Introducing Tupilak, Snowplow’s unified log fabric Snowplow London Meetup #3, 21 Sep 2016

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Introducing Tupilak,Snowplow’s unified log fabric
Snowplow London Meetup #3, 21 Sep 2016

Quick show of hands• Batch pipeline: how many here run the Snowplow batch
pipeline?
• Real-time pipeline: how many here run the Snowplow RT pipeline?
• Orchestration: how are you running, scaling, monitoring the real-time pipeline?
• Anything else: who here is evaluating Snowplow or just curious?

From the beginning, Snowplow RT was designed around small, composable workers…
Diagram from our Feb 2014 Snowplow v0.9.0 release post
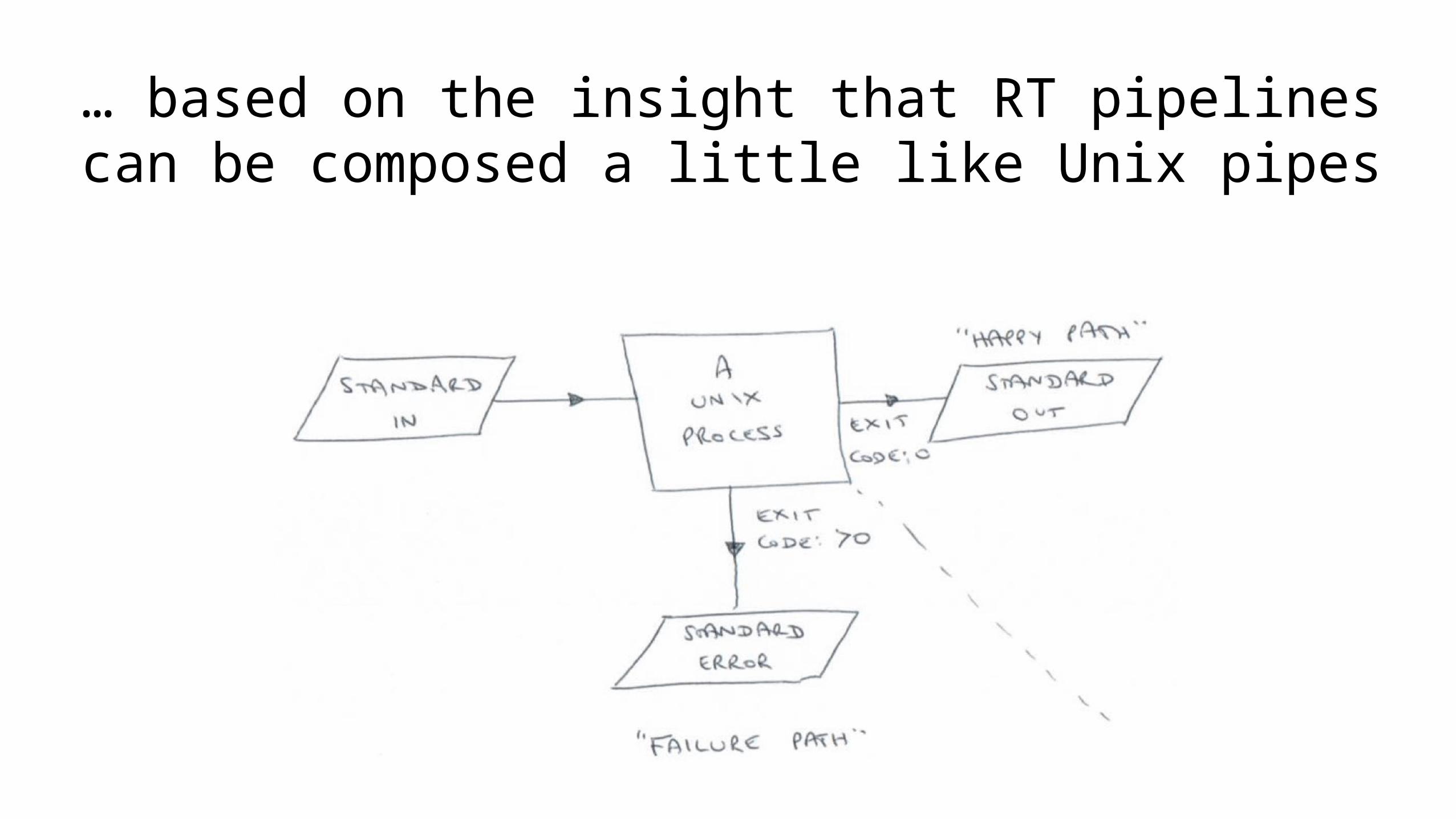
… based on the insight that RT pipelines can be composed a little like Unix pipes

