Statistical Analysis of Text •Statistical text analysis has a long history in literary analysis and in solving disputed authorship problems •First (?) is Thomas C. Mendenhall in 1887

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript
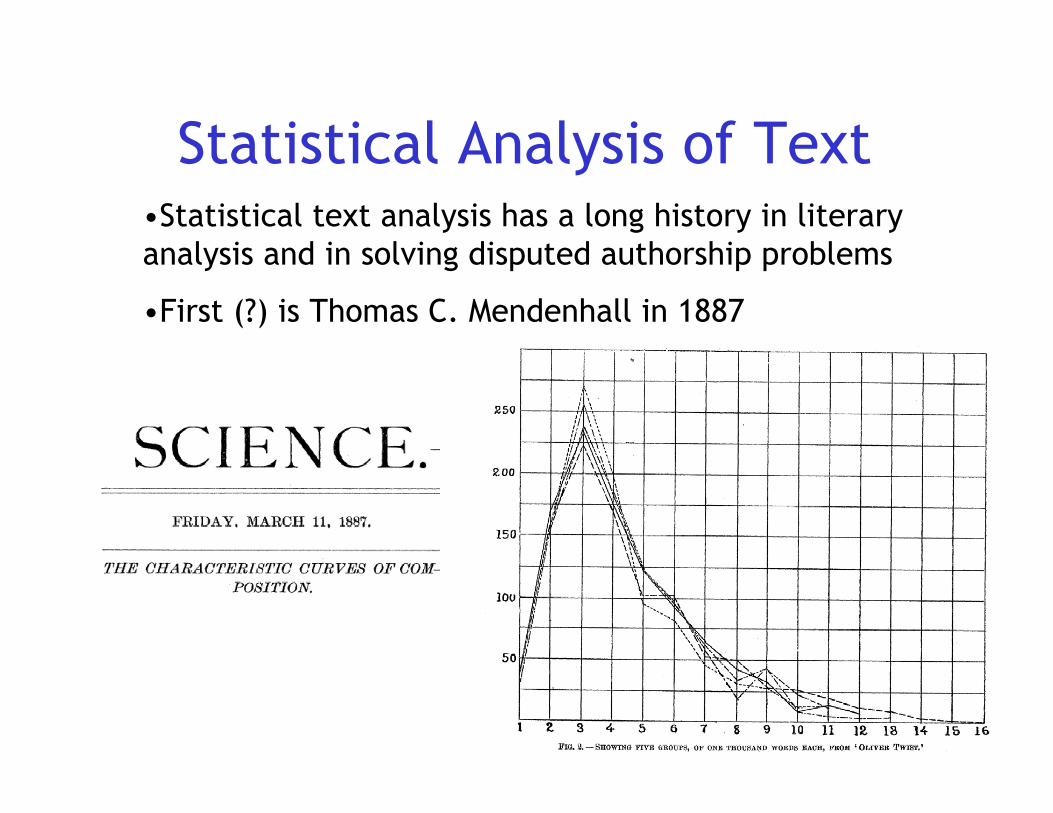
Statistical Analysis of Text•Statistical text analysis has a long history in literaryanalysis and in solving disputed authorship problems
•First (?) is Thomas C. Mendenhall in 1887

Mendenhall•Mendenhall was Professor of Physics at Ohio State and atUniversity of Tokyo, Superintendent of the USA Coastand Geodetic Survey, and later, President of WorcesterPolytechnic Institute
Mendenhall Glacier, Juneau, Alaska

X2 = 127.2, df=12


•Used Naïve Bayes with Poisson and Negative Binomialmodel
•Out-of-sample predictive performance

Today
• Statistical methods routinely used fortextual analyses of all kinds
• Machine translation, part-of-speech tagging,information extraction, question-answering,text categorization, etc.
• Not reported in the statistical literature

Text Categorization•Automatic assignment of documents withrespect to manually defined set of categories
•Applications automated indexing, spamfiltering, content filters, medical coding,CRM, essay grading
•Dominant technology is supervised machinelearning:
Manually classify some documents, thenlearn a classification rule from them(possibly with manual intervention)

•Documents usually represented as “bag ofwords:”
Document Representation
•xi’s might be 0/1, counts, or weights (e.g.tf/idf, LSI)
•Many text processing choices: stopwords,stemming, phrases, synonyms, NLP, etc.

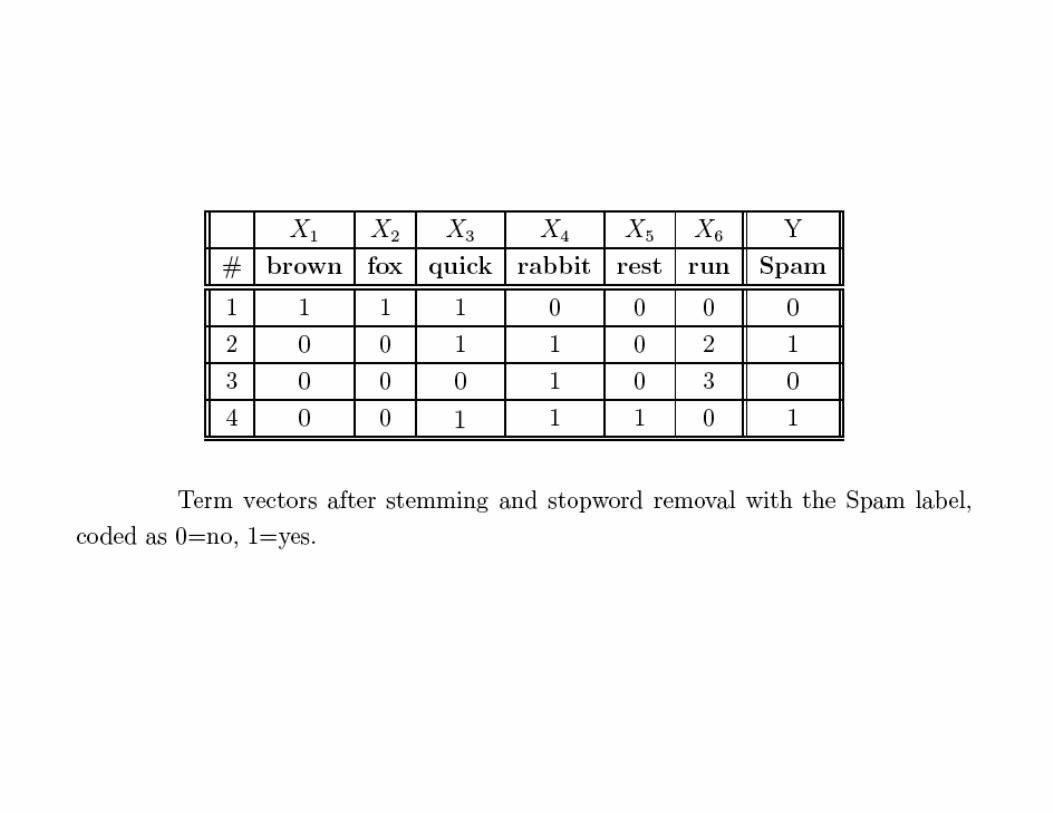
Naïve Bayes via a Toy Spam FilterExample
•Naïve Bayes is a generative model that makesdrastic simplifying assumptions
•Consider a small training data set for spam alongwith a bag of words representation


