Machine reconstruction of human control strategies Dorian Šuc Artificial Intelligence Laboratory Faculty of Computer and Information Science University of Ljubljana, Slovenia

Machine reconstruction of human control strategies Dorian Šuc Artificial Intelligence Laboratory Faculty of Computer and Information Science University.
Dec 25, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Machine reconstruction of human control strategies
Dorian Šuc
Artificial Intelligence Laboratory Faculty of Computer and Information Science
University of Ljubljana, Slovenia

Overview
• Skill reconstruction and behavioural cloning• The learning problem• A problem decomposition for behavioural
cloning (indirect controllers, experiments, advantages)
• Symbolic and qualitative skill reconstruction• Learning qualitative strategies: QUIN algorithm• QUIN in skill reconstruction• Conclusions

Skill reconstruction and behavioural cloning
• Motivation: – understanding of the human skill– development of an automatic controler
• ML approach to skill reconstruction: learn a control strategy from the logged data from skilled human operators (execution trace). Later called behavioural cloning (Michie, 93).
• Early work: Chambers and Michie(69), learning control by imitation also by Donaldson(60,64)

Behavioural cloning: some applications
• Original approach: clones usually induced as a direct mapping from states to actions in the form of trees or rule sets
• Successfully used in domains as: – pole balancing (Miche et al., 90)– piloting (Sammut et al., 92; Camacho 95)– container cranes (Urbančič, 94)– production line scheduling (Kerr and Kibira,
94)Reviews in Sammut(96), Bratko et al(98)

Learning problem
• Execution traces used as examples for ML to induce:– a control strategy (comprehensible, symbolic)– automatic controller (criterion of success)
• Operator’s execution trace: – a sequence of system states and corresponding
operator’s actions, logged to a file at a certain frequency
• Reconstruction of human control skill:– Skill: “know how” at subsymbolic level, operational– Strategy: explicitly described “know how” at symbolic
level

Container crane
X0=0 L0=20
load
trolley
X
L
Xg=60 Lg=32
Used in ports for load transportation
Used in ports for load transportation
Control forces: Fx, FL
State: X, dX,, d, L, dL
Control forces: Fx, FL
State: X, dX,, d, L, dL
Based on previous work of Urbančič(94)
Control task: transport the load from the start to the goal position

Learning problem, cont.
Fx FL X dX d L dL 0 0 0.00 0.00 0.00 0.00 20.00 0.00 2500 0 0.00 0.00 -0.00 -0.01 20.00 0.00 6000 0 0.00 0.01 -0.01 -0.02 20.00 0.00 10000 0 0.02 0.10 -0.07 -0.27 20.00 0.00 14500 0 0.12 0.31 -0.32 -0.85 20.00 0.00 14500 0 0.35 0.59 -0.95 -1.49 20.00 0.01 ….… … … … … … …….
Fx FL X dX d L dL 0 0 0.00 0.00 0.00 0.00 20.00 0.00 2500 0 0.00 0.00 -0.00 -0.01 20.00 0.00 6000 0 0.00 0.01 -0.01 -0.02 20.00 0.00 10000 0 0.02 0.10 -0.07 -0.27 20.00 0.00 14500 0 0.12 0.31 -0.32 -0.85 20.00 0.00 14500 0 0.35 0.59 -0.95 -1.49 20.00 0.01 ….… … … … … … …….

Problems of original approachDifficulties observed with the original approach:• No guarantee of inducing with high probability a
successful clone (Urbančič and Bratko, 94) • Low robustness of clones• Comprehensibility of clones; hard to understand
Michie(93,95) suggests that a kind problem decomposition could be helpful: “learning from exemplary performance requires more than mindless imitation”
Recent approaches to behavioural cloning (Stirling, 95; Bain and Sammut, 99; Camacho, 2000)

Related work
• Leech(86), probably the first goal-structured learning of control
• CHURPs(Stirling, 95): separates control skills in planning and actuation phases; focuses on planning component; assumes the goals are given
• GRAIL(Bain and Sammut, 99): learning goals by decision trees and effects by abduction;
• Incremental Correction model(Camacho, 2000): homeostatic and achievable goals; parametrised decision trees to learn goals; wrapper-approach

Our approach
Our goals: • transparency of the induced strategies• robust and successful controllers
Ideas:• Learning problem decomposition: (a) learning of the constraints
on operator’s trajectories, (b) learning of the system’s dynamics
• Generalized trajectory as a continuous subgoal• Symbolic and qualitative constraints, use of domain knowledge
Differences with related approaches: • continuous generalized trajectory • qualitative strategies

