Abstract— In this paper we describe a high performance environment, like cluster computers, with high accuracy obtained by use of C-XSC library. The C-XSC library is a (free) C++ class library for scientific computing for the development of numerical algorithms delivering highly accurate and automatically verified results by use of the interval arithmetic. These calculus in high accuracy must be available for some basic arithmetic operations, mainly the operations that accomplish the summation and dot product. Because of these aspects, we wish to use the high performance through a cluster environment where we have several nodes executing tasks or calculus. The communication will be done by message passing using the MPI communication library. To obtain the high accuracy in this environment extensions or changes in the parallel programs had done to guarantee that the quality of final result done on cluster, where several nodes collaborate for the final result of the calculus, maintain the same result quality obtained in one sequential high accuracy environment. To validate the environment developed in this work we done basic tests about the dot product, the matrix multiplications, the implementation of interval solvers for banded and dense matrices and the implementation of some numeric methods to solve linear systems with the high accuracy characteristic (some of the methods implemented are used in real life applications like hydrodynamic, agriculture and power electric systems). With these tests we done analysis and comparisons about the performance and accuracy obtained with and without the use of C-XSC library in sequential and parallel programs. With the implementation of these routines and methods will be open a large research field about the study of real life applications that need during their resolution (or in part of their resolution) to calculate arithmetic operations with more accuracy than the accuracy obtained by the traditional computational tools. Our software run on labtec (UFRGS) and Colorado (UPF) clusters. Nowadays we are working in the implementation of parallel versions of programs to solve linear systems (without and with high accuracy) and the optimization of C-XSC library on cluster computers. Keywords— Cluster computing, linear equations, numerical library, high accuracy, verified computing. Carlos Amaral Hölbig (E-mail: [email protected]) é professor do curso de Ciência da Computação do Instituto de Ciências Exatas e Geociências da Universidade de Passo Fundo, Passo Fundo (RS), Brasil. Tiarajú Asmuz Diverio (E-mail: [email protected]) é professor do Instituto de Informática da Universidade Federal do Rio Grande do Sul, Porto Alegre (RS), Brasil. Dalcidio Moraes Claudio (E-mail: [email protected]) é professor da Faculdade de Matemática da Pontifícia Universidade Católica do Rio Grande do Sul, Porto Alegre (RS), Brasil. I. INTRODUÇÃO A utilização de computadores para abordar problemas matemáticos fez com que novos algoritmos fossem desenvolvidos, visando, principalmente, a obtenção de um melhor desempenho computacional. Entretanto, quando se trabalha com Computação Científica, em especial para a resolução de aplicações reais de grande porte utilizando números em ponto-flutuante, deve-se preocupar com o controle dos erros gerados pelas computações numéricas, que muitas vezes podem produzir resultados totalmente errados devido, por exemplo, à inexatidão da representação numérica, já que o resultado gerado é apenas uma aproximação do resultado exato. Por isso, este trabalho visou a disponibilização em um ambiente paralelo, do tipo cluster de computadores, do paradigma da Computação Verificada e, em especial, da característica da alta exatidão. A alta exatidão na solução de um problema é obtida através da realização de cálculos intermediários sem arredondamentos como se fossem em precisão infinita. Ao final do cálculo, o resultado deve ser representado na máquina. O resultado exato real e o resultado representado diferem por um único arredondamento e, caso este seja representado através de intervalos, pode-se aplicar arredondamentos para cima e para baixo nesse valor real, transformando a resposta em um intervalo que contém o resultado real exato, onde os valores do intervalo representam os dois números de máquina localizados antes e depois do resultado exato que se deseja representar. Esses cálculos em alta exatidão devem aplicados para algumas operações aritméticas básicas, em especial as que possibilitam a realização de somatório e de produto escalar. Com isso, utilizou-se o paralelismo obtido através de um ambiente de cluster de computadores, onde se tem vários nodos executando tarefas ou cálculos em conjunto, em conjunto com a aritmética de alta exatidão. A comunicação no ambiente foi realizada por troca de mensagens usando a biblioteca de comunicação Message Passing Interface (MPI). Para se obter a alta exatidão neste ambiente foram utilizadas rotinas de comunicação capazes de suportar a troca de valores representados em precisão estendida. Portanto, extensões ou adaptações nos programas paralelos foram realizadas para garantir que a qualidade do resultado final realizado em um cluster mantivesse a mesma qualidade do resultado obtido em uma única máquina (ou nodo) de um ambiente seqüencial com alta exatidão. Para a obtenção da alta exatidão foi utilizada a biblioteca científica chamada C++ Library for Extended Parallel Environment with High Accuracy for Resolution of Numerical Problems C. A. Hölbig, T. A. Diverio, D. M. Claudio 114 IEEE LATIN AMERICA TRANSACTIONS, VOL. 7, NO. 1, MARCH 2009

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Abstract— In this paper we describe a high performance
environment, like cluster computers, with high accuracy obtained by use of C-XSC library. The C-XSC library is a (free) C++ class library for scientific computing for the development of numerical algorithms delivering highly accurate and automatically verified results by use of the interval arithmetic. These calculus in high accuracy must be available for some basic arithmetic operations, mainly the operations that accomplish the summation and dot product. Because of these aspects, we wish to use the high performance through a cluster environment where we have several nodes executing tasks or calculus. The communication will be done by message passing using the MPI communication library. To obtain the high accuracy in this environment extensions or changes in the parallel programs had done to guarantee that the quality of final result done on cluster, where several nodes collaborate for the final result of the calculus, maintain the same result quality obtained in one sequential high accuracy environment. To validate the environment developed in this work we done basic tests about the dot product, the matrix multiplications, the implementation of interval solvers for banded and dense matrices and the implementation of some numeric methods to solve linear systems with the high accuracy characteristic (some of the methods implemented are used in real life applications like hydrodynamic, agriculture and power electric systems). With these tests we done analysis and comparisons about the performance and accuracy obtained with and without the use of C-XSC library in sequential and parallel programs. With the implementation of these routines and methods will be open a large research field about the study of real life applications that need during their resolution (or in part of their resolution) to calculate arithmetic operations with more accuracy than the accuracy obtained by the traditional computational tools. Our software run on labtec (UFRGS) and Colorado (UPF) clusters. Nowadays we are working in the implementation of parallel versions of programs to solve linear systems (without and with high accuracy) and the optimization of C-XSC library on cluster computers.
