Crawl Budget et Page Importance, entre mythe et réalité

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Crawl Budget et
Page Importance, entre
mythe et réalité

2Metz 24/11/2017
Plan de vol
1. Comment fonctionne Google
2. Crawl Budget & Page Importance
3. Comment suivre les variations du crawl
4. Best practices d’optimisation

3Metz 24/11/2017
J’adore que Google vous donne de l’importance…
ERLE
ALBERTONCUSTOMER
SUcCESS manager10 ans de dev / 5 ans de SEO dont 2
ans en tant que responsable SEO des
boutiques en ligne Orange et Sosh
spécialiste schema.orgseo monk
ONCRAWL
TRAinER
customer climax & GOOD IDEAS

4Metz 24/11/2017
• Google possède un index colossal, il ne peut pas tout crawler tout le temps
• Pour avoir la meilleure réponse il faut connaitre toutes les pages - découverte
• Pour avoir la meilleure réponse il faut la dernière version de la page - indexation
Google Key Insights
Google n’est pas philanthrope,
il doit optimiser ses coûts de traitement…

Google consomme annuellement
autant d’énergie que la ville de
San Francisco

6Metz 24/11/2017
Comment fonctionne Google ?
Google est un moteur de réponse, son objectif est d’être le plus
pertinent, exhaustif et à jour possible
Google n’est qu’un ensemble d’algorithmes qui sont exécutés sur
des machines consommant de l’énergie… cette consommation
d’énergie à un coût qui doit être optimisé

7Metz 24/11/2017
Plus une page est mise à jour
plus Google la visite
Plus une page est utile pour la découverte
de nouvelles URLs plus Google la visite
Plus une page est crawlée plus
elle est à jour dans l’index
8Metz 24/11/2017
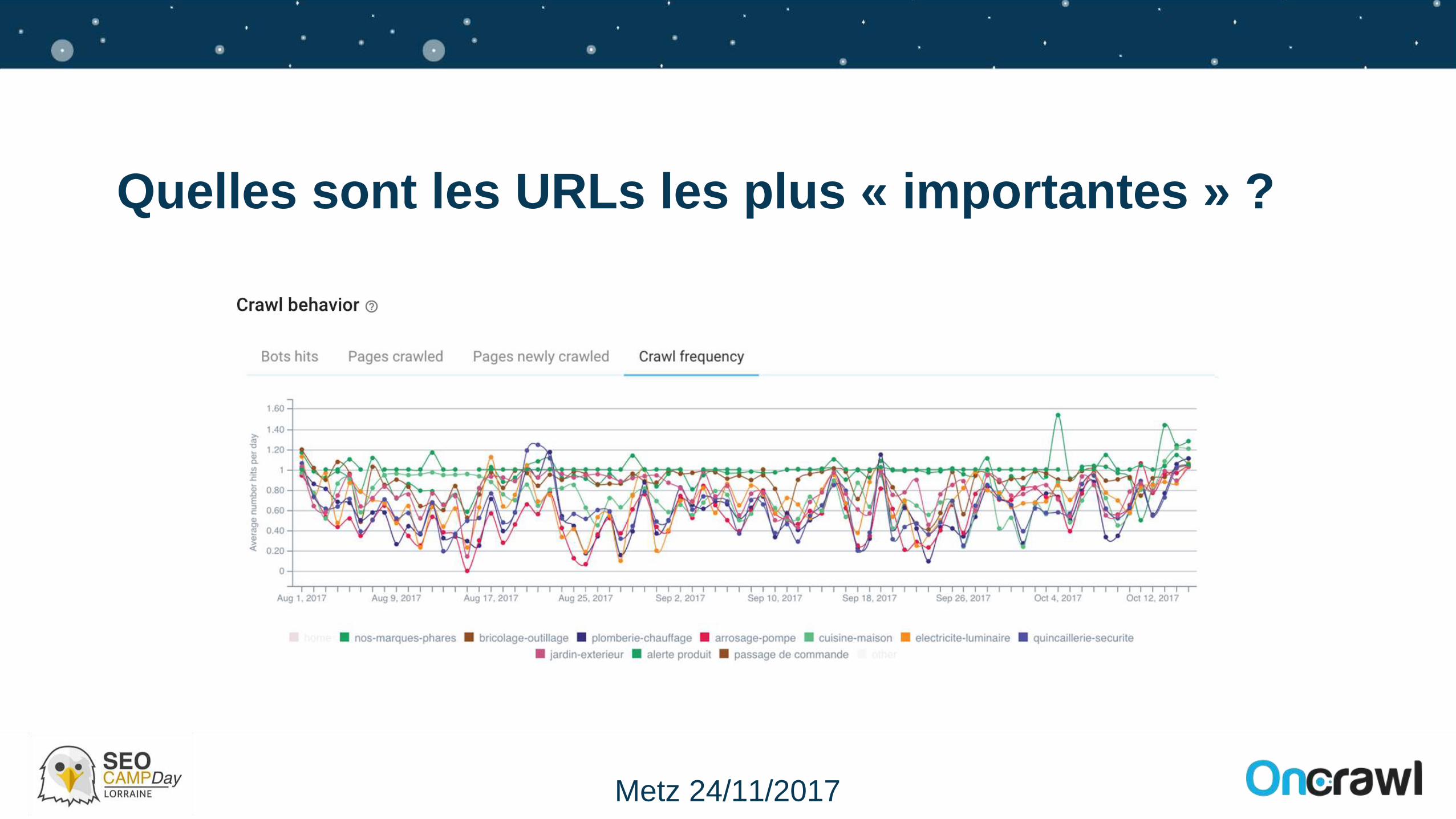
Quelles sont les URLs les plus « importantes » ?

