Data Ingestion with Spark UII Yogyakarta 1

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Data Ingestion with SparkUII
Yogyakarta
1

About Me
Sofian Hadiwijaya@[email protected]
Co Founder at Pinjam.co.idTech Advisor at Nodeflux.ioSoftware Innovator (IoT and AI) at Intel
2

3

4

5

Wikipedia big data
In information technology, big data is a loosely-defined term used to describe data sets so large and complex that they become awkward to work with using on-hand database management tools.
6Source: http://en.wikipedia.org/wiki/Big_data

How big is big?
• 2008: Google processes 20 PB a day• 2009: Facebook has 2.5 PB user data + 15 TB/day • 2009: eBay has 6.5 PB user data + 50 TB/day• 2011: Yahoo! has 180-200 PB of data• 2012: Facebook ingests 500 TB/day
7

That’s a lot of data
8Credit: http://www.flickr.com/photos/19779889@N00/1367404058/

So what?
s/data/knowledge/g
9

No really, what do you do with it?
• User behavior analysis• AB test analysis• Ad targeting• Trending topics• User and topic modeling• Recommendations• And more...
10

How to scale data?
11

Divide and Conquer
12

Parallel processing is complicated
• How do we assign tasks to workers?• What if we have more tasks than slots?• What happens when tasks fail?• How do you handle distributed synchronization?
13Credit: http://www.flickr.com/photos/sybrenstuvel/2468506922/

Data storage is not trivial• Data volumes are massive• Reliably storing PBs of data is challenging• Disk/hardware/network failures• Probability of failure event increases with number of machines
For example:1000 hosts, each with 10 disksa disk lasts 3 yearhow many failures per day?
14

Hadoop cluster
15
Cluster of machine running Hadoop at Yahoo! (credit: Yahoo!)

Hadoop
16

Hadoop provides
• Redundant, fault-tolerant data storage• Parallel computation framework• Job coordination
17http://hapdoop.apache.org

Joy
18Credit: http://www.flickr.com/photos/spyndle/3480602438/

Hadoop origins
• Hadoop is an open-source implementation based on GFS and MapReduce from Google• Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. (2003) The Google File System• Jeffrey Dean and Sanjay Ghemawat. (2004) MapReduce: Simplified Data Processing on Large Clusters. OSDI 2004
19
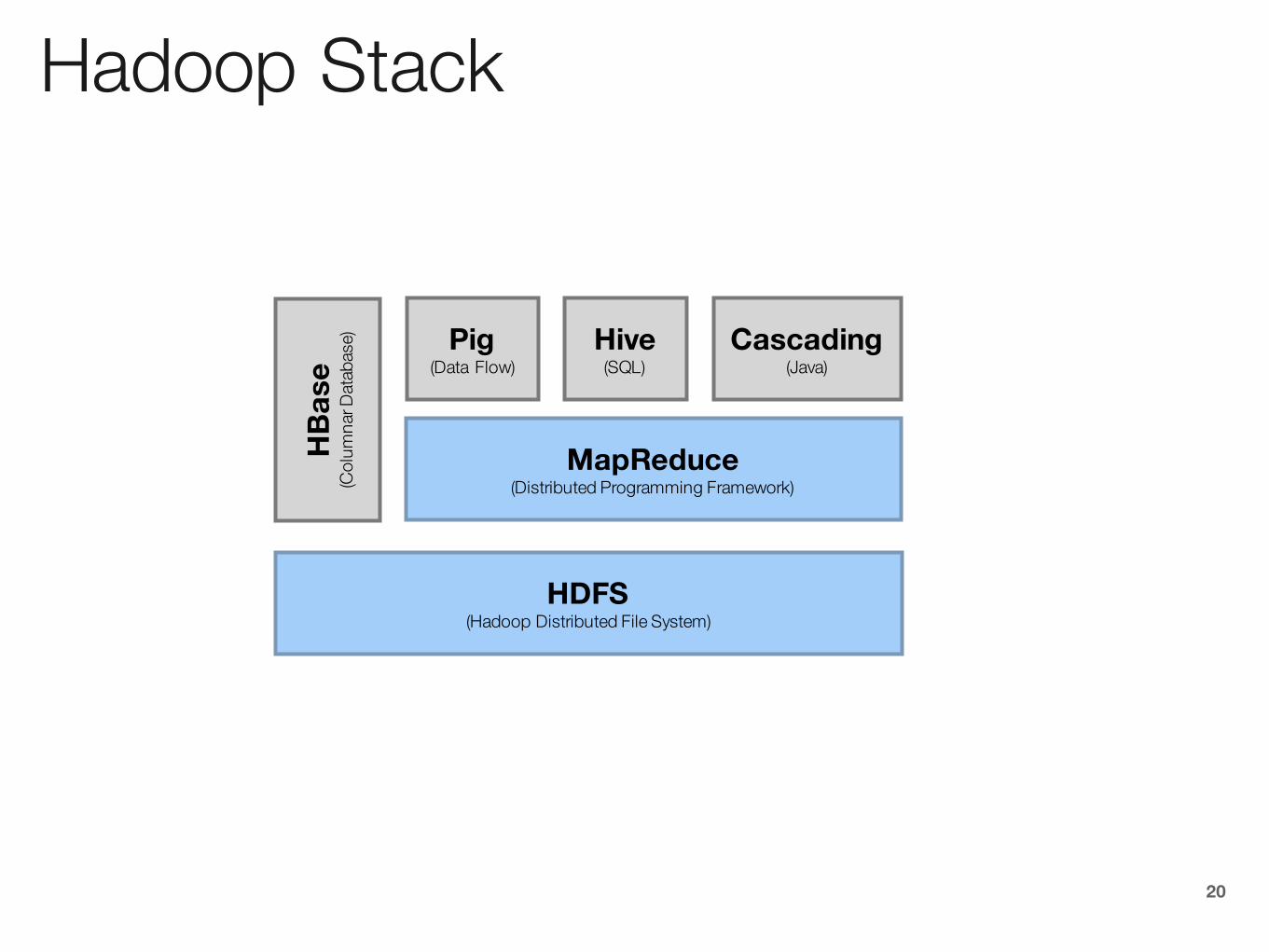
Hadoop Stack
20
MapReduce(Distributed Programming Framework)
Pig(Data Flow)
Hive(SQL)
HDFS(Hadoop Distributed File System)
Cascading(Java)
HBa
se(C
olum
nar D
atab
ase)

HDFS
21

HDFS is...
• A distributed file system• Redundant storage• Designed to reliably store data using commodity hardware• Designed to expect hardware failures• Intended for large files• Designed for batch inserts• The Hadoop Distributed File System
22

HDFS - files and blocks
• Files are stored as a collection of blocks• Blocks are 64 MB chunks of a file (configurable)• Blocks are replicated on 3 nodes (configurable)• The NameNode (NN) manages metadata about files and blocks• The SecondaryNameNode (SNN) holds a backup of the NN data• DataNodes (DN) store and serve blocks
23