Experimental domains
Container crane:• we used execution traces from (Urbančič,
94)Acrobot (DeJong, 95; Sutton, 96)• two link pendulum in a graviatational field;
swing-up taskBicycle riding (Randlov, Alstrm, 98) • drive the bike from the start to the goal
position; requires simultaneous balancing and goal-aiming
Simulators used in all experimentsMeasure of success: • time to accomplish the task
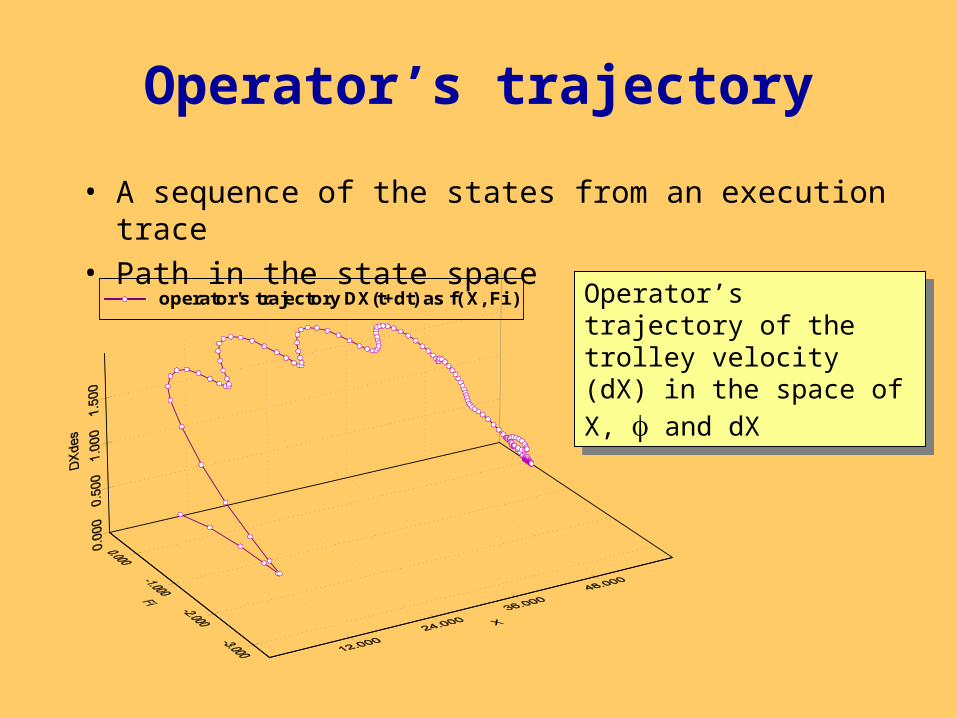
Operator’s trajectory
• A sequence of the states from an execution trace
• Path in the state spaceoperator's trajectory DX(t+dt) as f( X, Fi ) Operator’s trajectory of
the trolley velocity (dX) in the space of X, and dX
Operator’s trajectory of the trolley velocity (dX) in the space of X, and dX
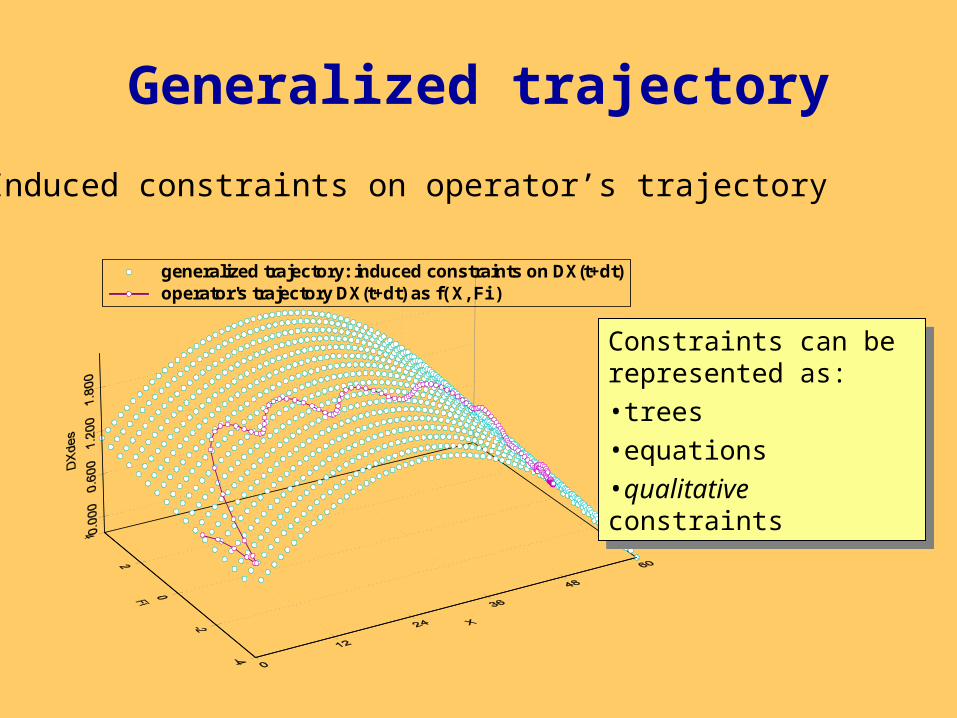
Generalized trajectory
generalized trajectory: induced constraints on DX(t+dt)operator's trajectory DX(t+dt) as f( X, Fi )
Induced constraints on operator’s trajectory
Constraints can be represented as:•trees•equations•qualitative constraints
Constraints can be represented as:•trees•equations•qualitative constraints