Naïve Bayes Machinery•We need a way to estimate:
•Via Bayes theorem we have:
or, on the log-odds scale:
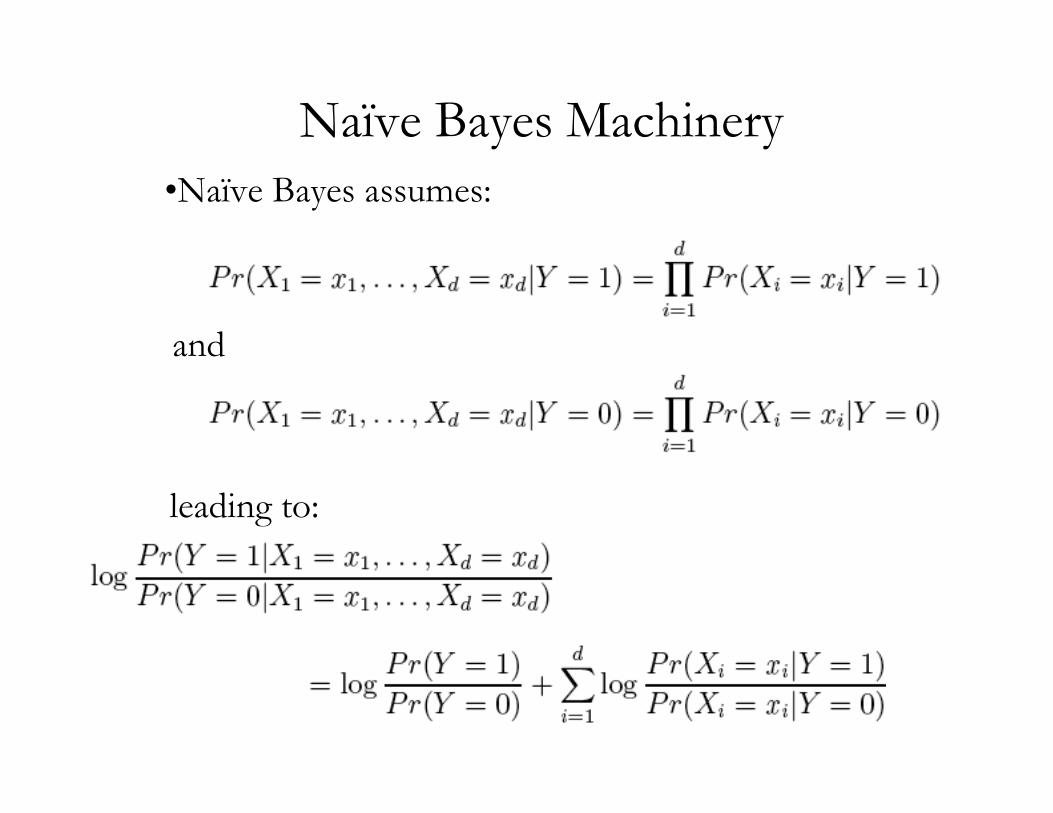
Naïve Bayes Machinery•Naïve Bayes assumes:
leading to:
and

Maximum Likelihood Estimation
weights of
evidence

Naïve Bayes Prediction
•Usually add a small constant (e.g. 0.5) to avoiddivide by zero problems and to reduce bias
•New message: “the quick rabbit rests”
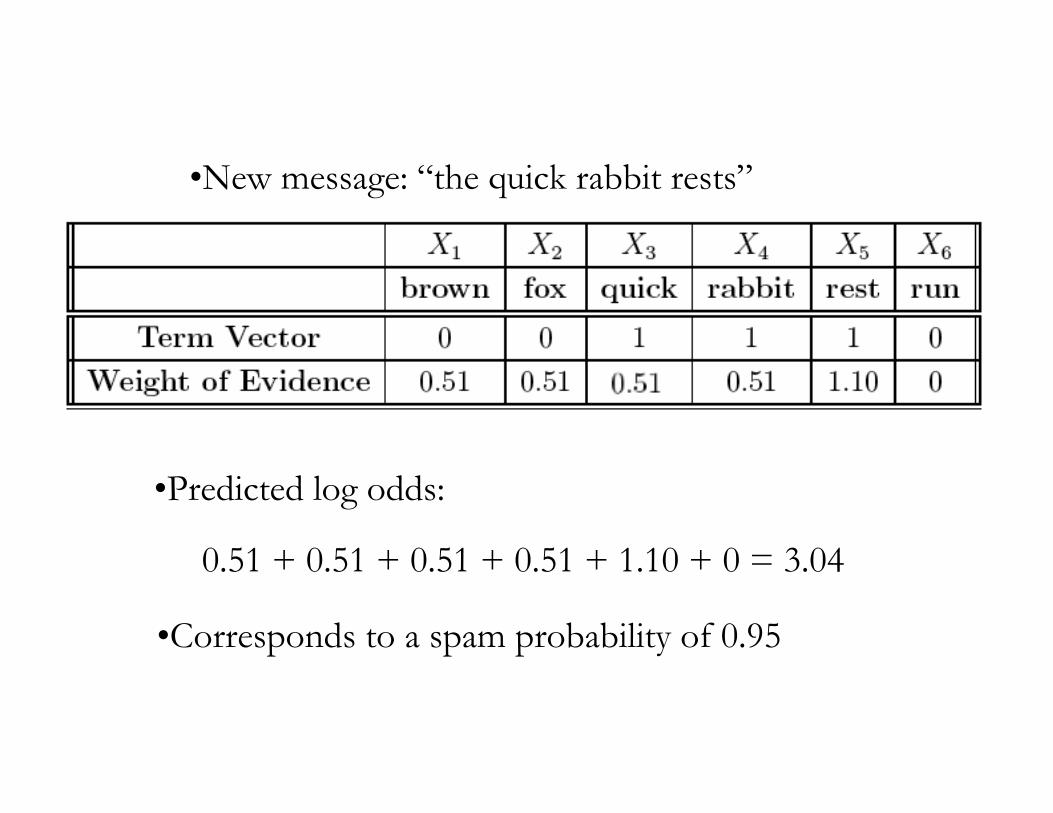
•New message: “the quick rabbit rests”
•Predicted log odds:
0.51 + 0.51 + 0.51 + 0.51 + 1.10 + 0 = 3.04
•Corresponds to a spam probability of 0.95

•Linear model for log odds of categorymembership:
Logistic Regression Model
• Conditional probability model
log = ∑ βj xij = βxi
p(y=1|xi)
p(y=-1|xi)