Keywords— Cluster computing, linear equations, numerical library, high accuracy, verified computing.
Carlos Amaral Hölbig (E-mail: [email protected]) é professor do curso de
Ciência da Computação do Instituto de Ciências Exatas e Geociências da Universidade de Passo Fundo, Passo Fundo (RS), Brasil.
Tiarajú Asmuz Diverio (E-mail: [email protected]) é professor do Instituto de Informática da Universidade Federal do Rio Grande do Sul, Porto Alegre (RS), Brasil.
Dalcidio Moraes Claudio (E-mail: [email protected]) é professor da Faculdade de Matemática da Pontifícia Universidade Católica do Rio Grande do Sul, Porto Alegre (RS), Brasil.
I. INTRODUÇÃO A utilização de computadores para abordar problemas matemáticos fez com que novos algoritmos fossem desenvolvidos, visando, principalmente, a obtenção de um melhor desempenho computacional. Entretanto, quando se trabalha com Computação Científica, em especial para a resolução de aplicações reais de grande porte utilizando números em ponto-flutuante, deve-se preocupar com o controle dos erros gerados pelas computações numéricas, que muitas vezes podem produzir resultados totalmente errados devido, por exemplo, à inexatidão da representação numérica, já que o resultado gerado é apenas uma aproximação do resultado exato.
Por isso, este trabalho visou a disponibilização em um ambiente paralelo, do tipo cluster de computadores, do paradigma da Computação Verificada e, em especial, da característica da alta exatidão.
A alta exatidão na solução de um problema é obtida através da realização de cálculos intermediários sem arredondamentos como se fossem em precisão infinita. Ao final do cálculo, o resultado deve ser representado na máquina. O resultado exato real e o resultado representado diferem por um único arredondamento e, caso este seja representado através de intervalos, pode-se aplicar arredondamentos para cima e para baixo nesse valor real, transformando a resposta em um intervalo que contém o resultado real exato, onde os valores do intervalo representam os dois números de máquina localizados antes e depois do resultado exato que se deseja representar. Esses cálculos em alta exatidão devem aplicados para algumas operações aritméticas básicas, em especial as que possibilitam a realização de somatório e de produto escalar.
Com isso, utilizou-se o paralelismo obtido através de um ambiente de cluster de computadores, onde se tem vários nodos executando tarefas ou cálculos em conjunto, em conjunto com a aritmética de alta exatidão. A comunicação no ambiente foi realizada por troca de mensagens usando a biblioteca de comunicação Message Passing Interface (MPI). Para se obter a alta exatidão neste ambiente foram utilizadas rotinas de comunicação capazes de suportar a troca de valores representados em precisão estendida. Portanto, extensões ou adaptações nos programas paralelos foram realizadas para garantir que a qualidade do resultado final realizado em um cluster mantivesse a mesma qualidade do resultado obtido em uma única máquina (ou nodo) de um ambiente seqüencial com alta exatidão. Para a obtenção da alta exatidão foi utilizada a biblioteca científica chamada C++ Library for Extended
Parallel Environment with High Accuracy for Resolution of Numerical Problems
C. A. Hölbig, T. A. Diverio, D. M. Claudio
114 IEEE LATIN AMERICA TRANSACTIONS, VOL. 7, NO. 1, MARCH 2009

Scientific Computing (C-XSC).
II. CONCEITOS BÁSICOS Para um melhor entendimento do ambiente que foi
implantado por esta pesquisa é necessária a revisão de alguns conceitos relacionados à Matemática da Computação e que poderão ser utilizados no ambiente através da biblioteca C-XSC. Estes conceitos baseiam-se no cálculo numérico com a verificação automática de resultados, o qual é de fundamental importância para muitas aplicações como, por exemplo, para a simulação e modelagem matemática.
Na análise clássica do erro em algoritmos numéricos, o erro em cada operação em ponto-flutuante é estimado. Na verdade, a possibilidade do resultado estar errado não é normalmente considerada. Do ponto de vista matemático, o problema da correção dos resultados é de grande importância para garantir a alta velocidade computacional atingida atualmente. Isto torna possível ao usuário distinguir entre inexatidão nos cálculos e as reais propriedades do modelo. No sentido de tornar possível o manuseio de milhões de adições e subtrações com o máximo de exatidão, é evidente que as capacidades da aritmética de ponto-flutuante tradicional têm que ser aumentadas. Dadas as possibilidades atuais, não há razão para que isto não possa ser feito em um chip, simulado por software ou pela combinação dos dois [14].
O grande objetivo da Computação Verificada ou Validação Numérica é possibilitar que o próprio computador possa rapidamente estabelecer se o cálculo realizado é ou não correto e útil para o problema que se quer solucionar. Neste caso, o programa pode escolher um algoritmo alternativo ou repetir o processo usando uma maior precisão.
Técnicas similares de Computação Verificada podem ser aplicadas para muitas áreas de problemas algébricos, tais como a solução de sistemas de equações lineares e não lineares, o cálculo de raízes, a obtenção de autovalores e de autovetores de matrizes, problemas de otimização, etc. Em particular, a validade e a alta exatidão da avaliação de expressões aritméticas e de funções no computador estão incluídas. Estas rotinas também funcionam para problemas com dados intervalares.
É importante ressaltar que para que se desenvolvam programas computacionais que tenham o paradigma da Computação Verificada é obrigatório o uso de todas as suas características, ou seja, o uso da aritmética de alta exatidão, dos métodos intervalares de inclusão e da convergência garantida pelo Teorema de Ponto Fixo de Brouwer [15], além do uso de algoritmos apropriados. Com a Computação Verificada é possível desenvolver métodos numéricos para a realização de computações científicas com verificação automática do resultado. Uma abordagem detalhada sobre a Computação Verificada e suas técnicas pode ser encontrada nos livros textos básicos da área, como os de Moore [18], Alefeld [1], Cláudio [3] e Kulisch [15].
