Prosiding Seminar Nasional Manajemen Teknologi XVI Program Studi MMT-ITS, Surabaya 14 Juli 2012 ISBN : 978-602-97491-5-1 C-4-1 CLUSTERING DOKUMEN SECARA HIERARKI BERBASIS FUZZY SET TIPE-2 TRAPEZOIDAL DAN TRIANGULAR DARI FREQUENT ITEMSET Susiana Sari 1*) , Agus Zainal Arifin danWijayanti Nurul Khotimah Informatics Department, Faculty of Information Technology, Sepuluh Nopember Institute of TechnologySurabaya Gedung Teknik Informatika ITS, Kampus ITS Sukolilo, Surabaya, 60111, Indonesia e-mail: [email protected] 1 , [email protected] 1 , [email protected] 1 ABSTRAK Dokumen teks meningkat secara eksplosif di internet. Mayoritas format dokumen tersebut tidak terstruktur dan pengelompokannya ambigu, sehingga mengakibatkan kesulitan dalam pencarian dan pengelolaan dokumen. Salah satu metode yang berfungsi untuk mengorganisasikan koleksi dokumen adalah clustering dokumen secara hierarki. Beberapa algoritma terkini mengelaborasikan teori fuzzy dengan frequent itemset untuk meningkatkan akurasi hasil clustering. Namun, fuzzy tersebut masih bertipe-1 yang tidak mampu mengatasi ambiguitas. Salah satu solusi yang bisa digunakan adalah fuzzy set tipe-2. Penelitian ini bertujuan untuk membangun sebuah metode clustering dokumen secara hierarki berbasis fuzzy set tipe-2 dari frequent itemsetuntuk meningkatkan kualitas hasil clustering. Metode clustering dokumen secara hierarki digunakan untuk merepresentasikan topik dokumen secara hierarki. Topik tersebut diwakili oleh label cluster bermaknayang diekstraksi darifrequent itemset.Fuzzy set tipe-2 dibangun dengan menggunakan trapezoidal sebagai fungsi keanggotaan atas dan triangular sebagai fungsi keanggotaan bawah. Metode penelitian ini telah diuji coba padadataset Classic4, Reuters, dan 20 NewsGroup. Dari hasil penelitian diperoleh nilai overall F-measure sebesar 0.58 pada dataset Classic4, 0.40 pada dataset Reuters, dan 0.39 pada dataset 20 NewsGroup.Penelitian ini menunjukkan bahwa metode tersebut mempunyai kinerja yang baik dalam meningkatkan kualitas hasil clustering dokumen. Kata kunci: clustering, fuzzyset tipe-2, trapezoidal, triangular, frequent itemset. PENDAHULUAN Clustering dokumen mempunyai peran penting sebagai tool yang mengorganisasikan koleksi dokumen menjadi koleksi cluster yang bermakna untuk meningkatkan efisiensi information retrieval (IR) dan manajemen dokumen (Nogueira, Camargo, & Rezende, 2011).Clustering dokumen kedalam struktur tree secara hierarki mampu meningkatkan efisiensi IR (Beil, Ester, & Xu, 2002), (Fung, 2002), (Chen, Tseng, & Liang, 2010). Namun, ada beberapa tantangan dalam clustering dokumen secara hierarki yaitu high dimensionality, scalability, accuracy, easy of browsing, dan meaningful cluster label (Beil, Ester, & Xu, 2002), (Fung, 2002), (Han & Kamber, 2006), (Chen, Tseng, & Liang, 2010). Beberapa Peneliti (Beil, Ester, & Xu, 2002), (Fung, 2002), (Hong, Lin, & Wang, 2003), (Chen, Tseng, & Liang, 2010) menggunakan frequent itemset dari association rule untuk manajemen dokumen. Metode tersebut mampu memecahkan permasalahan seperti reduksi dimensi, input jumlah cluster, dan kemudahan pencarian dengan label yang bermakna. Selanjutnya, Chen dkk (Chen, Tseng, & Liang, 2010) menunjukkan bahwa metode fuzzy frequent itemset-based hierarchical clustering (F 2 IHC) dapat menghindari overlappingcluster

