Man - Machine - Gene 1 Predicting cognitive ability, non-cognitive traits and educational attainment from teacher 2 assessments, short essays and the genome 3 Tobias Wolfram ∗ Felix C. Tropf † 4 Abstract 5 To what extent can nonstandard types of data predict psychological and social outcomes over the life 6 course? We leverage a unique British dataset to study the predictive utility of short essays written at 7 age 11 and genetic polymorphisms. Using state-of-the-art methods from natural language processing and 8 genomics, we find that both approaches predict cognitive ability, non-cognitive traits and educational 9 attainment with in part impressive precision: Performance based on the text samples (up to 61, 9 and 10 25%) mirrors that of teacher evaluations (up to 66, 19, 29%) obtained at the same age. Prediction from 11 genetic data is overall substantial, but measurably smaller (up to 17, 5, 19%). Combining all three sources 12 of data explains 38% of variation in educational attainment and 70% in cognitive ability, approaching 13 test-retest reliability of benchmark intelligence tests. We conclude that in order to improve predictive 14 performance in the social and behavioral sciences, more attention should be paid to nonstandard data 15 sources. 16 Prediction, the ability to assert that certain changes will be accompanied by or lead to other changes, lies 17 at the very heart of the scientific endeavour (p 339, Popper, 1962). This is no less true of the social and 18 behavioral sciences: The task of forecasting individual and collective behavior from the circumstances of the 19 present and past has been argued for by philosophers of science since the earlier days of the field, beginning 20 with the concept of social prediction (Kaplan, 1940) and the conclusion that the causal explanation of a 21 social phenomenon must also serve as the basis of its future prediction (Hempel and Oppenheim, 1948). 22 However, such appeals had not found lasting resonance in disciplinary practice, until recently: Over the 23 past few years numerous behavioral and social scientists began to argue for the importance of and potential 24 for prediction in their respective fields (Watts, 2014; Kleinberg et al., 2015; Cranmer and Desmarais, 2017; 25 Yarkoni and Westfall, 2017; Hofman et al., 2021), a development in part driven by the increased availability 26 of data, computational power and sophistication of machine learning algorithms (Rahal et al., 2021). 27 Such approaches can be especially beneficial when focusing on predicting life outcomes, allowing for the 28 ∗ Bielefeld University, Faculty of Sociology, Universitätsstraße 25, 33615 Bielefeld, Germany † École Nationale de la Statistique et de L’administration Économique, Center for Research in Economics and Statistics, 91764 Palaiseu, France 1

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Man - Machine - Gene1
Predicting cognitive ability, non-cognitive traits and educational attainment from teacher2
assessments, short essays and the genome3
Tobias Wolfram∗ Felix C. Tropf†4
Abstract5
To what extent can nonstandard types of data predict psychological and social outcomes over the life6
course? We leverage a unique British dataset to study the predictive utility of short essays written at7
age 11 and genetic polymorphisms. Using state-of-the-art methods from natural language processing and8
genomics, we find that both approaches predict cognitive ability, non-cognitive traits and educational9
attainment with in part impressive precision: Performance based on the text samples (up to 61, 9 and10
25%) mirrors that of teacher evaluations (up to 66, 19, 29%) obtained at the same age. Prediction from11
genetic data is overall substantial, but measurably smaller (up to 17, 5, 19%). Combining all three sources12
of data explains 38% of variation in educational attainment and 70% in cognitive ability, approaching13
test-retest reliability of benchmark intelligence tests. We conclude that in order to improve predictive14
performance in the social and behavioral sciences, more attention should be paid to nonstandard data15
sources.16
Prediction, the ability to assert that certain changes will be accompanied by or lead to other changes, lies17
at the very heart of the scientific endeavour (p 339, Popper, 1962). This is no less true of the social and18
behavioral sciences: The task of forecasting individual and collective behavior from the circumstances of the19
present and past has been argued for by philosophers of science since the earlier days of the field, beginning20
with the concept of social prediction (Kaplan, 1940) and the conclusion that the causal explanation of a21
social phenomenon must also serve as the basis of its future prediction (Hempel and Oppenheim, 1948).22
However, such appeals had not found lasting resonance in disciplinary practice, until recently: Over the23
past few years numerous behavioral and social scientists began to argue for the importance of and potential24
for prediction in their respective fields (Watts, 2014; Kleinberg et al., 2015; Cranmer and Desmarais, 2017;25
Yarkoni and Westfall, 2017; Hofman et al., 2021), a development in part driven by the increased availability26
of data, computational power and sophistication of machine learning algorithms (Rahal et al., 2021).27
Such approaches can be especially beneficial when focusing on predicting life outcomes, allowing for the28
∗Bielefeld University, Faculty of Sociology, Universitätsstraße 25, 33615 Bielefeld, Germany†École Nationale de la Statistique et de L’administration Économique, Center for Research in Economics and Statistics,
91764 Palaiseu, France
1

identification of individuals of elevated risk with respect to various socially relevant variables (Chandler et al.,29
2011; Kleinberg et al., 2015; Berk et al., 2019) in order to intervene. They furthermore might lead to a30
better understanding of the rigidity of life trajectories and outcomes (Salganik et al., 2020), including family31
planning, professional careers (Geyer et al., 2006), longevity and health (Lleras-Muney, 2005) as well as values32
and beliefs (Weakliem, 2002) and the risk of receiving a criminal conviction (Lochner and Moretti, 2004).33
For this, sociologists and economists stress the importance of educational attainment, as it has been shown to34
be a central stratum of life course trajectories and careers. Raising the level of educational attainment has for35
a long time been a major goal of policymakers and the extent to which education works as a “great equalizer”36
is often viewed as a central measure in determining the degree of meritocracy within a society (Bernardi and37
Ballarino, 2016) leading to sizable proportions of GDP being invested into educational institutions (p 244,38
OECD, 2021b).39
Nevertheless, in developed societies, educational attainment is completed relatively late in life: On average40
across OECD countries, more than half of 18-24 year-olds and even 16% in the age group of 25-29 year olds41
have not yet finished their education (p 54, OECD, 2021b), limiting its potential for forecasting purposes as42
an early warning sign of detrimental development and making it necessary to find measures predictive of life43
outcomes that are available earlier and therefore allow for intervention and educational streamlining (Hart,44
2016). Furthermore, it is questionable, to what extent educational attainment might in itself be just a proxy45
for cognitive ability and non-cognitive traits of the individual, with little value in itself (Caplan, 2019).46
A commonly used alternative, i.e. in the case of academic tracking (Baeriswyl et al., 2011), are teacher47
assessments, as it can be assumed that the judgment of a pedagogically trained professional who spends48
significant amounts of time with a student on a daily basis is capable of correctly evaluating his potential from49
an early age on. Indeed, meta-analyses indicate that teacher assessments show moderate to high correlations50
with important traits like academic achievement, cognitive ability, creativity and social skills (Urhahne and51
Wijnia, 2021). However, they might also exhibit potential biases related to factors like sex, class or race52
(Campbell, 2015).53
Due to such drawbacks, debate on a new measure of children’s abilities, educational attainment and subsequent54
2