Replication
• Multiple copies of a block are stored• Replication strategy:
• Copy #1 on another node on same rack• Copy #2 on another node on different rack
24
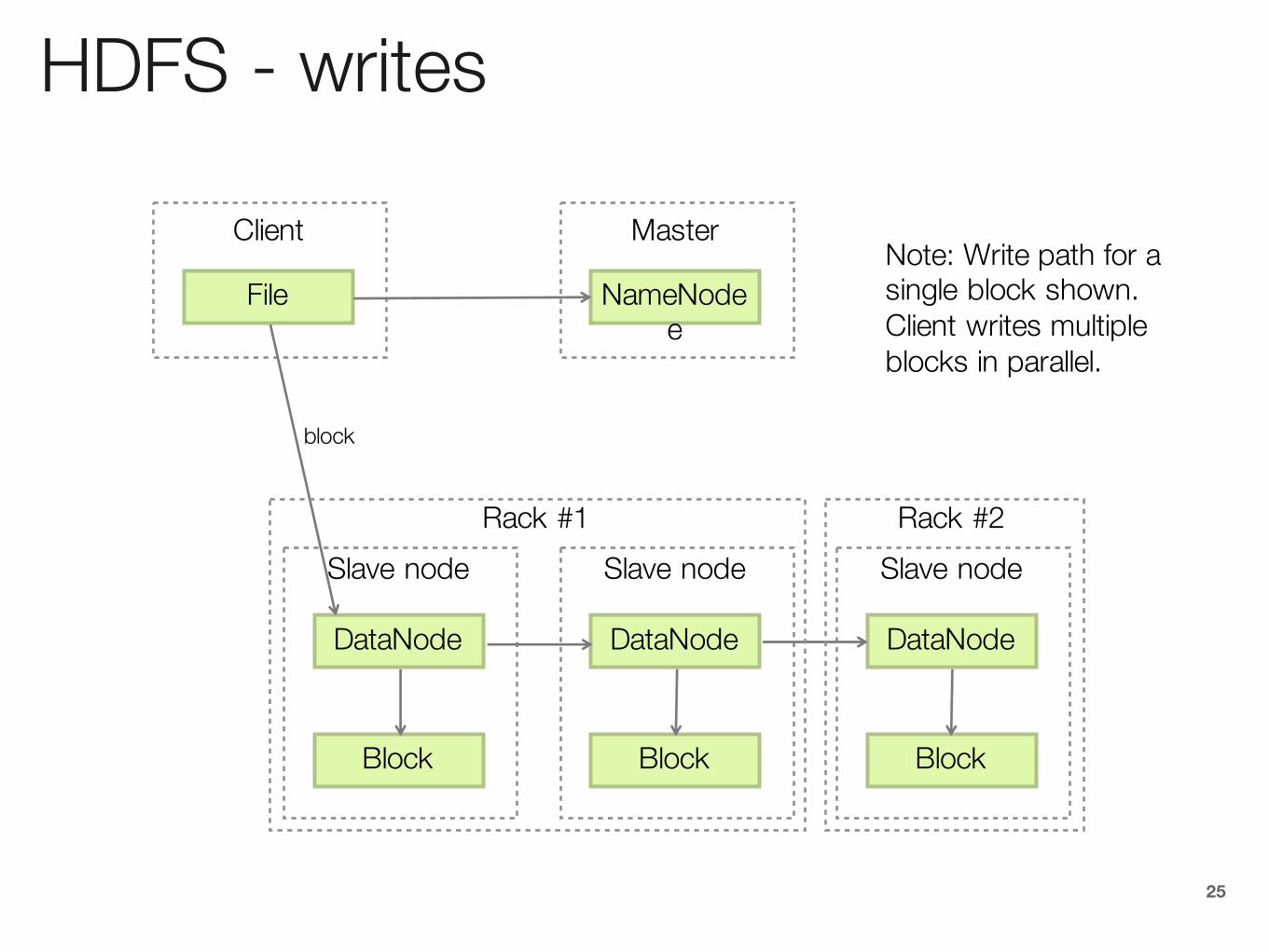
HDFS - writes
25
DataNode
Block
Slave node
NameNodee
Master
DataNode
Block
Slave node
DataNode
Block
Slave node
File
Client
Rack #1 Rack #2
Note: Write path for a single block shown. Client writes multiple blocks in parallel.
block
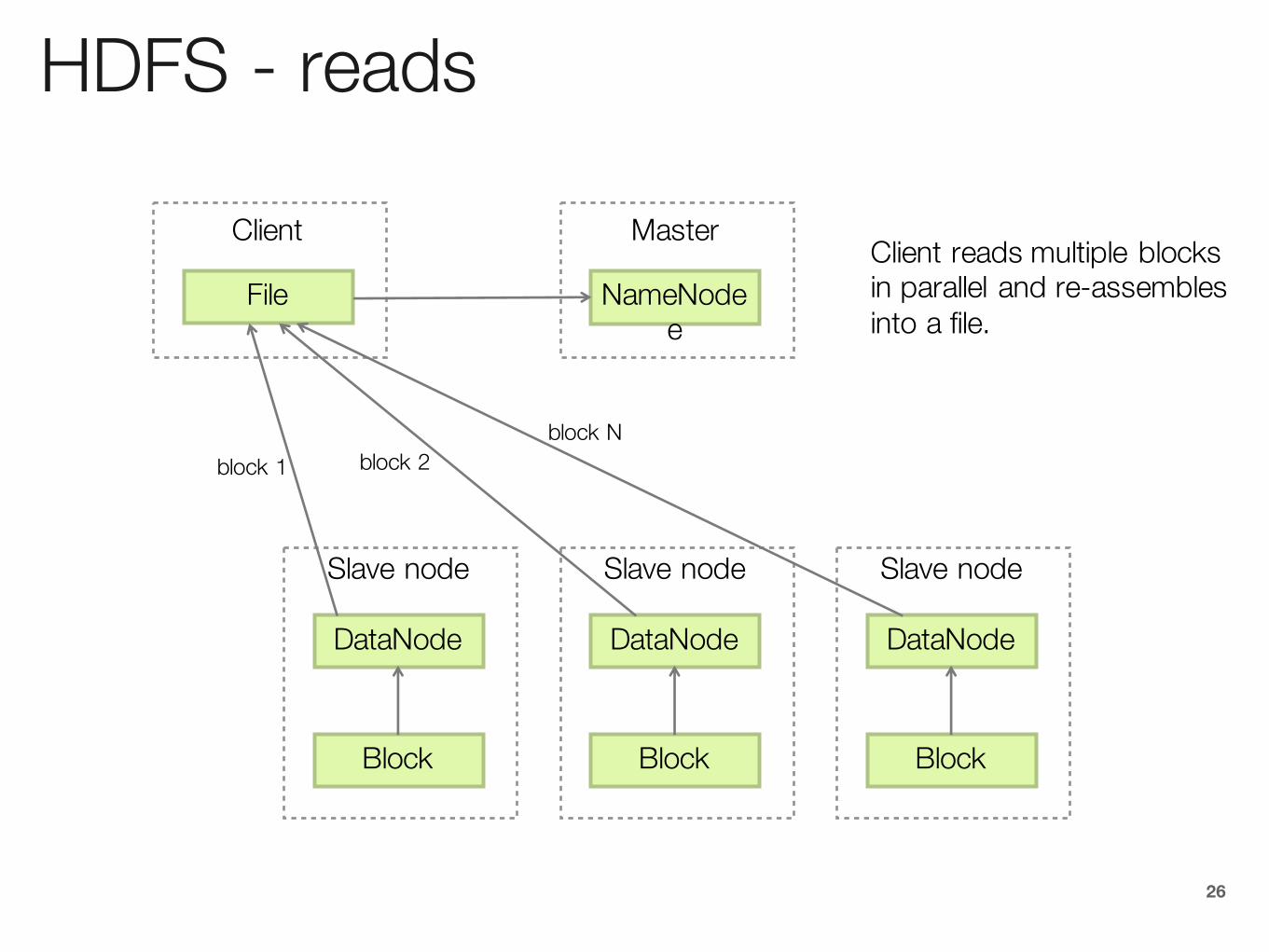
HDFS - reads
26
DataNode
Block
Slave node
NameNodee
Master
DataNode
Block
Slave node
DataNode
Block
Slave node
File
ClientClient reads multiple blocks in parallel and re-assembles into a file.
block 1 block 2block N

