Introduction to STATA Introduction to STATA About STATA About STATA Basic Operations Basic Operations Regression Analysis Regression Analysis Panel Data Analysis Panel Data Analysis

Introduction to STATA About STATA About STATA Basic Operations Basic Operations Regression Analysis Regression Analysis Panel Data Analysis Panel Data.
Mar 31, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Introduction to STATAIntroduction to STATA
About STATAAbout STATA Basic OperationsBasic Operations Regression AnalysisRegression Analysis Panel Data AnalysisPanel Data Analysis

About
STATA is modern and general command driven package for
statistical analyses, data management and graphics.
STATA provides commands to analyze panel data (cross-
sectional time-series, longitudinal, repeated-measures, and
correlated data), cross-sectional data, time-series data,
survival-time data, cohort study,…
STATA is user friendly.
STATA has an extraordinary set of reference books.
STATA has internet capabilities (installing new features,
updating)

Getting ready Download statadata.zip from Econ 511 website Unzip file statadata.zip to U:\stata

Basic Operations
Entering DataEntering Data
Exploring DataExploring Data
Modifying DataModifying Data
Managing DataManaging Data
Analyzing DataAnalyzing Data

Entering Data Insheet: Read ASCII (text) data created by a spreadsheet (.csv files only)
Infile: Read unformatted ASCII (text) data (space delimited files)
Input: Enter data from keyboard
Describe: Describe contents of data in memory or on disk
Compress: Compress data in memory
Save: Store the dataset currently in memory on disk in Stata data format
Count: Show the number of observations
List: List values of variables
Clear: Clear the entire dataset and everything else
Memory: Display a report on memory usage
Set memory: Set the size of memory

Example cd u:\stata dir insheet using hs0.csv (If file has variable name on the first line) Save hs insheet gender id race ses schtyp prgtype read write math science
socst using hs0_noname.csv, clear(If file doesn’t have variable name on the first line)
Count Describe Compress Clear use hs, clear (only for files in Stata files, can be use over internet) Memory set memory 5m (maximum: 256MB)

Exploring data Describe: Describe a dataset List List the contents of a dataset Codebook: Detailed contents of a dataset Log: Create a log file Summarize: Descriptive statistics Tabstat: Table of descriptive statistics Table: Create a table of statistics Stem: Stem-and-leaf plot Graph: High resolution graphs Kdensity: Kernal density plot Sort: Sort observations in a dataset Histogram: Histogram for continuous and categorical variables Tabulate: One- and two-way frequency tables Correlate: Correlations Pwcorr: Pairwise correlations Type: Display an ASCII file

Example use hs0, clear Describe List list gender-read Codebook log using unit1, text replace (open a existing log file called unit1
which will save all of the commands and the output in a text file and delete the contents and places the current log into the file
summarize summarize read math science write display 9.48^2 (note: variance is the sd (9.48) squared) summarize write detail sum write if read>=60 sum write if prgtype=="academic“ sum write in 1/40 tabulate prgtype, summarize(read) stem write graph box write log close (close the log file) type unit1.log (see what is in the log file)

Modifying Data label data: Apply a label to a data set Order: Order the variables in a data set label variable: Apply a label to a variable label define: Define a set of a labels for the levels of a categorical
variable label values: Apply value labels to a variable List: Lists the observations Rename: Rename a variable Recode: Recode the values of a variable Notes: Apply notes to the data file Generate: Creates a new variable Replace: Replaces one value with another value Egen: Extended generate - has special functions that can be used
when creating a new variable

Example Use hs0 Order id gender label variable schtyp "The type of school the student
attended." label define scl 1 public 2 private label values schtyp scl codebook schtyp list schtyp in 1/10 list schtyp in 1/10, nolabel encode prgtype, gen(prog) (create a new numeric version of the
string variable prgtype) label variable prog "The type of program in which the student
was enrolled." codebook prog list prog in 1/10 list prog in 1/10, nolabel

Example (cont) rename gender female (easier to work with since we don’t have to deal with 0s and
1s) label variable female "The gender of the student." label define fm 1 female 0 male label values female fm codebook female list female in 1/10, nolabel Gen total = read +write + math replace total = read + write + socst label variable total "The total of the read, write and socst." list race if race == 5 recode race 5 = . list race if race == . generate total = read + write + math sum total Codebook total notes race: values of race coded as 5 were recoded to be missing egen zread = std(read) (using special function std(.)) save hs1

