SUDS: Automatic Parallelization for Raw Processors Matthew Ian Frank May 23, 2003 Abstract A computer can never be too fast or too cheap. Com- puter systems pervade nearly every aspect of science, engineering, communications and commerce because they perform certain tasks at rates unachievable by any other kind of system built by humans. A computer sys- tem’s throughput, however, is constrained by that sys- tem’s ability to find concurrency. Given a particular target work load the computer architect’s role is to de- sign mechanisms to find and exploit the available con- currency in that work load. This thesis describes SUDS (Software Un-Do Sys- tem), a compiler and runtime system that can auto- matically find and exploit the available concurrency of scalar operations in imperative programs with ar- bitrary unstructured and unpredictable control flow. The core compiler transformation that enables this is scalar queue conversion. Scalar queue conversion makes scalar renaming an explicit operation through a process similar to closure conversion, a technique traditionally used to compile functional languages. The scalar queue conversion compiler transforma- tion is speculative, in the sense that it may introduce dynamic memory allocation operations into code that would not otherwise dynamically allocate memory. Thus, SUDS also includes a transactional runtime sys- tem that periodically checkpoints machine state, exe- cutes code speculatively, checks if the speculative exe- cution produced results consistent with the original se- quential program semantics, and then either commits or rolls back the speculative execution path. In addi- tion to safely running scalar queue converted code, the SUDS runtime system safely permits threads to specu- latively run in parallel and concurrently issue memory operations, even when the compiler is unable to prove that the reordered memory operations will always pro- duce correct results. Using this combination of compile time and runtime techniques, SUDS can find concurrency in programs where previous compiler based renaming techniques fail because the programs contain unstructured loops, and where Tomasulo’s algorithm fails because it se- quentializes mispredicted branches. Indeed, we de- scribe three application programs, with unstructured control flow, where the prototype SUDS system, run- ning in software on a Raw microprocessor, achieves speedups equivalent to, or better than, an idealized, and unrealizable, model of a hardware implementation of Tomasulo’s algorithm. Acknowledgments I believe that engineering is a distinctly social activity. The ideas in this thesis were not so much “invented” as they were “organically accreted” through my inter- actions with a large group of people. For the most part those interactions took place within the Computer Ar- chitecture Group at the Laboratory for Computer Sci- ence at MIT. That the Computer Architecture Group is such a productive research environment is a testament, in large part, to the efforts of Anant Agarwal. Anant somehow manages to, simultaneously, find and attract brilliant and creative people, keep them focused on big visions, and acquire the resources to turn those visions into realities. Anant also has the incredible ability to judge the difference between an engineering advance and a “tweak,” between the long term and the short. He’s occasionally wrong, but I’ve lost count of the number of times that I stubbornly went my own way only to discover, sometimes years later, that he had been right in the first place. If I’ve learned anything about how to do relevant computer engineering research, then I learned it from Anant. A student who is as bad at taking advice as I am ac- tually requires two advisors, so that he can be given a full amount of advice, even when he is ignoring half of what he is told. Saman Amarasinghe took on the thankless task of trying to keep me directed and fo- cused. He listened to my constant griping and com- plaining about our research infrastructure, and then patiently taught me how to use it correctly. Saman, somehow, always knows when to push me, when to back off, and when to give me a kick in the pants. The fact that I am graduating at all is as much a testament to Saman’s will power as it is to my own. 1

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

SUDS: Automatic Parallelization for Raw Processors
Matthew Ian Frank
May 23, 2003
Abstract
A computer can never be too fast or too cheap. Com-puter systems pervade nearly every aspect of science,engineering, communications and commerce becausethey perform certain tasks at rates unachievable by anyother kind of system built by humans. A computer sys-tem’s throughput, however, is constrained by that sys-tem’s ability to find concurrency. Given a particulartarget work load the computer architect’s role is to de-sign mechanisms to find and exploit the available con-currency in that work load.
This thesis describes SUDS (Software Un-Do Sys-tem), a compiler and runtime system that can auto-matically find and exploit the available concurrencyof scalar operations in imperative programs with ar-bitrary unstructured and unpredictable control flow.The core compiler transformation that enables this isscalar queue conversion. Scalar queue conversion makesscalar renaming an explicit operation through a processsimilar to closure conversion, a technique traditionallyused to compile functional languages.
The scalar queue conversion compiler transforma-tion is speculative, in the sense that it may introducedynamic memory allocation operations into code thatwould not otherwise dynamically allocate memory.Thus, SUDS also includes a transactional runtime sys-tem that periodically checkpoints machine state, exe-cutes code speculatively, checks if the speculative exe-cution produced results consistent with the original se-quential program semantics, and then either commitsor rolls back the speculative execution path. In addi-tion to safely running scalar queue converted code, theSUDS runtime system safely permits threads to specu-latively run in parallel and concurrently issue memoryoperations, even when the compiler is unable to provethat the reordered memory operations will always pro-duce correct results.
Using this combination of compile time and runtimetechniques, SUDS can find concurrency in programswhere previous compiler based renaming techniquesfail because the programs contain unstructured loops,and where Tomasulo’s algorithm fails because it se-quentializes mispredicted branches. Indeed, we de-
scribe three application programs, with unstructuredcontrol flow, where the prototype SUDS system, run-ning in software on a Raw microprocessor, achievesspeedups equivalent to, or better than, an idealized,and unrealizable, model of a hardware implementationof Tomasulo’s algorithm.
Acknowledgments
I believe that engineering is a distinctly social activity.The ideas in this thesis were not so much “invented”as they were “organically accreted” through my inter-actions with a large group of people. For the most partthose interactions took place within the Computer Ar-chitecture Group at the Laboratory for Computer Sci-ence at MIT. That the Computer Architecture Group issuch a productive research environment is a testament,in large part, to the efforts of Anant Agarwal. Anantsomehow manages to, simultaneously, find and attractbrilliant and creative people, keep them focused on bigvisions, and acquire the resources to turn those visionsinto realities.
Anant also has the incredible ability to judge thedifference between an engineering advance and a“tweak,” between the long term and the short. He’soccasionally wrong, but I’ve lost count of the numberof times that I stubbornly went my own way only todiscover, sometimes years later, that he had been rightin the first place. If I’ve learned anything about howto do relevant computer engineering research, then Ilearned it from Anant.
A student who is as bad at taking advice as I am ac-tually requires two advisors, so that he can be given afull amount of advice, even when he is ignoring halfof what he is told. Saman Amarasinghe took on thethankless task of trying to keep me directed and fo-cused. He listened to my constant griping and com-plaining about our research infrastructure, and thenpatiently taught me how to use it correctly. Saman,somehow, always knows when to push me, when toback off, and when to give me a kick in the pants. Thefact that I am graduating at all is as much a testamentto Saman’s will power as it is to my own.
1

Saman was also the main sounding board for most ofthe ideas described in this thesis. Saman was the firstto realize the importance and novelty of the programtransformations that I had been doing “by hand” forseveral years, and convinced me, at some point in 2000or 2001, that I needed to automate the process. Theresult of that suggestion is Chapters 3 through 6.
When a large research group works together formany years people’s ideas “rub off” on each other, andit becomes difficult (for me) to attribute specific ideasto their originators. The computer architecture groupat MIT is huge, and thus I’ve had the opportunity tointeract with a large number of people, most of whomhave had an influence on my work.
Ken Mackenzie acted as my de facto advisor whenI first came to MIT, (before Saman arrived, and whileAnant was on leave). Ken taught me how to do col-laborative research, and, more importantly, also honestresearch.
Jonathan Babb, in many ways, initiated the Rawproject, both in terms of the influence of his VirtualWires logic emulator on Raw’s communication net-works, and with his interest in reconfigurable comput-ing. Towards the beginning of the project we had dailyconversations (arguments) that would often last six oreight hours. Almost everything I know about com-puter aided design I learned from Jon.
Michael Taylor lead the Raw microprocessor imple-mentation effort, without which this work would havebeen impossible. In addition, I always went to Mikefor honest assessments of what I was doing, and forhelp in making my runtime implementations efficient.Moreover, Mike is largely responsible for pointing outthe usefulness of Dataflow techniques on my work.In particular, the deferred execution queues, describedin Chapter 3, are influenced by the communicationchannels that Mike created, and discussed with me atlength, while he was doing some work on mappingDataflow graphs to Raw during the early stages of theproject.
Walter Lee and I learned the SUIF compiler infras-tructure together. In addition to his massive contribu-tions to that infrastructure (which is also used by mycompiler), Walt has been my main sounding board forcompiler implementation issues. I don’t think my com-piler work would have succeeded without his patientguidance, and excellent instincts, on what will workand what won’t.
Andras Moritz and I had an extraordinarily produc-tive collaborative relationship during the time we wereat MIT together. In addition to actively contributing toearly versions of the SUDS runtime system, the workAndras and I did together on software based cachecontrollers influenced all aspects of the SUDS runtime
system.I had the pleasure, during my last few years at MIT,
of sharing an office with Nathan Shnidman. In addi-tion to being a good friend, and contributing to a funwork environment, Nate was always willing to listen tome rant about what I was working on. Nate was alsoalways willing to tell me about what he was workingon, and even better, explain it so I could understandit. In the process he taught me just about everythingI know about communication systems and signal pro-cessing.
Kevin Wilson and Jae-Wook Lee both contributed toearly versions of the SUDS runtime system. My con-versations with them informed many of the implemen-tation choices in the final prototype. Sam Larsen andRadu Rugina have each contributed pieces of the SUIFcompiler infrastructure that I use. Sam, like Walt, hasbeen a constant source of good advice on compiler im-plementation issues. Radu contributed the near pro-duction quality pointer analysis that all of us in theRaw project have depended on. Bill Thies has also pa-tiently let me rant about whatever was on my mind,and in return has educated me about array transfor-mations. Numerous technical conversations with KrsteAsanovic, Jason Miller, David Wentzlaf, Atul Adya,Emmett Witchel, Scott Ananian, Viktor Kuncak, LarryRudolph and Frans Kaashoek have informed my workin general. Frans Kaashoek both served on my thesiscommittee and also provided numerous helpful com-ments that improved the presentation of the disserta-tion.
I don’t believe any of my work would have beenpossible had I not been working with a group actuallyimplementing a microprocessor. In addition to manyof the people mentioned above, that implementationeffort involved Rajeev Barua, Faye Ghodrat, MichaelGordon, Ben Greenwald, Henry Hoffmann, Paul John-son, Jason Kim, Albert Ma, Mark Seneski, Devabhak-tuni Srikrishna, Mark Stephenson, Volker Strumpen,Elliot Waingold and Michael Zhang.
During the last year several of my colleagues at theUniversity of Illinois have been particularly helpful.Much of the presentation, in particular of the introduc-tory material, and of the compiler transformations, wasinformed by numerous conversations with Sanjay Pa-tel, Steve Lumetta and Nick Carter.
I have also benefited from a substantial amount oftechnical and administrative support, which I simplycould not have handled on my own. Among oth-ers, this support was provided by Rachel Allen, ScottBlomquist, Michael Chan, Cornelia Colyer, Mary AnnLadd, Anne McCarthy, Marilyn Pierce, Lila Rhoades,Ty Sealy, Frank Tilley, Michael Vezza and ShireenYadollahpour.
2

Financially, this work was supported in part byan NSF Graduate Research Fellowship and NSF andDarpa grants to the Fugu and Raw projects. WhileI was in graduate school, my wife, Kathleen Shan-non, earned all of the money required for our livingexpenses. My tuition for the last year was fundedthrough a fellowship generously arranged by AnantAgarwal through the Industrial Technology ResearchInstitute/Raw Project Collaboration. In addition, Ithank my colleagues in the Electrical and ComputerEngineering Department at the University of Illinoisfor their patience while I finished this work.
Finally, the emotional support provided by a num-ber of people has been more important to me than they,perhaps, realize. My parents unconditional love andsupport has been crucial. In Boston, Andras Moritz,Mike Taylor, Nate Shnidman, Tim Kelly and JefferyThomas were particularly supportive. In Illinois NickCarter, Sanjay Patel, Steve Lumetta and Marty Traverprovided a vital support network.
Most of all, I have relied on my wife, Kathleen Shan-non, and my children, Karissa and Anya. Their lovehas carried me through this period. Without them noneof this would have been possible, or worth doing.
I dedicate this work to the memories of my grandfa-thers, who taught me, by example, how to dream bigdreams and then make them happen.
Contents
1 Introduction 31.1 Technology Constraints . . . . . . . . . . 51.2 Finding Parallelism . . . . . . . . . . . . . 61.3 Contributions . . . . . . . . . . . . . . . . 81.4 Road Map . . . . . . . . . . . . . . . . . . 9
2 The Dependence Analysis Framework 102.1 The Flow Graph . . . . . . . . . . . . . . . 102.2 The Conservative Program Dependence
Graph . . . . . . . . . . . . . . . . . . . . . 112.3 The Value Dependence Graph . . . . . . . 15
3 Scalar Queue Conversion 153.1 Motivation . . . . . . . . . . . . . . . . . . 153.2 Road Map . . . . . . . . . . . . . . . . . . 183.3 Unidirectional Cuts . . . . . . . . . . . . . 193.4 Maximally Connected Groups . . . . . . . 193.5 The Deferred Execution Queue . . . . . . 213.6 Unidirectional Renaming . . . . . . . . . . 243.7 Wrapup . . . . . . . . . . . . . . . . . . . . 27
4 Optimal Unidirectional Renaming 284.1 “Least Looped” Copy Points . . . . . . . . 284.2 Lazy Dead Copy Elimination . . . . . . . 30
5 Extensions and Improvements to Scalar QueueConversion 325.1 Restructuring Loops with Multiple Exits . 335.2 Localization . . . . . . . . . . . . . . . . . 345.3 Equivalence Class Unification . . . . . . . 355.4 Register Promotion . . . . . . . . . . . . . 355.5 Scope Restriction . . . . . . . . . . . . . . 36
6 Generalized Loop Distribution 366.1 Critical Paths . . . . . . . . . . . . . . . . . 366.2 Unidirectional Cuts . . . . . . . . . . . . . 376.3 Transformation . . . . . . . . . . . . . . . 386.4 Generalized Recurrence Reassociation . . 40
7 SUDS: The Software Un-Do System 447.1 Speculative Strip Mining . . . . . . . . . . 457.2 Memory Dependence Speculation . . . . 47
7.2.1 A Conceptual View . . . . . . . . . 477.2.2 A Realizable View . . . . . . . . . 477.2.3 Implementation . . . . . . . . . . . 497.2.4 The Birthday Paradox . . . . . . . 50
7.3 Discussion . . . . . . . . . . . . . . . . . . 51
8 Putting It All Together 538.1 Simulation System . . . . . . . . . . . . . 538.2 Case Studies . . . . . . . . . . . . . . . . . 55
8.2.1 Moldyn . . . . . . . . . . . . . . . 558.2.2 LZW Decompress . . . . . . . . . . 578.2.3 A Recursive Procedure . . . . . . . 59
8.3 Discussion . . . . . . . . . . . . . . . . . . 60
9 Related Work 629.1 Scalar Queue Conversion . . . . . . . . . 629.2 Loop Distribution and Critical Path Re-
duction . . . . . . . . . . . . . . . . . . . . 649.3 Memory Dependence Speculation . . . . 64
10 Conclusion 66
1 Introduction
Computer programmers work under a difficult set ofconstraints. On the one hand, if the programs theyproduce are to be useful, they must be correct. A pro-gram that produces an incorrect result can be, literally,deadly. A medical radiation therapy machine that oc-casionally delivers the wrong dose can kill the patientit was intended to heal [76].
On the other hand, to be useful a program must alsoproduce its results in a timely manner. Again, the dif-ference can be critical. Aircraft collision avoidance sys-tems would be useless if it took them longer to detectan impending collision than for the collision to occur.
3

Similarly, today’s vision and speech recognition sys-tems work too slowly to be used as tools for interactingwith human beings.
After correctness, then, the computer engineer’smain area of focus is the “speed” or “performance” ofthe computer system. That this is the case, (and shouldremain so), is a consequence of the fact that perfor-mance can often be traded for other desirable kinds offunctionality. For example, in the low-power circuitsdomain, improved system throughput enables reducedpower consumption through voltage scaling [23]. Inthe software engineering domain, the widely used Javaprogramming language (first released in 1995) includesgarbage collection and runtime type checking featuresthat were considered too expensive when the C++ pro-gramming language was designed (circa 1985) [112].
Unfortunately, the twin goals of correctness andspeed conflict. To make it more likely that their pro-grams are correct, programmers tend to write theirprograms to run sequentially, because sequential pro-grams are easier to reason about and understand. Onthe other hand, the rate at which a computer can ex-ecute a program is constrained by the amount of con-currency in the program.
One solution to this conundrum is to allow the pro-grammer to write a sequential program in a standardimperative programming language, and then automat-ically convert that program into an equivalent concur-rent program by techniques that are known to be cor-rect. There are two relatively standard approaches forconverting sequential imperative programs into equiv-alent concurrent programs, Tomasulo’s algorithm [117,57, 104, 83, 105], and compiler based program re-structuring based on a technique called scalar expan-sion [68].
Each of these techniques presents the architect witha set of tradeoffs. In particular, Tomasulo’s algorithmguarantees the elimination of register storage depen-dences, and is relatively easily extended to speculateacross predictable dependences, but does so at the costof partially sequentializing instruction fetch. On theother hand, compiler based restructuring techniquescan find all of the available fetch concurrency in aprogram, and have relatively recently been extendedto speculate across predictable dependences, but havenot, prior to this work, been capable of eliminatingregister storage dependences across arbitrary unstruc-tured control flow. The SUDS automatic parallelizationsystem eliminates the tradeoffs between Tomasulo’s algo-rithm and compiler based program restructuring techniques.
Informally, renaming turns an imperative programinto a functional program. Functional programs havethe attribute that every variable is dynamically writtenat most once. Thus functional programs have no anti-
or output- dependences. The cost of renaming is thatstorage must be allocated for all the dynamically re-named variables that are live simultaneously. The par-ticular problem that any renaming scheme must solve,then, is how to manage the fixed, and finite, storageresources that are available in a real system.
Tomasulo’s algorithm deals with the register storageallocation problem by taking advantage of its inher-ently sequential fetch mechanism. That is, if Toma-sulo’s algorithm runs out of register renaming re-sources, it can simply stall instruction fetch. Becauseinstructions are fetched in-order, and sequentially, thepreviously fetched instructions that are currently usingregister renaming resources are guaranteed to makeforward progress and, eventually, free up the resourcesrequired to restart the instruction fetch mechanism.
Traditional compiler based renaming techniques,like scalar expansion, take a different approach, renam-ing only those scalars that are modified in loops withstructured control flow and loop bounds that are com-pile time constants. This enables the compiler to pre-allocate storage for scalar renaming, but limits the ap-plicability of this technique to structured loops that canbe analyzed at compile time.
The SUDS approach, in contrast, is to rename spec-ulatively. The SUDS compile time scheduler uses acompile time technique called scalar queue conversionto explicitly rename scalar variables. Scalar queueconversion dynamically allocates storage for renamedscalars, and thus can rename across arbitrary controlflow (even irreducible control flow). Unlike Toma-sulo’s algorithm, which depends on sequential fetchto avoid overflowing the finite renaming resources,SUDS fetches instructions from different parts of theprogram simultaneously and in parallel. As a result,scalar queue conversion’s dynamically allocated re-naming buffers may overflow.
SUDS deals with these overflow problems using acheckpointing and repair mechanism. SUDS periodi-cally checkpoints machine state, and if any of the re-naming buffer dynamic allocations should overflow,SUDS rolls back the machine state to the most recentcheckpoint and reexecutes the offending portion ofcode without renaming. In the (hopefully) commoncase the renaming buffers do not overflow.
Because SUDS can fetch multiple flows of control si-multaneously, and even when the control flow graphis unstructured or irreducible, SUDS exploits concur-rency that neither Tomasulo’s algorithm nor previouscompiler based renaming techniques can exploit. De-spite the fact that SUDS implements both scalar renam-ing and speculative checkpoint/repair in software, itis able to achieve speedups equal to, or better than,an idealized (unrealizable) hardware implementation
4

of Tomasulo’s algorithm.The next section explains why finding concurrency
is fundamental to computer system performance. Sec-tion 1.2 describes the SUDS approach to finding con-currency. Section 1.3 describes the specific technicalcontributions of this work.
1.1 Technology Constraints
Why is automatic parallelization important? There aretwo ways to make a computer system “faster.” The firstis to reduce the amount of time to execute each opera-tion. This goal can only be achieved by improved cir-cuit design and improved fabrication techniques.
The second technique is to increase the throughputof the system. This is the domain of the computer ar-chitect. In this section we will point out that the onlyway to increase system throughput is to increase thenumber of independent operations simultaneously inflight. And we will further demonstrate that technol-ogy constraints demand that system throughput canonly increase sublinearly in the amount of availableparallelism. Thus, architectural performance improve-ments depend on our ability to find parallelism in real worldworkloads.
One method for demonstrating this claim is to in-voke Little’s Law [78],
X = N/R. (1)
Little’s Law says that the system throughput, (numberof operations completed per unit time), X, is equal tothe quotient of the number of independent operationssimultaneously active in the system, N, and the timerequired to complete each operation, R.
Assuming that we can increase parallelism withoutincreasing operation latency, (i.e., R = O(1), which isnot true, as we will see subsequently), then the achiev-able system throughput is limited to the number ofindependent operations that can run simultaneously.That is, at best, X ∝ N.
Pipelining is one popular architectural technique forincreasing system throughput. In a pipelined designeach fundamental operation is divided into multiplestages of approximately equal latency, and latches areplaced between the stages. Assume that the time to ex-ecute each fundamental operation is tf (i.e., the time forjust the combinational logic) and the time to latch a re-sult is tl. Then if we divide the fundamental operationinto N pipeline stages we increase the latency of eachoperation from tf to Ntl + tf. Thus by Little’s Law
Xpipeline =N
Ntl + tf.
We can conclude two things from this derivation.First, as N grows, pipelining improves throughputonly to the limit of
limN→∞Xpipeline =
1
tl.
That is, pipelining throughput is limited to the maxi-mum rate at which we can cycle a latch in a particulartechnology.
Second, suppose we desire to pipeline until weachieve a desired fraction, fx, where 0 < fx < 1, ofthe maximum throughput 1/tl. Then
fx
tl=
N
Ntl + tf
and soN =
tf
tl
fx
1− fx.
The fraction fx/(1− fx) approximates a linear functionwhen fx is close to 0, but grows to infinity as fx ap-proaches 1. Thus only a small fraction (about half) ofthe maximum pipelining throughput is achievable, un-less we can find a way to grow N, the available op-eration parallelism, hyperbolically. Recent microproces-sor designs have come close to the limits of the linearregime [81, 3, 11], and thus future designs will needto find another approach if they are to achieve greatersystem throughput.
A second approach to increasing system throughputis to increase the number of functional units. If it werethe case that we could fetch the operands for each op-eration in constant time, then we would be able to in-crease throughput linearly as we increased the num-ber of independent operations available in the system.Unfortunately, this argument depends on the assump-tion that the functional units are executing work that iscompletely independent and that they never commu-nicate. If even a small constant fraction of the resultsproduced by each functional unit need to be communi-cated to another arbitrarily chosen functional unit, thenwe need to account for these communication costs inour calculation.
Recent analysis of technology scaling trends showsthat communication costs will be the dominant concernin computer architecture design by the year 2013 [81, 3,11]. For example, in 35nm technology, and assuming aclock cycle time equivalent to 8 fan-out-of-4 gate delaysit is expected that it will cost more than two hundredcycles to propagate a signal all the way across a chip.We can accurately model these assumptions with thefollowing simple abstract rules:
1. The propagation of information takes time linearin distance traveled.
5

dos = f(i)if s
t = g(i)u = h(i)*t = u
i = j(i)v = k(i)
while v
Figure 1: An example program.
2. The universe is finite dimensional.
3. Storing information consumes area linear in thequantity of information stored.
Thus, the area of the entire system is at least propor-tional to N, where N is the number of simultaneouslyactive independent operations. An arbitrary communi-cation operation in the system takes time proportionalto the distance traveled, which, on a two-dimensionalcomputer chip, will on average, be proportional to√N.1 Plugging the result R =
√N into Little’s Law
we are led to the conclusion that at best2
X ∝√N.
Thus, to improve computer system throughput by afactor of two, one must find at least four times as muchparallelism. Put another way, parallelism is the com-puter architect’s constrained resource, and thus im-proving parallelism is the most critical component tofuture improvements in computer system throughput.
1.2 Finding Parallelism
How, then, are we to find the parallelism required toimprove throughput in the next generation of com-puter architectures? The execution of a program canbe viewed as a process of unfolding the dynamic de-pendence graph of that program. The nodes of thisgraph correspond to arithmetic operations that need tobe performed, while edges in the graph correspond to apartial ordering of operations that needs to be enforcedif the program is to produce the correct results. Whenviewed in this way, then the process of finding paral-lelism becomes a process of finding operations in thedynamic dependence graph that don’t depend on one
1Online locality management techniques, like caching, might beable to reduce this distance somewhat, but it is an open questionwhether the benefits would be substantial. Even offline techniques,like VLSI circuit placement algorithms, typically produce results inthe range R ∝ N0.1 to R ∝ N0.3 [73, 36].
2I can find no previous publication of this argument, but the de-signers of the Tera computer system were clearly aware of it before1990 [5].
another. Much of the difficulty in finding parallelism inimperative programs comes from the fact that existingcompilers and architectures build dependence graphsthat are too conservative. They insert false dependencearcs that impede parallelism without affecting the cor-rectness of program execution.
The SUDS automatic parallelization system relies onthree basic principles:
1. Every imperative program can be converted into afunctional program by making renaming explicit.A functional (i.e., explicitly renamed) program hasthe attribute that every variable is (dynamically) writ-ten at most once thus functional programs have noanti- or output- dependences.
2. The flow dependences produced by following thesingle flow of control in the standard control flowgraph representation are more conservative thannecessary. Control dependence analysis produces amore accurate, and sparser, representation of ac-tual program structure that makes multiple flowsof control explicit.
3. Many true-dependences (in particular thoseon data structures in memory) and control-dependences can be further eliminated byspeculation.
Figure 1 shows an example of a simple loop withnon-trivial dependences. Figure 2 shows the conser-vative dynamic dependence graph of two iterationsof the loop. The figure is annotated with the depen-dences that limit parallelism. The variable i creates atrue-dependence, because the value written to variablei in the first iteration is used in the second iteration.The reads of variables s , t , u and v in the first itera-tion create anti-dependences with the writes of the corre-sponding variables in the second iteration. In this con-servative representation every operation is also flow-dependent on the branch that proceeds it. Finally, thereis a memory-dependence between the potentially conflict-ing store operations in the two iterations. We can seeby looking at the graph that, without any further im-provement this loop can execute at a maximum rate ofone iteration every six “cycles” (assuming that each in-struction takes a cycle to execute).
Figure 3 shows the benefits of renaming to re-move anti-dependences. Renaming creates a uniquelynamed location in which to hold each intermediatevalue produced by the program. Since each location iswritten exactly once the anti- and output-dependencesare eliminated [57]. Renaming improves the through-put of the example loop from one loop iteration everysix cycles to one loop iteration every five cycles.
6
s = f(i)
branch s
i = j(i)
s = f(i)
t = g(i)u = h(i)
store *t = u
t = g(i)u = h(i)
store *t = u
v = k(i)
i = j(i)
branch v
v = k(i)
branch s
branch v
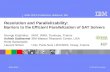
Figure 2: The conservative dynamic dependence graph generated from the code in Figure 1. Arcs represent depen-dences between instructions that must be honored for correct execution. Dotted arcs represent anti-dependencesthat can be removed through dynamic renaming. Dashed arcs represent flow dependences that can be removedthrough accurate control dependence analysis. The height of this conservative dynamic dependence graph is 12nodes, because there is a path through the graph of length 12. The throughput of this program would be oneiteration every six cycles.
s7 = f(i6)
branch s7
t7 = g(i6) u7 = h(i6) i7 = j(i6)
store *t7 = u7
store *t8 = u8
v7 = k(i7)
s8 = f(i7)
i8 = j(i7)
branch v7
branch s8
t8 = g(i7) u8 = h(i7)
v8 = k(i8)
branch v8
Figure 3: Dynamic renaming removes anti–dependences. The height of the graph has beenreduced from the 12 nodes of the conservative dynamicdependence graph to 10 nodes. The throughput hasbeen improved from one iteration every six cycles toone iteration every five cycles.
i7 = j(i6)
v7 = k(i7)
s8 = f(i7) i8 = j(i7)
branch v7
s7 = f(i6)
branch s7
t7 = g(i6)u7 = h(i6)
store *t7 = u7
store *t8 = u8
branch s8
t8 = g(i7)u8 = h(i7)
v8 = k(i8)
branch v8
Figure 4: Control dependence analysis removes con-servative branch-dependence arcs. The combinationof dynamic renaming and control dependence analy-sis has reduced the height of the graph to 7 nodes. Thethroughput has been improved to one iteration everythree cycles.
7

s7 = f(i6)
branch s7
t7 = g(i6) u7 = h(i6)
store *t7 = u7
i7 = j(i6)
v7 = k(i7) s8 = f(i7)i8 = j(i7)
branch v7 branch s8
t8 = g(i7) u8 = h(i7)
store *t8 = u8
v8 = k(i8)
branch v8
Figure 5: Speculation breaks predictable dependences. The graph height has been reduced to 5 nodes. The through-put has been improved to one iteration every cycle.
Figure 4 shows the results of applying control de-pendence analysis [40, 30]. This eliminates the flow-dependence between the branch statement on variables and later code (e.g., the statement “i = j(i) ”) thatexecute irrespective of whether the branch is taken ornot. The combination of renaming and control depen-dence analysis improves the throughput of the exam-ple loop from one loop iteration every six cycles to oneloop iteration every three cycles.
Figure 5 illustrates what happens when two of the re-maining dependences are eliminated using speculationtechniques. While there is a true control dependencebetween the branch at the end of the first iteration andthe execution of the code in the second iteration we canuse traditional branch speculation techniques [103, 132]to parallelize across this dependence with high proba-bility. The dependence between the stores in the twoiterations is necessary in a conservative sense, in thatthe addresses in t7 and t8 could be the same undersome program execution, but using memory dependencespeculation [44] we can take advantage of the idea thatprobabilistically the addresses in t7 and t8 are differ-ent.
These speculative dependences are monitored atruntime. The system checkpoints the state occasionallyand executes code in parallel, even though this maycause dependence violations that produce inconsistentstates. The runtime system later checks for (dynamic)violations. If the runtime system finds any violations,execution is temporarily halted, the system state is re-stored to and restarted at the most recent checkpoint.If such violations are rare then the system achieves theparallelization benefits.
Figure 5 demonstrates that the combination of re-naming, control dependence analysis and speculationhave found a substantial amount of parallelism in theoriginal code. While each iteration of the original loopincludes eight operations, we can (conceptually) im-prove the throughput to one loop iteration every cycle,
or eight instructions per cycle.This thesis addresses the issues involved in the
above example, in the context of SUDS (the Soft-ware Un-Do System), an “all-software” automaticparallelization system for the Raw microprocessor.SUDS performs explicit dynamic renaming by closure-converting C programs. SUDS exploits control inde-pendence by mapping control-independent code to in-dependent branch units on Raw. Finally, the SUDS run-time system speculates past loop control dependencepoints, which tend to be highly predictable, and allowsmemory operations to speculatively execute out of or-der.
1.3 Contributions
The main contribution of this thesis is a compiler trans-formation called scalar queue conversion. Scalar queueconversion is an instruction reordering algorithm thatsimultaneously renames scalar variables. Scalar queueconversion has at least five unique features.
1. Scalar queue conversion works on flow graphswith arbitrary control flow. The flow graph can beunstructured, or even irreducible.
2. Scalar queue conversion can move instructions outof loops with bounds that can not be determineduntil runtime.
3. Scalar queue conversion guarantees the elimina-tion of all scalar anti- and output- dependencesthat might otherwise restrict instruction reorder-ing. Thus scheduling algorithms based on scalarqueue conversion can make instruction orderingdecisions irrespective of register storage depen-dences.
4. Scalar queue conversion, unlike Tomasulo’s algo-rithm, can rename and reorder instructions acrossmispredicted branches whenever the reordered
8

