Lưu Vĩnh Trung. Tạp chí Khoa học Đại học Mở Thành phố Hồ Chí Minh, 59(2), 65-75 65 SỬ DỤNG KỸ THUẬT SO SÁNH CHUỖI KẾT HỢP TRÊN CÁC CHUỖI CÓ ĐỘ DÀI CHÊNH LỆCH LƯU VĨNH TRUNG Trường Đại học Mở Thành phố Hồ Chí Minh - [email protected] (Ngày nhận: 31/07/2017; Ngày nhận lại: 09/10/2017; Ngày duyệt đăng: 05/12/2017) TÓM TẮT Bài báo này giới thiệu một thang đo kết hợp các thuật giải so sánh chuỗi toàn cục và cục bộ để đánh giá sự tương tự giữa các cặp chuỗi ký tự. Qua thực nghiệm, thang đo được chứng minh về hiệu quả khi làm việc trên các chuỗi có độ dài chênh lệch so với các thang đo khác. Thang đo hữu ích trong việc phân cụm người dùng web, nhằm dự đoán và đáp ứng yêu cầu về thông tin của các nhóm người dùng khác nhau trong thời gian thực. Từ khóa: Khai phá dữ liệu web; Phân loại người dùng; So sánh chuỗi; Thương mại điện tử. Using glocal alignment to compare sequences of significantly different lengths ABSTRACT This paper introduces a “glocal” combinatorial algorithm between global and local alignments to evaluate the similarity of symbol sequence pairs. This approach empirically proves its merit compared to competitors working on sequences of significantly different lengths. The measure is also useful for clustering web audiences to predict and meet information needs of various groups of users in real-time. Keywords: E-commerce; Sequence alignment; User segmentation; Web mining. 1. Giới thiệu Kỹ thuật khai phá dữ liệu từ hành vi người dùng đang nhận được sự quan tâm ngày càng lớn của các nhà nghiên cứu, nhằm phục vụ các ứng dụng thương mại điện tử trong việc tìm hiểu nhu cầu người dùng web. Phân cụm (clustering) là một trong những kỹ thuật được chú ý nhất cho mục đích phát hiện các nhóm người dùng web tiềm ẩn có nhu cầu tương tự nhau. Sự hiểu biết về nhu cầu này giúp các ứng dụng thương mại điện tử cải tiến cách thức và nội dung cung cấp, để thông tin đến đúng người có nhu cầu nhằm tối ưu hóa lợi nhuận. Trong bài báo trước (Lưu Vĩnh Trung, 2017), chúng tôi đã trình bày cách tiếp cận dựa trên sự kết hợp của hai kỹ thuật so sánh chuỗi toàn cục và cục bộ, mà đại diện là Needleman-Wunsh và Smith-Waterman, dưới hình thức các điều kiện lọc dữ liệu. Cách tiếp cận đó được phát triển thành thang đo chính thức trong bài báo này. Thang đo của chúng tôi đã chứng tỏ ưu thế so với các thang đo khác khi làm việc trên dữ liệu gồm các chuỗi có độ dài tương phản, bị nhiễu hoặc không cân bằng. 2. Phương pháp nghiên cứu Cho tập xác định ∑ gồm các ký tự, chuỗi bất kỳ có độ dài k>0 là một bộ (tuple) k được tạo thành bằng các phần tử của ∑. Ví dụ, với ∑={A,B,C}, một tập S={s 1, s 2, s 3, … , s n } với n chuỗi xác định được tạo ra từ ∑ có thể gồm s 1 = AB , s 2 = ABC , … , s n= = ACB. Trong mô hình của chúng tôi, các phiên truy cập của người dùng có thể được xem như chuỗi các sự kiện truy cập trang web, và tập chuỗi S như trên đại diện cho các phiên truy cập (session). S được phân thành các cụm (cluster) sao cho các phiên làm việc trong cùng cụm tương tự nhau và khác biệt với các phiên làm việc trong các cụm khác. Dựa trên kết quả thực nghiệm về sự kết

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Lưu Vĩnh Trung. Tạp chí Khoa học Đại học Mở Thành phố Hồ Chí Minh, 59(2), 65-75 65
SỬ DỤNG KỸ THUẬT SO SÁNH CHUỖI KẾT HỢP
TRÊN CÁC CHUỖI CÓ ĐỘ DÀI CHÊNH LỆCH
LƯU VĨNH TRUNG Trường Đại học Mở Thành phố Hồ Chí Minh - [email protected]
(Ngày nhận: 31/07/2017; Ngày nhận lại: 09/10/2017; Ngày duyệt đăng: 05/12/2017)
TÓM TẮT
Bài báo này giới thiệu một thang đo kết hợp các thuật giải so sánh chuỗi toàn cục và cục bộ để đánh giá sự
tương tự giữa các cặp chuỗi ký tự. Qua thực nghiệm, thang đo được chứng minh về hiệu quả khi làm việc trên các
chuỗi có độ dài chênh lệch so với các thang đo khác. Thang đo hữu ích trong việc phân cụm người dùng web, nhằm
dự đoán và đáp ứng yêu cầu về thông tin của các nhóm người dùng khác nhau trong thời gian thực.
Từ khóa: Khai phá dữ liệu web; Phân loại người dùng; So sánh chuỗi; Thương mại điện tử.