Managing Data
Pwd: Show current directory (pwd=print working
directory)
dir or ls: Show files in current directory
cd Change directory
keep if: Keep observations if condition is met
Keep: Keep variables (dropping others)
Drop: Drop variables (keeping others)
append using: Append a data file to current file
Merge: Merge a data file with current file
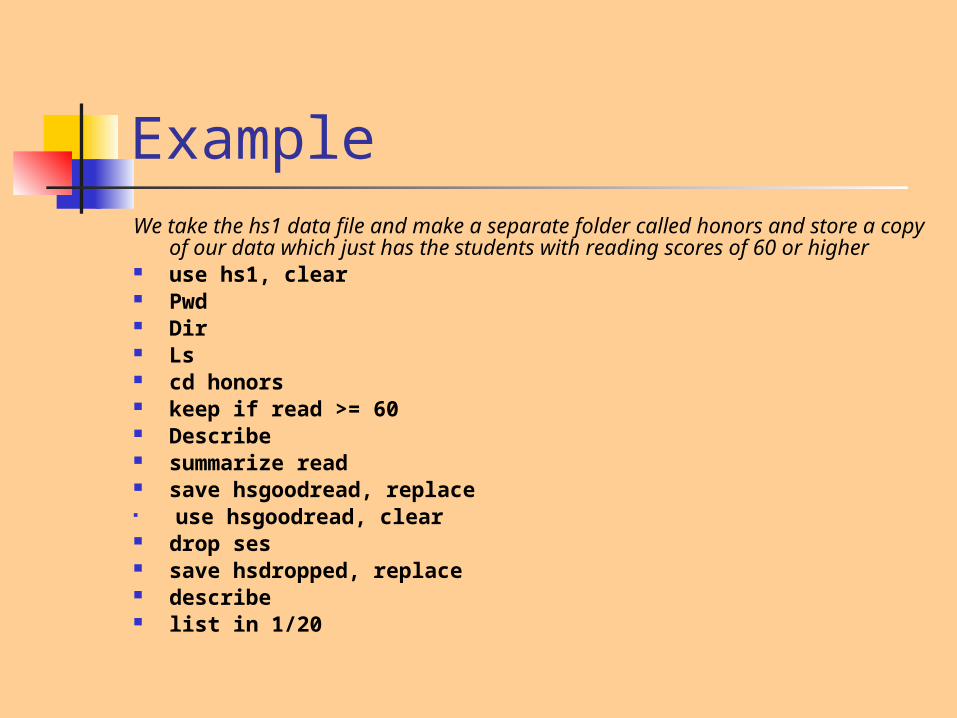
ExampleWe take the hs1 data file and make a separate folder called honors and
store a copy of our data which just has the students with reading scores of 60 or higher
use hs1, clear Pwd Dir Ls cd honors keep if read >= 60 Describe summarize read save hsgoodread, replace
use hsgoodread, clear drop ses save hsdropped, replace describe list in 1/20

Analyzing Data Ttest: t-test Regress: Regression Predict: Predicts after model estimation Kdensity: Kernel density estimates and graphs Pnorm: Graphs a standardized normal plot Qnorm: Graphs a quantile plot Rvfplot: Graphs a residual versus fitted plot Rvpplot: Graphs a residual versus individual predictor plot Xi: Creates dummy variables during model estimation Test: Test linear hypotheses after model estimation Oneway: One-way analysis of variance Anova: Analysis of variance Logistic: Logistic regression Logit: Logistic regression

Example use hs1, clear ttest write = 50 (This is the one-sample t-test, testing whether the sample of
writing scores was drawn from a population with a mean of 50 ) ttest write = read (This is the paired t-test, testing whether or not the mean of
write equals the mean of read) ttest write, by(female) (This is the two-sample independent t-test with pooled
(equal) variances) ttest write, by(female) unequal (This is the two-sample independent t-test
with separate (unequal) variances) oneway write prog anova write prog (Both of these commands perform a one-way analysis of
variance (ANOVA) anova write prog female prog*female (the anova command is used to
perform a two-way analysis of variance (ANOVA).) anova write prog female prog*female read, cont(read) (the anova
command performs an analysis of covariance (ANCOVA))

Example (cont) regress write read female (Plain vanilla OLS regression) regress write read female, robust (we run the regression with
robust standard errors. This is very useful when there is heterogeneity of variance. This option does not affect the estimates of the regression coefficients.)
predict p (The predict command calculates predictions, residuals, influence statistics, and the like after an estimation command. The default shown here is to calculate the predicted scores)
predict r, resid (When using the resid option the predict command calculates the residual)
pnorm r ( produces a normal probability plot and it is another method of testing whether the residuals from the regression are normally distributed)
Rvfplot (generates a plot of the residual versus the fitted values; it is used after regress or anova)
rvpplot read (produces a plot of the residual versus a specified predictor and it is also used after regress or anova.