9Metz 24/11/2017
Plus une page est à jour dans l’index plus
la réponse à la requête est qualifiée
Fréquence de Crawl et
Ranking sont étroitement liés

10Metz 24/11/2017
Crawl Budget
C’est le crédit que Google alloue
à l’ensemble de ses robots pour
parcourir les URLs d’un site web

11Metz 24/11/2017
Répartition des hits par bot (1 journée / granularité 10min) :
Mediapartners-Google
Adsbot-Google desktop
Googlebot 2.1 desktop
Googlebot 2.1 mobile
Adsbot-Google Mobile
Le crawl budget est réparti entre tous les bots Google

Metz 24/11/2017
Comment fonctionne
le crawl de Google?

13Metz 24/11/2017
Schedulers : Définir une liste des URLs à crawler pour la session de crawl
Crawlers : Vérifier quelles URLs sont autorisées au crawl
Chaque session de crawl commence par un hit sur le robots.txt, puis les
sitemap.xml, enfin les crawlers dépilent la liste des URLs à analyser
Cette liste d’url, conçue à l’avance, est établie grâce à un
algorithme qui classe les pages en fonction d’un score
d’importance
Comment fonctionne le crawl de Google
www.google.com/search/howsearchworks/crawling-indexing/

14Metz 24/11/2017
Page importance
C’est un score qui est affecté à chaque
page pour évaluer sa place dans la liste
des URLs à analyser
fr.oncrawl.com/2017/page-importance-google/

15Metz 24/11/2017
Les brevets d’optimisation de crawl
• US 8666964 B1 : Managing items in crawl schedule
• US 8707312 B1 : Document reuse in a search engine crawler
• US 8037054 B2 : Web crawler scheduler that utilizes sitemaps from websites
• US 7305610 B1 : Distributed crawling of hyperlinked documents
• US 8407204 B2 : Minimizing visibility of stale content in web searching including
revisine web crawl intervals of documents
• US 8386459 B1 : Scheduling a recrawl
• US 8042112 B1 : Scheduler for search engine crawler
www.google.com/patents

16Metz 24/11/2017
Comment optimiser le crawl de
Google ?