life course outcomes has recently gained traction: Genetic data (Hart, 2016; Plomin, 2018; Morris et al.,55
2020). While birth weight as an early biological proxy has been introduced to economic research a while ago,56
twin studies pointed towards strong genetic influences on educational achievement (Krapohl et al., 2014),57
attainment (Silventoinen et al., 2020) and other socioeconomic factors (Marks, 2017). Today, more and more58
studies can attribute these effects directly to actual variants in the genome i.e. Lee et al. (2018), allowing for59
the direct prediction of education and other outcomes from genotyped data (Selzam et al., 2017; von Stumm60
et al., 2020), in theory starting from the point of conception.61
Furthermore, there is growing evidence for the existence of a completely different, early available measure62
that contains valuable information about the individual: Textual data. Alvero et al. (2021) show that content63
and style of an essay are related to household income and SAT scores. Writing samples allow for modest64
prediction of personality facets Fast and Funder (2008); Cutler et al. (2021), mental health (Rodriguez et al.,65
2010), cognitive ability (Abramov and Yampolskiy, 2019) and educational achievement (Cöltekin, 2020).66
Rapid recent advances in deep learning based natural language processing (i.e. Brown et al., 2020) that have67
not been utilized in any of the aforementioned studies imply that the ceiling for text-based prediction of life68
outcomes might not have been reached yet.69
In this paper, we for the first time contrast the predictive power of teacher assessments (man), deep-70
learning-based prediction from textual data (machine), and genomic data (gene) in respect to cognitive,71
non-cognitive traits and educational attainment. In addition, we analyze the role of cognitive, non-cognitive72
and discriminatory factors contributing to the different prediction techniques.73
In order to achieve this goal, we rely on a unique data source: The National Child Development Study (NCDS,74
Power and Elliott, 2006), an ongoing British birth cohort study started in 1958. At age 11, participants were75
requested to write an essay under the theme “Imagine you are 25.” of roughly 250 word length. At the same76
time, teachers were asked to give an assessment of the respondents abilities and behaviors. Eventually, in77
2002, blood samples of participants were collected and later genotyped (see Materials & Methods).78
Both essays and genotyping results confront us with the challenges of unstructured big data and require79
extensive feature engineering. We therefore leverage state-of-the-art deep learning language models (Vaswani80
3

et al., 2017) and over 500 lexicographic metrics to create more than 1000-dimensional numerical representations81
of each essay. Likewise, we reduce the complexity of our genetic data, which encompasses more than 35 million82
single nucletoide polymorphisms (SNPs): By utilizing publicly available summary statistics of genome-wide83
association studies (GWAS) we use different subsets of all available SNPs to construct polygenic scores (PGS)84
for a set of 33 curated traits, likely to be associated with our outcomes of interest in a multi-polygenic score85
approach to trait prediction (Krapohl et al., 2018). In contrast, only 22 items are used for teacher evaluations86
(see SI for a detailed list). Thus constructed covariates are used as cross-validated input to an ensembled87
array of established machine learning algorithms in the SuperLearner-framework (Van der Laan et al., 2007;88
Polley and Van Der Laan, 2010) to maximize prediction while guarding against overfitting.189
Figure 1: Overview of the research design: Genes, essays and teacher assessments are used to constructcovariates as input to an ensembling algorithm (SuperLearner) that is used to predict cognitive ability,noncognitive traits and educational attainment.
Following this design (also schematically displayed in Figure 1), our research is highly relevant to various90
current debates in the social and behavioral sciences and the broader societal discourse: First, the ability of91
computational social scientists to predict individual life outcomes in general has been questioned (Turkheimer92
and Waldron, 2000; Salganik et al., 2020). By looking at a broad range of variables measured at different93
points in time and multiple sets of innovative predictors, as well as by using best practices from the field of94
1All these aspects are described in more detail in the Materials & Methods section as well as in the SI.
4

machine learning, our work presents an important additional test of this gloomy prospect.95
Second, behavioral geneticists suggest that genetic factors are predictive of various life outcomes (Polderman96
et al., 2015), including psychological ones as well as educational attainment. Twin studies suggest that genes97
explain up to 50% of individual differences, while out of sample predictions based on molecular data remain98
smaller at around 17 percent (Okbay et al., 2022). Given the apparently consistent ability of genetic variants99
to predict education across Western populations (Rietveld et al., 2013), and the interpretation of non-genetic100
variation as unsystematic (Plomin, 2011) or luck (Jencks et al., 1972) and therefore unpredictive, it is even101
debated to use genes as incremental information for college admission (Plomin, 2018; Harden, 2021). Our102
direct comparison of genomic prediction to textual data and teacher assessments provides an important103
benchmark in debates on the applicability of genetic predictors in an educational context (Hart, 2016; Plomin,104
2018; Morris et al., 2020).105
Finally, the juxtaposition of “man” against “machine” has a long tradition (Jones, 2013) and progress in the106
fields of robotics and artificial intelligence (Silver et al., 2018; Brown et al., 2020) not only in the context of107
manual but also cognitive tasks and health care is causing a surge of “automation anxiety” (Feigenbaum and108
Gross, 2020) in developed countries. In this sense, AI-based automation of teaching is a key-issue in current109
debates on technology and education (Selwyn, 2021), as already a growing industry is dedicated to the task110
of automating essay scoring (Foltz et al., 2020). At the same time, automated essay evaluation might be111
considered as an opportunity, not only to support teachers but also for neutral assessments in contrast to112
human evaluation (Alvero et al., 2021).113
In the following, we investigate first the general predictive power of man, machine and gene on cognitive114
ability as well as non-cognitive traits which have been highlighted complementary for educational success115
of students during childhood, at the same or close to the time both the essays have been written and the116
teachers provided their assessments of the students’ abilities (age 11). Next, we quantify the predictability of117
educational attainment at age 33 by all three predictors separately, incrementally, and jointly and compare118
those results with alternative measures from the scientific literature. Finally, in particular in the context of119
the man and machine comparison, we investigate both predictive measures of the assessments and mediating120
5