Today, we see a growing number of async micro-services making up Snowplow RT
Stream Collector
Stream Enrich Kinesis S3
Kinesis Elasticsearc
hKinesis Tee (coming soon)
Redshift dripfeeder (design stage)
User’s AWS Lambda function
User’s KCL worker app
User’s Spark
Streaming job

But managing this kind of complexity has some major challenges
“How do we monitor this
topology, and alert if
something (data loss;
event lag) is going wrong?”
“How do we scale our
streams and micro-services to handle event
peaks and troughs
smoothly?”
“How do we re-configure or upgrade our
micro-services without breaking things?”

Snowplow Batch has evolved a deep technical stack to handle these challenges

We asked, what should the equivalent underlying fabric be for Snowplow RT?

Enter Tupilak!
“A tupilak was an avenging monster fabricated by a
shaman by using animal parts (bone, skin, hair, sinew, etc). The creature was given life by ritualistic chants. It was then
placed into the sea to seek and destroy a specific enemy.”

Today Tupilak serves 3 key functions for the Snowplow RT pipeline (Managed Service)
Monitoring
Auto-scaling
Alerting
• Visualizing the complex stream + worker topology in one place
• Indicating micro-services which are failing or falling behind (“lagging”)
• Auto-scaling the number of shards in each Kinesis stream• Auto-scaling the number of EC2 instances running each micro-
service
• Notifying our ops team in the case of a failing or lagging micro-service via PagerDuty

