Taming Big Data Leonardo Gamas

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Taming Big Data
Leonardo Gamas

Leonardo Gamas
Software Engineer @ JusBrasil
@leogamas

What is Spark?
"Apache Spark™ is a fast and general engine for large-
scale data processing."

One engine to rule them all?
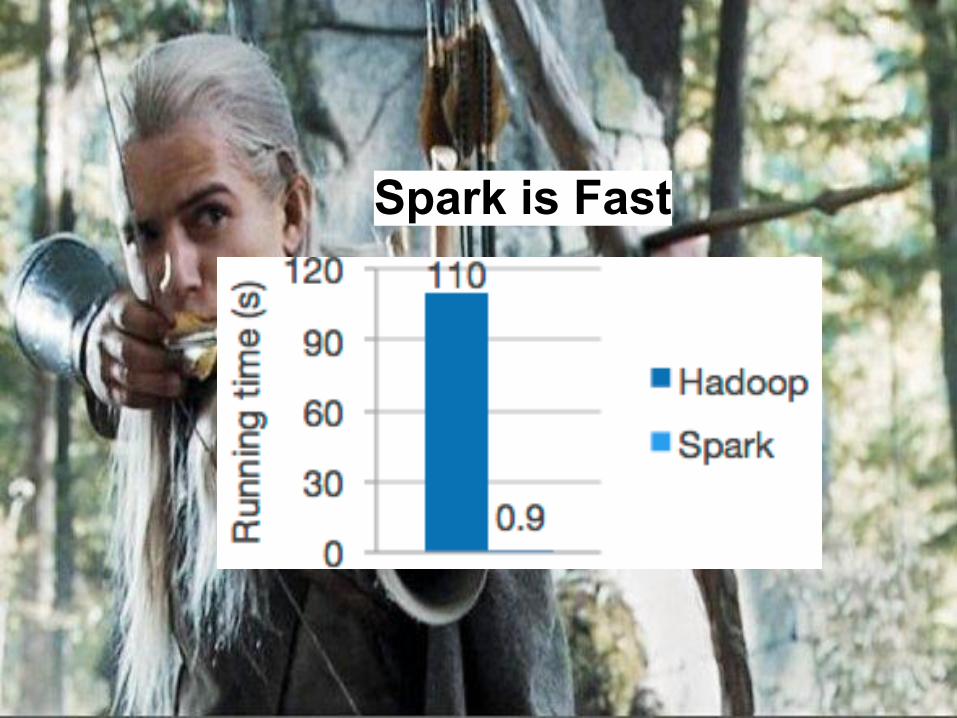
Spark is Fast

Spark is Integrated

Spark is simple
file = spark.textFile("hdfs://...") file.flatMap(lambda line: line.split()) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a+b)