What about DataNode failures?
• DNs check in with the NN to report health• Upon failure NN orders DNs to replicate under-replicated blocks
27Credit: http://www.flickr.com/photos/18536761@N00/367661087/

MapReduce
28

MapReduce is...
• A programming model for expressing distributed computations at a massive scale• An execution framework for organizing and performing such computations• An open-source implementation called Hadoop
29

Typical large-data problem
• Iterate over a large number of records• Extract something of interest from each• Shuffle and sort intermediate results• Aggregate intermediate results• Generate final output
30
Map
Reduce
(Dean and Ghemawat, OSDI 2004)
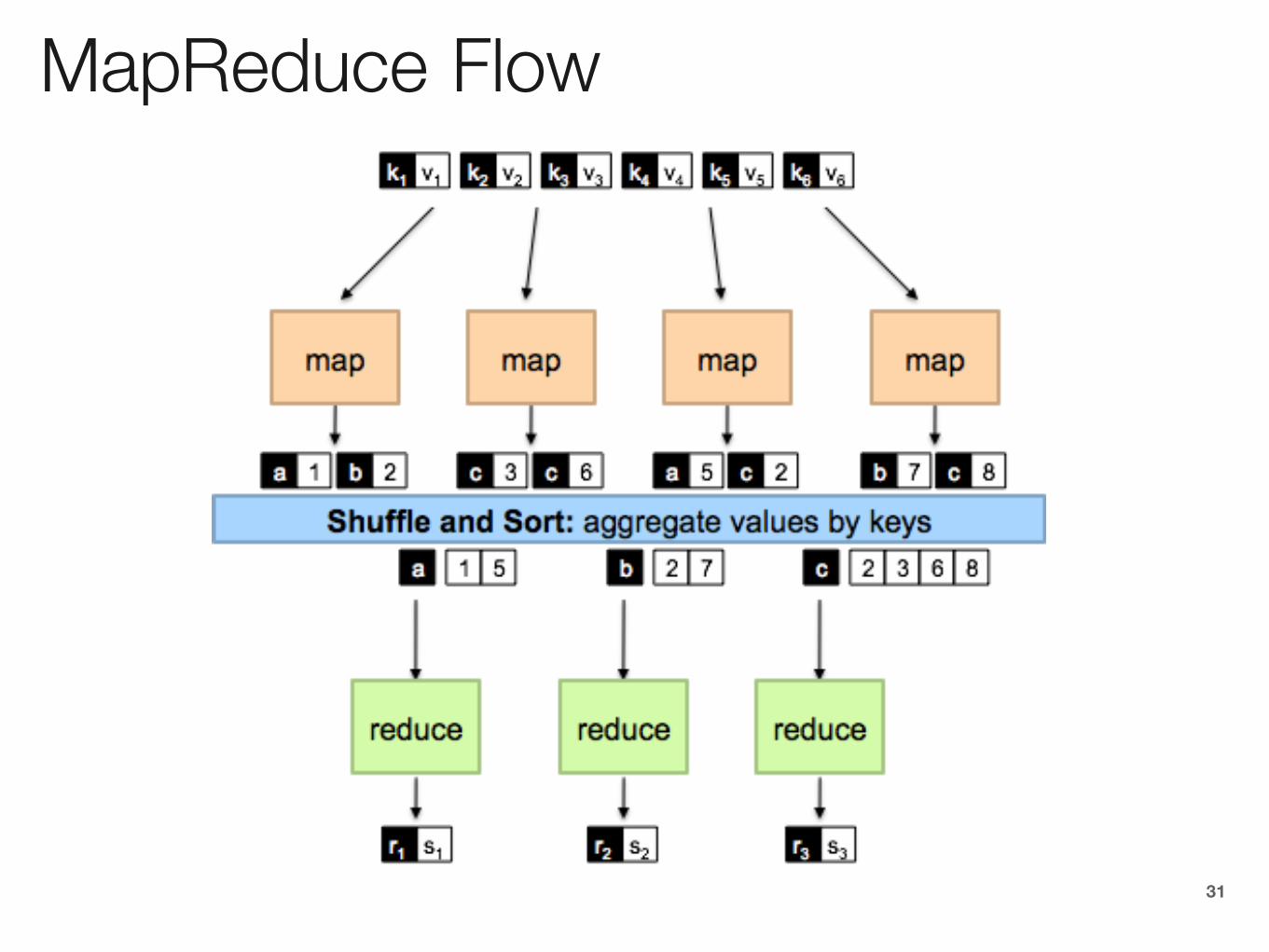
MapReduce Flow
31

MapReduce architecture
32
TaskTracker
Task
Slave node
JobTracker
Master
TaskTracker
Task
Slave node
TaskTracker
Task
Slave node
Job
Client

What about failed tasks?
• Tasks will fail• JT will retry failed tasks up to N attempts• After N failed attempts for a task, job fails• Some tasks are slower than other• Speculative execution is JT starting up multiple of the same task• First one to complete wins, other is killed
33Credit: http://www.flickr.com/photos/phobia/2308371224/

MapReduce - Java API• Mapper:void map(WritableComparable key,
Writable value,OutputCollector output,Reporter reporter)
• Reducer:void reduce(WritableComparable key,
Iterator values,OutputCollector output,Reporter reporter)
34

MapReduce - Java API• Writable
• Hadoop wrapper interface• Text, IntWritable, LongWritable, etc
• WritableComparable
• Writable classes implement WritableComparable• OutputCollector
• Class that collects keys and values• Reporter
• Reports progress, updates counters• InputFormat
• Reads data and provide InputSplits• Examples: TextInputFormat, KeyValueTextInputFormat
• OutputFormat
• Writes data• Examples: TextOutputFormat, SequenceFileOutputFormat
35

MapReduce - Counters are...
• A distributed count of events during a job• A way to indicate job metrics without logging• Your friend
• Bad:System.out.println(“Couldn’t parse value”);
• Good:reporter.incrCounter(BadParseEnum, 1L);
36

MapReduce - word count mapperpublic static class Map extends MapReduceBase
implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);private Text word = new Text();
public void map(LongWritable key, Text value,OutputCollector<Text, IntWritable> output,Reporter reporter) throws IOException {
String line = value.toString();StringTokenizer tokenizer = new StringTokenizer(line);while (tokenizer.hasMoreTokens()) {word.set(tokenizer.nextToken());output.collect(word, one);
}}
}
37

MapReduce - word count reducerpublic static class Reduce extends MapReduceBase implements
Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key,Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output,Reporter reporter) throws IOException {
int sum = 0;while (values.hasNext()) {sum += values.next().get();
}output.collect(key, new IntWritable(sum));
}}
38

MapReduce - word count mainpublic static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);conf.setCombinerClass(Reduce.class);conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);}
39

MapReduce - running a job
• To run word count, add files to HDFS and do:
$ bin/hadoop jar wordcount.jar org.myorg.WordCount input_dir output_dir
40

MapReduce is good for...
• Embarrassingly parallel algorithms• Summing, grouping, filtering, joining• Off-line batch jobs on massive data sets• Analyzing an entire large dataset
41

MapReduce is ok for...
• Iterative jobs (i.e., graph algorithms)• Each iteration must read/write data to disk• IO and latency cost of an iteration is high
42

