Thesis Topic PERFORMANCE IMPROVEMENT OF MULTIMEDIA CONTENT DELIVERY Presented to- Dr. K.M. Azharul Hasan Associate Professor and Head of the department Computer Science and Engineering, Khulna University of Engineering & Technology Presented by- Md. Nahid Rahman 0607004 Md. Anwarul Alam 0607028

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 1/35
Thesis Topic
PERFORMANCE IMPROVEMENT OF MULTIMEDIA CONTENTDELIVERY
Presented to-
Dr. K.M. Azharul Hasan
Associate Professor and
Head of the department
Computer Science and Engineering,
Khulna University of Engineering & Technology
Presented by-
Md. Nahid Rahman 0607004
Md. Anwarul Alam 0607028

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 2/35
Chapter 1
INTRODUCTION
1.1 Introduction
Universal access to multimedia information is now the principal motivation behind the design of next-generation computer and communications networks. Furthermore, products are beingdeveloped to extend the capabilities in all existing network connections to support multimediatraffic. The content of multimedia is always in an unfair state while delivering through thenetwork causing multimedia packet loss a great deal. This unfairness should be minimized asmuch as possible. A lot of research is going on regarding this problem such as Active QueueManagement (AQM). Researchers are proposing new algorithms for managing queues such asRandom Early Detection as RED [5], [12], BLUE [7],[10], and Random Exponential Marking asREM to provide fairness. We are interested in multimedia communications that is, we are
interested in the transmission of multimedia information over networks. By multimedia, wemean data, voice, graphics, still images, audio, and video. Multimedia applications have differentrequirements from text-based applications. An audio stream, for example, requires that data isreceived in a timely fashion and is more forgiving of lost data. If a data packet arrives at the player too late, it misses the time it is needed to be played. This phenomenon, called jitter, causesgaps in the sound heard by the user. In many cases, a late data packet in a multimedia applicationcontributes nothing to the playback and is equivalent to a loss. Small losses in the playback stream can be replaced with substitute data or concealed so that the listener does not notice.When designing a multimedia application, a protocol must be chosen that provides a solution for timing issues such as jitter as well as loss. TCP is ineffective due to the overhead of
retransmission and ignorance of timing factors. While it provides a service with no loss of data, itdoes not support any time constraints. Data can arrive at a receiver with unbounded delay. UDP,conversely, provides a ³best effort´ service that is timely. It does not, however, offer anyguarantees on data loss. With UDP, potentially all data sent can be lost. To provide a balance between the delay of TCP and the loss of UDP, we are mainly focusing on the agent thattransmits/receives the multimedia packet named as UDPmm stands for UDP Multimedia. InUDPmm we took some features from TCP and added them to UDP. It is a fairly reliable methodof transmitting data over a network.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 3/35
1.2 Problem Statement
The internet today is changing quickly. The increase in existence of peer to peer programs andother high traffic programs causes a lot of internet traffic. These expansions of internet traffic provoke problems in the quality of service (QoS), like packet loss and overload, so a stable
internet cannot be guaranteed. Furthermore, analysis of internet traffic is also very useful for developing effective and efficient traffic engineering schemes and for network operators andmanagement. There has been a great deal of research and development in the field of multimedianetworking. There are several methods available for solving multimedia issues related on routers,the intermediate nodes between end systems. Some of these solutions involve router queuingalgorithms used to decide when a message should be sent or deleted when there is congestion.Also, there are Quality of Service (QoS) algorithms that allow for the reservation of network resources. The QoS [3] of today¶s best-effort network does not deliver the performance requiredfor a wide range of interactive and multimedia applications that have demanding delay and bandwidth requirements. Multimedia packets expect to have bandwidth fairness, load balancing,less packet dropping, fair queuing, proper link utilization etc. Internet routers today employtraditional FIFO queuing (called µµdrop-tail¶¶ queue management). Random Early Detection(RED) is a router-based congestion control mechanism that seeks to reduce the long-termaverage queue length in routers [2]. A RED router monitors queue length statistics and probabilistically drops arriving packets even though space exists to enqueue the packet. Suchµµearly drops¶¶ are performed as a means of signaling TCP flows (and others that respond to packet loss as an indicator of congestion) that congestion is incipient in the router. Flows shouldreduce their transmission rate in response to loss (as outlined above) and thus prevent router queues from overÀowing. Under RED, routers compute a running weighted average queue length
that is used to determine when to send congestion notifications back to end-systems. Congestionnotification is referred to as µµmarking¶¶ a packet. For standard TCP end-systems, a RED router drops marked packets to signal congestion through packet loss. If the TCP end-systemunderstands packet-marking, a RED router marks and then forwards the marked packet. RED¶smarking algorithm depends on the average queue size and two thresholds, minth and maxth.When the average queue size is below minth, RED acts like a drop-tail router and forwards all packets with no modifications. When the average queue size is between minth and maxth, REDmarks incoming packets with a certain probability. When the average queue size is greater thanmaxth, all incoming packets are dropped. The more packets a Àow sends, the higher the probability that its packets will be marked. In this way, RED spreads out congestion noti¿cations
proportionally to the amount of space in the queue that a Àow occupies. The RED thresholdsminth and maxth, the maximum drop probability maxp, and the weight given to new queue sizemeasurements wq, play a large role in how the queue is managed. Recommendations on settingthese RED parameters specify that maxth should be set to three times minth, wq should be set to0.002, or 1/512, and maxp should be 10%.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 4/35
There are several other techniques too such as Adaptive RED. Adaptive RED (ARED) is amodification to RED which addresses the difficulty of setting appropriate RED parameters.ARED adapts the value of maxp so that the average queue size is halfway between minth andmaxth. The maximum drop probability, maxp is kept between 1% and 50% and is adaptedgradually. ARED includes another modi¿cation to RED, called µµgentle RED¶¶. In gentle RED,
when the average queue size is between maxth and 2 * maxth, the drop probability is variedlinearly from maxp to 1, instead of being set to 1 as soon as the average is greater than maxth.When the average queue size is between maxth and 2 * maxth, selected packets are no longer marked, but always dropped. ARED¶s developers provide guidelines for the automatic setting of minth, maxth, and wq. Setting minth results in a trade-o between throughput and delay. Larger queues increase throughput, but at the cost of higher delays. The rule of thumb suggested by theauthors is that the average queuing delay should only be a fraction of the round-trip time (RTT).If the target average queuing delay is target delay and C is the link capacity in packets per second, then minth should be set to target delay * C/2. The guideline for setting maxth is that it
should be 3 * minth, resulting in a target average queue size of 2 * minth. The weightingfactor wq controls how fast new measurements of the queue a ect the average queue size andshould be smaller for higher speed links. This is because a given number of packet arrivals on afast link represent a smaller fraction of the RTT than for a slower link. It is suggested that wq beset as a function of the link bandwidth, speci¿cally, 1 - exp(-1/C).
Although many extensions to RED have been proposed, we used RED in our study because it isthe base, which leads us to many AQM techniques and because we believe RED is the mostlikely to be standardized and deployed. Now it is the AQM technique which we used in our multimedia data transfer. But what is more important in our technique is to know about TCP and
UDP. The Internet protocols, TCP and UDP, have been established for several decades. Bothhave been implemented countless times on different computing platforms with differentmodifications and have been relentlessly studied and tested. The result is a set of stable protocols. In a TCP protocol receiver always sends back acknowledgement to the sender. So,sender sends packet again if there is no acknowledgement found. In this way packet drops rarely.TCP Reno provides two methods of detecting packet loss: the expiration of a timer and thereceipt of three duplicate acknowledgements. Whenever a new packet is sent, the retransmissiontimer (RTO) is set. If the RTO expires before the packet is acknowledged, the packet is assumedto be lost. When the RTO expires, the packet is retransmitted, ssthresh is set to 1/2 cwnd, cwnd isset to 1 segment, and the connection re-enters slow-start. Fast retransmit speci¿es that a packet
can be assumed lost if three duplicate ACKs are received. This allows TCP Reno to avoid alengthy timeout during which no data is transferred. When packet loss is detected via threeduplicate ACKs, fast recovery is entered. In fast recovery, ssthresh is set to 1/2 cwnd, and cwndis set to ssthresh +3. For each additional duplicate ACK received, cwnd is incremented by 1segment. New segments can be sent as long as cwnd allows. When the ¿rst ACK arrives for theretransmitted packet, cwnd is set back to ssthresh. Once the lost packet has been acknowledged,TCP leaves fast recovery and returns to congestion avoidance. Fast recovery also provides a

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 5/35
transition from slow start to congestion avoidance. If a sender is in slow-start and detects packetloss through three duplicate ACKs, after the loss has been recovered, congestion avoidance isentered. The only other way to enter congestion avoidance is if cwnd > ssthresh. In many cases,though, the initial value of ssthresh is set to a very large value, so packet loss is often the onlytrigger to enter congestion avoidance. TCP Reno can only recover from one packet loss during
fast retransmit and fast recovery. Additional packet losses in the same window may require thatthe RTO expire before being retransmitted. The exception is when cwnd is greater than 10segments. In this case, Reno could recover from two packet losses by entering fast recoverytwice in succession. This causes cwnd to e ectively be reduced by 75% in two RTTs. There areways following which TCP detects congestion and retransmits packets. But the way TCP worksis not suitable for multimedia data transfer. Multimedia data transfer demands somethingdifferent, because cost of TCP is more. That¶s why the usage of TCP for multimedia data transfer was proved ineffective. Then everyone went to UDP for solution. UDP (User DatagramProtocol ) is a simple OSI transport layer protocol for client/server network applications based
on Internet Protocol (IP). UDP is the main alternative to TCP and one of the oldest network protocols in existence, introduced in 1980. UDP is often used in video conferencing applicationsor computer games specially tuned for real-time performance. To achieve higher performance,the protocol allows individual packets to be dropped (with no retries) and UDP packets to bereceived in a different order than they were sent as dictated by the application. On the other handfor a UDP protocol no acknowledgement system is present. Therefore packet drops frequentlywhen the queue is full. The most important reason UDP was chosen over TCP is that UDP doesnot implement retransmission. But here in this case a problem also rose. There was no facility for detecting congestion. So if packets were lost no techniques to detect it. As we see a new protocolfor multimedia content delivery is a very must needed situation which can take advantage of
these and combine the facilities of both TCP and UDP. And that¶s the problem we have triedhere to solve.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 6/35
1.3 Scope
Solving multimedia issues. Deciding when a message should be sent or deleted when there is congestion. Delivering the performance required for a wide range of interactive and
multimedia applications that have demanding delay and bandwidthrequirements.
