What Does the Archivist’s Directive Foretell for Autocategorization of the Government’s Records? Attorneys and Algorithms: The Case for Technology-Assisted Review and Categorization ARMA NOVA Spring 2013 Chapter Seminar Arlington, VA February 27, 2013 Jason R. Baron Director of Litigation Office of General Counsel National Archives and Records Administration

What Does the Archivist’s Directive Foretell for Autocategorization of the Government’s Records? Attorneys and Algorithms: The Case for Technology-Assisted.
Dec 16, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

What Does the Archivist’s Directive Foretell for Autocategorization of the Government’s Records?
Attorneys and Algorithms: The Case for Technology-Assisted Review and Categorization
ARMA NOVA Spring 2013 Chapter Seminar Arlington, VA
February 27, 2013
Jason R. BaronDirector of Litigation
Office of General CounselNational Archives and Records Administration

Homage to Carl Linnaeus (1707-1778)
2

Linnaean classification of the animal kingdom
Kingdom: Animalia Phylum: Chordata Subphylum: Vertebrata Superclass: Tetrapoda Class: Mammalia Subclass: Theria Infraclass: Eutheria Cohort: Unguiculata Order: Primata Suborder: Anthropoidea Superfamily: Hominoidae Family: Hominidae Subfamily: Homininae Genus: Homo Subgenus: Homo (Homo) Specific epithet: sapiens
3

4
Which category?

5

We have entered the era whereBig Data is ….
6

7
Presidential Memorandum

Presidential Memorandum
8
From President Obama’s Memorandum on Managing Government Records, dated 11/28/11:
“Decades of technological advances have transformed agency operations, creating challenges and opportunities for agency records management. Greater reliance on electronic communication and systems has radically increased the volume and diversity of information that agencies must manage. With proper planning, technology can make these records less burdensome to manage and easier to use and share. But if records management policies and practices are not updated for a digital age, the surge in information could overwhelm agency systems, leading to higher costs and lost records.”

A New Era of Government
“[P]roper records management is the backbone of open Government.” President Obama’s Memorandum dated November 28, 2011
re “Managing Government Records” http://www.whitehouse.gov/the-press-office/2011/11/28/presidential-memorandum-
managing-government-records

Archivist/OMB Directive
10
M-12-18, Managing Government Records Directive, dated 8/24/12:
1.1 By 2019, Federal agencies will manage all permanent records in an electronic format.
1.2 By 2016, Federal agencies will manage both permanent and temporary email records in an accessible electronic format.
http://www.whitehouse.gov/sites/default/files/omb/memoranda/2012/m-12-18.pdf

Archivist/OMB Directive
11
M-12-18, Managing Government Records Directive, dated 8/24/12:
II.A.3 Investigate and stimulate applied research in automated technologies to reduce the burden of records management responsibilities
--A.3.1 NARA, the Federal CIO Council, and the Federal Records Council will work with private industry and other stakeholders to produce economically viable automated records management solutions. By December 31, 2013, NARA will produce a comprehensive plan in collaboration with its stakeholders to describe suitable approaches for the automated management of email, social media, and other types of digital record content, including advanced search techniques . . . .
--A.3.2. By December 31, 2014, the Federal CIO Council and the Federal Records Council, working with NARA, will obtain external involvement for the development of open source records management solutions
http://www.whitehouse.gov/sites/default/files/omb/memoranda/2012/m-12-18.pdf

Archivist/OMB Directive
12
M-12-18, Managing Government Records Directive, dated 8/24/12:
II.A.5 Evaluate the feasibility for secure “data at rest” storage and management services for Federal agency-owned electronic records
By December 31, 2013, NARA will determine the feasibility of establishing a secure cloud-based service to store and manage unclassified electronic records on behalf of agencies. This basic, shared service will adhere to NARA records management regulations and provide standards and tools to preserve records and make them accessible within their originating agency until NARA performs disposition.
http://www.whitehouse.gov/sites/default/files/omb/memoranda/2012/m-12-18.pdf

Email is still the 800 lb. gorilla of ediscovery
(see 36 CFR 1236.22 (2009))

14
Beyond email: text messaging, social media, etc.

Conversation starter, February 2013
Cabinet agency comes to NARA with a problem: we have 5 billion preserved emails… can you please help us?

16
NARA Moving to the Cloud for Email with Embedded RM/Autocategorization

17
Process Optimization Problem 1: The transactional toll of user-based recordkeeping schemes (“as is” RM)

18
…. and the need for better, automated solutions ….

The demise of RM….
John Mancini, President of AIIM: “If by traditional records management you mean
manual systems—even if they are computerized – then I would say traditional records management is dead. The idea that we could get busy people to care about our complicated retention schedules, and drag and drop documents into folders, and manually apply metadata document by document according to an elaborate taxonomy will soon seem as ridiculous as asking a blacksmith to work on a Ferrari.”