and confounding factors respectively of their association with educational attainment.121
Results122
Essays, Teacher Assessments and Genes predict Cognitive and non-cognitive Traits123
First, we find quite substantial predictive power of both teacher evaluation and our essay-based deep learning124
(DL) algorithm: For cognitive ability at age 11 66% (64%-68% over all cross-validation folds, see Figure 2125
A) of individual differences in a general factor of cognitive ability can be predicted by teacher assessments,126
and 61% (58%-64% over all cross-validation folds) by essay-based DL. More specifically, for reading (Man =127
57%; Machine = 56%), verbal (Man = 57%; Machine = 54%), mathematical (62%; 53%) and non-verbal128
ability (45%; 36%), this is lower. Genetic predictions are in most cases measurable, but substantially smaller129
with 17% variance explanation in the prediction sample for general factor of cognitive ability and 14%, 13%,130
17% and 11% for reading, verbal, mathematical and non-verbal skills. In contrast, prediction is overall much131
weaker for non-cognitive traits such as job aspiration (Man = 12%; Machine = 9%; Gene = 4%), scholastic132
motivation (9%; 8%; 5%), externalizing (19%; 8%; 4%) and internalizing behavior (8%; 3%; 0%).133
Comparable prediction of Man, Machine, Genes and cognitive, non-cognitive skills.134
All three approaches predict educational attainment (see Fig. 2 B). Again, teacher assessment shows the135
highest prediction (29%), followed by DL (25%) and PGS predictions (19%). Combining teachers’ evaluation136
and the essay-based prediction only marginally improves the human prediction by 7% (2 percentage points,137
pp), but additional information from the teacher improves the DL prediction one quarter (6 pp). Polygenic138
prediction adds substantially to man (24%; 7 pp) and DL prediction (28%; 7 pp). Incrementally to the two139
other approaches, each man (19%; 6 pp), machine (6%; 2 pp) and gene (23%; 7 pp) add information to the140
prediction.141
The joint overall prediction of 38% is indeed comparable to the prediction based on cognitive abilities measured142
at age 11 as well as non-cognitive abilities (Fig. 2 C). The Figure also includes birth weight as a predictor143
since this has long been a biological proxy also in the social sciences associated with positive life course144
6
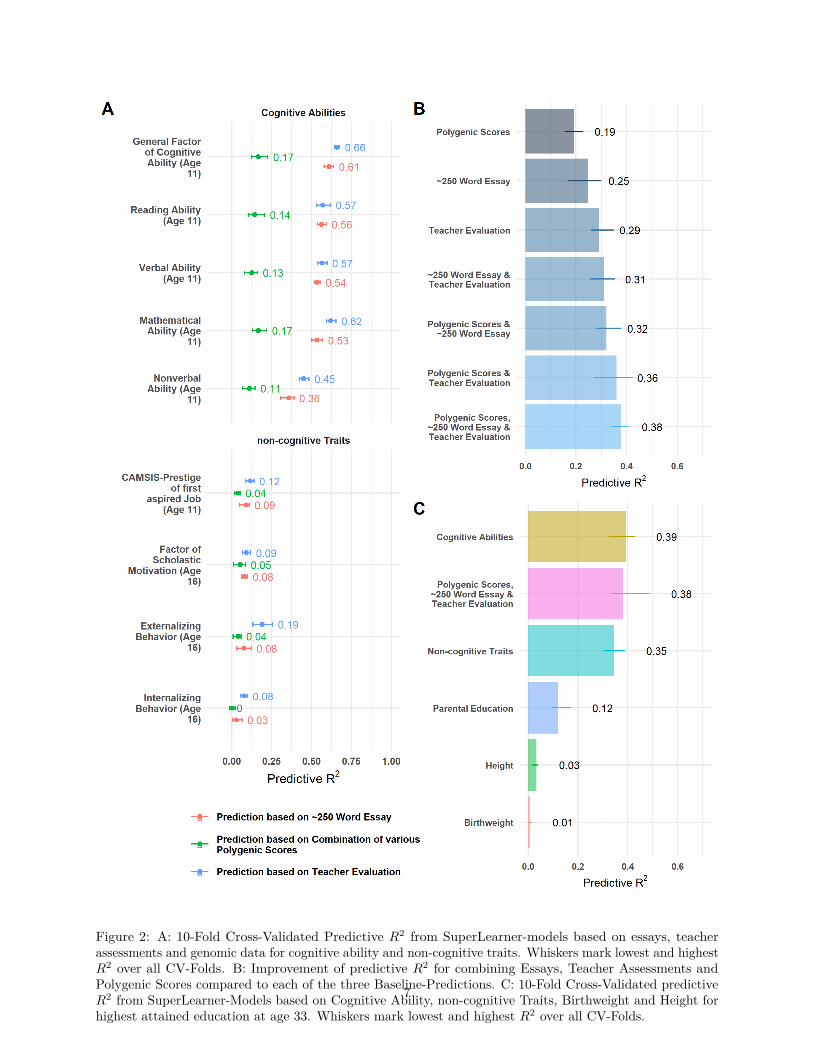
Figure 2: A: 10-Fold Cross-Validated Predictive R2 from SuperLearner-models based on essays, teacherassessments and genomic data for cognitive ability and non-cognitive traits. Whiskers mark lowest and highestR2 over all CV-Folds. B: Improvement of predictive R2 for combining Essays, Teacher Assessments andPolygenic Scores compared to each of the three Baseline-Predictions. C: 10-Fold Cross-Validated predictiveR2 from SuperLearner-Models based on Cognitive Ability, non-cognitive Traits, Birthweight and Height forhighest attained education at age 33. Whiskers mark lowest and highest R2 over all CV-Folds.
7