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Prosiding Seminar Nasional Manajemen Teknologi XVIProgram Studi MMT-ITS, Surabaya 14 Juli 2012
ISBN : 978-602-97491-5-1C-4-1
CLUSTERING DOKUMEN SECARA HIERARKI BERBASIS FUZZYSET TIPE-2 TRAPEZOIDAL DAN TRIANGULAR DARI FREQUENT
ITEMSET
Susiana Sari1*), Agus Zainal Arifin danWijayanti Nurul KhotimahInformatics Department, Faculty of Information Technology,
Sepuluh Nopember Institute of TechnologySurabayaGedung Teknik Informatika ITS, Kampus ITS Sukolilo, Surabaya, 60111, Indonesiae-mail: [email protected], [email protected], [email protected]
ABSTRAK
Dokumen teks meningkat secara eksplosif di internet. Mayoritas format dokumen tersebuttidak terstruktur dan pengelompokannya ambigu, sehingga mengakibatkan kesulitan dalampencarian dan pengelolaan dokumen. Salah satu metode yang berfungsi untukmengorganisasikan koleksi dokumen adalah clustering dokumen secara hierarki. Beberapaalgoritma terkini mengelaborasikan teori fuzzy dengan frequent itemset untuk meningkatkanakurasi hasil clustering. Namun, fuzzy tersebut masih bertipe-1 yang tidak mampu mengatasiambiguitas. Salah satu solusi yang bisa digunakan adalah fuzzy set tipe-2. Penelitian inibertujuan untuk membangun sebuah metode clustering dokumen secara hierarki berbasis fuzzyset tipe-2 dari frequent itemsetuntuk meningkatkan kualitas hasil clustering. Metodeclustering dokumen secara hierarki digunakan untuk merepresentasikan topik dokumen secarahierarki. Topik tersebut diwakili oleh label cluster bermaknayang diekstraksi darifrequentitemset.Fuzzy set tipe-2 dibangun dengan menggunakan trapezoidal sebagai fungsikeanggotaan atas dan triangular sebagai fungsi keanggotaan bawah. Metode penelitian initelah diuji coba padadataset Classic4, Reuters, dan 20 NewsGroup. Dari hasil penelitiandiperoleh nilai overall F-measure sebesar 0.58 pada dataset Classic4, 0.40 pada datasetReuters, dan 0.39 pada dataset 20 NewsGroup.Penelitian ini menunjukkan bahwa metodetersebut mempunyai kinerja yang baik dalam meningkatkan kualitas hasil clusteringdokumen.
Kata kunci: clustering, fuzzyset tipe-2, trapezoidal, triangular, frequent itemset.
PENDAHULUAN
Clustering dokumen mempunyai peran penting sebagai tool yang mengorganisasikankoleksi dokumen menjadi koleksi cluster yang bermakna untuk meningkatkan efisiensiinformation retrieval (IR) dan manajemen dokumen (Nogueira, Camargo, & Rezende,2011).Clustering dokumen kedalam struktur tree secara hierarki mampu meningkatkanefisiensi IR (Beil, Ester, & Xu, 2002), (Fung, 2002), (Chen, Tseng, & Liang, 2010). Namun,ada beberapa tantangan dalam clustering dokumen secara hierarki yaitu high dimensionality,scalability, accuracy, easy of browsing, dan meaningful cluster label (Beil, Ester, & Xu,2002), (Fung, 2002), (Han & Kamber, 2006), (Chen, Tseng, & Liang, 2010).