Language support
● Scala● Java● Python

Community
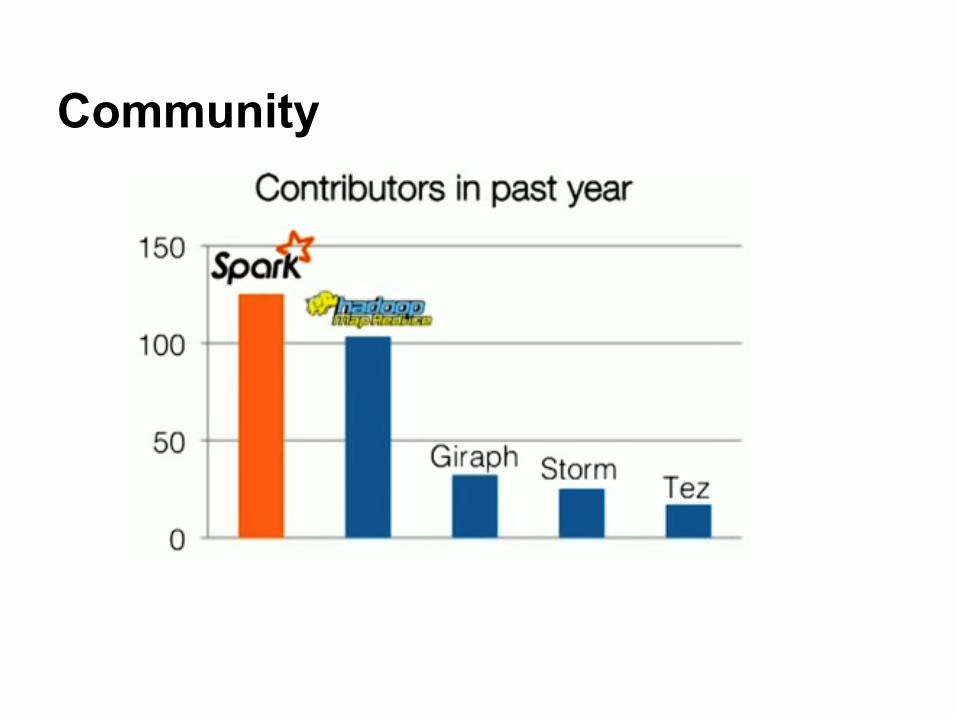
Community

Who is using Spark?

RDD
ResilientDistributedDataset
"Fault-tolerant collection of elements that can be operated on in parallel"

Dataset● Transformations
○ RDD => RDD○ Lazy
● Actions○ RDD => Stuff○ Not lazy
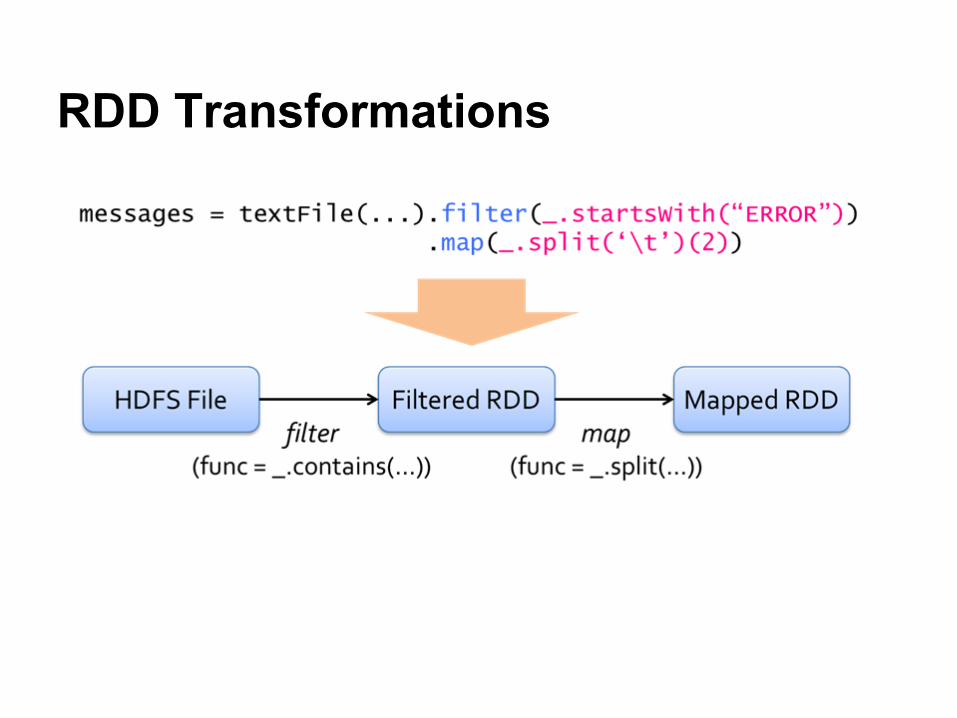
RDD Transformations

