Running head: REPRODUCING AFFECTIVE NORMS 1 Reproducing affective norms with lexical co-occurrence statistics: Predicting valence, arousal, and dominance Gabriel Recchia ([email protected]) Institute for Intelligent Systems, University of Memphis Max M. Louwerse ([email protected]) Tilburg Center for Cognition and Communication, Tilburg University Institute for Intelligent Systems, University of Memphis Corresponding author: Dr. Gabriel Recchia [email protected] Institute for Intelligent Systems, University of Memphis 365 Innovation Drive, Suite 303, Memphis, TN 38152, USA 970-412-7073 / fax: 901-678-1336

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Running head: REPRODUCING AFFECTIVE NORMS 1
Reproducing affective norms with lexical co-occurrence statistics:
Predicting valence, arousal, and dominance
Gabriel Recchia ([email protected])
Institute for Intelligent Systems, University of Memphis
Max M. Louwerse ([email protected])
Tilburg Center for Cognition and Communication, Tilburg University
Institute for Intelligent Systems, University of Memphis
Corresponding author:
Dr. Gabriel Recchia [email protected] Institute for Intelligent Systems, University of Memphis 365 Innovation Drive, Suite 303, Memphis, TN 38152, USA 970-412-7073 / fax: 901-678-1336

Running head: REPRODUCING AFFECTIVE NORMS 2
Abstract
Human ratings of valence, arousal, and dominance are frequently used to study the cognitive
mechanisms of emotional attention, word recognition, and numerous other phenomena in
which emotions are hypothesized to play an important role. Collecting such norms from
human raters is expensive and time consuming. As a result, affective norms are available for
only a small number of English words, are not available for proper nouns in English, and are
sparse in other languages. This paper investigated whether affective ratings can be predicted
from length, contextual diversity, co-occurrences with words of known valence, and
orthographic similarity to words of known valence. Our bootstrapped ratings achieved
correlations with human ratings on valence, arousal, and dominance that are on par with
previously reported correlations across gender, age, education and language boundaries. We
release these bootstrapped norms for 26,978 English words.
Keywords: affective norms; valence; arousal; dominance; latent semantic analysis
Introduction
Emotion ratings are used by a variety of researchers in experimental psychology due to their
utility in investigating a wide range of topics. Researchers investigating the properties of
emotions and motivational states frequently rely upon words rated for valence, arousal, or
dominance to compare neural or behavioral responses to positive vs. negative stimuli (Landis,
2006; Lang, Bradley, & Cuthbert, 1998; Robinson, Moeller, & Ode, 2010; Schulte-Rüther,
Markowitsch, Fink, & Piefke, 2007; Verona, Sprague, & Sadeh, 2012). Many experimental
psychologists investigating the processes underlying word recognition and memory make use of
affective ratings to investigate the processing of emotion words (Gootjes, Coppens, Zwaan,

Running head: REPRODUCING AFFECTIVE NORMS 3
Franken, & Van Strien, 2011; Hamann & Mao, 2002; Hsieh et al., 2012; Scott, O'Donnell,
Leuthold, & Sereno, 2009, 2012), or to explore correlations between emotional ratings and other
lexical variables (Citron, Weekes, & Ferstl, 2012; Jasmin & Casasanto, 2012). Emotion ratings
of individual words have also been applied successfully in algorithms that estimated the valence
or arousal of entire sentences or texts, which have uses in the preparation of stimuli for
psycholinguistic studies (Calvo & D’Mello, 2010). Accurately estimating the valence of texts
requires large sets of emotion ratings, as do megastudies that investigate the relationship between
emotion ratings and reaction times on lexical decision or word reading (Kousta, Vigliocco,
Vinson, Andrews, & Del Campo, 2011; Larsen, Mercer, Balota, & Strube, 2008). Finally, there
is evidence to suggest that emotion words are processed qualitatively differently than other
abstract words (Altarriba & Bauer, 2004). These findings have been followed by increased
interest in the relationship between abstractness and emotion (Ferré, Guasch, & Moldovan, 2012;
Setti & Caramelli, 2005; Kousta et al., 2011; Tse & Altarriba, 2009; Yao & Wang, 2013;
Vigliocco et al., 2013), much of which relies upon lexical stimuli that have been rated for
valence, arousal and dominance.
The Affective Norms for English Words (ANEW) dataset (Bradley & Lang, 1999) remains the
most frequently used set of emotion norms. The original ANEW norms consisted of 1,034
words, and an update was published in 2010 bringing the total up to 2,477 words (Bradley &
Lang, 2010). Despite the recent introduction of a set of norms for 13,915 English lemmas
(Warriner, Kuperman, & Brysbaert, 2013), emotion ratings are hard to come by for many
languages: the largest sets of norms for Dutch, Spanish, Portuguese and Finnish consist of 4299,
1034, 1040, and 213 words respectively (Warriner et al., 2013).