Using glocal alignment to compare sequences of significantly different lengths ABSTRACT
This paper introduces a “glocal” combinatorial algorithm between global and local alignments to evaluate the
similarity of symbol sequence pairs. This approach empirically proves its merit compared to competitors working on
sequences of significantly different lengths. The measure is also useful for clustering web audiences to predict and
meet information needs of various groups of users in real-time.
Keywords: E-commerce; Sequence alignment; User segmentation; Web mining.
1. Giới thiệu Kỹ thuật khai phá dữ liệu từ hành vi
người dùng đang nhận được sự quan tâm ngày
càng lớn của các nhà nghiên cứu, nhằm phục
vụ các ứng dụng thương mại điện tử trong
việc tìm hiểu nhu cầu người dùng web. Phân
cụm (clustering) là một trong những kỹ thuật
được chú ý nhất cho mục đích phát hiện các
nhóm người dùng web tiềm ẩn có nhu cầu
tương tự nhau. Sự hiểu biết về nhu cầu này
giúp các ứng dụng thương mại điện tử cải tiến
cách thức và nội dung cung cấp, để thông tin
đến đúng người có nhu cầu nhằm tối ưu hóa
lợi nhuận.
Trong bài báo trước (Lưu Vĩnh Trung,
2017), chúng tôi đã trình bày cách tiếp cận
dựa trên sự kết hợp của hai kỹ thuật so sánh
chuỗi toàn cục và cục bộ, mà đại diện là
Needleman-Wunsh và Smith-Waterman, dưới
hình thức các điều kiện lọc dữ liệu. Cách tiếp
cận đó được phát triển thành thang đo chính
thức trong bài báo này. Thang đo của chúng
tôi đã chứng tỏ ưu thế so với các thang đo
khác khi làm việc trên dữ liệu gồm các chuỗi
có độ dài tương phản, bị nhiễu hoặc không
cân bằng.
2. Phương pháp nghiên cứu Cho tập xác định ∑ gồm các ký tự, chuỗi
bất kỳ có độ dài k>0 là một bộ (tuple) k được
tạo thành bằng các phần tử của ∑. Ví dụ, với
∑={A,B,C}, một tập S={s1, s2, s3,…, sn} với n
chuỗi xác định được tạo ra từ ∑ có thể gồm s1
= AB, s2 = ABC,…, sn= = ACB. Trong mô hình
của chúng tôi, các phiên truy cập của người
dùng có thể được xem như chuỗi các sự kiện
truy cập trang web, và tập chuỗi S như trên
đại diện cho các phiên truy cập (session). S
được phân thành các cụm (cluster) sao cho
các phiên làm việc trong cùng cụm tương tự
nhau và khác biệt với các phiên làm việc trong
các cụm khác.
Dựa trên kết quả thực nghiệm về sự kết
66 Lưu Vĩnh Trung. Tạp chí Khoa học Đại học Mở Thành phố Hồ Chí Minh, 59(2), 65-75
hợp giữa Needleman-Wunsh (NW) và Smith-
Waterman (SW) dưới dạng các điều kiện lọc
(Lưu Vĩnh Trung, 2017), chúng tôi phát triển
một thang đo chính thức S cho độ tương tự
của 2 chuỗi si và sj như sau:
(1)
Với NW(si,sj) và SW(si,sj) lần lượt là
điểm NW và SW của 2 chuỗi si và sj , l là độ
dài chuỗi dài hơn trong 2 chuỗi, thang đo NW
là +1 cho cặp phần tử giống nhau và -1 cho
cặp phần tử khác nhau. Với SW, thang đo
tương ứng là +2 và -1.
Một cách tiếp cận của các tác giả khác,
cũng dựa trên sự kết hợp giữa Needleman-
Wunsh và Smith-Waterman (Chordia và
Adhiya, 2011; Dimopoulos và cộng sự, 2010),
là thang đo kết hợp sử dụng tham số p, với p =
|si|/|sj| là tỷ lệ độ dài 2 chuỗi si và sj:
(2)
Để so sánh hiệu quả trong đánh giá độ
tương tự của các chuỗi giữa thang đo của
chúng tôi và các thang đo khác, ngoài thang
đo trên, một “competitor” nữa được đưa vào
thực nghiệm là thuật toán Dynamic Time
Warping (Petitjean và cộng sự, 2014), được
sử dụng phổ biến trong việc so sánh các chuỗi
sự kiện hoặc thời gian.
