Networks on chip: Evolution or Revolution? Luca Benini [email protected] DEIS-Universita’ di Bologna MPSOC 2004 L. Benini MPSOC 2004 2 Scalable VLIW Media Processor: • 100 to 300+ MHz • 32-bit or 64-bit Nexperia ™ System Buses • 32-128 bit General-purpose Scalable RISC Processor • 50 to 300+ MHz • 32-bit or 64-bit Library of Device IP Blocks • Image coprocessors • DSPs • UART • 1394 • USB … TM-xxxx D$ I$ TriMedia CPU DEVICE IP BLOCK DEVICE IP BLOCK DEVICE IP BLOCK . . . DVP SYSTEM SILICON PI BUS SDRAM MMI DVP MEMORY BUS DEVICE IP BLOCK PRxxxx D$ I$ MIPS CPU DEVICE IP BLOCK . . DEVICE IP BLOCK PI BUS TriMedia ™ MIPS ™ The evolution of SoC platforms n 2 Cores: Philips’ Nexperia PNX8850 SoC platform for High-end digital video (2001)

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
Networks on chip:Evolution or Revolution?
Luca [email protected]
DEIS-Universita’ di Bologna
MPSOC 2004
L. Benini MPSOC 2004 2
Scalable VLIW Media Processor:• 100 to 300+ MHz• 32-bit or 64-bit
Nexperia™
System Buses• 32-128 bit
General-purpose Scalable RISC Processor• 50 to 300+ MHz• 32-bit or 64-bit
Library of DeviceIP Blocks• Image coprocessors• DSPs• UART• 1394• USB…
TM-xxxxD$
I$
TriMedia CPU
DEVICE IP BLOCK
DEVICE IP BLOCK
DEVICE IP BLOCK
.
.
.
DVP SYSTEM SILICON
PI B
US
SDRAM
MMI
DV
P M
EM
OR
Y B
USDEVICE IP BLOCK
PRxxxxD$
I$
MIPS CPU
DEVICE IP BLOCK.
.
.DEVICE IP BLOCK
PI B
US
TriMedia™MIPS™
The evolution of SoC platforms
n 2 Cores: Philips’ Nexperia PNX8850 SoCplatform for High-end digital video (2001)

2
L. Benini MPSOC 2004 3
Running forward…
n Four 350/400 MHz StarCoreSC140 DSP extended cores
n 16 ALUs: 5600/6400 MMACS n 1436 KB of internal SRAM &
multi-level memory hierarchy n Internal DMA controller supports
16 TDM unidirectional channels, n Two internal coprocesssors
(TCOP and VCOP) to providespecial-purpose processing capability in parallel with the core processors
n 6 Cores: Motorola’s MSC8126 SoC platform for 3G base stations (late 2003)
L. Benini MPSOC 2004 4
What’s happening in SoCs?n Technology: no slow-down in sight!
n Faster and smaller transistors n … but slower wires, lower voltage, more noise!
n Design complexity: from 2 to 10 to 100 cores!n Design reuse is essentialn …but differentiation/innovation is key for winning
on the market!n Performance and power: GOPS for MWs!
n Performance requirements keep going upn …but power budgets don’t!

3
L. Benini MPSOC 2004 5
…and on-chip communication?
n Starting point: the “on chip bus”n Advances in protocolsn Advances in topologies
n Revolutionary approachesn Networks on chip
n Things are moving FASTn …but it’s evolution or revolution?
L. Benini MPSOC 2004 6
Outline
n Introduction and motivationn On-chip networkingn The HW-SW interface

4
L. Benini MPSOC 2004 7
On-chip bus Architecturen Many alternatives
n Large semiconductor firms (e.g. IBM Coreconnect, STMicro STBus)
n Core vendors (e.g. ARM AMBA)n Interconnect IP vendors (e.g. SiliconBackplane)
n Same topology, different protocols
L. Benini MPSOC 2004 8
AMBA bus
AHB: high-speed high-bandwidth multi-master bus
APB: Simplified processor forgeneral purpose peripherals
System-PeripheralBusCPU
EU IO
EU MemMem
CPU
AMBA High-speed bus Bridge
Master portSlave port

