenile delinquency“, • „legalization Marihuana“, • „air bag safety reducing injuries death facts“
speedup by factor 10at high precision/recall(relative to TA-sorted);
aggressive queue mgt.even yields factor 100at 30-50 % prec./recall

19/28
.Gov Expanded Querieson .GOV corpus with query expansion based on WordNet synonyms:50 keyword queries, e.g.: • „juvenile delinquency youth minor crime law jurisdiction offense prevention“, • „legalization marijuana cannabis drug soft leaves plant smoked chewed euphoric abuse substance possession control pot grass dope weed smoke“
TA-sorted Prob-sorted (smart)#sorted accesses 22,403,490 18,287,636elapsed time [s] 7908 1066max queue size 70896 400relative recall 1 0.88rank distance 0 14.5score error 0 0.035

20/28
Performance Results for IMDB Querieson IMDB corpus (Web site: Internet Movie Database):375 000 movies, 1.2 Mio. persons (html/xml) 20 structured/text queries with Dice-coefficient-based similaritiesof categorical attributes Genre and Actor, e.g.: • Genre {Western} Actor {John Wayne, Katherine Hepburn} Description {sheriff, marshall}, • Genre {Thriller} Actor {Arnold Schwarzenegger} Description {robot}
TA-sorted Prob-sorted (smart)#sorted accesses 1,003,650 403,981elapsed time [s] 201.9 12.7max queue size 12628 400relative recall 1 0.75rank distance 0 126.7score error 0 0.25

21/28
responsetime: 0.737: 0.944: 0.8
...
22: 0.723: 0.651: 0.652: 0.6
throughput: 0.6
92: 0.967: 0.9
...52: 0.944: 0.855: 0.8
Handling Ontology-Based Query Expansions
algorithm
B+ tree index on terms
57: 0.644: 0.4
...
performance
52: 0.433: 0.375: 0.3
12: 0.914: 0.8
...
28: 0.617: 0.5561: 0.544: 0.5
44: 0.4
ontology / meta-index
iq {max jonto(i) { sim(i,j)*sj(d)) }}
performance
response time: 0.7throughput: 0.6queueing: 0.3delay: 0.25...
consider expandable query „algorithm and ~performance“ with score
dynamic query expansion with incremental on-demand merging of additional index lists
+ much more efficient than threshold-based expansion+ no threshold tuning+ no topic drift

22/28
Outline
Motivation & Preliminaries
Prob-k: Efficient Approximative Top-k
• TopX: Top-k for XML

23/28
Top-k Search on XMLTA-style algorithm should handle also tag-value conditions such as title = algorithm and ~topic = ~performance using standard indexesand exact path conditions of the form /book//literature using path indexes (pre/post index, HOPI, etc.)
Example query (NEXI, XPath & IR): //book[about(.//„Information Retrieval“ „XML“) and .//affiliation[about(.// „Stanford“)] and .//reference[about(.// „Page Rank“)] ]//publisher//country
Handling arbitrary combinationsof tag-term conditions and path conditions
TopX Algorithm