Running head: REPRODUCING AFFECTIVE NORMS 4
Furthermore, there are no existing norms for proper nouns such as persons, places, or brands,
which would be particularly useful to researchers studying the processing of proper nouns. For
example, Wang, Zhu, Bastiaansen, Hagoort, and Yang (2013) found that emotional valence
modulated the amplitude of the N100 component for common nouns, but not for names. Names
also appear to be processed qualitatively differently in other ways: they are processed faster than
common nouns in category decision and semantic association tasks, but slower in phonological
decision (Müller, 2010; Proverbio, Mariani, Zani, & Adorni, 2009; Proverbio, Lilli, Semenza, &
Zani, 2001; Yen, 2006). However, most models of word recognition have focused only on
common nouns, and more work is needed to determine the degree to which existing models can
account for effects unique to the processing of proper nouns (Wang et al., 2013). Affective
norms that included proper nouns would greatly facilitate this kind of research. Finally, the
performance of sentiment detection algorithms is limited by the size of datasets of affective
norms (Gottron, Radcke, & Pickhardt, 2012). This is particularly true for algorithms that focus
on very short texts such as Twitter messages.
These concerns have motivated some researchers to investigate whether affective norms can be
automatically estimated via automatic procedures. The most extensive attempt has been
conducted by Bestgen and Vincze (2012). Their approach used Latent Semantic Analysis
(Landauer & Dumais, 1997), an algorithm for quantifying the degree to which terms are
associated in a large text corpus. LSA takes as input a matrix for which the value (i, j) of each
cell indicates the number of times word i occurs in document j. Each term is weighted so as to
reduce the influence of very frequent words, and singular value decomposition is applied to
factor the matrix into three new matrices U, S, and V’, whose product yields the original matrix.
By truncating to a fixed number of dimensions prior to computing the product, a new matrix of

Running head: REPRODUCING AFFECTIVE NORMS 5
lower rank can be obtained. This serves as a low-dimensional approximation of the original
matrix. Finally, the similarity between two words can be obtained by computing the cosine
between their corresponding rows. Because of the rank reduction step, there may be a high
cosine between two words that did not happen to co-occur in the same document, as long as they
occurred in similar documents. Therefore, words that are associated according to LSA appear in
similar linguistic contexts, making LSA a measure of higher-order co-occurrence (Landauer,
McNamara, Dennis, & Kintsch, 2007; Louwerse, et al., 2006).
Bestgen and Vincze calculated the closest associates to each word in the Touchstone Applied
Science Associates (TASA) corpus of high-school level English text on a variety of academic
topics. By computing the mean valence, arousal, and dominance of each word’s closest 30
associates in the vector space produced by LSA, they achieved correlations of .71, .56, and .60
with the ANEW norms on valence, arousal, and dominance, respectively, and released their
automatic estimates for 17,350 words. Unfortunately, their method did not make use of other
correlates of valence, arousal, and dominance, such as word frequency and length, and their
released set of norms was only 25% larger than the Warriner et al. (2013) dataset of norms
collected from study participants. Furthermore, their dataset is restricted to words appearing in
TASA and contains no proper nouns.
The aim of the current paper was to automatically estimate a large set of valence, arousal and
dominance ratings that includes proper nouns (names, places, and brands), and to evaluate the
performance of our method. If our automatically estimated valence, arousal, and dominance
ratings were to achieve correlations with human ratings that were comparable to previously
reported correlations among sets of human ratings, our method could be used to quickly generate
approximate valence, arousal, and dominance ratings for any set of stimuli. Due to the dearth of

Running head: REPRODUCING AFFECTIVE NORMS 6
non-English stimuli rated for valence, arousal, and dominance, such a method would be
particularly beneficial to researchers using affective stimuli in non-English languages, as well as
to researchers requiring stimuli for which affective ratings are not currently available. In Study 1,
we attempted to replicate Bestgen and Vincze (2012), but using a more scalable algorithm and
larger corpus, and using all words in Warriner et al. (2013) that did not appear in the ANEW
corpus as training data. In Study 2, we tested whether automatically derived correlations to
human valence, arousal, and dominance ratings could be improved further by integrating
additional variables correlated with valence, arousal, or dominance in the literature, as well as
additional variables that we hypothesized would contribute independent variance. One such
variable (mean valence/arousal/dominance of orthographically similar words) was explored in
further detail in Study 3 to gain further insight into why this variable proved particularly
predictive of affective ratings.
Study 1
The goal of Study 1 was to determine whether an approach similar to that of Bestgen and
Vincze (2012), which used a more scalable measure capable of being applied to large text
corpora, would be capable of achieving results similar to those reported previously in the
literature. Using a measure capable of being scaled to very large corpora is very helpful if one
wishes to obtain plausible associates of low-frequency words such as proper nouns. In previous
research, we and others have found that measures based on pointwise mutual information (PMI;
Church & Hanks, 1990) are capable of being scaled to corpora far larger than those on which it is
feasible to train LSA, and that PMI-based measures derived from very large corpora outperform
LSA-based measures derived from corpora the size of TASA (Recchia & Jones, 2009; Recchia