Beberapa Peneliti (Beil, Ester, & Xu, 2002), (Fung, 2002), (Hong, Lin, & Wang,2003), (Chen, Tseng, & Liang, 2010) menggunakan frequent itemset dari association ruleuntuk manajemen dokumen. Metode tersebut mampu memecahkan permasalahan sepertireduksi dimensi, input jumlah cluster, dan kemudahan pencarian dengan label yang bermakna.Selanjutnya, Chen dkk (Chen, Tseng, & Liang, 2010) menunjukkan bahwa metode fuzzyfrequent itemset-based hierarchical clustering (F2IHC) dapat menghindari overlappingcluster

Prosiding Seminar Nasional Manajemen Teknologi XVIProgram Studi MMT-ITS, Surabaya 14 Juli 2012
ISBN : 978-602-97491-5-1C-4-2
dan meningkatkan akurasi hasil clustering dokumen. Namun, metode tersebut menggunakanfuzzy set tipe-1.Fuzzy set tipe-1 yang memiliki fungsi keanggotaan yang tegas, tidak mampumemodelkan ketidakpastian secara langsung (Mendel & John, 2002). Disisi lain, metode fuzzyset tipe-2 memiliki fungsi keanggotaan interval yang mampu memodelkan ketidakpastiandalam mendefinisikan fungsi keanggotaan pada fuzzy set tipe-1 (Mendel & John, 2002),(Starczewski, 2009).
Fuzzy set tipe-2 memiliki duafungsi keanggotaan(membership function), yaitu fungsikeanggotaan atas (upper membership function) dan fungsi keanggotaan bawah (lowermembership function). Adapun bentuk fungsi keanggotaan dapat berupa sigmoidal, Gbell, tipeS, trapezoidal, dan triangular. Beberapa peneliti (Starczewski, 2009), (Chiao,2011)membuktikan bahwa jenis trapezoidal dan triangular dapat digunakan untuk data yangbersifat kompleks dan heterogen.Fungsi keanggotaan jenistrapezoidalmampumerepresentasikan masalah lebih realistis dan memiliki akurasi yang paling baik karenamemiliki core region yang lebih besar dari yang lain. Sedangkan fungsi keanggotaantriangular lebih efisien dalam mereduksi kompleksitas komputasi dan meningkatkan akurasi.
Penelitian ini bertujuan untuk membangun sebuah metode clustering dokumen secarahierarki berbasis fuzzy set tipe-2 dari frequent itemset untuk meningkatkan kualitas hasilclustering.Fuzzy set tipe-2 trapezoidal sebagai fungsi keanggotaan atas dan fuzzy tipe-2triangular sebagai fungsi keanggotaan bawah terhadap frequent itemset yang diperoleh dariassociation rule mining untuk meningkatkan akurasi clustering dokumen.