Reducing number of packets dropped in routers. Keep average queue size small. Leaving enough space for bursts. Providing lower interactive services. By keeping average queue size small end to end delays will be shorter. Avoiding packet collisions. Simulating the behavior of an imaginary multimedia application that
implements "five rate media scaling" that can respond to network congestion to
some extent by changing encoding and transmission policy pairs associated withscale parameter values.
1.4 Organization
The remainder of this paper is organized as follows:
Section 2 provides an overview of previous works. Section 3 introduces the UDPmm model.
Section 4 describes the simulation environment and parameter settings toevaluate the performance of the proposed framework. Section 5 presents some brief conclusions.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 7/35
Chapter 2
LITERATURE REVIEW
Nowadays bandwidth is the scarcest resource in networks. In P2P networks available bandwidthfor services is even lower, as the maintenance of P2P requires a part of the bandwidth and inaddition to this, asymmetric bandwidth capabilities are common. Asymmetric Digital Subscriber Lines (ADSL) connections are dominant in the Internet. This causes that asymmetric bandwidthavailability, differing down-link and up-link capabilities, have to be assumed as normal.Typically the out link provides less bandwidth, than the incoming link. However this results thatit may occur that not all incoming data can be processed and transmitted, as the out bandwidth isless than the in bandwidth. Congestion is a problem that may occur, when no suitablemechanisms are used. Common reliable protocols on the transport layer (like TCP) supportmechanisms to adapt the sending rate to characteristics of the network. It is important tounderstand TCP if one is to understand the historic, current and future architecture of the Internet protocols. Most applications on the Internet make use of TCP, relying upon its mechanisms thatensure safe delivery of data across an unreliable IP layer below. TCP (Transmission Control
Protocol) is the most commonly used protocol on the Internet. The reason for this is becauseTCP offers error correction. When the TCP protocol is used there is a "guaranteed delivery."This is due largely in part to a method called "flow control." Flow control determines when dataneeds to be re-sent, and stops the flow of data until previous packets are successfully transferred.This works because if a packet of data is sent, a collision may occur. When this happens, theclient re-requests the packet from the server until the whole packet is complete and is identical toits original. The sending rate is decreased using the congestion window principle, when packetloss is detected. Routers in the network can drop (or mark) packets intentionally in order tosignal to the flow sources to choke / decrease their sending rate. TCP interfaces between theapplication layer above and the network layer below. When an application sends data to TCP, itdoes so in 8-bit byte streams. It is then up to the sending TCP to segment or delineate the byte
stream in order to transmit data in manageable pieces to the receiver. It is this lack of 'record boundaries" which give it the name "byte stream delivery service". There is something more.Before two communicating TCPs can exchange data, they must first agree upon the willingnessto communicate. Analogous to a telephone call, a connection must first be made before two parties exchange information. TCP is popular for reliability. A number of mechanisms help provide the reliability TCP guarantees. Each of these is described briefly. First one is checksums.All TCP segments carry a checksum, which is used by the receiver to detect errors with either theTCP header or data. Secondly duplicate data detection. It is possible for packets to be duplicatedin packet switched network; therefore TCP keeps track of bytes received in order to discardduplicate copies of data that has already been received. Next one is retransmissions. In order toguarantee delivery of data, TCP must implement retransmission schemes for data that may be
lost or damaged. The use of positive acknowledgements by the receiver to the sender confirmssuccessful reception of data. The lack of positive acknowledgements, coupled with a timeout period (see timers below) calls for a retransmission. Next we get sequencing. In packet switchednetworks, it is possible for packets to be delivered out of order. It is TCP's job to properlysequence segments it receives so it can deliver the byte stream data to an application in order.Last one is timers. TCP maintains various static and dynamic timers on data sent. The sendingTCP waits for the receiver to reply with an acknowledgement within a bounded length of time. If the timer expires before receiving an acknowledgement, the sender can retransmit the segment.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 8/35
The connection establishment between two hosts by exchanging messages in order tocommunicate using TCP is known as the three-way handshake. To start, Host A initiates theconnection by sending a TCP segment with the SYN control bit set and an initial sequencenumber (ISN) we represent as the variable x in the sequence number field. At some moment later in time, Host B receives this SYN segment, processes it and responds with a TCP segment of its
own. The response from Host B contains the SYN control bit set and its own ISN represented asvariable y. Host B also sets the ACK control bit to indicate the next expected byte from Host Ashould contain data starting with sequence number x+1. When Host A receives Host B's ISN andACK, it finishes the connection establishment phase by sending a final acknowledgementsegment to Host B. In this case, Host A sets the ACK control bit and indicates the next expected byte from Host B by placing acknowledgement number y+1 in the acknowledgement field. Anexchange of source and destination ports to use for connection is also included in each sender¶ssegments. Once ISNs have been exchanged, communicating applications can transmit data between each other. Most of the discussion surrounding data transfer requires us to look at flowcontrol and congestion control techniques. A simple TCP implementation will place segmentsinto the network for a receiver as long as there is data to send and as long as the sender does not
exceed the window advertised by the receiver. As the receiver accepts and processes TCPsegments, it sends back positive acknowledgements, indicating where in the byte stream it is.These acknowledgements also contain the "window" which determines how many bytes thereceiver is currently willing to accept. If data is duplicated or lost, a "hole" may exist in the bytestream. A receiver will continue to acknowledge the most current contiguous place in the bytestream it has accepted. If there is no data to send, the sending TCP will simply sit idly by waitingfor the application to put data into the byte stream or to receive data from the other end of theconnection. If data queued by the sender reaches a point where data sent will exceed thereceiver's advertised window size, the sender must halt transmission and wait for further acknowledgements and an advertised window size that is greater than zero before resuming.Timers are used to avoid deadlock and unresponsive connections. Delayed transmissions areused to make more efficient use of network bandwidth by sending larger "chunks" of data atonce rather than in smaller individual pieces. In order for a connection to be released, four segments are required to completely close a connection. Four segments are necessary due to thefact that TCP is a full-duplex protocol, meaning that each end must shut down independently. Toterminate the connection, the application running on Host A signals TCP to close the connection.This generates the first FIN segment from Host A to Host B. When Host B receives the initialFIN segment, it immediately acknowledges the segment and notifies its destination applicationof the termination request. Once the application on Host B also decides to shut down theconnection, it then sends its own FIN segment, which Host A will process and respond with anacknowledgement. Flow control is a technique whose primary purpose is to properly match thetransmission rate of sender to that of the receiver and the network. It is important for thetransmission to be at a high enough rates to ensure good performance, but also to protect againstoverwhelming the network or receiving host. We note that flow control is not the same ascongestion control. Congestion control is primarily concerned with a sustained overload of network intermediate devices such as IP routers. TCP uses the window field, briefly described previously, as the primary means for flow control. During the data transfer phase, the windowfield is used to adjust the rate of flow of the byte stream between communicating TCPs.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 9/35
TCP congestion control and Internet traffic management issues in general is an active area of research and experimentation. This final section is a very brief summary of the standardcongestion control algorithms widely used in TCP implementations today. Slow Start, arequirement for TCP software implementations is a mechanism used by the sender to control thetransmission rate, otherwise known as sender-based flow control. This is accomplished through
the return rate of acknowledgements from the receiver. In other words, the rate of acknowledgements returned by the receiver determines the rate at which the sender can transmitdata. When a TCP connection first begins, the Slow Start algorithm initializes a congestionwindow to one segment, which is the maximum segment size (MSS) initialized by the receiver during the connection establishment phase. When acknowledgements are returned by thereceiver, the congestion window increases by one segment for each acknowledgement returned.Thus, the sender can transmit the minimum of the congestion window and the advertised windowof the receiver, which is simply called the transmission window. Slow Start is actually not veryslow when the network is not congested and network response time is good. For example, thefirst successful transmission and acknowledgement of a TCP segment increases the window totwo segments. After successful transmission of these two segments and acknowledgements
completes, the window is increased to four segments. Then eight segments, then sixteensegments and so on, doubling from there on out up to the maximum window size advertised bythe receiver or until congestion finally does occur. During the initial data transfer phase of a TCPconnection the Slow Start algorithm is used. However, there may be a point during Slow Startthat the network is forced to drop one or more packets due to overload or congestion. If thishappens, Congestion Avoidance is used to slow the transmission rate. However, Slow Start isused in conjunction with Congestion Avoidance as the means to get the data transfer going againso it doesn't slow down and stay slow. In the Congestion Avoidance algorithm a retransmissiontimer expiring or the reception of duplicate ACKs can implicitly signal the sender that a network congestion situation is occurring. The sender immediately sets its transmission window to onehalf of the current window size (the minimum of the congestion window and the receiver'sadvertised window size), but to at least two segments. If congestion was indicated by a timeout,the congestion window is reset to one segment, which automatically puts the sender into SlowStart mode. If congestion was indicated by duplicate ACKs, the Fast Retransmit and FastRecovery algorithms are invoked. As data is received during Congestion Avoidance, thecongestion window is increased. However, Slow Start is only used up to the halfway point wherecongestion originally occurred. This halfway point was recorded earlier as the new transmissionwindow. After this halfway point, the congestion window is increased by one segment for allsegments in the transmission window that are acknowledged. This mechanism will force thesender to more slowly grow its transmission rate, as it will approach the point where congestionhad previously been detected. When a duplicate ACK is received, the sender does not know if itis because a TCP segment was lost or simply that a segment was delayed and received out of order at the receiver. If the receiver can re-order segments, it should not be long before thereceiver sends the latest expected acknowledgement. Typically no more than one or twoduplicate ACKs should be received when simple out of order conditions exist. If however morethan two duplicate ACKs are received by the sender, it is a strong indication that at least onesegment has been lost. The TCP sender will assume enough time has lapsed for all segments to be properly re-ordered by the fact that the receiver had enough time to send three duplicateACKs. When three or more duplicate ACKs are received, the sender does not even wait for aretransmission timer to expire before retransmitting the segment (as indicated by the position of