Running head: REPRODUCING AFFECTIVE NORMS 7
& Louwerse, under review; Turney, 2001; Islam & Inkpen, 2006). Pointwise mutual information
is computed as
)()(),(log),( 2 yPxP
yxPyxPMI =
where P(x) and P(y) can each be calculated as the frequency of x and y (respectively) divided
by the total number of tokens in the corpus, and P(x, y) as the number of times that x and y co-
occur divided by the total number of tokens in the corpus (Manning & Schütze, 1999). An even
more useful measure of association is obtained if PMI scores are used to construct a second-
order-co-occurrence measure known as positive PMI cosines (Bullinaria & Levy, 2007). To
compute the positive PMI cosine between two words x and y, each is assigned a vector of N
components, where N is the number of words in the lexicon. Each element of each vector is
indexed with a particular word in the lexicon, and is populated with the corresponding PMI
score. For example, if the first element was indexed to the word time, then the first element of x’s
vector would be set to PMI(x, time), while the first element of y’s vector would be set to PMI(y,
time). Finally, elements containing negative values are set to zero, and the cosine between the
two vectors is computed.
Method
Following Bestgen and Vincze (2012), we split the set of words of interest into test and training
datasets. The test data consisted of all words in the ANEW norms, while the training data
consisted of all words in Warriner et al. (2013) that were not in the ANEW norms. We first
extracted all bigrams and trigrams appearing in the Google Web 1T 5-gram corpus (Brants &
Franz, 2006) that contained words in our test or training datasets. These were then used to
compute co-occurrences between each word in Warriner et al. (2013) and all words in the

Running head: REPRODUCING AFFECTIVE NORMS 8
training dataset with a window size of 2, as this was the window size at which Bullinaria and
Levy (2007) reported optimal performance. Positive PMI cosines were computed between all
words in the training set and all words in Warriner et al. (2013) and ANEW, according to the
method described by Bullinaria and Levy (2007).
Finally, for each word in the training set, we determined its k nearest neighbors using the
positive PMI cosine measure, where k ranged from 2 to 500. We then calculated the mean
valence of these k words, according to the Warriner et al. norms. As in Bestgen and Vincze
(2012), this value was treated the automatically estimated valence of the word. An analogous
procedure was used to automatically estimate the arousal and dominance of each word in the
training set. The correlation between the automatically estimated valence/arousal/dominance
values of the training words and human valence/arousal/dominance ratings were optimized at k =
15 (valence), 40 (arousal), and 60 (dominance). Finally, this procedure was followed in the same
way to estimate the valence, arousal, and dominance of each word in the test set, with the only
difference being that k was set to 15 when calculating valence, 40 when estimating arousal, and
60 when estimating dominance, rather than ranging from 2 to 500. That is, k was optimized on
the training set, not the test set.
Results and Discussion
On the test data, our method yielded correlations (Pearson’s r) of .74, .57, and .62 to ANEW
valence, arousal, and dominance ratings, respectively. These are comparable to those reported by
Bestgen and Vincze (2012), who reported correlations of .71, .56, and .60 to ANEW ratings of
valence, arousal, and dominance.
In sum, by replicating the process of Bestgen and Vincze (2012) but substituting a simpler,
more scalable method (trained on a very large dataset) instead of LSA (trained on the TASA

Running head: REPRODUCING AFFECTIVE NORMS 9
dataset), we were able to replicate (or slightly improve) Bestgen and Vincze’s results.
Improvements of these scores were extended in Study 2.
Study 2
In Study 2, we investigated whether these scores could be improved by making use of variables
which are correlated with valence, arousal, and/or dominance in the literature, and which can
also be computed automatically from text.
One variable that correlates with valence is word frequency (Augustine, Mehl, & Larsen,
2011). However, as frequency effects have been argued to be driven by contextual diversity—the
number of unique contexts, or documents, in which a word occurs (Adelman, Brown, &
Quesada, 2006) —we also decided to consider this variable as well. Furthermore, because word
length negatively correlates with word frequency, and because the valence of orthographic
neighbors has been shown to affect N200 and N400 amplitudes in lexical decision (Faïta-
Aïnseba, Gobin, Bouaffre, & Mathey, 2012), we also considered word length and the mean
valence, arousal, and dominance of a word’s orthographic neighbors as possible correlates of
valence, arousal, and dominance. The object of Study 2 was to determine whether including such
variables in a linear regression improved our ability to predict the affective ratings of words.
Method
The following variables were computed or retrieved from lexical norms for each of the words in
the training dataset used in Study 1: log frequency, retrieved from SUBTLEX-US (Brysbaert,
New, & Keuleers, 2012); contextual diversity, also retrieved from SUBTLEX-US; RSA scores,
computed as in Jasmin & Casasanto (2012); word length; and mean valence, arousal, and
dominance of the word’s nearest orthographic neighbors in the training set, according to several
measures of orthographic similarity. The first set of measures used were OLD1, OLD3, OLD5,