Connaitre les métriques qui sont prise en
compte dans le calcul de l’importance des
pages

18Metz 24/11/2017
Comment optimiser le crawl
• Localisation de la page dans le site
• Page Rank : TF/CF de la page
• Le Page Rank interne
• Type de document : PDF, HTML, TXT
• L’inclusion dans le sitemap.xml
• Le nombre de liens internes
• La variation des ancres
• Contenu de qualité : nombre de mots, peu de duplication
• L’importance de la page mère

19Metz 24/11/2017
Il faut appliquer toutes
ces règles aux pages les plus importantes

20Metz 24/11/2017
Calcul de la « Page Importance »
La notion de « Page Importance » n’est pas le Page Rank
• Localisation de la page dans le site – a profondeur sur le taux de crawl
• Page Rank : TF/CF de la page - Majestic
• Le Page Rank interne – InRank OnCrawl
• Type de document : PDF, HTML, TXT
• L’inclusion dans le sitemap.xml
• Le nombre de liens internes
• La variation des ancres
• Contenu de qualité : nombre de mots, peu de duplication
• L’importance de la page mère : les pages les plus prêt de la HP seront
favorisées
Il faut appliquer aux pages les plus importantes
toutes ces règles pour favoriser
le crawl de Google

21Metz 24/11/2017
Comment suivre
les variations du crawl ?
L’analyse des logs serveur et le croisement des données de crawl
permettent de comprendre
Quels sont les facteurs déclencheurs du crawl de Google?

22Metz 24/11/2017
Quelques exemples

23Metz 24/11/2017
PayloadAnalyser du temps de chargement
pour déterminer le temps maximum
de réponse du serveur

24Metz 24/11/2017
Réduire la profondeur des
pages
Le nombre de clicks – profondeur- depuis la Home
Page impact la crawlabilité
La profondeur impacte l’Activness de la page
Vos pages importantes doivent être à 3 clicks
maximum depuis la home page pour que Google
les estime importantes

25Metz 24/11/2017
Traquer Google lors de sa visite avec les fichiers de los
A chaque fois qu’un visiteur passe sur une page il laisse des traces dans des fichiers de logs
Google est un visiteur (presque) comme un autre il laisse ses traces et nous les analysons

26Metz 24/11/2017
Logs MonitoringCrawl Behavior
• Suivre les variations de crawls de Google sur chaque
segment du site
• Vérifier que toutes les pages importantes sont crawlées
• S’assurer que les pages non importantes ne consomment
pas le budget de crawl

27Metz 24/11/2017
Logs MonitoringSEO impact
• Vérifier que les visites SEO arrivent sur les pages
importantes
• Vérifier que toutes les pages importantes sont visitées
• S’assurer que les optimisations profitent au trafic SEO

28Metz 24/11/2017
Les bonnes pratiques
Une bonne optimisation est une modification qui va
maximiser les valeurs prisent en compte dans le calcul de
la Page Importance

29Metz 24/11/2017
Classer les pages
par importanceCréer des groupes en fonction des :
• Bot hits par jour / SEO visites par jour
• Visites SEO (logs/GS)
• De la profondeur dans le site
• Qualité technique (status code, temps de
chargement, …)
• Nombre de liens entrants (internes/externes)
• Nombre de variantes des ancres
• Nombre de mots dans les pages
• Par ratio de Near Duplicate Content

30Metz 24/11/2017
Vérifier les sitemaps
• Toutes les pages importantes sont elles dans les listées ?
• Pas de 40x, 50x ou 40x dans les sitemaps
• Vérifier les pages orphelines dans les sitemaps
Def : URLs dans le sitemap mais non maillée dans le site

31Metz 24/11/2017
HTML Quality
• Vérifier les Status code
retournés par le serveur durant le crawl
• Suivre les Load time
donne une information sur le temps de réponse serveur
TTFB et/ou TTLB

32Metz 24/11/2017
Distribution du
la popularité
• Vérifier que les pages importantes reçoivent beaucoup de
popularité : Inrank
• S’assurer que les pages importantes reçoivent les liens
les plus puissants
• Eviter les liens de toutes les pages vers toutes les
pages : Optimiser les Mega-menu et les footer