Let’s look at auto-scaling in particular
# Shards in Kinesis Stream
# EC2 Instances
• We scale the number of shards in each stream based on the read/write throughput we are seeing
Read/write throughput
• We scale the number of EC2 instances based on some fixed assumptions about the ratio between shards and workers
+-
+-
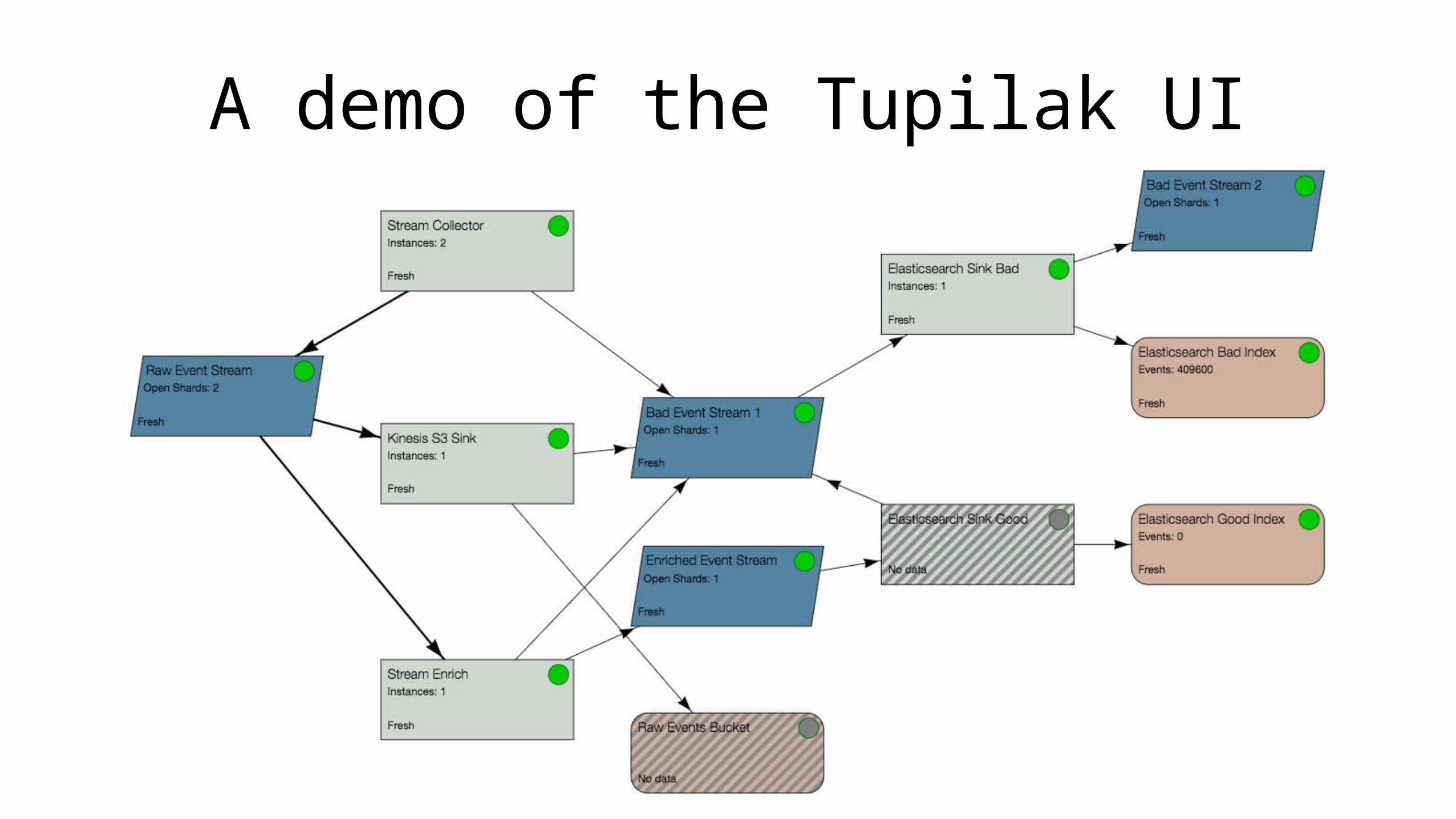
A demo of the Tupilak UI
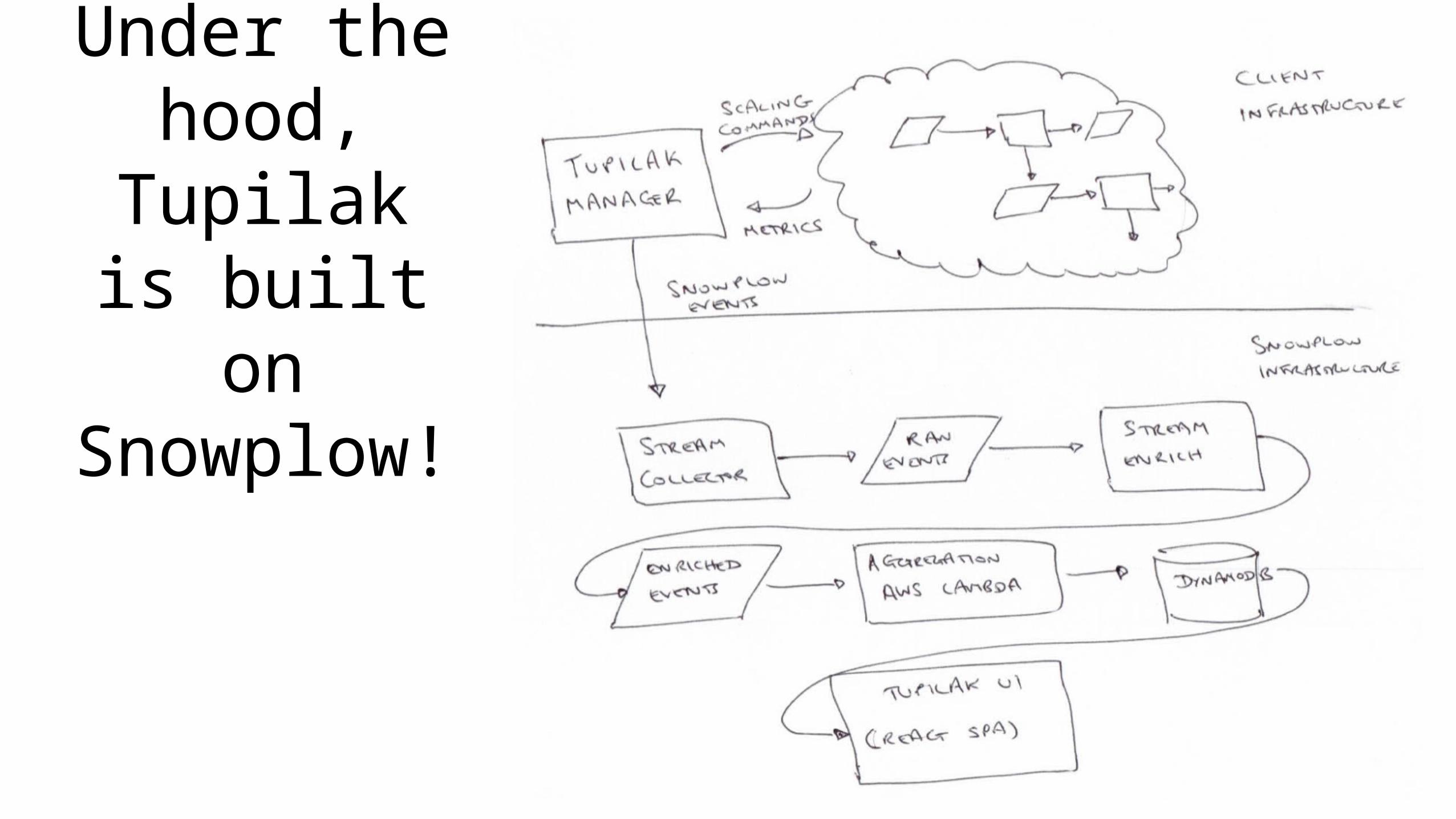
Under the hood,
Tupilak is built on
Snowplow!
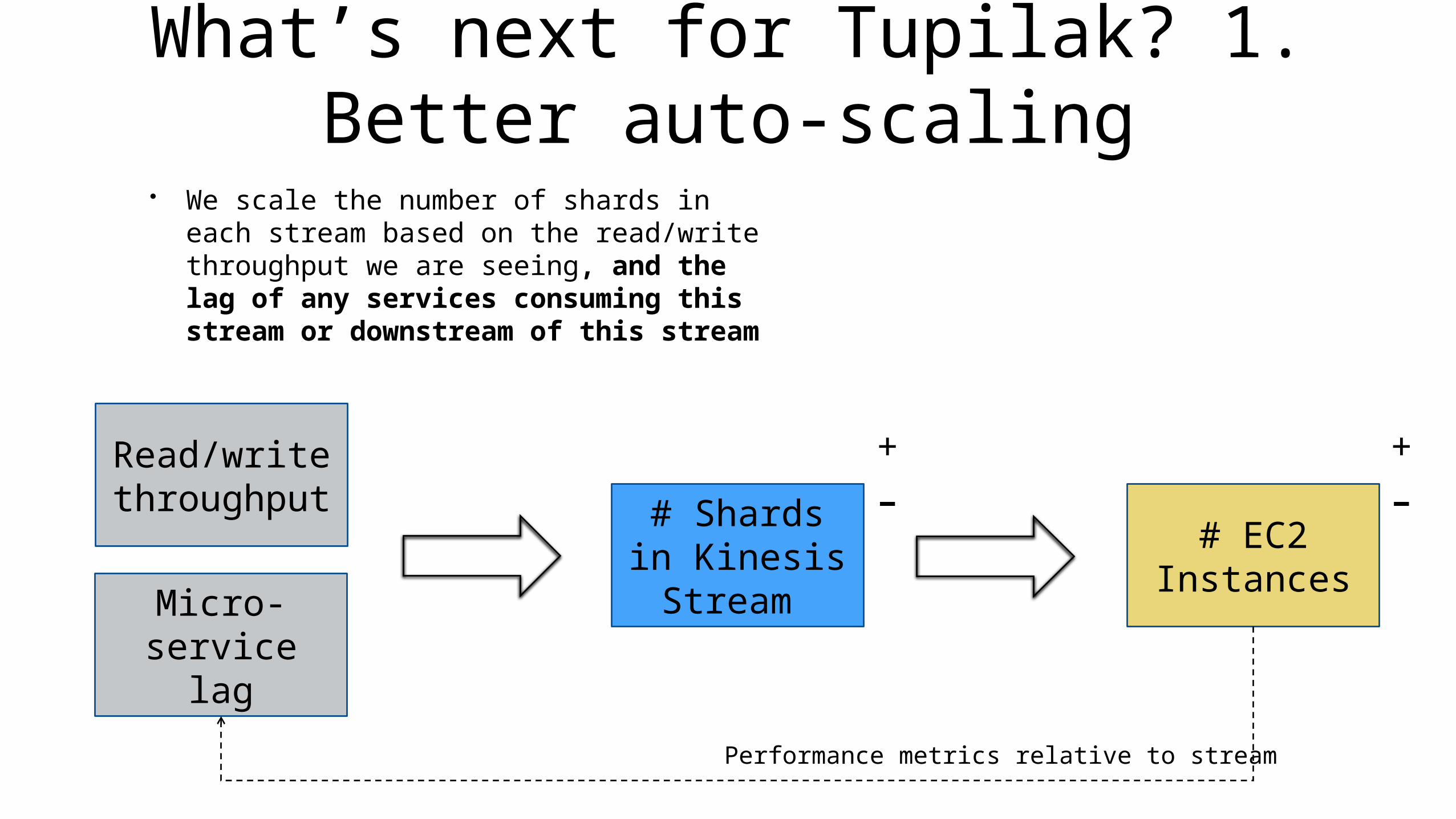
What’s next for Tupilak? 1. Better auto-scaling
# Shards in Kinesis Stream
# EC2 Instances
• We scale the number of shards in each stream based on the read/write