Anais do III Workshop de Iniciação Científica em Sistemas de Informação Castelmar Hotel – Florianópolis/SC – 17 a 20 de maio de 2016 XII Simpósio Brasileiro de Sistemas de Informação Promoção Organização Patrocínio Apoio

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Anais do III Workshop de Iniciação Científica em Sistemas de InformaçãoCastelmar Hotel – Florianópolis/SC – 17 a 20 de maio de 2016
XII Simpósio Brasileiro de Sistemas de Informação
Promoção Organização Patrocínio Apoio

III Workshop de Iniciação Científica em
Sistemas de Informação (WICSI)
Evento integrante do XII Simpósio Brasileiro de
Sistemas de Informação
De 17 a 20 de maio de 2016
Florianópolis – SC
ANAIS
Sociedade Brasileira de Computação – SBC
Organizadores Roberto Willrich
Vinícius Sebba Patto
Frank Augusto Siqueira
Patrícia Vilain
Realização
INE/UFSC – Departamento de Informática e Estatística/
Universidade Federal de Santa Catarina
Promoção
Sociedade Brasileira de Computação – SBC
Patrocínio Institucional
CAPES – Coordenação de Aperfeiçoamento de Pessoal de Nível Superior
CNPq - Conselho Nacional de Desenvolvimento Científico e Tecnológico
FAPESC - Fundação de Amparo à Pesquisa e Inovação do Estado de Santa Catarina

Catalogação na fonte pela Biblioteca Universitária
da
Universidade Federal de Santa Catarina
E56 a Workshop de Iniciação Científica em Sistemas de Informação (WICSI)
(3. : 2016 : Florianópolis, SC)
Anais [do] Workshop de Iniciação Científica em Sistemas de Informação
(WICSI) [recurso eletrônico] / Organizadores Roberto Willrich...[et al.] ;
realização Departamento de Informática e Estatística/UFSC ; promoção:
Sociedade Brasileira de Computação. – Florianópolis : UFSC/Departamento
de Informática e Estatística, 2016.
1 e-book
Evento integrante do XII Simpósio Brasileiro de Sistemas de Informação
Disponível em: http://sbsi2016.ufsc.br/anais/
Evento realizado em Florianópolis de 17 a 20 de maio de 2016.
ISBN 978-85-7669-319-2
1. Sistemas de recuperação da informação – Congressos. 2. Tecnologia
– Serviços de informação – Congressos. 3. Internet na administração pública
– Congressos. I. Willrich, Roberto. II. Universidade Federal de Santa
Catarina. Departamento de Informática e Estatística. III. Sociedade
Brasileira de Computação. IV. Título.
CDU: 004.65

III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
III WICSIIII Workshop de Iniciação Científica em Sistemas de Informação (WICSI)Evento integrante do XII Simpósio Brasileiro de Sistemas de Informação (SBSI)17 a 20 de Maio de 2016Florianópolis, Santa Catarina, Brazil.
Comitês
Coordenação Geral do SBSI 2016Frank Augusto Siqueira (UFSC)Patrícia Vilain (UFSC)
Coordenação do Comitê de Programa do WICSI 2016Roberto Willrich (UFSC)Vinicius Sebba Patto (UFG)
Comissão Especial de Sistemas de InformaçãoClodis Boscarioli (UNIOESTE)Sean Siqueira (UNIRIO)Bruno Bogaz Zarpelão (UEL)Fernanda Baião (UNIRIO)Renata Araujo (UNIRIO)Sérgio T. de Carvalho (UFG)Valdemar Graciano Neto (UFG)
Comitê de Programa Científico do WICSI 2016
Alexander Roberto Valdameri (FURB)Celia Ralha (UNB)Christiane Gresse von Wangenheim (UFSC)Clodis Boscarioli (UNIOESTE)Cristiane Ferreira (UFG)Daniel Kaster (UEL)Elisa Huzita (UEM)Ellen Francine Barbosa (ICMC-USP)Fabiana Mendes (UnB)Fabiane Barreto Vavassori Benitti (UFSC)Fatima Nunes (EACH-USP)Iwens Sene Jr (UFG)Jean Hauck (UFSC)João Porto de Albuquerque (ICMC-USP)Luanna Lopes Lobato (UFG)
Marcello Thiry (UNIVALI)Marcelo Morandini (USP)Maria Inés Castiñeira (UNISUL)Mauricio Capobianco Lopes (FURB)Merisandra Côrtes de Mattos (UNESC)Ovidio Felippe da Silva Júnior (UNIVALI)Pablo Schoeffel (UDESC)Renato Bulcão Neto (UFG)Renato Fileto (UFSC)Roberto Willrich (UFSC)Rosângela Penteado (UFSCar)Vinicius Sebba Patto (UFG)Vitório Mazzola (UFSC)
RevisoresAntônio Esteca (USP)Flávia Horita (USP)Kalinka Castelo Branco (USP)Lívia Castro Degrossi (USP)
iv

III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
RealizaçãoINE/UFSC – Departamento de Informática e Estatística/ Universidade Federal de Santa Catarina
PromoçãoSBC – Sociedade Brasileira de Computação
PatrocínioCAPES – Coordenação de Aperfeiçoamento de Pessoal de Nível SuperiorCNPq - Conselho Nacional de Desenvolvimento Científico e TecnológicoFAPESC - Fundação de Amparo à Pesquisa e Inovação do Estado de Santa CatarinaFAPEU - Fundação de Amparo à Pesquisa e Extensão Universitária
ApoioCentro Tecnológico - UFSCPixel Empresa júnior - UFSC
v

III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
Apresentação
A iniciação científica é a base para formar futuros pesquisadores em todas as áreas de conhecimento. Com essa convicção, a
Comissão Especial de Sistemas de Informação da SBC criou o Workshop de Iniciação Científica em Sistemas de Informação
(WICSI). O WICSI é um evento nacional para divulgação de resultados de trabalhos de pesquisa em nível de Graduação na
área de Sistemas de Informação. O objetivo do WICSI é incentivar o desenvolvimento de pesquisas de Iniciação Científica e,
para tanto, busca estimular futuros pesquisadores da comunidade de Sistemas de Informação a apresentar seus trabalhos.
Em 2016, foi realizada a terceira edição do WICSI, contando com 41 artigos submetidos e, destes, 13 foram aprovados
(32%) com rigorosa e competente avaliação realizada pelos revisores. Durante o evento, os artigos aprovados foram apresen-
tados oralmente pelos seus respectivos autores. Os temas tratados nos artigos envolvem o uso de técnicas de computação em
várias áreas de conhecimento ou atuação, tais como: metodologias de desenvolvimento de software, usabilidade, educação,
armazenamento e processamento de informações.
Agradecemos aos autores que submeteram seus trabalhos, aos revisores que prontamente nos atenderam e à coordenação
geral do SBSI 2016 pelo apoio para realização do III WICSI.
Florianópolis, Maio de 2016.
Roberto Willrich (UFSC)
Vinicius Sebba Patto (UFG)
Coordenação do WICSI 2016
vi

III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
Biografia dos Coordenadores do Comitê de Programa do WICSI 2016
Roberto Willrich possui graduação e mestrado em Engenharia Elétrica pela Universidade Fed-eral de Santa Catarina (1987 e 1991) e doutorado em Informática pela Université de ToulouseIII/França (Paul Sabatier) (1996). Ele realizou um estágio pós-doutoral no Laboratoire d’Analyseet d’Architecture des Systemes, LAAS, França (2005-2006). Atualmente é professor titular daUniversidade Federal de Santa Catarina. Tem experiência na área de Ciência da Computação,com ênfase em Repositórios Digitais, Web Semântica, Anotações Digitais, Informática na Edu-cação.
Vinícius Sebba Patto é professor adjunto pelo Instituto de Informática da Universidade Federalde Goiás. Possui doutorado em Ciência da Computação pelo LIP6 - Laboratoire d’Informatiquede Paris 6 (2010). Possui mestrado em Engenharia de Computação pela Universidade Federalde Goiás (2005) e graduação em Análise de Sistemas pela Universidade Salgado de Oliveira(2000). Tem experiência na área de Ciência da Computação e Sistemas de Informação, comênfase em Sistemas Inteligentes, atuando principalmente nas seguintes áreas: lógica nebulosa,sistemas multiagentes, sistemas de suporte a decisão, gerenciamento participativo, modelagemde dados, simulação, modelagem de sistemas e linguagens de programação.
vii

III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
Artigos TécnicosST1 - Aplicações e Aspectos Humanos de SI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1
Desenvolvimento de um Jogo Digital como Objeto de Aprendizagem em um Curso de Sistemas para Internet . . . . . . . . 1Alexandre Soares Silva (IFMS), Viviane Andrade da Silva (IFMS)
RNA Aplicada a Modelagem Hidrológica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5Marcos Rodrigo Momo (UNIFEBE), Pedro Sidnei Zanchett (UNIFEBE), Cristian Zimmermann de Araújo (UNIFEBE),Wagner Correia (UNIFEBE), Christian R.C. de Abreu (Prefeitura de Blumenau)
Terceirização de Sistemas de Informação no Setor Público: Uma Revisão Sistemática de Literatura . . . . . . . . . . . . . . . . . 9Matheus Icaro Agra Lins (IFAL), José da Silva Duda Junior (IFAL), Mônica Ximenes Carneiro da Cunha (IFAL)
Uma Comparação entre o Desenvolvimento de Aplicações Web Convencionais e Aplicações em Nuvem . . . . . . . . . . . . . 13Bruno Lopes (IFSP), Kleber Manrique Trevisani (IFSP)
ST2 - Desenvolvimento e Gestão Ágeis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
Seleção de Ferramenta de Gestão de Demandas de Desenvolvimento Ágil de Software para Órgão Público . . . . . . . . . .17Emilie Morais (UnB), Geovanni Oliveira (FGA/UnB), Rejane Maria da Costa Figueiredo (UnB), Elaine Venson (UnB)
Um Plugin para Discretização dos Dados para Suporte à Metodologia Agile ROLAP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21Luan S. Melo (UENP), André Menolli (UENP), Glauco C. Silva (UENP), Ricardo G. Coelho (UENP),Felipe Igawa Moskado (UENP)
ST3 - Desenvolvimento de Interfaces, Usabilidade e Testes em SI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .25
Análise de Usabilidade em Sistema de Resposta Audível automatizada, com base no Percurso Cognitivo,Critérios Ergonômicos de Bastien e Scapin e Heurísticas de Nielsen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25Aline Cristina Antoneli de Oliveira (UFSC), Maria José Baldessar (UFSC),Leonardo Roza Mello (Faculdade SENAI-Florianópolis), Priscila Basto Fagundes (Faculdade SENAI-Florianópolis)
Guia de Boas Práticas para Desenvolvimento de Interface e Interação para Desenvolvedores da PlataformaAndroid . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .31Guaratã Alencar Ferreira de Lima Junior (Faculdade AVANTIS), Rodrigo Cezario da Silva (Faculdade AVANTIS)
Automação de Testes em Sistemas Legados: Um Estudo de Caso para a Plataforma Flex . . . . . . . . . . . . . . . . . . . . . . . . . . . 35Augusto Boehme Tepedino Martins (UFSC), Jean Carlo Rossa Hauck (UFSC)
ST4 - Armazenamento e Processamento de Informações . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
Análise do uso de técnicas de pré-processamento de dados em algoritmos para classificação de proteínas . . . . . . . . . . . 39Lucas Nascimento Vieira (Univille), Luiz Melo Romão (Univille)
Desenvolvimento da Técnica Data Mining como Apoio à Tomada de Decisão no Sistema Hidrológico paraGeração de Estatística das Estações de Telemetria da Defesa Civil de Brusque - SC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43Jonathan Nau (UNIFEBE), Pedro Sidnei Zanchett (UNIFEBE), Wagner Correia (UNIFEBE),Antonio Eduardo de Barros Ruano (Univ. de Algarve, Portugal), Marcos Rodrigo Momo (UNIFEBE)
Uma arquitetura de banco de dados distribuído para armazenar séries temporais provenientes de IoT . . . . . . . . . . . . . 48Fernando Paladini (UFSC), Caique R. Marques (UFSC), Antonio Augusto Frohlich (UFSC), Lucas Wanner (UNICAMP)
viii

III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
Utilização e Integração de Bases de Dados Relacionais por meio de Foreign Tables para utilização emferramentas OLAP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52Felipe Igawa Moskado (UENP), André Menolli (UENP), Glauco C. Silva (UENP), Ricardo G. Coelho (UENP),Luan S. Melo (UENP)
Index of Authors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
ix

Desenvolvimento de um Jogo Digital como Objeto deAprendizagem em um Curso de Sistemas para InternetAlternative Title: Development of a Digital Game as learning
object in a Systems for the Internet CourseAlexandre Soares da Silva
Instituto Federal de Mato Grosso do Sul (IFMS)R. Treze de Maio, 3086, campus Campo Grande
Centro, Campo Grande - MS+55 (67) 3378-9500
Viviane Andrade da SilvaInstituto Federal de Mato Grosso do Sul (IFMS)
R. Treze de Maio, 3086, campus Campo GrandeCentro, Campo Grande - MS
+55 (67) [email protected]
RESUMODevido sua característica lúdica e multidisciplinar, jogos digitaissão utilizados nas mais diversas áreas como ferramentas e objetosde aprendizagem. Este artigo apresenta o desenvolvimento de umjogo digital, planejado para rodar em navegadores web, cujoconteúdo pretende contribuir para o desenvolvimento doraciocínio lógico e habilidades em solucionar problemas deestudantes de um curso Tecnológico de Sistemas para Internet. Amecânica do jogo exibe, na forma de puzzles interativos,problemas aplicados de lógica. Não obstante, sua arquiteturatambém permite a inserção destes puzzles criados de formaindependente, sem muitas restrições de projeto. Deste modo, ojogo é empregado como objeto de aprendizagem onde osestudantes colaboram implementando recursos adicionaisenquanto paralelamente praticam algumas das habilidadesdesejadas pelo curso.
Palavras-chaveJogos digitais; programação; objetos de aprendizagem; desenvolvimento web
ABSTRACTBecause its playful and multidisciplinary aspects, games are usedin several areas as tools and learning objects. This paper presentsthe development of a game designed to run on web browserswhich purpose is develop logical thinking and problems solvingskills in students of a Systems for the Internet Technology course.The game mechanism displays, as interactive puzzles, appliedlogic problems. Nevertheless, its architecture also allows theaddition of independently created puzzles, without many designconstraints. Thus, the game is used as an object of learning, wherestudents collaborate implementing additional features while at thesame time practicing some of the skills demanded by the course.
Permission to make digital or hard copies of all or part ofthis work for personal or classroom use is granted withoutfee provided that copies are not made or distributed forprofit or commercial advantage and that copies bear thisnotice and the full citation on the first page. To copyotherwise, or republish, to post on servers or to redistributeto lists, requires prior specific permission and/or a fee.SBSI 2016, May 17–20, 2016, Florianópolis, Santa Catarina, Brazil.Copyright SBC 2016.
Categories and Subject DescriptorsK.3.2 [Computers an Education]: Computer and Information Science Education – Information Systems education; K.8.0 [Personal Computing]: General – Games.
General TermsAlgorithms, Design
Keywordsdigital games; programing; learning objects; web development
1.INTRODUÇÃO Jogos digitais, videojogos ou ainda games, como são maiscomumente chamados, proveem uma forma lúdica de desenvolverdeterminada tarefa proposta pelo próprio jogo. Para determinadogrupo de jogos, existe um conjunto de funções comuns entre elescomo, por exemplo, algoritmos de ocultação de superfícies,rotinas de renderização, estruturas de dados para representar osatores, bibliotecas com funções matemáticas, dentre outros. Esteconjunto de funções comuns entre um determinado grupo de jogosé chamado motor ou engine. O motor existe para que, a cada novojogo não seja necessário implementar novamente todos osrecursos comuns, além de otimizar o tempo de desenvolvimento econsequentemente os custos.
Do mesmo modo, o projeto e desenvolvimento de um jogo digitalpor si só possui natureza multidisciplinar pois engloba arte,cultura, processamento gráfico, comunicação via rede,armazenamento de informações, engenharia de software,sonorização, dentre outras áreas. Portanto, engloba áreas dacomputação como computação gráfica, redes de computadores,engenharia de software, métodos numéricos, dentre outras.Levando em consideração esta multidisciplinaridade, em 2012iniciamos um projeto de desenvolvimento de um motor 2Dsimples para criação de jogos para web usando apenas recursosnativos dos navegadores como HTML5, CSS e JavaScript, semqualquer plugin ou extensão. Essa decisão foi tomada porque aintenção era criar um motor com objetivo primariamente didático,sem intenção de competir com os motores já existentes. A ideiaera de utilizá-lo como ferramenta para ensinar o funcionamentogeral de um motor de jogos partindo de um código muito maissimples do que os existentes. Os estudantes, neste caso do CST1
em Sistemas para Internet, poderiam modificá-lo, visualizar oefeito das alterações e ao mesmo tempo praticar programação em
1 Curso Superior de Tecnologia
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
1

JavaScript – linguagem de script na qual o motor foi construído.Todavia, o motor por si só não empolgava tanto os estudantes docurso que não participaram das etapas de seu desenvolvimento,era necessário desenvolver um jogo para que algo fosseefetivamente visualizado e jogado. Em 2014, iniciamos o projetode construção de um jogo digital intitulado Brain Adventure comobjetivo de auxiliar o aprendizado de algoritmos e programação.Trata-se de um cenário interativo com perspectiva isométrica ondea personagem interage com outros objetos (Figura 1) ou atoresque disparam puzzles (quebra-cabeças ou desafios de lógica).Baseados em desafios de lógica ou problemas algorítmicossimples, o objetivo dos quebra-cabeças era permitir aos estudantesconstruir um mapa mental dos tipos mais comuns de problemas delógica encontrados na programação, porém de uma forma maislúdica do que a convencional como, por exemplo, o problema datravessia de um rio por barco, onde um agricultor pode levarapenas a si mesmo e uma única de suas compras: o lobo, a cabra,ou a maçã (na literatura há variantes do puzzle com outros itens).Se forem deixados sozinhos em uma mesma margem, o lobo comea cabra, e a cabra come a maçã. O desafio consiste em atravessar asi mesmo e as suas compras para a margem oposta do rio,deixando cada compra intacta (Figura 2).
Com o amadurecimento do projeto e considerando os relatos dospróprios estudantes, vimos que a programação dos puzzles do jogodespertava mais interesse do que simplesmente jogá-lo. Alémdisso, é possível construí-los utilizando como base oconhecimento adquirido durante o próprio CST em Sistemas paraInternet. Quando finalizado, cada artefato desenvolvido pode serincluído no jogo completo devido a sua arquitetura desacoplada. Acriação de novos desafios para incrementar este jogo é umaalternativa na elaboração de atividades inerentes ao próprio cursocomo, por exemplo, atividades complementares, trabalhos dedisciplinas de desenvolvimento web ou programação decomputadores. Vale ressaltar que, mesmo sendo construídocolaborativamente pelos estudantes, o jogo não tem comopretensão substituir as aulas tradicionais, mas sim atuar como umaferramenta alternativa de aprendizagem auxiliando na construçãode habilidades previstas pelo projeto pedagógico do curso.
A Seção 2 apresenta a fundamentação teórica por trás da ideia doprojeto. Descrevemos pontos relevantes da metodologia dedesenvolvimento do jogo na Seção 3. Em seguida, na Seção 4,relatamos os resultados obtidos até o momento e posteriormenteconcluímos este trabalho na Seção 5.
Figura 2: Uma variação do desafio da travessia de compraspor um rio com interface arrastar e soltar. A ideia é que oestudante perceba estruturas condicionais que devem ser
utilizadas para solucionar o problema.
2.FUNDAMENTAÇÃO TEÓRICASegundo o Comitê de Padrões de Tecnologia de Aprendizagem daIEEE2, um objeto de aprendizagem pode ser caracterizado por umaentidade, digital ou não, que pode ser usada para aprendizagem,educação ou treinamento [4]. Wiley D. A. [9] dá uma visão maispróxima dos objetos deste trabalho, definindo um objeto deaprendizagem como qualquer recurso digital que pode ser reusadopara apoiar a aprendizagem. A ideia principal é quebrar oconteúdo educacional em pequenos pedaços que possam serreusados em vários ambientes de aprendizagem, tal qual noparadigma da programação orientada a objetos.
Objetos de aprendizagem já são amplamente utilizados nas maisdiversas áreas. Umas dessas áreas é a da programação decomputadores e competências relacionadas. Isso ocorrebasicamente porque a capacidade cognitiva dos estudantesnovatos em entender um problema é base fundamental para aleitura e escrita de programas; domínio dos conceitos básicos deprogramação é vital para a escrita de um bom programa [8]. Paraaprender a programar é necessário o entendimento correto dealguns conceitos abstratos, conhecimentos sobre linguagens deprogramação, ferramentas, habilidades de solucionar problemas,estratégias no planejamento e implementação de um programa.Além disso, o maior problema de programadores novatos não é deaprender os conceitos básicos, mas sim aprender como utilizá-los.Dois fatores cognitivos apresentam-se como prováveisresponsáveis por deixar o aprendizado a programar mais difícil –estilo de aprendizado e motivação [5]. Em outras palavras, épossível que exista um estilo de aprendizagem particular quepermita ao estudante adquirir habilidades de programação maisfacilmente, ou pode ser que os estudantes precisem de uma formaparticular de motivação. Neste sentido, um jogo digital, seconvenientemente projetado, pode ser usado como objeto deaprendizagem eficaz na construção do conhecimento e doraciocínio. De fato, atualmente os jogos digitais têm sidofrequentemente empregados como ferramentas lúdicas paraauxiliar no aprendizado na área de informação e comunicação,principalmente em relação a programação [1, 2, 3, 6, 7].
Se por um lado sua característica lúdica é um dos recursos maismotivadores de um jogo, grande parte dos jogos desenvolvidoscomo objetos de aprendizagem pertencem a categoria doschamados jogos sérios, ou jogos educativos; estes por sua vez nãopossuem a diversão como foco principal, o que em alguns casos,pode torná-lo uma atividade entediante. O jogo desenvolvidodurante este projeto tem como principal contribuição aparticipação dos estudantes também na sua criação,
2 Institute of Electrical and Electronics Engineers
Figura 1: Cenário isométrico com desafios. Desafios sãoindicados por um sinal: verde se solucionado, amarelo caso
iniciado mas ainda não solucionado ou vermelho se ainda nãofoi acessado.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
2

programaticamente; não se limita a um jogo disponível apenaspara ser jogado. Além disso, há liberdade de que cada desafio sejacriado independentemente dos outros, de certa forma, sem muitasrestrições de projeto. As únicas restrições impostas são: nãoutilizar plugins ou qualquer tecnologia que necessite instalação emanter apenas quebra-cabeças relacionados às competênciascognitivas desejadas nos estudantes.
3.METODOLOGIA DE PESQUISADefinidas as ideias iniciais do projeto de pesquisa, criamos umdocumento de game design descrevendo o enredo, cenário,personagens, fases e alguns quebra-cabeças, quais seriam oselementos de jogo e sua interação com o jogador. Nesta primeiraversão definimos 6 (seis) desafios de raciocínio lógico comoquebra-cabeças disponíveis. A escolha dos quebra-cabeças ébaseada em desafios de lógica retirados de livros sobre puzzlesclássicos ou aplicados a algoritmos. O objetivo era iniciar aimplantação do jogo e futuramente expandir a ideia para outroscursos da área. Nesta etapa, definimos também a arquiteturabásica do projeto: cada fase seria representada por uma páginaweb, em um cenário isométrico, onde haveriam objetos interativose cada um destes objetos poderiam disparar desafiospredeterminados. A escolha pela perspectiva isométrica deu-sepelo fato de ser possível trabalhar com gráficos 2D eposicionamento espacial de forma mais simples do que comgráficos 3D, mas ainda sim simulando um aspecto tridimensional.Não obstante, a modelagem tridimensional ocuparia um tempoconsiderável da equipe e o projeto poderia ter seu escopo alterado.
O passo seguinte foi selecionar um motor para jogos adequado.Primando por um motor com caráter mais didático do quecomercial, optamos pelo motor para jogos 2D desenvolvidodentro da própria instituição de ensino por membros do grupo depesquisa NIJOD – Núcleo Interdisciplinar de Pesquisa para JogosDigitais. Para a implementação da lógica dos desafios emanipulação das informações sobre os jogadores utilizamos atecnologia JSP3. Durante o processo, tomamos o cuidado depermitir o desenvolvimento dos quebra-cabeças sem aobrigatoriedade de conhecer o motor, recursos avançados doHTML5 ou qualquer outra tecnologia em especial. Assim, bastariaimplementar a página web com o desafio e em seguida acoplá-laao cenário principal. Este acoplamento funciona através de umaAPI do próprio jogo que recebe e envia dados no formato JSON4,
facilitando a integração. Essa integração não será necessariamentetarefa de quem implementou o desafio; por exemplo, cadaestudante pode criar uma parte do puzzle como o layout, a arte, alógica em JavaScript, a consulta e gravação das respostas nobanco de dados ou chamadas dos controladores e assim pordiante. A Figura 3 mostra a ideia básica da arquitetura do jogo. Oprojeto do banco de dados responsável por armazenar informaçõessobre jogadores, progressos e desafios foi criado após a definiçãode alguns dos desafios. Desejávamos uma modelagem queatendesse todos os desafios de forma genérica, fornecendo asrespostas, dicas, dentre outras informações sem a necessidade deremodelar a base de dados a cada novo desafio criado. Qualquerque seja o quebra-cabeça, ele pode possuir atributos comuns aosoutros, por exemplo, dicas, resposta, descrição e título.
3 Java Server Pages 4 JSON (JavaScript Object Notation) é um formato de dados levepara troca de informações.
Figura 3: Arquitetura básica do projeto do jogo
Criado o primeiro protótipo, o mesmo foi submetido a apreciaçãode alguns estudantes e professores através de apresentações. Issoserviu para reavaliar algumas decisões como, por exemplo,utilizar os mesmos desafios para todos os personagensdisponíveis, evitando assim comparações de gênero, idade, oucaracterísticas físicas com a dificuldade dos desafios. Reavaliandoas contribuições esperadas, a principal contribuição passou a ser apossibilidade de encaixar o desenvolvimento dos puzzles comoobjeto de aprendizagem, pois o interesse era maior em criarquebra-cabeças do que jogar. Planejamos então a aplicação dealgumas atividades (as quais serão expandidas futuramente):
Implementação de desafios completos e funcionais(layout, recursos, lógica) como parte de atividadescomplementares do curso.
Criação ou melhoria de layouts dos desafios ou telas dojogo (desenvolvimento web inicial)
Implementação da lógica e persistência de dados noservidor para os layouts já desenvolvidos.(desenvolvimento web mais avançado)
Implementação de algoritmos para os desafios comovalidação, respostas, contagem de pontos, etc.(programação de computadores)
Da mesma maneira vislumbramos a possibilidade de criaratividades relacionados ao jogo em projetos integradores outrabalhos em cursos técnicos da área.
4.RESULTADOSA princípio, o objetivo era criar um jogo para incentivar opensamento algorítmico nos estudantes do CST em Sistemas paraInternet. Entretanto, diante de sugestões da comunidadeacadêmica e consequentemente reavaliação dos objetivos, logopercebemos que projeto não permanecerá limitado a cursossuperiores, passando a ser considerado também uma boa opçãopara cursos técnicos da área.
Antes de publicar o primeiro protótipo jogável, optamos por usá-lo como ferramenta em algumas disciplinas do CST em Sistemaspara Internet local. A intenção era de que os estudantes criassemuma série de desafios para o jogo e em consequênciadisponibilizá-los à comunidade interna. Disciplinas comodesenvolvimento web, banco de dados, engenharia de software elinguagem de programação foram as primeiras planejadas. Ainiciativa foi mais bem recebida do que o jogo em si, mesmo nãohavendo opiniões negativas sobre o mesmo.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
3

Em linguagem de programação, um dos trabalhos da disciplina foicriar um jogo de dedução de palavras, similar ao clássico jogo daforca. Todos os estudantes frequentes finalizaram o trabalho, oque é um bom indicativo em relação a motivação. Na área dedesenvolvimento web a atividade foi propor uma layout web paraum dos diversos problemas disponibilizados pelo professor. Nestecaso, houve a participação de aproximadamente 80% da turma,não sendo tão efetivo. Ao questionar os estudantes, os mesmosalegaram que por causa da grande quantidade de avaliações etrabalhos no final do semestre priorizaram algumas disciplinasque precisaram de maior dedicação.
Ao ser apresentado ao primeiro semestre do curso, houve interessede aproximadamente 20 estudantes de um total de 30.Infelizmente, devido a algumas situações atípicas como troca deprofessores da disciplina e greve dos servidores as atividadesforam interrompidas. Neste meio tempo, dois estudantes do últimosemestre paralelamente desenvolveram desafios completos para ojogo, o que os ajudou a pontuar em atividades complementaresobrigatórias; os desafios destes estudantes foram mais simples,pois havia um projeto de uma versão do jogo para crianças, compuzzles menos complexos tais como jogo da memória, caça-palavras, coleta seletiva de lixo, dentre outros (Figura 4).
Os próximos passos são expandir a ideia para novas turmas, poisaté o momento todos os testes foram realizados com umaquantidade pequena de estudantes, em um único curso.
5.CONCLUSÃOMesmo atuando sobre uma amostra pequena de estudantes,tivemos alguns resultados interessantes, mas que podem sermelhorados. Ao contrário de trabalhos tradicionais comoimplementar um sistema de cadastro, criar um algoritmo semmotivação real ou modelar um banco de dados para um e-commerce, o desenvolvimento de parte de um jogo cria novasperspectivas: gerar um artefato com caráter mais lúdico einterativo do que as atividades tradicionais além da expectativa decriar algo para os próprios colegas.
A possibilidade de criar jogos com temas e públicos variadosdeixou também em aberto uma nova possibilidade: implementar aideia em outras áreas do conhecimento; não somente paratecnologia da informação, assumindo o papel de um objeto deaprendizagem que pode ser usado dentro ou fora de sala de aulas,tanto como instrumento de apoio como motivador no ensino eaprendizagem.
6.REFERÊNCIAS[1] Boyer, K., Buffum, P.S., et. al. 2015. ENGAGE: A Game-
based Learning Environment for Middle School Computational Thinking. SIGCSE 15 Proceedings of the 46th ACM Technical Symposium on Computer Science Education. Pages 440-440. ACM New York, NY, USA. ISBN: 978-1-4503-2966-8. DOI=http://dx.doi.org/10.1145/2676723.2691876
[2] Drake, P., Goadrich, M. 2014. Learn Java in N games. SIGCSE 14 Proceedings of the 45th ACM technical symposium on Computer science education. Pages 748-748. ACM New York, NY, USA. ISBN: 978-1-4503-2605-6. DOI=http://dx.doi.org/10.1145/2538862.2539009
[3] Ghannem, A. 2014. Characterization of serious games guided by the educational objectives. TEEM 14 Proceedings of the Second International Conference on Technological Ecosystems for Enhancing Multiculturality. Pages 227-233. ACM New York, NY, USA. ISBN: 978-1-4503-2896-8. DOI=http://dx.doi.org/10.1145/2669711.2669904
[4] IEEE 1484.12.1-2002. 2002. Draft Standard for Learning Object Metadata. IEEE Learning Technology Standards Committee (LTSC).15 July 2002. DOI= http://standards.ieee.org/findstds/standard/1484.12.1-2002.html
[5] Jenkins, T. 2002. On the Difficulty of Learning to Program. In Proceedings of the 3rd annual Conference of LTSN Centrefor Information and Computer Sciences. vol 4, pp.53-58. LTSN. August 23, 2002.
[6] John, M.D.H., et. al. 2003. Puzzles and games: addressing different learning styles in teaching operating systems concepts. SIGCSE 03 Proceedings of the 34th SIGCSE technical symposium on Computer science education. ACM New York, NY, USA. Volume 35 Issue 1, January 2003. Pages 182-186. DOI=http://dx.doi.org/10.1145/792548.611964
[7] Li, F.W.B., Watson, C. 2011. Game-based concept visualization for learning programming. MTDL 11 Proceedings of the third international ACM workshop on Multimedia technologies for distance learning. Pages 37-42. ACM New York, NY, USA. ISBN: 978-1-4503-0994-3. DOI=http://dx.doi.org/10.1145/2072598.2072607
[8] Matthews, R., Hin, H.S., Choo, K.A. 2009. Multimedia learning object to build cognitive understanding in learning introductory programming. MoMM 09 Proceedings of the 7th International Conference on Advances in Mobile Computing and Multimedia. Pages 396-400. ACM New York, NY, USA. 2009. ISBN: 978-1-60558-659-5. DOI=http://dx.doi.org/10.1145/1821748.1821824
[9] Wiley, D.A. 2000. Connecting learning objects toinstructional design theory: A definition, a metaphor, and ataxonomy. In D. A. Wiley (Ed.), The Instructional Use ofLearning Objects: Online Version. Utah State University,USA. DOI=http://reusability.org/read/chapters/wiley.doc
Figura 4: Exemplos de dois desafios desenvolvidos pelosestudantes como atividades complementares do curso
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
4

RNA Aplicada a Modelagem Hidrológica
Alternative Title: Applied ANN to Hydrologic ModelMarcos Rodrigo Momo
Centro Universitário de Brusque [email protected]
Wagner Correia
Centro Universitário de Brusque [email protected]
Pedro Sidnei Zanchet
Centro Universitário de Brusque [email protected]
Christian R. C. de Abreu
Prefeitura Municipal de Blumenau [email protected]
Cristian Zimmermann de Araújo
Centro Universitário de Brusque [email protected]
RESUMO
As inundações são fenômenos naturais que vem ocorrendo em
várias partes do mundo. Na região do Vale do Itajaí, na bacia
hidrográfica do rio Itajaí-Mirim, o histórico das enchentes é
extenso. Para minimizar os danos causados por estes eventos,
medidas estruturais de prevenção vêm sendo realizados, tais
como, a construção de uma barragem. Entretanto, entender a
evolução hidrológica destes eventos é de fundamental
importância para apoiar as atividades de monitoramento. Neste
sentido, este trabalho tem como objetivo desenvolver um
modelo hidrológico chuva-vazão, utilizando técnicas de Redes
Neurais Artificiais (RNAs) para simular o sistema hidrológico
no rio Itajaí-Mirim no Município de Brusque.
ABSTRACT Floods are natural phenomena that have occurred in various
parts of the world. In the region of Itajaí Vale, in the basin of the
Itajaí-Mirim River the history of flooding is extensive. To
minimize the damage caused by these events, structural
prevention measures have been carried out, such as the
construction of a dam. However, understanding the hydrological
evolution of these events is crucial to support the monitoring
activities. In this sense, his work aims to develop a hydrological
rainfall-runoff model, using techniques of the artificial neural
network to simulate the hydrological system in Itajaí-Mirim
River in the city of Brusque/SC.
Categories and Subject Descriptor I. [Computing Methodologies]: I.2. Artificial Intelligence:
I.2.6.Learning: Connectionism and neural nets.
General Terms Experimentation, Measurement, Verification.
Keywords Modelo Chuva-Vazão; Simulação Hidrológica; Redes Neurais
Artificiais; Hidrometeorologia.
1. INTRODUÇÃO As enchentes são fenômenos naturais que têm sido registrados
nas diversas partes do mundo e que muitas vezes geram
expressivos prejuízos ao homem e à natureza. Na região da
bacia hidrográfica do rio Itajaí-Açú, o histórico das enchentes é
bastante extenso devido principalmente ao relevo natural da área
e ao processo de ocupação ao longo dos rios deste vale. Os
primeiros registros de cheias datam de 1852. Na bacia do rio do
Itajaí-Mirim, as enchentes ocorrem periodicamente até os dias
atuais, sendo a mais recente ocorrida em 2011 quando o nível do
rio alcançou a marca de 13,03 metros no Município de Brusque.
As inundações situam-se entre os principais tipos de desastres
naturais na nossa região. São comumente deflagradas por chuvas
rápidas e fortes, chuvas intensas e de longa duração. Estes
fenômenos podem acontecer em regiões naturais, trazendo
alterações ambientais. Entretanto, também atingem locais
ocupados pelos seres humanos. Assim, as áreas urbanas, são as
mais delicadas, pois apresentam mais superfícies impermeáveis,
maior adensamento das construções. Além disso, a conservação
do calor e a poluição atmosférica propicia a aceleração dos
escoamentos, redução do tempo de pico e aumento das vazões
das máximas, causando danos cada vez maiores e sendo tratado
como desastres. O maior destes desastres nesta região foi de
deslizamentos acompanhados de enxurradas e enchentes, que
ocorreu em novembro de 2008 com o registro de 24 mortes, 6
pessoas desaparecidas, mais de 30.000 pessoas desalojadas ou
desabrigadas [3].
Na tentativa de monitorar e diminuir os danos causados por
estes desastres, alguns esforços estão sendo realizado em toda a
bacia do rio Itajaí. Na bacia do rio Itajaí-Mirim, área de estudo
deste trabalho, está em andamento o projeto para a construção
de uma barragem a montante do Município de Brusque,
localizada em Botuverá. Esta barragem terá a capacidade de
armazenamento do volume de 15.700.000 m³. Desta forma, a
expectativa é que a vazão máxima do rio Itajaí Mirim, em
Brusque seja reduzida de 720 m³/s para 570m³/s. Isso significa
dizer que se em 2011, durante o evento de cheias em Brusque, o
pico de 10,03 metros, baixaria para 8,75 metros. Além disso, a
barragem oferecerá potencial de abastecimento de água aos
municípios de Botuverá, Brusque, Itajaí e Balneário Camboriú.
Em 2012 a Prefeitura Municipal de Brusque mapeou toda a área
do Município e as cotas de inundação por ruas, denominadas de
Carta-Enchente e a Cota-Enchente, respectivamente. Este
mapeamento de áreas suscetíveis de inundação representa um
grande avanço para gestão e controle de cheias, possibilitando o
monitoramento em uma situação de possível ocorrência de
enchente. Recentemente a Defesa Civil de Brusque implantou
um sistema telemétrico para coleta de dados hidrológicos e
meteorológicos em vários pontos da bacia do rio Itajaí-Mirim,
possibilitando realizar o monitoramento hidrometeorológico em
tempo real. O sistema de telemetria instalado no Município de
Permission to make digital or hard copies of all or part of this work for
personal or classroom use is granted without fee provided that copies are
not made or distributed for profit or commercial advantage and that
copies bear this notice and the full citation on the first page. To copy
otherwise, or republish, to post on servers or to redistribute to lists,
requires prior specific permission and/or a fee. SBSI 2016, May 17–20,
2016, Florianópolis, Santa Catarina, Brazil. Copyright SBC 2016.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
5