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 10/35
the duplicate ACK in the byte stream). This process is called the Fast Retransmit algorithm.Immediately following Fast Retransmit is the Fast Recovery algorithm. Since the FastRetransmit algorithm is used when duplicate ACKs are being received, the TCP sender hasimplicit knowledge that there is data still flowing to the receiver. But the question was why? Thereason is because duplicate ACKs can only be generated when a segment is received. This is a
strong indication that serious network congestion may not exist and that the lost segment was arare event. So instead of reducing the flow of data abruptly by going all the way into Slow Start,the sender only enters Congestion Avoidance mode. Rather than start at a window of onesegment as in Slow Start mode, the sender resumes transmission with a larger window,incrementing as if in Congestion Avoidance mode. This allows for higher throughput under thecondition of only moderate congestion. Additionally a fair utilization of the bandwidth can beenforced by degrading the service for greedy flows. It¶s not only the matter of greedy flows;rather multimedia data transfer in a perfect manner is a big problem for many days. Increasingaccess to data communications is creating sweeping changes around the globe. More people areusing a wider range of services, requiring more data to be transported. As a result, there has beena surge of interest in designing low-loss and low-delay networks by encouraging users to adapt
to changing networks conditions using minimal information from the network. Ultimately the performance of a communications network will be judged by the Quality of Service (QoS) perceived by users. This end user QoS can be affected by many factors outside of the control of the network operators. For example, the quality of an MPEG-1 video stream, which has verylimited error suppression capabilities, will be perceptibly lower than that of a video service witherror suppression and correction capabilities built-in after both streams have been transportedacross an inherently lossy network like the Internet. The differences in the perceived quality willobviously be affected by the performance of the transport network, but the main differences willcome from the nature of the service being transported. Aggregate queuing delay or latency is theamount of time it takes the senders packet, once it enters the network, to be delivered to itsdestination. A packet is a form of data in a sequence of binary digits in a packet-switchednetwork. Transmission Control Protocol (TCP) divides a file into efficient sized packets that areseparately numbered. A simple packet contains an IP header, packet number protocol, sourceaddress (TCP sender), destination Internet address, and data. The TCP sends the packet into thenetwork where it is then routed through various links and hubs. Each link is connected to a hubserver that routes packets through routers and switches that have a queue size and possibly adifferent algorithm for handling queue congestion. The hub server¶s router and switches takeinput links and route the packets to the appropriate output link. When a packet enters a hubserver, it will be placed into a routers queue when there is congestion. If there is no congestionthe packet will be sent immediately with virtually zero delay. Depending on the length of thequeue and where the packet was placed in the queue determines the amount of the time it willreside in queue until it is sent. Once all the packets have arrived to its destination, the TCPreceiver will reassemble the file in the receiver TCP by putting the packets in-order andassembling the data back into a file. Current versions of TCP rely on loss as indicators of congestion. Clearly this is undesirable surely everyone wants to operate the network at low-levels of loss. On the other hand losses are good indicators of congestion and one needs other signals from the network to make congestion-control decisions with very little or no loss.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 11/35
UDP (User Datagram Protocol) is another commonly used protocol on the Internet. UDP (User Datagram Protocol) is a communications protocol that offers a limited amount of service whenmessages are exchanged between computers in a network that uses the Internet Protocol (IP).UDP is an alternative to the Transmission Control Protocol (TCP) and, together with IP, issometimes referred to as UDP/IP. Like the Transmission Control Protocol, UDP uses the Internet
Protocol to actually get a data unit (called a datagram) from one computer to another. UnlikeTCP, however, UDP does not provide the service of dividing a message into packets (datagrams)and reassembling it at the other end. Specifically, UDP doesn't provide sequencing of the packetsthat the data arrives in. This means that the application program that uses UDP must be able tomake sure that the entire message has arrived and is in the right order. Network applications thatwant to save processing time because they have very small data units to exchange (and thereforevery little message reassembling to do) may prefer UDP to TCP. The Trivial File Transfer Protocol (TFTP) uses UDP instead of TCP. UDP provides two services not provided by the IPlayer. It provides port numbers to help distinguish different user requests and, optionally,a checksum capability to verify that the data arrived intact. In the Open Systems Interconnection(OSI) communication model, UDP, like TCP, is in layer 4, the Transport Layer. Lacking
reliability, UDP applications must generally be willing to accept some loss, errors or duplication.Some applications such as TFTP may add rudimentary reliability mechanisms into theapplication layer as needed. Most often, UDP applications do not employ reliability mechanismsand may even be hindered by them. Streaming media, real-time multiplayer games and voiceover IP (VoIP) are examples of applications that often use UDP. In these particular applicationsloss of packets is not usually a fatal problem. If an application requires a high degree of reliability, a protocol such as the Transmission Control Protocol may be used instead. Potentiallymore seriously, unlike TCP, UDP based applications don't necessarily havegood congestion avoidance and control mechanisms. Congestion insensitive UDP applicationsthat consume a large fraction of available bandwidth could endanger the stability of the internet,as they frequently give a bandwidth load that is inelastic. Network-based mechanisms have been proposed to minimize potential congestion collapse effects of uncontrolled, high rate UDP trafficloads. Network-based elements such as routers using packet queuing and dropping techniquesare often the only tool available to slow down excessive UDP traffic. The Datagram CongestionControl Protocol (DCCP) is being designed as a partial solution to this potential problem byadding end host TCP-friendly congestion control behavior to high-rate UDP streams such asstreaming media. However, as UDP is never used to send important data such as web pages,database information, etc; UDP is commonly used for streaming audio and video. Streamingmedia such as Windows Media audio files (.WMA) , Real Player (.RM), and others use UDP because it offers speed! The reason UDP is faster than TCP is because there is no form of flowcontrol or error correction. The data sent over the Internet is affected by collisions, and errorswill be present. Remember that UDP is only concerned with speed. This is the main reason whystreaming media is not high quality. Now here in this state we should have a comparison of TCPvs. UDP. Based on ordering TCP rearranges data packets in the order specified but UDP does notorder packets. If ordering is required, it has to be managed by the application layer. Based onerror checking TCP does error checking but UDP does not have an option for error checking.Based on header size TCP header size is 20 bytes but UDP Header size is 8 bytes. Based onusage TCP is used in case of non-time critical applications but UDP is used for games or applications that require fast transmission of data. UDP's stateless nature is also useful for servers that answer small queries from huge numbers of client. Based on data reliability there is

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 12/35
absolute guarantee that the data transferred remains intact and arrives in the same order in whichit was sent for TCP but for UDP there is no guarantee that the message or packets sent wouldreach at all. So finally we have come to this conclusion that both TCP and UDP have importantuses but there is requirement for something more. Something new should be there that couldcombine the facilities of both TCP and UDP. Explicit Congestion Notification (ECN) has been
recently proposed to provide early indication to sources about imminent congestion in thenetwork. ECN marking is a mechanism to provide such information about the network tothe users. To provide ECN marks, the routers need to mark packets intelligently thatconveys information about the current state of the network to the users. Algorithms whichthe routers employ to convey such information are called as Active Queue Management(AQM) schemes. There are various AQM schemes that have been proposed in the literature.Active Queue Management (AQM) aims to detect congestion in the network before it becomessevere by overfilling the router queue. It means that the router tries to reduce the sending rate of the traffic sources by dropping or marking packets. There exist two approaches to indicatecongestion: Packets can be dropped and packets can be marked. First strategy requirescooperation of the endpoints and latter generates additional overhead through re-sending.
Endpoints have to react on marked packets as they have been dropped and decrease their throughput. With this the same improvement of bandwidth utilization can be achieved, butwithout additional overhead costs. Additionally some AQM mechanisms aim to reduce the bandwidth of greedy flows by dropping their packets at higher rates. There are more than 50 proposals for Active Queue Management schemes. They can be classified based on their mostimportant properties.
If we look at the main goal of these schemes, we will find that each scheme was designed toimprove some particular properties of the system. As there are often trade-offs between somegoals an AQM approach cannot satisfy all requirements at the same time. So some schemesfocus on small loss while other concentrates on high stability or fast responsiveness. Theapproaches of solutions of these schemes are of different types. The proposed AQM mechanismuses various underlying models to make decisions. Some rely on heuristics, others work deterministically and some even use ideas and theories from related research topics. Thisclassification points out the theory behind the proposed AQM mechanism.
Looking at the congestion measure technique we find that in general AQM schemes aim to prevent congestion by detecting them and notifying the traffic sources, i.e. some of the observed parameters are monitored to adjust the routers behavior. Typical congestion measures for AQM[1] are:
1. Current queue size (i.e. the current utilization of the buffer queue, not to confuse with the
queue capacity).2. Average queue size, which is computed from the current and previous queue sizes.3. Number of active flows, which can be observed by comparing and storing source/target
pairs from packet headers.4. Packet arriving rate, i.e. how many packets per time unit are arriving.