MapReduce is not good for...
• Jobs that need shared state/coordination• Tasks are shared-nothing• Shared-state requires scalable state store
• Low-latency jobs• Jobs on small datasets• Finding individual records
43
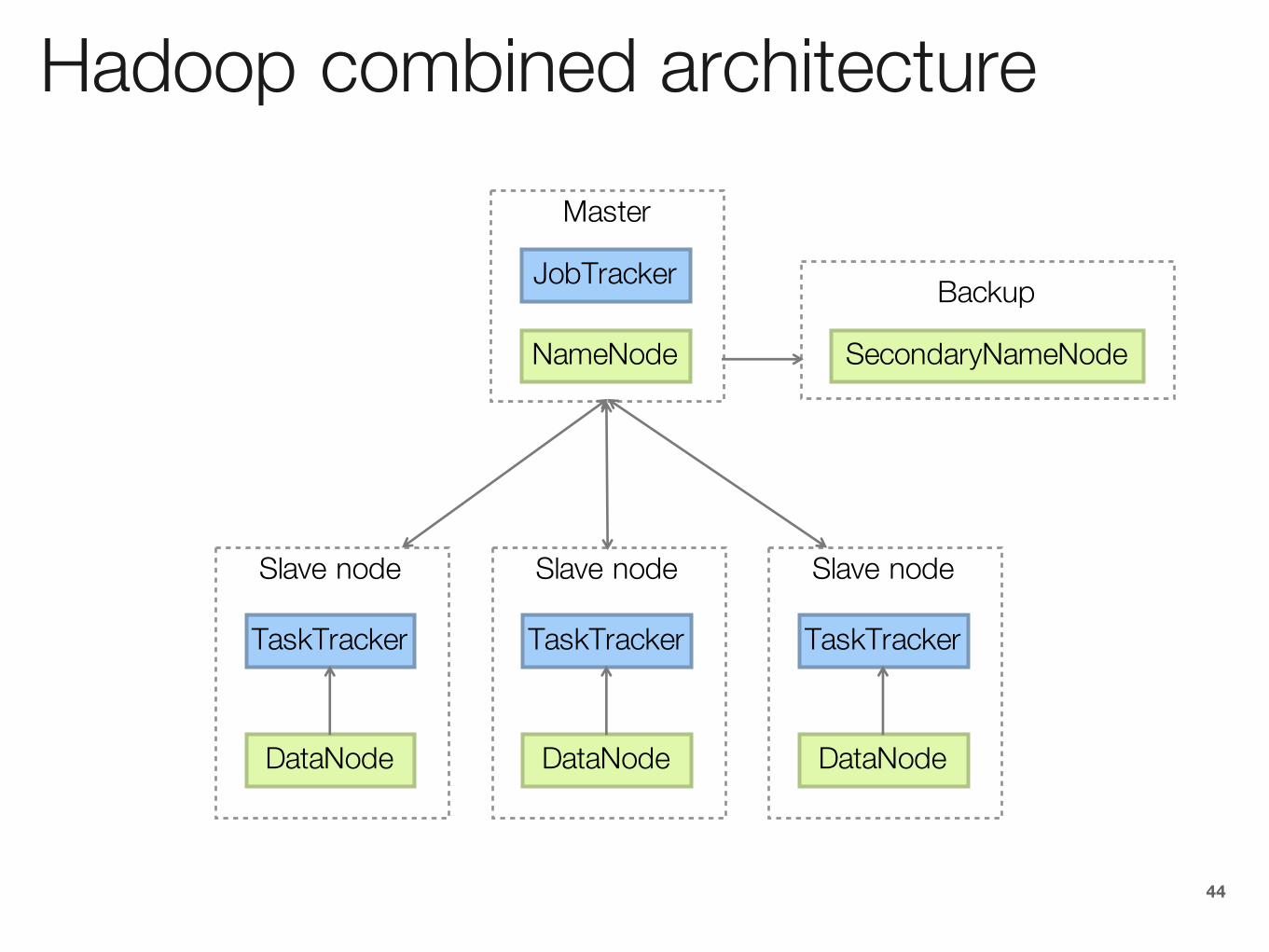
Hadoop combined architecture
44
TaskTracker
DataNode
Slave node
JobTracker
Master
TaskTracker
DataNode
Slave node
TaskTracker
DataNode
Slave node
SecondaryNameNode
Backup
NameNode