Brusque é de vital importância, pois por um lado permite
realizar o monitoramento hidrometeorológico da bacia em
tempo real, e por outro, viabiliza dados que subsidiam as
pesquisas científicas nas áreas de hidrologia e meteorologia.
Neste sentido, o objetivo deste trabalho é realizar a modelagem
hidrológica baseada em redes neurais artificiais (RNAs), visando
simular o comportamento hidrológico do rio Itajaí-Mirins,
durante as ocorrências de cheias pretéritas. Estas informações
poderão integrar ao conjunto de medidas preventivas que vem
sendo realizadas na bacia ao longo do tempo. Estas medidas têm
o objetivo de minimizar os danos causados pelos eventos de
cheias.
2. FUNDAMENTAÇÃO TEÓRICA
2.1 Modelos hidrológicos O modelo hidrológico é uma representação simplificada de um
sistema com o objetivo de entendê-lo e encontrar respostas para
distintas circunstâncias [10]. Através dos modelos hidrológicos
é possível encontrar respostas (saídas) de uma bacia hidrográfica
a partir de informações (entradas). A Figura 1 apresenta a
representação esquemática de um modelo
hidrológico
Na modelagem hidrológica são utilizadas ferramentas
matemáticas para representar o comportamento dos principais
elementos que compõe o ciclo hidrológico. Desta forma, o
objetivo é reproduzir os resultados mais próximos possíveis aos
resultados encontrados na natureza. Devida à grande
complexidade de se representar todos os fenômenos naturais, a
modelagem hidrológica trabalha com simplificações desses
fenômenos [8].
2.2 Modelo Chuva-Vazão Na literatura há uma grande quantidade de modelos chuva-
vazão, desde os mais simples, com métodos matemáticos, até os
mais complexos envolvendo modelos conceituais distribuídos
que consideram a variabilidade espacial e tempo de um evento
chuvoso, assim como as características da bacia [1]. Com a
evolução tecnológica, a modelagem chuva-vazão está sendo
aplicada para resolver situações específicas de como fazer
previsões de cheias, melhorando o ajuste dos parâmetros e
avaliando a interligação entre os parâmetros e as características
físicas da bacia [8].
Os principais usos destes modelos estão voltados para estudos
de comportamento de fenômenos hidrológicos, previsão de
nível, previsão de cenários de planejamento entre outros [10].
2.3 Previsão de nível do rio A previsão de nível do rio é a estimativa das condições em um
determinado tempo específico futuro [1]. A previsão pode ser
classificada em função do intervalo de tempo, como sendo de
curto prazo ou de longo prazo. Alguns exemplos de previsão de
longo prazo são para tempo de retorno de um evento de cheias,
relacionados às mudanças climáticas ou eventos cíclicos do tipo
El Niño e La Niña.
A previsão de curto prazo é realizada com horizontes pequenos
de tempo, variando de minutos até horas (ou dias). Estas
previsões são realizadas postos de medições a montante e dados
de precipitação ocorrida. São as mais utilizadas para controle de
inundações em regiões ribeirinhas [4].
2.4 Redes Neurais Artificiais (RNA) A RNA é um paradigma de aprendizado e processamento
automático inspirado na forma que funciona o sistema cerebral
humano. Através de interconexões de neurônios artificiais
colabora para produzir estímulos de saída.
Neurônios artificiais são funções matemáticas capazes de
receber uma série de entradas e emitir uma saída. Basicamente
um neurônio artificial da RNA é dado por três funções, são elas:
1) função de propagação, responsável por realizar a somatória
de cada entrada multicamada; 2) função de ativação, que
modifica a função anterior, caso a saída seja a mesma função
disponibilizada dada na função anterior, neste caso a função de
ativação não existe e 3) função de transferência que relaciona o
sinal de entrada com o sinal de saída da rede neural [5].
As Soluções baseadas em RNA iniciam de um conjunto de
dados de entrada suficientemente significativo com o objetivo
de que a rede aprenda automaticamente as propriedades
desejadas. O processo de adequação dos parâmetros da rede não
é obtido através de programação genérica e sim através do
treinamento neural. Neste sentido, para alcançar a solução
aceitável para um dado problema, é necessário previamente
adequar um tipo de modelo RNA e realizar a tarefa de pré-
processamento dos dados, os quais que formarão o conjunto de
treinamentos. Estas características permitem a RNA oferecer
diversas vantagens, tais como, capacidade de aprendizagem,
auto-organização, tolerância a falhas, flexibilidade e a obtenção
de resultados em tempo real. Redes neurais têm sido utilizadas
com sucesso em vários campos da ciência. Na hidrologia sua
aplicabilidade tem feito evoluir a modelagem de sistemas não
lineares[4]. As principais vantagens na utilização da
metodologia de RNA na modelagem de bacias hidrográficas são:
a) possibilitam a resolução de problemas complexos e não bem
definidos; b) podem ser aplicados em sistemas sem soluções
específicas; c) não requerem conhecimento detalhado dos
processos físicos; d) não potencializam erros de medição; e)
permitem otimizar os dados de entrada e dados de saída; f)
possibilitam treinamento contínuo da rede; g) baseado em dados
históricos, permite extrair informação e generalizar respostas
adequadas para cenários diferentes daqueles já ocorridos.
2.4.1 Arquitetura da RNA A rede neural é formada pelas camadas de entrada,
processamento e saída. Na camada de entrada, são apresentados
os dados de entradas da rede, que produzem sinais de saída,
estas por sua vez, estimularão os neurônios da camada
subsequente. Este processo segue até atingir a última camada,
chamada de camada de saída. Vale salientar que as camadas de
uma rede neural podem ter um ou vários neurônios por camadas.
Na Figura 2 se ilustra a arquitetura de uma rede neural [5].
Para resolver um dado problema, não existe, todavia, uma
solução bem definida para a escolha do número de camadas e de
Figura 1: Representação esquemática de um modelo
hidrológico [8].
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
6

neurônios a serem criados na rede. Se por um lado uma rede
muito complexa pode causar um superajustamento (overfiting).
Por outro lado, a simplicidade excessiva da rede pode não
conseguir reproduzir o comportamento desejado, mais
conhecido como mínimos locais [5]. Para alcançar a melhor
arquitetura da rede neural, para cada configuração devem-se
realizar simulações e análises de resultados, através das etapas
de treinamento e testes da rede.
3. METODOLOGIA DE PESQUISA
3.1 Atividades desenvolvidas Para atender aos objetivos deste trabalho foram realizadas as
seguintes atividades: 1–Criação das séries dados: consistiu na
identificação dos eventos de cheias pretéritas, ocorridos na bacia
do rio Itajaí Mirim e na obtenção dos dados dos níveis do rio
registrados nos pontos de Brusque e Vidal Ramos; 2–Criação,
treinamento e teste da RNA: nesta etapa foi utilizando o
software MatLab e o Toolbox Neural Network Tool [9]. Foram
criadas as RNAs, seguindo as seguintes etapas: a) divisão das
séries de dados para o treinamento e para os testes das RNAs; b)
treinamento da rede, que consistiu no ajuste dos pesos, no qual
se apresenta o conjunto de dados de entradas, para se obter a
saída desejada, c) testes das RNAs, com base das diversas
opções de configuração dos parâmetros de ajustes da rede
(número de neurônios, número de camadas, algoritmos de
treinamento etc.), foram realizados baterias de simulações para
encontrar o melhor resultado da RNA; 3-Análise de resultados:
com o objetivo de eleger a melhor configuração da RNA, para
cada simulação a análise de rendimento da rede, foi baseada no
coeficiente de determinação R². Este coeficiente permite obter o
ajuste entre o modelo de simulação e os dados observados que
variam entre 0 e 1. Desta forma, indica em percentagem o
quanto o modelo consegue explicar os valores observados,
quanto maior o valor de R² (mais próximo à 1), maior é o
rendimento do modelo, ou seja, melhor ele se ajusta à amostra.
3.2 Dados utilizados Para a realização deste trabalho, foram utilizados os dados do
nível do rio nos pontos de Brusque e Vidal Ramos, registrados
nas ocorrências de cheias dos seguintes eventos: 09/08/2011,
30/08/2011, 14/01/2012, 08/06/2014, 29/09/2014 e 01/10/2014.
Estes dados são provenientes da rede telemétrica de coleta de
dados hidrometeorológicos mantida pelo CEOPS/FURB [2]. O
ponto de Brusque é o local desejado da previsão de nível, ou
seja, na ponte Estaiada localizada centro da cidade.
3.3 Área de estudo A bacia hidrográfica do rio Itajaí-Mirim está localizada na
região do Vale do Itajaí entre as latitudes -27°6’2 e longitudes -
48°55’0. O rio Itajaí-Mirim faz parte da bacia do rio Itajaí-Açú,
que por sua vez, faz parte do sistema de drenagem da vertente
Atlântico. O rio Itajaí-Mirim com a área de drenagem de
1.700km² é a maior sub-bacia da bacia de drenagem do rio
Itajaí-Açú, fazendo parte da região hidrográfica do Vale do
Itajaí [6]. Esta bacia engloba um total de nove municípios: Vidal
Ramos, Presidente Nereu, Botuverá, Guabiruba, Brusque,
Gaspar, Ilhota, Camboriú e Itajaí. Suas nascentes encontram-se
na Serra dos Faxinais, a cerca de 1.000 metros de altitude, e
deságua na região estuarina do Itajaí-Açú, tendo o leito
principal, uma extensão aproximada de 170 km. A figura 3
ilustra a área de estudo.
4. RESULTADOS No total foram criadas 10 RNAs utilizando as mesmas séries de
dados para as fases de treinamento e teste. Nas simulações foram
alterados os parâmetros de configuração para cada rede testada.
Com base no coeficiente de determinação R², verificou-se que o
melhor rendimento do modelo foi com a seguinte configuração
da RNA: rede Feed_Forward BackPropagation, com 50
neurônios, 2 camadas, algoritmo de treinamento TRAINLN,
camada escondida função TANSIG e de saída função
PURELIN. Nesta configuração da RNA obteve um índice de R²
= 0,3686. A figura 4 ilustra o nível observado e o nível simulado
pela RNA.
Vale salientar que neste trabalho foram simuladas também as
redes neurais recorrentes Elman. Redes recorrentes são
adequadas para sistemas dinâmicos, entretanto, os resultados
obtidos para as mesmas séries de dados foram inadequados para
o estudo proposto.
Estudos similares ao apresentado aqui, utilizando RNA para
simulação hidrológica, nos quais mostraram uma eficiência na
utilização desta técnica. Em [11] utilizou técnicas de redes
Figura 2: Arquitetura da rede neural artificial [5].
Figura 3: Bacia hidrográfica Vale do Itajaí e sub-bacias [7].
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
7

neurais para realizar a previsão de cheias no rio Itajaí-Açú no
de Rio do Sul. O melhor desempenho foi com a RNA dom tipo
MLP com 9 neurônios na camada oculta. Para analisar a
performance do modelo, foram utilizados três coeficientes
estatísticos: Coeficiente de Eficiência de NS (Nash e Sutcliffe),
RMSE (Root Mean Square Error) e MAPE (Mean Absolute
Percentage Error), alcançando os valores de 0.9779, 0.0201 e
5.625, respectivamente.
No trabalho de [8] apresenta os resultados do modelo de
previsão hidrológica de curto prazo utilizando RNA. Para
verificar o rendimento do modelo, foi aplicado como estatística
de qualidade o coeficiente de NS e apresentou como o menor
resultado 0,91 e o maior resultado 0,97.
Em [12] apresenta um trabalho utilizando RNA de múltiplas
camadas para realizar a previsão de vazão mensal da bacia
hidrográfica do rio Piancó no Estado da Paraíba. A RNA
configurada com 15 neurônios na camada intermediária,
utilizando o coeficiente de NS, apresentou um resultado de 0,77.
Figura 4: Simulação hidrológica Observado/Simulado com
RNA.
Este trabalho permitiu obter informações relacionadas à
simulação do processo hidrológico na bacia hidrográfica do rio
Itajaí-Mirim durante um evento de cheias. Estas informações são
de vital importância para entender o clico hidrológico,
objetivando prever com antecedência a subida do nível do rio e
apoiar no monitoramento hidrológico em situações de eventos
de cheias. O serviço de monitoramento hidrometeorológico do
Município de Brusque atende de forma direta ou indiretamente,
uma população de cerca de 100 mil habitantes. Desta forma,
estas informações poderão ser integrados ao Sistema de
Informação da Defesa Civil de Brusque para apoiar na tomada
de decisão em situações iminentes às enchentes. Por outro lado,
a continuidade destes estudos viabilizará a geração de novos
conhecimentos hidrológicos da bacia e o fortalecimento da
parceria entre a Defesa Civil municipal, UNIFEBE e a
comunidade acadêmica em geral.
5. CONCLUSÃO Com base nestes resultados, verifica-se a necessidade de realizar
um levantamento de uma maior quantidade de dados
hidrometeorológicos da bacia, assim como a inserção de novos
pontos de medição do nível do rio. Intui-se que uma quantidade
maior de dados, viabilizará uma melhor qualidade na fase de
treinamento da RNA, melhorando o rendimento do modelo de
simulação hidrológica na bacia do rio Itajaí-Mirim.
Finalmente, vale destacar que a aplicabilidade das RNAs para
estudos hidrometeorológicos são promissoras, uma vez que
necessitam uma quantidade de dados relativamente pequena,
quando comparados aos modelos hidrológicos mais sofisticados
do tipo distribuídos, que consideram a variabilidade espacial nas
diversas variáveis do modelo, sendo necessário a discretização
da área, representando um conjunto elevado de parâmetros.
6. AGRADECIMENTOS Este trabalho de Iniciação Científica teve o apoio da Secretaria
de Estado da Educação de Santa Catarina, através da concessão
de bolsas com recursos do Artigo 170 da Constituição Estadual,
para os alunos de graduação regularmente matriculados na
UNIFEBE.
7. REFERENCIAS [1] CORDERO, Ademar; MOMO, Marcos Rodrigo; SEVERO,
Dirceu Luis. Prevenção de Cheias em Tempo Atual, com
um modelo ARMAX, para a Cidade de Rio do Sul-SC. In:
Simp. Brasileiro de Rec. Hídricos XIX, 2011, Maceió.
[2] CEOPS. Sistema de Alerta da Bacia do Rio Itajaí. 2016.
Disponível em: <www.ceops.furb.br>, Último acesso:
15/03/2016.
[3] Defesa Civil de Brusque. Estações de monitoramento
hidrometeorológico. 2016. Disponível em: <
http://defesacivil.brusque.sc.gov.br/monitoramento.php>,
Último acesso: 15/04/2016.
[4] DORNELLES, Fernando. Previsão contínua de níveis
fluviais com redes neurais utilizando previsão de
precipitação: investigação metodológica da técnica. 2007.
97 p. Dissertação-IPH, UFRGS, Porto Alegre, 2007.
[5] HAYKIN, S. Redes neurais: princípios e prática. 2ª edição,
São Paulo, Bookman, 2001, 900 p.
[6] HOMECHIN, M. Jr & A.C. BEAUMOR. Caracterização
da qualidade das águas do trecho médio do Rio Itajaí-
Mirim, S/C. Anais do VIII Congresso de Ecologia do
Brasil, 2007.
[7] BACIAS. Bacias Hidrográficas do Brasil. GEO-Conceição.
Disponível em:
<http://geoconceicao.blogspot.com.br/2011/08/bacias-
hidrograficas-do-brasil.html.>, Último acesso: 15/04/2016.
[8] MATOS, Alex Bortolon de. Efeito do controle de montante
na previsão hidrológica de curto prazo com redes neurais:
aplicação à bacia do Ijuí. 2012.75 f. Dissertação (Mestrado
em Recursos Hídricos e Saneamento Ambiental) –
PPRHSA, UFRGS, 2012.
[9] TOOLBOX S. I., The MathWorks - MatLab and
Simulation, T. MathWorks, Editor. 2016. Disponível em:
www.mathworks.com. Último acesso: 15/03/2016.
[10] TUCCI, C.E.M., Modelos hidrológicos, Porto Alegre,
UFRS/ABRH, 1998, 668 p.
[11] SOARES, D. G.; TEIVE, R.. C. G. Previsão de Cheias do
Rio Itajaí-Açu Utilizando Redes Neurais Artificiais. Anais
do Computer on the Beach, p. 308-317, 2015.
[12] SOUZA, W. S.; SOUZA, F. A. S. Rede neural artificial
aplicada à previsão de vazão da Bacia Hidrográfica do Rio
Piancó. Rev. Bras. Eng. Agr. Amb., v.14, p.173-180. 2010.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
8

Terceirização de Sistemas de Informação no Setor Público: Uma Revisão Sistemática de Literatura
Alternative Title: Information Systems Outsourcing in the Public Sector: A Sistematic Literature Review
Matheus Icaro Agra Lins Instituto Federal de Alagoas
R. Mizael Domingues, 75 - Centro, Maceió - AL
José da Silva Duda Junior Instituto Federal de Alagoas
R. Mizael Domingues, 75 - Centro, Maceió - AL
Mônica Ximenes Carneiro da Cunha
Instituto Federal de Alagoas R. Mizael Domingues, 75 - Centro,
Maceió - AL [email protected]
RESUMO A terceirização de sistemas de informação (TSI) tornou-se uma
estratégia bastante procurada pelas organizações nos últimos anos.
Inúmeros estudos encontrados na literatura tratam dos principais
aspectos que envolvem esse fenômeno no setor privado. Devido a
escassez de estudos direcionados ao setor público, esse artigo tem
como objetivo analisar publicações científicas com propósito de
elencar riscos, benefícios e motivações da terceirização de
sistemas de informação no setor público através de uma revisão
sistemática de literatura (RSL). Os resultados da RSL sinalizaram
diferença na frequência de citações relacionadas às motivações,
riscos e benefícios quando comparados ao setor privado. Tudo
isso mostra a importância deste levantamento para contribuir com
um trabalho em andamento que pretende fazer um mapeamento
quantitativo desses três fatores em instituições do setor público
em um estado do nordeste brasileiro, bem como para trabalhos
futuros.
ABSTRACT
Information Systems Outsourcing (ISO) has become a much
sought strategy by organizations in recent years. Numerous
studies in the literature deals with the main aspects surrounding
this phenomenon in the private sector. Due to the lack of studies
directed to the public sector, this article aims to analyze scientific
publications focused on this sector with purpose to list risks,
benefits and motivations through a systematic literature review
(SLR). The SLR results signed some difference in the frequency
of citations related to motivations, risks and benefits when
compared to the private sector. It shows the importance of this
survey to contribute with a work in progress which aims to make a
quantitative mapping of these risks, motivations and benefits in
public sector institutions in a state in northeastern Brazil, as well
as future works.
Categories and Subject Descriptors
A1 [Introductory and Survey]
General Terms
Management, Measurement, Documentation, Theory.
Palavras-Chave
Terceirização de SI; Setor Público; Outsourcing de TI.
Keywords
IS outsourcing; Public Sector; IT outsourcing.
1. INTRODUÇÃO O fenômeno da terceirização não é algo recente. Desde o século
XVIII, Ingleses e Franceses terceirizavam alguns serviços e
atividades especializadas [2][6]. Terceirização refere-se à prática
de transferir parte das atividades comerciais de uma empresa para
um fornecedor externo [1]. Geralmente atividades muito
específicas ou que não fazem parte dos interesses comerciais são
transmitidas para que empresas ou pessoas externas à organização
possam fazê-las de maneira melhor [2].
Empresas cujo negócio principal não está diretamente relacionado
a serviços de TI enxergam na terceirização algumas
possibilidades, dentre elas: ter acesso a novas tecnologias e
recursos humanos capacitados, direcionar os esforços para a
atividade principal e reduzir custos. Este último, por sua vez, é um
dos principais fatores motivadores indicados em estudos voltados
principalmente para empresas privadas [7][3].
O setor público tem seguido a tendência definida pelo setor
privado e atividades relacionadas a TI têm sido uma das que são
mais terceirizadas [13]. O risco de falhas nas parcerias enceta o
interesse dos órgãos públicos a se aprofundarem no formato de
gerência da terceirização, uma vez que a publicidade que cerca o
governo é fundamental para a gestão em exercício.
Apesar de alguns fatores motivadores da TSI no setor público
serem semelhantes aos do privado, como foco nas competências
centrais, melhoria na qualidade dos serviços e acesso à expertise
[11], estes diferem quanto ao grau de importância e a frequência
com que são mencionados. Inclusive existem aspectos dissonantes
entre eles, como a carência de recursos humanos causada por
inexistência de cargos na área de TI dentro das instituições, e
também problemas na contratação devido a restrições burocráticas
ocasionada por leis [10].
A escassez de estudos orientados ao setor público dificulta
comparações com a iniciativa privada, bem como o próprio
entendimento do comportamento do fenômeno neste setor.
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are
not made or distributed for profit or commercial advantage and that
copies bear this notice and the full citation on the first page. To copy
otherwise, or republish, to post on servers or to redistribute to lists,
requires prior specific permission and/or a fee.
SBSI 2016, May 17–20, 2016, Florianópolis, Santa Catarina, Brazil.
Copyright SBC 2016.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
9

Existem diferenças, principalmente no que tange riscos e
motivações [11][12]. Em virtude de tais diferenças entre setor
público e privado, não se pode fazer generalizações para estudar a
terceirização de SI como um todo. Para isso, é necessário um
aprofundamento no setor público com intuito de conseguir
conhecimento sólido de maneira a evitar viés nas pesquisas.
Este artigo apresenta os resultados de uma RSL, que teve como
objetivo realizar um levantamento de artigos existentes sobre os
riscos, benefícios e motivações que envolvem a terceirização de
sistemas de informação no setor público. A intenção foi sumarizar
as informações obtidas, com finalidade de criar um arcabouço
teórico que servirá como fonte para embasar um survey com
intuito de confrontar as visões dos fornecedores e contratantes a
respeito dos riscos, benefícios e fatores motivadores da parceria
público-privada que envolvem sistemas de informação.
A estruturação do restante do artigo é a seguinte: na seção 2 é
apresentado o procedimento metodológico, onde serão vistos os
conceitos de RSL, como foram definidos o protocolo e as etapas
da presente pesquisa; na seção 3 são exibidos os resultados das
buscas e seleções em torno das perguntas de pesquisa, além de
uma sucinta discussão. Por fim, as conclusões são apresentadas na
seção 4.
2. PROCEDIMENTO METODOLÓGICO 2.1 Revisão Sistemática
As revisões sistemáticas de literatura (RSL) são estudos
secundários que adotam um processo de pesquisa
metodologicamente bem definido para identificar, analisar e
interpretar as evidências disponíveis relacionadas a uma ou mais
questões de pesquisa especificas [8]. A RSL difere dos outros
tipos de revisões pelo fato de ser formalmente planejada e
executada de maneira metódica, dessa forma garante a
reprodutibilidade da pesquisa, proporcionando maior credibilidade
científica.
O ponto de partida de uma revisão sistemática se dá na elaboração
do protocolo de pesquisa, disponível em https://goo.gl/Yhg9Nh,
onde são listadas as questões de pesquisa e os procedimentos que
serão adotados durante a execução da revisão. Dessa forma, [9]
determinaram um conjunto de fases que são essenciais para o
desenvolvimento de uma RSL, sendo elas: planejamento,
execução e análise dos resultados.
As fases definidas por [9], e os conceitos de revisão sistemática
abordados por [8], serviram como diretrizes para a elaboração da
metodologia do presente trabalho. Os três aspectos (riscos,
benefícios, motivações) escolhidos como base para esta revisão
emergiram de estudos bibliográficos realizados por dois alunos de
iniciação científica que trabalharam neste artigo, em conjunto com
a orientadora. Observou-se durante o levantamento da literatura
que esses aspectos são costumeiramente citados quando se trata de
TSI de maneira geral. O propósito foi de ampliar os
conhecimentos acerca da terceirização de SI no setor público em
âmbito mundial. Dessa forma, foram elaboradas três questões de
pesquisa para serem respondidas após a obtenção dos estudos
primários. São elas:
Q1. Quais os riscos da terceirização de sistemas de informação
no setor público?
Q2. Quais as motivações da terceirização de sistemas de
informação no setor público?
Q3. Quais as benefícios da terceirização de sistemas de
informação no setor público?
2.2 Estratégias de pesquisa e seleção
Elaboradas as questões da pesquisa, o próximo passo consistiu na
definição dos termos de busca (strings de busca) que foram
elaborados a partir da identificação da população (setor público),
intervenção (terceirização de sistemas de informação,
terceirização de tecnologia da informação), em conjunto com os
termos correlatos à população e intervenção identificadas. Por
fim, foram realizadas combinações com palavras chaves e
operadores booleanos.
Assim sendo, foram construídas strings de busca com termos em
português e em inglês para cada questão.
Strings para Q1
Inglês: (("information systems outsourcing" OR "information
technology outsourcing" OR "IS outsourcing" OR "IT
Outsourcing") AND ("public sector" or "public service" OR
"public administration") AND (risk* or barrier* OR obstacle* or
challeng* or hurdle*))
Português: (("terceirização de sistemas de informação OR
terceirização de tecnologia da informação OR terceirização de SI
OR terceirização de TI) AND ("Setor público" OR "Serviço
público" OR "administração pública") AND (riscos OR
obstáculos OR barreiras OR desafios)).
Strings para Q2
Inglês: (("Information systems outsourcing" OR "Information
technology outsourcing" OR "IS outsourcing" OR "IT
Outsourcing") AND ("Public sector" OR "Public service" OR
"Public administration") AND (motivat* OR cause OR reason*))
Português: (("Terceirização de sistemas de informação” OR
“terceirização de tecnologia da informação” OR “terceirização de
SI” OR “terceirização de TI”) AND ("setor público" OR "serviço
público" OR “administração pública") AND (motivação OR
causa))
Strings para Q3
Inglês: (("information systems outsourcing" OR "information
technology outsourcing" OR "IS outsourcing" OR "IT
Outsourcing") AND ("public sector" OR "public service" OR
"public administration") AND (benefit* OR advantage*))
Português: (("terceirização de sistemas de informação OR
terceirização de tecnologia da informação OR terceirização de SI
OR terceirização de TI) AND ("setor público" OR "serviço
público" OR “administração pública") AND (benefícios OR
vantagens))
2.3 Seleção das bases de dados
Os termos de busca definidos foram aplicados nas bases de dados
estabelecidas no protocolo da pesquisa. A seleção das bases se
deu a partir do reconhecimento acadêmico em âmbito nacional e
internacional. Com isso as selecionadas para a pesquisa foram:
Periódicos da CAPES; ACM Digital Library; Science Direct; ISI
Web of Science; Scopus; IEEE Xplore Digital Library; Google
Scholar.
Vale salientar que as respectivas bases de dados possuem
particularidades com relação ao seu mecanismo de pesquisa, com
isso surgiu a necessidade de realizar pequenas adequações nas
strings para se adequar a base e assim obter resultados
satisfatórios.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
10

2.4 Estratégias de inclusão e exclusão
O procedimento para a inclusão e exclusão de documentos que
retornaram após a aplicação dos argumentos de pesquisa (strings
de busca) nas bases de dados se deu em dois momentos. No
primeiro momento, foram definidos no protocolo de pesquisa
como critérios de inclusão: a disponibilidade do documento na
internet para download e que esteja em formato PDF,
disponibilidade do documento em língua inglesa ou portuguesa, e
a delimitação do tempo de publicação de dez anos, ou seja,
publicados entre 2005 a 2015, tendo em vista que esta etapa da
pesquisa iniciou em novembro de 2015 e encerrou em março de
2016. Por fim, foram aceitos documentos que tratam de forma
primária ou secundária sobre motivações, riscos e benefícios da
TSI no setor público. Dessa forma, os critérios de exclusão foram
elaborados de forma que contrariem os critérios de inclusão.
No segundo momento foi realizada uma análise do título e das
palavras chaves com finalidade de reduzir a enorme gama de
resultados que havia sido retornada após a aplicação dos
argumentos. Ao término dessa análise restaram 239 documentos.
Eles tiveram seu resumo e conclusão lidos para confirmar se
estavam de acordo com o que foi estabelecido nos critérios de
inclusão, e no fim restaram 24 documentos relevantes, que foram
utilizados para responder as questões propostas pela revisão. A
tabela 1 exibe os resultados obtidos durante toda a fase de busca e
seleção dos documentos primários.
Tabela 1. Resultados das buscas por estudos primários nas
bases de dados.
3. RESULTADOS E DISCUSSÕES Dos 24 artigos que restaram após os processos de seleção,
identificou-se que, em alguns casos, um mesmo artigo tratava de
mais de um dos assuntos pesquisados: riscos, motivações e
benefícios. O Gráfico 1 mostra o número de artigos que está
diretamente ligado a cada uma das perguntas de pesquisa,
separando pelas bases de dados onde foram encontrados. No total,
17 artigos abordaram sobre motivações, 13 sobre riscos e 4 sobre
benefícios.
Gráfico 1. Quantidade de artigos por bases de dados que
falam em Motivação, Risco ou Benefício.
A seguir são apresentadas as respostas paras as questões de
pesquisa tendo como base os aspectos mais citados nos artigos
selecionados:
Q1. Quais os riscos da terceirização de sistemas de
informação no setor público?
Constatou-se que dos 24 documentos, 9 abordavam os riscos de
maneira primaria, e 4 de maneira secundaria. Dentre os resultados,
conforme a Tabela 2, ficou evidente a preocupação com questões
de segurança, uma vez que 6 dentre os 13 artigos que falam de
riscos, citam esse ponto. Isso ocorre, principalmente, pelo fato de
que os gestores das instituições públicas se preocupam
demasiadamente com possíveis vazamentos e acesso não
autorizado às informações que são confidenciais. Além de
prejudicar a organização e a população, pode também manchar a
imagem da corrente gestão do governo.
Observou-se também o elevado número de citações com relação a
dependência excessiva do fornecedor, fator que é refletido a partir
de outros riscos como, por exemplo, a perda de habilidades
críticas de TI. É comum que haja uma acomodação quando um
serviço é prestado de maneira eficiente, e isso acarreta na falta de
interesse da organização em fazer novos investimentos internos
para capacitação e melhoria das atividades. Apesar da perda de
habilidades de TI estar como um dos menos citados na tabela,
possui características gradativas, visto que a dificuldade em
manter tais habilidades abre espaço para a dependência.
Tabela 2. Principais riscos abordados nos artigos selecionados.
Q2. Quais as motivações da terceirização de sistemas de
informação no setor público?
A Tabela 3 sinaliza que a motivação relacionada a direcionar o
foco para as competências essenciais foi a mais citada. Em
segundo lugar está a redução de custos, que geralmente é a mais
citada nos estudos voltados para o setor privado. A intensidade de
citações sobre este fator é compreendida pela possibilidade de
direcionamento do foco da empresa para as atividades principais,
com canalização dos investimentos financeiros que seriam feitos
no setor de TI sendo remanejados para as tarefas centrais. Outra
motivação bastante citada foi a busca pela melhoria na qualidade
dos serviços, viabilizada pelo acesso às novas tecnologias e novas
expertises. Isso se dá pelo fato de os fornecedores de serviços
terceirizados geralmente dispõem de recursos humanos e
tecnológicos mais capacitados e avançados, possibilitando a
substituição de tecnologias defasadas e suprindo a falta de
profissionais, às vezes causada pela inexistência de cargos
específicos.
1ª Seleção 2ª Seleção
(Título e
Palavras-chave)
(Abstract e
Conclusão)
Periódicos Capes 32 7 4
ACM Digital library 45 13 1
Science Direct 564 28 3
ISI Web of Science 8 8 1
Scopus 26 7 1
IEEE 13 7 1
Google Scholar 2716 169 13
Total 3404 239 24
Fonte Quantidade
0 5
10 15 20
Motivações
Riscos
Benefícios
RISCOSQTD DE
CITAÇÕES
FREQUÊNCIA
DE CITAÇÕES
Questões de segurança 6 46%
Dependência excessiva do fornecedor 6 46%
Perda de competências centrais em TI 5 38%
Custos ocultos 4 31%
Perda de controle da atividade terceirizada 3 23%
Falta de experiência do fornecedor na atividade Terceirizada 3 23%
Diminuição da moral dos funcionários 3 23%
Qualificação dos funcionários do fornecedor 3 23%
Perda de flexibilidade dos serviços de TI 3 23%
Diferenças culturais 3 23%
Instabilidade financeira do fornecedor 2 15%
Perda de habilidades criticas de TI 2 15%
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
11