Entretanto, para se ter a Computação Verificada ou alguma de suas características é necessária à existência de alguma ferramenta computacional que as disponibilize. Para isso, esta pesquisa utilizou a biblioteca C-XSC que é uma biblioteca numérica para a Computação Científica baseada na linguagem C++. É uma ferramenta para o desenvolvimento de algoritmos
numéricos com a geração de resultados com alta exatidão e verificados automaticamente. Ela fornece um grande número de tipos de dados numéricos e operadores predefinidos. Estes tipos são implementados como classes da linguagem C++. Assim, o C-XSC permite a programação de alto nível de aplicações numéricas em C++. Ela está disponível para muitos ambientes computacionais que possuam um compilador C++ e obedece ao padrão ISO/IEC C++. Atualmente a versão disponível do C-XSC é 2.2.2 (o C-XSC é uma biblioteca de código aberto – open source). As características mais importantes desta biblioteca são: • Aritmética intervalar para números reais, complexos,
intervalares e intervalares complexos; • Vetores e matrizes dinâmicos; • Subarrays de vetores e matrizes; • Tipos de dados de alta precisão (dotprecision); • Operadores aritméticos predefinidos com alta exatidão; • Aritmética de múltipla precisão dinâmica e funções
padrão; • Controle de arredondamento para os dados de entrada e
saída; • Biblioteca de rotinas para a resolução de problemas
numéricos; • Resultados numéricos com rigor matemático.
Entretanto, uma pergunta deve ser respondida: Qual o
motivo da escolha da biblioteca C-XSC como a ferramenta que possibilitou o uso da alta exatidão nesta pesquisa? Essa escolha baseou-se, principalmente, a dois fatores: disponibilidade e usabilidade. Disponibilidade por ser uma biblioteca de código aberto e vir ao encontro da idéia dos grupos de pesquisa com qual esse trabalho está vinculado; e usabilidade por o C-XSC ser uma biblioteca baseada na linguagem C++, linguagem que está disponível em praticamente todos os ambientes computacionais e que proporciona que sejam desenvolvidos programas que possam utilizar, em conjunto, rotinas do C-XSC com outras bibliotecas científicas como, por exemplo, rotinas da biblioteca Basic Linear Álgebra Subroutines (BLAS) e da biblioteca MPI. Maiores detalhes sobre a biblioteca C-XSC podem ser obtidos em [4], [5] e [11] ou pelo endereço http://www.xsc.de.
A qualidade numérica obtida com o paradigma da Computação Verificada através da biblioteca C-XSC pode ser observada na resolução de alguns tipos de problemas numéricos como, por exemplo, na resolução verificada de sistemas lineares com matrizes do tipo densas e bandas, conforme detalhado em [6], [7], [8] e [13].
Pelo que foi exposto, um correto conhecimento destes conceitos é de fundamental importância para os usuários de ambientes paralelos do tipo clusters de computadores, pois, com isso, eles podem tirar o máximo de proveito não só da alta exatidão, mas também de sua utilização em conjunto com a aritmética intervalar. Além disso, estes usuários devem levar em consideração, também, requisitos importantes para se ter um programa de alto desempenho como a otimização do hardware (processador/rede), a adaptação do sistema operacional, o uso de middlewares específicos, a programação
AMARAL HÖLBIG et al.: PARALLEL ENVIRONMENT WITH 115

otimizada e o uso de algoritmos com eficiência comprovada, conforme detalhado em [17].
III. O AMBIENTE PARALELO COM ALTA EXATIDÃO
Nesta seção é descrito o processo que foi realizado para possibilitar o correto uso do C-XSC em clusters e a sua integração com a biblioteca de troca de mensagens MPI. No início desta pesquisa a versão do C-XSC utilizada no trabalho foi a versão 2.1 para PC (arquitetura x86) rodando Debian GNU/Linux 3.0 (kernel 2.4.22) com compilador gcc/g++ 3.3.2. Além deste ambiente, o C-XSC pode ser instalado em ambientes computacionais com sistemas operacionais MS-DOS, SunOS e HP-UX, ou seja, o C-XSC é facilmente portável para essas plataformas. A compilação de programas do C-XSC e o seu uso com o MPI são realizados normalmente conforme as regras da linguagem C/C++ e da biblioteca MPI.
Entretanto para que a continuação da pesquisa fosse possível era necessária uma completa integração do C-XSC com o MPI, pois, caso os algoritmos exigissem que um tipo específico de dado fosse enviado para outro processo, este deveria usar uma primitiva do MPI (como MPI_Send, por exemplo). Porém, nativamente, o MPI possui suporte apenas para os tipos do C/C++, como MPI_DOUBLE, MPI_FLOAT, MPI_INT,... Então foi necessário encontrar uma maneira de informar ao MPI como ele deveria enviar os tipos de dados do C-XSC (real, interval, complex, rmatrix, rvector, intvector, intmatrix, civector, cimatrix, cinterval). Este procedimento poderá ser realizado através do tipo MPI_BYTE, conforme apresentado em (1), onde var é qualquer uma das variáveis declaradas como um dos tipos especiais do C-XSC.
MPI_Send(&var,sizeof(var),MPI_BYTE,dest,tag,comm); (1)
Para os tipos de dados de alta exatidão (dotprecision,
idotprecision, cdotprecision e cidotprecision) este procedimento não funcionou. Durante a fase de depuração do código, observou-se que o receptor da mensagem havia recebido apenas 4 (quatro) bytes do remetente. Como as variáveis dotprecision devem armazenar o resultado sem arredondamento, é de se esperar que estas tenham um tamanho considerável em memória. Conforme [11], o tipo de dado dotprecision ocupa mais de 529 bytes em memória (sua estrutura é descrita na Fig. 1). Portanto, o que o MPI_Send estava fazendo era enviando um ponteiro de uma área de memória para o receptor. Com isso, pôde-se concluir que o tipo dotprecision é um ponteiro para a memória e que o MPI não consegue acessar o conteúdo do dado dotprecision. Caso fosse possível existir uma variável de tipo conhecida apontar diretamente para o conteúdo do dotprecision, provavelmente o MPI não teria dificuldades de enviar o conteúdo do dotprecision.