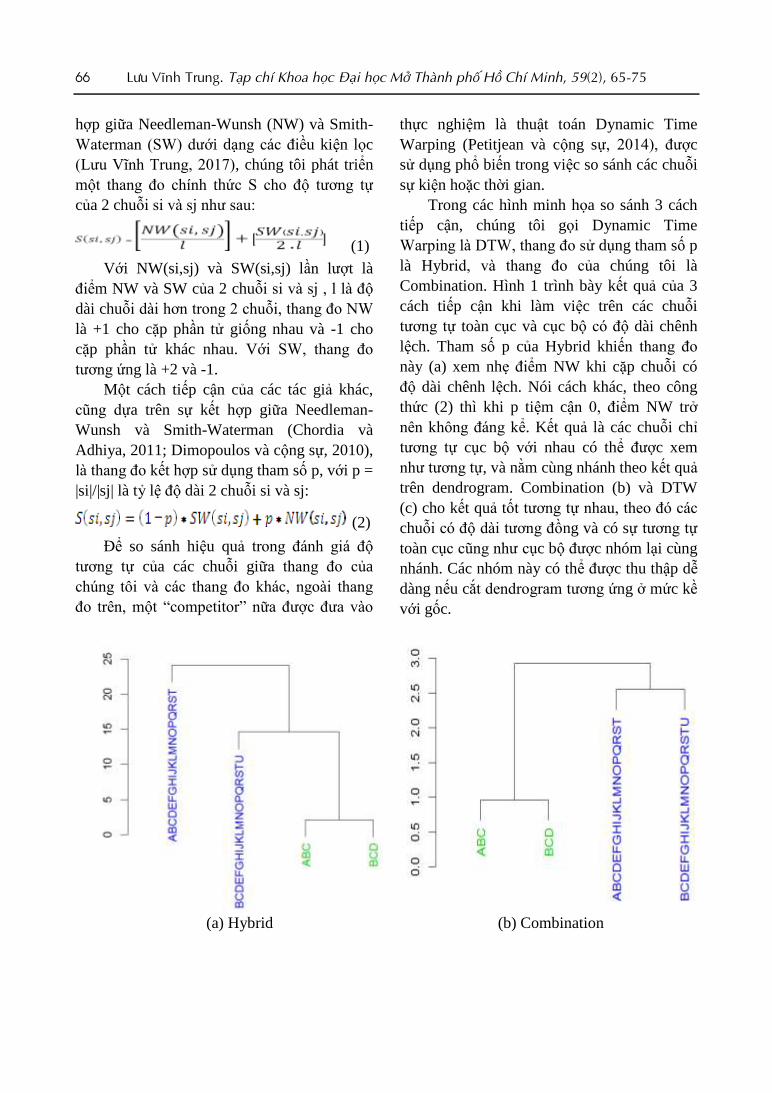
Trong các hình minh họa so sánh 3 cách
tiếp cận, chúng tôi gọi Dynamic Time
Warping là DTW, thang đo sử dụng tham số p
là Hybrid, và thang đo của chúng tôi là
Combination. Hình 1 trình bày kết quả của 3
cách tiếp cận khi làm việc trên các chuỗi
tương tự toàn cục và cục bộ có độ dài chênh
lệch. Tham số p của Hybrid khiến thang đo
này (a) xem nhẹ điểm NW khi cặp chuỗi có
độ dài chênh lệch. Nói cách khác, theo công
thức (2) thì khi p tiệm cận 0, điểm NW trở
nên không đáng kể. Kết quả là các chuỗi chỉ
tương tự cục bộ với nhau có thể được xem
như tương tự, và nằm cùng nhánh theo kết quả
trên dendrogram. Combination (b) và DTW
(c) cho kết quả tốt tương tự nhau, theo đó các
chuỗi có độ dài tương đồng và có sự tương tự
toàn cục cũng như cục bộ được nhóm lại cùng
nhánh. Các nhóm này có thể được thu thập dễ
dàng nếu cắt dendrogram tương ứng ở mức kề
với gốc.
(a) Hybrid (b) Combination

Lưu Vĩnh Trung. Tạp chí Khoa học Đại học Mở Thành phố Hồ Chí Minh, 59(2), 65-75 67
(c) DTW
Hình 1. Kết quả của Hybrid, Combination và DTW khi làm việc trên các chuỗi tương tự toàn
cục và cục bộ có độ dài chênh lệch
Với DTW, thuật toán này xem các phần tử
trùng lặp kề nhau trong một chuỗi như một phần
tử duy nhất. Hình 2 minh họa cơ chế này của
DTW, cho phép nhận dạng các chuỗi sự kiện
hoặc thời gian có hình dáng tương tự nhưng bị
nén hoặc giãn. Trong ngữ cảnh khai phá dữ liệu
người dùng web, cách tiếp cận này không phù
hợp vì nếu người dùng refresh nhiều lần một
trang web, hành vi đó không tương tự với người
dùng khác truy cập trang web đó chỉ một lần.
Hình 2. Cơ chế hoạt động của DTW đối với các phần tử trùng lặp nằm kề nhau khi so sánh 2
chuỗi. Chuỗi AAAABCD và ABCD được DTW đánh giá là trùng khớp nhau
Hình 3 cho thấy với các chuỗi có phần tử
trùng lặp, DTW không cho ra kết quả tốt như
Hình 1, Hybrid vẫn cho kết quả tương tự
Hình 1 vì đây là các chuỗi có độ dài khác
biệt. Chỉ có cách tiếp cận của chúng tôi vẫn
phù hợp để gom nhóm các chuỗi tương tự
nhau, đại diện cho những hành vi tương tự
của người dùng web.

