Stanford University The Stanford Hydra Chip Multiprocessor Kunle Olukotun The Hydra Team Computer Systems Laboratory Stanford University

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Stanford University
The Stanford Hydra Chip Multiprocessor
Kunle Olukotun
The Hydra Team
Computer Systems Laboratory
Stanford University

Stanford University
Technology Architecture
Transistors are cheap, plentiful and fast Moore’s law 100 million transistors by 2000
Wires are cheap, plentiful and slow Wires get slower relative to transistors Long cross-chip wires are especially slow
Architectural implications Plenty of room for innovation Single cycle communication requires localized blocks of logic High communication bandwidth across the chip easier to
achieve than low latency
Stanford University
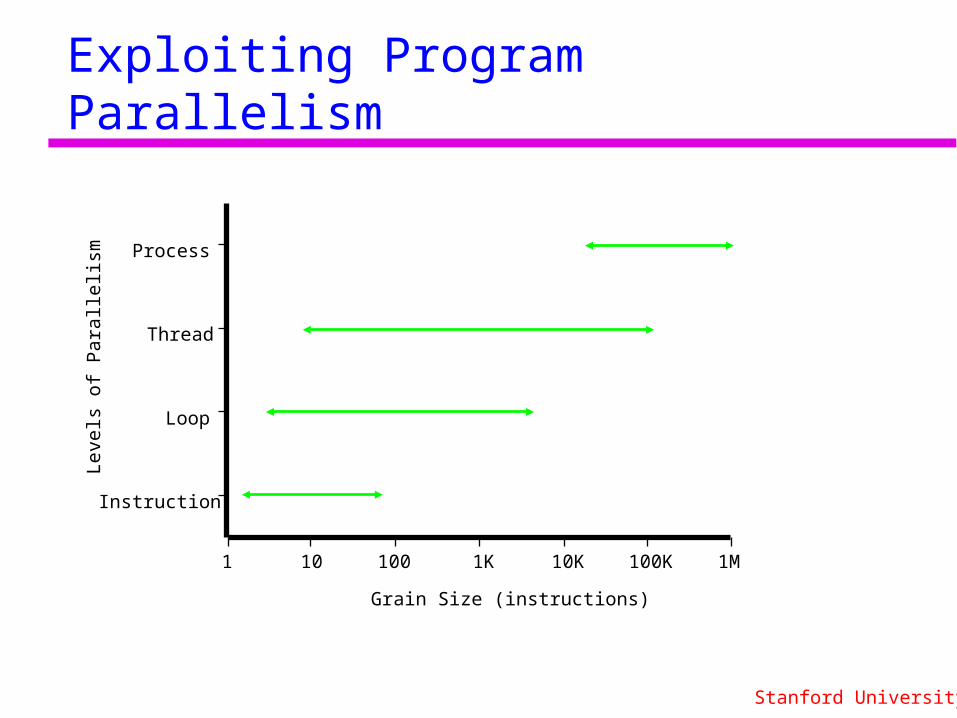
Exploiting Program Parallelism
Instruction
Loop
Thread
Process
Leve
ls o
f P
aral
lelis
m
Grain Size (instructions)
1 10 100 1K 10K 100K 1M

Stanford University
Hydra Approach
A single-chip multiprocessor architecture composed of simple fast processors
Multiple threads of control Exploits parallelism at all levels
Memory renaming and thread-level speculation Makes it easy to develop parallel programs
Keep design simple by taking advantage of single chip implementation