Fig. 1. Estrutura do tipo de dado dotprecision
Outra questão que deveria ser respondida era determinar a
quantidade de bytes que deveriam ser enviados. Utilizando uma ferramenta de depuração paralela (PADI), apresentada em [21] e desenvolvida no Grupo de Processamento Paralelo e Distribuído da Universidade Federal do Rio Grande do Sul, descobriu-se que, na verdade, o dotprecision era um ponteiro do tipo unsigned long. Portanto, o type casting (troca explícita de tipos) resolve o problema de acessar o conteúdo da variável, conforme (2). &unsigned long *envia; &dotprecision accu; (2) &envia = *(unsigned long **)(&accu);
Agora envia aponta para o mesmo conteúdo que accu. Na
nova chamada da primitiva do MPI (MPI_Send) em (1) basta trocar &(var) por envia. Entretanto continuava a questão do tamanho da seqüencia de bytes. Para resolver essa questão recorreu-se ao código fonte do C-XSC e descobriu-se que para alocar um dotprecision na memória, o C-XSC utiliza uma constante chamada BUFFERSIZE que possui 556 bytes. Com base neste fato, a nova chamada para o MPI_Send pode ser reescrita conforme (3).
MPI_Send(envia,BUFFERSIZE,MPI_BYTE,dest,tag,comm); (3)
Como o recebimento é análogo ao envio, o mesmo caminho
foi feito para o recebimento. Para os tipos de dados do C-XSC que não envolvem dados em alta exatidão procede-se conforme (1).
MPI_Recv(envia,BUFFERSIZE,MPI_BYTE,dest,tag,comm); (4)
Para os tipos dotprecision, faz-se o mesmo type casting
antes do recebimento, conforme (5).
&unsigned long *recebe; &dotprecision accu2; &recebe = *(unsigned long **)(&accu2); (5) MPI_Recv(recebe,BUFFERSIZE,MPI_BYTE,org,tag,comm,status);
Durante a realização dos testes constatou-se que, caso haja
a necessidade de enviar uma parte (tam_ped) de um vetor ou de uma matriz de uma só vez, é necessário utilizar &(var[0]) e sizeof(var[0])*tam_ped para o correto funcionamento do MPI_Send e do MPI_Recv nesse caso particular (a biblioteca C-XSC possui entre os seus tipos de dados os tipos matriz e vetor). Além disso, caso esteja-se enviando/recebendo variáveis de alta precisão do tipo intervalo de reais (idotprecision) ao invés de variáveis reais de alta precisão
116 IEEE LATIN AMERICA TRANSACTIONS, VOL. 7, NO. 1, MARCH 2009

(dotprecisions) conforme (3) e (5), deve-se trocar a variável BUFFERSIZE por 2*BUFFERSIZE visto que esse tipo de dado, por conter intervalos, tem o dobro do tamanho de um dado dotprecision.
Para validar o envio dos tipos rmatrix, imatrix, cmatrix, cimatrix, intmatrix, intvector, rvector, ivector, cvector, civector, real, interval, complex e cinterval, utilizou-se um teste bastante simples, que consistia em enviar vetores, matrizes ou simplesmente um número (conforme cada caso) de um processo para outro. Assim, necessariamente, os dados do C-XSC trafegaram na rede através das diretivas do MPI. Em todos os casos testados, o destinatário recebeu os dados corretamente.
Nos testes para o tipo de dado dotprecision foi utilizado o modelo de comunicação mestre-escravo. Nela o mestre inicializa e distribui os dados, e os escravos recebem as partes, fazem o cálculo parcial e devolvem o resultado para o mestre que, por sua vez, encarrega-se de juntar os resultados parciais. Neste caso, utilizou-se o cálculo de um produto escalar ótimo, onde ótimo significa que o resultado final difere do exato por apenas um arredondamento (alta exatidão) através da utilização de variáveis e funções de alta precisão do C-XSC.
Como exemplo descreve-se o teste do cálculo do produto escalar ótimo para vetores com tamanho de 180.000. Neste caso, o processo 0 (mestre) inicializou os vetores de dimensão 180000, dividindo igualmente (60000) entre três processos (1 até 3). Cada processo, de 1 até 3, executou o código apresentado na Fig. 2 para calcular o produto escalar ótimo parcial. O processo 0 (mestre) recebeu de cada processo escravo o cálculo do produto parcial (armazenado na variável de alta precisão accu), e executou o trecho de código apresentado na Fig. 3. Através deste processo, o mestre somou os produtos parciais (sem arredondamento) e os arredondou no final, utilizando a função rnd(). Com isso foi possível obter um resultado diferente do exato por apenas um arredondamento. A função accumulate() é uma função do C-XSC que realiza o produto escalar entre dois vetores sem arredondamentos (produto escalar ótimo), simulando registradores com precisão infinita. Ao final do processo, a função rnd arredonda o resultado em alta exatidão para um número do tipo real (equivalente ao double do C/C++) conforme especificado pelo padrão de aritmética binária em ponto-flutuante IEEE-754 [10].
accu = 0.0; for(i=Lb(a);i<=Ub(a);i++)
accumulate(accu,a[i],b[i]);
envia = *(unsigned long **)(&accu); MPI_Send(envia,BUFFERSIZE,MPI_BYTE,0,0,
MPI_COMM_WORLD); Fig. 2. Cálculo parcial do produto escalar ótimo em C-XSC com MPI
totalAccu = 0; for(i=1;i<size;i++) { recv = *(unsigned long **)(&accu);
MPI_Recv(recv,BUFFERSIZE,MPI_BYTE,i,0,
MPI_COMM_WORLD,&status); totalAccu += accu; } scalarProduct = rnd( totalAccu );
Fig. 3. Cálculo final do produto escalar ótimo em C-XSC com MPI
Conforme apresentado até o momento foi possível, através de uma série de atividades e testes, providenciar o uso correto da biblioteca C-XSC em ambientes do tipo de clusters de computadores e, consequentemente, realizar, de maneira correta e efetiva, a sua integração com a biblioteca de troca de mensagens MPI.
Destaca-se que, além da característica da alta exatidão que é o foco principal deste trabalho, este ambiente oferece à comunidade científica todas as características que possibilitam a implementação dos mais diversos métodos numéricos computacionais com as características da Computação Verificada possibilitando, com isso, no desenvolvimento de programas paralelos, o envio correto entre os processadores dos dados especiais da biblioteca C-XSC. Todo esse processo de uso e integração do C-XSC em clusters foi validado através do uso dos clusters do Instituto de Informática da UFRGS (cluster labtec), da Universidade de Passo Fundo (cluster Colorado) e do cluster da Universidade de Wuppertal – Alemanha (cluster ALiCEnext).