METODE
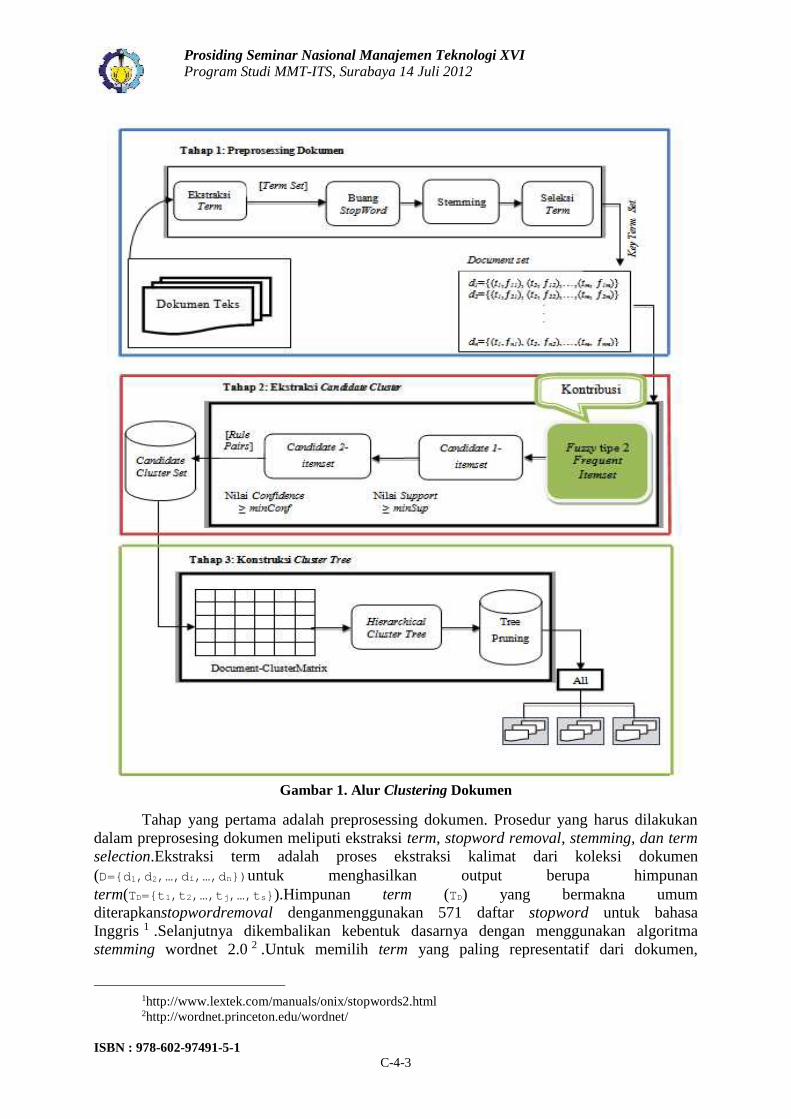
Metode clustering dokumen yang dibangun terbagi menjadi tiga tahaputama yaitudokumen preprocessing, ekstraksi candidate cluster, dan konstruksi cluster tree. Preprosesingdokumen digunakan untuk mentransformasikan dokumen ke dalam bentuk vektor matrix.Ekstraksi kandidat clusterdigunakan untuk menghasilkan koleksi kandidat cluster darifrequent itemset. Adapun konstruksi cluster tree digunakan untuk membentuk cluster treesecara hierarki dari kandidat cluster. Detail tentang metode penelitian digambarkan padaGambar 1.
Prosiding Seminar Nasional Manajemen Teknologi XVIProgram Studi MMT-ITS, Surabaya 14 Juli 2012
ISBN : 978-602-97491-5-1C-4-3
Gambar 1. Alur Clustering Dokumen
Tahap yang pertama adalah preprosessing dokumen. Prosedur yang harus dilakukandalam preprosesing dokumen meliputi ekstraksi term, stopword removal, stemming, dan termselection.Ekstraksi term adalah proses ekstraksi kalimat dari koleksi dokumen(D={d1,d2,…,di,…,dn})untuk menghasilkan output berupa himpunanterm(TD={t1,t2,…,tj,…,ts}).Himpunan term (TD) yang bermakna umumditerapkanstopwordremoval denganmenggunakan 571 daftar stopword untuk bahasaInggris 1 .Selanjutnya dikembalikan kebentuk dasarnya dengan menggunakan algoritmastemming wordnet 2.0 2 .Untuk memilih term yang paling representatif dari dokumen,
1http://www.lextek.com/manuals/onix/stopwords2.html2http://wordnet.princeton.edu/wordnet/
Prosiding Seminar Nasional Manajemen Teknologi XVIProgram Studi MMT-ITS, Surabaya 14 Juli 2012
ISBN : 978-602-97491-5-1C-4-4
dilakukan term selectionberdasarkan tf.idf, tf.df, dan tf2. Term yang mempunyai nilai bobotdiatasthreshold minimum tf.idf (),threshold minimum tf.df (), danthreshold minimumtf2()dipertahankan sebagai keyterm set. Untuk mendapatkan bobot setiap term digunakanpersamaan (1) untuk tf.idf, (2) untuk tf.df, dan (3) untuk tf.idf(Chen, Tseng, & Liang, 2010).
