Limits of Instruction-Level Parallelism Presentation by: Robert Duckles CSE 520 Paper being presented: Limits of Instruction-Level Parallelism David W. Wall WRL Research Report, November 1993

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

8/3/2019 Presentation Robert
http://slidepdf.com/reader/full/presentation-robert 1/18
Limits of Instruction-LevelParallelism
Presentation by: Robert Duckles
CSE 520
Paper being presented:Limits of Instruction-Level Parallelism
David W. WallWRL Research Report, November 1993

8/3/2019 Presentation Robert
http://slidepdf.com/reader/full/presentation-robert 2/18
What is ILP?
Instructions that do not have dependencies on each other;can be executed in any order.
r1 := 0[r9] r1 := 0[r9]r2 := 17 r2 := r1 + 174[r3] := r6 4[r2] := r6(has ILP) (no ILP)
Super-scalar machine – a machine that can issue multipleindependent instructions in the same clock cycle.

8/3/2019 Presentation Robert
http://slidepdf.com/reader/full/presentation-robert 3/18
Definition of Parallelism
Parallelism = (Number of Instructions) / (Number of Cycles it takes to execute)
r1 := 0[r9] r1 := 0[r9]r2 := 17 r2 := r1 + 174[r3] := r6 4[r2] := r6
Parallelism = 3 Parallelism = 1

8/3/2019 Presentation Robert
http://slidepdf.com/reader/full/presentation-robert 4/18
How much parallelism is there?
That depends how hard you want to look for it...
Ways to increase ILP: Register renaming Branch prediction Alias analysis Indirect-jump prediction

8/3/2019 Presentation Robert
http://slidepdf.com/reader/full/presentation-robert 5/18
Low estimate for ILP
Programs are made up of ―basic blocks‖— uninterrupted
sequences of instructions with no branches.
On average, in typical applications, basic blocks are ~10instructions long.
Each basic block has parallelism of around 3.

8/3/2019 Presentation Robert
http://slidepdf.com/reader/full/presentation-robert 6/18
High estimate for ILP
If you look beyond a basic block, at the entire scope of a program,studies have shown that an ―omniscient‖ scheduler can achieve
parallelism of > 1000 in some numerical applications.
―Omniscient‖ scheduling can be implemented by saving a trace of a program execution, and using an oracle to schedule it. Theoracle knows what will happen, and thus can create a perfectexecution schedule.
Practical, achievable ILP should be between 3 and 1000.

8/3/2019 Presentation Robert
http://slidepdf.com/reader/full/presentation-robert 7/18
Types of dependencies
Types of dependencies:
* True dependency - given the computations involved, the dependency must exist* False dependency - dependency happens to exist as an artifact of the code generationengine. E.g., two independent values are allocated to the same register by the compiler.
r1 := 20[r4] r2 := r1 + r4... ...r2 := r1 + 1 r1 := r17 - 1
(a) true data dependency (b) anti-dependency
r1 := r2 * r3 if r17 = 0 goto L...
... r1 := r2 + r3...
r1 := 0[r7] L:(c) output dependency (d) control dependency

8/3/2019 Presentation Robert
http://slidepdf.com/reader/full/presentation-robert 8/18
Register renaming
The compiler's register allocation algorithm can insert falsedependencies by assigning unrelated values to the sameregister. We can undo this damage by assigning each value to aunique register so that only true dependencies remain. However, machines have a finite number of registers, so wecan never guarantee perfect parallelism.

8/3/2019 Presentation Robert
http://slidepdf.com/reader/full/presentation-robert 9/18
Register renaming

8/3/2019 Presentation Robert
http://slidepdf.com/reader/full/presentation-robert 10/18
Alias analysis
We often have registers that point to a memory location or containa memory offset. Can two memory pointers point to the sameplace in memory? If so, there might be a dependency. We're not sure yet. We can try to inspect pointer values at runtime to see if they point
to overlapping memory.

8/3/2019 Presentation Robert
http://slidepdf.com/reader/full/presentation-robert 11/18
Alias analysis

8/3/2019 Presentation Robert
http://slidepdf.com/reader/full/presentation-robert 12/18
Limitations of branch prediction:
We can correctly predict around ~0.9 by counting which branches havebeen recently taken, and taking the most common one.