O cluster labtec faz parte do Laboratório de Tecnologias de Cluster (LabTeC) do Instituto de Informática da UFRGS. O LabTeC tem por objetivo oferecer uma formação complementar aos currículos da graduação e da pós-graduação da UFRGS, oferecendo cursos avançados e desenvolvendo pesquisa relacionada ao processamento de alto desempenho com clusters, de forma a capacitar futuros profissionais para a atuação com excelência nesta área. A configuração atual do cluster labtec, de seus nodos e do servidor de acesso é a seguinte:
• Configuração dos nodos: processador Dual Pentium III 1.1 Ghz, 1 Gb de memória RAM, HD SCSI de 18 Gb e Placa de rede Gigabit Ethernet;
• Servidor de acesso ao cluster (front-end): processador Dual Pentium IV Xeon 1.8 Ghz, 1 Gb de memória RAM, HD SCSI de 36 Gb e Placa de rede Gigabit Ethernet.
O labtec está equipado, atualmente, com um cluster da Dell de 20 nodos Pentium III 1 GHz biprocessados (totalizando 40 processadores), conectados por tecnologia Fast Ethernet. Do total de nodos, 8 estão permanentemente disponíveis para aplicações e treinamento em programação paralela e 12 são utilizados nos cursos de instalação e configuração.
O cluster ALiCEnext (Advanced Linux Cluster Engine, next generation) foi instalado na Universidade de Wuppertal em junho de 2004. Ele consiste de 1024 processadores AMD Opteron de 1.8 GHz (arquitetura de 64 bits) em 512 nodos conectados por tecnologia Gigabit Ethernet. Os processadores do ALiCEnext têm sistema operacional Linux e a biblioteca MPI como interface de comunicação.
O cluster Colorado da Universidade de Passo Fundo é composto por 8 máquinas do tipo PC, com sistema operacional Linux e placa de rede de 100 Megabit Enthernet e é estruturado da seguinte maneira:
• Servidor de acesso ao cluster (front-end): processador Intel Celeron 1.7 GHz, 128 Mb de memória RAM e HD de 40 Gb;
AMARAL HÖLBIG et al.: PARALLEL ENVIRONMENT WITH 117

• Configuração de 1 nodo: processador Pentium III 800 MHz, 128 Mb de memória RAM e HD de 40 Gb;
• Configuração de 6 nodos: processador AMD Atlhon 1.16 GHz, 128 Mb de memória RAM e HD de 40 Gb.
O cluster Colorado é utilizado atualmente nas pesquisas e para o ensino dos alunos do curso de Ciência da Computação da Universidade de Passo Fundo.
Nestes clusters, basicamente, os mesmos problemas de uso e integração foram encontrados e as mesmas soluções apresentadas nesta seção foram aplicadas de maneira satisfatória. Trabalhos relacionados à implementação de programas com as características da Computação Verificada em ambientes paralelos e a otimização de rotinas da biblioteca C-XSC podem ser encontrados em [9], [12], [16] e [22].
IV. VALIDAÇÃO DO AMBIENTE COMPUTACIONAL
Para validar o ambiente um conjunto de testes foram realizados. Estes testes foram divididos em três categorias: • Testes básicos: os testes do cálculo do produto escalar e
da multiplicação de matrizes foram de extrema importância para a validação deste trabalho. Com eles pode-se verificar a viabilidade do uso das características da Computação Verificada em ambientes paralelos através do seu envio/recebimento entre os processadores dos clusters utilizando, para isso, as funções da biblioteca de comunicação MPI. Foram realizados cálculos com valores do tipo double, real e interval, o que propiciou a realização da análise do desempenho do C-XSC frente a um programa em C/C++, conforme resultados apresentados nas Tabelas I e II e na Fig. 4. Obviamente, pelo modo como o C-XSC armazena e opera seus dados especiais (principalmente os de alta precisão), o desempenho obtido em C-XSC foi inferior ao em C/C++. Entretanto, desta avaliação pode-se concluir que um trabalho de otimização da biblioteca C-XSC poderá minimizar esse problema e que o comportamento (em termos de desempenho) dos programas em C-XSC é semelhante aos programas tradicionais e a manipulação dos tipos de dados especiais do C-XSC está ocorrendo corretamente nos clusters. É importante ressaltar a qualidade numérica dos resultados obtidos com o C-XSC quando os dados de entrada estão sujeitos a instabilidade numérica, conforme Tabelas III e IV, onde o vetor A = [1050, 1.25, 1050, 1.1, ..., 1050, 1.25, 1050, 1.1] e o vetor B = [1.0, 1.0, –1.0,–1.0, ..., 1.0, 1.0, –1.0, –1.0]. Este fato foi observado quando se realizou o cálculo do produto escalar em vetores com valores com grandezas muito diferentes o que, sem o uso da alta exatidão, provocaria erros de cancelamento e a obtenção de um resultado totalmente errado;