Qualitative and quantitative strategy
• Quantitative strategy: given with precise numerical
values or numeric constraints (decision tree, equation)
• Qualitative strategy may also use qualitative constraints. A qualitative strategy defines a set of quantitative strategies
We use qualitatively constrained functions (QCFs): monotonicity constraints as used in qualitative reasoning

Qualitatively constrained functions
• M+(x) arbitrary monotonically increasing fn. of x
• A QCF is a generalization of M+, similar to qual. proportionality predicates used in QPT(Forbus, 84)
Gas in the container:
Pres = c Temp / Vol , c = n R > 0
Gas in the container:
Pres = c Temp / Vol , c = n R > 0Temp=std & Vol Pres
Temp & Vol Pres
Temp & Vol Pres
Temp=std & Vol Pres
Temp & Vol Pres
Temp & Vol Pres
QCF: Pres = M+,-(Temp,Vol)QCF: Pres = M+,-(Temp,Vol)
Temp & Vol Pres ?
Temp & Vol Pres ?
Temp & Vol Pres ?
Temp & Vol Pres ?

Problem decomposition

Direct and indirect controllers
Original approach, BOXES, ASE/ACE
Original approach, BOXES, ASE/ACE
Our approach; Also CHURPs(Stirling, 95), GRAIL(Bain and
Sammut, 99), ICM(Camacho, 2000)
Our approach; Also CHURPs(Stirling, 95), GRAIL(Bain and
Sammut, 99), ICM(Camacho, 2000)

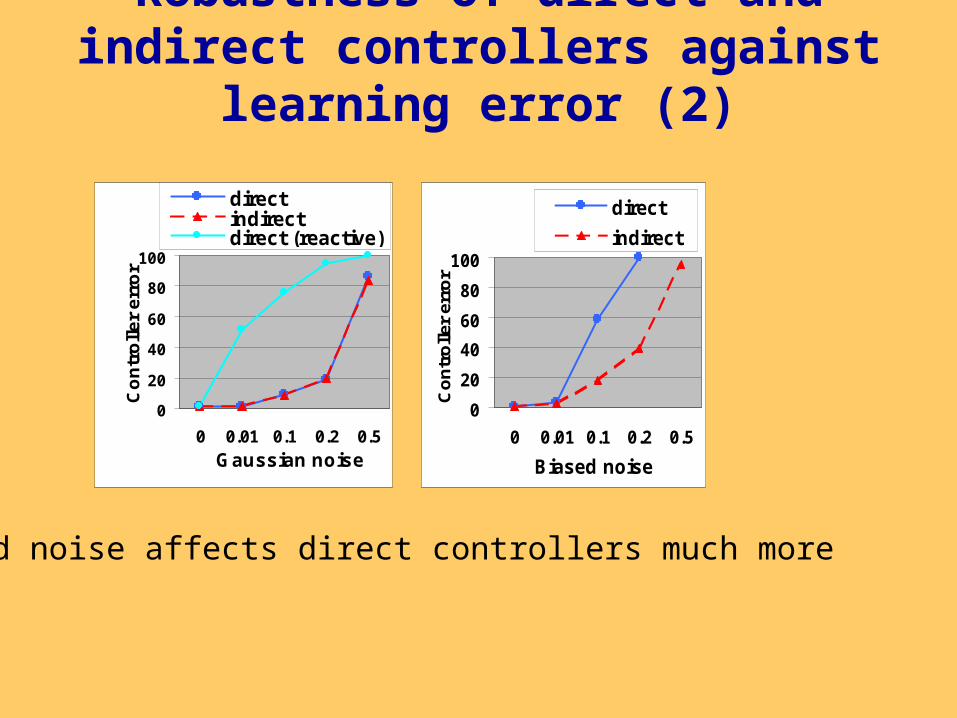
Robustness of direct and indirect controllers against learning error
• Experiment: modelling learning of direct and indirect controllers with some learning error:– direct controllers: “correct action” + noise()– indirect controllers: “correct trajectory” + noise()
• Two error models:– Gaussian noise– Biased Gaussian noise (all errors in the same
direction)
• Simple, deterministic, discrete time system:– Control task: reach and maintain the goal value Xg– Performance criterion: controller error in Xg
Robustness of direct and indirect controllers against learning error
(2)
0
20
40
60
80
100
0 0.01 0.1 0.2 0.5
Gaussian noise
Co
ntr
oll
er
err
or
directindirectdirect (reactive)
0
20
40
60
80
100
0 0.01 0.1 0.2 0.5
Biased noiseC
on
tro
ller
erro
r
direct
indirect
Biased noise affects direct controllers much more