5
L. Benini MPSOC 2004 9
AHB Bus architecture
Different wires
Dedicated wires
NO Bidirectional wires
L. Benini MPSOC 2004 10
AMBA basic transfer
For a write
For a read
Pipelining increasesBus bandwidth
6
L. Benini MPSOC 2004 11
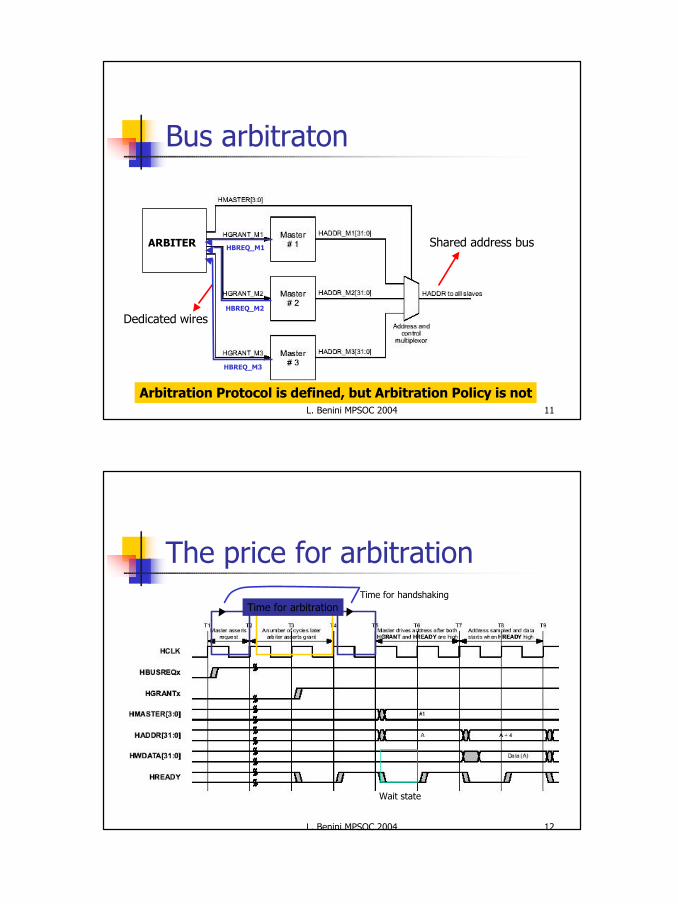
Bus arbitraton
ARBITER
Dedicated wires
Shared address bus
HBREQ_M3
HBREQ_M2
HBREQ_M1
Arbitration Protocol is defined, but Arbitration Policy is not
L. Benini MPSOC 2004 12
The price for arbitration
Time for arbitrationTime for handshaking
Wait state

7
L. Benini MPSOC 2004 13
Burst transfers
n Burst transfers amortize arbitration costn Grant bus control for a number of cyclesn Help with DMA and block transfersn Help hiding arbitration latency
n Requires safeguards against starvationn Split and error
L. Benini MPSOC 2004 14
Critical analysis: bottlenecks
n Protocoln Lacks parallelism
n In order completionn No multiple outstanding transactions: cannot hide slave wait states
n High arbitration overhead (on single-transfers)n Bus-centric vs. transaction-centric
n Initiators and targets are exposed to bus architecture (e.g. arbiter)
n Topologyn Scalability limitation of shared bus solution!

8
L. Benini MPSOC 2004 15
STBUS
n On-chip interconnect solution by STn Level 1-3: increasing complexity (and performance)
n Featuresn Higher parallelism: 2 channels (M-S and S-M)n Multiple outstanding transactions with out-of order completionn Supports deep pipeliningn Supports Packets (request and response) for multiple data transfersn Support for protection, caches, locking
n Deployed in a number of large-scale SoCs in STM
L. Benini MPSOC 2004 16
STBUS Protocol (Type 3)
Target
Initiator port Target port
Initiator
Request channel
Response channel
Transaction
Req Packet Resp Packet
Cell level
Packet level
Transaction level
Signal level

9
L. Benini MPSOC 2004 17
STBUS bottlenecks
n Protocol is not fully transaction-centricn Cannot connect initiator to target (e.g. initiator does not have control
flow on the response channel)
n Packets are atomic on the interconnectn Cannot initiate nor receive multiple packets at the same timen Large data transfers may starve other initiators
L. Benini MPSOC 2004 18
AMBA AXI
n Latest (2003) evolution of AMBAn Advanced eXtensible Interface
n Featuresn Fully transaction centric: can connect M to S with nothing in betweenn Higher parallelism: multiple channelsn Supports bus-based power managementn Support for protection, caches, locking
n Deployment: ??