33Metz 24/11/2017
La popularité interne à un impact sur les visites
34Metz 24/11/2017
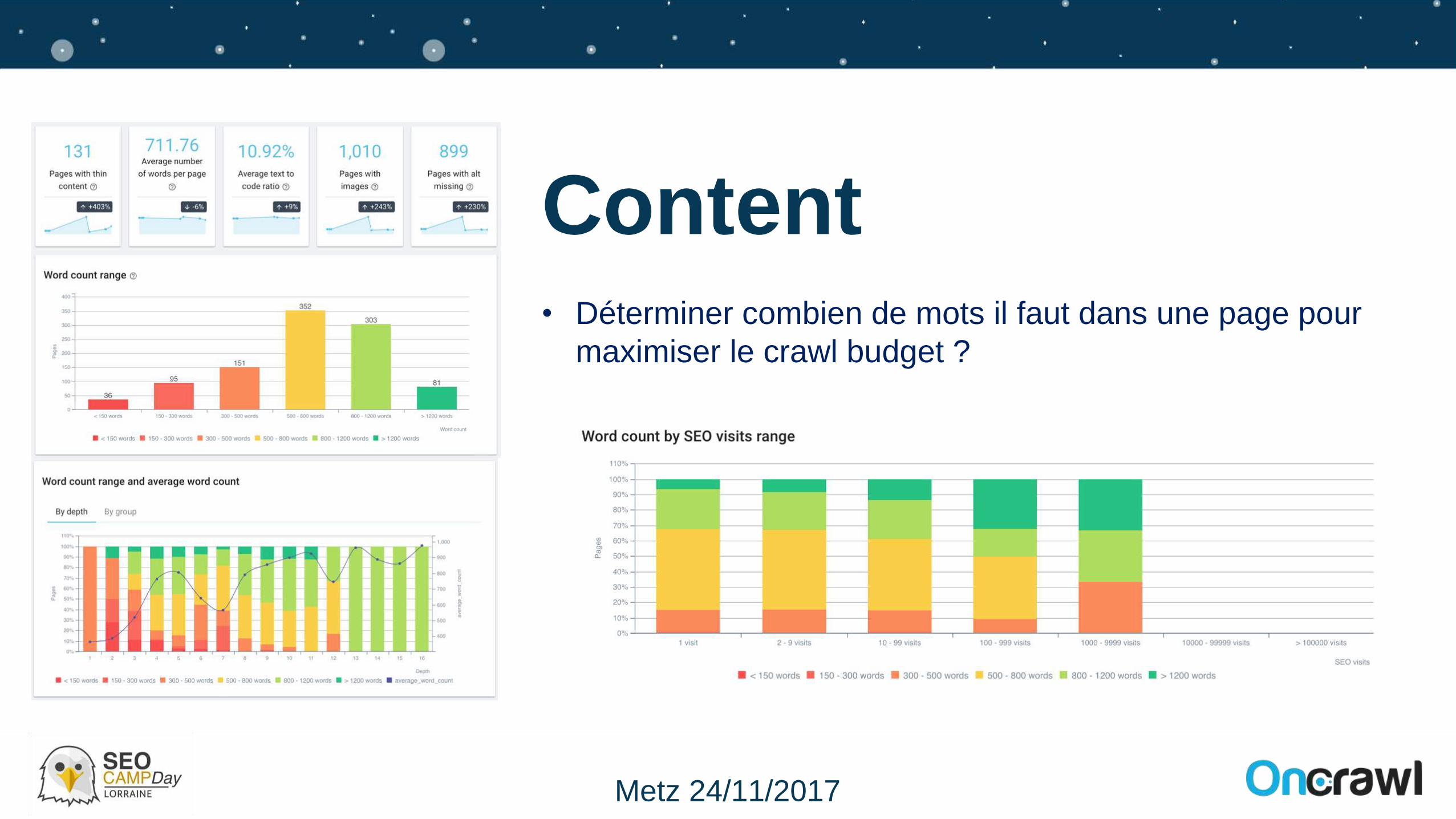
Content• Déterminer combien de