Example (cont) xi: regress write read i.prog (The xi prefix is used to dummy code categorical
variables such as prog. The predictor prog has three levels and requires two dummy-coded variables)
test _Iprog_2 _Iprog_3 (The test command is used to test the collective effect of the two dummy-coded variables; in other words, it tests the main effect of prog)
xi: regress write i.prog*read (create dummy variables for prog and for the interaction of prog and read)
test _IproXread_2 _IproXread_3 (tests the overall interaction) test _Iprog_2 _Iprog_3 (tests the main effect of prog) gen honcomp = write >= 60 (create a dichotomous variable called honcomp
(honors composition) to use as our dependent variable) tab honcomp
The logistic command defaults to producing the output in odds ratios but can display the coefficients if the coef option is used. The exact same results can be obtained by using the logit command, which produces coefficients as the default but will display the odds ratio if the or option is used:
logit honcomp read female logit honcomp read female, or

Logistic Regression Classical Regression vs Logistic Regression All of the previous regression examples have used continuous dependent variables. Logistic regression is used when the dependent variable is binary or dichotomous. Different Assumptions The population means of the dependent variables at each level of the independent
variable are not on a straight line, i.e., no linearity. The variance of the errors are not constant, i.e., no homogeneity of variance. The errors are not normally distributed, i.e., no normaility. Logistic Regression Assumptions: The model is correctly specified, i.e., 1. the true conditional probabilities are a logistic function of the indpendent
variables,2. no important variables are omitted,3. no extraneous variables are included, and4. the independent variables are measured without error. The cases are independent. The independent variables are not linear combinations of each other.
Perfect multicolinearity makes estimation impossible, while strong multicolinearity makes estimates imprecise.

Logistic Regression - 2Logit: Use admission into a graduate program in which 70% of the males and 30% of the
females are admitted - Let P equal the probability of being admitted. Let Q = 1 - P equal the probability of not being admitted. Let the odds of a male admitted be odds(M) = P/Q = P/1-P = .7/.3 = 2.3333 Let the odds of a female admitted be odds(F) = P/Q = P/1-P = .3/.7 = .42857 Let the odds ration, OR = odds(M)/odds(F) = 2.3333/.42857 = 5.44 The odds if being admitted to the program are about 5.44 times greater for males
then for females. Let logit(P) = log(odds) = ln(P/Q) = ln (P/1 - P) This results in the logistic regression equation logit(P) = a + bX.
In effect, this represents a transformation of the dependent variable such that the resulting logistic regression equation better meets the assumptions of linearity, normality and homogeneity of variance
Interpreting logit coefficients: Logistic slope coefficients can be interpreted as the effect of a unit of change in the
X variable on the predicted logits with the other variables in the model held constant. That is, how a one unit change in X effects the log of the odds when the other variables in the model held constant.
Interpreting Odds Ratios: Odds ratios in logistic regression can be interpreted as the effect of a one unit of
change in X in the predicted odds ratio with the other variables in the model held constant

Logistic Regression – 3Sample data set:
input apt gender admit 8 1 1 7 1 0 5 1 1 3 1 0 3 1 0 5 1 1 7 1 1 8 1 1 5 1 1 5 1 1 4 0 0 7 0 1 3 0 1 2 0 0 4 0 0 2 0 0 3 0 0 4 0 1 3 0 0 2 0 0 end

