VC theory, Support vectors and Hedged prediction technology

VC theory, Support vectors and Hedged prediction technology.
Dec 14, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

VC theory, Support vectors and Hedged prediction technology

Overfitting in classification
• Assume a family C of classifiers of points infeature space F. A family of classifiers is a map from CF to {0,1} (Negative and positive class).
• For each subset X of F and each c in C, c(X) defines a partitioning of X into two classes.
• C shatters X if every partitioning of X is accomplished by some c in C
• If every point set X of size d is shattered by C, then the VC dimension is at least d.
• If a point set of d+1 elements cannot be shattered by C, then the VC-dimension is at most d.

VC-dimension of hyperplanes
• The set of points on the line shatters any two points, but not three
• The set of lines in the plane shatters any three non-collinear points, but no four points.
• Any d+2 points in E^d can be partitioned into two blocks whose convex hulls intersect.
• VC-dimension of hyperplanes in E^d is thus d+1.

Why VC-dimension?
• Elegant and pedagogical, not very useful.• Bounds future error of classifier, PAC-learning.• Exchangeable distribution of (xi, yi).• For first N points, training error for c is
observed error rate for c.• Goodness of selecting from C a classifier with
best performance on training set depends on VC-dimension h:

Why VC-dimension?

Classify with hyperplanes
Frank Rosenblatt (1928 – 1971)
Pioneering work in classifying byhyperplanes in high-dimensional spaces.
Criticized by Minsky-Papert, sincereal classes are not normallylinearly separable.ANN research taken up again in1980:s, with non-linear mappingsto get improved separation.Predecessor to SVM/kernel methods

Find parallel hyperplanes
• Separate examples by wide margin hyperplanes (classifications).
• Enclose examples between hyperplanes (regression).
• If necessary, non-linearly map examples to high-dimensional space where they are better separated.
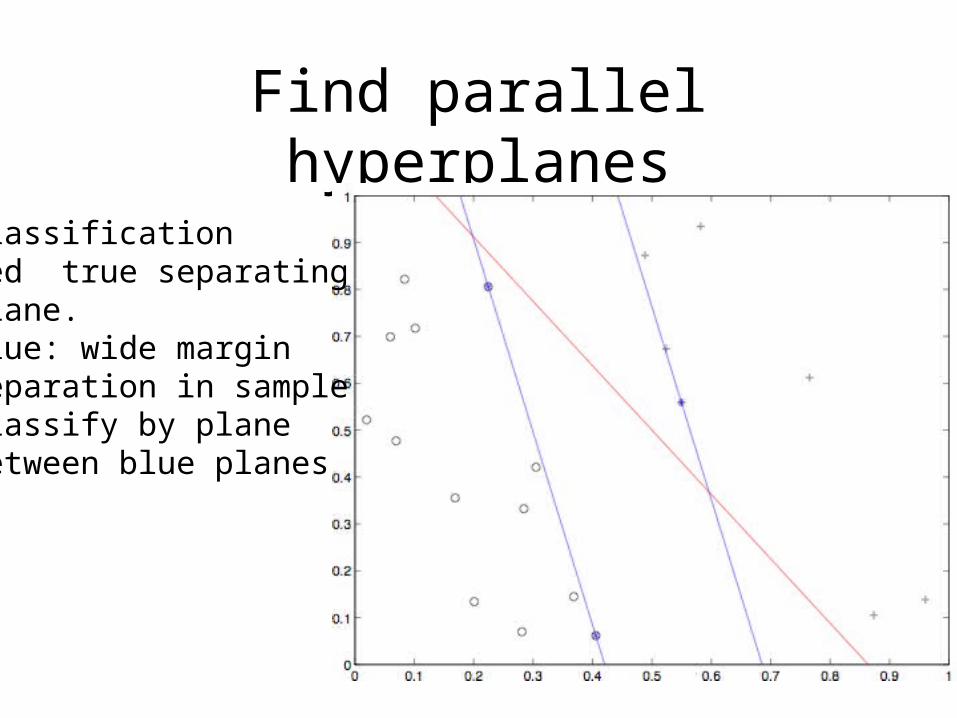
Find parallel hyperplanes
ClassificationRed true separatingplane.Blue: wide marginseparation in sampleClassify by planebetween blue planes
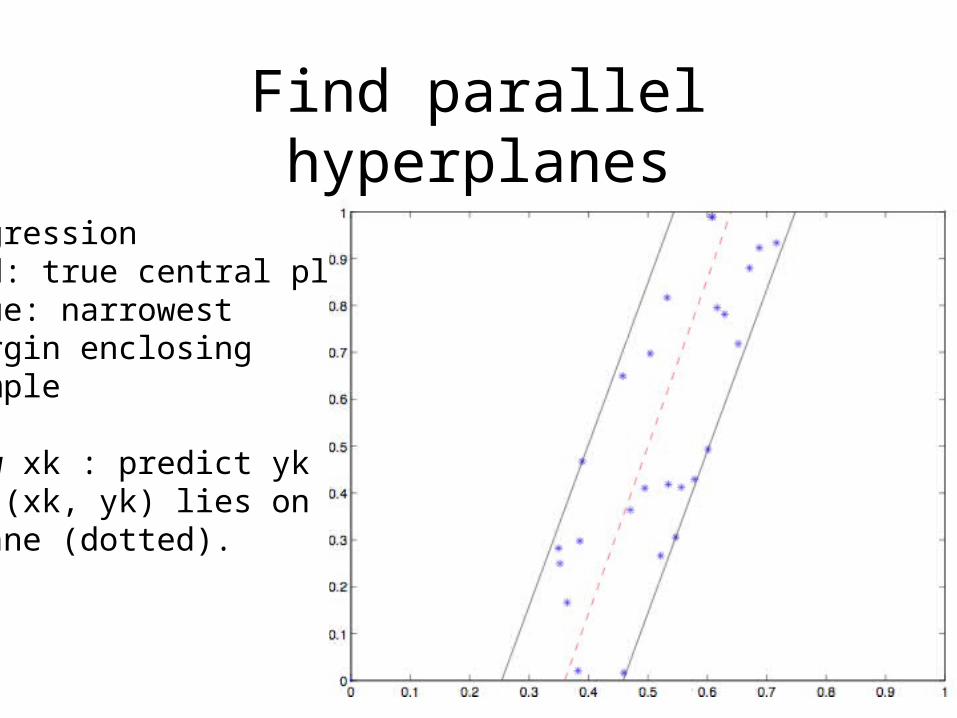
Find parallel hyperplanes
RegressionRed: true central plane.Blue: narrowest margin enclosing sample
New xk : predict ykso (xk, yk) lies on mid-plane (dotted).