instructions are not control dependent on thatbranch.
5. Scalar queue conversion is a speculative compilertransformation, in that it inserts dynamic mem-ory allocation operations into code that might nototherwise dynamically allocate memory. We de-scribe an efficient software based checkpoint re-pair mechanism that safely applies speculativecompiler optimizations.
In addition to describing scalar queue conversionthis thesis makes the following additional contribu-tions.
1. It shows how to move the renaming operationsintroduced by scalar queue conversion to mini-mize the runtime overheads introduced by scalarrenaming.
2. It shows how to use scalar queue conversion toimplement a generalized form of loop distributionthat can distribute loops that contain arbitrary in-ner loops.
3. It describes the pointer and array analysis issuesthat needed to be addressed when using scalarqueue conversion in a practical context.
4. It describes the SUDS software runtime system,which performs memory dependence speculationwhile only increasing the latency of memory oper-ations by about 20 machine cycles.
5. It provides a demonstration that the SUDS systemeffectively schedules and exploits parallelism inthe context of a complete running system on theRaw microprocessor.
It is my hope that the work in this thesis will serve asa starting point for the research that I believe needs tobe done to enable the next several generations of highperformance microprocessors. Tomasulo’s algorithmissues instructions out of order, but its ability to fetchout of order is limited by mispredicted branch points.To overcome this fetch limit the microprocessor mustsomehow transform a sequential thread into multiple,concurrent, threads of control. The research in this the-sis demonstrates the kinds of problems that need to beovercome when the sequential thread is both impera-tive and has completely arbitrary control flow.
1.4 Road Map
The rest of this thesis is structured as follows. Chap-ter 2 defines the relatively standard graph-theoretic
terms widely used in the compiler community. Read-ers with a strong background in compiler design canprofitably skip Chapter 2.3
The next four chapters describe scalar queue conver-sion. Chapter 3 describes the transformation, and ex-plains why scalar queue conversion is able to, prov-ably, eliminate all the scalar anti- and output- depen-dences that might otherwise inhibit a particular sched-ule. Chapter 4 discusses an optimization that im-proves scalar queue conversion’s placement of copy in-structions. Chapter 5 describes several extensions andimprovements that widen the applicability of scalarqueue conversion. Chapter 6 describes the generalizedloop distribution transformation that scalar queue con-version enables.
Several practical questions with regard to scalarqueue conversion are addressed in Chapter 7. The firstproblem is that scalar queue conversion introduces dy-namic memory allocation operations into loops thatmight not otherwise allocate memory dynamically.Thus, scalar queue conversion is unsafe in the sensethat it does not provide strict guarantees on the mem-ory footprint of the transformed program. Chapter 7describes an efficient software based checkpoint repairmechanism that we use to eliminate this problem. TheSUDS Software Un-Do System described in Chapter 7allows scalar queue conversion to be applied specula-tively. If scalar queue conversion introduces a dynamicmemory allocation error then SUDS rolls back execu-tion to a checkpointed state and runs the original ver-sion of the code. SUDS performs an additional impor-tant task in that it implements a memory dependencespeculation system that breaks (speculatively and atruntime) memory dependences that would otherwiseforbid the parallelization of many loops.
Chapter 8 describes the inter-relationship of thework described in Chapters 3 through 7 in the contextof a working system. Several case studies describe, insome detail, how, and why, the transformations are ap-plied to specific loops.
Chapter 9 describes the relationship of scalar queueconversion and generalized loop distribution to previ-ous work in program slicing, scalar expansion, loopdistribution, thread-level parallelization, critical pathreduction and data speculation. Chapter 10 concludes.
3But please keep in mind the difference between the value depen-dence graph (the graph comprising the scalar def-use chains, con-trol dependence arcs, and memory dependences) and the conserva-tive program dependence graph (the graph comprising the value depen-dence graph with additional edges for the scalar use-def and def-defchains). Both of these graphs are sometimes called “program depen-dence graphs” in the literature, but the difference is important in thework described in subsequent chapters.
9

sum = 0i = 0do
partial_sum = 0j = 0use(i, sum)do
use2(sum, partial_sum, i, j)partial_sum = partial_sum + 1j = next(j)c1 = cond1(i, j)
while c1i = i + 1sum = sum + partial_sumc2 = cond2(i)
while c2use(sum)
Figure 6: An example program with a doubly nestedloop.
2 The Dependence AnalysisFramework
As stated in Section 1.2 the SUDS approach to findingparallelism rests on three principles:
1. Dynamic renaming eliminates anti- and output-dependences.
2. Control dependence analysis eliminates conserva-tive flow-dependences.
3. Speculation eliminates some dynamically pre-dictable true- and control-dependences.
In this chapter we define basic terms and describe whatwe mean by a dependence.
2.1 The Flow Graph
To start with, let us define some basic terms. We willuse the term program to refer to the finite set of instruc-tions that specifies the set of operations that we wishto perform. For the purposes of the conceptual de-velopment in this chapter we choose a simple “controlflow graph” representation of programs. An exampleof some code is shown if Figure 6. The resulting controlflow graph is shown in Figure 7.
The nodes in the control flow graph representationrepresent instructions. Each instruction specifies an op-eration that changes some part of the underlying ma-chine state. The control flow graph has two additionalnodes, labeled begin and end that correspond to theinitial and final states of the program execution. The
BEGIN
END
1: sum = 0
2: i = 0
3: partial_sum = 0
4: j = 0
5: use(i, sum)
6: use2(sum, partial_sum, i, j)
7: partial_sum = partial_sum + 1
8: j = next(j)
9: c1 = cond1(i, j)
10: branch c1
(c1 = true)
11: i = i + 1
(c1 = false)
12: sum = sum + partial_sum
13: c2 = cond2(i)
14: branch c2 (c2 = true)
15: use(sum)
(c2 = false)
Figure 7: The control flow graph corresponding to theprogram in Figure 6.
10

edges in the control flow graph represent (programmerspecified) temporal constraints on the order of opera-tions. More specifically, if there is a directed path frominstruction A to instruction B in the control flow graph,then there may be a correct sequence of (dynamic) statetransitions where transition A occurs before transitionB. Note that Figure 7 includes an edge that flows di-rectly from the begin node to the end node. This edgerepresents the possibility that the program will not ex-ecuted at all. We will call the control flow graph edgesflow dependences.
The kinds of instructions permitted in our represen-tation include
1. 3-Address operations (e.g., a = b + c , where“a” is a register name, “b” and “c” are registernames or constants, and “+” is a binary operationwith no side effects. The semantics are that thecontents of register a are replaced with the valueproduced by performing the specified operationon the contents of registers b and c . We call a thedestination operand and b and c source operands.
2. Load instructions, x = *y , where “x” and “y” areregister names. The semantics are that the currentcontents of the memory location with address yare loaded into the x register.
3. Store instructions, *y = x , where “x” and “y” areregister names. The semantics are that the currentcontents of register x overwrite the value in thememory location with address given by register y .
4. Branch instructions, branch c , where “c” is aregister name. The semantics are that of a dynamicdecision point with respect to which of two outputedges we take out of the node.4
5. Call instructions, call p , where “p” is a registeror constant containing the identifier of some nodein some flow graph. The call instruction implicitlyplaces the identifier of its own node on an implicitstack, so that it can be used by the return instruc-tion.
6. Return instructions, return , that pop the identi-fier of a node off the top of the implicit stack, andreturn flow of control to the successor of that node.
7. Jump instructions, jump c , where “c” is a regis-ter name. It is assumed the register contains the
4We could have made state transitions on a program counter anexplicit part of the representation, but have chosen not to becausecontrol flow graphs are standard. Control flow graphs representtransitions on the program counter implicitly through the flow de-pendences, with branches representing the only points at which run-time information effects transitions on the program counter state.
identifier of some flow graph node, and controlflow is rerouted to that node. This permits “multi-way” branches, such are required to efficiently im-plement C switch statements.
The semantics of a particular program can be de-termined (operationally) by starting with a predeter-mined machine state with one register for each namedregister in the program, and a memory, and then step-ping through the control flow graph, performing thestate transitions specified by each instruction one at atime. We call the sequence of state transitions producedby this process the sequential order. A sequential orderfor two iterations of the outer loop of the flow graphin Figure 7 is shown in Figure 8. In this example, theinner loop executes three times during the first outerloop iteration and twice during the second. There are39 total instructions shown in this total order.
The question we are trying to address is whetherthere are sequences of state transitions, other than thesequential order, in which we can execute the statetransitions and get the same final state. That is, thesequential order is a total order on the set of state tran-sitions. We would like to find less restrictive partial or-ders that produce the same final state.
2.2 The Conservative Program Depen-dence Graph
The first observation we make is that the flow depen-dences on individual instructions are overly conserva-tive with respect to register operands. A combinationof standard dataflow analyses can produce less restric-tive orderings.
We say that given nodes d and n in a control flowgraph d dominates n if every directed path from beginto n passes through d [75]. Every node dominates it-self. For example, in Figure 7 node 14 dominates nodes14 and 15, but not end . This is because every path frombegin to node 15 goes through node 14, but there is apath (begin → end ) that does not go through node 14.The postdominance relation is defined similarly, with theflow graph reversed. Node d postdominates n if d ison every path from n to end . In Figure 7 node 15 post-dominates every node in the flow graph except nodesbegin and end .
We can also define the set of dominators of a node n,Dom[n], recursively as the least fixed point of the set ofsimultaneous equations:
Dom[n] = {n} ∪(⋂
p∈pred[n]Dom[p])∀n,
where we work downwards in the lattice of sets fromfull sets towards empty sets.
11

3: partial_sum = 0
4: j = 0
5: use(i, sum)
6: use2(sum, partial_sum, i, j)
7: partial_sum = partial_sum + 1
8: j = next(j)
9: c1 = cond1(i, j)
10: branch c1
6: use2(sum, partial_sum, i, j)
7: partial_sum = partial_sum + 1
8: j = next(j)
9: c1 = cond1(i, j)
10: branch c1
6: use2(sum, partial_sum, i, j)
7: partial_sum = partial_sum + 1
8: j = next(j)
9: c1 = cond1(i, j)
10: branch c1
11: i = i + 1
12: sum = sum + partial_sum
13: c2 = cond2(i)
14: branch c2
3: partial_sum = 0
4: j = 0
5: use(i, sum)
6: use2(sum, partial_sum, i, j)
7: partial_sum = partial_sum + 1
8: j = next(j)
9: c1 = cond1(i, j)
10: branch c1
6: use2(sum, partial_sum, i, j)
7: partial_sum = partial_sum + 1
8: j = next(j)
9: c1 = cond1(i, j)
10: branch c1
11: i = i + 1
12: sum = sum + partial_sum
13: c2 = cond2(i)
14: branch c2
Figure 8: The sequential ordering of the state transitions produced by two iterations of the outer loop of the flowgraph in Figure 7. The inner loop executes three times during the first outer loop iteration and twice during thesecond.
The dominance relation introduces a well definedpartial order on the nodes in a flow graph. Thus, wecan define a backward dependence edge as any edge froma node n to a node d that dominates n. We will infor-mally refer to any edge that is not a backward edge asa forward edge. (Note that this overloads the word “for-ward” somewhat since it includes edges x → y whereneither x nor y dominate the other). For example, inFigure 7 node 6 dominates node 10 so the edge 10→ 6
is a backedge in the flow graph.The intuitive reason that the dominance relation is
central to our analysis (as it is in most modern compileroptimizations) is that it summarizes information aboutall possible sequential orderings of state transitions, nomatter the initial state at the beginning of execution.That is, if node d dominates node n in the flow graph,then every sequential ordering generated from the flowgraph will have the property that the first appearanceof d will come before the first appearance of n. If noded does not appear in the sequential ordering, then noden can not appear either.
Given two nodes, we say that x strictly dominates wiff x dominates w and x 6= w. The dominance frontier ofa node x is the set of all edges v → w such that x dom-inates v, but does not strictly dominate w [75]. (Theoriginal work on dominance frontiers used the set ofnodesw, but the edge formulation is more accurate andmore useful. See, for example, [92].) In Figure 7 node6 dominate nodes 10, 14 and 15, but does not strictlydominate any of nodes 6, 3 or end , so the dominancefrontier of node 6 is the edges 10 → 6, 14 → 3 and15 → end . The postdominance frontier of node x is theset of all edges v→ w such that x postdominatesw, butdoes not strictly postdominate v (note that we have, es-sentially, reversed the edge).
The postdominance frontier gives us informationabout control dependence [40, 30]. In particular we saythat a node n is control dependent on edge x → y iff the
BEGIN
10: branch c1
14: branch c2
END
1: sum = 0
2: i = 0
15: use(sum)
3: partial_sum = 0
4: j = 0
5: use(i, sum)
11: i = i + 1
6: use2(sum, partial_sum, i, j)
7: partial_sum = partial_sum + 1
8: j = next(j)
9: c1 = cond1(i, j)
12: sum = sum + partial_sum
13: c2 = cond2(i)
Figure 9: The control dependences corresponding to theflow graph in Figure 7.
edge is in the postdominance frontier of n. The intu-itive reason for this is that the postdominance frontierrepresents the set of edges that cross from regions ofthe program wheren is not guaranteed to execute to re-gions of the program where n is guaranteed to execute.The nodes x in the control dependence edges are thusthe branch points that decide whether or not node nshould execute. For example, in Figure 7 the postdom-inance frontier of node 7 is the set of edges begin → 1,10 → 6 and 14 → 3, and indeed, it is exactly the be-gin node and the branches at nodes 10 and 14 that de-termine how many times node 7 will execute. (Recallthat one should think of the begin node as a branchthat decides whether or not the program will executeat all.) The complete set of control dependences for theflow graph from Figure 7 is shown in Figure 9.
For each node x that contains an instruction that hasregister r as a destination operand we call x a definitionof r. For each node y that contains an instruction thatuses register r as a source operand we call y a use of
12

3: partial_sum = 0
6: use2(sum, partial_sum, i, j)
7: partial_sum = partial_sum + 1
1: sum = 0
12: sum = sum + partial_sum
5: use(i, sum) 6: use2(sum, partial_sum, i, j)
12: sum = sum + partial_sum
15: use(sum)
Figure 10: The du-webs corresponding to variablespartial sum and sum for the flow graph from Fig-ure 7.
r. For example, in Figure 7 nodes 4 and 8 define thevariable j , while nodes 6, 8 and 9 use the variable j .
We say that a definition (use) x of register r reachesa node y if there exists a path from x to y in the flowgraph such that there is no other definition of register ron that path. For example, the definition of variable jat node 4 reaches node 8, because there is a path from 4to 8 with no other definition of j , but the definition atnode 4 does not reach node 9 because every path from4 to 9 goes through the definition at node 8.
More generally, given any directed graph (N,E) andsubsets Gen ⊂ N and Pass ⊂ N, we define the Reachingrelation on the graph with respect to Gen and Pass asthe set of nodes y ∈ N such that there is a path from anode x ∈ Gen to y such that all the intermediate nodeson the path are in Pass. Techniques for efficiently gen-erating the reaching relation can be found in any stan-dard undergraduate compiler textbook [4]. Typically itis found as the least fixed point of the equation
Reaching = Succs(Gen ∪ (Reaching ∩ Pass)).
Where Succs(X) = {n ∈ N|x ∈ X∧ (x→ n) ∈ E}.Then we can more specifically define the reaching def-
initions relation for a node x that defines a register r asthe solution to the Reaching relation where Gen = {x}and Pass is the set of nodes that do not define r. Like-wise the reaching uses relation for a node x that uses aregister r is the solution to the Reaching relation whereGen = {x} and Pass is the set of nodes that do not definer. For example, in Figure 7, the definition of variablej in node 8 reaches node 6 (through the path, 8, 9, 10,6). But the definition at node 8 does not reach node 5,because node 4 is not in the Pass set.
Of particular interest to us is the subset of the reach-ing definitions relation that relates the definitions to theuses of a particular register r. This subset of the reach-ing definitions relation is typically called the def-use-chains or du-chains for the variable r. A maximally con-nected subset of the du-chains for a particular register
r is called a du-web. The du-chains for variable j in Fig-ure 7 are 4→ 6, 4→ 8, 8→ 9, 8→ 6 and 8→ 8. This setof du-chains is also a du-web, since it is a connected set.The du-webs for variables partial sum and sum areshown in Figure 10. Given the du-chains for a registerr, the du-webs can be efficiently calculated by comput-ing the connected components (e.g., using depth firstsearch) on the graph of du-chains [68].
Similarly, the def-def-chains relation for the register ris the subset of the reaching defs relation that relatesthe definitions of r to other definitions of r. For exam-ple, 8 → 4 is a def-def chain for variable j in Figure 7.The use-def-chains for a variable r are the subset of thereaching uses of r that are also definitions. Note thatthe use-def chains are not simply the def-use chainsturned around backwards. For example, in Figure 77 → 12 is a def-use chain for variable partial sum,but 12 → 7 is not a use-def chain, because every pathfrom node 12 to node 7 must go through node 3, whichredefines partial sum.
We have defined the def and use chains with respectto registers only. We will also define a particularly con-servative set of dependences with respect to memoryoperations (load and store instructions). We say thatany memory operation, x, reaches memory operation, y,if there is a path from x to y in the control flow graph.(Pass is the set of all nodes). We say there is a memorydependence from x to y if at least one of x and y is a storeinstruction. (That is, we don’t care about load-load de-pendences).
Now we are ready to define the conservative pro-gram dependence graph, and relate the conservativeprogram dependence graph (which is a static represen-tation of the program) to the allowable dynamic order-ings of instructions.
We define the conservative program dependence graphas the graph constructed by the following procedure.Take the nodes from the control flow graph. For everypair of nodes, x, y, insert an edge, x → y, if there iseither a def-use-chain from x to y, a use-def-chain fromx to y, a def-def-chain from x to y, a memory depen-dence from x to y or a control dependence from x toy.5
Suppose the sequential execution of a control flowgraph on a particular initial state produces a partic-ular sequential (total) ordering of state transitions (asdescribed above for the semantics for control flowgraphs). Now for every pair of dynamic instructionnodes x, y, such that x comes before y in the sequentialordering, we insert an edge from x to y if there is anedge in the conservative program dependence graph
5We defined control dependence from edges to nodes, (i.e., (b →d) → n). Here we are using the standard node definition of controldependence, b→ n for simplicity.
13

3: partial_sum = 0
6: use2(sum, partial_sum, i, j)
4: j = 05: use(i, sum)
11: i = i + 1
12: sum = sum + partial_sum
7: partial_sum = partial_sum + 1
8: j = next(j)
6: use2(sum, partial_sum, i, j)
9: c1 = cond1(i, j)
10: branch c1
7: partial_sum = partial_sum + 1
8: j = next(j)
6: use2(sum, partial_sum, i, j)
9: c1 = cond1(i, j)
10: branch c1
7: partial_sum = partial_sum + 1 8: j = next(j)
9: c1 = cond1(i, j)
10: branch c1
13: c2 = cond2(i)
5: use(i, sum)
14: branch c2
3: partial_sum = 0 4: j = 0
6: use2(sum, partial_sum, i, j)
11: i = i + 1
12: sum = sum + partial_sum
7: partial_sum = partial_sum + 1
8: j = next(j)
6: use2(sum, partial_sum, i, j)
9: c1 = cond1(i, j)
10: branch c1
7: partial_sum = partial_sum + 1 8: j = next(j)
9: c1 = cond1(i, j)
10: branch c1
13: c2 = cond2(i)
14: branch c2
Figure 11: The conservative dynamic dependence graph for two iterations of the outer loop of the flow graph in Figure 7.The inner loop executes three times during the first outer loop iteration and twice during the second. The depth ofthe graph has been reduced to 26 instructions, from the 39 instructions in the sequential order shown in Figure 8.
between the corresponding (static) instruction nodes.We call the resulting graph the conservative dynamic de-pendence graph. The conservative dynamic dependencegraph corresponding to the sequential order shown inFigure 8 is shown in Figure 11.
The edges in the conservative dynamic dependencegraph have standard names [57], which we will alsouse. If the edge on the dynamic ordering was cre-ated because there was def-def-chain or use-def-chainin the conservative program dependence graph wecall the edge in the dynamic ordering a register stor-age dependence. We will sometimes distinguish betweenthese two types by calling them output-dependencesand anti-dependences, respectively. If the edge on thedynamic ordering was created because there was adef-use-chain in the conservative program dependencegraph we call the edge in the dynamic ordering a value-dependence, or less formally, a “true-dependence”. Ifthe edge on the dynamic ordering was created becausethere was a memory dependence from a store to a loadwe will call it a memory value dependence. If the edge onthe dynamic ordering was created because there wasa memory dependence from a load to a store we willcall it a memory anti-dependence. If the edge on the dy-namic ordering was created because there was a mem-ory dependence from a store to a store we will call it
a memory output-dependence. Finally, if the edge on thedynamic ordering was created because there was a con-trol dependence in the conservative program depen-dence graph we will call it a dynamic control dependence.
Note that the conservative dynamic dependencegraph is a directed acyclic graph, and thus defines apartial order on the state transitions during the execu-tion of the program. The value of the conservative pro-gram dependence graph comes from the fact that anysequence of these state transitions that obeys the partial or-dering demanded by the conservative dynamic dependencegraph will produce the same final state as the sequential or-dering. This can be argued informally by noticing thatwe have
1. Placed a total order on changes to the memorystate (through memory-dependences).
2. Guaranteed that every instruction executes afterthe branches in the sequential order that controlwhether or not that instruction executes (throughcontrol-dependences).
3. Placed a total order on changes to each individualregister state (through def-def-chains).
4. Guaranteed that source operands always receivethe value they would have received in the sequen-
14

tial order by placing each use of register r in theconservative dynamic dependence graph betweenthe same two defs of register r that it was betweenin the sequential order (through def-use and use-def chains).
We have gained some parallelization flexibility bymoving from the control flow graph to the conservativeprogram dependence graph, because we have movedfrom the total order on state transitions imposed bythe sequential order, to the somewhat less restrictivepartial order given by the conservative dynamic de-pendence graph. For example, in Figure 11 we havereduced the dependence distance to 26 nodes from the36 nodes shown in the sequential order from Figure 8.
2.3 The Value Dependence Graph
One of the main constraints to further parallelizationof the conservative program dependence graph is theexistence of a large number of storage dependences. InChapter 3 we will describe scalar queue conversion, acompiler transformation that can always add copies tothe flow graph that eliminate all register storage de-pendences. Thus, instruction scheduling algorithmscan make instruction ordering decisions irrespective ofregister storage dependences. In particular, instruc-tion scheduling algorithms can work on a less restric-tive graph than the conservative program dependencegraph.
To differentiate this graph from the conservative pro-gram dependence graph we will call it the value depen-dence graph. We define the value dependence graphas the graph constructed by the following procedure.Take the nodes from the control flow graph. For everypair of nodes, x, y, insert an edge, x → y, if there iseither a def-use-chain from x to y, a memory depen-dence from x to y or a control dependence from x to y.Thus the value dependence graph is the subgraph ofthe conservative program dependence graph createdby removing the use-def and def-def chains from theconservative program dependence graph.
Suppose the sequential execution of a control flowgraph on a particular initial state produces a partic-ular sequential (total) ordering of state transitions (asdescribed above for the semantics for control flowgraphs). Now for every pair of dynamic instructionnodes x, y, such that x comes before y in the sequentialordering, we insert an edge from x to y if there is anedge in the value dependence graph between the corre-sponding (static) instruction nodes. We call the result-ing graph the dynamic value graph. The dynamic valuegraph corresponding to the sequential order shown inFigure 8 is shown in Figure 12.
Renaming scalars to avoid register storage depen-dences produces substantial concurrency gains. Thisconcurrency comes at the cost of increasing the numberof simultaneously live values, and thus the requiredstorage space. For example, in Figure 12 we have re-duced the dependence distance to 10 nodes from the 26nodes in the conservative dynamic dependence graphfrom from Figure 11. As a result the graph is, infor-mally, both “shorter” and “fatter.” In the followingchapters we will describe scalar queue conversion, acompiler transformation that effects this renaming.
3 Scalar Queue Conversion
As described in the last chapter, scalar renaming is oneof the most effective techniques known for exposing in-struction concurrency in a program. In this section wewill show that the compiler can restructure the codeto eliminate all register storage dependences. The abil-ity to eliminate any register storage dependence meansthat instruction scheduling algorithms can make instruc-tion ordering decisions irrespective of register storage de-pendences. The increased flexibility results in schedulesthat would otherwise be impossible to construct.
We call this transformation to eliminate registerstorage dependences scalar queue conversion, becauseit completely generalizes the traditional technique ofscalar expansion [68] to arbitrary unstructured (evenirreducible) control flow, and provably eliminates allregister anti- and output-dependences that would vio-late a particular static schedule. In Chapter 6 we showhow to use scalar queue conversion as the key sub-routine to enable a generalized form of loop distribu-tion. Loop distribution is best viewed as a schedul-ing algorithm that exposes the available parallelism ina loop [68]. The loop distribution algorithm in Chap-ter 6 generalizes previous scheduling techniques byscheduling across code with completely arbitrary con-trol flow, in particular, code with inner loops. This gen-eralization is possible only, and exactly, because scalarqueue conversion guarantees the elimination of all reg-ister anti- and output-dependences.
3.1 Motivation
Consider node 6 in the flow graph in Figure 7. Supposewe want to run this instruction out of order. For ex-ample, execution of the operation “use2(sum, par-tial sum, i, j) ” might consume many cycles, andwe might wish to start execution of node 7 before node6 completed its work. Unfortunately there is a useof variable partial sum in node 6 and a definitionof partial sum in node 7, so dynamically executing
15

3: partial_sum = 0
6: use2(sum, partial_sum, i, j) 7: partial_sum = partial_sum + 1
4: j = 0
8: j = next(j)
5: use(i, sum)
6: use2(sum, partial_sum, i, j)
7: partial_sum = partial_sum + 1
9: c1 = cond1(i, j)
10: branch c1
8: j = next(j)
6: use2(sum, partial_sum, i, j) 7: partial_sum = partial_sum + 1
9: c1 = cond1(i, j)
10: branch c1
8: j = next(j)
12: sum = sum + partial_sum9: c1 = cond1(i, j)
10: branch c1
11: i = i + 1
13: c2 = cond2(i)
12: sum = sum + partial_sum
14: branch c2
3: partial_sum = 0 4: j = 05: use(i, sum) 11: i = i + 1
6: use2(sum, partial_sum, i, j)
7: partial_sum = partial_sum + 1
8: j = next(j)
6: use2(sum, partial_sum, i, j)7: partial_sum = partial_sum + 1
9: c1 = cond1(i, j)
10: branch c1
8: j = next(j)
9: c1 = cond1(i, j)
10: branch c1
13: c2 = cond2(i)
14: branch c2
Figure 12: The dynamic value graph for two iterations of the outer loop of the flow graph in Figure 7. The inner loopexecutes three times during the first outer loop iteration and twice during the second. The depth of the graph hasbeen reduced to 10 instructions, from the 39 instructions in the sequential order shown in Figure 8.
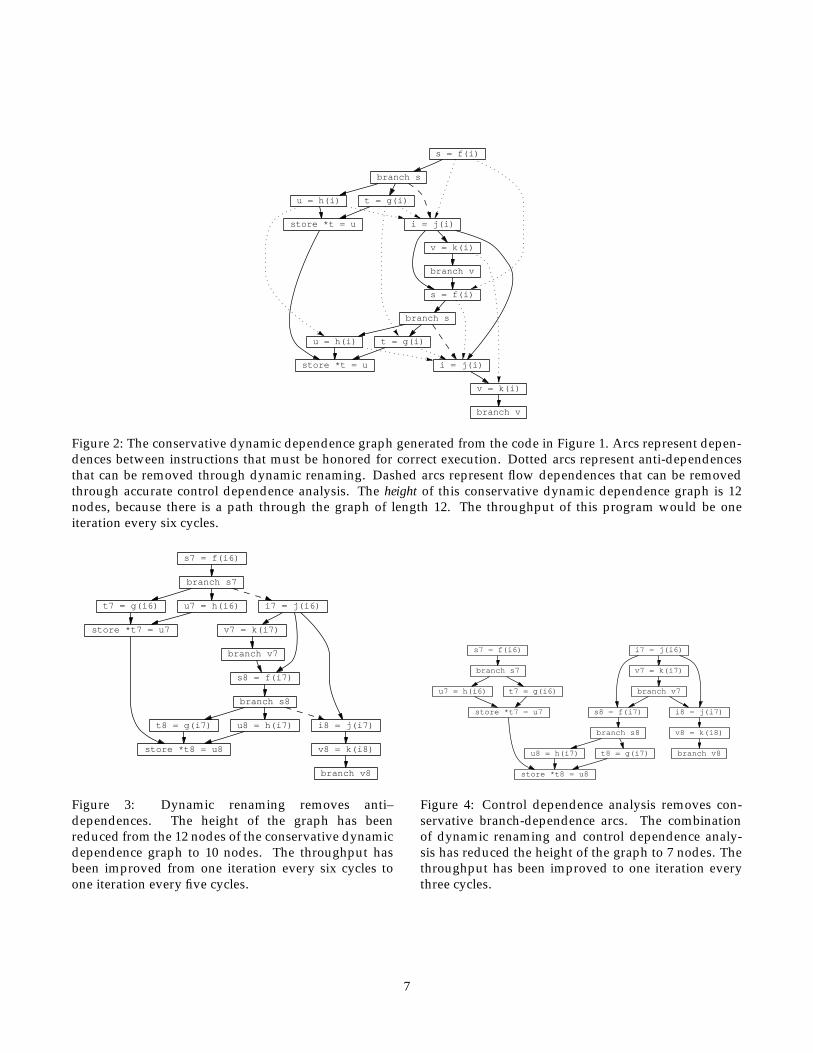
an instance of node 6 out of order with the immedi-ately following instance of node 7 could produce in-correct results. If, however, we were to make a copy ofthe variable partial sum into a new variable, called,for example partial sum tmp , then we could executenodes 6 and 7 in either order. This transformation isdemonstrated in Figure 13.
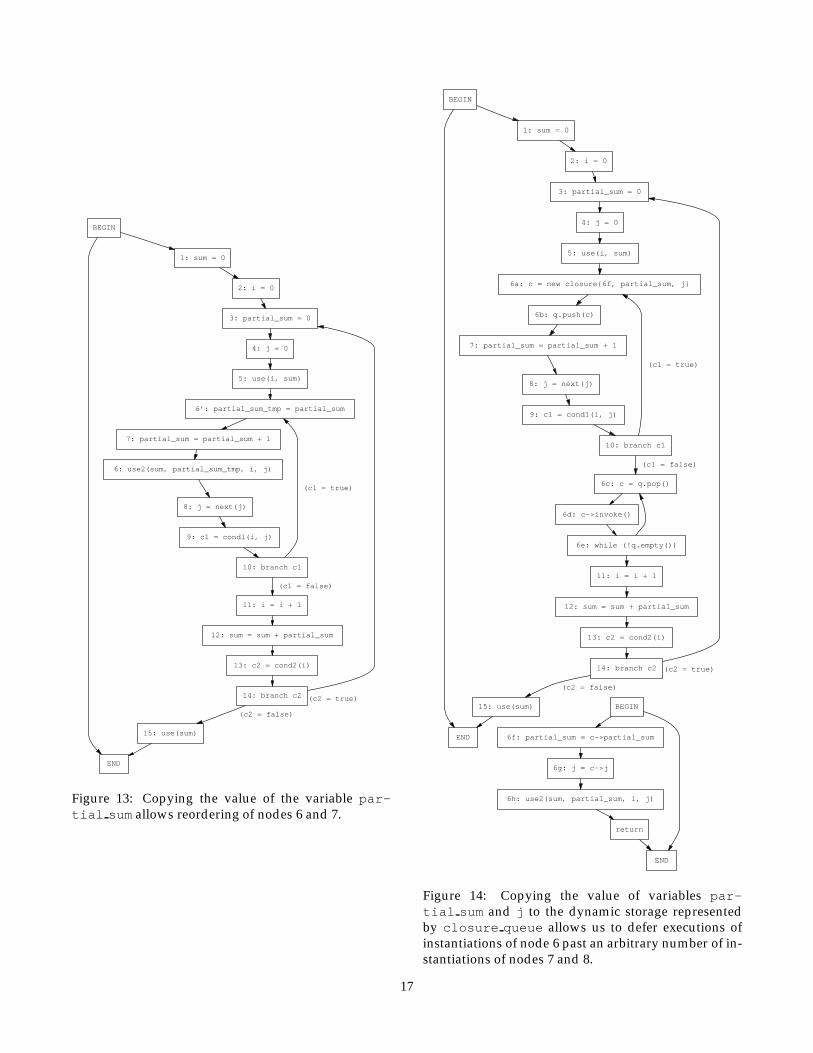
Suppose, however, that we want to defer executionof all dynamic instances of node 6 until after execu-tion of all the dynamic instances of node 7. In this casewe need to generalize the transformation so that ratherthan saving the values required by node 6 in a (stati-cally allocated) register, we save the values in dynami-cally allocated storage. By this process we can simulta-neously save the machine states required to execute anarbitrary number of dynamic instances of node 6.
More concretely, we turn node 6 into a closure. Aclosure can be thought of as a suspended computa-tion [72, 107]. It is typically implemented as a datastructure that contains a copy of each part of the staterequired to resume the computation, plus a pointer tothe code that will perform the computation. There arethen a set of operations that we can perform on a clo-sure:
1. We can allocate a closure by requesting a portion ofmemory from the dynamic memory allocator thatis sufficient to hold the required state plus codepointer.
2. We can fill a closure by copying relevant portionsof the machine state into the allocated memorystructure.
3. We can invoke a closure by jumping to (calling) the
closures code pointer and passing a pointer to theassociated data structure that is holding the rele-vant machine state.
Closures will be familiar to those who have used lexi-cally scoped programming languages. For example, inC++ and Java closures are called objects. In these lan-guages closures are allocated by calling operator new,filled by the constructor for the object’s class, and in-voked by calling one of the methods associated with theobject’s class.
In the general case we can defer execution of somesubset of the code by creating a closure for each de-ferred piece of code, and saving that closure on aqueue. Later we can resume execution of the deferredcode by invoking each member of the queue in FIFOorder. For example, Figure 14 demonstrates how weuse queues of closures to defer execution of every dy-namic instance of node 6 until after the execution ofevery dynamic instance of node 7.
The intuition behind this result is that every impera-tive program is semantically equivalent to some functionalprogram [72, 58, 7]. Since a functional program neveroverwrites any part of an object (but rather createsan entirely new object) there are no storage depen-dences. Another way to view the result is in termsof the dynamic register renaming performed by Toma-sulo’s algorithm [117, 57, 104, 83, 105]. Tomasulo’s al-gorithm performs a dynamic mapping of “virtual” reg-ister names to “physical” registers, each of which iswritten only once. After this renaming all register stor-age dependences are eliminated, because (conceptu-ally) no physical register ever changes its value. Thus,the instruction scheduling algorithm is less constrained
16
BEGIN
END
1: sum = 0
2: i = 0
3: partial_sum = 0
4: j = 0
5: use(i, sum)
6’: partial_sum_tmp = partial_sum
7: partial_sum = partial_sum + 1
6: use2(sum, partial_sum_tmp, i, j)
8: j = next(j)
9: c1 = cond1(i, j)
10: branch c1
(c1 = true)
11: i = i + 1
(c1 = false)
12: sum = sum + partial_sum
13: c2 = cond2(i)
14: branch c2 (c2 = true)
15: use(sum)
(c2 = false)
Figure 13: Copying the value of the variable par-tial sum allows reordering of nodes 6 and 7.
BEGIN
END
1: sum = 0
2: i = 0
3: partial_sum = 0
4: j = 0
5: use(i, sum)
6a: c = new closure{6f, partial_sum, j}
6b: q.push(c)
7: partial_sum = partial_sum + 1
8: j = next(j)
9: c1 = cond1(i, j)
10: branch c1
(c1 = true)
6c: c = q.pop()
(c1 = false)
6d: c->invoke()
6e: while (!q.empty())
11: i = i + 1
12: sum = sum + partial_sum
13: c2 = cond2(i)
14: branch c2 (c2 = true)
15: use(sum)
(c2 = false)
BEGIN
6f: partial_sum = c->partial_sum
END
6g: j = c->j
6h: use2(sum, partial_sum, i, j)
return
Figure 14: Copying the value of variables par-tial sum and j to the dynamic storage representedby closure queue allows us to defer executions ofinstantiations of node 6 past an arbitrary number of in-stantiations of nodes 7 and 8.
17

by register storage dependences.Tomasulo’s algorithm, however, fetches branches in
the order they are given by the flow dependences fromthe control flow graph. Similarly, existing techniquesfor proving the equivalence of imperative to functionalprograms [58, 7] rely on continuation passing style.Conversion to continuation passing style requires thatcontinuations nest in an order corresponding to flowdependences [6]. Scalar queue conversion, in contrast,places closure allocation and fill operations only wherethey are required in the value dependence graph. As a re-sult, scheduling algorithms based on scalar queue con-version (such as the generalized loop distribution al-gorithm described in Chapter 6), are not restricted tofetching a single sequential flow of control.
3.2 Road Map
The remainder of this chapter addresses the questionsof when it is legal to defer execution of a region ofcode, and where closures need to be created to per-form the renaming required by the requested code de-ferment. In Sections 3.3, 3.4, 3.5 and 3.6 we demon-strate that scalar queue conversion can defer any set ofinstructions that does not violate the dependences inthe value dependence graph. The additional registerstorage dependences of the conservative program de-pendence graph can be completely ignored.
Subsequent chapters deal with a number of practicalissues surrounding scalar queue conversion. In Chap-ter 4 we give an eager dead-copy elimination algorithm,motivated by algorithms that convert to SSA form, thatoptimizes (in a minimax sense) the number of dynamiccopy operations introduced by scalar queue conver-sion.
Section 5.1 demonstrates how to extend the resultsfrom this chapter from regions with single exits to re-gions with multiple exits. Section 5.2 shows how to usethe closures created by scalar queue conversion as a ba-sic unit of concurrency. Scalar queue conversion elim-inates scalar anti- and output- dependences, but doesnot eliminate memory dependences. Chapter 5 alsodescribes a set of program transformations that reduceor eliminate memory dependences, thus extending theapplicability of scalar queue conversion.
Chapter 6 additionally shows how to use scalarqueue conversion as the key enabling technology for ageneralized form of loop distribution. In particular, thegeneralized loop distribution transformation describedin Chapter 6 relies on the ability of scalar queue conver-sion to place closure allocation and fill operations onlyat points where they are required by the value depen-dence graph, rather than the more restrictive controlflow graph.
A key practical question with regard to scalar queueconversion is addressed in Chapter 7. The problemis that scalar queue conversion introduces dynamicmemory allocation operations (i.e., closure allocations)into loops that might not otherwise allocate memorydynamically. Thus, scalar queue conversion is unsafein the sense that it does not provide strict guaranteeson the memory footprint of the transformed program.In particular, a scalar queue converted program could,potentially, try to allocate more memory than is avail-able in the system, and thus create an error conditionthat would not have occured in the untransformed pro-gram.
Chapter 7 describes an efficient software basedcheckpoint repair mechanism that we use to eliminatethis problem. The SUDS Software Un-Do System de-scribed in Chapter 7 allows scalar queue conversion tobe applied speculatively. If scalar queue conversion in-troduces a dynamic memory allocation error conditionthen SUDS rolls back execution to a checkpointed stateand runs the original version of the code.
The relationship of scalar queue conversion toprogram slicing, scalar expansion, loop distribution,Tomasulo’s algorithm and thread level speculation isdescribed in Chapter 9.
Running Example
The concepts, definitions and proofs in the rest of thischapter are all illustrated with respect to an examplebased on the program shown in Figure 7. I have donemy best to choose the example such that it illustratesthe relationships between the relevant ideas, but so thatit is not so complicated as to overwhelm the reader.
The example problem is as follows. Suppose wewish to reschedule the loop in Figure 7 into two loops,one that does the work corresponding to nodes 2, 3,4, 7, 8, 9, 10, 11, 13 and 14, and one corresponding tonodes 1, 5, 6, 12 and 15. Is there a legal way to restruc-ture the code to effect this rescheduling? In this chapterwe will demonstrate that this transformation is legalexactly because the flow of value and control depen-dences across the partitioning of nodes in the region isunidirectional.
Consider a connected, single-entry, single-exit regionR of the flow graph. We induce the region flow graphby taking the set of nodes in the region and all theedges x → y such that both x and y are in the region.With the begin node we associate a set of definitionsfor variables that correspond to the def-use chains thatreach from nodes r 6∈ R to nodes r ∈ R. With the endnode we associate a set of uses for variables that cor-respond to the def-use chains that reach from nodesr ∈ R to nodes r 6∈ R. On the resulting region flow
18