Running head: REPRODUCING AFFECTIVE NORMS 10
OLD10, OLD15, and OLD20, that is, the mean valence of the nearest 1, 3, 5, 10, 15, or 20
orthographic neighbors according to the commonly used orthographic Levenshtein distance
measure, which has been shown to account for much more variance in lexical decision and word
naming times than traditional measures such as Coltheart’s N (Yarkoni, Balota, & Yap, 2008).
The second type of measure employed was the mean valence of “prefix neighbors,” that is, the
mean valence of all words that share the word’s longest prefix. For fireball, the longest prefix
shared by other words in the Warriner et al. training words is fire, so its mean prefix valence
would be the mean valence of all other training words that start with fire (firearm, firecracker,
firefight...) Analogous measures were constructed for arousal and dominance.
Three linear regression models were fit in a stepwise fashion, with dependent variables of
valence, arousal, and dominance, respectively. The stepwise linear regression procedure
employed (SPSS 20) iteratively adds variables that account for additional variance until the
model is no longer significantly improved by the addition of further variables. For valence,
arousal, and dominance log contextual diversity accounted for a hair more variance than
frequency, consistent with the literature (Adelman, Brown, & Quesada, 2006; Brysbaert & New,
2009). Similarly, mean valence/arousal/dominance of prefix neighbors was more correlated with
mean valence/arousal/dominance of orthographic Levenshtein distance neighbors after
controlling for the other independent variables, so only the former was entered into the
regression.
Regression models were fit to the training words’ valence, arousal, and dominance. Finally, the
resulting models were applied to produce estimated valence/arousal/dominance ratings for the
test words. Because the words in the test set occur in both the ANEW and Warriner norms, we

Running head: REPRODUCING AFFECTIVE NORMS 11
were able to obtain correlations between our estimated valence/arousal/dominance scores and
two sets of affective norms from human subjects.
Results
Pearson correlations between our estimated values of valence, arousal, and dominance for the
words in the test set were 80, .62, and .66 (respectively) for the ANEW norms, and .82, .64, and
.72 for the Warriner norms. For the regression with valence as the dependent variable, variables
accounting for significant levels of variance were mean valence of nearest semantic neighbors
(positive PMI cosines) in the training set, mean valence of nearest orthographic (prefix)
neighbors in the training set, log contextual diversity, and word length. When arousal was the
dependent variable, variables accounting for significant levels of variance were mean arousal of
nearest semantic neighbors (positive PMI cosines) in the training set, mean arousal of nearest
orthographic (prefix) neighbors in the training set, and word length. When dominance was the
dependent variable, variables accounting for significant levels of variance were mean dominance
of nearest semantic neighbors (positive PMI cosines) in the training set, mean dominance of
nearest orthographic (prefix) neighbors in the training set, log contextual diversity, and word
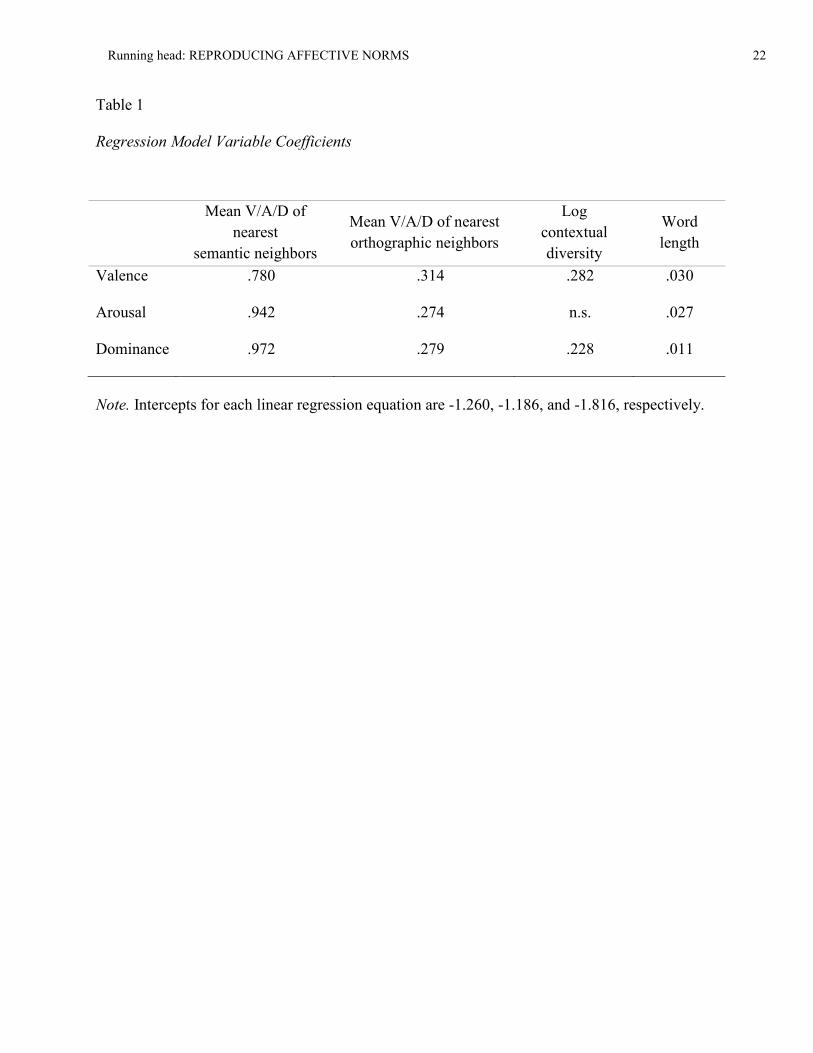
length. Coefficients for the final regression models are reported in Table 1.
== INSERT TABLE 1 HERE ==
Discussion
The procedure described estimates human ratings with correlations of .80-.82 (valence), .62-
.64 (arousal), and .66-.72 (dominance). For comparison, correlations of human ratings across
languages range from .85 to .97 for valence, .56 to .76 for arousal, and .77 to .83 for dominance
(Warriner et al., 2013). Warriner et al. also report that within the same language (English), split-
half reliabilities across human participants are .91 for valence, .69 for arousal, and .77 for