Logistic Regression – 4
Example 1: Categorical Independent Variable logit admit gender logistic admit genderExample 2: Continuous Independent Variable logit admit apt logistic admit apt Example 3: Categorical & Continuous Independent Variables logit admit gender apt logistic admit gender apt Example 4: Honors Composition using HSB Dataset Use hsb2, clear generate honors = (write>=60) (create dichotomous response variable) tabulate ses, generate(ses) (create dummy coding for ses) logit honors female ses1 ses2 read math test ses1 ses2 logistic honors female ses1 ses2 read math lfit (goodness-of-fit test) lstat
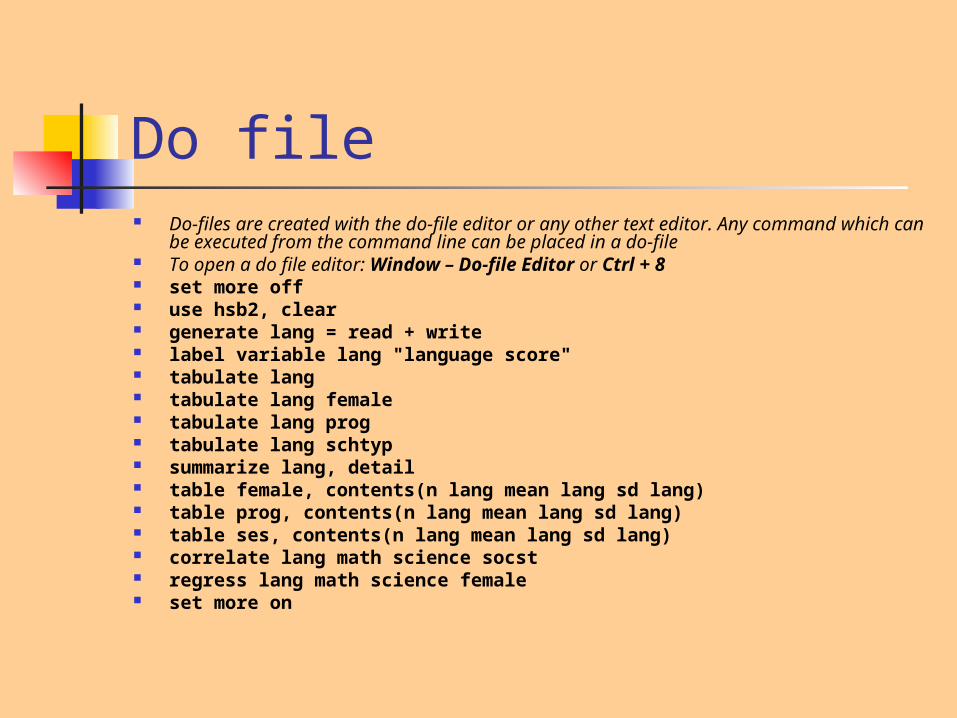
Do file Do-files are created with the do-file editor or any other text editor. Any
command which can be executed from the command line can be placed in a do-file
To open a do file editor: Window – Do-file Editor or Ctrl + 8 set more off use hsb2, clear generate lang = read + write label variable lang "language score" tabulate lang tabulate lang female tabulate lang prog tabulate lang schtyp summarize lang, detail table female, contents(n lang mean lang sd lang) table prog, contents(n lang mean lang sd lang) table ses, contents(n lang mean lang sd lang) correlate lang math science socst regress lang math science female set more on
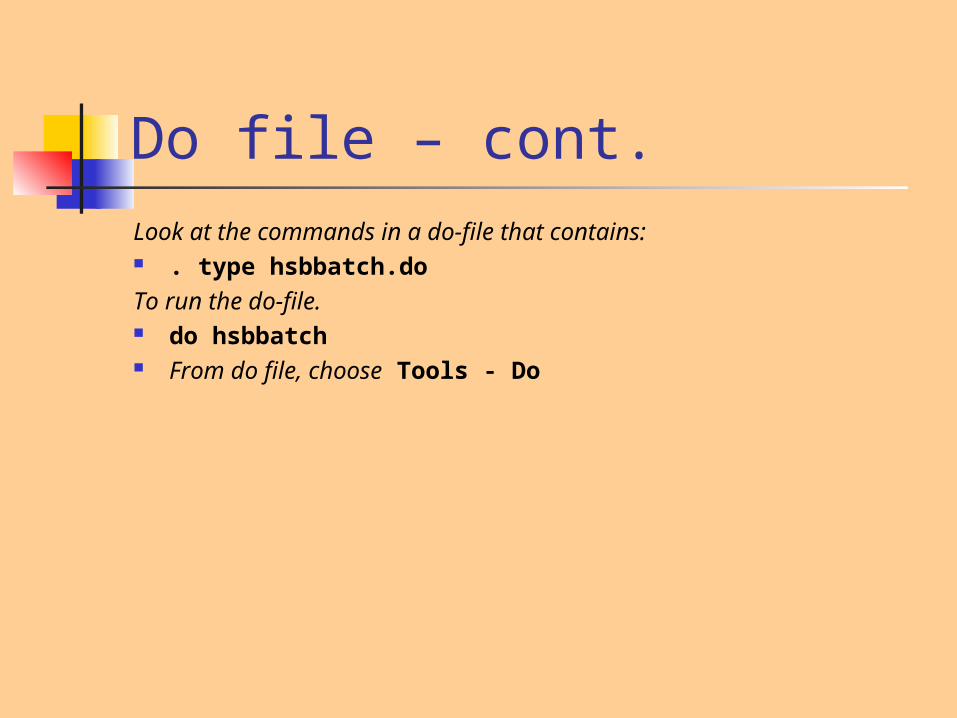
Do file – cont.Look at the commands in a do-file that contains: . type hsbbatch.doTo run the do-file. do hsbbatch From do file, choose Tools - Do