BEGIN
END
1: sum = 0
2: i = 0
3: partial_sum = 0
5: use(i, sum)
6: use2(sum, partial_sum, i, j)
4: j = 0
7: partial_sum = partial_sum + 1
8: j = next(j)
12: sum = sum + partial_sum
9: c1 = cond1(i, j)
10: branch c1
(c1 = true)
11: i = i + 1
(c1 = false)
13: c2 = cond2(i)
14: branch c2 (c2 = true)
15: use(sum)
(c2 = false)
Figure 15: Partitioning the outer loop into the two sub-sets, 2, 3, 4, 7, 8, 9, 10, 11, 13, 14 and 1, 5, 6, 12, 15 pro-duces a unidirectional cut because no dependence edgesflow from the second subset into the first. Cut depen-dence edges are shown in dotted lines. They all flowfrom the first subset into the second.
graph we calculate the value dependence graph. Re-call that this is the def-use chains, the memory depen-dence chains, and the control dependences calculatedon the flow graph. Note that we have explicitly usedthe value dependence graph, rather than the conserva-tive program dependence graph, which also includesuse-def and def-def chains, because these are exactlythe dependences that will be eliminated using scalarqueue conversion.
3.3 Unidirectional Cuts
Now we define a cut of the set of nodes in a region, R,as a partitioning of the set of nodes into two subsets,A, B such that A ∩ B = ∅ and A ∪ B = R. We say thata cut is unidirectional iff there are no edges x → y suchthat x ∈ B and y ∈ A. That is, all the edges eitherstay inside A, stay inside B or flow from A to B, and noedges flow from B to A. For example, given the regioncorresponding to the outer loop in Figure 15, the par-tition {2, 3, 4, 7, 8, 9, 10, 11, 13, 14} and {1, 5, 6, 12, 15} is aunidirectional cut because there are no def-use chains,
memory or control dependences flowing from the sec-ond set to the first.
In the following sections we will demonstrate thatby the process of queue conversion we can always trans-form a unidirectional cut A-B of a single-entry single-exit region into a pair of single-entry single-exit re-gions, that produce the same final machine state as theoriginal code, but have the feature that all of the in-structions from partition A execute (dynamically) be-fore all the instructions from partition B.
Any particular value dependence graph might havemany different unidirectional cuts. The criteria forchoosing a specific cut will depend on the reasonsfor performing the transformation. In Section 5.1 andChapter 6 we will discuss two different applications inwhich unidirectional cuts appear naturally. In particu-lar, we will present two different methods for finding aunidirectional cut efficiently, each depending on a dif-ferent set of goals.
3.4 Maximally Connected Groups
First we will show that we can create a “reasonable”flow graph that consists only of the nodes from subsetA of a unidirectionalA-B cut. The property that makesthis possible is that every maximally connected group ofthe nodes from subset B will have only a single exit.Thus we can remove a maximally connected subset ofnodes from subset B from the region flow graph and“fix-up” the breaks in the flow graph by connectingthe nodes that precede the removed set to the (unique)node that succeeds the removed set.
Given a unidirectional cut A-B of a flow graph thenwe will call a subset of nodes β ⊂ B in the graph a max-imally connected group iff every node in β is connectedin the flow graph only to other nodes of β or to nodesof A. That is, given β = B − β and nodes b ∈ β, b ∈ βthere are no edges b → b or b → b. For example,given the unidirectional cut shown in Figure 15 whereA = {2, 3, 4, 7, 8, 9, 10, 11, 13, 14} and B = {1, 5, 6, 12, 15},the maximally connected groups are the subsets {1},{5, 6}, {12} and {15} of B.
But now suppose that we are given a unidirectionalcutA-B. This means that there can be no control depen-dences from B to A. Informally, there are no branchesin B that can in any way determine when or if a node inA is executed. Now suppose that we are given a max-imally connected group β ⊂ B. If β has an exit edgeb → a (an edge where b ∈ β, a 6∈ β), then, because βis maximally connected it must be the case that a ∈ A.The node a can not be in B because then β would notbe maximally connected.
If there are two (or more) such exit edges, b0 → a0and b1 → a1, where b0 6= b1 then it must be the case
19

that there is a branch or set of branches in β that causesthe flow graph to fork. In particular, b0 and b1 musthave different control dependences, and at least one ofthose control dependences must be on a node insideβ. But a1 and a0 can not be control dependent on anynode inside β, because they are on the wrong side ofthe A-B cut.
Consider node a0. There is an edge from b0 to a0,thus there is at least one path from b0 to exit thatpasses through a0. But a0 is not control dependent onb0, so every path from b0 to exit must pass througha0. Thus a0 postdominates b0. Similarly, for everynode bi ∈ β such that there is any path from bi to b0,it must be the case that a0 postdominates bi.
Consider this set of bi ∈ β that are on a path to b0.Now, β is connected, thus there must either be a pathfrom bi to b1 or there must be a path from b1 to bi. Ifthere is a path from b1 to bi then there is a path fromb1 to b0 and thus a0 also postdominates b1. Supposethere is no path from b1 to b0, then there must be apath from one of the bi to b1. But we already knowthat every path from bi to exit goes through a0, soevery path from b1 to exit must go through a0. Thusa0 postdominates both b0 and b1.
By a similar argument a1 postdominates both b1 andb0. More specifically, a1 immediately postdominates b1,because there is a flow graph edge b1 → a1. Thus a0must postdominate a1 if it is to also postdominate b1.A similar argument shows that a1 must postdominatea0. Postdominance is a partial order, thus a0 = a1.So the maximally connected group β exits to a uniquenode in A.
As an example, consider Figure 16. This figureshows a flow graph containing an irreducible loop.Suppose that we would like to include node 4 (a branchinstruction) in set B of a unidirectional A-B cut. Wewill demonstrate that any maximally connected groupβ ⊂ B that contains node 4 must also contain nodes 8and 9, and will, therefore, exit through node 10. We cansee this by examining Figure 17, which shows controldependence graph corresponding to the flow graph inFigure 16. There is a cycle in the control dependencegraph between the two exit branches in nodes 4 and7. Thus if either of the exit branches for the irreducibleloop is included on one side of the unidirectional cut,then the other must as well, because we require that nocontrol dependences in a unidirectional cut flow fromB to A.
Given a unidirectional cut A-B of a flow graph wecan efficiently find all the maximally connected groupsβ ⊂ B as follows. First we scan the edges of the flowgraph to find all the edges bj → ai where bj ∈ B andai ∈ A. By the argument above the set of nodes aifound in this manner represent the set of unique exits
BEGIN
END
1: branch x
2: ...
(x = true)
3: ...
(x = false)
4: branch y
5: ...
(y = false)
9: ...
(y = true)
6: ...
7: branch z
(z = true)
8: ...
(z = false)
10: ...
11: ...
Figure 16: Any maximally connected subset of nodesfrom the bottom of a unidirectional cut always exits toa single point. In this case (an irreducible loop) if ei-ther node 4 or 7 is in the bottom of a unidirectional cutthen so must all the nodes 2, 4, 5, 6, 7, 8 and 9. Thus amaximally connected subset containing node 4 or node7 will exit to node 10.
BEGIN
1: branch x 10: ... 11: ...
2: ...
3: ...4: branch y
5: ... 6: ...7: branch z 9: ...
8: ...
Figure 17: The control dependence graph for the flowgraph in Figure 16 has a cycle between nodes 4 and 7.Thus both nodes must be on the same side of a unidi-rectional cut of the flow graph.
20

of maximal groups βi ⊂ B. Then for each ai we canfind the associated maximally connected group βi byperforming a depth first search (backwards in the flowgraph by following predecessor edges) starting at ai,and where we follow only edges that lead to nodes inB.
For example, recall that in Figure 15 the maximallyconnected subgroup {5, 6} exits to node 7. A backwardssearch from node 7 finds nodes 5 and 6 from set Bbut does not find node 12, because that would requiretraversing intermediate nodes (e.g., node 4) that are inset A.
Now we can create a flow graph that performs ex-actly the work corresponding to part A of the unidi-rectional A-B cut by removing each of the maximallyconnected groups of B one by one. Given a maxi-mally connected group βi ⊂ Bwith entry edges ayi0 →byi0, . . . , a
yin→ b
yin
and exits bxi0 → axi , . . . , bxin→
axi to the unique node axi , then we can remove βifrom the flow graph by removing all the nodes of βifrom the flow graph, and inserting the edges ayi0 →axi , . . . , a
yin→ axi . We call the resulting flow graph the
sliced flow graph for partition A.Figure 18 shows the sliced flow graph for the parti-
tion {2, 3, 4, 7, 8, 9, 10, 11, 13, 14}. The maximal groupsin the original flow graph (Figure 15) were the sets{5, 6}, and {12}. The entry edges to {5, 6} were {4 → 5}and {10 → 6}, while the exit edge was {6 → 7}. Thusin the sliced flow graph we remove nodes 5 and 6 andinsert edges {4→ 7} and {10→ 7}. Node 12 is removedand the edge {11 → 13} is inserted. Similarly, nodes 1and 15 have been removed and edges connecting theirentries to their exits have been inserted.
3.5 The Deferred Execution Queue
In addition to creating a flow graph that performs ex-actly the work corresponding to part A of a unidirec-tional A-B cut, we can also annotate the flow graphso that it keeps track of exactly the order in which themaximal groups βi ⊂ B will be executed. We do thisby creating a queue data structure at the entry point ofthe region flow graph. We call this queue the deferredexecution queue.
Every edge ayij → by
ij, ayij ∈ A, byij ∈ βi in the flow
graph represents a point at which control would haveentered the maximal group βi. Likewise, every edgebxik → axi , bxik ∈ βi, a
xi ∈ A, represents exactly the
points at which control would have returned to regionA.
Thus, after creating the sliced flow graph for parti-tionA, by removing the regions βi from the flow graph(as described in the previous section), we can place aninstruction along each edge ayij → axi that pushes the
BEGIN
END
2: i = 0
3: partial_sum = 0
4: j = 0
7: partial_sum = partial_sum + 1
8: j = next(j)
9: c1 = cond1(i, j)
10: branch c1
(c1 = true)
11: i = i + 1
(c1 = false)
13: c2 = cond2(i)
14: branch c2
(c2 = false)
(c2 = true)
Figure 18: The sliced flow graph for nodes 2, 3, 4, 7,8, 9, 10, 11, 13 and 14. For example, nodes 4 and 10(the entries to the maximal group consisting of nodes 5and 6) are connected to node 7, (the single exit node forgroup 5, 6).
21

BEGIN
END
1’: push(1)
BEGIN
2: i = 0
3: partial_sum = 0
4: j = 0
5’: push(5)
7: partial_sum = partial_sum + 1
8: j = next(j)
9: c1 = cond1(i, j)
10: branch c1
11: i = i + 1
(c1 = false)
6’: push(6)
(c1 = true)
12’: push(12)
13: c2 = cond2(i)
14: branch c2
(c2 = true)
15’: push(15)
(c2 = false)
BEGIN
BEGIN
END
5: use(i, sum)
6: use2(sum, partial_sum, i, j)
return
END
12: sum = sum + partial_sum
BEGIN
return
END
1: sum = 0
return
END
15: use(sum)
return
Figure 19: Queue conversion annotates the sliced flowgraph for A with instructions that record which max-imal groups of B would have executed, and in whatorder. Each maximal group of B is converted into itsown procedure.
corresponding code pointer for the node byij on to thedeferred execution queue. The edges ayij → axi executein exactly the order in which the βis would have exe-cuted in the original flow graph. Thus after executionof the sliced flow graph for partition A, the deferredexecution queue will contain all of the information weneed to execute the code from partition B in exactly thecorrect order and exactly the correct number of times.
We can accomplish this by converting each βi intoa procedure that contains a flow graph identical to theflow graph that corresponds to the original βi, but re-turns at each exit point of βi.6 Then we can recreate theoriginal execution sequence of partition B by poppingeach code pointer byij off the front of the deferred exe-cution queue and calling the corresponding procedure.
The queue conversion of our example program isshown in Figure 19. Push instructions for the appro-priate maximal group entry points have been insertedalong the edges begin → 2, 4 → 7, 10 → 7, 11 → 13and 14→ end . The maximal groups {1}, {5, 6}, {12} and{15} are each converted into a procedure.
Closure Conversion
If it were the case that there were no register storagedependences flowing from B toA then the deferred ex-ecution queue would be sufficient. Our definition ofa unidirectional A-B cut did not, however, exclude theexistence of use-def or def-def chains flowing from re-gion B to region A. Thus, we must solve the problemthat partitionAmight produce a value in register x thatis used in region B but then might overwrite the regis-ter with a new value before we have a chance to ex-ecute the corresponding code from partition B off thedeferred execution queue.
The problem is that the objects we are pushing andpopping on to the deferred execution queue are merelycode pointers. Instead, we should be pushing and pop-ping closures. A closure is an object that consists of thecode pointer together with an environment (set of name-value pairs) that represents the saved machine state inwhich we want to run the corresponding code. Thus aclosure represents a suspended computation.7
Consider the registers (variables) associated with theset of def-use chains that reach into a maximal groupβi ⊂ B. If we save a copy of the values associated witheach of these registers along with the code pointer, then
6If the underlying infrastructure does not support multiple-entryprocedures, then each maximal group βi can be further partitionedinto a set of subprocedures, each corresponding to a maximal basicblock of βi. Each subprocedure that does not exit βi tail calls [107]its successor(s) from βi.
7Closures that take no arguments, as is the case here, are some-times called thunks, but typically only in the context of compilingcall-by-name languages, which is not the case here.
22
BEGIN
END
1’: c1 = new closure{1}
2: i = 0
3: partial_sum = 0
4: j = 0
5’: c56 = new closure{5a, i, j, partial_sum}
7: partial_sum = partial_sum + 1
8: j = next(j)
9: c1 = cond1(i, j)
10: branch c1
11: i = i + 1
(c1 = false)
6’: c56 = new closure{6a, i, j, partial_sum}
(c1 = true)
12’: c12 = new closure{12a, partial_sum}
13: c2 = cond2(i)
14: branch c2
(c2 = true)
15’: c15 = new closure{15}
(c2 = false)
1’’: push(c1)
5’’: push(c56)
6’’: push(c56)
12’’: push(c12)
15’’: push(c15)
c = pop()
call c
while (!queue_empty())
BEGIN
END
5a: i = c->i
6a: i = c->i
BEGIN
5b: j = c->j
5c: partial_sum = c->partial_sum
5: use(i, sum)
6: use2(sum, partial_sum, i, j)
6b: j = c->j
6c: partial_sum = c->partial_sum
return
BEGIN
END
12a: partial_sum = c->partial_sum
BEGIN
12: sum = sum + partial_sum
return
END
1: sum = 0
return
END
15: use(sum)
return
Figure 21: Closure conversion ensures that each value crossing the cut gets copied into a dynamically allocatedstructure before the corresponding register gets overwritten.
23

3: partial_sum = 0
6: use2(sum, partial_sum, i, j)
7: partial_sum = partial_sum + 1
1: sum = 0
12: sum = sum + partial_sum
5: use(i, sum) 6: use2(sum, partial_sum, i, j)
12: sum = sum + partial_sum
15: use(sum)
2: i = 0
5: use(i, sum) 6: use2(sum, partial_sum, i, j) 9: c1 = cond1(i, j)
11: i = i + 1
4: j = 0
6: use2(sum, partial_sum, i, j)
8: j = next(j)
9: c1 = cond1(i, j)
Figure 20: Cuts in the du-webs for variables i , j , sumand partial sumgiven the cut from nodes 2, 3, 4, 7, 8,9, 10, 11, 13, 14 to nodes 1, 5, 6, 12, 15 (shown in bold).Def-use chains that cross the cut are shown as dottededges.
we can eliminate all the use-def chains that flow fromB to A, and replace them, instead, with use-def chainsthat flow only within partition A.
To convert each maximal group βi ⊂ B into a closurewe transform the code as follows.
1. Consider the graph of nodes corresponding to βi.For each of the entry nodes byij of this graph findthe set of nodes βij ⊂ βi reachable from b
yij
. Foreach set βij find the set of variables, Vij = {vijk}such that there is a def-use chain flowing from par-tition A into βij . (That is, there is a definition ofvijk somewhere in A and a use of vijk somewherein βij ). Figure 20 shows that this set can be eas-ily derived from the du-webs corresponding to theflow graph. For example, V
{12} = {partial sum}
and V{15} = ∅. The maximal group β
{5,6} has twoentry points, (at 5 and 6). In this case it happensthat V
{5,6},5 = V{5,6},6 = {i , j , partial sum}.
2. Consider each edge ayij → axi in the sliced flowgraph for partition A that corresponds to entrypoint byij of maximal group βi. Along this edgewe place an instruction that dynamically allocatesa structure with |Vij|+1 slots, then copies the values〈byij , vij1, . . . , vij|Vij|〉 into the structure, and thenpushes a pointer to this structure onto the deferredexecution queue. Figure 21 demonstrates this pro-cess. For example, along the edge 4 → 7 we have
placed instructions that allocate a structure con-taining the values of the code pointer, “5”, and thecopies of the values contained in variables, i , jand partial sum.
3. For each βi we create a procedure that takes a sin-gle argument, c , which is a pointer to the struc-ture representing the closure. The procedure hasthe same control flow as the original subgraphfor βi except that along each entry we place a se-quence of instructions that copies each entry fromeach slot of the closure into the correspondingvariable vik . Figure 21 shows that the two en-tries to the procedure corresponding to the max-imal group {5, 6} have been augmented with in-structions that copy the values of variables i , jand partial sum out of the corresponding clo-sure structure.
4. To invoke a closure from the deferred executionqueue we pop the pointer to the closure off thefront of the queue. The first slot of the correspond-ing structure is a pointer to the code for the proce-dure corresponding to βi. Thus we call this pro-cedure, passing as an argument the pointer to theclosure itself. In Figure 21 this process is shown to-wards the bottom of the original procedure, wherewe have inserted a loop that pops closures off thedeferred execution queue, and invokes them.
This completes the basic scalar queue conversiontransformation. Because a copy of each value reach-ing a maximal group βi is made just before the point inthe program when it would have been used, the correctset of values reaches each maximal group, even whenexecution of the group is deferred. Additionally, sincethe copy is created in partition A, rather than partitionB, we have eliminated any use-def chains that flowedfrom partition B to partition A. In the next section wewill demonstrate how to generalize the result to elim-inate def-def chains flowing from B to A. In Chap-ter 4 we will show how to move the closure creationpoints so that they least restrict further transformationsto partition A.
3.6 Unidirectional Renaming
In the previous section we demonstrated that we couldtransform a unidirectional A-B cut on a single-entrysingle-exit region into an equivalent piece of code suchthat all the instructions in partitionA run, dynamically,before all the instructions in partition B. Further wedemonstrated that we could do this even in the pres-ence of use-def chains flowing from partition B to par-tition A. In this section we will show that the result
24

BEGIN
END
1: sum = 0
2: i = 0
2’: i’ = i
3: partial_sum = 0
3’: partial_sum’ = partial_sum
4: j = 0
4’: j’ = j
5: use(i’, sum)
6: use2(sum, partial_sum’, i’, j’)
7: partial_sum = partial_sum + 1
7’: partial_sum’ = partial_sum
8: j = next(j)
8’: j’ = j
9: c1 = cond1(i, j)
10: branch c1
(c1 = true)
11: i = i + 1
(c1 = false)
11: i’ = i
12: sum = sum + partial_sum’
13: c2 = cond2(i)
14: branch c2 (c2 = true)
15: use(sum)
(c2 = false)
Figure 22: An example of statically renaming the vari-ables i , j and partial sum.
can be generalized, in a straightforward way, to A-Bcuts where there are additionally def-def chains flow-ing from partition B to partition A.
The result depends on the fact that given a unidi-rectional A-B cut, we can insert a new instruction any-where in the flow graph, and that if we give that in-struction a labeling that includes it in partition B, thenwe will not introduce any new control dependencesthat flow from partition B to partition A. (The oppo-site is not true. That is, if we place a new instructionin partition A at a point that is control dependent onan instruction in partition B, then we will introduce acontrol dependence edge that will violate the unidirec-tionality of the cut.)
For the remainder of the thesis we will assume thateach du-web in the program has been given a uniquename. This transformation is already done by mostoptimizing compilers because it is so common for pro-grammers to reuse variable names, even when the vari-ables are completely independent. For example, manyprogrammers reuse the variable name i for the indexof most loops. Once the du-webs are calculated, as de-scribed in Section 2.2, we iterate through the set of du-webs for each variable x, renaming all the uses and def-initions in each node in the ith web to xi. Thus we can,without loss of generality, talk about the du-web for aparticular variable.
Now consider the du-web for variable x on a unidi-rectional cutA-Bwhere some of the definitions of x arein A and some of the uses of x are in B. Thus, thereis a value dependence flowing from A to B. It may bethe case that there are definitions of x in B and uses ofx in A, but, because A-B is a unidirectional cut, it can-not be the case that there are any def-use chains reach-ing from B to A. Thus the du-web has a unidirectionalstructure, just as the value dependence graph did. (Infact, another way of seeing this is to observe that eachdu-web is an induced subgraph of the value depen-dence graph). For example, in the du-webs shown inFigure 20 one can observe that the def-use chains cross-ing the cut (shown with dotted edges) all flow in onedirection.
The du-web for variable x thus has a structure thatis almost renameable, except for those edges in the webthat cross the cut. Suppose, however that we were toplace a copy instruction “x’ = x ” directly after eachof the definitions of x from A that reach a use in B.Then we could rename all the definitions and uses ofx in B to x ′. The program will have exactly the samesemantics, but we will have eliminated all of the def-def chains flowing from B to A. We will call such arenaming of of a du-web that crosses a unidirectionalcut a unidirectional renaming.
An example of a unidirectional renaming is shown
25

3: partial_sum = 0
3’: partial_sum’ = partial_sum
7: partial_sum = partial_sum + 1
6: use2(sum, partial_sum’, i’, j’)
2: i = 0
7’: partial_sum’ = partial_sum
12: sum = sum + partial_sum’
2’: i’ = i
9: c1 = cond1(i, j)11: i = i + 1
5: use(i’, sum) 6: use2(sum, partial_sum’, i’, j’)
4: j = 0
11’: i’ = i
4’: j’ = j 8: j = next(j)
6: use2(sum, partial_sum’, i’, j’)
8’: j’ = j9: c1 = cond1(i, j)
Figure 23: The unidirectionally renamed du-webs forvariables i , j and partial sum.
in Figure 22. Each time one of the variables i , j andpartial sum is modified it is copied to a correspond-ing variable i’ , j’ or partial sum’ . The uses of i ,j and partial sum in partition B are then renamedto i’ , j’ and partial sum’ . The du-webs for thisunidirectional renaming are shown in Figure 23.
To see how unidirectional renaming eliminates back-wards flowing def-def chains, consider Figure 24. Weexamine the cut from the set of nodes {1, 2, 3, 4, 6, 7} tothe set {5, 8}. This is a unidirectional cut because all ofthe value and control dependences flow from the firstset to the second. Figure 25 shows the correspondingdu-web for variable x . There is, however, a def-defchain flowing from node 5 to node 7 (against the cutdirection).
Unidirectionally renaming the flow graph, as shownin Figures 26 and 27 solves this problem. After placingcopy instructions “x’ = x ” after the definitions thatreach across the cut, and renaming x to x’ in nodes 5and 7, all of the definitions of x are on one side of thecut while all of the definitions of x’ are on the otherside of the cut. Thus there are no def-def chains flowingacross the cut. All the def-def chains are now containedwithin one partition or the other.
Placing the copy instructions for the unidirectionalrenaming directly after the corresponding definition ofeach variable produces a correct result, but, in fact, wecan do better. We can maintain the program semanticsand eliminate the output dependences if we place thecopy instructions along any set of edges in the program
BEGIN
END
1: x = 1
2: branch
3: x = x + 3
4: branch
5: x = x + 5
6: branch
7: x = 7
(def-defchain)
8: use x
Figure 24: The cut separating nodes 1, 2, 3, 4, 6 and7 from nodes 5 and 8 is unidirectional because all thevalue and control dependences flow unidirectionally.The def-def chain flowing from node 5 to node 7 doesnot violate the unidirectionality of the cut.
1: x = 1
3: x = x + 3
5: x = x + 5
8: use x
7: x = 7
Figure 25: The du-web for variable x from the flowgraph in Figure 24. The cut is unidirectional becauseall the def-use chains flow in one direction across thecut. Dotted edges show cut edges.
26

BEGIN
END
1: x = 1
1’: x’ = x
2: branch
3: x = x + 3
4: branch
3’ x’ = x
5: x’ = x’ + 5
6: branch
7’: x’ = x
(def-defchain)
7: x = 7
8: use x’
Figure 26: After unidirectionally renaming the variablex the def-def chain between nodes 5 and 7 is elimi-nated, and replaced instead with a def-def chain fromnode 5 to node 7’. The new def-def chain does not crossthe cut because node 5 and 7’ are both in the same par-tition (indicated by nodes with a bold outline).
1: x = 1
1’: x’ = x 3: x = x + 3
5: x’ = x’ + 5
3’ x’ = x
8: use x’
7: x = 7
7’: x’ = x
Figure 27: The du-web for variables x and x’ fromthe flow graph in Figure 26. The cut is still unidirec-tional because all the def-use chains flow in one direc-tion across the cut. Dotted edges show cut edges. Now,however, there is no def-def chain crossing the cut be-cause definitions of variable x happen in one partition,while definitions of variable x’ happen in the other.
that have the property that they cover all the pathsleading from definitions of x in A that reach uses ofx in B and are not reached by any of the definitions ofx in B. In the next section we will show how to derivesuch a set of edges that is optimal, in the sense thatthey will execute only as often as the innermost loopthat contains both the definitions and the uses.
Thus given any unidirectional cut A-B we can in-sert copy instructions into each du-web that has edgesflowing from A to B and derive a semantically equiv-alent flow graph with the property that there are nodef-def chains flowing from B to A.
There is a second, perhaps more important, benefitof performing unidirectional renaming on the du-websthat cross the cut. This is that after renaming, closureconversion and a single pass of local copy propagation,all the uses of a variable will be entirely contained onone side of the cut or the other. That is, all commu-nication across the cut will occur through the deferredexecution queue. There will be no “shared” scalar vari-ables. Because of this property we perform unidirec-tional renaming on all du-webs that cross the cut, evenwhen there are no def-def chains that need to be bro-ken. Specific examples are given in Chapter 4 and Sec-tion 5.2.
3.7 Wrapup
In this chapter we demonstrated that, through the pro-cess of scalar queue conversion, we can restructure anyunidirectional cut of the true scalar dependences in any
27

program, and reschedule the code so that all of the in-structions in the top half of the cut run (dynamically)before all of the instructions in the bottom half. Scalarqueue conversion completely eliminates scalar anti- andoutput-dependences that might otherwise make thisrescheduling impossible.
In this chapter we described how to apply scalarqueue conversion to a single-entry single-exit region ofcode. Chapter 5 demonstrates how to extend the re-sult to regions of code with multiple exits, by a singleapplication of scalar queue conversion to a somewhatlarger region of code. Chapter 5 also describes a set oftransformations that eliminate memory dependencesfrom the program dependence graph, thus exposingunidirectional cuts in a wider variety of circumstances.Chapter 6 describes how to use scalar queue conver-sion as a subroutine of a generalized version of loopdistribution that can reschedule regions of code witharbitrary control flow (including inner loops).
Chapter 7 describes the SUDS Software Un-Do Sys-tem, which complements scalar queue conversion intwo ways. First, as mentioned above, scalar queue con-version is unsafe in the sense that it does not strictlyguarantee the amount of dynamic memory the trans-formed program will allocate. The SUDS system solvesthis problem by allowing scalar queue conversion tobe applied speculatively. SUDS checkpoints the systemstate, and then runs the transformed program. If thetransformation causes a memory allocation error, thenthe execution can be rolled back to the checkpointedstate, and resumed with the original (untransformed)code.
SUDS additionally complements scalar queue con-version by providing memory dependence specula-tion. Memory dependence speculation allows scalarqueue conversion to work across memory depen-dences that can not be handled by the techniques inChapter 5, and that would otherwise hide unidirec-tional cuts.
4 Optimal Unidirectional Renam-ing
In Chapter 3 we demonstrated that, through the pro-cess of scalar queue conversion, we could transforma unidirectional cut A-B on a single-entry single-exitregion into an equivalent piece of code such that allthe instructions in partition A run, dynamically, be-fore all the instructions in partition B. Further, in Sec-tion 3.6, we demonstrated that, through a process ofstatic unidirectional renaming, we could do this evenin the presence of use-def or def-def chains flowingfrom partition B to partition A. In this section we will
demonstrate that we can move the unidirectional re-naming points to a position in the flow graph that isoptimal, in the sense that we place them at the legalpoints in the graph such that they are in the outermostpossible loop.
We do this by implementing an eager form of par-tial dead code elimination [64]. The algorithm takesadvantage of two additional facts. First, that the copyinstructions we inserted for unidirectional renaming(Section 3.6) can be moved or replicated at any pointin the graph that is not reached by any other definitionthat is not a copy instruction. Additionally, we takeadvantage of a useful property of the static single as-signment (SSA) flow graph. After conversion to SSAevery use of a variable in the program will be reachedby only a single definition, and, further, that definitionwill dominate the use [30].
Informally, the algorithm moves copy instructionsdownward through join points in the flow graph un-til it reaches a join point that dominates a use. Thisnode has the property that it is the earliest (static) pointin the program where we can determine exactly thevalue that reaches the use. Then we use the partialdead code elimination algorithm to move the copy in-struction through the intervening branches in the flowgraph that might make the copy instruction less likelyto execute at all.
4.1 “Least Looped” Copy Points
The objective of optimal unidirectional renaming issimilar to the objective of conversion to static single as-signment form [30]. That is, we desire to connect eachuse of a variable with a single copy statement. The onlyplace where this condition might be violated is at joinpoints in the flow graph. That is, places in the flowgraph that two different definitions might reach. Butrecall the definition of the dominance frontier of a nodex. This is the set of edges in the flow graph that flow be-tween nodes y and zwhere all paths to y go through x,but where there are paths to z that do not go through x.In other words, z is a join node in the flow graph suchthat a definition at node x will no longer be unique.Consider, for example, the definitions of variable j inthe flow graph in Figure 28. The definition at node 8dominates nodes 9 and 10, but not node 6. So node 6 ison the dominance frontier of node 8, and indeed, twodefinitions of j can reach node 6. One from node 8 andthe other from node 4.
The key to the construction of static single assign-ment form is that it places copy instructions on the iter-ated dominance frontier of each definition. A straight-forward method of constructing the iterated domi-nance frontier for a set of definitions that are already
28