Possible advantages of indirect controllers
• Less prone to the departure from the operator’s trajectory
• More robust against change in the system’s dynamics and small changes in the task
• generalizing the trajectory is often easier than generalizing the actions
Generalized trajectory often easier to understand (less details)

Symbolic and qualitative skill reconstruction
GoldHorn(Križman, 98)GoldHorn(Križman, 98) LWR(Atkeson et al., 97)LWR(Atkeson et al., 97)
• Experiments in the crane and acrobot domains

Experiments in the crane domain
• GoldHorn induced the generalized trajectory of the trolley velocity:
dXdes= 0.902 – 0.018 X2 + 0.090 X + 0.050
Qualitative strategy:
if X Xmid then
dX = M+,+(X, )
else dX = M-,+(X, )
generalized trajectory: induced constraints on DX(t+dt)operator's trajectory DX(t+dt) as f( X, Fi )

Transforming qualitative into quantitative strategies
• By concretizing qualitative parameters into real, numeric values or real-valued functions
• First experiment: using randomly generated functions satisfying qualitative constraints and additional domain knowledge:– maximal and minimal values of the state variables– the trolley starts towards goal– the trolley stops at goal
• Second experiment: using additional domain knowledge

Efficiency of the qualitative strategy
• The results show that qualitative strategy is:– general (the proper selection of qualitative
parameters is not crucial)– successful: offers the space for controller
optimization
• Similar experiments in acrobot domain

Qualitative induction
• Motivation: our experiments with qualitative strategies (crane, acrobot)
• Usual classification learning problem, but learning of qualitative trees: – in leaves are qualitatively constrained
functions (QCFs); QCFs give constraints on the class change in response to a change in attributes
– internal nodes (splits) define a partition of the state space into areas with common qualitative behavior of the class variable