10
L. Benini MPSOC 2004 19
Multi-channel M-S interface
Master
Slave
Address Channel
Write channel
Read channel
Write response ch.
VALID
DATA
READY
Channel hanshaking
4 parallel channels are available!
L. Benini MPSOC 2004 20
Multiple outstanding transactions
n A transaction implies activity on multiple channelsn E.g Read uses the Address and Read channel
n Channels are fully decoupled in timen Each transaction is labeled when it is started (Address channel)n Labels, not signals, are used to track transaction opening and closingn Out of order completion is supported (tracking logic in master),
but master can request in order delivery
n Burst supportn Single-address burst transactions (multiple data channel slots)n Bursts are not atomic!
n Atomicity is trickyn Exclusive access better than locked access
11
L. Benini MPSOC 2004 21
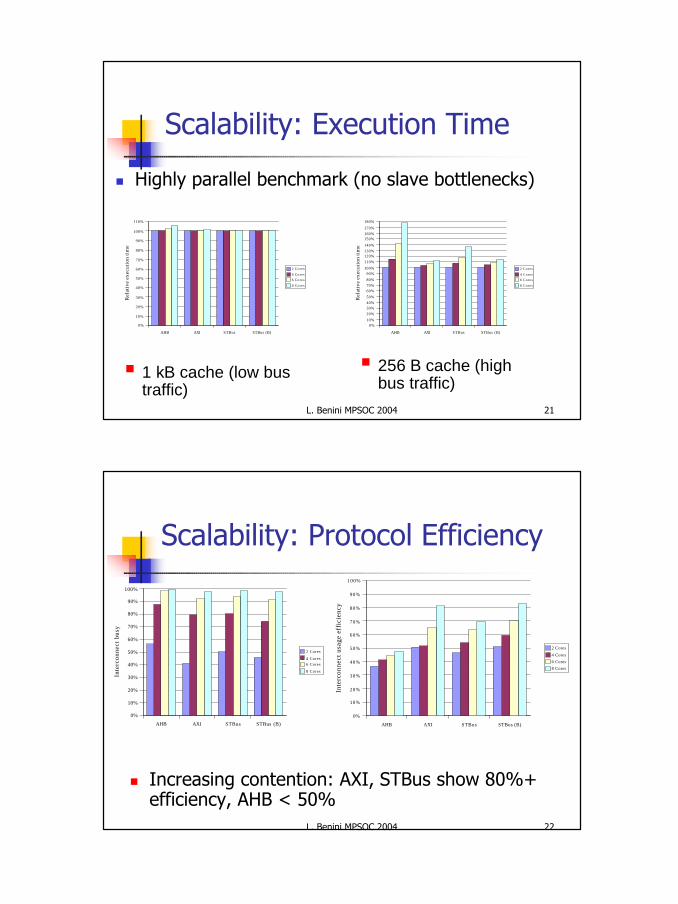
Scalability: Execution Time
n Highly parallel benchmark (no slave bottlenecks)
AHB AXI STBus STBus (B)
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
110%
2 Cores
4 Cores
6 Cores
8 Cores
Rel
ativ
e ex
ecut
ion
tim
e
AHB AXI STBus STBus (B)
0%10%20%30%40%50%60%70%80%90%
100%
110%120%130%140%
150%160%170%
180%
2 Cores
4 Cores
6 Cores
8 Cores
Rel
ativ
e ex
ecut
ion
tim
e
§ 1 kB cache (low bus traffic)
§ 256 B cache (high bus traffic)
L. Benini MPSOC 2004 22
Scalability: Protocol Efficiency
AHB AXI STBus STBus (B)
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
2 Cores
4 Cores
6 Cores
8 Cores
Inte
rcon
nect
usa
ge e
ffic
ienc
y
AHB AXI STBus STBus (B)
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
2 Cores
4 Cores6 Cores
8 Cores
Inte
rcon
nect
bus
y
n Increasing contention: AXI, STBus show 80%+ efficiency, AHB < 50%