Hadoop to Complicated
45

Welcome Spark
46

What is Spark?
Distributed data analytics engine, generalizing Map ReduceCore engine, with streaming, SQL, machine learning, and graph processing modules
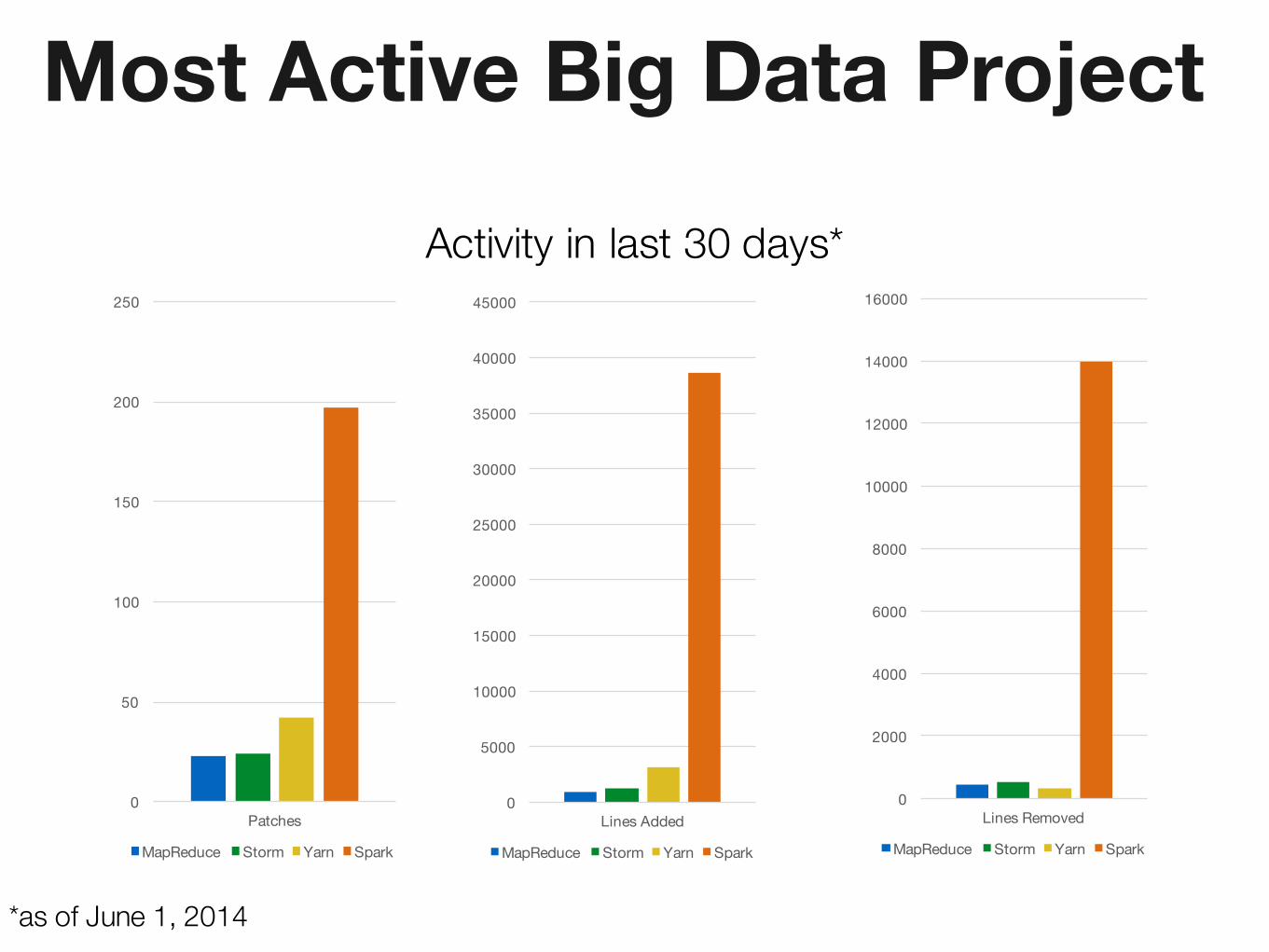
Most Active Big Data Project
Activity in last 30 days*
*as of June 1, 2014
0
50
100
150
200
250
Patches
MapReduce Storm Yarn Spark
0
5000
10000
15000
20000
25000
30000
35000
40000
45000
Lines Added
MapReduce Storm Yarn Spark
0
2000
4000
6000
8000
10000
12000
14000
16000
Lines Removed
MapReduce Storm Yarn Spark
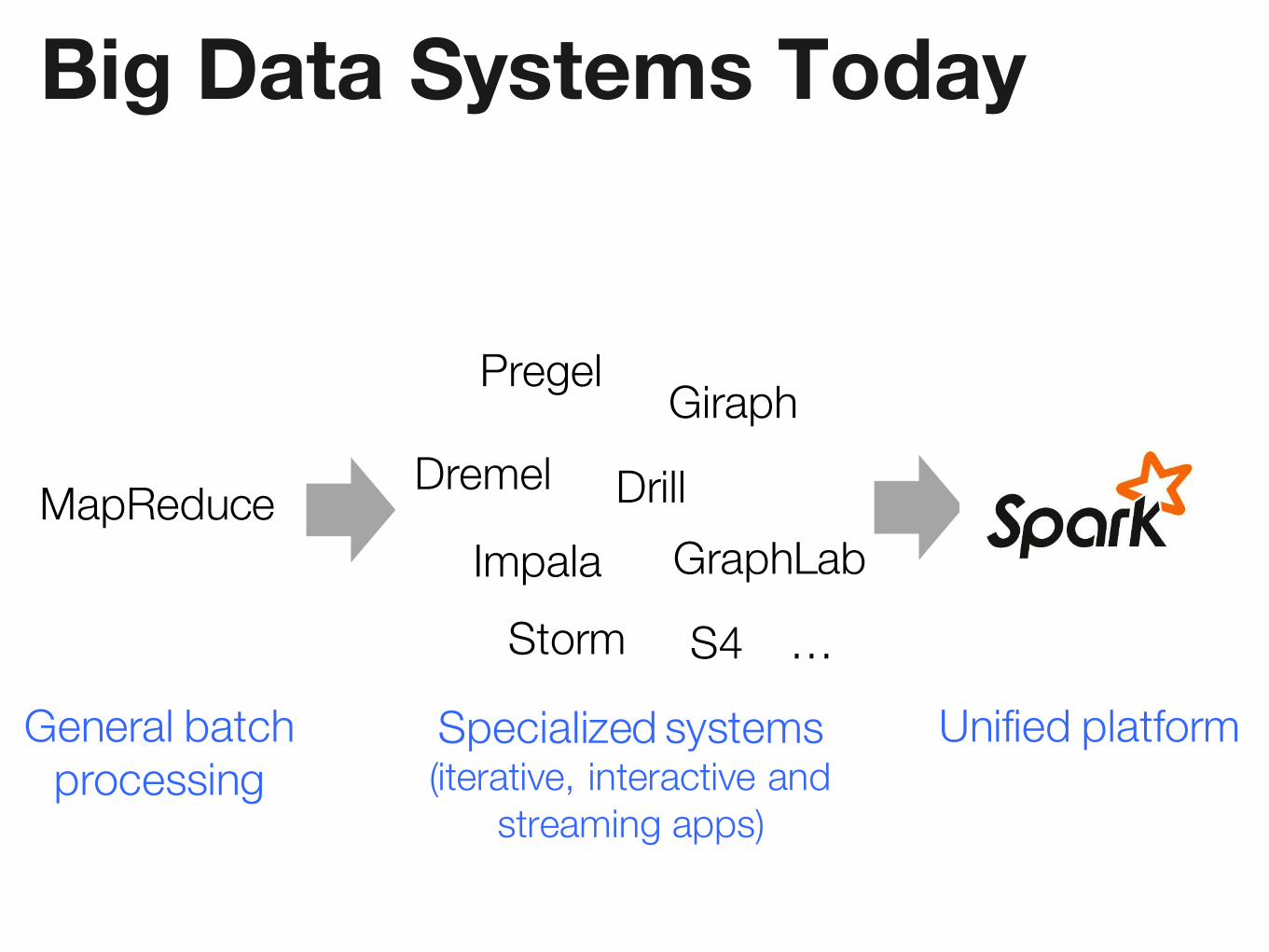
Big Data Systems Today
MapReduce
Pregel
Dremel
GraphLabStorm
Giraph
DrillImpala
S4 …
Specialized systems(iterative, interactive and
streaming apps)
General batchprocessing
Unified platform

Spark Core: RDDsDistributed collection of objects What’s cool about them?
• In-memory• Built via parallel transformations
(map, filter, …)• Automatically rebuilt on failure

Data Sharing in MapReduce
iter. 1 iter. 2 . . .
Input
HDFSread
HDFSwrite
HDFSread
HDFSwrite
Input
query 1
query 2
query 3
result 1
result 2
result 3
. . .
HDFSread
Slow due to replication, serialization, and disk IO

iter. 1 iter. 2 . . .
Input
What We’d Like
Distributedmemory
Input
query 1
query 2
query 3
. . .
one-timeprocessing
10-100× faster than network and disk
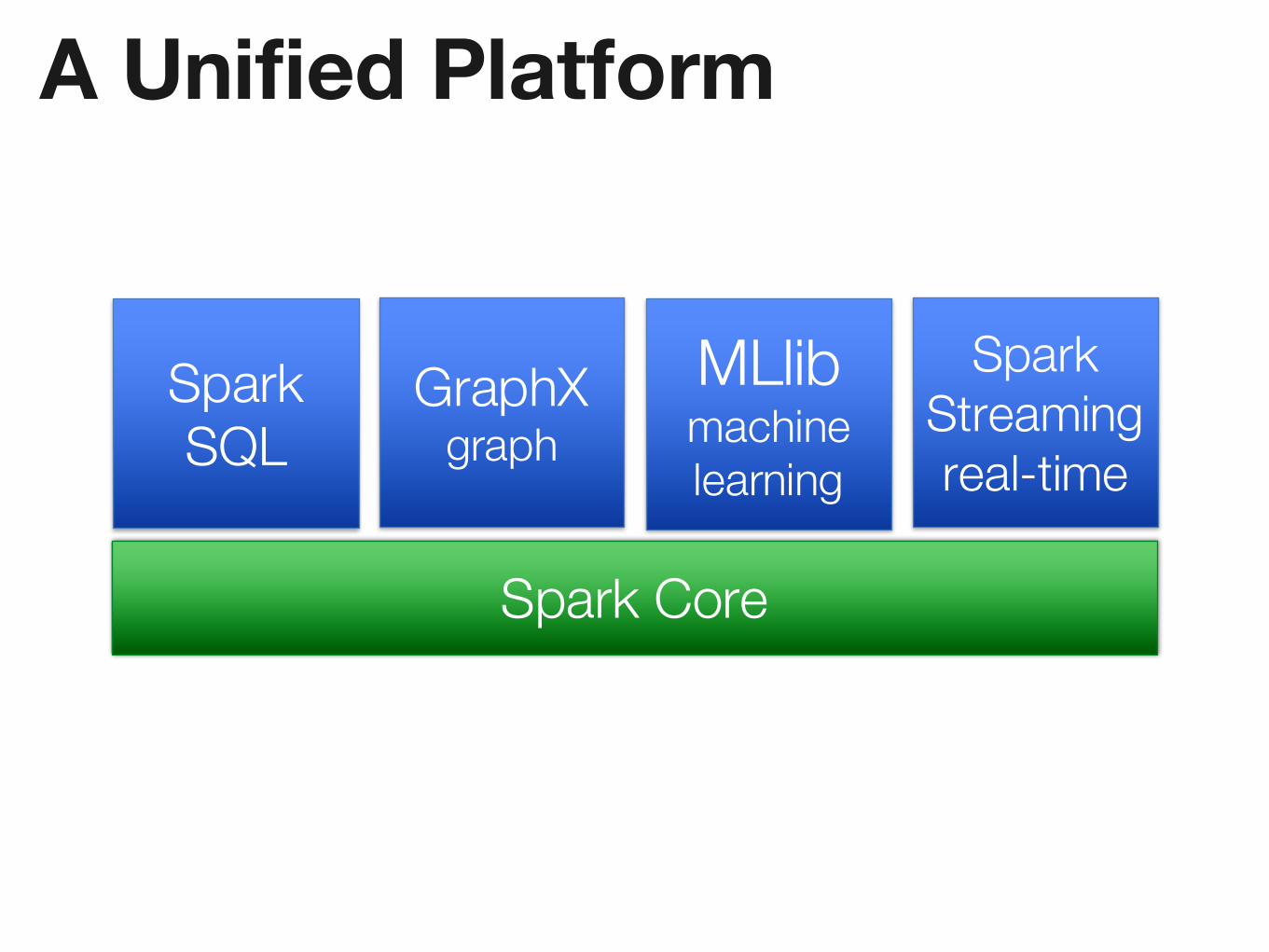
A Unified Platform
MLlibmachine learning
Spark Streamingreal-time
Spark Core
GraphXgraph
SparkSQL