Qualitatively constrained function (QCF)
• M+(x) arbitrary monotonically increasing fn. of x
• A QCF is a generalization of M+, similar to qual. proportionality predicates used in QPT(Forbus, 84)
Gas in the container:
Pres = c Temp / Vol , c = n R > 0
Gas in the container:
Pres = c Temp / Vol , c = n R > 0Temp=std & Vol Pres
Temp & Vol Pres
Temp & Vol Pres
Temp=std & Vol Pres
Temp & Vol Pres
Temp & Vol Pres
QCF: Pres = M+,-(Temp,Vol)QCF: Pres = M+,-(Temp,Vol)
Temp & Vol Pres ?
Temp & Vol Pres ?
Temp & Vol Pres ?
Temp & Vol Pres ?
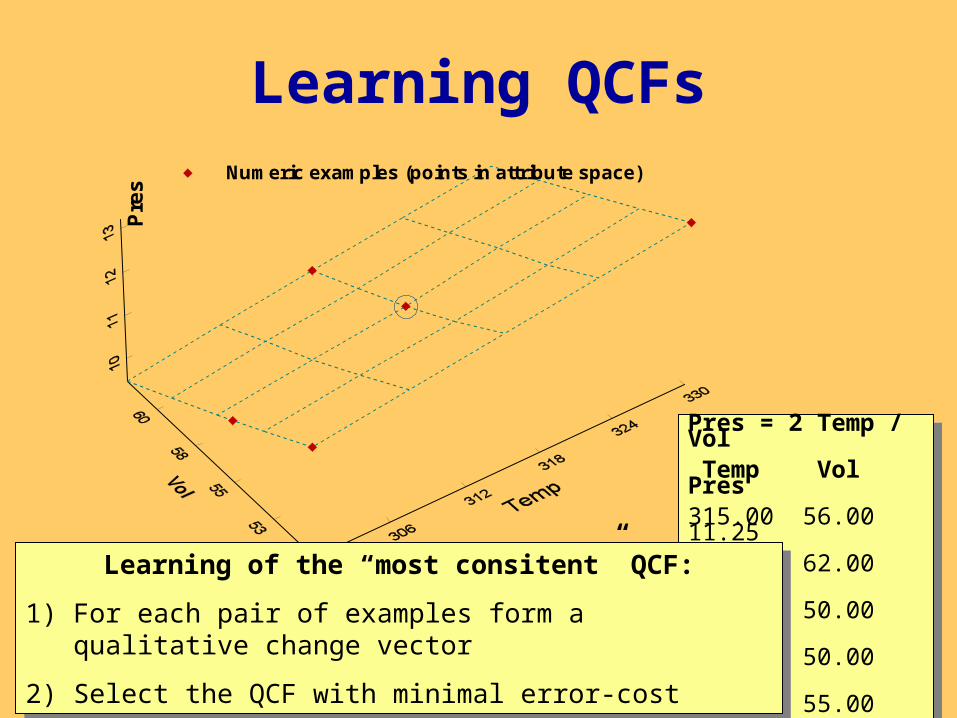
Learning QCFs
Pres = 2 Temp / Vol Temp Vol Pres315.00 56.00 11.25315.00 62.00 10.16330.00 50.00 13.20300.00 50.00 12.00300.00 55.00 10.90
Pres = 2 Temp / Vol Temp Vol Pres315.00 56.00 11.25315.00 62.00 10.16330.00 50.00 13.20300.00 50.00 12.00300.00 55.00 10.90
Pre
s
Numeric examples (points in attribute space)
Learning of the “most consitent” QCF:
1) For each pair of examples form a qualitative change vector
2) Select the QCF with minimal error-cost
Learning of the “most consitent” QCF:
1) For each pair of examples form a qualitative change vector