24/28
Problems Addressed by TopX
Problems: 1) content conditions (CC) on both tags and terms2) scores for elements or subtrees, docs as results3) score aggregation not necessarily monotonic4) test path conditions (PC), but avoid random accesses
Solutions: 0) disk space is cheap, disk I/O is not !1) build index lists for each tag-term pair 2) block-fetch all elements for the same doc in desc. order of MaxScore(e) = max{Score(e‘) | e‘ doc(e)}3) precompute and store scores for entire subtrees 4a) test PCs on candidates in memory4b) postpone evaluation of remaining PCs until after threshold test
Example query (NEXI, XPath & IR): //book[about(.//„Information Retrieval“ „XML“) and .//affiliation[about(.// „Stanford“)] and .//reference[about(.// „Page Rank“)] ]//publisher//country
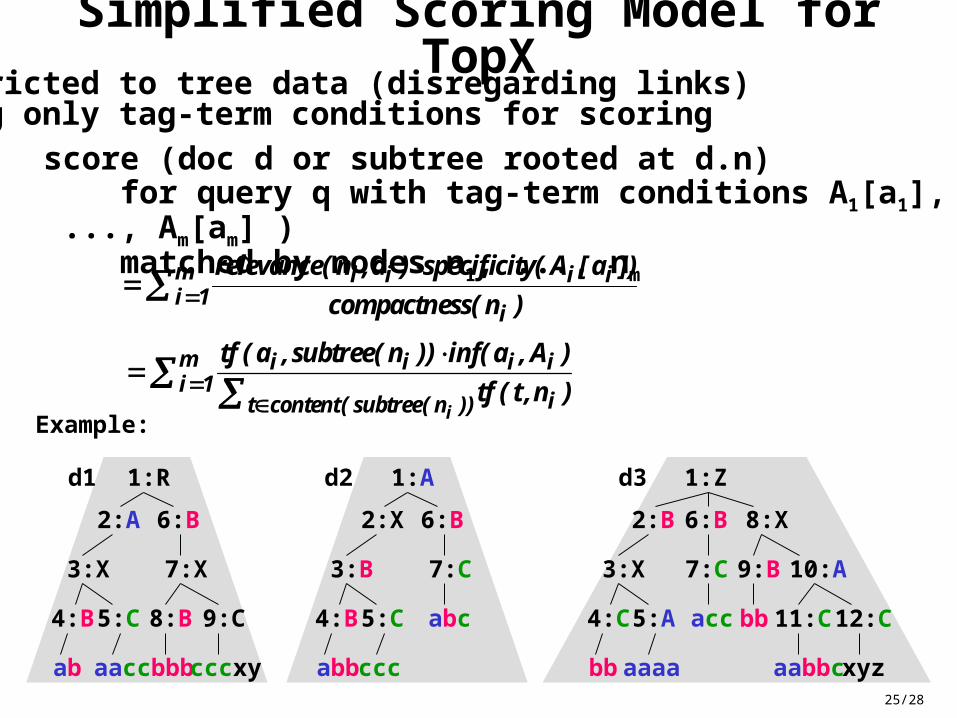
25/28
Simplified Scoring Model for TopX
2:A
1:R
6:B
3:X 7:X
4:B 5:C
aaccab
8:B 9:C
bbb cccxy
2:X
1:A
6:B
3:B 7:C
4:B 5:C
cccabb
abc
2:B
1:Z
3:X
4:C 5:A
aaaabb
6:B 8:X
7:C
acc
9:B 10:A
bb 11:C 12:C
aabbc xyz
d1 d2 d3
restricted to tree data (disregarding links)using only tag-term conditions for scoring
score (doc d or subtree rooted at d.n) for query q with tag-term conditions A1[a1], ..., Am[am] ) matched by nodes n1, ..., nm
Example:
m i i i ii 1
i
relevance( n ,a ) specificity( A [a ])
compactness( n )
i
m i i i ii 1
it content( subtree( n ))
tf ( a , subtree( n )) inf( a , A )
tf ( t ,n )
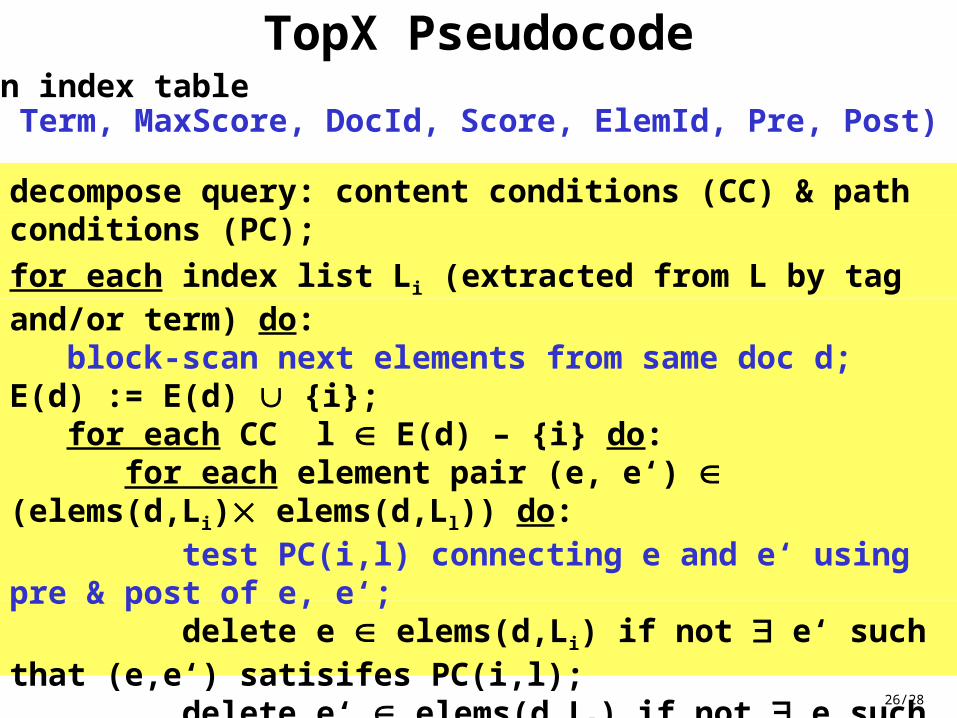
26/28
TopX Pseudocodebased on index table L (Tag, Term, MaxScore, DocId, Score, ElemId, Pre, Post)
decompose query: content conditions (CC) & path conditions (PC);