Spark SQL
Unify tables with RDDsTables = Schema + Data

Spark SQL
Unify tables with RDDsTables = Schema + Data = SchemaRDD
coolPants = sql("""SELECT pid, colorFROM pants JOIN opinions WHERE opinions.coolness > 90""")
chosenPair =coolPants.filter(lambda row: row(1) == "green").take(1)
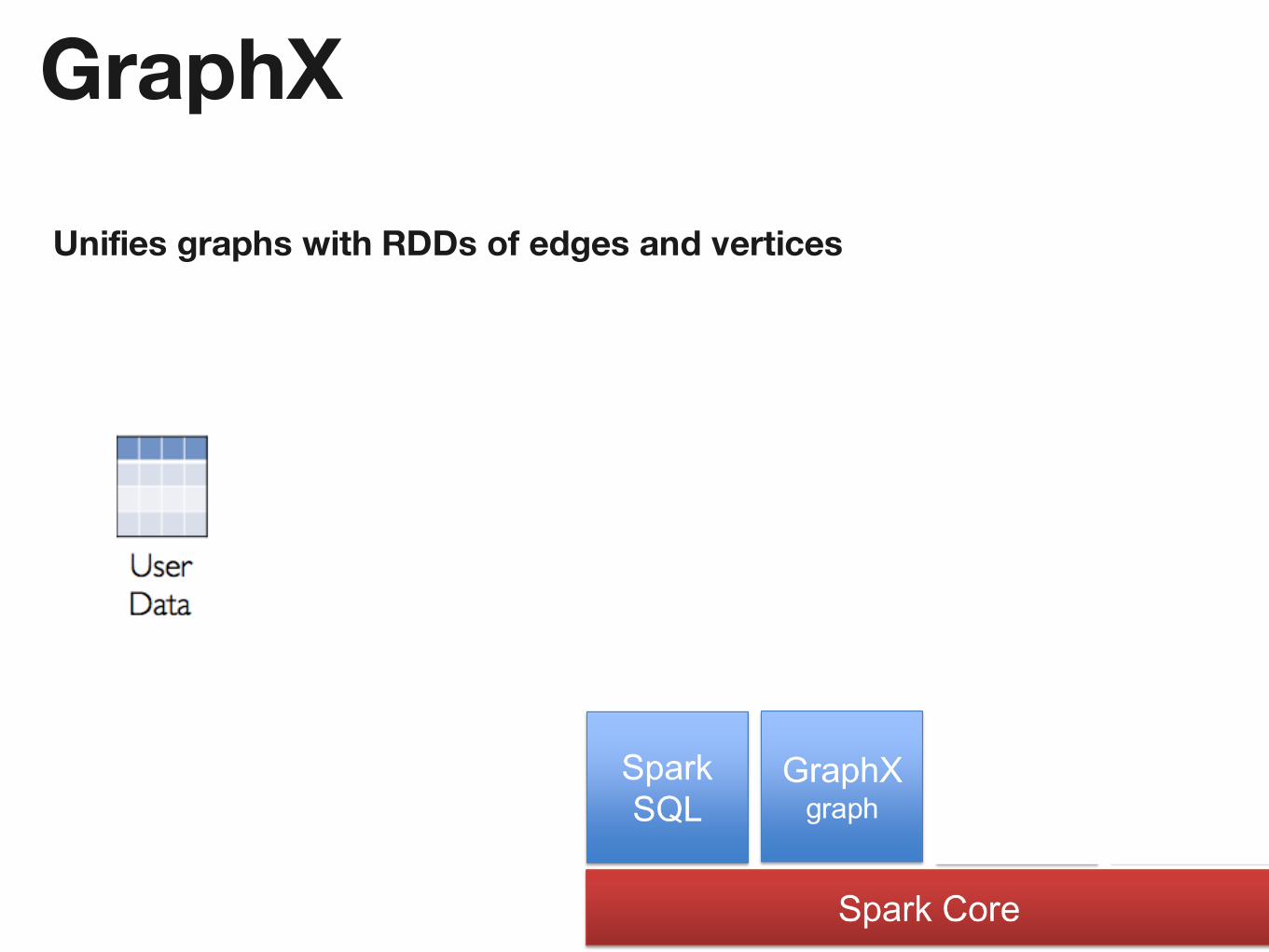
GraphX