RDD Transformations● map(func)● filter(func)● flatMap(func)● mapPartitions(func)● mapPartitionsWithIndex
(func)● sample(withReplacement,
fraction, seed)● union(otherDataset)● intersection(otherDataset) ● distinct([numTasks])● groupByKey([numTasks])
● reduceByKey(func, [numTasks])● aggregateByKey(zeroValue)
(seqOp, combOp, [numTasks])● sortByKey([ascending],
[numTasks])● join(otherDataset, [numTasks])● cogroup(otherDataset,
[numTasks])● cartesian(otherDataset)● pipe(command, [envVars])● coalesce(numPartitions)● repartition(numPartitions)
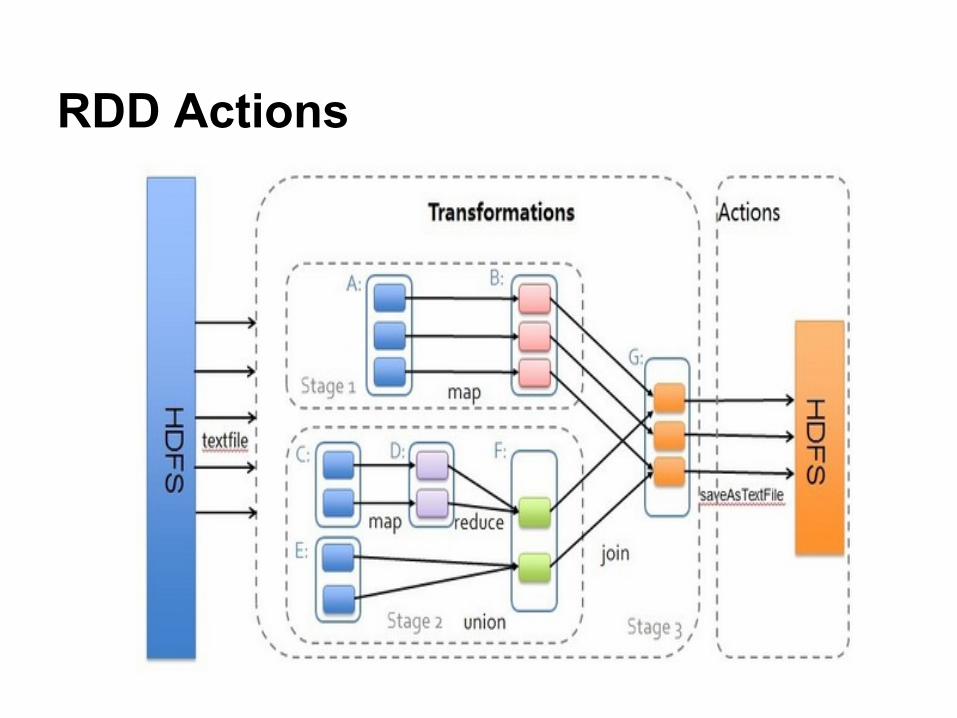
RDD Actions

RDD Actions
● reduce(func)● collect()● count()● first()● take(n)● takeSample
(withReplacement,num, [seed])
● takeOrdered(n, [ordering])● saveAsTextFile(path)● saveAsSequenceFile
(path) ● saveAsObjectFile(path) ● countByKey()● foreach(func)