RM wish list for 2013…. RM’s “easy button”: the elusive goal of zero
extra keystrokes to comply with RM requirements (capture)
A technology app that automatically tags records in compliance with RM policies and practices (categorize)
Supervised learning RM with minimal records officer or end user involvement (learn)
Rule-based and role-based RM Advanced search
20

21
NARA’s “Capstone” Policy: The Path Forward Email archiving in short term, synced to existing
proprietary software on email system Designation of key senior officials as creating
permanent records, consistent with existing records schedules
Additional designations of permanent records by agency component
“Smart” filters/categorical rules built in based on content, to the extent feasible to do
All non-senior official email records and non-tagged records designated as temporary to be held for set retention period.

A pyramid approach combines disposition policy with automated tools to bring FRA email under records management, preservation, and access
The position of the “set-point” for email capture depends on policy and resources: setting it higher allows use of tools now available to get 100% of email at lower volumes;* setting it lower means more records will be captured and smarter tools are needed to distinguish and disposition temporary- and non-record.
= permanent or top officials
= temporary or staff and support
Implementing an email archiving policy is feasible now, since tools are readily available to capture 100% of email traffic at the individual or organizational level, in formats that can be archived.
slider

23
Capture Requirements The system will capture and classify all NARA
communications in the system including email messages with attachments, email threads, calendar items, and tasks.
The email system will apply classifications to all captured objects. Default classifications are: permanent records, temporary records, or nonrecords.
All captured objects presumptively are records unless otherwise classified as non-record.
The most recent changes to objects and metadata will be maintained and not overwritten by default processes, unless intentionally specified (e.g., by subsequent crawls).
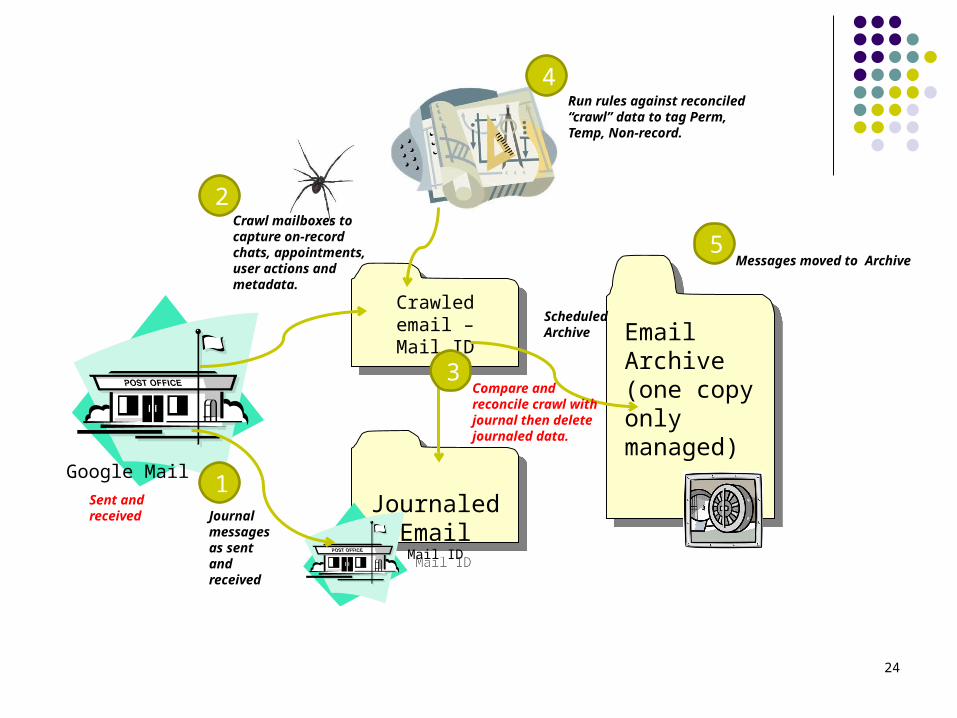
24
Crawled email – Mail ID
Crawled email – Mail ID
Email Archive (one copy only managed)
Email Archive (one copy only managed)
Google Mail
Crawl mailboxes to capture on-record chats, appointments, user actions and metadata.
Journaled Email
Mail ID
Journaled Email
Mail IDJournal messages as sent and received
ScheduledArchive
Compare and reconcile crawl with journal then delete journaled data.
Sent and received
1
2
3
4
5
Run rules against reconciled “crawl” data to tag Perm, Temp, Non-record.
Messages moved to Archive

How To Avoid A Train Wreck With Email Archiving….
25
Capture E-mail But Utilize Records Management!