outcomes as well as body height, which is an example from social psychology explaining socio-economic145
success (Stulp, 2013). However, those measures only predict education by 1% and 3%. Even one of the146
key sociological predictors of educational attainment, parental education, is only able to explain 12% of the147
variance.148
Cognitive Ability, Noncognitive Traits and Parental SES mediate the Prediction of Essays,149
Teacher Assessments and Genes on Educational Attainment.150
What pathways drive the association from Man, Machine and Gene to educational attainment? Next to151
race, parental socio-economic status (SES) and sex are potential discriminatory factors in school assessment152
(Campbell, 2015), beyond cognitive and non-cognitive skills which teachers are supposed to evaluate. They153
might also be caught by our DL algorithm from textual cues in the essays. Furthermore, recent research154
has shown, that polygenic scores for educational attainment capture both direct as well as indirect effects,155
the latter potentially being confounded by parental SES (Wang et al., 2021). To better understand the156
signals picked up by our nonstandard predictors, we fit a multiple mediation model including cognitive ability,157
non-cognitive traits and potential non-psychological confounders, namely height, birthweight, sex, parental158
SES (measured by education).159
Our model shows that measured factors explain most (85%) of the DL prediction, with cognitive ability160
emerging as the strongest factor (53%), followed by in total 17% for scholastic motivation and occupational161
aspiration, parental SES 9% and externalizing behavior 4%. The overall pattern for genetic prediction and162
teachers evaluation is very similar. However, for teachers’ evaluation, cognitive abilities explain only 40%163
of the association and overall only 70% can be explained. For the genetic prediction, cognitive ability only164
explains 26% and overall only half of the total effect can be explained.165
Discussion166
In this study, we have demonstrated that social and psychological traits can be predicted from nonstandard167
data, available at early stages in life. While previous studies have questioned the predictability of social168
and psychological variables, our best model is substantially above the range of predictive performance set in169
8
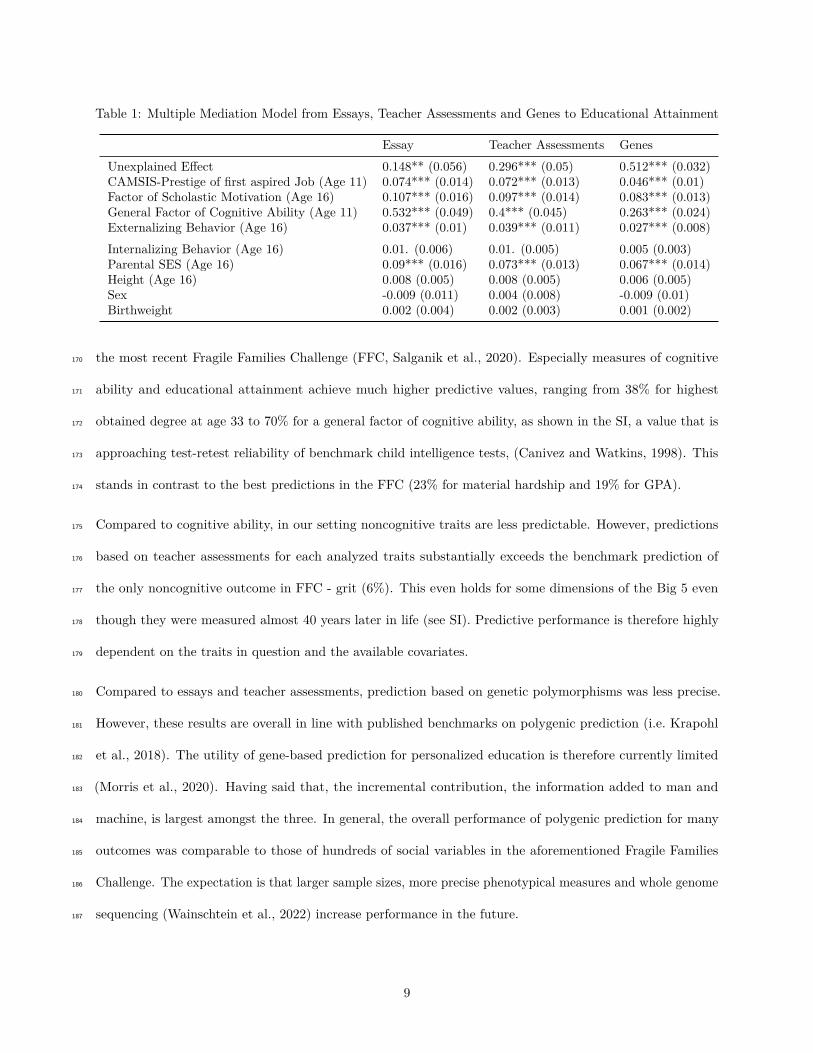
Table 1: Multiple Mediation Model from Essays, Teacher Assessments and Genes to Educational Attainment
Essay Teacher Assessments GenesUnexplained Effect 0.148** (0.056) 0.296*** (0.05) 0.512*** (0.032)CAMSIS-Prestige of first aspired Job (Age 11) 0.074*** (0.014) 0.072*** (0.013) 0.046*** (0.01)Factor of Scholastic Motivation (Age 16) 0.107*** (0.016) 0.097*** (0.014) 0.083*** (0.013)General Factor of Cognitive Ability (Age 11) 0.532*** (0.049) 0.4*** (0.045) 0.263*** (0.024)Externalizing Behavior (Age 16) 0.037*** (0.01) 0.039*** (0.011) 0.027*** (0.008)Internalizing Behavior (Age 16) 0.01. (0.006) 0.01. (0.005) 0.005 (0.003)Parental SES (Age 16) 0.09*** (0.016) 0.073*** (0.013) 0.067*** (0.014)Height (Age 16) 0.008 (0.005) 0.008 (0.005) 0.006 (0.005)Sex -0.009 (0.011) 0.004 (0.008) -0.009 (0.01)Birthweight 0.002 (0.004) 0.002 (0.003) 0.001 (0.002)
the most recent Fragile Families Challenge (FFC, Salganik et al., 2020). Especially measures of cognitive170
ability and educational attainment achieve much higher predictive values, ranging from 38% for highest171
obtained degree at age 33 to 70% for a general factor of cognitive ability, as shown in the SI, a value that is172
approaching test-retest reliability of benchmark child intelligence tests, (Canivez and Watkins, 1998). This173
stands in contrast to the best predictions in the FFC (23% for material hardship and 19% for GPA).174
Compared to cognitive ability, in our setting noncognitive traits are less predictable. However, predictions175
based on teacher assessments for each analyzed traits substantially exceeds the benchmark prediction of176
the only noncognitive outcome in FFC - grit (6%). This even holds for some dimensions of the Big 5 even177
though they were measured almost 40 years later in life (see SI). Predictive performance is therefore highly178
dependent on the traits in question and the available covariates.179
Compared to essays and teacher assessments, prediction based on genetic polymorphisms was less precise.180
However, these results are overall in line with published benchmarks on polygenic prediction (i.e. Krapohl181
et al., 2018). The utility of gene-based prediction for personalized education is therefore currently limited182
(Morris et al., 2020). Having said that, the incremental contribution, the information added to man and183
machine, is largest amongst the three. In general, the overall performance of polygenic prediction for many184
outcomes was comparable to those of hundreds of social variables in the aforementioned Fragile Families185
Challenge. The expectation is that larger sample sizes, more precise phenotypical measures and whole genome186
sequencing (Wainschtein et al., 2022) increase performance in the future.187
9

Judging the individual performance of our three approaches, teacher assessments achieved overall the best188
prediction. In light of their limited scope, this finding is quite remarkable. Provided they are more focused on189
a characteristic of interest, significantly better results might be obtained, stressing the importance of expert190
opinion in a time that emphasizes the potential for automation. Nevertheless, in most cases, textual samples191
were on par with the teacher-evaluation-based prediction. It is therefore possible to predict various traits to a192
surprising degree from a ~250 word essay using state-of-the-art natural language processing models. This in193
itself is a noteworthy achievement that warrants further research: Longer texts combined with more advanced194
models might lead to even better results.195
Potential automation anxiety due to work force replacement is not necessary given the unique contribution of196
teachers to the education prediction. However, since the DL is highly redundant to the human prediction,197
second essay corrections or other supportive tasks are potentially to be implemented given the high costs of198
the educational system in the UK (4.1% of GDP; in US it is 3.9% OECD, 2021a) annually.199
Our findings further open up an exciting avenue for many large social- and behavioral scientific surveys which200
so far to our knowledge do not contain anything comparable to the essays available in the dataset used in this201
study. So far, such data would have been of limited use to quantitative researchers. Our approach presents202
a promising example of how it can be made useful. In general, more research on the relationship between203
classic constructs from social- and behavioral sciences and textual data is necessary, especially in light of the204
rapidly growing use of such models in commercial contexts (Dale, 2021).205
Overall, given our results, simply accepting that successful prediction in the social and behavioral sciences is206
not possible, or only possible to a very limited extent, seems premature.207
10

Materials and Methods208
A more detailed report of the study design and variable construction is available in SI Appendix.209
Data210
Outcomes211
The dataset used for our analyses is the National Child Development Study (NCDS), an ongoing british birth212
cohort study started in 1958. We seek to evaluate the extent to which genomic data, teacher assessments,213
and the information embedded in the essays are able to predict 18 outcome variables that can be broadly214
categorized under three different themes: Cognitive abilities, non-cognitive traits and socioeconomic outcomes.215
Information on the generation of the outcome variables is provided in the appendix.216
Teacher Evaluations217
We use nine variables overall: At age 11, teachers of the respondents were asked to assess their students218
general knowledge, number work, use of books and oral ability on a scale from one to five, as well as certain219
behaviors and motor-abilities on a scale from one to three. In addition, a series of behavior descriptions220
was given to the teacher, who is asked to underline the descriptions which best fit the child. By summing221
the number of selected items, a quantitative assessment of the child’s adjustment to school is obtained for222
multiple categories of behavior.223
Essays224
Also at age 11, study participants were asked to write an essay under the theme “Imagine you are 25.” In total225
10,511 essays of varying length (ranging from 1 to 1239 words) were transcribed. We apply various approaches226
to extract the maximum amount of information from them, by using a pre-trained and publicly available,227
state-of-the-art deep-learning NLP model, RoBERTa (Liu et al., 2019) to extract representations of the first228
250 words of all essays in lower dimensional space. These embeddings capture the semantic importance of229
each word in context and allow to express the texts by numeric vectors along 768 dimensions. In addition,230
we measure 535 linguistic metrics of lexical diversity (TAALED, Kyle et al., 2021), lexical sophistication231
11