mots il faut dans une page pour
maximiser le crawl budget ?
35Metz 24/11/2017
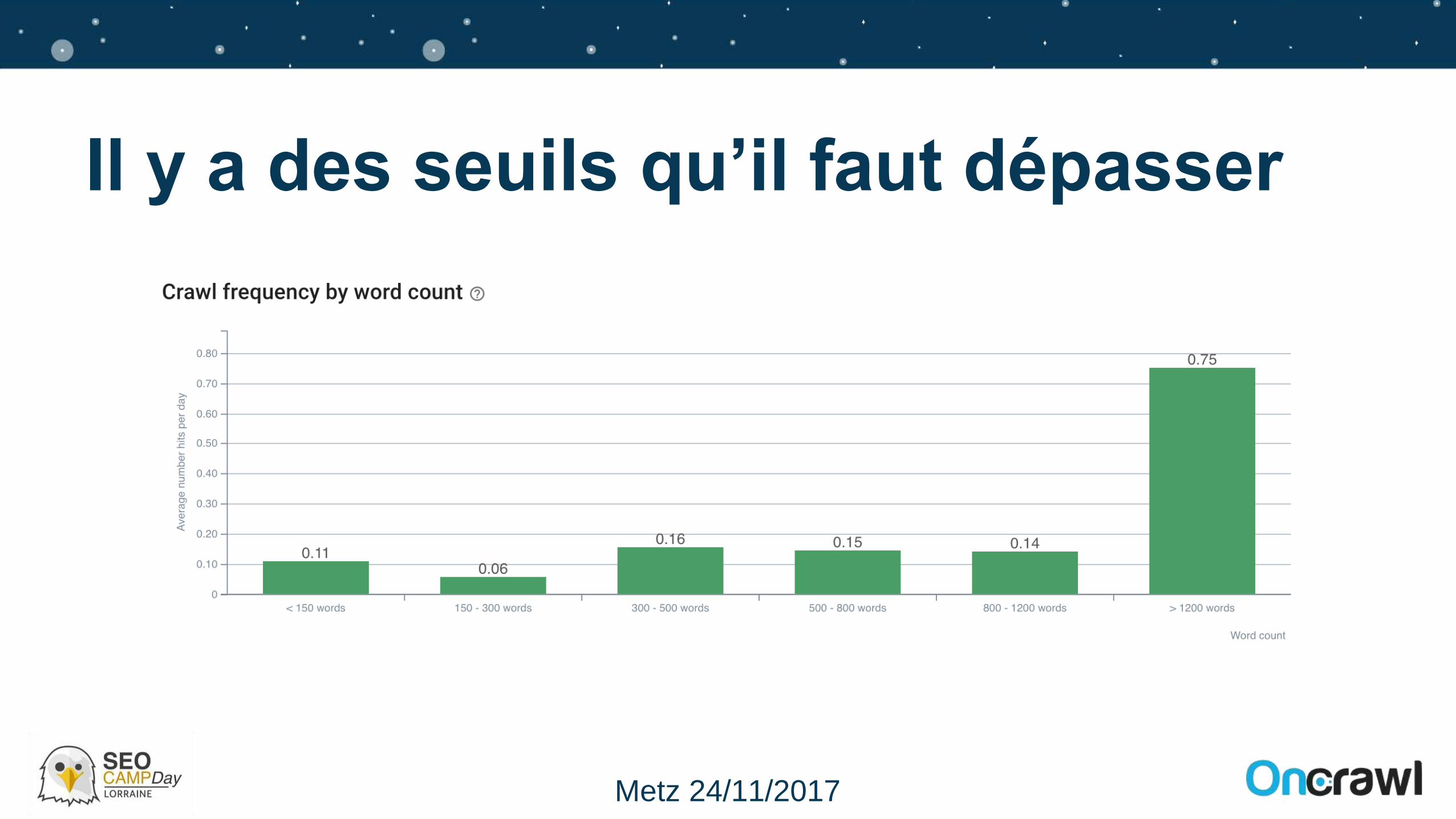
Il y a des seuils qu’il faut dépasser