BEGIN
END
1: sum = 0
2: i = 0
2’: i’ = i
3: i’ = ij’ = jpartial_sum’ = partial_sum
partial_sum = 0
3’: partial_sum’ = partial_sum
4: j = 0
4’: j’ = j
5: use(i’, sum)
6: j’ = jpartial_sum’ = partial_sum
use2(sum, partial_sum’, i’, j’)
7: partial_sum = partial_sum + 1
7’: partial_sum’ = partial_sum
8: j = next(j)
8’: j’ = j
9: c1 = cond1(i, j)
10: branch c1
(c1 = true)
11: i = i + 1
(c1 = false)
11: i’ = i
12: sum = sum + partial_sum’
13: c2 = cond2(i)
14: branch c2 (c2 = true)
15: use(sum)
(c2 = false)
Figure 28: After unidirectional renaming we placereplicas of each copy instructions at all the join pointsreachable by that copy instruction.
copy instructions is as follows. For each copy instruc-tion “x’ = x ”, replicate the instruction at each nodein the dominance frontier of the definition that has notalready been marked. Since the new instruction is alsoa new definition for the variable, the procedure mustiterate until it reaches a fixed point [30]. The caveat, inthis case, is that we must not place instruction replicasat any point in the graph that is also reached by a “real”definition of the variable x’ .
In Figure 28 we show how replicas of the copy in-structions “i’ = i ”, “j’ = j ” and “partial sum’= partial sum” are placed at the iterated dominancefrontier of the unidirectionally renamed flow graphfrom Figure 22.
More concretely, we proceed as follows. We aregiven a du-web for variable x over a unidirectional cutA-B. As described in Section 3.6 we give this web a uni-directional renaming by renaming x to x ′ in all nodesbelonging to B, and then inserting new copy instruc-tions, x ′ = x in the flow graph directly after the defini-tions of x in the original flow graph that both belong toA and reach one of the uses in B. The new copy instruc-tions are included in partition B, rather than A, andthus we are left with a semantically equivalent flowgraph that is still unidirectionally cut, but is guaran-teed not to have any def-def chains flowing from B toA.
We now define five subsets of the nodes in the uni-directionally renamed du-webs with original variablex and renamed variable x ′. The set Copy
x ′←x consistsof the set of nodes that contain newly inserted copy in-structions x’ = x . The set Defx is the set of nodes thatdefine x. The set Defx ′ is the set of nodes that definex ′ minus the set Copy
x ′←x. The set Usex is the set ofnodes that use xminus the set Copy
x ′←x. The set Usex ′is the set of nodes that use x ′.
Now recall the definition, from page 13 of the Reach-ing relation for subsets Gen and Pass of the set of nodesin a flow graph. This was the set of nodes for whichthere is a path in the flow graph from some node inGen, passing only through nodes in Pass. We then letIllegal
x ′←x be the set of nodes reached by Defx ′ . Thatis, we generate the Reaching relation with Gen = Defx ′and Pass = Defx ′ ∪Defx. Illegal
x ′←x is then the set ofpoints in the program at which inserting an instructionx’ = x might cause the program to produce incorrectresults.
Now let ItDomx ′←x be the set of nodes that corre-sponds to the iterated dominance frontier of Copy
x ′←x.If we place copy instructions at all the nodes inAllCopies = (ItDomx ′←x ∪ Copy
x ′←x) − Illegalx ′←x
we will have, by the properties of the iterated domi-nance frontier [30], found exactly the set of join nodesthrough which it would be legal to move the copy in-
29

structions.
4.2 Lazy Dead Copy Elimination
Now let Livex ′ be the set of nodes for which there isa path to a use of x ′, that does not pass through adefinition of x ′ [4]. We can generate Livex ′ by gener-ating Reaching on the reverse flow graph with Gen =Usex ′ and Pass = Defx ′ ∪ Copy
x ′←x. We can elimi-nate any dead copies by keeping only those on nodes inAllCopies∩Livex ′ , and deleting the rest, since the valuethey produce will never be used by any instruction. Forexample, in Figure 28 the copies of i at nodes 2’, and11’ are dead. Additionally, the copies of j at nodes 3,4’ and 8’ are dead, and the copies of partial sum aredead at nodes 3 and 3’. Removal of these dead copyinstructions is shown in Figure 29.
Finally, following Knoop et al [64], we defineReachingUses
x ′as the set of nodes that can be reached
by a use of x ′ without passing through a definition ofx ′. (“ReachingUses” corresponds to the complementof the set that Knoop et al call “Delayed”). Then ifwe let BadNodesx ′ = ReachingUses
x ′∪ Illegal
x ′←xwe can sink the copy instructions to the frontier be-tween BadNodesx ′ and BadNodesx ′ . That is, to edgesm → n in the flow graph where m ∈ BadNodesx ′and n ∈ BadNodesx ′ . Iteration of dead copy elimi-nation and copy sinking produces the optimal result.Figure 30 shows the sinking of the copy instructionpartial sum’ = partial sum at node 7’ from in-side the inner loop to a position in the outer loop justbefore the corresponding use.
Figure 31 shows what happens when optimal unidi-rectional renaming precedes scalar queue conversion.We point out two things when comparing Figure 31 toFigure 21. First, the scalars used by the two halvesof the partitioning are entirely distinct. The slicedflow graph corresponding to the top of the cut de-fines and uses only variables i , j and partial sum.The flow graphs for the closures produced by scalarqueue conversion define and use only variables i’ , j’ ,partial sum’ and sum. Second, note that unidirec-tional renaming has made it possible to avoid the extraqueueing and dequeuing of variable i that occurs inthe inner loop in Figure 21.
Finally, we note one additional feature of optimalunidirectional renaming. It tends to be the case that op-timal unidirectional renaming makes du-webs sparser.This is intuitively reasonable, given that the optimalunidirectional renaming process, like conversion toSSA form, puts copy instructions at the iterated dom-inance frontier of each definition. The result is thatmost (but not all) of the unidirectionally renamed useswill be reached by only a single definition. Com-
BEGIN
END
1: sum = 0
2: i = 0
3: i’ = ipartial_sum = 0
4: j = 0
5: use(i’, sum)
6: j’ = jpartial_sum’ = partial_sum
use2(sum, partial_sum’, i’, j’)
7: partial_sum = partial_sum + 1
7’: partial_sum’ = partial_sum
8: j = next(j)
9: c1 = cond1(i, j)
10: branch c1
(c1 = true)
11: i = i + 1
(c1 = false)
12: sum = sum + partial_sum’
13: c2 = cond2(i)
14: branch c2 (c2 = true)
15: use(sum)
(c2 = false)
Figure 29: After placement of copies on the iterateddominance frontier at most one copy instruction willreach each use, and the remaining copy instructionscan be dead-code eliminated.
30
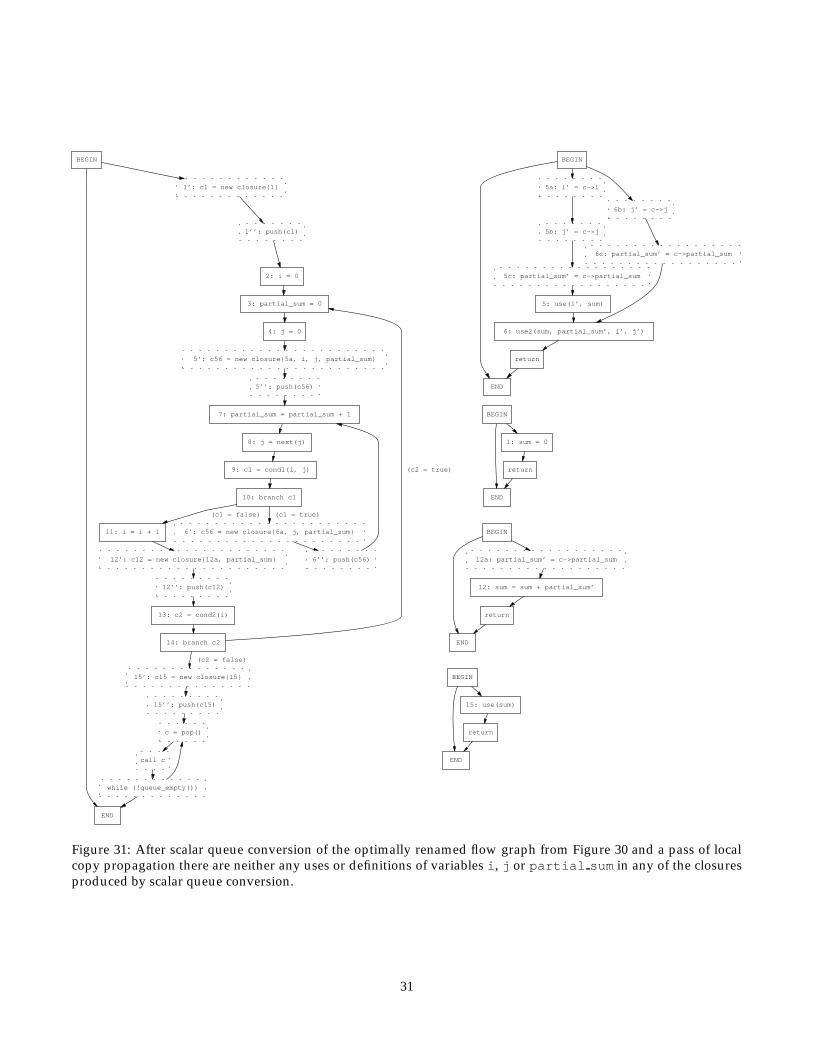
BEGIN
END
1’: c1 = new closure{1}
2: i = 0
3: partial_sum = 0
4: j = 0
5’: c56 = new closure{5a, i, j, partial_sum}
7: partial_sum = partial_sum + 1
8: j = next(j)
9: c1 = cond1(i, j)
10: branch c1
11: i = i + 1
(c1 = false)
6’: c56 = new closure{6a, j, partial_sum}
(c1 = true)
12’: c12 = new closure{12a, partial_sum}
13: c2 = cond2(i)
14: branch c2
(c2 = true)
15’: c15 = new closure{15}
(c2 = false)
1’’: push(c1)
5’’: push(c56)
6’’: push(c56)
12’’: push(c12)
15’’: push(c15)
c = pop()
call c
while (!queue_empty())
BEGIN
END
5a: i’ = c->i
6b: j’ = c->j
BEGIN
5b: j’ = c->j
5c: partial_sum’ = c->partial_sum
5: use(i’, sum)
6: use2(sum, partial_sum’, i’, j’)
6c: partial_sum’ = c->partial_sum
return
BEGIN
END
12a: partial_sum’ = c->partial_sum
BEGIN
12: sum = sum + partial_sum’
return
END
1: sum = 0
return
END
15: use(sum)
return
Figure 31: After scalar queue conversion of the optimally renamed flow graph from Figure 30 and a pass of localcopy propagation there are neither any uses or definitions of variables i , j or partial sum in any of the closuresproduced by scalar queue conversion.
31

BEGIN
END
1: sum = 0
2: i = 0
3: partial_sum = 0
4: j = 0
5: i’ = iuse(i’, sum)
6: j’ = jpartial_sum’ = partial_sum
use2(sum, partial_sum’, i’, j’)
7: partial_sum = partial_sum + 1
8: j = next(j)
9: c1 = cond1(i, j)
10: branch c1
(c1 = true)
11: i = i + 1
(c1 = false)
7’: partial_sum’ = partial_sum
12: sum = sum + partial_sum’
13: c2 = cond2(i)
14: branch c2(c2 = true)
15: use(sum)
(c2 = false)
Figure 30: We can “sink” the copy instruction in node7’ out of the inner loop.
3: partial_sum = 0
6’: partial_sum’ = partial_sum
7: partial_sum = partial_sum + 1
6: use2(sum, partial_sum’, i’, j’)
7’: partial_sum’ = partial_sum
12: sum = sum + partial_sum’
Figure 32: Optimal unidirectional renaming introducesadditional opportunities for static renaming. Thedu-chains for the variables partial sum and par-tial sum’ have been cut in such a way that the du-chains for partial sum’ actually form two indepen-dent webs.
pare, for example, the du-chains for partial sumandpartial sum’ after optimal unidirectional renaming(Figure 32) with the du-chains shown in Figure 23.After optimal unidirectional renaming the chains forpartial sum’ actually form two independent webs,and can thus be given different static names.
5 Extensions and Improvements toScalar Queue Conversion
Scalar queue conversion provides the basic mechanismfor renaming and rescheduling any unidirectional cutof a single-entry single-exit value dependence graph.In this chapter we discuss five practical extensions toscalar queue conversion. In Section 5.1 we demonstratehow to extend scalar queue conversion to single-entrymultiple-exit regions of a flow graph. A particularlyinteresting feature of this extension is that it is also anapplication of scalar queue conversion, because we usescalar queue conversion itself to separate the multi-exitregion from its successors in the flow graph. Section 5.2further demonstrates how to localize scalars to the clo-sures created by scalar queue conversion thereby en-abling concurrent execution.
Scalar queue conversion guarantees that we canreschedule any unidirectional cut of the value depen-dence graph. In Chapters 2, 3 and 4 we took a con-servative view of memory dependences by insertingedges in the value dependence graph for all load-after-store, store-after-load and store-after-store depen-dences. These, extra, conservative dependences may
32

restrict the applicability of scalar queue conversion be-cause they might create cycles in the value dependencegraph across what would otherwise be unidirectionalcuts. In Sections 5.3, 5.4 and 5.5 we discuss three meth-ods of improving the quality of memory dependenceinformation in the value dependence graph, wideningthe applicability of scalar queue conversion.
5.1 Restructuring Loops with Multiple Ex-its
The scalar queue conversion transformation given inChapter 3 is described only in terms of single-entrysingle-exit regions of flow graph. It turns out, how-ever, that a single application of scalar queue conver-sion to a single-exit region can be used to extract a mul-tiple exit subloop of that region. The main intuition isthat scalar queue conversion makes the continuations ofeach loop iteration explicit. That is, we can treat a re-gion of code as a computation that, along with the restof the work it does, also explicitly computes a “nextprogram counter.”
Given a flow graph we can identify a natural loopusing standard techniques. Recall that a back edge inthe flow graph is any edge b → h where h dominatesb. Then h is called the loop header, b is called the loopbranch, and every reducible loop can be uniquely iden-tified by its back edge. The natural loop associated witha back edge is defined to be the set of nodes that canreach b without going through h [4]. Further the loopexits are exactly those edges x → y where node x is anode in the loop and node y is a node outside the loop.
Consider the flow graph in Figure 33. Here the backedge is the edge from node 8 to node 1. The naturalloop associated with that back edge is the set of nodes{1, 2, 3, 5, 6, 7, 8}. The loop exits are the edge from node3 to node 4 and the edge from node 8 to node 9.
Given a natural loop with more than one exit, wetransform that loop into a single exit loop, using astripped-down version of scalar queue conversion, asfollows. We create a variable, k, and initialize it to 0at the top of the loop. We create a new loop branch b ′
that branches to the top of the loop if k = 0 and exitsthe loop otherwise. Then for every loop exit x → y inthe original loop we redirect the edge as x → y ′ → b ′
where y ′ is a new node that sets k to the label of node y.Finally, we insert a new node b ′′ after the exit from b ′
where b ′′ is a multiway branch that jumps to the labelstored in variable k.
This transforms the example flow graph as shown inFigure 34. Node 1 ′ initializes the continuation variablek . To exit from the loop nodes 3 and 8 now condition-ally set k to the correct non-zero value and then go tonode 8 ′. Node 8 ′ is now the only loop exit, and ex-
BEGIN
END
0: i = 0
1: block 1
2: c1 = cond(i)
3: branch c1
4: block 4
(c1 = true)
5: block 5
(c1 = false)
9: block 9
6: i = i + 1
7: c2 = i < N
8: branch c2
(c2 = true)
(c2 = false)
Figure 33: The flow graph for a loop with multiple ex-its.
33

BEGIN
END
0: i = 0
1’: k = 0
1: block 1
2: c1 = cond(i)
3: branch c1
4’: k = 4
(c1 = true)
5: block 5
(c1 = false)
8’: branch k
4: block 4
9: block 9
6: i = i + 1
7: c2 = i < N
8: branch c2
(c2 = true) 9’: k = 9
(c2 = false)
(k = 0)
8’’: jump k
(k != 0)
(k = 4)
(k = 9)
Figure 34: The loop of Figure 33 transformed so that ithas only a single exit.
its only when k is non-zero. Finally, when the loop isexited, node 8 ′′ uses the value stored in the continua-tion variable k to jump to the correct code, either block4 or block 9, depending on whether node 3 or node 8caused the loop to exit.
In the expected common case, where the loop is notexited, control flows the same way it would have inthe original code. The continuation variable k is ini-tialized to zero at the top of the loop iteration. Neitherloop exit is taken, so nodes 5, 6, 7 and 8 execute whilenodes 4 ′ and 9 ′ do not, and the value of k will be zerowhen node 8 ′ is reached. Thus, node 8 ′ branches backto node 1 ′ at the top of the loop.
A similar transformation has been implemented pre-viously in the loop distribution phase of the IBMPTRAN compiler [51]. The SUDS compiler implementsthe additional optimization that in the frequently ob-served case that all exit nodes xi exit to the same nodey along edges xi → y, then b ′ can simply exit to y andthe multiway branch b ′′ can be omitted. This optimiza-tion is particularly desirable, because it allows the con-tinuation variable, k to be treated as private to the loopbody during subsequent compiler phases.
5.2 Localization
We assume that each closure is given a unique activa-tion record when it is invoked. This requires heap al-location of activation records [71]. In practice this re-quires only a straightforward change to the code gener-ator, and produces code that is competitive with stackallocated activation records [9]. In this section we de-scribe how to localize scalars to a particular activa-tion record. More specifically, we show that throughthis localization process we can eliminate register stor-age dependences between invocations of closures, en-abling concurrent execution of the closures producedby scalar queue conversion.
In Chapter 4 we noted that optimal unidirectional re-naming tends to produce more static renaming oppor-tunities. As a result it tends to be the case that few du-chains flow between the closures produced by scalarqueue conversion. We take advantage of this by intro-ducing a notion of scope and, when possible, assignvariables to a scope smaller than the entire program.By scope we simply mean the lifetime of an activationrecord, and thus we assign variables to scopes by asso-ciating variables with activation records.
We follow the straightforward rules that
1. If all the nodes of the du-web for a particular vari-able x fall into partition A of a unidirectional A-Bcut. Then x is assigned the scope associated withthe procedure containing the sliced flow graph forA.
34

2. If all the nodes of the du-web for a particular vari-able x fall into the same procedure, βi, producedby scalar queue conversion, then x is assigned thescope associated with that procedure.
3. If the nodes of the du-web for a particular variablex fall into different procedures, then x is assignedthe scope of B. (This is the scope containing the setof procedures βi ⊂ B.)
Note that it is not necessary to have a global scope tocover the case that some of the nodes of a du-web arepart of A and some part of B, because after unidirec-tional renaming and scalar queue conversion each du-web is guaranteed to be entirely contained on one sideof the cut or the other.
For example, consider Figure 31. In this case thevariables i , j and partial sum can be localized tothe procedure on the left. The variables i’ , j’ andpartial sum’ can be localized to the procedure cor-responding to nodes 5 and 6. An independent versionof variable partial sum’ can be localized to the pro-cedure corresponding to node 12. Finally, the variablesum can be localized to the scope containing the set ofprocedures on the right side of the figure.
The result of this localization process is the elimina-tion of anti-dependences between different invocationsof the same procedure. For example, each closure forthe procedure corresponding to nodes 5 and 6 in Fig-ure 31 will have its own, private, copies of variables i’ ,j’ and partial sum’ in its own activation record,and thus these closures can be invoked concurrently.
5.3 Equivalence Class Unification
Our current compiler uses a context-sensitive inter-procedural pointer analysis [129, 97] to differentiatebetween memory accesses to different data structures.The result of the pointer analysis is a points-to setfor each load, store and call site in the flow graph.The points-to set is a conservative list of all the possi-ble allocation sites that could be responsible for allo-cating the memory touched by the operation in ques-tion. (Examples of “allocation sites” include points inthe flow graph that call the malloc() routine, decla-rations of global aggregates, and declarations of anyglobal scalars that might be aliased.)
The points-to sets resulting from the pointer analy-sis will be conservative in the sense that if the points-to sets for two instructions do not intersect, thenthe pointer analysis has proved that there is no situ-ation under which the two instructions might accessthe same memory location. As a result, we can re-move from the value dependence graph any memory
dependence chain between instructions having non-intersecting points-to sets.
This technique is now widely used in parallelizingcompilers whenever a decent pointer analysis is avail-able [108, 14, 19].
5.4 Register Promotion
The renaming operations of scalar queue conversionwork only for unaliased scalar variables. It is often thecase, however, that in some region of code some invari-ant pointer will be repeatedly loaded and stored. Whenthis is the case we can register promote [26, 79] the mem-ory location to a scalar for the duration of the region.Register promotion is a generalization/combinationof partial redundancy elimination and partial deadcode elimination, targeted at load and store operations.When register promotion can be applied, especiallywhen it can be applied to loops, it turns memory ref-erences into scalar references, which can then be re-named and rescheduled by scalar queue conversion.
Consider the following example of summing an ar-ray into a memory location (similar to an examplegiven by Cooper and Lu [26]):
*p = 0for (i = 0; i < N; i++)
x = *ppA = &A[i]y = *pAz = x + y*p = z
If the pointer analysis can guarantee that p and pAalways point to different memory locations then weknow that (a) the pointer p is invariant during the exe-cution of the loop and (b) memory references to the lo-cation pointed to by pA will never interfere with mem-ory references to the location pointed to by p.
Thus we can transform the code by allocating a “vir-tual register” (scalar), rp , loading *p into rp before thestart of the loop, storing rp back to *p after the end ofthe loop and replacing all references to *p inside theloop with references to rp . The resulting code is:
*p = 0rp = *pfor (i = 0; i < N; i++)
x = rppA = &A[i]y = *pAz = x + yrp = z
*p = rp
This enables scalar queue conversion on the newscalar variable rp .
The idea of using register promotion to improve par-allelism has been previously investigated in [19].
35

5.5 Scope Restriction
Scope restriction is an analysis performed at the frontend of the compiler that uses scoping information onaggregates (arrays and structures) to restrict the liveranges of the aggregates to the scope they were origi-nally declared in. The front end passes this informationto the back end by changing the stack allocated datastructure into a heap allocated data structure, with acall to a special version of malloc at the point wherethe object comes in to scope, and a call to a special ver-sion of free at the point(s) where the object goes outof scope.
The back end is augmented so that when it generatesthe reaching relation for memory dependence chainsit recognizes that the special version of free kills (i.e.,does not pass) definitions and uses of the correspond-ing pointer. Thus memory anti- and output- depen-dence chains that otherwise would have reached back-wards through loops can be eliminated before scalarqueue conversion. At code generation time if the callsto matching versions of malloc and free are still inthe same procedure, then they can be turned back intostack pointer increment/decrement operations.
This transformation relies on the programmer to de-clare each aggregate in the innermost scope in whichit might be accessed. While this programmer behavioris desirable, from a software engineering standpoint,popular programming languages, like ANSI-C, haveonly (relatively) recently started supporting automaticallocation of aggregates. Thus, scope restriction is notapplicable to “dusty deck” codes. If it is desired to sup-port parallelization of such programs then one shouldconsider incorporating an array privatization analysisin the compiler [77, 82, 118].
6 Generalized Loop Distribution
In this chapter we describe how to apply scalar queueconversion to enable a generalized form of loop dis-tribution that can reschedule any region of code witharbitrary control flow, including arbitrary looping con-trol flow. The goal of loop distribution is to transformthe chosen region so that any externally visible changesto machine state will occur in minimum time. Roughlyspeaking, then, we begin by finding externally visiblestate changes for the region in question, which we callcritical definitions. We then find the smallest partitionof the value dependence graph that includes the criticalnode, yet still forms a unidirectional cut with its com-plement. Finally we apply scalar queue conversion tocreate a provably minimal (and hopefully small) pieceof code that performs only the work that cyclically de-pends on the critical definition. For simplicity we will
present the transformation in terms of a single-entrysingle-exit region, R, of the value dependence graph.The transformation can be extended to multiple exit re-gions by applying the transformation from Section 5.1.
Section 6.4 discusses the relationship of generalizedloop distribution to recurrences, (roughly speaking, re-currences are loop carried dependences that are up-dated with only a single associative operator (e.g., ad-dition)). In particular, we demonstrate that generalizedloop distribution enables a broader class of recurrencesto be reassociated than can be handled with less pow-erful scheduling techniques.
Loop distribution is closely related to a variety of re-cently proposed scheduling techniques called “criticalpath reductions.” Section 9.2 describes this relation-ship, and how the generalized loop distribution tech-nique also extends critical path reduction transforma-tions.
6.1 Critical Paths
Consider again the example used throughout Chap-ters 2 and 3, which we replicate in Figure 35 for easeof reference. Roughly speaking, this loop has two loopcarried dependences, on the variables i and sum. Theother variables, (e.g., j , partial sum, c1 and c2 ) areprivate to each loop iteration, and thus are not part ofthe state changes visible external to the loop.
Following this intuitive distinction, we more con-cretely identify the critical definitions of a region. Wedo this by finding all uses (anywhere in the program)such that at least one definition dR within the regionR reaches the use and at least one definition from out-side the region dR reaches the use. Then we call thedefinition dR (the one inside region R) a critical defi-nition. To reiterate, intuitively, the critical definitionsrepresent changes to the part of the state that is visiblefrom outside the region. Critical definitions representpoints inside the region at which that visible state ischanged. (As opposed to region (loop) invariant andexternally invisible (private) state).
For the region corresponding to the outer loop in Fig-ure 35 the critical definitions are the nodes 11 and 12.Nodes 5, 6, 9 and 11, for example, are reached both bynode 11 (inside the loop) and node 2 (outside the loop),so node 11 is a critical definition for the loop. Likewise,nodes 5, 6 and 12 are reached both by node 12 (insidethe loop) and node 1 (outside the loop), so node 12 isalso a critical definition for the loop.
Next we construct the critical node graph. The nodesof the critical node graph are the critical definitions asdefined above. There is an edge in the critical nodegraph between nodes d0 and d1 exactly when there isa path from d0 to d1 in the value dependence graph.
36

BEGIN
END
1: sum = 0
2: i = 0
3: partial_sum = 0
4: j = 0
5: use(i, sum)
6: use2(sum, partial_sum, i, j)
7: partial_sum = partial_sum + 1
8: j = next(j)
9: c1 = cond1(i, j)
10: branch c1
(c1 = true)
11: i = i + 1
(c1 = false)
12: sum = sum + partial_sum
13: c2 = cond2(i)
14: branch c2 (c2 = true)
15: use(sum)
(c2 = false)
Figure 35: The control flow graph of the example loop.(This is the same as Figure 7, replicated here only forease of reference.)
11: i = i + 1
12: sum = sum + partial_sum
11: i = i + 1
12: sum = sum + partial_sum
Figure 36: The critical node graph (left) and the criticalnode dag (right) for the outer loop of the flow graph inFigure 35.
The critical node graph for the outer loop of the flowgraph from Figure 35 is shown on the left side of Fig-ure 36. There is a critical node graph edge from node11 to node 12 because there is a path in the dependencegraph 11 → 13 → 14 → 12. (The dependence fromnode 14 to node 12 is a control dependence, while theother edges in the path are due to scalar value depen-dences.)
Finally, we construct the critical node dag by collaps-ing cycles in the critical node graph. This isn’t strictlynecessary, but a cycle in the critical node graph repre-sents a sequence of state changes that is mutually de-pendent, and thus can’t be reordered. Thus we gain noflexibility by not collapsing, and the collapsed resultis easier to deal with. Note that a dag is just a picto-rial representation of a partial ordering. That is we saythat given two nodes a and b in the dag a < b if therea path from a to b in the dag. This partial orderingis well defined since there are no cycles in the criticalnode dag. The critical node dag for the outer loop ofthe flow graph from Figure 35 is shown on the rightside of Figure 36.
6.2 Unidirectional Cuts
We use the critical node dag to prioritize the instruc-tions in the value dependence graph into a sequence ofunidirectional cuts (see Chapter 3). There will be twiceas many priorities as there are levels in the critical nodedag.
We start by giving each critical node a priority cor-responding to its level in the critical node dag. Next,for each critical node we find all nodes in the value de-pendence graph that have a cyclic dependence with thecritical node. That is, given critical node d and noden, if there is a path from d to n in the value depen-dence graph and a path from n to d in the value de-pendence graph, then we give n the same priority asd. For example, in the loop in Figure 35 the cyclic path11 → 13 → 14 → 11 in the value dependence graphindicates that nodes 13 and 14 form a cycle with thecritical node 11.
All remaining nodes will receive priorities betweenthe critical node priorities. That is, for each node n findthe critical node dbelow with the highest priority, such thatthere is a path from n to dbelow in the value dependencegraph. Then give n a priority higher than dbelow’s prior-ity, but just lower than the priority of dbelow’s parent.
For example, in Figure 35 node 12 depends on node7. Node 7, in turn, is dependent on nodes 3, 4, 7, 8,9 and 10. (There exists, for example, the dependencepath 4 → 8 → 9 → 10 → 7.) None of these nodes hasa path in the value dependence graph leading to anyof nodes 11, 13 or 14. Thus we give nodes 3, 4, 7, 8, 9
37

11: i = i + 1
13: c2 = cond2(i)
14: branch c2
3: partial_sum = 0
4: j = 0
7: partial_sum = partial_sum + 1
8: j = next(j)
9: c1 = cond1(i, j)
10: branch c1
12: sum = sum + partial_sum
5: use(i, sum)6: use2(sum, partial_sum, i, j)
Figure 37: The Prioritization of the nodes in the outerloop of the flow graph in Figure 35.
and 10 a priority between the priority of node 11 andthe priority of node 12. The prioritization of the nodesfrom the outer loop of the flow graph of Figure 35 isshown in Figure 37.
More generally one can also solve the dual problem:find the critical node dabove with the lowest priority suchthat there is a path from dabove to n, and then give nany priority between that of dabove and dbelow. Note thatfor any node n with cyclic dependences with a criti-cal node dcrit it is the case that dabove = dbelow = dcrit, andthus the priority of these nodes will be set consistentlywith the above criteria. In the transformation describedbelow, it will turn out that cross-priority dependenceedges are more expensive to handle than dependenceedges within a priority, and the dual information couldbe used, in combination with a maxflow/mincut al-gorithm to minimize the number of cross-priority de-pendence edges. This will be investigated in futurework. In any case both the primal and dual problemscan be individually solved by a simple dataflow analy-sis based on depth-first search. The implemented algo-rithm uses only the primal information.
6.3 Transformation
For each priority we have a unidirectional cut from thehigher priorities to this priority and those below. Thuswe perform scalar queue conversion on each priority(from the bottom up) to complete our code transfor-mation.
There are, however, two subtleties. The first is thatas we perform scalar queue conversion on a unidirec-tionalA-B cut we must place instructions to create, andfill, closures into the graph of partition A for each max-imally connected group βi ⊂ B. The question thenarises as to which priority the closure creation and fillinstructions for each maximal group should belong to.We solve this problem by running the prioritizationalgorithm from Section 6.2 on the instructions intro-duced by each pass of scalar queue conversion. Notethat because we are working with unidirectional cutswe never introduce nodes that can “undo” any of thepriority decisions we have already made.
The second, practical, problem is that we are tryingto use loop distribution to schedule concurrency. Thatconcurrency exists in the non-critical priority groupsproduced by the prioritization scheme in Section 6.2.The problem is that the concurrency we have exposedis between iterations of the outer loop that we are dis-tributing. Thus we would like to create a thread foreach outer loop iteration, even if that thread invokesmany closures. We solve this problem by runningscalar queue conversion twice for the non-critical pri-ority groups.
38
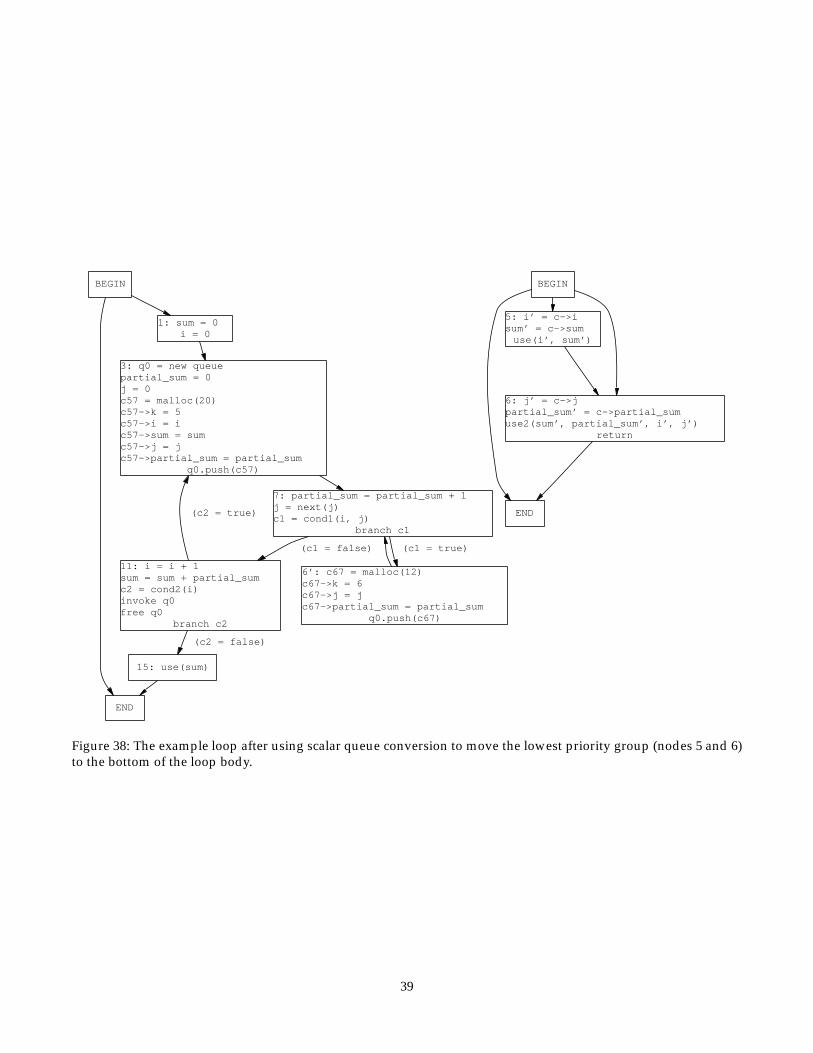
BEGIN
END
1: sum = 0i = 0
3: q0 = new queuepartial_sum = 0j = 0c57 = malloc(20)c57->k = 5c57->i = ic57->sum = sumc57->j = jc57->partial_sum = partial_sum
q0.push(c57)
7: partial_sum = partial_sum + 1j = next(j)c1 = cond1(i, j)
branch c1
11: i = i + 1sum = sum + partial_sumc2 = cond2(i)invoke q0free q0
branch c2
(c1 = false)
6’: c67 = malloc(12)c67->k = 6c67->j = jc67->partial_sum = partial_sum
q0.push(c67)
(c1 = true)
(c2 = true)
15: use(sum)
(c2 = false)
BEGIN
END
5: i’ = c->isum’ = c->sumuse(i’, sum’)
6: j’ = c->jpartial_sum’ = c->partial_sumuse2(sum’, partial_sum’, i’, j’)
return
Figure 38: The example loop after using scalar queue conversion to move the lowest priority group (nodes 5 and 6)to the bottom of the loop body.
39