Running head: REPRODUCING AFFECTIVE NORMS 12
dominance. Correlations are somewhat lower between English speakers of different genders
(male vs. female: rval = .79, raro = .52, rdom = .59), different ages (younger than 30 vs. older than
30: rval = .82, raro = .50, rdom = .59), and different educational backgrounds (rval = .83, raro = .47,
rdom = .61).
In all, the automatically estimated ratings obtained using this method are at least as correlated
with human ratings as male/female, old/young, and high/low education English speakers’ ratings
are with each other, and in some cases more so. The correlations with human ratings are on par
with or just below correlations between languages, and are less than ten points below the highest
correlations that could possibly be expected (namely, the aggregate split-half reliabilities across
speakers of the same language).
Much of the increase in performance over the method used in Study 1 was due to words having
similar levels of valence, arousal, and dominance to other words that shared similar prefixes. In
Study 3, we look at this variable in greater detail, investigating the lengths of the prefixes that
appear to be driving this effect most strongly.
Study 3
The “prefix neighbor” measure of orthographic similarity used in Study 2 is not commonly used.
Why would words sharing similar prefixes share similar levels of valence, arousal, and
dominance? The measure cannot be capturing similarities between different forms of the same
word, as the Warriner et al. norms only contain distinct lemmas. Nor can this variable’s
usefulness be explained by different forms of the same word appearing in the ANEW and
Warriner et al. norms, as the ANEW words constitute a subset of the Warriner et al. norms, and
were not included in the set of training words. As noted earlier, it may be that this measure
captures similarities between words that share meaningful morphemes (i.e., fireball, fireman,

Running head: REPRODUCING AFFECTIVE NORMS 13
firestorm may all have high levels of arousal due to their relation to the high-intensity word fire).
It is also possible that the effect is being driven by long, derivationally related words
(administration, administrator), or that words that begin with certain letters are inherently more
likeable than others (Alluisi & Adams, 1962; Nuttin, 1985). To gain some insight into what
might be driving this effect, we introduced variables representing the mean valence of all other
words sharing prefixes of particular lengths to get a sense of which prefix lengths are accounting
for the most unique variance.
Method
We reran the regression analyses described in Study 2 with mean valence of nearest prefix
neighbors replaced by 10 separate prefix measures: mean valence of all other words that start
with the same letter, mean valence of all other words that start with the same two letters, etc. An
analogous procedure was followed for arousal and dominance as well as valence. Analyses were
conducted with valence, arousal, and dominance as dependent variables.
Results and Discussion
Mean valence, arousal, and dominance of prefixes of all lengths except for 1, 7, 9, and 10
accounted for significant levels of unique variance in all three analyses. Although a word’s
valence was correlated with the mean valence of all other words beginning with the same letter (r
= .14, p < .01), the insignificance of length-1 prefixes in any regression analysis suggests that
this is an epiphenomenon of the distribution of longer prefixes across words. However, the fact
that mean valence, arousal, and dominance of length-2 prefixes did account for small but
significant levels of unique variance suggests that at least some short morphemes may be
predictive of valence, arousal, and dominance. For example, words beginning with the prefix
“un-” have lower valence (M = 4.35, SD = 1.23) than other words in the Warriner et al. norms (M