Panel DataCreat the do file as followed set matsize 160 use http://www.ats.ucla.edu/stat/stata/stat130/depress, clear sort group by group: summarize pre dep1 dep2 dep3 dep4 dep5 dep6 corr pre dep1 dep2 dep3 dep4 dep5 dep6 graph dep1 dep2 dep3 dep4 dep5 dep6, matrix half ttest pre, by(group) /* check to see if the groups differ on the pretest depression score */ hotel dep1 dep2 dep3 dep4 dep5 dep6, by(group)/*There isn't much of a difference
between groups on the pretest so let's try a Hotelling's T2 Using Hotelling's T2 we find a significant difference between the two groups. The T2 did not
make use of any of the information concerning the pretest but that's okay for the moment especially since we know that the pretest differences were not significant.*/
reshape long dep, i(subj) j(visit) regress dep pre group visit glm dep pre group visit, fam(gaus) link(iden) xtgee dep pre group visit, fam(gaus) link(iden) i(subj) t(visit) corr(ind) /*The three
previous analyses provide identical incorrect results. The common thread among them is that they all assume that the observations within the
subjects are independent. This seems, on the face of it, to be highly unlikely. Scores on the depression scale are not likely to be independent from one visit to the next.
Of the three, only xtgee makes the assumption concerning the correlations explicit.*/ xtcorr /* The xtcorr command shows structure of the correlation matrix*/ /* xt commands are used with cross-sectional time-series data */ xtsum dep

Panel data 2 /*We can analyze these data using compound symmetry for the correlational
structure. This approach can be tried using exchangable for the correlation matrix in xtgee */ xtgee dep pre group visit, fam(gaus) link(iden) i(subj) t(visit) corr(exc) xtcorr /*Note in particular the change in the standard errors between this analysis and the
previous one. Now let's try a different correlation structure, auto regressive with lag one.*/ xtgee dep pre group visit, fam(gaus) link(iden) i(subj) t(visit) corr(ar1) /*back up and reconsider the group by visit interaction. We will try a model with the interaction using the ar1 correlations. */ generate gxv = group*visit
xtgee dep pre group visit gxv, fam(gaus) link(iden) i(subj) t(visit) corr(ar1) /* The group by visit interaction still is not significant even though this may be a
better approach for testing it. So far we have been treating visit as a continuous variable. Is it possible that our analysis might change if we were to treat visit as a categorical
variable, the way that the anova did? Let's try one last analysis using xi to create dummy variables on-the-fly. */ xi: xtgee dep pre group i.visit, fam(gaus) link(iden) i(subj) corr(ar1)

Searching for help The help command can be used from the command line or from the
Help window. To use help the command must be spelled correctly and the full name of the command must be used. help contents will list all commands that can be accessed using help
help if help anova help regress The search command searches for information in Stata manuals,
FAQs, and Stata Technical Bulletins (STBs). The search options include: manual which restricts searches to the Stata Manual; author when searching for an author by name; stb which restricts searhes to STBs; faq which restricts searches to FAQs.The search command can be used from either the command line or the Help window.
search if search regression search ttest, manual Each copy of Stata comes with a built-in tutorital. Typing tutorial
brings up information about the tutorials. tutorial regress will bring up the tutorial on regression.
tutorial tutorial regress

End of Session
Related Documents











![[Bruderl] Applied Regression Analysis Using Stata](https://static.cupdf.com/doc/110x72/55cf96a7550346d0338ce88d/bruderl-applied-regression-analysis-using-stata.jpg)