Reinforcement Learning: Overview Cheng-Zhong Xu Wayne State University

Reinforcement Learning : Overview
Dec 30, 2015
Reinforcement Learning : Overview. Cheng-Zhong Xu Wayne State University. Introduction. - PowerPoint PPT Presentation
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Reinforcement Learning: Overview
Cheng-Zhong XuWayne State University

Introduction In RL, the learner is a decision-making agent that takes actions in
an environment state and receives reward (or penalty) for its actions. The action may cause the change of environment state. After a set of trial-and-error runs, it should learn the best policy: the sequence of actions that maximize the total reward Supervised learning: learning from examples provided by a teacher RL: learning with a critic (reward or penalty); goal-directed learning
from interaction Examples:
Game-playing: Sequence of moves to win a game Robot in a maze: Sequence of actions to find a goal
2C. Xu, 2008

3
Example: K-armed Bandit Given $10 to play on a slot machine with 5 levers: Each play costs $1; each pull of a lever may produce payoff of 0, 1$, 5$, 10$ Find the optimal policy that pay off the most.
Tradeoff between exploitation and explorationExploitation: continue to pull the lever that returns positive Exploration: try to pull a new one
Deterministic model The payoff of each lever is fixed,
but unknown in advance Stochastic model The pay of each lever is uncertainty,
with known or unknown probabilityC. Xu, 2008

K-armed Bandit in General In deterministic case:
Q(a): value of action a
Reward of act a is ra
Q(a)= ra
Choose a* if
Q(a*)=maxa Q(a)
In stochastic model: Reward is non-deterministic: p(r|a)
Qt(a): estimate of the value of act a at time t
Delta Rule
is learning factor Qt+1(a) is expected value and should converge to the mean of p(r|a) as t increases
4
1 1.t t t tQ a Q a r a Q a
C. Xu, 2008
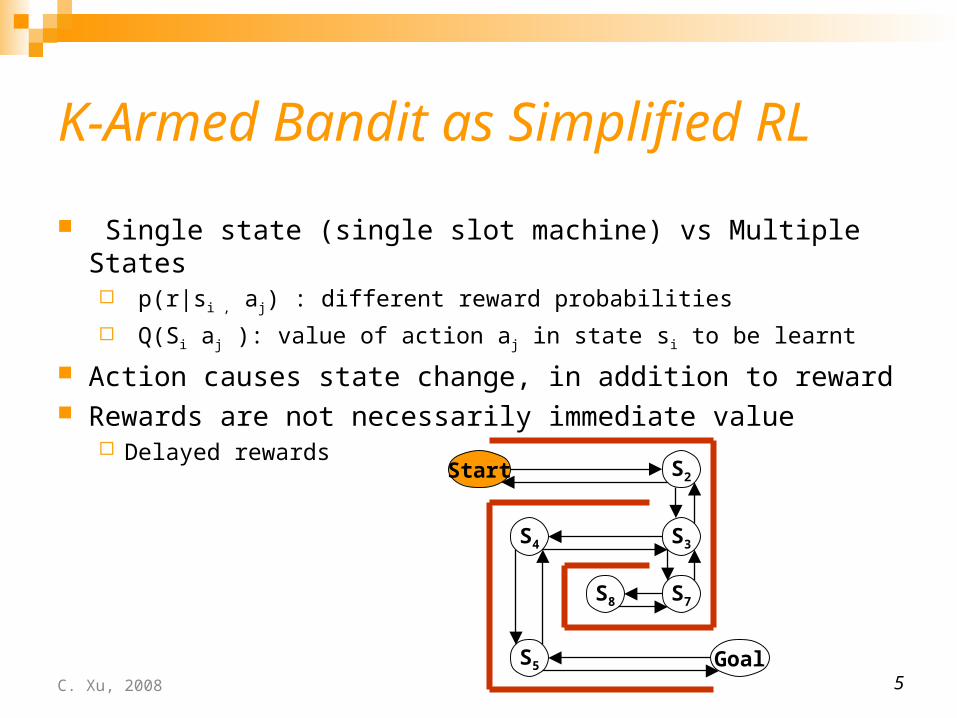
K-Armed Bandit as Simplified RL Single state (single slot machine) vs Multiple States
p(r|si , aj) : different reward probabilities
Q(Si aj ): value of action aj in state si to be learnt
Action causes state change, in addition to reward Rewards are not necessarily immediate value
Delayed rewards
5
Start S2
S3S4
S5 Goal
S7S8
C. Xu, 2008