Distributed

Distributed

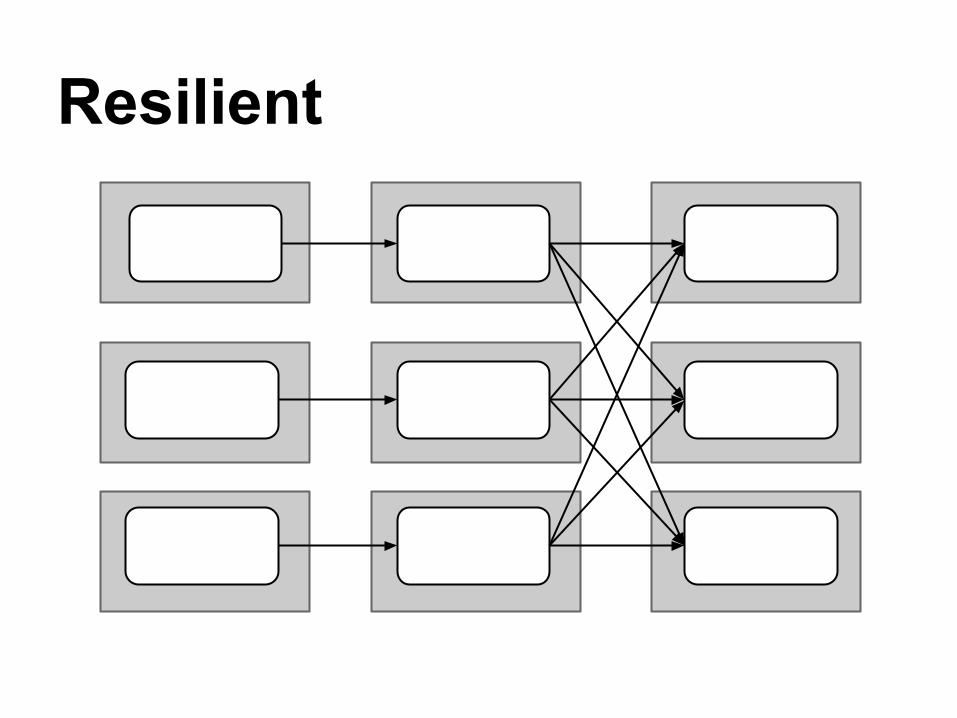
Resilient

Resilient
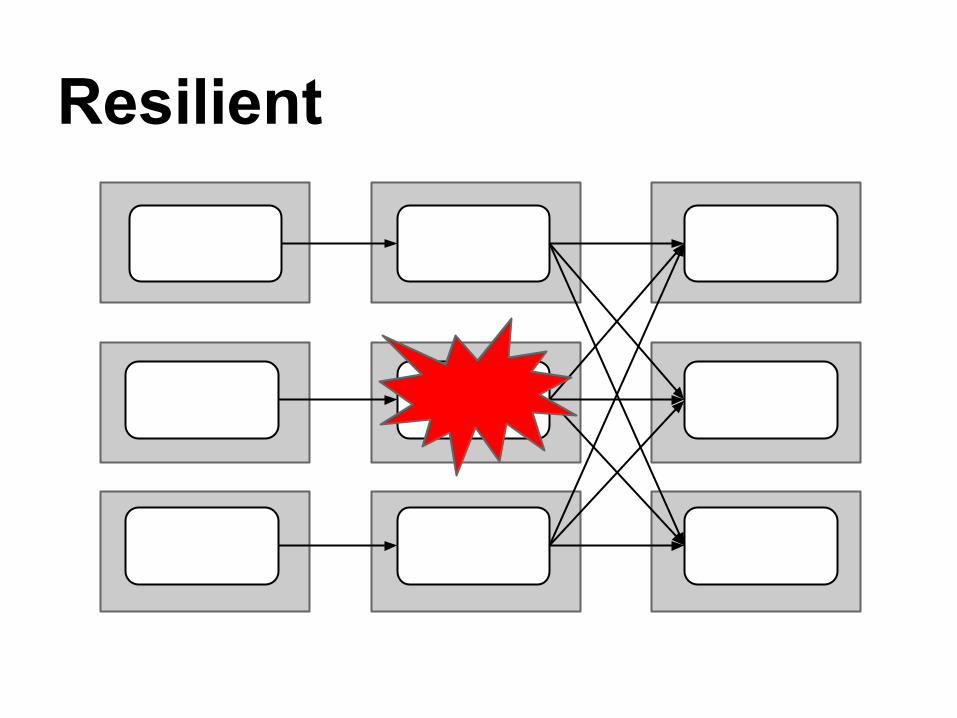
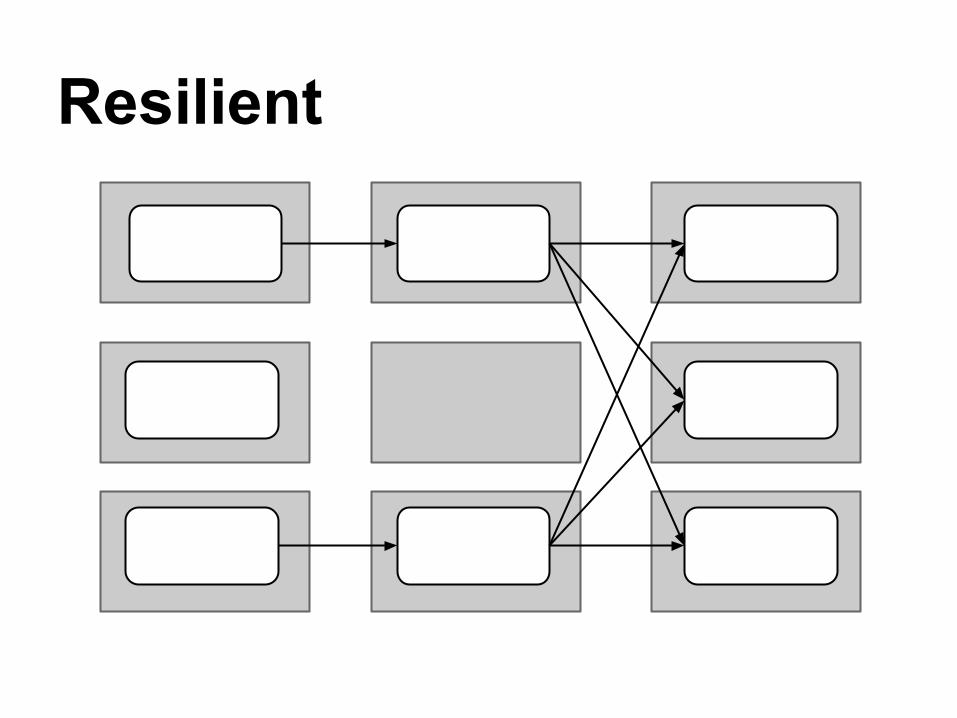
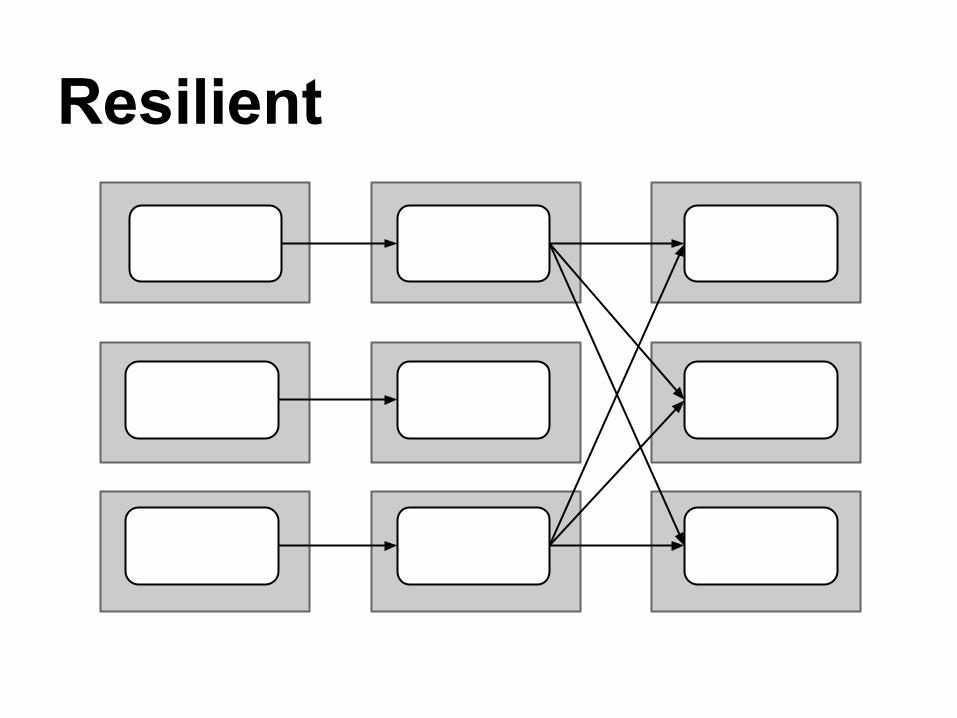
"RDDs track lineage information that can be used to efficiently recompute lost data."
Resilient
Resilient
Resilient
Resilient