36Metz 24/11/2017
Duplicate content
• Comprendre les problèmes techniques qui génèrent le
Duplicate Content
• Réduire le Near Duplicate Content
• Vérifier les balises canonicals
• Créer des contenus uniques
37Metz 24/11/2017
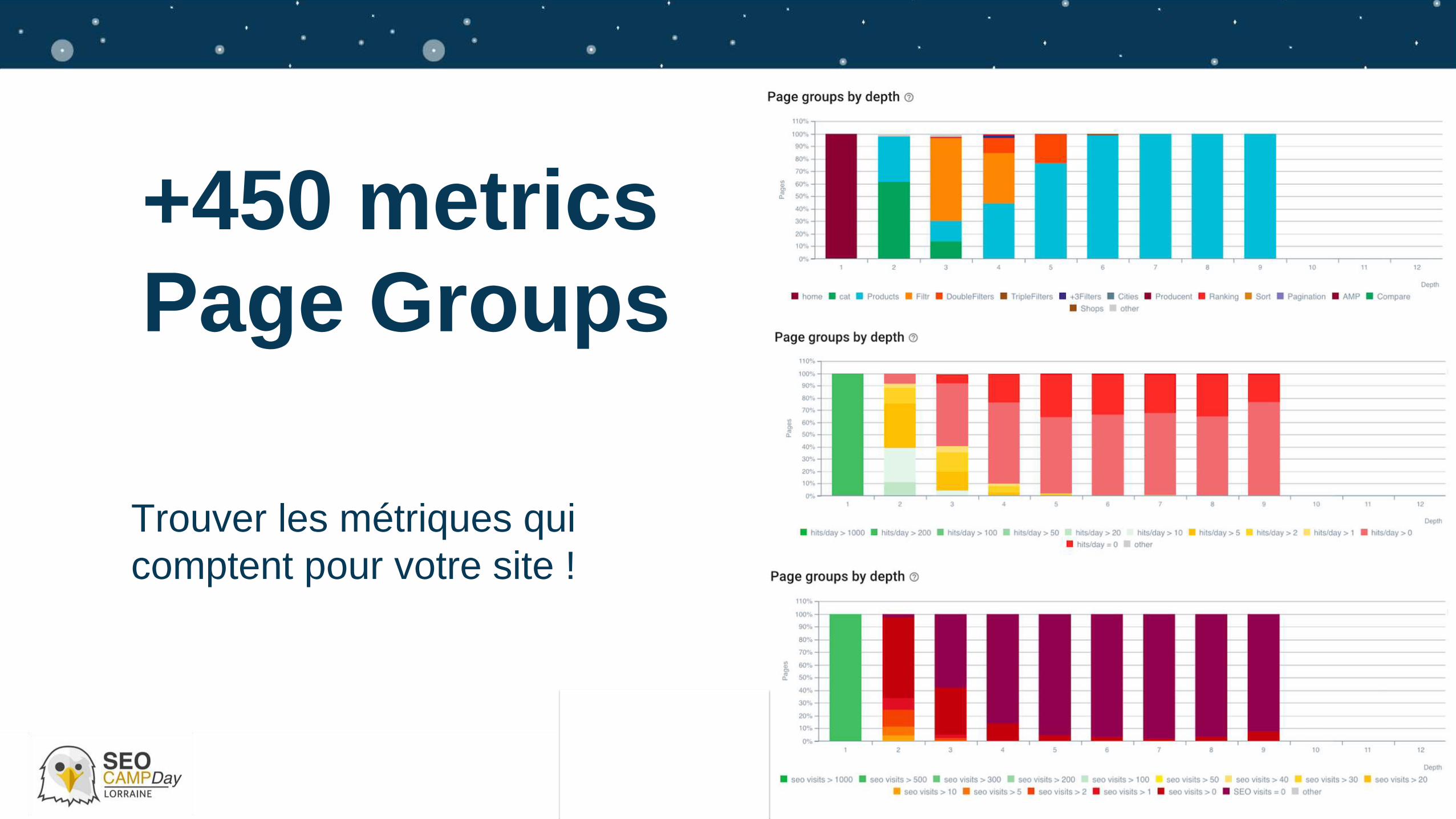
+450 metrics
Page Groups
Trouver les métriques qui
comptent pour votre site !

38Metz 24/11/2017
A Vous de Jouer !
Vous avez les clés pour comprendre quels
sont les métriques qui augmentent votre
Crawl Budget

Metz 24/11/2017
1 mois offertAnalyse de logs / Crawl
avec le code : seocampMetz

40Metz 24/11/2017

41Metz 24/11/2017
+500 Happy Customers

Metz 24/11/2017
We are the fastest growing player on the
market
Our biggest customer is crawling +100M
URLs / week
We have customers with over 20M filtered
logs lines / day
We are hiring !!!

Des questions ?
Related Documents