68 Lưu Vĩnh Trung. Tạp chí Khoa học Đại học Mở Thành phố Hồ Chí Minh, 59(2), 65-75
(a) Hybrid (b) Combination
(c) DTW
Hình 3. Kết quả của Hybrid, Combination và DTW khi làm việc trên các chuỗi tương tự
toàn cục và cục bộ có độ dài chênh lệch
3. Kết quả Để đánh giá khách quan hiệu quả của
cách tiếp cận của chúng tôi so với các
“competitor”, chúng tôi đã làm thực nghiệm
trên 10 tập dữ liệu tổng hợp, mỗi tập gồm
khoảng 520 chuỗi đại diện cho các phiên làm
việc của người dùng, được chia làm 3 nhóm
với đặc điểm như sau:
Nhóm 1: Khoảng 170 chuỗi với chiều dài
từ 20-22 ký tự, các chuỗi này tương tự cục bộ
với nhau, ví dụ: MNOPDFSEDF4EFSDF3F
SDSDF, MNOPPDPO4O3W3KER3KO3O22,
MNOPCSDCASDG632YUEWHBDH,…
Nhóm 2: Khoảng 170 chuỗi với chiều dài
từ 3-4 ký tự, các chuỗi này tương tự cục bộ
với nhau, ví dụ: MNZ, OP56, NPI,...
Lưu Vĩnh Trung. Tạp chí Khoa học Đại học Mở Thành phố Hồ Chí Minh, 59(2), 65-75 69
Nhóm 3: Khoảng 170 chuỗi với chiều dài
từ 18-20 ký tự, các chuỗi này chứa các ký tự
trùng lặp kề nhau, ví dụ: AAAAAAAAAAM
NBBBBBBBBB, XXXXXXXXXXNOYYY
YYYYYY,...
Các chuỗi này được phân cụm bằng 3
cách tiếp cận nêu trên và 3 phương pháp phân
chia cấp bậc phổ biến nhất, là single-linkage,
complete-linkage và average-linkage (PunJ và
Stewart, 1983). Kết quả thực nghiệm được mô
tả tại Bảng 1 cho thấy, giá trị trung bình μ của
độ tinh khiết (purity) trên 10 tập dữ liệu của
Combination luôn cao hơn và độ lệch chuẩn σ của Combination luôn thấp hơn hai cách tiếp
cận còn lại.
Bảng 1
Giá trị trung bình μ của độ tinh khiết và độ lệch chuẩn σ trên kết quả của 3 cách tiếp cận với 3
phương pháp phân chia cấp bậc trên 10 tập dữ liệu tổng hợp
Dữ liệu tổng hợp gốc
Hybrid DTW Combination
sing. comp. avg. sing. comp. avg. sing. comp. avg.
μ 100% 58.5% 100% 90.5% 85.5% 89.7% 100% 98.2% 100%
σ ±0% ±8.5% ±0% ±9.7% ±1.4% ±9.8% ±0% ±5.7% ±0%
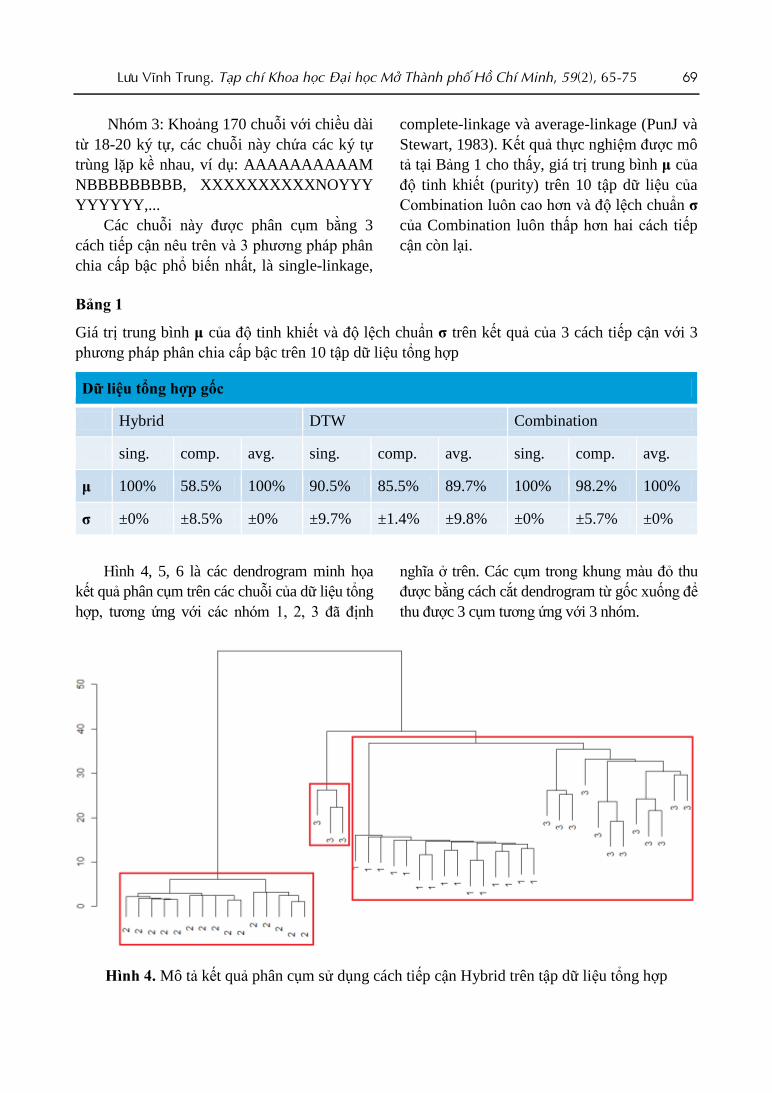
Hình 4, 5, 6 là các dendrogram minh họa
kết quả phân cụm trên các chuỗi của dữ liệu tổng
hợp, tương ứng với các nhóm 1, 2, 3 đã định
nghĩa ở trên. Các cụm trong khung màu đỏ thu
được bằng cách cắt dendrogram từ gốc xuống để
thu được 3 cụm tương ứng với 3 nhóm.