Now if we look at some most popular AQM schemes then the most simple will be DT: Drop Tail(active solution) [1]. The simplest way to handle router congestion is usually called Drop Tail. It

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 13/35
means that new packets are enqueued as long as there is place for them in the queue. If the queueis full because the send rate of the output link is smaller than the arrival rate at the input link, allnew packets are dropped.
Flow 1
Fig2.1: The figure shows the main principle of Drop Tail. Upon arrival of a new packet inthe system with a full queue the packet is dropped.
The goal of this algorithm is to solve congestion problem. It¶s solution approach is deterministic.It detects congestion based on Qcurrent and Qmax(If Qcurrent>= Qmax). It does not provide fair bandwidth allocation; rather it treats all flows equally. And as it is not fair, it is not alsomalicious-aware. It¶s required state is none, just drops packets on congestion. Basically it is themost intuitive strategy to cope with congestion.
Another most common and popular AQM scheme is RED (Random Early Detection). Basicallyit is the base of the most of the proposed AQM schemes. Sally Floyd and Van Jacobson presented a mechanism called Random Early Detection (RED) that aims congestion avoidance.Their work is motivated by the goal to keep average queue sizes in routers small. This is done bydropping or marking some packets that have a position in the queue exceeding a certainthreshold. For marking packets ECN can be used, indicating congestion on the route. System-wide parameters Qmin and Qmax de¿ne the threshold boundaries of the queue size. Upon arrivalof a new packet in the system the average queue size Qavg of the Àow is calculated andcompared to Qmin and Qmax. Qavg is updated each time a packet arrives with followingformula: Qavg = (1 íWq)* Qavg + Wq * Qcurr, where Wq is the weight of the former average
queue size and Qcurr the current queue size. When Qavg exceeds Qmax the packet is marked. Inthe case that Qavg is within the boundaries of Qmin and Qmax, the marking probability Pm iscalculated using following equation: Pm = Pavg / (1ícount*Pavg) , where count is the number of packets since the last marked packet and Pavg is de¿ned as followed:Pavg = Pmax m * (QavgíQmin) / (QmaxíQmin). The packet is marked with a probability of Pm, in this case count is reset. If the packet is not marked, count is incremented.
Drop Tail
INOUT

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 14/35
With this mechanism the average queue size can be controlled and congestion can be avoided.With the parameter Wq additionally the burst-awareness of the mechanism can be modeled.Qmin and Qmax de¿ne the expected range of queue length, Qmin de¿nes the minimum queuelength at which no packets are dropped, as Qavg exceeds Qmin the dropping probabilityincreases with increasing Qavg and count, up to the maximum dropping probability Pmax avg .
These parameters can be con¿gured to suit to different environments. Fairness is provided basedon the assumption that the number of dropped packets correlates with the utilization of the bandwidth by the speci¿c Àow.
The goal of the algorithm is to provide performance guarantees (delay, throughput). Its solutionapproach is heuristic. It detects congestion on Qavg, weighted average with burst awareness. Itdoes not allocate fair bandwidth, all flows has same dropping probability. It is not malicious-aware as well.
In order to stem the increasing packet loss rates caused by an exponential increase in network
traffic, the IETF considered the deployment of active queue management techniques such asRED. While active queue management can potentially reduce packet loss rates in the Internet,BLUE show that current techniques are ineffective in preventing high loss rates. The inherent problem with these queue management algorithms is that they use queue lengths as the indicator of the severity of congestion. In light of this observation, a fundamentally different active queuemanagement algorithm, called BLUE, is proposed, implemented and evaluated. BLUE uses packet loss and link idle events to manage congestion. Using both simulation and controlledexperiments, BLUE is shown to perform signi¿cantly better than RED both in terms of packetloss rates and buffer size requirements in the network. As an extension to BLUE, a noveltechnique based on Bloom ¿lters is described for enforcing fairness among a large number of
flows. In particular, Stochastic Fair BLUE (SFB) was also proposed and evaluated, a queuemanagement algorithm which can identify and rate-limit non-responsive flows using a very smallamount of state information. In order to remedy the shortcomings of RED, a fundamentallydifferent queue management algorithm called BLUE was proposed, implemented, and evaluated.Using both simulation and experimentation, it was shown that BLUE overcomes many of RED¶sshortcomings. RED has been designed with the objective to (1) minimize packet loss andqueueing delay, (2) avoid global synchronization of sources, (3) maintain high link utilization,and (4) remove biases against bursty sources. BLUE either improves or matches RED¶s performance in all aspects. BLUE converges to the ideal operating point in almost all scenarios,
even when used with very small buffers. The key idea behind BLUE is to perform queuemanagement based directly on packet loss and link utilization rather than on the instantaneous or average queue lengths. This is in sharp contrast to all known active queue management schemeswhich use some form of queue occupancy in their congestion management. BLUE maintains asingle probability, pm, which it uses to mark (or drop) packets when they are enqueued. If thequeue is continually dropping packets due to buffer overÀow, BLUE increments pm, thusincreasing the rate at which it sends back congestion noti¿cation. Conversely, if the queue

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 15/35
becomes empty or if the link is idle, BLUE decreases its marking probability. This effectivelyallows BLUE to ³learn´ the correct rate it needs to send back congestion noti¿cation. A variationto the algorithm in which the marking probability is updated when the queue length exceeds acertain value can be also shown. This modi¿cation allows room to be left in the queue for transient bursts and allows the queue to control queueing delay when the size of the queue being
used is large. Besides the marking probability, BLUE uses two other parameters which controlhow quickly the marking probability changes over time. The ¿rst is freeze time. This parameter determines the minimum time interval between two successive updates of pm. This allows thechanges in the marking probability to take effect before the value is updated again. While theexperiments ¿x freeze time as a constant, this value should be randomized in order to avoidglobal synchronization. The other parameters used, (1 and 2), determine the amount by which pm is incremented when the queue overÀows or is decremented when the link is idle. For theexperiments, 1 is set signi¿cantly larger than 2. This is because link underutilization can occur when congestion management is either too conservative or too aggressive, but packet loss occurs
only when congestion management is too conservative. By weighting heavily against packet loss,BLUE can quickly react to a substantial increase in traf¿c load. It is very much important to notethat there are a lot of ways in which pm can be managed. While the experiments study a smallrange of parameter settings, experiments with additional parameter settings and algorithmvariations have also been performed with the only difference being how quickly the queuemanagement algorithm adapts to the offered load. It is relatively simple process to con¿gureBLUE to meet the goals of controlling congestion. The ¿rst parameter, freeze time, should be set based on the effective round-trip times of connections multiplexed across the link in order toallow any changes in the marking probability to reÀect back on to the end sources beforeadditional changes are made. For long-delay paths such as satellite links, freeze time should be
increased to match the longer round-trip times. The second set of parameters 1 and 2 are set togive the link the ability to effectively adapt to macroscopic changes in load across the link at theconnection level. For links where extremely large changes in load occur only on the order of minutes, 1 and 2 should be set in conjunction with freeze time to allow pm to range from 0 to1 on the order of minutes. This is in contrast to current queue length approaches where themarking and dropping probabilities range from 0 to 1 on the order of milliseconds even under constant load. Over typical links, using freeze time values between 10ms and 500ms and setting1 and 2 so that they allow pm to range from 0 to 1 on the order of 5 to 30 seconds will allowthe BLUE control algorithm to operate effectively. It is also a very much important to note thatwhile BLUE algorithm itself is extremely simple, it provides a signi¿cant performanceimprovement even when compared to a RED queue which has been reasonably con¿gured. Butefficient multimedia data transfer does not rely on only these AQM schemes. The TCP or UDPwhich carry multimedia data have profound influence on the efficiency as well. Now we arelooking at these.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 16/35
Two critical characteristics of networks are transmission rate and transmission reliability. Thedesire to communicate using multimedia information affects both of these parameters profoundly. Transmission rate must be pushed as high as possible, and in the process,transmission reliability may suffer. This becomes even truer as we move toward the fullintegration of high-speed wireless networks and user mobility. What more is that for transporting
compressed multimedia lower speeds can be extremely limiting and performance limitations areexhibited through slow download times for images, lower frame rates for video, and perhapsnoticeable errors in packet voice and packet video.
According to these demands in the Internet, the most commonly used transport layer protocol isthe Transmission Control Protocol (TCP). TCP provides reliable, connection-oriented serviceand is thus well suited for data traffic as originally envisioned for the Internet. Unfortunately,one of the ways reliable delivery is achieved is by retransmission of lost packets. Since thisincurs delay, TCP can be problematical for the timely delivery of delay-sensitive multimediatraffic.