In the first pass we run scalar queue conversion withrespect to the loop body (i.e., not including the loopbackedge). This packages the entire work done for thatpriority group in each iteration into a deferred execu-tion queue (one deferred execution queue per itera-tion), which is then invoked. Figure 38 shows the re-sults of performing this scalar queue conversion on thelowest priority group (nodes 5 and 6) of the exampleloop. A deferred execution queue (q0) is created, andthe correct closures are pushed on to q0 to perform thelow priority work from the entire inner loop of a singleiteration of the outer loop.
In the second pass we run scalar queue conversionwith respect to the entire loop (including the loopbackedge). This creates a second deferred executionqueue with one closure per loop iteration. The closuresin this deferred execution queue can be invoked in par-allel because the prioritization analysis from Section 6.2has already determined that there are no dependencesbetween these closures. This second transformation isshown in Figure 39. A deferred execution queue (q1)is created. The closures (c13 ) on this queue receive thedeferred execution queue, q0 , created in the first passas a parameter. Then after the loop exits, the closureson deferred execution queue q1 can be invoked in con-currently.
Figure 40 shows the result of running scalar queueconversion on the lower priority critical path. Note thatwhile the original critical path consisted only of thenode “12: sum = sum + partial sum,” the pri-oritization algorithm has determined that the closurefilling operation “c57->sum = sum ” must be sched-uled at the same priority. Thus a pointer to the c57closure is passed as a parameter to the c12 closure sothat c12 can fill in the current value of the sumvariablebefore it is modified.
Figure 41 shows the end result of running general-ized loop distribution. After another two passes ofscalar queue conversion the work corresponding to theinner loop of the original code has been moved intoa deferred execution queue, q3 , the closures of whichcan be invoked concurrently.
6.4 Generalized Recurrence Reassociation
A common problem in the doubly nested loops thatare handled by the generalized loop distribution algo-rithm described in Sections 6.1, 6.2 and 6.3 is that criti-cal paths (loop carried dependences) of the outer loopwill often also contain nodes in the inner loop. Sincecritical paths represent cycles in the code that must berun sequentially, we would like to reduce the length ofthese paths when ever possible.
This section describes how we leverage generalized
loop distribution to shorten critical paths when the up-date operator in the critical path is associative.8 Whenthe update operator is associative we can often trans-form the code to make the dependence graph more“treelike.”
Consider the following code:
for ( int i = 0; i < N; i++)for ( int j = 0; j < M; j++)
use(sum)sum = sum + f[i][j]
The loop carried dependent variable sum is tradition-ally called a recurrence [68]. The critical path forthis recurrence contains the instruction “sum = sum+ f[i][j] ” in the inner loop. Using a combination ofstatic renaming and forward substitution [68] we willdemonstrate that because the update operator here isassociative we can move this critical node out of theinner loop, into the outer loop.
Briefly, recurrence reassociation introduces a tempo-rary variable that sums the values in the inner loop,and then adds the temporary to the original recurrencevariable only in the outer loop. This transformationproduces the following code:
for ( int i = 0; i < N; i++)int partial_sum = 0for ( int j = 0; j < M; j++)
use(sum + partial_sum)partial_sum = partial_sum + f[i][j]
sum = sum + partial_sum
Note that we have simultaneously introduced the tem-porary variable partial sum and forward substi-tuted the expression sum + partial sum into the in-ner loop statement use(sum) , creating the new innerloop statement use(sum + partial sum) .
The basic idea is that while any scheduling algo-rithm has to honor all the value dependences, gener-alized loop distribution, with scalar queue conversion,will eliminate all the anti-dependences. Thus recur-rence reassociation takes advantage of operation as-sociativity to turn loop-carried true-dependences intoanti-dependences. Generalized loop distribution theneliminates the anti-dependence during scheduling.
In this context we define reassociatable recurrence vari-ables to be loop-carried true-dependences that are mod-ified only with a single associative operator. Note, inparticular that in the example sum is both used andmodified inside the inner loop, but is still consideredto be a recurrence variable. Figure 42 shows sum’s de-pendence pattern.
8The most common associative operator is addition. Associativeoperators are binary operators with the property that (a + b) + c =a + (b + c). Other common programming operators having thisproperty are multiplication, “max” and “min.”
40
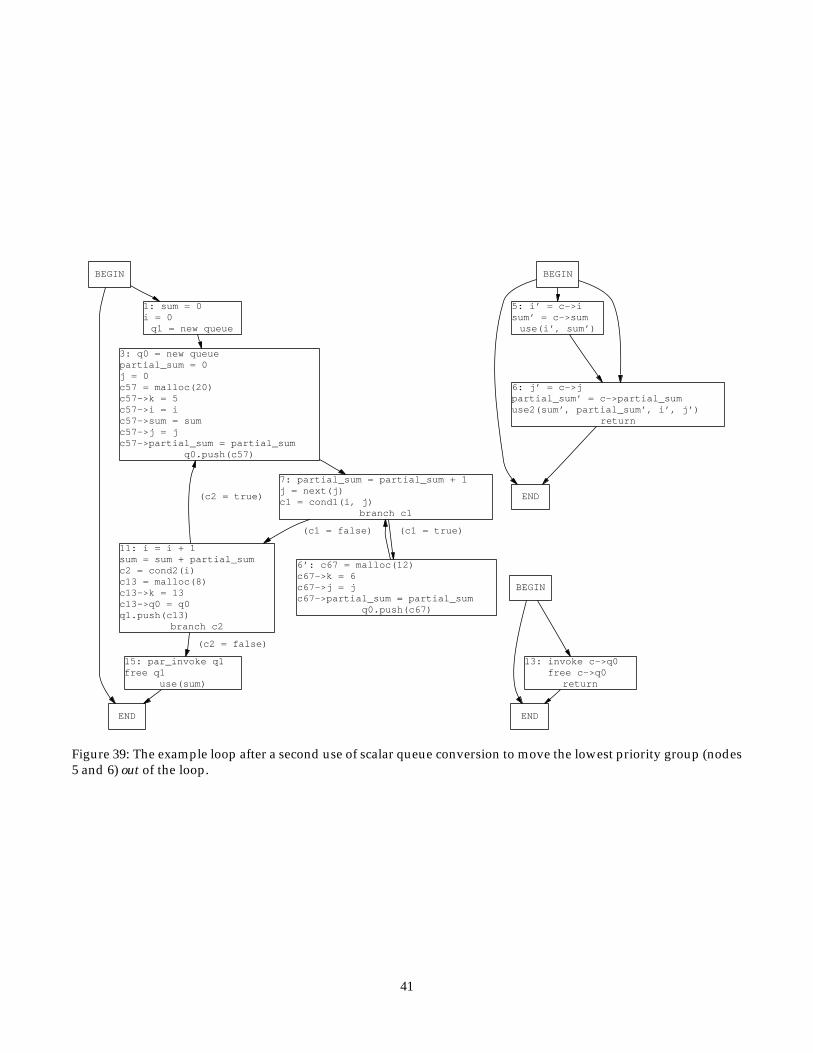
BEGIN
END
1: sum = 0i = 0q1 = new queue
3: q0 = new queuepartial_sum = 0j = 0c57 = malloc(20)c57->k = 5c57->i = ic57->sum = sumc57->j = jc57->partial_sum = partial_sum
q0.push(c57)
7: partial_sum = partial_sum + 1j = next(j)c1 = cond1(i, j)
branch c1
11: i = i + 1sum = sum + partial_sumc2 = cond2(i)c13 = malloc(8)c13->k = 13c13->q0 = q0q1.push(c13)
branch c2
(c1 = false)
6’: c67 = malloc(12)c67->k = 6c67->j = jc67->partial_sum = partial_sum
q0.push(c67)
(c1 = true)
(c2 = true)
15: par_invoke q1free q1
use(sum)
(c2 = false)
BEGIN
END
5: i’ = c->isum’ = c->sumuse(i’, sum’)
6: j’ = c->jpartial_sum’ = c->partial_sumuse2(sum’, partial_sum’, i’, j’)
return
BEGIN
END
13: invoke c->q0 free c->q0
return
Figure 39: The example loop after a second use of scalar queue conversion to move the lowest priority group (nodes5 and 6) out of the loop.
41
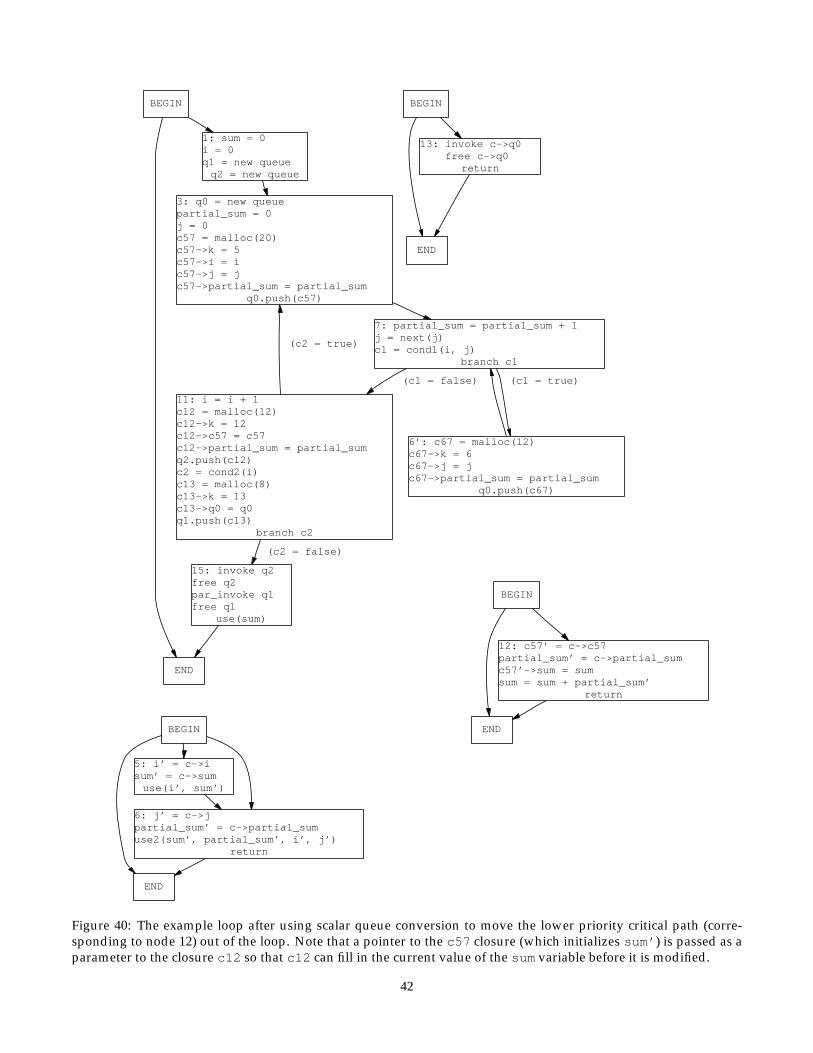
BEGIN
END
1: sum = 0i = 0q1 = new queueq2 = new queue
BEGIN
3: q0 = new queuepartial_sum = 0j = 0c57 = malloc(20)c57->k = 5c57->i = ic57->j = jc57->partial_sum = partial_sum
q0.push(c57)
7: partial_sum = partial_sum + 1j = next(j)c1 = cond1(i, j)
branch c1
11: i = i + 1c12 = malloc(12)c12->k = 12c12->c57 = c57c12->partial_sum = partial_sumq2.push(c12)c2 = cond2(i)c13 = malloc(8)c13->k = 13c13->q0 = q0q1.push(c13)
branch c2
(c1 = false)
6’: c67 = malloc(12)c67->k = 6c67->j = jc67->partial_sum = partial_sum
q0.push(c67)
(c1 = true)
(c2 = true)
15: invoke q2free q2par_invoke q1free q1
use(sum)
(c2 = false)
BEGIN
END
5: i’ = c->isum’ = c->sumuse(i’, sum’)
6: j’ = c->jpartial_sum’ = c->partial_sumuse2(sum’, partial_sum’, i’, j’)
return
BEGIN
END
13: invoke c->q0 free c->q0
return
END
12: c57’ = c->c57partial_sum’ = c->partial_sumc57’->sum = sumsum = sum + partial_sum’
return
Figure 40: The example loop after using scalar queue conversion to move the lower priority critical path (corre-sponding to node 12) out of the loop. Note that a pointer to the c57 closure (which initializes sum’ ) is passed as aparameter to the closure c12 so that c12 can fill in the current value of the sum variable before it is modified.
42
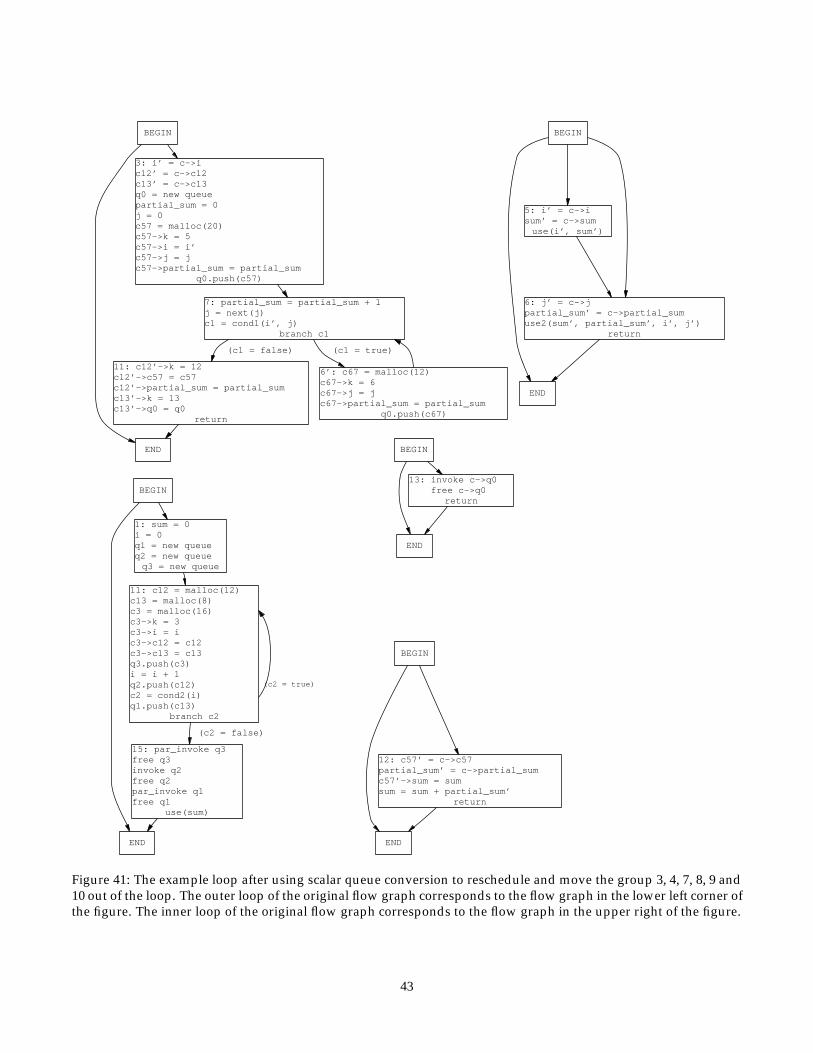
BEGIN
END
1: sum = 0i = 0q1 = new queueq2 = new queueq3 = new queue
11: c12 = malloc(12)c13 = malloc(8)c3 = malloc(16)c3->k = 3c3->i = ic3->c12 = c12c3->c13 = c13q3.push(c3)i = i + 1q2.push(c12)c2 = cond2(i)q1.push(c13)
branch c2
(c2 = true)
15: par_invoke q3free q3invoke q2free q2par_invoke q1free q1
use(sum)
(c2 = false)
BEGIN
END
3: i’ = c->ic12’ = c->c12c13’ = c->c13q0 = new queuepartial_sum = 0j = 0c57 = malloc(20)c57->k = 5c57->i = i’c57->j = jc57->partial_sum = partial_sum
q0.push(c57)
7: partial_sum = partial_sum + 1j = next(j)c1 = cond1(i’, j)
branch c1
11: c12’->k = 12c12’->c57 = c57c12’->partial_sum = partial_sumc13’->k = 13c13’->q0 = q0
return
(c1 = false)
6’: c67 = malloc(12)c67->k = 6c67->j = jc67->partial_sum = partial_sum
q0.push(c67)
(c1 = true)
BEGIN
BEGIN
END
5: i’ = c->isum’ = c->sumuse(i’, sum’)
6: j’ = c->jpartial_sum’ = c->partial_sumuse2(sum’, partial_sum’, i’, j’)
return
END
13: invoke c->q0 free c->q0
return
BEGIN
END
12: c57’ = c->c57partial_sum’ = c->partial_sumc57’->sum = sumsum = sum + partial_sum’
return
Figure 41: The example loop after using scalar queue conversion to reschedule and move the group 3, 4, 7, 8, 9 and10 out of the loop. The outer loop of the original flow graph corresponds to the flow graph in the lower left corner ofthe figure. The inner loop of the original flow graph corresponds to the flow graph in the upper right of the figure.
43

j
i
Figure 42: The dynamic dependence graph betweenupdates to the sum recurrence variable in the originalcode.
j
i
Figure 43: The dynamic dependence graph betweenupdates to the sum variable after recurrence reassoci-ation has been performed.
In the example, shown above, a temporary, par-tial sum has been introduced above the inner loop.Each use of sum has been converted to a use of sum+ partial sum. The update of sum in the inner loophas been changed to an update of partial sum andfinally, partial sum is added to sum after the innerloop is finished. At first glance it would appear thatwe have not improved the situation. But in fact, weare no longer modifying the variable sum in the innerloop. From the perspective of the outer loop, this sep-arates the modification of sum from its use. Figure 43shows how sum’s dependence pattern has changed.
Traditionally, reassociatable recurrence variables areconsidered to be those that are
1. Loop-carried true-dependences.
2. Updated only with a single associative operator(e.g., plus, times or max).
3. Unused except in the update operation(s) [68].
The simultaneous application of static renaming and for-ward substitution described above allows the third re-quirement to be circumvented in the case that we wantto move a critical update out of an inner loop.
7 SUDS: The Software Un-Do Sys-tem
Since scalar queue conversion can only break scalaranti- and output- dependences, additional solutionsare required to parallelize around memory depen-dences. The transformations described in Chapter 5are a necessary component to solving the memory de-pendence problem, but they are not sufficient. Morespecifically, any transformation that relies only on in-formation available at compile time can not legally re-move edges from the memory dependence graph thatare only usually irrelevant.
In this chapter we describe SUDS, the Software Un-Do System, which speculatively eliminates edges fromthe dependence graph. Informally, SUDS checkpointsthe machine state and then runs a piece of code that hasbeen parallelized assuming that certain dependences“don’t matter.” Once the code is done running SUDSchecks that the parallel execution produced a resultconsistent with sequential semantics. If the result isfound to be consistent, SUDS commits the changes andcontinues. If the result is found inconsistent, SUDSrolls back execution to the last checkpoint and re-runsthe code sequentially.
As shown in Figure 44, SUDS partitions Raw’s tilesinto two groups. Some portion of the tiles are des-ignated as compute nodes. The rest are designated as
44

Figure 44: An example of how SUDS allocates re-sources on a 72 tile Raw machine. The 64 gray tilesare memory nodes. The 8 white tiles, approximatelyin the middle, are worker nodes, the gray hatched tilenear the center is the master node. Loop carried de-pendences are forwarded between compute nodes inthe pattern shown with the arrow.
memory nodes. One of the compute nodes is designatedas the master node, the rest are designated as workersand sit in a dispatch loop waiting for commands fromthe master. The master node is responsible for runningall the sequential code.
SUDS parallelizes loops by cyclically distributing theloop iterations across the compute nodes. We call theset of iterations running in parallel a speculative strip.Each compute node runs the loop iterations assignedto it, and then all the nodes synchronize through themaster node.
In the next section we describe speculative strip min-ing, the technique SUDS uses to checkpoint and run aportion of a loop. In Section 7.2 we describe the SUDSruntime system component that efficiently checks thecorrectness of a particular parallel execution.
7.1 Speculative Strip Mining
Speculative strip mining is the technique SUDS usesto checkpoint and run a portion of a loop. Like tra-ditional strip mining techniques [1], speculative stripmining turns a loop into a doubly nested loop, whereeach invocation of the newly created inner loop iteratesa fixed number of times.
Speculative strip mining differs from traditionalstrip mining in that it generates the control structureshown in Figure 46. After the transformation, the outerloop body starts by checkpointing machine state. Thena speculative strip of 32 iterations are run. This innerloop is the loop that generalized loop distribution willbe applied to, and that the SUDS system will try to runspeculatively and in parallel.
A new variable, error , is introduced that is usedto keep track of any misspeculation that might happenduring the speculative strip. This variable can get setin any of three ways. First, the speculative strip runsfor exactly 32 iterations. If during any one of those 32iterations the loop condition variable, c , becomes set,then, semantically, the inner loop should have exitedin fewer than 32 iterations, and thus the error variablegets set. Second, the error variable is implicitly set ifany of the memory operations sent to the SUDS mem-ory dependence speculation system (described below)are found to have executed out of order. Third the er-ror variable will be set if any of the dynamic memoryallocation operations (those introduced by generalizedloop distribution) fail because of an out of memorycondition.
After the speculative strip runs, the error condi-tion is checked. If it is not set (hopefully the com-mon case), then the outer loop iteration is finished, anda new outer loop iteration will start. The process ofcheckpointing, running a speculative strip, and check-
45

do(LOOP BODY)
while !c
Figure 45: An arbitrary loop.
docheckpoint machine stateerror = falsefor i = 0; i < 32; i++
(LOOP BODY)error |= c
if (error)roll back to checkpointed statefor i = 0; (i < 32) && !c; i++
(LOOP BODY)while !c
Figure 46: The same loop after speculative strip mining. Ma-chine state is checkpointed. A strip of 32 iterations is run. Af-ter the strip completes the error variable is checked. It run-ning the strip caused any kind of misspeculation, (early exit fromthe loop, out-of-order memory access or a deferred executionqueue dynamic memory allocation error), then machine state isrolled back to the checkpoint, and the original code is run non-speculatively for up to 32 iterations to get past the misspecula-tion point.
ing the error condition will be repeated. If, on theother hand, the error condition is set, then the coderolls back to the checkpointed state, and a different copyof the inner loop is run.
In this case, the inner loop runs the original (unop-timized) loop body code. This “nonspeculative strip”runs for at most 32 iterations, but unlike the specula-tive strip, this strip runs sequentially and the originalloop conditional, c , is checked on every iteration forearly exit. Since generalized loop distribution is notapplied, the nonspeculative strip can not take an out-of-memory exception (unless the semantics of the orig-inal code would have done so). Since the loop is runsequentially, the memory operations can not executeout-of-order.
Speculative strip mining, as described here, worksonly on loops with a single exit. If we wish to applyspeculative strip mining to a loop with multiple ex-its then the transformation from Section 5.1 is appliedfirst. Note that speculative strip mining assumes thatthe loop conditional, c will be false if the loop is to con-tinue, and non-false if the loop is to exit. The trans-formation from Section 5.1, which turns multiple exitloops into single exit loops, produces condition vari-ables that have this property. If the loop was singleexit to begin with, and has a loop conditional with theopposite boolean sense, then a new loop conditionalmust be introduced, before applying speculative stripmining.
The “checkpoints” that speculative strip mining in-troduces need to be handled carefully. There are twoparts to this. The first has to do with “checkpoint-
ing” the memory state of the machine. The memorystate is typically enormous, and checkpointing the en-tire memory would be too costly. What the SUDS mem-ory dependence speculation system (described below)does instead, is to log all of the modifications to mem-ory requested during the speculative strip. Then, ifrollback is required, the log is “run backwards” to re-store the original memory state. If, after running thespeculative strip, rollback is not required, then the logis erased and reused.
The second part of checkpointing has to do with theregister (scalar) state of the machine. Speculative stripmining makes a copy of every scalar whose state mightvisibly change during the running of the speculativestrip. But, these variables are exactly the “loop car-ried dependences” that generalized loop distributionrecognizes in its critical path analysis. Thus specula-tive strip mining performs the critical definition anal-ysis described in Section 6.1. Any scalars identified ascritical during this analysis are copied into temporariesbefore the speculative strip. If rollback is required thevalues in the temporaries are copied back to the origi-nal scalars. If the speculative strip runs with no errorsthe temporaries are discarded.
Speculative strip mining allows generalized loopdistribution to legally introduce dynamic memory al-locations into the program. Because all memory opera-tions are logged during a speculative strip, and spec-ulative strip mining also makes copies of the (visi-ble) register state, any dynamic memory allocation er-ror introduced by generalized loop distribution can befixed. This checkpoint/repair mechanism allows a sec-
46

data memory:
last_read:
last_written:
Figure 47: A conceptual view of Basic Timestamp Or-dering. Associated with every memory location is apair of timestamps that indicate the logical time atwhich the location was last read and written.
ond, important, performance optimization. Because allmemory operations are logged, we can speculativelyexecute memory operations out-of-order. Thus, afterspeculative strip mining, and before generalized loopdistribution, we remove from the value dependencegraph all of the memory dependences that are carriedon the outer loop. These memory dependences can beremoved from the value dependence graph by gener-ating reaching information for memory operations onthe region flow graph for the loop body, with the loopback edge removed.
In addition to logging memory operations, if mem-ory operations are issued out-of-order, then the mem-ory access pattern must also be checked. The SUDSruntime memory dependence speculation system doesthis logging and checking. The memory dependencespeculation system is described in the next section.
7.2 Memory Dependence Speculation
The memory dependence speculation system is insome ways the core of the system. It is the fallbackdependence mechanism that works in all cases, evenif the compiler cannot analyze a particular variable.Since only a portion of the dependences in a programcan be proved by the compiler to be privatizable orloop carried dependences, a substantial fraction of thetotal memory traffic will be directed through the mem-ory dependence speculation system. As such it is nec-essary to minimize the latency of this subsystem.
7.2.1 A Conceptual View
The method we use to validate memory dependencecorrectness is based on Basic Timestamp Ordering [15],a traditional transaction processing concurrency con-trol mechanism. A conceptual view of the proto-col is given in Figure 47. Each memory locationhas two timestamps associated with it, one indicat-ing the last time a location was read (last read ) andone indicating the last time a location was written
timestampcache
log
datamemory
addr: data
last_readerlast_writer
tag
hash_entry
checkpointdata
addr
hash
node_id
compare
Figure 48: Data structures used by the memory depen-dence speculation subsystem.
(last written ). In addition, the memory is check-pointed at the beginning of each speculative strip sothat modifications can be rolled back in the case of anabort.
The validation protocol works as follows. As eachload request arrives, its timestamp (read time ) iscompared to the last written stamp for its memorylocation. If read time ≥ last written then the loadis in-order and last read is updated to read time ,otherwise the system flags a miss-speculation andaborts the current speculative strip.
On a store request, the timestamp (write time ) iscompared first to the last read stamp for its memorylocation. If write time ≥ last read then the store isin-order, otherwise the system flags a miss-speculationand aborts the current speculative strip.
We have implemented an optimization on store re-quests that is known as the Thomas Write Rule [15].This is basically the observation that if write time< last written then the value being stored by thecurrent request has been logically over-written with-out ever having been consumed, so the request canbe ignored. If write time ≥ last written thenthe store is in-order and last written is updated aswrite time .
7.2.2 A Realizable View
We can’t dedicate such a substantial amount of mem-ory to the speculation system, so the system is actu-ally implemented using a hash table. As shown in Fig-ure 48, each processing element that is dedicated as amemory dependence node contains three data struc-
47

Operation CostSend from compute node 1Network latency 4 + distanceMemory node 8Network latency 4 + distanceReceive on compute node 2Total 19 + 2 × distance
Figure 49: The round trip cost for a load operation is19 cycles + 2 times the manhattan distance between thecompute and memory node. The load operation alsoincurs additional occupancy of up to 40 cycles on thememory node after the data value is sent back to thecompute node.
tures in its local memory. The first is an array that isdedicated to storing actual program values. The nextis a small hash table that is used as a timestamp cacheto validate the absence of memory conflicts. Finally,the log contains a list of the hash entries that are in useand the original data value from each memory locationthat has been modified. At the end of each specula-tive strip the log is used to either commit the most re-cent changes permanently to memory, or to roll back tothe memory state from the beginning of the speculativestrip.
The fact that SUDS synchronizes the processing el-ements between each speculative strip permits us tosimplify the implementation of the validation protocol.In particular, the synchronization point can be used tocommit or roll back the logs and reset the timestampto 0. Because the timestamp is reset we can use the re-quester’s physical node-id as the timestamp for eachincoming memory request.
In addition, the relatively frequent log cleaningmeans that at any point in time there are only a smallnumber of memory locations that have a non-zerotimestamp. To avoid wasting enormous amounts ofmemory space storing 0 timestamps, we cache the ac-tive timestamps in a relatively small hash table. Eachhash table entry contains a pair of last read andlast written timestamps and a cache-tag to indicatewhich memory location owns the hash entry.
As each memory request arrives, its address ishashed. If there is a hash conflict with a different ad-dress, the validation mechanism conservatively flagsa miss-speculation and aborts the current speculativestrip. If there is no hash conflict the timestamp order-ing mechanism is invoked as described above.
Log entries only need to be created the first time oneof the threads in a speculative strip touches a memorylocation, at the same time an empty hash entry is al-
located. Future references to the same memory loca-tion do not need to be logged, as the original memoryvalue has already been copied to the log. Because weare storing the most current value in the memory itself,commits are cheaper, and we are able to implement afast path for load operations. Before going through thevalidation process, a load request fetches the requireddata and returns it to the requester. The resulting la-tency at the memory node is only 8 cycles as shownin Figure 49. The validation process happens after thedata has been returned, and occupies the memory nodefor an additional 14 to 40 cycles, depending on whethera log entry needs to be created.
In the common case the speculative strip completeswithout suffering a miss-speculation. At the synchro-nization point at the end of the speculative strip, eachmemory node is responsible for cleaning its logs andhash tables. It does this by walking through the en-tire log and deallocating the associated hash entry. Thedeallocation is done by resetting the timestamps in theassociated hash entry to 0. This costs 5 cycles per mem-ory location that was touched during the speculativestrip.
If a miss-speculation is discovered during the execu-tion of a speculative strip, then the speculative strip isaborted and a consistent state must be restored. Eachmemory node is responsible for rolling back its log tothe consistent memory state at the end of the previousstrip. This is accomplished by walking through the en-tire log, copying the checkpointed memory value backto its original memory location. The hash tables arecleaned at the same time. Rollback costs 11 cycles permemory location that was touched during the specula-tive strip.
The synchronization between speculative stripshelps in a second way. Hash table entries are onlydeleted in bulk, during the commit or rollback phases.Thus, we are guaranteed that between synchronizationpoints the hash table will only receive insertion andlookup requests. As a result, the hash table can be im-plemented using open addressing with double hash-ing [65]. (That is, if a hash of a key produces a con-flict, then we deterministically rehash the key until wefind an open entry). The SUDS implementation doesup to sixteen rehashes. Open addressing with doublehashing has the properties that it avoids the costs oflinked list traversal but still keeps the average numberof hashes low.9
9For example, when the hash table is half full, the average numberof rehashes will be 1 and the probability of not finding an open entrywithin sixteen rehashes will be 1
65536.
48