Tabela 3. Principais aspectos motivadores citados nos artigos
selecionados.
Q3. Quais as benefícios da terceirização de sistemas de
informação no setor público?
Apesar de restarem poucos documentos que falam em benefícios,
foi possível ter acesso às informações necessárias para responder
a pergunta supracitada. Em meio aos 24 artigos selecionados, 4
deles citaram algum tipo de benefício. Conforme ilustrado na
Tabela 4, a metade dos artigos apontou que um dos principais
benefícios é o acesso a novas capacidades e competências, visto
que, em muitas ocasiões, a equipe interna de TI não tem
habilidade e expertise necessária para gerenciar problemas mais
complexos e atender novas demandas. Consequentemente, junto
das novas competências e recursos, tecnologias inovadoras
aparecem como o segundo mais citado, seguido da melhoria na
qualidade dos serviços, que pode ser compreendido como
resultado da soma dos demais benefícios.
Tabela 4. Principais benefícios citados nos artigos.
4. CONCLUSÃO A revisão sistemática conduzida neste artigo identificou as
principais contribuições na literatura, nos últimos dez anos, para
terceirização de sistemas de informação no setor público.
Seguindo as etapas definidas no protocolo, foi possível responder
as três questões de pesquisa propostas.
Quanto aos riscos, os mais populares entre os artigos selecionados
foram questões relacionadas à segurança, dependência dos
fornecedores e perda das competências centrais de TI. As
principais motivações foram o foco nas competências essenciais
da organização, redução de custos e melhoria na qualidade dos
serviços. Já em relação aos benefícios, foi apontado o aumento na
flexibilidade dos serviços de TI, melhoria dos produtos e serviços
e acesso a novos recursos e habilidades.
Como trabalhos futuros pretende-se utilizar os conhecimentos
gerados por este artigo para compor um survey para aferir a
opinião de gestores públicos estaduais e municipais sobre
motivações, benefícios e riscos da parceria público-privada de
sistemas de informação, com vistas a atestar ou refutar as
informações preliminares obtidas na revisão sistemática.
REFERÊNCIAS
[1] GORLA, Narasimhaiah; CHIRAVURI, Ananth. 2011.
Information systems outsourcing success: a review. In: 2010
International Conference on E-business, Management
and Economics. 2011. p. 170-174.
[2] BERGAMASCHI, S. Modelos de gestão da terceirização
de Tecnologia da Informação: um estudo exploratório. Tese
(Doutorado em Administração) - Universidade de São Paulo,
São Paulo, 2004.
[3] PRADO, E. P. V.; TAKAOKA, H.. 2000. Terceirização da
Tecnologia de Informação: Uma Avaliação dos Fatores que
Motivam sua Adoção em Empresas do Setor Industrial de
São Paulo. Dissertação (Mestrado em Administração de
Empresas) - Universidade de São Paulo, São Paulo, 2000.
[4] LOH, L.; VENKATRAMAN, N.. 1992. Diffusion of
information technology outsourcing: influence sources and
the kodak effect. Information Systems Research, 1992.
[5] DIBBERN, J. et al.. 2004. Information Systems
Outsourcing: A Survey and Analysis of the Literature. The
DATA BASE for Advances in Information Systems, v.35,
n.4, 2004.
[6] DOMBERGER, Simon. 1998. The contracting
organization: a strategic guide to outsourcing. Oxford:
Oxford Univ. Press, 1998. 229p.
[7] LEITE, J. C.. 1994. Terceirização em informática. São
Paulo: Makron Books, 1994.
[8] KITCHENHAM, B. 2004. Procedures for performing
systematic reviews. Keele, UK, Keele University, v. 33, n.
TR/SE-0401, p. 28, 2004.
[9] BIOLCHINI, J. et al. 2005. Systematic Review in Software
Engineering. Engineering, v. 679, n. May, p. 165–176,
2005.
[10] CUNHA, M.X.C. 2011. Aspectos e Fatores Motivadores
da Terceirização de Sistemas de Informação no Setor
Público: Um Estudo em Instituições Públicas de Alagoas.
Tese (Doutorado em Administração) - Universidade Federal
de Pernambuco, Recife, 2011.
[11] COX, Michael, Martyn Roberts, and John Walton. 2011. IT
outsourcing in the public sector: experiences form local
government. The Electronic Journal Information Systems
Evaluation 14.2 (2011): 193-203.
[12] GANTMAN, Sonia. 2011. IT outsourcing in the public
sector: A literature analysis. Journal of Global Information
Technology Management, v. 14, n. 2, p. 48-83, 2011.
[13] LACITY, M. C.; Willcocks, L. 1997. Information systems
sourcing: examining the privatization option in USA public
administration [Electronic version]. Information Systems
Journal, 7 (1997), 85–108.
MOTIVAÇÃOQTD DE
CITAÇÕES
FREQUÊNCIA
DE CITAÇÕES
FOCO NA COMPETÊNCIA PRINCIPAL 12 71%
REDUÇÃO DE CUSTOS 11 65%
MELHORIA QUALIDADE DOS SERVIÇOS 10 59%
ACESSO A NOVAS TECNOLOGIAS/HABILIDADES 8 47%
FLEXIBILIDADE PARA RESPONDER RAPIDAMENTE
ÀS MUDANÇAS NA ÁREA DE TI6 35%
ESCASSEZ DE RECURSOS INTERNOS 6 35%
ACESSO A EXPERTISE 5 29%
FALTA DE CONHECIMENTO INTERNO/EXPERTISE 3 18%
COMPARTILHAMENTO DE RISCOS 2 12%
REDUÇÃO DE PROBLEMAS ROTINEIROS DE TI 2 12%
ATENDIMENTO A DEMANDAS URGENTES DE TI 1 6%
TRATAMENTO DE FUNÇÕES DIFÍCEIS DE GERENCIAR
OU FORA DE CONTROLE1 6%
PRESSÕES EXTERNAS 1 6%
PROBLEMAS COM RECRUTAMENTO DE PESSOAL 1 6%
BENEFÍCIOSQTD DE
CITAÇÕES
FREQUÊNCIA
DE CITAÇÕES
ACESSO A NOVAS CAPACIDADES, COMPETÊNCIAS E RECURSOS 2 50%
MELHORIA DOS PRODUTOS E SERVIÇOS 2 50%
AUMENTO DA FLEXIBILIDADE DOS SERVIÇOS 2 50%
REDUÇÃO DE CUSTOS 2 50%
ACESSO A NOVAS TECNOLOGIAS 2 50%
FOCO NAS COMPETÊNCIAS ESSENCIAIS 1 25%
MELHORIA DOS PROCESSOS E NEGÓCIOS 1 25%
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
12

Uma Comparação entre o Desenvolvimento de Aplicações
Web Convencionais e Aplicações em Nuvem Bruno Lopes†
IFSP - Instituto Federal de Educação, Ciência e Tecnologia de São Paulo
Rua José Ramos Júnior, 27-50 CEP 19470-000 - Pres. Epitácio - SP
Kleber Manrique Trevisani‡ IFSP - Instituto Federal de Educação, Ciência e
Tecnologia de São Paulo Rua José Ramos Júnior, 27-50
CEP 19470-000 - Pres. Epitácio - SP
ABSTRACT
This paper compare aspects related to development of a same
Web application, when developed to a cloud application provider
and when developed to a non-cloud environment. This
comparison are mainly concerned about highlight the differences
for developers.
RESUMO
Este artigo compara aspectos relacionados ao desenvolvimento de
uma mesma aplicação Web, quando desenvolvida para um
provedor de aplicações em nuvem e quando desenvolvida para um
ambiente não classificado como nuvem. Nessa comparação são
consideradas principalmente as diferenças relevantes para os
programadores.
__________________________
†Discente e ‡Docente do Curso Superior de Tecnologia em
Análise e Desenvolvimento de Sistemas
CCS
• Information systems ➝ Information systems applications ➝
Computing platforms; • Networks ➝ Networks services ➝
Cloud computing;
Palavras-chave
Cloud Computing, Software Development, Computing Platforms.
1. INTRODUÇÃO Computação em nuvem é um modelo que permite acesso sob
demanda, de maneira ubíqua e conveniente, por meio de uma rede
de computadores, a um conjunto compartilhado de recursos
computacionais (ex. redes, servidores, armazenamento, aplicações
e serviços) que podem rapidamente ser provisionados e liberados
com mínimo esforço de gerenciamento ou interação com o
provedor de serviços [1]. Os serviços oferecidos pela nuvem
variam desde aspectos de baixo nível, como a infraestrutura lógica
e física (IaaS - Insfrastructure as a Service), serviços no nível de
aplicação (SaaS - Software as a Service) e plataformas de
software (PaaS - Platform as a Service) [2].
Segundo [3], computação em nuvem é um termo utilizado para
descrever um ambiente de computação baseado em uma imensa
rede de servidores, sejam eles virtuais ou físicos. Um conjunto de
recursos como capacidade de processamento, conectividade,
plataformas, aplicações e serviços disponibilizados na Internet.
Com uma definição mais restrita, [4] descreve a computação em
nuvem referindo-se a aplicativos e serviços que são executados
em uma rede distribuída usando recursos virtualizados e acessados
por normas comuns de protocolo. Distingue-se pela noção de que
os recursos são virtuais e ilimitados e que detalhes dos sistemas
físicos de software são abstraídos.
Já [5], analisa a computação em nuvens sob uma ótica diferente, e
afirma que o surgimento do fenômeno conhecido como
computação em nuvem representa uma mudança fundamental na
forma como a tecnologia da informação (TI) é inventada,
desenvolvida, implantada, escalada, atualizada, mantida e
mensurada monetariamente.
2. OBJETIVOS E JUSTIFICATIVAS O mercado de computação em nuvens é dominado pela Amazon
seguida pelos seus concorrentes IBM, Apple, Cisco, Google,
Microsoft, Salesforce e Rackspace. Estima-se que o mercado
global de equipamentos em nuvem chegará a U$ 79,1 bilhões em
2018, em 2015 os gastos do usuário final em serviço de nuvem
podem ser maiores que US$ 180 bilhões [6].
Atualmente há uma considerável adesão de aplicações
implantadas em nuvens, como por exemplo, Google Drive, One
Drive, DropBox, ICloud, entre outras. No entanto, nota-se que as
aplicações mais difundidas têm o objetivo de armazenamento de
arquivos na nuvem e são classificadas como SaaS. Por outro lado,
o desenvolvimento de aplicações para provedores de serviço de
nuvens que oferecem PaaS, ainda não está amplamente
disseminado.
Este trabalho tem por objetivo comparar aspectos relacionados ao
desenvolvimento de uma determinada aplicação Web quando
desenvolvida para um provedor de serviços de nuvem que oferece
PaaS e quando desenvolvida para um ambiente não classificado
como nuvem (referenciada a partir desse ponto como aplicação
convencional). Foram levados em consideração nessa comparação
a dificuldade de desenvolvimento, a quantidade e qualidade das
bibliotecas de software disponibilizadas e a dificuldade de
implantação da infraestrutura necessária. Como resultado, serão
apresentados detalhes sobre o processo de desenvolvimento,
destacando as vantagens e desvantagens identificadas.
É importante ressaltar que o trabalho em questão foi totalmente
desenvolvido por um discente† e orientado por um docente‡,
ambos do curso superior de tecnologia em Analise e
Desenvolvimento de Sistemas do IFSP Campus Presidente
Epitácio.
3. DESENVOLVIMENTO
3.1 Descrição do cenário Considerando a necessidade de implementar operações CRUD
(Create, Retrieve, Update and Delete) para a grande maioria dos
sistemas de informação tradicionais, foi decidido que a aplicação
a ser desenvolvida deveria realizar tais operações. Devido a
limitações de tempo, somente foi possível implantar a aplicação
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
13

em um único provedor de serviços de nuvem, nesse caso, o GAE
(Google App Engine).
Para facilitar a comparação, decidiu-se que ambas aplicações
fossem desenvolvidas utilizando uma mesma linguagem de
programação e um mesmo ambiente de desenvolvimento. Nesse
contexto, foram selecionados a linguagem Java e o ambiente de
desenvolvimento integrado Eclipse. É importante destacar que o
GAE também suporta implantação de aplicações desenvolvidas
em Python e PHP [7].
Figura 1. Interface gráfica utilizada.
Com o mesmo objetivo, foi decidido que ambas aplicações
deveriam utilizar o mesmo layout para a interface gráfica,
conforme ilustrado pela Figura 1. Devido a utilização da mesma
linguagem de programação para o desenvolvimento das duas
aplicações, foi possível utilizar a mesma tecnologia para
elaboração de interfaces, nesse caso, o framework JSF (Java
Server Faces).
3.2 Persistência de dados A manipulação de dados pela aplicação convencional foi
realizada utilizando uma API da linguagem Java que descreve
uma interface comum para frameworks de persistência de dados
chamada JPA (Java Persistence API) além do sistema gerenciador
de banco de dados PostgreSQL. O servidor de aplicações
GlassFish também foi utilizado para implantar a aplicação.
No GAE somente é possível realizar o armazenamento utilizando
persistência de dados, não havendo possibilidade de selecionar um
sistema gerenciador de banco de dados, considerando que essa
tarefa é realizada de forma transparente e o programador não
precisa conhecer detalhes sobre o SGBD utilizado. O GAE
fornece um framework de persistência que permite o
armazenamento dos objetos instanciados, chamado Objectify [8].
A Figura 2 ilustra a interação entre os componentes importantes
para realizar a persistência de dados na aplicação convencional e
na aplicação desenvolvida para nuvem.
Figura 2. Interação entre os componentes. (a) Aplicação
convencional. (b) Aplicação em nuvem.
A plataforma de desenvolvimento GAE possui três formas de
armazenamento não relacionais (Bigtable, Blobstore, Google
Storage), todas elas utilizando a uma estrutura semelhante de
armazenamento, porém com algumas diferenças. O Bigtable é a
forma mais simples delas, porém limita o armazenamento de
arquivos do tipo blob (binários) a no máximo 1MB. O Blobstore
permite o armazenamento de arquivos maiores em relação ao
Bigtable, mas ele força o uso de uma URL única de upload [9].
Em relação a desempenho, o Google Storage é a melhor das três
opções de armazenamento do GAE. Adicionalmente, ele é de
simples utilização após seu funcionamento ser compreendido. O
Google Storage tem muito em comum com o Amazon S3, pois os
dois usam o mesmo protocolo e possuem a mesma interface
RESTful, considerando que as bibliotecas desenvolvidas para
trabalhar com o S3, como a JetS3t, também funcionam no Google
Storage [9].
Como a aplicação desenvolvida não necessita da utilização de
blobs (binários) com tamanhos grandes e nem muito espaço de
armazenamento, foi selecionado o modelo do Bigtable,
considerando que o mesmo oferece recursos suficientes para o
desenvolvimento da aplicação em nuvem proposta, além de
simplificar a implementação.
Para persistir um objeto no GAE, primeiramente é necessário
obter as informações preenchidas pelo usuário nos formulários
JSF, o que é possível utilizando métodos específicos do Manager
Bean.
A Figura 4 apresenta trechos de código que foram utilizados para
realizar a persistência de objetos nas aplicações desenvolvidas. É
possível observar que os dois métodos são bastantes similares,
porém o método da aplicação em nuvem utiliza o ofy(), que é
uma instancia da biblioteca Objectify utilizada para persistir os
dados na nuvem [8].
(a)
public Long save(Cliente c) {
ofy().save().entity(cliente).now();
return cliente.getId();
}
(b) public void persist(Cliente c) {
em.persist(c);
}
Figura 4. (a) Persistência no GAE. (b) Persistência JPA.
3.3 Detalhes do provedor de nuvem O desenvolvimento da aplicação em nuvem necessita de algumas
atividades adicionais em relação ao desenvolvimento da aplicação
convencional, como por exemplo, importar a biblioteca Objectify,
instalar o plugin GAE no IDE Eclipse e editar o arquivo de
configuração web.xml (Figura 3). Nesse arquivo, um elemento
listener deve indicar a classe Java responsável pelo registro das
entidades (classes) que serão persistidas no Objectify (Figura 3a).
A configuração do Objectify também precisa ser descrita no
arquivo web.xml para que o servidor tenha conhecimento que o
framework Objectify está sendo utilizado no projeto (Figura 3b).
O controle de threads na aplicação convencional é gerenciado
pelo próprio JSF. Entretanto, na aplicação em nuvem, esse
controle é realizado pelo GAE, obrigando o desenvolvedor a
desabilitar tal funcionalidade para evitar incompatibilidades com
o JSF (Figura 3c). Ainda dentro desse arquivo, deve ser indicado
o padrão de projeto que será utilizado pelo framework JSF, nesse
caso em específico (Figura 3d), o Front Controller [10].
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
14
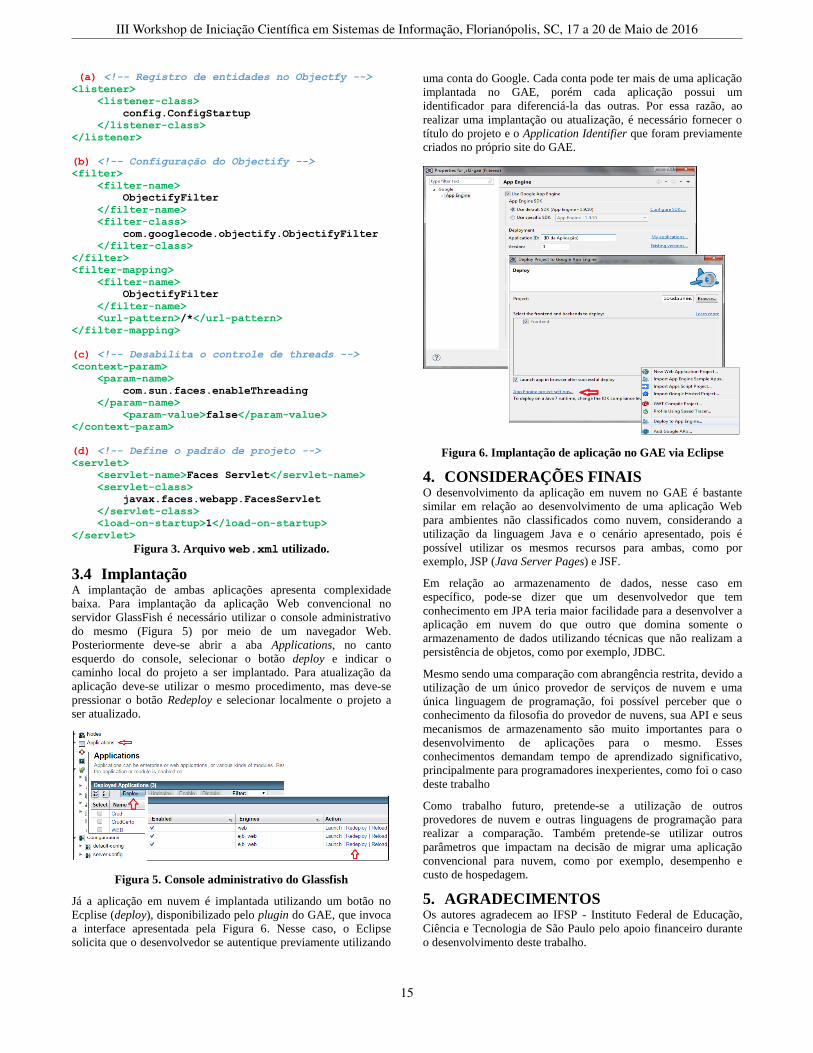
(a) <!-- Registro de entidades no Objectfy -->
<listener>
<listener-class>
config.ConfigStartup
</listener-class>
</listener>
(b) <!-- Configuração do Objectify -->
<filter>
<filter-name>
ObjectifyFilter
</filter-name>
<filter-class>
com.googlecode.objectify.ObjectifyFilter
</filter-class>
</filter>
<filter-mapping>
<filter-name>
ObjectifyFilter
</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
(c) <!-- Desabilita o controle de threads -->
<context-param>
<param-name>
com.sun.faces.enableThreading
</param-name>
<param-value>false</param-value>
</context-param>
(d) <!-- Define o padrão de projeto -->
<servlet>
<servlet-name>Faces Servlet</servlet-name>
<servlet-class>
javax.faces.webapp.FacesServlet
</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
Figura 3. Arquivo web.xml utilizado.
3.4 Implantação A implantação de ambas aplicações apresenta complexidade
baixa. Para implantação da aplicação Web convencional no
servidor GlassFish é necessário utilizar o console administrativo
do mesmo (Figura 5) por meio de um navegador Web.
Posteriormente deve-se abrir a aba Applications, no canto
esquerdo do console, selecionar o botão deploy e indicar o
caminho local do projeto a ser implantado. Para atualização da
aplicação deve-se utilizar o mesmo procedimento, mas deve-se
pressionar o botão Redeploy e selecionar localmente o projeto a
ser atualizado.
Figura 5. Console administrativo do Glassfish
Já a aplicação em nuvem é implantada utilizando um botão no
Ecplise (deploy), disponibilizado pelo plugin do GAE, que invoca
a interface apresentada pela Figura 6. Nesse caso, o Eclipse
solicita que o desenvolvedor se autentique previamente utilizando
uma conta do Google. Cada conta pode ter mais de uma aplicação
implantada no GAE, porém cada aplicação possui um
identificador para diferenciá-la das outras. Por essa razão, ao
realizar uma implantação ou atualização, é necessário fornecer o
título do projeto e o Application Identifier que foram previamente
criados no próprio site do GAE.
Figura 6. Implantação de aplicação no GAE via Eclipse
4. CONSIDERAÇÕES FINAIS O desenvolvimento da aplicação em nuvem no GAE é bastante
similar em relação ao desenvolvimento de uma aplicação Web
para ambientes não classificados como nuvem, considerando a
utilização da linguagem Java e o cenário apresentado, pois é
possível utilizar os mesmos recursos para ambas, como por
exemplo, JSP (Java Server Pages) e JSF.
Em relação ao armazenamento de dados, nesse caso em
específico, pode-se dizer que um desenvolvedor que tem
conhecimento em JPA teria maior facilidade para a desenvolver a
aplicação em nuvem do que outro que domina somente o
armazenamento de dados utilizando técnicas que não realizam a
persistência de objetos, como por exemplo, JDBC.
Mesmo sendo uma comparação com abrangência restrita, devido a
utilização de um único provedor de serviços de nuvem e uma
única linguagem de programação, foi possível perceber que o
conhecimento da filosofia do provedor de nuvens, sua API e seus
mecanismos de armazenamento são muito importantes para o
desenvolvimento de aplicações para o mesmo. Esses
conhecimentos demandam tempo de aprendizado significativo,
principalmente para programadores inexperientes, como foi o caso
deste trabalho
Como trabalho futuro, pretende-se a utilização de outros
provedores de nuvem e outras linguagens de programação para
realizar a comparação. Também pretende-se utilizar outros
parâmetros que impactam na decisão de migrar uma aplicação
convencional para nuvem, como por exemplo, desempenho e
custo de hospedagem.
5. AGRADECIMENTOS Os autores agradecem ao IFSP - Instituto Federal de Educação,
Ciência e Tecnologia de São Paulo pelo apoio financeiro durante
o desenvolvimento deste trabalho.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
15

6. REFERENCIAS
[1] Mell, Peter, and Tim Grance. "The NIST definition of cloud
computing." Communications of the ACM 53.6 (2010): 50.
[2] Coulouris, George F., Jean Dollimore, and Tim Kindberg.
Distributed systems: concepts and design. pearson education,
2005.
[3] Taurion, C. Cloud Computing-Computação em Nuvem.
Brasport, 2009.
[4] Sosinsky, B. Cloud computing bible. John Wiley & Sons,
2010.
[5] Marston, S., et al. "Cloud computing—The business
perspective." Decision support systems 51.1 (2011): 176-189.
[6] Mccue, TJ. Cloud Computing: United States Businesses Will
Spend U$13 Billion On it. Disponível em:
<http://www.forbes.com/sites/tjmccue/2014/01/29/cloud-
computing-united-states-businesses-will-spend-13-billion-
on-it/>. Acesso em: 10 Mar 2016.
[7] Google App Engine Docs. Disponível em: <https://cloud.
google.com/appengine/docs>. Acesso em: 10 Mar. 2016.
[8] Schnitzer, J. et. al. Introduction to Objectify: Loading,
Saving, and Deleting Data. Disponível em: <https://github.
com/objectify/objectify/wiki/BasicOperations>. Acesso em:
10 Mar 2016.
[9] Wheeler, J. Armazenamento do GAE com Bigtable,
Blobstore e Google Storage. 2011. Disponível em:
<www.ibm.com/developerworks/br/library/j-gaestorage/>.
Acesso em: 10 Mar 2016.
[10] MEDEIROS, H. Padrões de Projeto: Introdução aos Padrões
Front Controller e Command. Disponível em: <http://www.
devmedia.com.br/padroes-de-projetos-introducao-aos-
padroes-front-controller-e-command/30644>. Acesso em: 10
Mar 2016.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
16

Seleção de Ferramenta de Gestão de Demandas de Desenvolvimento Ágil de Software para Órgão Público
Alternative Title: Selection tool to support a process of demand management of agile development of a public organization
Emilie T. de Morais, Geovanni O. de Jesus, Rejane M. da C. Figueiredo, Elaine Venson
Information Technology Research and Application Center, Faculdade Gama, Universidade de Brasília, Brasil {emiliemoraist, geovannirock}@gmail.com, {rejanecosta, elainevenson}@unb.br
RESUMO
A contratação de fornecedores para serviços de Tecnologia da Informação (TI) é uma realidade em órgãos públicos federais. E o movimento dos órgãos na contratação de fábricas de software, a partir da adoção de metodologias ágeis, tem sido recorrente. Neste cenário, o apoio de uma ferramenta em processos de desenvolvimento ágil pode ser essencial, dada a quantidade de envolvidos e, muitas vezes, tendo os fornecedores geograficamente dispersos. Este trabalho teve como objetivo a identificação e configuração de ferramentas para apoio a um processo de gestão de demandas de desenvolvimento Ágil de software de um órgão público federal brasileiro. O estudo foi realizado em duas vertentes, a definição e execução de um processo de seleção de ferramentas e o emprego de estudo de caso para levantamento dos requisitos específicos. Como resultado foi definida e configurada uma ferramenta para um órgão. A ferramenta encontra-se em uso.
Palavras-Chave Ferramenta; Métodos ágeis; Backlog; Órgão público federal.
ABSTRACT The hiring of supplier for Information Technology (IT) is a reality for federal public organizations. And the movement of federal public organization in hiring companies for offshore software development, starting from the adoption of agile methodologies has been recurrent. In this scenario the support of a tool for agile software development processes might be essential, given the amount of involved parts and, many times, the offshore companies are geographically distant. The objective of this study was the identification and setting of a tool to support a process of demand management of agile software development of a Brazilian federal public organization. The study has been done in two aspects, the definition and the execution of tool selection process and the employment of the study of case for gathering the specific requirements. As result, it has been defined and set a tool for the
federal public organization. The tool is already in use.
Categories and Subject Descriptors D. Software. D.2 Software Engineering. D.2.2 Design Tools.
General Terms Management.
Keywords Tool; Agile methods; Backlog; Federal Public Organization.
1. INTRODUÇÃO Os órgãos públicos não são responsáveis, em sua maioria, pela produção de software, mas sim pela gestão de demandas para contratação desse tipo de serviço. A terceirização de serviços de desenvolvimento de software é uma realidade no setor público [3]. Nesse cenário a adoção da metodologia ágil tem sido crescente [2] [12] [13][16] [9].
Nos métodos ágeis os requisitos geralmente são gerenciados com papel e caneta, ou seja, com o uso de notas pregadas em um mural ou uma parede [5] [1]. Isso acontece visto que a maioria dos times ágeis é formada por poucas pessoas e estão alocadas no mesmo lugar. A gestão desse desenvolvimento normalmente é realizada no nível do time de desenvolvimento. Já no setor público, quando o serviço é terceirizado, o time é formado por integrantes de fábricas de software e deve ser realizada pelo contratante, que deve gerenciar as demandas de serviços prestados pelo contratado, que podem estar em outra região. Nesse cenário, é essencial o apoio ferramental para o gerenciamento das demandas de serviços, dos requisitos e do processo de execução.
Este trabalho faz parte de um Projeto de Pesquisa e Desenvolvimento, oriundo de um Termo de Cooperação entre uma universidade e um órgão público federal, denominado neste trabalho como Ministério. O Ministério possui um Processo de Gestão de Demandas de Desenvolvimento Ágil de Software (GeDDAS) [15]. Esse processo foi baseado no framework Scrum [11]. Um dos artefatos gerados é o Backlog do Produto1 [15].
O objetivo deste trabalho foi definir um processo de identificação e configuração de ferramentas para dar apoio à gestão de demandas de serviços do processo de desenvolvimento ágil.
Este trabalho está organizado em seções. Na Seção 2 é apresentada uma breve descrição de métodos ágeis e do framework Scrum. Na Seção 3, apresentam-se os materiais e 1 Lista de itens necessários ao produto. Origem única de
requisitos. [11]
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. SBSI 2016, May 17–20, 2016, Florianópolis, Santa Catarina, Brazil. Copyright SBC 2016.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
17

métodos adotados. Na Seção 4 apresentam-se a execução e análise do processo de seleção da ferramenta definido. Na Seção 5, as considerações finais.
2. MÉTODOS ÁGEIS A metodologia ágil tem atraído um grande interesse da indústria de software [6] e a adoção da metodologia tem crescido no setor público, como mostram os levantamentos feitos por [2], [9], [13] e [16]. No levantamento feito pelo TCU [2] é percebido que a abordagem mais adotada tem sido o Scrum.
2.1 Scrum O Scrum é definido como uma estrutura (framework) na qual se pode empregar vários processos ou técnicas [11]. O framework é composto de eventos, papéis e artefatos que auxiliam na busca das melhores práticas de gerenciamento, orientando atividades de desenvolvimento [11].
Os eventos que formam o Scrum são: Sprint, Cancelamento da Sprint, Reunião de Planejamento da Sprint, Reunião Diária, Retrospectiva da Sprint. E os papéis estabelecidos são: Product Owner (PO), Time de Desenvolvimento e Scrum Master [11].
Dentre os artefatos propostos pelo Scrum constam o Backlog do Produto e o Backlog da Sprint. Ambos consistem em uma lista dos requisitos inerentes ao produto que deve ser entregue. No caso do Backlog do Produto estão reunidos todos os itens que formam o produto completo e no Backlog da Sprint contém os itens referentes a um incremento de software [11].
3. METODOLOGIA DE PESQUISA Dado o objetivo de identificação, seleção e configuração de uma ferramenta para um órgão brasileiro, essa pesquisa é considerada descritiva [8], que geralmente utiliza a técnica de levantamento. Também foi empregada a técnica de estudo de caso.
Este trabalho foi dividido em três principais fases: Planejamento; Coleta e Análise de dados; e Redação dos resultados. No planejamento foram previstas duas vertentes: caracterização do objeto do estudo de caso, na qual são identificadas as demandas do processo de desenvolvimento e caracterizados os relacionamentos do órgão com seus usuários de negócio e seus fornecedores, e outra vertente, relacionada à definição e execução de um processo de seleção de ferramentas, composto pelas etapas: Identificação, Seleção e avaliação; Validação; e Treinamento. Na fase Coleta e análise de dados o processo estabelecido foi executado. Os resultados foram redigidos.
3.1 Caracterização do Objeto Foram caracterizados o órgão e seu processo de software.
3.1.1 Ministério O setor de TI do órgão é composto por uma Coordenação-Geral, uma Coordenação de Informática, duas Divisões, de Recursos e Administração de Rede e de Desenvolvimento de Sistemas e uma unidade de Serviço de Atendimento ao Usuário.
No contrato vigente, o Ministério possui quatro fornecedores: apoio à gestão, responsável por auxiliar nas atividades de acompanhamento dos projetos e sistemas; apoio técnico, que auxilia na garantia da qualidade; fábrica de software, responsável pelo desenvolvimento de sistemas e pela manutenção dos legados do Ministério; infraestrutura de TI, responsável pela infraestrutura.
Para desenvolvimento de software, o órgão possui dois processos, um baseado na metodologia tradicional e outro processo baseado no framework Scrum, conhecido como GeDDAS (Gestão de Demandas de Desenvolvimento Ágil de Software) [15].
3.1.2 Processo GeDDAS Dado que, neste trabalho, a identificação e configuração da ferramenta foi realizada para apoiar o processo de desenvolvimento de software do Ministério, nesta seção apresenta-se uma breve descrição do processo GeDDAS.
O GeDDAS [15] é composto por seis subprocessos: Planejar Projeto, Planejar Release, Executar Sprints, Atestar Qualidade da Release, Homologar Release e Implantar Release. E também são previstos papéis e artefatos [15].
Um dos artefatos definidos é o Backlog do Produto e da Sprint. O Backlog do Produto não é utilizado apenas no subprocesso de Implantar Release. Assim, a ferramenta adequada ao Ministério deve apoiar o emprego do Backlog em cada um dos subprocessos por cada um dos papéis responsáveis.
No emprego do Backlog, os itens: Funcionalidades; Defeitos; Histórias técnicas; Não Conformidades e Aquisição de Conhecimento e seus status devem ser monitorados.
Na Tabela 1 é apresentado o uso do Backlog de acordo com os papéis do processo.
Tabela 1. Relação entre os papéis e a utilização do Backlog
Emprego do Backlog Papéis Visualização dos itens Todos os envolvidos
Revisão (edição) dos itens Proprietário do Produto, Time de Desenvolvimento
Adição de itens de funcionalidades Proprietário do Produto, Usuários-chave
Adição de itens de não conformidade Proprietário do Produto, Equipe de Qualidade
Adição de itens de defeito Equipe de Qualidade
Adição de itens de história técnica e aquisição de conhecimento
Time de Desenvolvimento
Priorização dos itens Proprietário do Produto
Para a implantação do processo foi realizado um projeto-piloto [15], no qual a gestão do Backlog do Produto era realizada em uma planilha. Dessa forma, foi identificada a necessidade de uma ferramenta que apoiasse o processo principalmente o Backlog.
3.2 Processo de Seleção da Ferramenta O processo de seleção de ferramentas é composto pelas etapas: identificação, seleção e avaliação, validação e treinamento.
3.2.1 Identificação Na etapa de identificação foi realizada uma pesquisa bibliográfica para levantamento das ferramentas e definição de critérios de seleção de ferramentas adequadas ao Ministério. A revisão foi realizada pela busca em bases de dados, busca manual em conferências brasileiras e utilização do processo de snowballing2.
2 Identificação de estudos a partir de um estudo, através das referências ou dos trabalhos que citam este estudo. [10]
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
18

3.2.2 Seleção e Análise Na etapa de seleção foram definidos critérios de seleção e análise das ferramentas identificadas a partir da literatura, dos requisitos do Ministério e de seu processo de desenvolvimento de software.
3.2.3 Validação Na etapa de validação, uma vez selecionada a ferramenta, essa foi configurada segundo os requisitos do GeDDAS. Em seguida, a ferramenta configurada foi avaliada pelos envolvidos no processo.
3.2.4 Treinamento Nesta etapa, após a validação da ferramenta foram previstos treinamentos a distância e presencial para os usuários.
4. SELEÇÃO DAS FERRAMENTAS Nesta seção apresenta-se o processo de seleção das ferramentas.
4.1 Identificação das Ferramentas Para o levantamento das ferramentas nas bases de dados foram empregadas as palavras-chave em inglês: Requirements engineering, Agile practices, User story management, Software support, Agile Backlog Management, Sprint Planning, Application lifecycle Management, Global Software Development, Global Software Engineering, Tool, Process, Development, Methods, Task board, Project Management.
Em português, foi realizada a busca manual em duas conferências: CBSoft e SBSI considerando as publicações dos últimos cinco anos. Também foi utilizada a técnica de snowballing [10], buscando trabalhos a partir das referências.
Assim, foi possível identificar as seguintes ferramentas: (MS project, Rally, Trac, Mingle, ScrumWorks, JIRA, MS Team Foundation Server, XPlanner, OutSystem, AgileZen, TinyPM, Urban Turtle, Agile Tracking tool, Agilito, Agilo, Conchango Scrum, Digite, EmForge, Axsoft, WoodRanch, KLL Software, LeanKitKanban, Polarion, ScrumPad, Seenowdo, EMC, Silver Catalyst, Assembla) [1]; (Planbox, tinyPM, Agilo for track, ScrumDesk [5]); VersionOne [1][5][4]; Redmine [7][1] e (TargetProcess, ScrumWorks, Agilo for Scrum e FireScrum [4]).
4.2 Seleção e Análise das Ferramentas Foram estabelecidos alguns critérios para seleção das ferramentas. A motivação é apresentada na Error! Not a valid bookmark self-reference..
Tabela 2. Critérios para seleção das ferramentas
Motivações Critérios A gestão do Backlog deve ser o principal aspecto considerado, visto que motivou a adoção de uma ferramenta
Permitir o gerenciamento do Backlog, como a adição, edição e exclusão de itens, bem como a alocação em iterações e entregas
A aquisição de uma ferramenta não foi prevista pelo órgão, e não havia orçamento previsto
Ser gratuita
O processo de desenvolvimento utilizado prevê vários papéis que devem interagir com a ferramenta e esses papéis devem possuir diferentes permissões
Possuir configuração de perfis de acesso
Considerando os critérios estabelecidos foram selecionadas as ferramentas XPlanner, FireScrum, IceScrum e Redmine. Que, embora gratuitas, algumas apresentavam limitações de uso. Assim, como o órgão já utilizava o Redmine, em reunião com o Ministério, optou-se por avaliar esta. Foram levantados três plug-ins do Redmine para apoio ao desenvolvimento ágil: Backlogs, Scrum e Scrumbler.
No estudo realizado por Dimitrijević et al [5] foram definidas as seguintes categorias de critérios: Suporte a modelagem de papéis de usuário, Gestão de histórias de usuário e épicos, Suporte a testes de aceitação, Planejamento de release, Planejamento de iteração, Acompanhamento do processo. Aspectos como usabilidade, integração com outros sistemas e opção de customizações, foram utilizados por Azizyan et al [1].
Utilizando como base as categorias estabelecidas [5] [1] e os aspectos do processo GeDDAS, os critérios de avaliação foram estabelecidos e realizada a avaliação de cada plug-in, Tabela 3.
Tabela 3. Avaliação dos plug-ins do Redmine
Considerando a avaliação realizada, foi possível observar que o plug-in Backlogs atendeu a todos os critérios adotados. O Backlogs foi considerado o mais adequado para o contexto.
4.3 Validação da Ferramenta Com a seleção da ferramenta e do plug-in foi necessário configurá-los para o GeDDAS. Em seguida buscou-se a validação com os envolvidos no processo.
4.3.1 Configuração da Ferramenta e do Plug-in Considerando os aspectos do processo (Tabela 4), como os papéis, os status dos itens e o tipo de item do Backlog que pode ser criado, foram configurados: a pontuação das histórias, os tipos de itens do Backlog, o status dos itens, o perfil de usuário e as permissões necessárias.
Tabela 4. Itens configurados
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
19