= ∑ ∗ log | || ∈ , ∈ (1)= ∗ , = ∑ , = | ∈ , ∈| | (2)= ∗ (3)
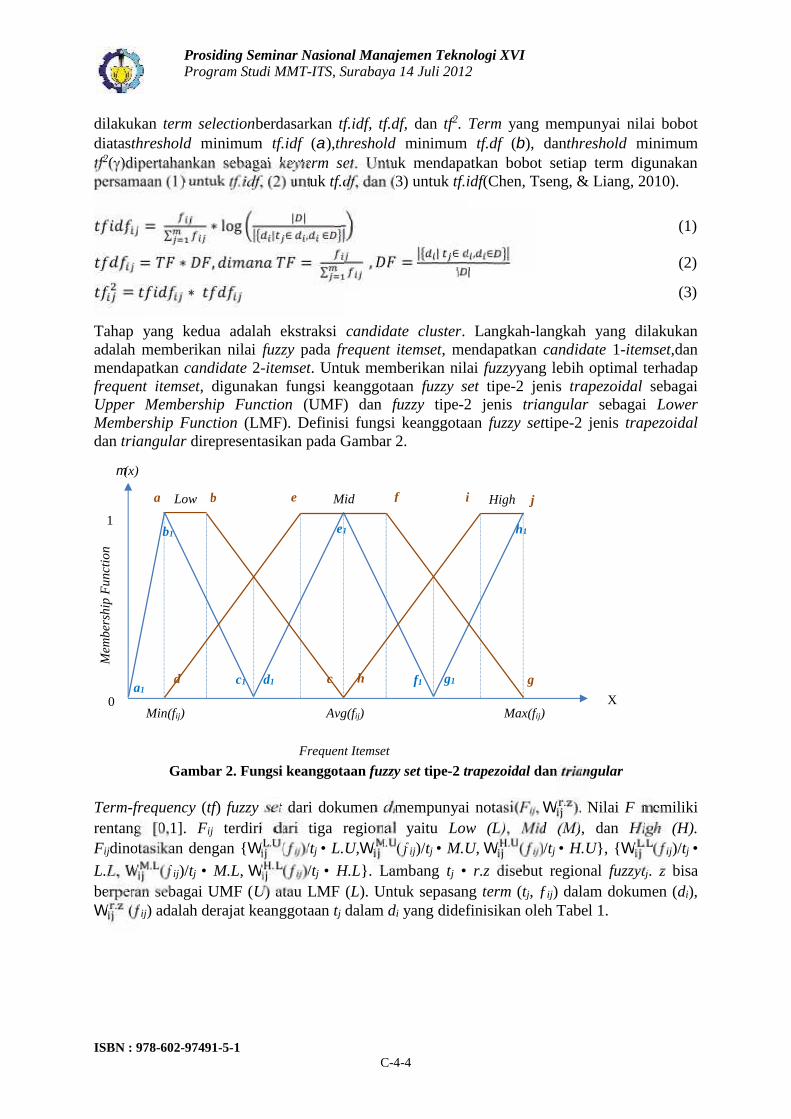
Tahap yang kedua adalah ekstraksi candidate cluster. Langkah-langkah yang dilakukanadalah memberikan nilai fuzzy pada frequent itemset, mendapatkan candidate 1-itemset,danmendapatkan candidate 2-itemset. Untuk memberikan nilai fuzzyyang lebih optimal terhadapfrequent itemset, digunakan fungsi keanggotaan fuzzy set tipe-2 jenis trapezoidal sebagaiUpper Membership Function (UMF) dan fuzzy tipe-2 jenis triangular sebagai LowerMembership Function (LMF). Definisi fungsi keanggotaan fuzzy settipe-2 jenis trapezoidaldan triangular direpresentasikan pada Gambar 2.
Gambar 2. Fungsi keanggotaan fuzzy set tipe-2 trapezoidal dan triangular
Term-frequency (tf) fuzzy set dari dokumen dimempunyai notasi(Fij, W . ). Nilai F memilikirentang [0,1]. Fij terdiri dari tiga regional yaitu Low (L), Mid (M), dan High (H).Fijdinotasikan dengan {W . (ƒij)/tj • L.U,W . (ƒij)/tj • M.U, W . (ƒij)/tj • H.U}, {W . (ƒij)/tj •L.L, W . (ƒij)/tj • M.L, W . (ƒij)/tj • H.L}. Lambang tj • r.z disebut regional fuzzytj. z bisaberperan sebagai UMF (U) atau LMF (L). Untuk sepasang term (tj, ƒij) dalam dokumen (di),W . (ƒij) adalah derajat keanggotaan tj dalam di yang didefinisikan oleh Tabel 1.
c
ba
a1
b1
c1d
e f
gh
i j
d1
e1
f1 g1
h1
Min(fij) Avg(fij) Max(fij)0
1
Low Mid High
X
Frequent Itemset
Mem
bers
hip
Fun
ctio
n
(x)

Prosiding Seminar Nasional Manajemen Teknologi XVIProgram Studi MMT-ITS, Surabaya 14 Juli 2012
ISBN : 978-602-97491-5-1C-4-5
Tabel 1. Definisi Fungsi Keanggotaan Fuzzy Tipe-2 Trapezoidal dan Triangular
Upper Membership Function (UMF) Lower Membership Function (LMF).= ⎩⎪⎨⎪⎧ 1, ≤ ≤−( − ) , ≤ ≤0, ≥
, , = min( )= min( ) +2.