2) Select the QCF with minimal error-cost
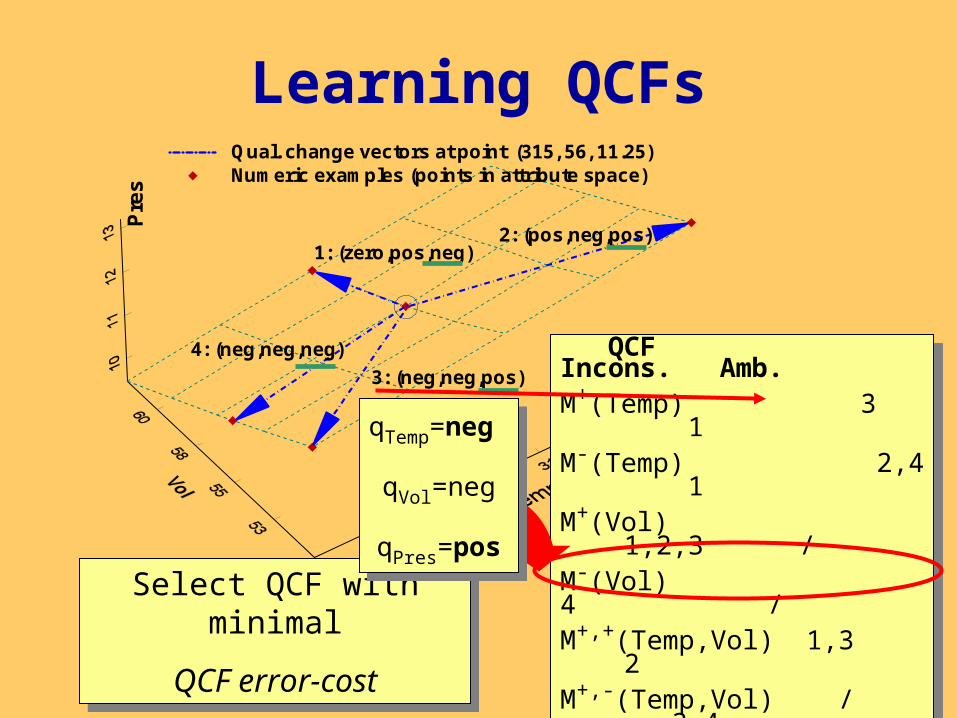
QCF Incons. Amb.M+(Temp)
M-(Temp)
M+(Vol)
M-(Vol)
M+,+(Temp,Vol)
M+,-(Temp,Vol)
M-,+(Temp,Vol)
M-,-(Temp,Vol)
QCF Incons. Amb.M+(Temp)
M-(Temp)
M+(Vol)
M-(Vol)
M+,+(Temp,Vol)
M+,-(Temp,Vol)
M-,+(Temp,Vol)
M-,-(Temp,Vol)
1: (zero,pos,neg)
4: (neg,neg,neg)
2: (pos,neg,pos)
Qual. change vectors at point (315, 56, 11.25)Numeric examples (points in attribute space)
3: (neg,neg,pos)
Pre
s
QCF Incons. Amb.M+(Temp) 3 1
M-(Temp)
M+(Vol)
M-(Vol)
M+,+(Temp,Vol)
M+,-(Temp,Vol)
M-,+(Temp,Vol)
M-,-(Temp,Vol)
QCF Incons. Amb.M+(Temp) 3 1
M-(Temp)
M+(Vol)
M-(Vol)
M+,+(Temp,Vol)
M+,-(Temp,Vol)
M-,+(Temp,Vol)
M-,-(Temp,Vol)
Learning QCFs
QCF Incons. Amb.M+(Temp) 3 1
M-(Temp) 2,4 1
M+(Vol) 1,2,3 /
M-(Vol) 4 /
M+,+(Temp,Vol) 1,3 2
M+,-(Temp,Vol) / 3,4
M-,+(Temp,Vol) 1,2 3,4
M-,-(Temp,Vol) 4 2
QCF Incons. Amb.M+(Temp) 3 1
M-(Temp) 2,4 1
M+(Vol) 1,2,3 /
M-(Vol) 4 /
M+,+(Temp,Vol) 1,3 2
M+,-(Temp,Vol) / 3,4
M-,+(Temp,Vol) 1,2 3,4
M-,-(Temp,Vol) 4 2
Select QCF with minimal
QCF error-cost
Select QCF with minimal
QCF error-cost
qTemp=neg
qVol=neg
qPres=pos
qTemp=neg
qVol=neg
qPres=pos