Therefore, for multimedia applications, many users often employ another transport layer protocolcalled User Datagram Protocol (UDP). Besides offering nearly direct access to IP, UDP is alsouseful for applications that communicate over Local Area Networks (LANs). Because wiredLANs are typically extremely reliable and has plenty of bandwidth available, their lack of error and congestion control is unimportant. Even though wired long-haul links have been exhibitingdecreasing error rates (due to widespread use of optical fiber), the statistical multiplexing of increasing traffic loads over wide-area links has replaced errors with congestion as the dominantloss factor on the Internet. Congestion is caused by temporary overloading of links with trafficthat causes transmission queues at network routers to build up, resulting in increased delays and
eventually packet loss. When such losses occur, indicating high levels of congestion, the bestremedy is to reduce the offered load to empty the queues and restore traffic to its long-termaverage rate. Unlike TCP, UDP simply offers connectionless, best-effort service over theInternet, thus avoiding the delays associated with retransmission, but not guaranteeing anythingabout whether data will be reliably delivered. For multimedia traffic, we need reliable delivery, but not necessarily perfect delivery, and we usually need low delay. Furthermore, we may needto put bounds on the variations in data arrival delay, often called jitter. One approach toachieving this level of service in today's packet switched networks is to develop connection-oriented protocols that have resolvable bandwidth guarantees. In recent years, network
requirements of this type have all been limped under the term Quality of Service (QoS).The Transmission Control Protocol (TCP) is the most popular one, since it supports manyadditional facilities compared to UDP. It offers a connection-oriented byte stream service thatappears to applications similar to writing (reading) to (from) a sequential file. TCP supportsreliable operation, flow and congestion control, and segmentation and reassembly of user data.TCP data segments are acknowledged by the receiving side in order. When arriving segmentshave a gap in their sequence, duplicate acknowledgments are generated for the last segment

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 17/35
received in sequence. Losses are detected by the sender either by timing out while waiting for anacknowledgment or by a series of duplicate acknowledgments implying that the next segment inthe sequence was lost in transit. Since IP provides an end-to-end datagram delivery service, TCPresembles a Go-Back-N link layer protocol transmitting datagrams instead of frames. On theother hand, IP can reorder datagrams, so TCP cannot assume that all gaps in the sequence
numbers mean loss. This is why TCP waits for multiple duplicate acknowledgments beforedeciding to assume that a datagram was indeed lost. During periods of low traffic or whenacknowledgments are lost, TCP detects losses by the expiration of timers. Since Internet routingis dynamic, a timeout value for retransmissions is continuously estimated based on the averagedround-trip times of previous data/acknowledgment pairs. A good estimate is very important:Large timeout values delay recovery after losses, while small values may cause prematuretimeouts and thus retransmissions to occur when acknowledgments are delayed, even in theabsence of loss. Recent versions of TCP make the key assumption that the vast majority of perceived losses are due to congestion, thus combining loss detection with congestion detection.
As a result, losses cause, apart from retransmissions, the transmission rate of TCP to be reducedto a minimum and then gradually to increase so as to probe the network for the highest load thatcan be sustained without causing congestion. Since the link and network layers do not offer anyindications as to the cause of a particular loss, this assumption is not always true, but it issufficiently accurate for the low-error-rate wired links. A conservative reaction to congestion iscritical in avoiding congestive collapse on the Internet with its ever-increasing traffic load.Finally we can reach this decision after all this literature review that peer-to-peer systems areemerging and popular networks now a days. The scalability of the system is limited by theavailable bandwidth in the system. There are no restrictions for devices of any type not to participate in peer-to-peer networks. So the diversity in the availability of resources in the
network is large. However, we focused in this document on the packet drop in the system. Nowadays ADSL connections dominate the connection of end users to the Internet. ADSLconnections provide different up-link and down-link bandwidth. User devices can downloadfaster, than they can upload. A system which relies on tight interaction of the end-user devices,like it is in P2P system, can cause congestion on the end-user device. More packets may bedownloaded to process than replies can be transmitted. This may lead to congestion in peers and packets have to be dropped. In the case that the network is to be used for loss-critical flows,dropping of packets is unacceptable. In order to provide guaranteed service for loss-critical flowseven in congested networks, peer-to-peer systems have to adopt Active Queue Managementmechanisms and as well as they should also choose some new technique in place of TCP andUDP which can provide better result, better performance and so on. AQM solutions decide inwhich cases incoming packets have to be dropped/marked to give the source of thecorresponding Àow feedback on the congestion. Furthermore, AQM mechanisms control theamount of bandwidth share a Àow is allowed to have in the system. First of all, packet prioritieshave to be introduced in the systems, so that flows can be classi¿ed as losscritical or loss-tolerant. Another point is, that flows in P2P systems need to be identi¿ed, which is challenging,

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 18/35
as there is no constant traf¿c Àow in the P2P overlay between source and destination peers. Oncethis is achieved several fair AQM mechanisms can be applied on P2P systems to provideguarantees on minimal loss. These improvements should be there in the AQM schemes but whatwe have here in our hand at this moment is very limited. But we will have to show the performance of our newly proposed UDPmm technique. That¶s why here we have selected very
basic AQM scheme and that is Random Early Detection (RED). We identi¿ed fairness beingimportant for P2P networks, as load balancing in the system is desired. Addtitionally having atarget interval for the system performance, measured by the lengh of the queue, enablesenhanced planing of the system¶s behavior. The amount of state a peer has to maintain has minor importance, as usually powerful peers participate in P2P networks. Still for the case that lesscapable peers are participating, the amount of required memory is to be considered. Weconcluded in this document that the oldest strategies Drop Tail and Explicit Congestion Noti¿cation are least complex but do not provide any desireable features, they just solve the problem ef¿ciently. The family of Random Early Detection mechanisms introduces fairness with
binding the dropping probability of a Àow to its bandwidth utilization. The RED based strategiesare heurisitics aiming to provide all flows the same share of bandwidth, hindering misbehavingflows to utilize bandwidth on the costs of other flows. Adaptive Virtual Queue aims to reach atradeoff between the delay time of packets and the throughput of the buffer. The ProportionalIntegral based solutions introduce a novel approach, they sense on the changes of the queuelength and not the queue length itself, aiming to avoid oscillations. Random ExponentialMarking introduces a pricing system to motivate senders to urilize cheaper, rarer used flows.BLUE uses bloom ¿lters to combine the dropping probabilities of several flows. For P2Psystems it is challenging to de¿ne flows. Once this is done, congestion is easier to detect usingcharacteristics of the queue, as its current or average length. Dynamic congestion detection
strategies, as applied in PI, PIP and BLUE are more complex to realize and they may beinef¿cient. Fairness is essential in a P2P system, as a single peer shall not be able to stress thenetwork on the costs of other peers. Here again most of the RED based approaches, REM andBLUE qualify. The other AQM mechanisms do not bind the dropping probability to the link utilization of a Àow. Most of the solutions define a fixed value or an interval for the target queuelength. This is desirable in context of P2P systems, as one can control with this tool the load oneach peer. However, some approaches like ARED and CHOKe aim to increase the diversity of flows in the queue. The effects of this on P2P networks are doubtable, evaluation is needed. Insome overlays this strategy may be contra productive. However, an optimal AQM mechanismfor several P2P scenarios has still to be found and evaluated. In this document we presented popular Active Queue Management mechanisms discussed in many literatures. Furthermore weanalyzed them and derived a new way, a new technique through which we may achieve our desired result. From overview on AQM solutions using with TCP or UDP we can deriverequirements for solutions for multimedia data transfer in P2P systems. And that solution whichwe have proposed here in this document is UDPmm.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 19/35

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 20/35
words it just very simply suggests the sender of the multimedia packet that to which rate themultimedia packet .should be sent from the sender to the receiver.
In case of TCP we know that TCP is a reliable stream delivery service that guarantees delivery of a data stream sent from one host to another without duplication or losing data. Since packet
transfer is not reliable, a technique known as positive acknowledgment with retransmission isused to guarantee reliability of packet transfers. This fundamental technique requires the receiver to respond with an acknowledgment message as it receives the data. The sender keeps a record of each packet it sends, and waits for acknowledgment before sending the next packet. The sender also keeps a timer from when the packet was sent, and retransmits a packet if the timer expires.The timer is needed in case a packet gets lost or corrupted. But here in our proposed idea itshould be noted that we never tried to retransmit the packet. We simply tried to reduce the packetloss. The packets which have already been lost during the transmission from sender to receiver isout of syllabus. We didn¶t try to resend them. What we tried is that from the next transmissionless number of packets are lost. So here is the difference from the TCP. One may ask that then
TCP may be better than our proposed idea. But we say that TCP is already been rejected in caseof multimedia data transfer from a sender node to a receiver node. What is currently used is onlyUDP. So our comparison was only with UDP.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 21/35
3.2 Problem Analysis
Two networking protocols, TCP and UDP dominate the Internet. Both protocols havelimitations when transmitting multimedia streams. TCP has high latency and no loss while UDPhas high loss and low latency, neither of which is good for multimedia. We created a new agent
for multimedia data transfer that is better suited for these streams by combining the properties of both TCP and UDP. UDPmm provides lower latency than TCP and lower loss than UDP bysaving some, but not all lost packets. It just proposes a new sending rate and that¶s all. UDPmm performed very well in our experiments and outperformed both TCP and UDP in respect to our queue size comparison. It exceeded the quality of TCP and UDP in all network conditions. Thisgreat phenomenon is caused by the way UDPmm reduces the sending rate of packets based onthose packets that don¶t arrive on time, which results in a lower loss rate than a non-retransmitting protocol such as UDP. UDPmm did perform good as well as UDP in thisinstance, it will do better than TCP in all network conditions. Although UDPmm currently lackssome functionality such as back-off and flow control, it has been shown experimentally that it performs better than UDP and TCP in most circumstances. Even though UDPmm may perform poorly in some specific condition of the network, other decision algorithms can be written to dealwith such conditions. UDPmm¶s flexibility and performance make it a desirable protocol for multimedia applications. Before implementing this application, the UDP agent implementation isexamined and one major problem is found. Since a UDP agent allocates and sends network packets, all the information needed for application level communication should be handed to theUDP agent as a data stream. However, the UDP implementation allocates packets that only havea header stack. Therefore, we need to modify the UDP implementation to add a mechanism tosend the data received from the application. Here one may have a question in mind that why we