throughput we are seeing, and the lag of any services consuming this stream or downstream of this stream
Read/write throughput
+-
+-
Micro-service lag
Performance metrics relative to stream
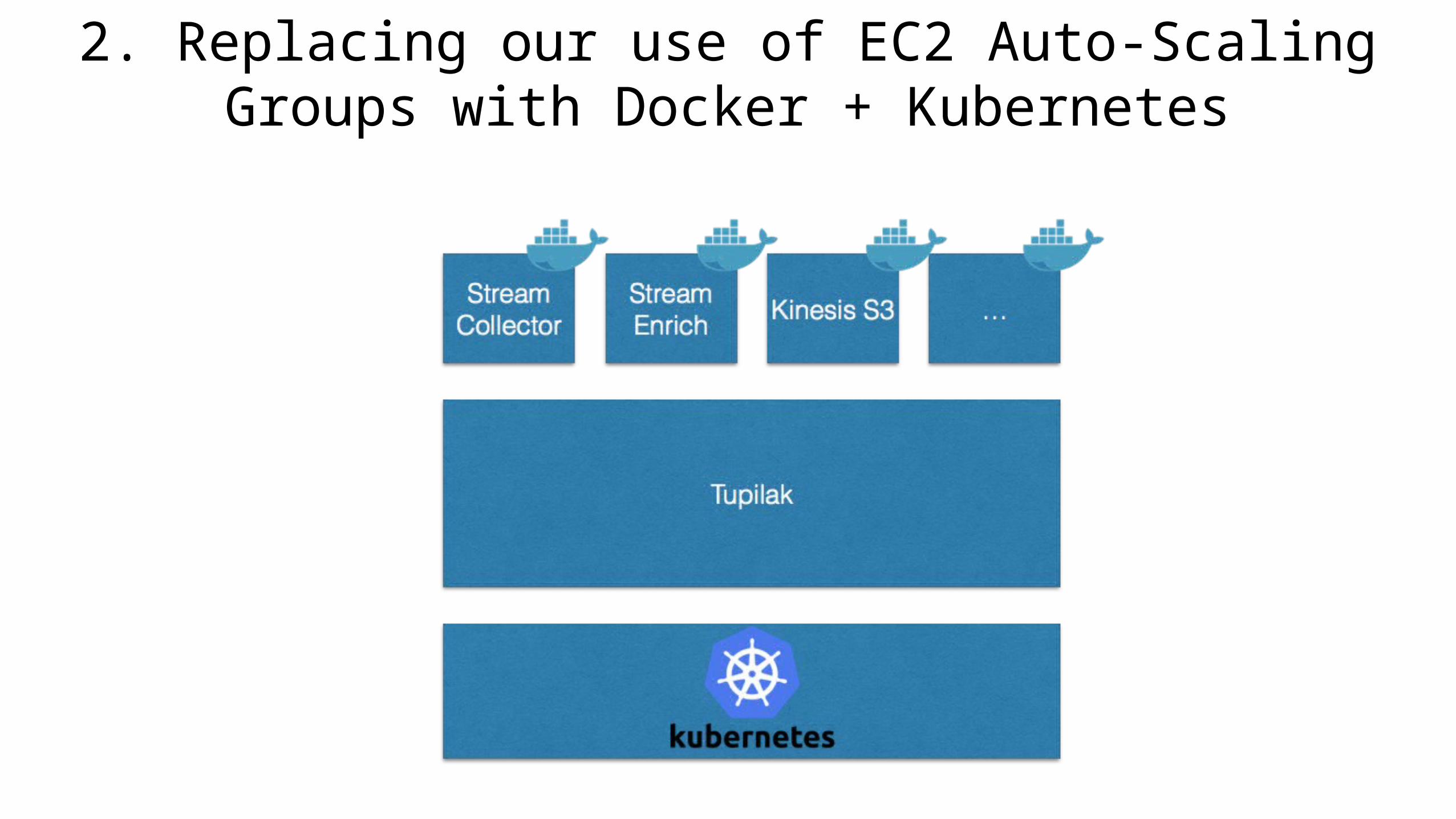
2. Replacing our use of EC2 Auto-Scaling Groups with Docker + Kubernetes

Questions?
Related Documents