Hình 4. Mô tả kết quả phân cụm sử dụng cách tiếp cận Hybrid trên tập dữ liệu tổng hợp
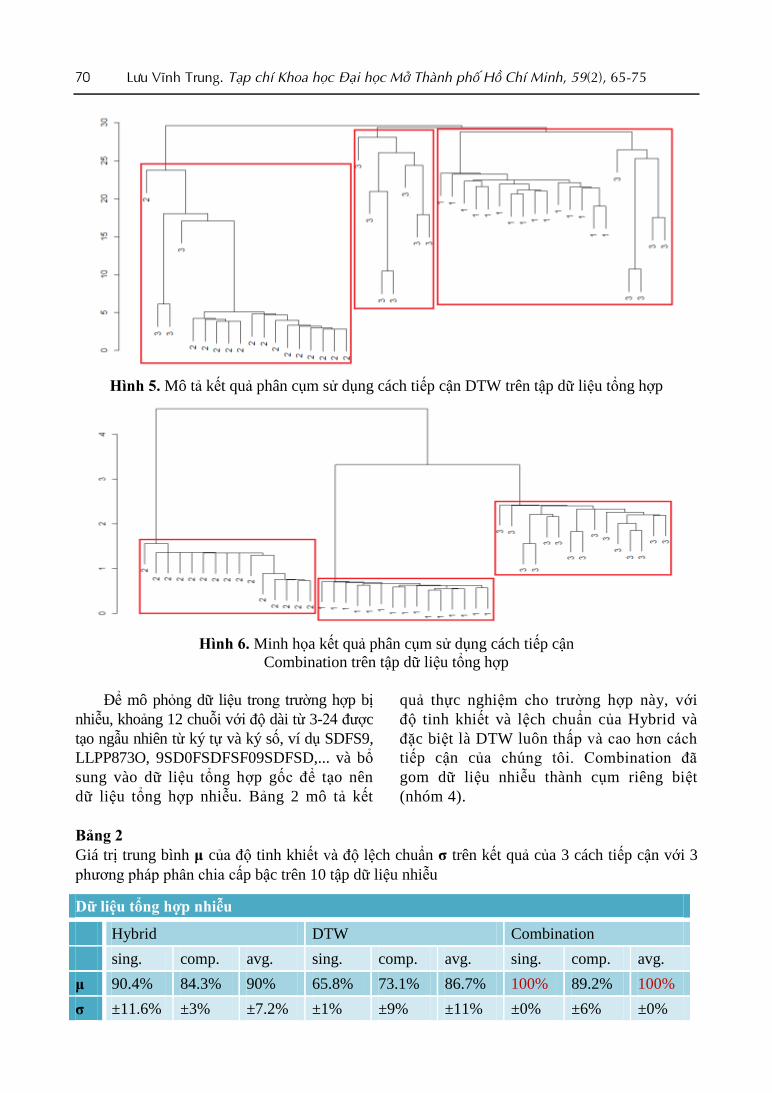
70 Lưu Vĩnh Trung. Tạp chí Khoa học Đại học Mở Thành phố Hồ Chí Minh, 59(2), 65-75
Hình 5. Mô tả kết quả phân cụm sử dụng cách tiếp cận DTW trên tập dữ liệu tổng hợp
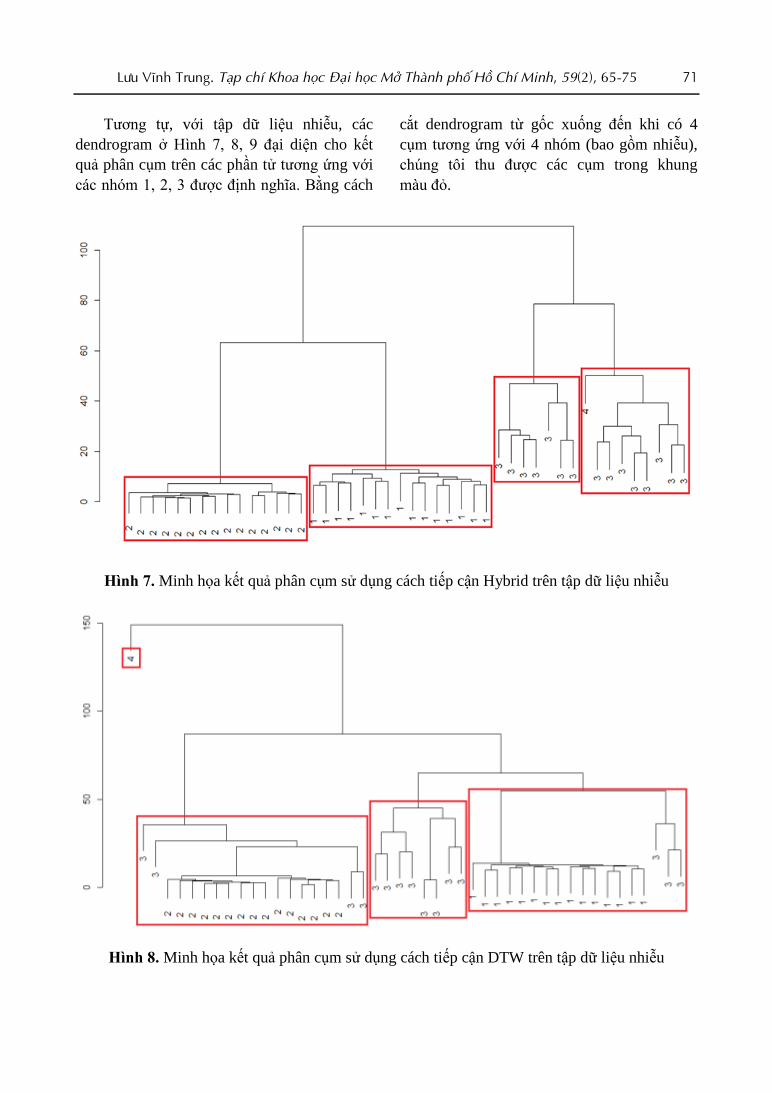
Hình 6. Minh họa kết quả phân cụm sử dụng cách tiếp cận
Combination trên tập dữ liệu tổng hợp
Để mô phỏng dữ liệu trong trường hợp bị
nhiễu, khoảng 12 chuỗi với độ dài từ 3-24 được
tạo ngẫu nhiên từ ký tự và ký số, ví dụ SDFS9,
LLPP873O, 9SD0FSDFSF09SDFSD,... và bổ
sung vào dữ liệu tổng hợp gốc để tạo nên
dữ liệu tổng hợp nhiễu. Bảng 2 mô tả kết
quả thực nghiệm cho trường hợp này, với
độ tinh khiết và lệch chuẩn của Hybrid và
đặc biệt là DTW luôn thấp và cao hơn cách
tiếp cận của chúng tôi. Combination đã
gom dữ liệu nhiễu thành cụm riêng biệt
(nhóm 4).
Bảng 2 Giá trị trung bình μ của độ tinh khiết và độ lệch chuẩn σ trên kết quả của 3 cách tiếp cận với 3
phương pháp phân chia cấp bậc trên 10 tập dữ liệu nhiễu
Dữ liệu tổng hợp nhiễu
Hybrid DTW Combination