4.3.2 Validação com os envolvidos Para a validação da ferramenta e plug-in foi realizada uma apresentação para o Ministério por meio de reunião com os envolvidos no processo, representantes da DISIS, fornecedor de apoio à gestão e fábrica de software. A ferramenta foi aprovada e as configurações no ambiente do Ministério foram realizadas.
4.4 Treinamento dos usuários O treinamento da ferramenta foi realizado presencialmente e a distância. Essa estratégia foi escolhida levando em consideração o fato da fábrica de software ser de outra cidade.
O Ministério possui a plataforma moodle. A equipe configurou a plataforma para treinamentos dos processos e ferramentas definidas. Pela plataforma, o treinamento a distância foi composto de vídeos, slides e exercícios de fixação referentes à configuração e utilização da ferramenta.
Para o treinamento presencial, professores e estudantes ministraram os cursos. A utilização da ferramenta e do seu plug-in foi simulada com os seus usuários em cada parte do processo.
Os treinamentos aconteceram no mês de janeiro a março de 2015, e foram direcionados a todos os envolvidos, desde usuários do negócio do Ministério (Proprietário do Produto), servidores do Ministério e fornecedores de fábrica e de apoio à gestão.
5. CONSIDERAÇÕES FINAIS A seleção, treinamento e configuração da ferramenta de suporte para o GeDDAS no Ministério fez parte de uma melhoria do processo, o que acarretou a substituição de planilhas para uma ferramenta mais apropriada para realização das atividades.
Embora, a escolha da ferramenta tenha sido para um contexto específico, os critérios analisados e a análise podem ser utilizados para seleção de uma ferramenta para um contexto semelhante. Atualmente, a ferramenta começou a ser utilizada em um projeto no Ministério e como trabalho futuro será realizado o monitoramento do uso da ferramenta.
6. AGRADECIMENTOS Nossos agradecimentos pelo apoio recebido da UnB.
7. REFERÊNCIAS [1] Azizyan, G., Magarian, M.K. and Kajko-Matsson, M. 2011. Survey of Agile Tool Usage and Needs. Agile Conference (AGILE), (Aug. 2011), 29–38.
[2] Brasil, Tribunal de Contas da União 2013. Acórdão 2314-33/13-Plenário. Levantamento de Auditoria. Conhecimento acerca da utilização de métodos ágeis nas contratações para desenvolvimentos de ágeis pela Administração Pública Federal.
[3] Brasil, Tribunal de Contas da União 2012. Guia de Boas
Práticas em Contratação de Soluções de Tecnologia da Informação.
[4] Cavalcanti, E., Maciel, T.M. de M. and Albuquerque, J. 2009. Ferramenta Open-Source para Apoio ao Uso do Scrum por Equipes Distribuídas. III Workshop de Desenvolvimento Distribuído de Software, (Oct. 2009), 51-60.
[5] Dimitrijević, S., Jovanović, J. and Devedžić, V. 2014. A comparative study of software tools for user story management. Information and Software Technology. (May 2014), 1-17. DOI = 10.1016/j.infsof.2014.05.012
[6] Dybå, T. and Dingsøyr, T. 2008. Empirical studies of agile software development: A systematic review. Information and Software Technology. 50, 9-10 (Aug. 2008), 833–859.
[7] Engum, E.., Racheva, Z. and Daneva, M. 2009. Sprint Planning with a Digital Aid Tool: Lessons Learnt. 35th Euromicro Conference on Software Engineering and Advanced Applications, 2009. SEAA ’09 (Aug. 2009), 259–262. [8] Gil, A.C. 2008. Como elaborar projetos de pesquisa. Atlas.
[9] Inglaterra National Audit Office 2012. Governance for Agile delivery. http://www.nao.org.uk/report/governance-for-agile-delivery-4/. [10] Jalali, S. and Wohlin, C. 2012. Systematic literature studies: database searches vs. backward snowballing. Proceedings of the ACM-IEEE international symposium on Empirical software engineering and measurement (Sep. 2012), 29–38. [11] Jeff Sutherland, K.S. 2011. Guia do SCRUM: Um Guia Definitio do SCRUM - As regras do Jogo. SCRUM Org.
[12] Melo, C. de O. and Ferreira, G.R. 2010. Adoção de métodos ágeis em uma Instituição Pública de grande porte-um estudo de caso. Workshop Brasileiro de Métodos Ágeis, Porto Alegre (Jun. 2010), 112-125. [13] Melo, C. de O., Santos, V., Katayama, E., Corbucci, H., Prikladnicki, R., Goldman, A. and Kon, F. 2013. The evolution of agile software development in Brazil. Journal of the Brazilian Computer Society. 19, 4 (Nov. 2013), 523–552.
[14] Software Development: Effective Practices and Federal Challenges in Applying Agile Methods: 2012. http://www.gao.gov/assets/600/593091.pdf. [15] Sousa, T.L. de, Figueiredo, R.M. da C., Venson, E., Kosloski, R.A.D. and Ribeiro Junior, L.C.M. 2016. Using Scrum in Outsourced Government Projects: An Action Research. 2016 49th Hawaii International Conference on System Science. (Jan. 2016), 5447-5456.
[16] Vacari, I. and Prikladnicki, R. 2015. Adopting Agile Methods in the Public Sector: A Systematic Literature Review. International Conference On Software Engineering And Knowledge Engineering, 27, 2015.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
20

Um Plugin para Discretização de Dados para Suporte àMetodologia Agile Rolap
Alternative Title: A Plugin for Discretization of Data to Support theMethodology Agile Rolap
Luan S. Melo, André Menolli, Glauco C. Silva, Ricardo G. Coelho, Felipe Igawa MoskadoUniversidade Estadual do Norte do Paraná – UENP
Centro de Ciências TecnológicasRod BR369 Km 64
[email protected], {menolli, glauco, rgcoelho}@uenp.edu.br, [email protected]
RESUMOOs ambientes de Business Intelligence (BI) dão apoio aosadministradores das empresas a tomarem decisões mais precisaspara sua organização. Esses ambientes, em geral, utilizam datecnologia de Data Warehouse (DW), que é um banco de dadosintegrado e voltado para consultas. Entretanto a construção de umDW é um processo custoso e demorado, tornando então umobstáculo principalmente para pequenas e médias empresas. Como intuito de reduzir este problema foi proposta a metodologiaAgile ROLAP, que visa auxiliar na utilização de ferramentasOLAP a partir das bases relacionais das empresas. Porém, osanalistas na maioria das vezes necessitam visualizar os dadoscategorizado (dados discretizados), sendo assim, algumas vezes épreciso realizar essas transformações. No entanto, a metodologiapreza por não fazer modificações dentro das bases físicas etambém por minimizar o processo de Extract, Transform andLoad (ETL), o qual é necessário para fazer a discretização dosdados. Assim, este trabalho apresenta o desenvolvimento deplugins para a ferramenta Kettle e que auxilie na discretização dedados de forma com que não sejam alteradas as bases originais.
Categories and Subject DescriptorsH.2.7 [Database Management]: Database Administration – datawarehouse and repository
H.2.8 [Database Management]: Database Applications – datamining
General TermsAlgorithms, Management, Performance.
KeywordsData Warehouse, Agile Rolap, Business Inteligence,Discretização.
ABSTRACTThe environments of Business Intelligence (BI) provide support tomanagers of companies to make more accurate decisions for yourorganization. These environments currently using the DataWarehouse technology (DW), which is an integrated database andprepared for query. However, the construction of a DW is a costlyand time consuming process, so making an obstacle mainly forsmall and medium companies. In order to reduce this problem,was proposed the Agile ROLAP methodology, which aims toassist in the use of OLAP tools from relational databases ofcompanies. However, managers most often need to viewcategorized data (discretized data), so sometimes thesetransformations are needed. Nevertheless, the methodologyrecommends not make changes in the physical basis and also tominimize the process Extract, Transform and Load (ETL), inwhich it is necessary to make the data discretization. Thus, thiswork presents the development of plugins for Kettle tool thatassists in the data discretization helping that the physicaldatabases are not changed.
1. INTRODUÇÃOAs empresas com o decorrer do tempo guardam uma grandequantidade de informações sobre a sua organização, e no intuitode utilizar as informações futuramente, muitas utilizam osambientes de Business Intelligence (BI),no qual estes ambientesauxiliam na análise dos dados de forma eficiente e na tomada dedecisão dos administradores da empresa, facilitando também oconhecimento sobre a sua organização.
A implementação de BI demanda custo e tempo, tornando assimalgo não trivial, pois é necessário um Data Warehouse (DW), noqual tem como finalidade armazenar informações sobre asatividades da empresa de forma consolidada.
O processo de criação de um DW normalmente é realizado demodo iterativo, porém, mesmo assim são necessários em torno de15 meses ou mais para o que entre em produção o primeiromódulo[1]. Sendo assim, foi proposto o método Agile ROLAP, noqual tem como seu objetivo corrigir alguns problemas encontradosna implantação de um DW.
O objetivo da metodologia Agile ROLAP é permitir umaimplementação de forma ágil de ambientes de BI em que seutilizem bancos de dados relacionais, e ao mesmo tempo permitira utilização de ferramentas OLAP projetadas para ambientestradicionais por meio de um servidor ROLAP[2].
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, or republish, to post on servers or to redistribu-te to lists, requires prior specific permission and/or a fee.
SBSI 2016, May 17–20, 2016, Florianópolis, Santa Catarina, Brazil.
Copyright SBC 2016.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
21

No entanto, é proposto no Agile ROLAP, que se utilize ummecanismo intermediário, no qual permita que os dados dediversas fontes de dados sejam integrados em uma única base,fazendo com que se mantenha o conceito de DW. Porém namaioria das vezes os dados das bases relacionais são de formacontinua, isto é, um dado continuo contém toda informação de umdeterminado domínio.
Entretanto, os administradores das empresas geralmente desejamque os dados estejam categorizados para que se possa fazeranalise dos mesmo de forma simples. Sendo assim, o processo detransformar dados contínuos em dados categorizados édenominado de discretização[3].
Contudo, não consta na metodologia Agile ROLAP para se tornarmais simples para sua criação, fez com a diminuísse a etapa doExtract, Transform and Load (ETL), sendo esta importante pararealização da discretização de dados. Portanto, é proposto nestetrabalho a realização de um plugin para a ferramenta Kettle, emque auxilie no processo de discretização de dados de forma comque não se altere as bases originais, mantendo o que foi propostona metodologia Agile ROLAP.
2. REVISÃO BIBLIOGRÁFICA
Esta seção apresenta uma visão geral de conceitos e elementos daconstrução de um Data Warehouse utilizando a metodologia AgileROLAP, assim como uma breve revisão sobre discretização dedados.
2.1 Agile ROLAPA necessidade de armazenar as dados de uma empresa e fazer umaanálise eficiente das mesmas é um processo muito importante nomercado atual, com isso originou-se o DW, no qual é um depósitode dados em que consiste em armazenar uma grande quantidadede dados sobre às atividades de uma empresa. O uso de um DWfavorece uma melhor análise de um grande volume de dados pormeio de ferramentas OLAP, auxiliando no processo de tomada dedecisão das grandes organizações.
DW é o resultado do processo de transformação dos dados obtidosde sistemas legados e de bancos de dados transacionais que ficamorganizados sob um formato compreensível ao usuário, auxiliandona tomada de decisão [4]. Além disso, o DW possui algumascaracterísticas no qual se diferencia de outros tipos de modelagemde dados, que são: Orientação por assunto, Integração, NãoVolatilidade e Não Variação no Tempo.
No entanto, como mencionado anteriormente, o processo decriação de um DW é custosa e demorada, o que muitas vezes setorna um empecilho para que, principalmente pequenas e médiasempresas o implantem. Dessa forma foi proposta a metodologiaAgile ROLAP, que tem como intuito mitigar alguns problemasencontrados na implantação de BI, principalmente diminuindotempo com o processo de Extract, Transform and Load (ETL) .Apesar da metodologia não utilizar o conceito tradicional de DW,consegue-se por meio de seu uso utilizar as ferramentas OnlineAnalytical Processing (OLAP) disponíveis no mercado.
Assim, a metodologia tem como intuito diminuir o tempodespendido no processo de ETL, pois não há necessidade de criaruma nova base de dados. Estima-se que mais de 1/3 do custo naelaboração de um DW se dá no processo de ETL [5]. Isto permiteque pequenas empresas possam usufruir de ferramentas OLAPvoltadas para ambientes de BI tradicionais, proporcionandoauxilio na tomada de decisão do administrador da organização
baseado nas informações geradas, assim podendo o administradorconhecer melhor sobre o seu negócio além de possibilitar umamelhor competição no mercado.Na Figura 1 é mostrado como é o funcionamento do AgileROLAP e a função de cada etapa apresentada na Figura 1 édescrita a seguir:
Físico: Representa bases de dados originais. Nestasestão armazenadas em tabelas todas as informações daempresa obtidas com o decorrer do tempo.
FDW: Tem como finalidade agrupar todas asinformações da empresa em uma única base de dados.Estas informações estão armazenadas em formas detabelas, porém são cópias das tabelas originais que estãoarmazenadas no Físico. Quando um usuário acessa atabela, que está em base utilizando a tecnologia deForeign Data Wrapper (FDW), consulta diretamente abase de origem de forma transparente, assim o usuárioacha que está acessando a base no PostgreSQL, mas naverdade está consultado os dados da base original. Comisso não tem o risco de que os dados da base originalnão sejam modificados, pois o FDW permite apenas ousuário a fazer consultas.
Schema: é um arquivo conhecido como schema XML.Esse arquivo realiza o mapeamento dos dados que estãoarmazenados na forma relacional, no caso no FDW, paraos dados que devem ser mostrados na forma dimensio-nal. Basicamente esse schema indica onde estão os valo-res dos atributos na perspectiva multidimensional nabase de dados relacional.
OLAP: On-line Analytical Processing (OLAP) é a umaforma de se analisar grandes dados sobre múltiplasperspectiva, no qual é amplamente utilizado nosambientes de BI, pois facilita a análise rápida dos dadosgerados na implantação de tal ambiente.
Figura 1. Funcionamento do Agile Rolap
2.2 Discretização de DadosO avanço da computação e tecnologia traz consigo grandes taxasde informações, sendo elas explosivas, e que tendem a crescermuito mais devido aos novos recursos tecnológicos que estãosurgindo no mercado atualmente [6].
Os dados dessa grande taxa de informação geralmente sãoextraídos de forma continua, isto é, tendem vir com toda ainformação de um determinado problema. Os administradores deempresas normalmente utilizam os dados categorizados parafazerem suas consultas nas bases de dados.
Sendo assim, muitas vezes há uma necessidade de se transformaros dados contínuos em dados categorizados, e essa transformaçãode dados é denominada de discretização de dados.
A discretização de dados normalmente é aplicadas nos atributosque são usados para a análise de classificação ou associação. Para
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
22

a realização da discretização de dados, ou seja, transformar umdado contínuo em categorizado envolve duas subtarefas: decidir onúmero de categorias; e determinar como mapear os valores doatributo contínuo entre essas categorias [3]. Na primeira subtarefa,os valores dos atributos contínuos são devidos em n intervalos,denominado ponto de divisão. Na segunda, os valores de umdeterminado intervalo são mapeados para o mesmo valor decategoria.
Existem dois tipos de discretização de dados[3]: Discretização sem Supervisão: Discretização não-supervisionada gera intervalos sem utilizar a informação daclasse, e é a única possibilidade na tarefa de agrupamento.Esse tipo de discretização possui duas abordagens: larguraigual (divide a faixa dos atributos em um número deintervalos especificados pelo usuário) e frequência igual(tenta colocar o mesmo número de objetos em cadaintervalo). Discretização Supervisionada: Os intervalos sãodeterminados em função dos valores do atributo e da classecorrespondente a cada valor. Esse tipo possui váriosmétodos, sendo um deles a entropia, sendo ela uma das maispromissoras para discretização.
A discretização de dados consiste em uma das etapas do processode Extract, Transform and Load (ETL). Como mencionadoacima, ela é realizada para que possa determinar um padrão dasinformações.
Um exemplo de uso da discretização dos dados é identificar afaixa etária das pessoas que alugam filmes em uma locadora.Suponha-se que no sistema possua somente a idade da pessoa,porém não consta a sua faixa etária, com isto é feita adiscretização dos dados, transformando a idade da pessoa emcategorias de idade, para que possam ser analisadas futuramente.
Contudo, ao realizar uma discretização pode ser necessário atransformação de atributos, no qual se refere a uma transformaçãoque seja aplicada a todos os valores de um atributo, que érealizado “se a apenas a magnitude de um atributo for importante,então os valores dos atributos podem ser transformados pegando-se o valor absoluto” [3]. Por exemplo, se ao invés de terarmazenado na base de dados a idade das pessoas e sim a data denascimento, antes de realizar a categorização dos dados, serianecessário transformar a data de nascimento em um atributocontínuo idade.
3. DESENVOLVIMENTO DO PLUGINCom o intuito a dar suporte às necessidades do administrador deempresas que visa consultar as fontes de dados de forma que osdados estejam categorizados, e para que pudesse agilizar oprocesso de implantação de um ambiente de BI utilizando ametodologia Agile ROLAP, foi desenvolvido um plugin dediscretização de dados.
O plugin de discretização de dados foi elaborado para serintegrado a outros plugins que dão suporte à metodologia AgileROLAP. Em uma das etapas desta metodologia é previsto que osdados de diversas fontes de dados, sejam agrupados em uma únicabase de dados, utilizando a tecnologia Foreign Data Wrapper(FDW). Com isso, é feito um mapeamento das bases de dadosrelacionais para uma base intermediária, sendo esta base criadadentro do Sistema de Gerenciamento de Banco de Dados (SGBD)PostgreSQL.
Assim, com intuito de manter os preceitos da metodologia, oplugin desenvolvido também utiliza o PostgreSQL para realizar assuas funcionalidades, pois caso sejam necessários criar novosatributos discretizados, estes serão criados na base intermediária enão nas bases de origem. Dessa maneira, para o funcionamento doplugin, são criadas views materializadas dentro da base de dadosintermediária. Uma view pode ser entendida com uma tabelavirtual, no qual se é criada por uma consulta. Isto acontece pois ametodologia Agile ROLAP preza para que não se altere as tabelasoriginais novos atributos são criados na view correspondente atabela original, acrescentando um novo campo, sendo este dadopor uma função que será responsável pela discretização dos dados.
Os plugins já desenvolvidos para a metodologia Agile ROLAP,foram implementados na ferramenta Pentaho Data Integration(Kettle), sendo este uma plataforma de integração de dados, quepossibilita a análise de dados de forma precisa, além de permitir aobtenção de dados de diversas fonte de dados e permite avisualização por meio de componentes visuais [7]. Foidesenvolvido um novo plugin pois necessitava de algo que não sealterasse a tabela original e que pudesse fazer discretizaçõesutilizando vários atributos.
Na Figura 2 é apresentada uma interface que mostra ofuncionamento da ferramenta Kettle. Nesta interface, pode-seobservar como é realizado o processo de ETL de forma prática esimples por meio de plugins que executam tarefas especificas,sendo então possível a realização de transformações complexasnos dados, no qual estes plugins tendem a convergir para umúnico objetivo.
Por a ferramenta Kettle ser open source, existem diversosplugins para as mais várias tarefas da ETL, inclusive que auxiliemna discretização de dados. No entanto, pelas particularidades dametodologia Agile ROLAP foi estabelecido que seria necessário odesenvolvimento de um novo plugin, que pudesse ser totalmenteintegrado à outros plugins já desenvolvidos para dar suporte àmetodologia.
Figura 2. Pentaho Data Integration (Kettle). Fonte: Pentaho (2016)
Sendo assim, o plugin de discretização de dados é apresentado naFigura 3. Como mostrado, este contém alguns campos que devemser preenchidos para o funcionamento do mesmo. Existem setecampos dentro do plugins que podem ser preenchidos, porém seisdeles são obrigatórios.
O primeiro campo é onde se dá o nome da view materializadacriada pelo plugin. O segundo campo obrigatório é “connection”,responsável por fazer a conexão com o banco de dados, estaconexão serve para pegar os atributos das tabelas e tambémservirá para indicar onde será criada a view materealizada. Oterceiro campo obrigatório é o campo tabela, responsável poridentificar qual tabela receberá os dados discretizados.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
23

O quarto campo é responsável por identificar qual tipo de funçãoserá usada para discretização, sendo elas: função criadas pelousuário; funções próprias do banco e uma outra que é novafunção. Cada função tem um objetivo especifico paradiscretização dos dados.
O quinto campo, obtém as funções já implementadas, porém estecampo só é liberado caso seja escolhida no campo “tipo defunção”, a opção diferente de “nova função”.
O sexto campo conterá atributos no qual a função receberá parafazer a discretização de dados. Para cada atributo selecionado énecessário clicar no botão “adicionar” para que o mesmo possa servinculado a regra da função.
O sétimo e último campo, só irá aparecer caso, no campo “tipo defunção”, for selecionado o atributo “nova função”. Neste caso iráser exibido um novo campo, que dará a liberdade de se criar umanova função para discretização dos dados.
Após todos os campos serem preenchidos, é realizadas então adiscretização dos dados, criando então uma view materializada jácom o novo campo criado no qual se refere a discretização dosdados.
Figura 3. Plugin de Discretização de Dados
4. RESULTADOS
A fim de verificar se o plugin desenvolvido é viável paradiscretização de dados e se adequa à metodologia Agile ROLAP,foram realizados dois testes, utilizando uma base de dadosexemplo Postgres, chamada Pagila, pela qual foi inspirada pelaDell DVD Store para elaboração da mesma.
Os testes foram feitos empregando a tabela “film” e utilizou oatributo “length” para fazer a discretização. Este atributo foiescolhido, pois contém a duração de cada filme e também porestar na forma continua, tornando necessário a discretizaçãodesses dados para que ele fique na forma categorizada. Definiram-se as categorias como sendo: curta, média e longa metragem,conforme encontrado na literatura.
No primeiro teste realizado, como não foi encontradas funçõesque possam realizar a categorização específica de tamanho defilmes, foi necessária a criação de uma nova função, no qual amesma foi elaborada no plugin.
O segundo teste realizado, foi utilizando a mesma função criadano teste anterior, porém neste caso, não foi executada a etapa decriação da função, pois a mesma já se encontrava na lista defunções criadas.
Com estes preliminares realizados, pode-se comprovar que oplugin é útil para a discretização dos dados, fácil de ser utilizado eo mesmo agiliza o processo de discretização dos dados, pois omesmo trabalha de forma intuitiva. Por fim, verificou-se que omesmo está totalmente de acordo com a metodologia AgileROLAP, que era um dos principais objetivos do plugin.
Como principal limitação, constou-se que para utilização doplugin é necessário o entendimento do mecanismo de criação defunções por meio de PL/SQL.
5. CONSIDERAÇÕES FINAISCom a proposição da metodologia Agile ROLAP [2], muitosdesafios surgiram na sua implantação, principalmente por nãoexistir ferramentas específicas para este fim. Com o tempo, foisendo percebido, que novos plugins eram necessários para que ametodologia se tornasse viável de ser implantada de forma fácil erápida, e assim atingir o seu principal objetivo. Dentre estesplugins identificados como necessários, está o de discretização dedados.
Assim, foram estudadas as necessidades específicas que esteplugin deveria abordar, assim como este deveria ser integrado aoutros plugins já existentes. Com o uso do plugin desenvolvido,verificou-se que, apesar de necessitar do entendimento domecanismo de criação de funções por meio de PL/SQL, para suautilização, os resultados foram satisfatórios, pois o mesmo agilizano processo de discretização de dados, já que o mesmo tem umainterface intuitiva e simples de ser usada.
6. AGRADECIMENTOSMeu agradecimento ao órgão CNPq (Conselho Nacional dePesquisas) pela bolsa que me foi concebida.
7. REFERÊNCIAS[1] MACHADO, Felipe N. R. “Tecnologia e Projeto de Data
Warehouse: Uma visão multidimensional” São Paulo: Érica 2010 5 ed.
[2] SOUZA, E. B.; MENOLLI, André; COELHO, Ricardo Gonçalves. 2014 Uma Metodologia Agile ROLAP para Implantação de Ambientes de Inteligência de Negócios. Em: X Escola Regional de Banco de Dados, São Francisco do Sul. Anais 10ª. edição da ERBD.
[3] MENDES, Luciana 2011. Data Mining – Estudo de Técnicas e Aplicações na Área Bancária in Faculdade De Tecnologia De São PauloFATECPaulo FATEC-SP.
[4] KIMBALL, R., Caseta, J. 2004. The Data Warehouse ETL Toolkit: Practical Techniques for Extracting, Cleaning, Conforming, and Delivering Data, John Wiley & Sons.
[5] MENOLLI, André 2006. A Data Warehouse Architeture em Layers for Science and Technology in Proceedings of the Eighteenth International Conference on Software Engineering Knowledge Engineering (SEKE'2006), San Francisco, CA, USA.
[6] BUENO, Michel Ferreira. 2012. Mineração de Dados: Aplicações, Eficiência e Usabilidade. Em Anais do Congresso de Iniciação Científica do INATEL.
[7] PENTAHO. 2014 Pentaho Data Integration: Power to access,prepare and blend all data. Pentaho Corporation Disponível em: <http://www.pentaho.com/product/data-integration/> em2014.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
24

Análise de Usabilidade em Sistema de Resposta Audível automatizada, com base no Percurso Cognitivo, Critérios
Ergonômicos de Bastien e Scapin e Heurísticas de Nielsen
Alternative title: Usability Analysis of Automated Voice Response System based on Cognitive Walkthrough, Bastien and Scapin’s
Ergonomic Criteria Bastien Nielsen’s Heuristics
Aline Cristina Antoneli de Oliveira1 Maria José Baldessar2
Programa de Pós Graduação em Engenharia e Gestão do Conhecimento – PPEGC/UFSC 1 2
[email protected] [email protected]
Leonardo Roza Melo3 Priscila Basto Fagundes4
Faculdade de Tecnologia SENAI Florianópolis 3 4 [email protected]
RESUMO
A presente pesquisa tem como objetivo realizar avaliação de
usabilidade de um sistema que realiza atendimento para uma
empresa de telefonia, que possui recursos de interface de resposta
audível. A técnica aplicada para navegação no sistema foi o
Percurso Cognitivo. A avaliação da usabilidade foi baseada em 13
princípios selecionados com base nos critérios ergonômicos
Bastien e Scapin e heurísticas de Nielsen. A partir da análise do
percurso cognitivo, foi gerada uma tabela de criticidade, onde foi
possível avaliar as heurísticas respeitadas e violadas. Espera-se que
as técnicas apresentadas evoluam para um modelo de avaliação de
usabilidade de URA’s (Unidades de Resposta Audível).
Palavras-Chave
Sistema de Resposta Audível, Heurísticas de Usabilidade, Percurso
Cognitivo.
ABSTRACT
This research aims to perform usability evaluation of a system that
performs service for a telephone company, which has voice
response interface features. The technique applied to navigation
system was the Cognitive Walkthrough. The evaluation of the
usability was based on 13 principles selected, which were based on
ergonomic criteria of Bastien and Scapin, and Nielsen’s heuristics.
From the cognitive walkthrough analysis, it generates a criticality
table, where it was possible to evaluate the respected and violated
heuristics. It is expected that the presented techniques evolve for
usability evaluation model for IVR’s (Interactive Voice Response)
systems.
Categories and Subject Descriptors
D.2.2 [Software Engineering]: Design tools and techniques – user
interfaces.
General Terms
Design, Human Factors.
Keywords
System Interactive Voice Response, Heuristics Usability,
Cognitive Walkthrough.
1. INTRODUÇÃO
Ao desenvolver uma interface homem-máquina (IHM), nem
sempre o projetista leva em conta certas diferenças que existem
entre as pessoas. Nem todos os humanos são iguais e as diferenças
podem implicar em problemas tanto para o projetista como para
quem vai usar as interfaces [3].
Problemas de interpretação podem atrapalhar ou impedir que
pessoas de diferentes particularidades executem tarefas simples ao
utilizar diversos tipos de interface. Pretende-se, neste trabalho,
avaliar o contexto das interfaces de resposta audível. As maiores
dificuldades encontradas por usuários neste tipo de interface são o
acompanhamento da informação, identificação de posição das
teclas e botões, navegação entre menus, dificuldades de adaptação
em novas ações, compreensão do áudio, entre outras.
A partir destas dificuldades, resolveu-se estudar melhorias de
usabilidade nesse segmento com a finalidade de facilitar o
entendimento dos usuários na utilização de interfaces de resposta
audível e facilitar a interatividade entre o homem e o sistema.
O presente trabalho objetiva, portanto, realizar avaliação de
usabilidade em um sistema que realiza atendimento para uma
empresa de telefonia, que conta com recursos de interface de
resposta audível. A avaliação será realizada com base na técnica do
Percurso Cognitivo[2], nos critérios ergonômicos de Bastien e
Scapin [1] e Heurísticas de Nielsen [10] [11] [12].
A utilização da técnica do Percurso Cognitivo juntamente com
Avaliações Heurísticas, normalmente são utilizadas para avaliação
de interfaces web, onde a interação é realizada basicamente através
de teclado [6] [7] [8]. Este trabalho, portanto, trouxe uma nova
perspectiva de utilização destas técnicas, aplicando-as em URA’s
(Unidades de Resposta Audível). A principal contribuição é trazer
à discussão a avaliação de usabilidade em interfaces de resposta
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are
not made or distributed for profit or commercial advantage and that copies
bear this notice and the full citation on the first page. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior
specific permission and/or a fee.
SBSI 2016, May 17–20, 2016, Florianópolis, Santa Catarina, Brazil. Copyright SBC 2016.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
25

audível. Alguns autores já realizaram pesquisas sobre a importância
de aplicação de métodos de avaliação de usabilidade, que
fundamentalmente foram desenvolvidos para navegação através de
teclado, em sistemas multimodais (onde há múltiplas interações
simultâneas de dados e voz) [10], e softwares leitores de tela [13].
As técnicas apresentadas também já foram aplicadas em avaliação
de usabilidade sistemas web [7]. Porém, este trabalho apresenta
estas técnicas em sistemas onde o usuário, através de um aparelho
telefônico, liga para um número e interage com um sistema de
resposta audível, e através das técnicas apresentadas, heurísticas de
usabilidade são avaliadas, o que o torna relevante devido ao fato
deste conjunto de métodos ainda não haver sido aplicado em
interfaces desse tipo.
A Seção 02 trata dos aspectos conceituais sobre URA. A Seção 3
traz a respeito da Interação Humano Computador, conceitos sobre
Multimodalidade e URA Multimodal. A Seção 4 apresenta os
procedimentos e métodos adotados para que fosse realizada a
avaliação de usabilidade na interface multimodal apresentada. A
seção 5 apresenta os resultados da avaliação realizada, trazendo o
resultado do percurso cognitivo, assim como a Tabela de
Criticidade, onde são realizadas sugestões de melhorias na interface
analisada. A Seção 6 apresenta uma reflexão sobre o que foi
realizado, assim como sugestões para a continuação deste trabalho.
2. INTERAÇÃO HUMANO-COMPUTADOR
(IHC) e UNIDADE DE RESPOSTA AUDÍVEL
(URA)
A URA é um sistema automatizado de atendimento ao usuário
muito utilizado por empresas de maior porte e de grande
comunicação via telefone. Com ela é possível atender ligações e
gerenciá-las em modo espera ou então transferi-las de acordo com
a especificação que o usuário disca no teclado do telefone. Para o
usuário, não é um sistema muito agradável, pois se vê obrigado a
interagir com uma espécie de robô. Já para as empresas, as URA’s
são de grande utilidade, visto que elas substituem pessoas,
redirecionam melhor as ligações sabendo exatamente para qual
setor encaminhar as mesmas e podem funcionar 24 horas por dia e
7 dias por semana, sem interrupções [10][15].
As interfaces de interação com computadores tem sido alvo de
diversas pesquisas nas últimas décadas. A IHC é a área responsável
pelo design, avaliação e implementação de sistemas
computacionais interativos para uso humano. Propicia o
desenvolvimento de sistemas mais amigáveis e úteis, provendo aos
usuários melhores experiências [17]. Procura também apoiar o
estudo de interfaces adaptativas e adaptáveis, objetivando melhores
maneiras de interação.
Alguns autores dizem que o ideal é que interfaces sejam o mais
minimalista possível, para que a operação do equipamento seja
possível com a menor necessidade de habilidade ou conhecimento
prévio. Deve ser intuitiva para qualquer pessoa, invisível, passando
despercebida [10].
A relação entre um dispositivo de entrada ou saída (microfone,
teclado, tela sensível ao toque) e uma linguagem de interação
(linguagem natural, manipulação direta) é chamada modalidade.
Consequentemente, a interação multimodal pode ser definida como
a utilização de duas ou mais modalidades para interagir com um
sistema [14].
3. TESTE DE PERCURSO COGNITIVO
O percurso cognitivo é um método de inspeção, realizado por
especialistas, sem a participação de usuários. O Método de
Percurso Cognitivo foi proposto em 1994 por Wharton, Rieman,
Lewis e Polson [2]. Seu principal objetivo é avaliar a facilidade de
aprendizado de um sistema interativo, através da exploração da sua
interface. Considera principalmente a correspondência entre o
modelo conceitual dos usuários e a imagem do sistema, no que
tange à conceitualização da tarefa, ao vocabulário utilizado e à
resposta do sistema a cada ação realizada [2]. Objetiva encontrar
problemas de usabilidade relacionados à aprendizagem dos passos
necessários para realizar as tarefas [8]. Permite que os especialistas
simulem o percurso das tarefas realizadas pelos usuários,
verificando se a cada passo o usuário conseguiria alcançar o
objetivo correto, evoluindo na interação com a interface [8].
A aplicação da técnica consiste em:
a) definir quem são os usuários da interface, analisando suas
características e comportamentos.
b) definir as tarefas típicas que serão analisadas.
c) definir a sequência de ações para a realização correta de
cada tarefa.
c) definir a interface a ser analisada, que é a descrição de
informações necessárias para que as tarefas sejam realizadas, como
requisitos e regras funcionais [8].
4. PROCEDIMENTOS E MÉTODOS
Para realizar as avaliações de usabilidade em interface de resposta
audível, utilizou-se a técnica do percurso cognitivo [2] juntamente
com as heurísticas de usabilidade de Nielsen [12] e os critérios
ergonômicos de Bastien e Scapin [1]. Para isso, foi selecionado um
sistema de resposta audível de uma empresa de telefonia. O critério
para a escolha do sistema foi feita com base na experiência do
pesquisador como usuário desta interface e cliente da referida
empresa. Necessário é mencionar que a experiência do especialista
no momento da utilização da interface é importante para a avaliação
do método a ser utilizado, pois como especialista ele precisa antever
os possíveis passos que os usuários realizarão para navegar pela
interface.
A presente pesquisa, classificada como qualitativa [5] [16], tem em
sua característica interpretativista [9], a visão de mundo do
pesquisador. Este fato foi levado em consideração na escolha do
sistema avaliado e mesmo que tenha sido com base em sua
experiência pessoal como usuário do sistema e cliente da empresa,
não influenciou nos resultados alcançados.
4.1 Aplicação do teste de Percurso Cognitivo
Para a aplicação do teste de percurso cognitivo foi criado um
cenário e proposta uma tarefa, que é ligar para a empresa telefonia,
que aqui será denominada X. O avaliador é o especialista.
5.1.1 Cenário
O usuário está enfrentando problemas de navegação e seu provedor
de Internet é a empresa X. Ele já é cliente da empresa há muito
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
26

tempo, todas as configurações do aparelho estão corretas, porém
existe um problema de navegação na Internet. Ele deve ligar para a
central de atendimento e tentar resolver o problema de navegação.
5.1.2 Tarefa
Ligar para a empresa X para tentar resolver um problema de
conexão com a Internet.
5.1.3 Sequência de ações
Passo 1 – Aguardar a URA informar qual é a opção referente ao
seu problema. Neste caso, o usuário não deve escolher nenhuma
opção e deixar a URA conduzir a ligação para a próxima etapa. A
URA informa que se o usuário quiser atendimento para outro
número, ele deve pressionar asterisco (*) em qualquer momento da
ligação.
Passo 2 – Neste passo, o usuário também não deve escolher
nenhuma opção, pois a URA o conduz para a próxima etapa para
resolver o problema. A URA informa que o usuário receberá um
torpedo com o protocolo inicial do atendimento e dá a opção do
usuário de digitar “1” para receber o protocolo naquele momento
ou que ele poderia aguardar em ligação para continuar.
Passo 3 – Aguardar a URA informar qual é a opção referente ao
problema do usuário. Neste caso, o usuário deve escolher a opção
“5”, que trata de como fazer, receber chamadas e acessar a Internet.
Passo 4 – Aguardar a URA informar qual é a opção referente ao
seu problema. Neste caso, o usuário escolher a opção “1”, “Se não
consegue acessar a Internet, digite 1”.
Passo 5 – Aguardar a URA informar qual é a opção referente ao
seu problema. Neste caso, escolher a opção 2 “Se você já
configurou e ainda permanece com dificuldades para acesso à
Internet, digite ‘2’”.
5.1.4 Questões aplicadas à execução do percurso
As questões aplicadas serão as seguintes:
I. Os usuários farão a ação correta para atingir o resultado
desejado?
II. O usuário perceberá que a ação correta está disponível?
III. O usuário associará o elemento de interface correto à meta
a ser atingida?
IV. Se a ação correta é tomada, o usuário perceberá que
progrediu em direção à solução da tarefa?
4.2 Análise heurística
Análise heurística é uma técnica de inspeção feita por especialistas,
que tomam como base princípios e orientações práticas de
usabilidade. Segundo o mesmo autor, o objetivo é identificar os
problemas de usabilidade existentes nas interfaces, através da
rigorosa aplicação desses princípios durante o processo de análise
[7].
Para a avaliação do sistema escolhido, foram utilizadas 13
recomendações, sendo que 07 (sete) delas foram escolhidas com
base nos 10 princípios de Jakob Nielsen [12], e 06 (seis) nos
critérios ergonômicos de Scapin e Bastien [1]. O critério utilizado
para a escolha destas recomendações é que, através de estudos do
pesquisador, as recomendações escolhidas são as mais adequadas
ao cenário da utilização do sistema de resposta audível. As
recomendações são:
H1. Visibilidade do status do sistema [12] - O sistema deve
informar aos usuários sobre o que está acontecendo, através de
feedback disparados a cada interação ou a cada escolha de opção.
H2. Correspondência entre o sistema e o mundo real [12] - O
sistema deve ter uma linguagem clara com os usuários. Com
palavras, frases e conceitos comuns ao usuário.
H3. Controle do usuário e liberdade [12] - Os usuários
eventualmente escolhem algumas funções do sistema por engano e
deverão precisar de uma “saída de emergência” clara e distinta para
sair daquela opção indesejada.
H4. Prevenção de erros [12] - Prevenção de erros significa
permitir que os erros não aconteçam.
H5. Reconhecimento em vez de recordação [12] - O usuário não
precisa ter que lembrar da informação anterior para passar para a
próxima etapa.
H6. Flexibilidade e eficiência de utilização [12] - O sistema deve
atender a ambos os usuários, inexperientes e experientes. Permitir
que os usuários possam personalizar ações mais frequentes.
H7. Estética e design minimalista [12] - Os diálogos não devem
conter informações desnecessárias ou raramente utilizadas, pois
irão competir com diálogos mais usuais confundindo ou poluindo a
visibilidade.
H8. Condução/convite [1] - O objetivo é conduzir o usuário a um
caminho correto na utilização do sistema.
H9. Condução/agrupamento e distinção de itens/agrupamento
e distinção por localização [1] - Proporciona mais facilidade a
todos os tipos de usuário, trata da organização dos itens de
informação levando em conta a relação que estes itens guardam
entre si.
H10. Condução/Feedback imediato [1] - Feedback é um retorno
imediato que o sistema deve oferecer após as ações executadas
pelos usuários.
H11. Carga de trabalho/Brevidade/ações mínimas [1] -
Minimiza e simplifica um conjunto de ações necessárias para o
usuário alcançar seu objetivo.
H12. Controle explícito/Controle do usuário [1] - Cabe ao
sistema deixar o usuário no controle dos processos, dando a
liberdade de cancelamento, reinício, retomada, interrupção ou a
finalização.
H13. Gestão de erros/Correção de erros [1] - Permitir a correção
de seus erros, o sistema deve oferecer meios que permitam que o
usuário corrija os erros de forma fácil e amigável.
Os problemas encontrados foram classificados em 3 graus de
criticidade: alta, média e baixa. Essa classificação tem o objetivo
de identificar quais são os problemas mais graves, que impedem a
interação do usuário com a interface; quais são medianos, que tem
grande chance de causar problemas na interação; e quais são leves,
que eventualmente podem causar problemas de interação. Os graus
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
27