Unifies graphs with RDDs of edges and vertices
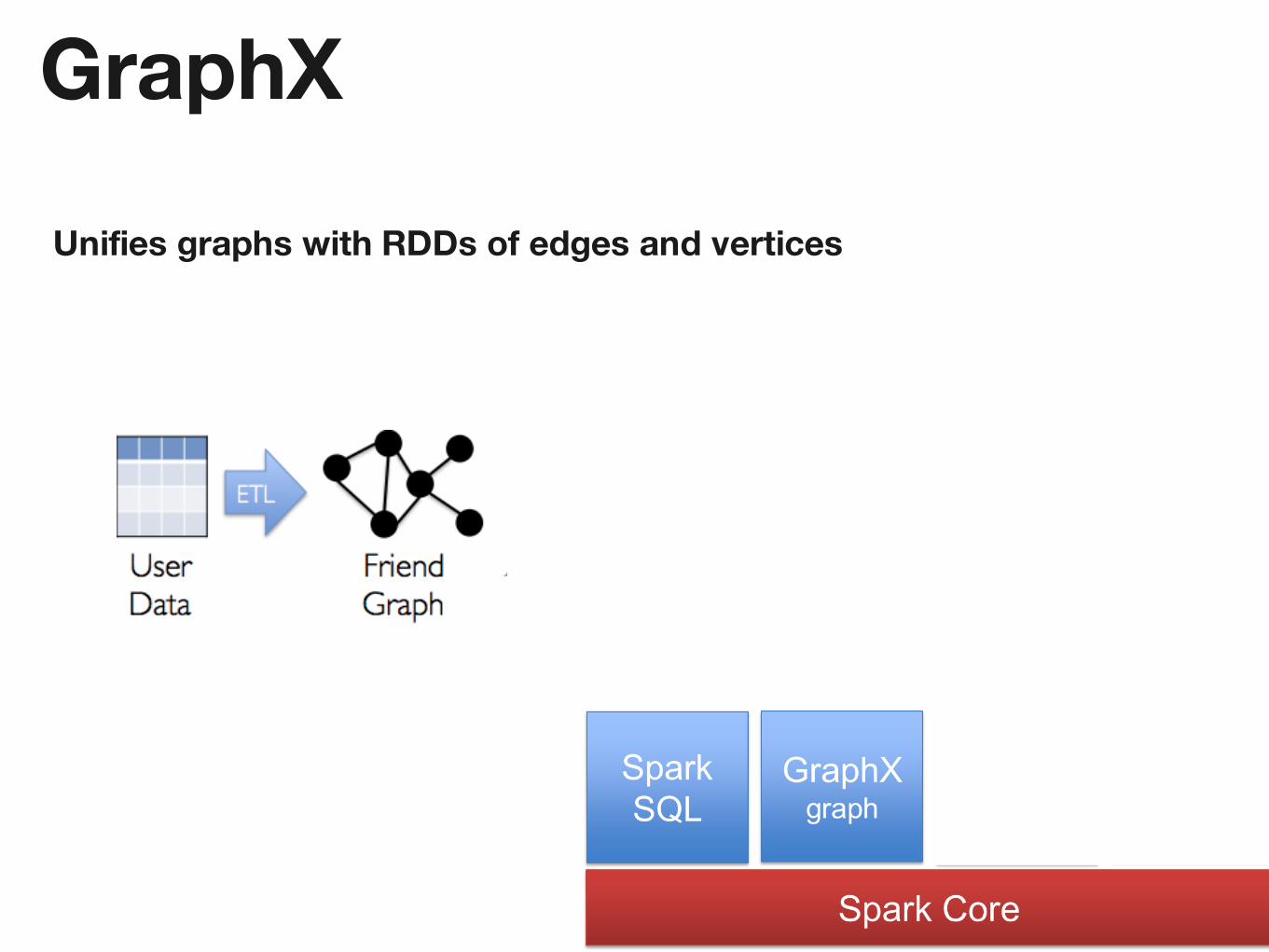
GraphX
Unifies graphs with RDDs of edges and vertices
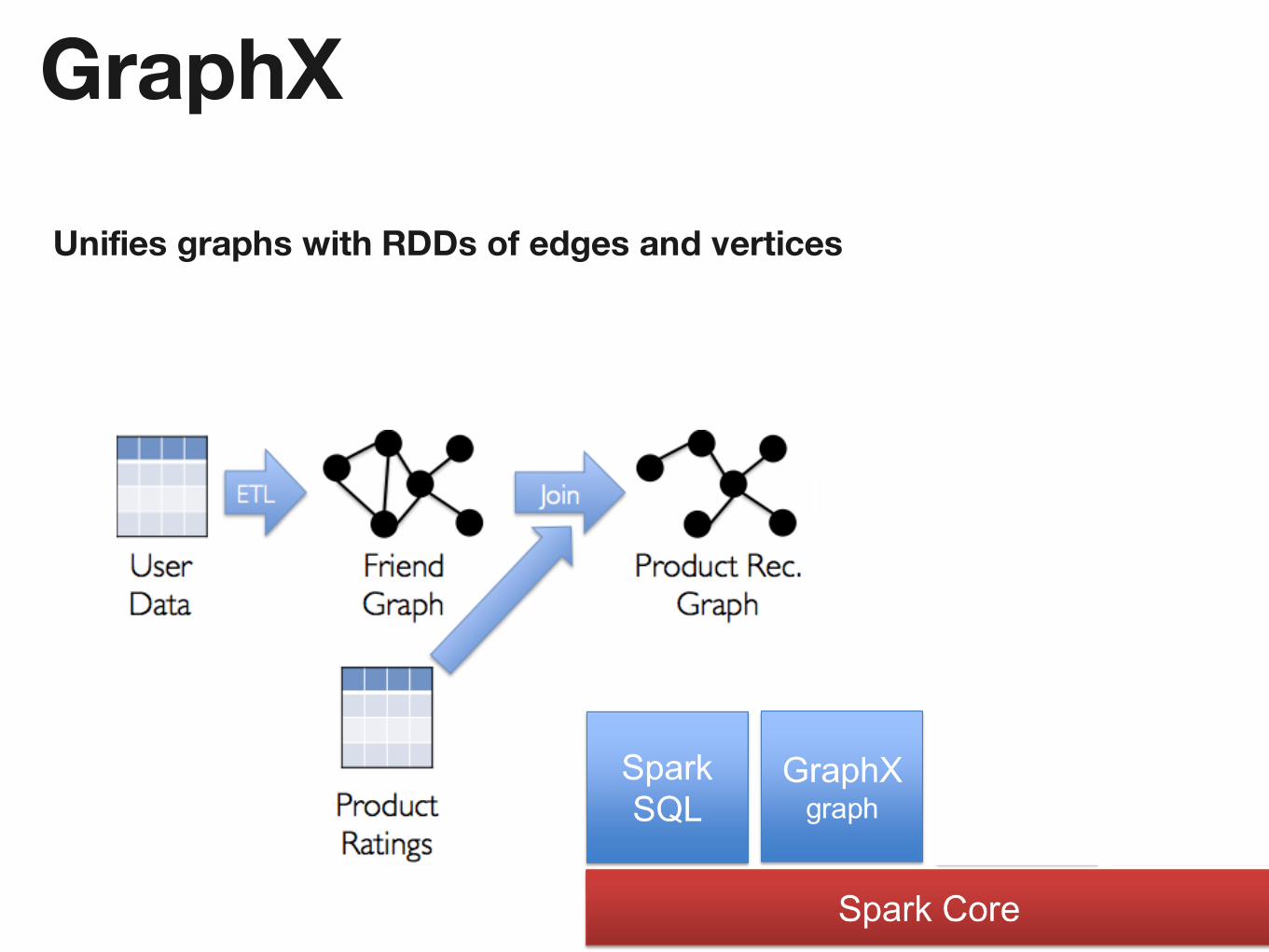
GraphX
Unifies graphs with RDDs of edges and vertices
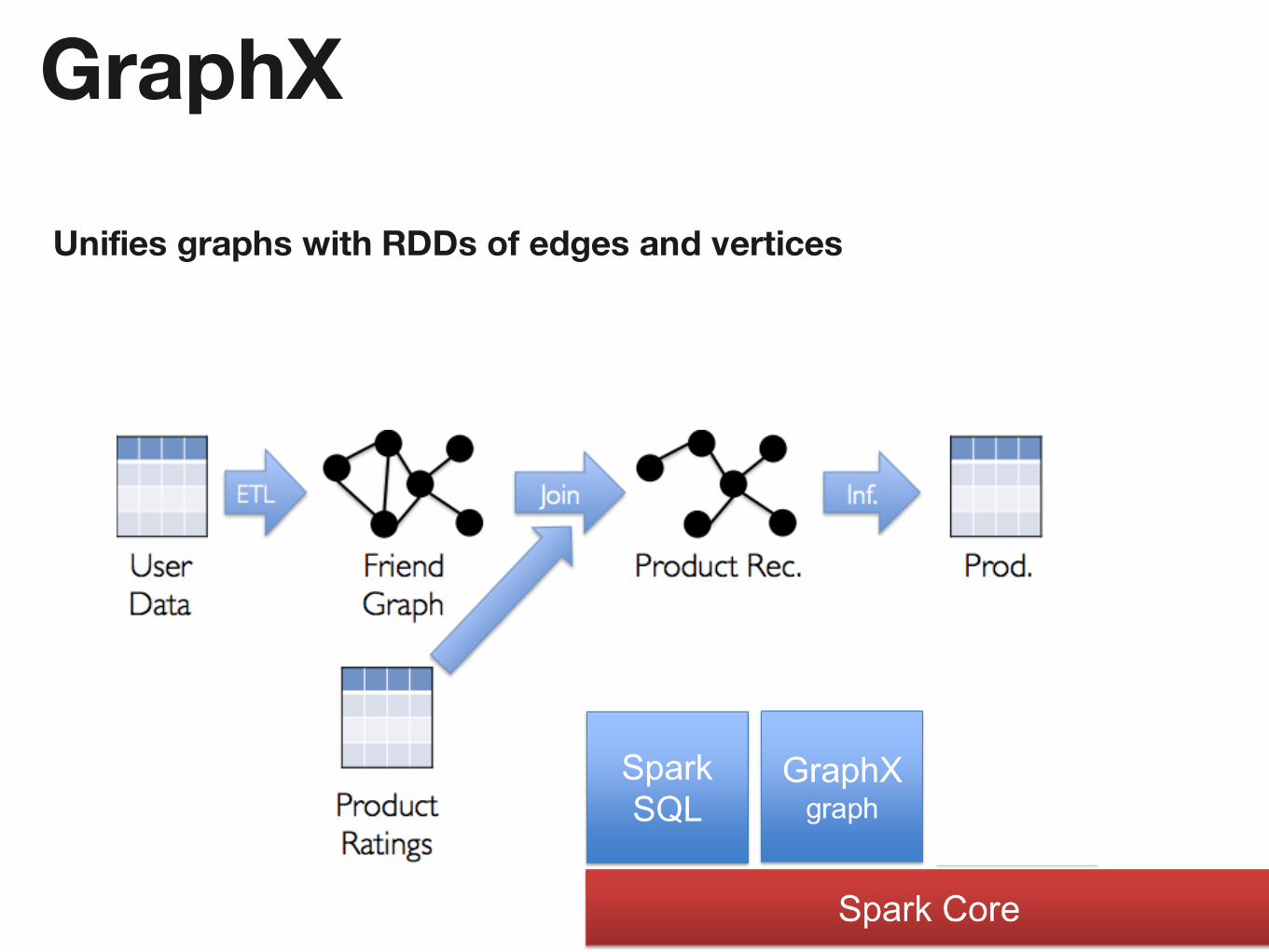
GraphX
Unifies graphs with RDDs of edges and vertices