(TAALES, Kyle et al., 2018) and sentiment (SEANCE, Crossley et al., 2017), 31 metrics of readability and232
grammatical and typographical error/word-ratios.233
Genomic Data234
For multiple subsets of NCDS participants genotyped data was available. We combined all available genomic235
data into a single file and restricted the available SNPs to those in common with the 1000 genomes reference236
panel. The final sample contains 37 772 588 variants on 6437 individuals. Using PRSice2 (Choi and O’Reilly,237
2019), we then applied publicly available summary statistics of genome-wide association studies to construct238
polygenic scores for a set of 33 curated traits (see appendix) likely to show associations with the outcomes in239
question, which span the realms of cognition, mental health, personality, physical composure, social behavior240
and substance abuse.241
Analytical Strategy242
SuperLearner243
To guarantee that we extract the maximum predictive validity from the three data sources of interest (teacher244
assessments, essays, genomic data), we use a so-called SuperLearner (Van der Laan et al., 2007; Polley and245
Van Der Laan, 2010) approach an ensembling algorithm that estimates the performance of a selection of246
machine learning models for predicting the analyzed outcomes based on cross-validation. From these, the247
SuperLearner determines a weighted average based on their performance. We run the SuperLearner with248
nested cross validation, using both 10 folds in the inner and the outer loop with the MSE as the cost function249
using the SuperLearner package in R.250
Input Algorithms251
We use a diverse range of state-of-the-art machine-learning models as input to the SuperLearner: Extreme252
Gradient Boosting, as implemented in the package xgboost (Chen et al., 2015), RandomForest, as implemented253
in the package ranger (Wright and Ziegler, 2015), a shallow neural network, as implemented in the package254
nnet, SVM with a Radial Basis Kernel, as implemented in the package ksvm, a simple linear regression model255
12

and the mean of the outcome in the training set. As an extremely large number of variables are extracted256
from the essays in the form of word embeddings, etc. the LASSO (implemented in glmnet) is used as a257
pre-screening algorithm to limit computation time.258
Evaluation Metric259
We focus on R2Holdout (or predictive R2) as our main evaluation criterion (Salganik et al., 2020), which can260
be viewed as the predictive equivalent of the well-known coefficient of variation R2. It rescales the squared261
error of a model’s prediction by the squared error when the prediction is only based on the mean value in the262
training set. For each cross-validation fold we compute263
R2Holdout = 1 −
∑i∈Holdout(yi − yi)2∑
i∈Holdout(yi − yT raining)2 .
Analogous to R2, a value of R2Holdout = 1 implies a perfect prediction, while R2
Holdout ≤ 0 indicates that the264
model performs worse than using just the sample mean for prediction.2265
2Five extreme outliers (> 10 SD) were identified in a single fold of a single trait (neuroticism) and set to the mean prediction.This does not influence results in any qualitative way but changes a misleading and not interpretable minimum fold R2
Holdout of-216 to 0.0024.
13

References266
Polina Shafran Abramov and Roman V Yampolskiy. Automatic iq estimation using stylometric methods. In267
Handbook of Research on Learning in the Age of Transhumanism, pages 32–45. IGI Global, 2019.268
AJ Alvero, Sonia Giebel, Ben Gebre-Medhin, Anthony Lising Antonio, Mitchell L Stevens, and Benjamin W269
Domingue. Essay content and style are strongly related to household income and SAT scores: Evidence270
from 60,000 undergraduate applications. Science advances, 7(42):eabi9031, 2021.271
Franz Baeriswyl, Christian Wandeler, and Ulrich Trautwein. «Auf einer anderen schule oder bei einer anderen272
lehrkraft hätte es für’s gymnasium gereicht»: Eine untersuchung zur bedeutung von schulen und lehrkräften273
für die übertrittsempfehlung. Zeitschrift für pädagogische Psychologie, 25(1):39–47, 2011.274
Richard Berk, Drougas Berk, and Drougas. Machine Learning Risk Assessments in Criminal Justice Settings.275
Springer, 2019.276
Fabrizio Bernardi and Gabriele Ballarino. Education, Occupation and Social Origin: A Comparative Analysis277
of the Transmission of Socio-Economic Inequalities. Edward Elgar Publishing, 2016.278
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind279
Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.280
Advances in neural information processing systems, 33:1877–1901, 2020.281
Tammy Campbell. Stereotyped at seven? Biases in teacher judgement of pupils’ ability and attainment.282
Journal of Social Policy, 44(3):517–547, 2015.283
Gary L Canivez and Marley W Watkins. Long-term stability of the wechsler intelligence scale for Chil-284
dren—Third edition. Psychological Assessment, 10(3):285, 1998.285
Bryan Caplan. The Case against Education. Princeton University Press, 2019.286
Dana Chandler, Steven D Levitt, and John A List. Predicting and preventing shootings among at-risk youth.287
American Economic Review, 101(3):288–92, 2011.288
14

Tianqi Chen, Tong He, Michael Benesty, Vadim Khotilovich, Yuan Tang, Hyunsu Cho, et al. Xgboost:289
Extreme gradient boosting. R package version 0.4-2, 1(4):1–4, 2015.290
Shing Wan Choi and Paul F O’Reilly. PRSice-2: Polygenic Risk Score software for biobank-scale data.291
Gigascience, 8(7):giz082, 2019.292
Cagrı Cöltekin. Predicting educational achievement using linear models. Proceedings of the GermEval 2020293
Task, 1:23–29, 2020.294
Skyler J Cranmer and Bruce A Desmarais. What can we learn from predictive modeling? Political Analysis,295
25(2):145–166, 2017.296
Scott A Crossley, Kristopher Kyle, and Danielle S McNamara. Sentiment Analysis and Social Cognition297
Engine (SEANCE): An automatic tool for sentiment, social cognition, and social-order analysis. Behavior298
research methods, 49(3):803–821, 2017.299
Andrew D Cutler, Stephen W Carden, Hannah L Dorough, and Nicholas S Holtzman. Inferring grandiose300
narcissism from text: LIWC versus machine learning. Journal of Language and Social Psychology, 40(2):301
260–276, 2021.302
Robert Dale. GPT-3: What’s it good for? Natural Language Engineering, 27(1):113–118, 2021.303
Lisa A Fast and David C Funder. Personality as manifest in word use: Correlations with self-report,304
acquaintance report, and behavior. Journal of personality and social psychology, 94(2):334, 2008.305
James Feigenbaum and Daniel P Gross. Automation and the fate of young workers: Evidence from telephone306
operation in the early 20th century. Technical report, National Bureau of Economic Research, 2020.307
Peter W Foltz, Duanli Yan, and André A Rupp. The past, present, and future of automated scoring. In308
Handbook of Automated Scoring, pages 1–10. Chapman and Hall/CRC, 2020.309
Siegfried Geyer, Örjan Hemström, Richard Peter, and Denny Vågerö. Education, income, and occupational310
class cannot be used interchangeably in social epidemiology. Empirical evidence against a common practice.311
Journal of Epidemiology & Community Health, 60(9):804–810, 2006.312
15