Maximum Likelihood Training
• Choose parameters (βj's) that maximizeprobability (likelihood) of class labels (yi's)given documents (xi’s)
• Tends to overfit• Not defined if d > n• Feature selection

• Feature selection is a discrete process –individual variables are either in or out.Combinatorial nightmare.
• This method can have high variance – a differentdataset from the same source can result in atotally different model
• Shrinkage methods allow a variable to be partlyincluded in the model. That is, the variable isincluded but with a shrunken co-efficient
• Elegant way to tackle over-fitting
Shrinkage Methods

s

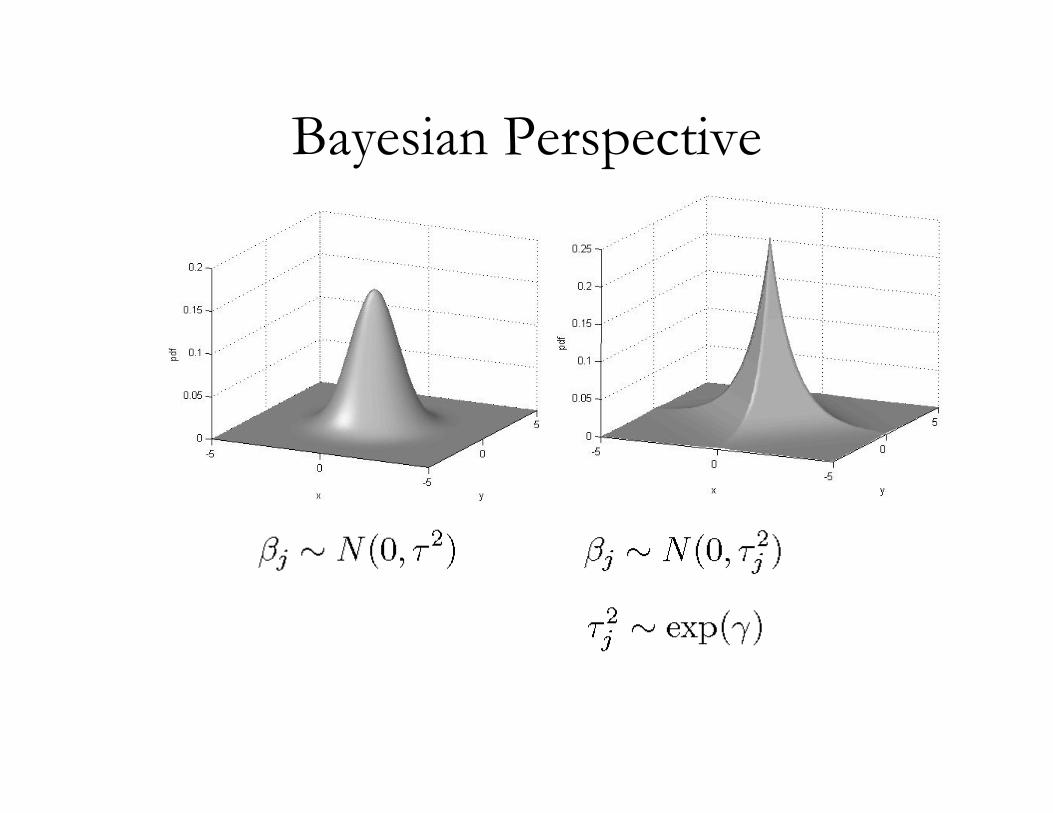
Bayesian Perspective

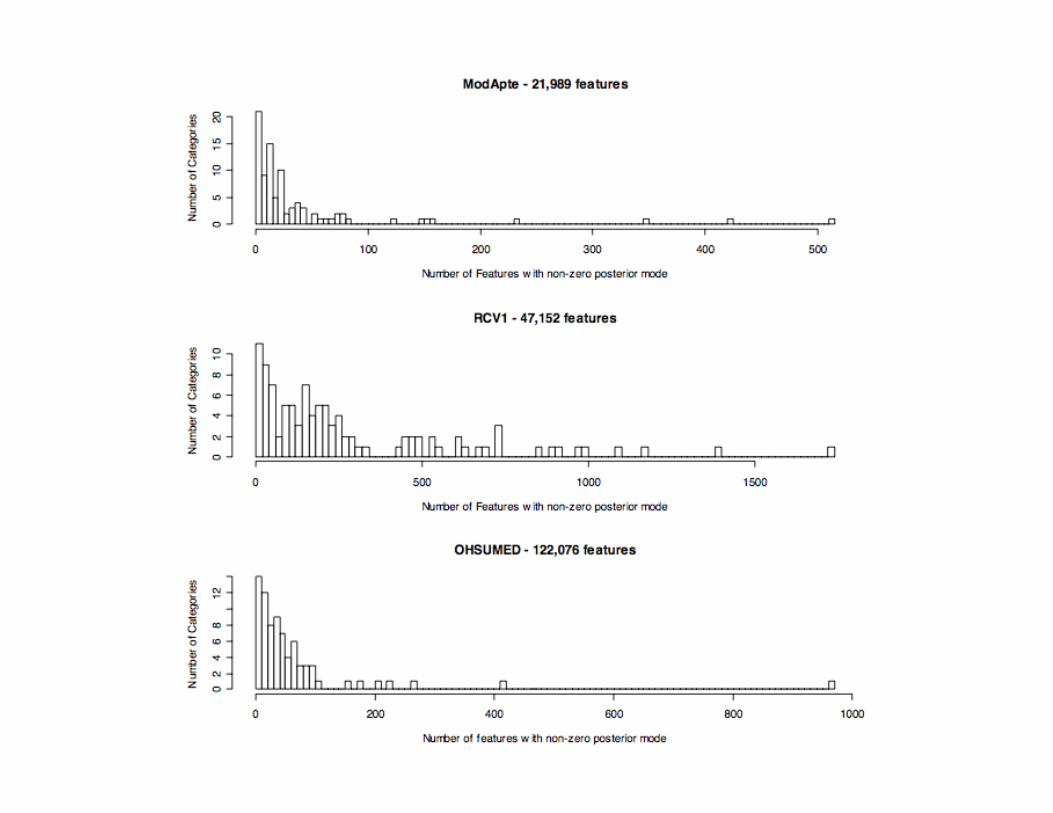
Data Sets
• ModApte subset of Reuters-21578– 90 categories; 9603 training docs; 18978 features
• Reuters RCV1-v2– 103 cats; 23149 training docs; 47152 features
• OHSUMED heart disease categories– 77 cats; 83944 training docs; 122076 features
• Cosine normalized TFxIDF weights