Multiplicação de Matrizes
150,63
34,13
19,59
115,52
916,23
4,60
664,08
83,01
1,00
10,00
100,00
1000,00
512 1024Ordem das matrizes
Tem
po e
m s
egun
dos
C/C++ Sequêncial C-XSC Sequêncial
C/C++ 8 processadores C-XSC 8 processadores
Fig. 4. Multiplicação de Matrizes em C/C++ e C-XSC
TABELA I MULTIPLICAÇÃO DE MATRIZES (TEMPOS EM SEGUNDOS)
Programa/Dimensão 512 1024
C/C++ sequêncial 19,59 150,63 C/C++ com 8 proc. 4,60 34,13 C-XSC sequêncial 115,52 916,23 C-XSC com 8 proc. 83,01 664,08
• Testes de métodos para sistemas lineares: com o objetivo
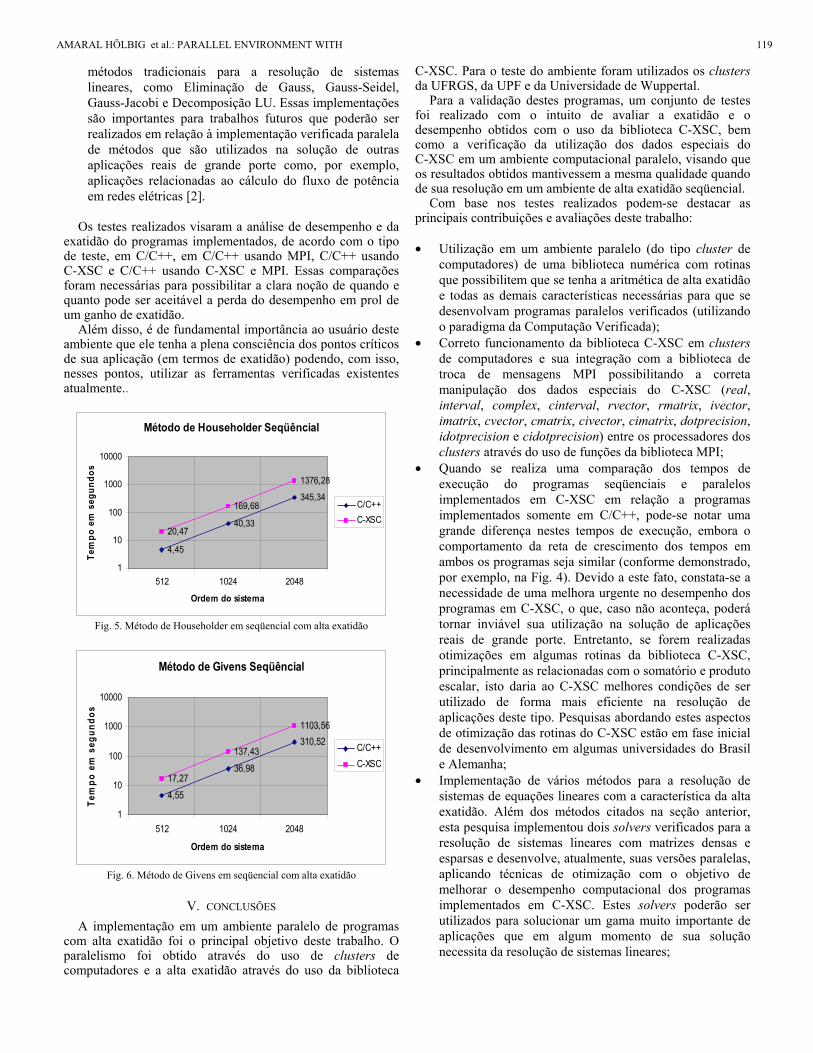
de comparar os programas implementados com e sem a característica da alta exatidão, foram implementados os métodos Gradiente Conjugado, Householder e Givens. Analisando os resultados obtidos e apresentados nas Fig. 5 e 6, pode-se verificar a semelhança do comportamento do desempenho das implementações, conforme fora observado nos testes sobre o produto escalar e a multiplicação de matrizes;
TABELA II
CÁLCULO DO PRODUTO ESCALAR (COM ALTA EXATIDÃO) NO CLUSTER COLORADO USANDO DADOS INTERVALARES DO C–XSC (TEMPOS EM
SEGUNDOS)
Vetor (n)/processadores np = 3 np = 4 45000 0.52525 0.47632 90000 0.95668 0.92494 180000 1.93502 1.84891 360000 3.85463 3.42321
TABELA III
CÁLCULO DO PRODUTO ESCALAR EM C/C++
Vetor (n) Resultado Obtido Resultado Exato
30000 – 3:300000000000000266453525910037... 1125 90000 – 3:300000000000000266453525910037... 3375 180000 – 3:300000000000000266453525910037... 6750
TABELA IV
CÁLCULO DO PRODUTO ESCALAR (COM ALTA EXATIDÃO) EM C–XSC
Vetor (n) Resultado Obtido Resultado Exato
30000 1124:99999999999931787897367030382... 1125 90000 3374:99999999999818101059645414352... 3375 180000 6749:99999999999636202119290828704... 6750
• Testes complementares: por fim, foram realizados testes
adicionais que abordaram implementações de alguns
118 IEEE LATIN AMERICA TRANSACTIONS, VOL. 7, NO. 1, MARCH 2009
métodos tradicionais para a resolução de sistemas lineares, como Eliminação de Gauss, Gauss-Seidel, Gauss-Jacobi e Decomposição LU. Essas implementações são importantes para trabalhos futuros que poderão ser realizados em relação à implementação verificada paralela de métodos que são utilizados na solução de outras aplicações reais de grande porte como, por exemplo, aplicações relacionadas ao cálculo do fluxo de potência em redes elétricas [2].
Os testes realizados visaram a análise de desempenho e da
exatidão do programas implementados, de acordo com o tipo de teste, em C/C++, em C/C++ usando MPI, C/C++ usando C-XSC e C/C++ usando C-XSC e MPI. Essas comparações foram necessárias para possibilitar a clara noção de quando e quanto pode ser aceitável a perda do desempenho em prol de um ganho de exatidão.
Além disso, é de fundamental importância ao usuário deste ambiente que ele tenha a plena consciência dos pontos críticos de sua aplicação (em termos de exatidão) podendo, com isso, nesses pontos, utilizar as ferramentas verificadas existentes atualmente..
Método de Householder Seqüêncial
4,45
40,33
345,34
20,47
169,68
1376,28
1
10
100
1000
10000
512 1024 2048
Ordem do sistema
Tem
po e
m s
egun
dos
C/C++C-XSC
Fig. 5. Método de Householder em seqüencial com alta exatidão
Método de Givens Seqüêncial
4,55
36,98
310,52
17,27
137,43
1103,56
1
10
100
1000
10000
512 1024 2048
Ordem do sistema
Tem
po e
m s
egun
dos
C/C++C-XSC
Fig. 6. Método de Givens em seqüencial com alta exatidão
V. CONCLUSÕES A implementação em um ambiente paralelo de programas
com alta exatidão foi o principal objetivo deste trabalho. O paralelismo foi obtido através do uso de clusters de computadores e a alta exatidão através do uso da biblioteca
C-XSC. Para o teste do ambiente foram utilizados os clusters da UFRGS, da UPF e da Universidade de Wuppertal.
