
Scaling SolrCloud to a large number of Collections
Jul 15, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript


Scaling SolrCloud to a Large Number
of Collections
Anshum Gupta
Lucidworks

• Anshum Gupta, Apache Lucene/Solr PMC member
and committer, Lucidworks Employee.
• Interested in search and related stuff.
• Apache Lucene since 2006 and Solr since 2010.
• Organizations I am or have been a part of:
Who am I?

Apache Solr is the most widely-used search solution on the planet.
Solr has tens of thousands of applications in production.
You use everyday.
8,000,000+Total downloads
Solr is both establishedand growing.
250,000+Monthly downloads
2,500+Open Solr jobs and the largest
community of developers.

Solr Scalability is unmatched
The traditional search use-case
• One large index distributed across multiple nodes
• A large number of users searching on the same data
• Searches happen across the entire cluster

— Arthur C. Clarke
“The limits of the possible can only be defined by
going beyond them into the impossible.”

• Analyze and find missing features
• Setup a performance testing environment on AWS
• Devise tests for stability and performance
• Find bugs and bottlenecks and fixes
Analyze, measure, and optimize

• The SolrCloud cluster state has information about all collections,
their shards and replicas
• All nodes and (Java) clients watch the cluster state
• Every state change is notified to all nodes
• Limited to (slightly less than) 1MB by default
• 1 node restart triggers a few 100 watcher fires and pulls from ZK
for a 100 node cluster (three states: down, recovering and active)
Problem #1: Cluster state and updates

• Each collection gets it’s own state node in ZK
• Nodes selectively watch only those states which they
are a member of
• Clients cache state and use smart cache updates
instead of watching nodes
• http://issues.apache.org/jira/browse/SOLR-5473
Solution: Split cluster state and scale

• Thousands of collections create a lot of state updates
• Overseer falls behind and replicas can’t recover or
can’t elect a leader
• Under high indexing/search load, GC pauses can
cause overseer queue to back up
Problem #2: Overseer Performance

• Optimize polling for new items in overseer queue -
Don’t wait to poll! (SOLR-5436)
• Dedicated overseers nodes (SOLR-5476)
• New Overseer Status API (SOLR-5749)
• Asynchronous and multi-threaded execution of
collection commands (SOLR-5477, SOLR-5681)
Solution - Improve the Overseer

• Not all users are born equal - A tenant may have a few very
large users
• We wanted to be able to scale an individual user’s data —
maybe even as it’s own collection
• SolrCloud could split shards with no downtime but it only splits
in half
• No way to ‘extract’ user’s data to another collection or shard
Problem #3: Moving data around

• Shard can be split on arbitrary hash ranges (SOLR-5300)
• Shard can be split by a given key (SOLR-5338, SOLR-5353)
• A new ‘migrate’ API to move a user’s data to another (new)
collection without downtime (SOLR-5308)
Solution: Improved data management