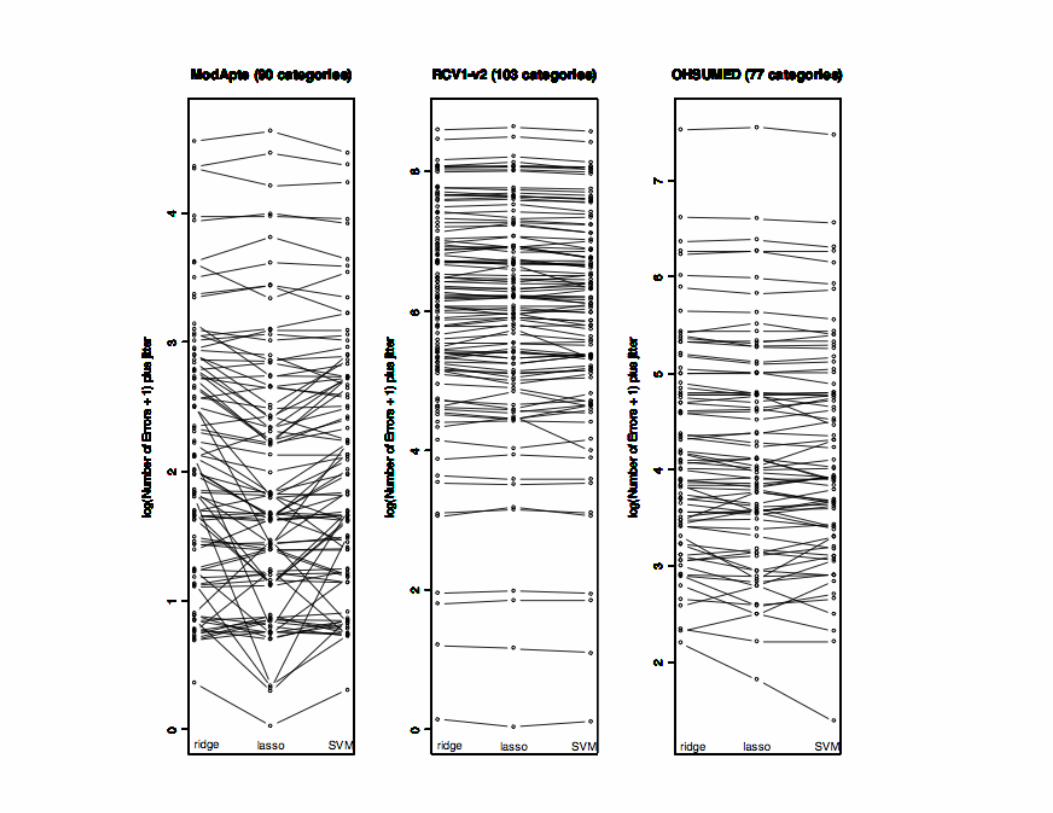
Dense vs. Sparse Models(Macroaveraged F1)
50.5857.2353.75SVM
41.3328.5446.20Ridge/5
42.5941.6145.80Ridge/50
36.9346.2738.82Ridge/500
42.9951.4039.71Ridge
51.3056.5452.03Lasso
OHSUMEDRCV1-v2ModApte

The Federalist• “The authorship of certain numbers of the ‘Federalist’
has fairly reached the dignity of a well-establishedhistorical controversy.” (Henry Cabot Lodge, 1886)
• Historical evidence is muddled
Table 1 Authorship of the Federalist Papers
Paper Number Author
1 Hamilton
2-5 Jay
6-9 Hamilton
10 Madison
11-13 Hamilton
14 Madison
15-17 Hamilton
18-20 Joint: Hamilton and Madison
21-36 Hamilton
37-48 Madison
49-58 Disputed
59-61 Hamilton
62-63 Disputed
64 Jay
65-85 Hamilton

•Used function words with Naïve Bayes with Poissonand Negative Binomial model
•Out-of-sample predictive performance

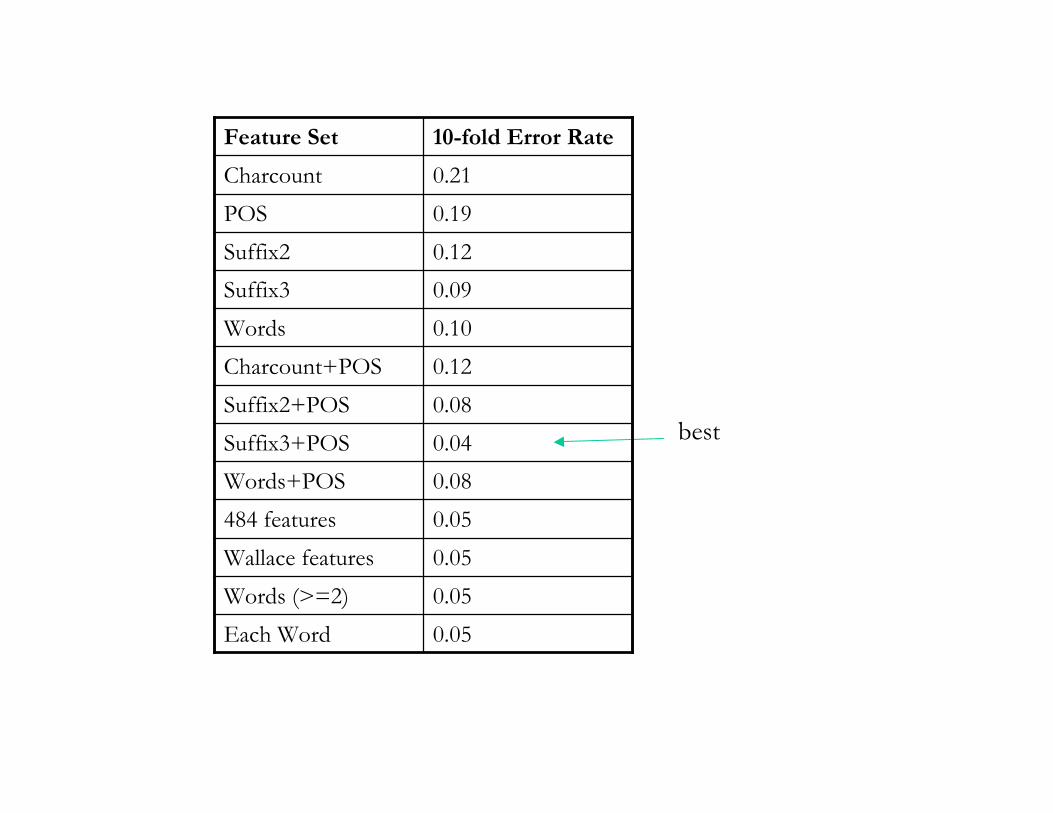
best
0.05Each Word
0.05Words (>=2)
0.05Wallace features
0.05484 features
0.08Words+POS
0.04Suffix3+POS
0.08Suffix2+POS
0.12Charcount+POS
0.10Words
0.09Suffix3
0.12Suffix2
0.19POS
0.21Charcount
10-fold Error RateFeature Set