12
L. Benini MPSOC 2004 23
Scalability: latency
2 Cores 4 Cores 6 Cores 8 Cores
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
STBus (B) write avgSTBus (B) write minSTBus (B) read avgSTBus (B) read minAXI write avgAXI write minAXI read avgAXI read min
Lat
ency
for
acc
ess
com
plet
ion
(cyc
les)
§ STBus management has less arbitration latency overhead, especially noticeable in low-contention conditions
L. Benini MPSOC 2004 24
Topology
n Single shared bus isclearly non-scalable
n Evolutionary pathn “Patch” bus topology
n Two approachesn Clustering & Bridgingn Multi-layer/Multibus
B
M
M
13
L. Benini MPSOC 2004 25
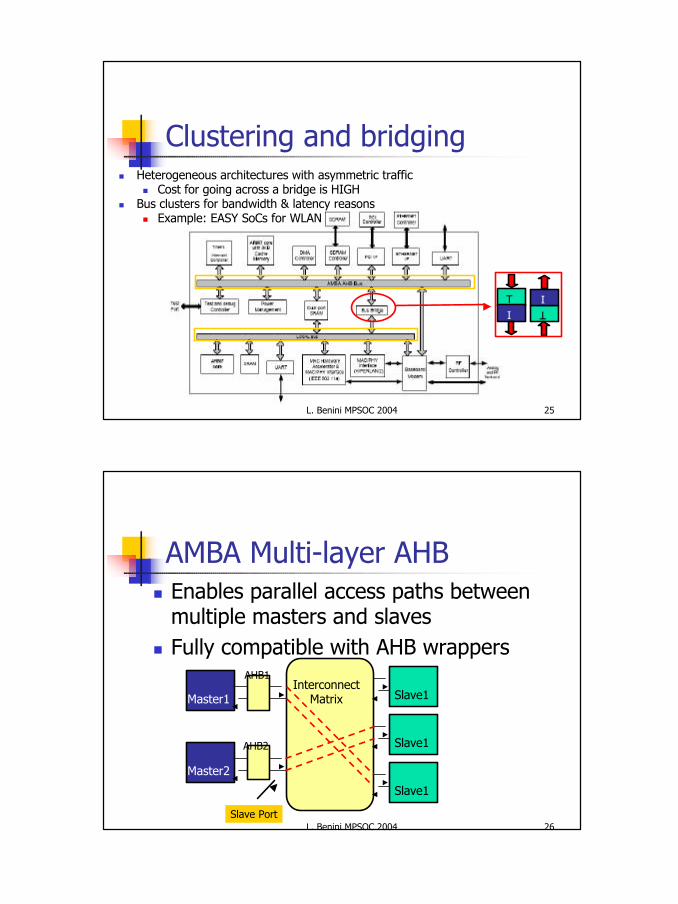
Clustering and bridgingn Heterogeneous architectures with asymmetric traffic
n Cost for going across a bridge is HIGHn Bus clusters for bandwidth & latency reasons
n Example: EASY SoCs for WLAN
T
I
T
I
L. Benini MPSOC 2004 26
AMBA Multi-layer AHBn Enables parallel access paths between
multiple masters and slavesn Fully compatible with AHB wrappers
Master1
Master2
Slave1Interconnect
Matrix
Slave1
Slave1
AHB1
AHB2
Slave Port
14
L. Benini MPSOC 2004 27
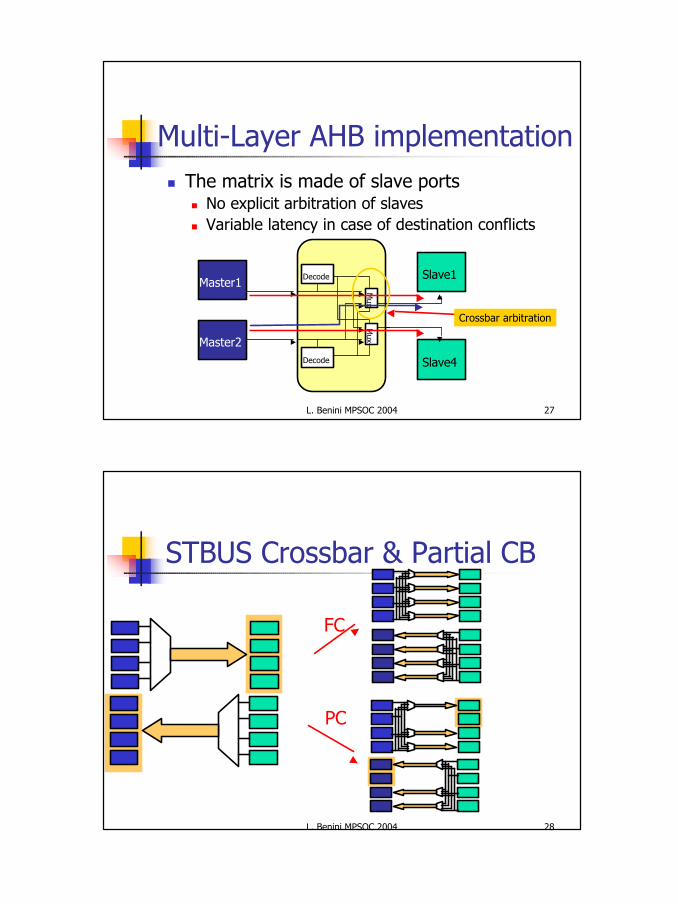
Multi-Layer AHB implementationn The matrix is made of slave ports
n No explicit arbitration of slavesn Variable latency in case of destination conflicts
Master1
Master2
Slave1
Slave4
Mux
Mux
Decode
Decode
Crossbar arbitration
L. Benini MPSOC 2004 28
STBUS Crossbar & Partial CB
PC
FC
15
L. Benini MPSOC 2004 29
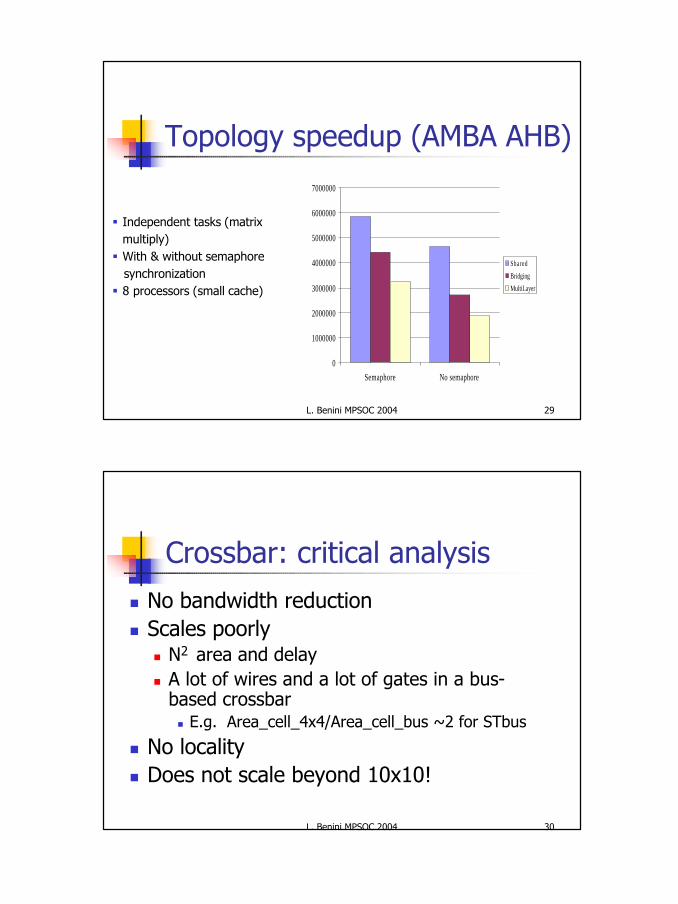
Topology speedup (AMBA AHB)
0
1000000
2000000
3000000
4000000
5000000
6000000
7000000
Semaphore No semaphore
Shared
Bridging
MultiLayer
§ Independent tasks (matrix multiply)§ With & without semaphore
synchronization§ 8 processors (small cache)
L. Benini MPSOC 2004 30
Crossbar: critical analysis
n No bandwidth reduction n Scales poorly
n N2 area and delayn A lot of wires and a lot of gates in a bus-
based crossbarn E.g. Area_cell_4x4/Area_cell_bus ~2 for STbus
n No localityn Does not scale beyond 10x10!
16
L. Benini MPSOC 2004 31
NoCs
§ More radical solutions in the long term
Ø NostrumØ HiNoCØ Linkoeping SoCBUSØ SPINØ Star-connected on-chip networkØ AetherealØ ProteoØXpipesØ… (at least 15 groups)
CPU
Memory
DSP
Memory
linkswitch
network interface
CPU
L. Benini MPSOC 2004 32
NOCs vs. Bussesn Packet-based
n No distinction address/data, only packets (but of many types)
n Complete separation between end-to-end transactions and data delivery protocols
n Distributed vs. centralizedn No global control bottleneckn Better link with placement and routing
n Bandwidth scalability, of course!
STBU
S an
d AX
I