7.2.3 Implementation
The SUDS memory dependence speculation system isdesigned to run on Raw microprocessors [123]. ARaw microprocessor can roughly be described as asingle-chip, distributed-memory multiprocessor. Un-like traditional distributed-memory multiprocessors,however, the Raw design is singularly focused aroundproviding low-latency, register-level communicationbetween the processing units (which we call tiles).In particular, the semantics of the network and net-work interface are carefully designed to remove mes-sage dispatch overheads [74, 115] and deadlock avoid-ance/recovery overheads [67] from the critical path.Because of these considerations, a single-word datamessage can be sent from one tile to a neighboring tile,and dispatched, in under six 4.44ns machine cycles.
Each Raw tile contains an eight-stage single-issueRISC microprocessor, about 96 Kbyte of SRAM caches,an interface to the on-chip interconnect, and one ofthe interconnect routers. The tiles on each chip are ar-ranged in a two-dimensional mesh, or grid, similar tothe structure shown in Figure 44. While each tile con-tains a general-purpose RISC microprocessor pipeline,it is sometimes more appropriate to view this micro-processor as a deeply pipelined programmable microcon-troller for a set of hardware resources that include anALU and some SRAM memory. This, in any case, isthe view I adopted for the implementation of the SUDSmemory dependence speculation system.
As shown in Figure 44, SUDS partitions Raw’s tilesinto two groups. Some portion of the tiles are des-ignated as compute nodes. The rest are designated asdedicated memory nodes. The memory nodes work to-gether to implement a logically shared memory on topof Raw’s physically distributed memory. Each time acompute node wishes to make a memory request fromthe logically shared memory it injects a message intothe on-chip interconnect directed at the memory nodethat owns the corresponding memory address. Theowner is determined by a simple xor-based hash of theaddress, similar to that used in some L1 caches [46].Thus, if there are 64 tiles dedicated as memory nodes,the logically shared memory can be viewed as beingbanked 64 ways.
After the request is injected, it travels through Raw’son-chip interconnect at one machine cycle per hop (ex-cept when the message turns, which takes two machinecycles). Messages are handled, at their destination, inthe order they are received, and atomically. The Rawnetwork interface provides support so that if, when arequest arrives, the tile processor is still busy process-ing a previously received request, the new request is
queued in a small buffer local to the destination tile.10
Protocol replies are sent on a network logically distinctfrom that used to send protocol requests, and storageto sink reply messages is preallocated before requestsare made, so the communication protocol is guaran-teed not to deadlock [67].
The hand optimized code at the memory node usesthe header of each arriving request to dispatch to theappropriate request handler in just two cycles in thecase of a load request, and seven cycles for store re-quests or control messages. The dispatch loop and loadrequest handler are optimized to minimize load replylatency, at the expense of slightly poorer overall band-width. The load handler thus accesses the requestedmemory location and injects the data reply messageto the requesting compute node before accessing thetimestamp cache or log. As a result, the total end-to-end latency observed by a compute node making aload request is 19 machine cycles + 2x the manhattandistance between the compute node and the memorynode. (Unless there is contention at the memory nodeor the memory node takes a cache miss while accessingthe requested memory location).
Consider, for example, the 72 node Raw systemshown in Figure 44, and assume the 225MHz clockspeed of the existing Raw prototype. The end-to-endmemory latency would be between 21 and 39 4.44nsmachine cycles, or between 93ns and 174ns. If we as-sume that each Raw tile has a 64Kbyte data cache, thenthe effective size of the logically shared memory ac-cessible with this latency is about 4Mbytes. (Actually,slightly less, since the data cache on each memory tileis used to store the timestamp cache and log in additionto any memory locations accessed.)
Given that half to three-fourths of this latency (be-tween 44ns and 125ns) is in Raw’s highly tuned in-terconnect, it is difficult to imagine that a dedicated,custom designed, cache controller could deliver signif-icantly lower latency in this technology.
A dedicated, custom designed, cache controllermight, however, deliver higher bandwidth. Eachtransaction handled by the SUDS memory dependencespeculation protocol requires access to, at least, one 64-bit timestamp cache entry, one 64-bit log entry, and a32-bit data memory access. One might improve thetransaction rate by accessing these data structures si-multaneously. In addition, each transaction must makeat least four decisions in the timestamp cache, based onthe requested address and timestamp. (Two of thesedecisions are to check that the correct hash entry has
10Raw’s network provides flow-control support so that if a des-tination node becomes heavily contended the sending nodes canbe stalled without either dropping packets or deadlocking the net-work [33, 32].
49

been found, the other two are for timestamp compar-isons). One might additionally improve the transactionrate by simultaneously generating, and dispatching on,these conditions.
Even without these optimizations, the SUDS mem-ory dependence speculation system delivers sufficient(although in no way superb) bandwidth. In the cur-rent system each of the eight worker nodes is allowedat most four outstanding store operations or one out-standing load operation. Thus there can be at mostthirty-two requests simultaneously active in the sixty-four memory banks. The maximum probability of ob-serving contention latency at a memory bank is thusless than 50%. Each transaction generates a total of be-tween 22 and 53 machine cycles of work at the mem-ory node (including the cost of commit), depending onwhether or not a timestamp cache entry needs to be al-located during the request. Thus, the SUDS memorydependence speculation system can deliver an averagethroughput of better than one transaction per machinecycle.
7.2.4 The Birthday Paradox
This section explains a fundamental limit of paral-lelism on essentially randomly generated dependencegraphs (such as one sees in many sparse matrix al-gorithms). The limitation basically boils down to the“birthday paradox” argument that with only 23 peoplein a room, the probability that some pair of them havethe same birthday is greater than 50%.11 As demon-strated here, the same argument shows that a memorydependence speculation system can expect to achievea maximum speedup proportional to 3
√n when ran-
domly updating a data structure of size n.Suppose we have b different processors, each of
which is updating a randomly chosen array element,Bi ∈ 1 . . . n. What is the probability that every proces-sor updates a different array element?
We have n ways of choosing the first array element,n − 1 ways of choosing the second array element, sothat it is different from the first, n − 2 ways of choos-ing the third array element so that it is different thanthe first two, and so on. Thus there are n!
(n−b)!ways
of assigning n array elements to b processors, so thatthe updates do not interfere. Yet there are a total ofnb ways of assigning n array elements to b processorsrandomly. Thus the probability, p, that all b accessesare non-interfering is
p =n!
nb(n − b)!. (2)
11The origin of the birthday paradox is obscure. Feller [39] cites apaper by R. von Mises, circa 1938, but Knuth [65], believes that it wasprobably known well before this.
n = 262144 n = 32768 n = 4096 n = 512 n = 64
|
1|
2|
4|
8|
16|
32|
64|
128|
256
|0.00
|5.00|10.00
|15.00
|20.00
|25.00
|30.00
|35.00
|40.00
|45.00
Parallelism
Spe
edup
Figure 50: Speedup curves for speculatively paralleliz-ing a loop that randomly updates elements of an ar-ray of length n as we change the number of processorsthat are running in parallel. The stars show the pointsat which parallelism equals 3
√n, as described in Equa-
tion 6.
Let us optimistically assume that, if a sequential pro-cessor can run b iterations in time b, that running inparallel on b processors, we can run b iterations in time1 if none of the accesses conflict (which occurs withprobability p), and time 1 + b if there is an access con-flict (which occurs with probability 1−p). The averagespeedup, S, will be
S =b
p + (1− p)(1 + b)=
b
1+ b(1− p). (3)
Note that the assumption that each speculative stripof parallel work is rerun from the beginning on mis-speculation, rather than from the point of failure, af-fects the result only by a small constant factor, sincethe point of failure will, on average, be about halfwayinto the speculative strip.
Speedup curves for a variety of n are shown in Fig-ure 50. As b varies on the x axis, the speedup increasesnearly linearly to some optimal point, but then falls offdramatically as the probability of conflicting iterationsstarts to increase.
Now let us find the point at which speedup is maxi-mized as a function of b. This will occur when dS/db =0. We work this out as follows. Let v = 1 + b(1 − p).Then S = b/v,
dv
db= −b
dp
db+ 1− p,
50

dS
db=
v− b dvdb
v2
=1− b dv
db+ b(1− p)
(1+ b(1− p))2
=1+ b2 dp
db
(1+ b(1− p))2.
Setting dS/db = 0 yields
dp
db=−1
b2. (4)
Equation 2 defines p using factorials, an integer func-tion for which the derivative is not well defined. Butwe can approximate dp/db by recalling the definitionof the derivative.12 We examine the function (p(b+h)−p(b))/h. Letting h = 1we get:
dp
db≈ p(b + 1) − p(b)
=n!
nb+1(n − (b + 1))!−
n!
nb(n − b)!
=−bn!
nnb(n − b)!
=−b
np.
Solving this differential equation yields
p ≈ e−b2/2n. (5)
Combining the condition on dp/db given by Equa-tion 4 with this approximation we get
−1
b2=−be−b
2/2n
n,
orb3 = neb
2/2n.
Let us approximate the solution to this equation asb∗ = c 3
√n. The error from this approximation is
n(c3 − ec2/(2 3
√n)). If c = 1 then the error is negative
for all n > 0. For c > 1 note that the error is positivewhenever c3 > ec
2/(2 3√n), or taking logarithms, when
n > c6/8(ln c3)3. If c = e1/6 ≈ 1.18136 then the erroris positive for all n > e. Thus for all n > e,
3√n ≤ b∗ ≤ 1.19 3
√n. (6)
This approximation is demonstrated in Figure 50,with stars placed at the optimal points, as calculated byEquation 6. Every time the array size is multiplied bya factor of 8, the maximum parallelism increases by afactor of only 2. The intuition behind this cubic result isthat as b increases, the probability of success decreasesapproximately proportional to b2 while the cost of fail-ure increases approximately as b.
12I am indebted to my father, David L. Frank, for suggesting thisapproach.
7.3 Discussion
Another way to think about a speculative concurrencycontrol system is to break it into two subsystems. Thefirst subsystem is the checkpoint repair mechanism.The second subsystem checks that a particular concur-rent execution produced a result consistent with a se-quential ordering of the program. In the SUDS system,the log provides checkpoint repair functionality, whilethe timestamp cache performs concurrency checking.
Section 7.2.4 discussed the fundamental limits inher-ent to any system that uses speculation to discoverconcurrency in essentially randomly generated depen-dence graphs. This section describes two implemen-tation choices made with respect to the design of theSUDS log and the qualitative impact those implemen-tation choices had on system performance. First, thelog implements a bulk commit mechanism instead ofa rolling commit mechanism. Second, the log designpermits only a single version of each memory locationto exist at any one time, rather than a more sophisti-cated approach where multiple values may be storedsimultaneously at a particular memory location.
The impact of several other design and implementa-tion choices is discussed in Chapters 8 and 10. Oneof the main themes of Chapter 8 involves an imple-mentation mistake with regard to the caching struc-ture implemented above the SUDS system. In fact, theSUDS concurrency control subsystem is designed insuch a way that implementing a better cache aboveSUDS would have been particularly easy, and Chap-ter 8 explains why I failed to do so. Chapter 10 dis-cusses a longer term issue having to do with flat ver-sus nested transaction models. In particular SUDS,like all existing memory dependence speculation andthread level speculation systems implements an inher-ently flat transaction model. Chapter 10 explains whyI believe that future concurrent computer architectureswill require nested transaction models.
Bulk Commit
The SUDS log is designed in such a way that commitonly happens, in bulk, at the end of a speculative strip.Many other memory dependence speculation systems,especially those based directly on Franklin and Sohi’sMultiscalar Address Resolution Buffer [43, 44], permitcommits to occur on a rolling basis. That is, Multiscalarsystems contain an implicit “commit token” that ispassed from thread to thread as each completes. Whena thread receives the token, the log entries correspond-ing to that thread are committed and flushed. Thus,in Multiscalar systems, the log commit operations oc-cur concurrently with program execution, as long as nomisspeculations occur.
51

SUDS, in contrast, runs a set of threads correspond-ing to a speculative strip, and then barrier synchronizesthe entire system before committing the logs. The costof this barrier synchronization step is not overlappedwith program execution, and one might worry that thesynchronization cost could overwhelm speedup gains.A simple implementation trick, however, amortizes thesynchronization cost across several thread invocations,making the effective cost nearly irrelevant. The trick isthat, in the SUDS implementation, a speculative stripcontains four times as many threads as there are exe-cution units in the system (thirty-two versus eight). Asa result, the runtime system only needs to synchronizeone-fourth as often, and the synchronization costs aresignificantly amortized.
While the cost of bulk synchronization is easilyamortized, the benefit is substantial. In particular, thework required for log entry allocation and garbage col-lection becomes nearly trivial. In SUDS, log entriesare allocated from a memory buffer in-order (with re-spect to the arrival of write requests). This can be ac-complished simply by incrementing a pointer into thisbuffer. Deallocation of buffer entries is even more triv-ial. The pointer is just reset to point to the beginning ofthe buffer.
With a rolling commit scheme, on the other hand, logentries would be committed in a different order thanthey were received. Thus the log manager either needsto keep log entries sorted in timestamp order, or elsedeallocation creates “holes” in the log buffer, forcingthe log manager to keep and manage an explicit freelist.
Single Version Concurrency Control
The second design choice with respect to the SUDS logis that the SUDS concurrency control system is basedon basic timestamp ordering [15], and thus makes onlya single version of each memory location available atany time. Memory dependence speculation systemsbased on the Multiscalar Address Resolution Buffer,in contrast, essentially implement multiversion times-tamp ordering [94].
This choice involves a tradeoff. On the one hand,multiversion timestamp ordering is capable of break-ing the memory anti-dependence between a load andthe following store to the same memory location. Onthe other hand, since there may be multiple versionsassociated with each memory location, each load oper-ation must now perform an associative lookup to findthe appropriate value.
The empirical question, then, becomes the relativeimportance of load latency to the cost of flagging somememory anti-dependences as misspeculations. Load
latency is almost always on the critical path, and isparticularly important in the SUDS runtime, since ev-ery load operation goes through the software imple-mented concurrency control system. How frequent,then, are memory anti-dependences between threadsin the same speculative strip?
The key empirical observation is that most short-term memory anti-dependences are caused by the stack al-location of activation frames, (rather than heap alloca-tion). That is, if two “threads” are using the samestack pointer, then register spills by the two threadswill target the same memory locations. Most contem-porary computer systems allocate activation frames ona stack, rather than the heap, because stacks provideslightly lower cost deallocation than does a garbagecollected heap [9]. The SUDS compiler allocates acti-vation frames on the heap, rather than a stack, simplybecause it was the most natural thing to do in a com-piler that was already closure converting.13 Thus, inthe SUDS system every thread in the speculative stripgets its own, distinct, activation frame, and registerspills between threads never conflict.
This separation of concerns between concurrencycontrol, on the one hand, and memory renaming, onthe other, enables the SUDS memory system to imple-ment a particularly low latency path for loads. TheSUDS log is specifically, and only, a mechanism for un-doing store operations. That is, for each store opera-tion, the store writes directly to memory, and the pre-vious value at that memory location is stored in the logso that the store can be “backed out,” if necessary. Thusload operations can read values directly from the mem-ory without touching the log at all.
Caching
Finally, we note the relationship of the SUDS concur-rency control mechanism to caching. Unlike other pro-posals for memory dependence speculation systems,SUDS does not integrate the concurrency control mech-anism with the cache coherence mechanism. Morespecifically, the SUDS concurrency control system sitsbelow the level of the cache coherence protocol in thesense that it assumes requests for each particular mem-ory location arrive in a globally consistent order. Thusdecisions about caching can be made almost indepen-dently of the concurrency control mechanism. Thecaveat is that most caching mechanisms are imple-mented at the level of multi-word cache lines, while theSUDS concurrency control mechanism is implementedat the level of individual memory words.
13“We should forget about small efficiencies, say about 97% of thetime: premature optimization is the root of all evil,” Knuth, Comput-ing Surveys, 6(4), 1974.
52

8 Putting It All Together
In this chapter we describe how all of the parts de-scribed in Chapters 3 through 7 fit together in the con-text of a working prototype SUDS system. The proto-type system is described in Section 8.1. Section 8.2 de-scribes, in some detail, several case studies of the useof generalized loop distribution to find concurrency.
SUDS is designed to run on Raw microprocessors.A Raw microprocessor can roughly be described as asingle-chip, distributed-memory multiprocessor. Un-like traditional distributed-memory multiprocessors,however, the Raw design is singularly focused aroundproviding low-latency, register-level communicationbetween the processing units (which we call tiles).In particular, the semantics of the network and net-work interface are carefully designed to remove mes-sage dispatch overheads [74, 115] and deadlock avoid-ance/recovery overheads [67] from the critical path.Because of these considerations, a single-word datamessage can be sent from one tile to a neighboring tile,and dispatched, in under six 4.44ns machine cycles.
As reported elsewhere [113, 114], each Raw chip con-tains a 4 by 4 array of tiles; multiple chips can be com-posed to create systems as large as 32 by 32 tiles. Acomplete prototype single chip Raw system, runningat 225 MHz, has been operational since February 2003.The processor was designed and implemented at MITover a period of six years by a team that included sev-eral dozen students and staff members (although therewere probably never more than a dozen people on theproject at any one time). The processor was fabricatedby IBM in their 0.15 micron SA-27E ASIC process.
8.1 Simulation System
We wanted to understand the properties of SUDS inthe context of systems with sizes of 72 tiles, rather thanthe 16 available in the hardware prototype. Thus, theresults in this thesis were generated on a system levelsimulator of the Raw microprocessor, called usstdl .14
The simulator is both relatively fast, allowing us torun big programs with large data sets, and accurate,providing cycle counts that are within about 10% ofthe cycle counts provided by the hardware prototype.(usstdl is more than 100x faster than the completelycycle accurate behavioral model used by the hardwaredesigners).
There are a few minor functional differences be-tween the simulator and the hardware prototype. First,
14The name usstdl is an acronym for “Unified SUDS Simulatorand Transactional Data Library,” because (for no particularly goodreason) both the simulator and library are checked in to the samesubtree of the local version control system.
the simulator does not model interconnect networkcontention. This is of little consequence to the resultsreported here, since the total message traffic in the sys-tem is sufficiently low compared to the available net-work bandwidth on the prototype. Although the sim-ulator does not simulate contention inside the intercon-nect, it does simulate contention at the network inter-faces to the tile processors.
The second functional difference between usstdland the hardware prototype is the addition of a secondset of load/store instructions. These instructions makeit possible to compile, and use, the C library routines(e.g., strcpy() ) so that they will work with either ar-rays stored in the local memory of a tile, or in the SUDSlogically-shared, speculative memory described in Sec-tion 7.2.2 and 7.2.3.
These load/store instructions work as follows. Theyexamine the high bit of the requested address. If thatbit is a 0, then the the request is destined for one ofthe software-based memory nodes described in Sec-tion 7.2.3. For these requests the machine constructs,and sends, an appropriate message to the memorynode, with the same instruction latencies that would beexperienced if the message were constructed in software onthe hardware prototype. This variety of load instruction(called “glw ”) does not have a destination register. In-stead, the requested data is returned by a message ar-riving in the register-mapped network interface.
The code generator is thus designed so that, when-ever the semantics of a load instruction are required,two instructions are generated. The first instruction isa glw instruction, which has one register operand spec-ifying the address to be loaded. The second instructioncopies the result out of the network interface registerto one of the general purpose registers. (Raw’s net-work interface registers are designed so that accessesto a register stall the processor until a message arrivesin that register).
If the high bit of the address in a glw instruction is a1, on the other hand, then the address is accessed fromthe tile’s local data cache and the data is fed back tothe network input register as if a data message had ar-rived from the interconnect. Because of this function-ality, loads and stores in the C library can be compiledusing glw and gsw instructions, instead of the normalload and store instructions. As a result, library routinescan access data from both the local data cache or fromthe logically shared memory without recompilation.
Since the latency of local loads is somewhat higherwhen a library is compiled with this scheme, the C li-brary routines are slightly slower when running underSUDS than they are when running on a conventionalmicroprocessor. On the other hand, the convenience ofnot having to compile multiple versions of the library,
53

and then determine which version should be used ineach circumstance amply makes up for the small lossin performance. (Consider, for example, the strcpyroutine from the C library. Without the glw and gsw in-structions we would have to compile four different ver-sions, one for each possible combination of the sourceand destination strings being in remote memory or onthe local stack. Worse, we would then need to deter-mine, for each call, where the two parameters were lo-cated, which would require whole program analysis.)
The final, and most important, functional differencebetween usstdl and the Raw hardware prototype isthe addition of a set of eight additional dedicated reg-isters for receiving messages from Raw’s dynamic net-work. Each message header includes an index into thisregister file, and when a message arrives it is directedto the register corresponding to that index. This sim-ply extends the “zero-cycle” message dispatch conceptfrom Raw’s other networks so that it works with theparticular network that is used by SUDS [115]. (TheRaw hardware prototype implements zero-cycle mes-sage dispatch on its “static” network, but not on the“dynamic” network that SUDS uses).
Microarchitecturally, adding zero-cycle dispatch toRaw’s dynamic network would be a straightforwardchange, in that it involves changes only in the reg-ister fetch stage of the local tile processor pipelines.From a performance standpoint, on the other hand, thischange was critical. For example, Section 7.2 gave abreakdown of the 21 cycle round trip cost of perform-ing a load in the SUDS speculative transactional mem-ory system. Without usstdl ’s zero-cycle message dis-patch support, the critical path cost of performing aload increases by more than 12 cycles. This greaterthan 50% cost increase for each message received at thecompute nodes is due entirely to the cost of messagedispatching in software. Without zero-cycle dispatchthe 2 to 3x SUDS speedup numbers reported belowwould be impossible to achieve. Instead SUDS wouldget slowdowns.
Programs running with the SUDS system are paral-lelized by a prototype SUIF based compiler that out-puts SPMD style C code. The transformations per-formed by this compiler are described in Chapters 3,4, 5, 6 and 7. The resulting code is compiled for the in-dividual Raw tiles using gcc version 2.8.1 with the -O3flag. Raw single-tile assembly code is similar to MIPSassembly code, so our version of the gcc code genera-tor is a modified version of the standard gcc MIPS codegenerator.
Comparison Systems
For comparison purposes I implemented simulatorsfor two additional systems. The first is a baseline,single-issue 8-stage pipelined RISC processor with aMIPS ISA (similar to a single Raw tile). Programs arecompiled directly to this system using the MIPS ver-sion of gcc 2.8.1 with the -O3 flag. The second compar-ison system is an eight-way issue superscalar runningan idealized version of Tomasulo’s algorithm. Thisprocessor also has a MIPS ISA and programs are com-piled directly to the system using the MIPS version ofgcc 2.8.1 with the -O3 flag.
The superscalar simulation is “idealized” in thesense that (a) the trace-fetch mechanism permits tracesto be contained in multiple arbitrary cache lines (i.e.,the instruction cache is arbitrarily multi-ported), (b) theprocessor has an effectively infinite set of physical reg-isters, (c) the processor has an effectively infinite setof functional units and (d) the processor has “perfect”zero-latency and infinite bandwidth, bypass networks,scheduling windows and register-file write back paths.The four ways in which the comparison superscalar isnot idealized are (a) it is limited to fetching a trace ofat most eight instructions per cycle, (b) a branch mis-prediction causes fetch to stall for two cycles, (c) the in-struction scheduler obeys register value dependencesand (d) only a single data store operation can occur ineach cycle. The store buffer implements load bypassingof stores with forwarding. The cache to memory inter-face permits an effectively infinite number of simulta-neous overlapping cache misses. Both the baseline, in-order, and comparison, out-of-order, models use a 32Kbit gshare branch predictor.
Memory Systems
The memory systems for the baseline (in-order) andcomparison (out-of-order) processors include a 4-wayassociative 64KByte combined I&D L1, 4 MByte L2with 12 cycle latency and 50 cycle cost for L2 misses toDRAM. The memory system for the SUDS simulationsis less idealized.
For the SUDS simulations we use a 72-tile Raw mi-croprocessor. Eight of these tiles are dedicated as“workers” and the other sixty-four are dedicated as“memory nodes.” Each of the worker tiles has a 4-way associative 64Kbyte combined I&D L1 cache thatis used only for caching instructions and thread-localstacks.
In the SUDS system the sixty-four memory tileswork together, as described in Section 7.2.2, to providea logically shared, speculative, L2 cache accessible tothe eight worker nodes. Since this L2 cache is imple-mented in software on the sixty-four memory nodes, it
54

has an effective size of slightly less than 64×64Kbyte =4 MBytes. This is because the instructions for the mem-ory dependence speculation software, the hash tabledata structures, and the log data structures, all com-pete for use of the 64Kbyte SRAM cache local to eachmemory tile. In the SUDS simulations L1 cache missesare assumed to take 50 cycles (this is equivalent to theL2 cache miss penalty for the baseline and superscalarsystems).
As described, above and in Section 7.2.2, the workernodes do not cache potentially shared data in their lo-cal L1 caches. Rather every access to potentially shareddata is forced to undergo the relatively expensive pro-cess of remotely accessing the software based memorydependence mechanism on one of the memory nodes.usstdl simulates every aspect of this process in fulldetail.
I chose all of these parameters simply because I wastrying to see whether, in the context of a large and com-plex system, generalized loop distribution was makinga difference. In all cases I have tried to bias the re-sults slightly toward the superscalar. The superscalar’s4 Mbyte L2 cache is of similar size to the 4 Mbytes ofcache collectively available on the SUDS memory sys-tem, thus any particular program has about the sameoff-chip miss rates on both systems. The L2 cache la-tency on the superscalar is lower (by a factor of almosttwo) than the minimum latency of a SUDS access tothe software based memory dependence system. Thesuperscalar L2 cache bandwidth is effectively unlim-ited, while the SUDS logically shared L2 cache has 64banks, each of which is limited (by the software basedprotocol) to servicing approximately one request every53 cycles (see Section 7.2.3).
Both systems can fetch at most eight useful, user-program, instructions per cycle. The superscalar modelis permitted to issue, dispatch, and execute an ef-fectively unlimited number of operations each cy-cle. usstdl accurately simulates the eight in-orderpipelines that SUDS has at its disposal. The scalaroperand matching/bypass network on the superscalarhas no latency. usstdl accurately models the inter-connect latencies of the implemented Raw hardwareprototype.
The superscalar model automatically, and in zero cy-cles, renames every scalar in to an effectively infiniteand zero-latency physical register file. The SUDS sys-tem renames, in software, into the deferred executionqueues created by the loop distribution compiler pass.These queues are stored in the L1 caches of the workernodes, must be accessed by load and store instructions,and can even suffer cache misses.
The same back end code generator is used for bothsystems (gcc 2.8.1) and is, at least, decent. Even this,
however, slightly favors the superscalar since the glwand gsw instructions are inserted by the parallelizingcompiler as volatile gcc inline assembly directives. Thesemantics of these directives are unknown to the gccback end, and thus somewhat restrict the compiler’sability to optimize or reorder code.
I have tried, for every architectural parameter thatI could think of, to either model that parameter thesame way (e.g., off chip memory access latency), orto bias the comparison towards the idealism of Toma-sulo’s algorithm and against the realistically imple-mentable version of Raw and SUDS. The Raw groupat MIT has demonstrated that the Raw hardware pro-totype, in IBM’s SA-27E ASIC process, can be clockedat 225 MHz. It is doubtful whether the idealized su-perscalar could be clocked at a similar rate, especiallygiven the (zero-cycle) latency chosen for its scalar by-pass network.
Thus I feel justified in making the qualitative claimthat, when running the same program under the ide-alized superscalar model and under SUDS on theusstdl simulator, then if the two runs have similar cy-cle counts, generalized loop distribution is finding at leastas much concurrency, if not more, than does Tomasulo’s al-gorithm. In fact, for two out of the three programs dis-cussed below, the result is unequivocal, because the cy-cle counts for SUDS are better than the cycle counts forthe idealized version of Tomasulo’s algorithm.
8.2 Case Studies
This section describes how generalized loop distribu-tion, the SUDS speculation system, and the other trans-formations described in this thesis interact in the con-text of three applications. We describe the applicationof generalized loop distribution to a molecular dynam-ics simulation program, a decompression program anda program that makes heavy use of recursion.
8.2.1 Moldyn
Moldyn is a molecular dynamics simulation, originallywritten by Shamik Sharma [102], that is difficult to par-allelize without speculation support. Rather than cal-culate allO(N2) pairwise force calculations every itera-tion, Moldyn only performs force calculations betweenparticles that are within some cutoff distance of one an-other (Figure 51). The result is that only O(N) forcecalculations need to be performed every iteration.
The original version of Moldyn recalculated allO(N2) intermolecular distances every 20 iterations.This made it impossible to run the program on any rea-sonably large data set. We rewrote the distance calcu-lation routine so that it would also run in O(N) time.
55

ComputeForces ( vector <particle> molecules,real cutoffRadius)
epot = 0.0foreach m in molecules
foreach m’ in m.neighbors()if (distance(m, m’) < cutoffRadiusSquare)
force_t force = calc_force(m, m’)m.force += forcem’.force -= forceepot += calc_epot(m, m’)
return epot
Figure 51: Pseudocode for ComputeForces , the Mol-dyn routine for computing intermolecular forces. Theneighbor sets are calculated every 20th iteration by call-ing the BuildNeigh routine (Figure 52).
BuildNeigh ( vector <list <int >> adjLists,vector <particle> molecules,real cutoffRadius)
vector <list <particle>> boxes
foreach m in moleculesint mBox = box_of(m.position())boxes[mBox].push_back(m)
foreach m in moleculesint mBox = box_of(m.position())foreach box in adjLists[mBox]
foreach m’ in boxif (distance(m, m’) <
(cutoffRadius * TOLERANCE))m.neighbors().push_back(m’);
Figure 52: Pseudocode for BuildNeigh , the Moldynroutine for recalculating the set of interacting particles.adjLists is a pre-calculated list of the boxes adjacentto each box.
This is accomplished by chopping the space up intoboxes that are slightly larger than the cutoff distance,and only calculating distances between particles in ad-jacent boxes (Figure 52). This improved the speed ofthe application on a standard workstation by three or-ders of magnitude.
Generalized loop distribution and SUDS can paral-lelize each of the outer loops (those labeled “foreachm in molecules ” in Figures 51 and 52). Althoughthe ComputeForces routine accounts for more than90% of program runtime on a standard workstation,each loop has different characteristics when run in par-allel, and it is thus instructive to observe the behaviorof the other two loops as well.
The first loop in the BuildNeigh routine movesthrough the array of molecules quickly. For eachmolecule it simply calculates which box the moleculebelongs in, and then updates one element of the (rel-atively small) boxes array. This loop does not paral-lelize well on the SUDS system because updates to theboxes array have a relatively high probability of con-flicting when run in parallel.
The second loop in the BuildNeigh routine isactually embarrassingly parallel, although potentialpointer aliasing makes it difficult for the compiler toprove that this loop is parallel. (The list data struc-tures, “m.neighbors() ,” are dynamically allocated,individually, at the same program point, and thus thepointer analysis package we are using puts them inthe same equivalence class). SUDS, on the other hand,handles the pointer problem by speculatively sendingthe pointer references to the memory nodes for resolu-tion. Since none of the pointer references actually con-flict, the system never needs to roll back, and this loopachieves scalable speedups.
The ComputeForces routine consumes the major-ity of the runtime in the program. For large problemsizes, the molecules array will be very large, whilethe number of updates per molecule stays constant, sothe probability of two parallel iterations of the outerloop updating the same element of the molecules ar-ray is relatively small. Unfortunately, while this loopparallelizes well up to about a dozen compute nodes,speedup falls off for larger numbers of compute nodesbecause of the birthday paradox problem with memorydependence speculation described in Section 7.2.4. (Re-call that this is a fundamental limitation of data specu-lation systems, not one unique to the SUDS system.)
Despite its small size and seemingly straight-forward structure, parallelization of the Compute-Forces routine required nearly every compiler trans-formation and analysis described in Chapters 5, 6 and7. The recurrence on the epot variable is reassociatedas described in Section 6.4. The memory accesses for
56