Polytomous LogisticRegression (PLR)
• Elegant approach to multiclass problems• Also known as polychotomous LR, multinomial
LR, and, ambiguously, multiple LR andmultivariate LR
P( yi= k | x
i) =
exp(!
!kx
i)
exp(!
!k '
xi)
k '
"
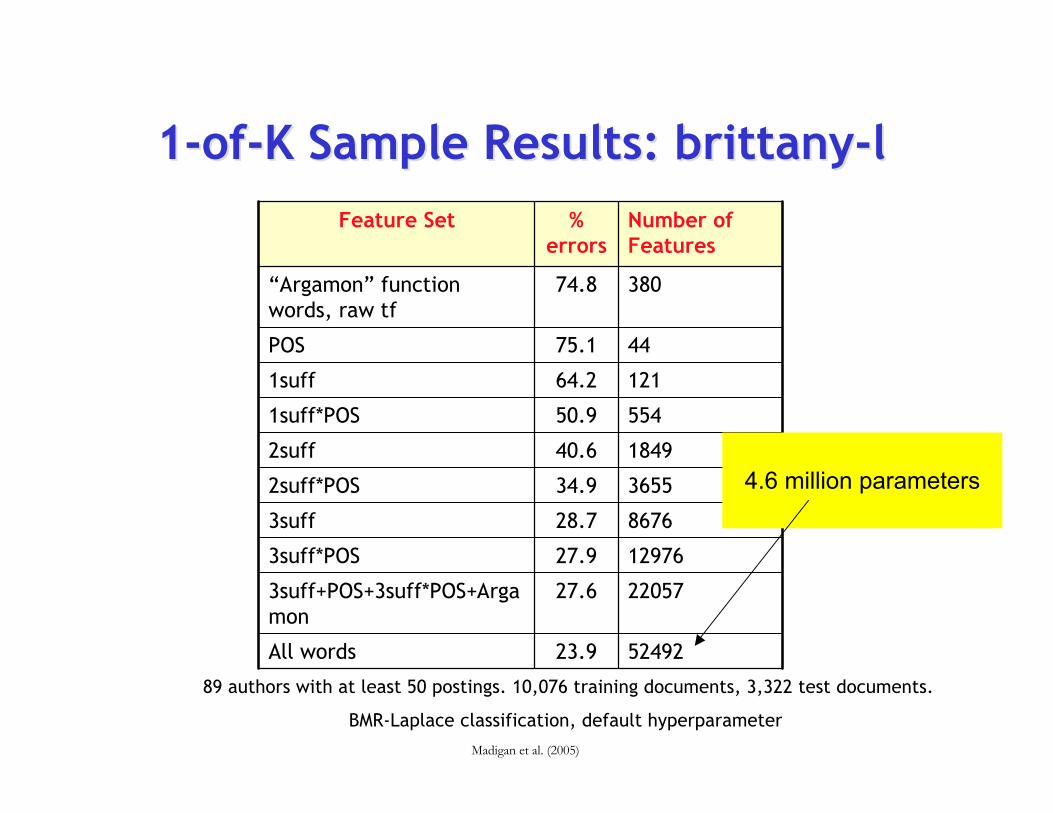
1-of-K Sample Results: brittany-l1-of-K Sample Results: brittany-l
5249223.9All words
2205727.63suff+POS+3suff*POS+Argamon
1297627.93suff*POS
867628.73suff
365534.92suff*POS
184940.62suff
55450.91suff*POS
12164.21suff
4475.1POS
38074.8“Argamon” functionwords, raw tf
Number ofFeatures
%errors
Feature Set
89 authors with at least 50 postings. 10,076 training documents, 3,322 test documents.
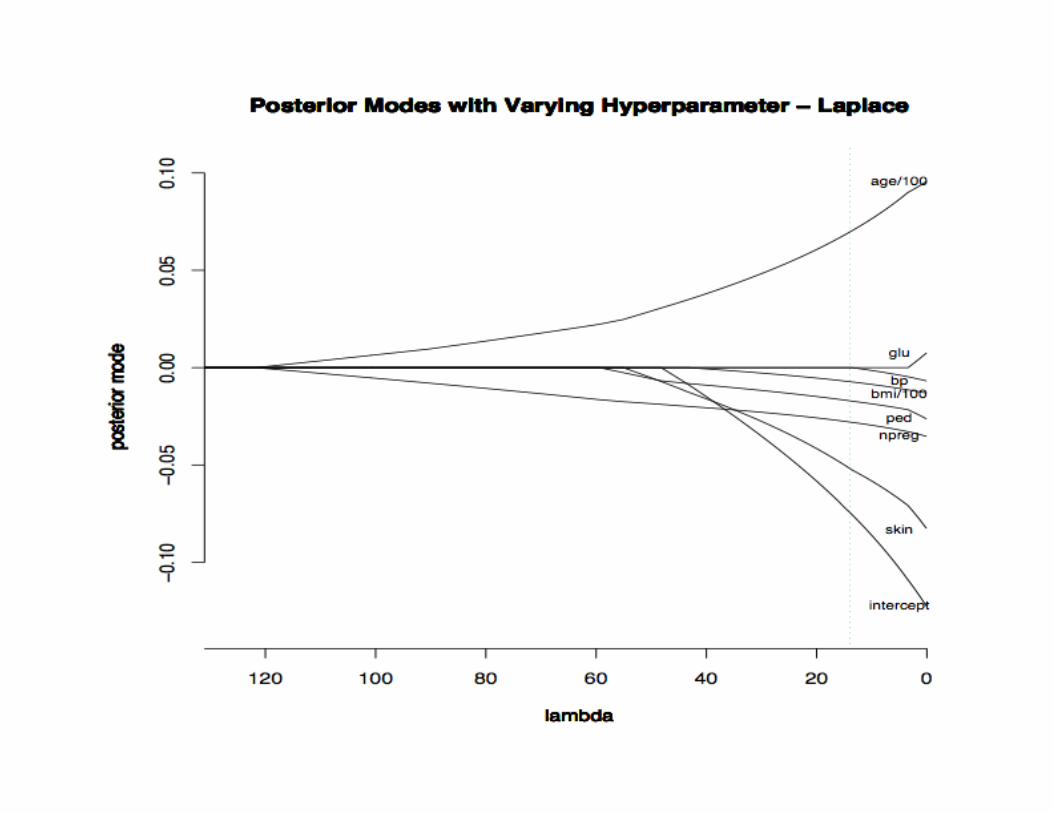
BMR-Laplace classification, default hyperparameter
4.6 million parameters
Madigan et al. (2005)