Resilient

RDDs are cacheable
access disk twice

RDDs are immutable

RDD Internals
● Partitions (Splits)● Dependencies● Action (how to retrieve data)● Location hint (pref)● Partitioner

Broadcast Variables

Deployment
● Mesos● YARN● Standalone
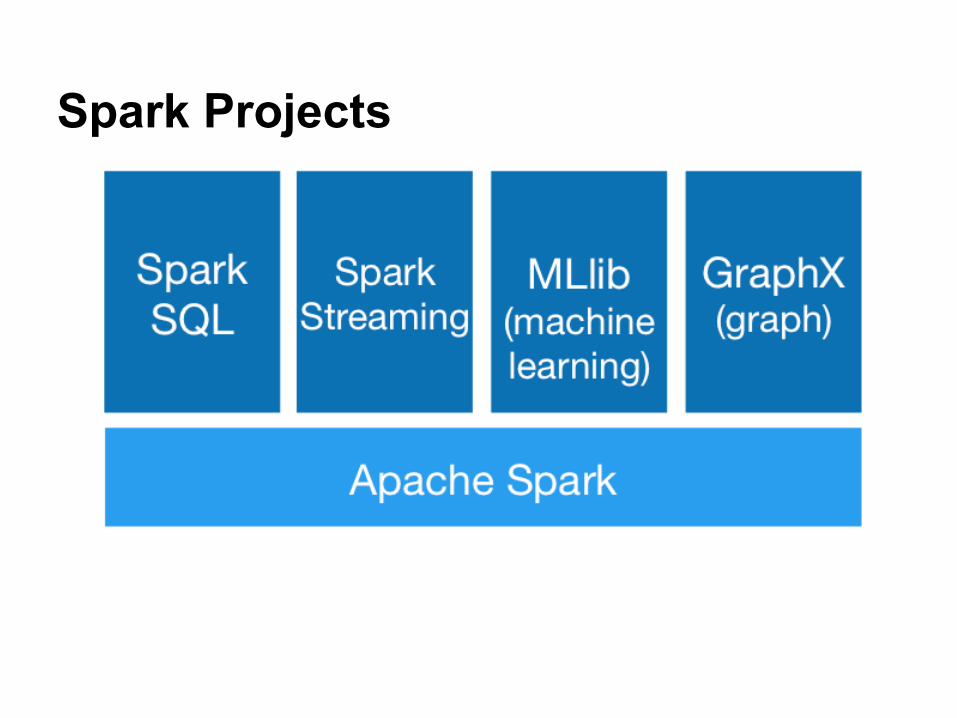
Spark Projects