Running head: REPRODUCING AFFECTIVE NORMS 14
= 5.07, SD = 1.27), t(13770) = 9.07, p < .001. If there are a greater number of positive than
negative morphemes in English—as is the case for lemmas in the Warriner et al. norms—then
this could be explained by the fact that “un-“ tends to invert a morpheme’s valence (Mulder,
Nijholt, den Uyl, & Terpstra, 2004). Automatic morphological analysis of words could provide a
more sophisticated way to capture such regularities and further improve automatic estimates of
affective norms.
== INSERT FIGURE 1 HERE ==
Conclusions
For languages for which affective norms are not available, it is common practice to use
emotional ratings to English glosses. Warriner et al. (2013) note that the high correlations
between emotional ratings of different languages justify this approach as a reasonable one to
take. By the same logic, we argue that it is justified to use affective ratings for words derived
from co-occurrence statistics when human ratings are unavailable or limited in scope. This is true
for numerous languages, as well as for entire classes of English words, such as proper names for
persons, places, and brands. Furthermore, more comprehensive sets of affective ratings have the
potential to improve dictionary-based approaches to sentiment detection (Gottron, Radcke, &
Pickhardt, 2012). Although the method described here can be used to bootstrap affective ratings
for any set of stimuli, we additionally release automatically-estimated norms for 26,978 English
words, including numerous names, places and brands, available in the supplementary materials.
Acknowledgments
This project was supported by a grant from the Intelligence Community Postdoctoral Research
Fellowship Program through funding from the Office of the Director of National Intelligence.

Running head: REPRODUCING AFFECTIVE NORMS 15
All statements of fact, opinion, or analysis expressed are those of the authors and do not reflect
the official positions or views of the Intelligence Community or any other U.S. Government
agency. Nothing in the contents should be construed as asserting or implying U.S. Government
authentication of information or Intelligence Community endorsement of the authors’ views.

Running head: REPRODUCING AFFECTIVE NORMS 16
References
Adelman, J. S., Brown, G. D., & Quesada, J. F. (2006). Contextual diversity, not word
frequency, determines word-naming and lexical decision times. Psychological Science,
17, 814-823.
Alluisi, E. A., & Adams, O. S. (1962). Predicting letter preferences: Aesthetics and filtering in
man. Perceptual and Motor Skills, 14(1), 123-131.
Altarriba, J., & Bauer, L. M. (2004). The distinctiveness of emotion concepts: A comparison
between emotion, abstract, and concrete words. American Journal of Psychology, 117,
389-410.
Augustine, A. A., Mehl, M. R., & Larsen, R. J. (2011). A positivity bias in written and spoken
English and its moderation by personality and gender. Social Psychological and
Personality Science, 2(5), 508-515.
Bestgen, Y., & Vincze, N. (2012). Checking and bootstrapping lexical norms by means of word
similarity indices. Behavior Research Methods, 44, 998-1006.
Bradley, M. M., & Lang, P. J. (1999). Affective norms for English words (ANEW): Stimuli,
instruction manual and affective ratings (Tech. Rep. No. C-1). Gainesville: Center for
Research in Psychophysiology, University of Florida.
Bradley, M. M., & Lang, P. J. (2010). Affective Norms for English Words (ANEW): Affective
ratings of words and instruction manual (Technical Report C-2). Gainesville: University
of Florida.
Brants, T., & Franz, A. (2006). Web 1T 5-gram Version 1. Philadelphia, PA: Linguistic Data
Consortium.