Para a validação destes programas, um conjunto de testes foi realizado com o intuito de avaliar a exatidão e o desempenho obtidos com o uso da biblioteca C-XSC, bem como a verificação da utilização dos dados especiais do C-XSC em um ambiente computacional paralelo, visando que os resultados obtidos mantivessem a mesma qualidade quando de sua resolução em um ambiente de alta exatidão seqüencial.
Com base nos testes realizados podem-se destacar as principais contribuições e avaliações deste trabalho:
• Utilização em um ambiente paralelo (do tipo cluster de
computadores) de uma biblioteca numérica com rotinas que possibilitem que se tenha a aritmética de alta exatidão e todas as demais características necessárias para que se desenvolvam programas paralelos verificados (utilizando o paradigma da Computação Verificada);
• Correto funcionamento da biblioteca C-XSC em clusters de computadores e sua integração com a biblioteca de troca de mensagens MPI possibilitando a correta manipulação dos dados especiais do C-XSC (real, interval, complex, cinterval, rvector, rmatrix, ivector, imatrix, cvector, cmatrix, civector, cimatrix, dotprecision, idotprecision e cidotprecision) entre os processadores dos clusters através do uso de funções da biblioteca MPI;
• Quando se realiza uma comparação dos tempos de execução do programas seqüenciais e paralelos implementados em C-XSC em relação a programas implementados somente em C/C++, pode-se notar uma grande diferença nestes tempos de execução, embora o comportamento da reta de crescimento dos tempos em ambos os programas seja similar (conforme demonstrado, por exemplo, na Fig. 4). Devido a este fato, constata-se a necessidade de uma melhora urgente no desempenho dos programas em C-XSC, o que, caso não aconteça, poderá tornar inviável sua utilização na solução de aplicações reais de grande porte. Entretanto, se forem realizadas otimizações em algumas rotinas da biblioteca C-XSC, principalmente as relacionadas com o somatório e produto escalar, isto daria ao C-XSC melhores condições de ser utilizado de forma mais eficiente na resolução de aplicações deste tipo. Pesquisas abordando estes aspectos de otimização das rotinas do C-XSC estão em fase inicial de desenvolvimento em algumas universidades do Brasil e Alemanha;
• Implementação de vários métodos para a resolução de sistemas de equações lineares com a característica da alta exatidão. Além dos métodos citados na seção anterior, esta pesquisa implementou dois solvers verificados para a resolução de sistemas lineares com matrizes densas e esparsas e desenvolve, atualmente, suas versões paralelas, aplicando técnicas de otimização com o objetivo de melhorar o desempenho computacional dos programas implementados em C-XSC. Estes solvers poderão ser utilizados para solucionar um gama muito importante de aplicações que em algum momento de sua solução necessita da resolução de sistemas lineares;
AMARAL HÖLBIG et al.: PARALLEL ENVIRONMENT WITH 119

• A união da Computação de Alto de Desempenho com a Computação Verificada, vai se tornar uma ferramenta chave para a resolução de aplicações críticas oriundas de áreas como a tecnologia espacial, bioinformática, engenharia automotiva e elétrica (cálculo da potência elétrica trifásica [19]), validação de plantas nucleares sem experimentos físicos reais ou a determinação da influência do solo dissipativo sobre sinais de comunicação [20]. Com o objetivo de tratar não somente problemas acadêmicos que estão longe das limitações impostas pelas necessidades industriais, softwares de alta confiabilidade e eficiência devem ser desenvolvidos para arquiteturas paralelas.
Conforme os resultados obtidos, destaca-se que a biblioteca
C-XSC deve ser utilizada, em um ambiente paralelo, como uma ferramenta de apoio ao cálculo de problemas com alta exatidão e não como a ferramenta computacional principal. Deve-se resolver um determinado problema utilizando ferramentas computacionais tradicionais e com desempenho computacional superior como, por exemplo, a BLAS e a Linear Algebra Package (LAPACK). E, caso tenha-se problemas com a qualidade do resultado, verifica-se no problema que está sendo trabalhado quais são as áreas ou rotinas mais cruciais a exatidão e, nessas áreas, a biblioteca C-XSC deverá ser utilizada procurando obter um resultado mais exato e confiável. No restante do problema sugere-se o uso de ferramentas tradicionais com o objetivo de não se ter uma grande perda de desempenho na solução do problema.
Além disso, sugere-se, ainda, que esta utilização seja realizada em conjunto com um estudo do método computacional que está sendo implementado, verificando a sua utilização mais adequada ao problema que se está querendo solucionar.
Não se pode deixar de lembrar que a biblioteca C-XSC foi desenvolvida com o objetivo bem claro de implementar programas intervalares e de alta exatidão voltados à resolução de problemas onde não se tenha condições de representar de maneira confiável a solução exata, problemas ou algoritmos instáveis numericamente ou sujeitos a erros de arredondamento e de cancelamento.
Além disso, é interessante descrever os principais pontos de pesquisa que estão sendo trabalhados atualmente com base nos resultados que foram obtidos neste trabalho: a otimização de algumas rotinas da biblioteca C-XSC através da implementação de novos algoritmos de somatório e do produto escalar, a inclusão de rotinas da BLAS e da LAPACK, de instruções em Assembly ou das funções Streaming SIMD Extensions (SSE) nos programas desenvolvidos em C-XSC e o uso das diretivas de otimização do compilador C++ da GNU.
No que se refere aos métodos numéricos computacionais está se buscando a adaptação de alguns métodos paralelos tradicionais para o suporte às técnicas da Computação Verificada, através do estudo da viabilidade de se fazer tal adaptação em busca de um equilíbrio entre o ganho de exatidão e a perda de desempenho.
Por fim, e provavelmente um dos maiores desafios desta pesquisa, é a identificação de novas aplicações reais de grande
porte e o estudo da viabilidade de sua solução através da Computação Verificada em clusters de computadores.
REFERÊNCIAS [1] G. Alefeld, J. Herzberger, An Introduction to Interval Computations.
New York: Academic Press, 1983. [2] L. V. Barboza, G. P. Dimuro, R. H. S. Reiser, “Towards Interval
Analysis of the Load Uncertainty in Power Electric Systems”, in VIII International Conference on Probability Methods Applied to Power Systems, Proceedings..., IEEE, Washington, pp.1–6, 2004.
[3] D. Claudio, J. Marins, Cálculo Numérico Computacional. São Paulo: Atlas, 1989.