Stanford University
Outline
Base Hydra Architecture Performance of base architecture Speculative thread support Speculative thread performance Improving speculative thread performance Hydra prototype design Conclusions
Stanford University
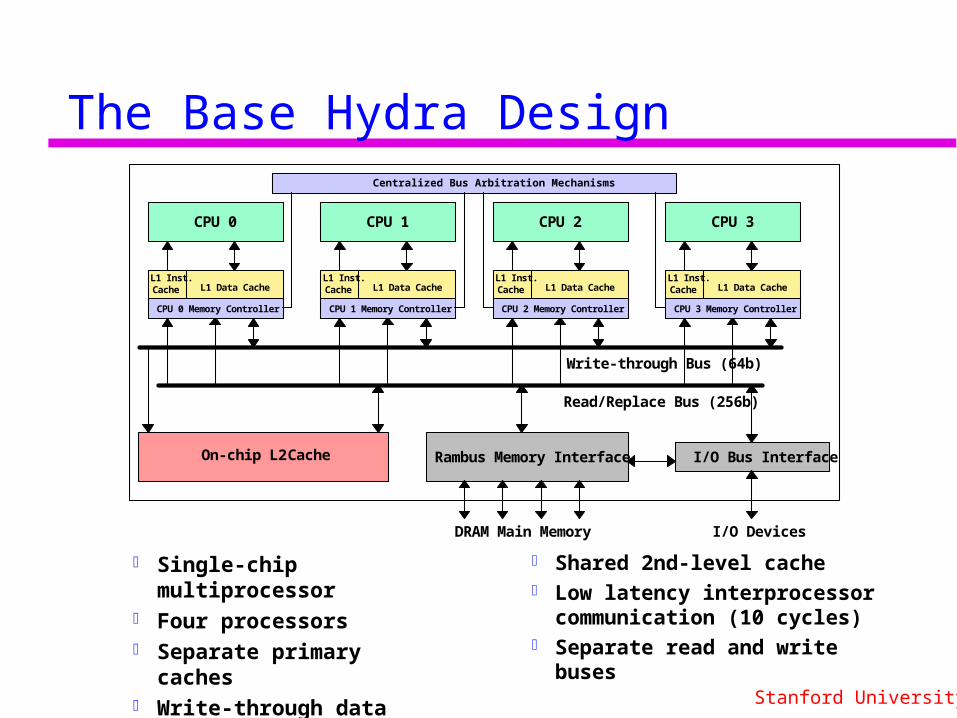
The Base Hydra Design
Shared 2nd-level cache Low latency interprocessor
communication (10 cycles) Separate read and write buses
Single-chip multiprocessor Four processors Separate primary caches Write-through data caches
to maintain coherence
Write-through Bus (64b)
Read/Replace Bus (256b)
On-chip L2 Cache
DRAM Main Memory
Rambus Memory Interface
CPU 0
L1 Inst. Cache L1 Data Cache
CPU 1
L1 Inst. Cache L1 Data Cache
CPU 2
L1 Inst. Cache L1 Data Cache
CPU 3
L1 Inst. Cache L1 Data Cache
I/O Devices
I/O Bus Interface
CPU 0 Memory Controller CPU 1 Memory Controller CPU 2 Memory Controller CPU 3 Memory Controller
Centralized Bus Arbitration Mechanisms
Stanford University
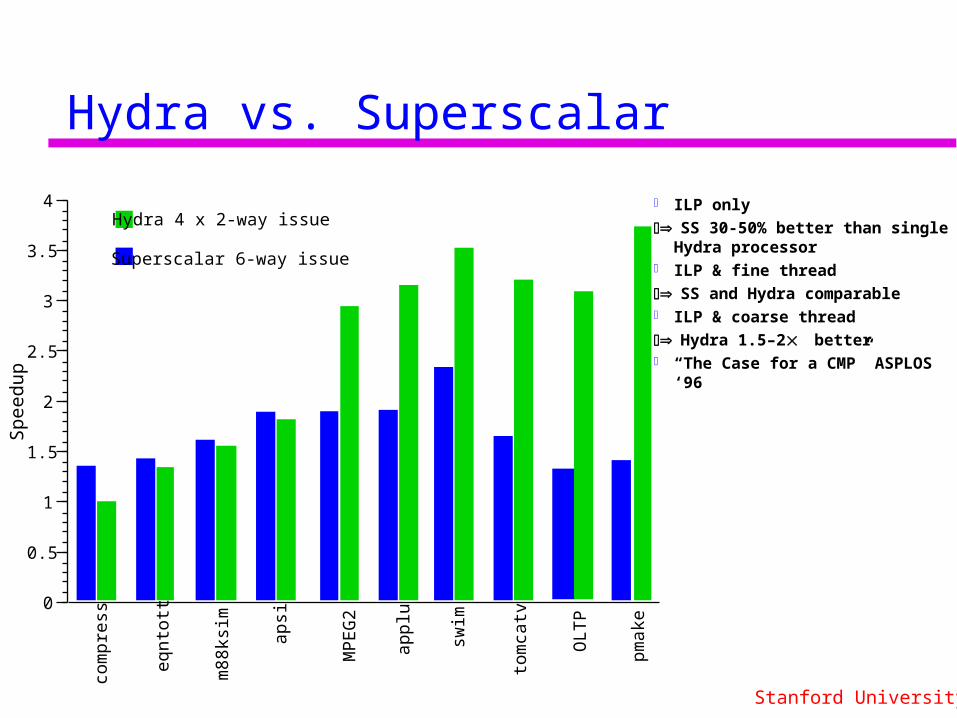
Hydra vs. Superscalar
ILP only
SS 30-50% better than single Hydra processor
ILP & fine thread
SS and Hydra comparable ILP & coarse thread
Hydra 1.5–2better “The Case for a CMP” ASPLOS ‘96
com
pres
s
m88
ksim
eqnt
ott
MP
EG
2
appl
u
apsi
swim
tom
catv
pmak
e
0
0.5
1
1.5
2
2.5
3
3.5
4
Spe
edup