Term Weighting
• How strongly does a particular word indiciatethe content of a document?
• Some clues:– Number of times word occurs in this document– Number of times word occurs in other
documents– Length of document
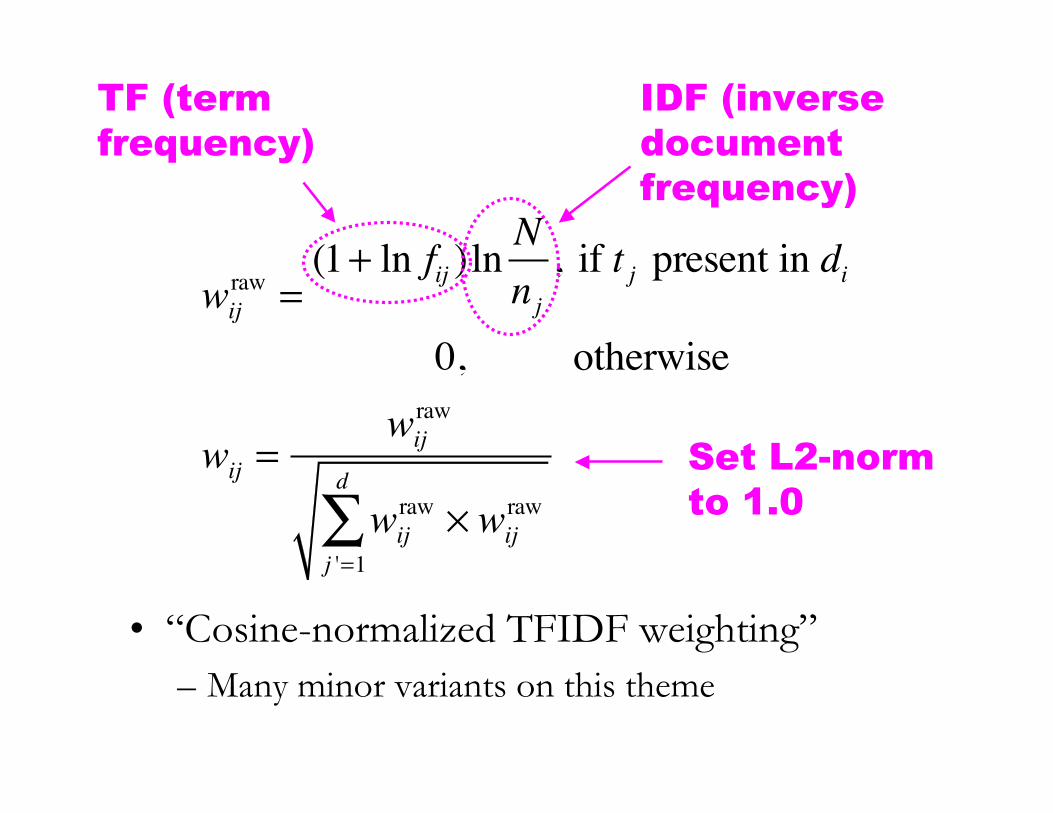
• “Cosine-normalized TFIDF weighting”– Many minor variants on this theme
TF (termfrequency)
wij
raw=
(1+ ln fij )lnN
nj, if t j present in di
0, otherwise
wij =wij
raw
wij
raw! wij
raw
j '=1
d
"
IDF (inversedocumentfrequency)
Set L2-normto 1.0

Variants on Term Weighting
• Explicit models of word frequency (e.g. Poisson mixtures,multinomial,...)
• Smoothing– Across similar documents– Across similar terms
• Trainable term weighting for complex features (e.g.Darmstadt indexing approach)

Domain Knowledge in TextClassification
• Certain words are positively or negativelyassociated with category
• Domain Knowledge: textual descriptionsfor categories
• Prior mean quantifies the strength of positiveor negative association
• Prior variance quantifies our confidence inthe domain knowledge
Aynur Dayanik

An Example Model(category “grain”)
Word Beta Word Beta
corn 29.78 formal -1.15
wheat 20.56 holder -1.43
rice 11.33 hungarian -6.15
sindt 10.56 rubber -7.12
madagascar 6.83 special -7.25
import 6.79 … …
grain 6.77 beet -13.24
contract 3.08 rockwood -13.61

Using Domain Knowledge (DK)• Give domain words higher mean or variance• Two methods: For each DK term t and category q, and
manually chosen C,– First method sets DK-based variance:
– Second method sets DK-based mode:
Here σ2 is variance for all other words chosen by 5-fold CVon training data
• Used TFxIDF weighting on the prior knoweldge documents tocompute significance(t, q)
variance(t,q) = C ! significance(t,q) !" 2
mode(t,q) = C ! significance(t,q) !"

Experiments• Data sets
1) TREC 2004 Genomics data:• Categories: 32 MeSH categories under “Cells” hierarchy• Documents: 3742 training and 4175 test• Prior Knowledge: MeSH category descriptions
2) ModApte subset of Reuters-21578• Categories: 10 most frequent categories• Documents: 9603 training and 3299 test• Prior Knowledge: keywords selected by hand (Wu & Srihari, 2004)
• Big (all training examples) and small size training data• Limited, biased data often the case in applications