de criticidade são proporcionais à prioridade com que os problemas
devem ser solucionados. Problemas de criticidade alta devem ser
resolvidos em curto prazo; problemas médios têm prioridade média
de resolução; e problemas de criticidade baixa podem ser
solucionados em longo prazo.
5 RESULTADOS E DISCUSSÕES
Após realizadas as tarefas, foi feito o cruzamento das informações
entre as questões do percurso cognitivo e os passos da tarefa
executada, onde foi avaliado se a etapa do sistema está de acordo
com os critérios de usabilidade escolhidos. Foi definido três tipos
de resposta para as questões: "Sim", "Sim, porém" e "Não”.
5.1 Análise do percurso cognitivo
A tarefa consistiu em ligar para a empresa X para resolver um
problema de conexão com a Internet. A tabela 1 apresenta os
resultados dos passos realizados pelo especialista ao utilizar a
interface multimodal, relacionando os passos apresentados em
5.1.3 e às questões do percurso cognitivo apresentadas em 5.1.4.
Tabela 01 – Resultado do percurso cognitivo
Passo 01
Questão I – Sim
Questão II - Sim, porém a opção a ser
escolhida não é informada pela URA, pois
ela deixa a opção “oculta”. O usuário deve
aguardar e não digitar. A URA, porém,
não informa isto ao usuário.
Questão III – Não
Questão IV – Sim
Passo 02
Questão I – Sim
Questão II – Sim
Questão III - Sim, porém somente
usuários mais experientes
compreenderão o que está sendo
solicitado.
Questão IV – Sim
Passo 03
Questão I - Sim, porém a URA informa
dados sobre conta e usuário deve aguardar
até informar a opção desejada.
Questão II - Sim, porém o usuário deve
aguardar vários segundos até a URA
informar outros dados e chegar na opção
desejada.
Questão III – Não
Questão IV - Sim, porém essa opção está
junto com outra função na mesma opção,
o que confunde o usuário.
Passo 04
Questão I – Sim
Questão II – Sim
Questão III – Sim
Questão IV - Sim, porém a falta
de feedback do sistema deixa o
usuário na dúvida, não informando
que o usuário avançou para a
próxima etapa.
Passo 05
Questão I – Sim Questão II – Sim Questão III – Sim Questão IV - Sim
Analisando a Tabela 01, percebe-se que no cruzamento das
respostas fornecidas, a avaliação do percurso identificou 12
respostas “Sim”, 6 respostas “Sim, porém” e 2 respostas “Não”.
Através desta análise, pode-se concluir que a tarefa proposta neste
sistema possui 60% das etapas para chegar ao objetivo estão claras
para o usuário.
Várias heurísticas dentre as levantadas em 5.2 foram
desrespeitadas. No próximo tópico, será possível verificar as
heurísticas e as recomendações para melhoria na navegabilidade da
URA analisada.
5.2 Análise Heurística
A análise heurística foi feita nos passos onde se passam as quatro
perguntas analisadas no percurso cognitivo. Foi criada uma legenda
para identificar cada heurística e apresentado na Tabela 02.
A tabela de criticidade é onde estão cruzadas todas as informações
levantadas no percurso cognitivo, quais princípios e heurísticas as
etapas desrespeitam, e o grau de criticidade que irá informar qual é
a prioridade na manutenção do produto e ainda indica as
recomendações cabíveis para cada problema.
Tabela 2 – Tabela de Criticidade
ID
Pro
ble
ma
Heu
ríst
icas
Des
resp
eit
adas
Rec
om
end
açõ
es
Cri
tici
dad
e
Passo 1
Questão II
A opção a ser escolhida não
é informada pela URA,
pois ela deixa opção
"oculta", nesse caso a
opção é "aguardar sem
digitar nada" e a URA não
informa desta forma,
entretanto, somente o
usuário mais experiente
consegue entender isso
H1,
H2,
H6,
H7,
H8,
H10
Informar a
opção a ser
escolhida, não
deixá-la oculta
e acrescentar
feedback
Média
Passo 2
Questão
III
Nesse caso a URA está
falando sobre torpedo com
protocolo e não sobre o
suporte que está sendo
buscado o que dificulta no
entendimento da tarefa
H2,
H6,
H7,
H8,
H9,
H10
Retirar a
mensagem
sobre torpedo
Média
Passo 3
Questão I
e II
O usuário deve aguardar
vários segundos até a URA
informar outros dados e
chegar na opção desejada
H1,
H7,
H8,
H9
Informar a
opção a ser
escolhida,
diminuir o
tempo de
resposta
Média
Passo 3
Questão
IV
Essa opção está junto com
outra na mesma escolha e
acaba confundindo o
usuário
H6,
H7,
H9
Separar as
opções
Média
Passo 4
Questão
IV
A falta do feedback do
sistema deixa o usuário na
dúvida, ela não informa que
avançou para a próxima
etapa
H1,
H6,
H10
Acrescentar
feedback
Média
No Passo 1, Questão II e Passo 2, Questão III, praticamente os
mesmos princípios foram violados. Elas iniciam com a opção do
menu a ser escolhida não sendo informada pela URA, deixando
opção "oculta". Neste caso a opção é "aguardar sem digitar nada" e
a URA não deixa esta informação explícita. Somente o usuário mais
experiente consegue compreender que deve aguardar, o que
dificulta no entendimento da tarefa fazendo com que a interface
desrespeite a heurística H1, “Visibilidade do status do sistema”.
Desrespeitou também a heurística H2, “Correspondência entre o
sistema e o mundo real”, onde o sistema deve ter uma linguagem
clara com os usuários. Com palavras, frases e conceitos comuns ao
usuário. A heurística H6, “Flexibilidade e eficiência de utilização”
também foi desrespeitada, pois o sistema deve atender a ambos os
usuários, inexperientes e experientes. O princípio H7, “Estética e
design minimalista” foi desrespeitado, pois os diálogos não devem
conter informações desnecessárias ou raramente utilizadas. O
princípio H8, “Condução/convite” foi desrespeitado, pois a URA
deveria conduzir o usuário a um caminho correto na utilização do
sistema e o princípio H10, “Condução/Feedback imediato” foi
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
28

desrespeitado, pois a URA deveria fornecer um retorno imediato
após as ações executadas pelos usuários.
No Passo 3, Questão I e II, a URA informa dados sobre conta e
usuário e demora alguns segundos para apresentar as opções
esperadas o que dificulta no entendimento da tarefa fazendo com
que a interface desrespeite o princípio H1, “Visibilidade do status
do sistema” e H7, “Estética e design minimalista”, onde os diálogos
não devem conter informações desnecessárias ou raramente
utilizadas. Desrespeitou também o princípio H8,
“Condução/convite”, onde o objetivo é conduzir o usuário a um
caminho correto na utilização do sistema e o princípio H9,
“Condução/agrupamento e distinção de itens/agrupamento e
distinção por localização”. Desrespeitou o princípio H10,
“Condução/Feedback imediato”, onde o feedback é um retorno
imediato que o sistema deve oferecer após as ações executadas
pelos usuários.
No Passo 3, Questão IV, essa opção está junto com outra na
mesma escolha e acaba confundindo o usuário, o que dificulta no
entendimento da tarefa fazendo com que a interface desrespeite o
princípio H6, “Flexibilidade e eficiência de utilização”.
Desrespeita também o princípio H7, “Estética e design
minimalista”, onde os diálogos não devem conter informações
desnecessárias ou raramente utilizadas, pois irão competir com
diálogos mais usuais confundindo ou poluindo a audibilidade.
Desrespeitou o princípio H9, “Condução/agrupamento e distinção
de itens/agrupamento e distinção por localização”.
No Passo 4, Questão IV, a falta do feedback do sistema deixa o
usuário na dúvida, não deixando claro que a navegação avançou
para a próxima etapa. Desrespeitou, portanto o princípio H1,
“Visibilidade do status do sistema”, onde o sistema deve informar
aos usuários sobre o que está acontecendo, através de feedback
disparados a cada interação ou a cada escolha de opção.
Desrespeitou o princípio H6, “Flexibilidade e eficiência de
utilização”, onde o sistema deve atender a ambos os usuários,
inexperientes e experientes. Desrespeitou o princípio H10,
“Condução/Feedback imediato”, onde o feedback é um retorno
imediato que o sistema deve oferecer após as ações executadas
pelos usuários.
6. CONSIDERAÇÕES FINAIS
A presente pesquisa teve o objetivo de realizar avaliação de
usabilidade em um sistema de telefonia, que conta com recursos de
interface de resposta audível. Foram escolhidos 13 critérios
selecionados a partir dos Critérios Ergonômicos de Bastien e
Scapin e as Heurísticas de Nielsen para a avaliação que se
enquadram nesse tipo de sistema.
O resultado esperado deste trabalho é que, através da estrutura
proposta, possa se consolidar um modelo que é capaz de realizar
avaliações de usabilidade de interfaces de resposta de voz que
podem ser monomodal ou multimodal. A ausência de trabalhos que
especificamente lidam com avaliações de usabilidade em URA’s
justificam a relevância do trabalho proposto.
Propomos que as técnicas possam ser aplicadas em outros sistemas,
monomodais ou multimodais, usando vários dispositivos de
interação simultâneas, tais como voz e teclado. Nós mostramos
neste trabalho a interação em um sistema de telefonia, mas muitos
outros tipos de serviços atualmente também utilizam interação
simultânea para servir os seus clientes, por exemplo, empresas de
cartões de crédito, operadoras móveis etc. O escopo deste trabalho
permitiu apresentar os testes realizados somente em um sistema de
telefonia, porém é interessante mencionar que os autores aplicaram
esta técnica também a outros sistemas de resposta audível, obtendo
resultados semelhantes, trazendo a possibilidade de validar as
técnicas como um futuro modelo.
As técnicas apresentadas, portanto, possuem potencial para evoluir
para um modelo de avaliação de usabilidade em sistemas de
interface de resposta audível. Sugere-se englobar testes de
usabilidade que envolvam usuários reais dos sistemas, não somente
especialistas. Seria interessante também que um conjunto de
especialistas apliquem o modelo proposto em outras interfaces
multimodais que envolvam URA’s, para que se verifique, com
outras pesquisas, a eficácia de um futuro modelo.
7. REFERÊNCIAS
[1] Bastien, C., and Scapin, D. Ergonomic Criteria for the
Evaluation of Human Computer Interfaces. INRIA (1993).
[2] Cathleen Wharton, John Rieman, Clayton Lewis, and Peter
Polson. The cognitive walkthrough method: a practitioner's guide.
In Usability inspection methods, Jakob Nielsen and Robert L.
Mack (Eds.). John Wiley & Sons, Inc., New York, NY, USA,
(1994) 105-140.
[3] Cordeiro, Renato, and Oliveira, Marcos Roberto, and
Chanquini, Thaís Pereira. Utilização de conceitos de interface
homem-máquina para adaptação da disciplina de requisitos do
RUP. São Paulo: Laboratório de Pesquisa em Ciência de Serviços.
Centro Paula Souza, (2009).
[4] Costa, José Fabiano da Serra, and Felipe, Ada Priscila
Machado, and Rodrigues, Monique de Menezes. Avaliação da
escolha de unidade de resposta audível (URA) através do Método
de Análise Hierárquica (AHP). In: Revista GEPROS,
Departamento de Engenharia de Produção da Faculdade de
Engenharia da UNESP, Bauru/SP, year 3, n. 3, (2008) 147-161
[5] Creswell, J. W. Projeto de pesquisa: Métodos qualitativo,
quantitativo e misto. 3. ed. Porto Alegre: Artmed, 2010. p. 177-
205.
[6] Leite, S. F. C. (2013). Inspeção de usabilidade aplicada a
métodos ágeis: um estudo de caso. Monografia de Bacharelado.
Universidade Federal de Lavras-MG.
http://repositorio.ufla.br/bitstream/1/5484/1/MONOGRAFIA_Ins
pecao_de_usabilidade_aplicada_a_metodos_ageis_um_estudo_de
_caso.pdf
[7] Loureiro, Eduardo. Inspeção de usabilidade. Centro
Universitário de Belo Horizonte, Uni-BH, (2007). Disponível em:
<http://eduardoloureiro.com/EduardoLoureiro_InspecaoUsabilida
de_Relatorio.pdf>. Acesso em: 06 out. 2015.
[8] Magrinelli, J. V. B. (2010). Avaliação de usabilidade de
sistema para gerenciamento apícola: o caso laborapix. Monografia
de Bacharelado. Universidade Federal de Lavras-MG.
http://repositorio.ufla.br/bitstream/1/5313/1/MONOGRAFIA_Ava
liacao_de_usabilidade_de_sistema_para_gerenciamento_apicola_
o_caso_laborapix.pdf
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
29

[9] Morgan, G. (1980). Paradigms, metaphors, and puzzle solving
in organization theory. Administrative science quarterly, 605-622.
[10] Nielsen, J., and Molich, R. Heuristic evaluation of user
interfaces, Proc. ACM CHI'90 Conf. (Seattle, WA, 1-5 April),
(1990) 249-256.
[11] Nielsen, J. Enhancing the explanatory power of usability
heuristics. (1994a). Proc. ACM CHI'94 Conf. (Boston, MA, April
24-28), 152-158.
[12] Nielsen, J.. Heuristic evaluation. In Nielsen, J., and Mack,
R.L. (Eds.). (1994b) Usability Inspection Methods, John Wiley &
Sons, New York, NY).
[13] Paes, D. M. C. (2015). Análise de problemas de
funcionalidade e usabilidade no processo de desenvolvimento do
software leitor de telas livre NVDA. Disponível em:
http://repositorio.ufla.br/bitstream/1/10743/1/TCC_An%C3%A1li
se_de_problemas_de_funcionalidade_e_usabilidade_no_processo
_de_desenvolvimento_do_software_leitor_de_telas_livre_nvda.pd
f
[14] Santos, M. A. D. (2013). Interface multimodal de interação
humano-computador em sistema de recuperação de informação
baseado em voz e texto em português.
http://repositorio.unb.br/bitstream/10482/14843/1/2013_Marcelo
AlvesdosSantos.pdf
[15] Torezan, Eduardo Luiz Dalpiaz. Implementação de funções
avançadas em um gateway voip. 56 f. Trabalho de Conclusão de
Curso (Graduação) - Curso de Engenharia de Telecomunicações,
Universidade Regional de Blumenau - FURB, Blumenau, (2006).
[16] Triviños, Augusto N.S. Introdução á pesquisa em ciências
sociais: a pesquisa qualitativa em educação. São Paulo: Atlas,
1987.
[17] Zuasnábar, D. H.; Cunha, A. M. da; Germano, J. S. 2003. Um
ambiente de aprendizagem via WWW Baseado em Interfaces
Inteligentes para o Ensino de Engenharia. In: COBENGE 2003,
Rio de Janeiro. Anais. Rio de Janeiro.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
30

Guia de Boas Práticas para Desenvolvimento de Interface e Interação para Desenvolvedores da Plataforma Android
Alternative Title: Good Practice Guide to Development of Interface and Interaction for developers of the Android Platform
Guaratã Alencar Ferreira de Lima Junior Faculdade AVANTIS
Curso de Sistemas de Informação Balneário Camboriú, SC, Brasil
Rodrigo Cezario da Silva Faculdade AVANTIS
Curso de Sistemas de Informação Balneário Camboriú, SC, Brasil
RESUMO
Alguns estudos apontam que a preocupação no desenvolvimento de
interfaces contribui para o sucesso de um projeto de softwares para
dispositivos móveis. Neste sentido, a Apple detém um processo
rigoroso para aprovação das aplicações desenvolvidas por terceiros
para seus dispositivos em sua loja. Em contraponto ao que acontece
na Apple, os aplicativos desenvolvidos para sua loja de aplicativos,
não passam por nenhum processo de aprovação. No entanto,
mesmo com a publicação das diretrizes de projeto “Android
Design”, as mesmas são tratadas pela maioria dos desenvolvedores
como conselhos a serem seguidos, não como obrigações a serem
cumpridas como são tratados os aspectos de design e interação do
guia da Apple. Neste sentido, este trabalho apresenta um guia
apoiado em boas práticas relacionadas a elementos de interface e
de interação aplicadas na plataforma da Apple para
desenvolvedores da plataforma Android. O objetivo é reunir a
essência do guia da Apple sem perder as características do Android.
Palavras-Chave
Interface. UI Design. Android Design.
ABSTRACT
Some studies indicate that the concern in the development of
interfaces contributes to the success of a software project for mobile
devices. In this sense, Apple has a rigorous process for the approval
of third-party applications for their devices in your store. In contrast
to what happens at Apple, applications developed for its application
store, do not go through any approval process. However, even with
the publication of design guidelines "Android Design", they are
treated by most developers as advice to be followed, not as
obligations to be fulfilled as the aspects of design and interaction of
the Apple Guide are treated. Thus, this work presents a guide
supported on good practices related to interface elements and
interaction applied to the Apple platform Android platform
developers. The goal is to gather the essence of Apple's tab without
losing the Android features.
Categories and Subject Descriptors
D.2.m [Software Engineering]: Miscellaneous
General Terms
Interface. UI Design. Android Design.
Keywords
Interface. UI Design. Android Design.
1. INTRODUÇÃO Em um mundo em que a tecnologia está cada vez mais presente na
vida das pessoas, seja em casa, em carros, nas ruas, e até mesmo
em nossa própria mão, podem ser citados diversos dispositivos,
como tablets, vídeo games, televisores e os smartphones que vem
se popularizando cada vez mais. Só em 2013, o envio de
smartphones pelo mundo chegou a um bilhão. Os aparelhos mais
procurados são os com telas grandes e os de baixo custo [1].
Através dos smartphones vem 80% dos acessos à internet, segundo
a [2], e do tempo total gasto nos smartphones, 89% são em
aplicativos. O uso de aplicações por usuários de smartphones pode
ser bem variado, segundo [3], boa parte usa para jogos, notícias,
mapas e navegação, redes sociais, música, entretenimento,
operações bancárias e outros. O mercado de aplicativos cresce no
mundo a cada ano com mais de 1,8 milhão de Apps disponíveis aos
usuários segundo [4].
Alguns estudos [5][6][7] apontam que a preocupação no
desenvolvimento de interfaces contribui para o sucesso de um
projeto de softwares para dispositivos móveis. No entanto, também
é sabido que desenvolvedores de software normalmente não têm o
conhecimento aprofundado sobre diversos aspectos de elaboração
de interface de usuário, a citar: usabilidade, ergonomia,
acessibilidade e demais conceitos de design centrado no usuário
[8]. Por sua vez, a Apple [9] detém um processo rigoroso para
aprovação das aplicações desenvolvidas por terceiros para seus
dispositivos em sua App Store. Segundo [9], o processo de
aprovação de aplicações na App Store existe para que a empresa
possa manter o status de qualidade conquistada junta aos seus
clientes. Neste sentido, a Apple [9] disponibiliza aos seus
desenvolvedores um guia chamado de “iOS Human Interface
Guidelines”. Neste guia são apresentados conceitos básicos de UI
Design, estratégias de design, tecnologias do Sistema iOS,
elementos de UI, entre outros. Cabe salientar que para que uma
aplicação seja aprovada no processo para ser comercializado na
App Store, é necessário que este passe por uma avaliação inicial em
relação ao cumprimento das recomendações presentes no guia de
interface da Apple, sendo que as principais causas de rejeições de
aplicações na App Store sejam devidas à violação as diretrizes
contidas no guia [10][11]. Também neste sentido, a Google [12]
apresenta um guia chamado de “Android Design”, que trata de
princípios básicos de design, materiais para design, dispositivos,
estilos, padrões, entre outros. Em contraponto do que acontece na
Apple, os aplicativos desenvolvidos para Play Store não passam por
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are
not made or distributed for profit or commercial advantage and that copies
bear this notice and the full citation on the first page. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior
specific permission and/or a fee.
SBSI 2016, May 17–20, 2016, Florianópolis, Santa Catarina, Brazil.
Copyright SBC 2016.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
31

nenhum processo de aprovação. Sendo assim, o guia da Google não
é imposto como obrigação em relação às observações nela feita
para o desenvolvimento de interface do usuário [13]. No entanto,
mesmo com a publicação das diretrizes de projeto “Android
Design”, as mesmas são tratadas pela maioria dos desenvolvedores
como conselhos a serem seguidos, não como obrigações a serem
cumpridas como são tratados os aspectos de design e interação do
guia da Apple [14]. Para [15], a postura da Google em cumprimento
das recomendações da guideline permite “liberdade de
criatividade”, sendo que um desenvolvedor pode optar em ignorar
completamente as diretrizes e criar o seu próprio design. [14]
contribui em destacar que a Google ainda carece de uma linguagem
de design focada na interface e interação do usuário. Para [14], a
guideline carece de sentido, coerência e uniformidade nos
elementos de interface do usuário. Além de haver relatos de que os
aplicativos disponibilizados na App Store apresentam maior
qualidade nas suas interfaces em relação os aplicativos da Google
Play [16]. Como resposta a esses problemas, existem propostas para
melhorias como a utilização de padrões de projetos [17][18],
interfaces adaptativas [19] e heurísticas [20][7]. No entanto,
diversos problemas ainda estão relacionados aos aspectos de
interface e interação com o usuário. Neste sentido, este trabalho
apresenta um guia apoiado em boas práticas relacionadas a
elementos de interface e de interação aplicadas na plataforma da
Apple para desenvolvedores da plataforma Android. Este trabalho
está estruturado na seguinte forma: na Seção 2, é apresentada a
fundamentação teórica. A seção 3, apresentada a metodologia de
pesquisa utilizada. Na Seção 4 é apresentada os resultados, sendo
este um Guia com boas práticas para desenvolvedores da
plataforma Android. E por fim, a Seção 5 apresenta as conclusões.
2. FUNDAMENTAÇÃO TEÓRICA Esta seção apresenta as referências nas quais se norteia este
trabalho. Parte-se da reflexão sobre a importância de um bom
design de interface; Interações com o usuário de dispositivos
móveis; e, conclui-se com as características da plataforma de
dispositivos móveis.
2.1 Importância de um bom design de
interface O design de uma interface é muito importante para o usuário [21],
pois os usuários ficam mais confortáveis em interagir com
interfaces que são fáceis de usar e entender e façam com que eles
consigam realizar suas tarefas com o mínimo de frustração. A
aparência de uma interface e o modo de navegação podem afetar
uma pessoa de várias formas. Por sua vez, se forem confusas e
ineficientes, dificultarão para as pessoas realizarem as tarefas que
gostariam, ou dependendo da aplicação, dificultará que as pessoas
façam seus trabalhos ou cometam erros. Interfaces mal projetadas
podem fazer com que pessoas se afastem do sistema
permanentemente, fiquem frustradas e podem aumentar o nível de
stress [21]. Para [21] a importância de um bom design pode ser
demonstrada de uma maneira interessante se tratando em termos
financeiros. Para as empresas, boas interfaces (no contexto deste
trabalho corresponde a presença das recomendações de usabilidade
apresentadas em [24]) podem trazer benefícios como satisfação do
trabalhador e maior produtividade. Economicamente, isso pode
trazer benefícios como custos mais baixos, levando em conta que
sistemas mais fáceis de usar requerem menos treinamento.
2.2 Interações com o usuário de dispositivos
móveis Também chamado de design de interações, de acordo com [22], é
um item que tem um foco maior no usuário, e em como será seu
comportamento a partir do momento em que ele abre a aplicação.
São utilizados elementos da interface, como botões, tipografia,
efeitos sonoros, ícones e cores para o usuário interagir com estes e
manipular o conteúdo da aplicação. Uma aplicação móvel com uma
boa interface deve ter uma boa interação do usuário com a tela, para
que o mesmo possa fazer suas tarefas da melhor forma possível. A
interface é onde o conteúdo que o usuário está buscando é exibido,
mas é através de ferramentas ou dispositivos que o usuário precisa
interagir com o conteúdo que está sendo exibido na interface. No
caso de computadores, essa interação ocorre através do mouse e do
teclado com o conteúdo que é exibido em um monitor. Em
dispositivos móveis, na maioria deles existe apenas uma tela, que
não é usada somente para a exibição do conteúdo, mas também para
a interação do usuário com o mesmo. O que faz com que
desenvolvedores considerem ergonomia, gestos, transições e
específicos padrões de interações de cada plataforma.
2.3 Características da plataforma de
dispositivos móveis Os dispositivos móveis têm suas características que podem ser
distintas dependendo da plataforma, no entanto algumas
características são similares. A plataforma iOS tem algumas
características únicas, devido a Apple ser rígida quanto a avaliação
de aplicativos antes de serem publicados, estes seguem um padrão
e qualidade, proporcionando uma ótima experiência ao usuário
[23]. Algumas características são similares às duas plataformas,
como modo de orientação da tela, transições entre telas e
aplicativos, e para a interação dos usuários com os aplicativos
existem gestos, ao invés de cliques.
3. METODOLOGIA DE PESQUISA Este trabalho quanto aos objetivos pode ser enquadrado como uma
pesquisa exploratória. Quanto aos procedimentos técnicos, foi
utilizado a pesquisa bibliográfica e pesquisa documental, sendo este
a primeira etapa realizada. A primeira etapa, oportunizou conhecer
as guidelines para desenvolvimento de interface das plataformas,
iOS e Android. A segunda etapa consistiu no desenvolvimento do
Guia, produto deste trabalho. Uma posterior etapa, compreendeu
em uma avaliação preliminar do guia a partir da visão de
especialistas.
4. RESULTADOS Nesta seção são apresentados os passos e processos adotados para
o desenvolvimento do guia de boas práticas para desenvolvimento
de interfaces para a plataforma Android. Para isso optou-se em
realizar uma comparação entre as recomendações da Apple
realizadas no “iOS Human Interface Guidelines” [9] e as
recomendações da Google no “Android Design” [12]. No guia [9],
são apresentados conceitos básicos de UI Design, estratégias de
design, tecnologias do Sistema iOS, elementos de UI, entre outros.
O guia [12] apresenta princípios básicos de design, materiais para
design, dispositivos, estilos, padrões, entre outros. Cabe dizer que,
houve a preocupação de seguir boas práticas que poderão ser
utilizadas na plataforma Android, e também não desrespeitam as
restrições adicionadas na nova versão do guia da Google. Para um
melhor entendimento para o desenvolvimento deste Guia, optou-se
em apresentar lado-a-lado as recomendações das plataformas iOS e
Android, organizada como (conforme retrata a Tabela 1): (i)
considerações básicas de UI (user interface) (6 recomendações);
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
32

(ii) estratégias de design (); e, (iii) elementos de UI. A User
Interface (UI), ou interface do usuário é a camada na qual o usuário
interage com a aplicação, tudo o que o usuário deseja fazer com a
aplicação, as tarefas que deseja executar, são feitos através de
interações com a interface.
Tabela 1. Classificação e organização do Guia
Classificações Recomendações
Considerações
básicas de UI
(user interface)
Conceitos Básicos para Interface
Layout e Adaptatividade
Navegação
Interatividade e Feedback
Animação
Cor e Tipografia
Estratégias de
design
Integridade Estética e Consistência
Manipulação Direta
Metáforas
Elementos de
UI
Barra de Status
Barra de Navegação
Barra de Ferramentas
Botões da Barra de Navegação e barra
de Ferramentas
Barra Tabulada
Barra de Busca
Barra de Escopo
Indicador de Atividade
Selecionador de Data
Paginador
Selecionador
Barra de Progresso
Controle de Recarga
Botão Segmentado
Slider
Stepper
Chaveador
Campo de Texto
Para compor esta interface são utilizados elementos de interface,
em conjunto com padrões para uso dos mesmos, cores e tipografia.
As estratégias de design consistem em vários componentes que são
utilizados para fazer com que a interface contenha os padrões e
elementos necessários para proporcionar uma boa experiência ao
usuário. No entendimento da [9], integridade estética trata de
aspectos da aparência visual de um software aplicada na interação
da sua interface. No entanto, este termo não é comumente utilizado
na literatura, sendo que talvez o termo mais apropriado seria
usabilidade. A Tabela 2 apresenta um exemplo elaborado na
construção do Guia, onde é descrito as recomendações para a
utilização da Barra de status. A norma ISO/IEC 9126-1 [24]
descreve que a usabilidade é composta de subcaracterísticas, sendo:
aprensibilidade, a capacidade do produto de software de possibilitar
que o usuário aprenda por si só a utilizar a aplicação;
operacionalidade, onde o produto dá a possibilidade ao usuário de
operá-lo e controlá-lo; inteligibilidade, sendo a capacidade do
software possibilitar o usuário de compreender se ele é apropriado
para o seu uso; e atratividade, o quanto o software é atraente ao
usuário.
Tabela 2. Elemento de Interface: Barra de Status (versão de desenvolvimento do guia)
Barra de Status
A Barra de status exibe informações importantes a respeito do dispositivo e do ambiente atual, como por exemplo, porcentagem de bateria,
data e hora ou sinal de comunicação.
IOS ANDROID
Usada para exibir informações importantes sobre o dispositivo e
o ambiente atual. Ex.: Hora, informações sobre bateria, sinal,
provedor, e outras informações do dispositivo que podem ou não
estar ativadas, como bluetooth ou wifi.
Características
É transparente;
Quando aparece está no topo da tela;
Não deve ser criada uma barra de status customizada, ela
pode ser escondida para mostrar toda a aplicação, mas não
customizada.
Evitar colocar conteúdo atrás da barra de status.
Pensar bem antes de esconder a barra, pois o usuário deverá
sair da aplicação para ver informações que ele poderia ver
diretamente na barra, sendo que ela é transparente, não
precisa necessariamente ser escondida, a não ser para jogos
ou vídeos.
No Android, a barra de status tem basicamente as mesmas
funcionalidades das utilizadas pela Apple (status da bateria,
horário, wi-fi, bluetooth e sinal do celular), com uma diferença
que nela também são exibidas as notificações de aplicativos.
Características
As mesmas características do IOS se aplicam aqui também.
A cor da barra de status deve seguir a cor primária da
aplicação, só que mais forte, seguindo a tonalidade 700 de
variação, podendo também ser transparente dependendo da
aplicação.
A barra de status exibe as notificações de aplicativos
através de ícones, estes que devem ser visualmente simples
evitando detalhes excessivos, facilitando assim com que o
usuário possa diferenciar os ícones que podem ali estar.
Estes ícones devem ser na cor branca com os detalhes
transparentes.
Recomendação do Guia
A barra de status deve estar obrigatoriamente posicionada na parte superior da tela. Deve-se seguir o padrão do material design para
definição da cor da barra (variação da tonalidade em 700 na escala de cor). A barra não deve ser customizada, no entanto pode ser ocultada
para uma melhora apresentação do conteúdo em rolagens para baixo, sendo restaurada quando houver rolagem da tela para cima. Em caso
de projetos de jogos ou apresentação de vídeos, para uma melhor imersão do usuário a barra de status poderá ser ocultada.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
33

Por sua vez, a consistência em uma aplicação é aquilo que faz com
que o usuário possa interagir com diferentes partes da aplicação
com a mesma facilidade, e também consiga usar várias aplicações
diferentes com esta mesma facilidade. Uma aplicação consistente
não é uma cópia de outra, mas segue todos os padrões com os quais
os usuários já estão acostumados e confortáveis em interagir, que
são encontrados em outras aplicações, fazendo com que o App
proporcione uma experiência consistente. Por sua vez, são
elementos de interface aqueles que são utilizados para fazer a
interação do usuário com a interface, através dos componentes que
os usuários realizam as tarefas ou atingem o objetivo que desejam
com a App. Estes elementos podem ser botões, barras de tarefas ou
navegações, menus, ícones, etc.
5. CONCLUSÃO A partir da revisão bibliográfica, evidenciou-se que Android não
tem um cuidado tão grande em relação à interface e interação, em
contraste ao que acontece à plataforma da Apple. Entende-se que a
utilização deste guia no desenvolvimento de interfaces pode trazer
benefícios tanto para usuários como para desenvolvedores.
Observa-se que os desenvolvedores são beneficiados com
observações e/ou recomendações em diversas características de
qualidade, como também no uso de cada elemento da maneira
correta, permitindo assim também aumentar a produtividade do
desenvolvedor. Os benefícios para o usuário, estão relacionados ao
seguimento dos padrões e boas práticas de design e interface, assim,
apresentando certa qualidade implícita. Por sua vez, uma avaliação
do guia foi realizada utilizando o método GQM (Goal Question
Metrics) de [25], do ponto de vista de um especialista na área de
usabilidade de software. A avaliação demonstrou indícios de
viabilidade de uso do guia no desenvolvimento de aplicativos para
plataforma Android, e recomendações para melhoria da mesma.
Como próximo passo, destaca-se que uma revisão mais sistemática
no guia poderia melhorar as recomendações. Entende-se que
adicionar mais plataformas como o Windows Phone, poderia
contribuir com mais recomendações no guia. Outro ponto que
poderia ser considerado seria a utilização de ilustrações nas
recomendações, tanto as positivas (o que fazer), como nas negativas
(o que não fazer). Além disso, a utilização de exemplo e
contraexemplos poderia melhorar o guia. Também se recomenda a
realização de avaliações, tanto na perspectiva de especialista, como
desenvolvedores e usuários.
6. REFERÊNCIAS [1] Pcworld, 1 billion smartphones shiped worldwide in 2013,
2013. Disponível em < http://goo.gl/tMV3Zf >. Acessado em
28/03/2015
[2] Smart Insights, Statistics on mobile usage and adoption to
inform your mobile marketing strategy, 2015. Disponível em
< http://goo.gl/paQFV>. Acessado em 28/03/2015
[3] Pew Research, The rise of apps culture, 2010. Disponível em
< http://goo.gl/Zwc5fK>. Acessado em 28/03/2015
[4] Sebrae, Aplicativos para celulares movem mercado
bilionário, 2014. Disponível em <http://goo.gl/tRp2zQ>.
Acessado em 28/03/2015
[5] Pereira, R. S., Costa, C. C., A importância do projeto de
interface no desenvolvimento, 2012. Disponível em <
http://goo.gl/1FJVcX>. Acessado em 28/03/2015
[6] Ellwanger, C., Santos, C. P., Moreira, G. J., Gamificação e
padrões de interface em dispositivos móveis: Uma aplicação
no contexto educacional, 2014. Disponível em <
https://goo.gl/Txjg5a>. Acessado em 08/12/2015
[7] Neto, O. J. M., Usabilidade da Interface de dispositivos
móveis: heurísticas e diretrizes para o design, 2013.
Dissertação de mestrado do Instituto de Ciências
Matemáticas e Computação – ICMC-USP. Disponível em
<http://goo.gl/JftkJi>. Acessado em 17/03/2015
[8] Runija, Pooja, Importance of user interface design for mobile
app success, 2014. Disponível em < https://goo.gl/9PRpbs>.
Acessado em 28/03/2015
[9] Apple, iOS Human Interface Guidelines, 2015. Disponível
em < https://goo.gl/Mmvw4d >. Acessado em 10/05/2015
[10] Woodridge, D., Schneider, M. 2012. O Negócio De Apps
Para IPhone E IPad - Criando E Comercializando Aplicativos
De Sucesso, Elsevier Editora: Rio de Janeiro
[11] Pilone, D., Pilone, T. 2013. Use a Cabeça! Desenvolvendo
para iPhone e iPad, 2 ed., Alta Books: Rio de Janeiro
[12] Google, Android Design, 2015. Disponível em
<http://goo.gl/Pd5g8>. Acessado em 17/03/2015
[13] Burton, M., Felker, D. 2014. Desenvolvimento de
Aplicativos Android para Leigos, Alta Books: Rio de Janeiro
[14] Falconer, Joel. What Will Android’s New Design Guidelines
Mean for the Platform? 2012. Disponível em <
http://goo.gl/iMnogt>. Acessado em 17/03/2015
[15] David, M., Murman, C., 2014. Designing Apps for Success:
Developing Consistent App Design Practices, Focal Press
[16] Komarov, A., Yermolayev. 2013. Designing For a Maturing
Android, Smashing Magazine. Disponível em
<http://goo.gl/Dse1wg>. Acessado em 17/03/2015
[17] Nunes, I.D., Correia, R.S., 2013. A Importância da
usabilidade no desenvolvimento de aplicativos para
dispositivos móveis. Disponível em <http://goo.gl/Fgt2r5>.
Acessado em 10/05/2015
[18] Unitid, Interaction designers, androidpatterns. Disponível em
<androidpatterns.com>. Acessado em 17/03/2015
[19] Júnior, M. A. P.; Castro, R. de O. 2011. Um estudo de caso
da plataforma Android com Interfaces Adaptativas, Revista
@LUMNI, Vol. 1 n. 1. Disponível em
<http://goo.gl/0DKIlP>. Acessado em 17/03/2015
[20] Rocha, L. C., et al., 2014. Heurísticas para avaliar a
usabilidade de aplicações móveis: estudo de caso para aulas
de campo em Geologia, In TISE 2014
[21] Stone et al,. 2004. User Interface Design and Evaluation,
Steve Krug. Disponível em <https://goo.gl/CQEdLz>.
Acessado em 10/05/2015
[22] Banga, C., Weinhold, J. 2014. Essential Mobile Interaction
Design, Pearson Education
[23] Dclick, Guideline iOS – Características da Plataforma – 1,
2012. Disponível em <http://goo.gl/Qyg8xM>. Acessado em
10/05/2015
[24] Abnt, Associação Brasileira De Normas Técnicas, NBR
ISO/IEC 9126-1: Engenharia de Software – Qualidade de
produto – parte 1: modelo de qualidade. Rio de Janeiro, 2003
[25] Basili, V., Caldiera, G., Rombach, H. D. Goal Question
Metric Approach, 1994, Encyclopedia of Software
Engineering, pp. 528-532, John Wiley & Sons, I
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
34