Superscalar 6-way issue
Hydra 4 x 2-way issue
OLT
P

Stanford University
Problem: Parallel Software
Parallel software is limited Hand-parallelized applications Auto-parallelized dense matrix FORTRAN applications
Traditional auto-parallelization of C-programs is very difficult Threads have data dependencies synchronization Pointer disambiguation is difficult and expensive Compile time analysis is too conservative
How can hardware help? Remove need for pointer disambiguation Allow the compiler to be aggressive

Stanford University
Solution: Data Speculation
Data speculation enables parallelization without regard for data-dependencies Loads and stores follow original sequential semantics Speculation hardware ensures correctness Add synchronization only for performance Loop parallelization is now easily automated
Other ways to parallelize code Break code into arbitrary threads (e.g. speculative subroutines ) Parallel execution with sequential commits
Data speculation support Wisconsin multiscalar Hydra provides low-overhead support for CMP
Stanford University
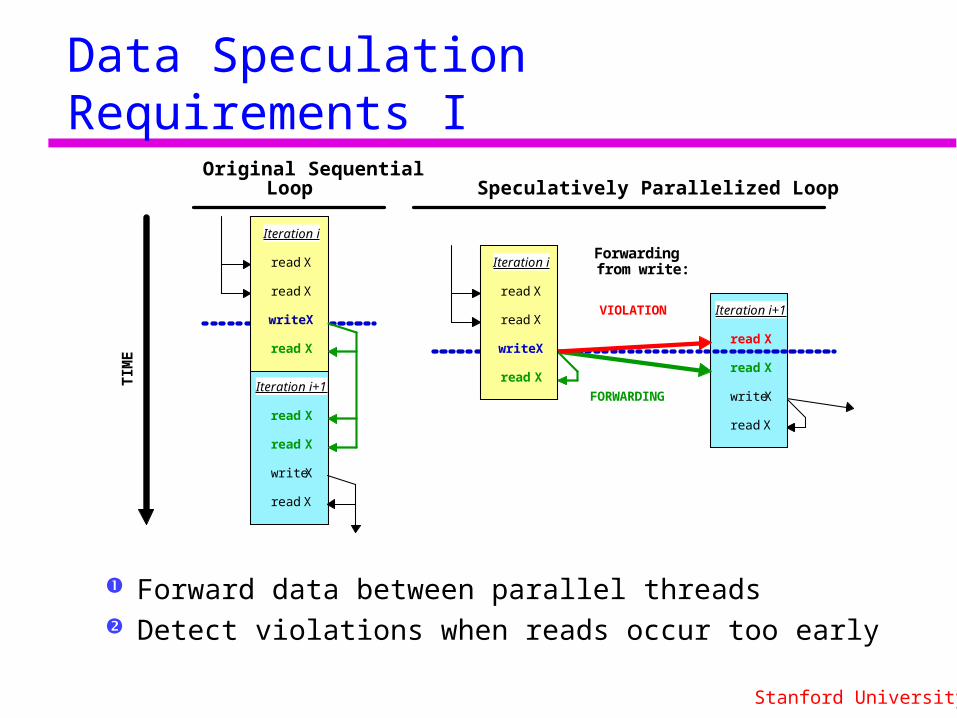
Data Speculation Requirements I
Forward data between parallel threads Detect violations when reads occur too early
Iteration i+1
read X
read X
read X
write X
Iteration i
read X
read X
read X
write X