have chosen UDP. In fact UDPmm operates above UDP and offers added functionality to thealready established protocol. The Internet protocols, TCP and UDP, have been established for several decades. Both have been implemented countless times on different computing platformswith different modifications and have been relentlessly studied and tested. The result is a set of stable protocols. Taking advantage of this, UDPmm has been designed to leverage off of UDP.Acceptance of UDPmm into the Internet community is easier since a UDPmm message isessentially the same as a UDP message. The most important reason UDP was chosen over TCPis that UDP does not implement congestion detection. Since UDPmm has its own specializedcongestion detection system, TCP would need to be replaced, while with UDP, with noretransmission system, this functionality could be added with no modification. Not only does
this make it easier to implement since UDP does not need to be rewritten, but also it maintainsthe stability and acceptance of the UDP protocol. The installation of the SRP protocol intofuture applications is easier, as well, because a layer can be added between UDP and theapplication leaving nothing further to be modified.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 22/35
3.3Design and implementation
We decided to take the CBR implementation and modify it to have the "five level media scaling"feature. We examined the C++ class hierarchy, and decided to name the class of this applicationas "MmApp" and implement as a child class of "Application". The matching OTcl hierarchy
name is "Application/MmApp". The sender and receiver behavior of the application isimplemented together in "MmApp". For the modified UDP agent that supports "MmApp", wedecided to name it "UdpMmAgent" and implement it as a child class of "UdpAgent". Thematching OTcl hierarchy name is "Agent/UDP/UDPmm". For the application levelcommunication, we decided to define a header of which the structure named in C++ "hdr_mm".First of all we had to edit some files. At first in the location : C:\cygwin\home\ns\ns-allinone-2.32\ns-2.32\common, we added two lines in the file packet.h, first one was, we added new typePT_Multimedia, and the second was Name_[PT_Multimedia] = ³Multimedia´. And secondly wemodified the ns-packet.tcl file in this location :C:\cygwin\home\ns\ns-allinone-2.32\ns-2.32\tcl\lib by adding the term Multimedia. Next in C:\cygwin\home\ns\ns-allinone-2.32\ns-2.32\common location , we added virtual int supportMM() and virtual void enableMM() thesetwo functions. Next in the C:\cygwin\home\ns\ns-allinone-2.32\ns-2.32\apps location, virtualvoid recv_msg() was added. And finally in the location C:\cygwin\home\ns\ns-allinone-2.32\ns-2.32\tcl\lib default values of some parameters were set. Thus we completed our configuration of NS2 to support our new agent. To build our UDPmm we had to include previously definedheader file of UDP. But we had to newly add some variables like seq to describe the multimediasequence number, the ack to check whether it is a acknowledgement packet or multimedia data packet, nbytes for determining bytes for multimedia packet and scale associated with data rate.To differentiate those packets which support multimedia we added a function named
supportMM() which returns 1 when it is invoked. Another function sendmsg was used to sendmultimedia data and recv to receive packets. To make the UDPMmAgent OTcl linkage class we just followed the rules from the built in UDP agent class.We defined the constructors. We havedistinguished the multimedia UDP packets by setting the ip priority bit to 15 that is maximum priority. When we had to create our own multimedia application file we had to add a portion a portion for receiver¶s received packet accounting. We had to add last_seq which mean sequencenumber of last received multimedia packet, last_scale which mean rate of last acknowledged packet, lost_pkts which mean number of lost packet since last acknowledged packet, recv_pktswhich indicate number of received packets since last acknowledgement. We had to define thetimer which sender uses to schedule next application data packet transmission time. We also had
to specify the timer which receiver uses to schedule next acknowledgement packet transmissiontime. When send timer expires then send acknowledgement packet function is called. Theconstructors also initializes the instances of timers.When sending multimedia starts someinformation is passed to UDPmm agent which will write to multimedia header after packetcreation.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 23/35
"UdpMmAgent" allocates one or more packets (depending on the simulated data packet size) andwrites the data to the multimedia header of each packet. a header class object,"MultimediaHeaderClass" that should be derived from "PacketHeaderCalss" is defined. Indefining this class, the OTcl name for the header ("PacketHeader/Multimedia") and the size of the header structure defined are presented. Bind_offset() must be called in the constructor of this
class. We also add lines to packet.h and ns-packet.tcl to add our "Mulltimedia" header to theheader stack. The sender needs a timer for scheduling the next application data packettransmission. We defined the "SendTimer" class derived from the "TimerHandler" class, andwrote its "expire()" member function to call "send_mm_pkt()" member function of the"MmApp" object. Then, we included an instance of this object as a private member of "MmApp"object referred to as "snd_timer_". To make the new application and agent running with our NSdistribution, we added two methods to "Agent" class as public. In the "command" member function of the "MmApp" class, there defined an "attach-agent" OTcl command. When thiscommand is received from OTcl, "MmApp" tries to attach itself to the underlying agent. Before
the attachment, it invoke the "supportMM()" member function of the underlying agent to check if the underlying agent support for multimedia transmission (i.e. can it carry data from applicationto application), and invokes "enableMM()" if it does.
Even though these two member functions are defined in the "UdpMmAgnet" class, it is notdefined in its base ancestor "Agent" class, and the two member functions of the general "Agent"class are called. We also need to add an additional member function "recv_msg(int nbytes, constchar*msg)" to "Application" class. After implementing all the parts of the application and agent,the last thing to do is to set default values for the newly introduced configurable parameters inthe "ns-default.tcl" file. After we've done all things in the checklist then we modified our
"Makefile" as needed (include "mm-app.o" and "udp-mm.o" in the object file list) and re-compiled our NS. We ran "make clean" and "make depend" before re-compile to modify NS,otherwise the new application might not transmit any packets.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 24/35
Chapter 4
SIMULATION SETUP AND RESULT
The current simulations were performed using the NS-2 version NS-2.32 on cygwin [8],[9] ,[11].To perform this experiment one must have to install cygwin and the NS-2.32. ns is an object
oriented simulator, written in C++, with an OTcl interpreter as a frontend. The simulator supports a class hierarchy in C++ (also called the compiled hierarchy in this document), and asimilar class hierarchy within the OTcl interpreter (also called the interpreted hierarchy in thisdocument). The two hierarchies are closely related to each other; from the user¶s perspective,there is a one-to-one correspondence between a class in the interpreted hierarchy and one in thecompiled hierarchy. The root of this hierarchy is the class TclObject. We created new simulator objects through the interpreter; these objects are instantiated within the interpreter, and areclosely mirrored by a corresponding object in the compiled hierarchy. The interpreted classhierarchy is automatically established through methods de¿ned in the class TclClass. user
instantiated objects are mirrored through methods de¿ned in the class TclObject. There are other hierarchies in the C++ code and OTcl scripts; these other hierarchies are not mirrored in themanner of TclObject. We had to established relationships between these two.
4.1 Evaluation Framework
The evaluation is based on the general UDP flow and our proposed approach. Three cases wereconsidered to evaluate the performance. At first the sources were both providing UDP packets.At that time the two variables of the RED AQM scheme were monitored. Those are current
queue and average queue. We saved the results in a file. Then we separated then and saved themin two different files. From those two files we plotted two graphs. From the graph we found theidea about the performance when general UDP agents are used to send packets. Then in thesecond scenario we used one general udp agent and another one our proposed agent. From thegenerated data we again plotted the graph and compared the result with the previous graph. Andat last we used our proposed agent as both the source agent. Again here we got two more graphs.Finally from the above graphs we finally get a clear idea about the overall performance.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 25/35
4.2 Experimental Setup
s1 s3\ /
5Mb,3ms \ 2Mb,10ms / 5Mb,3msr1 ------------ r25Mb,3ms / \ 5Mb,3ms
/ \s2 s4
Fig4.1: Simulation Scenario for UDPmm.
In the first scenario the video source s1and s2 both generate UDP packets to the receiver s3 ands4. Here the bandwidth of the links is shown in the figure. Same bandwidth was applied for thesource to router links and different bandwidth was applied for router r1 to router r2 link. And inthe second scenario the video source s1generate UDP packets which carry multimedia data ands2 generate UDPmm packets to the receiver s3 and s4 respectively. Here the bandwidth of thelinks is shown in the figure and those are same as the previous one. And in last scenario thevideo source s1 and s2 both generate UDPmm packets to the receiver s3 and s4. Here the bandwidth of the links is shown in the figure and here in this case thay are same as well. Thisvideo Àow competed with one on-off background traffic flow, which has an distribution withmean packet size of 1000 bytes and one FTP traffic flow with one big ¿le transfer. In 0 sec ftp packets are started and in 1 sec UDPmm packets are started. When the queue is full it startsdropping packet. So, receiver sends acknowledgement to the sender to reduce the flow. And
when the average packets in the queue are less than the expected limit more packets are sendagain. NAM which stands for Network Animator was used to show this simulation scenario in NS2. In the network animator we showed this scenario as well as we also showed the packettransfer from sender to receiver. The queuing of multimedia packets was also shown and we alsoobserved when the packets are dropped and when their sending rate is being adjusted.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 26/35
4.3 Performance Analysis
Let¶s see how the performance is improved due to the use of UDPmm agent rather than UDP for sending the packet. Before the simulation is start we set some values of the RED queue such as
threshold to 5, maximum threshold to 10 and average to 0. The result of the simulation is storedin the all.q file. All.q file contains the information of both current queue and average queueregarding time in miliseconds. We useed some shell scripting i.e. awk code to manipulate theresultant all.q file. We got two new file namely temp.a and temp.q. temp.a. temp.a contains theinformation of average queue only whereas temp.q contains only the current queuinginformation. We plotted this two file in the Xgraph and analyzed in different conditions. If theaverage queuing is much higher than the packet dropping is much higher too. We took this as a base condition and analyzed the Xgraph regarding this technique which is broadly illustrated below. One part of the ns-allinone package is 'xgraph', a plotting program which can be used tocreate graphic representations of simulation results. In this section, we will show a simple way
how did we create output files in your Tcl scripts which can be used as data sets for xgraph. Onthe way there, we also showed how to use traffic generators. Here one thing should be noted thatthe technique we presented here is one of many possible ways to create output files suitable for xgraph. But we used the way what we thought would be the best. At first the procedure creates aftp packet transmission and it is continued for first 1 second. We showed this using network animator. While we put the data in the graphs then all the times we collected the data of currentqueue size and average queue size in a file named all.q. And then we separated the data of current queue size and average queue size from that file and wrote them in two separate files.Then from those two files we directly plotted the data in the graphs. There were two data in thosefiles. One was time and another one was queue size with respect to that time. Here queue sizemeans current queue size and average queue size. But these data will be available in two separatefiles. Then from those two graphs we will get an idea about how much packets are enqueued andhow much packets are being dropped or lost. Basically we just traced the two parameters of random early detection technique and those two are curq_ and ave_. There may be several other ways to analyze the performance but as our main goal was to reduce the loss of packet, so wethought that it would be better to show the current queue size and average queue size in graphs.As when queuing is less it means that less packets are being dropped and when queuing is moreit means that more packets are being lost. Even it may also occur that all the packets which are being sent are being dropped. But all the scenarios and all the cases can be understood from the
graph.