Automação de Testes em Sistemas Legados: Um Estudo de Caso para a Plataforma Flex
Alternative Title: Test Automation on Legacy Systems: A Case Study for Flex Platform
Augusto Boehme Tepedino Martins Departamento de Informática e Estatística -
INE/CTC Universidade Federal de Santa Catarina
(48) 9973-2889 [email protected]
Jean Carlo Rossa Hauck Departamento de Informática e Estatística -
INE/CTC Universidade Federal de Santa Catarina
(48) 3721-7507 [email protected]
RESUMO
A realização de testes demonstra cada vez mais sua importância nas
organizações que desenvolvem software. Realizar testes, no
entanto, é caro e demorado e automatizar testes é uma alternativa
interessante e tecnicamente viável. Sistemas legados comumente
apresentam limitações para a automação de testes e isso ocorre
também em sistemas Web desenvolvidos utilizando a plataforma
Flex. Assim, este trabalho apresenta o desenvolvimento da
automação de testes para plataforma Flex. Casos de teste são
elaborados, uma ferramenta é selecionada, os scripts de teste são
desenvolvidos e executados em um estudo de caso em uma empresa
de desenvolvimento de software. Os resultados observados
apontam indícios de que a automação de que testes pode aumentar
inicialmente os esforços de elaboração dos casos de teste mas
reduzem o tempo de execução, tendendo a gerar benefícios futuros.
Palavras-Chave
Testes. Integração. Automação. Flex.
ABSTRACT
Software testing is increasing its importance in software
development organizations. Performing tests, however, is costly
and time consuming and automate testing is an interesting and
technically viable alternative. Legacy systems often have
limitations for test automation and it occurs on Web systems
developed using the Flex platform. Thus, this work presents the
development of test automation for Flex platform. Test cases are
developed, a tool is selected, test scripts are defined and
implemented in a case study on a software development company.
The observed results indicate initial evidence that test automation
may initially increase the development efforts of the test cases but
reduce the runtime, tending to generate future benefits.
Categories and Subject Descriptors D.2.5 [Testing and Debugging]
1 http://www.adobe.com/products/flex.html
General Terms
Reliability, Verification.
Keywords
Test. Integration. Automation. Flex.
INTRODUÇÃO Com a tecnologia cada vez mais avançada, muitas pessoas acabam
não observando o quanto os softwares estão envolvidos em suas
vidas, possivelmente porque suas ações são de tal forma
transparentes aos seus usuários que se tornam algo trivial no seu
dia-a-dia.
Com essa dependência atual de softwares em grande parte das
atividades humanas, os produtos de software e o processo de
criação de um software passaram a ser objeto de estudo, mesmo que
um software gratuito venha a ser produzido, não será bem aceito se
não for de fácil manuseio ou se possuir defeitos nas suas
funcionalidades.
Especificamente falando de aplicativos que rodam na Web,
algumas características esperadas de qualidade, como:
disponibilidade de acesso, desempenho, evolução contínua e
segurança [1]. Entretanto, a qualidade esperada nem sempre é
alcançada. Algumas vezes, produtos de software têm sido entregues
aos clientes cobrindo apenas os requisitos funcionais
especificados, sem eliminar possíveis erros. Uma das maneiras de
garantir que a qualidade de um produto de software seja atendida,
e que as funcionalidades que o cliente necessita estejam presentes,
é a aplicação de testes de software.
Nesse sentido, a padronizações e a automação de testes destacam-
se na forma de garantir a qualidade de software. A padronização
dos testes, como por exemplo a documentação sobre casos de
testes, com o passo-a-passo de como o teste deve ser feito, diminui
a chance de variações na forma como os testes são realizados
interfiram nos seus resultados. Já a automação de testes tende a
diminuir a falha humana nos processos de testes. Assim, um grupo
menor de pessoas poderia automatizar alguns tipos de testes que
seriam repetidos toda vez que fosse necessário.
Assim, o presente trabalho apresenta um estudo de caso de
desenvolvimento de automação de testes para a plataforma Flex1
Permission to make digital or hard copies of all or part of this work for
personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies
bear this notice and the full citation on the first page. To copy otherwise,
or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee.
SBSI 2016, May 17–20, 2016, Florianópolis, Santa Catarina, Brazil.
Copyright SBC 2016.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
35
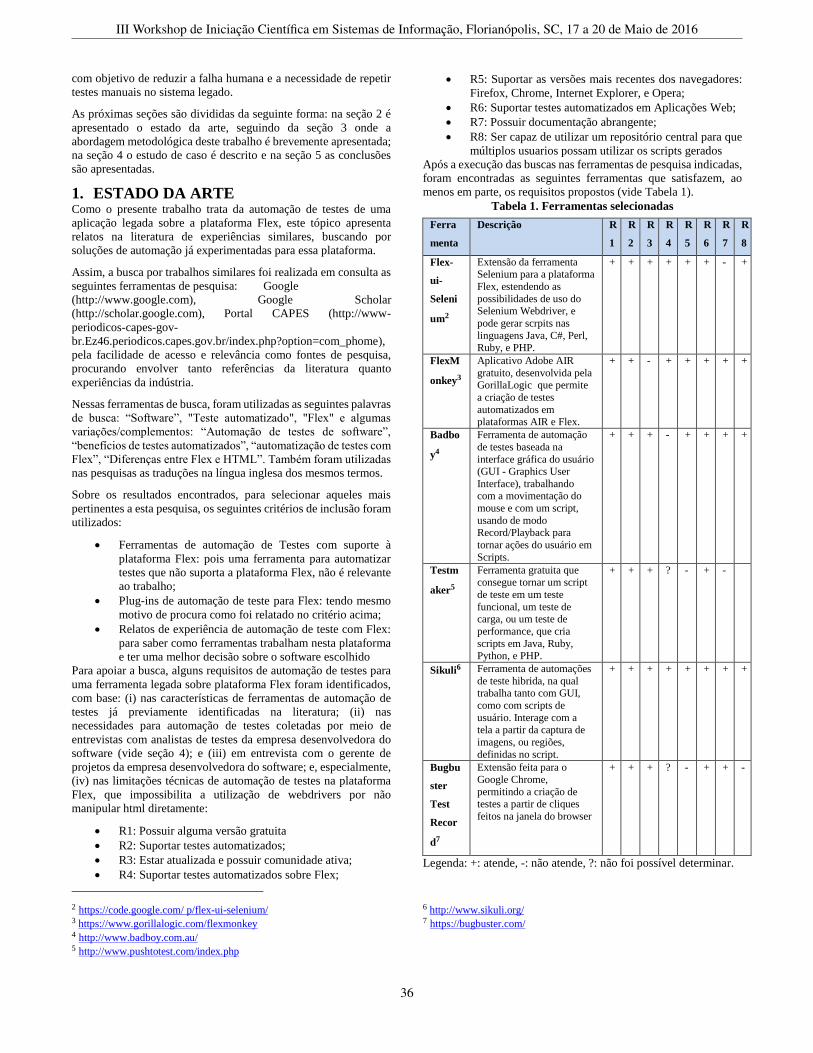
com objetivo de reduzir a falha humana e a necessidade de repetir
testes manuais no sistema legado.
As próximas seções são divididas da seguinte forma: na seção 2 é
apresentado o estado da arte, seguindo da seção 3 onde a
abordagem metodológica deste trabalho é brevemente apresentada;
na seção 4 o estudo de caso é descrito e na seção 5 as conclusões
são apresentadas.
1. ESTADO DA ARTE Como o presente trabalho trata da automação de testes de uma
aplicação legada sobre a plataforma Flex, este tópico apresenta
relatos na literatura de experiências similares, buscando por
soluções de automação já experimentadas para essa plataforma.
Assim, a busca por trabalhos similares foi realizada em consulta as
seguintes ferramentas de pesquisa: Google
(http://www.google.com), Google Scholar
(http://scholar.google.com), Portal CAPES (http://www-
periodicos-capes-gov-
br.Ez46.periodicos.capes.gov.br/index.php?option=com_phome),
pela facilidade de acesso e relevância como fontes de pesquisa,
procurando envolver tanto referências da literatura quanto
experiências da indústria.
Nessas ferramentas de busca, foram utilizadas as seguintes palavras
de busca: “Software”, "Teste automatizado", "Flex" e algumas
variações/complementos: “Automação de testes de software”,
“benefícios de testes automatizados”, “automatização de testes com
Flex”, “Diferenças entre Flex e HTML”. Também foram utilizadas
nas pesquisas as traduções na língua inglesa dos mesmos termos.
Sobre os resultados encontrados, para selecionar aqueles mais
pertinentes a esta pesquisa, os seguintes critérios de inclusão foram
utilizados:
Ferramentas de automação de Testes com suporte à
plataforma Flex: pois uma ferramenta para automatizar
testes que não suporta a plataforma Flex, não é relevante
ao trabalho;
Plug-ins de automação de teste para Flex: tendo mesmo
motivo de procura como foi relatado no critério acima;
Relatos de experiência de automação de teste com Flex:
para saber como ferramentas trabalham nesta plataforma
e ter uma melhor decisão sobre o software escolhido
Para apoiar a busca, alguns requisitos de automação de testes para
uma ferramenta legada sobre plataforma Flex foram identificados,
com base: (i) nas características de ferramentas de automação de
testes já previamente identificadas na literatura; (ii) nas
necessidades para automação de testes coletadas por meio de
entrevistas com analistas de testes da empresa desenvolvedora do
software (vide seção 4); e (iii) em entrevista com o gerente de
projetos da empresa desenvolvedora do software; e, especialmente,
(iv) nas limitações técnicas de automação de testes na plataforma
Flex, que impossibilita a utilização de webdrivers por não
manipular html diretamente:
R1: Possuir alguma versão gratuita
R2: Suportar testes automatizados;
R3: Estar atualizada e possuir comunidade ativa;
R4: Suportar testes automatizados sobre Flex;
2 https://code.google.com/ p/flex-ui-selenium/ 3 https://www.gorillalogic.com/flexmonkey 4 http://www.badboy.com.au/ 5 http://www.pushtotest.com/index.php
R5: Suportar as versões mais recentes dos navegadores:
Firefox, Chrome, Internet Explorer, e Opera;
R6: Suportar testes automatizados em Aplicações Web;
R7: Possuir documentação abrangente;
R8: Ser capaz de utilizar um repositório central para que
múltiplos usuarios possam utilizar os scripts gerados
Após a execução das buscas nas ferramentas de pesquisa indicadas,
foram encontradas as seguintes ferramentas que satisfazem, ao
menos em parte, os requisitos propostos (vide Tabela 1).
Tabela 1. Ferramentas selecionadas
Ferra
menta
Descrição R
1
R
2
R
3
R
4
R
5
R
6
R
7
R
8
Flex-
ui-
Seleni
um2
Extensão da ferramenta Selenium para a plataforma
Flex, estendendo as
possibilidades de uso do Selenium Webdriver, e
pode gerar scrpits nas
linguagens Java, C#, Perl, Ruby, e PHP.
+ + + + + + - +
FlexM
onkey3
Aplicativo Adobe AIR
gratuito, desenvolvida pela GorillaLogic que permite
a criação de testes
automatizados em plataformas AIR e Flex.
+ + - + + + + +
Badbo
y4
Ferramenta de automação
de testes baseada na
interface gráfica do usuário (GUI - Graphics User
Interface), trabalhando com a movimentação do
mouse e com um script,
usando de modo Record/Playback para
tornar ações do usuário em
Scripts.
+ + + - + + + +
Testm
aker5
Ferramenta gratuita que consegue tornar um script
de teste em um teste
funcional, um teste de carga, ou um teste de
performance, que cria
scripts em Java, Ruby, Python, e PHP.
+ + + ? - + -
Sikuli6 Ferramenta de automações
de teste hibrida, na qual trabalha tanto com GUI,
como com scripts de
usuário. Interage com a tela a partir da captura de
imagens, ou regiões,
definidas no script.
+ + + + + + + +
Bugbu
ster
Test
Recor
d7
Extensão feita para o
Google Chrome,
permitindo a criação de testes a partir de cliques
feitos na janela do browser
+ + + ? - + + -
Legenda: +: atende, -: não atende, ?: não foi possível determinar.
6 http://www.sikuli.org/ 7 https://bugbuster.com/
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
36

As ferramentas foram então instaladas e avaliadas uma a uma em
relação aos requisitos propostos. Após essa avaliação, a ferramenta
que melhor atendeu os requisitos foi a ferramenta Sikuli, que cobriu
todos os requisitos definidos.
2. ABORDAGEM METODOLÓGICA Nesta seção, são apresentadas as etapas da abordagem
metodológica do presente trabalho.
Segundo [2], pode-se definir um estudo de caso como um estudo
focado de um fenômeno em seu contexto, especialmente quanto
quando os limites entre o fenômeno e o contexto não podem ser
bem definidos. [2] indica também que é compreensível aplicar
estudos de caso às áreas relacionadas à engenharia de software tais
como desenvolvimento, operação e manutenção de software. Cada
uma das etapas é brevemente apresentada na sequência.
Planejamento: objetivos são definidos e o estudo de caso
é planejado;
Preparação: procedimentos e protocolos para coleta de
dados são definidos;
Coleta: execução e coleta de dados do estudo de caso;
Análise: onde os dados coletados são analisados e
extraídas as conclusões;
Relatório: onde os dados analisados são reportados.
A seção 4 a seguir detalha as principais etapas desta pesquisa no
contexto do estudo de caso.
3. ESTUDO DE CASO De acordo com [2], é essencial para o sucesso de um estudo de caso
que ele possua um bom planejamento. Assim, no contexto deste
trabalho, o estudo de caso foi planejado onde foram definidos: a
unidade de análise, os métodos utilizados para a coleta de dados,
cronograma, participantes, etc. De forma resumida, o planejamento
do estudo de caso é apresentado na sequência, iniciando pela
definição da unidade de análise.
3.1 Contextualização do Estudo de Caso A empresa SPECTO Tecnologia é uma empresa que iniciou suas
atividades no início da década de 90, e vem desenvolvendo
produtos atualmente por meio de três linhas de produtos: CXM
(gestão de atendimento), DCIM (gestão de datacenters), e BMS
(gestão de prédios inteligentes).
O presente estudo de caso é realizado na divisão de gestão de
datacenters (DCIM) da empresa. A DCIM tem como objetivo o
desenvolvimento de produtos de software para monitorar e
controlar o ambiente de datacenters, permitindo por exemplo,
alertar o usuário que um ambiente está com muita fumaça, ou que
um dispositivo de monitoramento foi desconectado, por exemplo.
O sistema utilizado neste estudo de caso é o DataFaz Unity, um
gerenciador de infraestrutura de datacenters, monitorando
parâmetros físicos de ambiente, tais como: umidade, temperatura,
energia, controle de acesso, etc. O sistema utiliza Flex para o
desenvolvimento de sua interface com o usuário e o back end é
desenvolvido em Java, com banco de dados tipicamente utilizado
sendo PostgreSQL.
Neste estudo de caso são envolvidos os membros das equipes
responsáveis pelos testes do sistema DataFaz Unity (membros da
equipe de garantia de qualidade de produto), sendo três analistas de
testes (dois formados em ciências da computação e um em
8http://www.oracle.com/technetwork/pt/java/javase/downloads/index.html 9 http://www.eclipse.org/downloads/ 10 http://www.jython.org/
automação) e dois testadores (graduandos de Ciências da
Computação)
3.2 Preparação A coleta de dados corresponde ao conjunto das operações, através
das quais o modelo de análise é submetido ao teste dos fatos e
confrontado com dados observáveis [3]. Como a principal pergunta
de pesquisa do presente trabalho consiste em: "Seria possível
automatizar testes para um software Flex de forma a reduzir o
esforço, tempo e retrabalho, tomando por base uma ferramenta já
existente para modelagem e automatização de testes?", os seguintes
dados foram planejados para serem coletados:
Quantidade de pontos de caso de uso;
Quantidade de erros encontrados na execução dos testes
automatizados;
Avaliação subjetiva dos resultados observados pelos
envolvidos na área de testes;
Quantidade de esforço realizado para a elaboração dos
casos de testes automatizados.
3.3 Execução e coleta de Dados O estudo de caso foi executado no período de 5 de Maio de 2015
até 10 de Setembro de 2015, após a análise de qual ferramenta de
automação seria utilizada.
A ferramenta Sikuli, conforme já apresentado, é uma ferramenta de
automação de testes de GUI que mescla Scripts com imagens, que
são procuradas quando o programa está rodando.
Segundo [4], a ideia de utilizar imagens para auxiliar na automação
de testes vem da própria forma como ocorre interação na
comunicação humana. Assim, na ferramenta Sikuli, as imagens são
utilizadas como parâmetros, de maneira similar a constantes
declaradas em qualquer linguagem de programação, onde o usuário
pode definir o nome da imagem, o grau de similaridade que procura
na tela, e aonde irá selecionar a tecla quando necessário.
Para utilizar a ferramenta, foi necessário instalar o Java JDK8.
Entretanto, durante os testes não foi possível integrá-la ao Eclipse9
e utilizar a linguagem Java pois não foi encontrada documentação
que facilitasse a utilização do script com a ferramenta. Assim, os
scripts de teste m implementados em Jython10.
Com a ferramenta instalada e pronta para executar os testes de
forma automatizada, foi preparado o ambiente com as demais
ferramentas necessárias e realizada a criação dos scripts de
automação de testes. Para efetuar os testes manuais, configurou-se
um computador para possuir o sistema DataFaz Unity instalado
localmente, e também o software Enterprise Architect11 utilizado
pela empresa para documentar a análise e modelagem do software
(para organizar e documentar os casos de uso e os casos de teste
com seus cenários), o PGadmin12 para administração do banco de
dados e recuperação do backup do banco de dados somente
contendo a configuração inicial.
Com esse ambiente instalado, foram elaborados os casos de teste
que seriam realizados tanto manualmente quanto de forma
automatizada, de forma a possibilitar a comparação mais objetiva
dos resultados da automação. Os casos de testes foram
documentados na ferramenta Enterprise Architect, conforme já
citado.
Foram elaborados, ao todo, dez casos de testes completos, cada um
possuindo de três a cinco diferentes cenários, tomando-se por base
11 http://www.sparxsystems.com.au/products/ea/ 12 http://www.pgadmin.org/
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
37

as principais funcionalidades do sistema Datafaz Unity. Os casos
de teste foram documentados seguindo as melhores práticas
definidas na norma ISO/IEC/IEEE 29119 [5]. Para cada caso de
teste foi realizada a implementação do seu correspondente em script
de teste automatizado
Cada um dos casos de teste foi então executado manualmente por
dois testadores diferentes e cada um dos scripts de teste
automatizado foi executado dez vezes em um mesmo computador.
Ao final dos testes, os analistas de teste e testadores foram
submetidos a um questionário de avaliação, composto de quatro
perguntas utilizando escala Likert de respostas, procurando
identificar as percepções sobre o resultado da aplicação dos testes
automatizados.
3.4 Análise dos Resultados Durante toda a execução dos testes, os dados de duração foram
coletados por meio do registro das tarefas no sistema de gerência
de projetos utilizado pela empresa13. Como resultado, conforme
esperado, foi percebido que o tempo necessário para elaboração dos
testes automatizados e manuais apresentou grande diferença,
devido ao tempo utilizado na elaboração dos Scripts de testes
automatizados, conforme mostra a Tabela 2.
Tabela 2 - Comparações entre teste manual e teste
automatizado
Métricas Teste Manual Teste
Automatizado Elaboração dos casos de teste 05h00min 05h00min
Elaboração Scripts de Testes
Automatizados
- 07h30min
Tempo médio de execução 00h08min 00h02min30seg
Total Duração 05h08min 12h32min30seg
Entretanto, conforme também mostra a Tabela 2, o tempo
necessário para execução dos testes automatizados foi
consideravelmente inferior. Espera-se que as futuras execuções dos
testes automatizados venham a compensar o maior esforço aplicado
na elaboração dos scripts de teste.
Além dos dados de tempo de execução, a partir da aplicação do
questionário, foi possível coletar a impressão subjetiva dos
participantes em relação aos resultados da automação de testes no
sistema legado utilizando plataforma Flex.
Tabela 3 - Resultados do questionário
Questões Concordam Facilidade na compreensão dos testes 80%
Cenários cobriram a funcionalidade proposta 80%
A infraestrutura disponibilizada para o ambiente de
testes foi satisfatória para a execução dos testes
80%
O tempo gasto com teste automatizado diminui esforços de custo e tempo com execuções repetitivas
100%
Conforme pode ser percebido pelas respostas dos participantes, a
automação de testes utilizando a ferramenta Sikuli, atendeu às
expectativas da maioria. Entretanto, foram percebidas
oportunidades de melhoria pela equipe, como por exemplo, a
possibilidade de integração direta com o Eclipse, possibilitando a
implementação dos scripts em Java.
3.4.1 Ameaças à validade Como tipicamente ocorre em estudos de caso [6] [7], o presente
trabalho somente foi aplicado em um único software de uma única
empresa, não sendo possível desta forma, generalizar seus
resultados a outras empresa e cenários, mesmo que positivos.
13 http://www.jexperts.com.br/category/pse/pse-pch/
Da mesma forma, a empresa possui poucos analistas de testes na
unidade organizacional do estudo de caso, fazendo com que os
resultados obtidos fossem escassos, mais analistas trariam mais
respostas, e o resultado da aplicação questionário seria mais
abrangente.
Além disso, o autor do trabalho teve participação ativa na execução
do trabalho, e este envolvimento direto pode gerar viés de
interpretação de dados coletados.
4. CONCLUSÕES Este trabalho apresenta uma experiência de automação de testes em
um sistema legado desenvolvido sobre plataforma Flex. Tendo em
mente as limitações de automação de testes em Flex, foram
analisadas diferentes abordagens de automação. Foi possível notar
que nenhuma ferramenta iria poder automatizar a aplicação em sua
totalidade, então foram criados requisitos para escolher qual
ferramenta seria utilizada no trabalho. A ferramenta Sikuli, que
cobriu a maior parte dos requisitos propostos, foi escolhida.
No contexto de um estudo de caso, casos de teste foram elaborados,
sendo implementados scripts de teste na linguagem aceita pelo
Sikuli. Os testes foram então executados de forma manual e
automatizada, em um ambiente controlado.
Os dados coletados de esforço e tempo durante a elaboração e
realização dos testes no estudo de caso levantam indícios de que o
ganho de tempo na automação de testes é pequeno inicialmente.
Espera-se, entretanto, que a organização envolvida no estudo de
caso obtenha benefícios diretos com a redução de custos de
retrabalho e aumento de confiabilidade da aplicação com a
execução dos testes automatizados em futuros releases do sistema.
Como trabalhos futuros planeja-se a integração dos testes
automatizados com a ferramenta de documentação e modelagem
dos testes. Além disso, seria importante expandir os casos de teste
automatizados para o restante das funcionalidades do sistema.
5. AGRADECIMENTOS Os autores agradecem aos membros da equipe da empresa Specto
que participaram do estudo de caso. Também agradecem a
cooperação e interesse da gerência da empresa no estudo de caso.
6. REFERENCES [1] Pressman, R. S. Engenharia de software: uma abordagem
profissional; Tradução Ariovaldo Griesi e Mario moro Feccio. 7ª ed. São Paulo: AMGH, 2011.
[2] Runeson, P., and M. Höst. "Guidelines for conducting and
reporting case study research in software engineering." Empirical Software Engineering 14.2, 2009.
[3] Quivy, R. et al. (1992). Manual de Investigação em Ciências Sociais. Lisboa: Gradiva.
[4] Yeh, Tom, Chang, Tsung-Hsiang, Miller, Robert C. (2009):
Sikuli: using GUI screenshots for search and automation. In:
Proceedings of the ACM Symposium on User Interface
Software and Technology, 2009, pp. 183-192. http://doi.acm.org/10.1145/1622176.1622213.
[5] International Organization for Standardization. ISO/IEC/IEEE 29119. Software Testing Standard. 2010.
[6] Zelkowitz, M. V. “An update to experimental models for
validating computer technology,” J. Syst. Softw., vol. 82, pp. 373–376, 2009.
[7] Yin, R. K. Applications of case study research, vol. 34
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
38

Análise do uso de técnicas de pré-processamento dedados em algoritmos para classificação de proteínas
Alternative Title: Analysis of the use of data pre-processing techniques inalgorithms to classification proteins
Lucas Nascimento VieiraDepto de Informática - Univille
Joinville - SC - [email protected]
Luiz Melo RomãoDepto de Informática - Univille
Joinville - SC - [email protected]
RESUMOMuitos problemas tem sido tratados pela bioinformatica, en-tre estes, se destaca a predicao de funcoes biologicas de pro-teınas. A complexidade deste tipo de aplicacao vem da pro-pria estrutura de organizacao da proteına que descreve estasfuncoes utilizando uma hierarquia estruturada em arvoresou em grafos acıclicos dirigidos. A maioria dos classifica-dores de proteınas disponıveis na literatura utiliza na etapade pre-processamento o metodo de discretizacao, que tem afuncao de transformar os atributos contınuos das bases dedados em intervalos discretos representados por atributosnominais. Este artigo ilustra a alteracao do funcionamentodo algoritmo HLCS-Multi que utiliza o metodo de discreti-zacao, para utilizar valores reais, que permitira estimativasmais precisas sobre os resultados.
Palavras-ChaveDescoberta do Connhecimento, Mineracao de Dados, Pre-Processamento
ABSTRACTMany problems have been dealt with by bioinformatics, amongwhich stands out the prediction of biological functions ofproteins. The complexity of this type of application co-mes from the protein organization structure that describesthese functions using a structured hierarchy tree or directedacyclic graph. Most protein binders available in the litera-ture uses the pre-processing step the discretization method,which has the function of transforming the continuous attri-butes of databases in discrete intervals represented by no-minal attributes. This article illustrates the change in thefunctioning of the HLCS-Multi algorithm that uses the dis-cretization method to use actual values, which will enablemore accurate predictions about the results.
Permission to make digital or hard copies of all or part of this work forpersonal or classroom use is granted without fee provided that copies arenot made or distributed for profit or commercial advantage and that copiesbear this notice and the full citation on the first page. To copy otherwise, torepublish, to post on servers or to redistribute to lists, requires prior specificpermission and/or a fee.SBSI 2016, May 17th-20th, 2016, Florianópolis, Santa Catarina, BrazilCopyright SBC 2016.
Categories and Subject DescriptorsH.4 [Information Systems]: Miscellaneous
General TermsInformation Systems
KeywordsKnowledge Discovery, Data Mining, Pre-Processing
1. INTRODUÇÃOMuitos problemas tem sido tratados pela bioinformatica,
entre estes, se destaca a predicao de funcoes biologicas deproteınas. A complexidade deste tipo de aplicacao vem dapropria estrutura de organizacao da proteına que descreveestas funcoes utilizando uma hierarquia estruturada em ar-vores ou em grafos acıclicos dirigidos.
Devido a essa diversidade de funcoes, as proteınas exer-cem papel fundamental em quase todos os fenomenos biolo-gicos, como producao de energia, defesa imunologica, contra-cao muscular, atividade neuroquımica e reproducao [2]. Deacordo com [4], as proteınas podem variar na sua composi-cao, sequencia e numero de aminoacidos, por isso, e possıveluma enorme variacao de sua estrutura e de sua funcao.
A maioria dos classificadores de proteınas disponıveis naliteratura utiliza na etapa de pre-processamento o metodode discretizacao ou normalizacao que podem ocasionar perdade informacao no processo de classificacao.
A proposta deste trabalho e desenvolver um algoritmopara a classificacao da funcao de proteınas que possa traba-lhar durante todas as etapas da extracao do conhecimentocom qualquer tipo de atributo, sendo este numerico ou ca-tegorico. Para isso, sera utilizado como base o algoritmoHLCS – Multi (Hierarchical Learning Classifier System Mul-tilabel) proposto em [11] que apresenta um modelo globalhierarquico multirrotulo para a predicao de problemas hi-erarquicos, mas que utiliza o metodo de discretizacao naetapa de pre-processamento
Alem desta secao introdutoria, o artigo foi dividido nasseguintes secoes. A fundamentacao teorica dos conceitosprincipais utilizados no trabalho. Em seguida e relatada ascaracterısticas do algoritmo HLCS – Multi e as alteracoespropostas para este projeto. Finalizando serao mostrados osresultados alcancados e as consideracoes finais do trabalho
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
39

2. FUNDAMENTAÇÃO TEÓRICAA Descoberta de Conhecimento em Banco de Dados (KDD
do ingles, Knowledge Discovery in Database), e um processode extracao de informacoes de base de dados, que cria rela-coes de interesse que nao sao observadas pelos especialistasno assunto.
O KDD pode ser visto como o processo de descoberta depadroes e tendencias por analise de grandes conjuntos dedados, tendo como principal etapa o processo de mineracao,consistindo na execucao pratica de analise e de algoritmosespecıficos que, sob limitacoes de eficiencia computacionaisaceitaveis, produz uma relacao particular de padroes a partirde dados. A extracao de conhecimento refere-se as etapasque produzem conhecimentos a partir de dados relaciona-dos, e sua principal caracterıstica e a extracao nao-trivial deinformacoes implicitamente contidas em uma base de dados[8].
A Figura 1 demonstra de uma maneira simplificada todasas fases do KDD.
Figura 1: Fases do Processo de KDD [8].
O produto esperado da extracao de conhecimento e umainformacao relevante para ser utilizada pelos tomadores dedecisao. Este processo leva a descoberta de informacoes aci-onaveis em grandes conjuntos de dados a procura de pa-droes consistentes, como regras de associacao ou sequenciastemporais, para detectar relacionamentos sistematicos entrevariaveis, detectando assim novos subconjuntos de dados.
O pre-processamento de dados e frequentemente tido comosendo uma fase que envolve uma grande quantidade de co-nhecimento de domınio. Entende-se que essa fase dependeda capacidade de analisar os dados e identificar problemasnos dados presentes. Esta fase de pre-processamento tende-se a consumir a maior parte do tempo dedicado no pro-cesso de descoberta do conhecimento. Como a necessidadede apresentar os dados em uma forma apropriada para atecnica de mineracao de dados escolhida, requer toda umapreparacao para a classificacao dos dados.
Conforme, [3] esta fase busca-se aprimorar a qualidadedos dados coletados. Frequentemente, os dados apresentamdiversos problemas, tais como grande quantidade de valo-res desconhecidos, ruıdo (atributos com valores incorretos),atributos de baixo valor preditivo, grande desproporcao en-tre o numero de exemplos de cada classe, entre outros.
Entre as tecnicas utilizadas na fase de pre-processamentode dados pode se citar o uso de tecnicas de discretizacao enormalizacao, que sao tecnicas que transformam atributosde dados contınuos, em valores categoricos.
O metodo de discretizacao tem a funcao de transformar osatributos contınuos das bases de dados em intervalos discre-tos representados por atributos nominais. A discretizacaopode ser dividida em duas principais categorias: aprendiza-gem supervisionada e nao supervisionada, que e uma areade inteligencia artificial, cujo o objetivo e desenvolver tec-nicas computacionais que possibilitem que o sistema tomedecisoes baseadas nas experiencias acumuladas. Conforme[11] na discretizacao supervisionada, existe uma interdepen-dencia entre os valores das variaveis e a classe das instanciasdo conjunto de treinamento, ja a nao supervisionada naoleva em consideracao a informacao de classes das instanciasdo conjunto de treinamento. De acordo com [6], o objetivoda discretizacao e reduzir o numero de valores das variaveiscontınuas, agrupando as em um numero n de intervalos.
A normalizacao de dados consiste em ajustar os valores decada atributo, de forma que os valores fiquem em pequenosintervalos. E uma serie de passos que e seguido para umprojeto de banco de dados, e a execucao desses passos irapermitir a criacao de um formato logico e adequado para asestruturas dos dados, permitindo o armazenamento consis-tente e eficiente dos dados.
Entretanto, o uso destas tecnicas podem ocasionar emperda de informacoes, pois em alguns casos estas tecnicasnao consideram a relacao entre atributos.
O uso de tecnicas de discretizacao ou normalizacao po-dem ser encontrados em diversos trabalhos disponıveis naliteratura, para a classificacao da funcao de proteınas. Osprincipais trabalhos identificados, nesta pesquisa foram: [7],[11], [1] e [5]
3. ALGORITMO HLCS MULTIConforme [11], o algoritmo Hierarchical Learning Classi-
fier System Multilabel (HLCS – Multi), apresenta uma so-lucao global hierarquica multirrotulo para a classificacao dafuncao de proteınas respeitando a hierarquia das classes emtodas as fases de desenvolvimento do sistema. E desenvol-vido especificamente para trabalhar com bases hierarquicase utiliza como modelo de desenvolvimento os Sistemas Clas-sificadores (LCS), que e um metodo que gera seus resultados
em um conjunto de regras no formato SE-ENTAO, que saorepresentacoes, de acordo com [9] mais compreensıveis doque outros modelos como redes neurais, maquinas de vetorde suporte entre outros. O HLCS – Multi e o primeiro mo-delo baseado em Sistemas Classificadores para a predicao deproblemas hierarquicos multirrotulo.
Para trabalhar com dados hierarquicos, o HLCS – Multiapresenta um componente especıfico para esta tarefa que eo componente de avaliacao dos classificadores. Este com-ponente tem a funcao de analisar as predicoes dos classi-ficadores considerando a hierarquia das classes. Alem docomponente de avaliacao, a arquitetura HLCS – Multi con-siste dos seguintes modulos: populacao de classificadores,componente AG, componente de desempenho e componentede cessao de creditos, que interagem entre si.
Em geral, o sistema HLCS – Multi cria sua populacao declassificadores atraves da analise dos exemplos do ambiente,que representam os dados de treinamento. A medida que oHLCS – Multi interage com o ambiente, por meio dos compo-nentes de desempenho e cessao de creditos, os classificadoressao avaliados e recebem um retorno na forma de uma re-compensa que impulsiona o processo de aprendizagem. Esteprocesso de aprendizagem tem a intervencao do componente
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
40