Spark Projects

Spark Projects
Spark Core
Spark Projects
Spark CoreSpark SQL
Spark Projects
Spark CoreSpark SQL
Spark Streaming
Spark Projects
Spark CoreSpark SQL
Spark Streaming Spark MLlib


Spark Projects
Spark CoreSpark SQL
Spark Streaming Spark MLlib
Spark GraphX

Spark SQLcase class Person(name: String, age: Int) //Class// Map RDDval people = sc.textFile("...")
.map(_.split(","))
.map(p => Person(p(0), p(1).trim.toInt)) //Register as tablepeople.registerTempTable("people")// Queryval teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")

Spark SQL - Hiveval sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
// Create table and load data
sqlContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value
STRING)")
sqlContext.sql("LOAD DATA LOCAL INPATH '...' INTO TABLE src")
// Queries are expressed in HiveQL
sqlContext.sql("FROM src SELECT key, value").foreach(println)

Spark Streaming

Spark Streaming

Spark Streamingval ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
ssc.start()
ssc.awaitTermination()
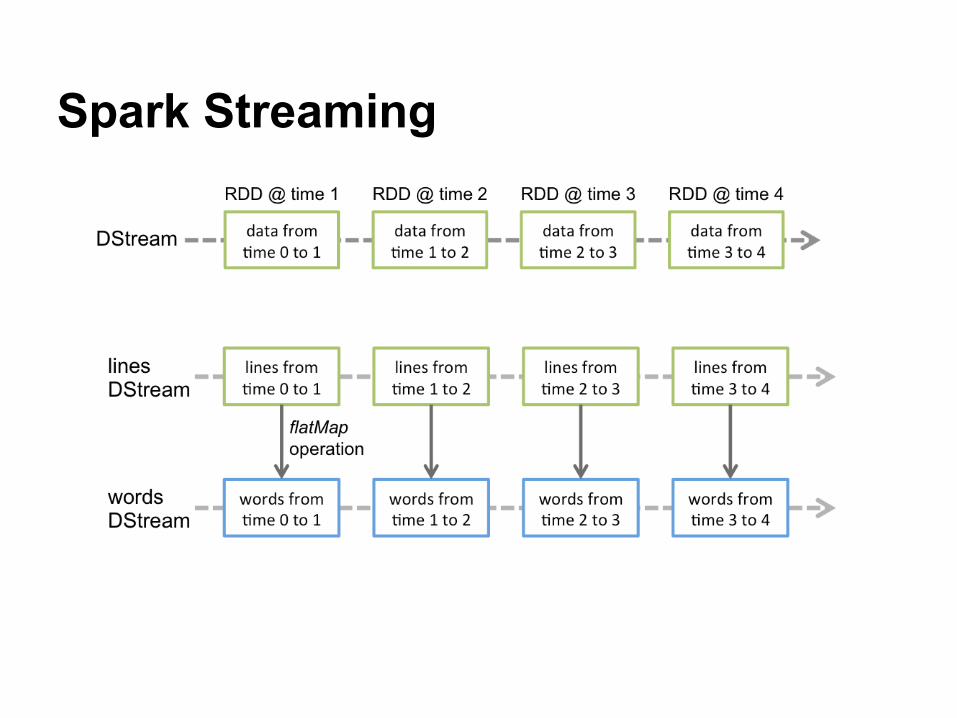
Spark Streaming