8/3/2019 Presentation Robert
http://slidepdf.com/reader/full/presentation-robert 13/18
Indirect-jump prediction
If we jump to an address that is not known at compile time--for example, if a destinationaddress is calculated into a register at runtime.
This is often the case for "return" constructs, where the the calling function's address isstored on the stack. In this case, we can do indirect-jump prediction.

8/3/2019 Presentation Robert
http://slidepdf.com/reader/full/presentation-robert 14/18
Latency
Multi-cycle instructions can greatly decrease parallelism

8/3/2019 Presentation Robert
http://slidepdf.com/reader/full/presentation-robert 15/18
Window size
The window size is the maximum number ofinstructions that can appear in the pending cyclelist.
8/3/2019 Presentation Robert
http://slidepdf.com/reader/full/presentation-robert 16/18
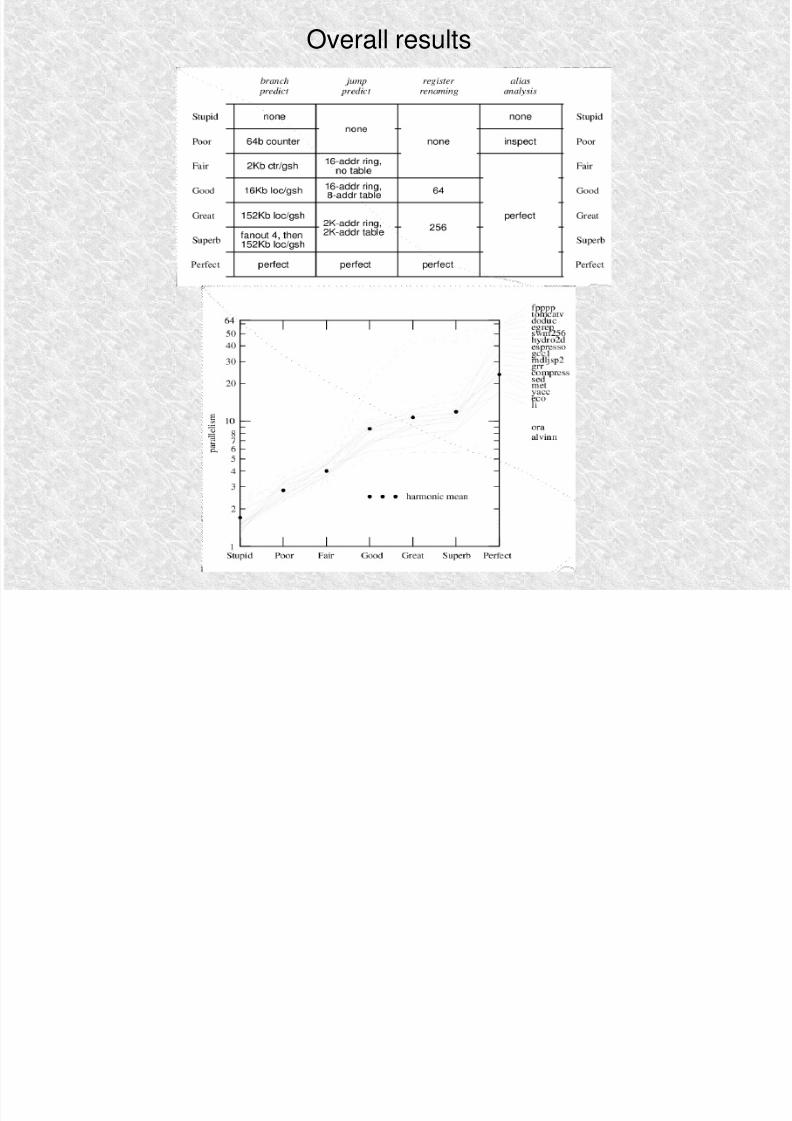
Overall results

8/3/2019 Presentation Robert
http://slidepdf.com/reader/full/presentation-robert 17/18
Conclusions: the ILP Wall
Even with ―perfect‖ techniques, most real applications hit an ILP limit of around 20 With reasonable, practical methods, it's even worse—it's
very difficult to get an ILP above 10.

8/3/2019 Presentation Robert
http://slidepdf.com/reader/full/presentation-robert 18/18
Relationship to Term Project
Our term project is about optimization techniques for AMD64Opteron/Athlon processors. Maximizing ILP is essential to getting the most performance
out of any processor. Branch prediction, register renaming, etc., are all particularlyrelevant optimizations
Related Documents