de avaliacao, que ajuda no calculo da recompensa avaliandoas predicoes do sistema conforme a sua hierarquia. No fimdesta etapa, os classificadores passam por um mecanismo deevolucao atraves do componente AG, que utiliza algoritmosgeneticos como base para a melhoria do conhecimento atualdo sistema.
A questao multirrotulo e trabalhada durante todas as eta-pas de treinamento e teste do modelo por meio de um pro-cesso de decomposicao das instancias e na forma de analisedas predicoes.
4. SOLUÇÃO PROPOSTAA solucao proposta neste artigo e chamada de HLCS –
MultiND (Hierarchical Learning Classifier System Multila-bel No Discretizate). Baseada no algoritmo HLCS – Multi,esta versao tem como diferencial a possibilidade de traba-lhar durante todas as etapas da extracao do conhecimentocom qualquer tipo de atributo, sendo este numerico ou ca-tegorico. Para isso foi realizada uma mudanca no algoritmoHLCS – Multi permitindo que as regras geradas pelo classi-ficador possam criar condicoes de intervalos entre os atribu-tos.
A primeira funcao do sistema e criar uma populacao inicialde classificadores, atraves de uma analise feita nas instan-cias da base de treinamento de tamanho N, que representaa fonte de dados do sistema. Para formar cada classifica-dor da populacao inicial, o algoritmo escolhe aleatoriamenteuma instancia da base de treinamento como modelo. Cadaatributo da instancia de treinamento sera criado uma con-dicao no classificador. Esta instancia sera definida por umacondicao que recebera como parametro OP, VL, A/I, sendo:
• OP: operador de relacao (=, <= ou >=)
• VL: valor da condicao
• A/I: opcao de ativa (A) ou inativa (I) da condicao, quesignifica se a condicao sera utilizada na classificacao ounao.
No inıcio as condicoes comecam com o operador de relacao(OP) “= ou <= ou =>” a escolha dos operadores de compa-racao ocorre de forma randomica. O valor da condicao (VL)recebe o valor do atributo da instancia em treinamento ealetoriamente, de acordo com a probabilidade definida nasconfiguracoes iniciais do algoritmo, e decidido se a condicaoficara ativa (A) ou inativa (I).
Conforme relatado anteriormente, esta versao tem comodiferencial a possibilidade de trabalhar com qualquer tipode atributo, sendo este numerico ou categorico, possibili-tando a leitura de bases com valores nominais e contınuos.Para isso, foi desenvolvido um metodo intermediario, o quale executado sempre na leitura de bases ou comparacao devalores, para analisar a sequencia de entrada de dados, as-sim tornando possıvel o processo de“parser”dos valores, quepossibilitou determinar sua estrutura gramatical, evitando anecessidade de realizar a discretizacao na base. Na geracaode regras iniciais passou a utilizar o metodo de operado-res randomicos, o qual pode retornar os operadores igual=, maior igual >= e menor igual <=, que foi modificadopara contemplar mais operadores. Com essas modificacoes,tornou-se necessario criar condicoes randomicas para as va-riaveis tambem, onde e resgatado um valor aleatorio dentrode um intervalo de mınimo e maximo retirado da primeira
lista de regras iniciais. Esta lista de mınimo e maximo ecriada apos a leitura da base de dados, e a cada geracaode regra inicial, assim evitando a necessidade de ler a listade regras novamente e aumentando a performance. Para amedicao da performance foi implementado metodos que re-gistraram o tempo inicial da execucao e tempo final, os quaissao relatados no fim do processo.
Alem das regras ja listadas, tambem foi alterado o algo-ritmo para sempre gerar uma nova populacao inicial, sempreque nao for identificada uma lista de regras iniciais para ogrupo corrente de atributos e valores que estao sendo proces-sados. Com essas alteracoes foi possıvel trabalhar durantetodas as etapas da extracao do conhecimento com qualquertipo de atributo, possibilitando a execucao do algoritmo embases com atributos nominais e contınuos, descartando a ne-cessidade de utilizar o metodo de discretizacao, tornando oalgoritmo mais eficaz e compreensıvel o bastante para queos pesquisadores consigam analisar e confiar nas predicoesrecebidas.
5. ANÁLISE DE DADOS E DISCUSSÃO DOSRESULTADOS
A fim de demonstrar os resultados obtidos com o HLCS– MultiND o algoritmo foi comparado com os resultados daversao HLCS – Multi publicados em [12]. Os experimentosforam realizados em tres conjuntos de dados de funcoes deproteınas, Cellcycle, Church e Derisi que foram utilizadosem [13] e estao disponıveis em (http://dtai. cs. kuleuven.be/clus /hmcdatasets). Estas bases contem informacoes declasses baseadas nos termos da Ontologia Genica (GO) esao organizadas em uma estrutura em forma de um DAG.A Tabela 1 apresenta os detalhes das bases utilizadas nestaexperiencia.
Tabela 1: Resumo dos conjuntos de dados utili-zados no experimento. A primeira coluna (’Basede dados’) define o nome da base de dados, a se-gunda coluna (’Trein.’) define o numero de exem-plos de treinamento, a terceira coluna (’Teste’) de-fine o numero de exemplos de teste, a quarta coluna(’Atrib.’) define o numero de atributos de cada basee a quinta coluna (’Classes’) define o numero de clas-ses na classe hierarquica.
Base de Dados Trein. Teste Atrib. ClassesCellcycle 2473 1278 77 4126Church 1627 1278 27 4126Derisi 2447 1272 63 4120
O desempenho dos resultados foi comparado utilizando asmedidas de precisa hierarquica (hP), revocacao hierarquica(hR) e Medida-hF (hF) proposto em [10]. Este metodo segueo padrao das conhecidas medidas de Revocacao, Precisaoe Medida – F, com as seguintes alteracoes: cada exemplopertence nao somente a sua classe, mas tambem a todos osancestrais da classe em um grafico hierarquico, exceto o noraiz.
Os experimentos foram realizados utilizando como proce-dimento o metodo de validacao cruzada fator 10 e os resul-tados sao descritos como valores-medios e desvio padrao.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
41

Tabela 2: Valores das medidas hR, hP e hF obtidasnos tres conjuntos de dados.
HLCS-MultihP hR hF
Cellcyle 0.2611 ± 0.04 0.4209 ± 0.02 0.3223 ± 0.03Church 0.2259 ± 0.02 0.6183 ± 0.03 0.3309 ± 0.04Derisi 0.2948 ± 0.03 0.5655 ± 0.03 0.3873 ± 0.03
HLCS-MultiNDhP hR hF
Cellcyle 0.2052 ± 0.05 0.1803 ± 0.04 0.1919 ± 0.05Church 0.2048 ± 0.04 0.1800 ± 0.06 0.1916 ± 0.05Derisi 0.2042 ± 0.04 0.1798 ± 0.05 0.1912 ± 0.05
De acordo com os testes, o HLCS – Multi mostrou me-lhores resultados do que o HLCS – MultiND nas tres basesanalisadas. Porem, segundo [9], um fator importante para apredicao da funcao de proteınas, e que o modelo de predi-cao desenvolvido, alem de ser eficaz, deve ser compreensıvelo bastante para que os pesquisadores consigam analisar econfiar nas predicoes recebidas. Sendo assim, a principalvantagem do modelo HLCS – MultiND com relacao a ver-sao HLCS – Multi e a forma com o qual o modelo apresentaos resultados gerados.
Um exemplo desta diferenca pode ser visto na tabela 3.Como o HLCS – Multi realiza o processo de discretizacao, asregras geradas sao imprecisas, pois utiliza intervalo de da-dos como valores dos atributos, dificultando o trabalho dospesquisadores. Entretanto no modelo proposto os resultadossao mais especıficos e faceis de serem interpretados.
Tabela 3: Exemplo de Regras geradas pelos Algorit-mos
Versao Exemplo Regra
HLCS – Multi
SE cln3-1=(0.041-0.828) ecln3-2=(-0.228-0.45) ee...e clb2-2=(-0.528-0.268)
ENTAOProteına e da classe GO0005634
HLCS - MultiND
SE cln3-1>=-0.828 ecln3-2<=-0.15 ee...e clb2-2>=-0.2158
ENTAOProteına e da classe GO0005634
6. CONCLUSÃOA contribuicao dessa pesquisa foi apresentar um estudo
de caso de mineracao de dados e o uso de tecnicas de pre-processamento de dados em algoritmos de classificacao deproteınas, alterando o funcionamento do algoritmo HLCS– Multi para uma nova versao chamada de HLCS - Mul-tiND (Hierarchical Learning Classifier System Multilabel NoDiscretizate). Esta versao foi desenvolvida para trabalhardurante todas as etapas da extracao do conhecimento comqualquer tipo de atributo, sendo este numerico ou catego-rico, diminuindo a perda de informacao causada pelo pro-
cesso de discretizacao e aumentando o grau de confiabilidadedos dados.
De acordo com os testes, os resultados apresentados peloalgoritmo HLCS – Multi, ainda sao melhores que os obti-dos pelo HLCS – MultiND. Entretanto e importante deixarclaro que as regras criadas pelo algoritmo proposto, sao maiscompreensıveis para que os pesquisadores consigam analisare confiar nas predicoes recebidas. Acredita-se que atravesde alguns ajustes neste modelo, e provavel que se consigaresultados parecidos ou ate superiores.
Pretende-se tambem realizar testes com outros tipos debase de dados para auxiliar no refinamento do algoritmo.
7. REFERÊNCIAS[1] R. T. Alves, M. R. Delgado, and A. A. Freitas.
Multi-label hierarchical classification of proteinfunctions with artificial immune systems. pages 1–12,2008.
[2] P. Balid and G. A. Pollastri. Machine-LearningStrategy for Protein Analysis. IEEE IntelligentSystems, 17, 2002.
[3] G. E. A. P. Batista. Pre-processamento de dados emaprendizado de maquina supervisionado. PhD thesis,Universidade de Sao Paulo, 2003.
[4] M. K. Campbell. Bioquımica. ArtMed, 2000.
[5] R. Cerri and A. C. P. L. F. Carvalho. New top-downmethods using svms for hierarchical multilabelclassification problems. In International JointConference on Neural Networks, pages 1–8. IEEE,2010.
[6] K. J. Cios, W. Pedrycz, R. W. Swiniarski, and L. A.Kurgan. Data Mining: A Knowledge DiscoveryApproach. Springer-Verlag New York, Inc., Secaucus,NJ, USA, 2007.
[7] A. Clare and R. D. King. Predicting gene function insaccharomyces cerevisiae. Bioinformatics, 19:42–49,2003.
[8] U. M. Fayyad, G. Piatetsky-Shapiro, P. Smyth, andR. Uthurusamy, editors. Advances in knowledgediscovery and data mining. American Association forArtificial Intelligence, Menlo Park, CA, USA, 1996.
[9] A. A. Freitas, D. C. Wieser, and R. Apweiler. On theimportance of comprehensible classification models forprotein function prediction. IEEE/ACM Trans.Comput. Biol. Bioinformatics, 7(1):172–182, Jan.2010.
[10] S. Kiritchenko, S. Matwin, and A. F. Famili.Functional annotation of genes using hierarchical textcategorization. In Proc. of the BioLINK SIG: LinkingLiterature, Information and Knowledge for Biology(held at ISMB-05, 2005.
[11] L. M. Romao. Classificacao Global HierarquicaMultirrotulo da Funcao de Proteınas UtilizandoSistemas Classificadores. PhD thesis, PontifıciaUniversidade Catolica do Parana, 2012.
[12] L. M. Romao and J. C. Nievola. HierarchicalMulti-label Classification Problems: An LCSApproach. Advances in Intelligent Systems andComputing, 373:97–104, 2015.
[13] C. Vens, J. Struyf, L. Schietgat, S. Dzeroski, andH. Blockeel. Decision trees for hierarchical multi-labelclassification. Mach. Learn., 73(2):185–214, Nov. 2008.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
42

Desenvolvimento da Técnica Data Mining Como Apoio à Tomada de Decisão no Sistema Hidrológico para Geração de Estatística das Estações de Telemetria da Defesa Civil
de Brusque – SC
Alternative Title: Development of Data Mining Techniques as Support for Decision Making in the Hydrological System for
Statistics Production of the Telemetry Stations of the Emergency Management in Brusque-SC
Jonathan Nau Centro Universitário de Brusque -
UNIFEBE Rua Dorval Luz, 123 Brusque – SC - Brasil
Antonio Eduardo de Barros Ruano
University of Algarve - Faro Email: [email protected]
Pedro Sidnei Zanchett Centro Universitário de Brusque -
UNIFEBE Rua Dorval Luz, 123 Brusque – SC - Brasil
Marcos Rodrigo Momo
UNIFEBE Rua Dorval Luz, 123 Brusque – SC - Brasil
Wagner Correia
Centro Universitário de Brusque - UNIFEBE
Rua Dorval Luz, 123 Brusque – SC - Brasil
RESUMO
A quantidade de informação dos sistemas hidrológicos cresce a
cada medição realizada pelas estações. Com um volume tão alto
de informações acaba ficando difícil extrair conhecimento
olhando só os dados. O processo de extração de conhecimento
(KDD) tem o objetivo de auxiliar a extração do conhecimento a
partir de grandes bases de dados. Pensando em facilitar a
extração de conhecimento das grandes bases do sistema
hidrológico elaborou-se este projeto de pesquisa que visa
implantar o processo KDD para geração de estatísticas das
estações de telemetria mantidas pela defesa civil de Brusque –
SC, com base em dados de níveis de chuva e do rio em Brusque
e região oferecendo apoio a decisão estratégica. Através do Data
Mining utilizando-se o modelo cubo de decisão por associação
será possível extrair diversas visões à gestão de negócio,
transformando-se numa ferramenta de ajuda para ganho de
tempo no controle e prevenção à enchentes com antecipação e
segurança à população. A decisão baseada no conhecimento
extraído das grandes bases será mais assertiva, desta forma as
informações passadas para toda a população terá algum grau de
confiança e não precisam mais serem baseadas em inferências
das pessoas que possuem a base de dados em mãos.
Palavras-Chave
Sistema de informação; Processo KDD; Data Mining.
Estatística.
ABSTRACT
The amount of information of hydrological systems grows each
measurement performed by the seasons. With such a high volume
of information ends up being difficult to extract knowledge just
looking at the data. The KDD process is intended to assist the
extraction of knowledge from large databases. Thinking about
facilitating the extraction of knowledge from large bases of the
hydrological system elaborated a work based on the KDD
process in an attempt to mine the data of hydrological systems
and extract knowledge to aid in decision making. A decision
based on knowledge extracted from large databases will be more
assertive in this way the information passed to the entire
population will have some degree of confidence and no longer
need to be based on inferences of the people who have the hands
on the database.
Keywords
Information System; KDD process; Data Mining. Statistic.
General Terms
Experimentation and Database Management.
Categories and Subject Descriptors
E.2 Data Storage Representations. G.3 Probability and
Statistics: Statistical software. H. Information Systems: H. 2.8.
Database Applications: Data mining.
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are
not made or distributed for profit or commercial advantage and that copies
bear this notice and the full citation on the first page. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior
specific permission and/or a fee.
SBSI 2016, May 17–20, 2016, Florianópolis, Santa Catarina, Brazil. Copyright SBC 2016.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
43

1. INTRODUÇÃO A cada dia que passa o volume de informação cresce
exponencialmente, obrigando o desenvolvimento de técnicas e
ferramentas que facilitem a busca e manipulação de todos esses
dados armazenados. A mineração de dados é uma tecnologia que
combina métodos tradicionais de análise de dados com algoritmos
sofisticados para processar grandes volumes de dados” [2].
O sistema hidrológico de Brusque gera muita informação através
das estações de telemetria que se localizam ao longo do rio Itajaí
Mirim, os sensores das estações captam o volume de chuva e o
nível do rio. Apesar de serem captadas apenas duas variáveis o
volume de informação é gigantesco devido a captura dos dados
ser em questão de minutos.
“Dados de nível de rios usados para controle de cheias podem
demandar a coleta e transmissão de dados a cada 10 minutos” [3].
Devido à grande quantidade de informação gerada pelas estações
de telemetria da defesa civil de Brusque, é fundamental adotar
técnicas de mineração de dados para identificar padrões e
anomalias que antes passavam despercebidas e que agora podem
ajudar na tomada de decisão, como por exemplo alertar a
população de uma possível enchente.
No momento a defesa civil de Brusque, não utiliza base de dados
históricas das estações de telemetria para tomada de decisões e
prestar orientações a sua população. As informações repassadas
são somente dos dados atualizados das estações. Esta pesquisa
teve por objetivo elaborar e aplicar técnicas de mineração de
dados na base de dados histórico da defesa civil para extrair
conhecimento que antes não se dava atenção e que agora podem
ser usados no processo de tomada de decisão.
2. METODOLOGIA DE EXTRAÇÃO DE
INFORMAÇÕES HIDROLÓGICAS O processo de extração de dados é conhecido pela sigla KDD
(knowledge-discovery in databases). O conceito deste processo se
trata da extração de dados de uma grande base de dados, a fim de
identificar padrões para adquirir conhecimento.
A extração de conhecimento de uma base de dados consiste em
duas grandes fases. A primeira trata da preparação dos dados, que
consiste em selecionar os dados que serão utilizados onde faz a
limpeza e a projeção destes dados. Já a segunda etapa trata da
mineração dos dados, se faz a escolha dos algoritmos e tarefas de
mineração, a interpretação de padrões e a consolidação do
conhecimento descoberto. Na figura 1 pode-se observar as fases
do processo KDD mais detalhadamente.
Figura 1. Etapas do processo KDD [1]
2.1 ETAPAS DO PROCESSO KDD Na primeira etapa é definida quais tipos de informação será
extraída de uma base de dados. Para o sistema hidrológico pode-
se definir como problemas as enchentes a ser analisado para uma
correta tomada de decisão. Na segunda fase o passo é realizar a
criação de um conjunto de dados que serão preparados para
posteriormente serem minerados. Utilizar-se-á três dados para a
mineração, que neste caso é o nível do rio, o nível de chuva e a
vazão do rio. Estes três dados serão importantes para a extração
de conhecimento de uma base de dados do sistema hidrológico.
A limpeza e o processamento dos dados serão trabalhados na
terceira fase do processo KDD. Nesta fase serão eliminados
ruídos dos dados que podem afetar a qualidade do conhecimento
extraído da base de dados. Como no sistema hidrológico os dados
são coletados automaticamente pelas estações de coleta, a
possibilidade de haver erros na leitura dos sensores é alta. Os
erros que ocorrem na leitura dos sensores são tratados como
ruídos no processo KDD e podem levar a uma conclusão
precipitada dos padrões identificados, devido a isso os ruídos
precisam ser eliminados. Por exemplo, nos dados armazenados
pela defesa civil de Brusque se possui muitos meses desde 1912
com falhas nas informações históricas coletadas, essas
informações primeiramente precisam ser tratadas para então se
prosseguir.
Nas figuras 02 e 03 observa-se claramente o ruído causado por
uma estação de telemetria da defesa civil de Brusque. A imagem
mostra que em dois horários a estação captou valores acima de
três mil milímetros de chuva, logo depois o nível caiu para zero e
o nível do rio não teve alteração em nenhum momento. Estes
ruídos vão precisar ser corrigidos pois afetam diretamente na
extração de conhecimento da base de dados, apenas esses dois
valores causam uma variação enorme no nível de chuva do mês
em questão.
Figura 2. Ruído de dados.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
44

Figura 3. Ruído de dados.
A correção dos dados é feita de maneira para acrescentar mais um
campo ao final da tabela, para que na mineração dos dados o
algoritmo saiba quais os dados que estão incorretos. Desta forma
além de eliminar os ruídos é possível treinar também o algoritmo
de forma que ele identifique os novos valores que estão sendo
registrados na base de dados, que com isso é possível garantir a
integridade dos dados e saber quando uma estação está
apresentando defeitos.
A quarta fase trata-se da redução e projeção dos dados, é mais
conhecida como transformação dos dados. Os dados precisam ser
armazenados e formatos de forma que os algoritmos consigam ser
aplicados e os dados possam ser minerados. Conforme figura 04
se utilizará apenas uma tabela com alguns campos (somente
números), para facilitar no momento da mineração dos dados. A
tabela vai conter como campos o código da estação de coleta, o
horário que foi realizado a coleta, os valores do nível do rio e das
chuvas.
Figura 4. Dados utilizados
A próxima grande etapa é a de mineração dos dados, esta grande
fase é composta por quatro fases menores, que vão desde a
escolha de tarefas de mineração até a consolidação do
conhecimento descoberto por meio da base de dados selecionada
anteriormente.
Na quinta fase vamos escolher quais serão as tarefas de mineração
que vão ser utilizadas. Nesta etapa se decide qual será o objetivo
dos processos de mineração dos dados, os mais comuns são os de
classificação, regressão e clusterização. No sistema hidrológico
vamos utilizar as três tarefas de mineração.
Segundo autores as três técnicas mais comuns no processo KDD
são:
Associação: Tem por objetivo a combinação de itens
considerados importantes, sendo que a presença de tal item
indica implicitamente na presença de outro item na mesma
transação. Este processo teve como precursor Agrawal, em
1993 [1].
Classificação: Classes de objetos são criadas para agrupar
objetos com características semelhantes. São utilizados
dados sobre o passado de determinada base para encontrar
padrões com valores significativos, aos quais irão levar a
regras sobre o futuro destes objetos.
Clusterização: Os dados heterogêneos são reagrupados em
grupos com características semelhantes, método conhecido
como clustering. A clusterização é a tarefa de segmentar uma
população heterogênea em um número de subgrupos (ou
clusters) mais homogêneos possíveis, de acordo com alguma
medida. O que diferencia a clusterização da classificação é a
não existência de grupos pré-definidos.
No sexto passo será escolhido os algoritmos de mineração de
dados. Os métodos selecionados para serem utilizados no sistema
hidrológico foram algoritmo associação, algoritmo de regressão
linear e algoritmo clusterização.
Descobrir o conhecimento oculto nas grandes bases de dados das
mais diversas organizações, seja de forma automática ou
semiautomática é o objetivo do Data Mining. Trata-se de um
processo da extração de padrões, considerados interessantes e não
corriqueiros, a partir de uma base de dados permitindo de forma
ágil e rápida a tomada de decisões.
Isto vem ao encontro de Cardoso e Machado [4] que definem o
Data Mining como uma técnica que faz parte de uma das etapas
da descoberta de conhecimento em banco de dados. Ela é capaz
de revelar, automaticamente, o conhecimento que está implícito
em grandes quantidades de informações armazenadas nos bancos
de dados de uma organização. Essa técnica pode fazer, entre
outras, uma análise antecipada dos eventos, possibilitando prever
tendências e comportamentos futuros, permitindo aos gestores a
tomada de decisões baseada em fatos e não em suposições.
A mineração de dados começa efetivamente no sétimo passo.
Nesta fase se irá minerar os dados na tentativa de identificar os
padrões de interesse, os interesses são necessários antes de
começar a mineração dos dados. Um interesse seria a previsão do
nível do rio nas horas seguintes, seria interessante também quais
são os meses que o risco de cheias aumenta, relação entre
quantidade chuva e nível do rio.
A tabela 01 demonstra a utilização do algoritmo EM
(expectation–maximization algorithm ou algoritmo de estimação
de máxima) para minerar dados dos níveis da chuva durante os
meses do ano. O algoritmo EM faz parte da técnica de mineração
conhecida como clusterização, o algoritmo é ideal para quando os
dados são realmente incompletos, quando existe perda de um
intervalo de dados na base de dados.
Tabela 1. Mineração de dados da chuva
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
45

A oitava fase é a interpretação dos dados obtidos por meio da
mineração de dados. A técnica do algoritmo EM consistiu em
dividir os dados em três cluster, cada cluster representa uma
massa de dados. O cluster 1 por exemplo representa apenas 2%
dos dados analisados, que correspondem a dezesseis meses em
que a precipitação de chuva chegou em aproximadamente 112
milímetros de chuva, com desvio padrão de 19 milímetros. Nele
ainda se observa que alguns meses tiveram mais ocorrência que
outros, como por exemplo, o mês de março com três ocorrências
e os meses de fevereiro e abril com duas ocorrências cada. Por sua
vez no cluster 2 temos uma média de 63 milímetros de
precipitação da chuva, este cluster possui um percentual de
ocorrência no valor de 30% e são destaques os meses de fevereiro,
março, setembro e dezembro. Por fim a precipitação que mais
ocorre em Brusque com 68% de ocorrência fica na média de 29
milímetros, com os meses de maio a agosto em destaque.
Esses dados mostram quais as possíveis eventualidades que
podem ocorrer durante o ano, por exemplo, o mês de agosto é
mais assertivo falar que as medias de precipitação da chuva vão
ficar em torno de 19 a 49 milímetros, pois sua a ocorrência dessa
media para esse mês é muito maior do que para as demais medias.
Outra mineração feita foi utilizando o algoritmo M5RULES [5],
que utilizou dados da estação de Botuverá e da estação de
Brusque. Os dados utilizados da estação de Botuverá foram o
acumulado de chuva do dia e a média do nível do rio também para
o dia, já na estação de Brusque foi apenas utilizado a média do rio
no dia.
O algoritmo funciona da seguinte forma: uma árvore de
aprendizado é aplicada sobre todo o conjunto de treinamento e
uma árvore podada é aprendida. Em seguida, a melhor
ramificação (de acordo com alguma heurística) gera uma regra e
a árvore é descartada. Todas as instâncias cobertas pela regra são
removidas do conjunto de dados, e o processo é aplicado de modo
recursivo para os exemplos restantes até que todas as instâncias
sejam cobertas por uma ou mais regras. Ao invés de criar uma
única regra de aprendizagem, constrói-se um modelo de árvore
completo em cada fase e faz-se da melhor ramificação uma nova
regra [6].
Portanto ao utilizar o algoritmo M5RULES se queria criar regras
na tentativa de modelar a forma como se comporta o rio. Na
mineração dos dados se obteve as cinco regras, que serão
exploradas abaixo:
Figura 5. Primeira regra.
Figura 6. Segunda regra;
Figura 7. Terceira regra
Figura 8. Quarta regra.
Figura 9. Quinta regra.
O nono e último passo é a consolidação do conhecimento
descoberto. Nesta fase irá incorporar os resultados nos sistemas,
nas documentações necessárias e nos relatórios para quem se
interessar. Neste ponto também se faz aferições de conflitos e a
resolução dos mesmos por meio do conhecimento extraído.
Para consolidar as regras propostas pelo algoritmo M5RULES é
necessário apenas ter os valores, utilizar as regras para realizar os
cálculos e chegar ao resultado final. Tem-se por exemplo o
seguinte conjunto de dados nível do rio em Botuverá com 0,66
metros, um volume de chuva no valor de 0,00 milímetros e o nível
do rio em Brusque com 1,38 metros. Utilizando a primeira regra
para o conjunto de informações chega-se a o valor aproximado de
1,351428 metros, que fica muito próximo ao valor esperado de
1,38 metros.
IF
Nível do rio em Botuverá <= 1.226
Nível do rio em Botuverá <= 0.977
Nível do rio em Botuverá > 0.559
Nível do rio em Botuverá > 0.73
THEN
Nível do rio em Brusque =
-0 * Acumulado de chuva em Botuverá
+ 0.0308 * Nível do rio em Botuverá
+ 1.3311 [251/57.511%]
IF
Nível do rio em Botuverá <= 1.393
Nível do rio em Botuverá > 0.554
THEN
Nível do rio em Brusque =
-0.0001 * Acumulado de chuva em Botuverá
+ 0.2425 * Nível do rio em Botuverá
+ 1.0899 [466/68.005%]
IF
Nível do rio em Botuverá <= 1.846
THEN
Nível do rio em Brusque =
0.0203 * Nível do rio em Botuverá
+ 1.4469 [192/55.59%]
IF
Nível do rio em Botuverá <= 2.793
THEN
Nível do rio em Brusque =
-0.003 * Acumulado de chuva em Botuverá
- 0.121 * Nível do rio em Botuverá
+ 1.8809 [57/54.89%]
Nível do rio em Brusque =
- 0.0254 * Acumulado de chuva em Botuverá
+ 1.1194 * Nível do rio em Botuverá
- 0.2767 [15/72.772%]
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
46

A primeira grande fase demanda mais tempo no processo KDD,
geralmente fica em torno de 80% do trabalho realizado durante a
extração do conhecimento de uma base de dados. As etapas que
foram descritas também podem ser repetidas durante a extração,
apesar de ser apresentado uma sequência para a extração dos
dados a mesma pode ser alterada conforme necessidade, também
é possível voltar para alguma etapa anterior caso seja necessário,
é aconselhável voltar para evitar erros na consolidação do
conhecimento.
3. CONCLUSÕES E TRABALHOS
FUTUROS A técnica Data Minning contribui para extração precisa e
inteligente dos dados obtidos pelas estações de telemetria do
município de Brusque SC, mantidas pela Defesa Civil para
análise dos problemas ocorridos com cheias, fornecendo
informações de apoio à decisão para técnicos da área e população
em geral, de forma simples e rápida.
Com este trabalho conseguiu-se exibir os meses em que mais
ocorre chuva e quais são os meses mais propícios para chuva
durante o ano, com essa informação é possível verificar os meses
de risco, planejar as estratégias durante o ano e disponibilizar a
informação para a população. Também foi possível com este
trabalho a criação de regras para inferir o nível do rio na cidade
de Brusque a partir dos dados da estação da cidade vizinha
Botuverá.
No sistema hidrológico de Brusque as técnicas de mineração de
dados para extração de conhecimento foram utilizadas pela
primeira vez com esse trabalho, o que resulta em um grande
avanço para a cidade e para a população. Mesmo exibindo algum
resultado ainda é necessário mais estudo na aérea de Data Mining
com foco nos sistemas hidrológicos. A utilização das redes
neurais se mostra interessante para ampliar mais este trabalho,
pois com as redes neurais consegue-se modelar a bacia do rio
Itajaí Mirim de forma a utilizar todas as estações disponíveis ao
longo do rio e saber com precisão qual o nível do rio na última
estação. As redes neurais também permitem que os novos dados
sejam validados a partir dos ruídos que já foram encontrados.
4. AGRADECIMENTOS Este trabalho de Iniciação Científica teve o apoio da Secretaria de
Estado da Educação de Santa Catarina, através da concessão de
bolsas com recursos do Artigo 170 da Constituição Estadual, para
os alunos de graduação regularmente matriculados na UNIFEBE.
5. REFERÊNCIAS [1]. AGRAWAL, R.; IMIELINSKI, T.; SWAMI, A. Mining
associations between sets of items in massive databases.
ACM-SIGMOD, 1993. Proceedings... Int’l Conference on
Management of Data, Washington D.C., May 1993.
[2] . ANTUNES, J. F. G.; OLIVEIRA, S. R. M.; RODRIGUES,
L. H. A. Mineração de dados para classificação das fases
fenológicas da cultura da cana-de-açúcar utilizando
dados do sensor modis e de precipitação. VIII Congresso
Brasileiro de Agroinformática. Bento Gonçalves, 2011.
[3]. BLAINSKI, É.; GARBOSSA, L. H. P.; ANTUNES, E. N.
Estações hidrometeorológicas automáticas: recomendações
técnicas para instalação. Disponível em:
<http://ciram.epagri.sc.gov.br/recomendacoes_tecnicas_par
a_instalacao_de_estacoes.pdf >. Acesso em: 25 fev. 2016.
[4]. CARDOSO, O. N. P., MACHADO, R. T. M. Gestão do
conhecimento usando data mining: estudo de caso na
Universidade Federal de Lavras. Revista de
Administração Pública. Rio de Janeiro 42(3): 495-528,
Maio/Jun. 2008.
[5] ALBERG, D.; LAST, M.; KANDEL, A. Knowledge
discovery in data streams with regression tree methods,
2011.
[6]. HOLMES, G.; HALL, M.; FRANK, E. Generating Rule
Sets from Model Trees. In: Twelfth Australian Joint
Conference on Artificial Intelligence, 1999.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
47

Uma arquitetura de banco de dados distribuído paraarmazenar séries temporais provenientes de IoT
Alternative title: A distributed database architecture to store time series from IoT
Fernando PaladiniFederal University of Santa
CatarinaFlorianópolis, Brazil
Caique R. MarquesFederal University of Santa
CatarinaFlorianópolis, Brazil
Lucas WannerUNICAMP
Campinas, [email protected]
Antônio Augusto FröhlichFederal University of Santa
CatarinaFlorianópolis, Brazil
RESUMOO crescimento das redes de sensores sem fio (WSN) e dossistemas de monitoramento de ambientes tem gerado dadosorganizados em series temporais. Bancos de dados relacio-nais nao sao ideais para o armazenamento de dados organi-zados em series temporais. Como alternativa, apresentamosuma solucao usando um banco de dados distribuıdo especı-fico para series temporais provenientes de redes de sensoressem fio. Durante 5 meses um sistema de monitoramento realcoletou e armazenou medicoes em diferentes grandezas uti-lizando a arquitetura proposta. A arquitetura mostrou sercapaz de armazenar milhoes de series temporais, sendo umambiente confiavel para insercoes e consultas; assim abrindocaminho para analise de dados com ferramentas como o Apa-che Spark.
Palavras-ChaveBig data; internet of things; database; time series; WSN;
ABSTRACTThe increasing interest in wireless sensor networks (WSN)and monitoring systems has generating measurements orga-nized as time series. Relational databases are not recom-mended to store time series data. As an alternative, we pro-pose a solution using a specific distributed database for timeseries from wireless sensor network. During five months, areal monitoring system collected and stored measurementsin different physical quantities using the proposed architec-ture. The architecture showed to be able to store millionsof time series, being a trustful environment to insertions
Permission to make digital or hard copies of all or part of this work forpersonal or classroom use is granted without fee provided that copies arenot made or distributed for profit or commercial advantage and that copiesbear this notice and the full citation on the first page. To copy otherwise, torepublish, to post on servers or to redistribute to lists, requires prior specificpermission and/or a fee.SBSI 2016, May 17th-20th, 2016, Florianópolis, Santa Catarina, BrazilCopyright SBC 2016.
and queries; making possible to analyze data using toolslike Apache Spark.
Categories and Subject DescriptorsC.2.4 [Distributed Systems]: Distributed databases; G.3[Probability and Statistics]: Time series analysis
KeywordsBig data; internet of things; database; time series; WSN;
1. INTRODUÇÃOCom o aumento do interesse em Internet das Coisas (IoT)
e Redes de Sensores Sem Fio (WSN), sistemas de monito-ramento de ambientes tem surgido [18, 19, 16] e gerado umgrande numero de medicoes em um curto perıodo de tempo,tornando-se importante para areas relacionadas a industria[17] e ao meio ambiente [5]. As medicoes podem ser fei-tas sobre diversas grandezas, tais como temperatura, umi-dade, turbidez da agua, consumo de energia, presenca, etc..Embora nao seja possıvel prever que tipos de medicoes se-rao realizadas, os dados medidos geralmente sao organiza-dos como series temporais (time series), que sao sequenciasde observacoes sobre uma grandeza realizadas ao longo dotempo. Como os sensores realizam medicoes periodicas emintervalos de tempo que podem variar de milissegundos atedias (de acordo com o ambiente), varios dados podem sergerados todos os dias. Banco de dados relacionais tradici-onais baseados em arquitetura scale-up e SQL, tais comoMySQL e PostgreSQL, nao escalam bem com as series tem-porais geradas por essas plataformas de monitoramento [2]por oferecerem recursos que nao sao otimizados para seriestemporais. Por exemplo, uma vez que dados de series tempo-rais sao observacoes realizadas em um determinado instantede tempo, nao e necessario modificar valores passados, destaforma, utilizar um banco de dados que suporta operacoes dealteracao de valores (update) e desnecessario.
Para solucionar o problema de escalabilidade para supor-tar melhor o armazenamento de series temporais proveni-entes de redes de sensores sem fio e proposto um banco de
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
48