sing. comp. avg. sing. comp. avg. sing. comp. avg.
μ 90.4% 84.3% 90% 65.8% 73.1% 86.7% 100% 89.2% 100%
σ ±11.6% ±3% ±7.2% ±1% ±9% ±11% ±0% ±6% ±0%
Lưu Vĩnh Trung. Tạp chí Khoa học Đại học Mở Thành phố Hồ Chí Minh, 59(2), 65-75 71
Tương tự, với tập dữ liệu nhiễu, các
dendrogram ở Hình 7, 8, 9 đại diện cho kết
quả phân cụm trên các phần tử tương ứng với
các nhóm 1, 2, 3 được định nghĩa. Bằng cách
cắt dendrogram từ gốc xuống đến khi có 4
cụm tương ứng với 4 nhóm (bao gồm nhiễu),
chúng tôi thu được các cụm trong khung
màu đỏ.
Hình 7. Minh họa kết quả phân cụm sử dụng cách tiếp cận Hybrid trên tập dữ liệu nhiễu
Hình 8. Minh họa kết quả phân cụm sử dụng cách tiếp cận DTW trên tập dữ liệu nhiễu
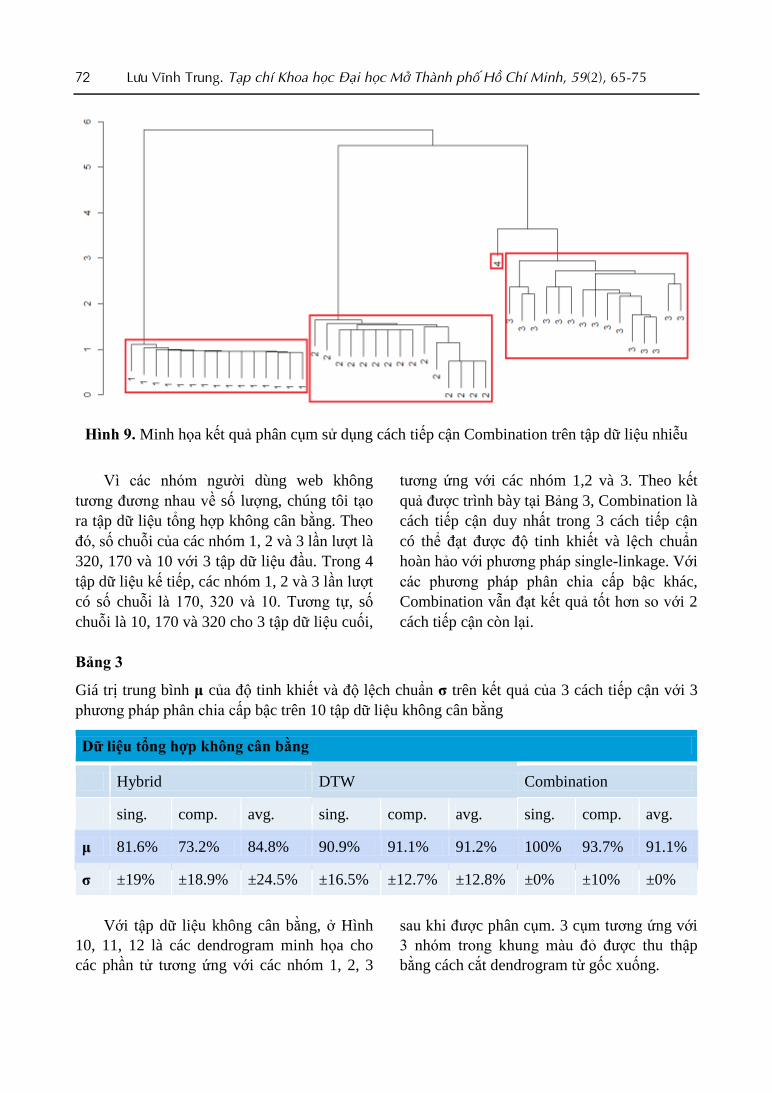
72 Lưu Vĩnh Trung. Tạp chí Khoa học Đại học Mở Thành phố Hồ Chí Minh, 59(2), 65-75
Hình 9. Minh họa kết quả phân cụm sử dụng cách tiếp cận Combination trên tập dữ liệu nhiễu
Vì các nhóm người dùng web không
tương đương nhau về số lượng, chúng tôi tạo
ra tập dữ liệu tổng hợp không cân bằng. Theo
đó, số chuỗi của các nhóm 1, 2 và 3 lần lượt là
320, 170 và 10 với 3 tập dữ liệu đầu. Trong 4