Learning qualitative tree
• For every possible split, split the examples into two subsets, find the “most consistent” QCF for both subsets and select the split minimizing tree-error cost (based on MDL)
• Algorithm ep-QUIN uses every pair of examples
• An improvement: heuristic QUIN algorithm that considers also locality and consistency of qualitative change vectors

Experimental evaluation in artificial domains
• On a set of artificial domains with uniformly distributed attributes; 2 irrelevant attributes
• Results by QUIN better than ep-QUIN• In simple domains QUIN finds qualitative
relations corresponding to our intuition

QUIN in bicycle riding
Control task: drive a bike from the start to the goal positionthe bike’s speed is assumed constantdifficult because balancing and goal-aiming must be
performed simultaneously
• Controlled by torque applied to the handlebars
• State: goalAngle, goalDist, , d, , d• QUIN: des = f(State)
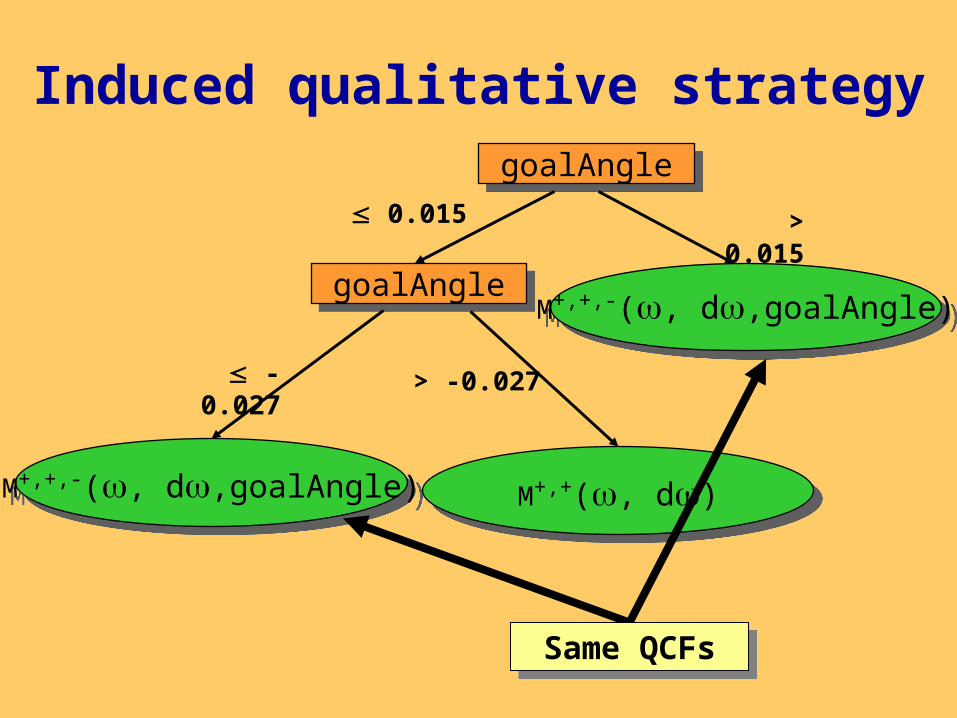
Induced qualitative strategy
goalAnglegoalAngle
0.015
> -0.027 -0.027
> 0.015
goalAnglegoalAngle
M+,+,-(, d,goalAngle)M+,+,-(, d,goalAngle)M+,+(, d)M+,+(, d)
M+,+,-(, d,goalAngle)M+,+,-(, d,goalAngle)
Same QCFsSame QCFs
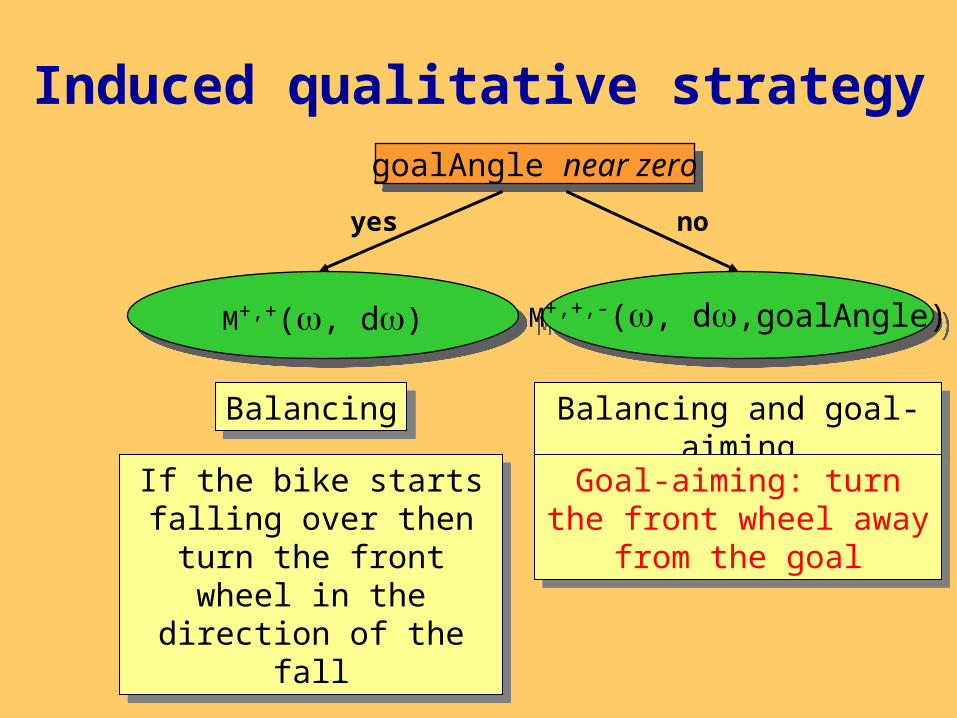
Induced qualitative strategy
goalAngle near zerogoalAngle near zero
yes no
M+,+(, d)M+,+(, d) M+,+,-(, d,goalAngle)M+,+,-(, d,goalAngle)
BalancingBalancing Balancing and goal-aimingBalancing and goal-aiming
Goal-aiming: turn the front wheel away from the goal
Goal-aiming: turn the front wheel away from the goal
If the bike starts falling over then turn the front wheel in the direction of
the fall
If the bike starts falling over then turn the front wheel in the direction of
the fall