[4] R. Hammer, et al., C–XSC Toolbox for Verified Computing I: basic numerical problems. New York: Springer–Verlag, 1995.
[5] W. Hofschuster, W. Krämer, “C–XSC 2.0: A C++ Class Library for Extended Scientific Computing”, Wuppertal, Germany: BUGH, Universität Wuppertal, 2001. (Preprint BUGHW-WRSWT 2001/1).
[6] C. Hölbig, W. Krämer, T. Diverio, “An Accurate and Efficient Selfverifying Solver for Systems with Banded Coefficient Matrix”, in G. R. Joubert, et al., Parallel Computing: Software Technology, Algorithms, Architectures, and Applications. London: Elsevier Science Publishers, pp.283–290, 2004.
[7] C. A. Hölbig, P. S. Morandi Júnior, B. F. K. Alcalde, T. A. Diverio, “Selfverifying Solvers for Linear Systems of Equations in C–XSC”, in R Wyrzykkowski, et al, Parallel Processing and Applied Mathematics. Berlin: Springer-Verlag, pp.292–297, 2004. (Lecture Notes in Computer Science, 3019).
[8] C. Hölbig, W. Krämer, “Selfverifing Solvers for Dense Systems of Linear Equations Realized in C–XSC”, Wuppertal, Germany: BUGH, Universität Wuppertal, 2003. (Preprint BUGHW-WRSWT 2003/1).
[9] Hölbig, C.A., Claudio, D.M., Diverio, T.A., “Use of C-XSC Interval Library on Cluster Computers” in IV International Conference on Numerical Analysis and Applied Mathematics, 2006. ICNAAM – 2006 Extended Abstracts, Wiley-VCH Verlag, Weinheim, v.1, pp.151-154, 2006.
[10] IEEE Standard for Binary Floating-Point Arithmetic, IEEE-754, 1985. [11] R. Klatte, et al., C–XSC - A C++ Class Library for Extended Scientific
Computing. New York: Springer-Verlag, 1993. [12] T. Kersten, “A case study for the use of verifying BLAS in a LAPACK
like verifying driver-routine for the solution of linear systems”, Revista de Informática Teórica e Aplicada, vol. 3, no.2, pp. 5-20, Dez. 1996.
[13] W. Krämer, U. Kulisch, R. Lohner, Numerical Toolbox for Verified Computing II: Advanced Numerical Problems. Berlin: Springer–Verlag, 1996. (not yet published)
[14] U. Kulisch, Advanced Arithmetic for the Digital Computer (Paperback). New York: Springer, 2002.
[15] U. Kulisch, W. Miranker, A New Approach to Scientific Computation. New York: Academic Press, 1983.
[16] M. Lerch, G. Tischler, J. Wolff v. Gudenberg, W. Hofschuster, W. Krämer, “filib++, a Fast Interval Library Supporting Containment Computations”, Wuppertal, Germany: BUGH, Universität Wuppertal, 2004. (Preprint BUGHW-WRSWT 2003/4).
[17] N. Maillard, “Algoritmos Matriciais em Processamento de Alto Desempenho”, in V Escola Regional de Alto Desempenho, SBC, Canoas, pp.33–56, 2005.
[18] R. Moore, Methods and Applications of Interval Analysis. Philadelphia: Society for Industrial and Applied Mathematics, 1979.
[19] E. A. C. Plata, H. E. Tacca, "Three Phase Power Using Wavelet Multiresolution Analysis.Part I: Mathematical Background", IEEE Latin America Transactions, Vol. 1, No. 1, pp. 15-20, Oct. 2003.
[20] C. L. S. Souza, R. M. S. Oliveira, W. H. Barros, "Computation of Ground Effects in a 3D-Outdoor Environment by the B-FDTD Method", IEEE Latin America Transactions, Vol. 5, No. 3, pp. 165-170, June 2007.
[21] D. Stringhini, “Depuração de Programas Paralelos - Projeto de uma interface intuitiva”. Tese (Doutorado em Ciência da Computação) — Instituto de Informática, Universidade Federal do Rio Grande do Sul, Porto Alegre, 2002.
120 IEEE LATIN AMERICA TRANSACTIONS, VOL. 7, NO. 1, MARCH 2009

[22] C. P. Ulrich, “Software for fast validated solution of linear systems”, Revista de Informática Teórica e Aplicada, vol. 3, no.2, pp. 21-34, 1996.
Carlos Amaral Hölbig ([email protected]) – possui graduação em Tecnologia em Processamento de Dados pela Universidade Católica de Pelotas (1993), mestrado (1996) e doutorado em Ciência da Computação pela Universidade Federal do Rio Grande do Sul (2005) na área de Informática Teórica – Matemática da Computação. Desenvolve pesquisas na área de Computação Científica, Matemática Intervalar e Processamento Paralelo. É Professor Titular II do
curso de Ciência da Computação da Universidade de Passo Fundo e líder do grupo de pesquisa de Computação Paralela e Sistemas Distribuídos (ComPaDi).
Tiarajú Asmuz Diverio ([email protected]) – possui graduação em Licenciatura em Matemática pela Universidade Federal do Rio Grande do Sul (1981), mestrado (1986) e doutorado em Ciência da Computação pela Universidade Federal do Rio Grande do Sul (1995). É Professor Adjunto da Universidade Federal do Rio Grande do Sul. Tem experiência na área de Ciência da Computação, com ênfase em Sistemas de Computação. Atuando principalmente nos seguintes temas: Computação e Processamento de Alto
Desempenho, Matemática Intervalar e Aritmética de Alta Exatidão.
Dalcidio Moraes Cláudio ([email protected]) – possui graduação em Bacharelado em Matemática pela Universidade Federal do Rio Grande do Sul (1973) e doutorado em Matemática Aplicada – Universidade de Karlsruhe – Alemanha (1979). Atualmente é professor adjunto da Pontifícia Universidade Católica do Rio Grande do Sul. Tem experiência na área de Ciência da Computação, com ênfase em Matemática da Computação, atuando principalmente nos seguintes
temas: intervalos, internet, ensino de matemática, cálculo e espaços coerentes.
AMARAL HÖLBIG et al.: PARALLEL ENVIRONMENT WITH 121
Related Documents