8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 27/35
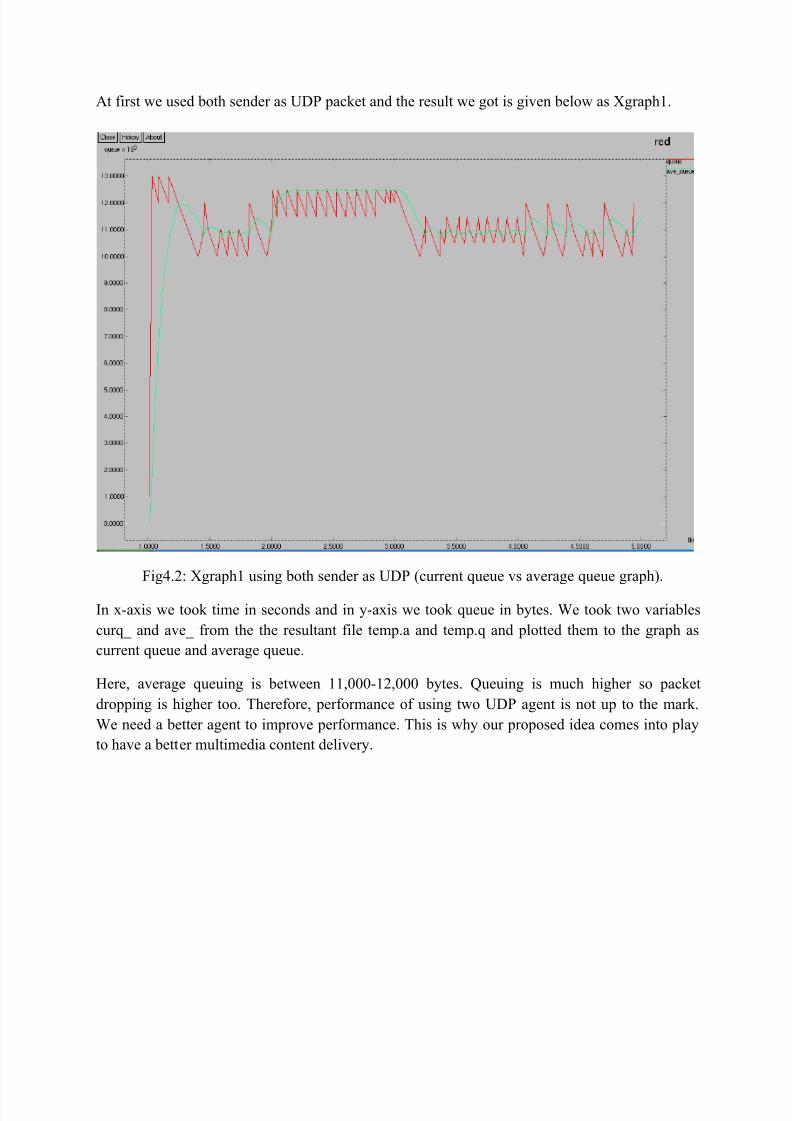
At first we used both sender as UDP packet and the result we got is given below as Xgraph1.
Fig4.2: Xgraph1 using both sender as UDP (current queue vs average queue graph).
In x-axis we took time in seconds and in y-axis we took queue in bytes. We took two variablescurq_ and ave_ from the the resultant file temp.a and temp.q and plotted them to the graph ascurrent queue and average queue.
Here, average queuing is between 11,000-12,000 bytes. Queuing is much higher so packetdropping is higher too. Therefore, performance of using two UDP agent is not up to the mark.We need a better agent to improve performance. This is why our proposed idea comes into playto have a better multimedia content delivery.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 28/35
If we send one packet as UDP and another as UDPmm we get the following as Xgraph2.
Fig4.3: Xgraph2 using one sender as UDP and another sender as UDPmm (current queue vs
average queue graph).
Similarly in x-axis we took time in seconds and in y-axis we took queue in bytes. We took twovariables curq_ and ave_ from the the resultant file temp.a and temp.q and plotted them to thegraph as current queue and average queue.
Now the average queuing is between 11,000 bytes and more stable than before. Average queuingis less than the previous one. Performance is increasing but not up to the mark yet.
What will happen if we send both packets as UDPmm is illustrated below.
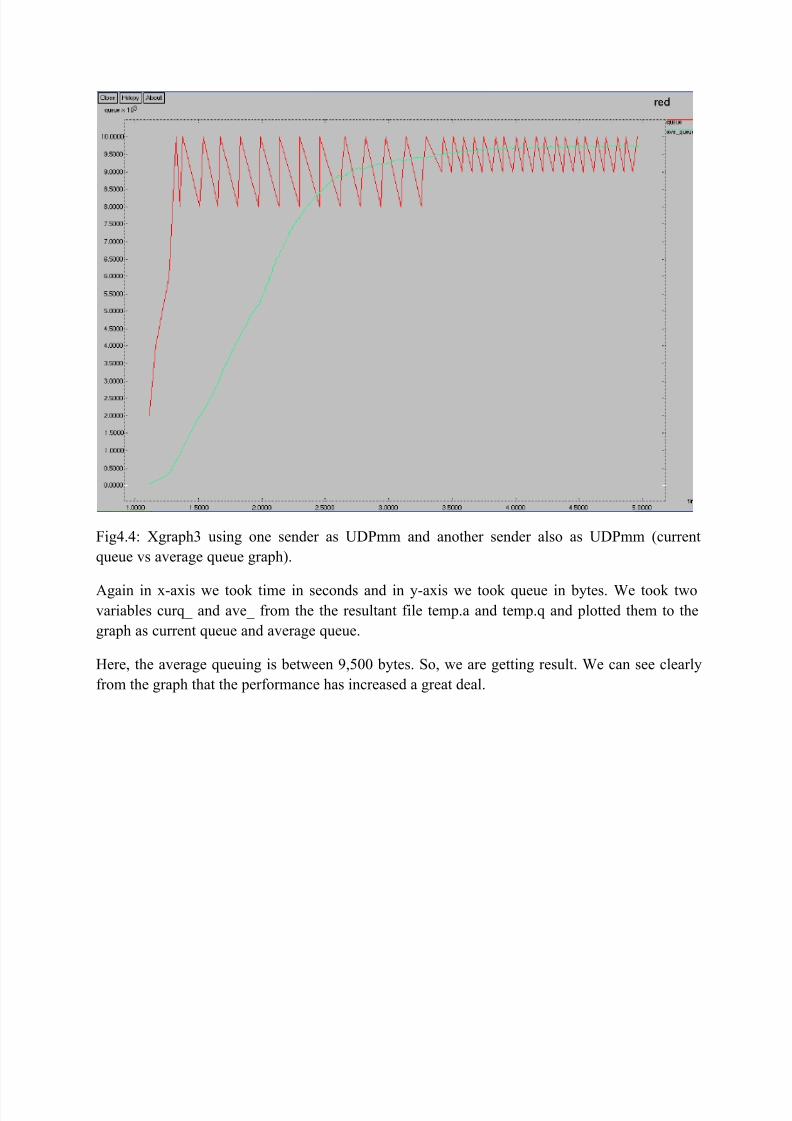
8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 29/35
Fig4.4: Xgraph3 using one sender as UDPmm and another sender also as UDPmm (currentqueue vs average queue graph).
Again in x-axis we took time in seconds and in y-axis we took queue in bytes. We took twovariables curq_ and ave_ from the the resultant file temp.a and temp.q and plotted them to thegraph as current queue and average queue.
Here, the average queuing is between 9,500 bytes. So, we are getting result. We can see clearlyfrom the graph that the performance has increased a great deal.