FORWARDING
VIOLATION
Original Sequential Loop Speculatively Parallelized Loop
Forwarding from write:
Iteration i+1
read X
read X
read X
write X
TIM
E
Iteration i
read X
read X
read X
write X
Stanford University
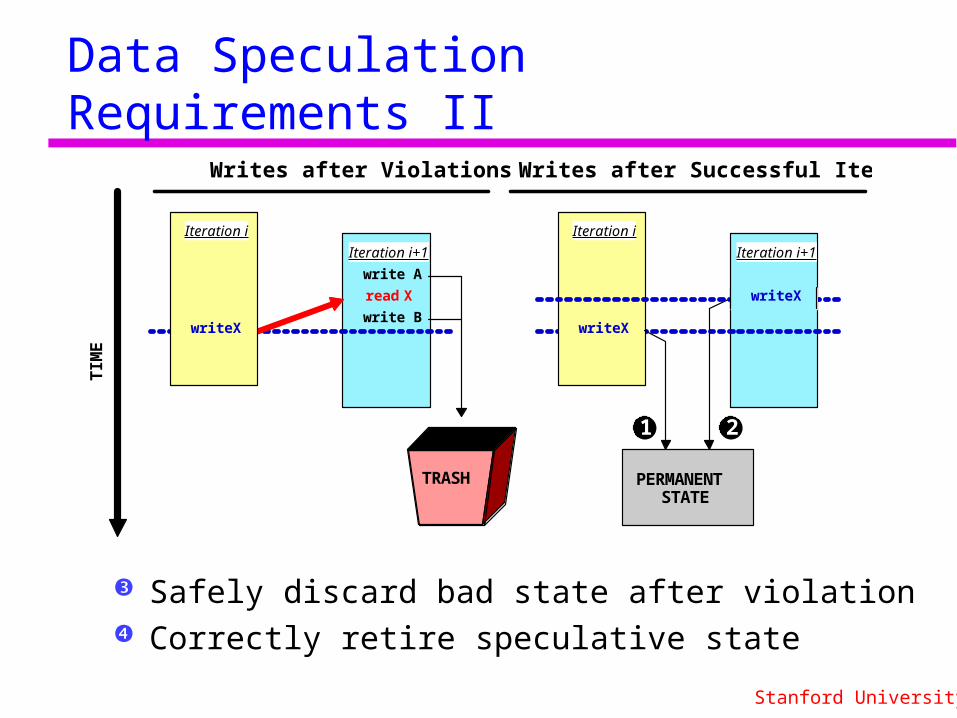
Data Speculation Requirements II
Safely discard bad state after violation Correctly retire speculative state
Iteration i+1
read X
TIM
E
Iteration i
write X
write A
write B
TRASH
Iteration i+1
Iteration i
write X
write X
PERMANENT STATE
21
Writes after Violations Writes after Successful Iterations
Stanford University
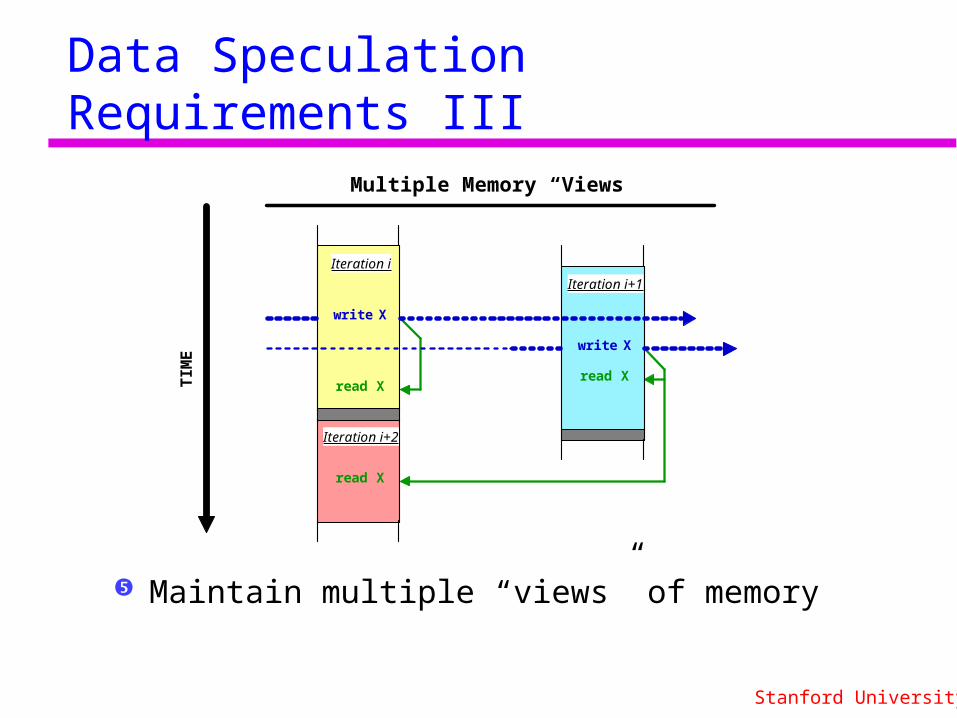
Data Speculation Requirements III
Maintain multiple “views” of memory
Iteration i+1
TIM
E
Iteration i
read X
write X
write X
read X
Multiple Memory “Views”
Iteration i+2
read X
Stanford University
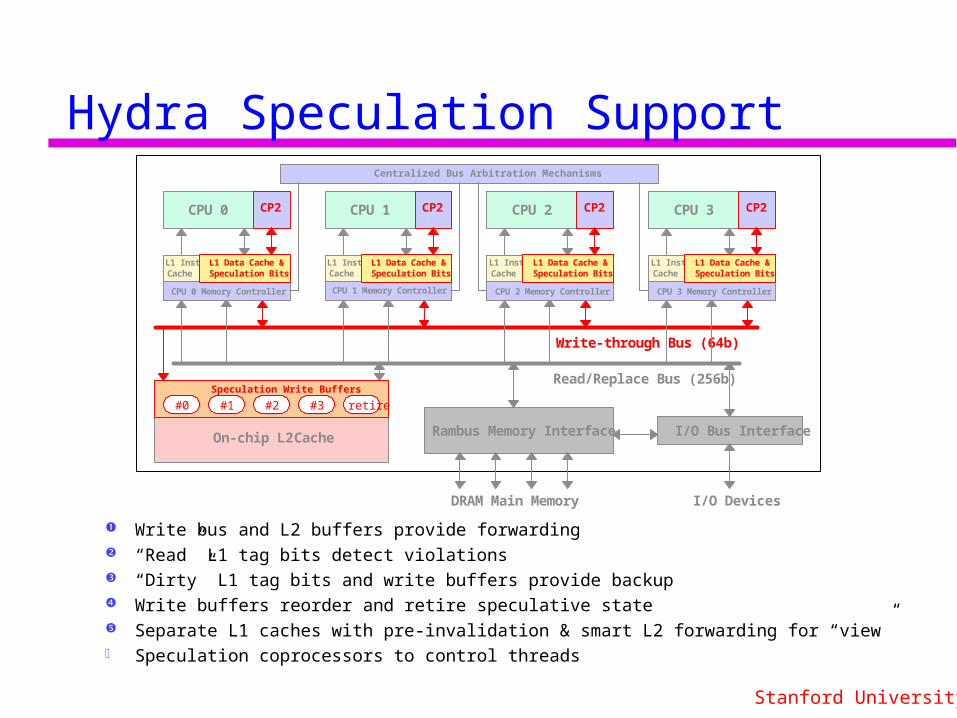
Hydra Speculation Support
Write bus and L2 buffers provide forwarding “Read” L1 tag bits detect violations “Dirty” L1 tag bits and write buffers provide backup Write buffers reorder and retire speculative state Separate L1 caches with pre-invalidation & smart L2 forwarding for “view” Speculation coprocessors to control threads
Write-through Bus (64b)
Read/Replace Bus (256b)
On-chip L2 Cache
DRAM Main Memory
Rambus Memory Interface
CPU 0
L1 Inst. Cache