• Lucene/Solr is designed for finding top-N search results
• Trying to export full result set brings down the system due
to high memory requirements as you go deeper
Problem #4: Exporting data
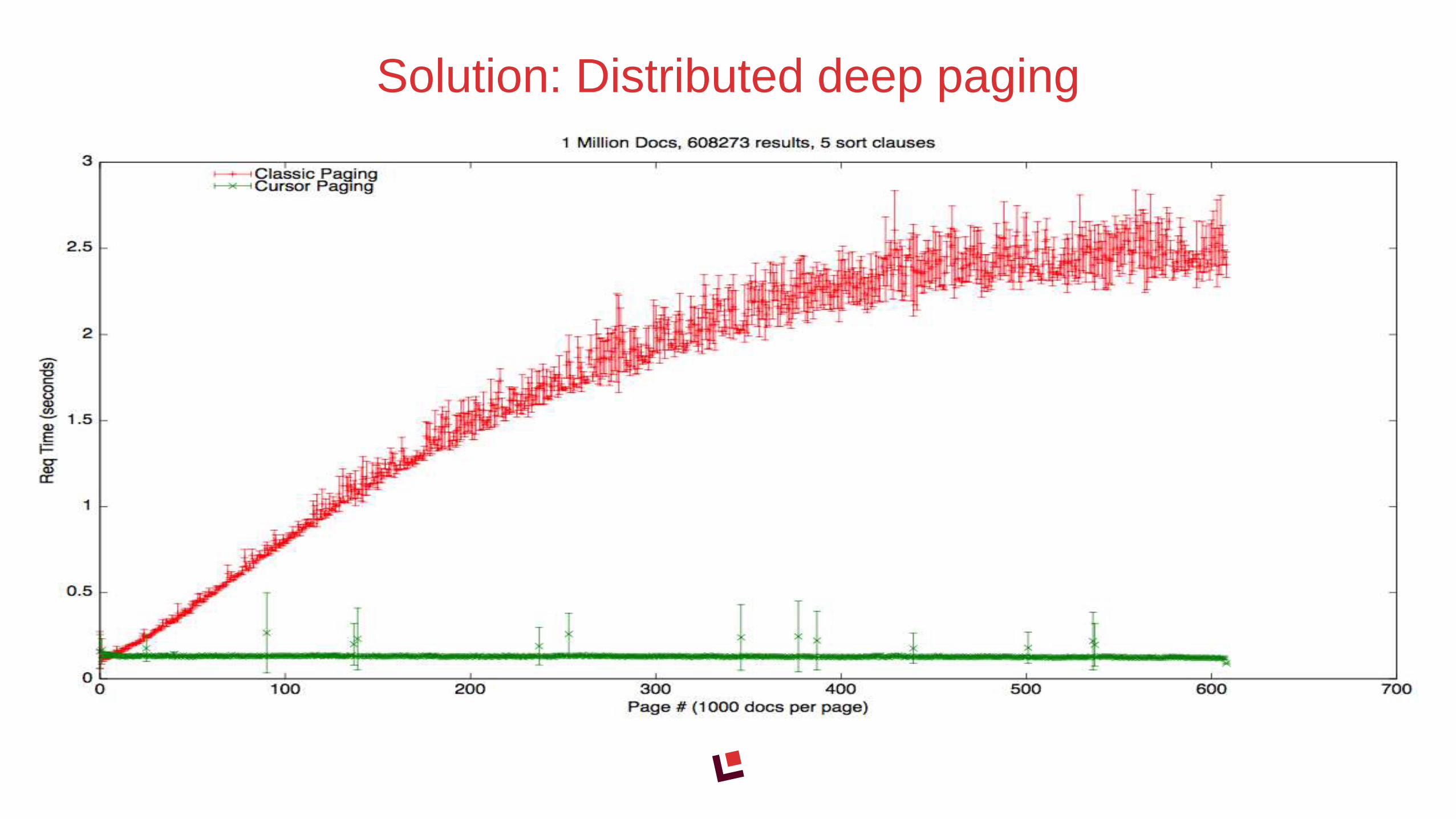
Solution: Distributed deep paging