tập dữ liệu kế tiếp, các nhóm 1, 2 và 3 lần lượt
có số chuỗi là 170, 320 và 10. Tương tự, số
chuỗi là 10, 170 và 320 cho 3 tập dữ liệu cuối,
tương ứng với các nhóm 1,2 và 3. Theo kết
quả được trình bày tại Bảng 3, Combination là
cách tiếp cận duy nhất trong 3 cách tiếp cận
có thể đạt được độ tinh khiết và lệch chuẩn
hoàn hảo với phương pháp single-linkage. Với
các phương pháp phân chia cấp bậc khác,
Combination vẫn đạt kết quả tốt hơn so với 2
cách tiếp cận còn lại.
Bảng 3
Giá trị trung bình μ của độ tinh khiết và độ lệch chuẩn σ trên kết quả của 3 cách tiếp cận với 3
phương pháp phân chia cấp bậc trên 10 tập dữ liệu không cân bằng
Dữ liệu tổng hợp không cân bằng
Hybrid DTW Combination
sing. comp. avg. sing. comp. avg. sing. comp. avg.
μ 81.6% 73.2% 84.8% 90.9% 91.1% 91.2% 100% 93.7% 91.1%
σ ±19% ±18.9% ±24.5% ±16.5% ±12.7% ±12.8% ±0% ±10% ±0%
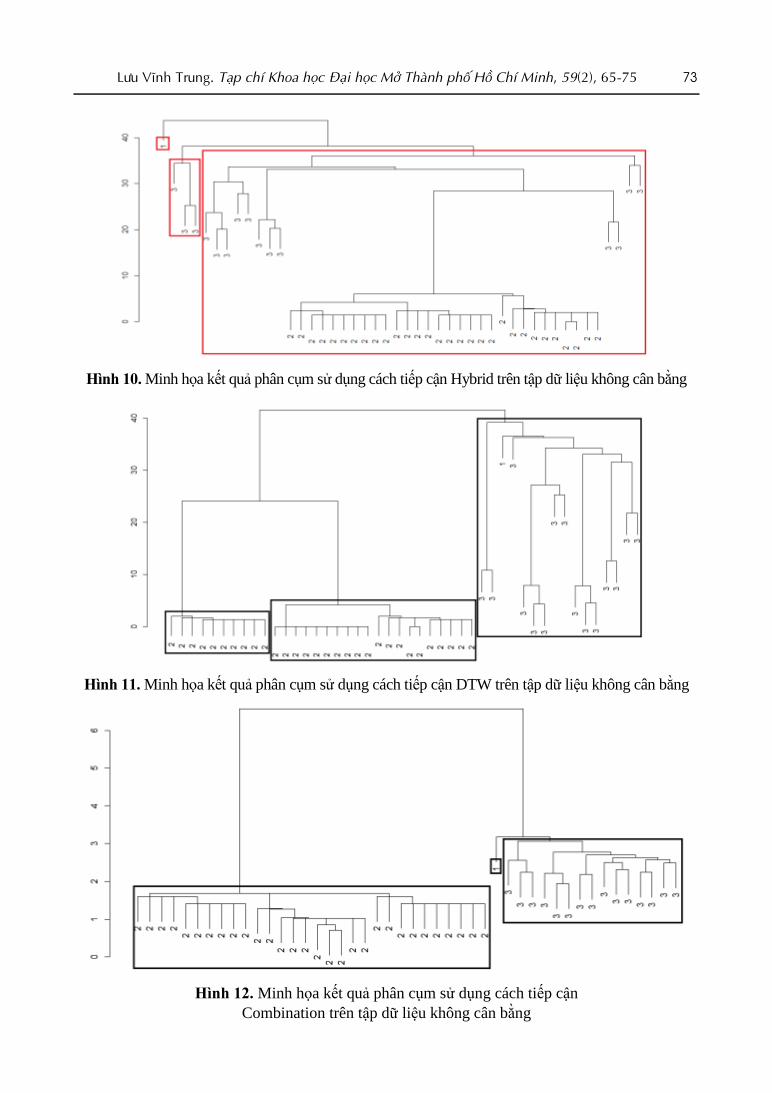
Với tập dữ liệu không cân bằng, ở Hình
10, 11, 12 là các dendrogram minh họa cho
các phần tử tương ứng với các nhóm 1, 2, 3
sau khi được phân cụm. 3 cụm tương ứng với
3 nhóm trong khung màu đỏ được thu thập
bằng cách cắt dendrogram từ gốc xuống.