Kathryn Paige Harden. The Genetic Lottery: Why DNA Matters for Social Equality. Princeton University313
Press, 2021.314
Sara A Hart. Precision education initiative: Moving toward personalized education. Mind, Brain, and315
Education, 10(4):209–211, 2016.316
Carl G Hempel and Paul Oppenheim. Studies in the Logic of Explanation. Philosophy of science, 15(2):317
135–175, 1948.318
Jake M. Hofman, Duncan J. Watts, Susan Athey, Filiz Garip, Thomas L. Griffiths, Jon Kleinberg, Helen319
Margetts, Sendhil Mullainathan, Matthew J. Salganik, Simine Vazire, Alessandro Vespignani, and Tal320
Yarkoni. Integrating explanation and prediction in computational social science. Nature, 595(7866):181–188,321
July 2021. ISSN 1476-4687. doi: 10.1038/s41586-021-03659-0.322
Christopher Jencks et al. Inequality: A reassessment of the effect of family and schooling in america. 1972.323
Steven E Jones. Against Technology: From the Luddites to Neo-Luddism. Routledge, 2013.324
Oscar Kaplan. Prediction in the social sciences. Philosophy of science, 7(4):492–498, 1940.325
Jon Kleinberg, Jens Ludwig, Sendhil Mullainathan, and Ziad Obermeyer. Prediction policy problems.326
American Economic Review, 105(5):491–95, 2015.327
Eva Krapohl, Kaili Rimfeld, Nicholas G. Shakeshaft, Maciej Trzaskowski, Andrew McMillan, Jean-Baptiste328
Pingault, Kathryn Asbury, Nicole Harlaar, Yulia Kovas, and Philip S. Dale. The high heritability of329
educational achievement reflects many genetically influenced traits, not just intelligence. Proceedings of the330
national academy of sciences, 111(42):15273–15278, 2014. doi: 10.1073/pnas.1408777111.331
Eva Krapohl, Hamel Patel, Stephen Newhouse, Charles J Curtis, Sophie von Stumm, Philip S Dale, Delilah332
Zabaneh, Gerome Breen, Paul F O’Reilly, and Robert Plomin. Multi-polygenic score approach to trait333
prediction. Molecular psychiatry, 23(5):1368–1374, 2018.334
Kristopher Kyle, Scott Crossley, and Cynthia Berger. The tool for the automatic analysis of lexical335
sophistication (TAALES): Version 2.0. Behavior research methods, 50(3):1030–1046, 2018.336
16

Kristopher Kyle, Scott A Crossley, and Scott Jarvis. Assessing the validity of lexical diversity indices using337
direct judgements. Language Assessment Quarterly, 18(2):154–170, 2021.338
James J. Lee, Robbee Wedow, Aysu Okbay, Edward Kong, Omeed Maghzian, Meghan Zacher, Tuan Anh339
Nguyen-Viet, Peter Bowers, Julia Sidorenko, Richard Karlsson Linnér, Mark Alan Fontana, Tushar340
Kundu, Chanwook Lee, Hui Li, Ruoxi Li, Rebecca Royer, Pascal N. Timshel, Raymond K. Walters,341
Emily A. Willoughby, Loïc Yengo, Maris Alver, Yanchun Bao, David W. Clark, Felix R. Day, Nicholas A.342
Furlotte, Peter K. Joshi, Kathryn E. Kemper, Aaron Kleinman, Claudia Langenberg, Reedik Mägi,343
Joey W. Trampush, Shefali Setia Verma, Yang Wu, Max Lam, Jing Hua Zhao, Zhili Zheng, Jason D.344
Boardman, Harry Campbell, Jeremy Freese, Kathleen Mullan Harris, Caroline Hayward, Pamela Herd,345
Meena Kumari, Todd Lencz, Jian’an Luan, Anil K. Malhotra, Andres Metspalu, Lili Milani, Ken K. Ong,346
John R. B. Perry, David J. Porteous, Marylyn D. Ritchie, Melissa C. Smart, Blair H. Smith, Joyce Y.347
Tung, Nicholas J. Wareham, James F. Wilson, Jonathan P. Beauchamp, Dalton C. Conley, Tõnu Esko,348
Steven F. Lehrer, Patrik K. E. Magnusson, Sven Oskarsson, Tune H. Pers, Matthew R. Robinson, Kevin349
Thom, Chelsea Watson, Christopher F. Chabris, Michelle N. Meyer, David I. Laibson, Jian Yang, Magnus350
Johannesson, Philipp D. Koellinger, Patrick Turley, Peter M. Visscher, Daniel J. Benjamin, and David351
Cesarini. Gene discovery and polygenic prediction from a genome-wide association study of educational352
attainment in 1.1 million individuals. Nature Genetics, 50(8):1112–1121, August 2018. ISSN 1546-1718.353
doi: 10.1038/s41588-018-0147-3.354
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke355
Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv356
preprint arXiv:1907.11692, 2019.357
Adriana Lleras-Muney. The relationship between education and adult mortality in the United States. The358
Review of Economic Studies, 72(1):189–221, 2005.359
Lance Lochner and Enrico Moretti. The effect of education on crime: Evidence from prison inmates, arrests,360
and self-reports. American economic review, 94(1):155–189, 2004.361
Gary N Marks. The contribution of genes and the environment to educational and socioeconomic attainments362
17

in Australia. Twin Research and Human Genetics, 20(4):281–289, 2017.363
Tim T Morris, Neil M Davies, and George Davey Smith. Can education be personalised using pupils’ genetic364
data? Elife, 9:e49962, 2020.365
OECD. Education at a Glance 2021: OECD Indicators. Organisation for Economic Co-operation and366
Development, Paris, 2021a.367
OECD. Education at a Glance 2021. 2021b. doi: https://doi.org/10.1787/b35a14e5-en.368
Aysu Okbay, Yeda Wu, Nancy Wang, Hariharan Jayashankar, Michael Bennett, Seyed Moeen Nehzati, Julia369
Sidorenko, Hyeokmoon Kweon, Grant Goldman, Tamara Gjorgjieva, Yunxuan Jiang, Barry Hicks, Chao370
Tian, David A. Hinds, Rafael Ahlskog, Patrik K. E. Magnusson, Sven Oskarsson, Caroline Hayward, Archie371
Campbell, David J. Porteous, Jeremy Freese, Pamela Herd, Chelsea Watson, Jonathan Jala, Dalton Conley,372
Philipp D. Koellinger, Magnus Johannesson, David Laibson, Michelle N. Meyer, James J. Lee, Augustine373
Kong, Loic Yengo, David Cesarini, Patrick Turley, Peter M. Visscher, Jonathan P. Beauchamp, Daniel J.374
Benjamin, and Alexander I. Young. Polygenic prediction of educational attainment within and between375
families from genome-wide association analyses in 3 million individuals. Nature Genetics, 54(4):437–449,376
April 2022. ISSN 1546-1718. doi: 10.1038/s41588-022-01016-z.377
Robert Plomin. Commentary: Why are children in the same family so different? Non-shared environment378
three decades later. International Journal of Epidemiology, 40(3):582–592, June 2011. ISSN 0300-5771.379
doi: 10.1093/ije/dyq144.380
Robert Plomin. Blueprint: How DNA Makes Us Who We Are. Mit Press, 2018.381
Tinca J. C. Polderman, Beben Benyamin, Christiaan A. de Leeuw, Patrick F. Sullivan, Arjen van Bochoven,382
Peter M. Visscher, and Danielle Posthuma. Meta-analysis of the heritability of human traits based on fifty383
years of twin studies. Nature Genetics, 47(7):702–709, July 2015. ISSN 1546-1718. doi: 10.1038/ng.3285.384
Eric C Polley and Mark J Van Der Laan. Super learner in prediction. 2010.385
Karl Raimund Popper. Conjectures and Refutations: The Growth of Scientific Knowledge, volume 15.386
Routledge, 1962.387
18