The Coming Age of Dark Archives (and the inability to provide access unless we have smart ways of extracting signal from noise)
Summit 2012 26
Improved review and case assessment: cluster docs thru use of software with minimal human intervention at front end to code “seeded” data set
Slide adapted from Gartner ConferenceJune 23, 2010 Washington, D.C.
Emerging New Strategies:“Predictive Analytics”

What is predictive coding a/k/a technology assisted review?
WHAT IT ISNT:▪ Email threading, near de-duplication,etc.▪ Boolean, proximity, fuzzy and concept search▪ Social network analysis and other visualization tools▪ Unsupervised machine learning (simply vector space retrieval or latent semantic indexing or clustering methods alone)
Source: M. Grossman, “Technology-Assisted Review: Evolving Case-Law and Practice,” ABA EDDE Committee eMeeting, Nov. 1, 2012 (“M. Grossman ABA Slideset 2012”)

Defining “predictive coding” or “TAR”
A process for prioritizing or coding a collection of electronic documents using a computerized system that harnesses human judgments of one or more subject matter experts on a smaller set of documents and then extrapolates those judgments to the remaining document population.
Also referred to as “supervised or active machine learning,” “computer-assisted review” or “technology-assisted review”
Source: Adapted from Grossman-Cormack Glossary of Technology Assisted Review, v. 1.0 (Oct 2012)

Two approaches to selecting the seed set
Random selection: documents selected at random from the collection, coded as relevant or not, and fed to the learning system
Problem: may miss certain types of relevant docs that are rare in the collection and therefore unrepresented in a random sample
Judgmental selection: documents are selected by an expert, using prior knowledge, or ad hoc searches, or other advanced tools, and then fed to the learning system
Problem: may miss certain types of relevant documents that are overlooked by the expert, or not identified by the search and analytic tools
Source: M. Grossman ABA Slideset 2012

31
The da Silva Moore Protocol
Supervised learning Random sampling Establishment of seed set Issue tags Iteration Random sampling of docs
deemed irrelevant

32
The In re Actos Protocol Sample from key custodians No seeding as such Experts trained on proprietary machine learning
system, and work together to make relevance judgments
System calculates “relevance” scores (1-100) for each document in sample set.
System chooses subsequent sample sets System decides on whether stability has been
reached to begin machine learning phase Parties agree upon the minimum relevance
score for subsequent manual review after machine learning completed.
Random set of documents below the minimum relevance score is reviewed by experts to verify low prevalence of relevant documents.

Judicial endorsement of predictive analytics in document review by Judge Peck in da Silva Moore v. Publicis Groupe (SDNY Feb. 24, 2012)
This opinion appears to be the first in which a Court has approved of the use of computer-assisted review. . . . What the Bar should take away from this Opinion is that computer-assisted review is an available tool and should be seriously considered for use in large-data-volume cases where it may save the producing party (or both parties) significant amounts of legal fees in document review. Counsel no longer have to worry about being the ‘first’ or ‘guinea pig’ for judicial acceptance of computer-assisted review . . . Computer-assisted review can now be considered judicially-approved for use in appropriate cases.

We should be leveraging the power of predictive analytics to improve information governance . . .
--RM
--Ediscovery
--Business intelligence

“The future is here. It is just not evenly distributed.”
--William Gibson
35

36
References
Sources Referencing Autocategorization & Predictive Coding
J.R. Baron & Simon J. Attfield, “Where Light in Darkness Lies: Preservation, Sensemaking, and Access Strategies for the Modern Digital Archive,” UNESCO Memory of the World in the Digital Age Conference, Vancouver, B.C. (2012), available at http://www.unesco.org/new/en/communication-and-information/events/calendar-of-events/events-websites/the-memory-of-the-world-in-the-digital-age-digitization-and-preservation/presentations-day-2/
J.R. Baron, “Law in the Age of Exabytes: Some Further Thoughts on ‘Information Inflation’ and Current Issues in E-Discovery Search, 17 Richmond J. Law & Technology (2011), see http://law.richmond.edu
N. Pace, “Where The Money Goes: Understanding Litigant Expenditures for Producing E-Discovery,” RAND Publication (2012), see http://www.rand.org/pubs/monographs/MG1208.html
TREC Legal Track Home Page, http://trec-legal.umiacs.umd.edu (includes bibliography for further reading)
Latest “Supervised Learning/Predictive Coding” Case Law: Da Silva Moore v. Publicis Groupe, 2012 WL 607412 (S.D.N.Y. Feb. 24, 2012), approved and
adopted in Da Silva Moore v. Publicis Groupe, 2012 WL 1446534, at *2 (S.D.N.Y. Apr. 26, 2012) EORHB v HOA Holdings, Civ. No. 7409-VCL (Del. Ch. Oct. 15, 2012) Global Aerospace Inc., et al. v. Landow Aviation, L.P., et al., 2012 WL 1431215 (Va. Cir. Ct. Apr. 23,
2012). In re Actos (Pioglitazone) Products, 2012 WL 3899669 (W.D. La. July 27, 2012) Kleen Products, LLC v. Packaging Corp. of America, 10 C 5711 (N.D. Ill.) (Nolan, M.J.)

37
Jason R. Baron
Director of Litigation
Office of General Counsel
National Archives and Records Administration
(301) 837-1499
Email: [email protected]
Related Documents