Spark Streamingdef updateFunction(newValues: Seq[Int], runningCount: Option
[Int]): Option[Int] = {
val newCount = ... // add the new values with the previous
Some(newCount)
}
val runningCounts = pairs.updateStateByKey[Int](updateFunction _)
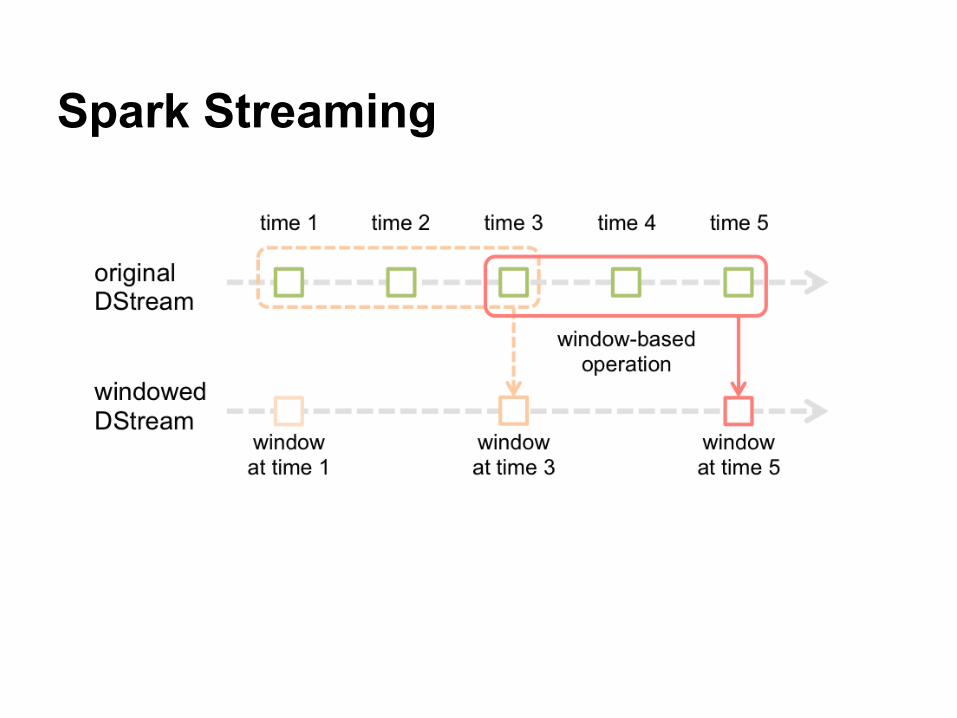
Spark Streaming

Spark MLlib
MLlib is Apache Spark's scalable machine learning library.

MLlib - Algorithms
● Linear Algebra● Basic Statistics● Classification and Regression
○ Linear model (SVM, Logistic regression, Linear Regression)
○ Decision trees○ Naive Bayes

MLlib - Algorithms
● Collaborative filtering (ALS)● Clustering (K-Means)● Dimensionality Reduction (SVD and PCA)● Feature extraction and transformation● Optimization (SGD, L-BFGS)

MLlib - K-Means
points = spark.textFile("hdfs://...") .map(parsePoint)
model = KMeans.train(points, k=10)
cluster = model.predict(testPoint)

MLlib - ALS Recommendationval data = sc.textFile("...")
val ratings = data.map(_.split(',') match { case Array(user, item,
rate) =>
Rating(user.toInt, item.toInt, rate.toDouble)
})
// Build the recommendation model using ALS rank = 10, iters = 20
val model = ALS.train(ratings, rank, numIterations, 0.01)
val recommendations = model.recommendProducts(userId, 10)

MLlib - Naive Bayesval data = sc.textFile("data/mllib/sample_naive_bayes_data.txt")
val training = data.map { line =>
val parts = line.split(',')
LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(' ')
.map(_.toDouble)))
}
val model = NaiveBayes.train(training, lambda = 1.0)