MeSH Prior Knowledge Example
• MeSH Heading: Neurons• Scope Note: The basic cellular units of
nervous tissue. Each neuron consists of abody, an axon, and dendrites. Their purposeis to receive, conduct, and transmit impulsesin the nervous system.
• Entry Term: Nerve Cells• See Also: Neural Conduction
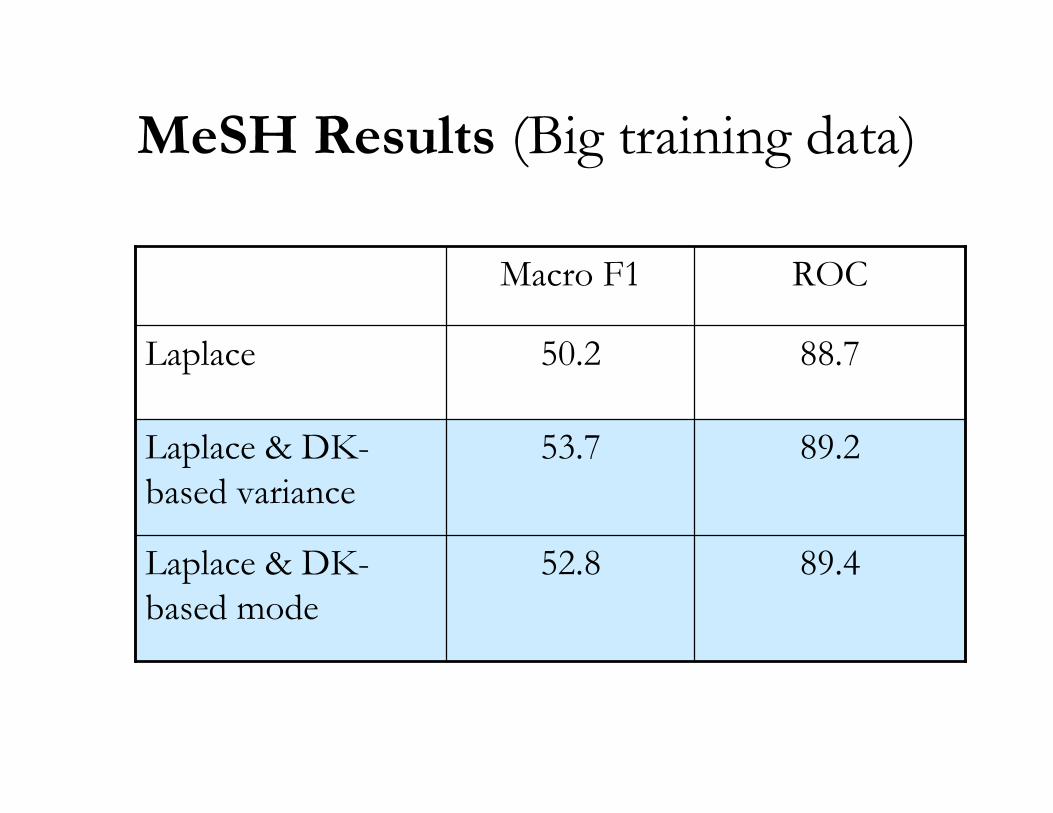
MeSH Results (Big training data)
89.452.8Laplace & DK-based mode
89.253.7Laplace & DK-based variance
88.750.2Laplace
ROCMacro F1
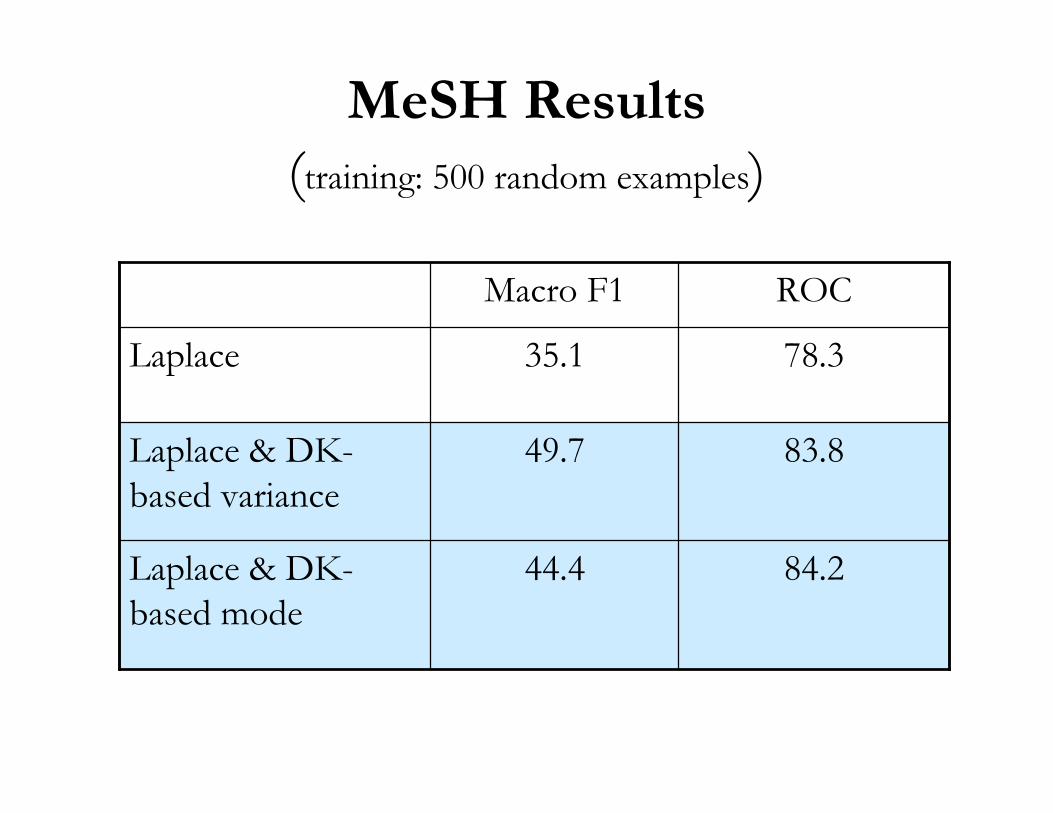
MeSH Results(training: 500 random examples)
84.244.4Laplace & DK-based mode
83.849.7Laplace & DK-based variance
78.335.1Laplace
ROCMacro F1