MLlib
Vectors, Matrices
MLlib
Vectors, Matrices = RDD[Vector]Iterative computation
Spark StreamingTime
Input

Spark Streaming
RDD
RDD
RDD
RDD
RDD
RDD
Time
Express streams as a series of RDDs over timeval pantsers = spark.sequenceFile(“hdfs:/pantsWearingUsers”)
spark.twitterStream(...).filter(t => t.text.contains(“Hadoop”)).transform(tweets => tweets.map(t => (t.user,
t)).join(pantsers).print()

What it Means for Users
Separate frameworks:
…HDFS read
HDFS writeET
L HDFS read
HDFS writetra
in HDFS read
HDFS writequ
ery
HDFS
HDFS read ET
Ltra
inqu
ery
Spark: Interactiveanalysis

Spark Cluster
65

Benefits of Unification
• No copying or ETLing data between systems• Combine processing types in one program• Code reuse• One system to learn• One system to maintain

Data Ingestion
67
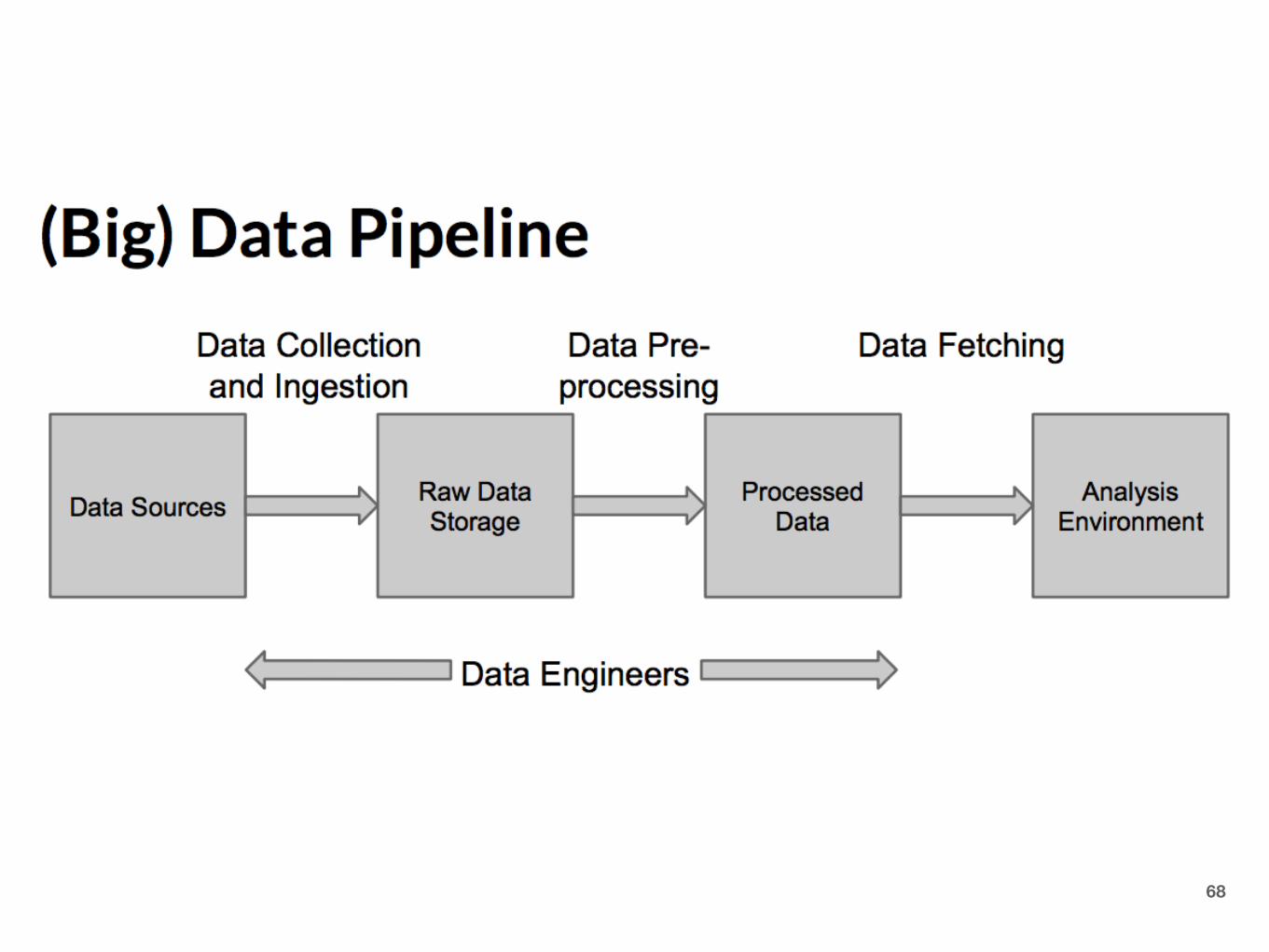
68

Collection vs Ingestion
69

Data collection
• Happens where data originates • “logging code” • Batch v. Streaming • Pull v. Push
70

Data Ingestion
• Receives data • Sometimes coupled with storage • Routing data
71

Related Documents