= ⎩⎪⎨⎪⎧ −( − ) , ≤ ≤−( − ) , ≤ ≤
= 0
.=⎩⎪⎨⎪⎧ −( − ) , ≤ ≤1, ≤ ≤−( − ) , ≤ ≤
, ℎ = ( )= + ( )2= ( ) +2.
= ⎩⎪⎨⎪⎧ −( − ) , ≤ ≤−( − ) , ≤ ≤
,= min( ) + ( )2= ( ).
= − ℎ( − ℎ) , ℎ ≤ ≤1, ≤ ≤, , ℎ = ( )
= + ( )2.
= 0, ≤−(ℎ − ) , ≤ ≤ ℎ,= ( ) + ( )2
adalah frekuensi minimum term di D, adalah frekuensi maksimum term di
D, dan = ( ).
Fuzzy frequent itemsetyang memiliki nilai support lebih besar dari threshold minimumsupport, dipertahankan sebagai candidate 1-itemset. Perhitungan nilai support sebuah termdiperoleh dari rasio antara nilai fuzzy frequent itemset dengan jumlah dokumen.Candidate 2-itemset adalah dua fuzzy frequent itemset yang memiliki nilai confidencelebih tinggi darithreshold minimum confidence.Kandidat cluster ( )diperoleh dari koleksi dokumen (D). dapat juga dinotasikan seperti ( , ,…, }atau (}. Kandidat cluster mempunyai 2-tuple yang
dinotasikan oleh = , , dimana adalah bagian dari D dan adalah fuzzy frequentitemset untuk menggambarkan . dinotasikan sebagai = , , … , ⊆ . adalahkoleksi key terms D dan q adalah jumlah key terms yang termasuk dalam . Koleksi kandidatcluster dinotasikan = , … , , , … , , dimana k adalah jumlah total kandidatcluster.
Tahap yang ketiga adalah konstruksi cluster tree. Adapun prosesnya terdiri dari tigalangkahyaitu membangun Document-Cluster Matrix (DCM), membangun cluster tree secarahierarki, dan tree pruning. DCMberfungsi untuk menempatkan setiap dokumen ke clusteryang tepat, sehingga masing-masing c berisi subset dari dokumen. Untuk mencapai tujuanini, didefinisikan dua matriks, yaitu Document-Term Matrix (DTM) dan Term-Cluster Matrix(TCM). DTM (W) adalah bobot term tj dalam dokumen di dan tj L1. Langkah pertama yangdilakukan adalah mempertimbangkan setiap candidate cluster = ( , ,…, ) dengan fuzzy
frequent itemset . dianggap sebagai titik acuan untuk menghasilkan target cluster. Untukmerepresentasikan tingkat kepentingan dokumen dalam candidate cluster , dihitungkemiripan term di di dan . DTM diilustrasikan pada Gambar 3.

Prosiding Seminar Nasional Manajemen Teknologi XVIProgram Studi MMT-ITS, Surabaya 14 Juli 2012
ISBN : 978-602-97491-5-1C-4-6
⋯⋯= ⋯⋮ ⋮ ⋮ ⋱ ⋮⋯
Gambar 3. Ilustrasi Document-Term Matrix
adalah bobot termtj dalam dokumen di dan λ adalah nilai minimumconfidence.TCM (G) adalah sebuah matriks p x k, yang diilustrasikan pada Gambar4. TCMuntuk 1 ≤ j ≤ p, 1 ≤ l ≤ k dihitung dengan menggunakan persamaan (10).