Lưu Vĩnh Trung. Tạp chí Khoa học Đại học Mở Thành phố Hồ Chí Minh, 59(2), 65-75 73
Hình 10. Minh họa kết quả phân cụm sử dụng cách tiếp cận Hybrid trên tập dữ liệu không cân bằng
Hình 11. Minh họa kết quả phân cụm sử dụng cách tiếp cận DTW trên tập dữ liệu không cân bằng
Hình 12. Minh họa kết quả phân cụm sử dụng cách tiếp cận
Combination trên tập dữ liệu không cân bằng

74 Lưu Vĩnh Trung. Tạp chí Khoa học Đại học Mở Thành phố Hồ Chí Minh, 59(2), 65-75
Ngoài dữ liệu tổng hợp được tạo ra,
chúng tôi cũng làm thực nghiệm trên tập dữ
liệu thật gồm 1500 phiên làm việc, được thu
thập từ trang web e-commerce. Vì số trang
web vượt quá kích thước bảng chữ cái, chúng
tôi sử dụng số đếm để đại diện cho các trang
web được truy cập trong phiên làm việc, ví dụ
0_146_0_146 tương ứng với phiên làm việc
gồm 4 trang web. Mặc dù không có các nhóm
được định nghĩa trước cho các phiên làm việc
như với dữ liệu tổng hợp, với Combination,
các phiên làm việc với độ dài tương tự nhau,
các trang tương tự nhau với thứ tự gần giống
nhau có xu hướng được phân vào cùng cụm
hơn, so với Hybrid và DTW. Hình 13, 14, 15
minh họa cho những kết quả phân cụm này,
với phương pháp phân chia cấp bậc single-
linkage.
Hình 13. Minh họa kết quả phân cụm sử dụng cách tiếp cận Hybrid
trên tập dữ liệu từ trang web e-commerce
Hình 14. Minh họa kết quả phân cụm sử dụng cách tiếp cận DTW trên tập dữ liệu từ trang web
e-commerce

Lưu Vĩnh Trung. Tạp chí Khoa học Đại học Mở Thành phố Hồ Chí Minh, 59(2), 65-75 75
Hình 15. Minh họa kết quả phân cụm sử dụng cách tiếp cận Combination trên tập dữ liệu từ
trang web e-commerce
4. Kết luận Thang đo giới thiệu trong bài báo này dựa
trên sự kết hợp của kỹ thuật so sánh chuỗi
toàn cục và cục bộ, qua thực nghiệm đã chứng
tỏ ưu thế của nó khi so sánh với một số cách
tiếp cận khác, đặc biệt với các chuỗi có độ dài
chênh lệch hoặc chứa các phần tử trùng lặp kề
nhau. Chúng tôi dự định tiếp tục so sánh cách
tiếp cận này với PAM/k-medoids, ROCK
hoặc Ward về hiệu quả phân cụm, cũng
như thay thế Needleman-Wunsch và Smith-
Waterman bằng Hamming hoặc Levenshtein
để mở rộng phạm vi ứng dụng của thang đo
nếu có thể
Tài liệu tham khảo
Chordia, B.S., & Adhiya, K.P. (2011). Grouping web access sequences using sequence alignment method. Indian
Journal of Computer Science and Engineering (IJCSE), 2(3), 308-314.
Dimopoulos, C., Makris, C., Panagis, Y., Theodoridis, E., & Tsakalidis, A. (2010). A web page usage prediction
scheme using sequence indexing and clustering techniques. Data & Knowledge Engineering, 69(4), 371-382.
Lưu Vĩnh Trung (2017). Phân loại người dùng web sử dụng kỹ thuật so sánh chuỗi. Tạp chí Khoa học Đại học Mở
Thành phố Hồ Chí Minh, 55(4), 12-17.
Petitjean, F., Forestier, G., Webb, G., Nicholson, A.E., Chen, Y., Keogh, E. (2014). Dynamic time warping
averaging of time series allows faster and more accurate classication. International Conference on Data
Mining, IEEE, 470-479.
Punj, G., & Stewart, D. W. (1983). Cluster analysis in marketing research: Review and suggestions for application.
Journal of marketing research, 134-148.
Related Documents