Running head: REPRODUCING AFFECTIVE NORMS 17
Brysbaert, M., & New, B. (2009). Moving beyond Kučera and Francis: a critical evaluation of
current word frequency norms and the introduction of a new and improved word
frequency measure for American English. Behavior Research Methods, 41, 977-990.
Brysbaert, M., New, B., & Keuleers, E. (2012). Adding part-of-speech information to the
SUBTLEX-US word frequencies. Behavior Research Methods, 44(4), 991-997.
Bullinaria, J., & Levy, J. (2007). Extracting semantic representations from word co-occurrence
statistics: A computational study. Behavior Research Methods, 39(3), 510-526.
Calvo, R. A., & D'Mello, S. (2010). Affect detection: An interdisciplinary review of models,
methods, and their applications. IEEE Transactions on Affective Computing, 1(1), 18-37.
Church, K. W., & Hanks, P. (1990). Word association norms, mutual information, and
lexicography. Computational Linguistics, 16(1), 22-29.
Citron, F. M., Weekes, B. S., & Ferstl, E. C. (2012). How are affective word ratings related to
lexicosemantic properties? Evidence from the Sussex Affective Word List. Applied
Psycholinguistics, 1(1), 1-19.
Faïta-Aïnseba, F., Gobin, P., Bouaffre, S., & Mathey, S. (2012). Event-related potential
correlates of emotional orthographic priming. NeuroReport, 23(13), 762-767.
Ferré, P., Guasch, M., Moldovan, C., & Sánchez-Casas, R. (2012). Affective norms for 380
Spanish words belonging to three different semantic categories. Behavior Research
Methods, 44(2), 395-403.
Gootjes, L., Coppens, L. C., Zwaan, R. A., Franken, I. H., & Van Strien, J. W. (2001). Effects of
recent word exposure on emotion-word Stroop interference: An ERP study. International
Journal of Psychophysiology, 79(3), 356-363.

Running head: REPRODUCING AFFECTIVE NORMS 18
Gottron, T., Radcke, O., & Pickhardt, R. (2013). On the temporal dynamics of influence on the
social semantic web. Semantic Web and Web Science (pp. 75-87). New York: Springer.
Hamann, S., & Mao, H. (2002). Positive and negative emotional verbal stimuli elicit activity in
the left amygdala. Neuroreport, 13(1), 15-19.
Hsieh, S., Foxe, D., Leslie, F., Savage, S., Piguet, O., & Hodges, J. R. (2012). Grief and joy:
Emotion word comprehension in the dementias. Neuropsychology, 26(5), 624-630.
Islam, A., & Inkpen, D. (2006). Second order co-occurrence PMI for determining the semantic
similarity of words. In Calzolari, N., et al. (Eds.), Proceedings of the International
Conference on Language Resources and Evaluation. Paper presented at LREC 2006, May
22-28, Genoa, Italy (pp. 1033-1038). Paris, France: European Language Resources
Association.
Jasmin, D., & Casasanto, D. (2012). The QWERTY Effect: How typing shapes the meanings of
words. Psychonomic Bulletin & Review, 19(3), 499-504.
Kousta, S. T., Vigliocco, G., Vinson, D. P., Andrews, M., & Del Campo, E. (2011). The
representation of abstract words: Why emotion matters. Journal of Experimental
Psychology: General, 140(1), 14-34.
Landauer, T. K., & Dumais, S. T. (1997). A solution to Plato's problem: The latent semantic
analysis theory of acquisition, induction, and representation of knowledge. Psychological
Review, 104(2), 211-240.
Landauer, T. K., McNamara, D. S., Dennis, S., & Kintsch, W. (eds.). (2007). Handbook of latent
semantic analysis (pp. 379-400). Mahwah, NJ: Erlbaum.
Landis, T. (2006). Emotional words: what's so different from just words? Cortex, 42(6), 823-830.

Running head: REPRODUCING AFFECTIVE NORMS 19
Lang, P. J., Bradley, M. M., & Cuthbert, B. N. (1998). Emotion, motivation, and anxiety: brain
mechanisms and psychophysiology. Biological Psychiatry, 44(12), 1248-1263.
Larsen, R. J., Mercer, K. A., Balota, D. A., & Strube, M. J. (2008). Not all negative words slow
down lexical decision and naming speed: Importance of word arousal. Emotion, 8(4),
445-452.
Louwerse, M.M., Cai, Z., Hu, X., Ventura, M., & Jeuniaux, P. (2006). Cognitively inspired
natural-language based knowledge representations: Further explorations of Latent
Semantic Analysis. International Journal of Artificial Intelligence Tools, 15,1021-1039.
Manning, C. D., & Schütze, H. (1999). Foundations of statistical natural language processing.
Cambridge, MA: MIT Press.
Mulder, M., Nijholt, A., Den Uyl, M., & Terpstra, P. (2004). A lexical grammatical
implementation of affect. Text, Speech and Dialogue (pp. 171-177). Berlin Heidelberg:
Springer.
Müller, H. M. (2010). Neurolinguistic findings on the language lexicon: The special. Chinese
Journal of Physiology, 53(6), 351–358.
Nuttin, J. M. (1985). Narcissism beyond Gestalt and awareness: The name letter effect.
European Journal of Social Psychology, 15, 353-361.
Proverbio, A. M., Lilli, S., Semenza, C., & Zani, A. (2001). ERP indexes of functional
differences in brain activation during proper and common names retrieval.
Neuropsychologia, 39(8), 815–827.
Proverbio, A. M., Mariani, S. Z., & Adorni, R. (2009). How are ‘Barack Obama’ and ‘President
Elect’ differentially stored in the brain? An ERP investigation on the processing of proper
and common noun pairs. PLoS ONE, 4(9), e7126.