Figura 1: Funcionamento do sistema de monitoramento.
dados distribuıdo especıfico para series temporais.A secao 2 apresenta uma analise sucinta do ambiente uti-
lizado na coleta das series temporais; a secao 3 descreve aarquitetura utilizada; a secao 4 mostra alguns resultados quepuderam ser observados a partir da arquitetura utilizada e,por fim, a secao 5 apresenta as conclusoes obtidas atravesda arquitetura apresentada para o problema descrito.
2. ANÁLISE DO AMBIENTEO predio Smart Solar Building, da Universidade Federal
de Santa Catarina (UFSC), possui 31 sensores EPOSMote[4]que somados observam 5 grandezas (temperatura, lumino-sidade, presenca, consumo das tomadas e consumo dos arcondicionados) e sao responsaveis pelo monitoramento e au-tomacao das instalacoes. A coleta de dados realizada poresses sensores tem como objetivo: (a) o monitoramento ea supervisao do predio; e (b) posterior analise dos dadosmensurados afim de criar uma automacao inteligente para opredio.
Utilizando o sistema operacional EPOS[3] e o protocoloTSTP[15], os EPOSMote reportam as medicoes realizadaspara um gateway, que tem como funcao se comunicar comum software SCADA (responsavel pelo monitoramento e su-pervisao dos sensores) e tambem enviar as medicoes para umbanco de dados, onde uma futura mineracao e analise de da-dos podera ser realizada. Uma visao geral do funcionamentodo sistema de monitoramento pode ser visto na Figura 1.
Cada grandeza e medida por um sensor em intervalos detempo que variam de 1 a 60 segundos, o que significa queos 31 sensores no Smart Solar Building podem gerar cercade 110 mil medicoes em apenas 1 hora de observacao. Demaneira similar, algumas dezenas de sensores podem gerardezenas de milhoes de medicoes em 1 mes de observacao.Desta forma o banco de dados que armazenara as medicoesprecisa ser robusto, suportar bilhoes de registros e uma in-gestao elevada de dados por segundo. Os dados em formatode serie temporal raramente serao atualizados e tem de terregistros que contenham, no mınimo, alguma marcacao detempo[2]. Com isso, um sistema de gerenciamento de bancode dados (SGBD) relacional pode possuir diversas opera-coes desnecessarias, oferecendo, por exemplo, as operacoesde update, transacoes entre dados e nao armazenando umamarcacao de tempo por padrao (necessitando o uso de ındi-ces especıficos). Uma alternativa ao relacional e necessaria.
3. ARQUITETURAA arquitetura do Smart Solar Building comeca com a
Tabela 1: Tipos de sensores do Smart Solar Building.Variavel UnidadePresenca Booleano (1 ou 0)
Temperatura Graus Celsius (◦C)Luminosidade Luminosidade (%)
Ar condicionado Watts (W)Consumo das tomadas Watts (W)
coleta de dados atraves de uma rede de sensores sem fio(WSN) composta por EPOSMotes, que se comunicam comum EPOSMote especıfico conectado a um computador (aoqual chamamos de Gateway). O computador possui um ser-vidor que recebe os dados via MODBUS e os estrutura paraserem enviados via HTTP para (1) um software SCADA(ScadaBR) e (2) um banco de dados. Porem, antes de osdados chegarem ao banco de dados e necessario realizar al-gumas conversoes de acordo com o tipo de dado recebido(temperatura, luminosidade, etc.), pois o dado medido nor-malmente nao se encontra na unidade desejada. Essa con-versao pode ser feita de duas maneiras: (a) no momentoda medicao do dado, utilizando o dispositivo que o mensu-rou; e (b) em algum momento na cadeia de armazenamentodo dado, utilizando algum computador ou servidor mais ro-busto. Como operacoes em ponto flutuante sao muito caraspara um dispositivo de Internet das Coisas e estes primampor economia de energia, escolhemos realizar a conversaodos dados em algum momento na cadeia de armazenamentodo dado, o que e feito por um programa denominado Lehder[11]. O Lehder e uma API intermediaria entre o Gateway eo banco de dados, sendo responsavel por receber os dadosdo Gateway (via HTTP), converte-los e enviar os dados jaconvertidos para o banco de dados.
Devido as caracterısticas das series temporais e os pro-blemas descritos, um banco de dados especıfico para seriestemporais, distribuıdo e robusto e desejado. Alem disso, umbanco de dados que esteja preparado para Big Data tam-bem garante a escalabilidade necessaria para numerosas eesparsas redes de sensores sem fio, o que pode ser necessariode acordo com o ambiente envolvido. Entre as opcoes debanco de dados com essas caracterısticas estao o InfluxDB[6], OpenTSDB [13], KairosDB [8], Prometheus [14] e outrosbancos de dados mais recentes e menores, como Warp10 [1],Newts [12], etc..
Para a nossa arquitetura escolhemos o KairosDB, que con-siste de uma interface que utiliza o Apache Cassandra comobanco de dados, otimizando-o para armazenamento de series
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
49

Figura 2: Numero de medicoes diarias feitas por sete sensores do Smart Solar Building.
Figura 3: Numero de medicoes realizadas por hora em 2 de marco de 2016 no Smart Solar Building.
Figura 4: Arquitetura do Smart Solar Building.
temporais. A escolha se deu justamente pelo KairosDB utili-zar o Apache Cassandra como banco de dados, que e um dosmais confiaveis e robustos banco de dados preparados paraBig Data [7]. O KairosDB fornece uma API HTTP paraingestao e consulta de dados, de forma que a comunicacaocom o Lehder e realizada via HTTP.
Uma visao geral da arquitetura descrita do Smart SolarBuilding pode ser vista na Figura 4. A tabela 1 mostra ostipos de sensores (ou variaveis medidas) existentes no SmartSolar Building.
4. RESULTADOSCom o ambiente configurado conforme a arquitetura des-
crita acima, pudemos armazenar 14.113.192 medicoes aolongo de 5 meses de funcionamento do Smart Solar Building,com o primeiro dado sendo armazenado em 20 de setembro
2015 e o ultimo em 3 de marco de 2016. O numero de medi-coes realizadas esta abaixo do previsto, pois o predio aindaesta em ambiente de teste, onde erros relacionados a indis-ponibilidade de rede, as falhas nos sensores, a configuracaodo ambiente e na falta de energia criaram intervalos conside-raveis de tempo onde nenhuma medicao pode ser realizada.
Um grafico exibindo quantas medicoes cada sensor reali-zou por dia (similar a Figura 2) foi disponibilizado online [9].
E importante notar que cada uma das 7 variaveis da Figura2 sao medidas por um e apenas um sensor, portanto ”Tem-peratura 1”nao e o numero de medicoes de todos os sensoresde temperatura, mas sim o numero de medicoes realizadopor um unico sensor. Como e possıvel observar na Figura 2,o numero de medicoes realizadas pelos sensores varia con-sideravelmente, mas em tempos de estabilidade se mantemno intervalo de 3 mil a 9 mil medicoes por dia. Enquantoisso, a media de medicoes realizadas por dia ao longo de 5meses (”Avg”) gira em torno de 5 mil medicoes por dia. Epossıvel notar atraves da Figura 3 (tambem disponıvel on-line [10]) que a ingestao de dados a cada hora nao e muitoalta, ficando na media de 302.8 medicoes por hora.
Alguns problemas de instabilidade no banco de dados fo-ram encontrados durante os meses de teste da arquitetura,mas todos estavam relacionados a ma configuracao do Apa-che Cassandra e limitacoes fısicas, como por exemplo faltade memoria RAM.
5. CONCLUSÃOO crescimento do interesse em Internet das Coisas (IoT) e
Redes de Sensores Sem Fio (WSN) tem se tornado evidentenos ultimos anos e a criacao de produtos baseados nessastecnologias e inevitavel. Bancos de dados relacionais tradi-cionais nao estao preparados para tal cenario, fazendo-se ne-
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
50

cessario o uso de bancos de dados especıficos para o problemade armazenamento de dados provenientes de WSN. Com aarquitetura apresentada foi possıvel otimizar um problemade armazenamento de milhoes de medicoes em um bancode dados distribuıdo e especıfico para series temporais. Em-bora uma elevada ingestao de dados nao tenha sido obtida, aarquitetura se mostrou estavel durante as insercoes e consul-tas realizadas (inclusive com testes preliminares utilizandoo Apache Spark para realizar analise dos dados). Conclui-se, portanto, que a arquitetura proposta pode suportar umambiente onde milhoes de medicoes serao feitas sem grandesproblemas, entretanto maiores testes precisam ser realizadospara descobrir se a arquitetura consegue escalar para bilhoesde medicoes.
Para trabalhos futuros e pretendido: (1) testar a arqui-tetura descrita com uma ingestao de dados mais elevada,podendo chegar a bilhoes de medicoes; (2) integrar a arqui-tetura com ferramentas de processamento de dados parale-las, tais como Apache Spark, e realizar mineracao de dadossobre os dados coletados; (3) armazenar dados de sensoresutilizando geolocalizacao ao inves de associar medicoes comum sensor especıfico.
6. REFERÊNCIAS[1] C. Data. Site oficial do Warp10.
http://www.warp10.io/. [Online; acessado em26-Fevereiro-2016].
[2] T. Dunning and E. Friedman. Time Series Databases:New Ways to Store and Access Data, pages 25–36.O’Reilly Media, 2014.
[3] A. A. Frohlich and W. Schroder-Preikschat. EPOS: anObject-Oriented Operating System. In 2nd ECOOPWorkshop on Object-Orientation and OperatingSystems, volume CSR-99-04 of ChemnitzerInformatik-Berichte, pages 38–43, Lisbon, Portugal,June 1999.
[4] A. A. Frohlich, R. Steiner, and L. M. Rufino. ATrustful Infrastructure for the Internet of Thingsbased on EPOSMote. In 9th IEEE InternationalConference on Dependable, Autonomic and SecureComputing, pages 63–68, Sydney, Australia, Dec. 2011.
[5] J. K. Hart and K. Martinez. Environmental sensornetworks: A revolution in the earth system science?Earth-Science Reviews, 78:177–191, 10 2006.
[6] InfluxData. Site oficial do InfluxDB.http://influxdata.com/. [Online; acessado em26-Fevereiro-2016].
[7] T. Ivanov, R. Niemann, S. Izberovic, M. Rosselli,K. Tolle, and R. V. Zicari. Performance evaluation ofenterprise big data platforms with hibench. In IEEETrustcom/BigDataSE/ISPA, pages 120–127, Helsinki,Finland, August 2015. IEEE.
[8] KairosDB. Site oficial do KairosDB.http://kairosdb.org/. [Online; acessado em26-Fevereiro-2016].
[9] LISHA. Contador de medicoes (dia a dia).https://iot.lisha.ufsc.br:3000/dashboard/db/
wicsi-contador-de-medicoes-dia-a-dia?from=
1444979068656&to=1457060399999. [Online; acessadoem 23-Marco-2016].
[10] LISHA. Contador de medicoes (hora a hora).https://iot.lisha.ufsc.br:3000/dashboard/db/
wicsi-contador-de-medicoes-hora-a-hora?from=
1456887600000&to=1456973999999. [Online; acessadoem 03-Marco-2016].
[11] LISHA. Repositorio Git Lehder.https://gitlab.com/lisha/lehder/. [Online;acessado em 29-Fevereiro-2016].
[12] Newts. Site oficial do Newts. http://newts.io/.[Online; acessado em 26-Fevereiro-2016].
[13] OpenTSDB. Site oficial do OpenTSDB.http://opentsdb.net/. [Online; acessado em26-Fevereiro-2016].
[14] Prometheus. Site oficial do Prometheus.http://prometheus.io/. [Online; acessado em26-Fevereiro-2016].
[15] D. Resner and A. A. Frohlich. Design Rationale of aCross-layer, Trustful Space-Time Protocol for WirelessSensor Networks. In 20th IEEE InternationalConference on Emerging Technologies and FactoryAutomation (ETFA 2015)., pages 1–8, Luxembourg,Luxembourg, Sept. 2015.
[16] R. Rushikesh and C. M. R. Sivappagari. Developmentof iot based vehicular pollution monitoring system. InInternational Conference on Green Computing andInternet of Things (ICGCIoT), pages 779–783. IEEE,October 2015.
[17] A. Tiwari, P. Ballal, and F. L. Lewis. Energy-efficientwireless sensor network design and implementation forcondition-based maintenance. ACM Transactions onSensor Networks (TOSN), 3, 3 2007.
[18] C. Xiaojun, L. Xianpeng, and X. Peng. Iot-based airpollution monitoring and forecasting system. InInternational Conference on Computer andComputational Sciences (ICCCS), pages 257–260.IEEE, January 2015.
[19] J. Zambada, R. Quintero, R. Isijara, R. Galeana, andL. Santillan. An iot based scholar bus monitoringsystem. In IEEE First International Smart CitiesConference (ISC2), pages 1–6. IEEE, October 2015.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
51

Utilização e Integração de Bases de Dados Relacionais por meio de Foreign Tables para utilização em
ferramentas OLAP. Alternative Title: Utilization and Integration Database Relational
by means of Foreign Tables for utilization in OLAP tools. Felipe Igawa Moskado, André Menolli, Glauco C. Silva, Ricardo G. Coelho, Luan S. Melo
Universidade Estadual do Norte do Paraná – UENP Centro de Ciências Tecnológicas
Rod. Br 369 Km 64 [email protected], {menolli,glauco,rgcoelho}@uenp.edu.br,[email protected]
RESUMO Os ambientes de Business Intelligence auxiliam os administradores das empresas a tomarem decisões mais precisas sobre o seu negócio. Estes ambientes normalmente utilizam o Data Warehouse que é um banco de dados integrado e voltado à consulta. No entanto, a implantação de um DW é muito cara e demorada, sendo um grande obstáculo, principalmente para pequenas e médias empresas. De forma a tentar minimizar estes problemas foi proposta a metodologia Agile ROLAP, que visa auxiliar na utilização de ferramentas OLAP a partir das bases relacionais das empresas. No entanto, a fim de não utilizar diretamente a base de dados original e integrar diferentes bases, propõe-se um mecanismo intermediário que utilize a tecnologia Foreign Data Wrapper. Assim este trabalho apresenta o desenvolvimento de plugins para a ferramenta Kettle que auxilie na criação de Foreign Tables e na integração de dados. Palavras-Chave Foreign Data Wrapper, Agile ROLAP, Data Warehouse, Business Intelligence. ABSTRACT The Business Intelligence environments assists the companies administrators take more accurate decisions about your businesses. These environments normally use the Data Warehouse, which is an integrated database and prepared for query. However, the implementation of a DW is very expensive and times consuming, and a great obstacle, mainly for small and medium enterprises. In order to try to minimize these problems was proposed the Agile ROLAP methodology, which aims to help in the use of OLAP tools from relational databases of companies. However, in order to not use directly the original database and integrate different databases, it is proposed an intermediate mechanism that uses the Foreign Data Wrapper technology. Thus, this work presents the development of plugins for Kettle tool that assists in the creation of Foreign Tables and data integration.
Categories and Subject Descriptors H.2.4 [Database Management]: Systems – Distributed databases. H.2.7 [Database Management]: Database Administration – data warehouse and repository. General Terms Algorithms, Management, Security. Keywords Foreign Data Wrapper, Agile ROLAP, Data Warehouse, Business Intelligence. 1. INTRODUÇÃO As empresas com o decorrer do tempo armazenam uma grande quantidade de informações sobre o seu negócio, e no intuito de utilizar as informações adquiridas no decorrer do tempo, muitas fazem uso de ambientes de Business Intelligence (BI). Estes ambientes de BI auxiliam na análise dos dados de forma eficiente e na tomada de decisão dos administradores da organização, facilitando também o conhecimento sobre o seu negócio. A implementação de BI não é algo trivial, demanda custo e tempo, pois é necessário um Data Warehouse (DW), que tem como finalidade armazenar informações relativas às atividades da organização de forma consolidada. O processo para a criação do DW geralmente é desenvolvido de modo iterativo, mas mesmo assim são necessários em média 15 ou mais meses para que o primeiro módulo entre em produção [1]. Segundo [2], o método Agile ROLAP tem por objetivo permitir a implantação de forma ágil de ambientes de BI que utilizem bancos de dados relacionais, e ao mesmo tempo permitam a utilização de ferramentas OLAP projetadas para ambientes tradicionais por meio de um servidor ROLAP. No entanto, é proposto no Agile Rolap, que se utilize um mecanismo intermediário que permita integrar os dados de diversas fontes de dados em uma única base, para que se mantenha o conceito de DW e que possa utilizar ferramentas de BI projetadas para serem utilizadas em DWs. Essa integração deve ocorrer de maneira transparente ao usuário, de forma a não migrá-los em uma nova base de dados, uma vez que esse é o conceito de integração utilizado nos DWs. Portanto, é proposta a criação de plugins para a ferramenta Kettle, que auxiliem que dados de diferentes fontes de dados sejam integrados
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. SBSI 2016, May 17–20, 2016, Florianópolis, Santa Catarina, Brazil. Copyright SBC 2016.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
52

em uma única base de dados PostgreSQL, permitdesses dados de fontes externas por meio dtecnologia Foreign Data Wrapper (FDW),melhor análise em conjunto dos dados [3]. 2. REVISÃO BIBLIOGRÁFICANesta seção são apresentados alguns dos principais conceitos bases para o desenvolvimento do trabalho. 2.1 AGILE ROLAP A necessidade de armazenar as informações da empresa e conseguir fazer uma análise eficiente das mesmas é um fator muito importante no mercado de hoje, com isso originouconceito de DW, que é um depósito de dados que consiste em armazenar uma grande quantidade de dados relativa às atividades de uma empresa. Além de favorecer uma melhor análise de um grande volume de dados por meio de ferramentas OLAP, facilitando e auxiliando na tomada de decisão dasDW é o resultado do processo de transformação dos dados obtidos de sistemas legados e de bancos de dados transacionais que ficam organizados sob um formato compreensível ao usuário, auxiliando na tomada de decisão [5]. No entanto, como mencionado anteriormente, o processo de criação de um DW é custosa e demorada, o que muitas vezes se torna um empecilho para que, principalmente pequenas e médias empresas o implantem. Dessa forma foi proposta a metodologia Agile ROLAPintuito mitigar alguns problemas encontrados BI, principalmente diminuindo tempo com o processo deTransformation Loading (ETL). Apesar da metodologia não utilizar o conceito tradicional de DW, consegueseu uso utilizar as ferramentas Online Analytical Processing (OLAP) disponíveis no mercado. Assim, a metodologia visa diminuir o tempo despendido nprocesso de ETL, pois não há necessidade de criar uma nova base de dados. Estima-se que mais de 1/3 do custo na elaboração de DW se dá no processo de ETL [4]. Isto permite empresas possam usufruir de ferramentas OLAPambientes de BI tradicionais, proporcionando auxilio na tomada de decisão do administrador da organização baseado nas informações geradas, assim podendo conhecer melhor sobrenegócio além de competir melhor no mercadoA Figura 1 mostra como é o funcionamento do função de cada etapa apresentada na Figura 1 é descrita a seguir:
Físico: representa bases de dados originais. das empresas estão armazenadas em FDW: Tem como finalidade agrupar todas as informações da empresa em uma única base de dados. Estas informações estão armazenadas em formas de tabelas, porém são mapeamentos para asoriginais que estão armazenadas no Físico. Quausuário acessa a tabela, o FDW consulta diretamente a base de origem de forma transparente, assim o usuário tem a impressão que está acessando a basena verdade está consultando os dados da base original. Com isso não tem o risco de quoriginal sejam modificados, pois o FDW permite apenas o usuário a fazer consultas. Schema: é um arquivo conhecido como Esse arquivo realiza o mapeamento dos dados que estão armazenados na forma relacional, no caso no FDW, para os dados que devem ser mostrados na forma dimensional. Basicamente esse
permitindo a consulta as por meio da utilização da
(FDW), possibilitando uma
EVISÃO BIBLIOGRÁFICA Nesta seção são apresentados alguns dos principais conceitos
necessidade de armazenar as informações da empresa e conseguir fazer uma análise eficiente das mesmas é um fator muito importante no mercado de hoje, com isso originou-se o
DW, que é um depósito de dados que consiste em tidade de dados relativa às atividades
de uma empresa. Além de favorecer uma melhor análise de um s por meio de ferramentas OLAP, omada de decisão das empresas.
transformação dos dados obtidos de sistemas legados e de bancos de dados transacionais que ficam organizados sob um formato compreensível ao usuário, auxiliando
No entanto, como mencionado um DW é custosa e
demorada, o que muitas vezes se torna um empecilho para que, principalmente pequenas e médias empresas o implantem. Dessa
ROLAP, que tem como problemas encontrados na implantação de
o processo de Extract . Apesar da metodologia não
utilizar o conceito tradicional de DW, consegue-se por meio de Online Analytical Processing
visa diminuir o tempo despendido no processo de ETL, pois não há necessidade de criar uma nova base
se que mais de 1/3 do custo na elaboração de um Isto permite que pequenas
de ferramentas OLAP voltadas para BI tradicionais, proporcionando auxilio na tomada
de decisão do administrador da organização baseado nas , assim podendo conhecer melhor sobre o seu
ócio além de competir melhor no mercado. como é o funcionamento do Agile ROLAP e a
apresentada na Figura 1 é descrita a seguir: dados originais. Os dados
em tabelas relacionais. Tem como finalidade agrupar todas as
informações da empresa em uma única base de dados. Estas informações estão armazenadas em formas de
mapeamentos para as tabelas originais que estão armazenadas no Físico. Quando um usuário acessa a tabela, o FDW consulta diretamente a base de origem de forma transparente, assim o usuário
que está acessando a base original, mas do os dados da base original.
Com isso não tem o risco de que os dados da base , pois o FDW permite apenas
é um arquivo conhecido como schema XML. o mapeamento dos dados que estão
armazenados na forma relacional, no caso no FDW, a os dados que devem ser mostrados na forma
dimensional. Basicamente esse schema indica onde
estão os valores dos atributos na perspectiva multidimensional na base de dados relacional. Ferramentas OLAPpara os usuários finaimapeados e podem e devem ser visualizados de maneira simples pelo responsável acessados por meio de um servidor ROLAP.
Figura 1 - Funcionamento do 2.2 FOREIGN DATA WRAPPERO FDW é um modelo para escrever um módulo para acessar dados externos baseado no padrão SQL/MED, este é um padrão para acessar objetos remotos [6]. aplicado este conceito no banco de dados PostgreSQLmesmo oferece um melhor suporte para essa tecnologiaestrutura é dividida em 3 partes dentro doBanco de Dados (SGBD) são: as Foreign Tables. Os Wrappers são drivers que apontam para de dados, além de existir um exemplo, na Figura 2 existe um que automaticamente aponta para um pois o PostgreSQL sabe que esse é o estão armazenados os dados originais.As Foreign Tables são cópias dabase de dados de origem. As mesmas mantém uma imagem de tempo real do que está sendo armazenado na tabela original e caso esta seja modificada é também tabelas não é possível fazer alterações nos dados, somente consultas. O “local” tables ou servidor armazenadas. Este local pode ser chamado de servidorservidores têm como objetivo fazer a conexdados externo, além de ser o local desejadas. Um wrapper pode ter vários servidores que apontam para diferentes bases de dados do mesmo banco de dados.
Figura 2 - Estrutura do ForeignApós ser criado toda a estrutura do FDW, esta tecnologia ao banco de dados PostgreSQL reunir inúmeros dados de
estão os valores dos atributos na perspectiva multidimensional na base de dados relacional. Ferramentas OLAP: São as ferramentas de consulta para os usuários finais. Nesta fase, os dados já foram mapeados e podem e devem ser visualizados de maneira
responsável da tomada de decisão, que são acessados por meio de um servidor ROLAP.
Funcionamento do Agile ROLAP
FOREIGN DATA WRAPPER O FDW é um modelo para escrever um módulo para acessar dados externos baseado no padrão SQL/MED, este é um padrão para acessar objetos remotos [6]. A Figura 2 ilustra como é
no banco de dados PostgreSQL, pois o esmo oferece um melhor suporte para essa tecnologia. A
estrutura é dividida em 3 partes dentro do Sistema Gerenciador de os Wrappers, os “local” tables, e
apontam para outros tipos de bancos um para o próprio PostgreSQL. Por
existe um wrapper chamado mysql_fdw, automaticamente aponta para um banco de dados MySQL, o PostgreSQL sabe que esse é o driver do MySQL e lá que
os dados originais. são cópias da estrutura das tabelas originais da
s mesmas mantém uma imagem de tempo real do que está sendo armazenado na tabela original e caso
também alterada a Foreign Table. Nestas tabelas não é possível fazer alterações nos dados, somente
ou servidor é onde as Foreign Tables são ste local pode ser chamado de servidor. Os
servidores têm como objetivo fazer a conexão com o banco de ser o local que armazena as tabelas
pode ter vários servidores que apontam para diferentes bases de dados do mesmo banco de dados.
Estrutura do Foreign Data Wrapper
pós ser criado toda a estrutura do FDW, esta tecnologia permite ao banco de dados PostgreSQL reunir inúmeros dados de
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
53
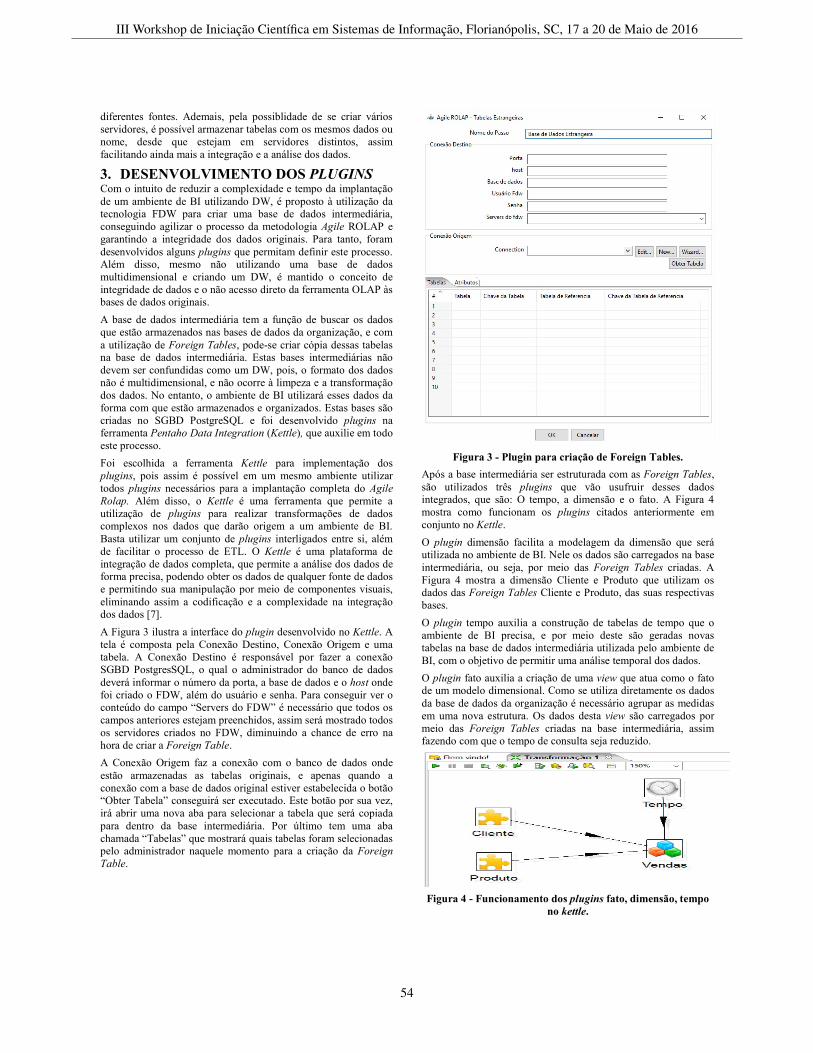
diferentes fontes. Ademais, pela possiblidade de se criar vários servidores, é possível armazenar tabelas com os mesmos dados ou nome, desde que estejam em servidores distintos, assim facilitando ainda mais a integração e a análise dos dados. 3. DESENVOLVIMENTO DOS PLUGINS Com o intuito de reduzir a complexidade e tempo da implantação de um ambiente de BI utilizando DW, é proposto à utilização da tecnologia FDW para criar uma base de dados intermediária, conseguindo agilizar o processo da metodologia Agile ROLAP e garantindo a integridade dos dados originais. Para tanto, foram desenvolvidos alguns plugins que permitam definir este processo. Além disso, mesmo não utilizando uma base de dados multidimensional e criando um DW, é mantido o conceito de integridade de dados e o não acesso direto da ferramenta OLAP às bases de dados originais. A base de dados intermediária tem a função de buscar os dados que estão armazenados nas bases de dados da organização, e com a utilização de Foreign Tables, pode-se criar cópia dessas tabelas na base de dados intermediária. Estas bases intermediárias não devem ser confundidas como um DW, pois, o formato dos dados não é multidimensional, e não ocorre à limpeza e a transformação dos dados. No entanto, o ambiente de BI utilizará esses dados da forma com que estão armazenados e organizados. Estas bases são criadas no SGBD PostgreSQL e foi desenvolvido plugins na ferramenta Pentaho Data Integration (Kettle), que auxilie em todo este processo. Foi escolhida a ferramenta Kettle para implementação dos plugins, pois assim é possível em um mesmo ambiente utilizar todos plugins necessários para a implantação completa do Agile Rolap. Além disso, o Kettle é uma ferramenta que permite a utilização de plugins para realizar transformações de dados complexos nos dados que darão origem a um ambiente de BI. Basta utilizar um conjunto de plugins interligados entre si, além de facilitar o processo de ETL. O Kettle é uma plataforma de integração de dados completa, que permite a análise dos dados de forma precisa, podendo obter os dados de qualquer fonte de dados e permitindo sua manipulação por meio de componentes visuais, eliminando assim a codificação e a complexidade na integração dos dados [7]. A Figura 3 ilustra a interface do plugin desenvolvido no Kettle. A tela é composta pela Conexão Destino, Conexão Origem e uma tabela. A Conexão Destino é responsável por fazer a conexão SGBD PostgresSQL, o qual o administrador do banco de dados deverá informar o número da porta, a base de dados e o host onde foi criado o FDW, além do usuário e senha. Para conseguir ver o conteúdo do campo “Servers do FDW” é necessário que todos os campos anteriores estejam preenchidos, assim será mostrado todos os servidores criados no FDW, diminuindo a chance de erro na hora de criar a Foreign Table. A Conexão Origem faz a conexão com o banco de dados onde estão armazenadas as tabelas originais, e apenas quando a conexão com a base de dados original estiver estabelecida o botão “Obter Tabela” conseguirá ser executado. Este botão por sua vez, irá abrir uma nova aba para selecionar a tabela que será copiada para dentro da base intermediária. Por último tem uma aba chamada “Tabelas” que mostrará quais tabelas foram selecionadas pelo administrador naquele momento para a criação da Foreign Table.
Figura 3 - Plugin para criação de Foreign Tables.
Após a base intermediária ser estruturada com as Foreign Tables, são utilizados três plugins que vão usufruir desses dados integrados, que são: O tempo, a dimensão e o fato. A Figura 4 mostra como funcionam os plugins citados anteriormente em conjunto no Kettle. O plugin dimensão facilita a modelagem da dimensão que será utilizada no ambiente de BI. Nele os dados são carregados na base intermediária, ou seja, por meio das Foreign Tables criadas. A Figura 4 mostra a dimensão Cliente e Produto que utilizam os dados das Foreign Tables Cliente e Produto, das suas respectivas bases. O plugin tempo auxilia a construção de tabelas de tempo que o ambiente de BI precisa, e por meio deste são geradas novas tabelas na base de dados intermediária utilizada pelo ambiente de BI, com o objetivo de permitir uma análise temporal dos dados. O plugin fato auxilia a criação de uma view que atua como o fato de um modelo dimensional. Como se utiliza diretamente os dados da base de dados da organização é necessário agrupar as medidas em uma nova estrutura. Os dados desta view são carregados por meio das Foreign Tables criadas na base intermediária, assim fazendo com que o tempo de consulta seja reduzido.
Figura 4 - Funcionamento dos plugins fato, dimensão, tempo
no kettle.
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
54

4. RESULTADOS A fim de verificar se a utilização de bases intermediárias, implantadas utilizando a tecnologia FDW, é viável em termos de desempenho se comparado ao DW tradicional, algum testes foram realizados. O Agile ROLAP não precisa necessariamente de uma base intermediária para ser implantado, os dados podem ser acessados diretamente das próprias bases transacionais utilizada pela organização, no entanto isto dificulta a integração dos dados, um dos preceitos do DW. Além disso, a implantação de ambientes de BI utilizando a própria base da organização faz com que seja necessária a permissão para que sejam realizadas modificações na estrutura do banco, o que é muito indesejável. Assim, é fortemente recomendado que na utilização do Agile ROLAP seja criada uma base de dados intermediária, que implementa a função de armazenar os dados adicionais necessários para implantar o ambiente de BI. Para realizar a comparação de desempenho, foi utilizada uma base de dados exemplo do Postgres, chamada Pagila. Foram realizados testes no qual a ferramenta OLAP acessa uma base intermediária de três formas distintas: os dados do fato em tabela, em view e em view materializada. Na Figura 5 é possível ver o desempenho obtido por cada tecnologia.
Figura 5 – Comparação do desempenho de acesso OLAP a
três tecnologias. Observando a Figura 5, percebe-se que a utilização de fatos em view tem um tempo de resposta gerado muito superior em relação à utilização de fatos em tabelas e fatos em views materializadas. Baseado nas comparações de tempo de resposta foi escolhida à utilização de fatos em views materializadas para a implementação método Agile ROLAP no ambiente de BI, pois não haverá necessidade de reconstruir o objeto quando os dados forem recarregados. Na Figura 6 é mostrado o desempenho obtido na implantação de ambientes de BI, utilizando o método Agile ROLAP, por meio de bases intermediárias usando FDW para obter os dados das bases transacionais. Nesta Figura, é comparado o desempenho do acesso aos dados por meio de ferramentas OLAP, quando os dados são armazenados utilizando a tecnologia FDW em comparação ao acesso dos dados quando estão armazenados diretamente na própria base de dados transacionais, e ainda comparando com a utilização de um DW. Percebe-se que a utilização de base de dados intermediária tem um desempenho inferior em relação ao método Agile ROLAP, que utiliza a própria base de dados transacionais da empresa, porém discrepância não foi tão significativa. Apenas na primeira consulta resultou em uma diferença expressiva, nas demais consultas o resultado foi equivalente ou muito próximo.
5. CONSIDERAÇÕES FINAIS O uso do FDW como base intermediária se mostrou uma alternativa viável para acessar de forma rápida os dados por meio de ferramentas OLAP. O uso do FDW permite o acesso aos dados das bases de origem de forma transparente, e ao mesmo tempo não modifica esta base, pois caso seja necessário criar novas tabelas, como as de Tempo, estas são criadas diretamente na base FDW. Além disso, permite a integração de diferentes bases, um preceito importante do DW. Os resultados do uso desta tecnologia se mostraram satisfatórios em termos de desempenho, o que mostra que seu uso é viável. Como principal limitação, no estado em se encontra os plugins, consegue-se acessar apenas dados de fontes de bases de dados relacionais, não conseguindo acesso a outros tipos de fontes de dados.
Figura 6 – Comparação do desempenho entre FDW, DW e
Bases de Origem. 6. AGRADECIMENTOS Meu agradecimento ao órgão Conselho Nacional de Pesquisas (CNPq) pela bolsa que me foi concebida. 7. REFERÊNCIAS [1] MACHADO, Felipe N. R. “Tecnologia e Projeto de Data
Warehouse: Uma visão multidimensional” São Paulo: Érica 2010 5 ed.
[2] SOUZA, Elielson B., MENOLLI, André L. A., COELHO, Ricardo G. “Um método Agile ROLAP para implementação de ambientes de inteligência de negócios”.
[3] SAVOV, Svetoslav. “How to use PostgreSQL Foreign Data Wrappers for external data management”
[4] MENOLLI, André L. A. “A Data Warehouse Architeture in Layers for Science and Tecnology” Proceedings of the Eighteenth International Conference on Software Engineering Knowledge Engineering (SEKE’2006), San Francisco, CA, USA.
[5] KIMBALL, Ralph., CASERTA, Joe “The Data Warehouse ETL Toolkit: Practical Techniques for Extracting, Cleaning, Conforming, and Delivering Data”
[6] AHMED, Ibrar., FAYYAZ, Asif., SHAHZAD, Amjad. “PostgreSQL Developer’s Guide”.
[7] PENTAHO. “Pentaho: Writing you own Pentaho Data Integration Plug-in”. Pentaho Community, 2014. http://wiki.pentaho.com/dislplay/EA/Writing+your+own+Pentaho+Data+Intagration+Plug-in. Acessado em 11 de março de 2016
III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
55

III Workshop de Iniciação Científica em Sistemas de Informação, Florianópolis, SC, 17 a 20 de Maio de 2016
Índice Remissivo
AAbreu, Christian R.C. de . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5Araújo, Cristian Z. de . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
BBaldessar, Maria J. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
CCoelho, Ricardo G. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .21, 52Correia, Wagner . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5, 43Cunha, Mônica X.C. da . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
DDuda Júnior, José da S. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
FFagundes, Priscila B. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25Figueiredo, Rejane M. da C. . . . . . . . . . . . . . . . . . . . . . . . . . . . 17Frohlich, Antonio A. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
HHauck, Jean C.R. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
LLima Junior, Guaratã A.F. de . . . . . . . . . . . . . . . . . . . . . . . . . . . 31Lins, Matheus I.A. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9Lopes, Bruno . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
MMarques, Caique R. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48Martins, Augusto B.T. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35Mello, Leonardo R. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25Melo, Luan S. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21, 52Menolli, André . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21, 52Momo, Marcos R. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .5
Morais, Emilie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17Moskado, Felipe I. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21, 52
NNau, Jonathan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
OOliveira, Aline C.A. de . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25Oliveira, Geovanni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
PPaladini, Fernando . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
RRomão, Luiz Melo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39Ruano, Antonio E. de B. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
SSilva, Alexandre S. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1Silva, Glauco C. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21, 52Silva, Rodrigo C. da . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31Silva, Viviane A. da . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
TTrevisani, Kleber M. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
VVenson, Elaine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17Vieira, Lucas N. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
WWanner, Lucas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .48
ZZanchett, Pedro S. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .5,43
56

Related Documents