= ∑ , , = ∑ = 1,∈ , ∈∑ ∈ , ∈ , (10)
⋯ ⋯ ⋯ ⋯= ⋯ ⋯⋮ ⋮ ⋱ ⋮ ⋮ ⋱ ⋮⋯ ⋯Gambar 4. Ilustrasi Term-Cluster Matrix
Setiap dalam TCM merepresentasikan derajat kepentingan key termtj dalam sebuah
candidate cluster dengan mengacu pada semua dokumen yang memiliki . Selanjutnya treedapat dibentuk sebagai dasar pruning dan struktur dasar browsing. Kedalaman clustertreesama dengan ukuran maksimum fuzzy frequent itemset.Berdasarkan DCM yang diperoleh,setiap dokumen hanya dapat diberikan terhadap satu target cluster.Metode tree pruningdigunakan untuk menggabungkan target cluster yang mirip pada level 1. Kemiripan inter-cluster antara dua target clusterc dan c , c ≠ c , didefinisikan oleh persamaan (11).Inter c , c = ∑ ∈ ,∑ ( ) ∑ ∈∈ (11)
dimana vix dan viyadalah dua entri untuk ∈ , ∈ . Nilai inter-sim mempunyairentang 0-1. Jika nilainya mendekati 1, maka kedua cluster memiliki kemiripan yang tinggi.Sehingga dua cluster tersebut harus digabung.
HASIL DAN PEMBAHASAN
Implementasi metode didukung oleh ProcessorIntel ® Core ™ i3-2120 CPU @3.30GHz (4CPUs), Memori4 GB, Java Development Kit 6 update 31 dan Netbeans IDE6.8.Untuk evaluasi metode, digunakandataset benchmarksyaitu 1000 dokumen dari datasetClassic4, 2000 dokumen daridataset Reuters, dan 2000 dokumen dari dataset 20NewsGroup.Setiap dataset memiliki karakteristik yang heterogen,sehingga nilai threshold ditentukan

Prosiding Seminar Nasional Manajemen Teknologi XVIProgram Studi MMT-ITS, Surabaya 14 Juli 2012
ISBN : 978-602-97491-5-1C-4-7
untuk mendapatkan akurasi terbaik. Informasi nilai thresholdterdapat dalam Tabel 1. Nilaithreshold minimum support(MinSup) ditentukan antara 20%-90%. Hasil dari percobaanpengaruh MinSupterhadap overall F-measuredicantumkan pada Tabel 2 dan jumlah clusterdicantumkan pada Tabel 4.Hasil kualitascluster dicantumkan pada Tabel 5.
Tabel 2. Informasi Nilai Threshold
DatasetThreshold
tf.idf tf.df tf2 MinConf I_SimClassic4 0.01 0.01 0.002 0.7 0.7
Reuters21578 0.028 0.01 0.005 0.6 0.620 NewsGroup 0.01 0.01 0.002 0.6 0.6
Tabel 3. Hasil Uji Coba Pengaruh Minimum Support terhadap Overall F-Measure
MinSup(%)
DatasetClassic4 Reuters 20 NewsGroup
FT2T2 FT1Tra FT1Tri FT2T2 FT1Tra FT1Tri FT2T2 FT1Tra FT1Tri20 0.58 0.58 0.58 0.39 0.39 0.40 0.39 0.39 0.4030 0.58 0.58 0.58 0.39 0.39 0.40 0.39 0.39 0.40
40 0.58 0.58 0.58 0.39 0.39 0.40 0.39 0.39 0.40
50 0.58 0.58 0.58 0.39 0.39 0.40 0.39 0.39 0.40
60 0.58 0.58 0.58 0.39 0.39 0.40 0.39 0.39 0.40
70 0.58 0.58 0.58 0.39 0.39 0.40 0.39 0.39 0.40
80 0.58 0.58 0.58 0.39 0.39 0.40 0.39 0.39 0.40
90 0.58 0.58 0.58 0.39 0.39 0.40 0.39 0.39 0.39
Tabel 4. Hasil Uji Coba Pengaruh Minimum Support terhadap Jumlah Cluster
MinSup(%)
DatasetClassic4 Reuters 20 NewsGroup