SUDS 3.38idealized superscalar 3.16
Figure 53: Comparison of speedups over an inorderpipeline for Moldyn running on SUDS versus a super-scalar.
the updates specified by the statement “m.force +=force ” are register promoted to the outer loop, as de-scribed in Section 5.4. Equivalence class unification(Section 5.3) is used to discover that there is no mem-ory dependence between the distance and force calcu-lations (which require the position of each molecule),and the updates to the force vector associated witheach molecule.
Speculative strip mining (Section 7.1) speculativelybreaks the (true) memory dependences between outerloop iterations caused by the force updates. Finally,generalized loop distribution (Section 6) finds two crit-ical nodes in the outer loop. One critical node corre-sponds to the “index variable” mand the other corre-sponds to the reassociated updates of the epot vari-able. The memory dependences between iterations ofthe outer loop are (speculatively) removed by spec-ulative strip mining, so generalized loop distributionidentifies the rest of the work in the outer loop (the dis-tance and force calculations and force updates) as par-allelizable.
Figure 53 shows the speedups of running Moldynwith an input dataset of 256,000 particles on SUDS andthe idealized superscalar. The baseline in order MIPSR4000 design achieves an average of only 0.223 instruc-tions per cycle (IPC). This is largely due to poor L1cache behavior. As is common with many numeri-cal/scientific workloads, the working set of this pro-gram is considerably larger than the caches. Thusthe program gets cache miss rates of about 5% duringBuildNeigh and 3% during ComputeForces .
The idealized superscalar design achieves an IPC ofabout 0.705, or about 3.16x speedup over the single is-sue in-order processor. This improvement is achievedlargely because the superscalar is able to overlap usefulwork with some of the cache miss latency.
The SUDS system achieves a speedup of about 3.38xover the single issue in-order processor. This despitethe fact that on the superscalar more than 95% of mem-ory accesses are to the L1 cache, while in the SUDS sys-tem only about one third of the memory accesses areto stack-allocatable values that can be stored in the L1.The other two thirds of the SUDS memory accesses arerouted directly to the logically shared L2 cache, and theSUDS L2 cache is roughly 2x slower than the super-scalar L2 cache, because it is implemented in software.Thus, we can conclude that the SUDS system is, some-
how, managing to overlap a great deal more work withthe long latency memory operations than is the ideal-ized superscalar.
The key to understanding the difference lies in acloser examination of the doubly nested loops thatconsume most of the program running time. In bothcases the number of times that the innermost loopwill execute is almost completely unpredictable. Thus,even though the prediction rate for this loop branchis very high (greater than 99%) the superscalar willtake a branch misprediction during almost every it-eration of the outer loop. The superscalar is thus re-stricted to finding parallelism in the inner loop, whilethe SUDS system exploits parallelism in the outer loop.In fact, the conditional inside the ComputeForcesloop makes things even worse for the superscalar. Thisbranch is not particularly predictable, and thus the su-perscalar is restricted to looking for parallelism overonly a relatively small number of iterations of the innerloop. The SUDS system is finding more concurrencylargely because it is able to exploit the control indepen-dence of the outer loop upon the inner loop branches.
8.2.2 LZW Decompress
Compression is a technique for reducing the cost oftransmitting and storing data. An example is the LZWcompression/decompression algorithm [126], widelyused in modems, graphics file formats and file com-pression utilities. Example pseudocode for the versionof LZW decompress used in the Unix compress utilityis shown in Figure 54. Each iteration of the outer loopreads a symbol from the input data stream, and tra-verses an adaptive tree data structure to output a (vari-able length) output string corresponding to the inputsymbol.
Note that the input data stream has been engineeredto remove redundant (easy to predict) patterns. Thus,while the branch prediction rate for any particularstatic branch is relatively good, the probability of per-forming an entire iteration of the outer loop withoutany branch mispredictions is close to 0. As a result,Tomasulo’s algorithm is limited to searching for con-currency in a relatively small window of instructions.
Generalized loop distribution and memory depen-dence speculation, on the other hand, can be used tosearch for concurrency between iterations of the outerloop. The structure of this loop is much more complexthan is that of the program described in the previoussection, and thus a considerable amount of analysisand transformation needed to be done to expose thisouter-loop concurrency.
First, several of the scalar variables (e.g., outptr )are globals and one is a call-by-reference parameter
57

outptr = 0incode = getcode(&input_buf)while ( incode > EOF )
int stackp = 0code_int code = incodechar_type the_stack[1<<BITS]
if (incode == CLEAR)free_ent = FIRSTif (check_error(&input_buf))
break; /* untimely death! */incode = getcode(&input_buf);
/* Special case for KwKwK string. */if ( code >= free_ent )
the_stack[stackp] = fincharstackp = stackp + 1code = oldcode
/* Generate output charactersin reverse order */
while ( code >= 256 )the_stack[stackp] = tab_suffix[code]stackp = stackp + 1code = tab_prefix[code]
the_stack[stackp] = tab_suffix[code]stackp = stackp + 1
/* And put them out in forward order */do
stackp = stackp - 1out_stream[outptr] = the_stack[stackp]outptr = outptr + 1
while ( stackp > 0 )
/* Generate the new tree entry. */if ( free_ent < maxcode )
tab_prefix[free_ent] = oldcodetab_suffix[free_ent] = tab_suffix[code]free_ent = free_ent + 1if (check_error(&input_buf)
break; /* untimely death! */
finchar = tab_suffix[code]oldcode = incodeincode = getcode(&input_buf)
Figure 54: Pseudocode for lzw decompress.
(input buf ). Since these scalars would normally bereferenced through loop carried dependent loads andstores, they must be register promoted before general-ized loop distribution runs. The input buf variableis referenced inside the getcode subroutine, and thusto enable register promotion, this subroutine needed tobe inlined.
The local array variable, the stack , must be pri-vatized. In this case the array privatization is per-formed using the scope restriction technique describedin Section 5.5. The equivalence class unification (Sec-tion 5.3) analysis proves that memory accesses tothe tab prefix , tab suffix and out stream datastructures are mutually independent.
Both the tab prefix and tab suffix data struc-tures are read and written in a data-dependent fash-ion during every iteration of the outer loop. This cre-ates true memory dependences between iterations ofthe outer loop. Speculative strip mining and mem-ory dependence speculation are used to dynamicallybreak these dependences when the data-dependent ac-cess pattern allows it.
Next the outptr recurrence variable is reassociated,because it is updated with an associative operator inthe second inner loop. Recall that this variable wasoriginally a global, and thus register promotion has al-ready been run to turn the references from memory op-erations into register accesses.
Finally, generalized loop distribution finds six criti-cal nodes in the loop. These correspond to updates tothe variables incode , finchar , outptr , oldcode ,free ent and input buf . When collapsing to thecritical node dag we discover that the updates to in-code , input buf , and free ent form a cyclic criticalpath. The updates to these variables are “intertwined”in the sense that they depend upon one another. in-code is data dependent on input buf (through thegetcode routine). The updates to input buf , in turn,are control dependent on the outer loop branch, whichis data dependent upon incode . Control dependencesform a cycle between free ent and incode .
Generalized loop distribution thus creates four se-quential loops corresponding to the four cyclic criticalpaths. The first sequential loop updates incode , in-put buf and free ent , and creates deferred execu-tion queues for all subsequent loops. The second se-quential loop corresponds to updating oldcode .
The next loop can be (speculatively) parallelized,and corresponds to evaluating the parts of the firstinner loop and the conditional for the “special case”that updates the, private, code and stackp variables,and to the conditional updates to tab prefix andtab suffix .
The third sequential loop corresponds to updating
58

SUDS 1.8idealized superscalar 2.0
Figure 55: Comparison of speedups over an inorderpipeline for lzw running on SUDS versus a super-scalar.
finchar . This is followed by another parallelizableloop that corresponds to all the updates to the privatearray, the stack . The iterations of this loop are prov-ably independent of one another, but the code in thisloop has also been reordered with respect to the up-dates to tab suffix performed in the previous spec-ulatively parallel loop. This is what makes speculativestrip mining necessary. Both parallel loops are part ofthe same strip, so the reordering of the code betweenthe two loop bodies can be checked and, if necessary,corrected.
The fourth sequential loop corresponds to updat-ing outptr . This enables the final parallelizable loop,which corresponds to the writes to out stream .
Figure 55 shows the speedups for the idealized su-perscalar and for SUDS compared to running lzw de-compress on the in-order single-issue pipeline. Nei-ther system does particularly well. The superscalaronly achieves a speedup of 2x, while SUDS achievesa speedup of 1.8x. Again the superscalar is limited byits inability to predict past the exits of the inner loops.
Generalized loop distribution actually finds a greatdeal more concurrency in this case than does the ide-alized version of Tomasulo’s algorithm. On the otherhand, this code is particularly memory intensive, and,on the in-order microprocessor, almost all of thesememory operations hit in the L1 cache. The SUDSmemory dependence speculation system, on the otherhand, dramatically increases the latency of access-ing the tab prefix and tab suffix data structures.While generalized loop distribution is finding enoughconcurrency to cover a substantial portion of this ad-ditional latency, it is not finding quite enough to com-pletely make up for the lack of L1 caching in this case.
8.2.3 A Recursive Procedure
Recursive procedural calls are another way of organiz-ing the control flow in a program. Procedural calls,however, are semantically equivalent to jumps, andthus can be automatically transformed to jumps usinggeneralizations of tail recursion elimination [107]. Inparticular, this generalization creates explicit trees ofactivation records, and saves continuations to and re-stores continuations from this tree [111, 107, 8].
If it is known that sibling procedure calls in the acti-vation tree do not depend upon one another, then it is
Traverse (node)read(node->parent)modify(node)foreach c in node->children
spawn Traverse(c)
Figure 56: Pseudocode for the tree traversal routinefrom the health program. The spawn keyword issimply an annotation that indicates that sibling calls toTraverse are guaranteed to correctly run concurrently.
legal to traverse the tree in either depth first or breadthfirst order [18, 96, 98]. The breadth first traversal tendsto execute sibling nodes in the tree concurrently, butdoes so at the cost of pushing continuations on to thefront, and popping continuations from the back, of aFIFO queue. Each of the pointers (to the front and backof the queue) thus forms an implicit critical node inthe resulting program. An additional issue with thisbreadth first implementation is that a child node may(but will not usually) execute concurrently with its par-ent, thus violating a true memory dependence.
I wanted to make sure that generalized loop distri-bution and the SUDS memory dependence specula-tion system were capable of handling these implicit de-pendences. For this purpose I chose a program calledhealth , written by Martin Carlisle, that was alreadyannotated with information about the legal concur-rency between sibling calls in its recursive tree traver-sal routine [20, 135].
Highly simplified pseudocode for the tree traversalroutine in health is shown in Figure 56. The spawnkeyword annotation was inserted by the author to in-dicate that it is legal to run sibling calls to the Tra-verse subroutine concurrently. Note that while it is le-gal to run sibling calls concurrently, it is not legal to runa child concurrently with its parent, because the childcall will read a memory location that may also be mod-ified by the parent. Also, note that, again, Tomasulo’salgorithm will be limited to searching for concurrencywithin a single call to the Traverse routine, becausethe probability of executing an entire call to Traversewithout any branch mispredictions is near 0.
Figure 57 demonstrates how the code in Figure 56is transformed to continuation passing style, and thenconverted to breadth first traversal, by introducing theexplicit fifo array, and head and tail pointers intothat array. Note that this transformation has not im-proved (or particularly degraded) the performance ofTomasulo’s algorithm, because it is still the case that,due to branch mispredictions, it can only search forconcurrency within a single iteration of the outer loop.
After speculative strip mining on this loop the twocritical nodes found by generalized loop distribution
59

while head < tailnode = fifo[head++]read(node->parent)modify(node)foreach c in node->children
fifo[++tail] = c
Figure 57: After conversion of the recursive Traver-sal routine to “continuation passing style,” and intro-duction of a fifo to make traversal breadth-first ratherthan depth-first. The routine now has the structure ofa loop that can be handled by generalized loop distri-bution.
SUDS 2.22idealized superscalar 1.92
Figure 58: Comparison of speedups over an inorderpipeline for health running on SUDS versus a super-scalar.
correspond to the updates to head and tail . In addi-tion, the tail variable is updated in the inner loop,and thus must be reassociated by generalized recur-rence reassociation.
When the loop distributed code is run concurrentlyunder the SUDS memory dependence speculation sys-tem it tends to be the case that there are very few mem-ory misspeculations. There do tend to be a few mem-ory misspeculations when the loop first starts to exe-cute, because the root of the tree attempts to executeconcurrently with its immediate children. After get-ting past this initial misspeculation phase however, thetree branches out widely enough that no more memorysystem conflicts occur.
As a result of these factors, the SUDS system runsthis code about 15% faster than does the idealizedmodel of Tomasulo’s algorithm. Again, this is despitethe fact that only about 50% of the memory accessesin this program are spills to activation frames that theSUDS system is capable of L1 caching. This program isparticularly memory intensive because the operationsperformed on each node involve linked list traversals.The working set for this program, moreover, is rela-tively small, and fits completely in the superscalar’s L1cache, so the superscalar is paying almost no latencyfor L2 cache accesses, while SUDS is paying L2 cachelatencies for approximately 50% of the loads operationsit performs.
8.3 Discussion
In this section I discuss three limitations of the SUDSprototype system, and ways in which they might beaddressed in future work. The first limitation is that
SUDS lacks an effective L1 cache. I will discuss sub-sequently why I believe this to be an implementa-tion error, rather than a more fundamental designflaw. The second limitation has to do with the scal-ability of the required compiler support. In particu-lar, both the lzw and health applications requiredinter-procedural analysis and inlining to perform therequired register promotion transformation describedin Section 5.4. It is not clear that the inlining trans-formation, in particular, will effectively scale to appli-cations that are significantly larger than the ones de-scribed here. Finally, I will discuss limitations on theparallel scalability of the SUDS system.
An additional limitation of the SUDS system, as withall existing memory dependence speculation systems,is that it implements a flat, rather than nested, trans-action protocol. As a result, only one granularity ofparallelism can be exploited at a time. This limitation,and some issues that need to be solved before it can beaddressed, are discussed in Chapter 10.
L1 Caching
In all three of the applications discussed above, SUDSachieved speedups approximately equal to, or betterthan, those achieved by the idealized model of Toma-sulo’s algorithm. In all cases the SUDS system was par-ticularly handicapped by its lack of L1 caching. Thelack of L1 caching in the SUDS system, however, isnot fundamental. As was mentioned briefly at the endof Section 7.3, it is relatively straight forward to add acaching system on top of SUDS, and in fact a softwarebased L1 cache was implemented on top of an earlierversion of SUDS [128].
The basic idea behind adding caching on top ofSUDS would be to implement a standard directorybased cache coherence scheme [21, 10, 2]. The key toa directory based cache coherence scheme is that thedirectory is guaranteed to see all the traffic to a par-ticular memory location, and in the same global orderthat is observed in all other parts of the system. Thus,the directory controller can simply forward the list ofrequests to the concurrency control system, which canthen process the information out-of-band.
This would all work fine, but our initial studiesshowed that the temporal locality exploitable by thisscheme is extremely low. This is true for several rea-sons. First, because the L1 caches are distributedamong eight execution units, an L1 fetch by one execu-tion unit does not improve the cache hit rate of any ofthe seven other execution units. There is another issue,which is not a problem, but that severely limits the tem-poral locality exploitable by an L1 cache implementedover the SUDS runtime. This is that the SUDS system
60

is already directing between 30% and 50% of the mem-ory traffic to the L1 cache in the form of (non-shared)accesses to activation frames. (Primarily for registerspills). While the register spill traffic does have a hightemporal locality of reference, the rest of the memorytraffic, which would be directed to the cache coherencesystem, does not [128].
The reason that the idealized superscalar is gettingL1 cache miss rates significantly better than is theSUDS system lies in the superscalar’s 8-word wideL1 cache lines. Essentially, the superscalar is able toprefetch useful data before it is required. The SUDS sys-tem, without L1 caching, is not able to leverage thisadvantage.
There are three reasons I did not implement coher-ent L1 caches for SUDS. The first had to do with mymisunderstanding the importance of the spatial local-ity exploited by wide cache lines. After the initial stud-ies showing the low temporal locality available in thememory system (both in Wilson’s thesis [128] and inseveral informal studies we never published), I becamemistakenly convinced that caching wouldn’t really buymuch.
The second reason I did not implement coherent L1caches for SUDS was that I wasn’t sure how to reconcileword-level concurrency control with multi-word cachelines. I now believe that information about the specificwords in a line that have been accessed can probably bepiggy-backed on the standard coherence messages, butmore work will need to be done to make this efficient.
The third reason I did not implement coherent L1caches for SUDS had to do with an, arguably, un-reasonable fixation that I had on implementing cachecontrollers in software. It turned out that while thiscan be spectacularly successful in specific cases [84], itworks rather less well for random access data mem-ories. Thus, as described in Wilson’s thesis [128], wewere unable to implement an L1 data cache with la-tencies that were significantly lower than the observedlatencies in the transactional L2 cache implemented inthe final SUDS prototype. In the future I plan to ad-dress this deficiency in the context of a hardware im-plemented L1 cache coherence scheme.
Compiler Scalability
A second question with regard to the SUDS prototypehas to do with the scalability of the compiler analy-ses and transformations. The scalar queue conversiontransformation, unidirectional renaming transforma-tion and generalized loop distribution transformationsare all intra-procedural. Although I have not done anycomplexity analysis on these algorithms, several of thecontrol flow graphs in the programs I looked at are rel-
atively large (hundreds of nodes), and on the occasionswhen I made the mistake of implementingO(N3) algo-rithms, I noticed immediately, and was forced to reim-plement.
The equivalence class unification and register pro-motion algorithms described in Sections 5.3 and 5.4, onthe other hand, require inter-procedural pointer anal-ysis. For this analysis I relied on Radu Rugina’s spantool, which is believed to scale, in practice, to programsthat are relatively large [97].
A potentially more severe problem was that sev-eral of these programs (and in particular lzw decom-press ) were written using global (scalar) variablesthat were modified inside subprocedures. In order toperform scalar queue conversion on these variables itwas necessary to promote them to registers used andmodified within the loop being transformed. To per-form this register promotion, however, required inlin-ing the corresponding subprocedures.
It is unlikely that such inlining will scale to pro-grams much larger than several tens of thousands oflines of code. It is an open question (and as far asI know, an unexamined question), whether there isa way of performing efficient inter-procedural regis-ter promotion. One approach might be to, on anprocedure-by-procedure basis, promote globals to call-by-reference parameters, and then promote call-by-reference to copy-in-copy-out. Effecting such a schemewould be an interesting direction for future research.
Parallel Scalability
A third question with regard to the SUDS prototypehas to do with the ability of the system to scale to largerdegrees of parallelism. The answer to this question ac-tually depends on the application one is looking at.In the case of the three applications discussed in thischapter, the answer is that they do not scale beyondabout eight compute nodes.
The reasons are threefold. First, parallel speedupsare limited by Amdahl’s law, and all of the applicationsconsidered here are “do-across” loops, rather than “do-all” loops. That is, these loops contain scalar loop car-ried dependences (the “critical nodes” identified bygeneralized loop distribution), and these loop carrieddependences limit the available parallelism. For ex-ample, the lzw program has six critical nodes, and thefraction of execution time spent in the sequential codecorresponding to these critical nodes grows as paral-lelism is increased. Informal experimentation showedthat lzw sped up by only an additional 2% when runon a system with 16 compute nodes instead of the 8node system described above.
The second impediment to speedup involves the
61

“birthday paradox” problem described in Section 7.2.4.Recall that this is a problem fundamental to all mem-ory dependence speculation systems, not one specificto the SUDS system. For example, the moldyn pro-gram modifies a sparse-matrix data structure in an ef-fectively random pattern. Informal experimentationshowed that moldyn exhibits speedup curves quali-tatively similar to those shown in Figure 50. In fact,the speedup curves for moldyn are worse than thoseshown in the figure, because the figure models only asingle update per thread, while in moldyn each threadmakes, on average, several hundred updates to theshared data structure. For the problem size of 256,000particles described in Section 8.2.1 maximum speedupoccured in a system with eight compute nodes. A six-teen compute node system exhibited less speedup dueto an increased number of concurrency violations ver-sus the eight node system.
The final impediment to parallel speedup involvesthe fundamentally distributed nature of the memorysystem, as described in Section 1.1. That is, as the sizeof the memory system grows, the average latency to ac-cess a random element in the memory system grows asthe square root of the memory size. This problem doesnot place any maximum limit on the speedup achiev-able by any application, but it does mean that one cannot expect performance to scale linearly as problemsize grows.
9 Related Work
This chapter describes the relationship of the work inthis thesis to previous work in scalar expansion, loopdistribution, program slicing, thread-level speculation,critical path reduction and data speculation.
9.1 Scalar Queue Conversion
The idea of renaming to reduce the number of stor-age dependences in the dependence graph has longbeen a goal of parallelizing and vectorizing compilersfor Fortran [68]. The dynamic closure creation doneby the queue conversion algorithm in Section 3 can beviewed as a generalization of earlier work in scalar ex-pansion [68, 29]. Given a loop with an index variableand a well defined upper limit on trip count, scalar ex-pansion turns each scalar referenced in the loop into anarray indexed by the loop index variable. The queueconversion algorithm works in any code, even whenthere is no well defined index variable, and no way tostatically determine an upper bound on the number oftimes the loops will iterate. Moreover, earlier meth-ods of scalar expansion are heuristic. Queue conver-
sion is the first compiler transformation that guaranteesthe elimination of all register storage dependences thatcreate cycles across what would otherwise be a unidi-rectional cut.
Given a loop containing arbitrary forward controlflow, loop distribution [68] can reschedule that graphacross a unidirectional cut [59, 51], but since loopdistribution does no renaming, the unidirectional cutmust be across the conservative program dependencegraph (i.e., including the register storage dependences).Queue conversion works across any unidirectional cutof the value dependence graph. Because scalar queueconversion always renames the scalars that would cre-ate register storage dependences, those dependencesneed not be considered during analysis or transforma-tion. It is sometimes possible to perform scalar ex-pansion before loop distribution, but loop distributionmust honor any register storage dependences that areremaining.
Moreover, existing loop distribution techniques onlyhandle arbitrary forward control flow inside the loop,and do so by creating arrays of predicates [59, 51]. Thetypical method is to create an array of three valuedpredicates for each branch contained in the loop. Thenon each iteration of the top half of the loop a predi-cate is stored for each branch (i.e., “branch went left”,“branch went right” or “branch was not reached dur-ing this iteration”). Any code distributed across thecut tests the predicate for its closest containing branch.This can introduce enormous numbers of useless tests,at runtime, for predicates that are almost never true.
Queue conversion, on the other hand, creates andqueues closures if and only if the dependent code isguaranteed to run. Thus, the resulting queues are (dy-namically) often much smaller than the correspondingset of predicate arrays would be. More importantly,queue conversion works across inner loops. Further,because queue conversion allocates closures dynami-cally, rather than creating static arrays, it can handlearbitrary looping control flow, in either the outer or in-ner loops, even when there is no way to statically de-termine an upper bound on the number of times theloops will iterate.
Feautrier has generalized the notion of scalar expan-sion to the notion of array expansion [38]. As withscalar expansion, Feautrier’s array expansion worksonly on structured loops with compile time constantbounds, and then only when the array indices areaffine (linear) functions of the loop index variables.Feautrier’s technique has been extended to the non-affine case [62], but only when the transformed ar-ray is not read within the loop (only written). Theequivalence class unification and register promotiontechniques described in Chapter 5 extend scalar queue
62

conversion to work with structured aggregates (e.g., Cstruct s), but not with arrays. Instead, scalar queueconversion relies on the memory dependence spec-ulation system described in Chapter 7 to parallelizeacross array references (and even arbitrary pointer ref-erences).
The notion of a unidirectional cut defined in Sec-tion 3.3 is similar to the notion, from software engineer-ing, of a static program slice. A static program slice istypically defined to be the set of textual statements in aprogram upon which a particular statement in the pro-gram text depends [125]. Program slices are often con-structed by performing a backward depth first searchin the value dependence graph from the nodes corre-sponding to the statements of interest[90]. This pro-duces a unidirectional cut.
In Section 3.4 we proved that we could produce anexecutable control flow graph that includes exactly thenodes from the top of a unidirectional cut of the valuedependence graph. Yang has proved the similar prop-erty, in the context of structured code, that an executableslice can be produced by eliding all the statementsfrom the program text that are not in the slice [131].Apparently it is unknown, given a program text withunstructured control flow, how to produce a controlflow graph from the text, elide some nodes from thegraph and then accurately back propagate the elisionsto the program text [13].15 Generalizations of Yang’sresult to unstructured control flow work only by insert-ing additional dependences into the value dependencegraph [13, 24], making the resulting slices larger andless accurate. The proof in Section 3.4 demonstratesthat when working directly with control flow graphs(rather than program texts) this extra work is unneces-sary, even when the control flow is irreducible.
Further, program slicing only produces the portionof the program corresponding to partition A of a uni-directional cut A-B. In Sections 3.5 and 3.6 we demon-strated how to queue and then resume a set of closuresthat reproduce the execution of partition B as well.
The reason queue conversion generalizes both loopdistribution and program slicing is that queue conver-sion makes continuations [111, 107, 8] explicit. That is, anytime we want to defer the execution of a piece of code,we simply create, and save, a closure that representsthat code, plus the suspended state in which to run thatcode. It is standard to compile functional languages bymaking closures and continuations explicit [107, 8], butthis set of techniques is relatively uncommon in com-pilers for imperative languages.
15A potential solution, of which I am unable to find any mentionin the literature, would be to associate information about goto state-ments with edges in the control flow graph, rather than nodes. Hope-fully, this will be investigated in the future.
In fact, the SSA based static renaming optimizationin Chapter 4 was anticipated by work from formal pro-gramming language semantics that demonstrates thatcontinuation passing style representations and SSAform flow graphs of imperative programs are seman-tically equivalent [58]. Based on this work, Appel hassuggested that a useful way of viewing the φ nodes atthe join points in SSA flow graphs is as the point inthe program at which the actual parameters should becopied into the formal parameters of the closure rep-resenting the code dominated by the φ node [7]. Thisroughly describes what the algorithm given in Chap-ter 4 does.
That is, given a maximal group β containing a useof variable x for which we are going to create a clo-sure, we rename x to x ′ (which can be viewed as theformal parameter). Then we introduce a new closure,containing the instruction x′ = x, at the φ point whichshares an environment containing x′ with β. It is usefulto view the new closure as simply copying the actualparameter, x, to the formal parameter x ′.
Traditional superscalar micro-architectures do re-naming only at the top of the stack by having the com-piler register allocate automatic variables and then re-naming the registers at runtime [117, 57, 104, 83, 105].This technique is used ubiquitously in modern archi-tectures because it performs at least enough renam-ing to reach the parallelism limits imposed by flowdependences [124]. Unfortunately, the renamed regis-ters are an extraordinarily constrained resource, mak-ing it impossible for superscalars to exploit flow de-pendences that can be eliminated through control de-pendence analysis [40].
Dataflow architectures [35, 34, 91, 28] do as much(or more) renaming as does queue conversion, but atthe cost of insisting that all programs be representedpurely functionally. This makes converting to dynam-ically allocated closures easy (because loops are repre-sented as recursive procedures), but substantially re-stricts the domain of applicability. Queue conversionworks on imperative programs, and, at least for scalarvariables, performs renaming in a similar way.
Even more troubling than the inability of dataflowarchitectures to execute imperative programs, was thatthey contained no provision for handling overflowof renaming buffers [27]. Recently, work on effi-cient task queue implementations for explicitly parallelfunctional programming languages [85] has been ex-tended to provide theoretical bounds on the renamingresources required by such systems [18, 17]. SUDS pro-vides constant bounded resource guarantees throughits checkpoint repair mechanism. This mechanism al-lows SUDS to rollback and sequentially reexecute anyprogram fragment that exhausts renaming resources
63

when run in parallel. Further, the SUDS memorydependence speculation mechanism allows SUDS toautomatically parallelize sequential programs, writtenin conventional imperative programming languages,rather than relying on programmers to explicitly par-allelize their programs.
The original motivation for queue conversion comesfrom previous work in micro-optimization. Micro-optimization has two components. The first, interfacedecomposition involves breaking up a monolithic inter-face into constituent primitives. Examples of this fromcomputer architecture include Active Messages as aprimitive for building more complex message passingprotocols [121], and interfaces that allow user level pro-grams to build their own customized shared memorycache coherence protocols [22, 70, 95]. Examples of thebenefits of carefully chosen primitive interfaces are alsocommon in operating systems research for purposes asdiverse as communication protocols for distributed filesystems [99], virtual memory management [50], andother kernel services [16, 55].
The second component of micro-optimization in-volves using automatic compiler optimizations (e.g.,partial redundancy elimination) to leverage the de-composed interface, rather than forcing the applica-tion programmer to do the work. This technique hasbeen used to improve the efficiency of floating-pointoperations [31], fault isolation [122], shared memorycoherence checks [100], and memory access serializa-tion [37, 14]. On Raw, micro-optimization across de-composed interfaces has been used to improve the ef-ficiency of both branching and message demultiplex-ing [74], instruction cache tag checks [84, 80], and datacache tag checks [86, 130].
Queue conversion micro-optimizes by making therenaming of scalar variables an explicit operation. Be-cause queue conversion renames into dynamic mem-ory, rather than a small register file, instructions can bescheduled over much longer time frames than they canwith Tomasulo’s algorithm. On the other hand, queueconversion can limit the costs of renaming to exactlythose points in a program where an anti- dependenceor output- dependence might be violated by a specificschedule. Further, we will show in Chapter 4 that, be-cause scalar queue conversion makes renaming an ex-plicit operation, the compiler can move the renamingpoint to a point in the program between the productionof a value and its consumption, thus minimizing thenumber of times the renaming must occur.
9.2 Loop Distribution and Critical Path Re-duction
As described above, generalized loop distribution gen-eralizes loop distribution [68, 59, 51], by using scalarqueue conversion to guarantee the elimination of allscalar anti- and output- dependences. Thus, general-ized loop distribution simultaneously does the workof scalar expansion and loop distribution. In addi-tion, generalized loop distribution distributes loopsthat contain arbitrary control flow, including innerloops.
A transformation similar to loop distribution, calledcritical-path reduction has been applied in the context ofthread-level speculative systems [120, 109, 133]. Ratherthan distribute a loop into multiple loops, critical-pathreduction attempts to reschedule the body of the loopso as to minimize the amount of code executed duringan update to a critical node. While the transformationis somewhat different than that performed by loop dis-tribution, loop distribution and critical-path reductionshare the goal of trying to minimize the time observedto update state visible outside the loop body.
Schlansker and Kathail [101] have a critical-path re-duction algorithm that optimizes critical paths in thecontext of superblock scheduling [53], a form of tracescheduling [41]. Vijaykumar implemented a critical-path reduction algorithm for the multiscalar proces-sor that moves updates in the control flow graph [120].Steffan et al have implemented a critical-path reductionalgorithm based on Lazy Code Motion [63] that movesupdate instructions to their optimal point [109, 133].As with previous loop distribution algorithms, none ofthese critical-path reduction algorithms can rescheduleloops that contain inner loops.
9.3 Memory Dependence Speculation
Timestamp based algorithms have long been used forconcurrency control in transaction processing systems.The memory dependence validation algorithm usedin SUDS is most similar to the “basic timestamp or-dering” technique proposed by Bernstein and Good-man [15]. More sophisticated multiversion timestampordering techniques [94] provide some memory re-naming, reducing the number of false dependences de-tected by the system at the cost of a more compleximplementation. Optimistic concurrency control tech-niques [69], in contrast, attempt to reduce the cost ofvalidation, by performing the validations in bulk at theend of each transaction.
Memory dependence speculation is even more sim-ilar to virtual time systems, such as the Time Warpmechanism [54] used extensively for distributed event
64

driven simulation. This technique is very much likemultiversion timestamp ordering, but in virtual timesystems, as in data speculation systems, the assign-ment of timestamps to tasks is dictated by the sequen-tial program order. In a transaction processing system,each transaction can be assigned a timestamp when-ever it enters the system.
Knight’s Liquid system [61, 60] used a method morelike optimistic concurrency control [69] except thattimestamps must be pessimistically assigned a priori,rather than optimistically when the task commits, andwrites are pessimistically buffered in private memo-ries and then written out in serial order so that dif-ferent processing elements may concurrently write tothe same address. The idea of using hash tables ratherthan full maps to perform independence validationwas originally proposed for the Liquid system.
Knight also pointed out the similarity between cachecoherence schemes and coherence control in transac-tion processing. The Liquid system used a bus basedprotocol similar to a snooping cache coherence proto-col [47]. SUDS uses a scalable protocol that is moresimilar to a directory based cache coherence proto-col [21, 10, 2] with only a single pointer per entry, some-times referred to as a Dir1B protocol.
The ParaTran system for parallelizing mostly func-tional code [116] was another early proposal that re-lied on speculation. ParaTran was implemented in soft-ware on a shared memory multiprocessor. The proto-cols were based on those used in Time Warp [54], withcheckpointing performed at every speculative opera-tion. A similar system, applied to an imperative, C like,language (but lacking pointers) was developed by Wenand Yelick [127]. While their compiler could identifysome opportunities for privatizing temporary scalars,their memory dependence speculation system was stillforced to do renaming and forward true-dependencesat runtime, and was thus less efficient than SUDS.
SUDS is most directly influenced by the Multiscalararchitecture [43, 106]. The Multiscalar architecture wasthe first to include a low-latency mechanism for ex-plicitly forwarding dependences from one task to thenext. This allows the compiler to both avoid the ex-pense of completely serializing do-across loops andalso permits register allocation across task boundaries.The Multiscalar validates memory dependence spec-ulations using a mechanism called an address resolu-tion buffer (ARB) [43, 44] that is similar to a hardwareimplementation of multiversion timestamp ordering.From the perspective of a cache coherence mechanismthe ARB is most similar to a full-map directory basedprotocol.
More recent efforts have focused on modifyingshared memory cache coherence schemes to support
memory dependence speculation [42, 48, 110, 66, 56,49]. SUDS implements its protocols in software ratherthan relying on hardware mechanisms. In the futureSUDS might permit long-term caching of read-mostlyvalues by allowing the software system to “perma-nently” mark an address in the timestamp cache.
Another recent trend has been to examine the pre-diction mechanism used by dependence speculationsystems. Some early systems [61, 116, 49] transmit alldependences through the speculative memory system.SUDS, like the Multiscalar, allows the compiler to stat-ically identify true-dependences, which are then for-warded using a separate, fast, communication path.SUDS and other systems in this class essentially stat-ically predict that all memory references that the com-piler can not analyze are in fact independent. Severalrecent systems [87, 119, 25] have proposed hardwareprediction mechanisms, for finding, and explicitly for-warding, additional dependences that the compiler cannot analyze.
Memory dependence speculation has also been ex-amined in the context of fine-grain instruction levelparallel processing on VLIW processors. The point ofthese systems is to allow trace-scheduling compilersmore flexibility to statically reorder memory instruc-tions. Nicolau [89] proposed inserting explicit addresscomparisons followed by branches to off-trace fix upcode. Huang et al [52] extended this idea to use pred-icated instructions to help parallelize the comparisoncode. The problem with this approach is that it requiresm× n comparisons if there arem loads being specula-tively moved above n stores. This problem can be al-leviated using a small hardware set-associative table,called a memory conflict buffer (MCB), that holds re-cently speculated load addresses and provides singlecycle checks on each subsequent store instruction [45].An MCB is included in the Hewlett Packard/Intel IA-64 EPIC architecture [12].
The LRPD test [93] is a software speculation systemthat takes a more coarse grained approach than SUDS.In contrast to most of the systems described here, theLRPD test speculatively block parallelizes a loop as ifit were completely data parallel and then tests to en-sure that the memory accesses of the different process-ing elements do not overlap. It is able to identify pri-vatizable arrays and reductions at runtime. A direc-tory based cache coherence protocol extended to per-form the LRPD test is described in [134]. SUDS takesa finer grain approach that can cyclically parallelizeloops with true-dependences and can parallelize mostof a loop that has only a few dynamic dependences.
65