Speculation Write Buffers
CPU 1
L1 Inst. Cache
CPU 2
L1 Inst. Cache
CPU 3
L1 Inst. Cache
I/O Devices
I/O Bus Interface
CPU 0 Memory Controller CPU 1 Memory Controller CPU 2 Memory Controller CPU 3 Memory Controller
Centralized Bus Arbitration Mechanisms
CP2 CP2 CP2 CP2
#0 #1 #2 #3 retire
L1 Data Cache & Speculation Bits
L1 Data Cache & Speculation Bits
L1 Data Cache & Speculation Bits
L1 Data Cache & Speculation Bits
Stanford University
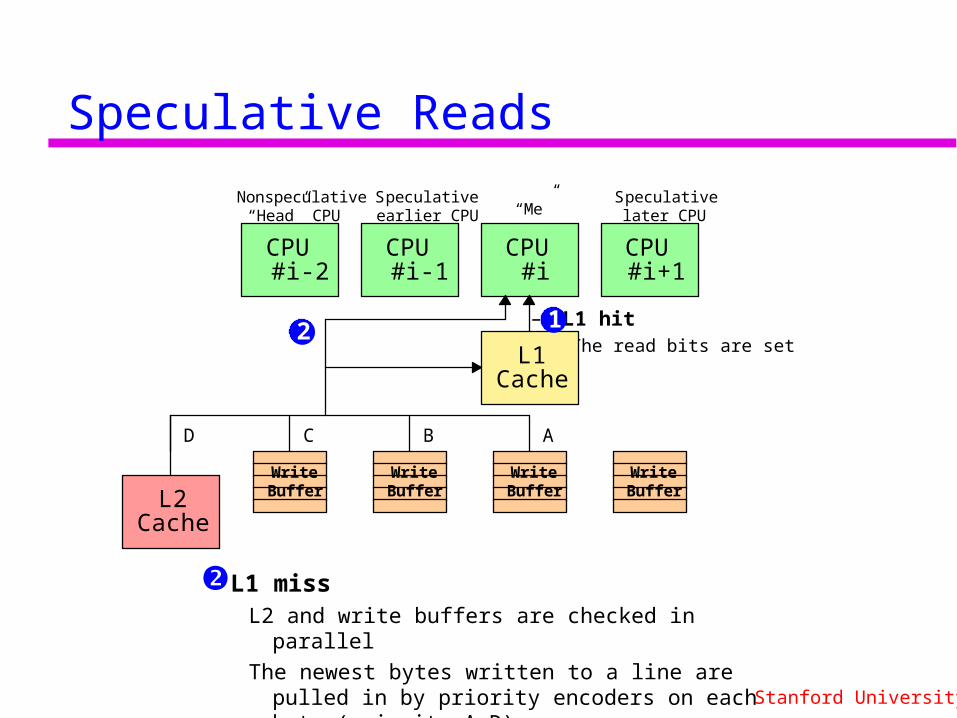
Speculative Reads
– L1 hitThe read bits are set
L1 missL2 and write buffers are checked in parallel
The newest bytes written to a line are pulled in by priority encoders on each byte (priority A-D)
CPU #i
CPU #i-1
CPU #i-2
CPU #i+1
Nonspeculative “Head” CPU
Speculativeearlier CPU
Speculative later CPU“Me”
L1 Cache
12
Write Buffer
Write Buffer
Write Buffer
Write Buffer
C B A
L2 Cache
D
Stanford University
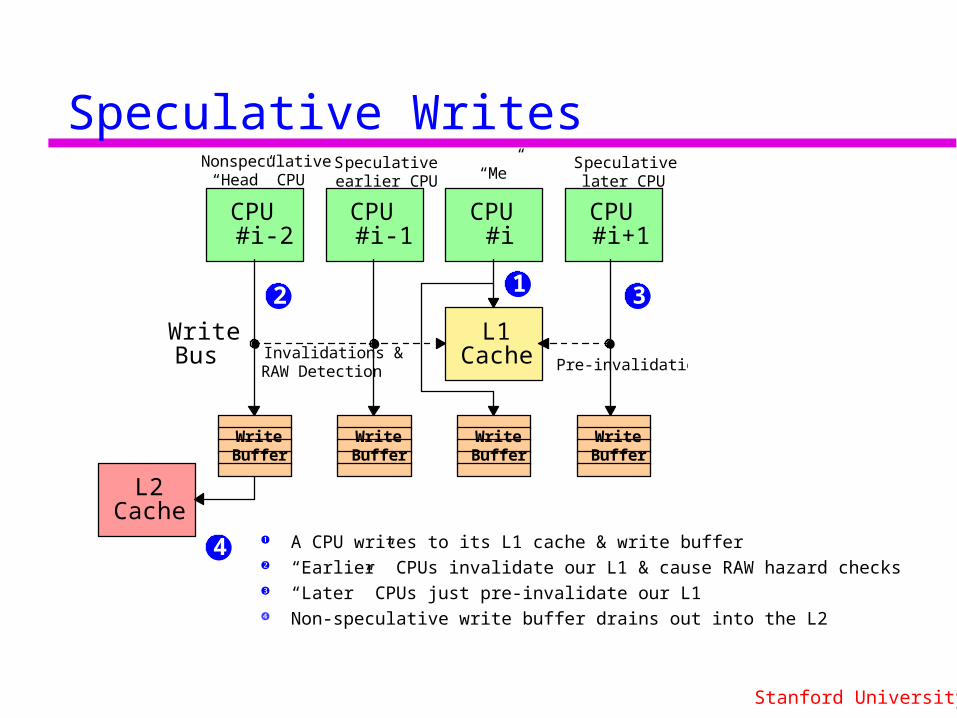
Speculative Writes
A CPU writes to its L1 cache & write buffer “Earlier” CPUs invalidate our L1 & cause RAW hazard checks “Later” CPUs just pre-invalidate our L1 Non-speculative write buffer drains out into the L2
CPU #i
CPU #i-1
CPU #i-2
CPU #i+1
Nonspeculative “Head” CPU “Me”
L1 Cache
12 3
L2 Cache
4
Invalidations & RAW Detection Pre-invalidations
Write Bus
Write Buffer