• Performance goals: 6 billion documents, 4000 queries/sec, 400
updates/sec, 2 seconds NRT sustained performance
• 5% large collections (50 shards), 15% medium (10 shards), 85%
small (1 shard) with replication factor of 3
• Target hardware: 24 CPUs, 126G RAM, 7 SSDs (460G) + 1 HDD
(200G)
• 80% traffic served by 20% of the tenants
Testing scale at scale
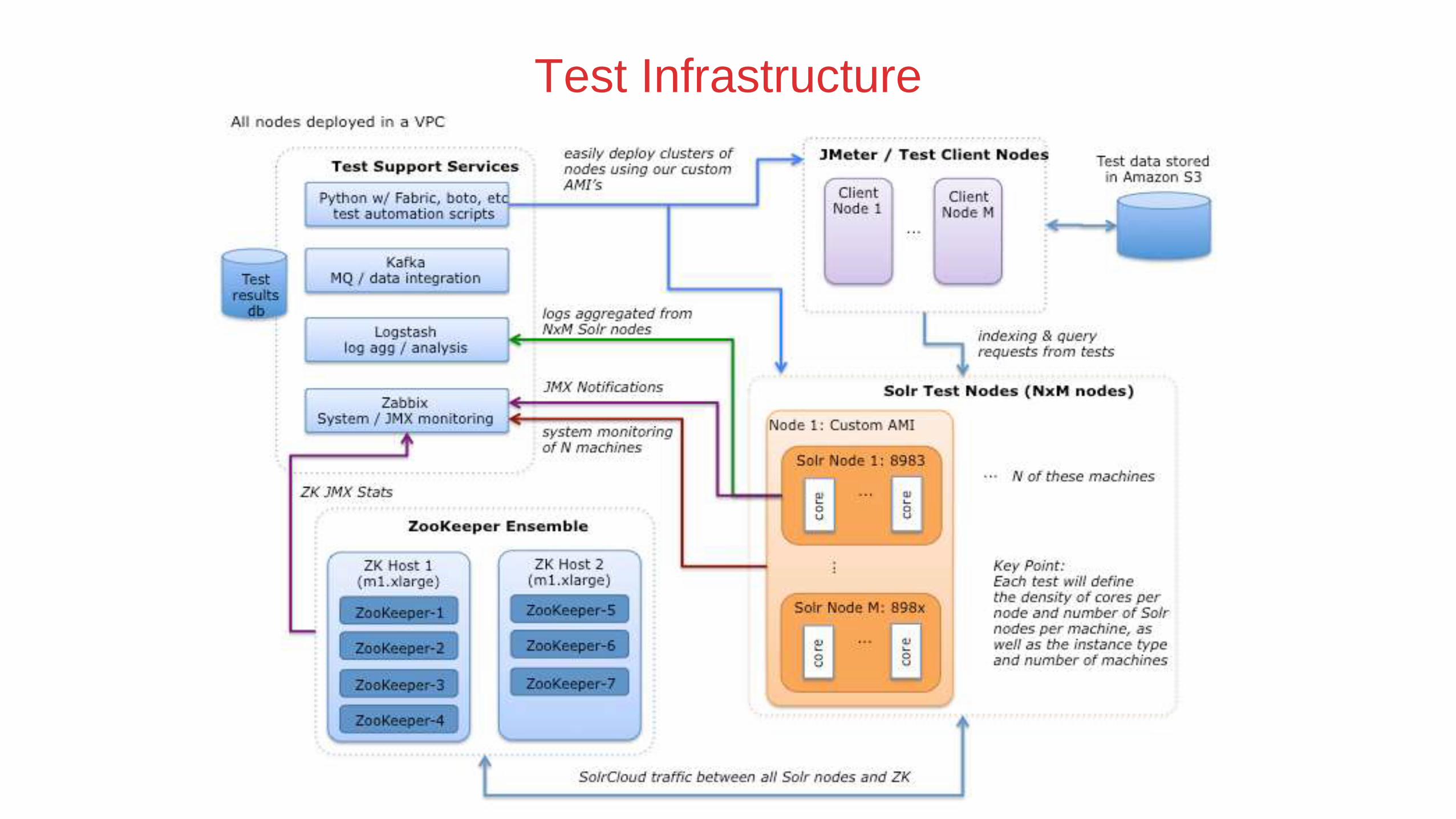
Test Infrastructure

Logging


• Tim Potter wrote the Solr Scale Toolkit
• Fabric based tool to setup and manage SolrCloud
clusters in AWS bundled with collectd and SiLK
• Backup/Restore from S3. Parallel clone commands.
• Open source!
• https://github.com/LucidWorks/solr-scale-tk
How to manage large clusters?

• Lucidworks SiLK (Solr + Logstash + Kibana)
• collectd daemons on each host
• rabbitmq to queue messages before delivering to log stash
• Initially started with Kafka but discarded thinking it is overkill
• Not happy with rabbitmq — crashes/unstable
• Might try Kafka again soon
• http://www.lucidworks.com/lucidworks-silk
Gathering metrics and analyzing logs

• Custom randomized data generator (re-producible
using a seed)
• JMeter for generating load
• Embedded CloudSolrServer using JMeter Java
Action Sampler
• JMeter distributed mode was itself a bottleneck!
• Solr scale toolkit has some data generation code
Generating data and load

• 30 hosts, 120 nodes, 1000 collections, 6B+ docs,
15000 queries/second, 2000 writes/second, 2 second
NRT sustained over 24-hours
• More than 3x the numbers we needed
• Unfortunately, we had to stop testing at that point :(
• Our biggest cluster cost us just $120/hour :)
Numbers

• Jepsen tests
• Improvement in test coverage
After those tests

• We continue to test performance
at scale
• Published indexing performance
benchmark, working on others
• 15 nodes, 30 shards, 1 replica,
157195 docs/sec
• 15 nodes, 30 shards, 2
replicas, 61062 docs/sec
And it still goes on…
• Setting up an internal
performance testing environment
• Jenkins CI
• Single node benchmarks
• Cloud tests
• Stay tuned!

Pushing the limits

• SolrCloud continues to be improved
• SOLR-6816 - Review SolrCloud Indexing Performance.
• SOLR-6220 - Replica placement strategy
• SOLR-6273 - Cross data center replication
• SOLR-5750 - Backup/Restore API for SolrCloud
• SOLR-7230 - An API to plugin security into Solr
• Many, many more
Not over yet

Connect @
http://www.twitter.com/anshumgupta
http://www.linkedin.com/in/anshumgupta/
Related Documents