for each index list Li (extracted from L by tag and/or term) do: block-scan next elements from same doc d; E(d) := E(d) {i}; for each CC l E(d) – {i} do: for each element pair (e, e‘) (elems(d,Li) elems(d,Ll)) do: test PC(i,l) connecting e and e‘ using pre & post of e, e‘; delete e elems(d,Li) if not e‘ such that (e,e‘) satisifes PC(i,l); delete e‘ elems(d,Ll) if not e such that (e,e‘) satisifes PC(i,l); bestscore(d) := jE(d) max{Score(e) | e elems(Lj)} + jE(d) highj; worstscore(d) := 0; if E(d) is complete then worstscore(d) := bestscore(d); ... // proceed with standard top-k algorithm test remaining PCs on d and drop d if not satisifed;
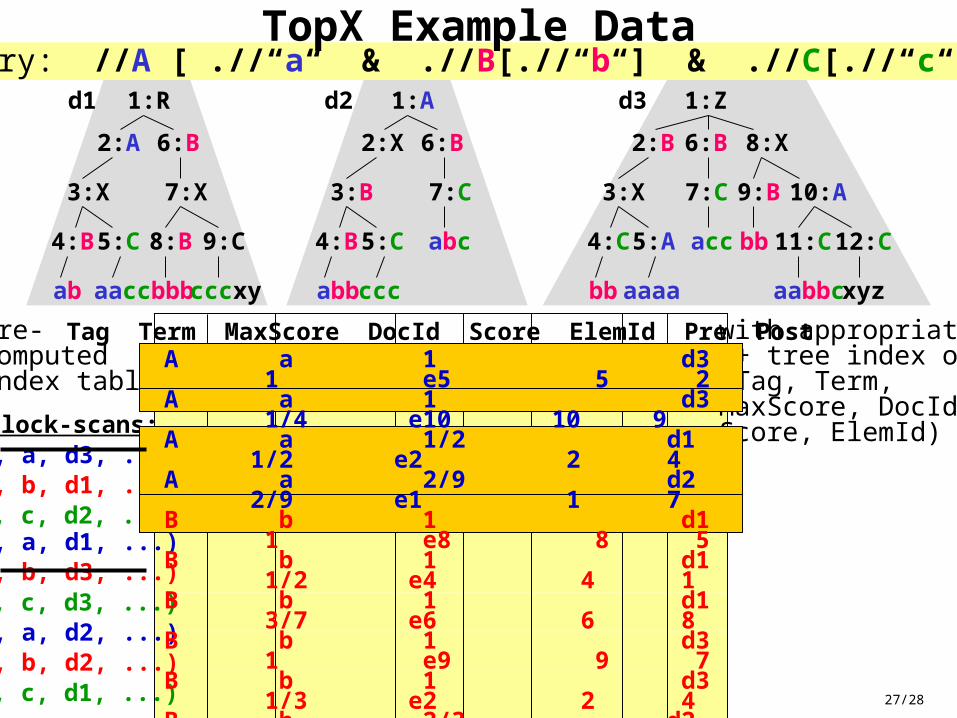
27/28
TopX Example DataExample query: //A [ .//“a“ & .//B[.//“b“] & .//C[.//“c“] ]
Tag Term MaxScore DocId Score ElemId Pre Post pre-computedindex table
with appropriateB+ tree index on(Tag, Term, MaxScore, DocId, Score, ElemId)
2:A
1:R
6:B
3:X 7:X
4:B 5:C
aaccab
8:B 9:C
bbb cccxy
2:X
1:A
6:B
3:B 7:C
4:B 5:C
cccabb
abc
2:B
1:Z
3:X
4:C 5:A
aaaabb
6:B 8:X
7:C
acc
9:B 10:A
bb 11:C 12:C
aabbc xyz
d1 d2 d3
block-scans:(A, a, d3, ...)(B, b, d1, ...)(C, c, d2, ...)(A, a, d1, ...)(B, b, d3, ...)(C, c, d3, ...)(A, a, d2, ...)(B, b, d2, ...)(C, c, d1, ...)
A a 1 d3 1 e5 5 2A a 1 d3 1/4 e10 10 9A a 1/2 d1 1/2 e2 2 4 A a 2/9 d2 2/9 e1 1 7 B b 1 d1 1 e8 8 5 B b 1 d1 1/2 e4 4 1 B b 1 d1 3/7 e6 6 8 B b 1 d3 1 e9 9 7 B b 1 d3 1/3 e2 2 4 B b 2/3 d2 2/3 e4 4 1 B b 2/3 d2 1/3 e3 3 3 B b 2/3 d2 1/3 e6 6 6 C c 1 d2 1 e5 5 2 C c 1 d2 1/3 e7 7 5 C c 2/3 d3 2/3 e7 7 5 C c 2/3 d3 1/5 e11 11 8 C c 3/5 d1 3/5 e9 9 6 C c 3/5 d1 1/2 e5 5 2
28/28
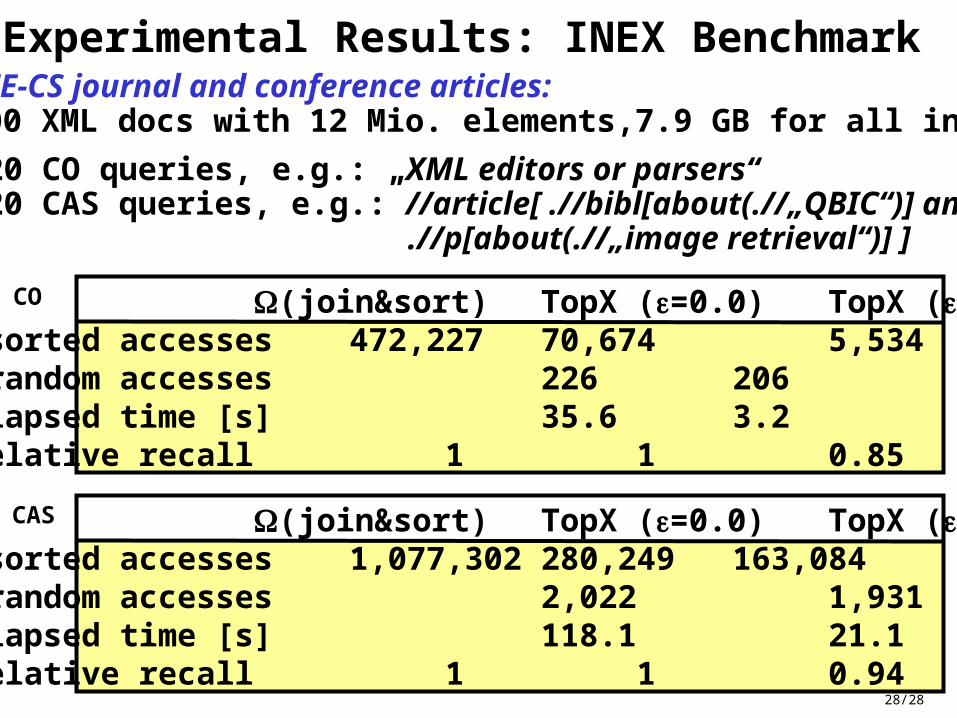
Experimental Results: INEX Benchmark