Transforming qualitative into quantitative strategies
• Transform QCFs into real valued functions by using simple domain knowledge:– maximal front wheel deflection– drive straight if bike is aiming at the goal: f(0,0,0)=0– balancing is more important than aiming at the goal
• 400 randomly generated quantitative strategies; 59.2% successful
• Test of robustness:– Change in the start state (58% successful)– Random displacement of the bicyclist from the mass
center (26% successful)

QUIN in crane domain
• Crane control requires trolley and rope control• Experiments with traces of 2 operators using
different control styles
• Rope control• QUIN: Ldes= f(X, dX, , d, dL)
• Often very simple strategy induced
Ldes= M+( X )
bring down the load as the trolley moves from the start to the goal position
Ldes= M+( X )
bring down the load as the trolley moves from the start to the goal position
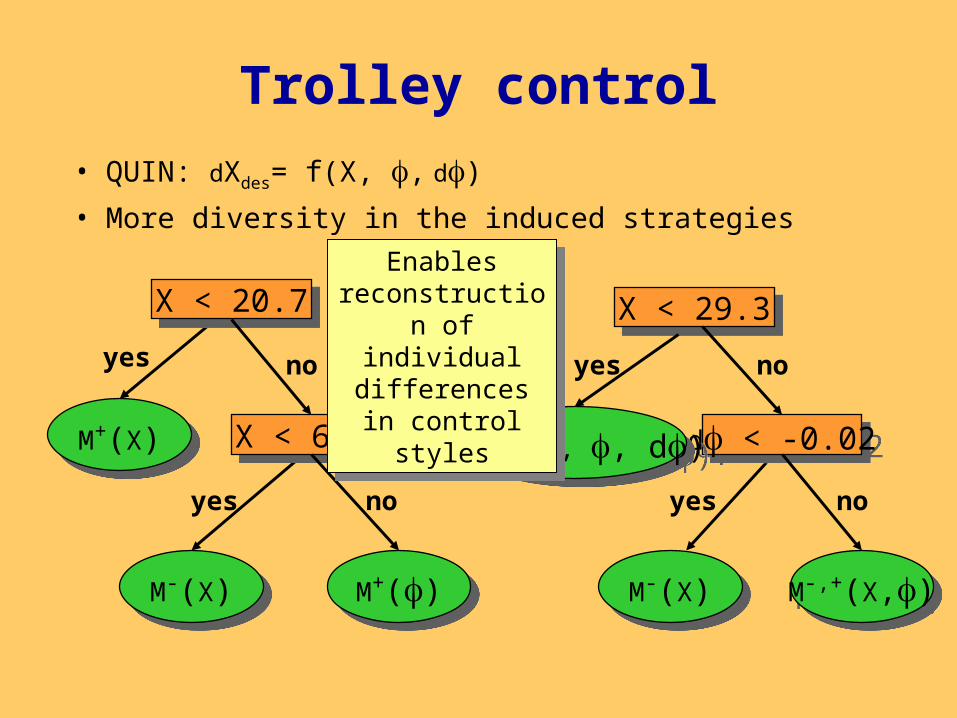
Trolley control
• QUIN: dXdes= f(X, , d)
• More diversity in the induced strategies
M-(X)M-(X) M+()M+()
X < 20.7X < 20.7
X < 60.1X < 60.1
X < 29.3X < 29.3
M+(X)M+(X) d < -0.02d < -0.02
M-(X)M-(X) M-,+(X,)M-,+(X,)
M+,+,-(X, , d)M+,+,-(X, , d)
yes
yes
yes
yes
no
no
no
no
Enables reconstruction of individual
differences in control styles
Enables reconstruction of individual
differences in control styles

Role of human intervention
• Approach facilitates the use of user knowledge• In our experiments the following types of
human intervention were used:– Selection of the dependent trajectory variable– Disregarding some state variables– Selection and analysis of induced equations– Using domain knowledge in transforming qualitative
into quantitative strategies
• According to empirical evidence different (sensible) choices and use of domain knowledge also give successful strategies

Contributions of the thesis
• A decomposition of the behavioural cloning problem into the learning of continuous generalized trajectory and system’s dynamics
• Modelling of human skill with symbolic and qualitative constraints
• QUIN algorithm for learning qualitative constraint trees
• Applying QUIN to skill reconstruction• Experimental evaluation in several dynamic
domains

Further work
• Applying QUIN in different domains where qualitative models preferred; QUIN improvements
• Qualitative simulation to generate possible explanations of a qualitative strategy
• Reducing the space of admissible controllers by qualitative reasoning
• Minimizing the trajectory constraints error in all the state variables would not require the selection of the dependent trajectory variable
Related Documents