From vector to scalar product

Soft Margins

Soft MarginsQuadratic programming goes through also with soft margins.Specification of softness constant C is part of most packages.
However, no prior rule for setting C is established, and experimentation is necessary for each application. Choice is between narrowing margin, allowing more outliers, and using a more liberal kernel (to be described).

SVM packages
• Inputs xi, yi, and KERNEL and SOFTNESS information
• Only output is , non-zero coefficients indicatesupport vectors.
• Hyperplane obtained by

Kernel Trick

Kernel Trick

Kernel TrickExample: 2D space (x1,x2). Map to 5D space(c1*x1, c2*x2, c3*x1^2, c4*x1*x2, c5*x2^2).
K(x,y)=(xy+1)^2 =2*x1*y1+2*x2*y2+x1^2*y1^2+x2^2*y2^2+2*x1*x2*y1*y2+1 =(x)(y),
Where (x)= ((x1,x2)) = (√2x1, √2x2, x1^2, √2x1*x2, x2^2).
Hyperplanes in R^5 are mapped back to conic sections in R^2!!
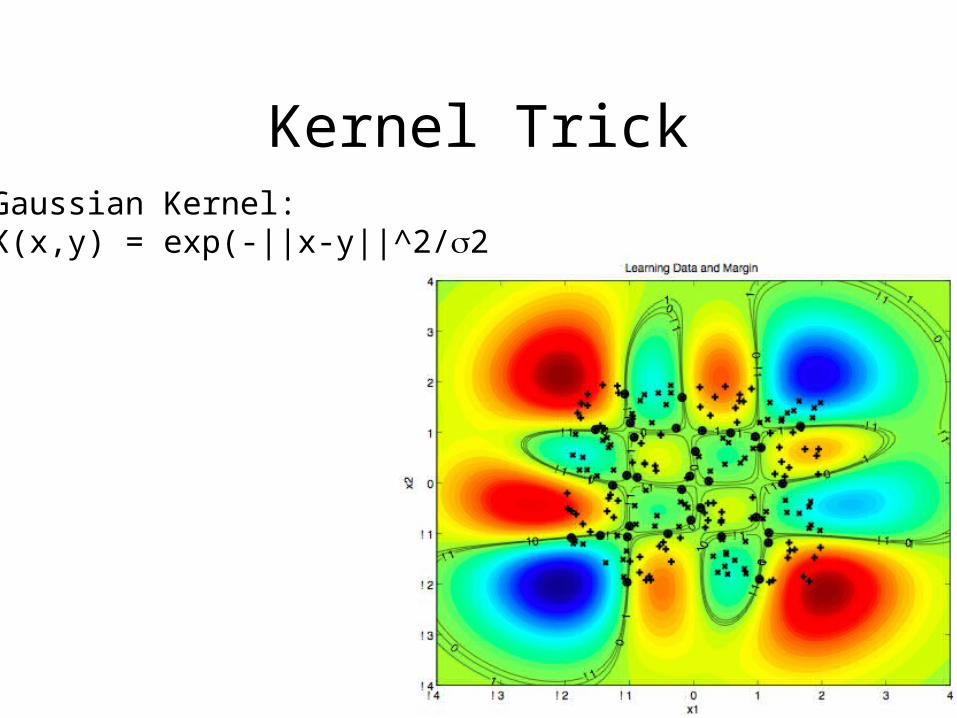
Kernel TrickGaussian Kernel:K(x,y) = exp(-||x-y||^2/2
Related Documents