(join&sort) TopX (=0.0) TopX (=0.1)#sorted accesses 472,227 70,674 5,534#random accesses 226 206elapsed time [s] 35.6 3.2relative recall 1 1 0.85
on IEEE-CS journal and conference articles:12,000 XML docs with 12 Mio. elements,7.9 GB for all indexes
20 CO queries, e.g.: „XML editors or parsers“ 20 CAS queries, e.g.: //article[ .//bibl[about(.//„QBIC“)] and .//p[about(.//„image retrieval“)] ]
CO
(join&sort) TopX (=0.0) TopX (=0.1)#sorted accesses 1,077,302 280,249 163,084#random accesses 2,022 1,931elapsed time [s] 118.1 21.1relative recall 1 1 0.94
CAS

29/28
INEX with Query Expansion
static expansion incremental merge(=0.8, =0.1) (=0.1)
#sorted accesses 471,128 533,385#random accesses 4,228 212elapsed time [s] 319.6 33.3max #terms 16 5 - 16
20 CO queries, e.g.: „XML editors or parsers“ 20 CAS queries, e.g.: //article[ .//bibl[about(.//„QBIC“)] and .//p[about(.//„image retrieval“)] ]
CO
CAS static expansion incremental merge(=0.8, =0.1) (=0.1)
#sorted accesses 814,123 1,271,379#random accesses 12,755 648elapsed time [s] 429.8 103.0max #terms 11 7 - 11

30/28
Conclusion: Ongoing and Future Work
Observation:Approximations with statistical guarantees are key toobtaining Web-scale efficiency(e.g., TREC’04 Terabyte benchmark: ca. 25 Mio. docs, ca. 700 000 terms, 5-50 terms per query)
Challenges:• Generalize TopX to arbitrary graphs• Efficient consideration of correlated dimensions• Integrated support for all kinds of XML similarity search: content & ontological sim, structural sim• Scheduling of index-scan steps and few random accesses• Integration of top-k operator into physical algebra and query optimizer of XML engine






