Write Buffer
Write Buffer
Write Buffer
Speculativeearlier CPU
Speculative later CPU

Stanford University
Speculation Runtime System
Software Handlers Control speculative threads through CP2 interface Track order of all speculative threads Exception routines recover from data dependency
violations Adds more overhead to speculation than hardware but
more flexible and simpler to implement Complete description in “Data Speculation Support for a
Chip Multiprocessor” ASPLOS ‘98 and “Improving the Performance of Speculatively Parallel Applications on the Hydra CMP” ICS ‘99

Stanford University
Creating Speculative Threads
Speculative loops for and while loop iterations Typically one speculative thread per iteration
Speculative procedures Execute code after procedure speculatively Procedure calls generate a speculative thread
Compiler support C source to source translator Pfor, pwhile Analyze loop body and globalize any local variables that
could cause loop-carried dependencies
Stanford University
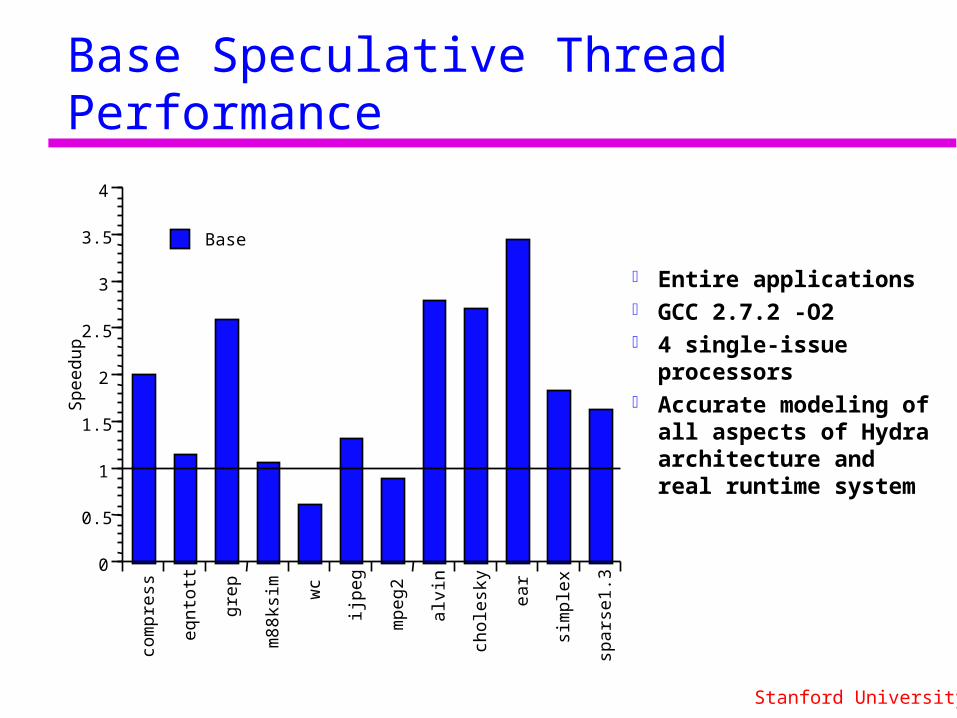
Base Speculative Thread Performance
Entire applications GCC 2.7.2 -O2 4 single-issue
processors Accurate modeling of
all aspects of Hydra architecture and real runtime system
com
pres
s
eqnt
ott
grep
m88
ksim wc
ijpeg
mpe
g2
alvi
n
chol
esky ea
r
sim
plex
spar
se1.