FT2T2 FT1Tra FT1Tri FT2T2 FT1Tra FT1Tri FT2T2 FT1Tra FT1Tri20 11 11 11 14 14 12 22 25 2130 11 11 10 14 14 12 22 26 2240 11 11 10 14 14 14 22 26 2250 11 11 10 14 14 11 22 26 2260 11 11 10 14 14 11 22 26 2170 11 11 10 14 14 11 22 26 2180 10 10 9 12 12 11 21 25 2090 10 10 7 12 12 11 21 25 18
*FT2T2: Fuzzy Tipe-2 Trapezoidal & Triangular; FT1Tra: Fuzzy Tipe-1 Trapezoidal; FT1Tri: Fuzzy Tipe-1Triangular
Tabel 5. Hasil Kualitas Cluster Dataset Classic4
FT2T2 FT1Tra FT1TriProblem Theory Cacm Problem Ca Study Case Problem ca
Cacm_745 Cisi_1410 Cran_249 Cacm_745 N.D* Cran_1151 Med_679 Cacm_745 N.D*
Med_378 Cran_285 Med_378 Cran_285 Med_378*N.D= No Doc
Dari Tabel 3. dapat dilihat bahwa overall F-measure yang dihasilkan fuzzy set tipe-2cenderung sama dengan fuzzy tipe-1.Dari Tabel 4. dapat dilihat bahwa semakin tinggiMinSup, semakin rendah jumlah cluster. Dari Tabel 5. dapat dilihat bahwa fuzzy set tipe-2selalu mengembalikan cluster yang informatif. Berbeda dengan fuzzy tipe-1 yangmenghasilkan cluster tanpa dokumen. Hal ini mengartikan bahwa fuzzy tipe-2 mampumenangani data derau yang dapat mempengaruhi kualitas cluster.

Prosiding Seminar Nasional Manajemen Teknologi XVIProgram Studi MMT-ITS, Surabaya 14 Juli 2012
ISBN : 978-602-97491-5-1C-4-8
KESIMPULAN DAN SARAN
Kesimpulan dari penelitian ini adalahfuzzysettipe-2 mampu menghasilkan cluster yangberkualitas dan akurasi clusteringdapat dipengaruhi oleh nilai threshold. Saran selanjutnyaadalah merubah fungsi keanggotaan fuzzy settipe-2 untuk meningkatkan akurasi clustering.
DAFTAR PUSTAKA
Beil, F., Ester, M., & Xu, X. (2002). Frequent Term-Based Text Clustering. KnowledgeDiscovery and Data Mining, 02, 436-442.
Chen, C.-L., Tseng, F. S., & Liang, T. (2010). Mining fuzzy frequent itemsets for hierarchicaldocument clustering. Information Processing and Management, 46, 193–211.
Chiao, K.-P. (2011, June 27-30). Multiple Criteria Group Decision Making with TriangularInterval Type-2 Fuzzy Sets. International Conference on Fuzzy Systems, 2575-2582.
Fung, B. C. (2002). Hierarchical Document Clustering Using Frequent Itemsets. MasterThesis, Simon Fraser University, Computing Science.
Han, J., & Kamber, M. (2006). Data Mining: Concepts and Techniques (Second Edition ed.).San Francisco, United States of America: Morgan Kaufmann.
Hong, T.-P., Lin, K.-Y., & Wang, S.-L. (2003). Fuzzy data mining for interesting generalizedassociation rules. Fuzzy Sets and Systems, 138 (2), 255–269.
Mendel, J. M., & John, R. I. (2002, April). Type-2 Fuzzy Sets Made Simple. Transactions onFuzzy Systems, 10 (2), 117-127.
Nogueira, T. M., Camargo, H. A., & Rezende, S. O. (2011). Fuzzy Rules for DocumentClassification to Improve Information Retrieval. International Journal of ComputerInformation Systems and Industrial Management Applications, 3, 210-217.
Starczewski, J. T. (2009). Efficient triangular type-2 fuzzy logic systems. InternationalJournal of Approximate Reasoning, 50, 799–811.
Related Documents