Chris Power and Jane Elliott. Cohort profile: 1958 British birth cohort (national child development study).388
International journal of epidemiology, 35(1):34–41, 2006.389
Charles Rahal, Mark Verhagen, David Kirk, et al. The rise of machine learning in the academic social sciences.390
Technical report, Center for Open Science, 2021.391
Cornelius A. Rietveld, Sarah E. Medland, Jaime Derringer, Jian Yang, Tõnu Esko, Nicolas W. Martin,392
Harm-Jan Westra, Konstantin Shakhbazov, Abdel Abdellaoui, Arpana Agrawal, Eva Albrecht, Behrooz Z.393
Alizadeh, Najaf Amin, John Barnard, Sebastian E. Baumeister, Kelly S. Benke, Lawrence F. Bielak,394
Jeffrey A. Boatman, Patricia A. Boyle, Gail Davies, Christiaan de Leeuw, Niina Eklund, Daniel S. Evans,395
Rudolf Ferhmann, Krista Fischer, Christian Gieger, Håkon K. Gjessing, Sara Hägg, Jennifer R. Harris,396
Caroline Hayward, Christina Holzapfel, Carla A. Ibrahim-Verbaas, Erik Ingelsson, Bo Jacobsson, Peter K.397
Joshi, Astanand Jugessur, Marika Kaakinen, Stavroula Kanoni, Juha Karjalainen, Ivana Kolcic, Kati398
Kristiansson, Zoltán Kutalik, Jari Lahti, Sang H. Lee, Peng Lin, Penelope A. Lind, Yongmei Liu, Kurt399
Lohman, Marisa Loitfelder, George McMahon, Pedro Marques Vidal, Osorio Meirelles, Lili Milani, Ronny400
Myhre, Marja-Liisa Nuotio, Christopher J. Oldmeadow, Katja E. Petrovic, Wouter J. Peyrot, Ozren401
Polašek, Lydia Quaye, Eva Reinmaa, John P. Rice, Thais S. Rizzi, Helena Schmidt, Reinhold Schmidt,402
Albert V. Smith, Jennifer A. Smith, Toshiko Tanaka, Antonio Terracciano, Matthijs J.H.M. van der403
Loos, Veronique Vitart, Henry Völzke, Jürgen Wellmann, Lei Yu, Wei Zhao, Jüri Allik, John R. Attia,404
Stefania Bandinelli, François Bastardot, Jonathan Beauchamp, David A. Bennett, Klaus Berger, Laura J.405
Bierut, Dorret I. Boomsma, Ute Bültmann, Harry Campbell, Christopher F. Chabris, Lynn Cherkas,406
Mina K. Chung, Francesco Cucca, Mariza de Andrade, Philip L. De Jager, Jan-Emmanuel De Neve, Ian J.407
Deary, George V. Dedoussis, Panos Deloukas, Maria Dimitriou, Gudny Eiriksdottir, Martin F. Elderson,408
Johan G. Eriksson, David M. Evans, Jessica D. Faul, Luigi Ferrucci, Melissa E. Garcia, Henrik Grönberg,409
Vilmundur Gudnason, Per Hall, Juliette M. Harris, Tamara B. Harris, Nicholas D. Hastie, Andrew C.410
Heath, Dena G. Hernandez, Wolfgang Hoffmann, Adriaan Hofman, Rolf Holle, Elizabeth G. Holliday,411
Jouke-Jan Hottenga, William G. Iacono, Thomas Illig, Marjo-Riitta Järvelin, Mika Kähönen, Jaakko412
Kaprio, Robert M. Kirkpatrick, Matthew Kowgier, Antti Latvala, Lenore J. Launer, Debbie A. Lawlor,413
Terho Lehtimäki, Jingmei Li, Paul Lichtenstein, Peter Lichtner, David C. Liewald, Pamela A. Madden,414
19

Patrik K. E. Magnusson, Tomi E. Mäkinen, Marco Masala, Matt McGue, Andres Metspalu, Andreas415
Mielck, Michael B. Miller, Grant W. Montgomery, Sutapa Mukherjee, Dale R. Nyholt, Ben A. Oostra,416
Lyle J. Palmer, Aarno Palotie, Brenda Penninx, Markus Perola, Patricia A. Peyser, Martin Preisig, Katri417
Räikkönen, Olli T. Raitakari, Anu Realo, Susan M. Ring, Samuli Ripatti, Fernando Rivadeneira, Igor418
Rudan, Aldo Rustichini, Veikko Salomaa, Antti-Pekka Sarin, David Schlessinger, Rodney J. Scott, Harold419
Snieder, Beate St Pourcain, John M. Starr, Jae Hoon Sul, Ida Surakka, Rauli Svento, Alexander Teumer,420
Henning Tiemeier, Frank JAan Rooij, David R. Van Wagoner, Erkki Vartiainen, Jorma Viikari, Peter421
Vollenweider, Judith M. Vonk, Gérard Waeber, David R. Weir, H.-Erich Wichmann, Elisabeth Widen,422
Gonneke Willemsen, James F. Wilson, Alan F. Wright, Dalton Conley, George Davey-Smith, Lude Franke,423
Patrick J. F. Groenen, Albert Hofman, Magnus Johannesson, Sharon L.R. Kardia, Robert F. Krueger,424
David Laibson, Nicholas G. Martin, Michelle N. Meyer, Danielle Posthuma, A. Roy Thurik, Nicholas J.425
Timpson, André G. Uitterlinden, Cornelia M. van Duijn, Peter M. Visscher, Daniel J. Benjamin, David426
Cesarini, and Philipp D. Koellinger. GWAS of 126,559 Individuals Identifies Genetic Variants Associated427
with Educational Attainment. Science (New York, N.Y.), 340(6139):1467–1471, June 2013. ISSN 0036-8075.428
doi: 10.1126/science.1235488.429
Aubrey J Rodriguez, Shannon E Holleran, and Matthias R Mehl. Reading between the lines: The lay430
assessment of subclinical depression from written self-descriptions. Journal of personality, 78(2):575–598,431
2010.432
Matthew J. Salganik, Ian Lundberg, Alexander T. Kindel, Caitlin E. Ahearn, Khaled Al-Ghoneim, Abdullah433
Almaatouq, Drew M. Altschul, Jennie E. Brand, Nicole Bohme Carnegie, Ryan James Compton, Debanjan434
Datta, Thomas Davidson, Anna Filippova, Connor Gilroy, Brian J. Goode, Eaman Jahani, Ridhi Kashyap,435
Antje Kirchner, Stephen McKay, Allison C. Morgan, Alex Pentland, Kivan Polimis, Louis Raes, Daniel E.436
Rigobon, Claudia V. Roberts, Diana M. Stanescu, Yoshihiko Suhara, Adaner Usmani, Erik H. Wang, Muna437
Adem, Abdulla Alhajri, Bedoor AlShebli, Redwane Amin, Ryan B. Amos, Lisa P. Argyle, Livia Baer-Bositis,438
Moritz Büchi, Bo-Ryehn Chung, William Eggert, Gregory Faletto, Zhilin Fan, Jeremy Freese, Tejomay439
Gadgil, Josh Gagné, Yue Gao, Andrew Halpern-Manners, Sonia P. Hashim, Sonia Hausen, Guanhua He,440
Kimberly Higuera, Bernie Hogan, Ilana M. Horwitz, Lisa M. Hummel, Naman Jain, Kun Jin, David441
20