MeSH Results(training: 5 positive and 5 random examples for each category)
83.335.8Laplace & DK-based mode
77.643.7Laplace & DK-based variance
65.929.3Laplace
ROCMacro F1
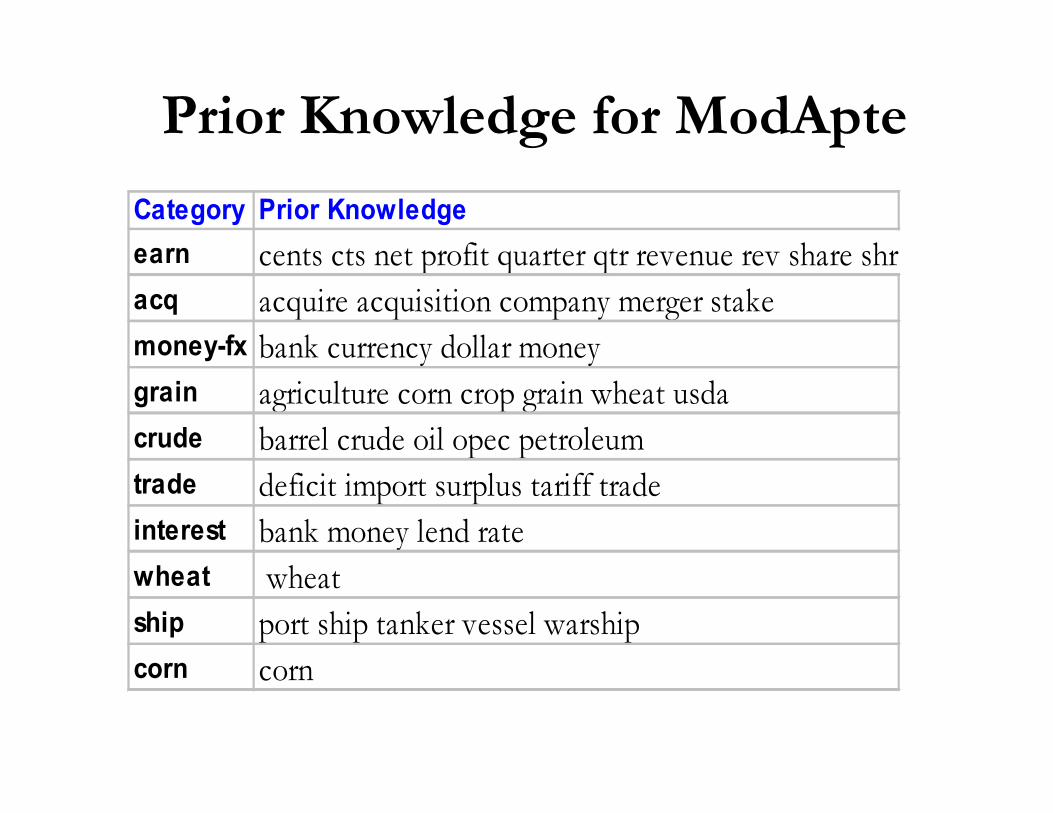
Prior Knowledge for ModApte
Category Prior Knowledge
earn cents cts net profit quarter qtr revenue rev share shr
acq acquire acquisition company merger stake
money-fx bank currency dollar money
grain agriculture corn crop grain wheat usda
crude barrel crude oil opec petroleum
trade deficit import surplus tariff trade
interest bank money lend rate
wheat wheat
ship port ship tanker vessel warship
corn corn
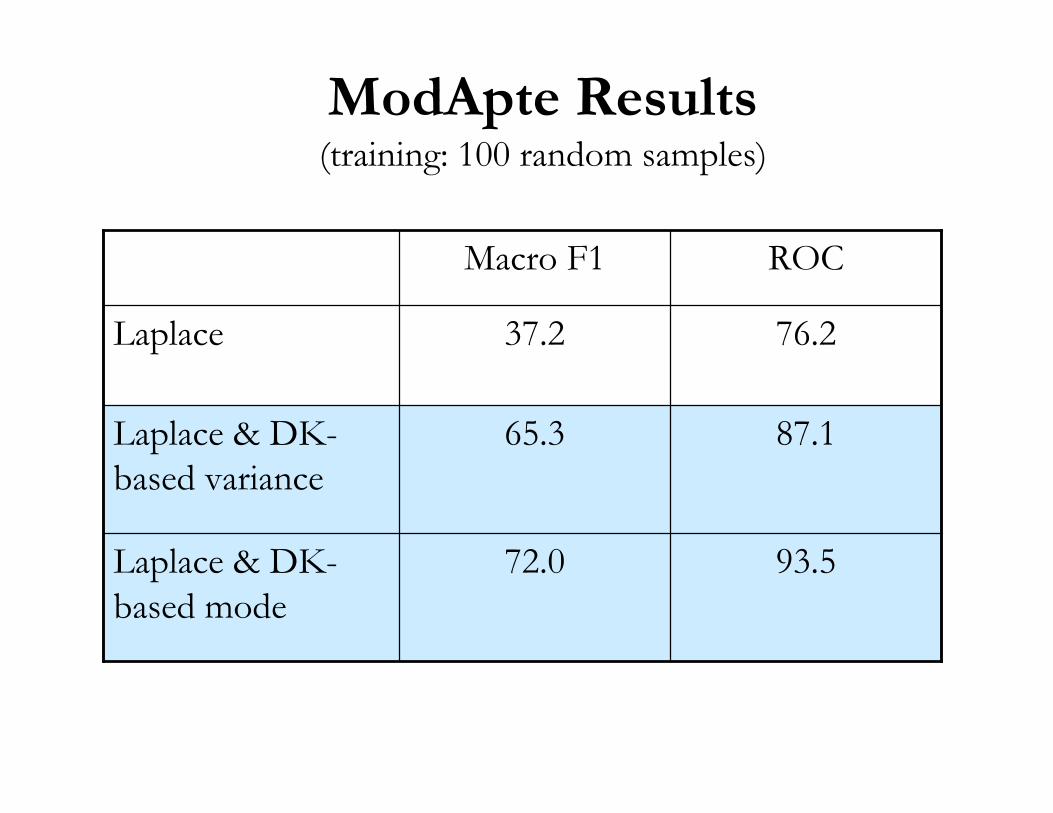
ModApte Results(training: 100 random samples)
93.572.0Laplace & DK-based mode
87.165.3Laplace & DK-based variance
76.237.2Laplace
ROCMacro F1
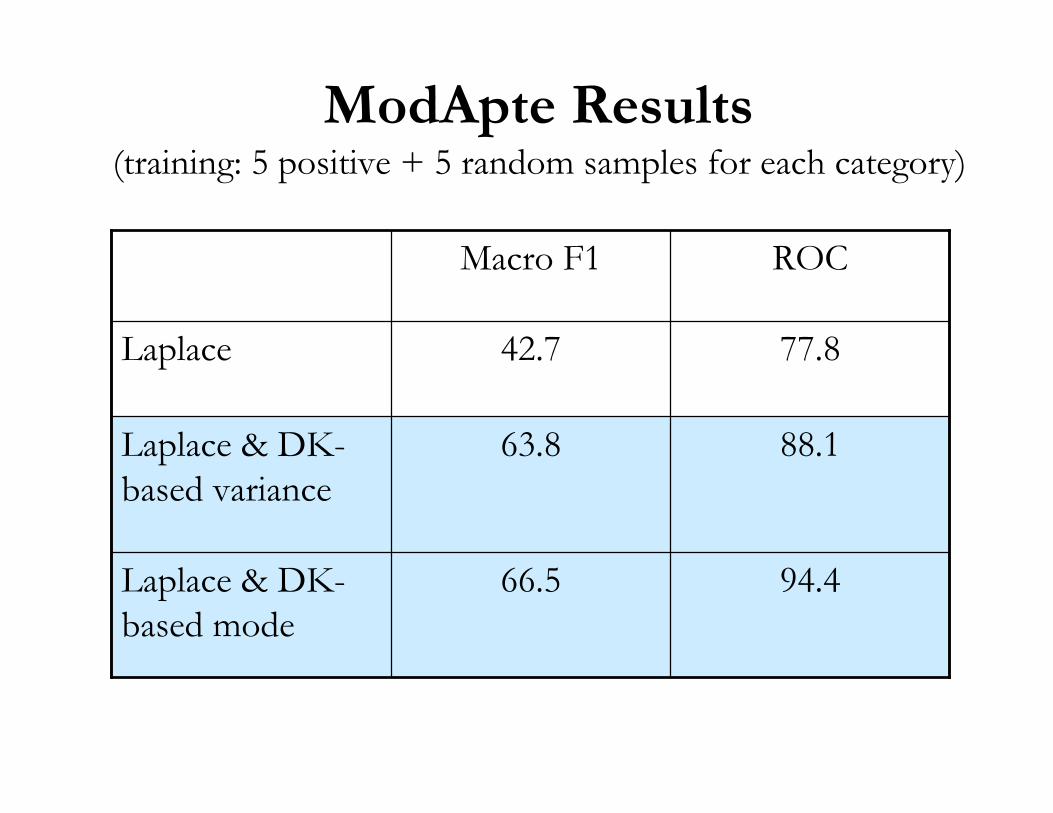
ModApte Results(training: 5 positive + 5 random samples for each category)
94.466.5Laplace & DK-based mode
88.163.8Laplace & DK-based variance
77.842.7Laplace
ROCMacro F1
Related Documents