17
L. Benini MPSOC 2004 33
The “power of NoCs”
Design methodologyClean separation at the session layer:
1. Define end-to-end transactions2. Define quality of service requirements3. Design transport, network, link, physical
Modularity at the HW level: only 2 building blocks1. Network interface2. Switch (router)
Scalability is supported from the ground up(not as an afterthought)
L. Benini MPSOC 2004 34
Building blocks: NI
n Session-layer interface with nodesn Back-end manages interface with switches
Front end
Backend
Standardized node interface @ session layer. Initiator vs. target distinction is blurred
1. Supported transactions (e.g. QoSread…)2. Degree of parallelism3. Session prot. control flow & negotiation
NoC specific backend (layers 1-4)1. Physical channel interface2. Link-level protocol3. Network-layer (packetization)4. Transport layer (routing)
Node Switches
18
L. Benini MPSOC 2004 35
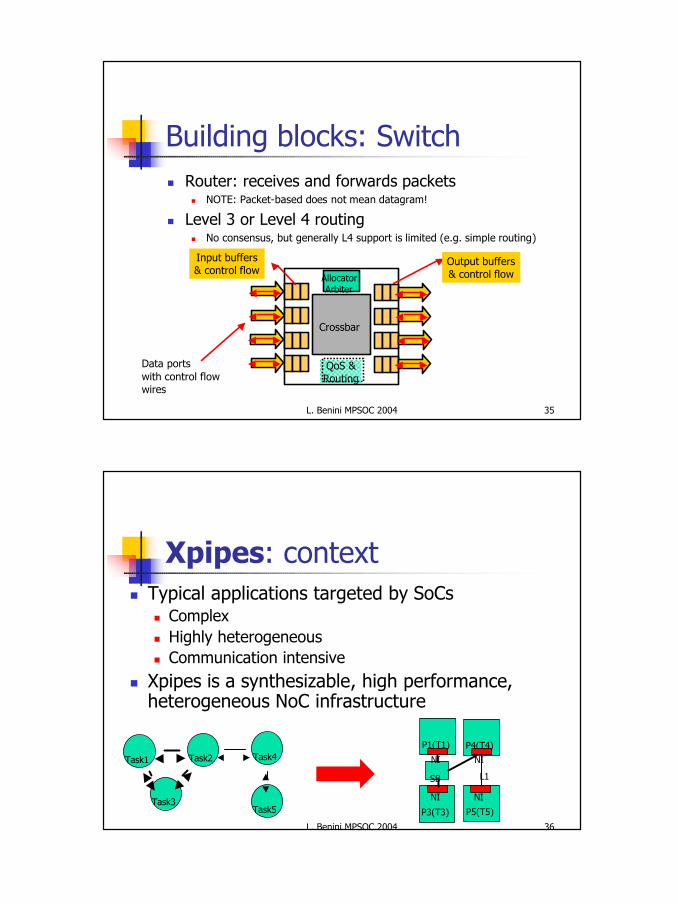
Building blocks: Switchn Router: receives and forwards packets
n NOTE: Packet-based does not mean datagram!
n Level 3 or Level 4 routingn No consensus, but generally L4 support is limited (e.g. simple routing)
Crossbar
AllocatorArbiter
Output buffers& control flow
Input buffers& control flow
QoS &Routing
Data portswith control flowwires
L. Benini MPSOC 2004 36
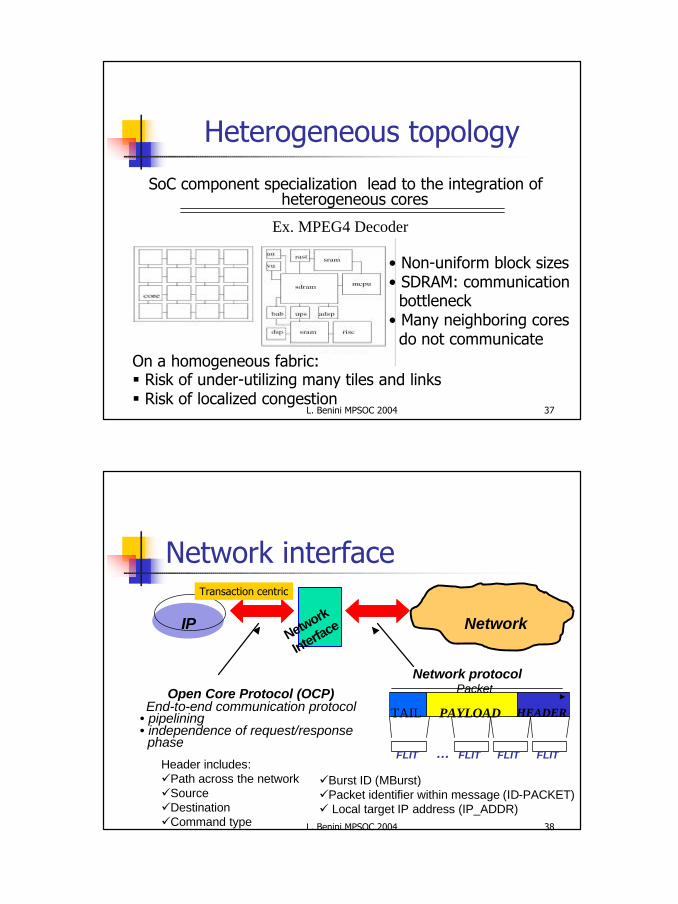
Xpipes: contextn Typical applications targeted by SoCs
n Complexn Highly heterogeneousn Communication intensive
n Xpipes is a synthesizable, high performance, heterogeneous NoC infrastructure
Task1 Task2 Task4
Task3
SB
Task5
P1(T1) P4(T4)
P3(T3) P5(T5)
NI
NINI
NI
L1
19
L. Benini MPSOC 2004 37
Heterogeneous topology
SoC component specialization lead to the integration of heterogeneous cores
Ex. MPEG4 Decoder
• Non-uniform block sizes• SDRAM: communication
bottleneck• Many neighboring cores
do not communicate
§ Risk of under-utilizing many tiles and links§ Risk of localized congestion
On a homogeneous fabric:
L. Benini MPSOC 2004 38
Network interface
Open Core Protocol (OCP)End-to-end communication protocol
• pipelining• independence of request/response
phase
Network protocol
IPNetwork
Interface Network
PAYLOAD HEADERTAIL
Packet
FLITFLITFLIT…FLITHeader includes:üPath across the networküSourceüDestinationüCommand type
üBurst ID (MBurst)üPacket identifier within message (ID-PACKET)ü Local target IP address (IP_ADDR)
Transaction centric