3
0
0.5
1
1.5
2
2.5
3
3.5
4
Spe
edup
Base

Stanford University
Improving Speculative Runtime System Procedure support adds overhead to loops
Threads are not created sequentially Dynamic thread scheduling necessary Start and end of loop: 75 cycles End of iteration: 80 cycles
Performance Best performing speculative applications use loops Procedure speculation often lowers performance Need to optimize RTS for common case
Lower speculative overheads Start and end of loop: 25 cycles End of iteration: 12 cycles (almost a factor of 7) Limit procedure speculation to specific procedures
Stanford University
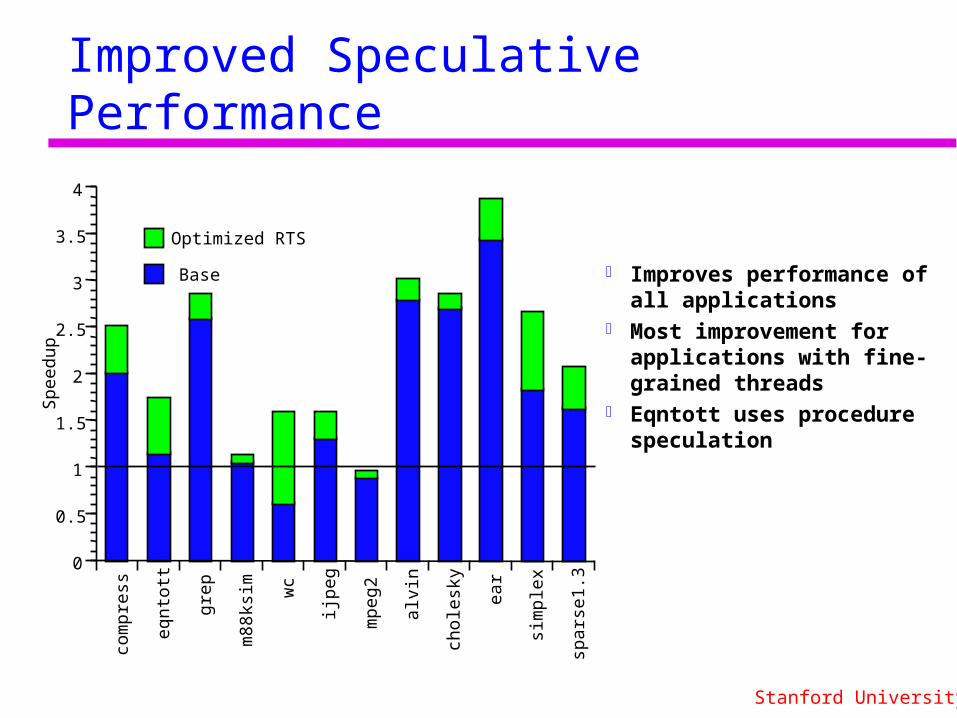
Improved Speculative Performance
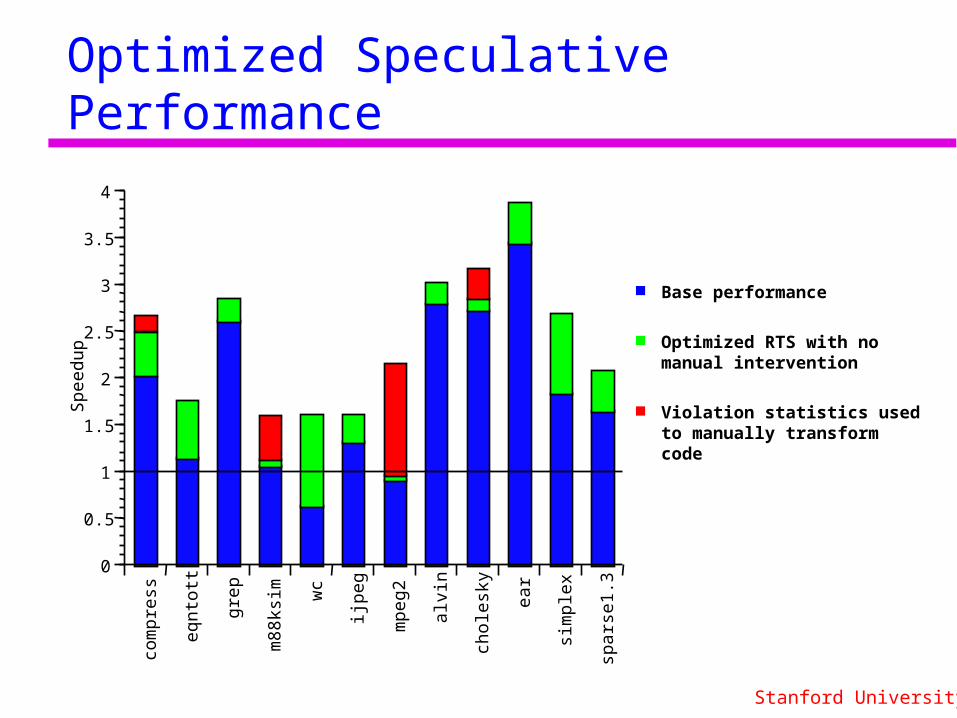
Improves performance of all applications
Most improvement for applications with fine-grained threads
Eqntott uses procedure speculation
com
pres
s
eqnt
ott
grep
m88
ksim wc
ijpeg
mpe
g2
alvi
n
chol
esky ea
r
sim
plex
spar
se1.