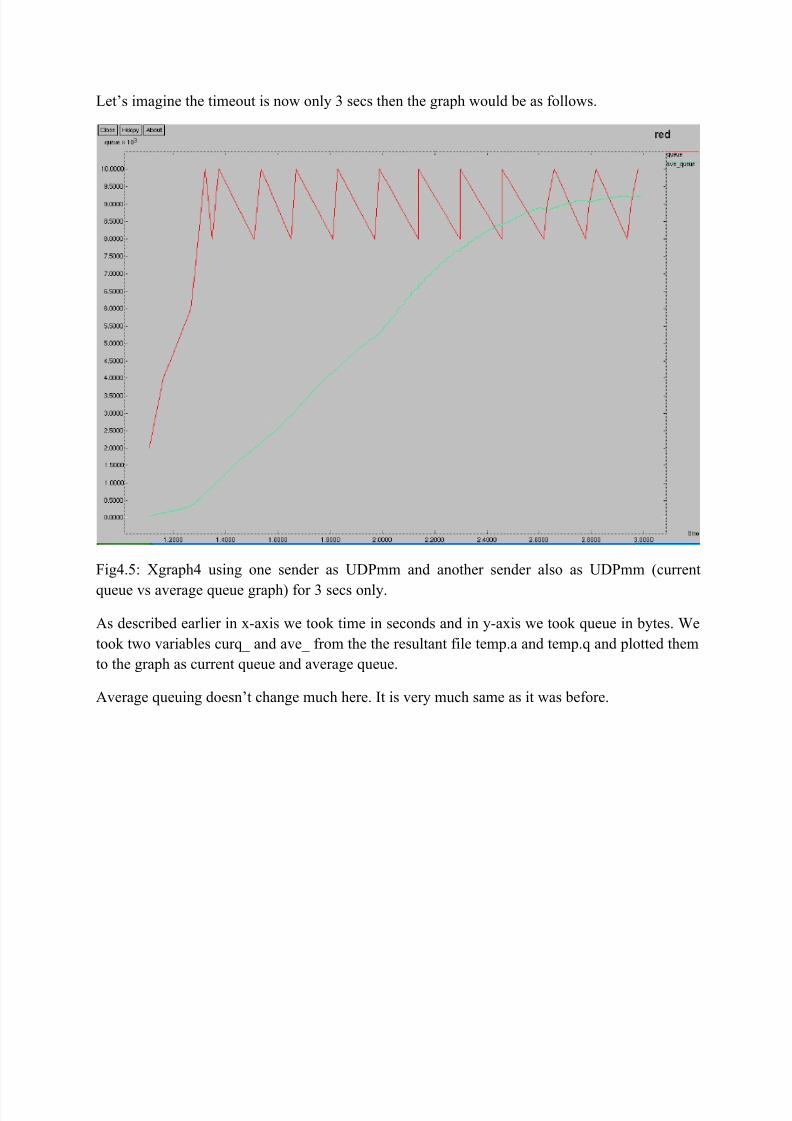
8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 30/35
Let¶s imagine the timeout is now only 3 secs then the graph would be as follows.
Fig4.5: Xgraph4 using one sender as UDPmm and another sender also as UDPmm (current
queue vs average queue graph) for 3 secs only.
As described earlier in x-axis we took time in seconds and in y-axis we took queue in bytes. Wetook two variables curq_ and ave_ from the the resultant file temp.a and temp.q and plotted themto the graph as current queue and average queue.
Average queuing doesn¶t change much here. It is very much same as it was before.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 31/35
Let¶s try now with 10 secs and analyze the result.
Fig4.6: Xgraph5 using one sender as UDPmm and another sender also as UDPmm (currentqueue vs average queue graph) for 10 secs only.
As described earlier in x-axis we took time in seconds and in y-axis we took queue in bytes. Wetook two variables curq_ and ave_ from the the resultant file temp.a and temp.q and plotted themto the graph as current queue and average queue.
Our Xgraph is very much stable resulting a better performance than the UDP.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 32/35
Chapter 5
CONCLUSION
5.1 CONCLUSION
Since the beginning, the Internet has been dominated with traffic from text based applicationssuch as telnet, ftp, and recently by http. With the emergence of new technologies and anincreased diversity of Internet use, there has been a new demand for non-text based applications, particularly multimedia. Examples of multimedia applications include video on demand andteleconferencing. But the best-effort model of the current internet becomes inadequate to facewith the very diverse requirements on network Quality of Service of the new multimediaapplications. The internet has perhaps become a victim of its own success. Many of those newapplications are based on the delivery of continuous media content. Thus, a key point to thesuccess of such applications is reducing the number of packets in the internal routers. In the case
of video transmission over a packet network, like the AQM techniques both the agents and protocols through which multimedia packets are being sent has also a great effect on the packetloss in the intermediate routers. Proper research is required in this field to reduce the packet lossin the intermediate routers. What is happening in absence of it is very much clear from MPEG-4video streaming. MPEG encodes video as a sequence of frames. Usually, video has a high degreeof temporal redundancy, i.e., information in successive frames are highly correlated. StandardMPEG encoders generate three types of compressed frames (I, P, B). In MPEG-4 terminology,each frame is equivalent to a Video Object Plane (VOP). An I frame is intra-coded, having nodependence on any other frames. Two types of motion prediction are used: Forward predictionwhere a previous frame is used as a reference decoding the current frame, and bidirectional
prediction, where both past and future frames are used as a reference. This last technique provides a better compression. The encoding of P frames uses forward prediction and theencoding of B frames use bidirectional prediction. As a consequence, the I frames are normallyare largest in size, followed by the P frames, and finally B frames. So reducing packet loss is proved to be very much important for multimedia data transmission. And that¶s why we havehere proposed a new scheme to improve performance of multimedia data transfer.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 33/35
5.2 SUMMARY
RED is a very much popular active queue management technique. It is the base of lots of AQMschemes. We used the base RED. That is we didn¶t make any changes in the RED scheme.Rather we implemented it directly. But what we did is that we changed the agent which carries
the multimedia data. Till now two agents were very much popular for multimedia data transfer.Those two were TCP and UDP. TCP was very much popular for long days. But after a long timeit was realized that TCP cannot fulfill the requirements of multimedia data transfer. Multimediadata transfer is different from other general data transfer. It requires something more somethingnew which can¶t be provided by TCP. Then everyone went to UDP for multimedia transfer problem solutions. These problems are discussed and described throughout the document. Thereis nothing to describe more. That¶s why we tried to provide a new technique, a new mechanismfor multimedia data transfer. We added some functionality of TCP to UDP to achieve better result. We were successful. We achieved our goal. But it is not enough or sufficient to throw atheory without any proof. So we have to show and prove that. We know that NS2 has two
different ways to show the output or result. One is NAM which stands for Network Animator.Another is XGRAPH. At first we showed our simulation our simulation using NAM. There weshowed the simulation scenario. We visually observed all the queues and all the senders as wellas receivers. It provided the scenario that packets are travelling from sender to receiver and theyare being queued. When congestion occurs packets are dropped according to RED. We may alsoused many other Active Queue Management schemes instead of RED but we thought that itwould be better that if we use the base AQM schemes for router management. Then after showing the simulation using the network animator we then used the XGRAPH to show theoutput graph. A very much popular way of comparing this type of comparison is time versus
current queue size and time versus average queue size. RED has very important two parametersor variables. Those are current queue (curq_) and average queue(ave_). We used these twovariable¶s value to show graphically what improvement we have made. We also followed that. Inthe X axis we plotted the time and along the Y axis we plotted the queue size. We used twodifferent colors for graph. So it was quite clear from the graph that the performance a lot. At irstwe sent from both the senders, UDP multimedia data packets. Later we used one UDPmultimedia data packet and another one is our proposed UDPmm multimedia data packets. Andlast of all we sent form both of the senders, our proposed UDPmm multimedia data packets.From the above XGRAPH it was clearly shown that our proposed model worked better. It clearlymakes the queue stable and reduces the number of packets to be queued.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 34/35
5.3 FUTURE PLAN
We insisted wholely on performance improvement of multimedia data transfer. To achieve thiswe just proposed a new udp agent. But in this field of multimedia performance improvement alot of work is going on active queue management. We may try to provide some improvement on
active queue management. There were a lot of ways a queue management can be improved.Because the active queue management schemes that are currently used, lack in many ways.Many of them still use RED as their basic technique and provide some improvement on it. Thereare also BLUE and many other active queue management which can be improved to meet therequirement of multimedia data transfer. So future work may be continued on active queuemanagement. New and better approach may be proposed on queue management. Already almost50 AQM has been proposed till now. Another very much important point here in this field is thatas we have made some improvements to UDP, this same approach may be applied on TCP. TCPmay be changed to adapt the requirement by the multimedia data transfer. And still work is goingon this field where a newly proposed technique is selective repeat. And works like these should
be carried on in future. And also we have proposed some modification in UDP. But thismodification can be applied in different way. Those ways can be examined just like this one.And then a comparison between them will give us the result that which way should be followedin future. What more is the combination of our proposed agent along with the any new better AQM may improve the performance a lot. Because it may be possible that though we haveimplemented our proposed technique with the RED active queue management but it may be oneof many other options. It may be ARED that means Adaptive random Early detection, it may beBLUE etc. So future work should be carried on these and certainly we hope that a better resultwill be found.

8/6/2019 n Report Thesis
http://slidepdf.com/reader/full/n-report-thesis 35/35
REFERENCES
[1] KÁLMÁN GRAF¿, KONSTANTIN PUSSEP, NICOLAS LIEBAU, RALF STEINMETZ,TAXONOMY OF ACTIVE QUEUE MANAGEMENT STRATEGIES IN CONTEXT OFPEER-TO-PEER SCENARIOS (2007).
[2] JERRY D. GIBSON, MULTIMEDIA COMMUNICATIONS (DIRECTIONS &INNOVATIONS) (2001)
[3] BARTEK WYDROWSKI AND MOSHE ZUKERMAN, QOS IN BEST EFFORT NETWORKS. (2002)
[4] KEVIN FALL, KANNAN VARADHAN, THE NS MANUAL (2010)
[5] SALLY FLOYD, VAN JACOBSON, RANDOM EARLY DETECTION GATEWAYS FOR CONGESTION AVOIDANCE (1993)
[6] KENNETH FRENCH, GEORGE OPRICA, MICHAEL PIECUCH, SRP ± AMULTIMEDIA NETWORK PROTOCOL (2000)
[7] WU-CHANG FENG, KANG G. SHIN, THE BLUE ACTIVE QUEUE MANAGEMENTALGORITHMS.
[8] EITAN ALTMAN, TANIA JIMENEZ, NS SIMMULATOR FOR BEGINNERS (2003)
[9] TUTORIAL FOR THE NETWORK SIMULATOR NS
[10] SUNITHA BURRI, BLUE: ACTIVE QUEUE MANAGEMENT (2004)
[11] SUNWOONG CHOI, NS-2 BASICS, TRACE ANALYSIS, ADD NEW AGENT, ADD NEW AGENT 2, PACKET HEADER.(2007)
[12] ARIJIT GANGULY, PASI LASSILA, A STUDY OF TCP-RED CONGESTIONCONTROL USING NS2(2001).
Related Documents