20
L. Benini MPSOC 2004 39
Switch (s-Xpipes)
Crossbar
AllocatorArbiter
•Plain latching of inputs•Buffering resources are on the output ports
•FIFOs for performance (tunable area/speed tradeoff)•Circular buffers for ACK/NACK management (minimal size if directlyattached to downstream component, can be larger for pipelined links)
•ACK/NACK flow control
•2-stage pipeline
•Tuned for high clock speeds
L. Benini MPSOC 2004 40
Example: MPEG4 decoder n Core graph representation with annotated
average communication requirements
21
L. Benini MPSOC 2004 41
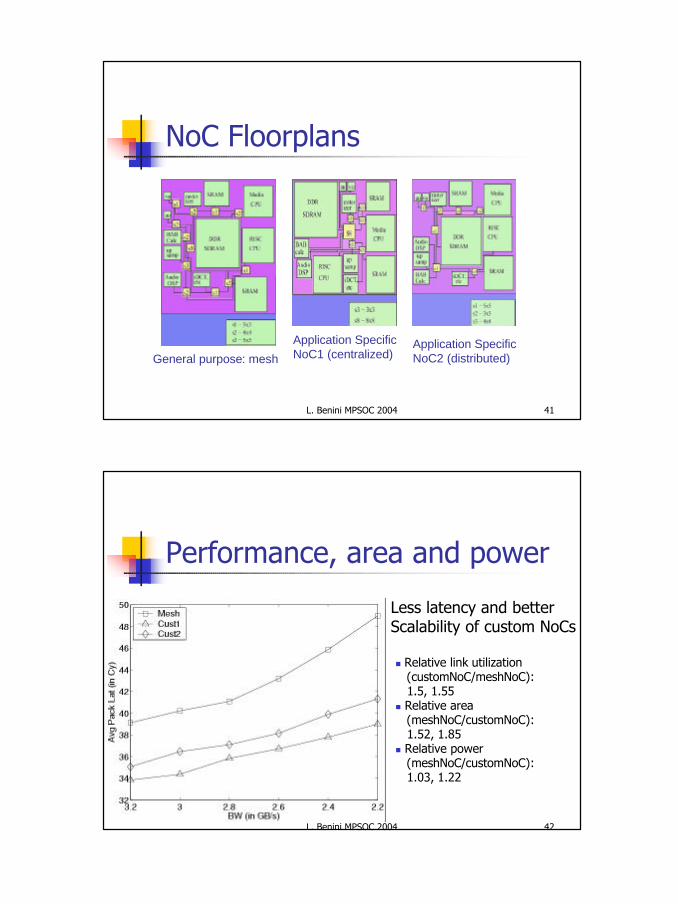
NoC Floorplans
General purpose: mesh
Application Specific NoC1 (centralized)
Application Specific NoC2 (distributed)
L. Benini MPSOC 2004 42
Performance, area and power
n Relative link utilization(customNoC/meshNoC):1.5, 1.55
n Relative area(meshNoC/customNoC):1.52, 1.85
n Relative power(meshNoC/customNoC):1.03, 1.22
Less latency and betterScalability of custom NoCs