GraphX is Apache Spark's API for graphs and graph-parallel
computation.
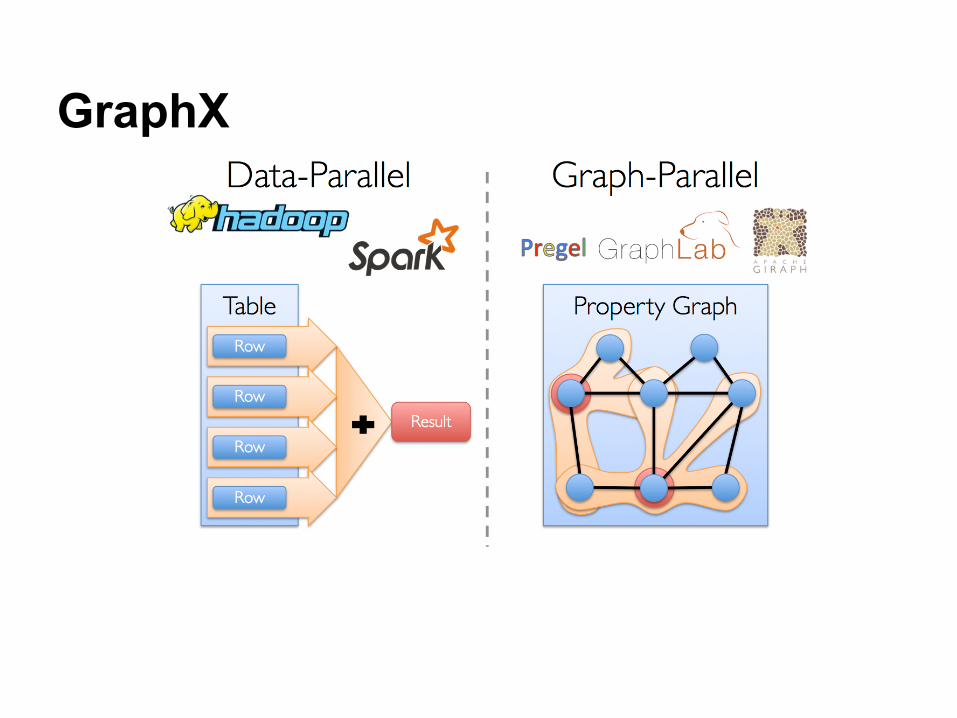
GraphX

GraphX

GraphX
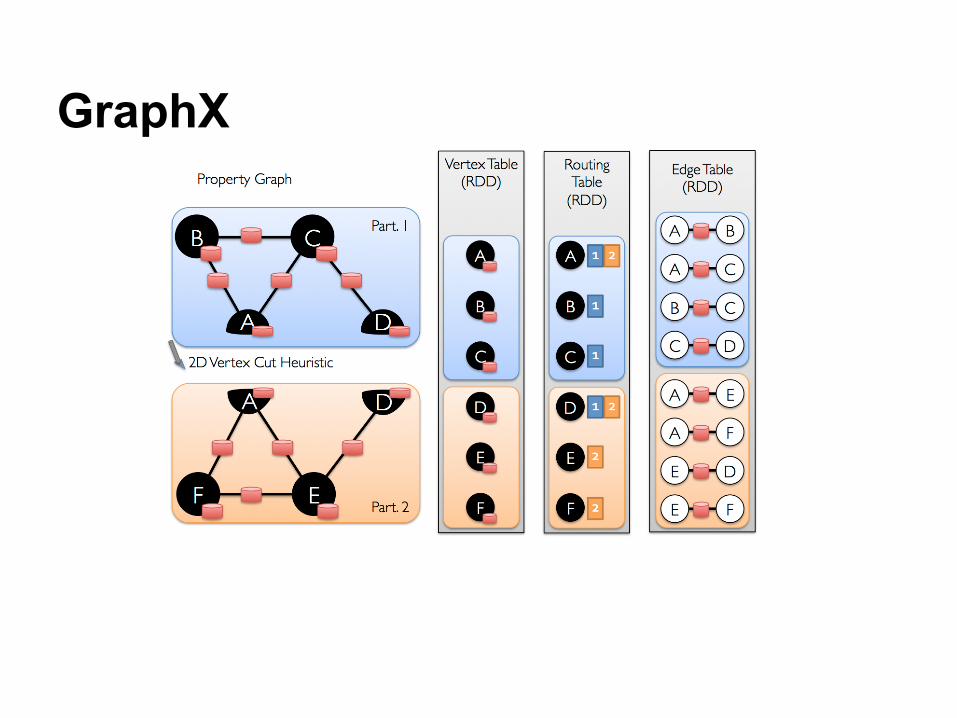
GraphX

GraphX - Algorithms
● Connected Components● Triangle Count● Strongly Connected Components● PageRank

// Run PageRank
val ranks = graph.pageRank(0.0001).vertices
// Join the ranks with the usernames
val users = sc.textFile("...").map { ... => (id, username)) }
val ranksByUsername = users.join(ranks).map {
case (id, (username, rank)) => (username, rank)
}
// Print the result
println(ranksByUsername.collect().mkString("\n"))
GraphX - PageRank

Questions?
Related Documents