30
0.5
1
1.5
2
2.5
3
3.5
4
Spe
edup
Base
Optimized RTS

Stanford University
Optimizing Parallel Performance
Cache coherent shared memory No explicit data movement 100+ cycle communication latency Need to optimize for data locality Look at cache misses (MemSpy, Flashpoint)
Speculative threads No explicit data independence Frequent dependence violations limit performance Need to optimize to reduce frequency and impact of data
violations Dependence prediction can help Look at violation statistics (requires some hardware support)

Stanford University
Feedback and Code Transformations
Feedback tool Collects violation statistics (PCs, frequency, work lost) Correlates read and write PC values with source code
Synchronization Synchronize frequently occurring violations Use non-violating loads
Code Motion Find dependent load-stores Move loads down in thread Move stores up in thread
Stanford University
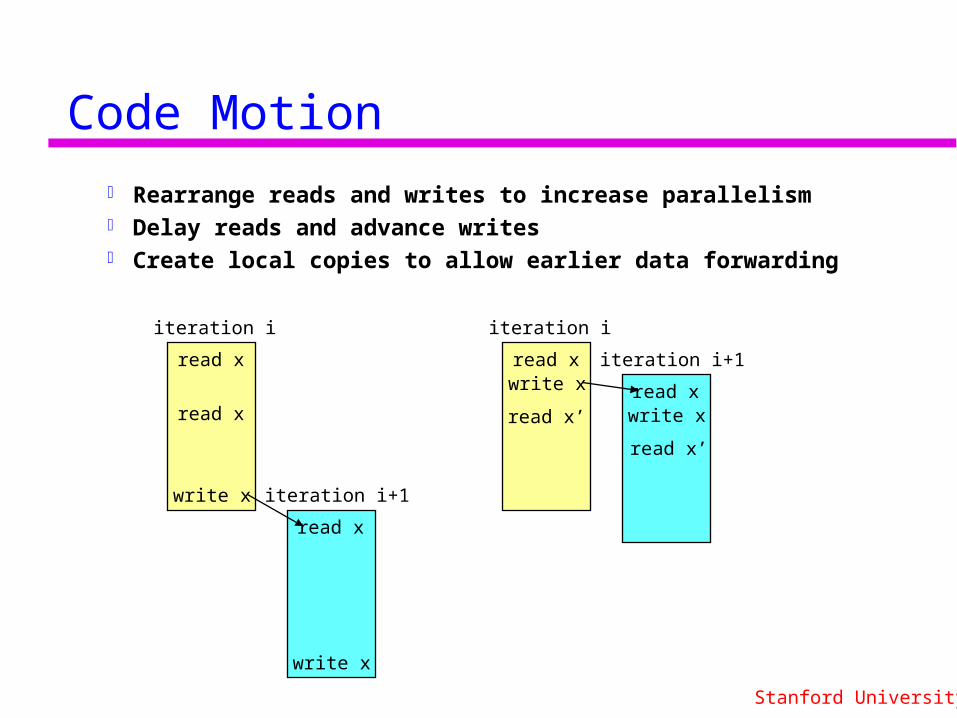
Code Motion
Rearrange reads and writes to increase parallelism Delay reads and advance writes Create local copies to allow earlier data forwarding
read x
write x
read x
write x
iteration i
iteration i+1
read xwrite x read x
write x
iteration i
iteration i+1
read x read x’
read x’
Stanford University
Optimized Speculative Performance
Base performance
Optimized RTS with no manual intervention
Violation statistics used to manually transform code
com
pres
s
eqnt
ott
grep
m88
ksim w
c
ijpeg
mpe
g2
alvi
n
chol
esky ea
r
sim
plex
spar
se1.
3
0
0.5
1
1.5
2
2.5
3
3.5
4
Spe
edup

Stanford University
Size of Speculative Write State
Max size determines size of write buffer for max performance
Non-head processor stalls when write buffer fills up
Small write buffers (< 64 lines) will achieve good performance
compress 24
eqntott 40
grep 11
m88ksim 28
wc 8
ijpeg 32
mpeg 56
alvin 158
cholesky 4
ear 82
simplex 14
32 byte cache lines
Max no. lines of write state
Stanford University
Hydra Prototype
Design based on Integrated Device Technology (IDT) RC32364 88 mm2 in 0.25m with 8 KB I, D and 128 KB L2
8 mm
11 mm

Stanford University
Conclusions
Hydra offers a new way to design microprocessors Single-chip MP exploits parallelism at all levels Low overhead support for speculative parallelism Provides high performance on applications with medium
to large-grain parallelism Allows performance optimization migration path for
difficult to parallelize fine-grain applications
Prototype Implementation Work out implementation details Provide platform for application and compiler
development Realistic performance evaluation

Stanford University
Hydra Team
Team Monica Lam, Lance Hammond, Mike Chen, Ben Hubbert,
Manohar Prahbu, Mike Siu, Melvyn Lim and Maciek Kozyrczak (IDT)
URL http://www-hydra.stanford.edu
Related Documents