22
L. Benini MPSOC 2004 43
NoC synthesis flow
In cooperation with Stanford Univ.
SUNMAP
Power Lib
Area Lib
Floor-planner
xpipesLibrary
xpipesCompiler
SystemCDesign
Simu-lation
MappingOnto
TopologiesTopologySelection
TopologyLibrary
RoutingFunction
Co-Design
Appln
L. Benini MPSOC 2004 44
Outline
n Introduction and motivationn On-chip networkingn The HW-SW interface
n Session layer and above
23
L. Benini MPSOC 2004 45
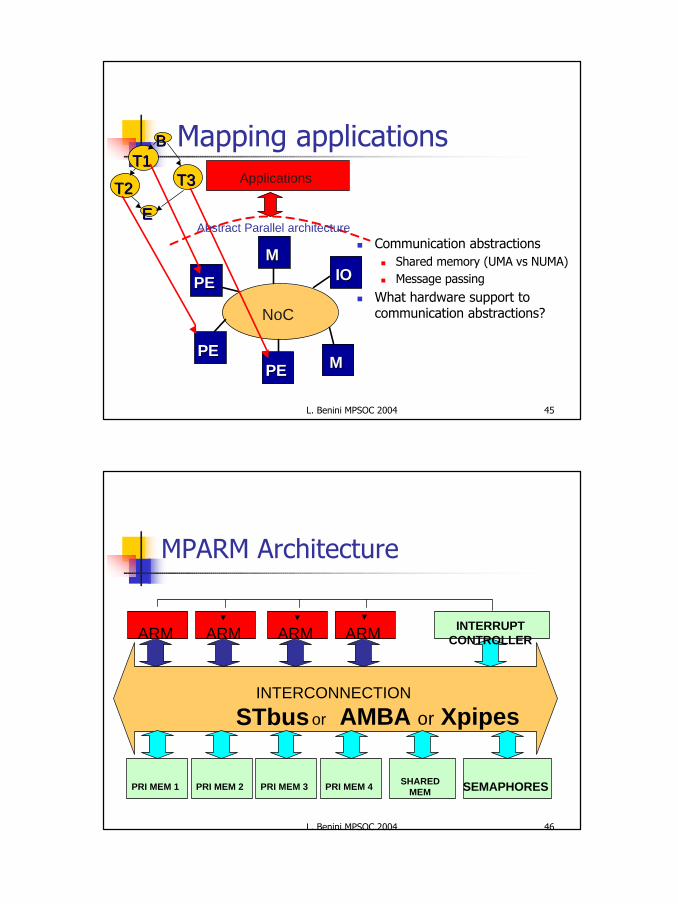
Mapping applicationsApplications
Abstract Parallel architecture
T1T1
T2T2 T3T3
BB
EE
PEPE
PEPE
NoC
PEPE
MM
MM
IOIO
n Communication abstractionsn Shared memory (UMA vs NUMA)n Message passing
n What hardware support to communication abstractions?
L. Benini MPSOC 2004 46
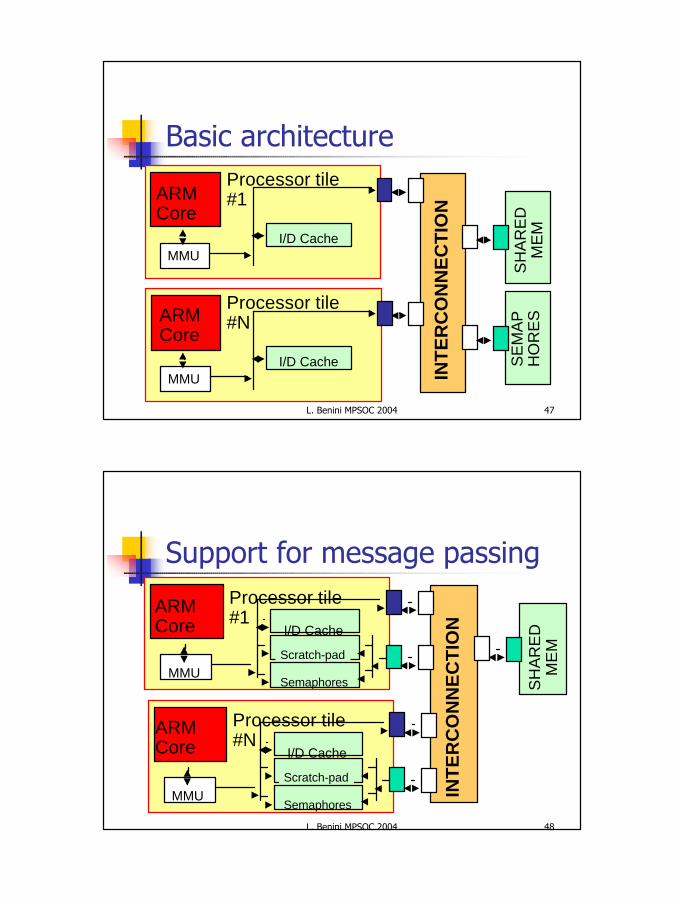
MPARM Architecture
INTERCONNECTION
ARM ARM INTERRUPTCONTROLLER
PRI MEM 4 SHARED MEM SEMAPHORES
ARM ARM
PRI MEM 3PRI MEM 2PRI MEM 1
STbusor AMBA or Xpipes
24
L. Benini MPSOC 2004 47
Basic architecture
MMUI/D Cache
INT
ER
CO
NN
EC
TIO
N
ARM Core
SH
AR
ED
M
EM
Processor tile#1
SE
MA
PH
OR
ES
MMUI/D Cache
ARM Core
Processor tile#N
L. Benini MPSOC 2004 48
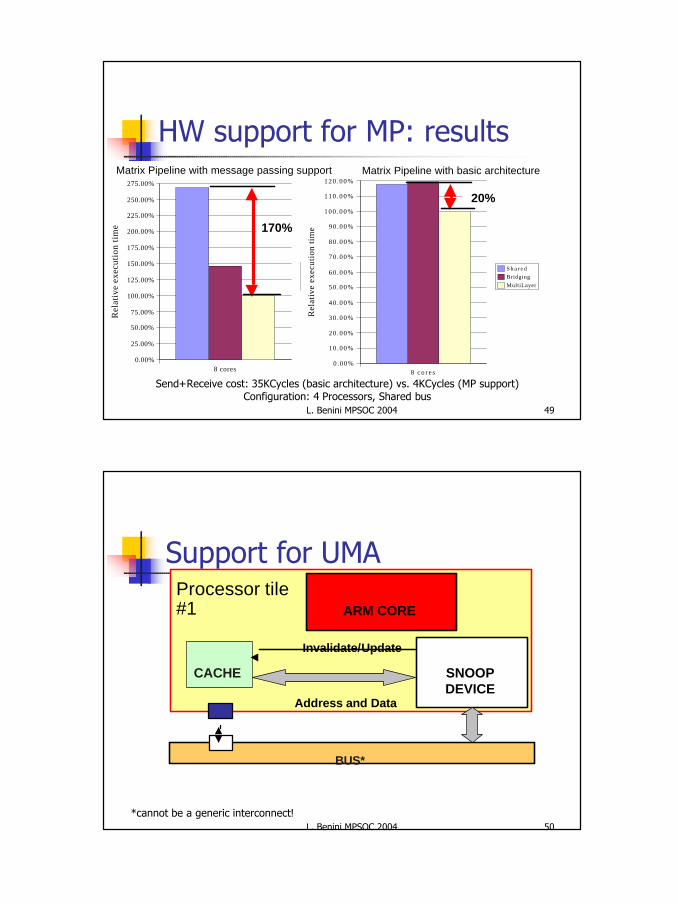
Support for message passing
MMU
I/D Cache
Scratch-pad
INT
ER
CO
NN
EC
TIO
N
ARM Core
SH
AR
ED
M
EM
Processor tile#1
Semaphores
MMU
I/D Cache
Scratch-pad
ARM Core
Processor tile#N
Semaphores
25
L. Benini MPSOC 2004 49
HW support for MP: results
8 cores0.00%
25.00%
50.00%
75.00%
100.00%
125.00%
150.00%
175.00%
200.00%
225.00%
250.00%
275.00%
SharedBridgingMultiLayer
Rel
ativ
e ex
ecut
ion
tim
e
8 c o r e s0 .00%
10 .00%
20 .00%
30 .00%
40 .00%
50 .00%
60 .00%
70 .00%
80 .00%
90 .00%
1 0 0 . 0 0 %
1 1 0 . 0 0 %
1 2 0 . 0 0 %
S h a r e dBridgingMultiLayer
Rel
ativ
e ex
ecut
ion
tim
e
Matrix Pipeline with basic architectureMatrix Pipeline with message passing support
170%
20%
Send+Receive cost: 35KCycles (basic architecture) vs. 4KCycles (MP support)Configuration: 4 Processors, Shared bus
L. Benini MPSOC 2004 50
ARM CoreARM CORE
Support for UMA
CACHE
BUS*
SNOOPDEVICE
Invalidate/Update
Address and Data
Processor tile#1
*cannot be a generic interconnect!