Jurgens, Patrick Kaminski, Areg Karapetyan, E. H. Kim, Ben Leizman, Naijia Liu, Malte Möser, Andrew E.442
Mack, Mayank Mahajan, Noah Mandell, Helge Marahrens, Diana Mercado-Garcia, Viola Mocz, Katariina443
Mueller-Gastell, Ahmed Musse, Qiankun Niu, William Nowak, Hamidreza Omidvar, Andrew Or, Karen444
Ouyang, Katy M. Pinto, Ethan Porter, Kristin E. Porter, Crystal Qian, Tamkinat Rauf, Anahit Sargsyan,445
Thomas Schaffner, Landon Schnabel, Bryan Schonfeld, Ben Sender, Jonathan D. Tang, Emma Tsurkov,446
Austin van Loon, Onur Varol, Xiafei Wang, Zhi Wang, Julia Wang, Flora Wang, Samantha Weissman,447
Kirstie Whitaker, Maria K. Wolters, Wei Lee Woon, James Wu, Catherine Wu, Kengran Yang, Jingwen448
Yin, Bingyu Zhao, Chenyun Zhu, Jeanne Brooks-Gunn, Barbara E. Engelhardt, Moritz Hardt, Dean Knox,449
Karen Levy, Arvind Narayanan, Brandon M. Stewart, Duncan J. Watts, and Sara McLanahan. Measuring450
the predictability of life outcomes with a scientific mass collaboration. Proceedings of the National Academy451
of Sciences, 117(15):8398–8403, April 2020. ISSN 0027-8424, 1091-6490. doi: 10.1073/pnas.1915006117.452
Neil Selwyn. Education and Technology: Key Issues and Debates. Bloomsbury Academic, London ; New York,453
3rd edition edition, December 2021. ISBN 978-1-350-14554-2.454
Saskia Selzam, Eva Krapohl, Sophie Von Stumm, Paul Francis O’Reilly, Kaili Rimfeld, Yulia Kovas, PS Dale,455
JJ Lee, and Robert Plomin. Predicting educational achievement from DNA. Molecular psychiatry, 22(2):456
267–272, 2017.457
Karri Silventoinen, Aline Jelenkovic, Reijo Sund, Antti Latvala, Chika Honda, Fujio Inui, Rie Tomizawa,458
Mikio Watanabe, Norio Sakai, Esther Rebato, Andreas Busjahn, Jessica Tyler, John L. Hopper, Juan R.459
Ordoñana, Juan F. Sánchez-Romera, Lucia Colodro-Conde, Lucas Calais-Ferreira, Vinicius C. Oliveira,460
Paulo H. Ferreira, Emanuela Medda, Lorenza Nisticò, Virgilia Toccaceli, Catherine A. Derom, Robert F.461
Vlietinck, Ruth J. F. Loos, Sisira H. Siribaddana, Matthew Hotopf, Athula Sumathipala, Fruhling Rijsdijk,462
Glen E. Duncan, Dedra Buchwald, Per Tynelius, Finn Rasmussen, Qihua Tan, Dongfeng Zhang, Zengchang463
Pang, Patrik K. E. Magnusson, Nancy L. Pedersen, Anna K. Dahl Aslan, Amie E. Hwang, Thomas M.464
Mack, Robert F. Krueger, Matt McGue, Shandell Pahlen, Ingunn Brandt, Thomas S. Nilsen, Jennifer R.465
Harris, Nicholas G. Martin, Sarah E. Medland, Grant W. Montgomery, Gonneke Willemsen, Meike Bartels,466
Catharina E. M. van Beijsterveldt, Carol E. Franz, William S. Kremen, Michael J. Lyons, Judy L. Silberg,467
21

Hermine H. Maes, Christian Kandler, Tracy L. Nelson, Keith E. Whitfield, Robin P. Corley, Brooke M.468
Huibregtse, Margaret Gatz, David A. Butler, Adam D. Tarnoki, David L. Tarnoki, Hang A. Park, Jooyeon469
Lee, Soo Ji Lee, Joohon Sung, Yoshie Yokoyama, Thorkild I. A. Sørensen, Dorret I. Boomsma, and Jaakko470
Kaprio. Genetic and environmental variation in educational attainment: An individual-based analysis of 28471
twin cohorts. Scientific Reports, 10(1):12681, July 2020. ISSN 2045-2322. doi: 10.1038/s41598-020-69526-6.472
David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc473
Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, et al. A general reinforcement learning474
algorithm that masters chess, shogi, and Go through self-play. Science (New York, N.Y.), 362(6419):475
1140–1144, 2018.476
Gert Stulp. Sex, stature and status: Natural selection on height in contemporary human populations. 2013.477
Eric Turkheimer and Mary Waldron. Nonshared environment: a theoretical, methodological, and quantitative478
review. Psychological bulletin, 126(1):78, 2000.479
Detlef Urhahne and Lisette Wijnia. A review on the accuracy of teacher judgments. Educational Research480
Review, 32:100374, 2021.481
Mark J Van der Laan, Eric C Polley, and Alan E Hubbard. Super learner. Statistical applications in genetics482
and molecular biology, 6(1), 2007.483
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser,484
and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30,485
2017.486
Sophie von Stumm, Emily Smith-Woolley, Ziada Ayorech, Andrew McMillan, Kaili Rimfeld, Philip S. Dale,487
and Robert Plomin. Predicting educational achievement from genomic measures and socioeconomic status.488
Developmental science, 23(3):e12925, 2020.489
Pierrick Wainschtein, Deepti Jain, Zhili Zheng, L Adrienne Cupples, Aladdin H Shadyab, Barbara McKnight,490
Benjamin M Shoemaker, Braxton D Mitchell, Bruce M Psaty, Charles Kooperberg, et al. Assessing the491
22

contribution of rare variants to complex trait heritability from whole-genome sequence data. Nature492
Genetics, pages 1–11, 2022.493
Biyao Wang, Jessie R Baldwin, Tabea Schoeler, Rosa Cheesman, Wikus Barkhuizen, Frank Dudbridge, David494
Bann, Tim T Morris, and Jean-Baptiste Pingault. Genetic nurture effects on education: A systematic495
review and meta-analysis. bioRxiv, 2021.496
Duncan J Watts. Common sense and sociological explanations. American Journal of Sociology, 120(2):497
313–351, 2014.498
David L Weakliem. The effects of education on political opinions: An international study. International499
Journal of Public Opinion Research, 14(2):141–157, 2002.500
Marvin N Wright and Andreas Ziegler. Ranger: A fast implementation of random forests for high dimensional501
data in C++ and R. arXiv preprint arXiv:1508.04409, 2015.502
Tal Yarkoni and Jacob Westfall. Choosing prediction over explanation in psychology: Lessons from machine503
learning. Perspectives on Psychological Science, 12(6):1100–1122, 2017.504
23
Related Documents