10 Conclusion
I believe that the time is right for a revival of some-thing similar to the “dataflow” architectures of the lastdecade. The dataflow machines of the past, however,had two problems. Fortunately, a system like SUDScan help to address these problems.
The first problem was that dataflow machines didnot run imperative programs, but only programs writ-ten in functional programming languages [35, 34, 91,85, 28, 18, 17].16 Scalar queue conversion can help ad-dress this problem because it converts scalar updatesinto function (closure) calls.
The second problem with dataflow machines wasthat their renaming mechanisms were not fundamen-tally deadlock free [27]. Checkpoint repair mecha-nisms, like that provided by the SUDS transactionalmemory speculation system, can help address thisproblem by rolling back to a checkpointed state when-ever the renaming mechanism overflows the availablebuffers.
On the other hand, dataflow machines have a desir-able property that the SUDS system does not. This isthat dataflow machines allow the expression of concur-rency at the finest granularity, while the runtime sys-tem can be made responsible for choosing the granu-larity most appropriate for the available resources [85,18, 17].
SUDS, like all existing memory dependence specu-lation and thread speculation systems, implements aflat transaction model, and thus allows only one levelof parallelism to be expressed in any particular loop.Consider the example program used throughout Chap-ters 2, 3 and 4 (shown in Figure 7). In this examplewe decided to use generalized loop distribution to par-allelize the outer loop, but, depending on the relativetrip counts of the inner and outer loops this choicecould have been disastrous. If the outer loop iteratesmany times while the inner loop iterates only a fewtimes then generalized loop distribution on the outerloop will work quite well. Most of the concurrencywould be discovered and exploited. The deferred ex-ecution queues, created by scalar queue conversion,would have stayed relatively small because the size ofthese queues is proportional to the trip count of the in-ner loop.
On the other hand, if the outer loop iterates onlya few times and the inner loop iterates many times,
16More recent dataflow languages, like Cilk [18], permit impera-tive state updates. Unfortunately, the programmer is still forced towrite their parallel code in terms of recursive calls to stateless func-tions. This actually makes the problem worse, since unlike the purefunctional languages used in early dataflow machines, Cilk providesno way for the compiler to automatically check that programmershave not unwittingly inserted data races into their programs.
then applying generalized loop distribution to theouter loop would produce poor results. The systemwould try to exploit concurrency only in the outer loop.Meanwhile, each iteration of the outer loop would cor-respond to a thread, and that thread would create adeferred execution queue corresponding to the workin the inner loop. Since the inner loop executes manytimes, the deferred execution queues grow large, andcould potentially overflow the available memory re-sources. This overflow would invoke the (relativelyexpensive) checkpoint recovery mechanism. Thus, theloop would end up executing completely sequentiallywith the added cost of attempting and then abortingeach speculative strip.
One solution to this problem has been to developheuristic compiler analyses to try to guess which loopswill be most profitable to parallelize [133]. Another(not very attractive) solution would be to apply specu-lative strip mining and generalized loop distribution toevery loop, and then use a runtime predictor to decidewhich loop in each loop nest should be speculativelyparallelized.
Combining dataflow with scalar queue conversionand transactional concurrency control might providean attractive alternative. In this case scalar queue con-version could be applied to every unidirectional cutin an imperative program that might expose concur-rency. The result would be that (except for memorydependences) the program would be, essentially, trans-formed into a fine grain, functional, dataflow program.The runtime system could then, as in lazy task sys-tems [85, 18, 17] dynamically choose to invoke each clo-sure either as a conventional procedure call or as a con-current thread as parallel resource become available.
To actually build such a system one would have tosolve a number of problems. There are at least twoproblems that seem particularly difficult (and there-fore, fun) to me. The first is how to reconcile the nestedconcurrency exposed by the system with the specula-tive transactional model. SUDS, like all other exist-ing memory dependence and thread speculation sys-tems, implements a flat transaction model. Theoreticalnested transaction processing protocols have been pro-posed [88, 54], but actual, efficient, implementations ofsuch systems seem to be in short supply. In nestedtransaction systems even seemingly simple problems,like efficient timestamp implementation, seem to re-quire baroque solutions (see, for example, [116]). A sec-ond problem has to do with how one could extend theexisting work on dynamic memory dependence pre-diction [87, 119, 25] to nested transaction systems.
Perhaps then, this dissertation, in the end, raisesmore questions than it answers. In the introduction Istated that the SUDS system was built on three tech-
66

niques. They were dynamic scalar renaming, controldependence analysis, and speculation. I believe thatthese three techniques are necessary for finding and ex-ploiting concurrency. On the other hand, I have notshown, (and do not believe), that these three tech-niques are sufficient for finding and exploiting concur-rency. I like to think that this dissertation brings us astep closer to the goal of building a microprocessor thateffectively finds and exploits concurrency in the kindsof programs that programmers really write. Reachingthat goal will, I think, require a journey that is bothlong and enjoyable.
References
[1] Walid Abu-Sufah, David J. Kuck, and Duncan H.Lawrie. On the performance enhancement of pag-ing systems through program analysis and transforma-tions. IEEE Transactions on Computers, C-30(5):341–356,May 1981.
[2] Anant Agarwal, Richard Simoni, John Hennessy, andMark Horowitz. An evaluation of directory schemesfor cache coherence. In 15th International Symposiumon Computer Architecture, pages 280–289, Honolulu, HI,May 1988.
[3] Vikas Agarwal, M.S. Hrishikesh, Stephen W. Keckler,and Doug Burger. Clock rate versus IPC: The end ofthe road for conventional microarchitectures. In Pro-ceedings of the 27th Annual International Symposium onComputer Architecture (ISCA), June 2000.
[4] Alfred V. Aho, Ravi Sethi, and Jeffrey D. Ullman. Com-pilers: Principles, Techniques and Tools. Addison-Wesley,1986.
[5] Robert Alverson, David Callahan, Daniel Cummings,Brian Koblenz, Allan Porterfield, and Burton Smith.The Tera computer system. In Proceedings of the Inter-national Conference on Supercomputing, June 1990.
[6] Andrew W. Appel. Compiling with Continuations. Cam-bridge University Press, 1992.
[7] Andrew W. Appel. SSA is functional programming.SIGPLAN Notices, 33(4), 1998.
[8] Andrew W. Appel and Trevor Jim. Continuation-passing, closure-passing style. In Proceedings of theSymposium on Principles of Programming Languages,1989.
[9] Andrew W. Appel and Zhong Shao. Empirical andanalytic study of stack versus heap cost for languageswith closures. Journal of Functional Programming, 6(1),1996.
[10] James Archibald and Jean-Loup Baer. An economicalsolution to the cache coherence problem. In 11th In-ternational Symposium on Computer Architecture, pages355–362, Ann Arbor, MI, June 1984.
[11] Semiconductor Industry Association. Internationaltechnology roadmap for semiconductors, 2001.
[12] David I. August, Daniel A. Connors, Scott A. Mahlke,John W. Sias, Kevin M. Crozier, Ben-Chung Cheng,Patrick R. Eaton, Qudus B. Olaniran, and Wen meiW. Hwu. Integrated predicated and speculative exe-cution in the IMPACT EPIC architecture. In 25th Inter-national Symposium on Computer Architecture (ISCA-25),pages 227–237, Barcelona, Spain, June 1998.
[13] Thomas Ball and Susan Horwitz. Slicing programswith arbitrary control flow. In Proceedings of the 1st In-ternational Workshop on Automated and Algorithmic De-bugging, 1993.
[14] Rajeev Barua, Walter Lee, Saman P. Amarasinghe, andAnant Agarwal. Maps: A compiler-managed memorysystem for Raw machines. In Proceedings of the 26th An-nual International Symposium on Computer Architecture,pages 4–15, Atlanta, GA, May 2–4 1999.
[15] Philip A. Bernstein and Nathan Goodman. Timestamp-based algorithms for concurrency control in dis-tributed database systems. In Proceedings of the SixthInternational Conference on Very Large Data Bases, pages285–300, Montreal, Canada, October 1980.
[16] Brian N. Bershad, Stefan Savage, Przemysław Pardyak,Emin Gun Sirer, Marc E. Fiuczynski, David Becker,Craig Chambers, and Susan J. Eggers. Extensibility,safety and performance in the SPIN operating system.In Proceedings of the Fifteenth ACM Symposium on Oper-ating Systems Principles, pages 267–284, Copper Moun-tain Resort, CO, December 3-6 1995.
[17] Guy E. Blelloch, Phillip B. Gibbons, and Yossi Matias.Provably efficient scheduling for languages with fine-grained parallelism. Journal of the ACM, 46(2):281–321,1999.
[18] Robert D. Blumofe and Charles E. Leiserson. Schedul-ing multithreaded computations by work stealing. InProceedings of the 35th Annual Symposium on Founda-tions of Computer Science, Santa Fe, NM, pages 356–368,November 1994.
[19] Mihai Budiu and Seth Copen Goldstein. Optimizingmemory accesses for spatial computation. In Proceed-ings of the 1st International ACM/IEEE Symposium onCode Generation and Optimization, March 2003.
[20] Martin C. Carlisle and Anne Rogers. Software cachingand computation migration in Olden. In Proceedingsof the Fifth ACM Symposium on Principles and Practice ofParallel Programming, pages 29–38, Santa Barbara, CA,July 1995.
[21] Lucien M. Censier and Paul Feautrier. A new solutionto coherence problems in multicache systems. IEEETransactions on Computers, C-27(12):1112–1118, Decem-ber 1978.
[22] David Chaiken and Anant Agarwal. Software-extended coherent shared memory: Performance andcost. In Proceedings of the 21st Annual International
67

Symposium on Computer Architecture, pages 314–324,Chicago, Illinois, April 18–21, 1994.
[23] Anantha P. Chandrakasan, Samuel Sheng, andRobert W. Brodersen. Low power CMOS digital de-sign. IEEE Journal of Solid-State Circuits, 27(4):473–484,April 1992.
[24] Jong-Deok Choi and Jeanne Ferrante. Static slicing inthe presence of GOTO statements. ACM Transactions onProgramming Languages and Systems, 16(4):1097–1113,1994.
[25] George Z. Chrysos and Joel S. Emer. Memory depen-dence prediction using store sets. In 25th InternationalSymposium on Computer Architecture (ISCA-25), pages142–153, Barcelona, Spain, June 1998.
[26] Keith D. Cooper and John Lu. Register promotion inC programs. In Proceedings of the ACM SIGPLAN ’97Conference on Programming Language Design and Imple-mentation, pages 308–319, Las Vegas, NV, June 1997.
[27] David E. Culler and Arvind. Resource requirementsof dataflow programs. In Proceedings of the 15th AnnualInternational Symposium on Computer Architecture, pages141–150, May 1988.
[28] David E. Culler, Seth Copen Goldstein, Klaus ErikSchauser, and Thorsten von Eicken. TAM: A compilercontrolled threaded abstract machine. Journal of Paralleland Distributed Computing, June 1993.
[29] Ron Cytron and Jeanne Ferrante. What’s in a name?The value of renaming for parallelism detection andstorage allocation. In Proceedings of the 16th Annual In-ternational Conference on Parallel Processing, pages 19–27,St. Charles, IL, August 1987.
[30] Ron Cytron, Jeanne Ferrante, Barry K. Rosen, Mark N.Wegman, and F. Kenneth Zadeck. Efficiently comput-ing static single assignment form and the control de-pendence graph. ACM Transactions on ProgrammingLanguages and Systems, 13(4):451–490, 1991.
[31] William J. Dally. Micro-optimization of floating-pointoperations. In Proceedings of the Third International Con-ference on Architectural Support for Programming Lan-guages and Operating Systems, pages 283–289, Boston,MA, April 3–6, 1989.
[32] William J. Dally. Virtual-channel flow control.IEEE Transactions on Parallel and Distributed Systems,3(2):194–205, 1992.
[33] William J. Dally and Charles L. Seitz. Deadlock-free message routing in multiprocessor interconnectionnetworks. IEEE Transactions on Computers, 36(5):547–553, 1987.
[34] J. B. Dennis. Dataflow supercomputers. IEEE Computer,13(11):48–56, November 1980.
[35] Jack B. Dennis and David Misunas. A preliminary ar-chitecture for a basic data flow processor. In Proceedingsof the International Symposium on Computer Architecture(ISCA), pages 126–132, 1974.
[36] Wilm E. Donath. Placement and average interconnnec-tion lengths of computer logic. IEEE Transactions onCircuits and Systems, 26(4):272–277, April 1979.
[37] John R. Ellis. Bulldog: A Compiler for VLIW Archi-tecture. PhD thesis, Department of Computer Sci-ence, Yale University, February 1985. Technical ReportYALEU/DCS/RR-364.
[38] Paul Feautrier. Array expansion. In Proceedings of theInternational Conference on Supercomputing, pages 429–441, July 1988.
[39] William Feller. An Introduction to Probability Theory andIts Applications, volume 1. Wiley, New York, NY, 3rdedition, 1968.
[40] Jeanne Ferrante, Karl J. Ottenstein, and Joe D. Warren.The program dependence graph and its use in opti-mization. ACM Transactions on Programming Languagesand Systems, 9(3):319–349, July 1987.
[41] Joseph A. Fisher. Trace Scheduling: A technique forglobal microcode compaction. IEEE Transactions onComputers, C-30(7):478–490, July 1981.
[42] Manoj Franklin. Multi-version caches for Multiscalarprocessors. In Proceedings of the First International Con-ference on High Performance Computing (HiPC), 1995.
[43] Manoj Franklin and Gurindar S. Sohi. The expandablesplit window paradigm for exploiting fine-grain par-allelism. In 19th International Symposium on ComputerArchitecture (ISCA-19), pages 58–67, Gold Coast, Aus-tralia, May 1992.
[44] Manoj Franklin and Gurindar S. Sohi. ARB: A hard-ware mechanism for dynamic reordering of memoryreferences. IEEE Transactions on Computers, 45(5):552–571, May 1996.
[45] David M. Gallagher, William Y. Chen, Scott A. Mahlke,John C. Gyllenhaal, and Wen mei W. Hwu. Dynamicmemory disambiguation using the memory conflictbuffer. In Proceedings of the 6th International Conferenceon Architectural Support for Programming Languages andOperating Systems (ASPLOS), pages 183–193, San Jose,California, October 1994.
[46] A. Gonzalez, M. Valero, N. Topham, and J.M. Parcerisa.Eliminating cache conflict misses through XOR-basedplacement functions. In Eleventh International Confer-ence on Supercomputing, 1997.
[47] James R. Goodman. Using cache memory to reduceprocessor-memory traffic. In 10th International Sym-posium on Computer Architecture, pages 124–131, Stock-holm, Sweden, June 1983.
[48] Sridhar Gopal, T. N. Vijaykumar, James E. Smith,and Gurindar S. Sohi. Speculative versioning cache.In Proceedings of the Fourth International Symposiumon High Performance Computer Architecture (HPCA-4),pages 195–205, Las Vegas, NV, February 1998.
[49] Lance Hammond, Mark Willey, and Kunle Olukotun.Data speculation support for a chip multiprocessor. InProceedings of the Eighth ACM Conference on Architectural
68

Support for Programming Languages and Operating Sys-tems, pages 58–69, San Jose, CA, October 1998.
[50] Kieran Harty and David R. Cheriton. Application-controlled physical memory using external page-cachemanagement. In Proceedings of the Fifth InternationalConference on Architectural Support for Programming Lan-guages and Operating Systems, pages 187–197, Boston,MA, October 12–15, 1992.
[51] Bor-Ming Hsieh, Michael Hind, and Ron Cryton. Loopdistribution with multiple exits. In Proceedings Su-percomputing ’92, pages 204–213, Minneapolis, MN,November 1992.
[52] Andrew S. Huang, Gert Slavenburg, and John PaulShen. Speculative disambiguation: A compilationtechnique for dynamic memory disambiguation. InProceedings of the 21st Annual International Sympo-sium on Computer Architecture (ISCA), pages 200–210,Chicago, Illinois, April 1994.
[53] W. W. Hwu, R. E. Hank, D. M. Gallagher, S. A. Mahlke,D. M. Lavery, G. E. Haab, J. C. Gyllenhaal, and D. I.August. Compiler technology for future microproces-sors. Proceedings of the IEEE, 83(12):1625–1640, Decem-ber 1995.
[54] David R. Jefferson. Virtual time. ACM Transactions onProgramming Languages and Systems, 7(3):404–425, July1985.
[55] M. Frans Kaashoek, Dawson R. Engler, Gregory R.Ganger, Hector Briceno, Russell Hunt, David Mazieres,Thomas Pinckney, Robert Grimm, John Janotti, andKenneth Mackenzie. Application performance andflexibility on Exokernel systems. In Proceedings of theSixteenth ACM Symposium on Operating Systems Princi-ples, pages 52–65, Saint-Malo, France, October 5-8 1997.
[56] Iffat H. Kazi and David J. Lilja. Coarse-grained specu-lative execution in shared-memory multiprocessors. InInternational Conference on Supercomputing (ICS), pages93–100, Melbourne, Australia, July 1998.
[57] Robert M. Keller. Look-ahead processors. ACM Com-puting Surveys, 7(4):177–195, December 1975.
[58] Richard A. Kelsey. A correspondence between contin-uation passing style and static single assignment form.In Proceedings of the ACM SIGPLAN Workshop on Inter-mediate Representations, January 1995.
[59] Ken Kennedy and Kathryn S. McKinley. Loop distribu-tion with arbitrary control flow. In Proceedings Super-computing ’90, pages 407–416, New York, NY, Novem-ber 1990.
[60] Thomas F. Knight, Jr. System and method for paral-lel processing with mostly functional languages, 1989.U.S. Patent 4,825,360, issued Apr. 25, 1989 (expired).
[61] Tom Knight. An architecture for mostly functional lan-guages. In Proceedings of the ACM Conference on Lisp andFunctional Programming, pages 88–93, August 1986.
[62] Kathleen Knobe and Vivek Sarkar. Array SSA form andits use in parallelization. In Proceedings of the 25th Sym-posium on Principles of Programming Languages (POPL),January 1998.
[63] Jens Knoop, Oliver Ruthing, and Bernhard Steffen.Lazy code motion. In Proceedings of the ACM SIGPLANConference on Programming Language Design and Imple-mentation, 1992.
[64] Jens Knoop, Oliver Ruthing, and Bernhard Steffen.Partial dead code elimination. In Proceedings of theACM SIGPLAN Conference on Programming LanguageDesign and Implementation, 1994.
[65] Donald Ervin Knuth. The Art of Computer Programming,volume 3. Addison-Wesley, Reading, MA, 2nd edition,1998.
[66] Venkata Krishnan and Josep Torrellas. Hardware andsoftware support for speculative execution of sequen-tial binaries on a chip-multiprocessor. In InternationalConference on Supercomputing (ICS), Melbourne, Aus-tralia, July 1998.
[67] John D. Kubiatowicz. Integrated Shared-Memory andMessage-Passing Communication in the Alewife Multipro-cessor. PhD thesis, Department of Electrical Engineer-ing and Computer Science, Massachusetts Institute ofTechnology, February 1998.
[68] David J. Kuck, R. H. Kuhn, David A. Padua, B. Lea-sure, and Michael Wolfe. Dependence graphs and com-piler optimizations. In Conference Record of the EighthAnnual ACM Symposium on Principles of ProgrammingLanguages, pages 207–218, Williamsburg, VA, January1981.
[69] H. T. Kung and John T. Robinson. On optimisticmethods for concurrency control. ACM Transactions onDatabase Systems, 6(2):213–226, June 1981.
[70] Jeffrey Kuskin, David Ofelt, Mark Heinrich, John Hein-lein, Richard Simoni, Kourosh Gharachorloo, JohnChapin, David Nakahira, Joel Baxter, Mark Horowitz,Anoop Gupta, Mendel Rosenblum, and John Hen-nessy. The Stanford FLASH multiprocessor. In Pro-ceedings of the 21st Annual International Symposium onComputer Architecture, pages 302–313, Chicago, Illinois,April 18–21, 1994.
[71] Butler W. Lampson. Fast procedure calls. In Proceedingsof the First International Conference on Architectural Sup-port for Programming Languages and Operating Systems,1982.
[72] Peter J. Landin. The mechanical evaluation of expres-sions. Computer Journal, 6(4):308–320, 1964.
[73] B.S. Landman and R.L .Russo. On pin versus blockrelationship for partitions of logic circuits. IEEE Trans-actions on Computers, 20(12):1469–1479, December 1971.
[74] Walter Lee, Rajeev Barua, Matthew Frank, Dev-abhatuni Srikrishna, Jonathan Babb, Vivek Sarkar,and Saman Amarasinghe. Space-time scheduling of
69

instruction-level parallelism on a Raw machine. In Pro-ceedings of the Eighth ACM Conference on ArchitecturalSupport for Programming Languages and Operating Sys-tems, pages 46–57, San Jose, CA, October 1998.
[75] Thomas Lengauer and Robert Endre Tarjan. A fast al-gorithm for finding dominators in a flowgraph. ACMTransactions on Programming Languages and Systems,1(1):121–141, 1979.
[76] Nancy G. Leveson and Clark S. Turner. An investiga-tion of the Therac-25 accidents. IEEE Computer, pages18–41, July 1993.
[77] Zhiyuan Li. Array privatization for parallel execu-tion of loops. In Conference Proceedings, 1992 Interna-tional Conference on Supercomputing, Washington, DC,July 1992.
[78] J.D.C. Little. A proof of the queueing formula L = λW.Operations Research, 9(3):383–387, May 1961.
[79] Raymond Lo, Fred C. Chow, Robert Kennedy, Shin-Ming Liu, and Peng Tu. Register promotion by partialredundancy elimination of loads and stores. In Proceed-ings of the ACM SIGPLAN ’98 Conference on Program-ming Language Design and Implementation, pages 26–37,Montreal, Quebec, June 1998.
[80] Albert Ma, Michael Zhang, and Krste Asanovıc. Waymemoization to reduce fetch energy in instructioncaches. In Workshop on Complexity-Effective Design,ISCA-28, Goteborg, Sweden, June 2001.
[81] Doug Matzke. Will physical scalability sabotage per-formance gains? IEEE Computer, 30(9):37–39, Septem-ber 1997.
[82] Dror E. Maydan, Saman P. Amarasinghe, and Mon-ica S. Lam. Array data-flow analysis and its use in ar-ray privatization. In Proceedings of the Symposium onPrinciples of Programming Languages, volume POPL-20,pages 2–15, Charleston, SC, January 1993.
[83] Wen mei W. Hwu and Yale N. Patt. Checkpoint re-pair for high-performance out-of-order execution ma-chines. IEEE Transactions on Computers, 36(12):1496–1514, 1987.
[84] Jason Eric Miller. Software based instruction cachingfor the RAW architecture. Master’s thesis, Departmentof Electrical Engineering and Computer Science, Mas-sachusetts Institute of Technology, May 1999.
[85] Eric Mohr, David A. Kranz, and Robert H. Halstead,Jr. Lazy task creation: A technique for increasing thegranularity of parallel programs. IEEE Transactions onParallel and Distributed Systems, 2(3):264–280, 1991.
[86] Csaba Andras Moritz, Matthew Frank, and SamanAmarasinghe. FlexCache: A framework for flexiblecompiler generated data caching. In Proceedings of the2nd Workshop on Intelligent Memory Systems, Boston,MA, November 12 2000. to appear Springer LNCS.
[87] Andreas Moshovos and Gurindar S. Sohi. Streamlininginter-operation memory communication via data de-pendence prediction. In 30th Annual International Sym-
posium on Microarchitecture (MICRO), Research TrianglePark, NC, December 1997.
[88] J. Eliot B. Moss. Nested Transactions: An Approach toReliable Distributed Computing. MIT Press, 1981.
[89] Alexandru Nicolau. Run-time disambiguation: Cop-ing with statically unpredictable dependencies. IEEETransactions on Computers, 38(5):663–678, May 1989.
[90] Karl J. Ottenstein and Linda M. Ottenstein. The pro-gram dependence graph in a software developmentenvironment. In Peter B. Henderson, editor, Proceed-ings of the ACM SIGSOFT/SIGPLAN Software Engineer-ing Symposium on Practical Software Development Envi-ronments (SDE), pages 177–184, Pittsburgh, PA, April1984.
[91] Gregory M. Papadopoulos and David E. Culler. Mon-soon: An explicit token-store architecture. In Proceed-ings of the International Symposium on Computer Architec-ture (ISCA), pages 82–91, 1990.
[92] Keshav Pingali and Gianfranco Bilardi. Optimal con-trol dependence and the roman chariots problem. ACMTransactions on Programming Languages and Systems,19(3), May 1997.
[93] Lawrence Rauchwerger and David Padua. The LRPDtest: Speculative run-time parallelization of loops withprivatization and reduction parallelization. In Proceed-ings of the SIGPLAN Conference on Programming Lan-guage Design and Implementation, pages 218–232, LaJolla, CA, June 1995.
[94] David P. Reed. Implementing atomic actions on decen-tralized data. ACM Transactions on Computer Systems,1(1):3–23, February 1983.
[95] Steven K. Reinhardt, James R. Larus, and David A.Wood. Tempest and Typhoon: User-level shared mem-ory. In Proceedings of the 21st Annual InternationalSymposium on Computer Architecture, pages 325–336,Chicago, Illinois, April 18–21, 1994.
[96] Radu Rugina and Martin C. Rinard. Automatic paral-lelization of divide and conquer algorithms. In Proceed-ings of the 1999 ACM SIGPLAN Symposium on Principlesand Practice of Parallel Programming (PPOPP), pages 72–83, Atlanta, GA, May 1999.
[97] Radu Rugina and Martin C. Rinard. Pointer analysisfor multithreaded programs. In Proceedings of the ACMSIGPLAN ’99 Conference on Programming Language De-sign and Implementation, pages 77–90, Atlanta, GA, May1999.
[98] Radu Rugina and Martin C. Rinard. Symbolic boundsanalysis of pointers, array indices, and accessed mem-ory regions. In Proceedings of the 2000 ACM SIGPLANConference on Programming Language Design and Imple-mentation (PLDI), pages 182–195, Vancouver, BC, June2000.
[99] Jerome H. Saltzer, David P. Reed, and David D. Clark.End-to-end arguments in system design. ACM Trans-actions on Computer Systems, 2(4):277–288, November1984.
70

[100] Daniel J. Scales, Kourosh Gharachorloo, and Chan-dramohan A. Thekkath. Shasta: A low over-head, software-only approach for supporting fine-grain shared memory. In Proceedings of the Seventh Inter-national Conference on Architectural Support for Program-ming Languages and Operating Systems, pages 174–185,Cambridge, MA, October 1–5, 1996.
[101] Michael Schlansker and Vinod Kathail. Critical pathreduction for scalar programs. In Proceedings of the 28thInternational Symposium on Microarchitecture, 1995.
[102] Shamik D. Sharma, Ravi Ponnusamy, Bogki Moon,Yuan shin Hwang, Raja Das, and Joel Saltz. Run-timeand compile-time support for adaptive irregular prob-lems. In Proceedings of Supercomputing, pages 97–106,Washington, DC, November 1994.
[103] James E. Smith. A study of branch prediction strate-gies. Proceedings of the International Symposium on Com-puter Architecture, ISCA-8:135–148, May 1981.
[104] James E. Smith and Andrew R. Pleszkun. Implement-ing precise interrupts in pipelined processors. IEEETransactions on Computers, 37(5):562–573, May 1988.
[105] Gurindar S. Sohi. Instruction issue logic for high-performance, interruptible, multiple functional unit,pipelined computers. IEEE Transactions on Computers,29(3):349–359, March 1990.
[106] Gurindar S. Sohi, Scott E. Breach, and T. N. Vijayku-mar. Multiscalar processors. In 22nd International Sym-posium on Computer Architecture, pages 414–425, SantaMargherita Ligure, Italy, June 1995.
[107] Guy Lewis Steele. RABBIT: A compiler for Scheme.Technical Report AITR-474, MIT Artificial IntelligenceLaboratory, May 1978.
[108] Bjarne Steensgaard. Sparse functional stores for imper-ative programs. In Proceedings of the ACM SIGPLANWorkshop on Intermediate Representations, January 1995.
[109] J. Gregory Steffan, Christopher B. Colohan, AntoniaZhai, and Todd C. Mowry. Improving value communi-cation for thread-level speculation. In Proceedings of theInternational Symposium on High Performance ComputerArchitecture (HPCA), February 2002.
[110] J. Gregory Steffan and Todd C. Mowry. The poten-tial for using thread-level data speculation to facilitateautomatic parallelization. In Proceedings of the FourthInternational Symposium on High-Performance ComputerArchitecture (HPCA-4), pages 2–13, Las Vegas, NV,February 1998.
[111] Christopher Strachey and Christopher P. Wadsworth.Continuations: A mathematical semantics for handlingfull jumps. Higher-Order and Symbolic Computation,13(1):135–152, April 2000. (Republication of OxfordUniversity Computing Laboratory Technical Mono-graph PRG-11, 1974).
[112] Bjarne Stroustrup. The Design and Evolution of C++.Addison-Wesley, 1994.
[113] Michael Taylor, Jason Kim, Jason Miller, David Went-zlaff, Fae Ghodrat, Ben Greenwald, Henry Hoffman,Jae-Wook Lee, Paul Johnson, Walter Lee, Albert Ma,Arvind Saraf, Mark Seneski, Nathan Shnidman, VolkerStrumpen, Matt Frank, Saman Amarasinghe, andAnant Agarwal. The Raw microprocessor: A computa-tional fabric for software circuits and general purposeprograms. IEEE Micro, March 2002.
[114] Michael Bedford Taylor, Jason Kim, Jason Miller,David Wentzlaff, Fae Ghodrat, Ben Greenwald, HenryHoffmann, Paul Johnson, Walter Lee, Arvind Saraf,Nathan Shnidman, Volker Strumpen, Saman Ama-rasinghe, and Anant Agarwal. A 16-issue multiple-program-counter microprocessor with point-to-pointscalar operand network. In Proceedings of the IEEE Inter-national Solid-State Circuits Conference, February 2003.
[115] Michael Bedford Taylor, Walter Lee, Saman Amaras-inghe, and Anant Agarwal. Scalar operand networks:On-chip interconnect for ILP in partitioned architec-tures. In Proceedings of the International Symposium onHigh Performance Computer Architecture, February 2003.
[116] Pete Tinker and Morry Katz. Parallel execution of se-quential scheme with ParaTran. In Proceedings of theACM Conference on Lisp and Functional Programming,pages 40–51, July 1988.
[117] R.M. Tomasulo. An efficient algorithm for exploitingmultiple arithmetic units. IBM Journal of Research andDevelopment, 11(1):25–33, January 1967.
[118] Peng Tu and David Padua. Automatic array privati-zation. In Proceedings of the 6th International Workshopon Languages and Compilers for Parallel Computing, pages500–521, Portland, OR, August 1993.
[119] Gary S. Tyson and Todd M. Austin. Improving theaccuracy and performance of memory communicationthrough renaming. In 30th Annual International Sympo-sium on Microarchitecture (MICRO), Research TrianglePark, NC, December 1997.
[120] T. N. Vijaykumar. Compiling for the Multiscalar Archi-tecture. PhD thesis, University of Wisconsin-MadisonComputer Sciences Department, January 1998.
[121] Thorsten von Eicken, David E. Culler, Seth CopenGoldstein, and Klaus Eric Schauser. Active Messages:a mechanism for integrated communication and com-putation. In Proceedings of the 19th Annual Interna-tional Symposium on Computer Architecture, pages 256–266, Gold Coast, Australia, May 19–21, 1992.
[122] Robert Wahbe, Steven Lucco, Thomas E. Anderson,and Susan L. Graham. Efficient software-based faultisolation. In Proceedings of the Fourteenth ACM Sym-posium on Operating Systems Principles, pages 203–216,Asheville, North Carolina, December 5-8 1993.
[123] Elliot Waingold, Michael Taylor, Devabhaktuni Srikr-ishna, Vivek Sarkar, Walter Lee, Victor Lee, Jang Kim,Matthew Frank, Peter Finch, Rajeev Barua, JonathanBabb, Saman Amarasinghe, and Anant Agarwal. Bar-ing it all to software: Raw machines. IEEE Computer,30(9):86–93, September 1997.
71

[124] David W. Wall. Limits of instruction-level parallelism.In Proceedings of the Conference on Architectural Supportfor Programming Languages and Operating Systems (ASP-LOS), volume IV, pages 176–188, April 1991.
[125] Mark Weiser. Program slicing. IEEE Transactions onSoftware Engineering, 10(4):352–357, July 1984.
[126] Terry Welch. A technique for high-performance datacompression. IEEE Computer, 17(6):8–19, June 1984.
[127] Chih-Po Wen and Katherine Yelick. Compiling sequen-tial programs for speculative parallelism. In Proceed-ings of the International Conference on Parallel and Dis-tributed Systems, Taiwan, December 1993.
[128] Kevin W. Wilson. Integrating data caching into theSUDS runtime system. Master’s thesis, Departmentof Electrical Engineering and Computer Science, Mas-sachusetts Institute of Technology, June 2000.
[129] Robert P. Wilson and Monica S. Lam. Efficient context-sensitive pointer analysis for C programs. In Proceed-ings of the ACM SIGPLAN Conference on ProgrammingLanguage Design and Implementation (PLDI), 1995.
[130] Emmett Witchel, Sam Larsen, C. Scott Ananian, andKrste Asanovıc. Direct addressed caches for reducedpower consumption. In Proceedings of the InternationalSymposium on Microarchitecture (MICRO), volume 34,Austin, TX, December 2001.
[131] Wuu Yang. A New Algorlthm for Semantics-Based Pro-gram Integration. PhD thesis, University of Wisconsin-Madison Computer Sciences Department, August1990.
[132] Tse-Yu Yeh and Yale N. Patt. Two-level adaptivetraining branch prediction. Proceedings of the Interna-tional Symposium on Microarchitecture, MICRO-24:51–61, November 1991.
[133] Antonia Zhai, Christopher B. Colohan, J. Gregory Stef-fan, and Todd C. Mowry. Compiler optimizationof scalar value communication between speculativethreads. Proceedings of the Conference on ArchitecturalSupport for Programming Languages and Operating Sys-tems, ASPLOS-X, October 2002.
[134] Ye Zhang, Lawrence Rauchwerger, and Josep Torrellas.Hardware for speculative run-time parallelization indistributed shared-memory multiprocessors. In FourthInternational Symposium on High-Performance ComputerArchitecture (HPCA-4), pages 162–173, Las Vegas, NV,February 1998.
[135] Craig B. Zilles. Benchmark Health considered harmful.Computer Architecture News, pages 4–5, January 2001.
72
Related Documents