26
L. Benini MPSOC 2004 51
Readers-writers: varying cache size
Cycles
0.8
0.85
0.9
0.95
1
1.05
1.1
512 1024 2048 4096
SW
WTI
WTU
Energy
0.8
0.85
0.9
0.95
1
1.05
1.1
1.15
1.2
1.25
1.3
512 1024 2048 4096
SW
WTI
WTU
Energy-Delay product
0.7
0.8
0.9
1
1.1
1.2
1.3
1.4
512 1024 2048 4096
SW
WTI
WTU
Power
0.7
0.8
0.9
1
1.1
1.2
1.3
1.4
512 1024 2048 4096
SW
WTI
WTU
L. Benini MPSOC 2004 52
Readers-writers: varying buffer size
Cycles
0.8
0.85
0.9
0.95
1
1.05
1.1
16 256 1024
SW
WTI
WTU
Energy
0.8
0.85
0.9
0.95
1
1.05
1.1
1.15
1.2
1.25
1.3
16 256 1024
SW
WTI
WTU
Energy-Delay product
0.7
0.8
0.9
1
1.1
1.2
1.3
1.4
16 256 1024
SW
WTI
WTU
Power
0.7
0.8
0.9
1
1.1
1.2
1.3
1.4
16 256 1024
SW
WTI
WTU

27
L. Benini MPSOC 2004 53
Conclusions
n Evolutionary shift from bus-based interconnect to NoCsn Well underway (there’s no stopping now)n Methodology/tooling is the main issue
n Platform challengesn Programming abstractionn HW/SW tradeoffs in session layer support
Related Documents