6
Elements of RL
st : State of agent at time t
at: Action taken at time t
In st, action at is taken, clock ticks and reward rt+1 is received and state changes to st+1
Next state prob: P (st+1 | st , at ) Markov system
Reward prob: p (rt+1 | st , at ) Initial state(s), goal state(s) Episode (trial) of actions from initial state to goal
C. Xu, 2008

7
Policy and Cumulative Reward
Policy, State value of a policy, Finite-horizon:
Infinite horizon:
tt sa: AS tsV
T
iitTtttt rErrrEsV
121
rate discount the is 10
1
13
221
iit
itttt rErrrEsV
C. Xu, 2008

8
Bellman’s equation
1
11
* *1 1 1
*1 1
1
1
11 1
1
1 1
* *
[ ]
max ,
max | ,
, | ,
Value of in
max
tt
t
t
t
t t t t
it t i
i
it t i
i
t t
t t t t ta
t ta
s
t t t t t ta
s
V s E r
E r r
V s E r P s s a V s
Q s a E r
E r E V s
V s Q s a a
P s
s
s a
*1 1,t tQ s a

State Value Function Example GridWorld: a simple MDP
Grid cell ~ environment states Four possible actions at each cell: n/s/e/w, one cell in
respective dir; Agent would remain in location, if its move would take it off
the grid, but with reward of -1; Other move receives reward of 0, except
Those moves out of states A and B; rewarding 10 for each move out of A (to A’) and 5 for move out of B (to B’)
Policy: the agent selects four actions with equal prob and assume =0.9
9

10
Environment, P (st+1 | st , at ), p (rt+1 | st , at ), is known
There is no need for exploration Can be solved using dynamic programming Solve for
Optimal policy
Model-Based Learning
111
1
|max t*
stttt
at
* sVa,ssPrEsVt
t
111
1
||max arg t*
stttttt
at sVa,ssPa,srEs*
tt
C. Xu, 2008

11
Value Iteration vs Policy Iteration
Policy iteration needs fewer iterations than value iteration
C. Xu, 2008

12
Model-Free Learning
Environment, P (st+1 | st , at ), p (rt+1 | st , at ), is not known model-free learning, based on both exploitation and exploration
Temporal difference learning: use the (discounted) reward received in the next time step to update the value of current state (action): 1-step TD Temporal difference: between the value of the
current action and the value discounted from the next state
C. Xu, 2008

13
Deterministic Rewards and Actions
is reduced to
Therefore, we have a backup update rule as
Initially, and its value increases as learning proceeds episode by episode.
11111
1
max|
tt*
as
tttttt* a,sQa,ssPrEa,sQ
tt
1111
max
tta
ttt a,sQra,sQt
1111
max
tta
ttt a,sQ̂ra,sQ̂t
ˆ , 0,t tQ s a
Start S2
S3S4
S5 Goal
S7S8
In maze, all rewards of intermediate states are zero in the first episode. We a goal is reached, we get reward r and the Q value of last state, say S5, is Updated as r. In the next episode, when S5 is reached,the Q value of its preceding state S4 is updated as 2r.
C. Xu, 2008

14
Nondeterministic Rewards and Actions
Uncertainty in reward and state change is due To presence of opponents or randomness in the environment.
Q-learning (Watkins & Dayan’92): we keep a running average for each pair of state-action
tttt
attttt a,sQ̂a,sQ̂ra,sQ̂a,sQ̂
t111
1
max
value of a sample of instances for each (st,at)
11111
1
max|
tt*
as
tttttt* a,sQa,ssPrEa,sQ
tt
C. Xu, 2008

15
Exploration Strategies
Greedy: choose action that maximizes the immediate reward
ε-greedy: with prob ε, choose one action at random uniformly, and choose the best action with prob 1-ε
Softmax selection:
To m gradually move from exploration to exploitation, temperature variable T could help the annealing process
,
,
1
e|
e
Q s a
Q s b
b
P a s
A
( , ) /
( , ) /
1
e|
e
Q s a T
Q s b T
b
P a s
A
C. Xu, 2008

Summary RL is a process of learning by interaction, in contrast to
supervised learning from examples. Elements of RL for an agent and its environment
state value function, state-action function (Q-value), reward, state change probability, policy
Tradeoff between exploitation and exploration Markov Decision Process Model-based learning
Value function in Bellman equation Dynamic programming
Model-free learning Temporal difference (TD) and Q-learning (timing average) to update
Q value Action selection for exploration
-greedy, softmax-based selection
16C. Xu, 2008
Related Documents