Running head: REPRODUCING AFFECTIVE NORMS 20
Recchia, G., & Jones, M. N. (2009). More data trumps smarter algorithms: Training
computational models of semantics on very large corpora. Behavior Research Methods,
41(3), 647-656.
Recchia, G., & Louwerse, M. M. (under review). Grounding the ungrounded: Estimating
locations of unknown place names from linguistic associations and grounded
representations.
Robinson, M. D., Moeller, S. K., & Ode, S. (2010). Extraversion and reward-related processing:
probing incentive motivation in affective priming tasks. Emotion, 10(5), 615-626.
Schulte-Rüther, M., Markowitsch, H. J., Fink, G. R., & Piefke, M. (2007). Mirror neuron and
theory of mind mechanisms involved in face-to-face interactions: a functional magnetic
resonance imaging approach to empathy. Journal of Cognitive Neuroscience, 19(8),
1354-1372.
Scott, G. G., O'Donnell, P. J., & Sereno, S. C. (2012). Emotion words affect eye fixations during
reading. Journal of Experimental Psychology: Learning, Memory, and Cognition, 38(3),
783-792.
Scott, G. G., O'Donnell, P. J., Leuthold, H., & Sereno, S. C. (2009). Early emotion word
processing: Evidence from event-related potentials. Biological Psychology, 80, 95-104.
Setti, A., & Caramelli, N. (2005). Different domains in abstract concepts. In L. B. B. G. Bara
(Ed.), Proceedings of the 27th Annual Conference of the Cognitive Science Society (pp.
1997-2002). Mahwah, NJ: Erlbaum.
Tse, C. S., & Altarriba, J. (2009). The word concreteness effect occurs for positive, but not
negative, emotion words in immediate serial recall. British Journal of Psychology,
100(1), 91-109.

Running head: REPRODUCING AFFECTIVE NORMS 21
Turney, P. (2001). Mining the Web for Synonyms: PMI-IR versus LSA on TOEFL. In L. De
Raedt & P. Flach (Eds.), Proceedings of the 12th European Conference on Machine
Learning (pp. 491-502). Berlin: Springer.
Verona, E., Sprague, J., & Sadeh, N. (2012). Inhibitory control and negative emotional
processing in psychopathy and antisocial personality disorder. Journal of Abnormal
Psychology, 121(1), 498-510.
Vigliocco, G., Kousta, S.-T., Della Rosa, P. A., Vinson, D. P., Tettamanti, M., Devlin, J. T., &
Cappa, S. F. (2013). The neural representation of abstract words: The role of emotion.
Cerebral Cortex, doi: 10.1093/cercor/bht025.
Wang, L., Zhu, Z., Bastiaansen, M., Hagoort, P., & Yang, Y. (2013). Recognizing the emotional
valence of names: An ERP study. Brain and Language, 125(1), 118-127.
Warriner, A. B., Kuperman, V., & Brysbaert, M. (2013). Norms of valence, arousal, and
dominance for 13,915 English lemmas. Behavior Research Methods, 45(4), 1191-1207.
Yao, Z., & Wang, Z. (2013). The effects of the concreteness of differently valenced words on
affective priming. Acta Psychologica, 143(3), 269-276.
Yarkoni, T., Balota, D. A., & Yap, M. J. (2008). Moving beyond Coltheart’s N: A new measure
of orthographic similarity. Psychonomic Bulletin & Review, 15, 971-979.
Yen, H.-L. (2006). Processing of proper names in Mandarin Chinese: A behavioral and
neuroimaging study. Ph.D. dissertation: Bielefeld University.
Running head: REPRODUCING AFFECTIVE NORMS 22
Table 1
Regression Model Variable Coefficients
Note. Intercepts for each linear regression equation are -1.260, -1.186, and -1.816, respectively.
Mean V/A/D of
nearest semantic neighbors
Mean V/A/D of nearest orthographic neighbors
Log contextual diversity
Word length
Valence .780 .314 .282 .030
Arousal .942 .274 n.s. .027
Dominance .972 .279 .228 .011

Running head: REPRODUCING AFFECTIVE NORMS 23
Figure Caption
Figure 1. Mean beta weights of models with differing prefix lengths across regressions with
valence, arousal, and dominance as dependent variables.
Related Documents









![IEEE TRANSACTIONS ON AFFECTIVE COMPUTING VOL. XXX, …Several affective computing methods [8], [9] used semantic annotations in terms of arousal and valence to capture the under-lying](https://static.cupdf.com/doc/110x72/5faf85500c275721d342a9ba/ieee-transactions-on-affective-computing-vol-xxx-several-affective-computing-methods.jpg)
